Embed Size (px)
Citation preview

Hochschule für Technik und Wirtschaft Berlin
Freie wissenschaftliche Arbeit zur Erlangung des akademischen Grades
Bachelor of Science in Wirtschaftsinformatik
Untersuchung und Vergleich ausgewählter Open-Source Data Mining-Tools
Bachelorthesis
im Fachbereich Wirtschaftswissenschaften II
im Studiengang Wirtschaftsinformatik
der Hochschule für Technik und Wirtschaft Berlin
vorgelegt von: Joschka Jericke
Storkower Straße 217 10367 Berlin Matrikel-Nr: s0528614
Erstbetreuer: Prof. Dr. Ingo Claßen Zweitbetreuer: Prof. Dr. Martin Kempa Abgabetermin: 09.10.2013

Inhaltsverzeichnis
II
Inhaltsverzeichnis
Inhaltsverzeichnis ............................................................................................... II
Abbildungsverzeichnis ....................................................................................... III
Einleitung............................................................................................................ 1
CRISP-DM .......................................................................................................... 2
Phase 1 Business Understanding .................................................................. 2
Phase 2 Data Understanding ......................................................................... 2
Phase 3 Data Preparation .............................................................................. 3
Phase 4 Data Modelling ................................................................................. 4
Phase 5 Evaluation ........................................................................................ 4
Phase 6 Deployment ...................................................................................... 5
Präsentation der zu vergleichenden Tools ......................................................... 6
Rattle-GUI ...................................................................................................... 6
Scikit-learn ..................................................................................................... 6
RapidMiner ..................................................................................................... 7
Orange ........................................................................................................... 8
Benutzeroberfläche und Funktionsweise ............................................................ 9
Rattle-GUI ...................................................................................................... 9
Scikit-learn ................................................................................................... 10
RapidMiner ................................................................................................... 13
Orange ......................................................................................................... 17
Evaluation......................................................................................................... 19
Datenschnittstellen ....................................................................................... 19
Datenexploration und Visualisierung ............................................................ 27
Data Mining Methoden ................................................................................. 41
Abschließendes Fazit ................................................................................... 44
Literaturverzeichnis ........................................................................................... VI
Weblinks ........................................................................................................... VII
Verwendeter Datensatz ................................................................................... VIII

Abbildungsverzeichnis
III
Abbildungsverzeichnis
Abbildung 1 Rattle - Benutzeroberfläche ............................................................ 9
Abbildung 2 RapidMiner Startansicht .............................................................. 13
Abbildung 3 RapidMiner Prozessansicht ......................................................... 14
Abbildung 4 RapidMiner Result Perspektive .................................................... 16
Abbildung 5 Orange Workflow .......................................................................... 18
Abbildung 6 Rattle Daten-Tab .......................................................................... 20
Abbildung 7 RapidMiner Repository………………………………………………..23
Abbildung 8 RapidMiner Operatoren ................................................................ 23
Abbildung 9 RapidMiner Model Import/Export .................................................. 25
Abbildung 10 RapidMiner Meta Data View ...................................................... 28
Abbildung 11 Rattle Datensatz ......................................................................... 29
Abbildung 12 Orange Data Table ..................................................................... 31
Abbildung 13 Rattle Explorer ............................................................................ 32
Abbildung 14 Rattle Beschreiben ..................................................................... 33
Abbildung 15 Rattle Fehlende anzeigen ........................................................... 34
Abbildung 16 Rattle Verteilungen ..................................................................... 35
Abbildung 17 Rattle Grafiken............................................................................ 36
Abbildung 18 RapidMiner - Iris ......................................................................... 37
Abbildung 19 RapidMiner SOM ........................................................................ 38
Abbildung 20 Orange Distributions .................................................................. 39
Abbildung 21 Klassifizierung Data Mining Methoden ....................................... 41

Abbildungsverzeichnis
IV
Tabellenverzeichnis
Tabelle 1 Rattle GUI ........................................................................................... 6
Tabelle 2 scikit-learn .......................................................................................... 6
Tabelle 3 RapidMiner ......................................................................................... 7
Tabelle 4 Orange ................................................................................................ 8

Einleitung
1
Einleitung
Die Vorliegende Arbeit befasst sich mit einer Untersuchung von Open-Source Da-
ta Mining Tools anhand definierter Kriterien. Eine allgemein anerkannte Definition
des Data Mining gibt es zurzeit noch nicht. Jedoch beschreibt eine sehr populäre
Definition das Data Mining als einen Prozess zum Auffinden von gültigen, interpre-
tierbaren Mustern in Datenbeständen, welche durch spezielle Analysemethoden
gefunden werden.1 Die neu gewonnen Informationen bzw. Zusammenhänge aus
den Unternehmensdatenbeständen können dann als eine Grundlage für strategi-
sche Entscheidungen herangezogen werden. Da das Einführen kommerzieller
Data Mining Software mit einem hohen Kostenaufwand verbunden ist, stellen ent-
sprechende Tools aus dem Open-Source Bereich eine Alternative dar. Im Rahmen
der Arbeit werden die folgenden vier Open-Source Data Mining Tools fokussiert:
Rattle GUI
Scikit-learn
RapidMiner
Orange Canvas
In einem ersten Teil wird auf ein Vorgehensmodell eingegangen, welches dem
Prozess des Data Mining im Unternehmen einen gewissen Rahmen gibt und
Gleichzeitig als Fundament für die Vergleichskriterien dient. Anschließend erfolgt
eine Präsentation der Tools und nachfolgend die Evaluation.
1 Vgl.(Gabriel, Gluchowski, & Pastwa, 2009, S. 121, zitiert nach: Fayyad, U. M.; Piatetsky-Shapiro, G.;
Smyth, P.; 1996 S. 37-54)

CRISP-DM
2
CRISP-DM
Der Cross Industry Standard Process for Data Mining (CRISP-DM) ist ein aus
sechs Phasen bestehendes Vorgehensmodell, welches durch das CRSIP-DM
Konsortium geschaffen wurde, um das Durchführen von Data Mining Projekten im
Unternehmen zu unterstützen. Die sechs Phasen sehen dabei die Aufgaben des
Business Understanding, Data Understanding, Data Preparation, Data Modeling
und der Evaluation vor.2 Im Folgenden werden die einzelnen Phasen genauer be-
schrieben.
Phase 1 Business Understanding
Die erste Phase des CRSIP-DM-Modells beinhaltet zusammenfassend das Defi-
nieren der Projektziele, die Erstellung eines Projektplans und das Überprüfen bzw.
Sicherstellen, der für das Projekt erforderlichen Ressourcen. Die Definition der
Projektziele sollte, nach Empfehlung des CRSIP-DM-Konsortiums, in zwei Schrit-
ten erfolgen. Als erstes werden die Ziele aus einer betriebswirtschaftlichen Sicht
beschrieben. Von dieser betrieblichen Sicht ausgehend, können dann die entspre-
chenden analytischen Ziele für das Data-Mining abgeleitet und formuliert werden,
um so das Erreichen, der aus betrieblicher Sicht, festgelegten Ziele, zu unterstüt-
zen.
Phase 2 Data Understanding
Nachdem in der ersten Phase eine Zielsetzung für das Projekt geschaffen wurde,
folgt in der zweiten Phase das Sammeln, Beschreiben und Explorieren von allen
Daten, welche für das Projekt benötigt werden oder relevant sein könnten. Dabei
können die Daten je nach informationsbedarf aus den verschiedensten Quellen,
Unternehmensinternen sowie extern stammen. Als primäre, unternehmensinterne
Quelle wird üblicherweise ein Data-Warehouse herangezogen, da hier bereits ein
Großteil der unternehmensbezogenen Daten als historische Datensammlung vor-
liegt. Diese können dann bedarfsgerecht, über das Erstellen von Data-Marts, ex-
trahiert werden und liegen in einer bereits aufbereiteten Form vor.3
Neben dem Sammeln der Daten, spielt in dieser Phase auch das Beschreiben
sowie Explorieren der Daten eine wichtige Rolle. Diese Aktivitäten sollten aus zwei
2 (IBM, 2010)
3vgl (Grabiel, Gluchowski, & Pastwa, 2009)

CRISP-DM
3
Gründen durchgeführt werden. Zum einen, um ein besseres Verständnis für die
Daten zu erlangen und zum anderem, um die Qualität der Daten einzuschätzen.
Eine erste oberflächliche Beschreibung der Daten erfolgt dann in der Regel an-
hand der Metadaten. Durch diese können erste Informationen über die Struktur
der Daten, wie den Datenumfang, den eingesetzten Datentypen und den zulässi-
gen Wertebereichen gewonnen werden. Über die Beschreibung durch Metadaten
ist es zudem möglich, erste Aussagen über die Qualität der Daten zu treffen, da
beispielsweise fehlende Werte (Missing Values) oder auch falsche Werte, welche
für den jeweiligen Datentyp nicht zulässig sind aufgedeckt werden.
Die Exploration der Daten beinhaltet hier das erste Anwenden von Methoden der
deskriptiven Statistik, durch welche erste, eventuell vorhandene Zusammenhänge
bzw. Muster in den Daten entdeckt werden können.4
Phase 3 Data Preparation
Die Data Preparation Phase umfasst sämtliche Aktivitäten, welche erforderlich
sind, um den Datenbestand für die nachfolgend einzusetzenden Analysemethoden
nutzbar zu machen. Dieser Schritt ist meist sehr ressourcenintensiv und kann bis
zu 80% der zeitlichen Ressourcen beanspruchen, insbesondere dann, wenn die
Daten aus verschiedenen Quellen stammen und so eine starke Heterogenität auf-
weisen.5
Die wesentlichen Aktivitäten dieser Phase sind hier aufgelistet:
Select Data: In diesem Schritt wird festgelegt, welche Attribute und Datens-
ätze für die Analysen selektiert bzw. exkludiert werden.
Integrate Data: Beinhaltet das Anwenden von Methoden zur Kombination
bestimmter Datentabellen, über zum Beispiel Join-Statements, um eine Ta-
belle so um Informationen zu ergänzen, welche für die Analysen von Rele-
vanz sein könnten.
Construct Data: Dieser Schritt bezieht sich auf das Konstruieren sogenann-
ter abgeleiteter Attribute. Abgeleitete Attribute entstehen zum Beispiel aus
Rechenoperationen über bereits vorhandene Attribute und ergänzen so die
Datentabelle um ein neues Merkmal.
4Vgl. (Grabiel, Gluchowski, & Pastwa, 2009)
5Vgl. (Grabiel, Gluchowski, & Pastwa, 2009)

CRISP-DM
4
Clean Data: Durch diese Teilaktivität, soll eine möglichst hohe Qualität der
Daten sichergestellt werden. Hier steht beispielsweise die Behandlung von
fehlenden oder fehlerhaften Werten sowie das Auffinden und Eleminieren von
Redundanzen in den Daten im Vordergrund.
Format Data: Die Datenformatierung befasst sich mit der Frage nach den zu
verwendenden bzw. erforderlichen Skalenniveau und Datentypen. Je nach-
dem welche Data-Mining Methode bzw. Algorithmus zum Einsatz kommen
soll, müssen die Attribute in einem hierfür geeignetem Skalenniveau vorliegen
und gegeben falls in dieses Überführt werden.
Phase 4 Data Modelling
Nachdem in der vorangegangenen Phase eine umfangreiche Aufarbeitung der
relevanten Daten stattgefunden hat, folgt in dieser 4. Phase des Data Modelling
der Einsatz bestimmter Modellierungs- bzw. Analysemethoden. Je nachdem wel-
che konkrete Data-Mining-Fragestellung für das Projekt gesetzt wurde, eignet sich
im Allgemeinen immer eine bestimmte Menge verschiedener Analysemethoden,
um entsprechende Ergebnisse zu produzieren. Innerhalb dieser Phase muss her-
ausgefunden werden, welches Modell am besten geeignet ist. Aus diesem Grund
besteht hier eine starke Rückkopplung zur Data-Preparation Phase, da die Daten
für die Modelle entsprechend aufbereitet werden müssen. Für jedes erstellte Mo-
dell erfolgt dann jeweils eine Abschätzung der Modellqualität bzw. Genauigkeit,
über die Berechnung geeigneter Maßzahlen, wobei für das jeweilige Modell auch
entsprechende Methoden existieren, um die Qualität/Gültigkeit zu schätzen. Die
Gültigkeit legt nahe, mit welcher Wahrscheinlichkeit die Aussagen des Modells
gelten.
Phase 5 Evaluation
Die Phase der Evaluation sieht sowohl eine Bewertung der Data-Mining Ergebnis-
se als auch eine Bewertung des gesamten Projektverlaufs vor. In der vorherigen
Phase wurden die Modelle anhand ihrer Gültigkeit aus einer technischen Sicht der
Daten-Analyse miteinander verglichen und beurteilt, so dass hier eine Vorauswahl
getroffen wurde. Nun geht es darum die Modelle aus Sicht der Betriebswirtschaft
zu bewerten, um zu sehen welcher Nutzen sich aus den Ergebnissen ziehen lässt

CRISP-DM
5
und ob die anfangs definierten Ziele auf Grundlage der Analysen erreicht werden
können6.
Die rückblickende Bewertung des gesamten Projektverlaufs befasst sich im We-
sentlichen mit aufgetretenen Problemen und damit einhergehend wie Data-Mining
Projekte zukünftig optimiert werden können. Nach dem Konsortium bestehen die
Projektergebnisse nicht nur aus den Analysergebnissen der Modelle an sich, son-
dern umfassen auch weitere Erkenntnisse, die während der Durchführung des
Data-Mining Projektes gemacht wurden. So kann es beispielsweise sein, dass
bestimmte Mängel in der Datenqualität zu Tage gebracht werden, welche nach
Möglichkeit optimiert werden sollten.
Phase 6 Deployment
Nachdem die Modelle umfassend aus technischer und betriebswirtschaftlicher
Sicht bewertet und im Idealfall für geeignet angesehen werden, geht es in dieser
letzten Phase darum, auf welche Art und Weise bzw. durch welche konkreten
Maßnahmen das neu gewonnene Wissen genutzt werden kann7.Zudem werden
die Projektergebnisse in einem finalen Report zur Verfügung gestellt.
6 Vgl. (Wirth & Hipp, 2013)
7 Vgl. (Grabiel, Gluchowski, & Pastwa, 2009)

Präsentation der zu vergleichenden Tools
6
Präsentation der zu vergleichenden Tools
Im folgendem werden die untersuchten Data-Mining Tools kurz mit ein paar er-
gänzenden Hintergrundinformationen vorgestellt.
Rattle-GUI
Offizielle Website/Herausgeber: http://rattle.togaware.com/
Untersuchte Version:8 2.6.26
Unterstützte Betriebssysteme: Ubuntu und Debian GNU/Linux,
MS-Windows, Mac-OS
Tabelle 1 Rattle-GUI
Rattle ist eine Erweiterung der Statistikprogrammiersprache bzw. Entwicklungs-
umgebung R und stellt dem Anwender eine grafische Benutzeroberfläche zur Ver-
fügung. Entwickelt wurde Rattle vor dem Hintergrund, um für den Anwender be-
stimmte Funktionalitäten von R auch ohne nähere Kenntnis der R-Syntax zugäng-
lich zu machen. Die dem Rattle-GUI zugrunde liegende Entwicklungsumgebung R
wurde in C geschrieben und gilt als eines der mächtigsten Statistik bzw. Data-
Mining-Werkzeuge9. Eine Installation von R muss als Voraussetzung auf dem Sys-
tem vorhanden sein. Das Rattle-GUI-Package wird dann über eine einfache R-
Syntax innerhalb der R-Entwicklungsumgebung mit allen erforderlichen Libraries
heruntergeladen. Das Starten von Rattle erfolgt dann ebenfalls über einen einfa-
chen R-Befehl.
Scikit-learn
Offizielle Website/Herausgeber: http://scikit-learn.org/
Untersuchte Version:10 0.14
Unterstützte Betriebssysteme: Ubuntu ,Debian GNU/Linux,
MS-Windows, Mac-OS
Tabelle 2 scikit-learn
8 stand 29.07.2013
9 (Graham, 2011)
10 Stand 29.07.2013

Präsentation der zu vergleichenden Tools
7
Scikit-learn ist eine Library für die Programmiersprache Python, welche eine Men-
ge von Machine-Learning bzw. Data-Mining Funktionalitäten implementiert. Das
Projekt zur Entwicklung von Scikit-learn wurde 2007 gestartet. Einen ersten offizi-
ellen Release gab es im Februar 2010. 11
RapidMiner
Offizielle Website/Herausgeber: http://rapid-i.com/
Untersuchte Version:12 5.3.013
Unterstützte Betriebssysteme: Ubuntu ,Debian GNU/Linux,
MS-Windows, Mac-OS
Tabelle 3 RapidMiner
Entwickelt sowie offiziell zur Verfügung gestellt wird der RapidMiner durch das
Unternehmen Rapid-I, welches sich auf Softwarelösungen und Dienstleistungen
im Bereich Data-Mining spezialisiert hat. Die ursprüngliche Entwicklung des Ra-
pidMiner begann 2001 an der Universität Dortmund. Später gründeten die Ent-
wickler das Unternehmen Rapid-I, welches sich mit der Weiterentwicklung sowie
Wartung des Rapidminer befasst.13
Neben der als Community-Edition erhältlichen Open-Source Variante, steht der
RapidMiner auch als Lizenzpflichtige Enterprise-, Big-Data- sowie OEM-Edition
zur Verfügung, welche sich im Wesentlichen hinsichtlich der Skalierbarkeit und im
Support, seitens Rapid-I unterscheiden.14Neben Data-Mining stellt der RapidMiner
auch ETL Funktionalitäten zur Verfügung.
Der RapidMiner wurde in Java geschrieben und erfordert eine installierte Java-
Laufzeitumgebung.
11
Vgl. (scikit-learn.org) 12
Stand 29.07.2013 13
Vgl (Mierswa) 14
Vgl http://rapid-i.com/content/view/181/190/lang,de/

Präsentation der zu vergleichenden Tools
8
Orange
Offizielle Website/Herausgeber: http://orange.biolab.si/
Untersuchte Version:15 2.7
Unterstützte Betriebssysteme: Ubuntu ,Debian GNU/Linux,
MS-Windows, Mac-OS
Tabelle 4 Orange
Die Data Mining Software Orange basiert auf Python und wurde an der “Faculty of
Computer and Information Science“ der Universität Ljubljana Slovenia entwickelt.
Orange wird über eine grafische Benutzeroberfläche bedient.
15
Stand 29.07.2013
Benutzeroberfläche und Funktionsweise
9
Benutzeroberfläche und Funktionsweise
Nachdem die einzelnen Data-Mining Tools im vorangegangenen Kapitel kurz vor-
gestellt wurden, soll innerhalb dieses Kapitels ein erster Eindruck von den Tools
vermittelt sowie deren Funktionsweise verdeutlicht werden, welche sich zuweilen
grundlegend voneinander unterscheiden. Die Tools werden hierbei jeweils einzeln
vorgestellt.
Rattle-GUI
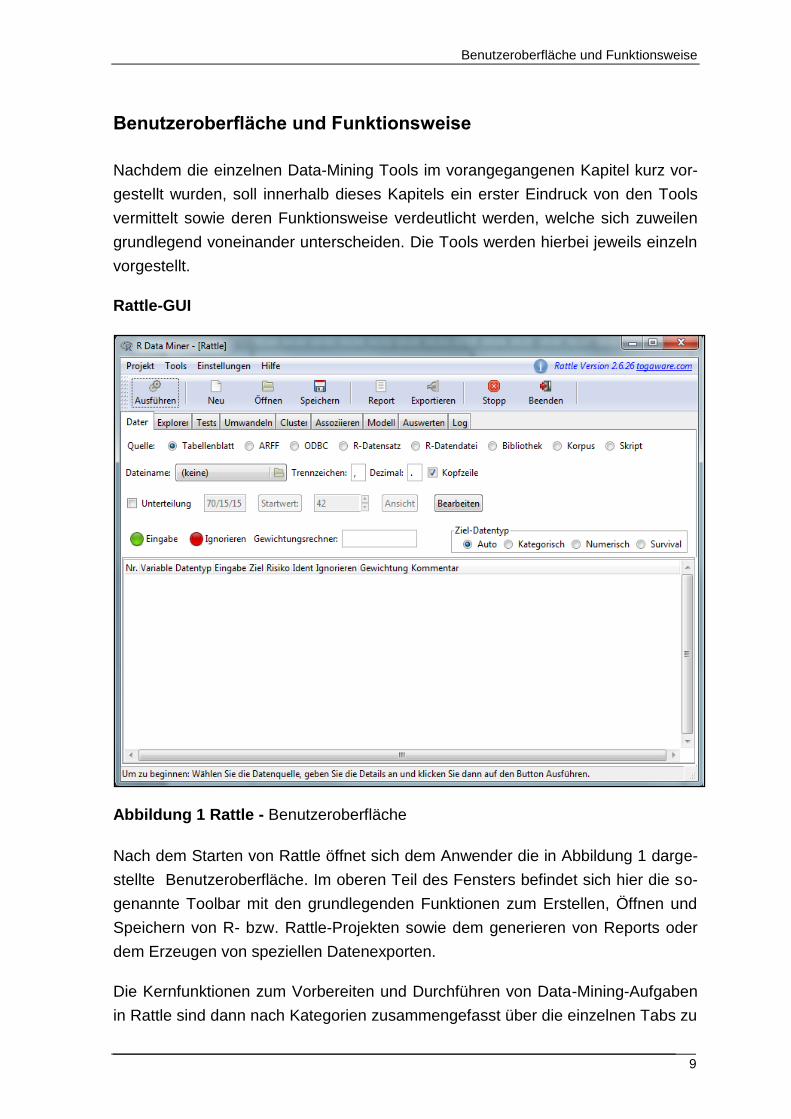
Abbildung 1 Rattle - Benutzeroberfläche
Nach dem Starten von Rattle öffnet sich dem Anwender die in Abbildung 1 darge-
stellte Benutzeroberfläche. Im oberen Teil des Fensters befindet sich hier die so-
genannte Toolbar mit den grundlegenden Funktionen zum Erstellen, Öffnen und
Speichern von R- bzw. Rattle-Projekten sowie dem generieren von Reports oder
dem Erzeugen von speziellen Datenexporten.
Die Kernfunktionen zum Vorbereiten und Durchführen von Data-Mining-Aufgaben
in Rattle sind dann nach Kategorien zusammengefasst über die einzelnen Tabs zu

Benutzeroberfläche und Funktionsweise
10
erreichen, welche unter der Toolbar angeordnet sind. Die Kategorisierung sowie
Reihenfolge der hier angeordneten Tabs ist dabei so ausgelegt, dass der Anwen-
der im groben von links nach rechts durch die Tabs navigiert. Innerhalb eines
Tabs werden dann die entsprechenden Konfigurationen vorgenommen, welche
nach jeder Änderung über den in der Toolbar befindlichen „Ausführen“ - Button,
bestätigt werden müssen.
Der untere Bereich der Benutzeroberfläche liefert eine entsprechende Ausgabe
der Ergebnisse, welche über das jeweilige Tabs generiert wurden. Das Ausgabe-
feld liefert hier nur Ergebnisse in Textform.
Zu erwähnen ist, dass Rattle lediglich eine Teilmenge der Gesamtfunktionalitäten
von R verfügbar ist. Da Rattle über einen R Befehl gestartet wird, läuft die R Ent-
wicklungsumgebung stets parallel zu Rattle. In Rattle generierte grafische Darstel-
lungen, werden in der R Umgebung ausgegeben
Scikit-learn
Im Kontrast zu den anderen, im Rahmen dieser Arbeit untersuchten Data-Mining
Tools, gibt es in Scikit-learn kein grafisches Userinterface, sodass das Data-
Mining Aufgaben hier direkt über die Programmierung in Python durchgeführt wer-
den. Für die verschiedenen Data-Mining Modelle bzw. Algorithmen implementiert
die Scikit-learn Library eine Vielzahl von Klassen, welche wiederum in Packages
bzw. Modulen organisiert sind. Je nachdem welches Data-Mining Modell zum Ein-
satz kommen soll, wird ein sogenanntes Estimator-Objekt der entsprechenden
Klasse instanziiert.
Als Datengrundlage arbeiten bzw. erwarten Estimator-Objekte 2-dimensionale
NumPy-Arrays, welche besonders für die Bearbeitung von umfangreichen, nume-
rischen Daten geeignet sind. Implementiert werden diese durch ein spezielles
NumPy Erweiterungs-Modul, welches als Voraussetzung für die Verwendung von
Scikit-learn vorhanden sein muss. NumPy-Arrays beinhalten die Daten dann in
einer (n_samples, n_features) Form, wobei über den Parameter n_samples die
Anzahl der Zeilen und über n_features die Anzahl der Attribute bzw. Spalten re-
präsentiert wird16. Ein Datensatz „x“, bei dem eine Zielvariable durch eine Regres-
sionen oder Klassifikationen geschätzt werden soll, enthält die folgenden zwei At-
tribute: „x.data“ sowie „x.target“. Das „.target“ Attribut beinhaltet die Zielvariablen
bzw. das label, welches Vorhergesagt werden soll, während das „.data“ Attribut
16
Vgl. (astroml)

Benutzeroberfläche und Funktionsweise
11
die Input-Datensätze enthält. Beide Attribute basieren auf NumPy-Arrays.
Damit Estimator-Objekte mit den Daten arbeiten können, implementieren diese
standardisierten Methoden, wobei hier eine Spezifikation zwischen Supervised-
und Unsupervised Estimator-Objekten vorgenommen wird. Eine standardisierte
Methode, welche durch alle Estimator-Objekte gegeben ist, ist die „model.fit()“ Me-
thode. Als Parameter werden hier entsprechend die „.data“ bzw. „.target“ Attribute
zum Lernen der Modelle übergeben. Bei supervised Lernalgorithmen beide Attri-
bute, in der Form „model.fit(X, y)“ und bei Unsupervised lediglich das .data Attri-
but, in der Form „model.fit(X)“.
Eine ausschließlich von supervised Estimator-Objekten implementierte Methode
ist die „model.predict()“ Methode .Diese wird angewandt nachdem das Model ge-
lernt wurde und erwartet als Übergabeparameter ein neuen Arraydatensatz, um
für diesen, auf Grundlage des gelernten Modells, das entsprechende label vorher-
zusagen.
Zur Veranschaulichung der Vorgehensweise wird hier ein Beispiel geliefert, wel-
ches in Anlehnung an ein scikit-learn Tutorial entstanden ist17. Als Datengrundlage
kommt hierfür der Iris-Datensatz zum Einsatz.
From sklearn.dataset import load_iris
Iris = load_iris()
X, y = iris.data, iris.target
from sklearn.svm import LinearSVC
clf = LinearSVC()
clf = clf.fit(X, y)
X_new = [ [ 5.0, 3.6, 1.3, 0.25] ]
clf.predict (X_new)
array([0], dtype=int32)
list(iris.target_names)
['setosa', 'versicolor', 'virginica']
17
Vgl. ( http://www.astroml.org/sklearn_tutorial/general_concepts.html#supervised-learning-unsupervised-
learning-and-scikit-learn-syntax)

Benutzeroberfläche und Funktionsweise
12
Als erstes erfolgt hier ein Import des Iris Beispieldatensatzes aus dem
sklearn.datasets Modul. Über eine Hilfsmethode wird der Variablen „Iris“ der im-
portierte Beispieldatensatz als NumPy-Array übergeben. Da der Iris-Datensatz ein
typisches Beispiel zur Klassifizierung darstellt, verfügt dieser über ein .data sowie
.target -Array. Im Beispiel wird der Variablen „y“ über „iris.target“ das label-array
zugewiesen. Die Variable „X“ erhält über das „iris.data“ Attribut die Input-
Datensätze. Als Modell soll ein Support Vector Machine Algorithmus (SVC) zum
Einsatz kommen. Das sklearn.svm package enthält für diesen verschiedene Im-
plementierungen. Importiert wird in diesem Fall die Klasse für einen linearenSVC,
welcher anschließend anhand der Variablen „clf“ als Estimator-Objekt instanziiert
wird. Wie bereits erwähnt, verfügen sämtliche Estimator-objekte über eine .fit Me-
thode, über welche dem Lernalgorithmus das NumPy Datenarray übergeben wird.
Im Beispiel erhält das Estimator-Objekt die Inputdaten „X“ und die Zielvariable „y“
als Übergabeparameter. Nachdem das Modell gelernt wurde, wird ein neuer Ar-
ray-Datensatz „X_new“ erstellt und dem gelernten Modell zur Klassifizierung, über
die „clf.predict“ Methode übergeben. Die Ausgabe liefert dann den Index-Wert des
vorhergesagten labels, In diesem Fall 0. Über die „iris.traget_names“ Methode,
kann das Array mit den Klassennamen ausgegeben, sodass für den Datensatz
„x_new“ das label „setosa“ geschätzt wurde.
Benutzeroberfläche und Funktionsweise
13
RapidMiner
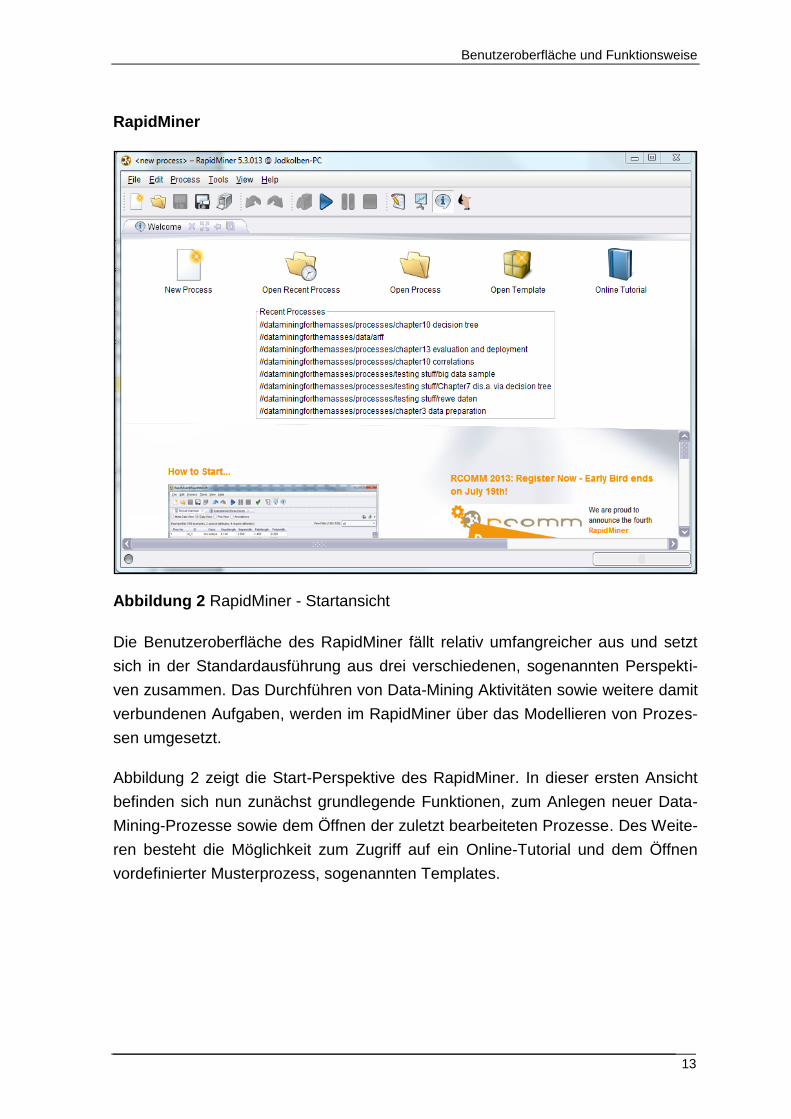
Abbildung 2 RapidMiner - Startansicht
Die Benutzeroberfläche des RapidMiner fällt relativ umfangreicher aus und setzt
sich in der Standardausführung aus drei verschiedenen, sogenannten Perspekti-
ven zusammen. Das Durchführen von Data-Mining Aktivitäten sowie weitere damit
verbundenen Aufgaben, werden im RapidMiner über das Modellieren von Prozes-
sen umgesetzt.
Abbildung 2 zeigt die Start-Perspektive des RapidMiner. In dieser ersten Ansicht
befinden sich nun zunächst grundlegende Funktionen, zum Anlegen neuer Data-
Mining-Prozesse sowie dem Öffnen der zuletzt bearbeiteten Prozesse. Des Weite-
ren besteht die Möglichkeit zum Zugriff auf ein Online-Tutorial und dem Öffnen
vordefinierter Musterprozess, sogenannten Templates.
Benutzeroberfläche und Funktionsweise
14
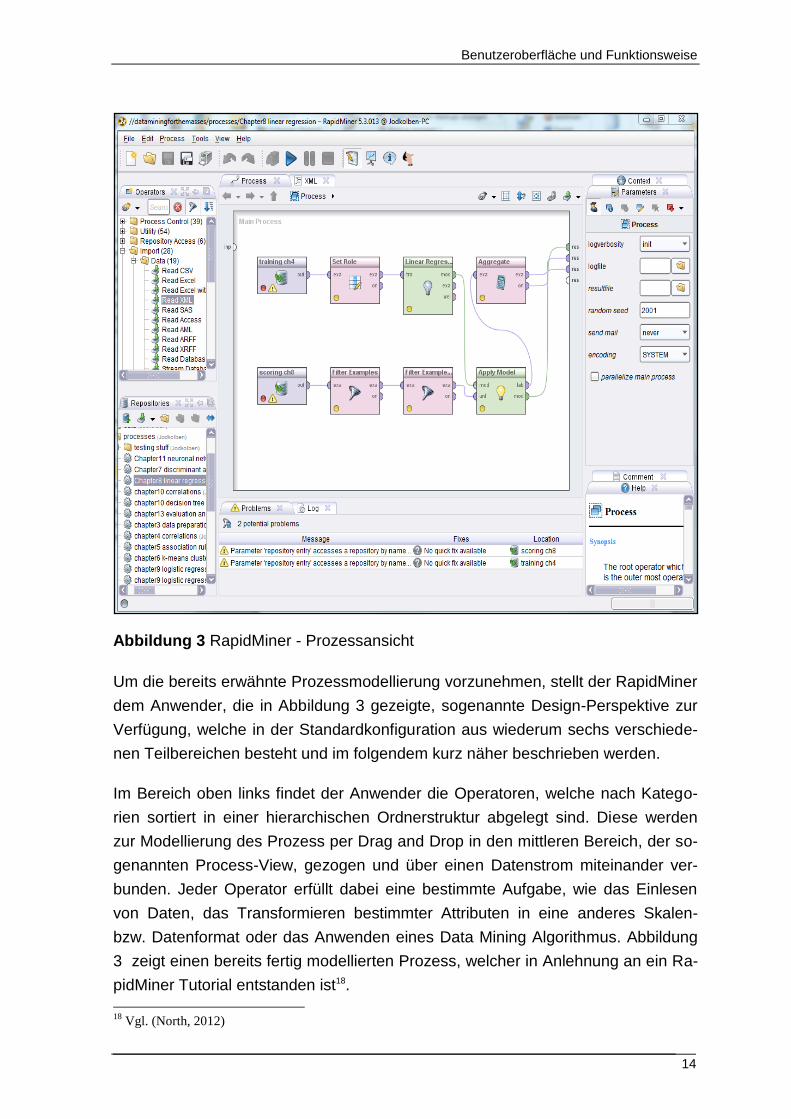
Abbildung 3 RapidMiner - Prozessansicht
Um die bereits erwähnte Prozessmodellierung vorzunehmen, stellt der RapidMiner
dem Anwender, die in Abbildung 3 gezeigte, sogenannte Design-Perspektive zur
Verfügung, welche in der Standardkonfiguration aus wiederum sechs verschiede-
nen Teilbereichen besteht und im folgendem kurz näher beschrieben werden.
Im Bereich oben links findet der Anwender die Operatoren, welche nach Katego-
rien sortiert in einer hierarchischen Ordnerstruktur abgelegt sind. Diese werden
zur Modellierung des Prozess per Drag and Drop in den mittleren Bereich, der so-
genannten Process-View, gezogen und über einen Datenstrom miteinander ver-
bunden. Jeder Operator erfüllt dabei eine bestimmte Aufgabe, wie das Einlesen
von Daten, das Transformieren bestimmter Attributen in eine anderes Skalen-
bzw. Datenformat oder das Anwenden eines Data Mining Algorithmus. Abbildung
3 zeigt einen bereits fertig modellierten Prozess, welcher in Anlehnung an ein Ra-
pidMiner Tutorial entstanden ist18.
18
Vgl. (North, 2012)

Benutzeroberfläche und Funktionsweise
15
Im unteren, linken Bereich befindet sich dann das RapidMiner-Repository, also ein
Verzeichnis, zur strukturierten Organisation importierter Daten, angelegter Daten-
bankverbindungen, erstellten Prozessen und anderen Datenobjekten, wie gespei-
cherten Ergebnissen oder auch Reports.
Der Teilbereich direkt unter der Process-View macht den Anwender während der
Prozessmodellierung auf eventuell vorhandene Probleme im Prozess aufmerksam
und liefert gegebenenfalls Korrektur Vorschläge. Ein Fehler könnte beispielsweise
in einem falsch gewähltem Datentyp oder Skalenniveau bestehen, welches zur
Weiterverarbeitung durch den nachfolgenden Operator nicht geeignet ist.
Im Bereich rechts außen findet der Anwender dann die Parameter-View, über wel-
che die Konfiguration der einzelnen Operatoren erfolgt. Je nachdem welcher Ope-
rator selektiert wurde, erhält der Anwender hier die entsprechenden Parameter zur
Konfiguration. Der letzte Bereich unter der Parameter-View liefert dann eine Be-
schreibung zur Funktionsweise des jeweils gewählten Operator und gibt dem An-
wender darüber hinaus die Möglichkeit jeden Operator mit eigens angelegten
Kommentaren zu versehen.
Benutzeroberfläche und Funktionsweise
16
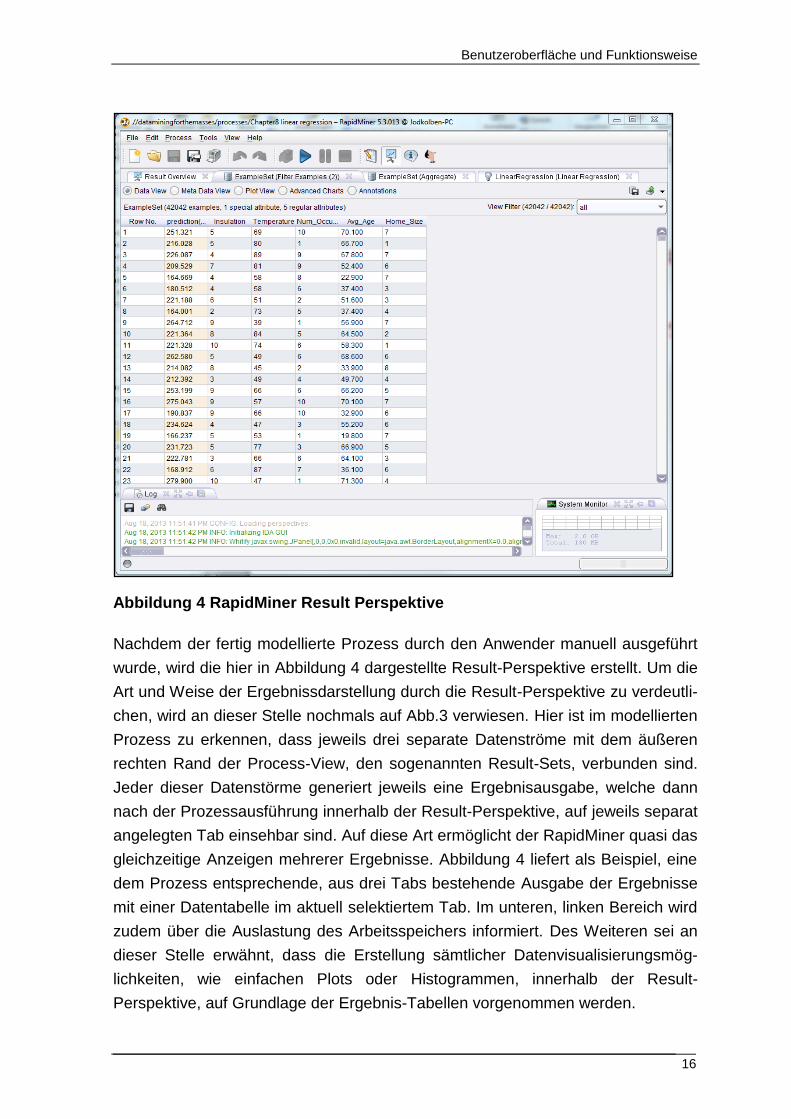
Abbildung 4 RapidMiner Result Perspektive
Nachdem der fertig modellierte Prozess durch den Anwender manuell ausgeführt
wurde, wird die hier in Abbildung 4 dargestellte Result-Perspektive erstellt. Um die
Art und Weise der Ergebnissdarstellung durch die Result-Perspektive zu verdeutli-
chen, wird an dieser Stelle nochmals auf Abb.3 verwiesen. Hier ist im modellierten
Prozess zu erkennen, dass jeweils drei separate Datenströme mit dem äußeren
rechten Rand der Process-View, den sogenannten Result-Sets, verbunden sind.
Jeder dieser Datenstörme generiert jeweils eine Ergebnisausgabe, welche dann
nach der Prozessausführung innerhalb der Result-Perspektive, auf jeweils separat
angelegten Tab einsehbar sind. Auf diese Art ermöglicht der RapidMiner quasi das
gleichzeitige Anzeigen mehrerer Ergebnisse. Abbildung 4 liefert als Beispiel, eine
dem Prozess entsprechende, aus drei Tabs bestehende Ausgabe der Ergebnisse
mit einer Datentabelle im aktuell selektiertem Tab. Im unteren, linken Bereich wird
zudem über die Auslastung des Arbeitsspeichers informiert. Des Weiteren sei an
dieser Stelle erwähnt, dass die Erstellung sämtlicher Datenvisualisierungsmög-
lichkeiten, wie einfachen Plots oder Histogrammen, innerhalb der Result-
Perspektive, auf Grundlage der Ergebnis-Tabellen vorgenommen werden.

Benutzeroberfläche und Funktionsweise
17
Orange
Abb. 1 Orange Benutzeroberfläche
Ähnlich wie im RapidMiner werden auch in Orange sämtliche Data Mining Aufga-
ben und damit zusammenhängende Funktionen der Datenexploration sowie Vor-
bereitung über das Zusammenbauen von Workflows umgesetzt. Die Benutzer-
oberfläche ist weit weniger komplex als die vom RapidMiner. Nach dem Start von
Orange, gelangt der Anwender zur der in Abbildung 5 dargestellten Benutzerober-
fläche, in welcher die Modellierung der Workflows vorgenommen wird. Hauptbe-
standteile der Workflows sind hier die sogenannten Widgets, welche sich katego-
risch geordnet auf der linken Seite des User-Interface befinden. Die Übersicht ist
hier größer als im RapidMiner, dafür aber ist der Funktionsumfang wesentlich ge-
ringer.
Die Widgets werden einzeln per Drag and Drop auf der Modellierungsfläche plat-
ziert und zum Informationsaustausch über Channels miteinander verbunden, wo-
bei jedes Widget im Prinzip über beliebig viele ein- sowie ausgehende Channels
Informationen mit weiteren Widgets austauschen kann. Anders als im RapidMiner
erfolgt in Orange keine Prozessausführung. Möchte der Anwender bestimmte Er-

Benutzeroberfläche und Funktionsweise
18
gebnisse einsehen, so erhält er diese über das direkte Ausführen des entspre-
chenden Widgets, was zum Öffnen eines extra Fensters führt.
Um einen Prozessablauf etwas näher zu veranschaulichen, zeigt die folgende Ab-
bildung einen modellierten Workflow im Detail.
Abbildung 5 Orange Workflow
Das „File“-Widget dient zum Einlesen einer Quelldatei und ist mit einer weiteren
kleinen Menge Widgets verbunden. Führt der Anwender das Widget „Data Table“
aus, so erhält er eine einfache tabellarische Darstellung, der eingelesenen Quell-
datei. Über die Ausführung der farblich in Rot gehaltenen Widgets „Attribute Statis-
tics“, „Distributions“ sowie „Scatter Plot“ sind für den Anwender die entsprechen-
den Visualisierungen der Daten jeweils einzeln aufrufbar. Im unteren Teil des
Workflows erfolgt, nach einer genaueren Selektierung, der zu verwenden Attribute
bzw. Spalten, das Anwenden eines Naive Bayes-Klassifikator. Die vorgenommene
Klassifizierung des Naive Bayes Algorithmus ist anschließend über die Ausführung
des Nomogram interaktiv einsehbar. Ausgewählte Widgets werden im weiteren
Verlauf detaillierter behandelt.

Evaluation
19
Evaluation
Datenschnittstellen
Das erste Vergleichskriterium befasst sich mit einer Untersuchung der Daten-
schnittstellen. Da für Data-Mining Aktivitäten herangezogene Daten aus verschie-
denen Quellen stammen und in unterschiedlichen Datenformaten vorliegen kön-
nen, stehen hier zum einen die Möglichkeiten zum Datenimport sowie die Konnek-
tivität zu Datenbanken Im Fokus. Des Weiteren werden auch Datenschnittstellen
nach außen hin untersucht, da durch diese einerseits die Wiederverwendbarkeit
von gelernten Modellen gewährleistet wird und andererseits Veränderungen an
den Datensätzen, welche im Rahmen der Datenvorbereitung durchgeführt wurden,
reproduziert werden können. Wurden am Trainingsdatensatz bestimmte Trans-
formationen vorgenommen, um ein Modell zu Lernen, so müssen die gleichen
Transformationen auch am Scoring Datensatz erfolgen.
Ein weiteres Kriterium, im Zusammenhang mit dem Austausch von Data-Mining
Modellen, ist der auf XML-basierende Predictive Model Markup Language Stan-
dard (PMML), dessen Weiterentwicklung von Data Mining Group (DMG) vorange-
trieben wird. Entwickelt wurde dieser, um einen einheitlichen Standard zum Aus-
tausch von gelernten Data-Mining Modellen zwischen verschiedenen Data-Mining
Tools zu schaffen.
Ein Vergleich der Datenschnittstellen wird nach den folgenden Kriterien durchge-
führt:
Datenbankkonnektivität
Möglichkeit zur Übergabe von SQL-Abfragen
Import Trennzeichenbasierender Datenformate
Import von Datenformaten anderer Statistik- bzw. DataMining Software
PMML Unterstützung
Reproduzierbarkeit durchgeführter Veränderungen am Datenbestand
Import sowie Export gelernter Modelle zwischen verschiedenen Instanzen der
jeweiligen Tools

Evaluation
20
In Rattle findet der Nutzer die Optionen zu einem ersten Datenimport im „Daten“-
Tab. Die folgende Abbildung zeigt hierbei den zugehörigen Ausschnitt des aktiven
Daten-Tab aus der Benutzeroberfläche:
Abbildung 6: Rattle Daten-Tab
Die Auswahl der gewünschten Datenquelle erfolgt hier über die Selektion des ent-
sprechenden Radio-Buttons. Die in Abbildung 6 selektierte Option „Tabellenblatt“,
dient zum Import sämtlicher Trennzeichenbasierter Datenformate, wie dem .txt-,
.csv- sowie dem MS-Excel .xls(x) -Datenformat. Rechts daneben findet der An-
wender die Möglichkeit zum Importieren von Daten in Wekas ARRF-Datenformat.
Das Herstellen einer Datenbankverbindung erfolgt in Rattle ausschließlich über
den Open Database Connectivity Standard (ODBC), welche entsprechend über
den ODBC-Button konfiguriert wird. Hier trägt der Anwender die Datenbank-URL
bzw. den Data-Source-Name (DSN) zum Ansteuern der gewünschten Quelldaten-
bank ein. In der Regel muss vorher eine Konfiguration des DSN im Betriebssys-
tem vorgenommen werden, wobei für MS-Windows so gut wie alle Datenbankan-
bieter einen entsprechenden ODBC-Treiber zur Verfügung stellen und Rattle somit
alle gängigen Datenbanksysteme ansprechen kann. Allerdings ist hier zu erwäh-
nen, dass über diese Methode keine Möglichkeit besteht, Datenbankabfragen per
SQL-Syntax zu übergeben. Wurde die Datenbankverbindung hergestellt kann der
Anwender lediglich einzelne Tabellen über eine Dropdown-Liste auswählen und
unter Angabe einer Zeilenbeschränkung importieren, sodass hier beim Zugriff auf
relationale Datenbanken keine eine bedarfsgerechte Informationsbereitstellung
per SQL-Abfrage stattfinden kann.
Eine weitere Option ist das Importieren von R-Datensätzen. Hierbei referenziert
Rattle sämtliche Datensätze, welche per R-Syntax innerhalb der, dem Rattle GUI
zugrunde liegenden, R-Entwicklungsumgebung eingelesen wurden. Über eine
Dropdown-Liste kann der Anwender diese einsehen und eine Auswahl treffen. Als
besonders nützlich erweist sich diese Funktion deshalb, da auf diese Art der Um-

Evaluation
21
fang der möglichen Datenformate zur Verwendung in Rattle zunimmt. So stellt die
R-Umgebung per Syntax beispielsweise Möglichkeiten zum Einlesen von Daten-
formaten anderer Statistikprogrammen wie SPSS oder SAS zur Verfügung. Dar-
über hinaus implementiert eine spezielle R-Library den SQL Standard, sodass
über diesen Umweg Tabellen per SQL Abfrage aus einer Datenbank nach R als
R-Datensatz geladen und in Rattle genutzt werden können.19
Die nächste Option trägt die Bezeichnung „R-Datendatei“ und ermöglicht dem An-
wender das Einlesen von Datensätzen, welche im R eigenen .rdata Datenformat
vorliegen. Sämtliche in R eingelesen Datensätze lassen sich in diesem Format
speichern, wobei eine R-Datendatei mehrere Tabellen beinhalten kann. Von den
zur Verfügung stehenden Tabellen kann in Rattle stets eine Tabelle als Daten-
grundlage selektiert und geladen werden.
Der Radiobutton „Bibliothek“ liefert an sich keine weiteren Funktionen zum Import
externer Dateien, sondern stellt dem Anwender eine Auswahl von speziellen R
Beispieldatensätzen, welche in den jeweiligen R-Libraries vorliegen, zur Verfü-
gung. Über die nachfolgende Option „Korpus“ lassen sich Daten zum Text-Mining
importieren.
Der aktuelle Projektfortschritt kann als Rattle-Projektdatei gespeichert werden. Die
importierten Datensätze werden hierbei mit sämtlichen Änderungen und den ge-
bauten Modellen als .rattle Datei gespeichert werden. Rattle Projektdateien stellen
hier also eine Möglichkeit zum Austausch von Modellen zwischen verschiedenen
Rattle Instanzen zur Verfügung.
Um Durchgeführte Aktivitäten bzw. Änderungen an den Daten später zu reprodu-
zieren, kann der Anwender auf den R-Code zurückgreifen, welcher stets parallel
zu durchgeführten Befehlen in Rattle aufgezeichnet wird. Dieser befindet sich im
Log- Tab und kann als R-Skript exportiert werden. Auf die Weise lassen sich die
durchgeführten Änderungen am Datenbestand später nachvollziehen bzw. durch
einfache Ausführung des R-Codes am scoring Datensatz wiederholen.
Ein PMML Export durch Rattle ist gegeben. Importieren lassen sich Modelle via
PMML allerdings noch nicht. Ausgeführt werden Datenexporte, über die in Abbil-
dung 5 zu sehende, „Exportieren“ Schaltfläche. Je nachdem auf welchem Tab sich
der Anwender beim betätigen dieser Schaltfläche befindet, werden entsprechende
Datenexporte ermöglicht. Innerhalb des Modell Tabs, kann so das dort gebaute
19
Vgl. (Graham, 2011)

Evaluation
22
Modell als PMML exportieren werden, während auf dem Log-Tab ein Export des
R-Code möglich ist.
Scikit-learn stellt über das sklearn.datasets Package eine Menge von Methoden
zum Laden von Daten bereit. Diese sind in der API in zwei Kategorien, den soge-
nannten Loader- und den Sample-Generator Methoden aufgeteilt. Über die Samp-
le-Generator Methoden kann der Anwender simulierte Zufallsdatensätze generie-
ren, wobei hier für verschiedene Data Mining Problemstellungen aus den Berei-
chen der Regressionsanalyse oder dem Clustering passende Datensätze erzeugt
werden können. Die verfügbaren Sample-Generatoren fallen somit relativ umfang-
reich aus.
Über die Loader Methoden können dann entweder bereits vorhandene Beispielda-
tensätze oder Daten aus externen Quellen geladen werden. Zum direkten Laden
von Daten gibt es neben den mitgelieferten Beispieldatensätzen, wie dem Irisda-
tensatz, Möglichkeiten zum Zugriff auf Online-Repositories. So kann der Anwen-
der über die „datasets.fetch_mldata()“ Methode direkt auf das online verfügbare,
öffentliche Datenarchiv des machine learning data set repository (mldata.org) zu-
greifen, in dem nach aktuellem Stand20 über 848 Datensätze zur freien Verwen-
dung verfügbar sind. Das mldata.org Repository wird durch das, von der Europäi-
schen Union gegründete, Pascal-Network unterstützt, welches sich intensiv mit
der Weiterentwicklung von Data-Mining bzw. Machine Learning Technologien be-
fasst.
Neben dem Zugriff auf Online Repositories, umfassen die Loader Methoden eine
weitere Möglichkeit zum Laden extern vorliegender Datensätze. Diese besteht im
Laden des speziellen SVMLIGHT/LIBSVM Datenformat, über die „data-
set.svmlight_file()“ - Methode. LIBSVM ist ein textbasierendes Datenformat, wel-
ches speziell für Aufgaben der Klassifikationen sowie Regression unter Anwen-
dung von Support Vector Machine Lernalgorithmen (SVM) entwickelt wurde.
Macht man sich auf die Suche nach online verfügbaren Datensätzen in diesem
Format, stellt man fest, dass die Auswahl hier noch eingeschränkt ist.
Zum Laden einfacher, textbasierender Datenformate, welche auf lokalen Daten-
trägern vorliegen, liefert die Scikit-learn Library direkt keine weiteren Möglichkei-
ten. Da Scikit-learn allerdings auf NumPy Arrays zurückgreift, kann der Anwender
die numpy.loadtxt Methode verwenden, um numerische Werte zu importieren, wo-
bei per Parameterübergabe jedes Trennzeichen definiert werden kann.
20
Stand 10.08.2013

Evaluation
23
numpy.loadtxt (fname, dtype=<type 'float'>, comments='#', delimiter=None, con-
verters=None, skiprows=0, usecols=None, unpack=False, ndmin=0)
Um gelernte Modelle in einer anderen scikit-learn Instanz wiederverwenden zu
können, ist es möglich Modelle über das Python pickle-Modul zu exportieren,
durch welches ein gelerntes Modell „x“ über die pickle.dump(x) Methode in einem
speziellen pickle-Objekt gespeichert werden kann.
Der RapidMiner stellt dem Anwender prinzipiell zwei verschiedene Vorgehenswei-
sen zum Datenimport zur Verfügung. Zum einen lassen sich vorliegende Daten
direkt in das RapidMiner Repository überführen und zum anderen gibt es im Ra-
pidMiner eine hohe Anzahl von Operatoren, mit denen die Daten dann während
der Prozessausführung eingelesen werden können.
Abbildung 7 RapidMiner - Repository Abbildung 8 RapidMiner - Operatoren
Abbildung 6 zeigt für einen Überblick der importierbaren Datenformate einen Aus-
schnitt der Repository-View, inklusive dem geöffnetem Kontextmenü zum Daten-
import. Wie zu sehen lassen sich hier csv-, MS Excel-, XML- sowie das MS-
Access .mdb Datenformat einlesen. Die „Import Database Table“ Funktion erlaubt
den Einsatz von SQL Abfragen über eine bereits vorkonfigurierte Datenbankver-
bindung, wobei die Ergebnisstabelle der SQL Abfrage dabei anschließend direkt in
das lokale Repository überführt wird. Zusätzlich ist zu sagen, dass sämtliche Da-

Evaluation
24
ten bei einem Import in das Repository in ein RapidMiner eigenes Datenformat
überführt werden. Zur weiteren Verwendung der Daten in der Prozessmodellie-
rung gibt es dann einen speziellen „Retrieve“ Operator.
Da der RapidMiner auf Java basiert, erfolgt die Herstellung einer Datenbankver-
bindung per JDBC. Entsprechende JDBC Treiber sind, mit Ausnahme von Oracle
db, für alle gängigen Datenbanksysteme bereits in der Treiber Bibliothek vorhan-
den. Ein Vorteil durch welchen zuweilen auch die ETL-Funktionalitäten deutlich
werden ist, dass der RapidMiner zum Management der Datenbankverbindungen
über ein Tool verfügt, durch welches beliebig viele Verbindungen konfiguriert und
gespeichert werden können. Beim Bauen der Prozesse kann dann so der Zugriff
auf mehrere Datenbanken erfolgen.
Innerhalb des Repositories erfolgt dann der Zugriff auf die vordefinierten Daten-
bankverbindungen, innerhalb des „DB“ Knoten. Über die Baumstruktur lassen sich
die verfügbaren Tabellen aus der jeweiligen Datenbank einsehen und in den Pro-
zess importieren. Abbildung 6 liefert hier ein Beispiel für eine aktive Datenbank-
verbindung mit der Bezeichnung „local my sql“ und einer dort verfügbaren Tabelle
„rapidminer_testtable“.
Abbildung 7 zeigt einen Ausschnitt der Operator-View mit den verfügbaren Opera-
toren zum Datenimport. Der Umfang an möglichen Datenformaten ist hier größer
als beim direkten Import via Repository. Wie zu sehen unterstützt auch der Ra-
pidMiner neben den Trennzeichenbasierten und Wekas ARFF Format, Datenfor-
mate gängiger Statistikprogramme, wie SPSS, Stata und DasyLab. Der „Read
AML“ Operator liest das RapidMiner eigene Datenformat ein.
Eine Besonderheit ist, dass der Anwender zwei Alternativen zum Lesen aus Da-
tenbanken hat, den „Read Database“ sowie den „Stream Database“ -Operator.
Der Read Database Operator liest das Ergebnis der Datenbankabfrage direkt in
den Hauptspeicher, während der „Stream Database“ alternativ ein inkrementelles
Auslesen der Datenbank ermöglicht. Hierbei erfolgt ein stufenweisen Laden der
Daten in sogenannten Batches, was den Zugriff auf sehr umfangreiche Tabellen
möglich macht. Zu bemerken ist hier allerdings, dass über diesen Operator keine
SQL-Querys übergeben werden können, sondern lediglich einzelne Tabellen se-
lektiert werden.
In Bezug auf die PMML Unterstützung lässt sich feststellen, dass hierfür über den
Update Assistenten eine spezielle Extension geladen werden muss, die den Ra-
pidMiner um einen „Write PMML“ Operator ergänzt. Über diesen können gelernte

Evaluation
25
Modelle dann als XML im PMML Dialekt exportiert werden. Ein Austausch von
gelernten Modellen zwischen verschiedenen RapidMiner Instanzen erfolgt eben-
falls per XML. Durch den Einsatz entsprechender „Write Model“- bzw. „Read Mo-
del“ Operatoren, lassen sich Modelle als XML exportieren und dann in einem neu
angelegten Prozess oder einer anderen RapidMiner Installation wiederverwenden.
Zur Veranschaulichung zeigt die nachfolgende Abbildung ein kleines Beispiel, wo-
bei zu erwähnen ist, dass hier der Modellimport und Export im gleichen Prozess
stattfinden.
Abbildung 9 RapidMiner - Model Import/Export
Im dargestellten Prozess wird auf Grundlage eines Trainingsdatensatzes ein Deci-
sion Tree berechnet und anschließend über den „Write Model“ Operator exportiert.
Das berechnete Modell wird dann per „Read Model“ Operator eingelesen und über
den „Apply Model“ Operator auf einen neuen Scoring-Datensatz angewandt, um
hier dann die Klassifizierung einer Zielvariablen vorzunehmen. Das Einlesen und
Anwenden des berechneten Modells auf den Zieldatensatz kann dabei, anders als
in diesem Beispiel, in einer anderen RapidMiner Installation stattfinden.
Neben dem Austausch RapidMiner eigener Modelle, steht dem Anwender auch
eine Extension zur Integration von Modellen bzw. Algorithmen der Weka Data Mi-
ning Software zur Verfügung, sodass in Weka gelernte Modelle ebenfalls impor-
tiert werden können. Darüber hinaus lässt sich auch die interne XML Beschrei-
bung der gesamten Prozesskonfiguration exportieren, um so den gesamten mo-
dellierten Prozessablauf in einer anderen RapidMiner-Instanz zu reproduzieren.
Zu den Datenexportmöglichkeiten lässt sich weiterhin sagen, dass der RapidMiner

Evaluation
26
neben dem csv und xls Format, sämtliche Daten aus dem Repository auch in We-
kas ARFF Format schreiben kann.
In Orange ist der Umfang an unterstützten Datenformaten im Vergleich zum Ra-
pidMiner und Rattle am geringsten. Neben den Trennzeichenbasierenden Forma-
ten werden das ARFF sowie das, aus scikit-learn bekannte, libsvm Datenformat
unterstützt. Das Einlesen von Datenformaten anderer Statistikprogramme, wie im
RapidMiner, ist hier nicht gegeben.
Zur Herstellung einer Datenbankverbindung gibt es in Orange, innerhalb der Kate-
gorie „Prototypes“, zwei verschiedene Widgets. Eines dient zur Verbindungsher-
stellung via DSN, bei dem anderen erfolgt der Datenbankzugriff über das Eintra-
gen der Verbindungsdaten, wobei hier zurzeit lediglich MySQL und Postgres Da-
tenbanken unterstützt werden. Beide Widgets bieten die Möglichkeit für SQL Ab-
fragen. Eine PMML Unterstützung ist in der untersuchten Version nicht gegeben.
Ein Austausch von gelernten Modellen ist aber, wie auch in Scikit-learn, über das
pickle-modul möglich. So können mithilfe des Widgets „Save Classifier“ Modelle
als Pickle Datei exportiert werden.

Evaluation
27
Datenexploration und Visualisierung
Wie in der Beschreibung des CRISP-DM Modelles deutlich wurde, erfolgt vor dem
eigentlichen Einsatz der Data-Mining Methoden, ein umfassendes Explorieren
bzw. Beschreiben der Daten, anhand statistischer Maßzahlen sowie dem Einsatz
verschiedener Visualisierungsmöglichkeiten. Innerhalb dieses Kapitels folgt eine
Darstellung, welche Möglichkeiten die einzelnen Tools hier bieten und wie diese
umgesetzt sind. Ein erstes Vergleichskriterium befasst sich hierbei mit den zur
Verfügung stehenden Kenngrößen aus der deskriptiven Statistik, durch welche
sich dem Anwender ein erster Eindruck von der Verteilung der Daten erschließt.
Das Hauptaugenmerk liegt in diesem Zusammenhang auf den folgenden Kenn-
zahlen der deskriptiven Statistik, welche hier aufgeführt werden:
absolute und relative Häufigkeitsverteilung nummerischer sowie kategorischer
Merkmale
Lagemaße: Modus, Arithmetische Mittel, Median, Quantile
Streuungsmaße: Spannweite, Varianz, Schiefe- und Wölbungsmaß
Darstellung von Informationen innerhalb der Metadaten-Übersicht
Grundsätzlich stellen hinsichtlich der definierten Kennzahlen Orange, Rattle sowie
der RapidMiner dem Anwender eine gewisse Auswahl zur Verfügung. Das scikit-
learn Package fokussiert sich mehr auf die DataMining Modellierungsmethoden
und verzichtet hier auf Implementierungen zur reinen Darstellung statistischer
Kennzahlen. In Rattle fallen die Möglichkeiten zur Darstellung der Kennzahlen am
umfangreichsten aus und decken die definierten Kennzahlen komplett ab. In
Orange und dem RapidMiner fehlen die Maßzahlen für das Schiefe- und Wöl-
bungsmaß. Weiterhin gibt es im RapidMiner keine genaue Darstellung der Merk-
malswerte von Quantilen. Zwar liefert der RapidMiner die Möglichkeit zum Gene-
rieren von Box Plots, welche das 0.25- sowie 0.75 Quantil grafisch Kennzeichnen,
jedoch werden die zughörigen Merkmalswerte nicht ausgegeben. Zudem ist die
Skalierung der Werteskala zu grob und bietet keine weitere Möglichkeit zu einer
Interaktiven Bearbeitung, sodass die Quantile bestenfalls geschätzt werden kön-
nen. In Orange fehlen das Schiefe- und Wölbungsmaß. Generiert werden die
Kennzahlen im RapidMiner innerhalb der Metadaten-Übersicht, während Orange
eine Darstellung der Kennzahlen über das „Attribute Statistics“- Widget vornimmt.
In Rattle lassen sich Kennzahlen über das „Explorer“-Tab generieren.

Evaluation
28
Zur Veranschaulichung der Kennzahlen im RapidMiner stellt die folgende Abbil-
dung die Metadaten-Übersicht des RapidMiner dar. Als Datengrundlage kommt
hierbei ein öffentlich verfügbarer Datensatz zum Einsatz, welcher im Rahmen ei-
nes RapidMiner Tutorial zur Verfügung steht.21
Abbildung 10 RapidMiner - Meta Data View
Die Metadaten-Übersicht zeigt die Attribute des Datensatzes mit den entspre-
chenden Datentypen und den Rollen, wobei im RapidMiner eine Festlegung der
Rollen sowie Datentypen über den, in Kapitel 4 angesprochenen, Wizard zum Da-
tenimport vorgenommen wird. In den Spalten „Statistics“ sowie „Range“ findet der
Anwender hier erste grundlegende Statistiken. „Range“ liefert für numerische Wer-
te die Spannweite und für kategorische die möglichen Ausprägungen zusammen
mit den absoluten Häufigkeiten. Über die Spalte „Statistics“ sind dann für numeri-
sche Attribute das arithmetische Mittel sowie die Varianz einsehbar. Für kategori-
sche Attribute liefert „Statistics“ den Modus, also die Merkmalsausprägung, welche
am häufigsten vorkommt und dazu, die mit „least“ gekennzeichnete Ausprägung
mit der geringsten Häufigkeit. Über Fehlende Werte wird in der Anwender in der
Spalte rechts außen informiert. In der Standardausführung enthält der RapidMiner
keine weiterführenden Möglichkeiten zum Generieren von Kennzahlen bzw. dem
Beschreiben von Daten in Textform.
Ähnlich wie im RapidMiner gibt es auch in Rattle eine Metadaten-Übersicht in wel-
cher allerdings keine Darstellung von statistischen Kennzahlen stattfindet. Die Me-
tadaten-Übersicht öffnet sich dem Anwender direkt nach dem Einlesen der Quell-
datei, innerhalb des Daten-Tabs. Die folgende Abbildung zeigt in diesem Zusam-
menhang eine Darstellung mit dem RapidMiner Datensatz.
21
URL: https://sites.google.com/site/dataminingforthemasses/
Evaluation
29
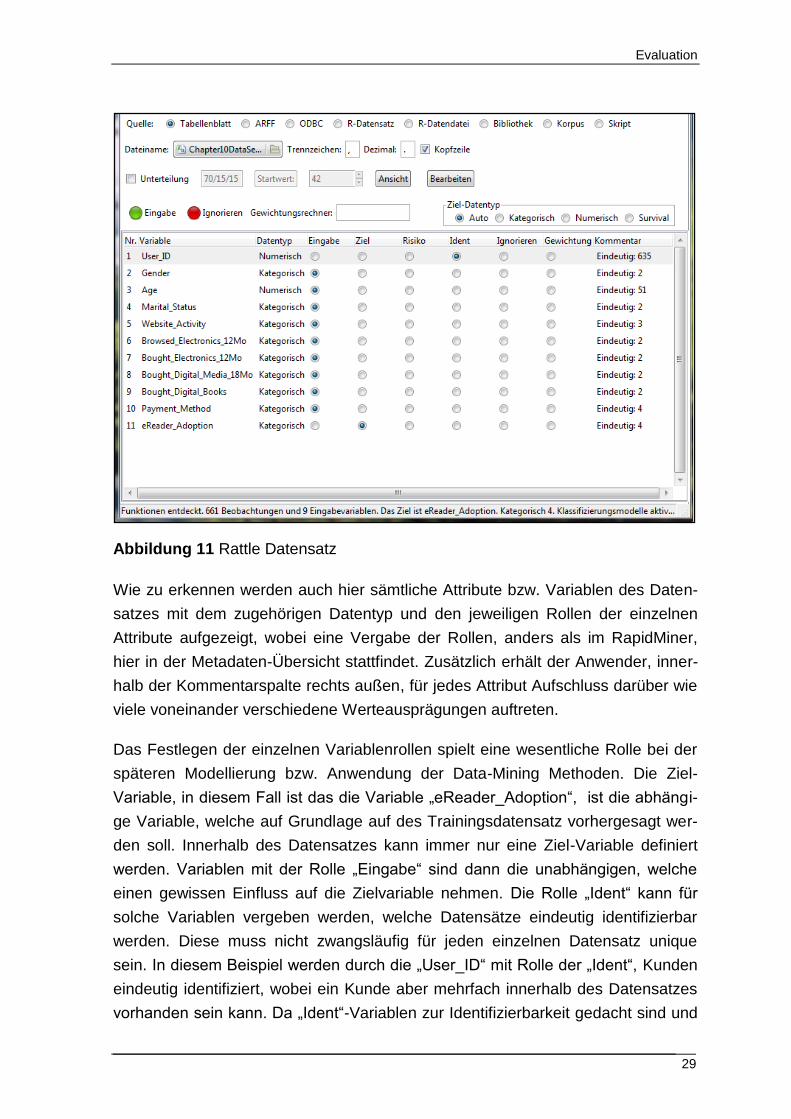
Abbildung 11 Rattle Datensatz
Wie zu erkennen werden auch hier sämtliche Attribute bzw. Variablen des Daten-
satzes mit dem zugehörigen Datentyp und den jeweiligen Rollen der einzelnen
Attribute aufgezeigt, wobei eine Vergabe der Rollen, anders als im RapidMiner,
hier in der Metadaten-Übersicht stattfindet. Zusätzlich erhält der Anwender, inner-
halb der Kommentarspalte rechts außen, für jedes Attribut Aufschluss darüber wie
viele voneinander verschiedene Werteausprägungen auftreten.
Das Festlegen der einzelnen Variablenrollen spielt eine wesentliche Rolle bei der
späteren Modellierung bzw. Anwendung der Data-Mining Methoden. Die Ziel-
Variable, in diesem Fall ist das die Variable „eReader_Adoption“, ist die abhängi-
ge Variable, welche auf Grundlage auf des Trainingsdatensatz vorhergesagt wer-
den soll. Innerhalb des Datensatzes kann immer nur eine Ziel-Variable definiert
werden. Variablen mit der Rolle „Eingabe“ sind dann die unabhängigen, welche
einen gewissen Einfluss auf die Zielvariable nehmen. Die Rolle „Ident“ kann für
solche Variablen vergeben werden, welche Datensätze eindeutig identifizierbar
werden. Diese muss nicht zwangsläufig für jeden einzelnen Datensatz unique
sein. In diesem Beispiel werden durch die „User_ID“ mit Rolle der „Ident“, Kunden
eindeutig identifiziert, wobei ein Kunde aber mehrfach innerhalb des Datensatzes
vorhanden sein kann. Da „Ident“-Variablen zur Identifizierbarkeit gedacht sind und

Evaluation
30
im Normalfall keinen Einfluss auf die Zielvariable nehmen, werden diese bei der
späteren Modellierung in Rattle außer Acht gelassen. Über das Setzen der „Igno-
rieren“- Rolle können Variablen ebenfalls aus statistischen Betrachtungen und Da-
ta-Mining Modelle herausgenommen werden.
Beim Einlesen der Datensätze fällt auf, dass Rattle einerseits den Datentyp auto-
matisch bestimmt und darüber hinaus, eine automatische Schätzung bzw. Verga-
be der Variablenrollen vornimmt. Nach dem Laden des oben verwendeten Bei-
spieldatensatzes, wurde das Attribut „eReader_Adoption“ automatisch als Zielva-
riable ermittelt. Diese Schätzung wird in Rattle auf Grundlage bestimmter Ent-
scheidungsregeln getroffen22. So wird zur automatischen Ermittlung der Zielvariab-
len, die Anzahl der voneinander verschiedenen Werteausprägungen, der einzel-
nen Attribute herangezogen. Ist diese Anzahl möglichst gering bzw. kleiner als
Fünf, stellt das entsprechende Attribut eine potentielle Zielvariable dar. Hierbei
prüft Rattle zuerst das letzte Attribut im Datensatz, da sich in vielen öffentlich ver-
fügbaren Datensätzen der Standard etabliert hat, bei dem die Zielvariable stets als
letztes Attribut am Ende des Datensatzes steht. Tritt innerhalb des Datensatzes
eine Variable auf, welche für jeden Datensatz einen einmalig vorhandenen Wert
annimmt, so wird diese als „Ident“ Rolle definiert.
Neben den Entscheidungsregeln über die Anzahl der Werteausprägungen sowie
der Reihenfolge der Attribute, erkennt Rattle die Variablenrollen auch anhand be-
stimmter Strings innerhalb der Attributbezeichnungen. Enthält die Attributbezeich-
nung den String „TARGET“ zu Beginn, so wird diese als Zielvariable erkannt.
Hierbei konnte festgestellt werden, dass diese Methode Vorrang hat gegenüber
der Variablenrollen-Ermittlung durch die Entscheidungsregeln.
In Bezug auf die Datentypen lässt sich feststellen, dass Rattle hinsichtlich des
Skalenniveaus lediglich eine Differenzierung zwischen kategorialen und numeri-
schen Werten vornimmt. Kategoriale mit nur zwei möglichen Merkmalsausprägun-
gen, also dichotome Merkmale bzw. Attribute, werden nicht extra als solche ge-
kennzeichnet.
Bei Orange fällt auf, dass eine Meta-Daten-Übersicht mit einer Beschreibung der
einzelnen Attribute, wie diese In Rattle und dem RapidMiner gegeben ist, nicht
vorhanden ist. Beim Einlesen der Quelldatei erhält der Anwender lediglich einen
groben Überblick über die Anzahl der Attribute sowie Datensätze. Dafür sticht hier
22
Vgl. (Graham, 2011 s.96)
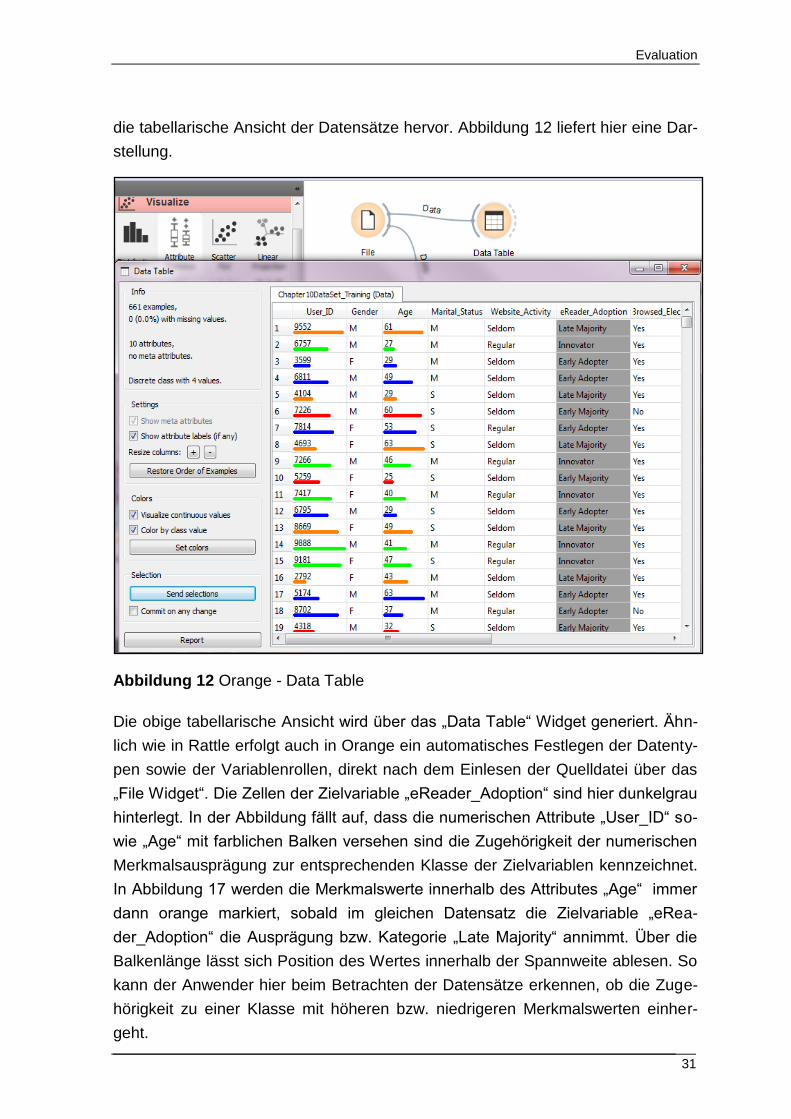
Evaluation
31
die tabellarische Ansicht der Datensätze hervor. Abbildung 12 liefert hier eine Dar-
stellung.
Abbildung 12 Orange - Data Table
Die obige tabellarische Ansicht wird über das „Data Table“ Widget generiert. Ähn-
lich wie in Rattle erfolgt auch in Orange ein automatisches Festlegen der Datenty-
pen sowie der Variablenrollen, direkt nach dem Einlesen der Quelldatei über das
„File Widget“. Die Zellen der Zielvariable „eReader_Adoption“ sind hier dunkelgrau
hinterlegt. In der Abbildung fällt auf, dass die numerischen Attribute „User_ID“ so-
wie „Age“ mit farblichen Balken versehen sind die Zugehörigkeit der numerischen
Merkmalsausprägung zur entsprechenden Klasse der Zielvariablen kennzeichnet.
In Abbildung 17 werden die Merkmalswerte innerhalb des Attributes „Age“ immer
dann orange markiert, sobald im gleichen Datensatz die Zielvariable „eRea-
der_Adoption“ die Ausprägung bzw. Kategorie „Late Majority“ annimmt. Über die
Balkenlänge lässt sich Position des Wertes innerhalb der Spannweite ablesen. So
kann der Anwender hier beim Betrachten der Datensätze erkennen, ob die Zuge-
hörigkeit zu einer Klasse mit höheren bzw. niedrigeren Merkmalswerten einher-
geht.

Evaluation
32
Wie bereits erwähnt, fallen in Rattle die Möglichkeiten einer statistischen Be-
schreibung der Daten über das „Explorer Tab“ am umfangreichsten aus. Befindet
sich der Anwender im aktiven „Explorer Tab“, so wird dieses weiterhin in die Un-
terkategorien Zusammenfassung, Verteilung, Korrelationen, Hauptkomponenten
und Interaktiv gegliedert. Über den aktiven Radio-Button „Zusammenfassen“ er-
reicht der Anwender im Wesentlichen die grundlegenden Lagemaße.
Abbildung 13 Rattle - Explorer
Über das Zuschalten der einzelnen Checkboxen kann dann definiert werden, wel-
che Maßzahlen bzw. Lagemaße innerhalb des Textfeldes ausgegeben werden
sollen. Jede Checkbox liefert immer eine bestimmte Ausgabe an Maßzahlen und
stellt diese in einer einheitlichen Art und Weise dar. So liefert eine aktivierte
Checkbox „Zusammenfassung“, in einer ersten tabellarischen Darstellung, die
möglichen Merkmalsausprägungen für jedes kategoriale Merkmal. Anschließend
werden für jedes numerische Attribut die einfache Maßzahlen der Spannweite,
Mittelwerte und Median sowie das erste und dritte Quartil aufgezeigt. Kategoriale
Merkmalausprägungen werden zusammen mit den entsprechenden absoluten
Häufigkeitsverteilung ausgegeben. Über Kurtosis und Schiefe lassen sich das
Schiefe- sowie Wölbungsmaße hinzufügen.
Als besonders positiv lässt sich in Rattle die Checkbox „Beschreiben“ herausstel-
len, welche eine sehr hilfreiche Darstellung zum Erkennen von Ausreißern bei
numerischen Werten liefert. Die folgende Abbildung zeigt hierfür ein Beispiel.

Evaluation
33
Abbildung 14 Rattle - Beschreiben
Die aktive Checkbox „Beschreiben“ generiert für numerische als auch kategori-
sche Attribute eine Reihe von Maßzahlen. Betrachtet man hier das numerische
Attribut „Age“, so erhält man zur Beschreibung der Häufigkeitsverteilung, die
Merkmalswerte bestimmter Quantile und zusätzlich, im unteren Bereich der Abbil-
dung, die jeweils fünf niedrigsten sowie höchsten Merkmalsausprägungen. Das
größte und kleinste Quantil, welche jeweils dargestellt werden, sind das 0.95-
Quantil sowie das 0.5-Quantil. So erkennt man bei dem 0.95- Quantil, dass 0.95
aller Beobachtungen bzw. Datensätze kleiner sind als der Merkmalswert an die-
sem Quantil. Zusammen mit fünf höchsten Merkmalswerten kann dann relativ ein-
fach festgestellt werden, ob das Attribut ungewöhnlich hohe Merkmalswerte ent-
hält. Analog kann man ungewöhnlich niedrige über das 0.5-Quantil zusammen mit
den fünf niedrigsten Merkmalswerten finden.
Des Weiteren liefert Rattle eine sehr sinnvolle Möglichkeit um eventuell vorhande-
ne Strukturen beim Vorkommen von fehlenden Werten zu erkennen. Diese er-
reicht man über die Checkbox „Fehlende anzeigen“. Abbildung 12 zeigt hier ein
Beispiel, welches in Anlehnung an das Togaware Rattle Tutorial entstanden ist.

Evaluation
34
Abbildung 15 Rattle - Fehlende anzeigen23
Wie in der Abbildung zu sehen, führt die aktive Checkbox „Fehlende anzeigen“ zur
Ausgabe einer Matrix, welche spaltenweise die Attribute des Datensatzes abbildet.
Zu beachten in dieser Abbildung ist, dass nach dem Attribut „Occupation“ ein Zei-
lenumbruch erfolgt. Die Zeilen stehen nun im Grunde genommen für die Kombina-
tionsmöglichkeiten mit denen fehlende Werte bzw. Missing Values in den Attribu-
ten gemeinsam auftreten können. Jede Zeile stellt eine Kombinationsmöglichkeit
dar. Die erste Spalte sagt aus wie oft dieses Muster bzw. Kombinationsmöglichkeit
auftritt. Befindet sich in der Zelle eines Attributs der Wert 1, so heißt das, dass für
das entsprechende Attribut keine Missing Values auftreten, wohingegen der Wert
0 das Vorhandensein von Missing Values aufzeigt. Schaut man sich die erste Zei-
le an, sieht man, dass in keinem Attribut Missing Values auftreten, wobei dies bei
1899 Datensätzen der Fall ist. Betrachtet man hingegen die dritte Zeile, so erkennt
man hier, dass bei hier 100 Datensätzen In den Attributen „Employment“ und „Oc-
cupation“ zugleich, fehlende Werte auftauchen. Dies könnte ein Indiz dafür sein,
dass zwischen diesen beiden Attributen eine Art Zusammenhang beim Auftreten
von Missing Values existiert. Die letzte Zeile liefert immer die Gesamtanzahl an
Missing Values in einem Attribut.
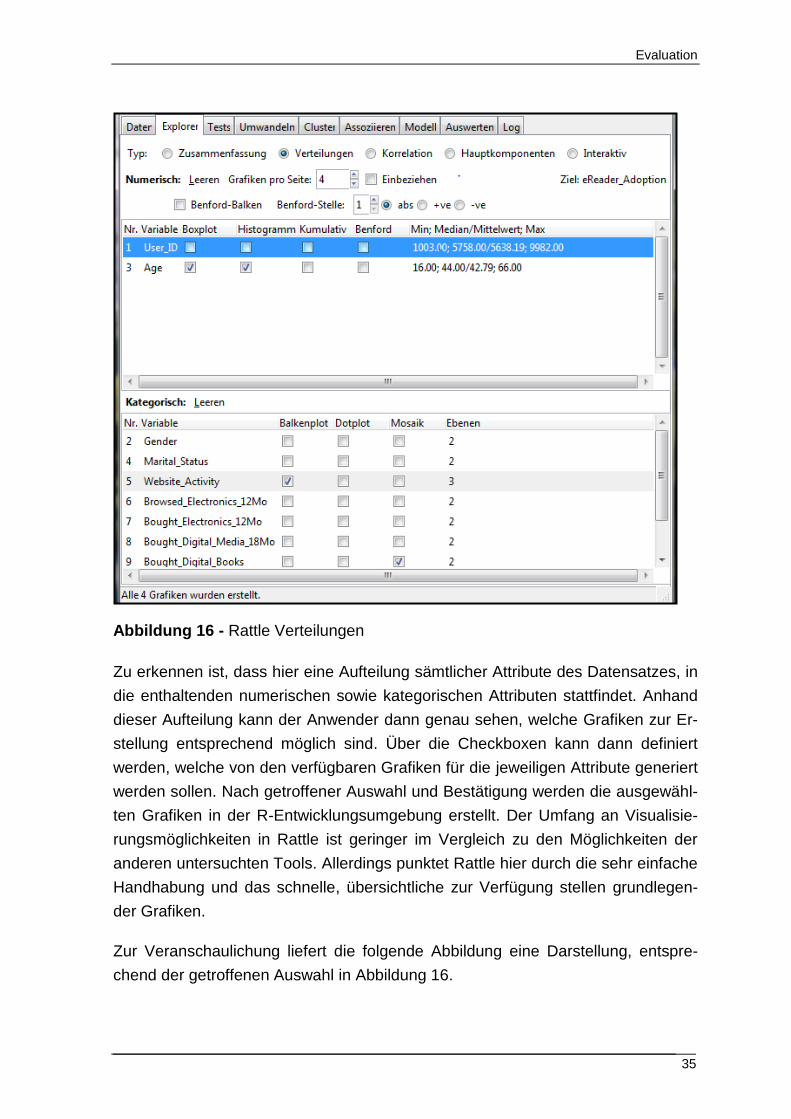
Zu den Visualisierungsmöglichkeiten lässt sich sagen, dass sich in Rattle auf sehr
anwenderfreundliche Art, übersichtliche Darstellungen erzeugen lassen. Zu errei-
chen sind diese ebenfalls innerhalb des Explorer-Tabs, über den Radio Button
„Verteilungen“. Die nachfolgende Abbildung liefert hierzu eine Übersicht, wobei
auch hierfür der RapidMiner Datensatz als Datengrundlage zum Einsatz kommt.
23
Vgl. (http://datamining.togaware.com/survivor/Missing.html)
Evaluation
35
Abbildung 16 - Rattle Verteilungen
Zu erkennen ist, dass hier eine Aufteilung sämtlicher Attribute des Datensatzes, in
die enthaltenden numerischen sowie kategorischen Attributen stattfindet. Anhand
dieser Aufteilung kann der Anwender dann genau sehen, welche Grafiken zur Er-
stellung entsprechend möglich sind. Über die Checkboxen kann dann definiert
werden, welche von den verfügbaren Grafiken für die jeweiligen Attribute generiert
werden sollen. Nach getroffener Auswahl und Bestätigung werden die ausgewähl-
ten Grafiken in der R-Entwicklungsumgebung erstellt. Der Umfang an Visualisie-
rungsmöglichkeiten in Rattle ist geringer im Vergleich zu den Möglichkeiten der
anderen untersuchten Tools. Allerdings punktet Rattle hier durch die sehr einfache
Handhabung und das schnelle, übersichtliche zur Verfügung stellen grundlegen-
der Grafiken.
Zur Veranschaulichung liefert die folgende Abbildung eine Darstellung, entspre-
chend der getroffenen Auswahl in Abbildung 16.
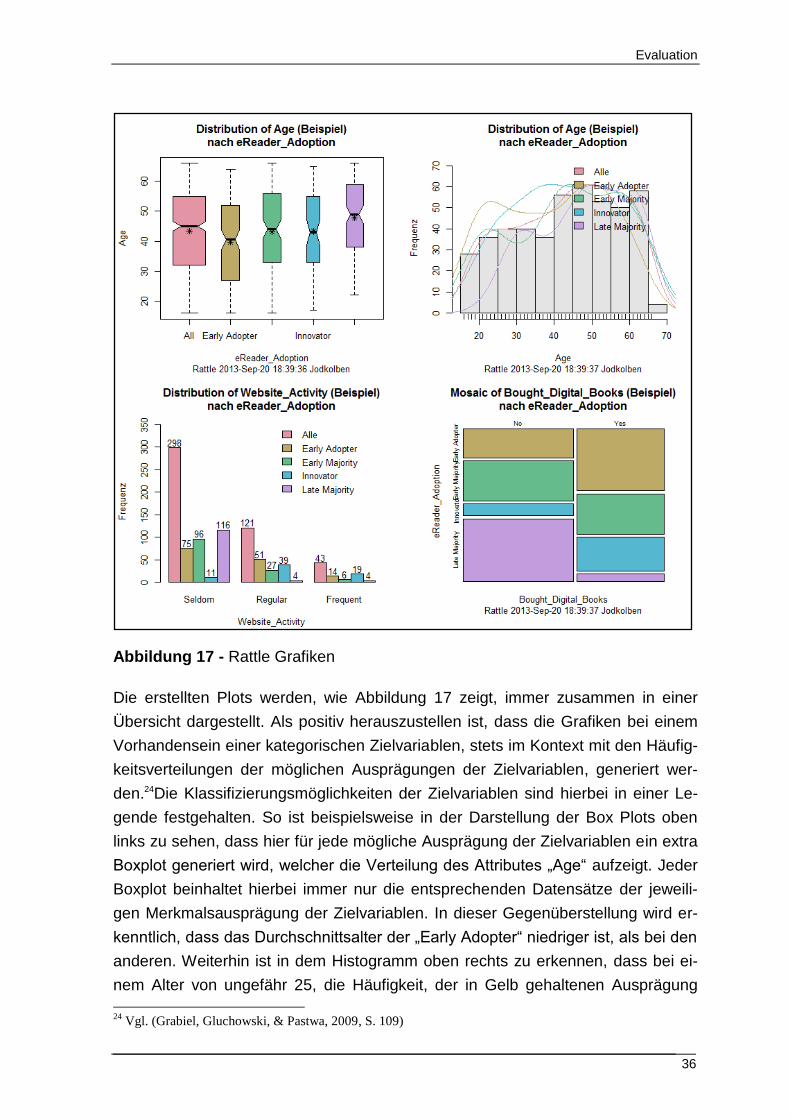
Evaluation
36
Abbildung 17 - Rattle Grafiken
Die erstellten Plots werden, wie Abbildung 17 zeigt, immer zusammen in einer
Übersicht dargestellt. Als positiv herauszustellen ist, dass die Grafiken bei einem
Vorhandensein einer kategorischen Zielvariablen, stets im Kontext mit den Häufig-
keitsverteilungen der möglichen Ausprägungen der Zielvariablen, generiert wer-
den.24Die Klassifizierungsmöglichkeiten der Zielvariablen sind hierbei in einer Le-
gende festgehalten. So ist beispielsweise in der Darstellung der Box Plots oben
links zu sehen, dass hier für jede mögliche Ausprägung der Zielvariablen ein extra
Boxplot generiert wird, welcher die Verteilung des Attributes „Age“ aufzeigt. Jeder
Boxplot beinhaltet hierbei immer nur die entsprechenden Datensätze der jeweili-
gen Merkmalsausprägung der Zielvariablen. In dieser Gegenüberstellung wird er-
kenntlich, dass das Durchschnittsalter der „Early Adopter“ niedriger ist, als bei den
anderen. Weiterhin ist in dem Histogramm oben rechts zu erkennen, dass bei ei-
nem Alter von ungefähr 25, die Häufigkeit, der in Gelb gehaltenen Ausprägung
24
Vgl. (Grabiel, Gluchowski, & Pastwa, 2009, S. 109)

Evaluation
37
„Early Adopter“, einen kleinen Ausschlag nach oben annimmt, was auf einen
eventuellen Zusammenhang zwischen einen niedrigem Alter und dem frühen Er-
werb eines E-Books hindeuten könnte.
Ein kleiner Negativpunkt der grafischen Darstellung in Rattle ist, dass die Ausgabe
der Grafiken immer in einer standardisierten Form erfolgt und keine weitere inter-
aktive Bearbeitung möglich ist.
Die Visualisierungsmöglichkeiten im RapidMiner fallen hingegen sehr umfangreich
aus und bieten im Vergleich zu den anderen Tools eine größere Auswahl. Erstellt
werden diese innerhalb der sogenannten Plot-View der Result-Perspektive. Da der
Umfang hier sehr groß ist, werden im Folgenden einzelne Besonderheiten her-
ausgestellt. Eine davon ist, dass der RapidMiner, zusammen mit Scikit-learn, das
Bauen von dreidimensionalen Scatter-Plots ermöglicht. Abbildung 16 zeigt einen
solchen, mit dem Iris-Datensatz als Datengrundlage.
Abbildung 18 RapidMiner - Iris
Sämtliche Grafiken werden im RapidMiner dann über das auf der linken Seite be-
findliche Menü interaktiv gestaltet. Hier in Abbildung 16 ist zu sehen, dass auf je-
der Achse ein Attribut des Iris-Datensatzes abgebildet wird und eine Einfärbung
der einzelnen Punkte nach dem label, also der Klassenzugehörigkeit der einzel-
nen Punkte zu der kategorischen Zielvariablen erfolgt. Der 3D Scatter Plot lässt

Evaluation
38
sich beliebig drehen. Auffällig ist hierbei der große Abstand der Merkmalswerte,
der Gattung „Iris-setosa“ (Blau markiert) zu den Merkmalswerten der anderen bei-
den Gattungen (Grün und Rot markiert), zwischen denen es zum Teil Überschnei-
dungen zwischen den Datenpunkten gibt. Neben einfachen Scatterplots gibt es im
RapidMiner auch komplexere Grafiken, durch welche der RapidMiner hervorsticht.
Eine davon ist die sogenannte Self-Organizing Map (SOM). Diese sind, so wie
Scatter Plots, dafür geeignet, um die Abstände zwischen numerischen Datenpunk-
ten zu visualisieren, wobei in der SOM eine besondere Art und Weise der Veran-
schaulicht eingesetzt wird. Die folgende Abbildung zeigt eine SOM. Entstanden ist
diese in Anlehnung an ein RapidMiner Tutorial.25
Abbildung 19 - RapidMiner SOM
Als Datengrundlage wurde auch hier der Iris-Datensatz verwendet. Anhand der
farblichen Markierung lassen sich die zugehörigen label zu den Datenpunkten ein-
sehen. Die Idee hinter der SOM ist es, die Distanzen zwischen den Datenpunkten
über eine Art Landschaft mit Gebirgen und Gewässern kenntlich zu machen, wo-
bei Gebirge eine hohe- und Gewässer eine niedrige Distanz implizieren. Analog
zum dem 3D Scatter Plot in Abbildung 16 ist auch zu erkennen, dass die Daten-
punkte der Gattung „Iris-setosa“ näher zusammen liegen und einen größeren Ab-
stand zu denen aus den anderen Gattungen aufweisen.
25
Vgl. (http://rapidminerresources.com/index.php?page=pre-processing-visualisation)
Evaluation
39
Zu dem Umfang an Visualisierungsmöglichkeiten in Orange lässt sich sagen, dass
diese im Vergleich eher im Mittelfeld anzusiedeln sind und sich in etwa mit denen
von Rattle vergleichen lassen. 3-Dimensionale Grafiken, wie im RapidMiner und
scikit-learn gibt es nicht. Hierfür punktet Orange allerdings durch die hohe Interak-
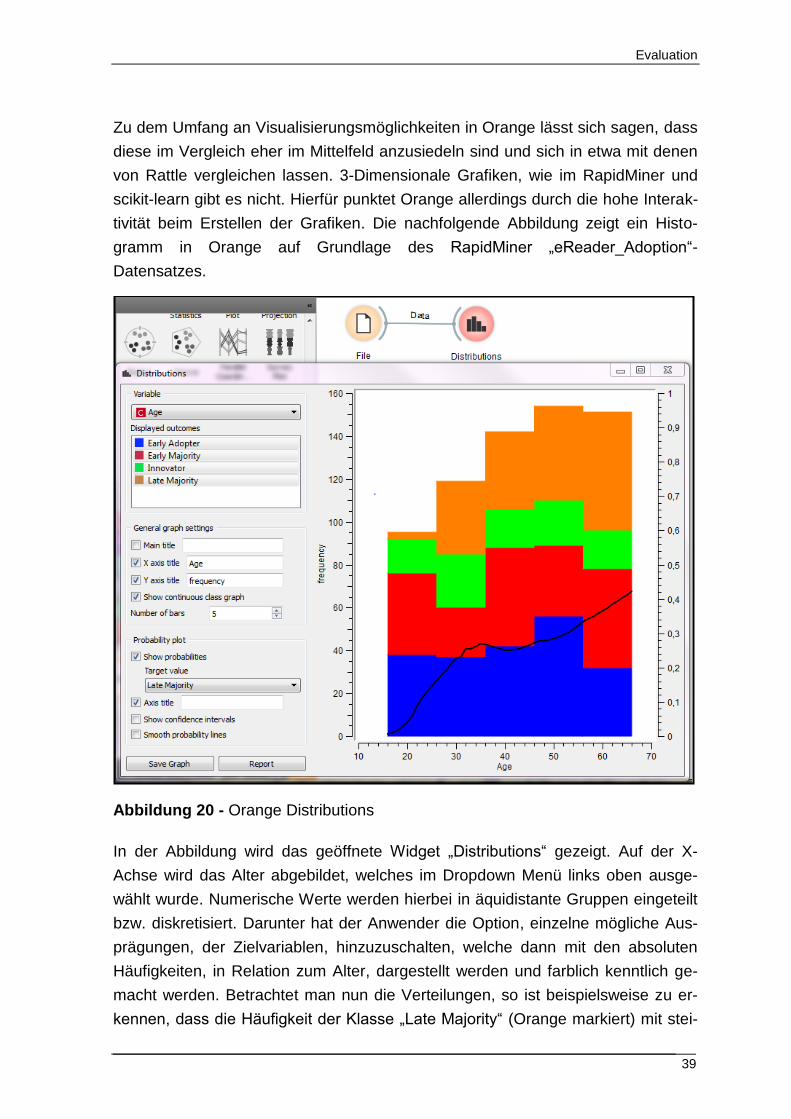
tivität beim Erstellen der Grafiken. Die nachfolgende Abbildung zeigt ein Histo-
gramm in Orange auf Grundlage des RapidMiner „eReader_Adoption“-
Datensatzes.
Abbildung 20 - Orange Distributions
In der Abbildung wird das geöffnete Widget „Distributions“ gezeigt. Auf der X-
Achse wird das Alter abgebildet, welches im Dropdown Menü links oben ausge-
wählt wurde. Numerische Werte werden hierbei in äquidistante Gruppen eingeteilt
bzw. diskretisiert. Darunter hat der Anwender die Option, einzelne mögliche Aus-
prägungen, der Zielvariablen, hinzuzuschalten, welche dann mit den absoluten
Häufigkeiten, in Relation zum Alter, dargestellt werden und farblich kenntlich ge-
macht werden. Betrachtet man nun die Verteilungen, so ist beispielsweise zu er-
kennen, dass die Häufigkeit der Klasse „Late Majority“ (Orange markiert) mit stei-

Evaluation
40
gendem Alter zunimmt. Darüber hinaus gibt es hier die zuschaltbare Option „Pro-
pability Plot“. Durch diese wird dem Histogramm eine schwarze Linie hinzugefügt,
welche die relative Häufigkeit einer selektierbaren Merkmalsausprägung der Ziel-
variablen visualisiert. In der Abbildung wird hier sehr schnell der Zusammenhang
zwischen dem Alter und einer steigenden Häufigkeit von „Late Majority“ deutlich.

Evaluation
41
Data Mining Methoden
Ein wesentlicher Hauptbestandteil der untersuchten Tools, sind die zur Verfügung
stehenden Data Mining-Modellierungsmethoden, welche innerhalb dieses Kapitels
einem Vergleich unterzogen werden. Um hierfür eine erste grobe Aussage bezüg-
lich des Umfangs, der jeweils verfügbaren Modellierungsmethoden zu treffen, wird
als Grundlage auf eine allgemein anerkannte Kategorisierung von Data Mining
Methoden zurückgegriffen. Diese sieht eine grobe Aufgliederung sämtlicher Data
Mining Verfahren in die vier verschiedenen Aufgabenbereiche der Assoziation,
Klassifikation, Segmentierung und Regression bzw. Prognose vor26. Die folgende
Abbildung liefert in diesem Zusammenhang eine hierarchische Übersicht.
Abbildung 21 Klassifizierung Data Mining Methoden27
Grundsätzlich lässt sich feststellen, dass der RapidMiner, Rattle sowie Orange für
sämtliche der vier Aufgabenbereiche des Data Mining entsprechende Algorithmen
implementieren. Scikit-learn deckt die Bereiche der Klassifikation, Regression und
Segmentierung ab und lässt lediglich Algorithmen für die Assoziations-Analyse
vermissen. Innerhalb der Aufgabenbereiche unterscheiden sich die Tools aller-
dings hinsichtlich der Anzahl an verfügbaren Data Mining-Algorithmen. Abbildung
26
Vgl. (Grabiel, Gluchowski, & Pastwa, 2009, Seite 134, zitiert nach: Bankhofer, U., 2004, Seite 395-412 ) 27
URL :http://www.dataminingarticles.com/data-mining-introduction/data-mining-techniques/

Evaluation
42
20 zeigt in einer hierarchischen Übersicht, die den Aufgabenbereichen zugehöri-
gen Data Mining Methoden bzw. Modelle und weiterhin verschiedene Algorithmen,
mit denen ein bestimmte Data Mining Methode ausgeführt werden kann. Um bei
dem Vergleich der Data Mining Methoden weiter in die Tiefe zu gehen, wir als
Grundlage eines der Haupteinsatzgebiete des Data Mining, das customer relati-
onship management, herangezogen, welches sich im Wesentlichen mit dem Auf-
bauen und dem Stärken von Kundenbeziehungen befasst, um diese möglichst
profitabel zu halten. Im Rahmen der Recherchearbeiten wurde in diesem Zusam-
menhang ein Forschungsbericht gefunden, welcher sich mit der Anwendung von
Data Mining Methoden im CRM befasst und die hierfür relevantesten Methoden
herausstellt. Das CRM wird im Rahmen des Berichtes als ein Prozess mit den vier
Phasen der Customer Identification, Attraction, Retention und des Customer De-
velopment definiert, wobei für jede dieser Phasen bestimmte Data Mining Metho-
den eine besonders häufige Anwendung in der Praxis finden. Diese werden im
folgendem kurz dargestellt und als Vergleichsgrundlage herangezogen:28
Apriori Algorithmus: Der Apriori Algorithmus dient zum Auffinden von Asso-
ziationsregeln zwischen den Attributen eines Datensatzes. Ein oft ge-
brauchtes Beispiel hierfür ist die Warenkorbanalyse.
Neuronale Netzwerke: Mithilfe von Neuronalen Netzwerken können sowohl
numerische als kategorische Attribute vorherbestimmt werden. Die Funkti-
onsweise orientiert sich an idealisierten Neuronen, sodass ein neuronales
Netz als eine Art gerichteter, gewichteter Graph verstanden werden kann.29
Decision Trees: Entscheidungsbäume bzw. Decision Trees können zur
Klassifikation von kategorischen Attributen verwendet werden. Ein Vorteil
der Decision Trees ist, dass die Darstellung der berechneten Ergebnisse
leicht interpretiert werden kann. Hierbei werden über eine hierarchische
Baumstruktur Entscheidungsregeln dargestellt, welche zugleich die Ge-
wichtung der einzelnen Attribute deutlich machen.
K-means Clustering: Über den K-Means Clustering Algorithmus werden Da-
tensätze bzw. Objekte, anhand nummerischer Werteausprägungen in so-
genannte Cluster gruppiert. Grundlage für die Einteilung in Cluster sind die
Distanzen zu den Mittelwerten der einzelnen Cluster, sodass am Ende zu-
einander ähnliche Objekte bzw. Datensätze in einem Cluster liegen.
28
Vgl. (Ngai, Xiu, & Chau, 2009) 29
Vgl.( http://cs.uni-muenster.de/Professoren/Lippe/lehre/skripte/wwwnnscript/prin.html)

Evaluation
43
K-Nearest neighbour: Der K-Nearest neighbour Algorithmus kann sowohl
zur Klassifikation als auch Regression verwendet werden. Die Zuordnung
bei der Klassifikation erfolgt hier über Distanzmaße.
lineare Diskriminanz-Analyse: Die lineare Diskriminanz-Analyse nimmt eine
Vorhersage kategorischer Attribute auf Grundlage nummerischer Inputvari-
ablen vor.
lineare und logistische Regressionsmodelle: Lineare Regressionsmodelle
schätzen den Wert einer nummerischen, abhängigen Zielvariablen. Die Be-
rechnung des Schätzwertes wird auf Grundlage der Stärke der Abhängig-
keit zwischen den einflussnehmenden Inputvariablen und der Zielvariablen
vorgenommen.
Support Vector Machines: Support Vector Machines können für Aufgaben
der binären Klassifikationen oder Regressionen verwendet werden, wobei
als Inputvariablen ausschließlich nummerische Attribute unterstützt werden.
Klassifikation per Naive Bayes: Naive Bayes Modelle werden zur Klassifika-
tion verwendet und können diese auf Grundlage von nummerischen und
kategorischen Input-Variablen vornehmen. Ein Vorteil des Naive Bayes ist,
dass dieser schon anhand einer kleinen Menge an Trainingsdaten Klassifi-
kationen vornehmen kann.
Bezüglich der Modellierungsmethoden lässt sich feststellen, dass hier lediglich der
RapidMiner sämtliche Algorithmen unterstützt. In Rattle fehlen Implementierung
für Naive Bayes, K-Nearest neighbour und der Diskriminanz-Analyse. Orange hin-
gegen unterstützt sämtliche Modelle bis auf die Diskriminanz-Analyse. Da scikit-
learn keine Algorithmen zur Assoziationsanalyse implementiert, fehlt hier der Apri-
ori Algorithmus.

Evaluation
44
Abschließendes Fazit
Insgesamt lässt sich sagen, dass sämtliche Tools über bestimmte Vor- und Nach-
teile verfügen. Der RapidMiner kann am effizientesten in bestehende Unterneh-
mens IT-Strukturen integriert werden, da dieser über die umfangreichsten Mög-
lichkeiten zu einem Datenimport verfügt und darüber hinaus über ein Management
zur Konfiguration von parallel bestehenden Datenbankverbindungen. Des Weite-
ren ist im RapidMiner der Umfang an Modellierungsmöglichkeiten unter den unter-
suchten Tools am größten. Rattle liefert eine sehr umfassende Beschreibung der
Daten anhand statistischer Maßzahlen und stellt diese in einer sehr übersichtli-
chen und sinnvollen Weise dar. In gleicher Weise punktet Rattle durch das an-
wenderfreundliche Generieren von Grafiken, welche dann in einer übersichtlichen
Darstellung im Zusammenhang mit den Häufigkeitsverteilungen der Zielvariablen
dargestellt werden. Im Vergleich ist jedoch der Umfang an Modellierungsalgorith-
men in Rattle am geringsten. Orange hat seine Vorteile in der starken Interaktivität
der Widgets beim Visualisieren der Daten, verfügt jedoch über die geringsten
Möglichkeiten zu einem Datenimport. Die Data Mining Algorithmen sind im Kon-
text der CRM-Analyse umfassender als in Rattle, decken jedoch nicht alle definier-
ten Algorithmen ab In Scikit-learn konnten Möglichkeiten zur Assoziationsanalyse
nicht gefunden werden. Von diesen abgesehen verfügt scikit-learn über ein sehr
mächtiges Repertoire an Data Mining Algorithmen. Zudem setzt scikit-learn stark
auf einen direkten Datenimport über Online-Repositories und fokussiert sich mehr
auf die Verarbeitung nummerischer Datensätze.
Eine PMML Unterstützung ist ausschließlich durch Rattle und den RapidMiner ge-
geben, wobei ein interner Austausch von gelernten Modellen zwischen verschie-
denen Instanzen der jeweiligen Tools jedoch bei allen möglich ist.

Literaturverzeichnis
VI
Literaturverzeichnis
Roland Gabriel, Peter Gluchowski, Alexander Pastwa: Data Warehouse & Data
Mining, W3L (2009)
Dr. Matthew North: Data Mining for the Masses (2012)
Dr. Graham Williams: Data Mining with Rattle and R, Springer (2011)
Ian H. Witten, Eibe Frank: Data Mining Practical Machine Learning Tools and
Techniques, (2005)
Bankhofer, U.: Data Mining und seine betriebswirtschaftliche Relevanz, in: Be-
triebswirtschaftliche Forschung und Praxis, Heft 4, (2004)
Fayyad, U. M.; Piatetsky-Shapiro, G.; Smyth, P.: From Data Mining to Knowledge
Discovery in Databases: an overview, in: Advances in Knowledge Discovery and
Data Mining, Menlo Park (1996)
IBM: CRSIP-DM 1.0 (2010)

Weblinks
VII
Weblinks
Dataminingarticles.com, URL:http://www.dataminingarticles.com/data-mining-
introduction/data-mining-techniques/ [Stand: 22.September 2013]
E.W.T. Ngai, Li Xiu, “Application of data mining techniques in customer relation-
ship management: A literature review and classification”, URL:
http://cjou.im.tku.edu.tw/bi2009/DM-usage.pdf
http://cs.uni-muenster.de, URL: http://cs.uni-
muenster.de/Professoren/Lippe/lehre/skripte/wwwnnscript/prin.html
https://sites.google.com/site/dataminingforthemasses/Chapter07_DataSet_Trainin
g.csv
http://scikit-learn.org/stable/tutorial/basic/tutorial.html
http://www.astroml.org/sklearn_tutorial/general_concepts.html

Verwendeter Datensatz
VIII
Verwendeter Datensatz
Dr. Matt North, URL: “https://sites.google.com/site/dataminingforthemasses/”

Eidesstattliche Versicherung
Ich versichere hiermit, dass ich die vorliegende Bachelorthesis selbstständig und
ohne fremde Hilfe angefertigt und keine andere als die angegebene Literatur be-
nutzt habe. Alle von anderen Autoren wörtlich übernommenen Stellen wie auch
die sich an die Gedankengänge anderer Autoren eng anlehnenden Ausführungen
meiner Arbeit sind besonders gekennzeichnet. Diese Arbeit wurde bisher in glei-
cher oder ähnlicher Form keiner anderen Prüfungsbehörde vorgelegt und auch
nicht veröffentlicht.
Berlin, den 29. September 2013




![Data Mining Studie 2013 | Praxistest & Benchmarking€¦ · RapidMiner fälschlicherweise als nominal er-kannt [siehe Abb.29]. Dieser Umstand lässt sich in RapidMiner](https://img.pdfslide.tips/doc/110x75/5b0139497f8b9af1148dd132/data-mining-studie-2013-praxistest-benchmarking-rapidminer-flschlicherweise.jpg)
























