Embed Size (px)
Citation preview

Utilisation des réseaux de neuronestemporels pour le pronosticet la surveillance dynamique
Etude comparative de trois réseauxde neurones récurrents
Nicolas Palluat— Daniel Racoceanu— Noureddine Zerhouni
Laboratoire d’Automatique de Besançon, LAB - UMR CNRS 659624 rue Alain Savary, F-25000 Besançon
{npalluat, daniel.racoceanu, zerhouni}@ens2m.fr
RÉSUMÉ.L’objet de cet article consiste en un état de l’art des réseaux de neurones temporelset d’une comparaison de trois réseaux de neurones récurrents les plus représentatifs pour desapplications de surveillance dynamique et de pronostic. Les critères de sélection de ces ré-seaux se situent à deux niveaux : temporel et architectural.Suite à l’application de ces critères,trois réseaux récurrents se distinguent : le RRBF, le R2BF etle DGNN. Des tests utilisant unbenchmark de surveillance dynamique et un benchmark de pronostic nous permettent d’évaluerles performances des trois réseaux temporels en termes de temps de calcul et de capacité detraitement.
ABSTRACT.This article gives a state of the art of temporal neural networks and a comparisonof three recurrent neural network which are most representative for applications of dynamicmonitoring and prognosis. The criteria of selection of these networks are at two levels: atemporal criterion and an architectural criterion. Following the application of these criteria,three recurrent networks seem relevant: the RRBF, the R2BF and the DGNN. Tests using abenchmark of dynamic monitoring and a benchmark of prognosis enable us to evaluate theperformances of the three temporal networks in term of computing and processing capacitytime.
MOTS-CLÉS :réseau de neurones temporel, surveillance dynamique, pronostic, réseau de neu-rones récurrent, RRBF, R2BF, DGNN, apprentissage
KEYWORDS:temporal neural network, dynamic monitoring, prognosis, recurrent neural network,RRBF, R2BF, DGNN, learning
RSTI - RIA. Volume 19 – n˚ 6/2005, pages 911 à 948

912 RSTI - RIA. Volume 19 – n˚ 6/2005
1. Introduction
Les systèmes de production ont connu un important élan technologique tout aulong de ces dernières années. Cette complexité technologique ajoutée à d’autrescontraintes économiques incite les industriels à une plus grande attention à la main-tenance de leur système de production. Une des fonctions lesplus importantes de lamaintenance est représentée par la surveillance industrielle. Celle-ci se décompose endeux fonctions :
– la détection d’une défaillancequi consiste à reconnaître une déviation par rap-port au fonctionnement attendu. Elle peut être signalée parune alarme ;
– le diagnostic d’une fautequi permet de déterminer la localisation de l’organedéfaillant et l’identification des causes de la défaillance. Celui-ci se décompose à sontour en deux parties :
- la localisation d’une fautequi revient à déterminer la région physique dusystème dans laquelle la défaillance s’est produite ;
- l’ identification de la causequi permet de déterminer précisément l’origine dela défaillance détectée.
Les méthodologies de surveillance se basent sur deux concepts :méthodes de sur-veillance en l’absence de modèles du procédé, et méthodes de surveillance avec mo-dèles. Le modèle d’un système est généralement difficile à obtenir, surtout pour dessystèmes complexes soumis à des aléas ou reconfigurables. Pour des raisons de flexi-bilité et d’adaptabilité, nous nous sommes donc orientés vers une des méthodes desurveillance sans modèle et plus précisément par reconnaissance de formes. Cette mé-thode utilise entre autres les réseaux de neurones artificiels qui donnent des résultatsintéressants grâce à :
– leur capacité d’apprentissage,
– leur parallélisme dans le traitement,
– leur capacité de faire face à des problèmes inhérents à la non-linéarité des sys-tèmes,
– leur rapidité de traitement quand ils sont implémentés en circuit intégré.
La base de connaissances pour la phase d’apprentissage est obtenue grâce à desoutils (historiques, superviseurs, GMAO. . .) capables de donner le lien entre les ef-fets observés ou mesurés et les conséquences (modes de fonctionnement, causes desdéfaillances, prédiction).
L’utilisation des réseaux de neurones pour des applications industrielles telles quela détection dynamique, le diagnostic et le pronostic exigela prise en compte de l’as-pect temporel. Dans cette optique, nous nous proposons d’effectuer un état de l’artdes réseaux de neurones temporels, en essayant d’établir les critères nous permettantde sélectionner les meilleures configurations en vue des applications de surveillancedynamique et de pronostic.

RNT pour la surveillance dynamique 913
Cet article est structuré en trois sections. La section suivante est consacrée à l’utili-sation des réseaux de neurones temporels pour la surveillance industrielle. Un état del’art des réseaux de neurones temporels est ainsi présenté.Les critères de classificationde ces réseaux nous conduisent aux réseaux de neurones temporels les plus adaptés àla surveillance : les réseaux de neurones récurrents. Dans un deuxième temps, nous dé-crivons succinctement les 3 structures sélectionnées : le RRBF, le R2BF et le DGNN.Une adaptation des structures des 3 réseaux de neurones récurrents est nécessaire pourleur utilisation dans le domaine de la surveillance dynamique et du pronostic. Uneétude comparative à travers des benchmarks correspondants, fait ainsi l’objet d’unetroisième section de l’article.
2. Utilisation des réseaux de neurones temporels pour la surveillanceindustrielle
Afin d’effectuer une surveillance dynamique d’un système industriel à l’aide desréseaux de neurones, il est nécessaire de leur implémenter la notion temporelle.Comme l’explique Chappelieret al.dans (Chappelier, 1996; Chappelieret al., 2001),il existe actuellement deux grandes familles de réseaux de neurones temporels : lesréseaux de neurones dont le temps peut être représenté par unmécanisme externe, etceux dont le temps peut être représenté par un mécanisme interne (figure 1).
Réseaux de neurones temporels
Représentation implicite du temps
Représentation interne du temps
- TDRBF - TDNN - Nettalk
Temps au niveau de la connexion �
/ f(a) � t
Temps au niveau des neurones
Modèle algébrique
Modèle biologique �
/ f(a,t)
- KohoTemp
- Klaassen et Dev - Azmy et Vibert
- Jacquemin - ADAM - Amit - ATDNN
Représentation explicite du temps
- R²BF
- Jordan - Elman
- LRGF - Hopfield - DGNN - RRBF
Représentation externe du temps
Figure 1. Classification des réseaux de neurones temporels

914 RSTI - RIA. Volume 19 – n˚ 6/2005
Représentation externe du temps
La façon la plus immédiate de représenter le temps dans les réseaux de neuronesest d’utiliser ce qui est appelé une représentation spatiale du temps. L’informationtemporelle que contiennent les données est alors transformée en une information spa-tiale, c’est-à-dire une forme qu’il s’agit de reconnaître.Ce type de représentation dutemps fait donc appel à un mécanisme externe qui est chargé deretarder ou de rete-nir un certain temps les données, ce qui conduit à l’appeler également représentationexterne du temps. C’est le cas par exemple des TDNN (Langet al., 1988) : le tempsest uniquement représenté par une transformation en espace. Ils sont principalementappliqués dans le domaine de la reconnaissance de la parole.
Cette représentation présente plusieurs désavantages. Tout d’abord elle supposel’existence d’une interface avec le monde extérieur dont lerôle est de retarder oude retenir les données jusqu’au moment de leur utilisation dans le réseau : commentconnaître l’instant où les données doivent être traitées c’est-à-dire comment définir lataille de la fenêtre ?
Ensuite, le fait d’utiliser une fenêtre temporelle (ou des retards) de longueur finieet déterminéea priori soit par la plus longue information à traiter, soit en supposantla même longueur pour toutes les données, présente un seconddésavantage.
Enfin, c’est dans la nature même de la représentation spatiale que se pose la diffi-culté de différencier une position temporelle relative d’une position temporelle abso-lue.
Représentation interne du temps
Pour palier aux inconvénients de l’utilisation d’une fenêtre temporelle, il existe unautre type de représentation pour lequel le temps est pris encompte par l’effet qu’ilproduit, ce qui conduit à doter le réseau de propriétés dynamiques, d’où le nom dereprésentation dynamique du temps. Autrement dit, cela revient à donner au réseau lacapacité de mémoriser des informations temporelles.
Nous trouvons à l’intérieur de cette représentation dynamique du temps deux sous-catégories : la représentation implicite du temps et la représentation explicite du temps.
La prise en compte implicite de temps est réalisée en réintroduisant en entrée duréseau l’état précédent du réseau (ou une partie de celui-ci). C’est le cas des réseauxrécurrents d’Elman (1990) et de Jordan (1986).
Représenter explicitement le temps dans le modèle neuromimétique employé peutse faire au seul niveau des liaisons du réseau ou au niveau du neurone lui-même.Comme exemples d’architectures introduisant le temps au niveau des retards sy-naptiques, nous pouvons citer entre autres les travaux de Béroule (1987), d’Amit(1988) et de Jacquemin (1994). Pour des architectures introduisant le temps au ni-veau du neurone, nous pouvons nous intéresser aux travaux réalisés sur les cartesauto-organisatrices de Kohonen, dont une vue d’ensemble est donnée dans Barretoetal. (2001).

RNT pour la surveillance dynamique 915
Dans le cadre de notre étude – surveillance continue d’un système de production– la représentation externe du temps ne convient pas du fait de la notion de fenêtretemporelle. En effet, il est, d’une part, difficile de définirla taille de la fenêtre utile,et d’autre part, la taille de cette fenêtre modifie directement la taille du réseau. Nousnous sommes donc orientés vers une représentation interne du temps. Elle n’inclut pasd’éléments dynamiques externes. Elle ne nécessite donc pasde connaissancesa prioridu système. De plus, la dimension du vecteur d’entrée est réduite car il n’est plusnécessaire de présenter les valeurs précédentes des entrées et des sorties à l’entréedu réseau. Parmi les deux nouvelles catégories qui se sont présentées, le choix dela représentation implicite du temps nous a paru la plus judicieuse pour sa facilitéd’intégration et ses algorithmes d’apprentissage plus faciles à mettre en œuvre. Il esttoutefois bon de noter que ce type de réseau, appelé réseau deneurones récurrent,possède aussi une faiblesse en ce qui concerne la définition de la taille de la mémoirecomme l’a montré Bengioet al.(1993), mais nous avons considéré que cette faiblesseétait insignifiante par rapport aux qualités de ces réseaux ainsi que par rapport aucontexte d’application.
Après ce premier choix, de nombreux réseaux s’offrent à nous, il est donc néces-saire de définir un nouveau critère pour limiter ce nombre. Aucours de nos recherchesbibliographiques, nous avons pu établir que l’on pouvait classer la plupart des réseauxde neurones suivant la réponse de leurs neurones : réponses globales (fonction d’acti-vation sigmoïdale, par exemple) et réponses locales (fonction d’activation gaussienne,par exemple). Le choix d’une réponse locale ou d’une réponseglobale déterminerales caractéristiques principales du réseau. En effet, un réseau temporel à représenta-tion externe du temps donnant une réponse globale, comme le NETtalk (Sejnowskietal., 1986), possède une très bonne capacité de généralisation.Toutefois, lors d’un nou-vel apprentissage, tous les paramètres du réseau doivent être recalculés. On utiliserade préférence ce type de réseaux pour les problèmes d’interpolation. Par contre, pourun réseau donnant une réponse locale, comme le TDRBF (Berthold, 1994), la sortiedu réseau est non nulle si le vecteur d’entrée est proche d’unvecteur appris, et nullesinon. Lors d’un nouvel apprentissage, seule une partie desparamètres du réseau estgénérée, car seuls quelques neurones ont une réponse non nulle. Ces réseaux pourrontêtre utilisés pour résoudre les problèmes d’extrapolation.
En appliquant ce critère à la représentation établie précédemment, nous obtenonsla représentation de la figure 2.
Nous pouvons noter que dans la représentation implicite du temps, le critère archi-tectural n’a pas fourni deux familles distinctes de réseauxmais trois. En effet, certainsréseaux comme le RRBF (Recurrent Radial Basis Function), que nous verrons plusloin, possèdent plusieurs types de neurones ayant chacun leur fonction. Si nous fai-sons le choix de placer le RRBF dans la famille des réponses locales puisque sa sortiecorrespond à un comportement de cette famille, nous ne considérons pas le fait qu’enentrée il utilise une réponse globale pour gérer le temps. L’inverse étant aussi vrai,nous avons donc fait le choix de créer cette nouvelle catégorie.

916 RSTI - RIA. Volume 19 – n˚ 6/2005
Réseaux de neurones temporels
Représentation implicite du temps
Représentation explicite du temps
Temps au niveau de la connexion �
/ f(a) � t
Temps au niveau des neurones
- TDRBF - TDNN - Nettalk
Réponse globale
Réponse locale
Représentation externe du temps
Représentation interne du temps
Modèle algébrique
Modèle biologique �
/ f(a,t)
- R²BF - Jordan - Elman
Réponse globale
Réponse locale
Réponse mixte
- RRBF - DGNN
- LRGF - Hopfield - DGNN
- DGNN
Critère principal: intégration de la notion temporelle
Critère secondaire: architecture
- KohoTemp
- Klaassen et Dev - Azmy et Vibert
- Jacquemin - ADAM - Amit - ATDNN
Figure 2. Classification des réseaux de neurones temporels à l’aide dedeux critères(temporel et architectural)
Nous développons par la suite la partie concernant les réseaux de neurones récur-rents dans l’optique d’une application en surveillance continue et prédiction.
Pour notre étude de surveillance en ligne, nous effectuerons des opérations de clas-sification et de prédiction. Dans le cas d’une classification, il est important que le ré-seau de neurones puisse donner un degré de pertinence à sa réponse et ainsi, lors d’undegré faible pour chaque réponse, ne pas donner de fausses réponses. L’aspect localrépondant à cette condition nous éliminons ainsi les réseaux utilisant une réponse glo-bale tels que les réseaux de Jordan, Elman et de Hopfield. Maisce choix n’élimine t’ilpas la deuxième condition dans cette étude, l’utilisation dans le cadre du pronostic ?La réponse est négative car le pronostic correspond à un problème d’extrapolation, quiest le cadre d’utilisation de l’aspect local.
Il nous reste donc le choix entre la famille des réponses locales et celle des réponsesmixtes. Ne pouvant exclure aisément l’une des deux familles, nous avons fait le choixd’étudier trois réseaux de ces deux familles.
Le choix des réseaux vient du fait que nous voulions un réseauappartenant à lafamille des réponses locales (le DGNN, qui appartient aussiaux deux autres famillessuivant le choix effectué dans son architecture), un autre appartenant à la famille desréponses mixtes (le RRBF). Le choix du troisième réseau (le R2BF) se justifie par lefait que la récurrence peut se faire soit sur une seule couchesoit sur plusieurs couches.

RNT pour la surveillance dynamique 917
Nous appelons récurrence sur une couche, toute connexion entre deux neurones (iet j, i et j pouvant être égaux) de la même couche (entrée, cachée ou sortie). Touteconnexion entre deux neurones de couches différentes (de p vers k, p> k, par exemplesortie sur entrée) sera appelée récurrence sur plusieurs couches. Le RRBF et le R2BFappartiennent tous deux à la famille des réponses mixtes mais le RRBF a sa récurrencesur une couche et le R2BF a sa récurrence entre plusieurs couches.
En ce qui concerne le choix du RRBF (Zemouriet al., 2001) en particulier, ilprovient de la simplicité du réseau, de la prise en compte du temps et des algorithmesd’apprentissages, et des études déjà faites sur le sujet dans les domaines qui nousintéressent. Pour le DGNN, et particulièrement pour le développement de Ferariuet al.(2002), il provient du choix, fait par les auteurs, d’utiliser les algorithmes génétiquespour déterminer l’architecture optimale en fonction du problème posé. Cette facultéest particulièrement intéressante pour surveiller un système et pour pronostiquer unedéfaillance. Enfin pour le R2BF, et notamment pour le développement de Frasconietal. (1996), nous l’avons choisi car il possède un comportement semblable à celui d’unautomate, et une récurrence entre plusieurs couches.
Par la suite, nous présentons de manière plus détaillée ces trois réseaux, afin demieux apprécier les qualités et les défauts de chacun.
3. Descriptions des trois réseaux de neurones récurrents
3.1. Le RRBF (Recurrent Radial Basis Function) - RRFR (Réseau Récurrent àFonction Radiale)
Le réseau RRBF est conçu dans le cadre d’une utilisation en diagnostic et pronos-tic.
3.1.1. Architecture
Le réseau RRBF est un réseau RBF dont on a modifié la couche d’entrée afin d’in-troduire la notion dynamique. En effet, les neurones d’entrées ne sont plus linéairesmais bouclés avec une sigmoïde comme fonction d’activation(figure 3).���� � ��� Figure 3. Réseaux RRBF
Le réseau de neurones RRBF (Zemouriet al., 2001) utilise une représentation in-terne implicite du temps. Cet aspect dynamique est obtenu par une récurrence des

918 RSTI - RIA. Volume 19 – n˚ 6/2005
connexions au niveau des neurones de la couche d’entrée. Cesauto connexions pro-curent aux neurones d’entrée une capacité de prise en compted’un certain passé desdonnées en entrée. Nous pouvons ainsi qualifier l’ensemble de ces neurones bouclésde mémoire dynamiquedu réseau de neurones. Le réseau RRFR est donc doté dedeux types de mémoires : une mémoiredynamique(couche d’entrée) pour la priseen compte de la dynamique des données en entrée, et une mémoire statique(couchecachée) pour mémoriser les prototypes. La couche de sortie représente la couche dedécision. (Zemouriet al., 2003)
3.1.2. Avantages et inconvénients du RRBF
La principale qualité de cette architecture réside dans la séparation de la mémoiredynamique de la mémoire statique qui fait de ce réseau une architecture aisée à com-prendre et à mettre en œuvre. Par contre, il est bien évident que les paramètres qui lecaractérisent sont primordiaux pour une bonne couverture du domaine sans provoquerun phénomène de surapprentissage.
3.2. Le R2BF (Recurrent Radial Basis Function)
Le réseau R2BF est conçu pour avoir un comportement comparable à un automate.Il peut ainsi être utilisé pour l’inférence inductive des grammaires régulières.
3.2.1. Architecture
Le réseau R2BF est un réseau de neurones récurrent constituéde 4 couches : unecouche d’entrée, deux couches cachées (une couche RBF et unecouche d’état), etenfin d’une couche de sortie. Pour les taches d’analyse de séquence, la couche desortie est constituée d’un seul neurone sigmoïdal dont la sortie est représentée parx0(t). � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � ! � � � � � � � � " � � � � � � � # �$%%&'()*Figure 4. L’architecture du réseau R2BF

RNT pour la surveillance dynamique 919
Le nombre de neurones par couche est notén(l). Chaque neurone de la couchel
est référencé par son indexi(l), i(l) = 1(l), . . . , n(l).
Pour chaque neurone des couches intermédiaires, nous avons:
– ai(l)(t) : activation du neuronei(l)
– xi(l)(t) : sortie du neuronei(l)
3.2.2. Avantages et inconvénients du R2BF
Cette architecture, initialement prévue pour l’inférenceinductive des grammairesrégulières devra certainement être modifiée si nous souhaitons l’appliquer à nos pro-blématiques de pronostic et de surveillance dynamique. Lesauteurs proposent dessolutions pour l’algorithme d’apprentissage à l’aide de différentes méthodes qui pour-ront être appliquées telle que la méthode hybride définie parMoodyet al. (1989).
3.3. Le DGNN (Dynamic General Neural Network)
Les réseaux DGNN sont basés à la fois sur la structure des PMC et sur celle desRBF permettant ainsi d’utiliser les avantages de chacune d’entre elles : les capacitésde généralisation des PMC et l’efficacité calculatoire des RBF. Le but principal de cesréseaux est de permettre la résolution des problèmes d’identification dans les systèmesnon linéaires. Devant la difficulté à sélectionner des modèles convenant à la résolutiondu problème complexe, les auteurs proposent une méthode basée sur les algorithmesgénétiques permettant de déterminer la topologie et les paramètres adéquats des ré-seaux DGNN.
3.3.1. Topologie du DGNN+,-. / 0123 4 5678 9 +,:. / 0;23 4 5<78 9= >-. / ?
θ@-. /AB BC σ = >:. /@:. /DEF G DHF G = IJ K L
θMN OPQRSTU
VFigure 5. Topologie du DGNN

920 RSTI - RIA. Volume 19 – n˚ 6/2005
Le réseau DGNN est constitué de 3 couches : une couche d’entrée (p entrées), unecouche cachée (n neurones à fonction d’activation sigmoïde ou gaussienne),et unecouche de sortie. Le réseau est défini par les paramètres suivants :
FHsij : filtre synaptique correspondant à la connexion de l’entréej vers le neuronecachéi ;
FHai etFHo
i : respectivement filtre d’activation et filtre de sortie du neurone cachéi ;
FOsi : filtre synaptique correspondant à la connexion du neuronei vers le neuronede sortie ;
FOa et FOo : respectivement filtre d’activation et filtre de sortie du neurone desortie ;
θ : biais du neurone à fonction d’activation sigmoïde et biaisdu neurone de sortie ;
c etσ : centre et déviation standard du neurone à fonction d’activation gaussienne.
Les bouclages locaux au niveau synaptique, de l’activationet de la sortie, sontimplémentés en incluant des filtres ARMA (Auto-Regressive Moving Average) dansla topologie.
Afin de déterminer la topologie optimale du DGNN ainsi que sesparamètres, unalgorithme basé sur les algorithmes génétiques est utilisé(Ferariuet al., 2002).
3.3.2. Avantages et inconvénients du DGNN
Le principal avantage dans cette méthode se situe au niveau de la procédure degénération du DGNN qui ne nécessite aucune information sur le gradient des critères.Les modèles neuronaux obtenus se caractérisent à la fois parune bonne précision deleurs résultats et la simplicité de leurs architectures, l’utilisateur doit introduire unnombre réduit de paramètres par rapport à une création manuelle d’un réseau DGNN.Par contre, cette méthode nécessite une grande capacité calculatoire.
4. Application
Afin de comparer au mieux les différentes architectures ainsi que les différentsalgorithmes d’apprentissage établis par les auteurs, nousproposons d’effectuer deuxséries de tests. La première aura pour thème le pronostic à l’aide d’un benchmark d’unfour à gaz (Box-Jenkins Furnace Data1), et la seconde la surveillance dynamique àl’aide d’un benchmark sur la surveillance d’un bras de robot(Robot Execution Fai-lures2).
1. Benchmark disponible sur le site du IEEE Neural Network Council : http://neural. s.nthu.edu.tw/jang/ben hmark/.2. Benchmark disponible sur le site de l’Université de Californie à Irvine :http://kdd.i s.u i.edu/databases/robotfailure/robotfailure.html.

RNT pour la surveillance dynamique 921
4.1. Pronostic
4.1.1. Présentation du benchmark
Dans le four à gaz utilisé pour ce benchmark, de l’air et du méthane ont été com-binés afin d’obtenir un mélange de gaz qui contient du CO2 (Dioxyde de Carbone).Le débit de gaz entrant constitue la série d’entréeu(t) et la concentration en CO2 lasortiey(t). Dans cette expérimentation, 293 paires successives d’observation (u(t),y(t)) ont été lues à partir d’un enregistrement continu à intervalle régulier de 9 se-condes. L’objectif du réseau de neurones est de déterminer la sortie à l’instantt + 1en connaissant l’entrée et la sortie aux instants précédents. Le schéma de la figure 6représente le four ainsi que les entrées et la sortie du réseau.
W X Y Z [ \ ] Z^ Z \ _ ` ^ Z Y_ X a \ _ _ Z ^ b Yc X d e b ] Z f [ gZ ^ b _ [ ^ b h \ h b i i j ` ^ a Z ^ b _ [ b e ` ^] Z j k l h m h b i i \ h b im h b i m h b n o iFigure 6. Application au pronostic de la sortie d’un four à gaz
Nous illustrons les courbes représentatives (figure 7) du couple entrée-sortie dufour à gaz, avec en trait continu les séquences de la phase d’apprentissage et la partieen pointillé les séquences de la phase de prédiction.
Figure 7. Courbes représentatives du couple entrée-sortie du four à gaz

922 RSTI - RIA. Volume 19 – n˚ 6/2005
4.1.2. Pronostic en utilisant le réseau RRBF
Le réseau RRBF utilisé pour le benchmark du four à gaz est celui de la figure 8.
p q r s t up q r uv q r uFigure 8. Schématisation du réseau RRBF pour le pronostic
Le traitement s’effectue par une prise en compte directe de l’entrée plus la mémo-risation des entrées précédentes. L’apprentissage s’effectue en deux étapes :
– un apprentissage non supervisé ;
– un apprentissage supervisé.
L’apprentissage non supervisé permet de déterminer les centres et les rayons desneurones gaussiens. Pour déterminer les centres, nous avons choisi d’utiliser l’algo-rithme Fuzzy C-mean Clustering développé par Bezdek (1981). Cet algorithme estanalogue à l’algorithme k-mean clustering. Le but est de construire une pseudo par-tition floue constituée dec sous-ensembles flous. Les points sont alors assignés (demanière floue) à un sous-ensemble en déterminant la distanceau centre des sous-ensembles.
Dans un premier temps, nous allons définir les différentes variables nécessaires àl’algorithme (Billups, 2001).
Soit X :={
x1, x2, . . . , xn}
un ensemble den données. Un sous-ensemble floudeX est représenté par la fonctionA : X → [0, 1] , appelée fonction d’adhésion, oùA
(
xi)
représente le degré d’appartenance au pointxi. Ainsi, par exemple,A(
xi)
= 1
indique quexi est entièrement défini dans le sous-ensemble flou,A(
xi)
= 0 indiquequexi n’est pas défini dans le sous-ensemble etA
(
xi)
= 0, 8 indique quexi estvraisemblablement, mais non certainement, dans le sous-ensemble.
Une pseudo partition floue deX est une famille dec sous-ensembles flous deX ,notée parP = {A1, A2, . . . , Ac} satisfaisant les équations :
c∑
i=1
Ai
(
xk)
= 1 pourk = 1, 2, . . . , n

RNT pour la surveillance dynamique 923
Soit une pseudo partitionP = {A1, A2, . . . , Ac} donnée, lesc centresv1, v2, . . . , vc sont calculés par la formule suivante :
vi =
n∑
k=1
[Ai (xk)]m
xk
n∑
k=1
[Ai (xk)]mpouri = 1, 2, . . . , c
Oùm > 1 est un nombre réel qui gouverne l’influence du rang d’appartenance.
Une fois les centres calculés, un index de performance pour la partition floue peutêtre déterminé selon la formule :
Jm (P ) =n∑
k=1
c∑
i=1
[Ai (xk)]m ‖xk − vi‖22
Plus cet index de performance est faible, meilleure est la pseudo partition floue.
L’algorithme utilisé permet de trouver un minimum local deJm (P ).
Posert = 0. Sélectionner une pseudo partition floue initialeP 0. Choisirm > 1 etc.Répéter
Calculer lesc centresvt1, v
t2, . . . , v
tc en utilisantP t.
[Sélectionner une nouvelle pseudo partitionP t+1 en utilisant la procédure sui-vante :]Pour chaquexk ∈ X faire
Si ( xk − vt
i
2> 0 pour touti = 1, 2, . . . , c) Alors
At+1
i (xk) =
24 cXj=1
xk − vti
2 xk − vtj
2
! 1
m−1
35−1
Fin SiSi ( xk − vt
i
2= 0 pour un ou plusieursi) Alors
poserI =�i | xk − vt
i
= 0
et définirAt+1
i (xk) pour i ∈ I
avec un nombre réel non négatif satisfaisantPi∈I
Ai
�xk�
= 1, et
pouri /∈ I , At+1
i (xk) = 0Fin Si
Fin Pour[Calcul de la distance entre deux pseudo partitions]��P t+1 − P t
�� := maxi∈1,...,c,k∈1,...,n
��At+1
i (xk)− Ati (xk)
�� ;Si (��P t+1 − P t
�� > ε) Alorst← t + 1 ;
Fin Sijusqu’à ce que(
��P t+1 − P t�� 6 ε)
L’algorithme montre une convergence quel que soitm appartenant à1 < m < ∞.Le choix optimal dem reste une question ouverte. Dans notre travail, nous avonsutilisém = 2.

924 RSTI - RIA. Volume 19 – n˚ 6/2005
L’avantage d’une méthode intégrant la notion floue provientdu fait que l’al-gorithme est beaucoup moins sensible à des petites perturbations des données. Parexemple, dans une méthode non floue, si un point est pratiquement équidistant entredeux centres, une petite variation peut le faire changer de sous-ensemble (un grandchangement pour une petite perturbation). Au contraire, dans une méthode floue, lesdegrés d’appartenance changent continuellement, donc unepetite perturbation dansles données entraînera un petit changement dans les centres.
La méthode Fuzzy C-mean Clustering permet de déterminer lescentres des neu-rones gaussiens. Pour déterminer les rayons, nous utilisons la méthode tirée de l’al-gorithme RCE (Restricted Coulomb Energy) introduit par Hudak (1992), caractériséepar la formule suivante :
Pour tout i, j = 1, 2, . . . , c et i 6= j faire
σi = max {σ : Ri (vj) < θ} avecRi (vj) = exp
�−‖vj−vi‖2
σ2
i
�Fin Pour
Figure 9. Exemple de calcul de rayons avec la méthode de l’algorithme RCE. Un seuilθ permet d’ajuster ces rayons
La deuxième partie de l’apprentissage consiste en l’utilisation d’un algorithmesupervisé, en l’occurrence la méthode de régression linéaire qui permettra de calculerles poids de la couche cachée vers la couche de sortie.
Soit :
– R : la sortie des neurones gaussiens
– Y : la sortie du réseau
– W : la matrice des poids entre les neurones gaussiens et les neurones de sortievérifiant l’équation :Y = R · W
W est la matrice cherchée dans cette deuxième partie de l’apprentissage. Commel’a démontré Michelli (1986), il existe une classe de fonctions (gaussiennes, multiqua-
RNT pour la surveillance dynamique 925
dratique. . .) où la matriceR est non singulière. Donc, la matrice de pondération peuts’écrire sous la forme :
W = R−1 · Y
Pour la séquence d’apprentissage, à chaque échantillonnage, nous présentons lesvaleurs de l’entrée à l’instantt et les valeurs de la sortie à l’instantt et t + 1.
Pour la séquence de prédiction, seules les valeurs de l’entrée et de la sortie à l’ins-tantt sont présentées. Le réseau donne la valeur de la sortie estimée à l’instantt + 1.
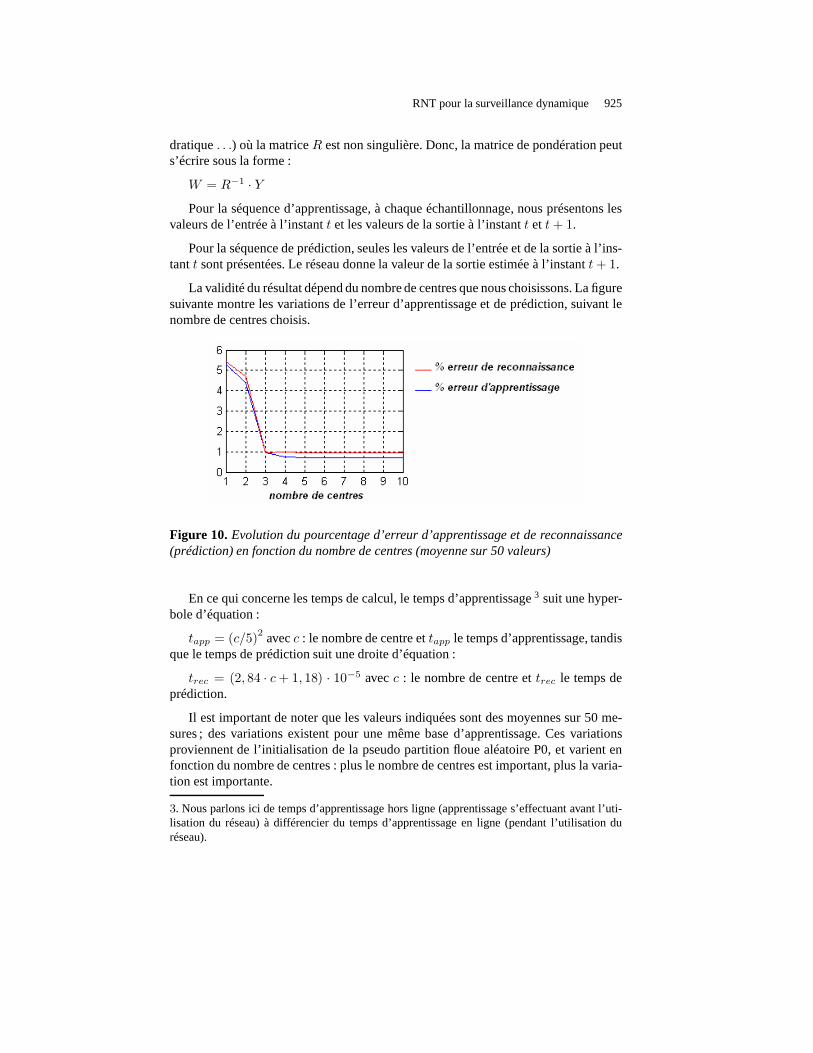
La validité du résultat dépend du nombre de centres que nous choisissons. La figuresuivante montre les variations de l’erreur d’apprentissage et de prédiction, suivant lenombre de centres choisis.
Figure 10. Evolution du pourcentage d’erreur d’apprentissage et de reconnaissance(prédiction) en fonction du nombre de centres (moyenne sur 50 valeurs)
En ce qui concerne les temps de calcul, le temps d’apprentissage3 suit une hyper-bole d’équation :
tapp = (c/5)2 avecc : le nombre de centre ettapp le temps d’apprentissage, tandis
que le temps de prédiction suit une droite d’équation :
trec = (2, 84 · c + 1, 18) · 10−5 avecc : le nombre de centre ettrec le temps deprédiction.
Il est important de noter que les valeurs indiquées sont des moyennes sur 50 me-sures ; des variations existent pour une même base d’apprentissage. Ces variationsproviennent de l’initialisation de la pseudo partition floue aléatoire P0, et varient enfonction du nombre de centres : plus le nombre de centres est important, plus la varia-tion est importante.
3. Nous parlons ici de temps d’apprentissage hors ligne (apprentissage s’effectuant avant l’uti-lisation du réseau) à différencier du temps d’apprentissage en ligne (pendant l’utilisation duréseau).
926 RSTI - RIA. Volume 19 – n˚ 6/2005
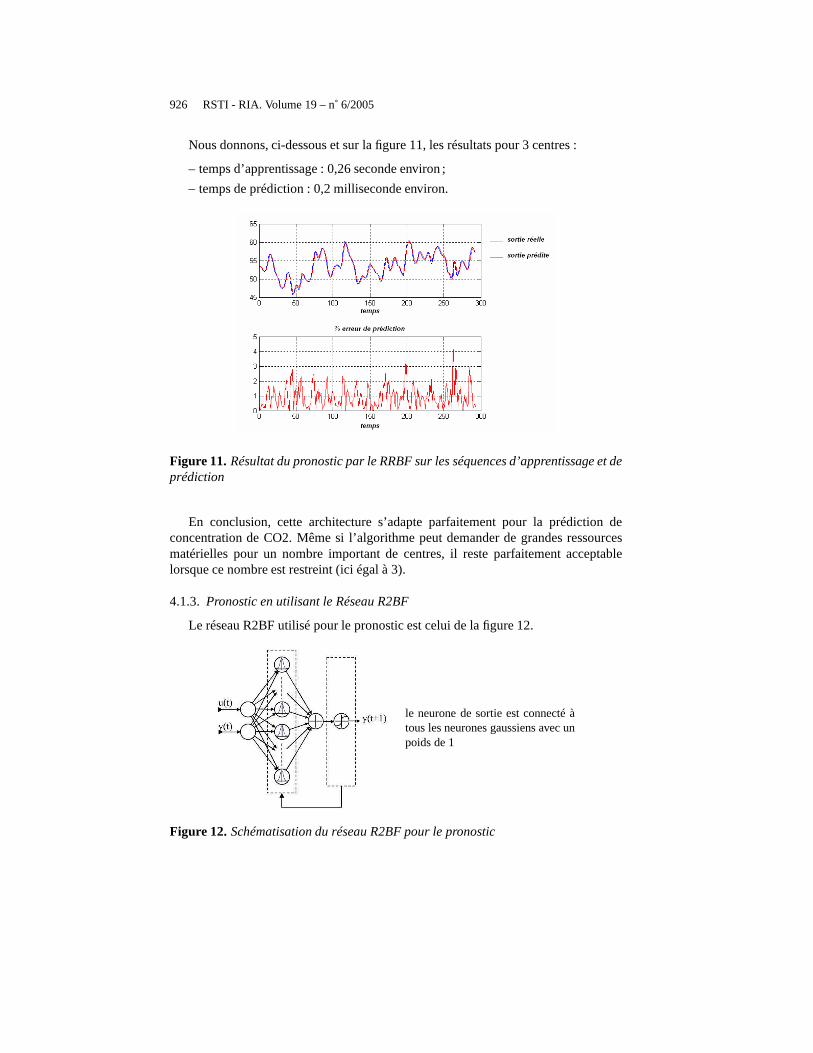
Nous donnons, ci-dessous et sur la figure 11, les résultats pour 3 centres :
– temps d’apprentissage : 0,26 seconde environ ;
– temps de prédiction : 0,2 milliseconde environ.
Figure 11. Résultat du pronostic par le RRBF sur les séquences d’apprentissage et deprédiction
En conclusion, cette architecture s’adapte parfaitement pour la prédiction deconcentration de CO2. Même si l’algorithme peut demander degrandes ressourcesmatérielles pour un nombre important de centres, il reste parfaitement acceptablelorsque ce nombre est restreint (ici égal à 3).
4.1.3. Pronostic en utilisant le Réseau R2BF
Le réseau R2BF utilisé pour le pronostic est celui de la figure12.
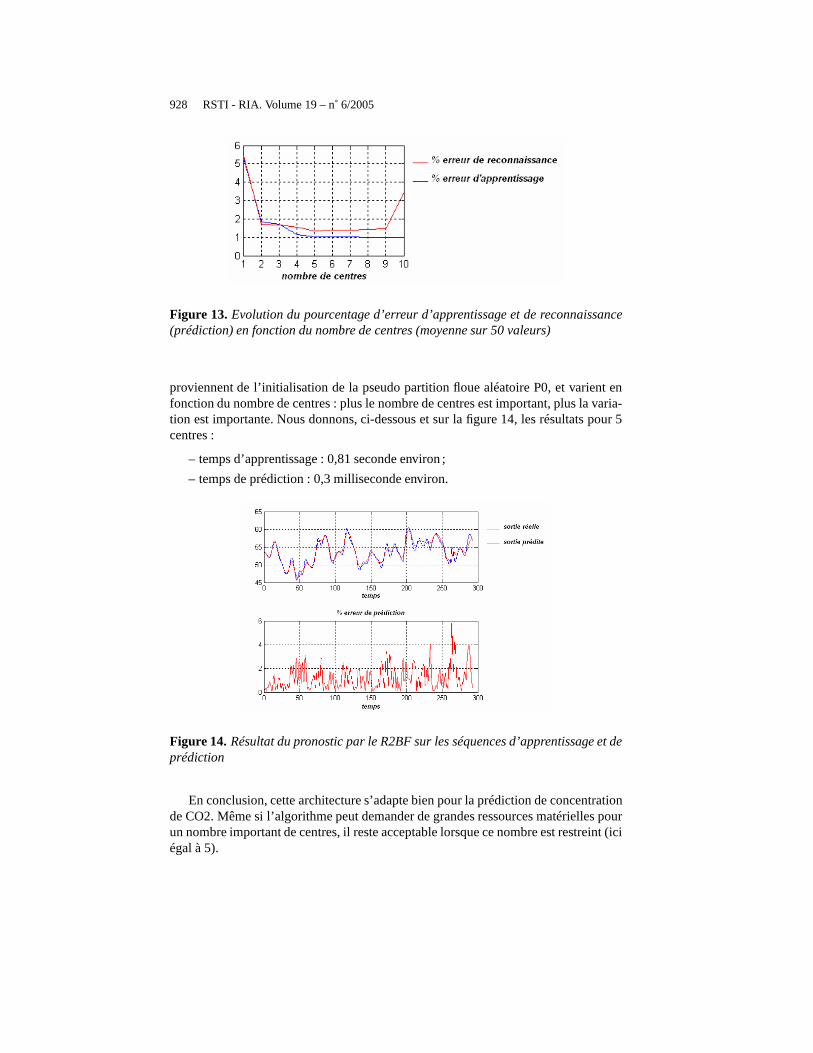
le neurone de sortie est connecté àtous les neurones gaussiens avec unpoids de 1
Figure 12. Schématisation du réseau R2BF pour le pronostic

RNT pour la surveillance dynamique 927
Le traitement s’effectue par une prise en compte directe de l’entrée. La mémo-risation des états précédents s’effectue par le bouclage dela sortie sur les neuronesgaussiens. L’apprentissage s’effectue en deux étapes : unepartie non supervisée pourla détermination des centres à l’aide de la méthode Fuzzy C-mean clustering (étudiéepour le RRBF dans la partie précédente) et des rayons à l’aidede la méthode tirée del’algorithme RCE, ainsi qu’une seconde partie supervisée àl’aide d’une méthode derégression linéaire.
La première partie de l’apprentissage est pratiquement identique à celle dévelop-pée pour le RRBF. La différence se situe au niveau de la sortiedu réseau. En effet, lasortie entre en compte dans la détermination des centres desneurones gaussiens. Nousconsidérons donc dans la phase d’apprentissage que cette sortie est optimale. Passonsà la deuxième partie de l’apprentissage.
Soit :
– R : la sortie des neurones gaussiens
– Y : la sortie du réseau
– W : la matrice des poids entre les neurones gaussiens et les neurones de sortievérifiant l’équation :
Y = R · W
W est la matrice cherchée dans cette deuxième partie de l’apprentissage. Selon(Michelli, 1986), il existe une classe de fonctions (gaussiennes, multiquadratique. . .)où la matriceR est non singulière. Donc la matrice de pondération peut s’écrire sousla forme :
W = R−1 · Y
Pour la séquence d’apprentissage, nous présentons, à chaque échantillonnage, lesvaleurs de l’entrée à l’instantt, de la sortie à l’instantt et à l’instantt + 1.
Pour la séquence de prédiction, seules les valeurs de l’entrée et de la sortie à l’ins-tantt sont présentées. Le réseau donne la valeur de la sortie estimée à l’instantt + 1.
La validité du résultat dépend du nombre de centres que nous choisissons. La fi-gure 13 montre les variations de l’erreur d’apprentissage,et de prédiction suivant lenombre de centres choisi.
En ce qui concerne les temps de calcul, le temps d’apprentissage suit une hyperboled’équation :
tapp = (c/5, 6)2 avecc : le nombre de centre ettapp le temps d’apprentissage,
tandis que le temps de prédiction suit une droite d’équation:
trec = (4, 48 · c + 2, 65) · 10−5 avecc : le nombre de centre ettrec le temps deprédiction.
Il est important de noter que les valeurs indiquées sont des moyennes sur 50 me-sures. Des variations existent pour une même base d’apprentissage. Ces variations
928 RSTI - RIA. Volume 19 – n˚ 6/2005
Figure 13. Evolution du pourcentage d’erreur d’apprentissage et de reconnaissance(prédiction) en fonction du nombre de centres (moyenne sur 50 valeurs)
proviennent de l’initialisation de la pseudo partition floue aléatoire P0, et varient enfonction du nombre de centres : plus le nombre de centres est important, plus la varia-tion est importante. Nous donnons, ci-dessous et sur la figure 14, les résultats pour 5centres :
– temps d’apprentissage : 0,81 seconde environ ;
– temps de prédiction : 0,3 milliseconde environ.
Figure 14. Résultat du pronostic par le R2BF sur les séquences d’apprentissage et deprédiction
En conclusion, cette architecture s’adapte bien pour la prédiction de concentrationde CO2. Même si l’algorithme peut demander de grandes ressources matérielles pourun nombre important de centres, il reste acceptable lorsquece nombre est restreint (iciégal à 5).

RNT pour la surveillance dynamique 929
4.1.4. Pronostic en utilisant le réseau DGNN
Afin de simplifier l’aspect du réseau DGNN que nous souhaitonsutiliser, nousintroduisons les simplifications suivantes (figure 15) :
wxyz {xyz|}xyz ~���� ����� � ��� �������� ��wwyz����|}w�y � }wxy � �� � �����w�yz����|}�yz ~���� ����� � �������� �� ������ �������� ������ � �
Figure 15. Simplification du réseau DGNN
Après modification, le réseau DGNN utilisé pour le pronosticest celui de la figure16. ��� ¡�� ¡��¢£ Figure 16. Schématisation du réseau DGNN pour le pronostic
Le traitement s’effectue par une prise en compte directe de l’entrée. L’apprentis-sage s’effectue avec l’algorithme basé sur les algorithmesgénétiques développé parFerariuet al. (2002). Il permet à partir d’une population de DGNN admissibles dedéterminer le réseau optimal pour l’application désirée. Pour cela, une optimisationmulticritères est appliquée et résolue dans le sens de Pareto (la solution est repré-sentée par une famille de points nommée ensemble Pareto optimal). Six critères sontconsidérés et organisés en deux niveaux de priorité :
Niveau 1 :
– f1 : Somme des carrés des erreurs de la sortie pour l’ensemble des donnéesd’apprentissage = Mesure de la précision du modèle neural. Les valeurs du critèresont estimées après l’application d’une procédure d’optimisation locale (Recherchegénétique standard ou procédure d’optimisation suggérée par Salomon (1998)).

930 RSTI - RIA. Volume 19 – n˚ 6/2005
Niveau 2 :
– f2 : nombre de neurones cachés actifs ;
– f3 : nombre de connections actives entre les entrées du réseau et les neuronescachés actifs ;
– f4 : nombre de filtres de sortie actifs ;
– f5 : somme des ordres des numérateurs et dénominateurs, correspondant à tousles filtres de sortie actifs ;
– f6 : somme des ordres des numérateurs et dénominateurs, correspondant à tousles filtres synaptiques et d’activations actifs.
A chaque critère est associé un but qui définit les bornes de lavaleur du critère.
L’algorithme peut être schématisé comme suit :
- Créer une population hiérarchique initiale contenantNind individus.- Vérifier l’exactitude des topologies codées (avec des actions correctives au besoin) etcalculer les valeurs réelles des buts.- Appliquer une procédure d’optimisation locale, pourNO_ITERitérations, aux gènesparamétriques actifs de chaque chromosome.- Evaluer les chromosomes selon tous les critères considérés et calculer les valeurs d’ap-titude.Répéter
Pour chaque sous-populationfaire- Sélectionner les parents pour la phase de reproduction.- Appliquer les opérateurs de croisement et de mutation.- Vérifier l’uniformité de la progéniture (avec des actions correctives aubesoin).- Appliquer une procédure d’optimisation locale, pourNO_ITERitéra-tions, aux gènes paramétriques actifs de chaque progéniture.- Evaluer la progéniture et calculer les valeurs d’aptitude.- Insérer la progéniture dans la population, selon la stratégie de réservationde Pareto.- Une fois àNO_MIGRgénérations, échanger les individus avec l’autresous-population (étape de migration).- Adapter les buts et calculer les valeurs d’aptitude.
Fin Pour- Déterminer le(s) meilleur(s) individu(s) de la seconde sous-population.
jusqu’à ce que(MAX_GENgénérations)- Déterminer le(s) meilleur(s) individu(s) de toutes les générations.- (Option) Entraîner avec une procédure d’optimisation locale le modèle neuronal sé-lectionner, pour un grand nombre d’itérations.- Fin de l’algorithme.
Enfin l’algorithme d’optimisation locale utilisé est l’algorithme de Salomon (1998)qui est défini ci-après.

RNT pour la surveillance dynamique 931
A chaque itération t, la procédure démarre d’un point donné−→xt , puis elle génèreλ candidats tests (progénitures)
−→ti avec i = 1, . . . , λ et
−→ti = −→xt + −→zi . Tous les
composants de tous les vecteurs de mutations−→zi ont une distribution gaussienne demoyenne nulle et de déviation standardλt/
√n avecn le nombre de composantes de
−→xt . En utilisant l’information donnée par tous les candidats tests, la procédure calcule
alors un vecteur unitaire−→et qui pointe dans la direction estimée du gradientf−→gt , qui estune somme pondérée des vecteurs
−→ti et qui peut dévier de façon significative du vrai
gradient.
−→et =f−→gt f−→gt
avecf−→gt =λP
i=1
�f(−→ti )− f (−→xt)
��−→ti −−→xt
�La fonctionf permet de déterminer la valeur du critèref1.
Après le calcul du vecteur unitaire−→et , la procédure effectue le pas d’itération etadapte la taille de ce dernier. Pour cela, elle doit effectuer au moins deux tests avecune taille de pas différente suivant la direction du gradient estimée :σt.ζ et σt/ζ avecζ ≈ 1, 8 qui est un facteur de variation. La procédure effectue finalement un pas avecle meilleur résultat.
σt+1 =
�σtζ, si f (−→xt − σtζ
−→et ) 6 f (−→xt − (σt/ζ)−→et )σt/ζ, sinon
−−→xt+1 = −→xt − σt+1−→et
Si nous appliquons cet algorithme au cas du DGNN, nous obtenons :
- Déterminer les gènes paramétriques actifs du réseau :n
- Créer un vecteur−→x0 regroupant ces données.- Déterminer un pas initialσ0
Répéter- Générerλ vecteurs de mutations :−→zi de dimension :n × 1, de distributiongaussienne de moyenne := 0 et de déviation standard :=σt/
√n
- Générerλ candidats tests :−→ti = −→xt +−→zi
- Déterminer le vecteur unitaire−→et :
−→et =f−→gt
. f−→gt
avecf−→gt =λP
i=1
�f(−→ti )− f (−→xt)
��−→ti −−→xt
�Si (f (−→xt − σt · ς · −→et ) 6 f (−→xt − (σt/ς) · −→et )) Alors
σt+1 = σt · ζSinon
σt+1 = σt/ςFin Si−−→xt+1 = −→xt − σt+1 · −→et
jusqu’à ce que(NO_ITERitérations)- Insérer les gènes paramétriques modifiés dans le réseau
932 RSTI - RIA. Volume 19 – n˚ 6/2005
Pour effectuer les essais, nous utiliserons les paramètressuivants :
– Nind : nombre d’individus de la population : 500
– NO_ITER: nombre d’itération dans l’algorithme d’optimisation locale : 75
– MAX_GEN: nombre de générations dans l’algorithme principal : 80
– NO_MIGR: indice de la génération pour laquelle s’effectue l’échange d’indivi-dus entre les deux sous populations : 20
– n : nombre maximums de neurones dans la couche cachée : 3
– Les paramètres des filtres et des neurones sont tous comprisentre -1 et 1.
– λ : nombre de candidats tests : 100
– ζ : facteur de variation du pas : 1,8
– σ0 : taille du pas initial. Nous l’avons déterminé en fonction de la valeur ducritèref1 : Plusf1 augmente, plusσ0 baisse.
Pour la séquence d’apprentissage, nous présentons, à chaque échantillonnage, lesvaleurs de l’entrée à l’instantt, de la sortie à l’instantt et à l’instantt + 1.
Pour la séquence de prédiction, seules les valeurs de l’entrée et de la sortie à l’ins-tantt sont présentées. Le réseau donne la valeur de la sortie estimée à l’instantt + 1.
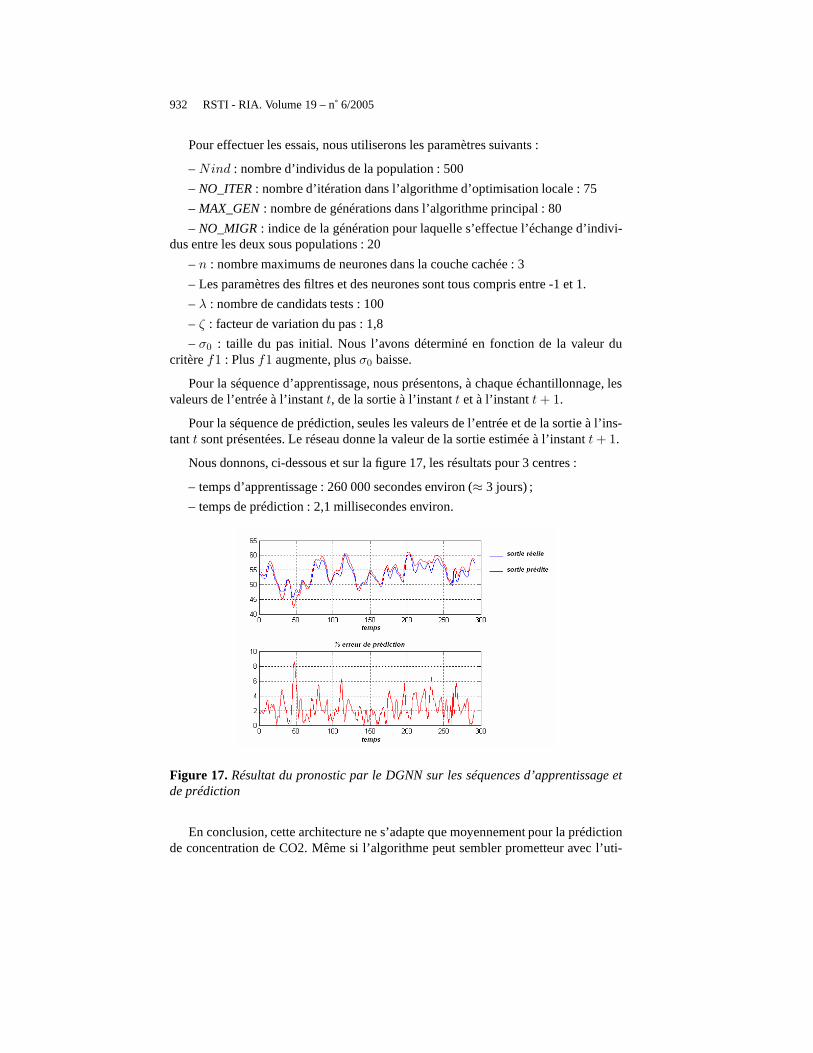
Nous donnons, ci-dessous et sur la figure 17, les résultats pour 3 centres :
– temps d’apprentissage : 260 000 secondes environ (≈ 3 jours) ;
– temps de prédiction : 2,1 millisecondes environ.
Figure 17.Résultat du pronostic par le DGNN sur les séquences d’apprentissage etde prédiction
En conclusion, cette architecture ne s’adapte que moyennement pour la prédictionde concentration de CO2. Même si l’algorithme peut sembler prometteur avec l’uti-
RNT pour la surveillance dynamique 933
lisation d’algorithme génétique, il reste cependant décevant quant au temps de calculet au résultat obtenu. Un résultat plus intéressant pourrait être obtenu avec un plusgrand nombre de neurones dans la couche cachée mais cela augmenterait de façonconsidérable le temps de calcul.
4.1.5. Synthèse sur l’utilisation de réseaux de neurones récurrents pour le cas dupronostic
Reprenons les résultats de chacun des réseaux :
1) RRBF :
- erreur moyenne de 0,86 % ;
- temps d’apprentissage de 0,26 seconde ;
- temps de reconnaissance de 0,2 milliseconde ;
2) R2BF :
- erreur moyenne de 1,25 % ;
- temps d’apprentissage de 0,81 seconde ;
- temps de reconnaissance de 0,3 milliseconde ;
3) DGNN :
- erreur moyenne de 2,37 % ;
- temps d’apprentissage de 260 000 secondes (≈ 3 jours) ;
- temps de reconnaissance de 2,1 millisecondes ;
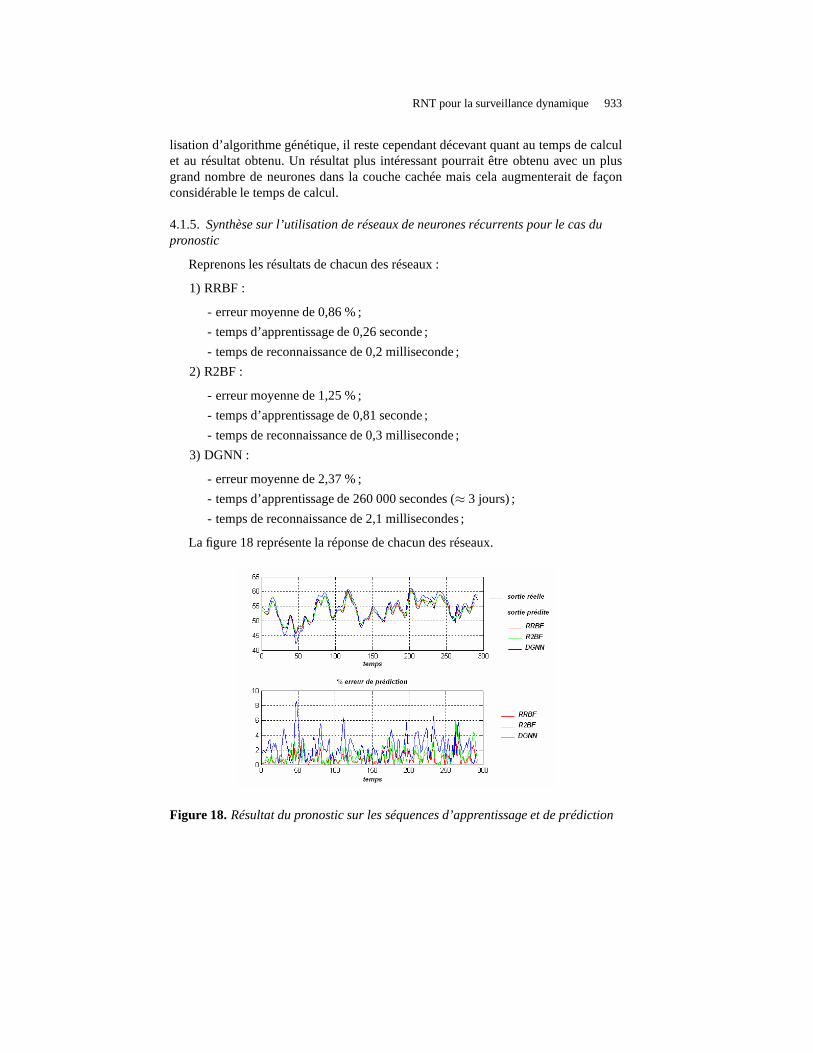
La figure 18 représente la réponse de chacun des réseaux.
Figure 18. Résultat du pronostic sur les séquences d’apprentissage etde prédiction

934 RSTI - RIA. Volume 19 – n˚ 6/2005
Sachant que le meilleur réseau est celui dont l’erreur de prédiction est la plus faibletout au long de la séquence, le réseau RRBF serait le meilleurréseau. Pourtant, le ré-seau R2BF est aussi particulièrement intéressant dans ces résultats. Le réseau DGNNtermine en dernière position du fait de ses résultats moins satisfaisant. Avec un plusgrand nombre de neurones dans la couche cachée, ce réseau donnerait sûrement demeilleurs résultats, mais cela augmenterait considérablement le temps de calcul. Ence qui concerne ce temps d’apprentissage, le réseau RRBF estune nouvelle fois leplus intéressant. Le réseau R2BF, avec un temps trois fois plus long est parfaitementacceptable puisqu’il reste inférieur à la seconde. Ce tempsest important car dans lespremiers temps d’utilisation du réseau, il est possible qu’il y ait de nombreuses sé-quences d’apprentissage pour mettre à jour la base de donnéed’apprentissage afind’effectuer une prédiction plus précise, tout en évitant lesur apprentissage. Le DGNNavec ses trois jours de calculs est en dernière position.
Il est important de noter que cette séquence de test ne comportait pas de phased’apprentissage en ligne. Si un tel cas devait être traité, les algorithmes choisis né-cessitant l’utilisation de l’ensemble de la base donneraitdes résultats équivalents àun apprentissage hors ligne. Donc pour un système dont la réactivité est plutôt lentecomme le four à gaz, les réseaux RRBF et R2BF seraient applicables contrairementau DGNN. Sinon, il est nécessaire que le temps d’échantillonnage soit supérieur autemps d’apprentissage. Nous comprenons donc bien que plus le temps d’apprentissageest court, plus les possibilités d’applications sont grandes.
Maintenant que nous avons pu analyser et comparer les résultats de ces réseaux surle benchmark du pronostic, voyons leurs capacités dans le domaine de la surveillancedynamique.
4.2. Surveillance dynamique
4.2.1. Présentation du benchmark
Cette base de données contient des mesures de force et de couples sur un robotaprès détection de l’erreur. Chaque erreur est caractérisée par 15 relevés sur les cap-teurs de force et de couple récupérés à intervalles réguliers débutés juste après ladétection de l’erreur.
Les auteurs4 ont proposé 5 bases de données, chacune définissant un problèmed’apprentissage différent :
LP1 : Problème dans l’approche du bras pour une prise de pièce;
LP2 : Problème dans le transfert d’une pièce ;
LP3 : Position de la pièce après un problème durant le transfert ;
4. Luis Seabra Lopes and Luis M. Camarinha-Matos, Universidade Nova de Lisboa, Monte daCaparica, Portugal, 23 avril 1999 (Benchmark disponible sur le site de l’Université de Californieà Irvine :http://kdd.i s.u i.edu/databases/robotfailure/robotfailure.html )

RNT pour la surveillance dynamique 935
LP4 : Problème dans l’approche du bras pour un dépôt de pièce ;
LP5 : Problème dans le mouvement du bras avec la pièce.
Nous nous intéressons au problème LP2, qui concerne la collision du bras de robotlors du transfert de la pièce. Cette base de données propose 5classes de sortie avec lesrépartitions suivantes :
– Fonctionnement normal 42,6 %– Collision avant 12,8 %– Collision arrière 14,9 %– Collision à droite 10,6 %– Collision à gauche 19,1 %
De plus, parmi les informations fournies par les auteurs, nous nous limitons auxinformations capteurs de force pour simplifier l’étude des différents réseaux.
¤ ¥ ¦ ¦ § ¨ § ¥ ©ª « ª © ¬¤ ¥ ¦ ¦ § ¨ § ¥ ©ª § ® ¤̄ ¥ ¦ ¦ § ¨ § ¥ ©° ± ¥ § ¬ ¯¤ ¥ ¦ ¦ § ¨ § ¥ © °² ª ³ ´ µ ¯
Figure 19. Différents types de collision de la pince
¶ · ¸ ¹ º » ¼ ½ ¾ º¿ À ¼ Á ºÂ¿ Ã Ä ¿ Å Ä ¿ Æ Ç ¿ ÿ Å¿ Æ ¿ À È Á ¹ ÉÀ È È º Ê º È ¹ È À ¼Ê · ˶ À Ë Ë É ½ ÉÀ È · Ì · È ¹¶ À Ë Ë É ½ ÉÀ È · ¼ ¼ É Í ¼ º¶ À Ë Ë É ½ ÉÀ È Î ¾ ¼ À ɹ º¶ À Ë Ë É ½ ÉÀ È Î Ï ·» Á Ð ºÑ Ò ½º ·» ¾ ºÈ º» ¼ À È º ½¼ Ò Á » ¼ ¼ º È ¹ ½Figure 20. Application de surveillance d’un bras de robot (Manipulateur pneuma-tique Schrader)

936 RSTI - RIA. Volume 19 – n˚ 6/2005
Les deux figures précédentes (figures 19 et 20) présentent de façon schématiquel’application de surveillance d’un bras de robot et les quatre types de défaillancespouvant se produire (le relevé des valeurs s’effectue toutes les 21 ms).
Pour effectuer l’apprentissage des différents réseaux, nous avons effectué le choixd’une séquence pour chaque catégorie que nous présentons sur la figure 21. Chaqueséquence de défaillance (catégories "collision avant", "collision arrière", "collisiondroite" et "collision gauche") est précédée d’une séquencede bon fonctionnement(catégorie "fonctionnement normal")
Figure 21. Séquences correspondant aux différents types de collision
Nous pouvons remarquer que le choix effectué pour la collision arrière peut sur-prendre. En effet, la différence entre le bon fonctionnement (entre 1 et 15) et la dé-faillance (entre 16 et 30) est minime. Pourtant, un tel choixest important car si nousavions choisi en apprentissage une séquence telle que cellede la figure 22, lors del’identification, le réseau identifierait la première séquence comme une séquence ap-partenant à la catégorie "fonctionnement normal".
Figure 22. Autre séquence pour représenter la collision arrière
4.2.2. Surveillance dynamique en utilisant le réseau RRBF
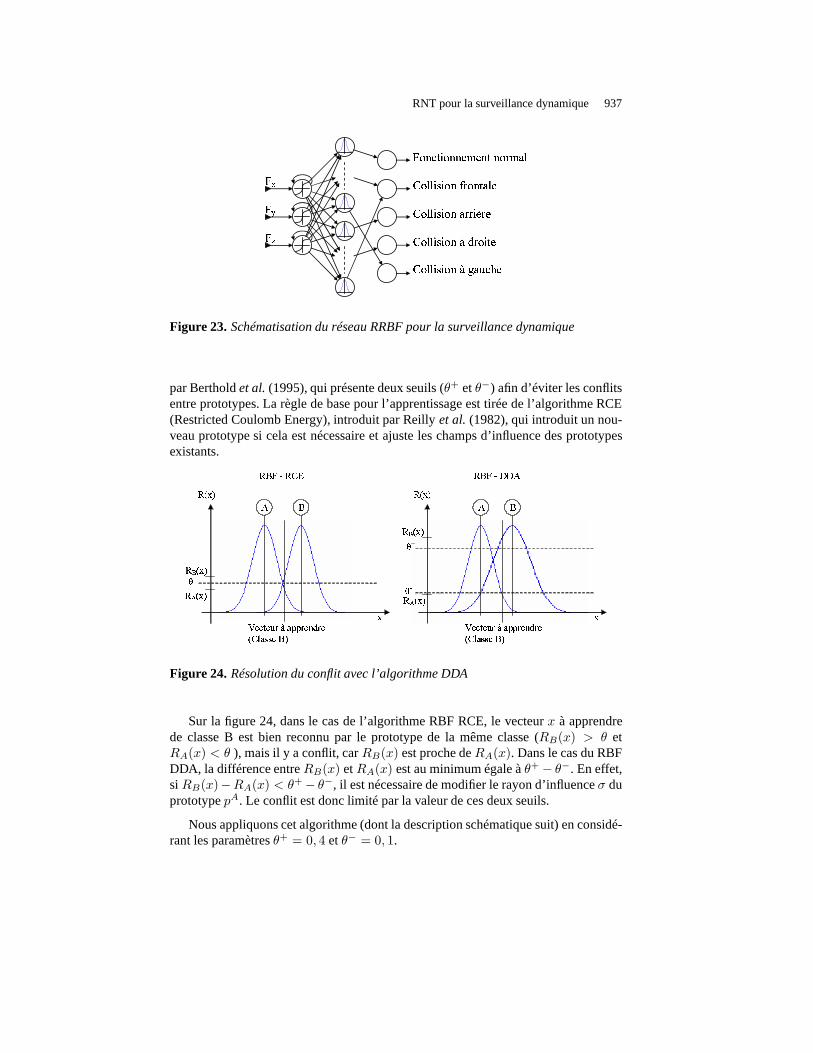
Le réseau RRBF utilisé pour la surveillance dynamique est représenté sur la fi-gure 23.
La dynamique du réseau est assurée par un neurone bouclé en entrée. Ce neuroneest configuré afin d’avoir la plus longue mémoire possible. Lataille de la mémoirestatique (neurone gaussien) et ses paramètres (centres et rayons d’influences) sont dé-terminés par l’algorithme d’apprentissage DDA (Dynamic Decay Adjustment), définit
RNT pour la surveillance dynamique 937
Ó ÔÓ ÕÓ ÖÓ × Ø Ù Ú Û × Ø Ø Ü Ý Ü Ø Ú Ø × Þ Ý ß àá × à à Û â Û × Ø ã Þ × Ø Ú ß à Üá × à à Û â Û × Ø ß Þ Þ Û ä Þ Üá × à à Û â Û × Ø å æ Þ × Û Ú Üá × à à Û â Û × Ø å ç ß è Ù é Ü
Figure 23. Schématisation du réseau RRBF pour la surveillance dynamique
par Bertholdet al.(1995), qui présente deux seuils (θ+ etθ−) afin d’éviter les conflitsentre prototypes. La règle de base pour l’apprentissage esttirée de l’algorithme RCE(Restricted Coulomb Energy), introduit par Reillyet al. (1982), qui introduit un nou-veau prototype si cela est nécessaire et ajuste les champs d’influence des prototypesexistants.
êë ì
í îí ïð ñ ò ê óð ô ò ê ó
õ ö ÷ ø ö ù ú û ü ý ý ú ö þ ÿ ú öò � � ü � � ö ì óêë ì
íð ñ ò ê óð ô ò ê ó õ ö ÷ ø ö ù ú û ü ý ý ú ö þ ÿ ú öò � � ü � � ö ì óð ì � � ð � � ð ì � � � � ë� � � �
Figure 24. Résolution du conflit avec l’algorithme DDA
Sur la figure 24, dans le cas de l’algorithme RBF RCE, le vecteur x à apprendrede classe B est bien reconnu par le prototype de la même classe(RB(x) > θ etRA(x) < θ ), mais il y a conflit, carRB(x) est proche deRA(x). Dans le cas du RBFDDA, la différence entreRB(x) etRA(x) est au minimum égale àθ+ − θ−. En effet,si RB(x)−RA(x) < θ+ − θ−, il est nécessaire de modifier le rayon d’influenceσ duprototypepA. Le conflit est donc limité par la valeur de ces deux seuils.
Nous appliquons cet algorithme (dont la description schématique suit) en considé-rant les paramètresθ+ = 0, 4 etθ− = 0, 1.

938 RSTI - RIA. Volume 19 – n˚ 6/2005
Répéter[Initialisation des poids de sortie]
Pour tout prototypei de classek pki faire
Aki ← 0 ;
Fin Pour[Itération d’apprentissage]Pour tout vecteur d’apprentissagex de classec faire
Si (∃pci : Rc
i (x) ≥ θ+) AlorsAc
i ← Aci + 1 ;
Sinon[Création d’un nouveau prototype]ajouter un nouveau prototypepc
mc+1 avec :rc
mc+1 ← x ;[A noter pour un premier neurone, le rayon aura la valeur qui per-met de couvrir le maximum l’espace admissible]σc
mc+1 ← maxk 6=c∧16j6mk
�σ : Rc
mc+1
�rk
j
�< θ−
;
Acmc+1 ← 1 ;
mc ← mc + 1 ;Fin Si[Ajustement des zones de conflits]Pour toutk 6= c, 1 6 j 6 mk faire
σkj ← max
�σ : Rk
j (x) < θ−
;Fin Pour
Fin Pourjusqu’à ce que(plus de modifications du réseau (ajout de prototype et/ou modificationdes rayons d’influences))
Pour la séquence d’apprentissage, nous présentons, à chaque échantillonnage, lesvaleurs des 3 capteurs de force Fx, Fy et Fz ainsi que la classeassociée. L’apprentis-sage des 5 séquences est assez court : 1,029 secondes.
Pour la séquence de reconnaissance, seules les valeurs des capteurs sont présen-tées. Le réseau donne une réponse à chaque échantillon. Pourdéterminer cette catégo-rie, nous utilisons le maximum de la réponse de chaque sortie, en n’imposant aucunseuil. Pour cela, le temps de calcul est d’environ 2 millisecondes.
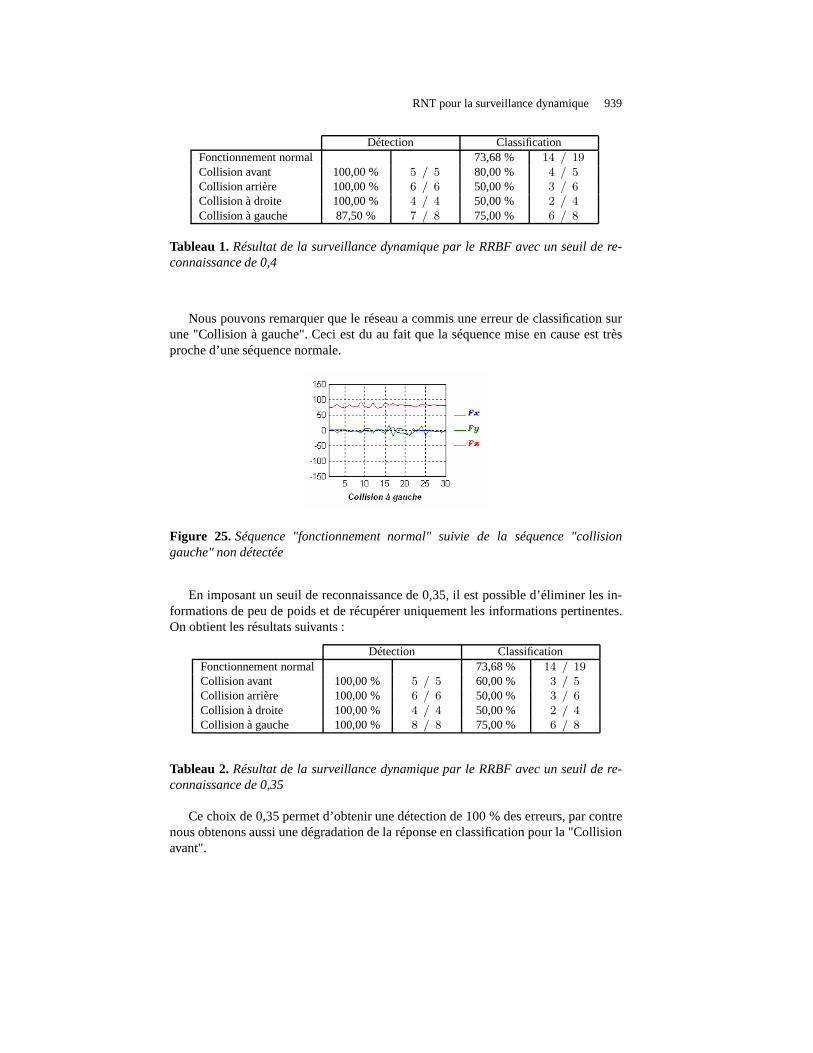
Pour vérifier la validité du réseau, nous récupérons la réponse du réseau à chaquefin de séquence et nous la comparons au résultat théorique. Nous pouvons ainsi dé-terminer le pourcentage de détection et le pourcentage de classification. Le premiercorrespond au nombre de fois où le réseau a détecté la collision par rapport au nombrede fois où la collision s’est produite, et le deuxième, au nombre de fois où le réseaua déterminé la bonne catégorie de la séquence par rapport au nombre de fois où cettecatégorie a été enregistré. Les résultats sont présentés dans le tableau ci-après.
RNT pour la surveillance dynamique 939
Détection ClassificationFonctionnement normal 73,68 % 14 / 19Collision avant 100,00 % 5 / 5 80,00 % 4 / 5Collision arrière 100,00 % 6 / 6 50,00 % 3 / 6Collision à droite 100,00 % 4 / 4 50,00 % 2 / 4Collision à gauche 87,50 % 7 / 8 75,00 % 6 / 8
Tableau 1.Résultat de la surveillance dynamique par le RRBF avec un seuil de re-connaissance de 0,4
Nous pouvons remarquer que le réseau a commis une erreur de classification surune "Collision à gauche". Ceci est du au fait que la séquence mise en cause est trèsproche d’une séquence normale.
Figure 25.Séquence "fonctionnement normal" suivie de la séquence "collisiongauche" non détectée
En imposant un seuil de reconnaissance de 0,35, il est possible d’éliminer les in-formations de peu de poids et de récupérer uniquement les informations pertinentes.On obtient les résultats suivants :
Détection ClassificationFonctionnement normal 73,68 % 14 / 19Collision avant 100,00 % 5 / 5 60,00 % 3 / 5Collision arrière 100,00 % 6 / 6 50,00 % 3 / 6Collision à droite 100,00 % 4 / 4 50,00 % 2 / 4Collision à gauche 100,00 % 8 / 8 75,00 % 6 / 8
Tableau 2.Résultat de la surveillance dynamique par le RRBF avec un seuil de re-connaissance de 0,35
Ce choix de 0,35 permet d’obtenir une détection de 100 % des erreurs, par contrenous obtenons aussi une dégradation de la réponse en classification pour la "Collisionavant".

940 RSTI - RIA. Volume 19 – n˚ 6/2005
En conclusion, nous pouvons dire que le réseau RRBF fonctionne parfaitementpour la détection d’erreur. En ce qui concerne les erreurs declassification, ellespeuvent venir de la pauvreté de la base d’apprentissage, ainsi que des trop faiblesdifférences entre les séquences de catégories différentes. L’avantage de ce neuroneréside dans l’utilisation de la mémoire statique et de son algorithme d’apprentissagesimple et stable. En effet, avec la même base, l’apprentissage peut être fait un grandnombre de fois. On trouvera toujours le même nombre de centres, les mêmes rayons,et donc les mêmes résultats en classification. Ce n’est pas lecas avec les réseaux quivont suivre.
4.2.3. Surveillance dynamique en utilisant le réseau R2BF
Le réseau R2BF utilisé pour la surveillance dynamique est lesuivant :
Tous les neurones de sortie sontconnectés à tous les neurones gaus-siens avec un poids de 1
Figure 26. Schématisation du réseau R2BF pour la surveillance dynamique
Si nous comparons cette architecture à celle présentée dansla section 3.2, nouspouvons remarquer l’absence de la couche de sortie. Elle s’explique par le fait que lasortie de tous les neurones sigmoïdaux est à prendre en compte. L’ajout d’une couchede sortie consisterait alors à connecter chacun de ces neurones à un neurone de sortielinéaire avec un poids de 1. Cet ajout ne présentant pas d’intérêt, nous l’avons omis.
La première partie de l’apprentissage est identique à celledéveloppée pour leR2BF (section 4.1.3), nous passerons directement à la deuxième partie.
La deuxième partie de l’apprentissage consiste en l’utilisation d’un algorithmesupervisé, en l’occurrence la méthode de régression linéaire, qui permettra de calculerles poids des connexions de la couche cachée vers la couche desortie.
Reprenons les équations définies dans la section 3.2, et utilisons les notations sui-vantes :
– R : la sortie des neurones gaussiens :R = X (1)
– E : activation des neurones sigmoïdaux :E = A (2)
– W : matrice des poids entre les neurones gaussiens et les neurones sigmoïdauxvérifiant l’équation :E = R · W

RNT pour la surveillance dynamique 941
– Y : sortie des neurones sigmoïdaux :Y = X (2) =1
1 + exp (−E)
W est la matrice cherchée dans cette deuxième partie de l’apprentissage. SelonMichelli (1986), la matrice de pondération peut s’écrire sous la forme suivante :
W = R−1 · E
De plus, dans la partie d’apprentissage, Y est connu. Nous avons par conséquent :
Y =1
1 + exp (−E)d’où E = − ln
(
Y −1 − 1)
D’où :
W = −R−1 · ln(
Y −1 − 1)
Pour la séquence d’apprentissage, nous présentons, à chaque échantillonnage, lesvaleurs des 3 capteurs de force Fx, Fy et Fz ainsi que la classeassociée.
Pour la séquence de reconnaissance, seules les valeurs des capteurs sont présen-tées. Le réseau donne une réponse à chaque échantillon. Pourdéterminer cette ca-tégorie, nous utilisons le maximum de la réponse de chaque sortie, sans imposer deseuil.
Pour vérifier la validité du réseau, nous récupérons la réponse du réseau à chaquefin de séquence et nous la comparons au résultat théorique. Nous pouvons ainsi dé-terminer le pourcentage de détection et le pourcentage de classification. Le premiercorrespond au nombre de fois où le réseau a détecté la collision par rapport au nombrede fois où la collision s’est produite, et le deuxième, au nombre de fois où le réseaua déterminé la bonne catégorie de la séquence par rapport au nombre de fois où cettecatégorie a été effective.
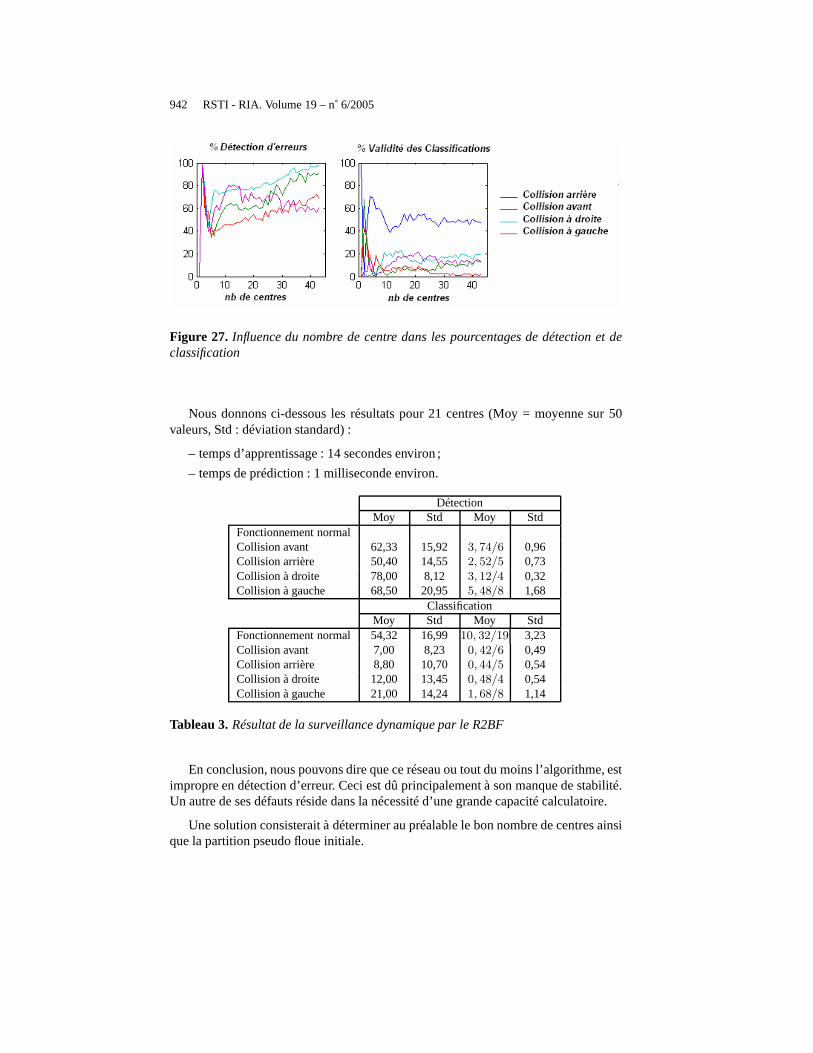
Contrairement à l’algorithme DDA utilisé dans le RRBF, l’algorithme Fuzzy C-mean ne détermine pas le nombre de centres. Ce nombre est à choisir au lancementde l’algorithme. Ce choix est important car il détermine la fiabilité du réseau. La fi-gure 27 montre l’influence du nombre de centres dans les pourcentages de détectionet classification.
En ce qui concerne les temps de calcul, le temps d’apprentissage suit une hyperboled’équation :
tapp = (c/6)2 avecc : le nombre de centre ettapp le temps d’apprentissage, tandisque le temps de reconnaissance suit une droite d’équation :
trec = (4, 15 · c + 3, 19) · 10−5 avecc : le nombre de centre ettrec le temps dereconnaissance
Il est important de noter que les valeurs indiquées sont des moyennes sur 50mesures, de grandes variations existent pour une même base d’apprentissage. Cettevariation provient de l’initialisation de la pseudo partition floue aléatoire P0.
942 RSTI - RIA. Volume 19 – n˚ 6/2005
Figure 27. Influence du nombre de centre dans les pourcentages de détection et declassification
Nous donnons ci-dessous les résultats pour 21 centres (Moy =moyenne sur 50valeurs, Std : déviation standard) :
– temps d’apprentissage : 14 secondes environ ;
– temps de prédiction : 1 milliseconde environ.
DétectionMoy Std Moy Std
Fonctionnement normalCollision avant 62,33 15,92 3, 74/6 0,96Collision arrière 50,40 14,55 2, 52/5 0,73Collision à droite 78,00 8,12 3, 12/4 0,32Collision à gauche 68,50 20,95 5, 48/8 1,68
ClassificationMoy Std Moy Std
Fonctionnement normal 54,32 16,99 10, 32/19 3,23Collision avant 7,00 8,23 0, 42/6 0,49Collision arrière 8,80 10,70 0, 44/5 0,54Collision à droite 12,00 13,45 0, 48/4 0,54Collision à gauche 21,00 14,24 1, 68/8 1,14
Tableau 3.Résultat de la surveillance dynamique par le R2BF
En conclusion, nous pouvons dire que ce réseau ou tout du moins l’algorithme, estimpropre en détection d’erreur. Ceci est dû principalementà son manque de stabilité.Un autre de ses défauts réside dans la nécessité d’une grandecapacité calculatoire.
Une solution consisterait à déterminer au préalable le bon nombre de centres ainsique la partition pseudo floue initiale.

RNT pour la surveillance dynamique 943
4.2.4. Surveillance dynamique en utilisant le réseau DGNN
Afin de simplifier l’aspect du réseau DGNN que nous souhaitonsutiliser, nousappliquons les simplifications établies dans la section 4.1.4. Nous obtenons ainsi leréseau suivant :� �� � � � � � � � � �� � � � � � � � � �� � � � � � �� � � � � � � � �� � � � � � �� � � � � � �� �� � � � � � �� � � � �� � �
! � �" � �Figure 28. Schématisation du réseau DGNN pour la surveillance dynamique
En comparant cette architecture à celle présentée dans la section 3.3.1, nous pou-vons remarquer l’utilisation de 5 sorties au lieu d’une. Ce point est important car ilaugmente, de manière significative le nombre de paramètres àgérer et la complexitédu réseau.
Reprenons l’algorithme de génération de Ferariuet al. (2002) présenté dans lasection 4.1.4. Il est nécessaire de définir différents paramètres :
– Nind : nombre d’individus de la population : 500
– NO_ITER: nombre d’itération dans l’algorithme d’optimisation locale : 75
– MAX_GEN: nombre de générations dans l’algorithme principal : 300
– n : nombre maximums de neurones dans la couche cachée : 100
– NO_MIGR: indice de la génération pour laquelle s’effectue l’échange d’indivi-dus entre les deux sous populations : 20
– Les paramètres des filtres et des neurones sont tous pris entre -1 et 1.
Enfin l’algorithme d’optimisation locale utilisé est l’algorithme de Salomon (1998)qui a été défini dans la section 4.1.4.
Avec de tels paramètres, les temps de calcul seraient énormes : ≈ 2 700 heurespour l’apprentissage, pour des résultats qui ne seraient pas forcément meilleurs queles résultats obtenus avec le RRBF ou le R2BF. Pour cela, nousavons effectué destests de simulation avec les paramètres opérationnels suivants :
– Nind : nombre d’individus de la population : 10
– NO_ITER: nombre d’itération dans l’algorithme d’optimisation locale : 30
– MAX_GEN: nombre de générations dans l’algorithme principal : 20
– n : nombre maximums de neurones dans la couche cachée : 20

944 RSTI - RIA. Volume 19 – n˚ 6/2005
– NO_MIGR: indice de la génération pour laquelle s’effectue l’échange d’indivi-dus entre les deux sous populations : 10
– Les paramètres des filtres et des neurones sont tous pris entre -1 et 1.
Bien entendu avec de tels paramètres, nous allons obtenir unrésultat qui n’a quetrès peu de chance d’être un optimum global mais de grandes chances d’être un opti-mum local.
Nous donnons les résultats ci dessous après une seule simulation :
– temps d’apprentissage : 13 423 secondes environ ;
– temps de prédiction : 20 millisecondes environ.
Détection ClassificationFonctionnement normal 0,00 % 0 / 19Collision avant 80,00 % 4 / 5 80,00 % 4 / 5Collision arrière 66,67 % 4 / 6 0,00 % 0 / 6Collision à droite 50,00 % 2 / 4 0,00 % 0 / 4Collision à gauche 100,00 % 8 / 8 0,00 % 0 / 8
Tableau 4.Résultat de la surveillance dynamique par le DGNN
En conclusion, nous pouvons dire que ce réseau présente plusd’intérêt dans lathéorie que dans la pratique. Son grand défaut se situe dans les capacités calculatoiresgigantesques qui lui sont nécessaires pour effectuer le moindre apprentissage. Il n’estdonc pas utilisable pour une application industrielle où nous pourrions avoir à ajouterde nouvelles données à apprendre assez souvent dans les premiers mois d’utilisation.
4.2.5. Synthèse sur l’utilisation de réseaux de neurones récurrents pour lasurveillance dynamique
Reprenons les résultats de chacun des réseaux :
1) RRBF :
- temps d’apprentissage de 1,03 secondes ;
- temps de reconnaissance de 2 millisecondes ;
2) R2BF :
- temps d’apprentissage de 14 secondes ;
- temps de reconnaissance de 1 milliseconde ;
3) DGNN5 :
- temps d’apprentissage de 13 423 secondes ;
- temps de reconnaissance de 20 millisecondes.
5. Les valeurs indiquées sont données pour un résultat local lors d’une unique simulation avecdes paramètres réduits.
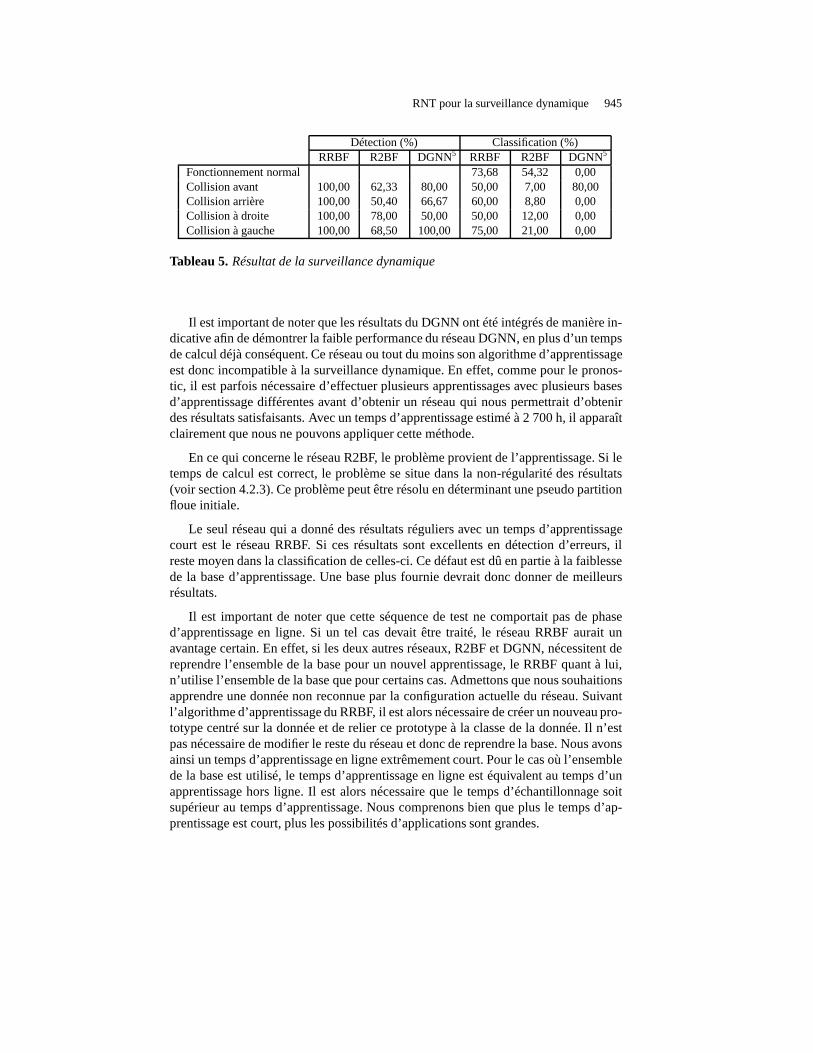
RNT pour la surveillance dynamique 945
Détection (%) Classification (%)RRBF R2BF DGNN5 RRBF R2BF DGNN5
Fonctionnement normal 73,68 54,32 0,00Collision avant 100,00 62,33 80,00 50,00 7,00 80,00Collision arrière 100,00 50,40 66,67 60,00 8,80 0,00Collision à droite 100,00 78,00 50,00 50,00 12,00 0,00Collision à gauche 100,00 68,50 100,00 75,00 21,00 0,00
Tableau 5.Résultat de la surveillance dynamique
Il est important de noter que les résultats du DGNN ont été intégrés de manière in-dicative afin de démontrer la faible performance du réseau DGNN, en plus d’un tempsde calcul déjà conséquent. Ce réseau ou tout du moins son algorithme d’apprentissageest donc incompatible à la surveillance dynamique. En effet, comme pour le pronos-tic, il est parfois nécessaire d’effectuer plusieurs apprentissages avec plusieurs basesd’apprentissage différentes avant d’obtenir un réseau quinous permettrait d’obtenirdes résultats satisfaisants. Avec un temps d’apprentissage estimé à 2 700 h, il apparaîtclairement que nous ne pouvons appliquer cette méthode.
En ce qui concerne le réseau R2BF, le problème provient de l’apprentissage. Si letemps de calcul est correct, le problème se situe dans la non-régularité des résultats(voir section 4.2.3). Ce problème peut être résolu en déterminant une pseudo partitionfloue initiale.
Le seul réseau qui a donné des résultats réguliers avec un temps d’apprentissagecourt est le réseau RRBF. Si ces résultats sont excellents endétection d’erreurs, ilreste moyen dans la classification de celles-ci. Ce défaut est dû en partie à la faiblessede la base d’apprentissage. Une base plus fournie devrait donc donner de meilleursrésultats.
Il est important de noter que cette séquence de test ne comportait pas de phased’apprentissage en ligne. Si un tel cas devait être traité, le réseau RRBF aurait unavantage certain. En effet, si les deux autres réseaux, R2BFet DGNN, nécessitent dereprendre l’ensemble de la base pour un nouvel apprentissage, le RRBF quant à lui,n’utilise l’ensemble de la base que pour certains cas. Admettons que nous souhaitionsapprendre une donnée non reconnue par la configuration actuelle du réseau. Suivantl’algorithme d’apprentissage du RRBF, il est alors nécessaire de créer un nouveau pro-totype centré sur la donnée et de relier ce prototype à la classe de la donnée. Il n’estpas nécessaire de modifier le reste du réseau et donc de reprendre la base. Nous avonsainsi un temps d’apprentissage en ligne extrêmement court.Pour le cas où l’ensemblede la base est utilisé, le temps d’apprentissage en ligne estéquivalent au temps d’unapprentissage hors ligne. Il est alors nécessaire que le temps d’échantillonnage soitsupérieur au temps d’apprentissage. Nous comprenons bien que plus le temps d’ap-prentissage est court, plus les possibilités d’applications sont grandes.

946 RSTI - RIA. Volume 19 – n˚ 6/2005
5. Conclusion
La première partie de cet article constitue une contribution à l’état de l’art et àla classification des réseaux de neurones temporels. Les critères se basent sur deuxconcepts : l’intégration de la notion temporelle et la nature de la réponse. D’un pointde vue temporel, nous retrouvons une représentation externe et interne (implicite ouexplicite) du temps. Concernant la nature de la réponse, le choix se situe par rapport àson aspect local et global.
Après avoir effectué un choix parmi les différentes structures pour des applica-tions de pronostic et de surveillance dynamique, nous avonsextrait trois réseaux deneurones récurrents : le RRBF, le R2BF et le DGNN.
Dans une deuxième partie du travail, nous avons effectué la présentation des troisréseaux de neurones récurrents, de leur algorithme d’apprentissage et de leur utilisa-tion.
Enfin, dans une dernière partie de l’article, nous avons développé ces réseaux pourdes applications de pronostic et de surveillance dynamique. Une étude comparative estainsi menée autour de deux benchmarks spécifiques aux domaines concernés. Le pre-mier constitue une prédiction de la concentration de CO2 d’un four à gaz (pronostic).Le second détermine le type de collision d’un bras de robot (surveillance dynamique).
Les résultats des deux séquences de test ont montré que le réseau RRBF était leplus efficace des trois réseaux, à la fois par ses résultats que par ses temps d’appren-tissage. Pour le réseau R2BF, ses résultats moyens dans la surveillance dynamique nepermettent pas de l’employer dans cette situation. Un algorithme d’apprentissage plusperformant permettrait sûrement une révision de ce jugement. Enfin, pour le DGNN,son algorithme d’apprentissage extrêmement demandeur de capacité calculatoire nelui permet pas d’être implanté aisément. Pour des applications de surveillance dyna-mique et de pronostic, notre choix se portera donc sur le réseau RRBF.
Par ailleurs, nous avons constaté que ce réseau présente un intérêt certain du pointde vue de l’apprentissage en ligne. Ce point est extrêmementimportant. En effet, ce ré-seau possède d’une part une architecture simple (séparation de la mémoire dynamiqueet de la mémoire statique) et d’autre part, les temps d’exécutions des algorithmesd’apprentissage sont relativement courts. Dans l’optiqued’un transfert industriel dece concept, des travaux sont menés au Laboratoire d’Automatique de Besançon, afind’intégrer ce réseau dans un système de surveillance temps réel avec apprentissage dis-tant. Par ailleurs, une intégration de ce concept est envisagée dans un module d’aide àla décision développé dans le cadre d’une plate-forme de e-maintenance faisant l’ob-jet du projet européen PROTEUS6. Enfin, de futurs travaux en diagnostic sont prévuspour le traitement de données symboliques à l’aide de la logique floue et du neuro-flou.
6. PROTEUS - A generic platform for e-maintenance. ITEA european project - Site Web :http://www.proteus-iteaproje t. om/

RNT pour la surveillance dynamique 947
6. Bibliographie
Amit D. J., « Neural network counting chimes »,Proceeding National Academy of Science USA,vol. 85, p. 2141-2145, 1988.
Barreto G., Araújo A., « Time in self-organizing maps : An overview of models »,InternationalJournal of Computer Research, vol. 10, n˚ 2, p. 139-179, 2001.
Bengio Y., Frasconi P., Simard P., « The problem of learning long-term dependencies in re-current networks »,Proc. of the IEEE International Conference on Neural Networks, SanFrancisco, p. 1183-1195, 1993.
Béroule D., « Guided propagation inside a topographic memory », IEEE : 1st internationalconference on neural networks, vol. 4, p. 469-476, 1987.
Berthold M. R., « The TDRBF : A Shift invariant radial basis function network »,Fourth IrishNeural Networks Conference - INNC’94, Dublin, p. 7-12, 1994.
Berthold M. R., Diamond J., « Boosting the Performance of RBFNetworks with DynamicDecay Adjustment »,in , G. Tesauro, , D. S. Touretzky, , T. K. Leen (eds),Advances inNeural Information Processing Systems, vol. 7, MIT Press, Cambridge, MA, p. 521-528,1995.
Bezdek J. C.,Pattern recognition with fuzzy objective function algorithms, Plenum Press, NewYork, 1981.
Billups S. C., « Lead Compound Optimization Using Gene Expression Profiling »,Final reportof the CU-Denver mathematics clinic, 2001.
Chappelier J.-C., RST : une architecture connexionniste pour la prise en compte de relationsspatiales et temporelles, PhD thesis, École Nationale Supérieure des Télécommunications,Janvier, 1996.
Chappelier J.-C., Gori M., Grumbach A., « Time in connectionist models »,Lecture Notes inArtificial Intelligence Serie, vol. 1828, p. 105-134, 2001.
Elman J. L., « Finding Structure in Time »,Cognitive Science, vol. 2, n˚ 14, p. 179-211, 1990.
Ferariu L., Marcu T., « Evolutionary design of dynamic neural networks applied to systemidentification »,15th Triennal World Congress, IFAC, 2002.
Frasconi P., Gori M., Maggini M., Soda G., « Representation of Finite State Automata in Re-current Radial Basis Function Networks »,Machine Learning, vol. 23, n˚ 1, p. 5-32, 1996.
Hudak M. J., « RCE Classifiers : Theory and Practice »,Cybernetics and Systems : An Interna-tional Journal, vol. 23, p. 483-515, 1992.
Jacquemin C., « A Temporal Connectionist Approach to Natural Language »,SIGART Bulletin,vol. 5, n˚ 3, p. 12-22, Juillet, 1994.
Jordan M. I., Serial Order : A Parallel Distributed Processing Approach, Technical Report n˚ICS Report No. 8604, Institute for Cognitive Science, University of California, San Diego,1986.
Lang K. J., Hinton G. E., A time delay neural network architecture for speech recognition,Technical Report n˚ CMU-cs-88-152, Carnegie-Mellon University, Pittsburgh PA, 1988.
Michelli C. A., « Interpolation of scattered data : distancematrices and conditionally positivedefinite functions »,Constructive Approximation, vol. 2, p. 11-22, 1986.
Moody J., Darken C., « Fast learning in networks of locally-tuned processing units »,NeuralComputation, vol. 1, n˚ 2, p. 281-294, 1989.

948 RSTI - RIA. Volume 19 – n˚ 6/2005
Reilly D. L., Cooper L. N., Elbaum C., « A neural model for category learning »,BiologicalCybernetics, vol. 45, p. 35-41, 1982.
Salomon R., « Evolutionary Algorithms and Gradient Search :Similarities and Differences »,IEEE Transactions on Evolutionary Computation, vol. 2, n˚ 2, p. 45-55, July, 1998.
Sejnowski T., Rosenberg C., « NETtalk : A parallel network that learns to read aloud »,EE andCS Technical Report No. JHU/EECS-86/01, 1986.
Zemouri R., Racoceanu D., Zerhouni N., « The RRBF : Dynamic representation of time in radialbasis function network »,Proc. of the 8th IEEE International Conference on EmergingTechnologies and Factory Automation, ETFA’2001, vol. 2, p. 737-740, Octobre, 2001.
Zemouri R., Racoceanu D., Zerhouni N., « Réseaux de neuronesrécurrents à fonctions de baseradiales : RRFR, application au pronostic »,Revue d’Intelligence Artificielle, RSTI sérieRIA, vol. 16, n˚ 3, p. 307-338, 2003.





























