Embed Size (px)
Citation preview

Computer MathematicsWeek 5
Source coding and compression
College of Information Science and Engineering
Ritsumeikan University

last week
Input / OutputController
Universal Serial Bus PCI Bus
Mouse Keyboard, HDD GPU, Audio, SSD
Central Processing Unit
addressbus
CU
PCIR
ALU
registers
PSR
DR
operationselect
incrementPC
AR
RandomAccessMemory
0
4
8
16
20
24
28
databus
binary representations of signed numbers
• sign-magnitude, biased
• one’s complement, two’s complement
signed binary arithmetic
• negation
• addition, subtraction
• signed overflow detection
• multiplication, division
width conversion
• sign extension
floating-point numbers
2

this week
Mouse Keyboard GPU Audio
Input / OutputController
Universal Serial Bus PCI Bus
Central Processing Unit
addressbus
CU
PCIR
ALU
registers
PSR
DR
operationselect
incrementPC
AR
RandomAccessMemory
0
4
8
16
20
24
28
databus
HDD SSD Net
coding theory
• source coding
information theory concept
• information content
binary codes
• numbers
• text
variable-length codes
• UTF-8
compression
• Huffman’s algorithm
3

coding theory
coding theory studies
• the encoding (representation) of information as numbers
and how to make encodings more
• efficient (source coding)
• reliable (channel coding)
• secure (cryptography )
4

binary codes
a binary code assigns one or more bits to represent some piece of information
• number
• digit, character, or other written symbol
• colour, pixel value
• audio sample, frequency, amplitude
• etc.
codes can be
• arbitrary, or designed to have desirable properties
• fixed length, or variable length
• static, or generated dynamically for specific data
5
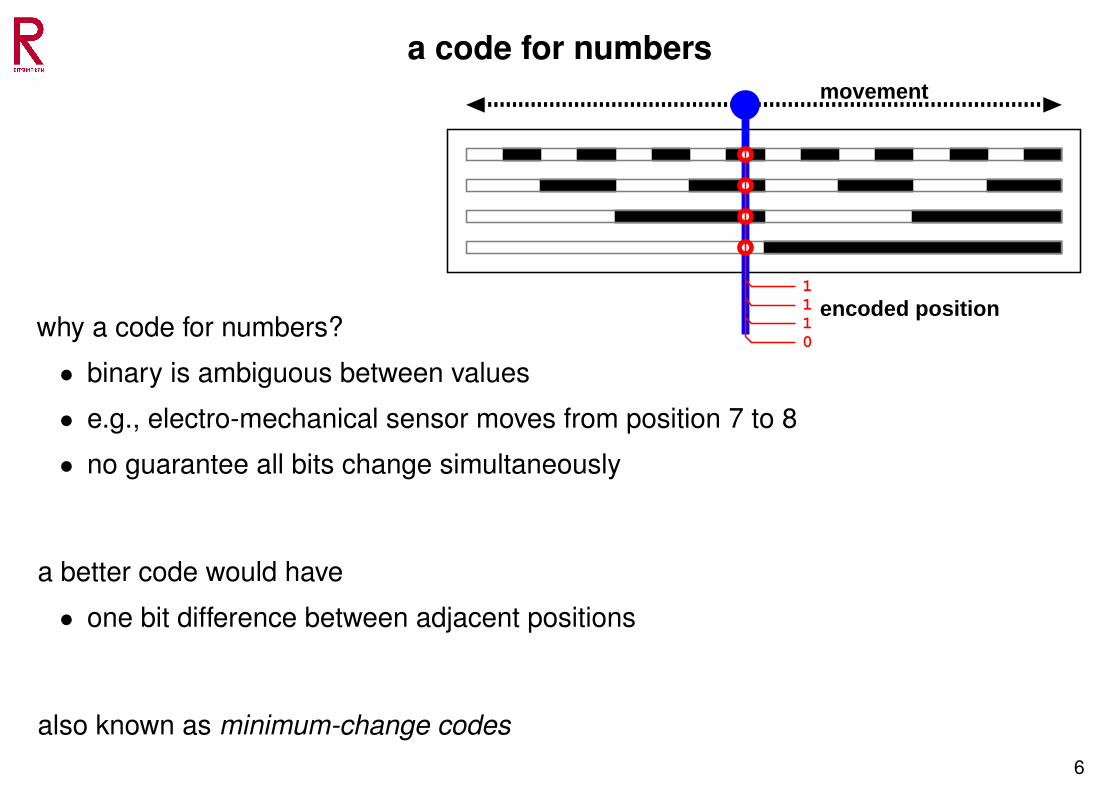
a code for numbers
1110
movement
encoded positionwhy a code for numbers?
• binary is ambiguous between values
• e.g., electro-mechanical sensor moves from position 7 to 8
• no guarantee all bits change simultaneously
a better code would have
• one bit difference between adjacent positions
also known as minimum-change codes6

reflected binary code
begin with a single bit encoding two positions (0 and 1)
• this has the property we need:– only one bit changes between adjacent positions
01
0011
1-bit2-bit3-bit
0110
refle
ct
0011
0110
refle
ct
00001111
1100
0110
to double the size of the code...
• repeat the bits by reflecting them– the two central positions now have the same code
• prefix the first half with 0, and the second half with 1
• this still has the property we need:– only the newly-added first bit changes between the two central positions
this is Gray code, named after its inventor
7
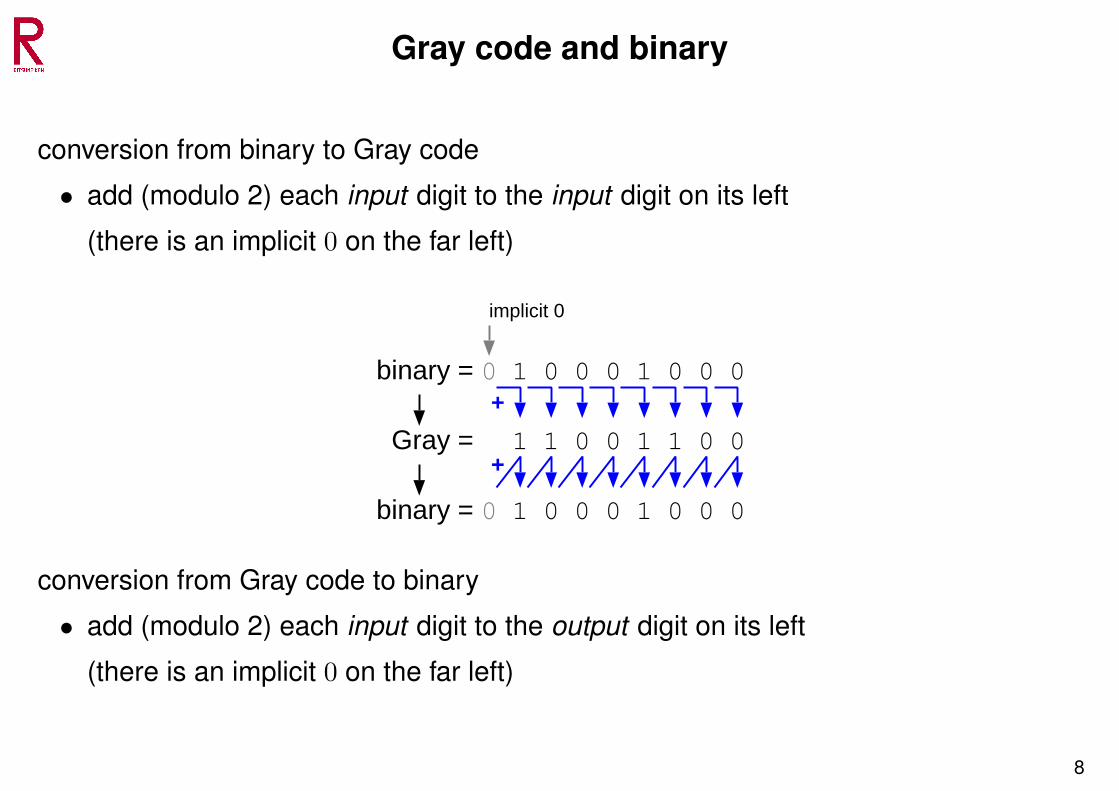
Gray code and binary
conversion from binary to Gray code
• add (modulo 2) each input digit to the input digit on its left
(there is an implicit 0 on the far left)
binary
implicit 0
1 0 0 0 1 0 0 0
Gray 1 0 0 1 0 0
binary 1 0 0 0 1 0 0 0
0+
1 1
0
+
=
=
=
conversion from Gray code to binary
• add (modulo 2) each input digit to the output digit on its left
(there is an implicit 0 on the far left)
8

binary and Gray code rotary encoders
9

high-resolution Gray code rotary encoder
10

fixed length codes for text
Baudot code (5 bits) → International Telegraph Alphabet (ITA) No. 2 (5 bits) → ASCII (7+1 bits)
11

fixed length codes for text: ASCII
ASCII (American Standard Code for Information Interchange)
• latin alphabet, arabic digits
• common western punctuation and mathematical symbols
the ASCII codes, in hexadecimal:
mos
tsig
nific
antd
igit
least significant digit0 1 2 3 4 5 6 7 8 9 A B C D E F
0 NUL SOH STX ETX EOT ENQ ACK BEL BS HT NL VT NP CR SO SI
1 DLE DC1 DC2 DC3 DC4 NAK SYN ETB CAN EM SUB ESC FS GS RS US
2 SP ! " # $ % & ’ ( ) * + , - . /3 0 1 2 3 4 5 6 7 8 9 : ; < = > ?4 @ A B C D E F G H I J K L M N O5 P Q R S T U V W X Y Z [ \ ] ^6 ‘ a b c d e f g h i j k l m n o7 p q r s t u v w x y z { | } ~ DEL
text:hex encoding:
H48
e65
l6C
l6C
o6F
␣20
t74
h68
e65
r72
e65
!21
12

fixed length codes for text: UTF-32
Unicode is a mapping of all written symbols to numbers
• modern languages, ancient languages, math/music/art symbols(and far too many useless emoticons)
• 21-bit numbering, usually written ‘U+hexadecimal-code’
• first 127 Unicode characters are the same as ASCII(hexadecimal)
name symbol Unicode ASCIIasterisk * U+2A 2A
star F U+2605 n/ashooting star U+1F320 n/a
UTF (Unicode Transformation Format) is an encoding of Unicode in binary
UTF-32 is a fixed length encoding
• each character’s number is represented directly as a 32-bit integer
13

variable length codes for text: UTF-8
UTF-32 is wasteful
• most western text uses the 7-bit ASCII subset U+20 – U+7F
• most other modern text uses characters with numbers < 216
– kana are in the range U+3000 – U+30FF– kanji are in the range U+4E00 – U+9FAF
UTF-8 is a variable length encoding of Unicode
• characters are between 1 and 4 bytes long
• first byte encodes the length of the character
• most common Unicode characters are encoded as one, two or three UTF-8 bytes
number of bits code points byte 1 byte 2 byte 3 byte 4
7 0016 – 7F16 0xxxxxxx211 (5 + 6) 008016 – 07FF16 110xxxxx2 10xxxxxx216 (4 + 6 + 6) 080016 – FFFF16 1110xxxx2 10xxxxxx2 10xxxxxx221 (3 + 6 + 6 + 6) 01000016 – 10FFFF16 11110xxx2 10xxxxxx2 10xxxxxx2 10xxxxxx2
↑ number of leading ‘1’s encodes the length in bytes
U+2605 (‘F’) = 0010 011000 0001012 = 111000102 100110002 100001012 = E2 98 851614

information theory
how much information is carried by a message?
• information is conveyed when you learn something new
if the message is predictable (e.g., series of ‘1’s)
• minimum information content
• zero bits of information per bit transmitted
if the message is unpredictable (e.g., series of random bits)
• maximum information content
• one bit of information per bit transmitted
if the probability of receiving a given bit (or symbol, or message) ‘x’ is Px, then
information content of x = log2
(1
Px
)bits
15

variable length encoding of known messages
messages often use only a few symbols from a code
e.g., in typical English text
• 12.702% of letters are ‘e’
• 0.074% of letters are ‘z’
considering their probability in English text
• ‘e’ conveys few bits of information (log2(1/0.12702) = 2.98 bits)
• ‘z’ conveys many bits of information (log2(1/0.00074) = 10.4 bits)
and yet they are both encoded using 8 bits of UTF-8 (or ASCII)
if we know the message in advance we could construct an encoding optimised for it
• make high-probability (low information) symbols use few bits
• make low-probability (high information) symbols use more bits
this is the goal of source coding, or ‘compression’
16
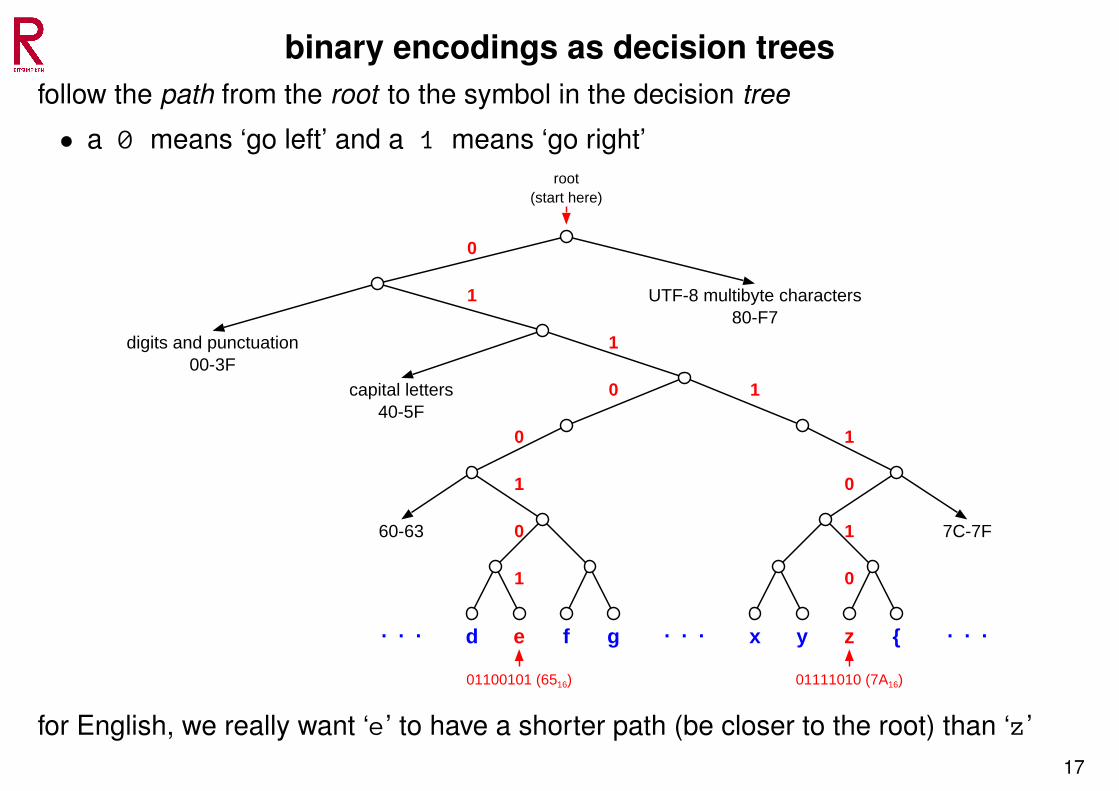
binary encodings as decision treesfollow the path from the root to the symbol in the decision tree
• a 0 means ‘go left’ and a 1 means ‘go right’
60-63
{z
1
0
0
1
1
e
1
0
0
0
1
1
1
digits and punctuation00-3F
capital letters40-5F
d gf yx
01100101 (6516) 01111010 (7A16)
7C-7F
UTF-8 multibyte characters80-F7
0
root(start here)
. . . . . . . . .
for English, we really want ‘e’ to have a shorter path (be closer to the root) than ‘z’17

Huffman coding
Huffman codes are variable-length codes that are optimal for a known message
the message is analysed to find the frequency (probability) of each symbol
a binary encoding is then constructed, from least to most probable symbols
• create a list of ‘subtrees’ containing just each symbol labeled with its probability
• repeatedly– remove the two lowest-probability subtrees s, t
– combine them into a new subtree p
– label p with the sum of the probabilities of s and t
– insert p into the list
• until only one subtree remains
the final remaining subtree in the list is an optimal binary encoding for the message
18

Huffman coding exampleknown message ‘googling’: f symbol P (s)
1 l i n 1/8 (3.00 bits of information)2 o 2/8 (2.00 bits)3 g 3/8 (1.42 bits)
repeatedly combine two lowest-probability subtrees
1. 3
gol i n
21 1 1
2. 3
go
l i
n
2
1 1
1 2
3. 33
g
ol i n
21 1 1
2
4. 53
3
go
l i
n
2
1 1
1 2
5. 8
53
3
go
l i
n
2
1 1
1 2
0 1
0 1 0 1
0 1
code table: symbol encodingn 00o 01l 100i 101g 11
encoded message:g11
o01
o01
g11
l100
i101
n00
g11
message length: 64 bits (UTF-8) vs. 18 bits (encoded)compression ratio: 64/18 = 3.6
actual information: 3× 3.0 + 2× 2.0 + 3× 1.42 = 17.26 bitsencoding optimal? d17.26e = 18 ( ..
^)
19

common source coding algorithmszip
• Huffman coding with a dynamic encoding tree
• tree updated to keep most recent common byte sequences efficiently encoded
video
• mp2, or MPEG-2 (Moving Picture Expert’s Group layer 2), for DVDs
• mp4, or MPEG-4, for web video
• avi (Audio Video Interleave), wmv (Windows Media Video), flv (Flash Video)
lossy audio (decoded audio has degraded quality and is permanently damaged)
• mp3, or MPEG-3 (Motion Picture Expert’s Group layer 3)
• AAC (Apple Audio Codec), wma (Windows Media Audio)
lossless audio (decoded audio is identical to the original)
• ALAC (Apple Lossless Audio Codec)
• FLAC (Free Lossless Audio Codec)
(CODEC = coder-decoder, a program that both encodes and decodes data)
20
next week
Input / OutputController
Universal Serial Bus PCI Bus
Mouse GPU
Central Processing Unit
addressbus
CU
PCIR
ALU
registers
PSR
DR
operationselect
incrementPC
AR
RandomAccessMemory
0
4
8
16
20
24
28
databus
Keyboard HDD Audio SSD Net
coding theory
• channel coding
information theory concept
• Hamming distance
error detection
• motivation
• parity
• cyclic redundancy checks
error correction
• motivation
• block parity
• Hamming codes
21

homework
practice converting between binary and gray code
• write a Python program to do it
practice encoding and decoding some UTF-8 characters
• write a Python program to do it
practice constructing Huffman codes
• write a Python program to do it
ask about anything you do not understand
• it will be too late for you to try to catch up later!
• I am always happy to explain things differently and practice examples with you
22

glossary
ASCII — American Standard Code for Information Interchange. A 7-bit encoding of the westernalphabet, digits, and common punctuation symbols. Almost always stored one character per 8-bitbyte.
binary code — a code that assigns a pattern of binary digits to represent each distinct piece ofinformation, such as each symbol in an alphabet.
channel coding — the theory of information encoding for the purpose of protecting it againstdamage.
compression — an efficient encoding of information that reduces its size when stored ortransmitted.
cryptography — an encoding of information for the purpose of protecting it from unauthorisedaccess.
encoding — a mapping of symbols or messages onto patterns of bits.
fixed length — an encoding in which every symbol is encoded using the same number of bits.
Gray code — an encoding of numbers with the property that adjacent values differ by only onebit.
information content — the theoretical number of bits of information associated with a symbol ormessage.
minimum-change — an encoding of symbols in which adjacent codes differ by only one bit.
23

path — a route through a tree from the root to some given node.
root — the topmost node in a tree.
source coding — the theory of information encoding for the purpose of reducing its size.
tree — a hierarchical structure representing parent-child relationships between nodes.
Unicode — a numbering of all symbols used in modern and ancient written languages, and otherwritten systems of representation such as music.
UTF-32 — a fixed length encoding of Unicode in which each character’s number is encodeddirectly in a 32-bit integer.
UTF-8 — a variable length encoding of Unicode in which each character’s number is encoded inone, two, three or four bytes.
UTF — Unicode Transformation Format. A family of binary encodings for Unicode characters.
variable length — an encoding in which different symbols are encoded using different numbersof bits.
24





























