Embed Size (px)
Citation preview

1
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Organizacja i Architektura Komputerów
Wprowadzenie
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
prof. dr hab. in . Ryszard Pe!ka
e-mail: [email protected]
Literatura
[1] W. Stallings, Organizacja i architektura
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
komputerów, WNT, 2004 (t!um. wydania 4)
[2] B.S. Chalk, Organizacja i architektura komputerów, WNT, 1998
[3] P. Metzger, Anatomia PC, Helion, 2007
[4] A. Kowalczyk, Asembler, Croma, 1999
[5] A. Skorupski, Podstawy budowy i dzia ania komputerów,
WK#, 2005
4
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Literatura uzupe niaj!ca
[1] D.A. Patterson, J.L. Hennessy, Computer Organization
and Design: The Hardware/Software Interface, Morgan
Kaufmann, 3rd edition, 2005
[2] J.P. Hayes, Computer Architecture Organization,
McGraw-Hill, 4th edition, 2002
[3] W. Stallings, Computer Organization and Architecture,
Prentice Hall, 6th edition, 2003
5
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Internet
[1] Computer Architecture WWW Home Page
http://www.cs.wisc.edu/~arch/www
strona Uniwersytetu Wisconsin
[2] AMD web site
http://www.amd.com
[3] Intel Developer’s Site
http://developer.intel.com
6
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Plan przedmiotu
Wprowadzenie
– Podstawowe poj$cia, terminologia
– Co to jest architektura komputerów?
– Co to jest organizacja komputerów?
– Bloki funkcjonalne komputerów
– Podstawowe zasady wspó!pracy bloków funkcjonalnych
7
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Plan przedmiotu (cd.)
Historia i ewolucja komputerów– wp!yw technologii na rozwój komputerów
– wydajno%& komputerów
– programy testuj"ce wydajno%& (benchmarki)
Arytmetyka komputerów– kody liczbowe, konwersja kodów
– operacje arytmetyczne
– arytmetyka zmiennopozycyjna
Uk!ady i bloki cyfrowe– bramki, przerzutniki, rejestry, liczniki, multipleksery
– pó!sumator i sumator
– jednostka arytmetyczno-logiczna ALU
– uk!ady mno enia i dzielenia
8
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Plan przedmiotu (cd.)
Procesor (CPU)
– standardowa architektura procesora
– jednostka wykonawcza i steruj"ca
– cykl wykonania rozkazu
– stos
– przerwania
Architektury wspó!czesnych procesorów
– ogólna architektura procesorów IA-32 i IA-64
– rejestry
– segmentacja pami$ci

9
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Plan przedmiotu (cd.)
J$zyk asemblera– j$zyk asemblera i wysokiego poziomu
– tryby adresowania argumentów
– formaty instrukcji
– lista instrukcji (ISA), grupy instrukcji
instrukcje przes!a'
operacje arytmetyczne
operacje logiczne, operacje na bitach
skoki, p$tle, instrukcje steruj"ce
– przyk!ady programów
– makroasemblery
– debugery
10
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Plan przedmiotu (cd.)
Pami$&
– technologie wytwarzania pami$ci
– pami$ci RAM, SRAM, DRAM
– pami$ci ROM, PROM, EEPROM i Flash
– wspó!praca procesora z pami$ciami
– bezpo%redni dost$p do pami$ci (DMA)
– segmentacja i stronicowanie
– pami$& wirtualna
Pami$& cache
– hierarchia systemu pami$ci
– metody odwzorowywania pami$ci cache
– spójno%& pami$ci cache
11
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Plan przedmiotu (cd.)
Potok instrukcji (pipeline)
– dzia!anie przetwarzania potokowego
– przewidywanie skoków
– optymalizacja potoku instrukcji
– przyk!ady implementacji
Architektura superskalarna
– przyk!ady procesorów
12
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Plan przedmiotu (cd.)
Architektura RISC
– Podstawowe w!asno%ci
– Banki i okna rejestrów
– Przetwarzanie potokowe w architekturze RISC
– Przyk!ady procesorów
– Porównanie architektur RISC i CISC
Architektura VLIW
Zagadnienia fakultatywne:
– Przetwarzanie równoleg!e, systemy wieloprocesorowe
– Architektury wielordzeniowe
Podsumowanie
13
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Egzamin
pisemny test– oko!o 10 zada' sprawdzaj"cych
znajomo%& g!ównych zagadnie'poruszanych na wyk!adach
– zadania koncepcyjne i rachunkowe
– tematyka w ca!o%ci zwi"zana z wyk!adem
– szczegó!owe zagadnienia egzaminacyjne i przyk!ady zada' – w trakcie wyk!adu
14
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Wyniki i obecno"# na wyk adach
0
10
20
30
40
50
60
70
80
90
100
Obecno"#
>75%
Obecno"#
< 30%
pozytywnie
negatywnie
Dane z roku akademickiego 2006/2007 – dla wybranych grup studentów poddanych ankietyzacji
15
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Architektura i organizacja (1)
Architektura to atrybuty komputera „widoczne”dla programisty:
– lista instrukcji, liczba bitów stosowana do reprezentacji danych, mechanizm I/O, techniki adresowania
– np. czy dost$pna jest operacja mno enia?
Organizacja oznacza sposób implementacji architektury
– sygna!y steruj"ce, interfejsy, technologia wykonania pami$ci itp.
– np. czy mno enie jest realizowane sprz$towo, czy przez sekwencj$ dodawa'?
16
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Architektura i organizacja cd.
... the attributes of a [computing] system as seen by the programmer, i.e. the conceptual structure and functional behavior, as distinct from the organization of the data flows and controls the logic design, and the physical implementation.
– Amdahl, Blaaw, and Brooks, 1964
(...atrybuty systemu komputerowego widziane przez programist$, tzn. koncepcyjna struktura i zachowanie funkcjonalne, w odró nieniu od organizacji przep!ywu danych, sterowania uk!adami logicznymi i fizycznej implementacji)

17
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Architektura i organizacja cd.
Hardware Design
Software Design
18
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Architektura i organizacja cd.
wszystkie procesory Intel x86 maj" podobn"
podstawow" architektur$
to zapewnia zgodno%& programow"
– przynajmniej w dó! (backward compatibility)
organizacja poszczególnych wersji procesorów
Intel x86 jest ró na
19
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Architektura i organizacja cd.
Architektura komputera =
architektura listy instrukcji + ...
20
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Ewolucja poj$cia „architektura”
1950s to 1960s: Computer Architecture Course:
Computer Arithmetic
1970s to mid 1980s: Computer Architecture Course:
Instruction Set Design, especially ISA appropriate for compilers
1990s: Computer Architecture Course:Design of CPU, memory system, I/O system, Multiprocessors, Networks
2010s: Computer Architecture Course:
Self adapting systems? Self organizing structures?DNA Systems/Quantum Computing?
John Kubiatowicz, Berkeley University
21
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Przyk ady ISA (Instruction Set Architecture)
Digital Alpha v1, v3 ... 1992
HP PA-RISC v1.1, v2.0 1986
Sun Sparc v8, v9 1987
MIPS / ARM MIPS I, II, III, IV, V, 10k, 20k, 1986
ARM7, ARM9, ARM11, Cortex
Intel / AMD 8086,80286,80386, 1978
80486,Pentium, MMX,
Pentium II, III, IV, ...
22
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Funkcje i g ówne bloki komputera
Funkcje
– przechowywanie danych
– przesy!anie danych
– przetwarzanie danych
– funkcje steruj"ce
Bloki funkcjonalne
– pami$&
– podsystem I/O
– procesor (arytmometr)
– procesor (uk!ad steruj"cy)
23
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Bloki funkcjonalne komputera
Od 1946 r. komputery niezmiennie sk!adaj" si$ z 5 tych samych bloków:
Pami !
Wej"cie
Procesor
Sterowanie
Arytmometr Wyj"cie
24
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
... ale ró%ni! si$ wydajno"ci!
http://hrst.mit.edu/hrs/apollo/public/index.htm
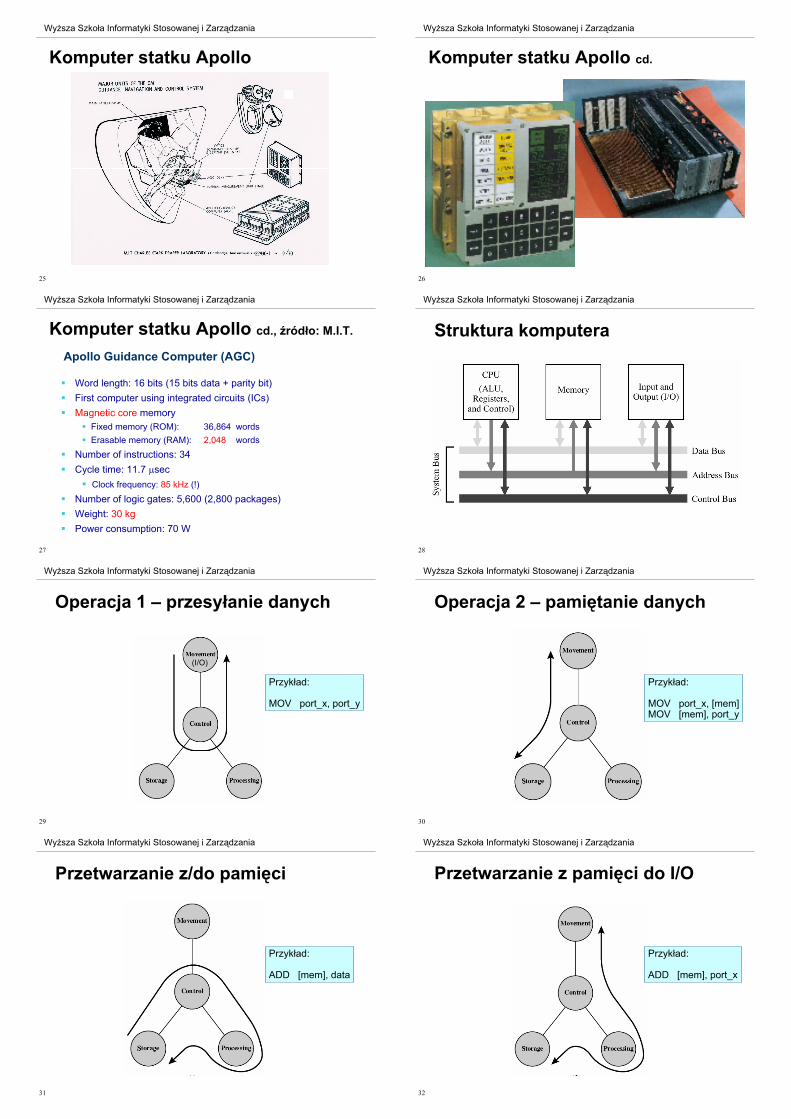
25
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Komputer statku Apollo
26
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Komputer statku Apollo cd.
27
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Komputer statku Apollo cd., &ród o: M.I.T.
Apollo Guidance Computer (AGC)
! Word length: 16 bits (15 bits data + parity bit)
! First computer using integrated circuits (ICs)
! Magnetic core memory
! Fixed memory (ROM): 36,864 words
! Erasable memory (RAM): 2,048 words
! Number of instructions: 34
! Cycle time: 11.7 sec
! Clock frequency: 85 kHz (!)
! Number of logic gates: 5,600 (2,800 packages)
! Weight: 30 kg
! Power consumption: 70 W
28
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Struktura komputera
29
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Operacja 1 – przesy anie danych
(I/O)
Przyk!ad:
MOV port_x, port_y
30
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Operacja 2 – pami$tanie danych
Przyk!ad:
MOV port_x, [mem]MOV [mem], port_y
31
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Przetwarzanie z/do pami$ci
Przyk!ad:
ADD [mem], data
32
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Przetwarzanie z pami$ci do I/O
Przyk!ad:
ADD [mem], port_x

33
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Struktura komputera – wysoki poziom
Computer
Main
Memory
Input
Output
Systems
Interconnection
Peripherals
Communications
lines
Central
Processing
Unit
Computer
34
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Struktura CPU
Computer
Arithmetic
and
Logic Unit
Control
Unit
Internal CPU
Interconnection
Registers
CPU
I/O
Memory
System
Bus
CPU
35
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Struktura uk adu sterowania
CPU
Control
Memory
Control Unit
Registers and
Decoders
Sequencing
LogicControl
Unit
ALU
Registers
Internal
Bus
Control Unit
36
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Przyk adowa organizacja
TI SuperSPARCtm TMS390Z50 in Sun SPARCstation20
Floating-point Unit
Integer Unit
Inst
Cache
Ref
MMU
Data
Cache
Store
Buffer
Bus Interface
SuperSPARC
L2 CC
MBus Module
MBus
L64852MBus control
M-S Adapter
SBus
DRAM
Controller
SBusDMA
SCSI
Ethernet
STDIO
serial
kbdmouse
audio
RTC
Boot PROM
Floppy
SBus
Cards
37
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Podstawowe poj$cia
Pami$#– w ogólnym znaczeniu – blok funkcjonalny do przechowywania
informacji na okre%lonym no%niku (zwykle magnetycznym lub pó!przewodnikowym)
– pami$& RAM – pami$& pó!przewodnikowa zbudowana z przerzutników (SRAM) lub tranzystorów MOS (DRAM)
Rejestr– pami$& o niewielkiej pojemno%ci (najcz$%ciej 8, 16, 32 lub 64
bitów) wbudowana do procesora lub innego uk!adu cyfrowego VLSI, wykonana zwykle jako SRAM (zbiór przerzutników)
ALU (arithmetic-logic unit)– arytmometr, g!ówny element bloku wykonawczego procesora
zdolny do realizacji podstawowych operacji arytmetycznych i logicznych
FP (floating-point)– zmiennoprzecinkowy zapis liczb (znak, mantysa, wyk!adnik)
38
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Podstawowe poj$cia cd.
Pami$# cache– nazywana podr$czn" lub kieszeniow" – dodatkowa pami$&
buforowa umieszczona mi$dzy g!ówn" pami$ci" komputera (operacyjn") a procesorem; jej zadaniem jest przyspieszenie komunikacji procesora z pami$ci" g!ówn"
Potok instrukcji (pipeline)– ci"g instrukcji (zwykle kilku lub kilkunastu) pobranych przez
procesor i wykonywanych etapami, tak jak na ta%mie produkcyjnej
Procesor superskalarny– procesor z wieloma potokami instrukcji i wieloma uk!adami
wykonawczymi (arytmometrami)
Zegar– generator impulsów taktuj"cych bloki funkcjonalne systemu
cyfrowego
39
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Podstawowe poj$cia cd.
J$zyk asemblera
– j$zyk programowania operuj"cy elementarnymi instrukcjami
zrozumia!ymi dla procesora
J$zyk wysokiego poziomu (C, C++, C#, Python, Java)
– j$zyk programowania operuj"cy z!o onymi instrukcjami,
niezrozumia!ymi dla procesora; program przed wykonaniem musi
by& przet!umaczony na j$zyk asemblera
Szyna, magistrala
– zbiór linii przesy!aj"cych sygna!y mi$dzy blokami cyfrowymi
systemu (adresy, dane, sygna!y steruj"ce)
I/O – input/output
– uk!ady wej%cia/wyj%cia do komunikacji z otoczeniem
40
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Podstawowe poj$cia cd.
Architektura CISC (np. Pentium)
– Complex Instruction Set Computer
– procesor wykorzystuj"cy bogaty zestaw (list$) instrukcji i liczne
sposoby adresowania argumentów; charakterystyczn" cech"
jest zró nicowana d!ugo%& instrukcji (w bajtach) i czas ich
wykonania
Architektura RISC (np. PowerPC, MIPS, ARM)
– Reduced Instruction Set Computer
– procesor wykorzystuj"cy niewielki zbiór elementarnych
rozkazów o zunifikowanej d!ugo%ci i takim samym czasie
wykonania

41
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Podsumowanie
Architektura komputera oznacza jego w!a%ciwo%ci
„widziane” przez programist$ (struktura rejestrów, lista
instrukcji itp..)
Organizacja komputera oznacza konkretn"
implementacj$ (realizacj$) architektury przy u yciu
okre%lonych uk!adów i bloków cyfrowych
Komputer sk!ada si$ z 5 podstawowych elementów:
uk!adu wykonawczego, uk!adu sterowania, pami$ci,
uk!adów wej%cia i wyj%cia
Uk!ad wykonawczy i steruj"cy tworz" jednostk$
centraln" (CPU)

1
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Organizacja i Architektura Komputerów
Ewolucja komputerów i ich architektury
2
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
ENIAC – pierwszy komputer
Electronic Numerical Integrator And Computer
konstruktorzy: Eckert and Mauchly
University of Pennsylvania
obliczenia trajektorii pocisków (balistyka)
pocz"tek projektu: 1943
zako#czenie projektu: 1946
– za pó$no by wykorzysta% ENIAC w II wojnie &wiatowej
u ywany do 1955
3
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
ENIAC Eckert and Mauchly
1st working electronic
computer (1946)
18,000 Vacuum tubes
1,800 instructions/sec
3,000 ft3
4
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
ENIAC – programowanie
5
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
ENIAC – serwis
Wymiana
uszkodzonej
lampy
wymaga!a
sprawdzenia
18 000
mo liwo&ci
6
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Testowanie komputera
g!ównym narz'dziem jest
oscyloskop
stosuje si' specjalne
matryce do generowania
testowych sekwencji
bitów
7
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
ENIAC – parametry techniczne
arytmetyka dziesi'tna (nie dwójkowa)
20 akumulatorów po 10 cyfr w ka dym
programowany r'cznie prze!"cznikami
18,000 lamp, 70,000 rezystorów, 10,000 kondensatorów,
6,000 prze!"czników
masa 30 ton
powierzchnia 1,500 stóp2, (30 x 50 stóp)
pobór mocy 140 kW
5,000 operacji dodawania na sekund' (0,005 MIPS)
8
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
EDSAC 1 - 1949
Maurice Wilkes
1st store program computer
650 instructions/sec
1,400 ft3
http://www.cl.cam.ac.uk/UoCCL/misc/EDSAC99/

9
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Architektura von Neumanna
program przechowywany w pami'ci
program i dane rezyduj" we
wspólnej pami'ci
ALU pracuje na danych dwójkowych
jednostka steruj"ca interpretuje
i wykonuje rozkazy pobierane z pami'ci
jednostka steruj"ca zarz"dza systemem I/O
Princeton Institute for Advanced Studies – IAS (tak samo nazwano prototypowy komputer)
zako#czenie projektu: 1952
10
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
John von Neumann
1903 – 1957
matematyk ameryka#ski pochodzenia w'gierskiego
od 1933 profesor ISA w Princeton
od 1937 cz!onek Akademii Nauk w Waszyngtonie
od 1954 cz!onek Komisji do Spraw Energii Atomowej
USA
1945 – 1955: dyrektor Biura Projektów Komputerów
Cyfrowych w USA
11
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Architektura von Neumanna
12
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
IAS – parametry
1000 s!ów po 40 bitów
– arytmetyka dwójkowa
– format instrukcji 2 x 20 bitów
Zbiór rejestrów (zawarty w CPU)
– Memory Buffer Register (MBR - rejestr bufora pami'ci)
– Memory Address Register (MAR - rejestr adresowy)
– Instruction Register (IR - rejestr instrukcji)
– Instruction Buffer Register (IBR - rejestr bufora instrukcji)
– Program Counter (PC - licznik rozkazów)
– Accumulator (A - akumulator)
– Multiplier Quotient (MQ - rejestr ilorazu)
13
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
IAS – strukturaCentral Processing Unit
Main
Memory
Arithmetic and Logic Unit
Program Control Unit
Input
Output
MBR
Arithmetic & Logic Circuits
MQAccumulator
MAR
Control
Circuits
IBR
IR
PC
Instructions
& Data
Address
14
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Pierwsze komputery komercyjne
1947 - Eckert-Mauchly Computer Corporation
UNIVAC I (Universal Automatic Computer)
– 1950 - US Bureau of Census, obliczenia biurowe
powstaje Sperry-Rand Corporation
koniec lat 50-tych - UNIVAC II
– wi'ksza szybko&%
– wi'ksza pami'%
15
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
IBM
produkcja urz"dze# do perforowania kart
1953 - model 701
– pierwszy komputer IBM oferowany na rynku
– obliczenia naukowe
1955 - model 702
– zastosowania biurowe (banki, administracja)
pocz"tek serii komputerów 700/7000
16
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Pami ! ferrytowa
radykalna poprawa niezawodno&ci
brak ruchomych cz'&ci
pami'% nieulotna
relatywnie niski koszt
wi'ksze pojemno&ci

17
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Tranzystor
nast'pca lamp
znacznie mniejszy
ta#szy
mniejszy pobór mocy
wykonany z pó!przewodnika
wynaleziony w 1947 w Bell Labs
William Shockley et al.
Raytheon CK722
1954
18
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
2 generacja komputerów
podstawowym elementem jest tranzystor
NCR & RCA – „ma!e” komputery
IBM 7000
DEC - 1957
– model PDP-1
19
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Minikomputery – IBM 360
IBM 360/40
• 1964 rok
• 1.6 MHz CPU
• 32 – 256 KB RAM
• $ 225 000
1964
IBM 360 zast'puje seri' 7000
– brak kompatybilno&ci
pierwsza rodzina popularnych
komputerów
– podobne lub identyczne
listy instrukcji
– podobny lub taki sam OS
– rosn"ca szybko&%
– wzrost liczby uk!adów I/O (terminali)
– wzrost pojemno&ci pami'ci
– kolejne modele kosztuj"coraz wi'cej
pojawiaj" si' emulatory dla serii 7000 - /1400
20
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
DEC PDP – 8
1964
pierwszy minikomputer
klimatyzacja pomieszczenia
nie jest wymagana
mie&ci si' na biurku
cena $16,000
– dla porównania IBM 360 kosztuje $100k+
wbudowane aplikacje & OEM
nowatorska struktura szyn (OMNIBUS)
21
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Pmi ! pó"przewodnikowa
1970
Fairchild
rozmiar pojedynczego rdzenia ferrytowego– ca!a pami'% ma teraz taki rozmiar jak wcze&niej
komórka 1-bitowa
pojemno&% 256 bitów
odczyt nie niszczy zawarto&ci
znacznie wi'ksza szybko&% ni dla pami'ci ferrytowych
pojemno&% podwaja si' co rok
22
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Rozwój mikroelektroniki
podstawowy element – uk!ad scalony
uk!ady SSI, potem MSI, wreszcie LSI i VLSI
seryjna produkcja uk!adów scalonych na bazie
krzemu
23
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Generacje uk"adów elektronicznych
lampa – 1946 -1957
tranzystor – 1958 -1964
uk!ady scalone ma!ej skali integracji (SSI) – od 1965– do 100 elementów w uk!adzie
&rednia skala integracji (MSI) - od 1971– 100 - 3,000 elementów w uk!adzie
wielka skala integracji (LSI) – 1971 - 1977– 3,000 - 100,000 elementów w uk!adzie
bardzo wielka skala integracji (VLSI) - 1978 do dzi&– 100,000 - 100,000,000 elementów w uk!adzie
ultra wielka skala integracji (UVLSI) – koniec lat 90’– ponad 100,000,000 elementów w uk!adzie
24
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
25
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Prawo Moore’a
opisuje tempo wzrostu liczby elementów w uk!adzie
Gordon Moore – wspó!za!o yciel Intela
liczba tranzystorów w uk!adzie podwaja si' co roku
od roku 1970 wzrost zosta! nieco zahamowany– liczba tranzystorów podwaja si' co 18 miesi'cy
koszt uk!adu pozostaje niemal bez zmian
wi'ksza g'sto&% upakowania elementów skraca po!"czenia, przez co wzrasta szybko&% uk!adów
zmniejsza si' rozmiar uk!adów
zmniejszaj" si' wymagania na moc zasilania i ch!odzenie
mniejsza liczba po!"cze# w systemie cyfrowym poprawia niezawodno&%
26
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Prawo Moore’a
27
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Prawo Moore’a
28
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
2 prawo Moore’a
Koszt uruchomienia produkcji nowego uk!adu CPU UVLSI
wzrasta wyk!adniczo
Ko
szt
wd
r o#e
nia
pro
du
kc
ji u
k"a
du
w m
l n$
29
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Wzrost pojemno$ci DRAM
Rok Rozmiar
1980 64 Kb
1983 256 Kb
1986 1 Mb
1989 4 Mb
1992 16 Mb
1996 64 Mb
1999 256 Mb
2002 1 Gb
2010 ?30
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Rozwój mikroprocesorów i DRAM
1
10
100
1000
10000
100000
1980 1985 1990 1995 2000 2005
CPU Memory
Perf
orm
an
ce
31
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Szybko$! DRAM i CPU
Szybko&% procesorów ros!a pr'dzej ni
szybko&% pami'ci RAM
Jakie problemy wynikaj" st"d dla konstruktorów
komputerów?
32
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
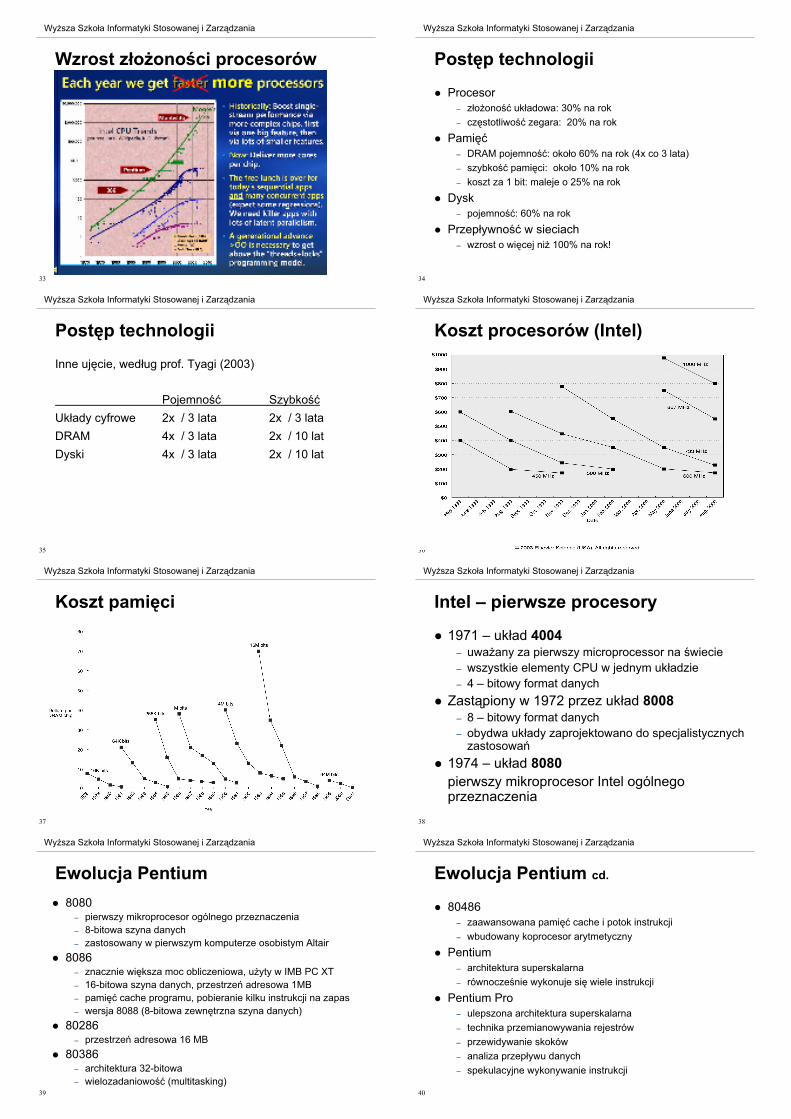
Rozwi%zania (DRAM vs. CPU)
zwi'kszy% liczb' bitów odczytywanych w jednym cyklu
– DRAM powinna by% „szersza” a nie „g!'bsza”
zmieni% interfejs DRAM– pami'% cache
zmniejszy% cz'sto&% dost'pów do pami'ci– bardziej skomplikowana pami'% cache umieszczona
w CPU
zwi'kszy% przep!ywno&% szyn– szyny typu high-speed
– szyny hierarchiczne
33
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Wzrost z"o#ono$ci procesorów
34
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Post p technologii
Procesor
– z!o ono&% uk!adowa: 30% na rok
– cz'stotliwo&% zegara: 20% na rok
Pami'%
– DRAM pojemno&%: oko!o 60% na rok (4x co 3 lata)
– szybko&% pami'ci: oko!o 10% na rok
– koszt za 1 bit: maleje o 25% na rok
Dysk
– pojemno&%: 60% na rok
Przep!ywno&% w sieciach
– wzrost o wi'cej ni 100% na rok!
35
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Post p technologii
Inne uj'cie, wed!ug prof. Tyagi (2003)
Pojemno&% Szybko&%
Uk!ady cyfrowe 2x / 3 lata 2x / 3 lata
DRAM 4x / 3 lata 2x / 10 lat
Dyski 4x / 3 lata 2x / 10 lat
36
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Koszt procesorów (Intel)
37
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Koszt pami ci
38
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Intel – pierwsze procesory
1971 – uk!ad 4004 – uwa any za pierwszy microprocessor na &wiecie
– wszystkie elementy CPU w jednym uk!adzie
– 4 – bitowy format danych
Zast"piony w 1972 przez uk!ad 8008– 8 – bitowy format danych
– obydwa uk!ady zaprojektowano do specjalistycznych zastosowa#
1974 – uk!ad 8080
pierwszy mikroprocesor Intel ogólnego przeznaczenia
39
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Ewolucja Pentium
8080– pierwszy mikroprocesor ogólnego przeznaczenia
– 8-bitowa szyna danych
– zastosowany w pierwszym komputerze osobistym Altair
8086– znacznie wi'ksza moc obliczeniowa, u yty w IMB PC XT
– 16-bitowa szyna danych, przestrze# adresowa 1MB
– pami'% cache programu, pobieranie kilku instrukcji na zapas
– wersja 8088 (8-bitowa zewn'trzna szyna danych)
80286– przestrze# adresowa 16 MB
80386– architektura 32-bitowa
– wielozadaniowo&% (multitasking)40
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Ewolucja Pentium cd.
80486
– zaawansowana pami'% cache i potok instrukcji
– wbudowany koprocesor arytmetyczny
Pentium
– architektura superskalarna
– równocze&nie wykonuje si' wiele instrukcji
Pentium Pro
– ulepszona architektura superskalarna
– technika przemianowywania rejestrów
– przewidywanie skoków
– analiza przep!ywu danych
– spekulacyjne wykonywanie instrukcji

41
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Ewolucja Pentium cd.
Pentium II– technologia MMX
– przetwarzanie grafiki, audio & video
Pentium III– dodatkowe instrukcje zmiennoprzecinkowe dla grafiki 3D
Pentium 4– uwaga – pierwsze oznaczenie cyfr" arabsk", a nie rzymsk" !
– dalsze ulepszenia FPU i operacji multimedialnych
Itanium / Itanium 2– architektura 64-bitowa
– EPIC – Explicit Paralell Instruction Computing
– rejestry 128-bitowe
– Instrukcje 41-bitowe w pakietach 128-bitowych (3 instr.
+ 5 bitów pokazuj"cych typ i wspó!zale no&ci)
42
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Granice technologii ?
Dzi& (2008) Intel i AMD stosuj"
technologi' 90 / 65 nm, trwaj"
prace nad wdro eniem technologii
45 nm
43
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Granice technologii ?
44
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
45
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Trend rozwoju technologii
46
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Wspó"czesny procesor
Intel Core 2 Duo: Courtesy: Intel Corp.
P4HT: Courtesy: Intel Corp.
47
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Technologia wielowarstwowa
48
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Technologia wielowarstwowa cd..
Fragment procesora UVLSI, zdj'cie z mikroskopu elektronowego
Courtesy IBM Corp.

49
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Prognozy bywaj% niedok"adne
Twój PC w 2005 roku wed ug J. Breechera, Clarc
University, 2002
zegar procesora 8 GHz
pojemno&% pami'ci RAM 1 GB
pojemno&% dysku 240 GB (0,24 TB)
Potrzebujemy kolejnych jednostek miar:
Mega Giga Tera !!!
50
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Prognozy bywaj% niedok"adne cd..
ITRS -International Technology Roadmap for Semiconductors
prognozaz 1999 roku
YEAR 2002 2005 2008 2011 2014
TECHNOLOGY 130 nm 100 nm 70 nm 50 nm 35 nm
CHIP SIZE 400 mm2
600 mm2
750 mm2
800 mm2
900 mm2
NUMBER OFTRANSISTORS(LOGIC)
400 M 1 Billion 3 Billion 6 Billion 16 Billion
DRAMCAPACITY
2 Gbits 10 Gbits 25 Gbits 70 Gbits 200 Gbits
MAXIMUMCLOCKFREQUENCY
1.6 GHz 2.0 GHz 2.5 GHz 3.0 GHz 3.5 GHz
MINIMUMSUPPLYVOLTAGE
1.5 V 1.2 V 0.9 V 0.6 V 0.6 V
MAXIMUMPOWERDISSIPATION
130 W 160 W 170 W 175 W 180 W
MAXIMUMNUMBER OFI/O PINS
2500 4000 4500 5500 6000
51
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
50 lat rozwoju komputerów
52
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Systemy „desktop” i wbudowane
53
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Rynek procesorów RISC
2001 2007
MIPS
14%
ARM
66%
SHx
10%
PowerPC
8%
Other
1%
SPARC
1%
MIPS
11%
ARM
75%
SHx
8%
Other
2%PowerPC
3%
SPARC
1%
54
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
&a'cuch pokarmowy
Big Fishes Eating Little Fishes
55
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
1988 Computer Food Chain
PCWork-station
Mini-computer
Mainframe
Mini-supercomputer
Supercomputer
Massively Parallel Processors
56
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
2008 Computer Food Chain
Mini-supercomputer
MPPs, clusters
Mini-computer
PCWork-station
Mainframe
Supercomputer Now who is eating whom?
Server

57
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Komputery przysz"o$ci
• Molecular Computing• http://www.nytimes.com/2002/10/25/technology/25COMP.html?ex=
1036558800&en=10e57e62ea60c115&ei=5062
• http://pcquest.ciol.com/content/technology/10004402.asp
• http://www.ddj.com/articles/2000/0013/0013b/0013b.htm
• DNA Computing• http://arstechnica.com/reviews/2q00/dna/dna-1.html
• http://www.englib.cornell.edu/scitech/w96/DNA.html
• Quantum Computing• http://www.qtc.ecs.soton.ac.uk/lecture1/lecture1a.html
• http://www.mills.edu/ACAD_INFO/MCS/CS/S01MCS125/QuantumComputing/
concepts.html
• http://www.cs.caltech.edu/~westside/quantum-intro.html
58
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Podsumowanie
pierwszy komputer – ENIAC
architektura von Neumanna – IAS
prawo Moore’a
generacje uk!adów cyfrowych i komputerów
szybko&% procesorów ro&nie w wi'kszym tempie ni
szybko&% pami'ci – konsekwencje i rozwi"zania
ewolucja procesorów x86
granice technologii
komputery przysz!o&ci

1
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Organizacja i Architektura Komputerów
Wydajno#$ komputerów
2
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Metryki marketingowe
MIPS– Millions Instructions Per Second
– (liczba instrukcji / 106) / czas CPU
MFLOPS– Millions Float Point Operations Per Second
– (liczba operacji FP / 106) / czas CPU
Zalety MIPS, MFLOPS i innych MOPS– Prosta i zrozumia!a dla laików definicja, !atwo#$ okre#lenia
Wady– Metryki MIPS i MFLOPS zale " od architektury ISA tote
porównanie ró nych architektur jest niemo liwe
– Dla ró nych programów wykonywanych przez ten sam komputer otrzymuje si% ró ne warto#ci metryk
– W skrajnych przypadkach metryki MIPS i MFLOPS mog" dawa$odwrotne wyniki ni metryki oparte na pomiarach CPU time
3
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Przyk ady metryki MIPS (Intel)
Procesor Data Liczba tranzystorów MIPS
4004 11/71 2300 0.06
8008 4/72 3500 0.06
8080 4/74 6000 0.1
8086 6/78 29000 0.3
8088 6/79 29000 0.3
286 2/82 134000 0.9
386 10/85 275000 5
486 4/89 1.2M 20
Pentium 3/93 3.1M 100
Pentium Pro 3/95 5.5M 300
Pentium III (Xeon)
Pentium 4 HT
2/99
10/2002
10M
108M
500
>1000
4
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Czas w systemie komputerowym
polecenie time w systemie UNIX
Przyk!ad:
90.7u 12.9s 2:39 65%
user CPU time = 90.7 s
system CPU time = 12.9 s
elapsed time = 2 min 39 s (159 s)
user CPU/elapsed = 65 % = (90.7 + 12.9)/159
5
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Wydajno!" komputera
Wydajno#$ - Computer Performance
– czas oczekiwania na wynik
Response time (latency)
– przepustowo#$ systemu
Throughput
Przedmiotem uwagi OAK jest szczególnie
– czas CPU wykorzystany przez u ytkownika
User CPU time
czas zu yty przez CPU na wykonanie programu
6
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Wydajno!" cd.
Metryki wydajno#ci procesora
CPI (cycles per instruction) – #rednia liczba cykli procesora potrzebna do wykonania instrukcji wi" e si% z:
– architektur" listy instrukcji (ISA)
– implementacj" ISA
n(CPI)instructiopercyclesclockavgns/pgmInstructiocycles/pgmclockCPU
timecycleclockcycles/pgmCPU clock ion timeCPU execut
. !
!
7
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Wydajno!" cd.
Definicja wydajno#ci
Maszyna X jest n razy szybsza od maszynyY je#li
x
xtimeExecution
1ePerformanc !
nePerformanc
ePerformanc
y
x !
8
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Wydajno!" cd.
Aby okre#li$ wydajno#$ komputera nale y:
– zmierzy$ czas wykonania programu testowego (benchmark)
Aby obliczy$ czas wykonania nale y zna$:
– czas trwania cyklu CPU (z danych katalogowych CPU)
– !"czn" liczb% cykli CPU dla danego programu
Aby oszacowa$ liczb% cykli CPU w programie nale y zna$:
– liczb% instrukcji w programie
– przeci%tn" warto#$ CPI (average CPI)

9
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Wydajno!" cd.
Cz%stotliwo#$ zegara CPU (CPU clock rate)
– liczba cykli na sekund% (1 Hz = 1 cykl / s)
– CPU cycle time = 1/CPU clock rate
Przyk!ad: Pentium4 2.4 GHz CPU
0.4167 ns
s100.4167
102.4
1
timecycleCPU
9
9
!
!
!
"
10
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Wydajno!" cd.
Liczba cykli zegara CPU w programie
– liczba cykli = liczba instrukcji ?
– b!"d !
– ró ne instrukcje wymagaj" ró nej liczby cykli dla ró nych komputerów
Wa na uwaga:
– zmiana czasu cyklu CPU (cz%stotliwo#ci zegara) cz%sto
powoduje zmian% liczby cykli potrzebnych do wykonania ró nych instrukcji
11
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Definicja CPI
&rednia liczba cykli na instrukcj% CPI (average cycles
per instruction)
gdzie:
– CPIi – liczba cykli potrzebnych do wykonania instrukcji typu i
– ICi – liczba instrukcji typu i w programie
– IC – ogólna liczba instrukcji w programie
– Fi - wzgl%dna cz%sto#$ wyst%powania instrukcji typu i w
programie
###
!!
! !$%
&'(
) !
!n
i
ii
n
i
i
i
n
1i
ii
FCPIIC
ICCPI
IC
ICCPI
CPI11
12
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Przyk ad wykorzystania CPI
Za!ó my, e typowy program wykonywany przez CPU
analizowanego systemu komputerowego ma
nast%puj"c" charakterystyk%:
– cz%sto#$ wyst%powania operacji FP = 25%
– CPI operacji FP = 4.0
– CPI innych instrukcji = 1.33
– cz%sto#$ wyst%powania operacji FPSQR = 2%
– CPI operacji FPSQR = 20
13
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Przyk ad wykorzystania CPI cd.
Konstruktorzy chc" zwi%kszy$ wydajno#$ systemu
przez przeprojektowanie CPU. Maj" dwa alternatywne
rozwi"zania:
Które z tych rozwi"za' jest lepsze w sensie metryki
(CPU time) ?
1. Zmniejszy$ CPI operacji FPSQR z 20 do 2
2. Zmniejszy$ CPI wszystkich operacji FP do 2
14
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Przyk ad wykorzystania CPI cd.
Rozwi"zanie:
Nale y zauwa y$, e zmienia si% tylko CPI, natomiast liczba instrukcji
cz%stotliwo#$ zegara pozostaje bez zmiany.
Obliczamy CPIorg przed dokonaniem zmian w procesorze:
CPIorg = (4 x 25%) + (1.33 x 75%) = 2.0
Obliczamy CPInew FPSQR dla procesora z ulepszonym uk!adem
obliczania pierwiastka odejmuj"c od CPIorg zysk spowodowany
ulepszeniem:
CPInewFPSQR = CPIorg – 2% x (CPIoldFPSQR – CPIof new FPSQR)
= 2.0 – 2% x (20 – 2) = 1.64
15
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Przyk ad wykorzystania CPI cd.
Obliczamy CPI new FP dla procesora z ulepszonym ca!ym blokiem FPU
CPI new FP = (75% x 1.33) + (25% x 2.0) = 1.5
Odpowied(: ulepszenie ca!ego bloku FP jest lepszym rozwi"zaniem ni
ulepszenie samego uk!adu obliczania FPSQR, poniewa
CPI new FP = 1.5 < CPI new FPSQR = 1.64
16
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Przyk ad wykorzystania CPI doko#czenie
Obliczmy wzrost wydajno#ci systemu po ulepszeniu
uk!adu FPU
33.15.1/0.2 !!!
!
!!
FPnew
org
FPnew
org
FPnew
org
FPnew
CPI
CPI
CPIcycleClockIC
CPIcycleClockIC
timeCPU
timeCPUSpeedup

17
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Problem
Je#li dwa komputery maj" tak" sam" architektur% ISA, to
które z wymienionych wielko#ci b%d" w obu przypadkach
identyczne?
– cz%stotliwo#$ zegara
– CPI
– czas wykonania programu (CPU time)
– liczba instrukcji (IC)
– MIPS
Odpowied(: CPI i liczba instrukcji (IC)
18
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Wydajno!" - wspó zale$no!ci
Liczba
instrukcji
CPI Cykl zegara
Program X
Kompilator X X
Lista instrukcji X X
Organizacja X X
Technologia X
19
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Prawo AmdahlaOkre#la wspó!czynnik poprawy wydajno#ci Speed up w rezultacie ulepszenia systemu komputerowego
Gdzie:
Fracenh – wspó!czynnik wykorzystania ulepszonej cz%#ci systemu (w sensie czasu), np. Fracenh = 0.3 oznacza, e ulepszona cz%#$ jest wykorzystywana przez 30% czasu wykonania programu
Speedupenh – wspó!czynnik poprawy wydajno#ci ulepszonej cz%#ci systemu
* +
* +enh
enh
enhnew
old
overall
enh
enh
enholdnew
Speedup
FracFrac
CPUtime
CPUtimeSpeedup
Speedup
FracFracCPUtimeCPUtime
,"
!!
-.
/01
2," !
1
1
1
20
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Prawo Amdahla – przyk ad
Dla wcze#niej analizowanego przyk!adu dotycz"cego ulepszenia bloków realizuj"cych obliczenia FP i FPSQR otrzymujemy nast%puj"ce wyniki:
ten sam wynik co uzyskany wcze#niej przy u yciu analizy CPI
* +
* +33.1
75.0
1
0.2
5.05.01
1
22.182.0
1
10
2.02.01
1
!!
,"
!
!!
,"
!
FP
FPSQR
Speedup
Speedup
21
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Jeszcze jeden przyk ad
Za!ó my, e dost%p do pami%ci cache jest 10 razy szybszy ni
dost%p do pami%ci operacyjnej. Za!ó my ponadto, e pami%$ cache
jest wykorzystywana przez 90% czasu. Obliczy$ wspó!czynnik
wzrostu wydajno#ci systemu spowodowany dodaniem pami%ci cache.
– Proste zastosowanie prawa Amdahla
* +
* +5.3
0.19
1
10
0.90.91
1
cacheiazastosowanzSpeedup
cachepracyczasu%cachepracyczasu%1
1Speedup
!!
,"
!
,"
!
22
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Pomiary wydajno!ci
W profesjonalnych badaniach wydajno#ci komputerów wykorzystuje si% pomiar czasu wykonania rzeczywistych programów
– najlepiej jest u y$ typowych aplikacji, które b%d" wykonywane przez system podczas normalnej eksploatacji
– lub wykorzysta$ klasy aplikacji, np. kompilatory, edytory, programy oblicze' numerycznych, programy graficzne itp.
Krótkie programy testowe (benchmarks)
– wygodne dla architektów i projektantów
– !atwe w standaryzacji testów
SPEC (System Performance Evaluation Cooperative)
– http:// www.spec.org
– producenci sprz%tu uzgodnili zestawy programów testowych (benchmarków)
– warto#ciowe wyniki do oceny wydajno#ci komputerów i jako#ci kompilatorów
23
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
SPEC benchmarks
SPEC89 – 1989
Benchmark
0
100
200
300
400
500
600
700
800
gcc
ep
resso
sp
ice
doduc
nasa7 li
eq
nto
tt
matr
ix300
fpppp
tom
ca
tv
10 krótkich testów
wynik w postaci jednej liczby,
#redniej wa onej
24
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
SPEC benchmarks cd.
Druga runda – 1992
– SPECint92 – zestaw 6 programów testowych operuj"cych na
liczbach ca!kowitych (integer)
– SPECfp92 – zestaw 14 programów testowych operuj"cych na
liczbach zmiennoprzecinkowych
– SPECbase
Trzecia runda – 1995
– SPECint95 – zestaw 8 programów (integer)
– SPECfp95 – zestaw 10 programów (FP)
– SPECint_base95 i SPECfp_base95

25
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
SPEC’95 – zestaw testów
26
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
SPECint95 - przyk ad
27
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
SPEC’2000
28
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
SPEC_2006 zestaw testówCFP 2006
CINT 2006
29
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
30
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
31
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Raporty CFP - przyk ady
2.8 GHz
32
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
SYSmark 20021 Intel's advanced 0.13
micron process and 512K
L2 Cache, 400-MHz
system bus, PC800-40
RDRAM
2 Intel's advanced 0.13
micron process and 512K
L2 Cache, 533-MHz
system bus, PC1066-32
RDRAM
3 Intel® Pentium® 4
Processor 3.06 GHz
supporting Hyper-
Threading Technology
33
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
SYSmark 2002 cd.
34
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
SYSmark 2002
Internet Content Creation:
• Adobe* Photoshop* 6.01
• Adobe Premiere* 6.0
• Macromedia Dreamweaver 4
• Macromedia Flash 5
• Microsoft Windows Media
Encoder* 7.1
Office Productivity:
• Dragon* Naturally
Speaking* Preferred v5
• McAfee* VirusScan 5.13
• Microsoft* Access 2002
• Microsoft Excel* 2002
• Microsoft Outlook 2002
• Microsoft PowerPoint* 2002
• Microsoft Word* 2002
• Netscape* Communicator*
6.0
• WinZip* 8.0
35
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Benchmarki dla amatorów
Karty graficzne– 3DMark SE
Dyski– HDTach
– WinBench
Procesory– SPECcpu2006
– SYSmark 2002
Pami#ci– ScienceMark 1.0
Kompletny system komputerowy– PCMark
36
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Architektury superkomputerów
37
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Procesory w superkomputerach
38
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Procesory w superkomputerach
39
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Moc obliczeniowa - przewidywania
40
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Wydajno ! i architektura

41
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Podsumowanie
Metryki wydajno$ci komputera– CPU time, CPI
– metryki komercyjne MIPS, MFLOPS
Prawo Amdahla – wp!yw ulepsze% systemu na wydajno$&
Benchmarki– SPEC’89
– SPEC’92
– SPEC’95
– SPEC’2000 i 2006
– SYSmark 2002

1
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Organizacja i Architektura Komputerów
Arytmetyka komputerów
2
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Alfabet: 0, 1
Dane w komputerach s" reprezentowane wy!"cznie przy
u yciu alfabetu dwójkowego (binarnego)
3
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Bity, bajty, s owa
Bity s" grupowane w wi#ksze zespo!y o d!ugo$ci
b#d"cej pot#g" liczby 2:
– tetrada: 4 bity (nibble)
– bajt: 8 bitów
– s!owo: 16, 32, 64 lub 128 bitów
– podwójne s!owo (doubleword)
– pó!s!owo (halfword)
D!ugo$% s!owa zale y od organizacji komputera
4
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Kody liczbowe
22
33
44
55
66
77
88
99
1010
1111
1212
1313
1414
1515
1616
1010011110010100111100
12111221211122
110330110330
2033020330
1011210112
36233623
24742474
17481748
13401340
10091009
938938
7C17C1
6BA6BA
5E55E5
53C53C
bbaaza (
za (ra
dix
radix
))
dwdwóójkowy (binarny)jkowy (binarny)
ookktaltalnyny
dziesidziesi##tnytny
szesnastkowy, heksadecymalny, szesnastkowy, heksadecymalny,
‘‘hexhex’’
Podstawy u ywane w systemach cyfrowych
5
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Kod szesnastkowy HEX
Powszechnie u ywany przez programistów programuj"cych w j#zyku asemblera
Skraca d!ugo$%notacji liczby
&atwa konwersja na kod NKB i odwrotnie
Ka da tetrada reprezentuje cyfr#szesnastkow"
Cyfra HEX kod binarny
0 00001 00012 00103 00114 01005 01016 01107 01118 10009 1001A 1010B 1011C 1100D 1101E 1110F 1111
6
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Konwersja HEX – radix 10
7
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Konwersja binarna – HEX
8
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Kod BCD cyfra
dziesi#tna BCD
0 0000
1 0001
2 0010
3 0011
4 0100
5 0101
6 0110
7 0111
8 1000
9 1001
Kody od 1010 do 1111
nie s! u"ywane
BCD (binary coded decimal)
– ka da cyfra dziesi#tna jest
reprezentowana jako 4 bity
– kod opracowany dla
wczesnych kalkulatorów
– przyk!ad: 35910 =
= 0011 0101 1001bcd
– kod !atwy do zrozumienia
przez cz!owieka, niewygodny
dla komputerów

9
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Porz!dek bajtów w pami#ci
Problem
– Pami#% jest zwykle adresowana bajtami
– Jak zapisa% w pami#ci s!owo 32-bitowe ?
0x13579BDF0x13579BDF
ss owo 32owo 32--
bitowebitowe
w kodzie HEXw kodzie HEX
8 bit8 bitóóww
......
12481248
ad
ad
resy??
1249 resy
1249
12501250
12511251
......
10
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Kolejno$% bajtów w pami#ci
Rozwi"zanie
– podziel s!owo na bajty
– zapisz kolejne bajty w kolejnych komórkach
0x13579BCF0x13579BCF
ka"da cyfra HEX
reprezentuje tertad#, zatem
dwie cyfry tworz! bajt
8 bitów
0x13579BCF0x13579BCF0x13579BCF0x13579BCF0x13579BCF0x13579BCF0x13579BCF0x13579BCF0x13579BCF0x13579BCF0x13579BCF0x13579BCF0x13579BCF0x13579BCF0x13579BCF0x13579BCF......
1 bajt tutaj1248
ad
ad
resy
nast#pny bajt tutaj 1249 re
sy
kolejny bajt tutaj 1250
ostatni bajt tutaj 1251
......
11
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Kolejno$% bajtów cd.
W jakiej kolejno$ci zapisywa% bajty?
– Zaczynaj"c od najbardziej znacz"cego (“big” end)?
......
0x130x13 1248 adre
sy
1249
1250
1251
......
0x13579BDF0x13579BDF
kierunek kierunek
0x570x57
0x9B0x9B
0xDF0xDF
analizyanalizy
12
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Kolejno$% bajtów cd.
W jakiej kolejno$ci zapisywa% bajty?
– Zaczynaj"c od najmniej znacz"cego (“little” end)?
......
0xDF0xDF 1248
aadre
sy
dre
sy
1249
1250
1251
......
0x13579BDF0x13579BDF
kierunek kierunek
0x9B0x9B
0x570x57
0x130x13
analizyanalizy
13
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Kolejno$% bajtów cd.
Stosuje si# dwa sposoby zapisu s!ów w pami#ci
Big Endian
– most significant byte in lowest address
– store least significant byte in highest address
Little Endian
– store least significant byte in lowest address
– store most significant byte in highest address
14
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Kolejno$% bajtów cd.
Wybór wersji kolejno$ci zapisu bajtów zale y od
konstruktorów procesora
– Big Endian
Motorola 680x0 (Amiga/Atari ST/Mac)
IBM/Motorola PowerPC (Macintosh)
MIPS (SGI Indy/Nintendo 64)
Motorola 6800
– Little Endian
Intel 80x86/Pentium (IBM PC)
Rockwell 6502 (Commodore 64)
MIPS (Sony Playstation/Digital DECstation)
– Niektóre procesory (np. MIPS) mo na konfigurowa% zarówno w
trybie Big Endian jak i Little Endian
15
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
ALU
Jednostka arytmetyczno-logiczna (ALU – arithmetic-logic unit) wykonuje operacje arytmetyczne na liczbach w kodzie dwójkowym
ALU jest centralnym blokiem komputera; wszystkie inne bloki funkcjonalne s!u " do w!a$ciwej obs!ugi ALU
Proste ALU wykonuje operacje na liczbach ca!kowitych (integer)
Bardziej z!o one ALU mo e wykonywa% operacje zmiennoprzecinkowe FP na liczbach rzeczywistych
Najcz#$ciej ALU_INT i ALU_FP (FPU – Floating Point Unit) s"wykonane jako dwa osobne bloki cyfrowe
– FPU mo e by% wykonane jako osobny uk!ad scalony (koprocesor)
– FPU mo e by% wbudowane do procesora
16
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
ALU – wej$cia i wyj$cia
• CU – uk!ad sterowania (Control Unit)
• Registers – rejestry wbudowane do CPU
• Flags – wska'niki, znaczniki stanu, flagi, warunki: zespó! wska'ników
bitowych okre$laj"cych specyficzne w!a$ciwo$ci wyniku operacji
(zero, znak, przeniesienie itp.)

17
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
ALU – symbol logiczny
Kod operacji pochodzi z uk!adu sterowania (CU)
Liczba bitów wyniku jest taka sama jak liczba bitów argumentów (operandów) – w tym przyk!adzie wynosi 32
ALU nie tylko generuje bity wska'ników, ale tak e uwzgl#dnia poprzedni stan wska'ników
32
32
32
operacja
wynikoperacji
a
b
ALU
wska&niki
18
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Wieloznaczno$% informacji
Co oznacza poni szy zapis?
10010111
• Liczb ca!kowit" bez znaku: 151
• Liczb ca!kowit" w kodzie znak-modu!: - 23
• Liczb ca!kowit" w kodzie uzupe!nie# do dwóch: - 105
• Znak w rozszerzonym kodzie ASCII (IBM Latin 2): $
• Kod operacji procesora x86: XCHG AX,DI
To zale%y od kontekstu
19
Wy%sza Szko!a Informatyki Stosowanej i Zarz"dzania
Liczby ca kowite bez znaku
u%ywane s" tylko cyfry 0 i 1
!
"#
$
##
$
%$
1
0
0121
2
1,0...
n
i
i
i
inn
aA
aaaaaA
kod ten bywa nazywany NKB
(naturalny kod binarny)
zakres reprezentacji liczb dla
s!owa n-bitowego wynosi:
<0, 2 i – 1>
dla n = 8: <0, 255>
dla n = 16: <0, 65 535>
Przyk!ady:
00000000 = 0
00000001 = 1
00101001 = 41
10000000 = 128
11111111 = 255
20
Wy%sza Szko!a Informatyki Stosowanej i Zarz"dzania
Kod znak-modu (ZM)
Najbardziej znacz"cy bit
oznacza znak
0 oznacza liczb dodatni"
1 oznacza liczb ujemn"
Przyk!ad
+18 = 00010010
#18 = 10010010
Problemy
Uk!ady arytmetyczne musz"osobno rozpatrywa& bit znaku
i modu!
Wyst puj" dwie reprezentacje zera:
+0 = 00000000
#0 = 10000000
&&
'
&&
(
)
$#
$
$
"
"
#
$
#
#
$
#
2
0
1
2
0
1
12
02
n
i
ni
i
n
i
ni
i
agdya
agdya
A
21
Wy%sza Szko!a Informatyki Stosowanej i Zarz"dzania
Kod uzupe nie! do 2 (U2)
Najbardziej znacz"cy bit
oznacza znak liczby
0 – liczba dodatnia
1 – liczba ujemna
Tylko jedna reprezentacja
zera:
+0 = 00000000
Ogólna posta& U2:
Przyk!ady:
+3 = 00000011
+2 = 00000010
+1 = 00000001
+0 = 00000000
-1 = 11111111
-2 = 11111110
-3 = 11111101"#
$
#
#*#$
2
0
1
122
n
i
i
i
n
n aaA
22
Wy%sza Szko!a Informatyki Stosowanej i Zarz"dzania
Konwersja NKB – U2
liczba
binarna
liczba
U2
dodatnia
ujemna
uzupe nienie0 1 1 0
+1
23
Wy%sza Szko!a Informatyki Stosowanej i Zarz"dzania
Zalety kodu U2
Jedna reprezentacja zera
Uk!ady arytmetyczne (ALU) maj" prostsz" budow
(wyka%emy to pó'niej)
Negacja (zmiana znaku liczby) jest bardzo prosta:
3 = 00000011
uzupe!nienie do 1(negacja boolowska) 11111100
dodanie 1 11111101
#3 = 11111101
24
Wy%sza Szko!a Informatyki Stosowanej i Zarz"dzania
Kod U2 – ilustracja geometryczna

25
Wy%sza Szko!a Informatyki Stosowanej i Zarz"dzania
Wada kodu U2
Zakres reprezentowanych liczb jest niesymetryczny
najmniejsza liczba: #2n#1 (minint)
najwi ksza liczba: 2n#1#1 (maxint)
dla n=8
najmniejsza liczba: #128
najwi ksza liczba: +127
dla n=16
najmniejsza liczba: #32 768
najwi ksza liczba: +32 767
26
Wy%sza Szko!a Informatyki Stosowanej i Zarz"dzania
Negacja w U2 – przypadki specjalne
0 = 00000000
negacja bitowa 11111111
dodaj 1 do LSB +1
wynik 1 00000000
przepe!nienie jest ignorowane
wi c 0 = 0 +
128 = 10000000
negacja bitowa 01111111
dodaj 1 do LSB +1
wynik 10000000
wi c ( 128) = 128 X
Wniosek:
nale%y sprawdza& bit znaku po negacji
(powinien si zmieni&)
27
Wy%sza Szko!a Informatyki Stosowanej i Zarz"dzania
Konwersja d ugo"ci s owa w U2
Liczby dodatnie uzupe!nia si wiod"cymi zerami
+18 = 00010010
+18 = 00000000 00010010
Liczby ujemne uzupe!nia si wiod"cymi jedynkami
18 = 10010010
18 = 11111111 10010010
Ogólnie bior"c, powiela si bit MSB (bit znaku)
28
Wy%sza Szko!a Informatyki Stosowanej i Zarz"dzania
Dodawanie i odejmowanie w U2
Obydwie operacje wykonuje si u%ywaj"c zwyk!ego
dodawania liczb dwójkowych
Nale%y sprawdza& bit znaku, aby wykry& nadmiar
(overflow)
Odejmowanie wykonuje si przez negowanie odjemnej i
dodawanie:
a b = a + ( b)
Do realizacji dodawania i odejmowania potrzebny jest
zatem tylko uk!ad negacji bitowej i sumator
29
Wy%sza Szko!a Informatyki Stosowanej i Zarz"dzania
Uk ad dodawania i odejmowania U2
30
Wy%sza Szko!a Informatyki Stosowanej i Zarz"dzania
Mno#enie
Mno%enie liczb dwójkowych jest znacznie
bardziej z!o%one od dodawania i odejmowania
Podstawowy algorytm jest taki sam jak przy
pi(miennym mno%eniu liczb:
– okre(la si iloczyny cz"stkowe dla ka%dej cyfry
mno%nika
– kolejne iloczyny cz"stkowe nale%y umieszcza& z
przesuni ciem o jedn" pozycj (kolumn ) w lewo
– nale%y doda& do siebie iloczyny cz"stkowe
31
Wy%sza Szko!a Informatyki Stosowanej i Zarz"dzania
Przyk ad mno#enia (liczby bez znaku)
1011 mno%na (11 w kodzie dziesi tnym)
x 1101 mno%nik (13 w kodzie dziesi tnym)
1011 iloczyny cz"stkowe
0000 Uwaga: je(li bit mno%nika jest równy 1,
1011 iloczyn cz"stkowy jest równy mno%nej,
1011 w przeciwnym przypadku jest równy 0
10001111 wynik mno%enia (143 w kodzie dziesi tnym)
Uwaga #1: wynik ma podwójn" d!ugo(&; potrzebujemy s!owa
o podwójnej precyzji
Uwaga #2: powy%szy algorytm funkcjonuje tylko dla liczb bez
znaku; je(li przyj"& kod U2 mno%na = 5,
mno%nik = 3, natomiast iloraz wynosi!by 113,
co oczywi(cie jest nieprawd"32
Wy%sza Szko!a Informatyki Stosowanej i Zarz"dzania
Uk ad mno#enia liczb bez znaku

33
Wy%sza Szko!a Informatyki Stosowanej i Zarz"dzania
Przyk ad mno#enia liczb bez znaku
wynik mno%enia
34
Wy%sza Szko!a Informatyki Stosowanej i Zarz"dzania
Mno#enie liczb bez znaku cd.
35
Wy%sza Szko!a Informatyki Stosowanej i Zarz"dzania
Mno#enie liczb ze znakiem
Prosty algorytm podany wcze(niej nie dzia!a
Rozwi"zanie 1
– zamieni& czynniki ujemne na dodatnie
– pomno%y& liczby korzystaj"c z podanego wcze(niej
algorytmu
– je(li znaki czynników (przed wykonaniem negacji)
by!y ró%ne, zanegowa& iloczyn
Rozwi"zanie 2
– algorytm Booth’sa
36
Wy%sza Szko!a Informatyki Stosowanej i Zarz"dzania
Algorytm Booth’sa
Q-1 dodatkowy bit
(przerzutnik) pami taj"cy
najmniej znacz"cy bit
rejestru Q opuszczaj"cy ten
rejestr przy przesuni ciu w
prawo
Przesuni cie arytmetyczne w
prawo – przesuni cie z
powieleniem bitu znaku
37
Wy%sza Szko!a Informatyki Stosowanej i Zarz"dzania
Przyk ad dzia ania metody Booth’sa
iloczyn: 3 x 7 = 21 testowane bity: 10 A:=A-M
01 A:=A+M
38
Wy%sza Szko!a Informatyki Stosowanej i Zarz"dzania
Algorytm Booth’sa (znak dowolny)
39
Wy%sza Szko!a Informatyki Stosowanej i Zarz"dzania
Dzielenie Dzielenie liczb dwójkowych jest znacznie bardziej skomplikowane
od mno%enia
Liczby ujemne sprawiaj" spore k!opoty (Stallings, s. 341-342)
Podstawowy algorytm podobny do dzielenia liczb na papierze: kolejne operacje przesuwania, dodawania lub odejmowania
Przyk!ad: dzielenie liczb bez znaku:Iloraz
(Quotient)
001111
00001101
100100111011
1011
0011101011
1011
100
Dzielnik
(Divisor)Dzielna
(Dividend)
Reszty
cz"stkowe
(Partial
Remainders) Reszta
(Remainder)
40
Wy%sza Szko!a Informatyki Stosowanej i Zarz"dzania
Liczby rzeczywiste
Liczby z cz (ci" u!amkow"
Mo%na je zapisa& korzystaj"c z kodu NKB i dodatkowo znaków ‘-’ oraz ‘.’
1001.1010 = 24 + 20 +2-1 + 2-3 =9.625
Problem: gdzie znajduje si kropka dziesi tna?
W sta!ym miejscu?– rozwi"zanie niedobre z punktu widzenia metod numerycznych
Na zmiennej pozycji?– jak poda& informacj o miejscu po!o%enia kropki?

41
Wy%sza Szko!a Informatyki Stosowanej i Zarz"dzania
Liczby zmiennoprzecinkowe (FP)b
it z
na
ku
przesuni$ty
wyk adnik
(exponent)mantysa (significand or mantissa)
Warto(& liczby: +/- 1. mantysa x 2 wyk!adnik
Podstawa 2 jest ustalona i nie musi by& przechowywana
Po!o%eniu punktu dziesi tnego jest ustalone: na lewo od
najbardziej znacz"cego bitu mantysy
42
Wy%sza Szko!a Informatyki Stosowanej i Zarz"dzania
FP – mantysa
Mantysa jest zapisana w kodzie U2
Wyk!adnik jest zapisany z przesuni ciem (excess or
biased notation)
– np. przesuni cie równe 127 oznacza:
– 8-bitowe pole wyk!adnika
– zakres liczb 0-255
– od przesuni tego wyk!adnika nale%y odj"& 127 aby otrzyma&
prawdziw" warto(&
– zakres warto(ci wyk!adnika -127 to +128
43
Wy%sza Szko!a Informatyki Stosowanej i Zarz"dzania
FP – normalizacja
Liczby FP s" zwykle normalizowane, tzn. wyk!adnik jest tak dobierany, aby najbardziej znacz"cy bit (MSB) mantysy by! równy 1
Poniewa% bit ten jest zawsze równy 1, nie musi by&przechowywany. Dlatego 23-bitowe pole mantysy w rzeczywisto(ci odpowiada mantysie 24-bitowej, z cyfr" 1 na najbardziej znacz"cej pozycji (mantysa mie(ci si zatem w przedziale od 1 do 2
Uwaga: w notacji naukowej FP (Scientific notation) liczby s" normalizowane inaczej, tak aby mantysa mia!a jedn"znacz"c" cyfr przed kropk" dziesi tn", np. 3.123 x 103
44
Wy%sza Szko!a Informatyki Stosowanej i Zarz"dzania
FP – przyk ad
1,1010001 x 210100 = 0 10010011 10100010000000000000000
- 1,1010001 x 210100 = 1 10010011 10100010000000000000000
1,1010001 x 2-10100 = 0 01101011 10100010000000000000000
- 1,1010001 x 2-10100 = 1 01101011 10100010000000000000000
pozycje mantysy
uzupe niane s% zerami
45
Wy%sza Szko!a Informatyki Stosowanej i Zarz"dzania
Zakres reprezentacji liczb FP
Dla formatu 32-bitowego
8-bitowy wyk!adnik
+/- 2256 , 1.5 x 1077
Dok!adno(&
– efekt nierównomiernego pokrycia osi liczb
rzeczywistych (zmienna warto(& LSB mantysy)
– 23-bitowa mantysa: 2-23 , 1.2 x 10-7
– oko!o 6 pozycji dziesi tnych
46
Wy%sza Szko!a Informatyki Stosowanej i Zarz"dzania
Zakresy liczb FP i U2 (format 32-bitowy)
47
Wy%sza Szko!a Informatyki Stosowanej i Zarz"dzania
Standard IEEE 754
Dwa warianty: 32- i 64-bitowy format liczb
8- lub 11-bitowy wyk!adnik (bias = 127 lub 1023)
IEEE 754 dopuszcza ponadto tzw. formaty rozszerzone (extended
formats) dla oblicze# po(rednich w systemach cyfrowych
48
Wy%sza Szko!a Informatyki Stosowanej i Zarz"dzania
ANSI/IEEE Standard Floating-Point Format (IEEE 754)
Revision (IEEE 754R) is being considered by a committee
Short (32-bit) format
Long (64-bit) format
Sign Exponent Significand
8 bits, bias = 127, –126 to 127
11 bits, bias = 1023, –1022 to 1023
52 bits for fractional part (plus hidden 1 in integer part)
23 bits for fractional part (plus hidden 1 in integer part)
Short exponent range is –127 to 128
but the two extreme values
are reserved for special operands
(similarly for the long format)
The two ANSI/IEEE standard floating-point formats.

49
Wy%sza Szko!a Informatyki Stosowanej i Zarz"dzania
Standard IEEE 754
W rzeczywisto(ci standard IEEE 754 jest bardziej skomplikowany:
– dodatkowe dwa bity: guard i round
– cztery warianty zaokr"glania
– liczba dodatnia podzielona przez 0 daje niesko#czono(&
– niesko#czono(& dzielona przez niesko#czono(& daje NaN (not a number)
– niektóre procesory nie s" w pe!ni zgodne z IEEE 754, skutki s" na ogó! niedobre (Pentium bug)
50
Wy%sza Szko!a Informatyki Stosowanej i Zarz"dzania
Some features of ANSI/IEEE standard floating-point formats
Feature Single/Short Double/Long
Word width in bits 32 64
Significand in bits 23 + 1 hidden 52 + 1 hidden
Significand range [1, 2 – 2–23] [1, 2 – 2–52]
Exponent bits 8 11
Exponent bias 127 1023
Zero (±0) e + bias = 0, f = 0 e + bias = 0, f = 0
Denormal e + bias = 0, f 0represents ±0.f - 2–126
e + bias = 0, f 0represents ±0.f - 2–1022
Infinity (.!) e + bias = 255, f = 0 e + bias = 2047, f = 0
Not-a-number (NaN) e + bias = 255, f 0 e + bias = 2047, f 0
Ordinary number e + bias % [1, 254]e % [–126, 127]represents 1.f - 2e
e + bias % [1, 2046]e % [–1022, 1023]represents 1.f - 2e
min 2–126 / 1.2 - 10–38 2–1022 / 2.2 - 10–308
max / 2128 / 3.4 - 1038 / 21024 / 1.8 - 10308
51
Wy%sza Szko!a Informatyki Stosowanej i Zarz"dzania
Arytmetyka FP +/-
W arytmetyce FP dodawanie i odejmowanie s"
bardziej z!o%onymi operacjami ni% mno%enie i
dzielenie (powodem jest konieczno(& tzw.
wyrównywania sk!adników)
Etapy dodawania i odejmowania
– Sprawdzenie zer
– Wyrównanie mantys (i korekcja wyk!adników)
– Dodawanie lub odj cie mantys
– Normalizowanie wyniku
52
Wy%sza Szko!a Informatyki Stosowanej i Zarz"dzania
Arytmetyka FP x / 0
Etapy mno%enia i dzielenia
– sprawdzenie zer
– dodawanie/odejmowanie wyk!adników
– mno%enie/dzielenie mantys (uwaga na znak)
– normalizacja
– zaokr"glanie
– Uwaga: wszystkie wyniki oblicze# po(rednich
powinny by& wykonywane w podwójnej precyzji
53
Wy%sza Szko!a Informatyki Stosowanej i Zarz"dzania
Mno#enie FP
54
Wy%sza Szko!a Informatyki Stosowanej i Zarz"dzania
Dzielenie FP
55
Wy%sza Szko!a Informatyki Stosowanej i Zarz"dzania
Podsumowanie
Zapis s!ów w pami ci (Endian)
Reprezentacje liczb: NKB, ZM, U2, BCD, HEX
Ogólna charakterystyka ALU
Operacje na liczbach ca!kowitych bez znaku
Operacje na liczbach ca!kowitych ze znakiem
Mno%enie – algorytm Booth’sa
Liczby zmiennoprzecinkowe FP
Formaty liczb FP, IEEE 754
Operacje na liczbach FP
1
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Organizacja i Architektura Komputerów
Elementy i bloki cyfrowe
2
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
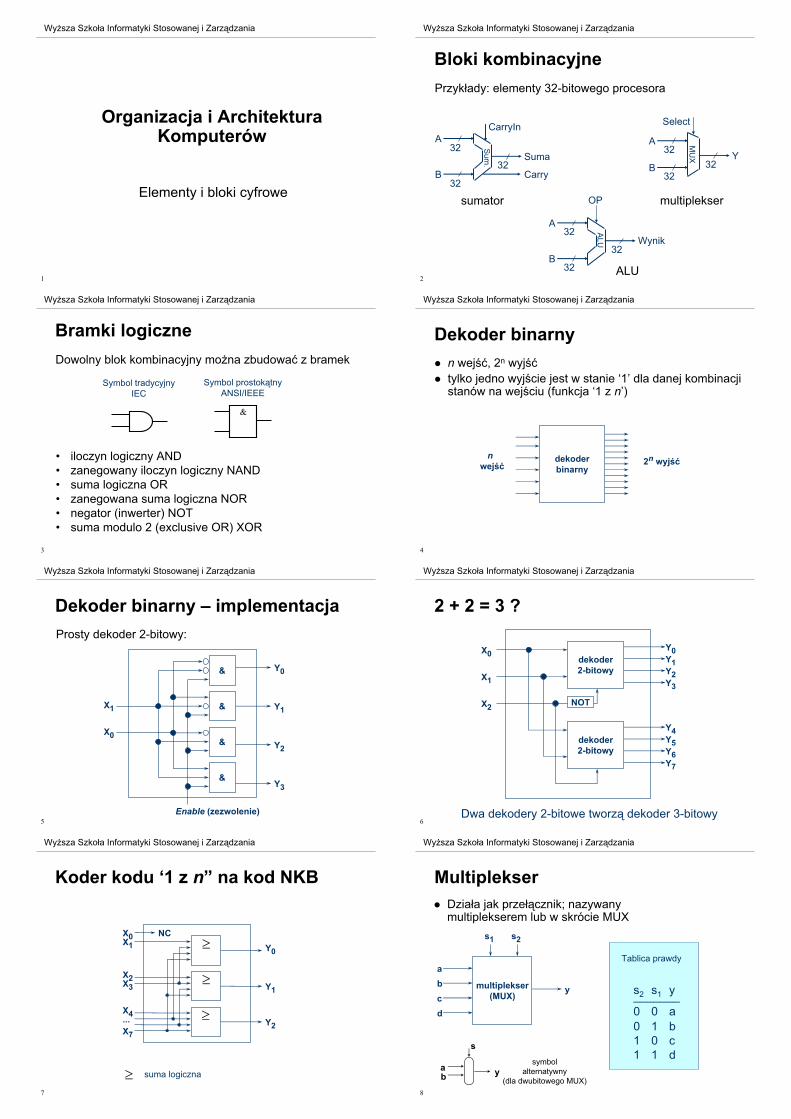
Bloki kombinacyjne
Przyk!ady: elementy 32-bitowego procesora
32
32
A
B32
Suma
Carry
32
32
A
B32
Wynik
OP
32A
B32
Y32
Select
Sum
.
MU
X
ALU
CarryIn
multipleksersumator
ALU
3
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Bramki logiczne
Dowolny blok kombinacyjny mo na zbudowa# z bramek
Symbol prostok"tny
ANSI/IEEESymbol tradycyjny
IEC
&
• iloczyn logiczny AND
• zanegowany iloczyn logiczny NAND
• suma logiczna OR
• zanegowana suma logiczna NOR
• negator (inwerter) NOT
• suma modulo 2 (exclusive OR) XOR
4
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Dekoder binarny
n wej$#, 2n wyj$#
tylko jedno wyj$cie jest w stanie ‘1’ dla danej kombinacji stanów na wej$ciu (funkcja ‘1 z n’)
dekoder
binarny
n
wej !2n wyj !
5
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Dekoder binarny – implementacja
Prosty dekoder 2-bitowy:
&
&
&
&
X1
X0
Y0
Y1
Y2
Y3
Enable (zezwolenie)6
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
2 + 2 = 3 ?
dekoder
2-bitowy
Y0Y1Y2Y3
dekoder
2-bitowy
Y4Y5Y6Y7
NOT
X0
X1
X2
Dwa dekodery 2-bitowe tworz" dekoder 3-bitowy
7
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Koder kodu ‘1 z n” na kod NKB
Y0
Y1
Y2
X1
X2X3
X4...
X7
X0 NC
suma logiczna
8
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Dzia!a jak prze!"cznik; nazywanymultiplekserem lub w skrócie MUX
Multiplekser
multiplekser
(MUX)
a
b
c
d
y
s1 s2
Tablica prawdy
s2 s1 y_______
0 0 a
0 1 b
1 0 c
1 1 ds
yab
symbol
alternatywny
(dla dwubitowego MUX)

9
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Multiplekser – implementacjas1 s2
dekoder
&
&
&
&
a
y
b
c
d
10
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Multiplekser grupowy
MUX
A
B
C
D
S
Y
MUX
a0b0c0d0
s0 s1
y0
MUX
a3b3c3d3
y3
S
MUX
A
B
C
D
Y
4
4
4
4
2
4
11
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
J"zyk VHDL – przyk#ad
entity MUX32X2 is
generic (output_delay : TIME := 4 ns);
port(A,B: in vlbit_1d(31 downto 0);
DOUT: out vlbit_1d(31 downto 0);
SEL: in vlbit);
end MUX32X2;
architecture behavior of MUX32X2 is
begin
mux32x2_process: process(A, B, SEL)
begin
if (vlb2int(SEL) = 0) then
DOUT <= A after output_delay;
else
DOUT <= B after output_delay;
end if;
end process;
end behavior;
• VHDL – Very (High
Speed Integrated
Circuit) Hardware
Description Language
• Opracowany w latach
80-tych przez
Departament Obrony
USA
• Norma IEEE Standard
1076 (1987, 1993,
2001)
12
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Pó#sumator – HA (half adder)
ba
babababa
!"
#!#"!#!"
Carry
)()()()(Sum
a b Sum Carry
0 0 0 0
0 1 1 0
1 0 1 0
1 1 0 1
HAa
b
Sum
cout
&
&
a
bcout
Sum
13
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Sumator: HA + HA = A (adder)
sumator
a b cin Sum cout
0 0 0 0 0
0 0 1 1 0
0 1 0 1 0
0 1 1 0 1
1 0 0 1 0
1 0 1 0 1
1 1 0 0 1
1 1 1 1 1
a
b
cin
Sum
cout
pó#-
sumator
pó#-
sumator
a
b
cinSum
cout
14
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Sumator wielobitowy, szeregowy
a7 b7
sum7
$
a7 b6
sum6
c7
$
a1 b1
sum1
$
a0 b0
sum0
. . . .cout c2 c1 c0c6
$. . . .
• Szeregowa propagacja przeniesie% (ripple-carry)
• Wada: d!ugi czas ustalania wyniku; sygna! przeniesienia
propaguje przez wszystkie stopnie sumatora
15
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Sumator równoleg#y (4-bitowy)
Okre$lamy funkcj& gi generuj"c" przeniesienie i funkcj& piokre$laj"c" propagacj& przeniesienia
iii
iii
bap
bag
%"
"
Kolejne przeniesienia mo na teraz zapisa# w postaci:
3334
2223
1112
1
####
####
####
#
#"
#"
#"
#"
iiii
iiii
iiii
iiii
cpgc
cpgc
cpgc
cpgc
16
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Sumator równoleg#y cd.
a nast&pnie, po dokonaniu podstawie%, w postaci:
iiiiiiiiiiiiiiii
iiiiiiiiiii
iiiiiii
iiii
cppppgpppgppgpgc
cpppgppgpgc
cppgpgc
cpgc
1231231232334
12121223
1112
1
#############
########
####
#
####"
###"
##"
#"
wprowadzaj"c oznaczenia:
iiiiii
iiiiiiiiiiii
ppppp
gpppgppgpgg
123)3,(
123123233)3,(
####
##########
"
###"
otrzymujemy ostatecznie:
iiiiii cpgc)3,()3,(4 ###
#"

17
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Sumator równoleg#y cd.
Równanie z poprzedniego slajdu okre$laj" metod&
nazywan" CLA – carry-look-ahead, w której przeniesienia
s" generowane przez blok CLA:
CLA
33 ## ii pg22 ## ii pg
11 ## ii pg ii pg
11 bramek AND + 5 bramek OR
1#ic
ic4#ic
3#ic 2#ic)3,( #iip)3,( #iig
18
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Sumator równoleg#y cd.
Budujemy z bramek zmodyfikowany sumator 1-bitowy:
$
ia ib
ic
isum
ipig
&
=1
=1
ic
ibia
isumipig
=
=1 bramka XOR
19
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Sumator równoleg#y cd.
4-bitowy sumator z równoleg!" generacj" przeniesie%
$
ia ib
ic
isum
ipig
$
1#ia 1#ib
1#ic
1#isum
1#ip1#ig
$
2#ia 2#ib
2#ic
2#isum
2#ip2#ig
$
3#ia 3#ib
3#ic
3#isum
3#ip3#ig
CLA 4#ic
)3,( #iig )3,( #iip
20
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Sumator równoleg#y doko$czenie
Ustalanie wyniku oraz propagacja przeniesie% w metodzie CLA s"
znacznie szybsze ni w metodzie ripple-carry:
propagacja ripple CLA
c1 do ci+1 4.8 4.8 czas propagacji w ns
c1 do ci+2 9.6 5.6
c1 do ci+3 14.4 6.4
c1 do ci+4 19.2 4.8
U ywaj"c 4-bitowego sumatora CLA z poprzedniego slajdu mo na
budowa# sumatory 8-, 12-, 16-, b"d' ogólnie 4 x n bitowe
Sumatory CLA mo na !"czy# tak, by przeniesienia mi&dzy nimi
propagowa!y szeregowo (ripple), lub wprowadzi# uk!ad CLA
drugiego poziomu, zbudowany na takiej samej zasadzie jak uk!ad
CLA pierwszego poziomu
21
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Budujemy ALU
Za!o enia projektowe
– 4-bitowe argumenty A i B
– 4-bitowy wynik operacji
– Operacje arytmetyczne
dekrementacja A
inkrementacja A
dodawanie A+B
odejmowanie A–B
– Operacje logiczne
negacja A (uzupe!nienie do 1)
iloczyn logiczny A and B
to samo$# A
suma logiczna A or B
– Wska'niki: przeniesienie i nadmiar
ALU
Sterowanie Wska%niki
A B
f(A,B)
4
4 4
22
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Krok 1A B
Sumator z funkcj" odejmowania
$S
S Funkcja Opis
0 A+B Dodawanie
1 A+B’+1 Odejmowanie
c4
F
$
=1
$
=1
$
=1
$
=1
a0a3 a2 a1b3 b2 b1 b0
S
c4
f3 f2 f1 f0
23
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Krok 2
Wniosek z kroku 1: sumator z ekstenderem mo e realizowa# wi&cej funkcji ni samo dodawanie
Ogólna koncepcja ALU:
a3 a2 a1 a0b3 b2 b1 b0
$ $ $ $
LE AE LE AE LE AE LE AE
x0x1x2x3 y0y1y2y3
c4 c0
f3 f2 f1 f0
LE – logic extender, AE – arithmetic extender
24
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Krok 3 – projekt AE
M S1 S0 Funkcja F X Y c0
1 0 0 dekrementacja A–1 A 1...11 0
1 0 1 dodawanie A+B A B 0
1 1 0 odejmowanie A+B’+1 A B’ 1
1 1 1 inkrementacja A+1 A 0...00 1
M S1 S0 bi yi
1 0 0 0 1
1 0 0 1 1
1 0 1 0 0
1 0 1 1 1
1 1 0 0 1
1 1 0 1 0
1 1 1 0 0
1 1 1 1 0
Tablica prawdy
M wybór funkcji: 1 – arytmetyczne,
0 – logiczne
S1, S0 wybór operacji
yi stan na wyj$ciu i-tego bloku AE
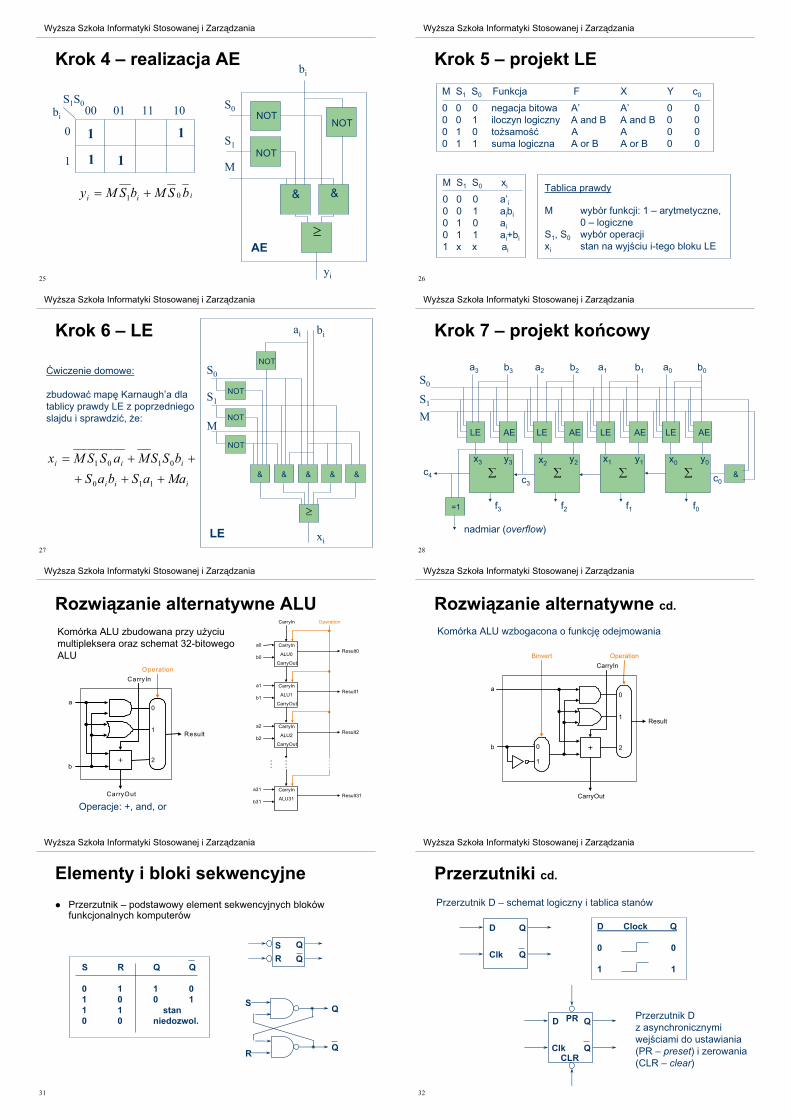
25
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Krok 4 – realizacja AEb
i
AE
&
NOT
&
NOT
NOT00 01 11 10
0
1
S1S
0
bi
1
1 1
1
S0
S1
M
iii bSMbSMy 01#"
yi
26
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Krok 5 – projekt LE
M S1 S0 Funkcja F X Y c0
0 0 0 negacja bitowa A’ A’ 0 0
0 0 1 iloczyn logiczny A and B A and B 0 0
0 1 0 to samo$# A A 0 0
0 1 1 suma logiczna A or B A or B 0 0
M S1 S0 xi
0 0 0 a’i0 0 1 aibi
0 1 0 ai
0 1 1 ai+bi
1 x x ai
Tablica prawdy
M wybór funkcji: 1 – arytmetyczne,
0 – logiczne
S1, S0 wybór operacji
xi stan na wyj$ciu i-tego bloku LE
27
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Krok 6 – LE
iii
iii
MaaSbaS
bSSMaSSMx
###
##"
110
0101
LE
bi
xi
S0
S1
M
NOT
NOT
NOT
NOT
& & & & &
ai
(wiczenie domowe:
zbudowa# map& Karnaugh’a dla
tablicy prawdy LE z poprzedniego
slajdu i sprawdzi#, e:
28
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Krok 7 – projekt ko$cowy
a3 a2 a1 a0b3 b2 b1 b0
c4 $ $ $ $
LE AE LE AE LE AE LE AE
x0x1x2x3 y0y1y2y3
f0f1f2f3
c0&
=1
c3
S0
S1
M
nadmiar (overflow)
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Rozwi zanie alternatywne ALU
Result31
a31
b31
Result0
CarryIn
a0
b0
Result1
a1
b1
Result2
a2
b2
Operation
ALU0
CarryIn
CarryOut
ALU1
CarryIn
CarryOut
ALU2
CarryIn
CarryOut
ALU31
CarryIn
Komórka ALU zbudowana przy u yciu
multipleksera oraz schemat 32-bitowego
ALU
b
0
2
Result
Operation
a
1
CarryIn
CarryOut
Operacje: +, and, or
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Rozwi zanie alternatywne cd.
Komórka ALU wzbogacona o funkcj# odejmowania
0
2
Result
Operation
a
1
CarryIn
CarryOut
0
1
Binvert
b
31
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Elementy i bloki sekwencyjne
Przerzutnik – podstawowy element sekwencyjnych bloków funkcjonalnych komputerów
S
R
Q
QS R Q Q
0 1 1 0
1 0 0 1
1 1 stan
0 0 niedozwol.
S
RQ
Q
32
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Przerzutniki cd.
Przerzutnik D – schemat logiczny i tablica stanów
D Clock Q
0 0
1 1
D
Clk
Q
Q
D
Clk
Q
Q
PR
CLR
Przerzutnik D
z asynchronicznymi
wej$ciami do ustawiania
(PR – preset) i zerowania
(CLR – clear)
33
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Przerzutniki cd.
Przerzutnik J-K – schemat logiczny
J
K
Q
Q
PR
CLR
>Clk
J K Clock Q
0 0 bez zmian
0 1 0
1 0 1
1 1 stan przeciwny
4-bitowy licznik binarny z przeniesieniami szeregowymi
>
J
K
Q
X0
>
J
K
Q
X1
>
J
K
Q
X2
>
J
K
Q
X3
Vcc
34
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Rejestry• Najcz#$ciej zbudowany z
zatrzaskowych przerzutników typu D
(latch)
• Je$li WE = 1, stan Data In zostaje
wraz z opadaj"cym zboczem zegara
wpisany do rejestru i przeniesiony na
wyj$cie Data OutClk
Data In
Write Enable
n n
Data Out
• W technice komputerowej najcz#$ciej wykorzystuje si# rejestry przesu-
waj"ce, które oprócz zapami#tywania n-bitowego s!owa mog" je przesuwa%
• Najprostsze rejestry przesuwaj"ce przesuwaj" swoj" zawarto$% tylko w
jednym kierunku o 1 pozycj# (1 bit)
• Bardziej z!o one rejestry przesuwaj" dane w obu kierunkach (SL – shift left,
SR – shift right)
• Na wyj$ciu ALU znajduje si# zwykle szybki rejestr przesuwaj"cy (barrel
shifter)
35
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Plik (bank) rejestrów
Clk
busW
WE
3232
busA
32
busB
5 5 5
RW RA RB
32 32-bit
Registers
Przyk!adowy plik rejestrów pokazany obok sk!ada si# z 32 rejestrów:
– dwie 32-bitowe szyny wyj$ciowe busAi busB
– jedna 32-bitowa szyna wej$ciowa: busW
– sygna! zegara ma znaczenie tylko przy zapisie; przy odczycie uk!ad dzia!a jak uk!ad kombinacyjny
Rejestry s" wybierane przez:
– RA – numer rejestru wyprowadzanego na szyn# busA
– RB – numer rejestru wyprowadzanego na szyn# busB
– RW – numer rejestru zapisywanego z szyny busW je$li WE=1
Przyk!ad pliku
rejestrów o organizacji
32 x 32 bity
36
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Pami!"
Szyny
– jedna szyna wej$ciowa: Data In
– jedna szyna wyj$ciowa: Data
Out
S!owo n-bitowe zapisane w
pami#ci jest wybierane przez:
– adres o d!ugo$ci zale nej od
pojemno$ci pami#ci
– sygna! WE = 1
Sygna! zegara Clock (CLK)
– sygna! CLK ma znaczenie tylko
przy zapisie
– przy odczycie uk!ad zachowuje
si# jak kombinacyjny
Clk
DataIn
WE
n n
DataOut
Adres
Schemat logiczny bloku
pami#ci n-bitowej
(wyidealizowany)
37
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Elementy trzystanowe W systemach komputerowych cz#sto zachodzi potrzeba !"czenia
wyj$% ró nych uk!adów cyfrowych na wspólnej szynie. Wygodnym rozwi"zaniem s" wyj$cia trzystanowe. W trzecim stanie (wysokiej impedancji) wyj$cie stanowi wysok" impedancj# umo liwiaj"c"traktowanie po!"czenia jako rozwarcie.
Inwertery i bufory z wyj$ciem trzystanowym s" cz#sto u ywane do po!"czenia uk!adów z szynami (bus drivers)
– dwa drivery umo liwiaj" realizacj# po!"czenia dwukierunkowego
– dodatkowym zadaniem driverów jest wzmocnienie sygna!u, dzi#ki czemu szyny mog" by% d!u sze
enableout
enablein
Uk!ad Szyna
38
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Multiplikator
39
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Przyk#ad mno$enia
1 1 0 1
1 0 1 10 0 0 00
C Reg A
Stan
pocz"tkowy
1 1 0 1
3
Counter
0
1
1101 (13)
x1011 (11)
40
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Qo =1: dodaj mno$n
1 1 0 1
1 0 1 10
C Reg A
1 1 0 1
1 1 0 1
3
0
1
41
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Przesu% wynik cz stkowy
1 1 0 1
1 1 0 10
C Reg A
0 1 1 0
wynik cz"stkowy
2
0
1
dekrementuj
licznik
42
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Qo =1: dodaj mno$n
1 1 0 1
1 1 0 11
C Reg A
0 0 1 1
2
0
1
wynik cz"stkowy
43
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Przesu% wynik cz stkowy
1 1 0 1
1 1 1 00
C Reg A
1 0 0 1
Qo =0
1
0
0
wynik cz"stkowy
44
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Qo=0: przesu% (nie dodawaj)
1 1 0 1
0 1 1 10
C Reg A
0 1 0 0
po przesuni#ciu:
0
0
1
wynik cz"stkowy
45
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Qo=1: dodaj mno$n
1 1 0 1
1 1 1 11
C Reg A
0 0 0 1
0
1
1
wynik cz"stkowy
46
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Przesu% (koniec, Z=1)
1 1 0 1
1 1 1 10
C Reg A
1 0 0 0
0
1
wynik ko&cowy
47
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Podsumowanie
Elementy i bloki kombinacyjne– bramki, bufory (w tym trzystanowe)
– kodery i dekodery
– multipleksery
Synteza pó!sumatora i sumatora (look-ahead)
Synteza ALU
Elementy i bloki sekwencyjne– przerzutniki
– liczniki
– rejestry
– pliki rejestrów
– pami#ci
Metody opisu bloków cyfrowych (j#zyk VHDL)
Synteza uk!adu mno enia
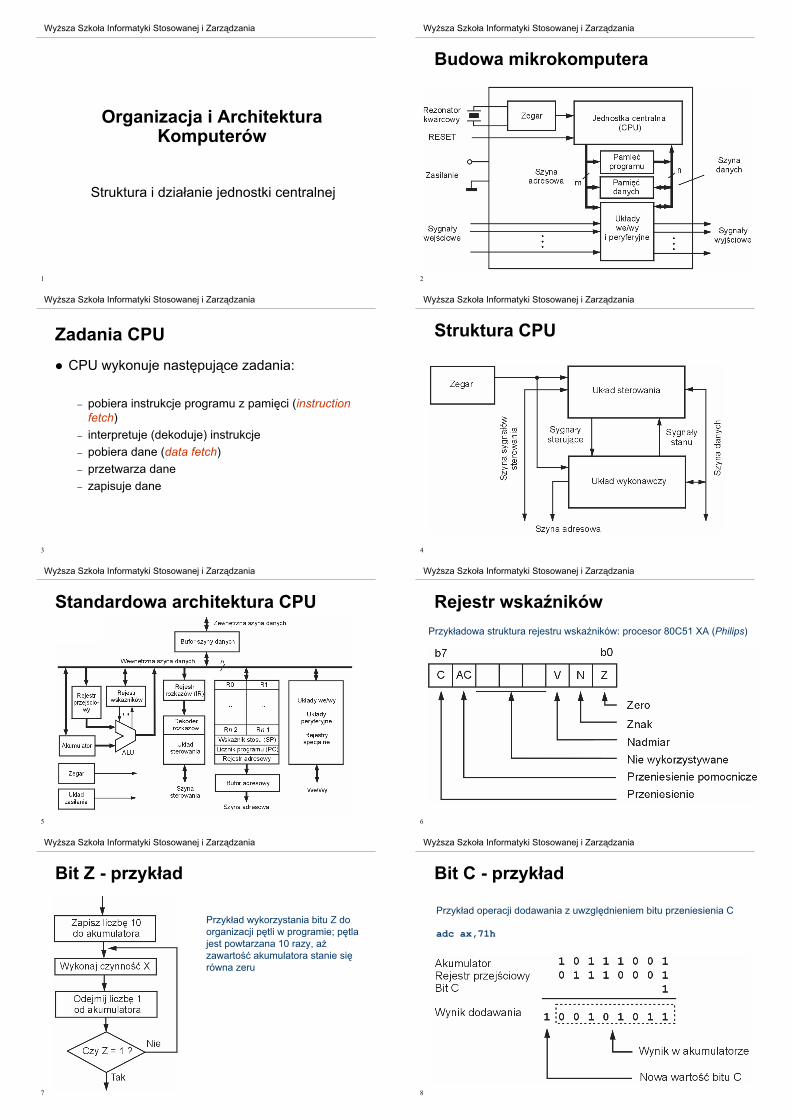
1
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Organizacja i Architektura Komputerów
Struktura i dzia!anie jednostki centralnej
2
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Budowa mikrokomputera
3
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Zadania CPU
CPU wykonuje nast#puj"ce zadania:
– pobiera instrukcje programu z pami#ci (instruction
fetch)
– interpretuje (dekoduje) instrukcje
– pobiera dane (data fetch)
– przetwarza dane
– zapisuje dane
4
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Struktura CPU
5
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Standardowa architektura CPU
6
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Rejestr wska ników
Przyk!adowa struktura rejestru wska$ników: procesor 80C51 XA (Philips)
7
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Bit Z - przyk!ad
Przyk!ad wykorzystania bitu Z do
organizacji p#tli w programie; p#tla
jest powtarzana 10 razy, a
zawarto%& akumulatora stanie si#
równa zeru
8
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Bit C - przyk!ad
Przyk!ad operacji dodawania z uwzgl#dnieniem bitu przeniesienia C
adc ax,71h

9
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Stos – operacja zapisu
• typowa notacja w j#zyku
asemblera:
push x
• w podanym przyk!adzie stos
rozbudowuje si# w stron#
wzrastaj"cych adresów pami#ci
(np. Intel x51)
• wiele innych procesorów
wykorzystuje stos rozbudowywany
w stron# malej"cych adresów, np.
Intel Pentium, Motorola 68HC16
10
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Stos – operacja odczytu
• typowa notacja w j#zyku
asemblera:
pop x
• w podanym przyk!adzie stos
rozbudowuje si# w stron#
wzrastaj"cych adresów pami#ci
11
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Funkcje i w!a"ciwo"ci stosu
Stos jest pami#ci" typu LIFO (last-in-first-out)
Typowe zastosowania stosu
– przy wywo!aniu podprogramu zapami#tuje adres powrotu do programu g!ównego
– przy przej%ciu do programu obs!ugi przerwania zapami#tuje adres powrotu do przerwanego programu
– s!u y do chwilowego przechowywania zawarto%ci rejestrów w celu uwolnienia ich do innych zada'
– mo e by& u yty do przekazywania parametrów do podprogramów
Programista musi dba& o zbilansowanie liczby operacji zapisu i odczytu oraz o zachowanie w!a%ciwej kolejno%ci zapisu i odczytu (odczyt warto%ci przebiega w odwrotnej kolejno%ci ni przy zapisie)
Programista musi dba& o to, by stos nie rozrós! si# nadmiernie i nie przekroczy! limitu pami#ci (stack overflow) – cz#sty b!"d w przypadku programów rekurencyjnych lub przy wyst"pieniu niesko'czonej p#tli
12
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Stos – wywo!anie podprogramu
Ilustracja wykorzystania stosu do zapami#tania adresu powrotu
(zawarto%ci licznika rozkazów IP) przy wywo!aniu podprogramu
(asembler Pentium)
Program g!ówny:
...
...
call read_key
...
...
Podprogram:
read_key proc near
...
...
ret
read_key endp
zapisz IP
na stos
odczytaj IP
ze stosu
Uwaga: rejestr IP (instruction pointer)
bywa w wielu innych procesorach
nazywany PC (program counter)
13
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Rejestry
Niewielka pami#& robocza CPU do przechowywania tymczasowych wyników oblicze'
Liczba rejestrów i ich funkcje ró ni" si# dla ró nych procesorów
Rejestry mog" pe!ni& rozmaite funkcje:
– Rejestry ogólnego przeznaczenia (GP – general purpose)
– Rejestry danych (np. akumulator)
– Rejestry adresowe
– Rejestr wska$ników (stanu, warunków, flag)
Architektura oparta na rejestrach GP jest bardzie elastyczna przy programowaniu, ale procesor jest bardziej z!o ony a czas wykonania rozkazu d!u szy
Architektura oparta na specjalizowanych rejestrach upraszcza budow# procesora i przyspiesza wykonanie rozkazu, ale ogranicza programist#
14
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Rejestry cd.
Typowa liczba rejestrów GP w CPU: 8 – 32
– mniej rejestrów GP – cz#stsze odwo!ania do pami#ci
– znaczne zwi#kszenie liczby rejestrów GP nie wp!ywa znacz"co na zmniejszenie liczby odwo!a' do pami#ci
Rozmiar rejestru
– wystarczaj"cy do przechowywania adresu
– wystarczaj"cy do przechowywania pe!nego s!owa danych
Cz#sto mo na !"czy& ze sob" dwa rejestry, dzi#ki czemu mo na !atwo reprezentowa& typowe formaty danych w j#zykach wysokiego poziomu, np. w C:
– double int a
– long int a
15
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Rejestry cd.
Przyk!ad architektury pliku rejestrów: procesor Motorola 68HC12
16
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Rejestry cd.
Rejestr wska$ników w procesorze Motorola 68HC12
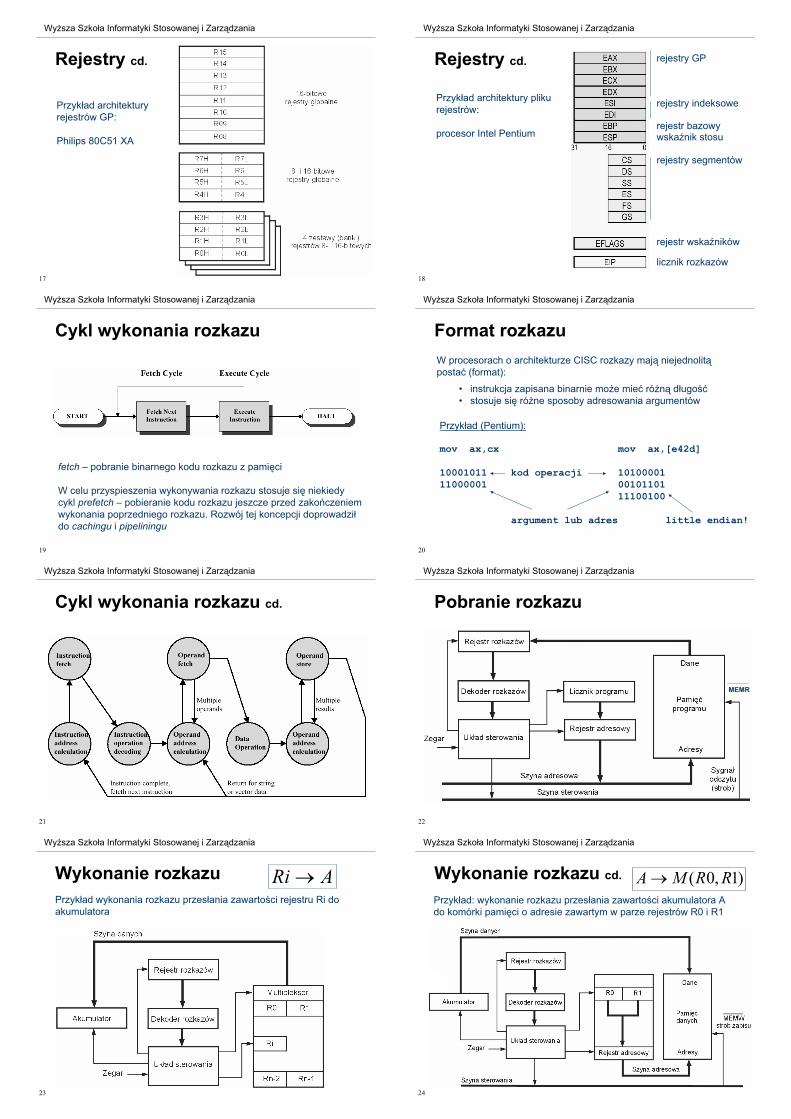
17
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Rejestry cd.
Przyk!ad architektury
rejestrów GP:
Philips 80C51 XA
18
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Rejestry cd. rejestry GP
rejestry indeksowe
rejestr bazowywska$nik stosu
rejestry segmentów
rejestr wska$ników
licznik rozkazów
Przyk!ad architektury pliku
rejestrów:
procesor Intel Pentium
19
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Cykl wykonania rozkazu
fetch – pobranie binarnego kodu rozkazu z pami#ci
W celu przyspieszenia wykonywania rozkazu stosuje si# niekiedy
cykl prefetch – pobieranie kodu rozkazu jeszcze przed zako'czeniem
wykonania poprzedniego rozkazu. Rozwój tej koncepcji doprowadzi!
do cachingu i pipeliningu
20
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Format rozkazu
W procesorach o architekturze CISC rozkazy maj" niejednolit"
posta& (format):
• instrukcja zapisana binarnie mo e mie& ró n" d!ugo%&
• stosuje si# ró ne sposoby adresowania argumentów
Przyk!ad (Pentium):
mov ax,cx mov ax,[e42d]
10001011 kod operacji 10100001
11000001 00101101
11100100
argument lub adres little endian!
21
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Cykl wykonania rozkazu cd.
22
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Pobranie rozkazu
MEMR
23
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Wykonanie rozkazu ARi Przyk!ad wykonania rozkazu przes!ania zawarto%ci rejestru Ri do
akumulatora
24
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Wykonanie rozkazu cd. )1,0( RRMA
Przyk!ad: wykonanie rozkazu przes!ania zawarto%ci akumulatora A
do komórki pami#ci o adresie zawartym w parze rejestrów R0 i R1

25
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Wykonanie rozkazu cd.
)1,0( RRMA Przebiegi w trakcie pobrania i wykonania rozkazu:
26
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Wykonanie rozkazu cd.
Analizowane poprzednio rozkazy w prostych procesorach 8-bitowych zajmuj" tylko 1 bajt zawieraj"cy kod operacji
– informacja o rejestrach bior"cych udzia! w operacji mie%ci si#na kilku bitach w kodzie operacji
– wymagany jest tylko jeden cykl dost#pu do pami#ci w fazie fetch
– w przypadku rozkazu nie trzeba dost#pu do pami#ci przy zapisie wyniku
– w przypadku rozkazu potrzebny jest jeden cykl dost#pu do pami#ci przy zapisie wyniku
ARi
)1,0( RRMA
27
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Wykonanie rozkazu cd.
Przyk!ad rozkazu wielobajtowego:
add a,7bh ;dodaj do akumulatora liczb 7b
;zapisan! w kodzie hex
wykonanie
IR M(PC) ;pobierz kod operacji do IR
PC PC+1 ;inkrementuj licznik programu PC
Temp M(PC) ;za"aduj do Temp argument z pami ci
PC PC+1 ;inkrementuj PC
A ALU+ ;prze#lij wynik dodawania A+Temp do A
28
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Wykonanie rozkazu cd.
Przyk!ad rozkazu wielobajtowego
add a,[1c47h] ;dodaj do A zawarto#$ komórki ;o adresie 1c47 w kodzie hex
wykonanie
IR M(PC) ;pobierz kod operacji do IR
PC PC+1 ;inkrementuj licznik programu PC
RAH M(PC) ;"aduj bardziej znacz!cy bajt adresu
PC PC+1 ;inkrementuj PC
RAL M(PC) ;"aduj mniej znacz!cy bajt adresu
PC PC+1 ;inkrementuj PC
Temp M(RA) ;"aduj dodajnik do rejestru Temp
A ALU+ ;prze#lij wynik dodawania do A
29
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Cykl rozkazowy – wnioski
Wykonanie programu polega na wykonaniu ci"gu cykli
rozkazowych
Cykl rozkazowy sk!ada si# z dwóch podstawowych faz:
cyklu pobrania rozkazu i wykonania rozkazu
W zale no%ci od d!ugo%ci kodu rozkazu i sposobu
adresowania argumentów wykonanie rozkazu zajmuje
ró n" liczb# elementarnych cykli maszynowych
realizowanych przez jednostk# steruj"c"
Elementarne operacje sk!adaj"ce si# na wykonanie
rozkazu s" nazywane mikrooperacjami (!OP)
30
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Instrukcje i mikrooperacje
31
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Uk!ad sterowania
Zadaniem jednostki steruj"cej jest wygenerowanie sekwencji sygna!ów
steruj"cych, które spowoduj" wykonanie sekwencji mikrooperacji
realizuj"cej dany rozkaz
32
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Sterowanie w prostym CPU

33
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Mikrooperacje i sterowanie
Przyk!ad realizacji prostej operacji dla CPU z poprzedniego rysunku:
add ac,[adres]
cykl mikrooperacja sygna"y steruj!ce
t1 MAR PC C2
t2 MBR memory C5
PC PC+1
t3 IR MBR C4
t4 MAR IR(adres) C8
t5 MBR memory C5
t6 AC AC+MBR C6,C7,C9
34
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Uk!ad sterowania cd.
Zastosowanie dekodera
upraszcza budow# uk!adu
sterowania
35
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Warianty realizacji CU
Stosuje si# dwa sposoby realizacji jednostki steruj"cej:
• w postaci typowego uk!adu sekwencyjnego (hardwired CU)
• z wykorzystaniem mikroprogramowania (microprogrammed CU)
• Jednostka CU typu hardwired :
• Zaprojektowana jako uk!ad sekwencyjny – automat o
sko'czonej liczbie stanów (FSM – finite state machine), z
wykorzystaniem klasycznych metod syntezy uk!adów
sekwencyjnych
• Zalety: du a szybko%& dzia!ania, zoptymalizowana liczba
elementów logicznych
• Wada: trudna modyfikacja w razie konieczno%ci zmiany projektu
• Jednostki CU typu hardwired s" preferowane w architekturze
RISC36
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Mikroprogramowanie
Mikroprogramowana jednostka CU (M.V. Wilkes, 1951):
Sekwencje sygna!ów steruj"cych s" przechowywane w wewn#trznej pami#ci CU i tworz" mikroprogram; ka dy rozkaz CPU ma w!asny kod mikroprogramu
Praca CU polega na sekwencyjnym odczytywaniu kolejnych s!ów mikroprogramu
Zalety:
– przejrzysta, usystematyzowana budowa CU
– !atwo%& modyfikacji pami#ci mikroprogramu
Wady:
– mniejsza szybko%& dzia!ania w porównaniu z jednostk" CU typu hardwired
– wi#ksza liczba elementów logicznych (w tym pami#ciowych)
37
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Mikroprogra-mowanie cd.
Schemat funkcjonalny
mikroprogramowanej
jednostki steruj"cej
38
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Kodowanie mikrorozkazów
kodowanie poziome
kodowanie pionowe
39
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Przerwanie
Przerwanie
(Interrupt)
Program g!ówny
Program obs!ugi
przerwania
(Interrupt handler)
40
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Koncepcja systemu przerwa#

41
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Przerwania –zysk czasu CPU
1,2,3 – program g!ówny
4 – inicjacja operacji I/O
5 – obs!uga przerwania
bez przerwa'
z przerwaniami
42
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Przerwania zewn$trzne
Przerwania zewn$trzne (interrupts) spowodowane
zdarzeniem poza CPU, sygnalizowane sygna!em
doprowadzonym do odpowiedniego wej%cia procesora
– Maskowane – sygnalizowane przez wej%cie INTR; CPU
reaguje na przerwanie maskowane je%li bit zezwolenia na
przerwanie IF w rejestrze wska$ników (w Pentium EFLAGS)
jest ustawiony
– Niemaskowane – sygnalizowane przez wej%cie NMI; CPU
zawsze reaguje na takie przerwanie
43
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Przerwania wewn$trzne - wyj%tki
Wyj%tki (exceptions) powoduj" takie same efekty jak
przerwania zewn#trzne, ale s" wynikiem realizacji
programu
– B!$dy – w przypadku wykrycia b!#du uniemo liwiaj"cego
wykonanie instrukcji CPU generuje wyj"tek
– Wyj%tki programowane – generowane celowo przez
programist# przy u yciu specjalnych instrukcji (INTO, INT3,
INT, BOUND – Pentium)
44
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Cykl rozkazu a przerwania
45
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Przerwania – problemy projektowe
1. Jak zapobiec interferencji programu g!ównego i handlera
(obydwa dzia!aj" na tych samych zasobach CPU) ?
2. W jakim obszarze pami#ci nale y umie%ci& programy obs!ugi
przerwa' (handlery) ?
3. Je%li w systemie jest wiele $róde! przerwa', jak rozpozna&, które
z urz"dze' zg!osi!o przerwanie ?
4. Co zrobi&, je%li jednocze%nie wyst"pi wi#cej ni jedno "danie
przerwania ?
46
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Przerwania – handler (problem 1)
Przyk!ad realizacji wspó!pracy programu g!ównego z handlerem (Pentium)
(1)
EFLAGS stos
I,T flags = 0
CS stos
IP stos
IP:CS hand_1
(2)
IP stos
CS stos
EFLAGS stos
program g!ówny handler
instrukcja 1 hand_1 proc far
instrukcja 2 push ax
instrukcja 3 push bp
instrukcja 4 ...
... ...
... pop bp
pop ax
iret
hand_1 endp
(1)
(2)
• czynno%ci (1) i (2) s" wykonywane automatycznie przez CPU• ochron# rejestrów w handlerze (w tym przypadku ax i bp) programista
musi zorganizowa& samodzielnie
47
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Adresy handlerów (problem 2)
• Sposób rozmieszczenia adresów handlerów przerwa' i wyj"tków
jest w wi#kszo%ci procesorów ustalony na sta!e przez producenta
CPU – u ytkownik mo e definiowa& cz#%& adresów, reszta jest
ustalona przez system
• Najcz#%ciej adresy handlerów s" umieszczone na samej górze
(Motorola) lub na samym dole przestrzeni adresowej (Intel)
Przyk!ad: adresy handlerów przerwa' w MC68HC12
watchdog
NMINMI59 x NMI
48
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Przerwania wielokrotne (problemy 3 i 4)
Zablokowanie (maskowanie przerwa')
– CPU ignoruje kolejne sygna!y przerwa' i wykonuje aktualny
handler
– zg!oszenia przerwa' s" pami#tane; CPU zacznie je obs!ugiwa&
w kolejno%ci zg!oszenia, po zako'czeniu wykonywania
aktualnego handlera
Przerwania priorytetowe
– obs!uga przerwa' o ni szym priorytecie mo e by& przerywana
przez przerwania o wy szym priorytecie
– po zako'czeniu obs!ugi przerwania o wy szym priorytecie CPU
wraca do obs!ugi przerwania o ni szym priorytecie
49
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Przerwania wielokrotne - sekwencyjne
50
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Przerwania wielokrotne - zagnie&d&one
51
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Cykl rozkazu
Diagram cyklu
rozkazowego z
uwzgl#dnieniem obs!ugi
wyj"tków i przerwa'
52
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Identyfikacja ród!a przerwa" (1)
Organizacja prostego
systemu identyfikacji
przerwa przez
programowe
przegl!danie (polling)
53
Wy"sza Szko#a Informatyki Stosowanej i Zarz!dzania
Identyfikacja ród!a przerwa" (2)
Organizacja systemu identyfikacji $ród#a przerwa z #a cuchowaniem
urz!dze I/O (daisy-chain)54
Wy"sza Szko#a Informatyki Stosowanej i Zarz!dzania
Identyfikacja ród!a przerwa" (3)
Prosty uk#ad realizuj!cy przerwania wektoryzowane
55
Wy"sza Szko#a Informatyki Stosowanej i Zarz!dzania
Podsumowanie
Struktura i dzia#anie CPU– rejestr wska$ników
– plik rejestrów
– segmentacja pami%ci
Stos
Budowa i dzia#anie jednostki steruj!cej– cykl wykonania rozkazu
– warianty realizacji jednostki steruj!cej
– mikroprogramowana jednostka steruj!ca
Przerwania– koncepcja systemu przerwa , przerwania i wyj!tki
– handlery i ich adresy, przerwania wektoryzowane
– przerwania wielokrotne
– identyfikacja $ród#a przerwania

1
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Organizacja i Architektura Komputerów
Pami#$ cache
2
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Wydajno !: CPU i pami"!
Memory density and capacity have grown along with the CPU
power and complexity, but memory speed has not kept pace.
1990 1980 2000 2010
1
10
10
Re
lati
ve p
erf
orm
ance
Calendar year
Processor
Memory
3
6
3
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Pami"! cache – koncepcja
niewielka, ale szybka pami#$ RAM
umieszczona mi#dzy CPU a pami#ci" g!ówn"
(operacyjn")
mo e by$ umieszczona w jednym uk!adzie scalonym z
CPU lub poza CPU
4
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Pami"! cache – koncepcja
CPUCache
(fast)
memory
Main
(slow)
memory
Reg
file
Cache is transparent to user;
transfers occur automaticallyLine
Word
5
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Hierarchiczny system pami"ci
Tertiary Secondary
Main
Cache 2
Cache 1
Reg’s $Millions $100s Ks
$10s Ks
$1000s
$10s
$1s
Cost per GB Access latency Capacity
TBs
10s GB
100s MB
MBs
10s KB
100s B
min+
10s ms
100s ns
10s ns
a few ns
ns
Speed
gap
Names and key characteristics of levels in a memory hierarchy.6
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Po#$czenie CPU z cache
Level-2 cache
Main memory
CPU CPU registers
Level-1 cache
Level-2 cache
Main memory
CPU CPU registers
Level-1 cache
(a) Level 2 between level 1 and main (b) Level 2 connected to “backside” bus
Cleaner and
easier to analyze
Cache memories act as intermediaries between the superfast
processor and the much slower main memory.
7
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Dzia#anie pami"ci cache
CPU "da odczytu pami#ci
sprawdza si#, czy potrzebne dane znajduj" si#w cache
je%li tak, nast#puje szybki odczyt z cache
je%li nie, przesy!a si# potrzebny blok danych z pami#ci g!ównej do cache
nast#pnie "dane dane s" przesy!ane do CPU
pami#$ cache jest wyposa ona w znaczniki (tags) pozwalaj"ce ustali$, które bloki pami#ci g!ównej s" aktualnie dost#pne w pami#ci cache
8
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Zasady lokalno ci
Lokalno%$ w sensie czasu: je%li CPU odwo!uje si#
do okre%lonej komórki pami#ci, jest
prawdopodobne, e w najbli szej przysz!o%ci
nast"pi kolejne odwo!anie do tej komórki
Lokalno%$ w sensie przestrzeni adresowej: je%li
CPU odwo!uje si# do okre%lonej komórki pami#ci,
jest prawdopodobne, e w najbli szej przysz!o%ci
nast"pi odwo!anie do s"siednich komórek pami#ci

9
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Terminologia
cache hit (trafienie): sytuacja, gdy "dana informacja znajduje si# w pami#ci cachewy szego poziomu
cache miss (chybienie, brak trafienia): sytuacja, gdy "danej informacji nie ma w pami#ci cachewy szego poziomu
line, slot (linijka, wiersz, blok): najmniejsza porcja (kwant) informacji przesy!anej mi#dzy pami#ci" cache, a pami#ci" wy szego poziomu. Najcz#%ciej stosuje si# linijki o wielko%ci 32 bajtów
10
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Terminologia cd.
hit rate (wspó!czynnik trafie&): stosunek liczby trafie& do !"cznej liczby odwo!a& do pami#ci
miss rate (wspó!czynnik chybie&): 1 – hit rate
hit time (czas dost#pu przy trafieniu): czas dost#pu do "danej informacji w sytuacji gdy wyst"pi!o trafienie. Czas ten sk!ada si# z dwóch elementów:
– czasu potrzebnego do ustalenia, czy "dana informacja jest w pami#ci cache
– czasu potrzebnego do przes!ania informacji z pami#ci cache do procesora
11
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Terminologia cd.
miss penalty (kara za chybienie): czas potrzebny
na wymian# wybranej linijki w pami#ci cache i
zast"pienie jej tak" linijk" z pami#ci g!ównej,
która zawiera "dan" informacj#
czas hit time jest znacznie krótszy od czasu
miss penalty (w przeciwnym przypadku
stosowanie pami#ci cache nie mia!oby sensu!)
12
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Problemy
W jaki sposób ustali$, czy "dana informacja znajduje
si# w pami#ci cache?
Je%li ju ustalimy, e potrzebna informacja jest w
pami#ci cache, w jaki sposób znale'$ j" w tej pami#ci
(jaki jest jej adres?)
Je%li informacji nie ma w pami#ci cache, to do jakiej
linijki j" wpisa$ z pami#ci g!ównej?
Je%li cache jest pe!na, to wed!ug jakiego kryterium
usuwa$ linijki aby zwolni$ miejsce na linijki sprowadzane
z pami#ci g!ównej?
W jaki sposób inicjowa$ zawarto%$ pami#ci cache?
13
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Odwzorowanie bezpo rednie
direct-mapped cache
ka dy blok (linijka) w pami#ci g!ównej jest
odwzorowywana (przyporz"dkowana) tylko
jednej linijce w pami#ci cache
poniewa cache jest znacznie mniejsza od
pami#ci g!ównej, wiele ró nych linijek pami#ci
g!ównej jest odwzorowanych na t" sam" linijk#
w cache
14
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Funkcja odwzorowuj$ca
Najprostsza metoda odwzorowania polega na
wykorzystaniu najmniej znacz"cych bitów
adresu
Na przyk!ad, wszystkie linijki w pami#ci g!ównej, których adresy ko&cz" si# sekwencj" 000 b#d"
odwzorowane na t" sam" linijk# w pami#ci
cache
Powy sza metoda wymaga, by rozmiar pami#ci
cache (wyra ony w linijkach) by! pot#g" liczby 2
15
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Odwzorowanie bezpo rednie
00001 00101 01001 01101 10001 10101 11001 11101
00
0
Cache
Memory
001
01
0
01
1
100
101
110
11
1
16
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Co znajduje si" w linijce 000?
Wci" nie wiemy, która linijka z pami#ci g!ównej (z wielu mo liwych) znajduje si# aktualnie w konkretnej linijce pami#ci cache
Musimy zatem zapami#ta$ adres linijki przechowywanej aktualnie w linijkach pami#ci cache
Nie trzeba zapami#tywa$ ca!ego adresu linijki, wystarczy zapami#ta$ tylko t# jego cz#%$, która nie zosta!a wykorzystana przy odwzorowaniu
T# cz#%$ adresu nazywa si# znacznikiem (tag)
Znacznik zwi"zany z ka d" linijk" pami#ci cachepozwala okre%li$, która linijka z pami#ci g!ównej jest aktualnie zapisana w danej linijce cache

17
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Znaczniki – ilustracja
Pami"! g#ówna
0000
0001
0010
0011
0100
0101
0110
0111
1000
1001
1010
1011
1100
1101
1110
1111
ZnacznikiDane
18
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Inicjalizacja cache
Pocz"tkowo pami#$ cache jest pusta
– wszystkie bity w pami#ci cache (w!"cznie z bitami
znaczników) maj" losowe warto%ci
Po pewnym czasie pracy systemu pewna cz#%$
znaczników ma okre%lon" warto%$, jednak
pozosta!e s" nadal wielko%ciami losowymi
Jak ustali$, które linijki zawieraj" rzeczywiste
dane, a które nie zosta!y jeszcze zapisane?
19
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Bit wa%no ci (valid bit)
Nale y doda$ przy ka dej linijce pami#ci cache
dodatkowy bit, który wskazuje, czy linijka zawiera wa ne
dane, czy te jej zawarto%$ jest przypadkowa
Na pocz"tku pracy systemu bity wa no%ci s" zerowane,
co oznacza, e pami#$ cache nie zawiera wa nych
danych
Przy odwo!aniach CPU do pami#ci, w trakcie
sprawdzania czy potrzebne dane s" w cache nale y
ignorowa$ linijki z bitem wa no%ci równym 0
Przy zapisie danych z pami#ci g!ównej do pami#ci cache
nale y ustawi$ bit wa no%ci linijki
20
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Rewizyta w cache
Memory Valid
0000
0001
0010
0011
0100
0101
0110
0111
1000
1001
1010
1011
1100
1101
1110
1111
TagsData
21
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Prosta symulacja cache
U yjemy prostej struktury z pami#ci" cache L1
zbudowan" tylko z czterech linijek, podobn" do
opisanej wcze%niej
Za!o ymy, e na pocz"tku bity wa no%ci zosta!y
wyzerowane
22
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Za#o%enie: sekwencja odwo#a& CPU do pami"ci
Adres Adres binarny Linijka hit / miss
3 0011 11 (3)
8 1000 00 (0) miss
2 0010 10 (2) miss
4 0100 00 (0) miss
3 0011 11 (3) hit
00 (0)
miss
8 1000 miss
23
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Address Binary Address Slot hit or miss
3 0011 11 (3)
8 1000 00 (0) miss
2 0010 10 (2) miss
4 0100 00 (0) miss
3 0011 11 (3) hit
00 (0)
miss
8 1000 miss
Slot Tag DataV
00
01
10
1124
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Address Binary Address Slot hit or miss
3 0011 11 (3)
8 1000 00 (0) miss
2 0010 10 (2) miss
4 0100 00 (0) miss
3 0011 11 (3) hit
00 (0)
miss
8 1000 miss
Slot Tag DataVInicjalizacja
bitów
wa no%ci00
01
10
11
0
0
0
0
25
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Address Binary Address Slot hit or miss
3 0011 11 (3)
8 1000 00 (0) miss
2 0010 10 (2) miss
4 0100 00 (0) miss
3 0011 11 (3) hit
00 (0)
miss
8 1000 miss
Slot Tag DataVFirst Access
00
01
10
11
0
0
0
1 00 Mem[3]26
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Address Binary Address Slot hit or miss
3 0011 11 (3)
8 1000 00 (0) miss
2 0010 10 (2) miss
4 0100 00 (0) miss
3 0011 11 (3) hit
00 (0)
miss
8 1000 miss
Slot Tag DataV2nd Access
00
01
10
11
1
0
0
1 00 Mem[3]
10 Mem[8]
27
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Address Binary Address Slot hit or miss
3 0011 11 (3)
8 1000 00 (0) miss
2 0010 10 (2) miss
4 0100 00 (0) miss
3 0011 11 (3) hit
00 (0)
miss
8 1000 miss
Slot Tag DataV3rd Access
00
01
10
11
1
0
0
1 00 Mem[3]
10 Mem[8]
28
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Address Binary Address Slot hit or miss
3 0011 11 (3)
8 1000 00 (0) miss
2 0010 10 (2) miss
4 0100 00 (0) miss
3 0011 11 (3) hit
00 (0)
miss
8 1000 miss
Slot Tag DataV4th Access
00
01
10
11
1
0
1
1 00 Mem[3]
10 Mem[8]
00 Mem[2]
29
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Address Binary Address Slot hit or miss
3 0011 11 (3)
8 1000 00 (0) miss
2 0010 10 (2) miss
4 0100 00 (0) miss
3 0011 11 (3) hit
00 (0)
miss
8 1000 miss
TagV DataSlot
00
01
10
11
1
0
1
1 00 Mem[3]
10 Mem[8]
00 Mem[2]
01 Mem[4]
5th Access
30
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Address Binary Address Slot hit or miss
3 0011 11 (3)
8 1000 00 (0) miss
2 0010 10 (2) miss
4 0100 00 (0) miss
3 0011 11 (3) hit
00 (0)
miss
8 1000 miss
Slot Tag DataV6th Access
01 Mem[4]00
01
10
11
1
0
1
1 00 Mem[3]
00 Mem[2]
10 Mem[8]
31
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Problem
Za!o enia projektowe:
– 32-bitowe adresy (232 bajtów w pami#ci g!ównej, 230 s!ów
4-bajtowych)
– 64 KB cache (16 K s!ów). Ka da linijka przechowuje 1 s!owo
– Odwzorowanie bezpo%rednie (Direct Mapped Cache)
Ile bitów b#dzie mia! ka dy znacznik?
Ile ró nych linijek z pami#ci g!ównej b#dzie
odwzorowanych na t# sam" linijk# w pami#ci cache?
Ile bitów b#dzie zajmowa$ !"cznie kompletna linijka w
pami#ci cache? (data + tag + valid).
32
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Rozwi$zanie
Pami#$ zawiera 230 s!ów
Cache zawiera 16K = 214 linijek (s!ów).
Ka da linijka mo e przechowywa$ jedn" z 230/214 =
216 linijek pami#ci g!ównej, st"d znacznik musi mie$
16 bitów
216 linijek w pami#ci g!ównej ma !"czn" pojemno%$
równ" 64K linijek – taki obszar jest
przyporz"dkowany ka dej linijce w pami#ci cache
("czna pojemno%$ pami#ci cache wyra ona w bitach
wynosi 214 x (32+16+1) = 49 x 16K = 784 Kb
(98 KB!)

33
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Problem z zapisem
Write through – zapis jednoczesny: dane s"
zapisywane jednocze%nie do cache i pami#ci g!ównej.
– Zaleta: zapewnienie sta!ej aktualno%ci danych w pami#ci
g!ównej (memory consistency)
– Wada: du y przep!yw danych do pami#ci
Write back – zapis opó'niony: aktualizuje si# tylko
pami#$ cache. Fakt ten odnotowuje si# w specjalnym
dodatkowym bicie (dirty, updated). Przy usuwaniu
linijki z cache nast#puje sprawdzenie bitu i
ewentualna aktualizacja linijki w pami#ci g!ównej.
– Zaleta: mniejszy przep!yw danych do pami#ci
– Wada: problemy ze spójno%ci" danych w pami#ci
34
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Zapis jednoczesny (write through)
ProcesorCache
Write Buffer
DRAM
W metodzie write through procesor zapisuje dane
jednocze%nie do cache i do pami#ci g!ównej
– w zapisie do pami#ci g!ównej po%redniczy bufor
– przepisywanie danych z bufora do pami#ci g!ównej obs!uguje
specjalizowany kontroler
Bufor jest niewielk" pami#ci" FIFO (first-in-first-out)
– typowo zawiera 4 pozycje
– metoda dzia!a dobrze, je%li czesto%$ operacji zapisu jest
znacznie mniejsza od 1 / DRAM write cycle
35
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Projekt cache - przyk#ad
Za!o enia projektowe:
– 4 s!owa w linijce
do przeprowadzenia odwzorowania pami#ci u ywamy
adresów linijek
adres linijek jest okre%lany jako adres/4.
przy odwo!aniu ze strony CPU potrzebne jest pojedyncze
s!owo, a nie ca!a linijka (mo na wykorzysta$ multiplekser
sterowany dwoma najmniej znacz"cymi bitami adresu)
– Cache 64KB
16 Bajtów w linijce
4K linijek
36
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Projekt cache - rozwi$zanieAddress (showing bit positions)
16 12 Byte
offset
V Tag Data
Hit Data
16 32
4K
entries
16 bits 128 bits
Mux
32 32 32
2
32
Block offsetIndex
Tag
31 16 15 4 32 1 0
37
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Wielko ! linijki a wydajno !
Przyk!ad: DecStation 3100 cache z linijk"o rozmiarze 1 lub 4 s!ów
Rozmiar Miss Rate
Program
gcc 1 6.1% 2.1% 5.4%
spice 1 1.2% 1.3% 1.2%
gcc
spice
4 2.0% 1.7% 1.9%
linijki Instrukcje Dane Instr. + Dane
4 0.3% 0.6% 0.4%
38
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Czy du%a linijka jest lepsza?
Zwi#kszanie rozmiaru linijki (przy ustalonym rozmiarze
pami#ci cache) oznacza, e liczba linijek
przechowywanych w pami#ci jest mniejsza
– konkurencja o miejsce w pami#ci cache jest wi#ksza
– parametr miss rate wzrasta
Prosz# rozwa y$ skrajny przypadek, gdy ca!a pami#$
cache tworzy jedn" du " linijk#!
39
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Rozmiar linijki a miss rate
Rozmiar cache (bajty)
Miss
Rate
0%
5%
10%
15%
20%
25%
16
32
64
12
8
25
6
1K
4K
16K
64K
256K
Rozmiar linijki (bajty)
40
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Rozmiar linijki a miss penalty
Im wi#kszy jest rozmiar linijki, tym wi#cej czasu potrzeba na przes!anie linijki mi#dzy pami#ci" g!ówn" a pami#ci" cache
W przypadku chybienia czas sprowadzenia linijki wzrasta (parametr miss penalty ma wi#ksz" warto%$)
Mo na budowa$ pami#ci zapewniaj"ce transfer wielu bajtów w jednym cyklu odczytu, ale tylko dla niewielkiej liczby bajtów (typowo 4)
Przyk!ad: hipotetyczne parametry dost#pu do pami#ci g!ównej:
– 1 cykl CPU na wys!anie adresu
– 15 cykli na inicjacj# ka dego dost#pu
– 1 cykl na transmisj# ka dego s!owa
Parametr miss penalty dla linijki z!o onej z 4 s!ów:
1 + 4x15 + 4x1 = 65 cykli.

41
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Wydajno ! cache
)redni czas dost#pu do pami#ci
AMAT – average memory access time
AMAT = Hit time + Miss rate x Miss penalty
Poprawa wydajno%ci pami#ci cache polega na
skróceniu czasu AMAT przez:
1. ograniczenie chybie& (zmniejszenie miss rate,
zwi#kszenie hit rate)
2. zmniejszenie miss penalty
3. zmniejszenie hit time
42
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Wydajno ! cache
Wydajno%$ cache zale y g!ównie od dwóch czynników:
– miss rate
Zale y od organizacji procesora (hardware) i od przetwarzanego programu (miss rate mo e si# zmienia$).
– miss penalty
Zale y tylko od organizacji komputera (organizacji pami#ci i czasu dost#pu do pami#ci)
Je%li podwoimy cz#stotliwo%$ zegara nie zmienimy adnego z tych parametrów (czas dost#pu do pami#ci pozostanie taki sam)
Dlatego parametr speedup wzro%nie mniej ni dwukrotnie
43
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Wydajno ! cache - przyk#ad
Za!ó my, e w pami#ci cache z odwzorowaniem bezpo%rednim co 64 element pami#ci jest odwzorowany w tej samej linijce. Rozwa my program:
for (i=0;i<10000;i++) {
a[i] = a[i] + a[i+64] + a[i+128];
a[i+64] = a[i+64] + a[i+128];
}
a[i], a[i+64] i a[i+128] u ywaj" tej samej linijki
Pami#$ cache jest w powy szym przyk!adzie bezu yteczna
44
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Jak zmniejszy! miss rate?
Oczywi%cie zwi#kszenie pami#ci cache
spowoduje ograniczenie chybie&, czyli
zmniejszenie parametru miss rate
Mo na te zmniejszy$ miss rate ograniczaj"c
konkurencj# przy obsadzie linijek pami#ci cache
– Trzeba pozwoli$ linijkom z pami#ci g!ównej na
rezydowanie w dowolnej linijce pami#ci cache
45
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Odwzorowanie skojarzeniowe
Fully associative mapping
Zamiast odwzorowania bezpo%redniego zezwalamy na
lokacj# linijek w dowolnym miejscu pami#ci cache
Teraz sprawdzenie czy dane s" w pami#ci cache jest
trudniejsze i zajmie wi#cej czasu (parametr hit time
wzro%nie)
Potrzebne s" dodatkowe rozwi"zania sprz#towe
(komparator dla ka dej linijki pami#ci cache)
Ka dy znacznik jest teraz kompletnym adresem linijki w
pami#ci g!ównej
46
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Odwzorowanie skojarzeniowe
Bit
wa%no ciPami"!
0000
0001
0010
0011
0100
0101
0110
0111
1000
1001
1010
1011
1100
1101
1110
1111
ZnacznikiDane
47
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Rozwi$zanie kompromisowe
Odwzorowanie skojarzeniowe jest bardziej elastyczne, dlatego parametr miss rate ma mniejsz" warto%$
Odwzorowanie bezpo%rednie jest prostsze sprz#towo, czyli ta&sze w implementacji
– Ponadto lokalizacja danych w pami#ci cache jest szybsza (parametr hit time ma mniejsz" warto%$)
Szukamy kompromisu mi#dzy miss rate a hittime.
Rozwi"zanie po%rednie: odwzorowanie sekcyjno-skojarzeniowe (set associative)
48
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Set Associative Mapping
Ka da linijka z pami#ci g!ównej mo e by$ulokowana w pewnym dozwolonym podzbiorze linijek pami#ci cache
Poj#cie n-way set associative mapping(odwzorowanie n-dro ne sekcyjno-skojarzeniowe) oznacza, e istnieje n miejsc (linijek) w pami#ci cache, do których mo e trafi$dana linijka z pami#ci g!ównej placed.
Pami#$ cache jest zatem podzielona na pewn"liczb# podzbiorów linijek, z których ka dy zawiera n linijek

49
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Porównanie odwzorowa&Przyk!ad: cache sk!ada si# z 8 linijek, rozpatrujemy lokalizacj#
linijki z pami#ci g!ównej o adresie 12
Linijka 12 mo e si#
znale'$ w jednej z dwóch
linijek zbioru 0
Linijka 12 mo e si# znale'$
w dowolnej linijce cacheLinijka 12 mo e si#
znale'$ tylko w linijce 4
1
2Tag
Data
Block # 0 1 2 3 4 5 6 7
Search
Direct mapped
1
2Tag
Data
Set # 0 1 2 3
Search
Set associative
1
2Tag
Data
Search
Fully associative
50
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Wydajno ! a n-dro%no ! cache
Performance improvement of caches with increased associativity.
4-way Direct 16-way 64-way
0
0.1
0.3
Mis
s r
ate
Associativity
0.2
2-way 8-way 32-way
51
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Odwzorowanie n-dro%ne
Odwzorowanie bezpo%rednie jest szczególnym
przypadkiem n-dro nego odwzorowania sekcyjno-
skojarzeniowego przy n = 1 (1 linijka w zbiorze)
Odwzorowanie skojarzeniowe jest szczególnym
przypadkiem n-dro nego odwzorowania sekcyjno-
skojarzeniowego przy n równym liczbie linijek w pami#ci
cache
Poprzedni przyk!ad pokazuje, e odwzorowanie
4-dro ne mo e nie dawa$ zauwa alnej poprawy
wydajno%ci cache w porównaniu z odwzorowaniem
2-dro nym.
52
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Algorytm wymiany linijek
W metodzie odwzorowania bezpo%redniego nie
mamy wyboru przy zast#powaniu linijek –
problem strategii wymiany linijek nie istnieje
W metodzie odwzorowania sekcyjno-
skojarzeniowego nale y okre%li$ strategi#
wyboru linijek, które maj" by$ usuni#te przy
wprowadzaniu do cache nowych linijek
53
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Algorytm LRU
LRU: Least recently used.
– system zarz"dzania pami#ci" cache rejestruje histori# ka dej linijki
– je%li trzeba wprowadzi$ do cache now" linijk#, a w dopuszczalnym zbiorze linijek nie ma wolnego miejsca, usuwana jest najstarsza linijka.
– przy ka dym dost#pie do linijki (hit) wiek linijki jest ustawiany na 0
– przy ka dym dost#pie do linijki wiek wszystkich pozosta!ych linijek w danym zbiorze linijek jest zwi#kszany o 1
54
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Implementacja LRU
Realizacja algorytmu LRU jest wykonywana sprz#towo
Obs!uga LRU w pami#ciach 2-dro nych jest !atwa –
wystarczy tylko 1 bit aby zapami#ta$, która linijka (z
dwóch) w zbiorze jest starsza
Algorytm LRU w pami#ciach 4-dro nych jest znacznie
bardziej z!o ony, ale stosowany w praktyce
W przypadku pami#ci 8-dro nych sprz#towa realizacja
LRU staje si# kosztowna i skomplikowana. W praktyce
u ywa si# prostszego algorytmu aproksymuj"cego
dzia!anie LRU
55
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Wielopoziomowa pami"! cache
Wielko ! pami"ci cache wbudowanej do procesora jest
ograniczona ze wzgl"dów technologicznych
Ekonomicznym rozwi#zaniem jest zastosowanie
zewn"trznej pami"ci cache L2
Zwykle zewn"trzna pami"! cache jest szybk# pami"ci#
SRAM (czas miss penalty jest znacznie mniejszy ni$ w
przypadku pami"ci g%ównej)
Dodanie pami"ci cache L2 wp%ywa na projekt pami"ci
cache L1 – d#$y si" do tego, by parametr hit time dla
pami"ci L1 by% jak najmniejszy
56
Wy$sza Szko%a Informatyki Stosowanej i Zarz#dzania
Wspólna a rozdzielona cache
We wspólnej pami"ci cache dane i instrukcje s# przechowywane razem (architektura von Neumanna)
W rozdzielonej pami"ci cache dane i instrukcje s# przechowywane w osobnych pami"ciach (architektura harwardzka)
Dlaczego pami"! cache przechowuj#ca instrukcje ma znacznie mniejszy wspó%czynnik miss rate?
Size Instruction Cache Data Cache Unified Cache
1 KB 3.06% 24.61% 13.34%
2 KB 2.26% 20.57% 9.78%
4 KB 1.78% 15.94% 7.24%
8 KB 1.10% 10.19% 4.57%
16 KB 0.64% 6.47% 2.87%
32 KB 0.39% 4.82% 2.48%
64 KB 0.15% 3.77% 1.35%
128 KB 0.02% 2.88% 0.95%

57
Wy$sza Szko%a Informatyki Stosowanej i Zarz#dzania
Wspólna a rozdzielona cache
Które rozwi#zanie zapewnia krótszy czas dost"pu
AMAT?
– pami"! rozdzielona: 16 KB instrukcje + 16 KB dane
– pami"! wspólna: 32 KB instrukcje + dane
Za%o$enia:
– nale$y u$y! danych statystycznych dotycz#cych miss rate z
poprzedniego slajdu
– zak%adamy, $e 75% dost"pów do pami"ci dotyczy odczytu
instrukcji, a 25% dost"pów dotyczy danych
– miss penalty = 50 cykli
– hit time = 1 cykl
– operacje odczytu i zapisu zajmuj# dodatkowo 1 cykl, poniewa$
jest tylko jeden port dla instrukcji i danych
58
Wy$sza Szko%a Informatyki Stosowanej i Zarz#dzania
Wspólna a rozdzielona cache
AMAT = %instr x (instr hit time + instr miss rate x instr miss penalty) +
%data x (data hit time + data miss rate x data miss penalty)
Dla rozdzielonej pami"ci cache:
AMAT = 75% x (1 + 0.64%x 50) + 25% x (1 + 6.47% x 50) = 2.05
Dla wspólnej pami"ci cache:
AMAT = 75% x (1 + 2.48%x 50) + 25% x (1 + 2.48% x 50) = 2.24
W rozwa$anym przyk%adzie lepsz# wydajno ! (krótszy czas dost"pu AMAT) zapewnia rozdzielona pami"! cache
59
Wy$sza Szko%a Informatyki Stosowanej i Zarz#dzania
Przyk ad – cache w Pentium
Processor Chip
L1 Data
1 cycle latency
16KB
4-way assoc
Write-through
32B lines
L1 Instruction
16KB, 4-way
32B lines
Regs. L2 Unified
128KB--2 MB
4-way assoc
Write-back
32B lines
Main
Memory
Up to 4GB
60
Wy$sza Szko%a Informatyki Stosowanej i Zarz#dzania
Podsumowanie
Zasada lokalno ci
Hierarchiczny system pami"ci
Koncepcja budowy i dzia%ania pami"ci cache
Metody odwzorowania pami"ci g%ównej i pami"ci cache– odwzorowanie bezpo rednie (mapowanie bezpo rednie)
– odwzorowanie asocjacyjne (pe%na asocjacja)
– cz" ciowa asocjacja
Zapis danych i problem spójno ci zawarto ci pami"ci
Wydajno ! pami"ci cache, metody optymalizacji, ograniczenia
Wymiana linijek w pami"ci cache - algorytm LRU
Przyk%ady organizacji i architektury pami"ci cache
Wspólna a rozdzielona pami"! cache

1
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Organizacja i Architektura Komputerów
Przetwarzanie potokowe.
Architektury superskalarne
2
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Pipelining – wprowadzenie
Pipelining: technika wykonywania ci"gu instrukcji, w której kilka kolejnych instrukcji jest wykonywanych równolegle
Przyk!ad: pralnia
Ania, Basia, Celina i Dorotamaj" po kompletnym !adunku odzie y, do prania, wysuszenia i wyprasowania
Pranie trwa 30 minut
Suszenie zajmuje 40 minut
Prasowanie trwa 20 minut
A B C D
3
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Wersja 1 – pralnia sekwencyjna
A
B
C
D
30 40 20 30 40 20 30 40 20 30 40 20
6 7 8 9 10 11 pó noc
czas
Kole
jno !
za
da"
Sekwencyjne pranie 4 !adunków zajmuje 6 godzin4
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Wersja 2 – pralnia potokowa
A
B
C
D
6 7 8 9 10 11 pó noc
czas
30 40 40 40 40 20
• Metoda „start ASAP”
• Pranie 4 !adunków
zajmuje 3,5 godziny
• Speedup 6/3,5 = 1,7
Ko
l ejn
o !
za
da"
5
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Pipelining – wnioski
Pipelining nie zmienia czasu wykonania pojedynczej instrukcji (latency), wp!ywa natomiast na czas wykonania ci"gu instrukcji (throughput)
Cz#sto$% z jak" pracuje potok jest ograniczona przez czas pracy najwolniejszego stopnia w potoku (slowest pipeline stage)
Wiele instrukcji jest wykonywanych równolegle (instruction levelparallelism)
Potencjalne zwi#kszenie wydajno$ci jest tym wi#ksze, im wi#ksza jest liczba stopni w potoku
Du e zró nicowanie czasu trwania operacji w poszczególnych stopniach ogranicza wzrost wydajno$ci
Czas potrzebny na nape!nienie potoku i opró nienie go ogranicza wzrost wydajno$ci
6
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Wnioski cd.
Architektura RISC zapewnia lepsze wykorzystanie
mo liwo$ci przetwarzania potokowego ni architektura
CISC. W architekturze RISC:
– instrukcje maj" tak" sam" d!ugo$%
– wi#kszo$% operacji dotyczy rejestrów
– odwo!ania do pami#ci, które mog" ewentualnie powodowa%
kolizje s" rzadsze i wyst#puj" tylko w przypadku specjalnie do tego celu u ywanych instrukcji load i store
W architekturze CISC instrukcje maj" ró n" d!ugo$%,
wyst#puje bogactwo sposobów adresowania danych w
pami#ci
7
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Cykl prefetch
Najprostsza wersja przetwarzania potokowego
Pobranie kolejnej instrukcji (cykl fetch) wymaga dost#pu do pami#ci
Wykonanie instrukcji zazwyczaj nie wymaga dost#pu do pami#ci
Wniosek: mo na pobra% nast#pn" instrukcj# z pami#ci podczas wykonywania poprzedniej instrukcji
Metoda nazywana „pobraniem wst#pnym” -instruction prefetch
8
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Prefetch cd.
Wprowadzenie cyklu prefetch poprawia wydajno$% (ale
nie podwaja):
– pobranie kodu operacji trwa zwykle krócej ni faza wykonania
mo e pobiera% wi#cej ni jeden rozkaz w fazie prefetch?
– ka dy rozkaz skoku powoduje utrat# korzy$ci z fazy prefetch
Wnioski s" niejednoznaczne:
– z jednej strony korzystnie by!oby zwi#kszy% liczb# stopni w
potoku
– z drugiej jednak d!ugi potok w przypadku skoku musi by%
opró niony i nape!niony od nowa

9
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Punkt wyj!cia – brak potoku
Uk!adkombinacyjny
R
E
G
300ps 30ps
Clock
latency = 330ps
throughput = 3.12 GOPS
System
bez potoku
(przyk ad)
Op1 Op2 Op3??
Czas
– Ka da operacja musi by% zako&czona zanim zacznie si#wykonywanie nast#pnej operacji
– W podanym przyk!adzie czas wykonania operacji wynosi 330ps
10
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Potok 3-stopniowy
– Wykonanie kolejnych instrukcji zaczyna si# co120ps
– 3 instrukcje s" wykonywane równolegle
– Czas oczekiwania na wykonanie instrukcji wzrós! z 330ps do 360ps, ale przepustowo$% wzros!a z 3.12 do 8.33 GOPS
R
E
G
Clock
uk!adkomb.
R
E
G
uk!adkomb.
R
E
G
uk!adkomb.
100ps 20ps 100ps 20ps 100ps 20ps
latency = 360ps
throughput = 8.33 GOPS
Czas
Op1
Op2
Op3
??
Op4
11
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Diagramy czasowe
Bez potoku
– Kolejna operacja nie mo e si# zacz"% przed zako&czeniem poprzedniej
3-stopniowy potok
– Do 3 instrukcji wykonuje si# równolegle
Time
OP1
OP2
OP3
Time
A B C
A B C
A B C
OP1
OP2
OP3
A, B, C – fazy wykonania
instrukcji
12
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Ograniczenie – ró"nice opó#nie$
R
e
g
Clock
R
e
g
Comb.
logic
B
R
e
g
Comb.
logic
C
50 ps 20 ps 150 ps 20 ps 100 ps 20 ps
latency = 510 ps
throughput = 5.88 GOPS
Comb.
logic
A
Time
OP1
OP2
OP3
A B C
A B C
A B C
– Przepustowo$% ograniczona przez najwolniejszy stopie&
– Pozosta!e (szybsze) stopnie s" przez znaczny czas bezczynne
– Nale y d" y% do budowy potoku o zbli onych czasach operacji w poszczególnych stopniach
13
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
G %boki potok – problemy
latency = 420 ps, throughput = 14.29 GOPSClock
R
e
g
Comb.
logic
50 ps 20 ps
R
e
g
Comb.
logic
50 ps 20 ps
R
e
g
Comb.
logic
50 ps 20 ps
R
e
g
Comb.
logic
50 ps 20 ps
R
e
g
Comb.
logic
50 ps 20 ps
R
e
g
Comb.
logic
50 ps 20 ps
– W miar# wyd!u ania (zwi#kszania g!#boko$ci) potoku opó'nienia rejestrów staj" si# coraz bardziej znacz"ce
– Procentowy udzia! czasu opó'nienia rejestrów w potoku:
1-stopie&: 6.25%
3-stopnie: 16.67%
6-stopni: 28.57%
– Problem ma du e znaczenie, poniewa wspó!czesne procesory o du ej wydajno$ci maj" coraz g!#bsze potoki
14
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Cykl wykonania instrukcji
15
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Typowe 6 stopni potoku
Pobranie instrukcji (fetch instruction - FI)
Dekodowanie instrukcji (decode instruction - DI)
Obliczenie adresu argumentu (calculate operand – CO)
Pobranie argumentu (fetch operand – FO)
Wykonanie instrukcji (execute instruction - EI)
Zapis wyniku (write - WO)
16
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Potok 6-stopniowy
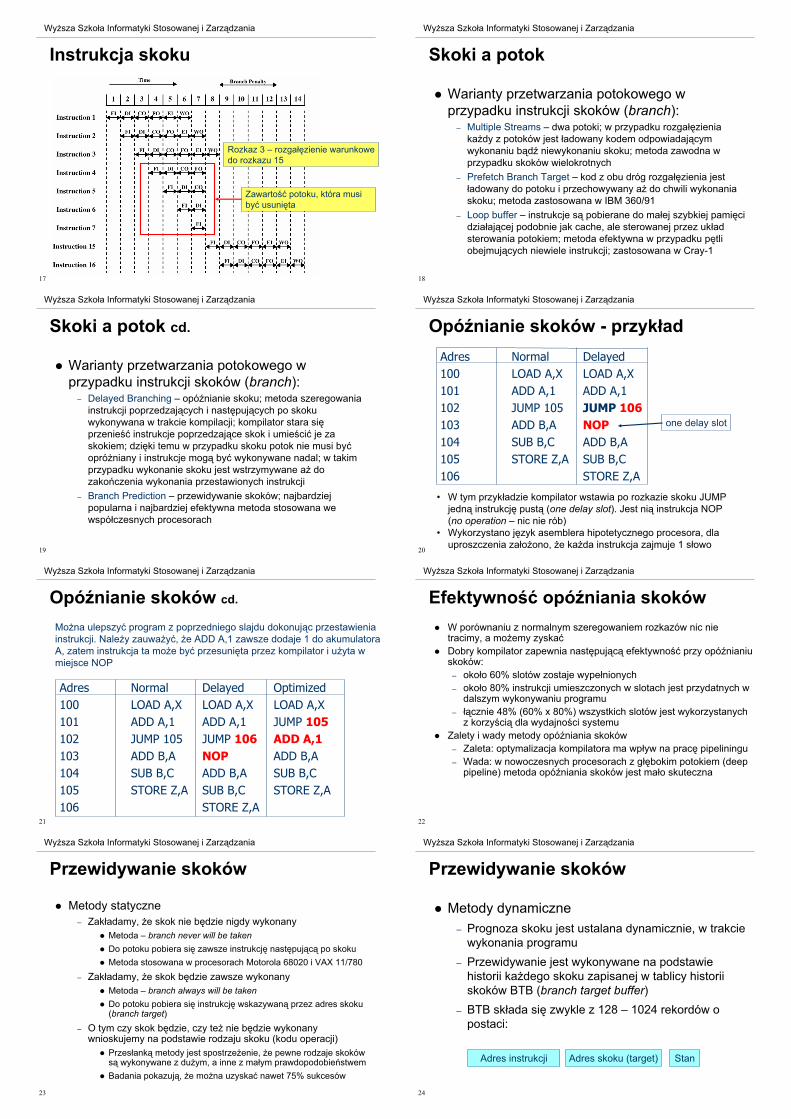
17
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Instrukcja skoku
Rozkaz 3 – rozga!#zienie warunkowe
do rozkazu 15
Zawarto$% potoku, która musi
by% usuni#ta
18
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Skoki a potok
Warianty przetwarzania potokowego w
przypadku instrukcji skoków (branch):– Multiple Streams – dwa potoki; w przypadku rozga!#zienia
ka dy z potoków jest !adowany kodem odpowiadaj"cym
wykonaniu b"d' niewykonaniu skoku; metoda zawodna w
przypadku skoków wielokrotnych
– Prefetch Branch Target – kod z obu dróg rozga!#zienia jest
!adowany do potoku i przechowywany a do chwili wykonania
skoku; metoda zastosowana w IBM 360/91
– Loop buffer – instrukcje s" pobierane do ma!ej szybkiej pami#ci
dzia!aj"cej podobnie jak cache, ale sterowanej przez uk!ad
sterowania potokiem; metoda efektywna w przypadku p#tli
obejmuj"cych niewiele instrukcji; zastosowana w Cray-1
19
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Skoki a potok cd.
Warianty przetwarzania potokowego w
przypadku instrukcji skoków (branch):– Delayed Branching – opó'nianie skoku; metoda szeregowania
instrukcji poprzedzaj"cych i nast#puj"cych po skoku
wykonywana w trakcie kompilacji; kompilator stara si#
przenie$% instrukcje poprzedzaj"ce skok i umie$ci% je za
skokiem; dzi#ki temu w przypadku skoku potok nie musi by%
opró niany i instrukcje mog" by% wykonywane nadal; w takim
przypadku wykonanie skoku jest wstrzymywane a do
zako&czenia wykonania przestawionych instrukcji
– Branch Prediction – przewidywanie skoków; najbardziej
popularna i najbardziej efektywna metoda stosowana we
wspó!czesnych procesorach
20
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Adres Normal Delayed
100 LOAD A,X LOAD A,X
101 ADD A,1 ADD A,1
102 JUMP 105 JUMP 106
103 ADD B,A NOP
104 SUB B,C ADD B,A
105 STORE Z,A SUB B,C
106 STORE Z,A
• W tym przyk!adzie kompilator wstawia po rozkazie skoku JUMP
jedn" instrukcj# pust" (one delay slot). Jest ni" instrukcja NOP
(no operation – nic nie rób)
• Wykorzystano j#zyk asemblera hipotetycznego procesora, dla
uproszczenia za!o ono, e ka da instrukcja zajmuje 1 s!owo
Opó#nianie skoków - przyk ad
one delay slot
21
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Opó#nianie skoków cd.
Mo na ulepszy% program z poprzedniego slajdu dokonuj"c przestawienia
instrukcji. Nale y zauwa y%, e ADD A,1 zawsze dodaje 1 do akumulatora
A, zatem instrukcja ta mo e by% przesuni#ta przez kompilator i u yta w
miejsce NOP
Adres Normal Delayed Optimized
100 LOAD A,X LOAD A,X LOAD A,X
101 ADD A,1 ADD A,1 JUMP 105
102 JUMP 105 JUMP 106 ADD A,1
103 ADD B,A NOP ADD B,A
104 SUB B,C ADD B,A SUB B,C
105 STORE Z,A SUB B,C STORE Z,A
106 STORE Z,A22
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Efektywno!& opó#niania skoków
W porównaniu z normalnym szeregowaniem rozkazów nic nie tracimy, a mo emy zyska%
Dobry kompilator zapewnia nast#puj"c" efektywno$% przy opó'nianiu skoków:
– oko!o 60% slotów zostaje wype!nionych
– oko!o 80% instrukcji umieszczonych w slotach jest przydatnych w dalszym wykonywaniu programu
– !"cznie 48% (60% x 80%) wszystkich slotów jest wykorzystanych z korzy$ci" dla wydajno$ci systemu
Zalety i wady metody opó'niania skoków
– Zaleta: optymalizacja kompilatora ma wp!yw na prac# pipeliningu
– Wada: w nowoczesnych procesorach z g!#bokim potokiem (deeppipeline) metoda opó'niania skoków jest ma!o skuteczna
23
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Przewidywanie skoków
Metody statyczne
– Zak!adamy, e skok nie b#dzie nigdy wykonany
Metoda – branch never will be taken
Do potoku pobiera si# zawsze instrukcj# nast#puj"c" po skoku
Metoda stosowana w procesorach Motorola 68020 i VAX 11/780
– Zak!adamy, e skok b#dzie zawsze wykonany
Metoda – branch always will be taken
Do potoku pobiera si# instrukcj# wskazywan" przez adres skoku (branch target)
– O tym czy skok b#dzie, czy te nie b#dzie wykonany wnioskujemy na podstawie rodzaju skoku (kodu operacji)
Przes!ank" metody jest spostrze enie, e pewne rodzaje skoków s" wykonywane z du ym, a inne z ma!ym prawdopodobie&stwem
Badania pokazuj", e mo na uzyska% nawet 75% sukcesów
24
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Przewidywanie skoków
Metody dynamiczne
– Prognoza skoku jest ustalana dynamicznie, w trakcie
wykonania programu
– Przewidywanie jest wykonywane na podstawie
historii ka dego skoku zapisanej w tablicy historii
skoków BTB (branch target buffer)
– BTB sk!ada si# zwykle z 128 – 1024 rekordów o
postaci:
Adres instrukcji Adres skoku (target) Stan

25
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Predykcja skoków – diagram BTB
Stan: 11
Stan: 01 Stan: 00
Stan: 10
Przyk!adowe
kodowanie
stanów:
00 – mocna hipoteza
o braku skoku
01 – s!aba hipoteza
o braku skoku
10 – s!aba hipoteza
o skoku
11 – mocna hipoteza
o skoku
26
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Rozmiar BTB
Im wi#kszy jest rozmiar BTB (czyli im wi#cej rekordów
mie$ci tablica), tym bardziej trafne jest przewidywanie
skoków
(rednia liczba
Rozmiar BTB trafnych prognoz [%]
16 40
32 50
64 65
128 72
256 78
512 80
1024 85
2048 87
27
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
G %boko!& potoku
Wyniki bada& pokazuj", e istnieje teoretyczna
optymalna warto$% g!#boko$ci potoku równa oko!o 8
stopni
– z jednej strony im g!#bszy potok, tym lepiej dzia!a równoleg!e
przetwarzanie instrukcji
– z drugiej strony g!#boki potok w przypadku 'le przewidzianego
skoku powoduje du " strat# czasu (branch penalty)
W nowych procesorach stosuje si# ulepszone warianty
przetwarzania potokowego (hyperpipeline) dostosowane
do pracy z bardzo szybkim zegarem
– w takich procesorach optymalna g!#boko$% potoku jest wi#ksza
i dochodzi nawet do 20 (przyk!ad – Pentium 4)
28
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
G %boko!& potoku cd.
Liczba stopni przetwarzania danych typu integer w potokach
popularnych procesorów
CPU liczba stopni w potoku
P 5
MMX 6
P-Pro 12
P-II 12
P-III 10
P-4 20
M1-2 7
K5 7
K6 6
K7 11
P – Pentium
M – Cyrix
K – AMD
29
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Zjawisko hazardu
Równoleg!e przetwarzanie instrukcji w potoku prowadzi cz#sto do
niekorzystnych zjawisk nazywanych hazardem. Hazard polega na
braku mo liwo$ci wykonania instrukcji w przewidzianym dla niej
cyklu. Wyró nia si# trzy rodzaje hazardu:
1. Hazard zasobów (structural hazard) – kiedy dwie instrukcje odwo!uj"
si# do tych samych zasobów
2. Hazard danych (data hazard) – kiedy wykonanie instrukcji zale y od
wyniku wcze$niejszej, nie zako&czonej jeszcze instrukcji znajduj"cej
si# w potoku
3. Hazard sterowania (control hazard) – przy przetwarzaniu instrukcji
skoków i innych instrukcji zmieniaj"cych stan licznika rozkazów (np.
wywo!ania podprogramów)
Hazard sterowania zosta! omówiony ju wcze$niej – teraz
zajmiemy si# hazardem zasobów i danych
30
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Zjawisko hazardu cd.
Podstawowym sposobem rozwi"zywania problemów
wynikaj"cych z hazardu jest chwilowe zatrzymanie
potoku na jeden lub wi#cej cykli zegara. W tym celu do
potoku wprowadza si# tzw. przegrody (stalls), które s"
faktycznie operacjami pustymi („bubbles”)
Przegrody wp!ywaj" oczywi$cie na zmniejszenie
wydajno$ci CPU
Ze wzgl#du na wyst#powanie zjawisk hazardu
rzeczywista wydajno$% CPU jest zawsze mniejsza od
wydajno$ci teoretycznej, obliczonej przy za!o eniu e
hazardy nie wyst#puj"
31
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Hazard zasobów
Nazywany te hazardem strukturalnym lub konfliktem zasobów (resource conflict)
Powodem hazardu tego typu jest jednoczesne "danie dost#pu do tego samego zasobu (zwykle pami#ci) przez dwa ró ne stopnie potoku
Typowy hazard zasobów wyst#puje, gdy jedna z instrukcji wykonuje !adowanie danych z pami#ci podczas gdy inna ma by% w tym samym cyklu !adowana (instruction fetch)
Rozwi"zanie polega na wprowadzeniu jednej (lub kilku przegród). W efekcie wzrasta CPI i spada wydajno$%procesora
32
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Hazard zasobów - przyk ad
czas (cykle zegara)
Mem
Load
Instr 1
Instr 2
Instr 3
Instr 4
ALUMem Reg Mem Reg
ALUMem Reg Mem Reg
ALUMem Reg Mem Reg
ALUReg Mem Reg
ALUMem Reg Mem Reg
!danie odczytu z pami"ci
Cykl IF instr 3
Kole
jne instr
ukcje

33
Wy#sza Szko$a Informatyki Stosowanej i Zarz!dzania
Hazard zasobów – przyk ad cd.
czas (cykle zegara)
Mem
Load
Instr 1
Instr 2
Instr 3
ALUMem Reg Mem Reg
ALUMem Reg Mem Reg
ALUMem Reg Mem Reg
ALUReg Mem Reg
Kole
jne instr
ukcje
stall
34
Wy#sza Szko$a Informatyki Stosowanej i Zarz!dzania
Hazard danych
Hazard danych wyst"puje, poniewa# potok zmienia
kolejno%& operacji odczytu/zapisu argumentów w
stosunku do kolejno%ci, w jakiej te operacje wyst"puj! w
sekwencyjnym zapisie programu
Przyk$ad: add ax,bx
mov cx,ax
Instrukcja mov cx,ax ma pobra& zawarto%& akumulatora
ax, podczas gdy potok jeszcze nie okre%li$ tej zawarto%ci
w poprzedniej instrukcji dodawania
35
Wy#sza Szko$a Informatyki Stosowanej i Zarz!dzania
Hazard typu RAW
Wyró#nia si" trzy typy (rodzaje) hazardu danych: RAW,
WAR i WAW:
Hazard RAW (read after write) wyst"puje gdy pojawi si"
#!danie odczytu danych przed zako'czeniem ich zapisu
Przyk$ad (taki sam jak na poprzednim slajdzie)
add ax,bx
mov cx,ax
36
Wy#sza Szko$a Informatyki Stosowanej i Zarz!dzania
Hazard typu WAR
Hazard WAR (write after read) wyst"puje gdy pojawi si"#!danie zapisu danych przed zako'czeniem ich odczytu
Przyk$ad:
mov bx,ax
add ax,cx
CPU chce zapisa& do akumulatora ax now! warto%&równ! sumie ax+cx, podczas gdy instrukcja przes$ania mov jeszcze nie odczyta$a starej zawarto%ci ax i nie przes$a$a jej do rejestru bx
37
Wy#sza Szko$a Informatyki Stosowanej i Zarz!dzania
Hazard typu WAW
Hazard WAW (write after write) wyst"puje gdy pojawi si"#!danie zapisu danych przed zako'czeniem wcze%niejszej operacji zapisu
Przyk$ad:
mov ax,[mem]
add ax,bx
CPU chce zapisa& do akumulatora ax now! warto%& równ!sumie ax+bx, podczas gdy poprzednia instrukcja nie zd!#y$a jeszcze pobra& do ax zawarto%ci komórki pami"ci [mem]
38
Wy#sza Szko$a Informatyki Stosowanej i Zarz!dzania
Problem
Czy mo#e powsta& hazard danych RAR (read after read) ?
Przyk$ad:
add bx,ax
mov cx,ax
Odpowied(: taka sytuacja nie powoduje hazardu danych, poniewa# zawarto%& rejestru ax nie zmienia si". Mo#e natomiast wyst!pi& konflikt równoczesnego dost"pu (hazard zasobów). Problem mo#na rozwi!za& stosuj!c rejestry typu dual-port
39
Wy#sza Szko$a Informatyki Stosowanej i Zarz!dzania
Zapobieganie hazardom danych
Najprostsz! metod! jest, jak poprzednio, zatrzymywanie
potoku (stalls)
– metoda ta obni#a wydajno%& CPU i jest stosowana w
ostateczno%ci
Szeregowanie statyczne (static scheduling)
– wykonywane programowo podczas kompilacji
– polega na zmianie kolejno%ci instrukcji, tak aby zlikwidowa&
hazardy
– likwidacja hazardów nie zawsze jest mo#liwa
– dobre kompilatory potrafi! usun!& znaczn! cz"%& potencjalnych
hazardów danych
40
Wy#sza Szko$a Informatyki Stosowanej i Zarz!dzania
Szeregowanie statyczne
Przyk$ad:
Kod oryginalny Kod po uszeregowaniu
add ax,15 add ax,15
mov cx,ax mov [mem],bx
mov [mem],bx mov cx,ax
Zmiana kolejno%ci instrukcji nie wp$ywa na dzia$anie
programu
Hazard RAW zosta$ zlikwidowany, poniewa# instrukcja
dodawania zd!#y by& wykonana przed pobraniem
argumentu przez instrukcj" przes$ania ax do cx

41
Wy#sza Szko$a Informatyki Stosowanej i Zarz!dzania
Szeregowanie dynamiczne
Dynamic scheduling – wspólna nazwa technik polegaj!cych na usuwaniu problemów z hazardem danych w trakcie wykonywania programu, a nie w fazie kompilacji
– realizacja sprz"towa w CPU
– najwa#niejsze techniki:
wyprzedzanie argumentów (operand forwarding)
wyprzedzanie wyników operacji (result forwarding)
– w procesorach superskalarnych stosuje si" ponadto
notowanie (scorebording)
przemianowywanie rejestrów (register renaming)
42
Wy#sza Szko$a Informatyki Stosowanej i Zarz!dzania
Procesory superskalarne
Procesory, które wykonuj! równolegle wi"cej ni# jeden
rozkaz (paralelizm na poziomie rozkazu)
Podstawowe bloki funkcjonalne CPU s! zwielokrotnione:
– dwa potoki (lub wi"cej)
– kilka jednostek ALU (zwykle osobne ALU dla operacji integer i
FP)
Termin „superskalarny” u#yty po raz pierwszy w 1987
roku oznacza, #e CPU przetwarza w danej chwili kilka
argumentów skalarnych (liczb), a nie tylko jedn!
wielko%& skalarn!
43
Wy#sza Szko$a Informatyki Stosowanej i Zarz!dzania
Procesor superskalarny - koncepcja
44
Wy#sza Szko$a Informatyki Stosowanej i Zarz!dzania
Superskalar – koncepcja cd.
45
Wy#sza Szko$a Informatyki Stosowanej i Zarz!dzania
Superskalar cd.
Porównanie koncepcji CPU:
1) z potokiem instrukcji
2) z superpotokiem
3) superskalarnej
Superpotok jest taktowany
podwójn! czesto%ci! zegara
Rozwi!zanie superskalarne
zapewnia najwi"ksz!
wydajno%&
46
Wy#sza Szko$a Informatyki Stosowanej i Zarz!dzania
Superskalar- problemy
Zagadnienie
wspó$zale#no%ci instrukcji
w procesorach
superskalarnych jest
jeszcze trudniejsze ni#
problem hazardów w
pojedynczym potoku
47
Wy#sza Szko$a Informatyki Stosowanej i Zarz!dzania
Superskalar – problemy cd.
W celu odpowiedniego wykorzystania zalet architektury
superskalarnej stosuje si" rozmaite techniki:
Przemianowywanie rejestrów – metoda usuwania uzale#nie'
mi"dzy instrukcjami przy u#yciu zbioru pomocniczych rejestrów
Okna rejestrów – parametry s! przekazywane w bloku rejestrów
nazywanym oknem; zmiana bloku (i tym samym parametrów)
wymaga zmiany samego wska(nika okna
Statyczna optymalizacja kodu (w fazie kompilacji)
Zaawansowane dynamiczne metody szeregowania instrukcji
(parowanie, technika zmiany kolejno%ci wykonywania rozkazów –
out-of-order completion)
Ze wzgl"du na swoje cechy architektura RISC znacznie lepiej
sprzyja technice superskalarnej ni# architektura CISC
48
Wy#sza Szko$a Informatyki Stosowanej i Zarz!dzania
Superskalar– przyk ad
Uproszczony schemat
blokowy procesora
superskalarnego
UltraSparc IIi (Sun)

49
Wy#sza Szko$a Informatyki Stosowanej i Zarz!dzania
Podsumowanie
Koncepcja przetwarzania potokowego– g$"boko%& potoku
– potok a skoki – przewidywanie skoków
– zjawisko hazardu
sterowania
danych
zasobów
– szeregowanie statyczne i dynamiczne
Architektura superskalarna– metody zwi"kszania wydajno%ci
– przemianowywanie rejestrów
– okna rejestrów
– statyczne i dynamiczne szeregowanie rozkazów

1
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Organizacja i Architektura Komputerów
Architektury IA-32 i IA-64
2
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Architektura IA-32
Intel Architecture 32– pierwszy procesor IA-32 – 8086 (1978)
– podstawowa architektura utrzymana do 1993 r (pierwszy procesor Pentium – superskalar, 2 potoki)
Architektura P6– pierwszy procesor – Pentium Pro (1995)
3-potokowy superskalar
5 jednostek wykonawczych
8+8KB L1 cache, 256 KB L2 cache
– Pentium III (1999)
16+16 KB L1 cache, 256 lub 512 L2 cache
Streaming SIMD Extension (SSE) – równoleg!e operacje na spakowanych 32-bitowych liczbach FP w rejestrach SSE o rozmiarze 128 bitów
– Pentium III Xeon – ulepszona pami#$ cache
3
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Pentium CPU (1993)• dwa potoki U i V
• instrukcje s"
dobierane parami
4
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Mikroarchitektura P6
Zapocz"tkowana w Pentium Pro (1995)
– U ywana w procesorach Intel wcze%niejszych od P4
– Mieszana architektura CISC-RISC
lista instrukcji typu CISC
translacja kodu programu na ci"g mikrooperacji RISC
– 3 potokowy superskalar, out-of-order execution
14-stopniowy potok instrukcji
– Potok sk!ada si# z 3 cz#%ci:
wydawanie instrukcji: in-order
wykonanie instrukcji: out-of-order (RISC core)
ko&czenie instrukcji (retire): in-order
5
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Mikroarchitektura P6 cd.
6
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Mikroarchitektura P6 cd.
7
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
P6 – Pentium III Xeon
8
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Pentium 4
Nazwa projektu: Willamette
Architektura NetBurst
G!#boki potok – 20 stopni
– zaprojektowany do pracy z szybkim zegarem >1,5 GHz
– ró ne cz#%ci CPU pracuj" z ró n" cz#stotliwo%ci" zagara
Trzy sekcje:
– wydawanie instrukcji (dispatch) – in-order
– wykonanie instrukcji – out-of-order
– ko&czenie instrukcji – in-order
Technologia SSE2
– ulepszone technologie MMX i SSE
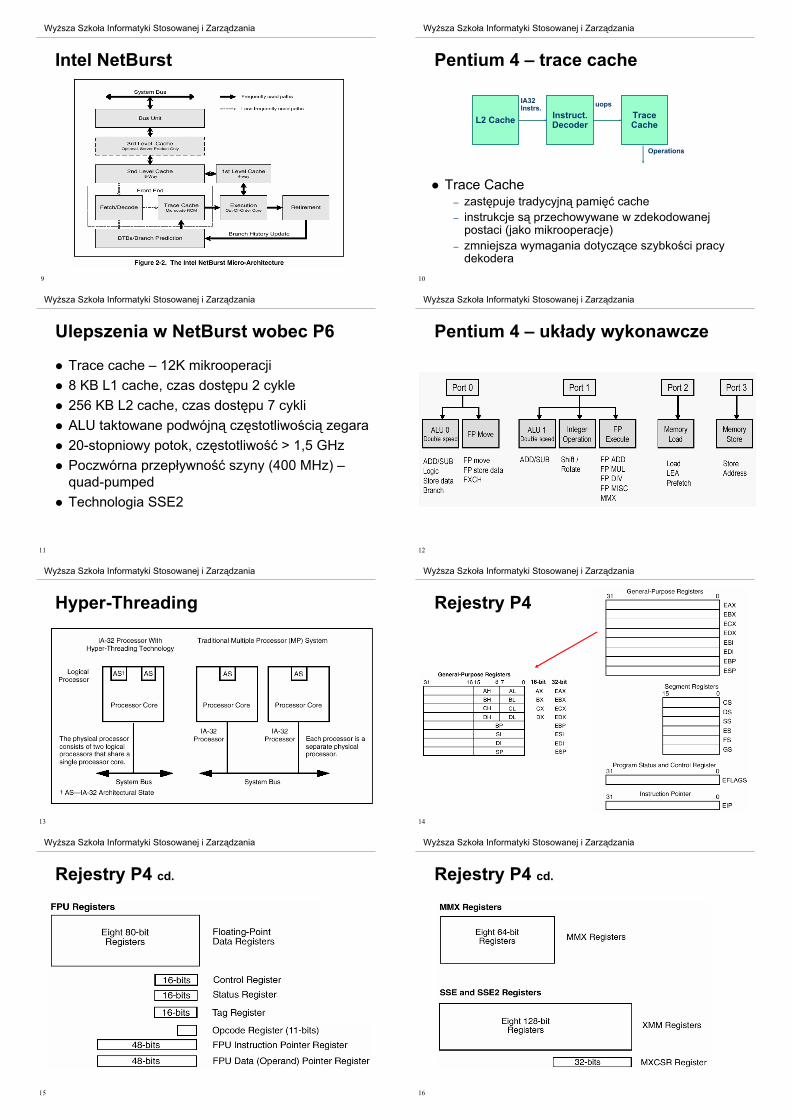
9
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Intel NetBurst
10
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Pentium 4 – trace cache
L2 CacheInstruct.Decoder
TraceCache
IA32Instrs.
uops
Operations
Trace Cache– zast#puje tradycyjn" pami#$ cache
– instrukcje s" przechowywane w zdekodowanej postaci (jako mikrooperacje)
– zmniejsza wymagania dotycz"ce szybko%ci pracy dekodera
11
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Ulepszenia w NetBurst wobec P6
Trace cache – 12K mikrooperacji
8 KB L1 cache, czas dost#pu 2 cykle
256 KB L2 cache, czas dost#pu 7 cykli
ALU taktowane podwójn" cz#stotliwo%ci" zegara
20-stopniowy potok, cz#stotliwo%$ > 1,5 GHz
Poczwórna przep!ywno%$ szyny (400 MHz) –
quad-pumped
Technologia SSE2
12
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Pentium 4 – uk ady wykonawcze
13
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Hyper-Threading
14
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Rejestry P4
15
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Rejestry P4 cd.
16
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Rejestry P4 cd.
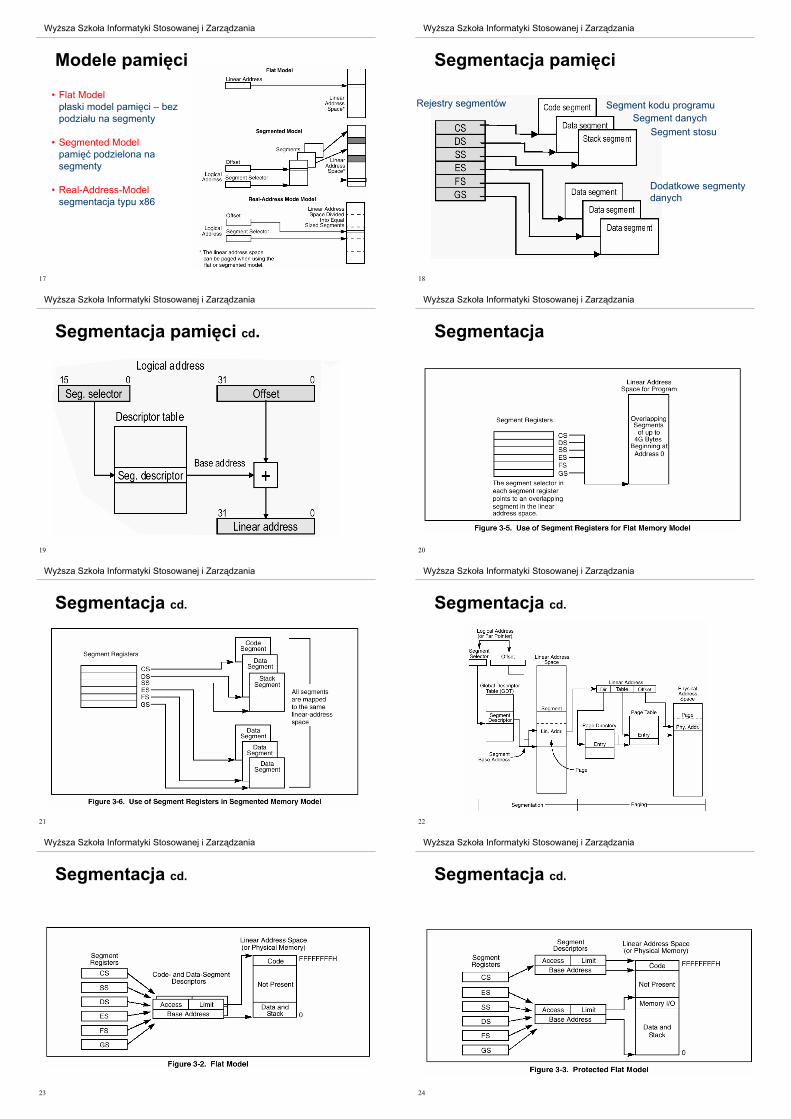
17
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Modele pami!ci
• Flat Model
p!aski model pami#ci – bez
podzia!u na segmenty
• Segmented Model
pami#$ podzielona na
segmenty
• Real-Address-Model
segmentacja typu x86
18
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Segmentacja pami!ci
Rejestry segmentów Segment kodu programu
Segment danych
Segment stosu
Dodatkowe segmenty
danych
19
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Segmentacja pami!ci cd.
20
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Segmentacja
21
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Segmentacja cd.
22
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Segmentacja cd.
23
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Segmentacja cd.
24
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Segmentacja cd.
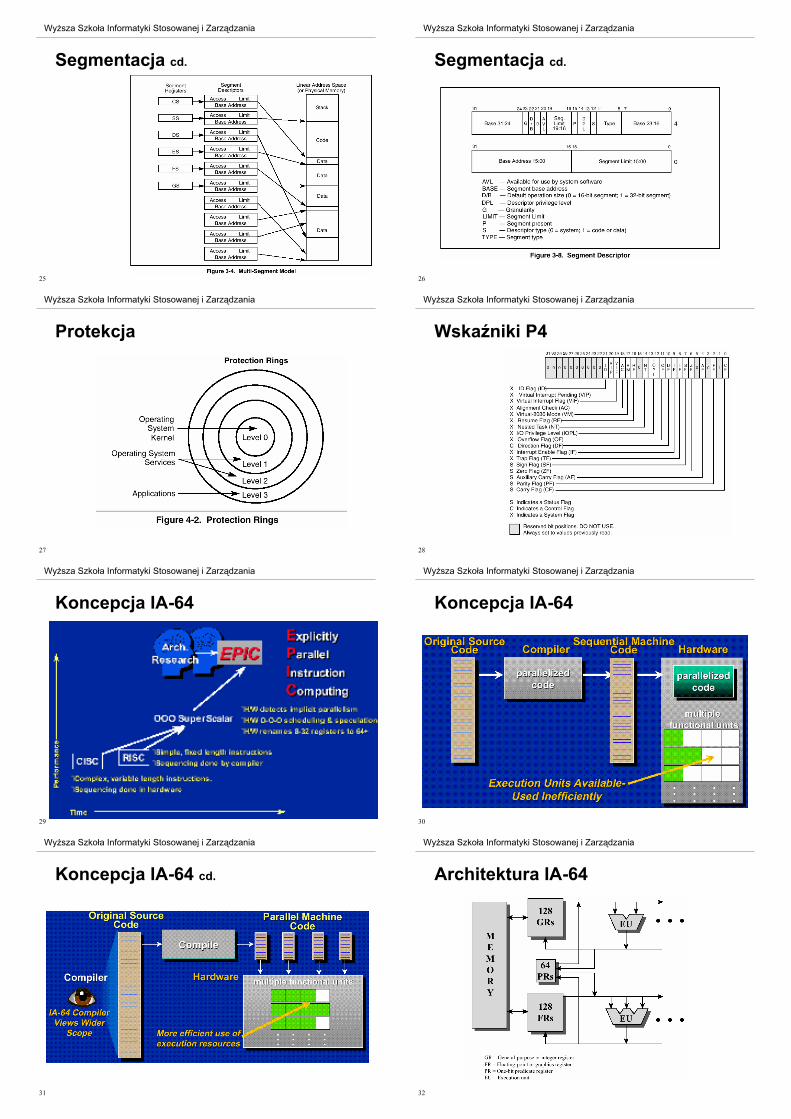
25
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Segmentacja cd.
26
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Segmentacja cd.
27
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Protekcja
28
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Wska"niki P4
29
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Koncepcja IA-64
30
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Koncepcja IA-64
31
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Koncepcja IA-64 cd.
32
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Architektura IA-64
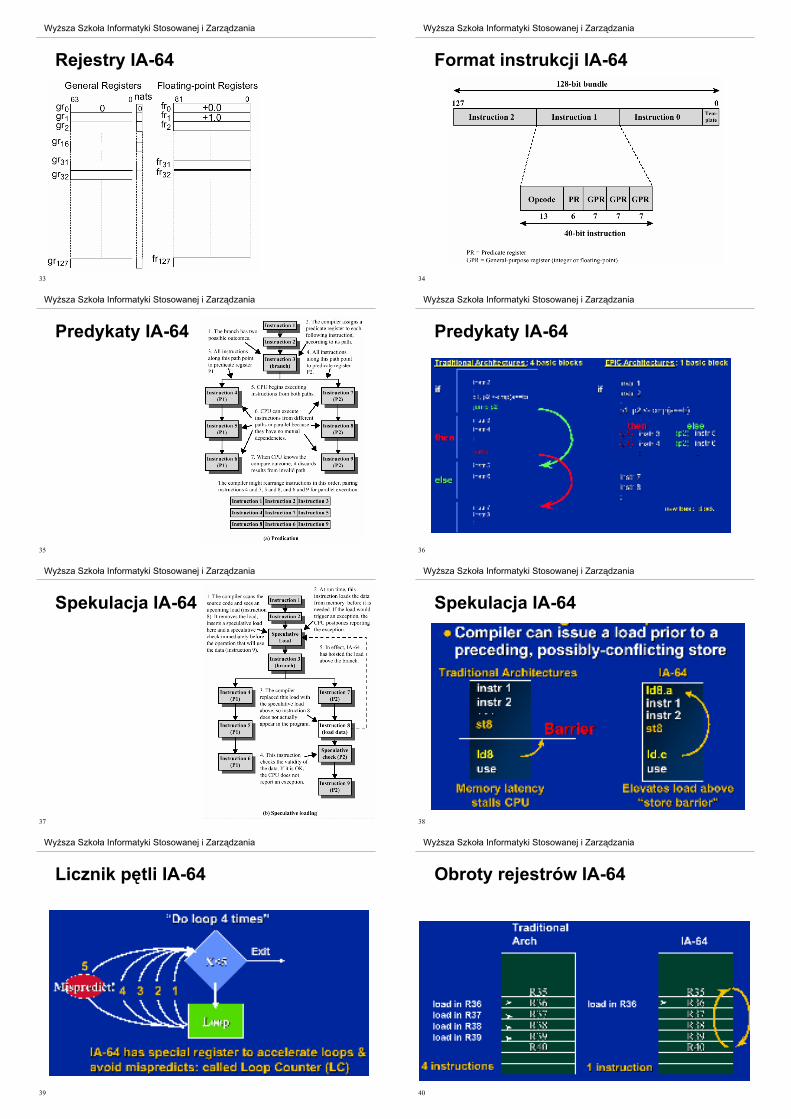
33
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Rejestry IA-64
34
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Format instrukcji IA-64
35
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Predykaty IA-64
36
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Predykaty IA-64
37
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Spekulacja IA-64
38
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Spekulacja IA-64
39
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Licznik p!tli IA-64
40
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Obroty rejestrów IA-64
41
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Pami!# IA-64 – proces
42
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Pami!# IA-64 – proces
43
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Pami!# IA-64 – system
44
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Pami!# IA-64 – regiony
45
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Architektura IA-64
Itanium
– opracowany w 2000 roku
– oko!o 10 mln tranzystorów
Itanium 2
– opracowany w 2002 roku
– cache L3 on chip
– 6 jednostek ALU
– linijka L1 – 64 bajty
46
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Podsumowanie
Mikroarchitektura P6
Architektura Pentium 4– NetBurst
– trace cache
– Hyper-Threading
Modele pami#ci
Segmentacja pami#ci
Protekcja
Architektura IA-64 (Itanium)– EPIC (wariant VLIW)
– predykaty
– spekulacja
– organizacja pami#ci (regiony)

1
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Organizacja i Architektura Komputerów
Architektura listy instrukcji – ISA
2
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Lista instrukcji
Zbiór polece# (instrukcji) zrozumia!ych dla CPU
– lista instrukcji powinna by$ funkcjonalnie pe!na, tzn.
umo liwia$ zapis dowolnego algorytmu
Instrukcje s" zapisywane w postaci binarnej
– ka da instrukcja ma swój unikatowy kod binarny (kod
operacji)
W programach %ród!owych zapisanych w j&zyku
asemblera zamiast kodów binarnych stosuje si&
zapis symboliczny operacji
– np. add, mov
3
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Elementy instrukcji
1. Kod operacji (op code), okre'la czynno'$ wykonywan"
przez instrukcj&
2. Wskazanie na argument %ród!owy (source operand)
3. Wskazanie na argument docelowy (destination operand)
4. Wskazanie na kolejn" instrukcj& programu, która ma by$
wykonana jako nast&pna
Przyk!ad: mov ax,cx ;prze lij cx do ax
Mnemonik
(rodzaj operacji)Argument %ród!owyArgument
docelowy
Element 1) jest obligatoryjny, elementy 2) – 4) s" opcjonalne
4
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Reprezentacja instrukcji
Posta$ symboliczna (j&zyk asemblera)
mov ax,cx
Zapis funkcjonalny
ax cx
Posta$ binarna w pami&ci programu
10001011
11000001
w postaci binarnej kod operacji jest zapisywany jako
pierwszy, dalej nast&puj" argumenty
5
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Reprezentacja instrukcji cd.
Typowy format instrukcji z odniesieniami do dwóch
argumentów
Kod operacji Argument 1 Argument 2
Binarny kod
operacji okre'laj"cy
jednoznacznie
rodzaj rozkazu;
zdeterminowany
przez mnemonik
instrukcji (np. MOV,
ADD itp.)
Odniesienie do
argumentu nr. 1
• jawnie (wprost)
podana warto'$
argumentu lub
• adres lub
• inne wskazanie na
argument
Odniesienie do
argumentu nr. 2
• jawnie (wprost)
podana warto'$
argumentu lub
• adres lub
• inne wskazanie na
argument
6
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Liczba argumentów
Istotnym czynnikiem przy projektowaniu ISA jest liczba argumentów (lub odniesie# do argumentów) zawartych w instrukcji
– wp!yw na d!ugo'$ s!owa instrukcji oraz z!o ono'$ CPU
– du a liczba argumentów wymaga d!ugiego s!owa instrukcji
Rozwa my, ile argumentów wymaga instrukcja dodawania ADD
– je'li chcemy doda$ do siebie zawarto'$ dwóch komórek pami&ci potrzebujemy dwóch adresów
– gdzie umie'ci$ wynik dodawania? Potrzebny jest trzeci adres
– która instrukcja w programie ma by$ wykonana jako nast&pna?
zwykle domy'lnie przyjmuje si&, e b&dzie to kolejna instrukcja w programie, ale czasem chcemy wykona$ skok w inne miejsce programu
do wskazania miejsca skoku potrzebny jest czwarty adres
7
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Liczba argumentów cd.
W praktyce procesory czteroadresowe nie s" stosowane
– zbyt skomplikowana budowa CPU
– d!ugie s!owo instrukcji
– nie zawsze instrukcja wymaga a czterech adresów
Wi&kszo'$ instrukcji wymaga jednego, dwóch lub
najwy ej trzech adresów
– adres kolejnej instrukcji w programie jest okre'lany przez
inkrementacj& licznika rozkazów (z wyj"tkiem instrukcji skoków)
Rozwa my ci"g instrukcji hipotetycznego procesora
wykonuj"cego obliczenie warto'ci wyra enia:
Y = (A - B) / (C + (D * E))
8
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Przyk ad – procesor 3–adresowy
Je'li mamy procesor 3 – adresowy, mo emy okre'li$adresy dwóch argumentów i adres wyniku.
Poni ej podano sekwencj& instrukcji obliczaj"c" warto'$wyra enia:
Y = (A - B) / (C + (D * E))
SUB R1, A, B ; Rejestr R1 ! A – B
MUL R2, D, E ; Rejestr R2 ! D * E
ADD R2, R2, C ; Rejestr R2 ! R2 + C
DIV R1, R1, R2 ; Rejestr R1 ! R1 / R2
Instrukcje 3-adresowe s" wygodne w u yciu, bowiem mo na wskaza$ adres wyniku. Nale y zauwa y$, e w podanym przyk!adzie oryginalne zawarto'ci komórek A, B, C, D i E nie zosta!y zmienione

9
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Procesor 2–adresowy
Jak zmniejszy$ liczb& adresów?– d" ymy do skrócenia s!owa instrukcji i uproszczenia budowy
CPU
Typowa metoda polega na domy'lnym za!o eniu odno'nie adresu wyniku operacji
– wynik jest umieszczany w miejscu, sk"d pobrano jeden z argumentów %ród!owych
– taka metoda oczywi'cie niszczy (zamazuje) pierwotn" warto'$argumentu
Najcz&'ciej przyjmuje si&, e wynik jest umieszczany w miejscu, sk"d pobrano pierwszy argument (np. Pentium)
– pierwszy argument mo e si& znajdowa$ w rejestrze, komórce pami&ci itp.
10
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Przyk ad – procesor 2–adresowy
Przy za!o eniu, e argumenty znajduj" si& w rejestrach, podana sekwencja instrukcji oblicza warto'$ wyra enia:
Y = (A-B) / (C + (D * E))
SUB A, B ; Rejestr A ! A - BMUL D, E ; Rejestr D ! D * EADD D, C ; Rejestr D ! D + CDIV A, D ; Rejestr A ! A / D
Otrzymujemy ten sam wynik co wcze'niej, ale teraz zawarto'$ rejestrów A i D uleg!a zmianie
11
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Przyk ad – procesor 2–adresowy cd.
Je'li chcemy zachowa$ oryginaln" zawarto'$
rejestrów, musimy skopiowa$ j" do innych
rejestrów:
MOV R1, A ; Kopiuj A do rejestru R1MOV R2, D ; Kopiuj D do rejestru R2SUB R1, B ; Rejestr R1 ! R1-BMUL R2, E ; Rejestr R2 ! R2*EADD R2, C ; Rejestr R2 ! R2+CDIV R1, R2 ; Rejestr R1 ! R1 / R2
Teraz wszystkie rejestry A-E zostaj" zachowane,
ale kosztem kilku dodatkowych instrukcji
12
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Procesor 1–adresowy
W instrukcji jawnie wskazany jest tylko jeden argument
Drugi argument znajduje si& w domy'lnym miejscu
– zwykle w akumulatorze
– akumulator w ró nych j&zykach asemblera ma ró ne oznaczenie, najcz&'ciej A, AX, ACC
Wynik jest umieszczany równie w domy'lnym miejscu, typowo w akumulatorze
– warto'$ drugiego argumentu zostaje zniszczona (zamazana przez wynik operacji)
13
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Przyk ad – procesor 1–adresowy
Obliczamy warto'$ wyra enia: Y = (A-B) / (C + (D * E))
LDA D ; Load ACC with D
MUL E ; Acc ! Acc * E
ADD C ; Acc ! Acc + C
STO R1 ; Store Acc to R1
LDA A ; Acc ! A
SUB B ; Acc ! Acc-B
DIV R1 ; Acc ! Acc / R1
W wielu wczesnych komputerach stosowano procesory 1-adresowe, poniewa maj" one prostsz" konstrukcj&
Jak wida$ z powy szego przyk!adu, architektura 1-adresowa wymaga jednak d!u szych programów
14
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Procesor 0–adresowy
W skrajnym przypadku mo na stosowa$ instrukcje nie zawieraj"ce adresów
Obliczenia s" wykonywane na stosie
– argumenty umieszcza si& w odpowiedniej kolejno'ci na stosie
– operacje s" wykonywane na szczytowych komórkach stosu
– wynik umieszcza si& na szczycie stosu
Koncepcj& przetwarzania 0-adresowego poda! po raz pierwszy polski logik i filozof Jan (ukasiewicz (1878-1956)
– notacja beznawiasowa
– RPN – Reverse Polish Notation, odwrotna notacja polska
– stosowana w niektórych komputerach i kalkulatorach (np. HP)
– korzystaj"c z metody RPN opracowano ciekawe j&zyki programowania, np. FORTH
15
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Przyk ad – procesor 0–adresowy
Obliczamy wyra enie: Y = (A-B) / (C + (D * E))
PUSH B ; B
PUSH A ; B, A
SUB ; (A-B)
PUSH E ; (A-B), E
PUSH D ; (A-B), E, D
MUL ; (A-B), (E*D)
PUSH C ; (A-B), (E*D), C
ADD ; (A-B), (E*D+C)
DIV ; (A-B) / (E*D+C)
16
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Liczba adresów – wnioski
Wi&cej adresów– bardziej skomplikowane, ale te wygodne w u yciu
instrukcje
– d!u sze s!owo instrukcji
– wi&ksza liczba rejestrów
operacje na rejestrach s" szybsze ni operacje na zawarto'ci pami&ci
– krótsze programy (w sensie liczby instrukcji)
Mniej adresów– mniej skomplikowane instrukcje
– d!u sze programy (w sensie liczby instrukcji)
– krótszy cykl pobrania instrukcji
Wi&kszo'$ wspó!czesnych procesorów stosuje architektur& 2-adresow" lub 3-adresow"
Szczególne koncepcje ISA (RISC, VLIW, EPIC)

17
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Rodzaje argumentów
Adresy (addresses)
Liczby (numbers)
– Integer/floating point
Znaki (characters)
– ASCII
Dane logiczne (logical data)
– Bits or flags
18
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Format danych – Pentium
8 bit byte
16 bit word
32 bit double word
64 bit quad word
adresowanie pami&ci odbywa si& bajtami (ka dy
kolejny bajt w pami&ci ma swój adres)
dane 32-bitowe (double word) musz" by$
ulokowane pocz"wszy od adresu podzielnego
przez 4
19
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Interpretacja (kodowanie) danych
General – dowolna liczba binarna
Integer – liczba binarna ze znakiem (U2)
Ordinal – liczba ca!kowita bez znaku (NKB)
Unpacked BCD – jedna cyfra BCD na bajt
Packed BCD – 2 cyfry BCD na bajt
Near Pointer – 32-bitowy offset w segmencie
Bit field – pole bitowe, ci"g bitów
Byte String – ci"g bajtów
Floating Point – liczba zmiennoprzecinkowa
20
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Typy instrukcji
Data Transfer – przesy!anie danych (np. MOV)
Arithmetic – operacje arytmetyczne (np. ADD)
Logical – operacje logiczne (np. OR)
Conversion – konwersja danych, np. liczb binarnych na
BCD
I/O – operacje wej'cia/wyj'cia
System Control
– specjalne operacje systemowe, np. sterowanie stanem
procesora, zarz"dzanie protekcj" itp.
Transfer of Control (np. JMP)
– skoki, wywo!anie podprogramów itp..
21
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Tryby adresowania
Sposoby wskazywania na argumenty instrukcji
Podstawowe tryby adresowania u ywane we
wspó!czesnych procesorach:
– Register – rejestrowy, wewn&trzny
– Immediate – natychmiastowy
– Direct – bezpo'redni
– Register indirect – rejestrowy po'redni
– Base + Index – bazowo-indeksowy
– Register relative – wzgl&dny
– Stack addressing – adresowanie stosu
22
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Adresowanie rejestrowe
Argumenty operacji znajduj" si& w rejestrach procesora
Przyk!ad:mov al,bl ;prze lij bl do al
inc bx ;zwi!ksz bx o 1
dec al ;zmniejsz al o 1
sub dx,cx ;odejmij cx od dx
Poniewa procesory zawieraj" niewiele rejestrów GP,
wystarczy tylko kilka bitów do wskazania rejestrów w
instrukcji; ich kody s" zwykle umieszczone w kodzie
instrukcji
Zalety: krótki kod binarny instrukcji, szybkie wykonanie
23
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Adresowanie rejestrowe cd.
W procesorach RISC stosuje si& zwykle zasad&
pe!nej symetrii, która oznacza, e instrukcje
mog" operowa$ na dowolnych rejestrach
W procesorach CISC niektóre kombinacje
instrukcji i rejestrów nie s" dozwolone:
Przyk!ad (x86):mov cs,ds ;nie mo"na przesy#a$
;rejestrów segmentów
mov bl,bx ;rozmiary rejestrów
;musz% by$ takie same
;bl – 8 bitów, bx – 16 bitów
24
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Adresowanie natychmiastowe
Argument operacji znajduje si& w postaci jawnej w instrukcji, zaraz po kodzie operacji
Przyk!ady:mov bl,44 ;prze lij 44 (dziesi!tnie) do blmov ah,44h ;prze lij 44 (hex) do ahmov di,2ab4h ;prze lij 2ab4 (hex) do diadd ax,867 ;dodaj 867 (dec) do ax
Argument natychmiastowy jest pobierany przez procesor razem z kodem operacji, dlatego nie jest potrzebny osobny cykl pobrania argumentu (data fetch)
Tryb natychmiastowy mo na stosowa$ tylko w odniesieniu do sta!ych, których warto'ci s" znane w trakcie pisania programu

25
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Adresowanie bezpo!rednie
Instrukcje stosuj"ce adresowanie bezpo'rednie
odwo!uj" si& do argumentów umieszczonych w pami&ci
Adres argumentu w architekturze x86 sk!ada si& z
dwóch elementów: selektora segmentu i ofsetu (offset) i
jest zapisywany w postaci:
segment:offset
Przyk!ad
1045h:a4c7h
oznacza komórk& o adresie a4c7h w segmencie 1045h
Ofset bywa nazywany równie przesuni&ciem (ang.
displacement, w skrócie disp)
26
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Adresowanie bezpo!rednie cd.
Zwykle w instrukcjach podaje si& tylko ofset, natomiast
wskazanie na segment znajduje si& w domy'lnym
rejestrze
– Instrukcje operuj"ce na danych w pami&ci u ywaj" domy'lnie
rejestru DS.
– Instrukcje operuj"ce na stosie u ywaj" domy'lnie rejestru SS
– Instrukcje skoków u ywaj" domy'lnie segmentu CS
Je'li jest taka potrzeba, mo na zastosowa$ inny rejestr
segmentu ni domy'lny, wtedy adres trzeba poprzedzi$
tzw. prefiksem podaj"cym rejestr segmentu
Przyk!ad: mov ax,[di] ;domy'lny adres ds:di
mov ax,es:[di] ;adres es:di
27
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Adresowanie bezpo!rednie cd.
Obliczanie adresu efektywnego (EA) na
podstawie wskazania segmentu i ofsetu odbywa
si& na dwa ró ne sposoby, w zale no'ci od
zastosowanego modelu pami&ci.
Wyró nia si& dwa podstawowe rodzaje
segmentacji:
– Standardow" (segmented mode) stosowan"
powszechnie przez aplikacje 32-bitowe IA-32
– Tryb adresów rzeczywistych (real-address mode)
stosowan" w starych aplikacjach 16-bitowych
28
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Adresowanie bezpo!rednie cd.
W trybie segmentacji standardowej obliczanie adresu efektywnego na przebiega nast&puj"co:
– 16-bitowy rejestr segmentu zawiera selektor segmentu, który wskazuje pewien deskryptor segmentu w tablicy deskryptorów segmentów
– Z deskryptora segmentu pobiera si& 32-bitowy adres bazowy segmentu
– Adres efektywny oblicza si& jako sum& 32-bitowego adresu bazowego i 32-bitowego ofestu podanego w instrukcji
Przyk!ad– w trakcie wyk!adu
29
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Adresowanie bezpo!rednie cd.
W trybie adresów rzeczywistych obliczanie adresu efektywnego na przebiega nast&puj"co:
– 16-bitowy rejestr segmentu po pomno eniu przez 16 daje bezpo'rednio adres bazowy segmentu (nie stosuje si&deskryptorów segmentów)
– Adres efektywny oblicza si& jako sum& adresu bazowego i 16-bitowego ofsetu
Adres ds:offset jest zatem przekszta!cany na adres efektywny wed!ug zale no'ci:
EA = 16*ds + offset
Przyk!ad
– w trakcie wyk!adu
30
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Adresowanie bezpo!rednie cd.
Argument jest umieszczony w komórce pami&ci; adres tej komórki jest podany w instrukcji
Przyk!ady:mov al,DANA ;prze lij bajt z komórki
;pami!ci o adresie DS:DANA;do rejestru al.
mov ax,news ;prze lij ax do adresu DS:NEWS
Uwaga: x86 stosuje konwencj& little-endian, dlatego je'li za!o ymy, e offset DANA=1002h, pierwsza z powy szych przyk!adowych instrukcji b&dzie w pami&ci zapisana jako ci"g bajtów:
kod operacji0210
31
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Adresowanie bezpo!rednie cd.
Zamiast ofsetu w postaci nazwy symbolicznej mo na
poda$ ofset w postaci liczbowej (dziesi&tnie lub
szesnastkowo):
Przyk!ad: mov al,[1234h]
Nawias u yty w powy szym przyk!adzie wskazuje
kompilatorowi, e zastosowano adresowanie
bezpo'rednie
Je'liby nawias zosta! pomini&ty, kompilator
zinterpretowa!by argument jako natychmiastowy
– w powy szym przyk!adzie liczba 1234h zosta!aby potraktowana
jako gotowy argument natychmiastowy, a nie ofset adresu
argumentu znajduj"cego si& w pami&ci
32
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Adresowanie po!rednie rejestrowe
Adresowanie po'rednie rejestrowe dzia!a podobnie jak
adresowanie bezpo'rednie, z t" ró nic", e ofset jest
podany w rejestrze, a nie bezpo'rednio w instrukcji
– eby uzyska$ ofset trzeba zatem wykona$ dodatkowy, po'redni
krok polegaj"cy na si&gni&ciu do zawarto'ci rejestru
W procesorach x86 do adresowania rejestrowego po'redniego mo na wykorzystywa$ rejestry: bx, bp,
si, di
Nale y pami&ta$, e rejestry bx, si, di domy'lnie
wspó!pracuj" z rejestrem segmentu ds, natomiast
rejestr bp wspó!pracuje domy'lnie z rejestrem segmentu ss

33
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Adresowanie po!rednie rejestrowe
Przyk!ady:
mov cx,[bx]
– 16-bitowe s!owo z komórki adresowanej przez ofset w rejestrze bx w segmencie danych (ds) jest kopiowane do rejestru cx
mov [bp],dl
– bajt z dl jest kopiowany do segmentu stosu pod adres podany
w rejestrze bp
mov [di],[bx]
– przes!ania typu pami&$-pami&$ nie s" dozwolone (z wyj"tkiem
szczególnych instrukcji operuj"cych na !a#cuchach znaków –
stringach)
34
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Adresowanie bazowo-indeksowe
Podobne do adresowania rejestrowego po'redniego
Ró nica polega na tym, e ofset jest obliczany jako suma zawarto'ci dwóch rejestrów
Przyk!ad: mov dx,[bx+di]
Adresowanie bazowo-indeksowe jest przydatne przy dost&pie do tablic
– Rejestr bazowy wskazuje adres pocz"tku tablicy
– Rejestr indeksowy wskazuje okre'lony element tablicy
Jako rejestr bazowy mo na wykorzysta$ rejestry bp lub bx (uwaga: bx wspó!pracuje z ds, natomiast bpwspó!pracuje z ss)
Jako rejestry indeksowe mo na wykorzysta$ rejestry dilub si
35
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Adresowanie rejestrowe wzgl"dne
Podobne do adresowania bazowo-indeksowego
Ofset jest obliczany jako suma zawarto'ci rejestru bazowego lub indeksowego (bp, bx, di lub si) oraz
liczby okre'laj"cej baz&
Przyk!ad: mov ax,[di+100h]
powy sza instrukcja przesy!a do ax s!owo z komórki
pami&ci w segmencie ds o adresie równym sumie
zawarto'ci rejestru di i liczby 100h
Podobnie jak w innych trybach adresowych, rejestry bx,
di oraz si wspó!pracuj" domy'lnie z rejestrem
segmentu danych ds, natomiast rejestr bp wspó!pracuje
z rejestrem segmentu stosu ss
36
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Adresowanie rejestrowe wzgl"dne cd.
Adresowanie rejestrowe wzgl&dne jest alternatywnym (w stosunku do adresowania bazowo-indeksowego) sposobem dost&pu do elementów tablic
Przyk!ady:
mov array[si],bl
bajt z rejestru bl jest zapami&tany w segmencie danych, w tablicy o adresie pocz"tkowym (podanym przez nazw& symboliczn") array, w elemencie o numerze podanym w si
mov di,set[bx]
rejestr di jest za!adowany s!owem 16-bitowym z segmentu danych, z tablicy set, z elementu o numerze podanym w bx
37
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Adr. wzgl"dne bazowo-indeksowe
Adresowanie wzgl&dne bazowo-indeksowe jest kombinacj" dwóch trybów:
– bazowo-indeksowego
– rejestrowego wzgl&dnego
Przyk!ady:
mov dh,[bx+di+20h]
rejestr dh jest !adowany z segmentu danych, z komórki o adresie równym sumie bx+di+20h
mov ax,file[bx+di]
rejestr ax jest !adowany z segmentu danych, z komórki o adresie równym sumie adresu pocz"tkowego tablicy file, rejestru bx oraz rejestru di
mov list[bp+di],cl
rejestr cl jest zapami&tany w segmencie stosu, w komórce o adresie równym sumie adresu pocz"tkowego tablicy list, rejestru bp oraz rejestru di
38
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Adresowanie stosu
Jest u ywane przy dost&pie do stosu
Przyk!ady
popf ;pobierz s!owo wska%ników (flagi) ze stosu
pushf ;wy'lij s!owo wska%ników na stos
push ax ;wy'lij ax na stos
pop bx ;odczytaj bx ze stosu
push ds ;wy'lij rejestr segmentu ds na stos
pop cs ;odczytaj rejestr segmentu ze stosu
push [bx] ;zapisz komórk& pami&ci o adresie podanym
;w bx na stos
39
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Adresowanie danych – uwaga
We wszystkich przyk!adach z kilkunastu ostatnich plansz
ilustruj"cych tryby adresowania argumentów u yto dla uproszczenia wy!"cznie rejestrów 8-bitowych (np. al, ah,
bl) lub 16-bitowych (np. ax, bx, cx)
W ogólnym przypadku, w architekturze IA-32 mo na
równie u ywa$ rejestrów 32-bitowych. Wówczas w podanych przyk!adach mog!yby wyst"pi$ rejestry eax,
ebx itd.
40
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Adresowanie w instrukcjach skoku
Adres w instrukcjach skoków mo e mie$ ró n" posta$:
– krótk" (short)
– blisk" (near)
– dalek" (far)
Adresy mog" by$ podane w ró ny sposób:
– Wprost w cz&'ci adresowej instrukcji – tryb bezpo'redni (direct)
– W rejestrze
– W komórce pami&ci adresowanej przez rejestr

41
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Skoki krótkie (short)
Adres jest jednobajtow" liczb" w kodzie U2
Skok polega na dodaniu tej liczby do rejestru IP
Krótki skok ma zakres od –128 do +127 bajtów w stosunku do aktualnej warto'ci IP i odbywa si& w obr&bie tego samego segmentu wskazanego przez cs
Przyk!ad:
label2 jmp short label1
....
label1 jmp label2
Uwaga: w pierwszej instrukcji skoku trzeba u y$ s!owa short aby wskaza$ kompilatorowi, e skok jest krótki, poniewa podczas kompilacji w tym miejscu nie wiadomo jeszcze jaka jest jego d!ugo'$. W drugiej instrukcji skoku s!owo short jest zb&dne. Kompilator sam zoptymalizuje kod i zastosuje skok krótki, poniewa znana jest ju odleg!o'$ do etykiety label2
42
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Skoki bliskie (near)
Skok mo e by$ wykonany do dowolnej instrukcji w obr&bie segmentu wskazanego przez aktualn" warto'$ w rejestrze cs
W trybie adresów rzeczywistych adres skoku jest 16-bitowy,
natomiast segment ma rozmiar 64 kB
W trybie segmentowym IA-32 adres jest 32-bitowy
Ogólna posta$ skoku:
jmp near ptr etykieta_docelowa
Przyk!ad:
jmp near ptr dalej
....
....
dalej ...
43
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Skoki dalekie (far)
Skok mo e by$ wykonany do dowolnej instrukcji w obr&bie
dowolnego innego segmentu
W rozkazie skoku nale y poda$ nie tylko adres skoku tak jak w
przypadku skoków bliskich, ale ponadto równie now" warto'$rejestru segmentu cs
Ogólna posta$ skoku:
jmp far ptr etykieta_docelowa
etykieta docelowa znajduje si& w innym segmencie kodu programu
ni instrukcja skoku
Elementy instrukcji skoku dalekiego s" w zakodowanej instrukcji
przechowywane w nast&puj"cej kolejno'ci: kod operacji skoku, ofset(adres skoku), nowa zawarto'$ cs. Ofset i cs s" przechowywane w
postaci little-endian
44
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Skoki – przyk ady
jmp ax ; skocz w obr&bie tego samego segmentu
; do adresu podanego w ax
jmp near ptr [bx]
; skocz w obr&bie tego samego segmentu
; do adresu wskazanego w komórce pami&ci; w segmencie danych wskazanej przez bx
jmp table[bx]
; skocz w obr&bie tego samego segmentu; do adresu wskazanego w wektorze table,
; przechowywanym w segmencie danych,; w elemencie o numerze podanym w bx
45
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Tryby adresowania – podsumowanie
Pentium
Adresy 32-bitowe
46
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Tryby adresowania – podsumowanie
Pentium
Adresowanie pami&ci
Adresy 16-bitowe
47
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Tryby adresowania – podsumowanie
Pentium – adresy 32-bitowe
48
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Tryby adresowania – podsumowanie
Pentium – ró nice adresowania 32- i 16-bitowego

49
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Tryby adresowania – podsumowanie
• Sk"d procesor Pentium wie czy adres jest 32- czy 16-bitowy?
• Wykorzystuje si& bit D w deskryptorze segmentu CS
D = 0
» domy'lny rozmiar argumentów i adresów – 16 bitów
D = 1
» domy'lny rozmiar argumentów i adresów – 32 bity
• Programista mo e zmieni$ warto'ci domy'lne
• W Pentium instrukcj& mo na poprzedzi$ tzw. Prefiksem
(jednobajtowym przedrostkiem, który zmienia domy'lne d!ugo'ci
argumentów i adresów)
66H prefiks zmiany d!ugo'ci argumentu
67H prefiks zmiany d!ugo'ci adresu
• Stosuj"c prefiksy mo na miesza$ ze sob" tryby 32- i 16-bitowe
50
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Tryby adresowania – podsumowanie
Przyk!ad: niech domy'lnym trybem b&dzie tryb 16-bitowy
Przyk ad 1: zmiana rozmiaru argumentu
mov ax,123 ==> b8 007b
mov eax,123 ==> 66 | b8 0000007b
Przyk ad 2: zmiana d!ugo'ci adresu
mov ax,[ebx*esi+2] ==> 67 | 8b0473
Przyk ad 3: zmiana rozmiaru argumentu i d!ugo'ci adresu
mov eax,[ebx*esi+2] ==> 66 | 67 | 8b0473
51
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Podsumowanie
Sposób zapisu instrukcji
– mnemonik, argumenty
– zapis w j&zyku asemblera, zapis funkcjonalny, zapis binarny
Liczba adresów instrukcji
– procesory 3-, 2-, 1- i 0-adresowe
Tryby adresowania argumentów (danych)
Tryby adresowania programu w instrukcjach skoków

1
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Organizacja i Architektura Komputerów
J#zyk asemblera (Pentium)
2
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Asembler i j zyki wysokiego poziomu
Niektóre instrukcje j#zyka C mo na zast"pi$ pojedynczymi
instrukcjami w j#zyku asemblera
3
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Asembler i j zyki wysokiego poziomu
Wi#kszo%$ instrukcji j#zyka C jest jednak równowa na
wi#kszej liczbie instrukcji w j#zyku asemblera
4
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Program w j zyku asemblera
Trzy rodzaje polece&
– Instrukcje
Mówi" procesorowi co ma robi$
S" wykonywane przez CPU, rodzaj instrukcji jest okre%lony przez
kod operacji (Opcode)
– Dyrektywy (pseudo-ops)
Wskazówki dla kompilatora (asemblera) dotycz"ce procesu
t!umaczenia
Nie s" wykonywane przez CPU, nie generuj" instrukcji w kodzie
wynikowym programu
– Macro
Sposób skróconego zapisu grupy instrukcji
Technika podobna do podprogramów, ale realizowana na
poziomie kompilacji, a nie w trakcie wykonania podprogramu
5
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Linia programu asemblera
Format linii programu w j#zyku asemblera:[label] mnemonic [operands] [;comment]
– Pola w nawiasach [ ] s" opcjonalne
– Etykieta s!u y do dwóch celów:
Oznacza instrukcje, do których s" wykonywane skoki
Oznacza identyfikatory zmiennych i sta!ych, do których
mo na w programie odwo!ywa$ si# przez nazw# etykiety
– Mnemonik okre%la rodzaj operacji, np. add, or
– Operandy (argumenty) oznaczaj" dane
wykorzystywane przez instrukcj#
W Pentium instrukcje mog" mie$ 0, 1, 2 lub 3 operandy
6
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Linia programu asemblera cd.
– Komentarze, zaczynaj" si# od znaku %rednika
Mog" by$ umieszczone w tej samej linii co instrukcja lub
tworzy$ osobn" lini#
Przyk!ad
repeat: inc result ;zwi ksz zmienn! result o 1
CR equ 0dh ;znak powrotu karetki (CR)
– W powy szym przyk!adzie etykieta repeat umo liwia wykonanie
skoku do instrukcji inc
– Etykieta CR oznacza sta!" o nazwie CR i o warto%ci 0dh nadanej
przez dyrektyw# equ
7
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Alokacja danych
Deklaracja zmiennych w j#zyku wysokiego poziomu, np. w j#zyku C:char response
int value
float total
double average_value
Okre%la– Wymagany rozmiar pami#ci (1 bajt, 2 bajty, ...)
– Nazw# (etykiet#) identyfikuj"c" zmienn" (response, value, ...)
– Typ zmiennej (int, char, ... )
Ta sama liczba binarna mo e by$ interpretowana w ró ny sposób, np. 1000 1101 1011 1001 oznacza
– Liczb# –29255 (signed integer)
– Liczb# 36281 (unsigned)
8
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Alokacja danych cd.
W j#zyku asemblera do alokacji danych u ywa si#dyrektywy define
– Rezerwuje miejsce w pami#ci
– Etykietuje miejsce w pami#ci
– Inicjalizuje dan"
Dyrektywa define nie okre%la typu danej
– Interpretacja typu danej jest zale na od programu, który operuje na danej
Dyrektywy define s" lokalizowane w cz#%ci .DATAprogramu
Ogólny format dyrektywy define:
[var-name] d? init-value [,init-value], ...

9
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Alokacja danych cd.
Mamy 5 rodzajów dyrektywy define:
db definiuj bajt (alokacja 1 bajtu)
dw definiuj s!owo (alokacja 2 bajtów)
dd definiuj podwójne s!owo (alokacja 4 bajtów)
dq definiuj poczwórne s!owo (alokacja 8 bajtów)
dt definiuj 10 bajtów (alokacja 10 bajtów)
Przyk!ady:
sorted db ‘y’
response db ? ;brak inicjalizacji
value dw 25159
float1 dq 1.234
10
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Alokacja danych cd.
Wielokrotne definicje mog" by$ zapisane w postaci skróconej
Przyk!ad
message db ‘B’db ‘y’db ‘e’db 0dhdb 0ah
mo na zapisa$ jako:
message db ‘B’,’y’,’e’,0dh,0ah
lub w jeszcze bardziej skróconej postaci:
message db ‘Bye’,0dh,0ah
11
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Alokacja danych cd.
Wielokrotna inicjalizacja– Dyrektywa DUP umo liwia nadanie tej samej warto%ci wielu
obiektom (bajtom, s!owom. itd.)
– Tablica o nazwie marks z!o ona z 8 s!ów mo e by$zadeklarowania i wst#pnie wyzerowana w nast#puj"cy sposób:
marks dw 8 DUP (0)
Przyk!ady:
table dw 10 DUP (?) ;10 s"ów, bez ;inicjalizacji
message db 3 DUP (‘Bye!’) ;12 bajtów ;zainicjowanych jako ;‘Bye!Bye!Bye!’
name1 db 30 DUP (‘?’) ;30 bajtów, ka#dy ;zainicjowany jako ;znak ‘?’
12
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Alokacja danych cd.
Dyrektywa DUP mo e by$ zagnie d ana
Przyk!ad
stars db 4 DUP(3 DUP (‘*’),2 DUP (‘?’),5 DUP (‘!’))
rezerwuje 40 bajtów i nadaje im warto%$:
***??!!!!!***??!!!!!***??!!!!!***??!!!!!
Przyk!ad
matrix dw 10 DUP (5 DUP (0))
– definiuje macierz 10 x 5 i wst#pnie zeruje jej elementy
– t# sam" deklaracj# mo na zapisa$ jako:
matrix dw 50 DUP (0)
13
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Alokacja danych cd.
Podczas kompilacji asembler buduje tablic# symboli, w której umieszcza napotkane w programie etykiety, w tym etykiety oznaczaj"ce dane
Przyk!ad:
14
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Alokacja danych cd.
Rozmiary danych w j#zyku asemblera i
odpowiadaj"ce im typy danych w j#zyku C
15
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Alokacja danych cd.
Dyrektywa label
– Jest innym sposobem nadania nazwy danym umieszczonym w pami#ci
– Ogólny format:
name label type
– Dost#pnych jest pi#$ typów danych
byte 1 bajt
word 2 bajty
dword 4 bajty
qword 8 bajtów
tword 10 bajtów
16
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Alokacja danych cd.
Dyrektywa label
Przyk!ad
.DATA
count label word
Lo_count db 0
Hi_count db 0
.CODE
...
mov Lo_count,al
mov Hi_count,cl
– count oznacza warto%$ 16-bitow" (dwa bajty)
– Lo_count oznacza mniej znacz"cy bajt
– Hi_count oznacza bardziej znacz"cy bajt

17
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Adresowanie argumentów
Adresowanie rejestrowe (register)
– Argumenty znajduj" si# w wewn#trznych rejestrach
CPU
– Najbardziej efektywny tryb adresowania
Przyk!ady
mov eax,ebx
mov bx,cx
– Instrukcja mov
mov destination, source
– Kopiuje dane z source do destination
18
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Adresowanie argumentów cd.
Adresowanie natychmiastowe (immediate)
– Argument jest zapisany w instrukcji jako jej cz#%$
– Tryb jest efektywny, poniewa nie jest potrzebny osobny cykl
!adowania argumentu
– U ywany w przypadku danych o sta!ej warto%ci
Przyk!ad
mov al,75
– Liczba 75 (dziesi#tna) jest !adowana do rejestru al
(8-bitowego)
– Powy sza instrukcja u ywa trybu rejestrowego do wskazania
argumentu docelowego oraz trybu natychmiastowego do
wskazania argumentu 'ród!owego
19
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Adresowanie argumentów cd.
Adresowanie bezpo%rednie (direct)
– Dane znajduj" si# w segmencie danych
– Adres ma dwa elementy: segment:offset
– Ofset w adresowaniu bezpo%rednim jest podawany w instrukcji,
natomiast wskazanie na segment odbywa si# z wykorzystaniem domy%lnego rejestru segmentu (DS), chyba e w instrukcji
zastosowano prefiks zmiany segmentu na inny
Je%li w programie u ywamy etykiet przy dyrektywach db,
dw, label, ....
– Asembler oblicza ofset na podstawie warto%ci liczbowej etykiety
– W tym celu wykorzystywana jest tablica symboli
20
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Adresowanie argumentów cd.
Adresowanie bezpo%rednie
Przyk!admov al,response
Asembler zast#puje symbol response przez jego liczbow" wato%$ (ofset) z tablicy symboli
mov table1,56
Za!ó my, e obiekt table1 jest zadeklarowany jako
table1 dw 20 DUP (0)
Instrukcja mov odnosi si# w tym przypadku do pierwszego elementu wektora table1 (elementu o numerze 0)
W j#zyku C równowa ny zapis jest nast#puj"cy:
table1[0] = 56
21
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Adresowanie argumentów cd.
Adresowanie bezpo%rednie – problemy
– Tryb bezpo%redni jest wygodny tylko przy
adresowaniu prostych zmiennych
– Przy adresowaniu tablic powstaj" powa ne k!opoty
Jako przyk!ad warto rozwa y$ dodawanie elementów tablic
Adresowanie bezpo%rednie nie nadaje si# do u ycia w
p#tlach programowych z iteracyjnie zmienianym
wska'nikiem elementów tablic
– Rozwi"zaniem jest zastosowanie adresowania
po%redniego (indirect)
22
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Adresowanie argumentów cd.
Adresowanie po%rednie (indirect)
– Ofset jest okre%lony po%rednio, z wykorzystaniem rejestru
– Tryb ten czasem jest nazywany po%rednim rejestrowym
(register indirect)
– Przy adresowaniu 16-bitowym ofset znajduje si# w jednym z rejestrów: bx, si lub di
– Przy adresowaniu 32-bitowym ofset mo e znajdowa$ si# w
dowolnym z 32-bitowych rejestrów GP procesora
Przyk!admov ax,[bx]
– Nawiasy [ ] oznaczaj", e rejestr bx zawiera ofset, a nie
argument
23
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Adresowanie argumentów cd.
U ywaj"c adresowania po%redniego mo na
przetwarza$ tablice przy pomocy p#tli
programowej
Przyk!ad: sumowanie elementów tablicy
– Za!aduj adres pocz"tkowy tablicy (czyli ofset) do rejestru bx
– Powtarzaj nast#puj"ce czynno%ci w p#tli
Pobierz element z tablicy u ywaj"c ofsetu z bx
– Wykorzystaj adresowanie po%rednie
Dodaj element do bie "cej sumy cz#%ciowej
Zmie& ofset w bx aby wskazywa! kolejny element w tablicy
24
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Adresowanie argumentów cd.
(adowanie ofsetu do rejestru
– Za!ó my, e chcemy za!adowa$ do bx ofset tablicy o nazwie table1
– Nie mo emy zapisa$:mov bx,table1
– Dwa sposoby za!adowania ofsetu do bx
Z wykorzystaniem dyrektywy offset
– Operacja zostanie wykonana podczas kompilacji
Z wykorzystaniem instrukcji lea (load effective address)
– Operacja zostanie wykonana przez CPU w trakcie realizacji
programu

25
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Adresowanie argumentów cd.
Wykorzystanie dyrektywy offset
– Poprzedni przyk!ad mo na rozwi"za$ pisz"c
mov bx,offset table1
Wykorzystanie instrukcji lea
– Ogólny format instrukcji lea
lea register,source
– Zastosowanie lea w poprzednim przyk!adzie
lea bx,table1
26
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Adresowanie argumentów cd.
Co lepiej zastosowa$ – offset czy lea ?
– Nale y stosowa$ dyrektyw# offset je%li tylko jest to mo liwe
Dyrektywa offset wykonuje si# podczas kompilacji
Instrukcja lea wykonuje si# w trakcie realizacji programu
– Czasem u ycie instrukcji lea jest konieczne
Je%li dana jest dost#pna tylko w trakcie wykonywania programu
– np. gdy dost#p do danej jest przez indeks podany jako parametr
podprogramu
Mo emy zapisa$
lea bx,table[si]
aby za!adowa$ bx adresem elementu tablicy table1, którego
indeks jest podany w rejestrze si
W tym przypadku nie mo na u y$ dyrektywy offset
27
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Instrukcje przes!a" danych Najwa niejsze instrukcje tego typu w asemblerze Pentium to:
mov (move) – kopiuj dan"
xchg (exchange) – zamie& ze sob" dwa argumenty
xlat (translate) – transluje bajt u ywaj"c tablicy translacji
Instrukcja mov
– Format
mov destination,source
– Kopiuje warto%$ z source do destination
– Argument 'ród!owy source pozostaje niezmieniony
– Obydwa argumenty musz" mie$ ten sam rozmiar (np. bajt, s!owo itp.)
– Source i destination nie mog" równocze%nie oznacza$adresu pami#ci
Jest to cecha wi#kszo%ci instrukcji Pentium
Pentium ma specjalne instrukcje, które u!atwiaj" kopiowanie bloków danych z pami#ci do pami#ci
28
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Instrukcje przes!a" danych cd.
W instrukcji mov mo na stosowa$ 5 ró nych kombinacji
trybów adresowania:
Tryby te mo na stosowa$ równie we wszystkich innych
instrukcjach Pentium z dwoma argumentami
29
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Instrukcje przes!a" danych cd.
Niejednoznaczno%$ operacji mov
Za!ó my nast#puj"c" sekwencj# deklaracji:. DATA
table1 dw 20 DUP (0)
status db 7 DUP (1)
W podanej ni ej sekwencji instrukcji przes!a& dwie ostatnie sa niejednoznaczne:
mov bx,offset table1
mov si,offset status
mov [bx],100
mov [si],100
Nie jest jasne, czy asembler ma u y$ bajtu czy s!owa do reprezentacji liczby 100
30
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Instrukcje przes!a" danych cd.
Niejednoznaczno%$ instrukcji mov z poprzedniego
przyk!adu mo na usun"$ u ywaj"c dyrektywy ptr
Ostatnie dwie instrukcje mov z poprzedniej planszy
mo na zapisa$ jako:mov word ptr [bx],100
mov byte ptr [si],100
– S!owa word i byte s" nazywane specyfikacj" typu
Mo na u ywa$ ponadto nast#puj"cych specyfikacji typu:
– dword – dla warto%ci typu doubleword
– qword – dla warto%ci typu quadword
– tword – dla warto%ci z!o onych z 10 bajtów
31
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Instrukcje przes!a" danych cd.
Instrukcja xchg
Ogólny formatxchg operand1,operand2
Zamienia warto%ci argumentów operand1 i operand2
Przyk!adyxchg eax,edx
xchg response,cl
xchg total,dx
Bez instrukcji xchg operacja zamiany argumentów
wymaga!aby dwóch instrukcji mov i pomocniczego
rejestru
32
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Instrukcje przes!a" danych cd.
Instrukcja xchg jest przydatna przy konwersji
16-bitowych danych mi#dzy formatami little-
endian i big-endian
Przyk!ad
xchg al,ah
Zamienia dane w ax na przeciwny format endian
Pentium ma podobn" instrukcj# bswap do
konwersji danych 32-bitowych:
bswap 32-bit_register
Instrukcja bswap dzia!a tylko na rejestrach 32-bitowych

33
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Instrukcje przes!a" danych cd.
Instrukcja xlat transluje bajty
Formatxlatb
Przed u yciem instrukcji xlat nale y:
– W rejestrze bx umie%ci$ adres pocz"tkowy tablicy translacji
– al Musi zawiera$ indeks do tablicy (indeksowanie zaczyna si#
od warto%ci równej 0)
– Instrukcja xlat odczytuje z tablicy translacji bajt wskazany
przez indeks i zapisuje go w al
– Warto%$ w al zostaje utracona
Tablica translacji mo e mie$ najwy ej 256 elementów (rejestr al jest 8-bitowy)
34
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Instrukcje przes!a" danych cd.
Przyk!ad dzia!ania instrukcji xlat – szyfrowanie– Cyfry na wej%ciu: 0 1 2 3 4 5 6 7 8 9
– Cyfry na wyj%ciu: 4 6 9 5 0 3 1 8 7 2
.DATA
xlat_table db ‘4695031872’
...
.CODE
mov bx,offset xlat_table
getCh al
sub al,’0’ ;konwersja cyfry (ASCII) na indek
xlatb
putCh al
35
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Instrukcje asemblera - przegl#d
Oprócz omówionych instrukcji przes!a& danych procesor Pentium realizuje wiele innych operacji.
Najwa niejsze grupy operacji w Pentium:– Instrukcje arytmetyczne
– Instrukcje skoków
– Instrukcje p#tli
– Instrukcje logiczne
– Instrukcje przesuni#$ logicznych (shift)
– Instrukcje przesuni#$ cyklicznych (rotate)
W dalszej cz#%ci wyk!adu s" omówione najwa niejsze instrukcje z tych grup, które pozwalaj" napisa$ wiele prostych, ale bardzo u ytecznych programów w j#zyku asemblera
36
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Instrukcje arytmetyczne
Instrukcje inc oraz dec
Format:inc destination
dec destination
Dzia!aniedestination = destination +/– 1
Argument destination mo e by$ 8-, 16- lub 32-bitowy, w pami#ci lub w rejestrze
– Nie mo na stosowa$ trybu natychmiastowego
Przyk!adyinc bx ; bx = bx + 1
dec value ; value = value – 1
37
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Instrukcje arytmetyczne cd.
Instrukcja dodawania add
Formatadd destination,source
Dzia!aniedestination = destination + source
Przyk!adyadd ebx,eax
add value,35
U ycie inc eax jest lepsze ni add eax,1
– Instrukcja inc jest krótsza w kodzie binarnym
– Obydwie instrukcje wykonuj" si# w tym samym czasie
38
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Instrukcje arytmetyczne cd.
Instrukcja odejmowania sub
Formatsub destination,source
Dzia!aniedestination = destination - source
Przyk!adysub ebx,eax
sub value,35
U ycie dec eax jest lepsze ni sub eax,1
– Instrukcja dec jest krótsza w kodzie binarnym
– Obydwie instrukcje wykonuj" si# w tym samym czasie
39
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Instrukcje arytmetyczne cd.
Instrukcja porównania cmp
Formatcmp destination,source
Dzia!aniedestination – source
– zarówno destination jak i source nie ulegaj" zmianie, CPU wykonuje jedynie wirtualne odejmowanie by porówna$argumenty (zbada$ relacj# mi#dzy nimi: >, =)
Przyk!adycmp ebx,eax
cmp count,100
Instrukcja cmp jest u ywana razem z instrukcjami skoków warunkowych do realizacji rozga!#zie& w programie uzale nionych od relacji mi#dzy argumentami cmp
40
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Instrukcje skoków
Skok bezwarunkowy jmp
Formatjmp label
Dzia!anie– CPU przechodzi do realizacji instrukcji oznaczonej etykiet"label
Przyk!ad – niesko&czona p#tlamov eax,1
inc_again:
inc eax
jmp inc_again
mov ebx,eax ; ta instrukcja nigdy si ; nie wykona

41
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Instrukcje skoków cd.
Skoki warunkowe
Formatj<cond> label
Dzia!anie– CPU przechodzi do realizacji instrukcji oznaczonej etykiet" label je%li
warunek <cond> jest spe!niony
Przyk!ad – testowanie wyst"pienia znaku powrotu karetki CRgetCh al
cmp al,0dh ; 0dh = ASCII CR
je CR_received
inc cl
...
CR_received:
...
42
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Instrukcje skoków cd.
Wybrane instrukcje skoków warunkowych
– Argumenty w poprzedzaj"cej instrukcji cmp sa
traktowane jako liczby ze znakiem
je skocz gdy równe (equal)
jg skocz gdy wi#ksze (greater)
jl skocz gdy mniejsze (less)
jge skocz gdy wi#ksze lub równe (greater or equal)
jle skocz gdy mniejsze lub równe (less or equal)
jne skocz gdy ró ne (not equal)
43
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Instrukcje skoków cd.
Skoki warunkowe mog" równie testowa$ stan
poszczególnych bitów w rejestrze wska'ników (eflags)
jz skocz gdy zero (jump if ZF = 1)
jnz skocz gdy nie zero (jump if ZF = 0)
jc skocz gdy przeniesienie (jump if CF = 1)
jnc skocz gdy brak przeniesienia (jump if CF = 0)
Instrukcja jz jest synonimem je
Instrukcja jnz jest synonimem jne
44
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Instrukcje skoków cd.
Instrukcja p#tli loop
Formatloop target
Dzia!anie– Dekrementuje cx i skacze do etykiety target je%li cx nie jest
zerem
– Przed wej%ciem w p#tl# do rejestru cx nale y wpisa$ liczb#powtórze& p#tli
Przyk!admov cx,50 ; licznik p tli = 50
repeat: ; etykieta pocz!tku p tli
... ; instrukcje stanowi!ce
... ; tre$% p tli
loop repeat ; koniec p tli
...
45
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Instrukcje skoków cd.
Poprzedni przyk!ad jest równowa ny zapisowimov cx,50 ; licznik p tli = 50
repeat: ; etykieta pocz!tku p tli
... ; instrukcje stanowi!ce
... ; tre$% p tli
dec cx ; dekrementuj licznik
jnz repeat
...
Nieco zaskakuj"cy jest fakt, e para instrukcji dec oraz
jnz wykonuje si# szybciej ni instrukcja loop z
przyk!adu na poprzedniej planszy
46
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Instrukcje logiczne
Formatand destination,source
or destination,source
not destination
Dzia!anie– Wykonuje odpowiedni" operacj# logiczn" na bitach
– Wynik jest umieszczany w destination
Instrukcja test jest odpowiednikiem instrukcji and, ale nie niszczy destination (podobnie jak cmp) tylko testuje argumentytest destination,source
47
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Instrukcje logiczne cd.
Przyk!ad – testowanie, czy w rejestrze al jest liczba parzysta, czy nieparzysta
test al,01h ; testuj najmniej znacz!cy bit al
jz liczba_parzysta
liczba_nieparzysta:
... ; przetwarzaj przypadek liczby ; nieparzystej
jmp skip
liczba_parzysta:
... ; przetwarzaj przypadek liczby ; parzystej
skip:
...
48
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Instrukcje przesuni $ logicznych
Format
– Przesuni#cia w lewo
shl destination,count
shl destination,cl
– Przesuni#cia w prawo
shr destination,count
shr destination,cl
Dzia!anie
– Wykonuje przesuni#cie argumentu destination w lewo lub w
prawo o liczb# bitów podan" w count lub w rejestrze cl
– Zawarto%$ rejestru cl nie ulega zmianie

49
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Instrukcje przesuni $ logicznych
Bit opuszczaj"cy przesuwany obiekt trafia do bitu przeniesienia w
rejestrze wska'ników
Na woln" pozycj# wprowadzany jest bit równy zero
50
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Instrukcje przesuni $ logicznych
Liczba count jest argumentem natychmiastowym
– Przyk!ad
shl ax,5
Specyfikacja count o warto%ci wi#kszej ni 31 jest
niedozwolona
– Je%li podana liczba count jest wi#ksza ni 31 instrukcja u yje
tylko 5 najmniej znacz"cych bitów count
Wersja instrukcji z u yciem rejestru cl jest przydatna,
je eli liczba bitów, o które nale y przesun"$ argument
jest znana dopiero w czasie wykonania programu
51
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Instrukcje przesuni $ cyklicznych
Dwa typy instrukcji rotate
– Przesuni#cie cykliczne przez bit przeniesienia
rcl (rotate through carry left)
rcr (rotate through carry right)
– Przesuniu#cie cykliczne bez pitu przeniesienia
rol (rotate left)
ror (rotate right)
Format instruckji rotate jest taki sam jak instrukcji
shift
– Mo na stosowa$ natychmiastowy argument count lub
podawa$ liczb# pozycji, o które ma nast"pi$ rotacja u ywaj"c rejestru cl
52
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Instrukcje przesuni $ cyklicznych
Instrukcje przesuni#$ cyklicznych z wy!"czeniem bitu
przeniesienia dzia!aj" wed!ug poni szego diagramu:
53
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Instrukcje przesuni $ cyklicznych
Instrukcje przesuni#$ cyklicznych z udzia!em bitu
przeniesienia dzia!aj" wed!ug poni szego diagramu:
54
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Definiowanie sta!ych
Asembler przewiduje dwa sposoby definiowania sta!ych:– Dyrektywa equ
Definicja nie mo e by$ zmieniona
Mo na definiowa$ !a&cuchy (strings)
– Dyrektywa =
Definicja mo e by$ zmieniona
Nie mo na definiowa$ !a&cuchów
Definiowanie sta!ych zamiast podawanie ich w instrukcjach w postaci natychmiastowej ma dwie wa ne zalety:
– Poprawia czytelno%$ programu
– U!atwia dokonywanie zmian w programie (wystarczy zmieni$definicj# i przekompilowa$ program, zamiast zmienia$wszystkie wyst"pienia sta!ych liczbowych)
55
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Definiowanie sta!ych
Dyrektywa equ
Sk!adnianame equ expression
– Przypisuje warto%$ wyra enia expression sta!ej o nazwie name
– Wyra enie jest obliczane podczas kompilacji
Podobne dzia!anie jak #define w j#zyku C
Przyk!adyNUM_OF_ROWS equ 50
NUM_OF_COLS equ 10
ARRAY_SIZE equ NUM_OFROWS * NUM_OF_COLS
Mo na tak e definiowa$ !a&cuchy znaków, np.JUMP equ jmp
56
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Definiowanie sta!ych
Dyrektywa =
Sk!adnianame = expression
– Dzia!anie podobne dzia!anie jak dla dyrektywy equ
– Dwie zasadnicze ró nice
Redefiniowanie jest dozwolone
count = 0
...
count = 99
jest legalnym zapisem
– Nie mo na definiowa$ sta!ych !a&cuchów i przedefiniowywa$s!owa kluczowe asemblera lub mnemoniki instrukcji
– Przyk!ad Zapis JUMP = jmp jest nielegalny

57
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Przyk!ady programów
W za!"czonym pliku programy_asm.pdf znajduj" si#
teksty 'ród!owe kilku prostych programów napisanych w
j#zyku asemblera procesora Pentium:
– BINCHAR.ASM – konwersja tekstu ASCII na reprezentacj#
binarn"
– HEXI1CHAR.ASM – konwersja tekstu ASCII na kod
szesnastkowy
– HEX2CHAR.ASM – konwersja tekstu ASCII na kod szesnastkowy z wykorzystaniem instrukcji xlat
– TOUPPER.ASM – konwersja ma!ych liter na du e litery przez
manipulacj# znakami
– ADDIGITS.ASM – sumowanie poszczególnych cyfr w liczbie
58
Wy sza Szko!a Informatyki Stosowanej i Zarz"dzania
Podsumowanie
Linie programu asemblerowego
Alokacja danych
Tryby adresowania argumentów
– rejestrowy, natychmiastowy, bezpo%redni, po%redni
Instrukcje przes!a& danych
Przegl"d najwa niejszych instrukcji asemblera Pentium
– instrukcje arytmetyczne, skoki bezwarunkowe i warunkowe,
instrukcje logiczne, przesuni#cia logiczne i cykliczne
Definiowanie sta!ych
Przyk!ady programów





























