Embed Size (px)
Citation preview

Twitter解析サービス
YAPC::Asia 2010 yusukebe
2010/10/16

• Yusuke Wada • 和田裕介 • (株)ワディット • http://search.cpan.org/~yusukebe/

注意事項
• NoSQLな話はあまりしません • 理由について後ほど言及します

クロール&表示型サービス • Plaggerブーム時代から個人で作成
CDTube これ☆ほしい YourAVHost
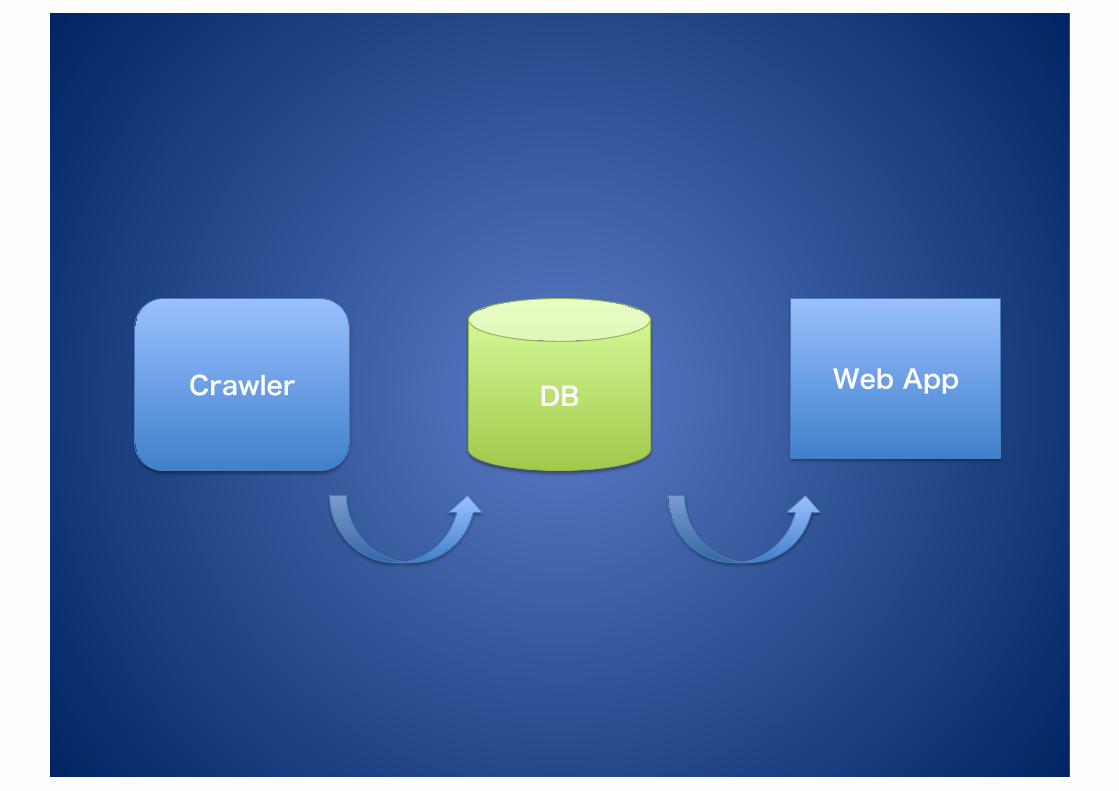
Web App DB Crawler

基本システム構成 • リソース – オリコンランキング情報/RSS/Google Blog Search結果/各種API
• クローラー – LWP::UserAgent/WebService::Simple/XML::Feed
• DB – MySQL
• Webアプリ – DBIx::Class/Catalyst

リソースとしての Twitterの登場
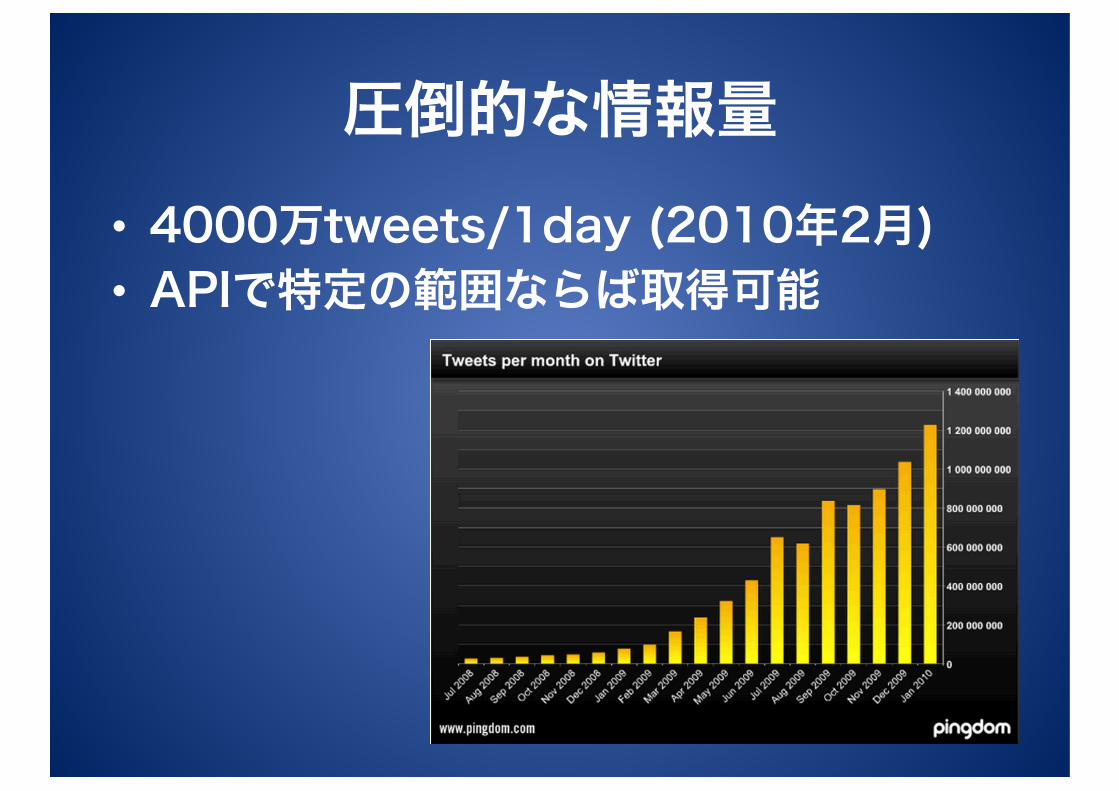
圧倒的な情報量 • 4000万tweets/1day (2010年2月) • APIで特定の範囲ならば取得可能

Twib • Twitterホットエントリー • つぶやかれているURLを収集 • 人気順に並べる • 先行サービス tweetmeme/topsy
http://twib.jp/
Top of yesterday.

Version 0.01 • 2009/8/4 リリース • 取得tweet数 3万tweets/1day • 1週間で機能拡張

Version 0.02 • 2010/7/5 • 放置していたものに手を加える • 80万 tweets/1day • 携帯アプリ twittie との連携

Version 0.03 • 2010/8/27 • バックエンドシステム刷新 • mongoDB / gearmand • 新UI

Version 0.04 • 2010/9/1 • mongoDBの急遽取りやめ

運用環境 • 自宅サーバ • App/DBx2/Worker
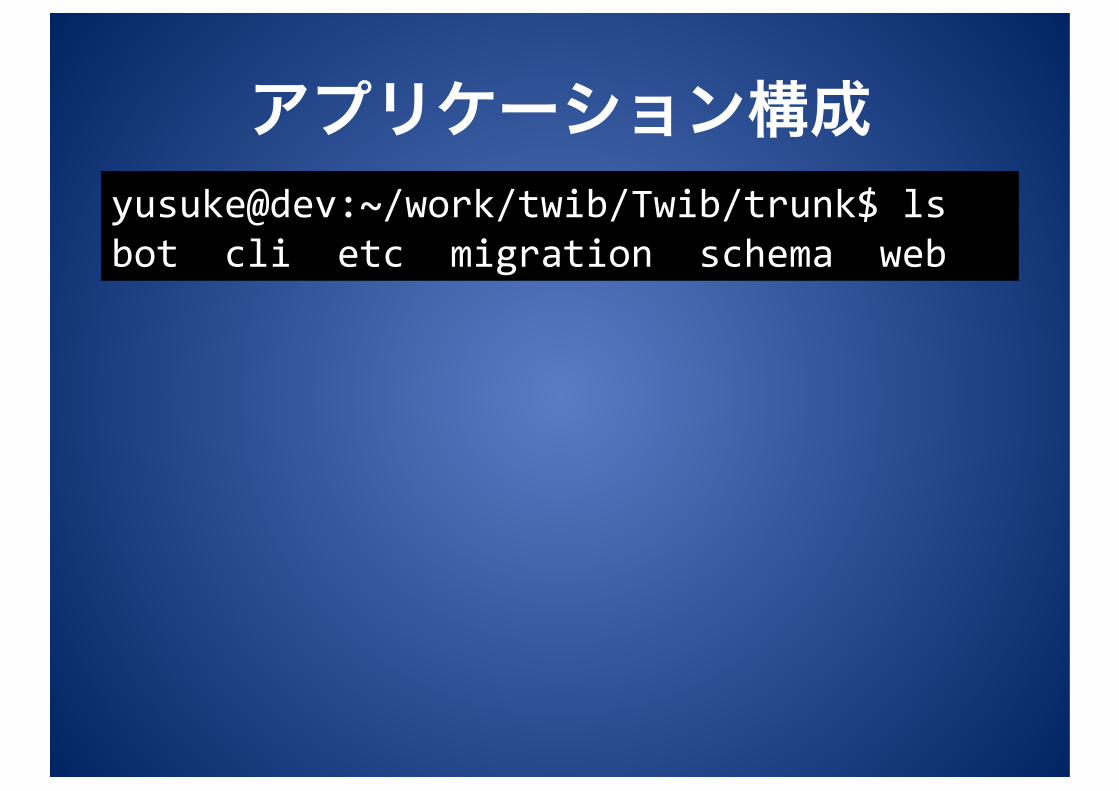
アプリケーション構成 yusuke@dev:~/work/twib/Twib/trunk$ ls bot cli etc migration schema web

Twitter解析のポイント • tweetの更新が非常に速い • データ量が多くなりがち
• とにかくtweetを速くどこかへ格納する • 解析する際に非同期で処理をする • 情報のプライオリティを決める

tweetの取得 • Search API と Streaming API の併用
Package Twib::CLI::Reader::Feed; use JSON::XS; use LWP::UserAgent;
Package Twib::CLI::Reader::Stream; use AnyEvent::Twitter::Stream;

解析を非同期で行う • URLの情報(タイトル/要約…)を取得する必要がある=解析
• tweetを取得してそのまま解析していたら間に合わない

ジョブキューによる非同期処理 • Job – 仕事 = 仕事の名前とパラメタ
• Client – 仕事を投げる人
• Worker – 仕事をする人
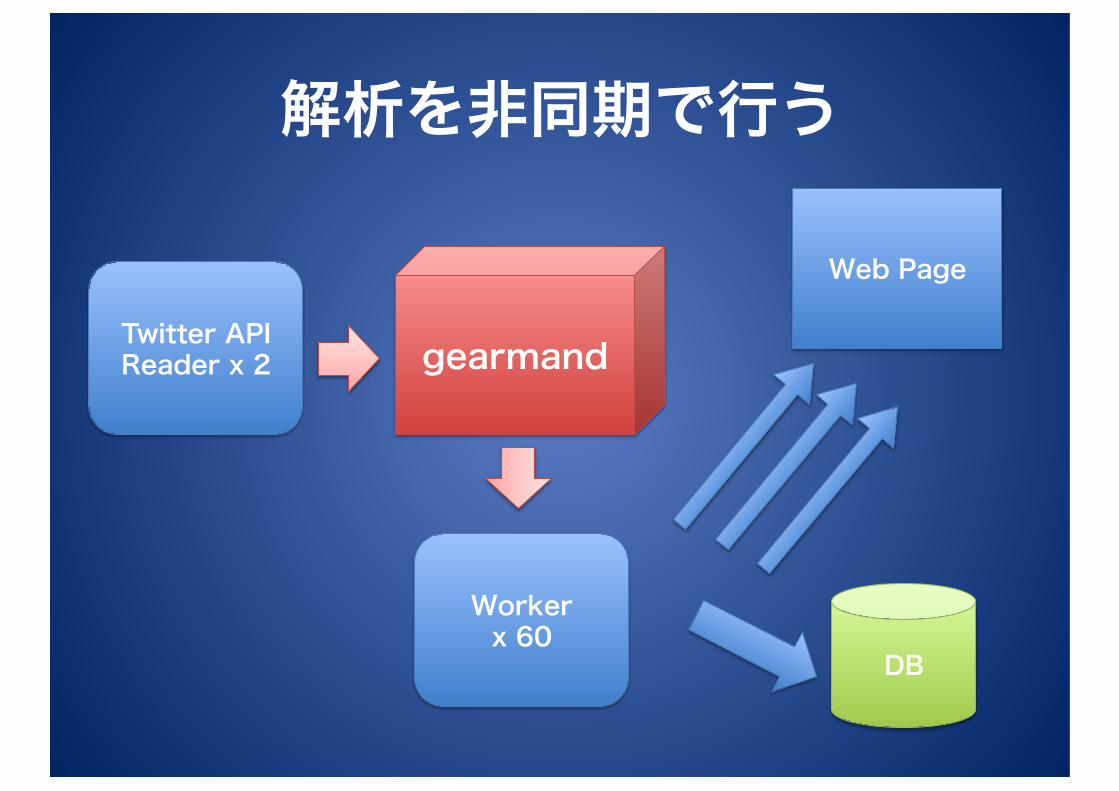
解析を非同期で行う
Web Page
Twitter API Reader x 2 gearmand
Worker x 60
DB
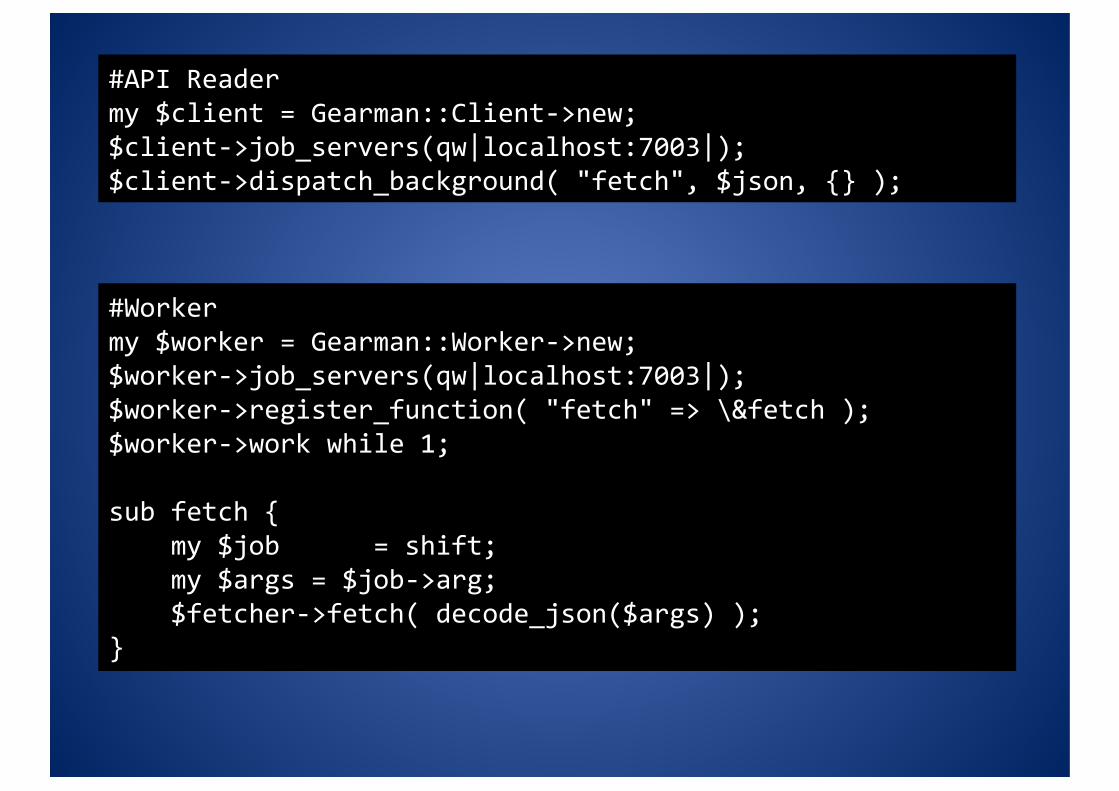
#API Reader my $client = Gearman::Client‐>new; $client‐>job_servers(qw|localhost:7003|); $client‐>dispatch_background( "fetch", $json, {} );
#Worker my $worker = Gearman::Worker‐>new; $worker‐>job_servers(qw|localhost:7003|); $worker‐>register_function( "fetch" => \&fetch ); $worker‐>work while 1;
sub fetch { my $job = shift; my $args = $job‐>arg; $fetcher‐>fetch( decode_json($args) ); }

Webページ情報の取得 • 短縮URL – リダレイクト先をみて「展開」させる – tweetされたURL ‒ 展開されたURLのペアをキャッシュ
• 要約HTMLの取得 – HTML::LDRFullFeed by tokuhirom
• RSS Reader で 全文表示するためのXpathを含むwedata
– HTML::ExtractContent • 特徴画像の抽出 – Content-TypeとContent-Lengthを見て判断

扱うデータ Post – comment – url – user_name
Link – url – title – summary – image_url
LinkAttribute – created_on – tweet_count

情報のプライオリティを決める • 少ないリソースでいかに更新が速く大きくなりがちなデータを処理するか
• Twibの場合は「直近のランキング情報」に価値がある
• 優先度の高いデータにリソースをさく • DELETEしてもいいデータを決めておく
LinkAttribute > Link > Post

バックエンドの評価 • ギョブキュー – 信頼性を無視して速さ優先ならばgearman
• DB – 最低限のカラム構成のDBをオンメモリーに載せるMySQL戦略

mongoDBを採用した理由 捨てた理由
• Shardingの容易さ • リソースコントロールが難しい • そもそも物理的に制限がある • 方針を決めて独自のパーティショニングでMySQLを使った方がよい

特化した機能はAPI化させる • 画像API • http://image.twib.jp/counter/http://twib.jp/
• http://image.twib.jp/user/yusukebe – Redirect to : http://a1.twimg.com/profile_images/15300142/profile_childfood_normal.jp
• http://image.twib.jp/favicon?url=http://yusukebe.com/
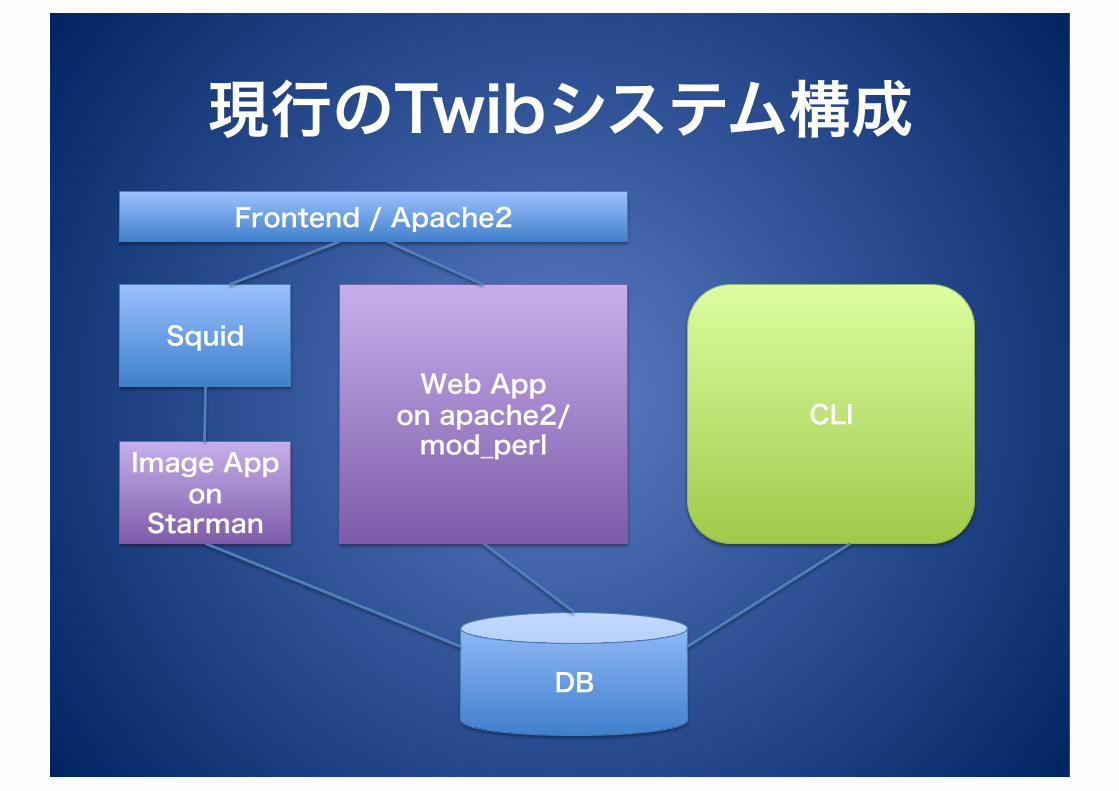
現行のTwibシステム構成 Frontend / Apache2
Squid
Image App on
Starman
Web App on apache2/mod_perl
DB
CLI

ポイントのまとめ • tweetを速く集める • プライオリティを決めてデータを扱う • ボトルネック候補 – Job Queue – DB 周り

Twitter解析アプリの可能性 • 一般的なクロール&表示型サービス – SELECT > INSERT/UPDATE
• Twitter解析アプリ – INSERT/UPDATE > SELECT ?
• 更新頻度の高いシステムを個人で作れてしまう

休日プログラミングのネタとしてTwitterアプリはいかが?