Embed Size (px)
Citation preview

Zależności w danych. Korelacja i regresja
Agnieszka Nowak – Brzezińska
SMAD

Korelacja Zależność korelacyjna pomiędzy cechami X i Y
charakteryzuje sie tym, że wartościom jednej cechy są przyporządkowane ściśle określone wartości średnie drugiej cechy.

• Celem analizy korelacji jest stwierdzenie, czy między badanymi zmiennymi zachodzą jakieś zależności, jaka jest ich siła, jaka jest ich postać i kierunek.
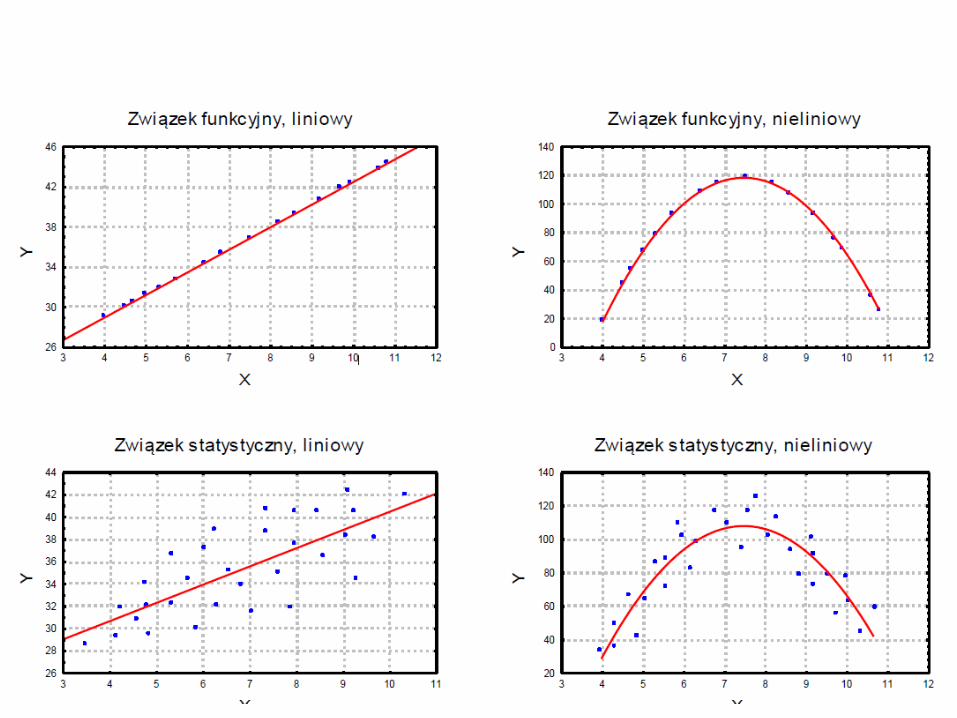
• Współzależność między zmiennymi może być dwojakiego rodzaju: funkcyjna lub stochastyczna (probabilistyczna).
• Istota zależności funkcyjnej polega na tym, że zmiana wartości jednej zmiennej powoduje ściśle określoną zmianę wartości drugiej zmiennej. W przypadku zależności funkcyjnej: określonej wartości jednej zmiennej (X) odpowiada jedna i tylko jedna wartość drugiej zmiennej (Y).
• Zależność probabilistyczna występuje wtedy, gdy wraz ze zmianą wartości jednej zmiennej zmienia się rozkład prawdopodobieństwa drugiej zmiennej. Szczególnym przypadkiem jest zależność korelacyjna, które polega na tym, że określonym wartościom jednej zmiennej odpowiadają ściśle określone średnie wartości drugiej zmiennej. Możemy wtedy ustalić, jak zmieni się – średnio biorąc – wartość zmiennej zależnej Y w zależności od wartości zmiennej niezależnej X.

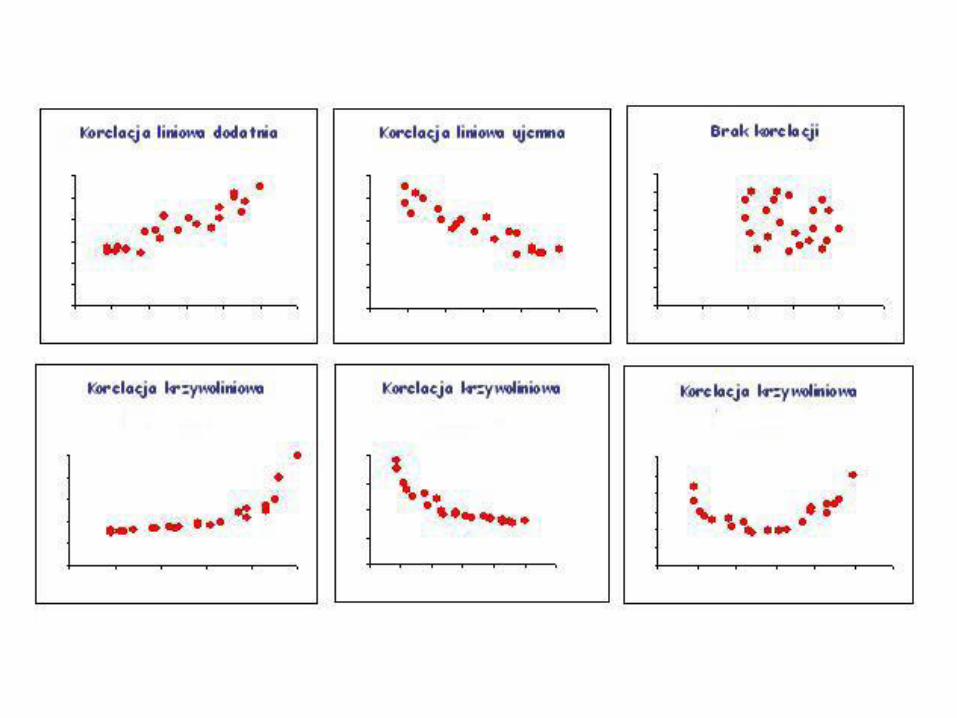
• Siłę liniowego związku pomiędzy dwiema zmiennymi, jest współczynnik korelacji z próby r. Przyjmuje wartości z przedziału domkniętego <-1;1>.
• Wartość -1 oznacza występowanie doskonałej korelacji ujemnej (punkty leżą dokładnie na prostej, skierowanej w dół), a wartość 1 oznacza doskonałą korelację dodatnią (punkty leżą dokładnie na prostej, skierowanej w górę). Wartość 0 oznacza brak korelacji liniowej.
• Wzór za pomocą którego oblicza się współczynnik korelacji ma postać:
• Gdzie xi i yi oznaczają odpowiednio wartości zmiennych x i y, a 𝑥 i 𝑦 średnie wartości tych zmiennych.

Koniecznie zrobić wykres rozrzutu • Po obliczeniu wartości współczynnika korelacji zawsze zalecane jest
utworzenie wykresu rozrzutu.
• To po to, by wizualnie stwierdzić, czy badany związek rzeczywiście najlepiej opisuje funkcja liniowa. Może być tak, że wyliczona wartość współczynnika jest bliska 0, ale między zmiennymi występuje zależność, tyle że nieliniowa.



Badanie istotności korelacji
• Współczynnik korelacji r (z próby) stanowi ocenę współczynnika korelacji q w zbiorowości generalnej i w związku z tym jest obciążony pewnym błędem. Współczynnik korelacji jest statystyką, w związku z czym powinien być traktowany jako zmienna losowa.
• Jeśli zatem N-elementowa próba została pobrana ze zbiorowości generalnej o dwuwymiarowym rozkładzie normalnym z parametrem q=0, a więc gdy zmienne X i Y są nieskorelowane i zarazem niezależne, to zmienna losowa o postaci:
• Ma rozkład t Studenta o N-2 stopniach swobody.
• W praktyce oznacza, to , że formułujemy hipotezę zerową:
H0: q=0 i hipotezę alternatywną H1: q ≠ 0
A następnie porównujemy wartość graniczną alfa z wartością obliczoną t i podejmujemy odpowiednią decyzję odnośnie H0


• Ogólna postać miary korelacji:
• > cor( var1, var2, method = "method")
• Opcja domyślna to miara korelacji Pearsona
• cor(var1, var2)
• Gdy chcemy miary Rang Spearmana:
• cor(var1, var2, method = "spearman")
• gdy chcemy użyć zbioru danych zamiast osobnych zmiennych:
• cor(dataset, method = "pearson")

Istotność korelacji
• Jeśli chcemy poznać stopień istotności korelacji między badanymi zmiennymi musimy użyć dodatkowo funkcji do testowania korelacji: cor.test()
• > cor.test(var1, var2, method = "method")
Domyślnie stosowana jest tu także miara Pearsona. >cor.p = cor.test(var1, var2)
Jeśli chcemy użyć innej musimy ją określić: >cor.s = cor.test(var1, var2, method = "spearman")

Wynik
• > cor.s
• Spearman's rank correlation rho
• data: y and x1
S = 147.713, p-value = 0.00175
alternative hypothesis: true rho is not equal to 0
sample estimates:
rho
0.7362267
• >



Reprezentacja graficzna korelacji. Funkcja plot()
> plot(x.var, y.var)
• Gdy chcemy nadać tytuły osiom x i y
> plot(x.var, y.var, xlab="X-axis", ylab="Y-
axis")
• Gdy chcemy ingerować w symbol punktu na wykresie
> plot(x.var, y.var, pch=16)
• Chcąc dodać linię najlepszego dopasowania do rozrzutu punktów:
> abline(lm(y.var ~ x.var)

Korelacja w R krok po kroku
znaczenie Komenda w środowisku R
Odczyt danych z wskazanej lokalizacji your.data = read.csv(file.choose())
Podłączenie do danych spoza R attach(your.data)
Wybór miary korelacji. Domyślna jest „pearson„.Inne możliwe to "kendal" oraz "spearman„
your.cor = cor(var1, var2, method = "pearson")
Wyświetlenie wartości korelacji your.cor
Korelacja parami cor.mat = cor(your.data, method = "pearson“)
Określenie istotności korelacji cor.test(var1, var2, method="spearman")
Wyświetlenie wykresu rozrzutu. Punkt jako otwarte kółko
plot(x.var, y.var, xlab="x-label", ylab="y-label", pch=21))
Dopasowanie linii regresji abline(lm(y.var ~ x.var)





Kiedy korelogram ?
• Jeżeli obie cechy X i Y są mierzalne, to analizę zależności rozpoczynamy od sporządzenia korelogramu.
• Korelogram jest to wykres punktowy par {(xi , yi)}.
• W kartezjańskim układzie współrzędnych O(x,y) pary te odpowiadają punktom o współrzędnych (x,y).
Jeżeli otrzymamy bezwładny zbiór punktów, który nie przypomina kształtem wykresu znanego związku funkcyjnego, to powiemy że pomiędzy cechami X i Y nie ma zależności.

• Na rysunkach smuga punktów układa się wzdłuż linii prostej.
• Czyli istnieje zależność pomiędzy cechami X i Y i jest to związek liniowy; zależność liniowa.
Zależność liniowa

Rysunek (z lewej) – za mało danych. Zebrano dane (punkty obwiedzione kwadratem) i z korelogramu wynika brak zależności. W rzeczywistości jest zależność liniowa. Rysunek (z prawej) – nietypowe dane. Trzy ostatnie punkty (odseparowane) to dane nietypowe. Sugerują zależność nieliniową (parabola). Po odrzuceniu tych nietypowych informacji widać, że jest wyraźna zależność liniowa.
Błędy we wnioskowaniu o zależności cech X i Y

Zależność nieliniowa
Na rysunku widać, że smuga punktów układa sie w kształt paraboli. Powiemy zatem, że istnieje zależność pomiędzy cechami X i Y i jest to związek nieliniowy; zależność nieliniowa.

korelogram
• Pakiet corrgram – install.package(corrgram) – on potrzebuje pakietów: seriation, TSP

> corrgram(mtcars, order=TRUE, lower.panel=panel.shade,upper.panel=panel.pie,
text.panel=panel.txt,main="Car Milage Data in PC2/PC1 Order")
>
http://www.statmethods.net/advgraphs/correlograms.html

corrgram(x, order = , panel=, lower.panel=, upper.panel=,
text.panel=, diag.panel=)
• x is a data frame with one observation per row. • order=TRUE will cause the variables to be ordered using principal component
analysis of the correlation matrix. • panel= refers to the off-diagonal panels. You can use lower.panel= and
upper.panel= to choose different options below and above the main diagonal respectively.
• text.panel= and diag.panel= refer to the main diagnonal. Allowable parameters are given below. • off diagonal panels panel.pie (the filled portion of the pie indicates the magnitude of the correlation) panel.shade (the depth of the shading indicates the magnitude of the correlation) panel.ellipse (confidence ellipse and smoothed line) panel.pts (scatterplot) • main diagonal panels
panel.minmax (min and max values of the variable) panel.txt (variable name).





Korelacja w zbiorze faithful
> duration = faithful$eruptions
# the eruption durations > waiting = faithful$waiting
# the waiting period > cor(duration, waiting)
# apply the cor function [1] 0.90081

• Niech x i y będą zmiennymi losowymi o ciągłych rozkładach.
• xi oraz yi oznaczają wartości prób losowych tych zmiennych (i=1,2,..,n),
• natomiast
• - wartości średnie z tych prób.
• Wówczas estymator współczynnika korelacji liniowej definiuje się następująco:
• Ogólnie współczynnik korelacji liniowej dwóch zmiennych jest ilorazem kowariancji i iloczynu odchyleń standardowych tych zmiennych:
.
Im bardziej wartość współczynnika korelacji jest bliska wartości 1, tym większa (dodatnia) zależność liniowa między zmiennymi x i y. Gdy współczynnik korelacji jest blisko wartości -1, oznacza to tzw. ujemną korelację liniową. Wartość bliska 0 oznacza brak zależności między badanymi zmiennymi.

INTERPRETACJA współczynnika korelacji rxy
Znak współczynnika rxy mówi nam o kierunku zależności. I tak: • znak plus – zależność liniowa dodatnia, tzn. wraz ze wzrostem
wartości jednej cechy rosną średnie wartości drugiej z cech, • znak minus – zależność liniowa ujemna, tzn. wraz ze wzrostem
wartości jednej cechy maleją średnie wartości drugiej z cech. Wartosc bezwzględna współczynnika korelacji, czyli |rxy|, mówi nam o
sile zależności. Jeżeli wartość bezwzględna |rxy|: • jest mniejsza od 0,2, to praktycznie brak związku liniowego pomiędzy
badanymi cechami, • 0,2 – 0,4 - zależność liniowa wyraźna, lecz niska, • 0,4 – 0,7 - zależność liniowa umiarkowana, • 0,7 – 0,9 - zależność liniowa znacząca, • powyżej 0,9 - zależność liniowa bardzo silna.

przykład
• W grupie 7 studentów badano zależność pomiędzy oceną z egzaminu z programowania (Y), a liczbą dni poświęconych na naukę (X).

Korelogram
• Wykres rozproszenia – graficzne przedstawienie próbki w postaci punktów na płaszczyźnie O(x,y).

Współczynnik korelacji liniowej Pearsona rxy
• Współczynnik rxy jest miernikiem siły związku prostoliniowego między dwoma cechami mierzalnymi.
• Związkiem prostoliniowym nazywamy taką zależność, w której jednostkowym przyrostom jednej zmiennej (przyczyny) towarzyszy, średnio biorąc, stały przyrost drugiej zmiennej (skutku).
• Wzór na współczynnik korelacji liniowej Pearsona jest wyznaczany poprzez standaryzację kowariancji.

yxxyyyxxn
xyyxn
i
)()(1
),cov(),cov( 1
1
1
Kowariancja jest średnią arytmetyczną iloczynu odchyleń wartości zmiennych X i Y od ich średnich arytmetycznych:
• cov(x,y) = 0 – brak zależności korelacyjnej;
• cov(x,y) < 0 – ujemna zależność korelacyjna;
• cov(x,y) > 0 – dodatnia zależność korelacyjna.
•
• Kowariancja przyjmuje wartości liczbowe z przedziału: [-s(x)s(y), +s s(x)s(y)], gdzie s(x) i s(y) są odchyleniami standardowymi odpowiednich zmiennych.
• Jeżeli cov(x,y) = -s(x)s(y), to między zmiennymi istnieje ujemny związek funkcyjny. Przy dodatnim związku funkcyjnym cov(x,y) = +s(x)s(y).
• Kowariancja charakteryzuje współzmienność badanych zmiennych, ale jej wartość zależy od rzędu wielkości, w jakich wyrażone są obydwie cechy, co powoduje, że nie można jej wykorzystać w sposób bezpośredni do porównań.

współczynnik korelacji linowej Pearsona, wyznaczony przez standaryzację kowariancji:
• To unormowany miernik natężenia i kierunku współzależności liniowej dwóch zmiennych mierzalnych X i Y :
•
• Współczynnik korelacji liniowej Pearsona jest miarą unormowaną, przyjmującą wartości z przedziału: -1 < rxy <+1.
• Dodatni znak współczynnika korelacji wskazuje na istnienie współzależności pozytywnej (dodatniej), ujemny zaś oznacza współzależność negatywną (ujemną).
)()(
),cov(
ysxs
yxrr yxxy

• Widać tutaj wyraźną zależność liniową (dodatnią).
• Obliczamy współczynnik korelacji (Pearsona).
• UWAGA ! Liczebność populacji jest mała (n=7). Użyjemy tak małego przykładu tylko dlatego, aby sprawnie zilustrować procedurę liczenia.
• Obliczanie średnich, wariancji oraz kowariancji.

INTERPRETACJA W badanej grupie studentów wystąpiła bardzo silna dodatnia (znak plus) zależność liniowa pomiędzy czasem nauki (cecha X), a uzyskaną oceną z egzaminu (cecha Y). Oznacza to, że wraz ze wzrostem czasu poświęconego na naukę rosła w tej grupie uzyskiwana ocena.

• W pewnym Urzędzie Stanu Cywilnego pewnego dnia przeprowadzono badanie nowo zawartych małżeństw wg wieku żony i męża. Wyniki badania losowo pobranych par przedstawiono niżej.
• Określić siłę i kierunek zależności między badanymi zmiennymi.

• Na podstawie analizy diagramu punktowego (korelacyjnego) można stwierdzić, że zależność między badanymi zmiennymi ma charakter prostoliniowy. Dlatego też siłę i kierunek zależności można ocenić przy użyciu współczynnika korelacji liniowej Pearsona.
• Aby go obliczyć należy wykonać obliczenia pomocnicze:

• Średni wiek kobiet zawierających w badanym dniu związek małżeński wynosi:
• lat. Średni wiek mężczyzny wynosi: lat. • • W celu obliczenia współczynnika korelacji liniowej Pearsona
niezbędna jest znajomość odchyleń standardowych obydwu cech: • • Odchylenie standardowe wieku kobiet jest równe: • • Odchylenie standardowe wieku mężczyzn jest równe: • • Dysponując powyższymi informacjami możemy obliczyć
współczynnik korelacji liniowej Pearsona: •
5,2310:235 x
8,2310:238 y
lat 3,810
5,142)(
s(x)
n
1i
2
n
xxi
lat 1,410
6,169)(
s(y)
n
1i
2
n
yyi
7396,0
86,01,48,310
134
2
xy
xy
r
r

Zatem współczynnik korelacji liniowej Pearsona jest równy:
Na tej podstawie można stwierdzić, że między liczbą sal a liczbą uczniów w szkole zachodzi dosyć silna dodatnia zależność korelacyjna.
Zmienność jednej cechy jest w 46,42% wyjaśniona zmiennością drugiej
4642,0
68,07,27,65
120
2
xy
xy
r
r
.


Dane jakościowe
• Często jest tak, że dane dla których chcemy mierzyć korelację, nie są danymi ilościowymi. Wtedy nie możemy użyć współczynnika korelacji liniowej Pearsona.
• Współczynnik korelacji rang Spearmana został opracowany właśnie dla takich przypadków.

WSPÓŁCZYNNIK KORELACJI RANG (Spearmana)
Współczynnik korelacji rang (Spearmana) rS używamy w przypadku gdy:
1. choć jedna z badanych cech jest cecha jakościowa (niemierzalna), ale istnieje możliwość uporządkowania (ponumerowania) wariantów każdej z cech;
2. cechy maja charakter ilościowy (mierzalny), ale liczebność zbiorowości jest mała (n<30).
Numery jakie nadajemy wariantom cech noszą nazwę rang.
UWAGA ! W procesie nadawania rang stymulanty porządkujemy malejąco, a destymulanty rosnąco.
UWAGA ! W procesie nadawania rang może zdarzyć sie więcej niż 1 jednostka o takiej samej wartości cechy (np. k jednostek). Wówczas należy na chwile nadać tym jednostkom kolejne rangi.
Następnie należy zsumować takie rangi i podzielić przez k (otrzymamy w ten sposób średnią rangę dla tej grupy k jednostek). W ostateczności każda jednostka z tych k jednostek otrzyma identyczną rangę (średnia dla danej grupy k jednostek).

Wartość współczynnika korelacji rang (Spearmana) potwierdza bardzo silną, dodatnią (znak plus) zależność pomiędzy czasem nauki (X), a uzyskaną oceną (Y).

Współczynnik korelacji kolejnościowej (rang) Spearmana
Współczynnik ten służy do opisu siły korelacji dwóch cech, szczególnie wtedy, gdy mają one charakter jakościowy i istnieje możliwość uporządkowania obserwacji w określonej kolejności.
Miarę tę można stosować również do badania zależności między cechami ilościowymi w przypadku niewielkiej liczby obserwacji.
Współczynnik rang Spearmana obliczamy ze wzoru:
)1(
6
12
1
2
nn
d
r
n
i
i
s
Gdzie: di – różnice między rangami odpowiadających sobie wartości cechy xi i cechy yi (i=1, 2, ..., n).

współczynnik korelacji rang Spearmana
Jednym ze współczynników korelacji obliczanych dla danych rangowych jest, określony wzorem
gdzie
Własności:
Współczynnik rS przyjmuje wartości z przedziału [-1; 1].
Wartość rS = 1 oznacza, że istnieje całkowita zgodność uporządkowań wg rang ai i bi .
Wartość rS = -1 oznacza z kolei pełną przeciwstawność uporządkowań między rangami.
Wartość rS = 0 oznacza brak korelacji rang.

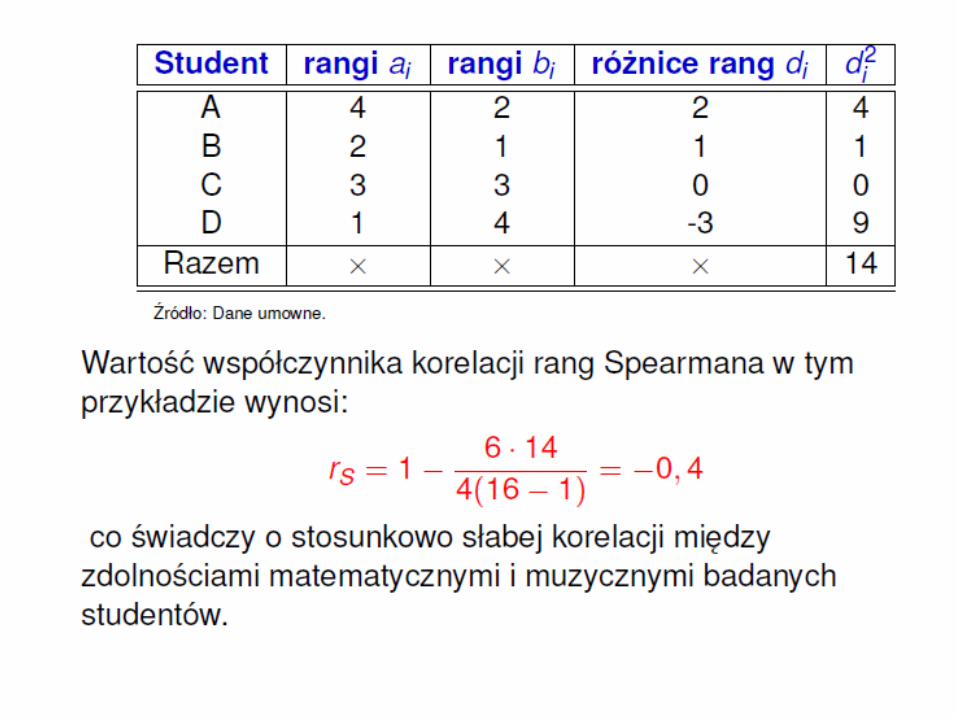
przykład
• Przypuśćmy, że porządkujemy 4 studentów w zależności od stopnia ich zdolności matematycznych, zaczynając od studenta najlepszego, któremu przydzielamy numer 1, a kończąc na studencie najsłabszym, któremu przydzielamy numer 4 (ocenę zdolności powierzamy np. ekspertowi)
• Mówimy wówczas, że studenci zostali uporządkowani w kolejności rang, a numer studenta jest jego rangą.
• Oznaczmy rangi poszczególnych studentów przez ai .
• Przykładowo, niech: a1 = 4; a2 = 2; a3 = 3; a4 = 1; co oznacza, że w badanej grupie, ustawionej w kolejności alfabetycznej, pierwszy student (oznaczmy go umownie literą A) jest najsłabszy, student B – dobry, student C – słaby, a student D – najlepszy.

• Analiza korelacji i regresji jest działem statystyki zajmującym się badaniem związków i zależności pomiędzy rozkładami dwu lub więcej badanych cech w populacji generalnej.
• Termin regresja dotyczy kształtu zależności pomiędzy cechami. Dzieli się na analizę regresji liniowej i nieliniowej.
• W przypadku analizy nieliniowej, graficzną reprezentacją współzależności są krzywe wyższego rzędu np. parabola.
• Pojęcie korelacji dotyczy siły badanej współzależności. Analiza regresji i korelacji może dotyczyć dwóch i większej ilości zmiennych (analiza wieloraka). W tym miejscu zajmować się będziemy jedynie najprostszym przypadkiem regresji prostoliniowej dwóch zmiennych.

Współczynnik determinacji
r = 0 r2 = 0
r = .80 r2 = .64
r = 1 r2 = 1
Współczynnik korelacji r dostarcza miar stopnia zależności między danych
Współczynnik determinacji r2 dostarcza miary siły tej zależności.
Informuje on o tym,
jaka część zmienności całkowitej zmiennej losowej Y została wyjaśniona regresją liniową względem X.

Współczynnik determinacji R2
• r2 jest często używany i nosi nazwę współczynnika determinacji. Jest to frakcja zmienności wartości Y, które można wytłumaczyć najmniejszych kwadratów regresji y na xi.
• Współczynniki korelacji, których wielkość wynosi:
• od 0,9 i 1,0 wskazują zmienne, które bardzo silnie skorelowane.
• od 0,7 do 0,9 wskazują zmienne wysoce skorelowane.
• od 0,5 do 0,7 to zmienne umiarkowanie skorelowane.
• od 0,3 do 0,5 zmienne, które mają niską korelację.
Możemy łatwo zauważyć, że:
0,9 <|r| <1,0 odpowiada 0,81 <r2 <1,00;
0,7 <|r| <0,9 odpowiada 0,49 <r2 <0,81;
0,5 <|r| <0,7 odpowiada 0,25 <r2 <0,49;
0.3 <|r| <0,5 wiąże się z 0,09 <r2 <0,25
oraz 0,0 <|r|<0,3 odpowiada z 0,0 <r2 <0.09.

Kwadrat współczynnika korelacji z próby nazywany jest współczynnikiem
determinacji i jest on, drugim poza współczynnikiem korelacji miernikiem
siły związku między zmiennymi.
Interpretacja współczynnika determinacji – podaje on w jakiej części
zmienność jednej cechy jest wyjaśniona przez drugą cechę.

r = .93
r2 = (.93)2
r2 = .86
Współczynnik determinacji

Korelacja nieliniowa
• jest trudniejsza do interpretacji.
• Czym charakteryzuje się nieliniowość lub liniowość korelacji (oprócz linii w diagramie)?
• W przypadku, gdy korelacja jest liniowa można stwierdzić, iż wartości y wzrastają lub opadają proporcjonalnie (współmiernie) do wzrostu lub spadku wartości x. Kierunek korelacji jest tylko jeden i nie zmienia się.

Przy korelacji nieliniowej…
• istnieją przynajmniej dwie trudności w interpretacji. • Pierwsza polega na nieproporcjonalnej przemianie y, podczas gdy x
zmienia się równomiernie. Dlatego jest wyraźnie trudniej wyjaśnić zmiany y.
• Drugi problemem jest fakt, iż nieliniowa korelacja może być w jednej części dodatnia, a w drugiej ujemna.
• Proste do zrozumienia jest stwierdzenie: im więcej uczeń się uczy, tym wyższe są jego wyniki. Każdy rozumie też kolejną prawidłowość: im więcej sportowiec trenuje, tym lepsze są jego osiągnięcia.
• Ale wszystko nie jest tak proste: ostatni przykład może w sposób przejrzysty pokazać trudności w interpretacji korelacji nieliniowej.
• Osiągnięcia sportowca wzrastają tylko do pewnej granicy. Za tą granicą przedłużanie czasu treningu może spowodować zmniejszanie osiągnięć.
• Jest to znane zjawisko przetrenowania (sportowiec zbyt dużo trenował).

Do punktu A korelacja jest dodatnia, od tego punktu dalej ujemna (więcej treningu przynosi niższe wyniki). Przykład jest wprawdzie nieco uproszczony, bo celowo zaniedbane zostało doświadczenie, iż wzrost wyników ma swoje granice bez względu na trening (czyli: zarówno w przypadku liniowej, jak i dodatniej korelacji, wyniki nie wzrastałyby w nieskończoność). Jednak uproszczenie to nie zmienia istoty spostrzeżenia, iż nieliniową korelację interpretuję się o wiele trudniej niż liniową.

Stosunek korelacji eyx
• Stosunek korelacji eyx – gdy nie ma zależności średnie poziomy cechy Y wewnątrz grup pokrywają się ze średnią ogólna cechy Y
• Miara ta spełnia warunek:
• 0<eyx < 1
• |ryx| <= eyx
• Współczynnik koreacji r nie jest czuły na zależności krzywoliniowe. Gdy zależność jest nieliniowa, wówczas miara koncentracji wyników pomiarów względem krzywej regresji może być tzw. Stosunkiem korelacyjnym:

Stosunek korelacyjny
• określa stosunek pomiędzy dwoma zmiennymi, których zależność przyczynowo skutkowa jest określona (x zależy od y).
• Jeżeli zależność ta nie jest znana to należy określić nx|y.
• nx|y = 0: brak korelacji miedzy badanymi zmiennymi (tzn. brak zależności zmiennej y od x)
• nx|y = 1: zależność pomiędzy x i y jest funkcyjna
• nx|y = rx|y: zależność liniowa

Współczynnik determinacji Równolegle do wskaźników korelacyjnych korzysta się ze
współczynników determinacji:
wyrażonych w procentach.
Współczynnik determinacji informuje o tym, w ilu procentach zmiany zmiennej zależnej są spowodowane (zdeterminowane) zmianami zmiennej niezależnej.
yxxy ee i
22 100 i 100 yxxy ee

Wariancje międzygrupowe zmiennych X i Y są obliczane ze wzorów:
• Gdzie są odpowiednio średnimi warunkowymi zmiennych X i Y
• a są średnimi ogólnymi obliczonymi z rozkładów brzegowych.
k
i
iii
k
j
jij
nyyn
ys
nxxn
xs
1
.
22
1
.
22
)(1
)(
)(1
)(
ij yx oraz
yx oraz
Wariancje wewnątrzgrupowe zmiennych X i Y
k
i
iii
k
j
jjj
nysn
ys
nxsn
xs
1
.
22
1
.
22
)(1
)(
)(1
)(Wskaźnik korelacyjny zmiennej X względem
zmiennej Y określa zatem wzór:
Z czego wynika, że wskaźnik korelacyjny zmiennej Y względem zmiennej X określa wzór:
)(
)(
xs
xse
j
xy
)(
)(
ys
yse i
yx 10 e
Są one równe 0, gdy cechy są nieskorelowane, 1 – gdy między badanymi zmiennymi zachodzi zależność funkcyjna.

przykład
• Wylosowano 100 rodzin i zbadano je pod względem liczby dzieci pozostających na całkowitym utrzymaniu i standardu ekonomicznego rodziny, określonego przez średni miesięczny dochód przypadający na członka rodziny.
• Za pomocą stosunku korelacyjnego określić siłę związku korelacyjnego standardu ekonomicznego względem liczny dzieci w rodzinie.

• W pierwszej kolejności obliczamy średnią ogólną i wariancję ogólną cechy Y:
79,0100
25)9,24(50)9,23(15)9,22(10)9,21()(
9,2100
254503152101
2222
ys
y
2,15
1241
5,110
133261
56,225
143112
25,340
104303
75,320
15453
4/5
3/4
2/3
1/2
0/1
x
x
x
x
x
y
y
y
y
y
Następnie obliczamy wartości średnich warunkowych rozkładów cechy Y:

• Po zakończeniu kalkulacji obliczamy wariancję średnich warunkowych:
56,0100
5)9,22,1(10)9,25,1(25)9,256,2(40)9,225,3(20)9,275,3()(
222222
iys
Podstawiając obliczone wartości do wzoru na wskaźnik korelacyjny otrzymujemy:
709,0
842,079,0
56,0
2
yx
yx
e
e
Uzyskany wynik świadczy o silnej zależności standardu ekonomicznego rodziny od liczby dzieci. W niemal 71% przypadków
zmiany standardu ekonomicznego rodziny mogą być wyjaśnione zmianami liczby posiadanych dzieci.
Jest to zależność jednostronna – liczba dzieci nie zależy od standardu ekonomicznego.

Wpływ zmiennej objaśniającej jest wpływem, który znajduje się w centrum uwagi. Rozproszenie z nim związane jest więc wyjaśnione.
Wpływem pozostałych czynników badacz jest zainteresowany jedynie ubocznie.
Dlatego też rozproszenie powiązane z nimi nazywa się rozproszeniem niewyjaśnionym. Poniższy rysunek ilustruje korelację między zmienną objaśniającą x i objaśnianą y.
Poniższe wykresy pokazują kilka możliwych przypadków korelacji…

Wariancja wyjaśniona i niewyjaśniona
• Podział wariancji na wyjaśnioną i niewyjaśnioną jest wyidealizowany. Przesłanką tego podziału jest niezależność x od pozostałych czynników. W praktyce zdarza się to jedynie incydentalnie. Takie uproszczenie bardzo ułatwia zrozumienie zasady pomiaru korelacji.
• Należy jednak pamiętać, iż procedura ta jest trochę nieścisła. W interpretacji należy uwzględniać różnicę między ideałem i realnością.
• Stosunek pomiędzy wariancją wyjaśnioną a wariancją całkowitą wskazuje z jaką silą x oddziałuje na y. Stosunek ten nazywa się indeksem korelacji. Oto wzór do obliczania indeksu korelacji:

Interpretacja
• Wartości indeksu wahają się od 0 do 1. Wartość zero oznacza brak korelacji między x i y (wyjaśniona wariancja równa się zeru, co oznacza, iż x nie oddziałuje na y).
• Wartość 1 oznacza, że korelacja jest najsilniejsza (niewyjaśniona wariancja równa się zeru, co oznacza, iż tylko x oddziałuje na y). Taka korelacja jest już funkcją.
• Należy jeszcze raz podkreślić, iż indeks korelacji nie może przekraczać wartości 1! Ta zasada odnosi się do wszystkich miar współzależności.

przykład







Zapamiętać…
• Co to jest korelacja, jakie są jej własności ?
• Kiedy stosować korelację rang Spearmana a kiedy Pearsona ?
• Kiedy korelacja jest dodatnia / ujemna ?
• Jak opisywać dany zbiór danych (jakie wskaźniki)?
• Jak zrobić wykres częstości ?

![Zależności w danych. Korelacja. Regresja.zsi.ii.us.edu.pl/~nowak/smad/SMAD_w2.pdf · [Sobczyk str. 209-210, wyd.1991] • Na podstawie analizy diagramu punktowego (korelacyjnego)](https://img.pdfslide.tips/doc/110x75/5c75dadf09d3f2941e8bca10/zaleznosci-w-danych-korelacja-nowaksmadsmadw2pdf-sobczyk-str-209-210.jpg)