Embed Size (px)
Citation preview

Toruń, 2004
Zbigniew S. Szewczak Podstawy Systemów Operacyjnych
Wykład 7
Planowanie przydziału procesora.

Odrabianie wykładów
☛ czwartek, 1.04.2004, S7, g. 12.00 za 19.05
☛ czwartek, 15.04.2004, S7, g. 12.00 za 12.05

Planowanie przydziału procesora
☛ Podstawowe pojęcia☛ Kryteria planowania☛ Algorytmy planowania☛ Planowanie wieloprocesorowe☛ Planowanie w czasie rzeczywistym☛ Ocena algorytmów

Podstawowe pojęcia
☛ Idea wieloprogramowania: wiele procesów dzieli(niepodzielny zasób) CPU
☛ Celem wieloprogramowania jest maksymalnewykorzystanie jednostki centralnej (CPU)
☛ Planowanie przydziału procesora (ang. CPUsheduling) jest kluczową funkcją w każdymsystemie operacyjnym operacyjnym albowiemjest realizacją idei wieloprogramowania

Fazy procesu
☛ CPU-I/O - wykonanie procesu składa się z fazyprocesora (ang. CPU burst) i fazy we/wy (ang.I/O burst)
☛ Krzywa częstości zatrudnień procesora makształt wykładniczy lub hiperwykładniczy
☛ Proces ograniczony przez we/wy ma wielekrótkich faz procesora, proces ograniczony przezprocesor ma mało długich faz procesora
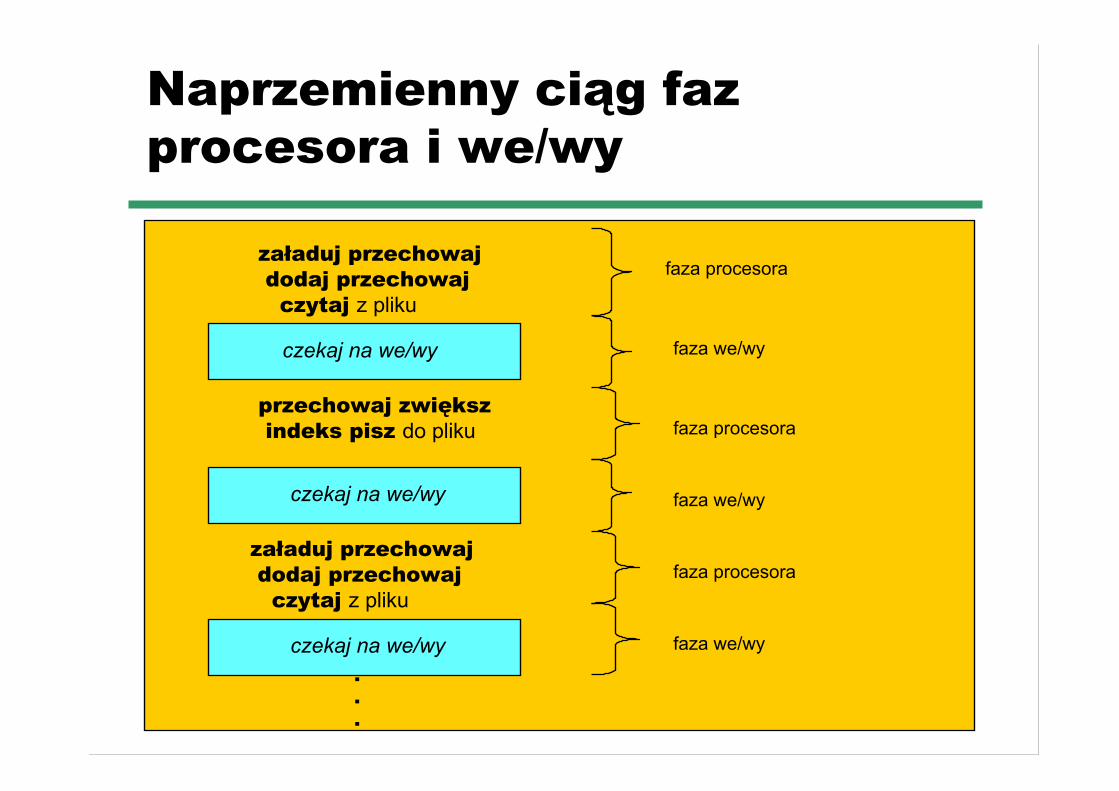
Naprzemienny ciąg fazprocesora i we/wy
załaduj przechowaj dodaj przechowaj czytaj z pliku
przechowaj zwiększ indeks pisz do pliku
załaduj przechowaj dodaj przechowaj czytaj z pliku
czekaj na we/wy
czekaj na we/wy
czekaj na we/wy
faza procesora
faza procesora
faza procesora
faza we/wy
faza we/wy
faza we/wy...
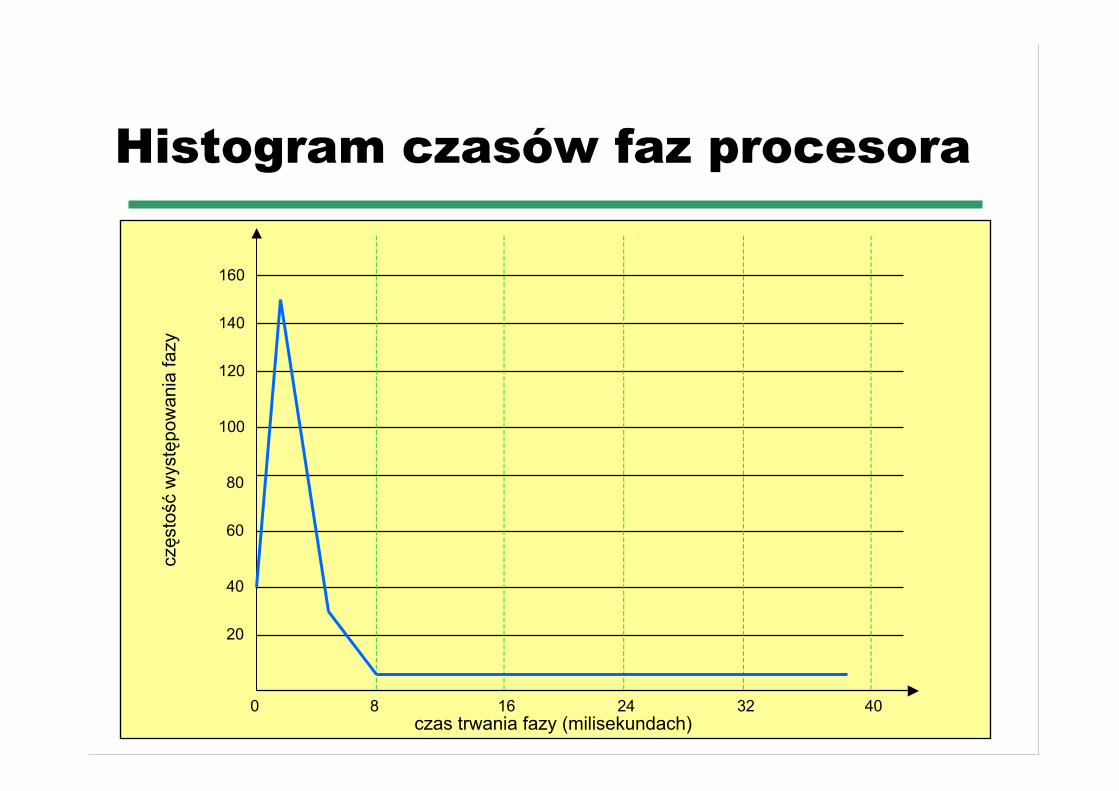
Histogram czasów faz procesora
16 24 32 4080
20
40
60
80
100
120
140
160
czas trwania fazy (milisekundach)
czę
stość
wys
tępo
wan
ia fa
zy

Planista przydziału procesora
☛ Planista (krótkoterminowy) przydziału procesora(ang. CPU scheduler) wybiera jeden processpośród przebywających w pamięci procesówgotowych do wykonania i przydziela mu procesor
☛ Decyzje o przydziale procesora podejmowane są1. gdy proces przeszedł od stanu aktywności do czekania (np. z
powodu we/wy)2. gdy proces przeszedł od stanu aktywności do gotowości (np.
wskutek przerwania)3. gdy proces przeszedł od stanu czekania do gotowości (np. po
zakończeniu we/wy)4. gdy proces kończy działanie
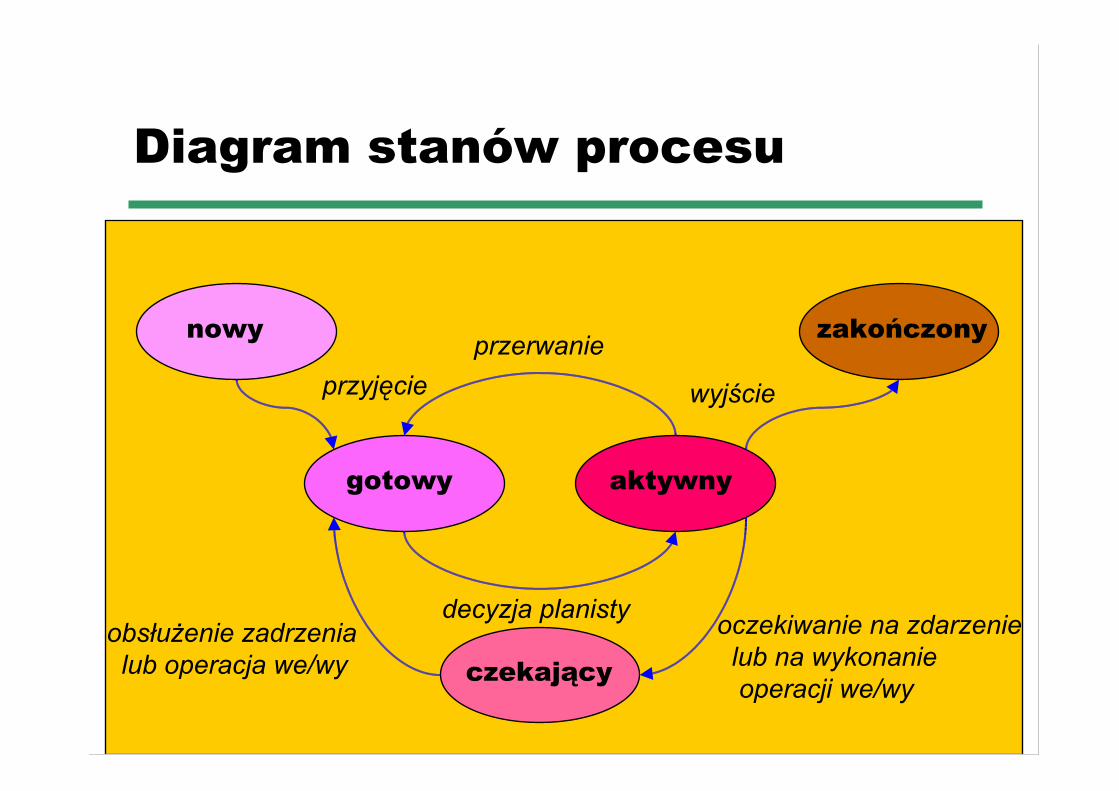
Diagram stanów procesu
nowy
gotowy aktywny
zakończony
czekający
przerwanieprzyjęcie wyjście
decyzja planistyobsłużenie zadrzenia lub operacja we/wy
oczekiwanie na zdarzenie lub na wykonanie operacji we/wy

Planista przydziału procesora(c.d.)
☛ Planowanie w sytuacji 1 i 4 nazywamyniewywłaszczeniowym (ang. nonpreemptive)
☛ Każde inny algorytm planowania nazywamywywłaszczeniowym (ang. preemptive)
☛ Planowanie bez wywłaszczeń : proces, któryotrzyma procesor, zachowuje go tak długo ażnie odda go z powodu przejścia w stanoczekiwania lub zakończenia (nie wymagazegara)☛ użyta w systemie Windows 3.1 i Apple Macintosh

Planista przydziału procesora(c.d.)
☛ Planowanie wywłaszczające: drogie i ryzykowne☛ Co się stanie gdy wywłaszczony zostanie proces
w trakcie wykonywania funkcji systemowej (np.zmiany danych w blokach opisu kolejki we/wy)?
☛ UNIX czeka z przełączeniem kontekstu dozakończenia wywołania systemowego lub dozablokowania procesu na we/wy
☛ Nie można wywłaszczać procesu gdywewnętrzne struktury jądra są niespójne
☛ Blokowanie przerwań przy wejściu doryzykownych fragmentów kodu jądra

Ekspedytor
☛ Ekspedytor (ang. dispatcher) jest modułem,który faktycznie przekazuje procesor dodyspozycji procesu wybranego przez planistękrótkoterminowego; obowiązki ekspedytora to☛ przełączanie kontekstu☛ przełączanie do trybu użytkownika☛ wykonanie skoku do odpowiedniej komórki w programie
użytkownika w celu wznowienia działania programu
☛ Opóźnienie ekspedycji (ang. dispatch latency) toczas, który ekspedytor zużywa na wstrzymaniejednego procesu i uaktywnienie innego

Kryteria planowania
☛ Definicje☛ Wykorzystanie procesora - procesor musi być nieustannie
zajęty pracą☛ powinno się mieścić od 40% (słabe obciążenie systemu) do
90% (intensywna eksploatacja)
☛ Przepustowość (ang. throughput) - liczba procesówkończących w jednosce czasu: długie procesy 1 nagodzinę, krótkie - 10 na sekundę
☛ Czas cyklu przetwarzania (ang. turnaround time) – czasmiędzy nadejściem procesu do systemu a chwilą jegozakończenia: suma czasów czekania na wejście dopamięci, czekania w kolejce procesów gotowych,wykonywania we/wy, wykonania (CPU)

Kryteria planowania (c.d.)
☛ Czas oczekiwania - suma okresów, w których proces czekaw kolejce procesów gotowych do działania
☛ Czas odpowiedzi (ang. response time) - ilość czasu międzywysłaniem żądania a pojawieniem się odpowiedzi (bezczasu potrzebnego na wyprowadzenie odpowiedzi np. naekran). Czas odpowiedzi jest na ogół uzależniony odszybkości działania urządzenia wyjściowego

Kryteria optymalizacji
☛ Maksymalne wykorzystanie procesora☛ Maksymalna przepustowość☛ Minimalny cykl przetwarzania☛ Minimalny czas oczekiwania☛ Minimalny czas odpowiedzi
☛ minimalizowanie wariancji czasu odpowiedzi☛ mało algorytmów minimalizujących wariancję☛ pożądany system z sensownym i przewidywalnym czasem
odpowiedzi

Planowanie metodą FCFS☛ Pierwszy zgłoszony, pierwszy obsłużony (ang.
first-come, first-served - FCFS)☛ Implementuje się łatwo za pomocą kolejek FIFO
- blok kontrolny procesu dołączany na konieckolejki, procesor dostaje PCB z czoła kolejki
☛ Przykład: Proces Czas trwania fazy P1 24 P2 3 P3 3
☛ Przypuśćmy, że procesy nadejdą w porządku:P1 , P2 , P3

Planowanie metodą FCFS (c.d.)
☛ Diagram Gantta dla FCFS
☛ Czas oczekiwania dla P1 = 0; P2 = 24; P3 = 27☛ Średni czas oczekiwania: (0 + 24 + 27)/3 = 17
milisekund
P1 P2 P3
24 27 300

Planowanie metodą FCFS (c.d.)
☛ Przypuśćmy, że procesy nadejdą w porządkuP2 , P3 , P1
☛ Diagram Gantta
☛ Czas oczekiwania dla P1 = 6; P2 = 0; P3 = 3☛ Średni czas oczekiwania (6 + 0 + 3)/3 = 3☛ Średni czas oczekiwania znacznie lepszy☛ Dlaczego?
P2 P3 P1
0 3 6 30

Planowanie metodą FCFS (c.d.)
☛ Założmy, ze mamy jeden proces P ograniczonyprzez procesor i wiele procesów ograniczonychprzez we/wy (Q,R,..)☛ proces P uzyskuje procesor i procesy Q,.. kończą we/wy☛ urządzenia we/wy są bezczynne☛ proces P kończy swoją fazę procesora, procesy Q,...
zadziałają szybko (mają krotkie fazy procesora bo sąograniczone przez we/wy)
☛ proces P uzyskuje procesor, procesy Q,.. kończą we/wy...
☛ Efekt konwoju (ang. convoy effect) - procesyczekają aż wielki proces odda procesor

Planowanie metodą FCFS (c.d.)
☛ Algorytm FCFS jest niewywłaszczający☛ Proces utrzymuje procesor do czasu aż zwolni
go wskutek zakończenia lub zamówi operacjęwe/wy
☛ Algorytm FCFS jest kłopotliwy w systemach zpodziałem czasu bowiem w takich systemachważne jest uzyskiwanie procesora w regularnychodstępach czasu

Planowanie metodą SJF
☛ Algorytm napierw najkrótsze zadanie (ang. shortest-job-first - SJF) wiąże z każdym procesem długośćjego najbliższej z przyszłych faz procesora. Gdyprocesor staje się dostępny wówczas zostajeprzydzielony procesowi o najkrótszej następnejfazie (gdy fazy są równe to mamy FCFS)
☛ Algorytm może być☛ wywłaszczający - SJF usunie proces jeśli nowy proces w
kolejce procesów gotowych ma krótszą następną fazę procesoraod czasu do zakończenia procesu; metoda najpierw najkrótszypozostały czas (ang. shortest-remaining-time-first - SRTF)
☛ niewywłaszczający - pozwól procesowi zakończyć

SJF niewywłaszczający
Proces Czas trwania fazyP1 6P2 8P3 7
P4 3☛ SJF (niewywłaszczający)
☛ Średni czas oczekiwania:☛ (3 + 16 + 9 + 0)/4 = 7
P1 P3 P2P4
0 3 9 16 24

SJF wywłaszczający
Proces Czas przybycia Czas trwania fazy P1 0 8
P2 1 4 P3 2 9 P4 3 5
☛ SRTF
☛ Średni czas oczekiwania:☛ ((10-1) + (1-1) + (17-2) + (5-3))/4 = 26/4=6.5
P1 P2 P3P4 P1
0 1 5 2610 17

Następna faza procesora
☛ SJF jest optymalny: daje minimalny średni czasoczekiwania
☛ Nie ma sposobu na poznanie długości następnejfazy, możemy ją jedynie oszacować
☛ Można tego dokonać wyliczając średniąwykładniczą poprzednich faz procesora
☛ t(n) = długość n-tej fazy procesora☛ s(n+1) = przewidywana długość nast. fazy☛ a - liczba z przedziału [0,1], zwykle 0.5☛ Definiujemy s(n+1) = a*t(n) + (1-a)*s(n)

Następna faza procesora (c.d.)
☛ a=0☛ s(n+1) = s(n)☛ niedawna historia nie ma wpływu
☛ a=1☛ s(n+1) = t(n)☛ jedynie najnowsze notowanie długości fazy ma wpływ
☛ Jeśli rozwiniemy wzór to s(n+1) = a*t(n) +(1-a)*a*t(n-1) + .... (1-a)^j*a*t(n-j) + ..... ..+(1-a)^(n+1)*s(0)
☛ Ponieważ a i (1-a) są mniejsze od 1 to każdynastępny składnik ma mniejszą wagę
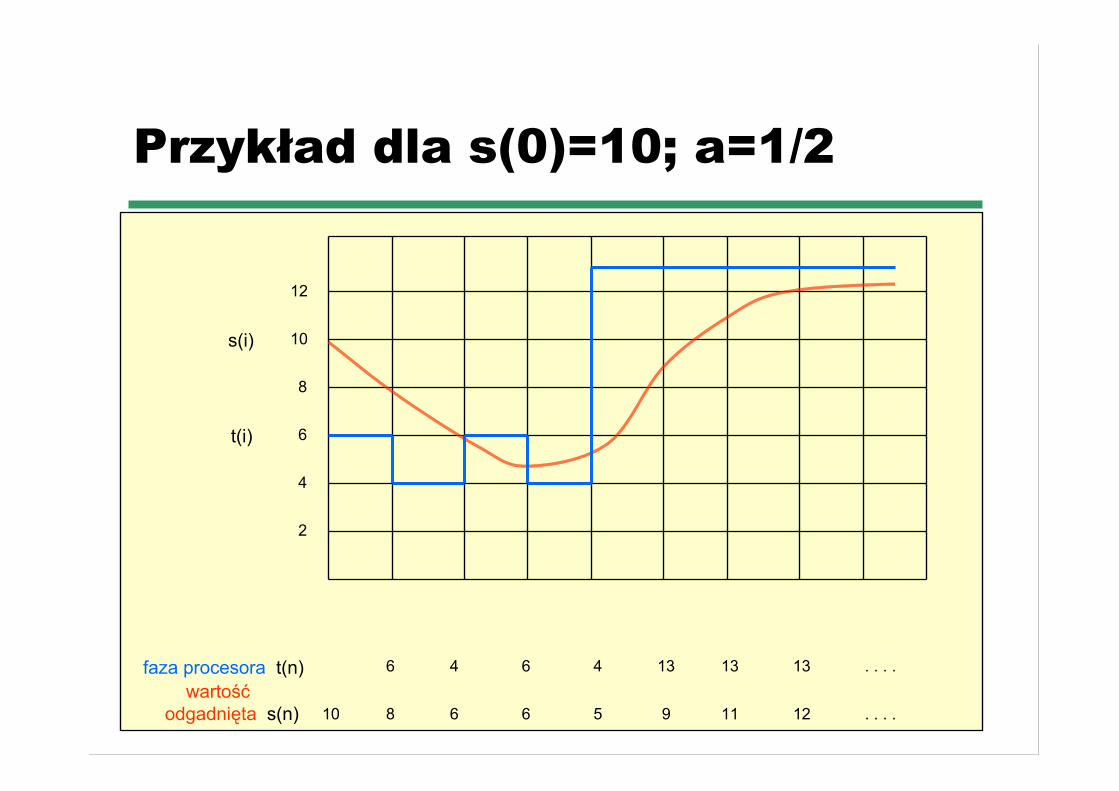
Przykład dla s(0)=10; a=1/2
6 4 6 4 13 13 13 . . . .
8
2
4
6
10
12
8 6 6 5 9 11 12 . . . .
faza procesora t(n) wartość odgadnięta s(n)
t(i)
s(i)
10

Planowanie priorytetowe
☛ SJF jest przykładem planowania priorytetowego(ang. priority scheduling) w którym każdemuprocesowi przypisuje się priorytet (liczbę)
☛ Priorytety należą do pewnego skończonegopodzbioru liczb naturalnych np. [0..7], [0,4095]
☛ nice {+|- n} polecenie☛ Procesor przydziela się procesowi o najwyższym
priorytecie (jeśli równe - FCFS)☛ wywłaszczające☛ niewywłaszczające
☛ SJF - priorytet jest odwrotnością następnej fazy

Przykład: 0 - najwyższy priorytet
Proces Czas trwania fazy PriorytetP1 10 3P2 1 1P3 2 4
P4 1 5 P5 5 2
☛ średni czas oczekiwania:☛ (6 + 0 + 16 + 18 + 1)/5 = 41/5 = 8.2
P2 P3P1 P4
0 1 6 16 19
P5
18

Planowanie priorytetowe
☛ Problem: nieskończone zablokowanie (ang.indefinite blocking) lub głodzenie (ang. starvation)- procesy o małym priorytecie mogą nigdy niedostać czasu procesora
☛ W 1973 r. w wycofywanym w MIT z eksploatacjiIBM 7094 wykryto zagłodzony niskopriorytetetowyproces przedłożony do wykonania w 1967 r.
☛ Rozwiązanie: postarzanie (ang. aging) polegającena podwyższeniu priorytetu procesów oczekującychjuż zbyt długo

Planowanie rotacyjne
☛ Planowanie rotacyjne (ang. round-robin - RR,time-slicing) zaprojektowano dla systemów zpodziałem czasu
☛ Każdy proces otrzymuje małą jednostkę czasu,nazywaną kwantem czasu (ang. time quantum,time slice) zwykle od 10 do 100 milisekund. Gdyten czas minie proces jest wywłaszczany iumieszczany na końcu kolejki zadań gotowych(FCFS z wywłaszeniami)

Planowanie rotacyjne (c.d.)
☛ Jeśli jest n procesów w kolejce procesówgotowych a kwant czasu wynosi q to każdyproces otrzymuje 1/n czasu procesora porcjamiwielkości co najwyżej q jednostek czasu.
☛ Każdy proces czeka nie dłużej niż (n-1)*qjednostek czasu
☛ Wydajność algorytmu☛ gdy q duże to RR przechodzi w FCFS☛ gdy q małe to mamy dzielenie procesora (ang. processor
sharing) ale wtedy q musi być duże w stosunku doprzełączania kontekstu (inaczej mamy spowolnienie)
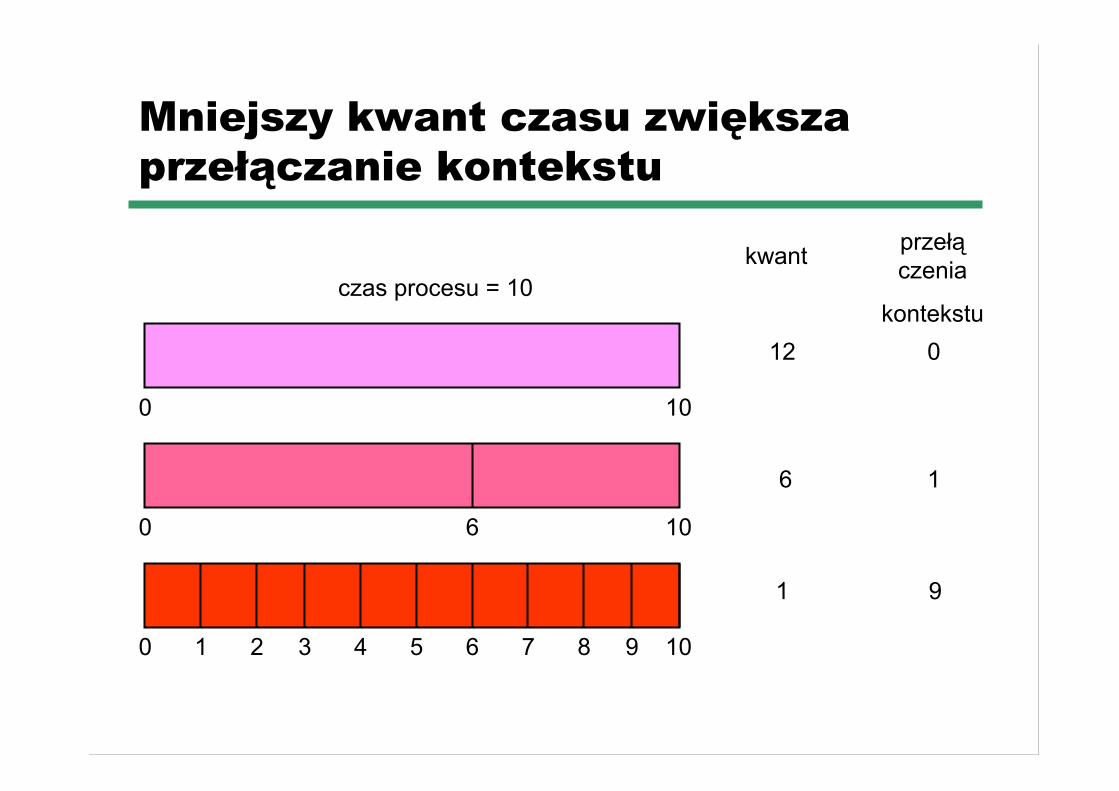
Mniejszy kwant czasu zwiększaprzełączanie kontekstu
10
10
10
czas procesu = 10
0
0
0
6
1 2 3 4 5 6 7 8 9
kwant przełączenia
kontekstu12 0
6 1
1 9

Czas cyklu przetwarzania zależyod kwantu czasu
P1
P2
P3
P4
1 2 3 4 5 6 7 8
9.0
9.5
10.0
10.5
11.0
11.5
12.0
12.5
kwant czasu
śre
dni c
zas
cykl
u pr
zetw
arza
nia 6
3
1
7
czas proces

RR - średni czas cykluprzetwarzania z kwantem = 6
Proces Czas trwania fazyP1 6
P2 3P3 1P4 7
☛ Diagram Gantta
☛ Średni czas cyklu przetwarzania ☛ (6+9+10+17)/4=42/4=10,5
0
P1 P2 P3 P4
6 9 10 17
P4
16

RR - średni czas cykluprzetwarzania z kwantem = 5
Proces Czas trwania fazyP1 6
P2 3P3 1P4 7
☛ Diagram Gantta
☛ Średni czas cyklu przetwarzania ☛ (15+8+9+17)/4=49/4=12,25
0
P1 P2 P3 P4
5 8 9 17
P4P1
14 15

Wielopoziomowe planowaniekolejek
☛ Wielopoziomowe planowanie kolejek (ang.mulitilevel queue scheduling ) polega na tym, żekolejka procesów gotowych zostaje podzielonana oddzielne (pod)kolejki☛ procesy pierwszoplanowe (ang. foreground) - interakcyjne☛ procesy drugoplanowe (ang. background) - wsadowe
☛ Każda z kolejek ma swój własny algorytmszeregujący☛ pierwszoplanowa - RR☛ drugoplanowa - FCFS

Wielopoziomowe planowaniekolejek (c.d.)
☛ Między kolejkami także należy dokonać wyborualgorytmu planowania☛ planowanie priorytetowe tzn. obsłuż najpierw wszystkie
procesy pierwszoplanowe potem drugoplanowe -możliwość zagłodzenia procesu drugoplanowego
☛ porcjowanie czasu (ang. time slice) - każda kolejkaotrzymuje pewną porcję czasu procesora, któryprzydzielany jest każdej z kolejek np.
☛ 80% kolejka pierwszoplanowa z algorytmem RR☛ 20% kolejka drugoplanowa z algorytmem FCFS
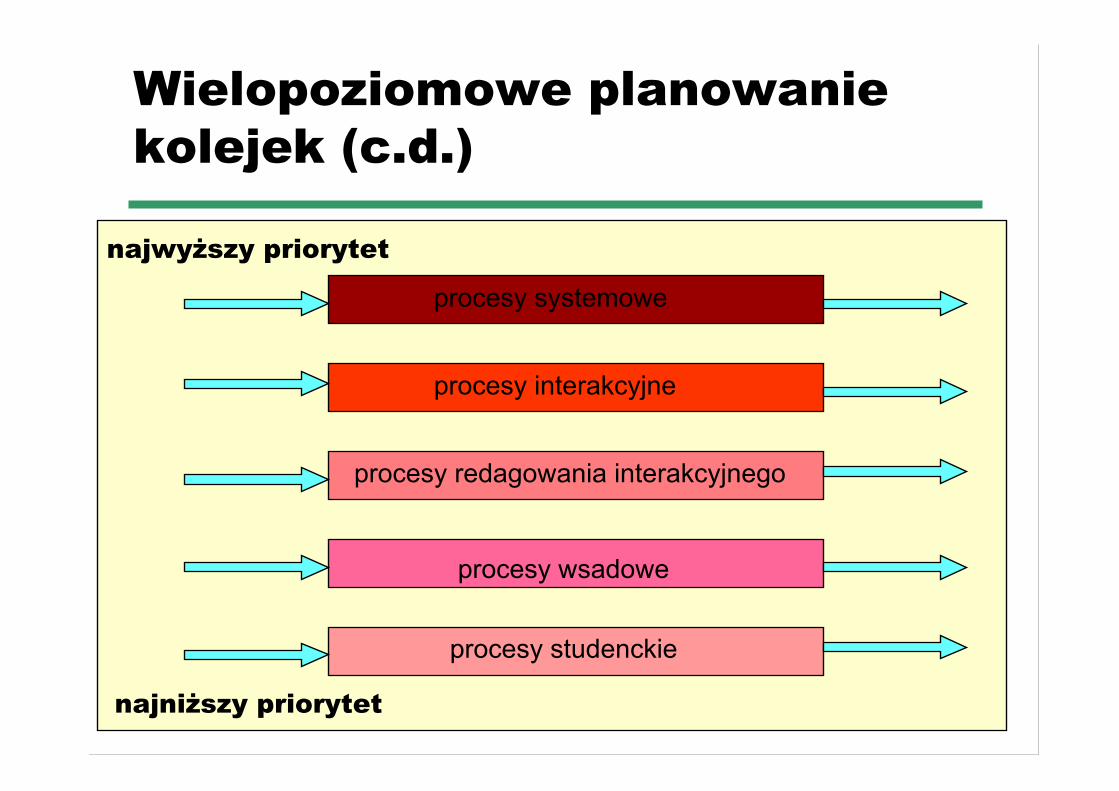
Wielopoziomowe planowaniekolejek (c.d.)
najniższy priorytet
najwyższy priorytet
procesy systemowe
procesy interakcyjne
procesy redagowania interakcyjnego
procesy wsadowe
procesy studenckie

Kolejki wielopoziomowe zesprzężeniem zwrotnym
☛ Kolejki wielopoziomowe z sprzężeniem zwrotnym(ang. multilevel feedback queue scheduling)umożliwiają przesuwanie procesów między kolejkami
☛ Proces, który zużywa za dużo procesora możnazdymisjonować poprzez przesunięcie go do kolejki oniższym priorytecie i dzięki temu zapobieczagłodzeniu innych procesów
☛ Postępowanie takie prowadzi do pozostawieniaprocesów ograniczonych przez we/wy orazinterakcyjnych w kolejkach o wyższych priorytetach
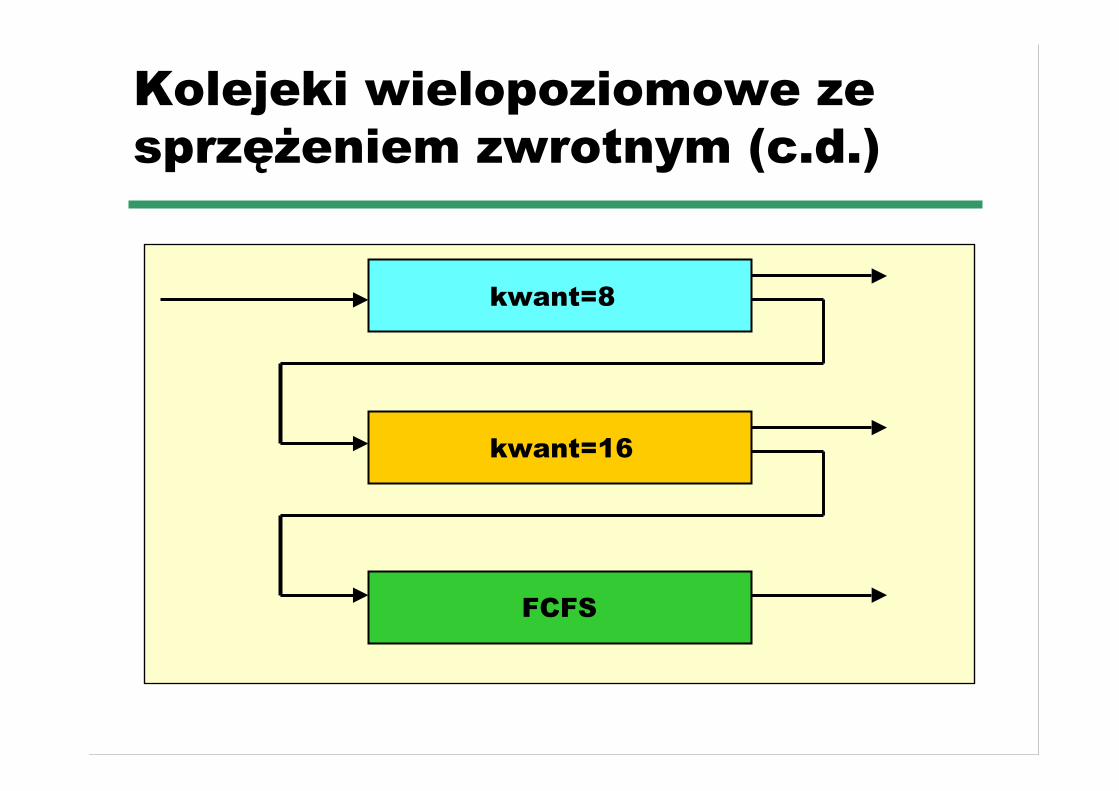
Kolejeki wielopoziomowe zesprzężeniem zwrotnym (c.d.)
kwant=8
kwant=16
FCFS

Kolejeki wielopoziomowe zesprzężeniem zwrotnym (c.d.)
☛ Trzy koleki:☛ Q0 – kwant czasu 8 milisekund☛ Q1 – kwant czasu 16 milisekund☛ Q2 – FCFS
☛ Planowanie☛ nowe zadanie wchodzi do kolejki Q0 obsługiwanej przez
FCFS. Zadanie dostaje 8 milisekund i jeśli się nie zmieściw tym czasie zostaje przeniesione na koniec kolejki Q1
☛ W kolejce Q1 zadanie jest znów obsługiwane przezalgorytm FCFS i dostaje dodatkowe 16 milisekund. Jeśliponownie nie zmieści się w tym czasie zostaje wywłaszonedo kolejki Q2

Kolejki wielopoziomowe zesprzężeniem zwrotnym (c.d.)
☛ Algorytm ten daje najwyższy priorytet procesomo fazie nie większej niż 8ms, procesy o faziemiędzy 8ms i 24ms są także szybkoobsługiwane; długie procesy wchodzą do kolejki2 i są obsługiwane (FCFS) w cyklach pracyprocesora nie wykorzystanych przez procesy zkolejek 0 i 1
☛ Planowanie ze sprzężeniem zwrotnym jestnajogólniejszym i najbardziej złożonymalgorytmem planowania przydziału procesora

Kolejeki wielopoziomowe zesprzężeniem zwrotnym (c.d.)
☛ Planista wielopoziomowych kolejek zesprzężeniem zwrotnym jest określony zapomocą następujących parametrów☛ liczba kolejek☛ algorytm planowania dla każdej kolejki☛ metody użytej do decydowania o awansowaniu (ang.
upgrade) procesu do kolejki o wyższym priorytecie☛ metody użytej do decydowania o zdymisjonowaniu (ang.
demote) procesu do kolejki o niższym priorytecie☛ metody wyznaczenia kolejki, do której trafia proces
potrzebujący obsługi

Planowanie wieloprocesorowe☛ Planowanie wieloprocesorowe (ang. multiple-
processor scheduling) komplikuje się wraz zewzrostem liczby procesorów i ich architektury
☛ Wypróbowano wiele metod planowania i nieznaleziono najlepszej
☛ Procesory mogą być homogeniczne (identyczne)lub heterogeniczne (różne)
☛ Planowanie wieloprocesorowe heterogeniczne -na danym procesorze można wykonaćprogramy, które zostały przetłumaczone naodpowiadający mu zbiór rozkazów; sieciowesystemy operacyjne

Planowanie wieloprocesorowe(c.d.)
☛ Planowanie wieloprocesorowe homogeniczne☛ dzielenie obciążeń (ang. load sharing) - wspólna kolejka
dla wszystkich procesorów☛ każdy procesor sam planuje swoje działanie, oba operują na
tej samej kolejce procesów gotowych (ryzykowne - wymagabardzo starannego zaprogramowania) - wieloprzetwarzaniesymetryczne
☛ jeden procesor jest nadrzędny (ang. master), innepodporządkowane (ang. slave) - wieloprzetwarzanieasymetryczne (ang. asymmetric multiprocessing)

Planowanie w czasierzeczywistym☛ Rygorystyczne systemy czasu rzeczywistego -
wymóg zakończenia zadania krytycznego wgwarantowanym czasie☛ rezerwacja zasobów (ang. resource reservation)
gwarantujących wykonanie zadania☛ planista odrzuca zadanie jeśli nie może ich zarezerwować
☛ Łagodne systemy czasu rzeczywistego - procesyo decydującym znaczeniu mają priorytet nadsłabiej sytuowanymi☛ priorytety procesów czasu rzeczywistego nie mogą maleć z
upływem czasu☛ można np. zakazać dymisjonowania procesów czasu
rzeczywistego

Planowanie w czasierzeczywistym (c.d.)
☛ opóźnienie ekspediowania procesów do procesora musibyć małe aby proces czasu rzeczywistego nie musiałczekać (Solaris: 100ms (z wywłaszczeniami 2ms))
☛ musimy zezwolić na wywłaszczanie funkcji systemowych☛ poprzez wstawienie w długotrwałych funkcjach systemowych
punktów wywłaszczeń (ang. preemption points)☛ wywłaszczanie całego jądra, struktury danych jądra muszą być
chronione za pomocą mechanizmów synchronizacji (Solaris2)
☛ wysokopriorytetowe procesy nie mogą czekać nazakończenie niskopriorytetowych; sytuacja gdy proceswysokopriorytetowy czeka na zakończenie procesu oniższym priorytetcie nosi nazwę odwrócenia priorytetów(ang. priority inversion)
☛ protokół dziedziczenia priorytetów(ang. priority- inheritance)-w czasie użycia zasobów proces dziedziczy wysoki priorytetu
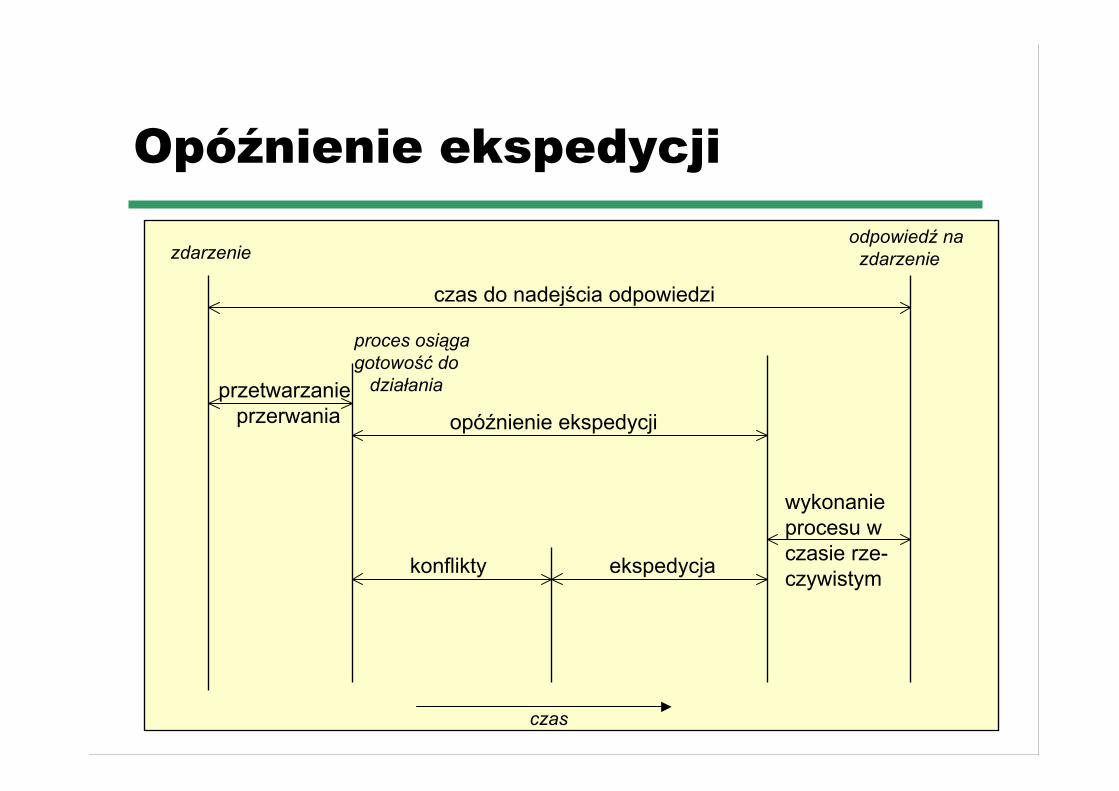
Opóźnienie ekspedycji
czas
konflikty ekspedycja
opóźnienie ekspedycji
wykonanie procesu w czasie rze-czywistym
czas do nadejścia odpowiedzi
przetwarzanie przerwania
proces osiąga gotowość do działania
zdarzenieodpowiedź na zdarzenie

Ocena algorytmów
☛ Modelowanie deterministyczne - przyjmuje siękonkretne, z góry określone obciążenie roboczesystemu i definiuje zachowanie algorytmu wwarunkach tego obciążenia. Jest to odmianaoceny analitycznej (ang. analytic evaluation)☛ dla danego zbioru procesów mających zadane
uporządkowanie i wyrażone w milisekundach fazyprocesora rozważamy algorytmy planowania (FCFS, SJF,RR (o zadanym kwancie czasu) , itp.)
☛ Pytanie: który algorytm minimalizuje czas oczekiwania?

Ocena algorytmów (c.d)
☛ Modelowanie deterministyczne jest proste iszybkie, daje konkretne liczby pozwalającedokonać wyboru algorytmu planowania
☛ Modelowanie deterministyczne wymaga jednakspecyficznych sytuacji i dokładnej wiedzydlatego nie zasługuje na miano ogólnieużytecznego

Zadanie - przykład
Proces Czas trwania fazyP1 f1
P2 f2P3 f3P4 f4P5 f5
☛ Zakładając, że wszystkie procesy przybyły wchwili 0, porównać algorytmy FCFS, SJF i RR(kwant = q ) metodą deterministyczną

Ocena algorytmów (c.d.)
☛ Modele obsługi kolejek - analiza obsługi kolejekw sieciach(ang. queueing-network analysis)☛ Wzór Little’a: n = l*W - liczba procesów opuszczających
kolejkę musi się równać liczbie procesów przychodzących☛ n - średnia długość kolejki☛ W - średni czas oczekiwania w kolejce☛ l - ilość nowych procesów na sekundę
☛ Symulacja sterowana rozkładami☛ ma ograniczoną dokładność☛ taśma śladów zdarzeń rzeczywistego systemu może
poprawić dokładność
☛ Implementacja - kosztowna ale dokładna ocena
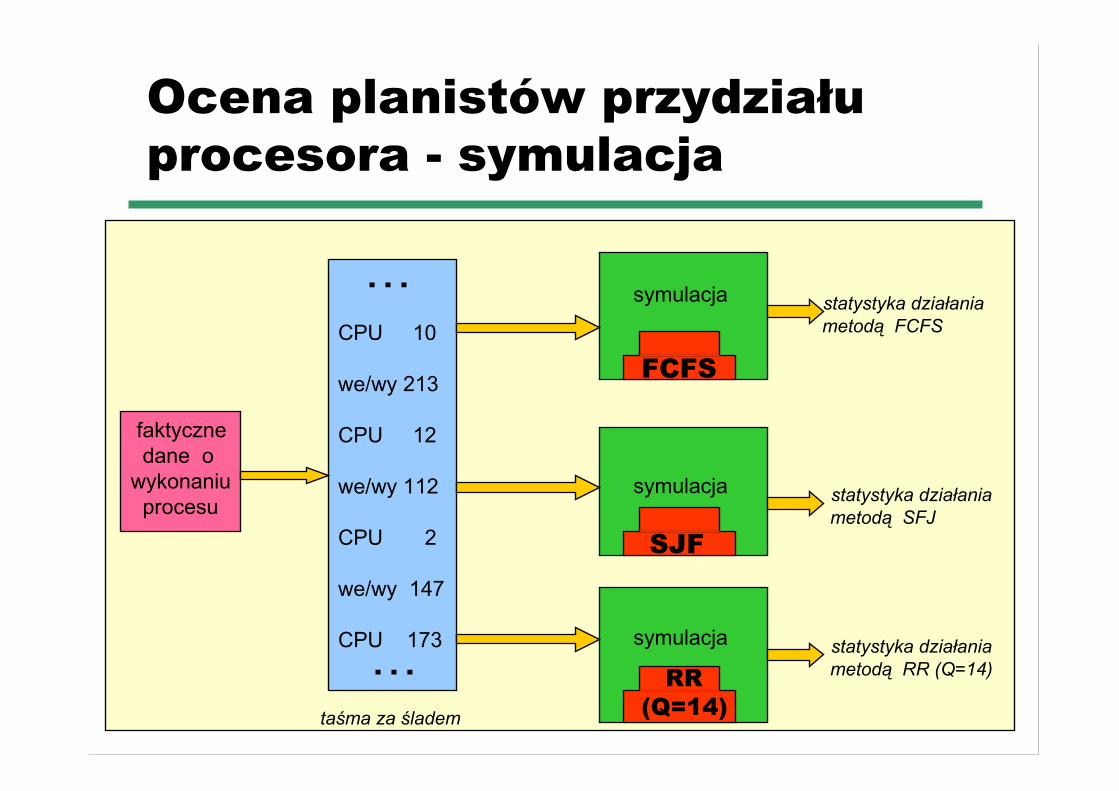
Ocena planistów przydziałuprocesora - symulacja
. . .
CPU 10 we/wy 213 CPU 12 we/wy 112 CPU 2 we/wy 147 CPU 173 . . .
symulacja
symulacja
symulacja
faktyczne dane o wykonaniu procesu
FCFS
SJF
RR (Q=14)
statystyka działania metodą RR (Q=14)
statystyka działania metodą SFJ
statystyka działania metodą FCFS
taśma za śladem

Przykład: Solaris 2
☛ 4 klasy: real time, system, time sharing, interactive☛ Priorytet globalny i priorytety w obrębie klas☛ Proces potomny dziedziczy klasę i priorytet☛ Klasa domyślna time sharing
☛ wielopoziomowe kolejki ze sprzężeniem zwrotnym☛ większy priorytet <-> mniejszy kwant czasu
☛ Klasa interactive:większy priorytet dla aplikacji X-ów☛ Klasa system - procesy jądra
☛ proces działa, aż zostanie zablokowany lub wywłaszczony
☛ Wątki o tym samym priorytecie - planowanie RR

Przykłady poleceń w Solaris 2
☛ vmstat licznik [przedział]☛ licznik - liczba raportów☛ przedział - przerwa między raportami (w sek.)
☛ vmstat 5 4☛ r - ilość działających procesów czekających na CPU☛ cs - ilość przełączeń kontekstu☛ us - procent cykli CPU w trybie użytkownika☛ sy - procent cykli CPU w trybie jądra☛ id - procent niewykorzystanych cykli CPU
☛

Przykłady poleceń w Solaris 2(c.d.)
☛ dispadmin -l☛ dispadmin -g -c TS
☛ ts_quantum - kwant czasu☛ ts_tqexp - nowy priorytet po wykorzystaniu czasu☛ ts_slpret - nowy priorytet po wyjściu z uśpienia☛ ts_maxwait - maksymalny czas pozostawania gotowym☛ ts_lwait - nowy priorytet po przekroczeniu ts_maxwait
☛ priocntl -d -i all

Przykład: Windows 2000
☛ Planowanie priorytetowe z wywłaszczeniami☛ Wątek jest wykonywany aż zostanie wywłaszczony
przez proces o wyższym priorytecie, zakończy,zużyje kwant czasu, wykona blokujące wywołaniesystemowe (np. we/wy)
☛ 32 priorytety(kolejki procesów), 6 klas priorytetów,7 relatywnych priorytetów w obrębie klas (API)
☛ NORMAL - priorytet domyślny w klasie☛ Proces wybrany na ekranie ma zwiększany trzy
razy kwant czasu

Podsumowanie (1)
☛ Planowanie przydziału procesora polega napodjęciu decyzji co do wyboru procesu z kolejkiprocesów gotowych
☛ Przydziału procesora do wybranego procesudokonuje ekspedytor
☛ Najprostszy algorytm to „pierwszy lepszy” FCFS☛ Optymalny algorytm (tj. dający najkrótszyśredni czas oczekiwania) to „najkrótszynajlepszy” SJF

Podsumowanie (2)
☛ W systemach z podziałem czasunajodpowiedniejsze jest planowanie rotacyjne,które każdemu z procesów w kolejce procesówgotowych przydziela jednakowy kwant czasu☛ problem: wybór kwantu czasu
☛ kwant za duży mamy FCFS☛ kwant za mały wtedy zbyt częste przełączanie kontekstu
☛ Algorytm RR jest wywłaszczający, FCFS niejest, SJF może być taki i taki

Podsumowanie (3)
☛ Algorytmy wielopoziomowego planowaniakolejek pozwalają na używanie różnychalgorytmów dla różnych klas kolejek☛ pierwszoplanowa kolejka procesów interakcyjnych (RR)☛ drugoplanowa kolejka wsadowa (FCFS)☛ przemieszczanie procesów w kolejkach ze sprzężniem
☛ Metody pomagające wybierać właściwealgorytmy planowania kolejek☛ analityczne do określania wydajności algorytmu☛ symulacyjne pozwalające określić zachowanie procesu na
reprezentatywnych próbkach procesów☛ implementacja (kosztowna)





























