
Compiler ConstructionRegular expressions
Scanning
Gorel Hedin
Reviderad 2013–01–23.a
2013
Compiler Construction 2013 F02-1
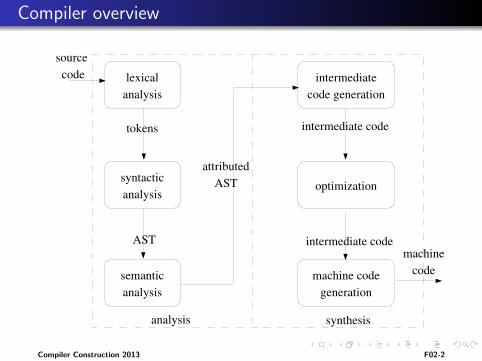
Compiler overview
lexicalanalysis
syntacticanalysis
semanticanalysis
intermediatecode generation
machine codegeneration
optimization
AST
source code
machinecode
tokens intermediate code
intermediate code
attributedAST
analysis synthesis
Compiler Construction 2013 F02-2

Compiler phases
scannersource code
tokens
parser
AST builder
parse tree
AST
regular expressions
contextfree grammar
(implicit)
(explicit)
lexical analysis
syntactic analysis
Compiler Construction 2013 F02-3

Typical tokens
example lexemes
Reserved words(keywords)
Identifiers
Literals
Operators
Separators
Compiler Construction 2013 F02-4

Typical tokens
example lexemes
Reserved words if then else begin(keywords)
Identifiers i alpha k10
Literals 123 3.1416 ’A’ “text”
Operators + ++ !=
Separators ; , (
Compiler Construction 2013 F02-5

Non-tokens
example lexemes
whitespace
comments
Compiler Construction 2013 F02-6

Non-tokens
example lexemes
whitespace ’ ’ tab newline formfeed
comments /* comment */ //eol comment
Compiler Construction 2013 F02-7

Formal languages
An alphabet, Σ, is a set of symbols. (Nonempty and finite)
A string is a sequence of symbols. (Each string is finite)
A formal language, L, is a set of strings. (Can be infinite)
We would like to have rules or algorithms for deciding if a certainstring over the alphabet belongs to the language or not.
Compiler Construction 2013 F02-8

Formal languages
An alphabet, Σ, is a set of symbols. (Nonempty and finite)
A string is a sequence of symbols. (Each string is finite)
A formal language, L, is a set of strings. (Can be infinite)
We would like to have rules or algorithms for deciding if a certainstring over the alphabet belongs to the language or not.
Compiler Construction 2013 F02-8

Example: Languages over binary numbers
Suppose we have the alphabet Σ = {0, 1}
Example languages:
The set of all possible combinations of zeros and ones:L0 = {0, 1, 00, 01, 10, 11, 000, ...}All binary numbers without unnecessary leading zeros:L1 = {0, 1, 10, 11, 100, 101, 110, 111, 1000, ...}All binary numbers with two digits:L2 = {00, 01, 10, 11}...
Compiler Construction 2013 F02-9

Example: Languages over UNICODE
Here, the alphabet Σ is the set of UNICODE characters
Example languages:
All possible Java keywords: {”class”, ”import”, public”, ...}All possible lexemes corresponding to Java tokens.
All possible lexemes corresponding to Java whitespace.
All binary numbers
...
Compiler Construction 2013 F02-10

Example: Languages over Java tokens
Here, the alphabet Σ is the set of Java tokens
Example languages:
All syntactically correct Java programs
All that are syntactically incorrect
All that are compile-time correct
All that terminate
(undecidable)
...
Compiler Construction 2013 F02-11

Example: Languages over Java tokens
Here, the alphabet Σ is the set of Java tokens
Example languages:
All syntactically correct Java programs
All that are syntactically incorrect
All that are compile-time correct
All that terminate (undecidable)
...
Compiler Construction 2013 F02-11

Defining languages using rules
Increasingly powerful:
Regular expressions
Context-free grammars
Attribute grammars
Compiler Construction 2013 F02-12

Regular expressions (core notation)
RE read is called
a a symbol
M | N M or N alternative
M N M followed by N concatenation
ε the empty string epsilon
M∗ zero or more M repetition (Kleene star)
(M)
where a is a symbol in the alphabet (e.g., {0, 1} or UNICODE)and M and N are regular expressions
Each regular expression defines a language over the alphabet(a set of strings that belong to the language).
Priorities: M | N P∗ = M | (N (P∗))
Compiler Construction 2013 F02-13

Example
a | b c∗
means
{a, b, bc, bcc, bccc, ...}
Compiler Construction 2013 F02-14

Example
a | b c∗
means
{a, b, bc, bcc, bccc, ...}
Compiler Construction 2013 F02-14
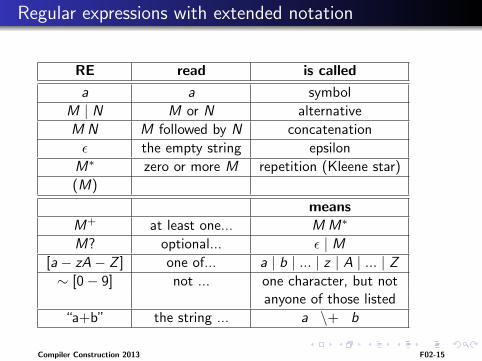
Regular expressions with extended notation
RE read is called
a a symbol
M | N M or N alternative
M N M followed by N concatenation
ε the empty string epsilon
M∗ zero or more M repetition (Kleene star)
(M)
meansM+ at least one... MM∗
M? optional... ε | M[a− zA− Z ] one of... a | b | ... | z | A | ... | Z∼ [0− 9] not ... one character, but not
anyone of those listed
“a+b” the string ... a \+ b
Compiler Construction 2013 F02-15

Exercise
Write a regular expression that defines the language of all decimalnumbers, like
3.14 0.75 4711 0 ...
But not numbers lacking an integer part. And not numbers with adecimal point but lacking a fractional part. So not numbers like
17. .236 .
Leading and trailing zeros are allowed. So the following numbersare ok:
007 008.00 0.0 1.700
a) Use the extended notation.b) Then translate the expression to the core notation.c) Then write an expression that disallows leading zeros.
Compiler Construction 2013 F02-16

Solution
a)
[0− 9]+ (. [0− 9]+)?
b)
(0 | ... | 9) (0 | ... | 9)∗ (ε | (. ((0 | ... | 9) (0 | ... | 9)∗)))
c)
0 (. [0− 9]+)? | [1− 9] [0− 9]∗ (. [0− 9]+)?
Compiler Construction 2013 F02-17
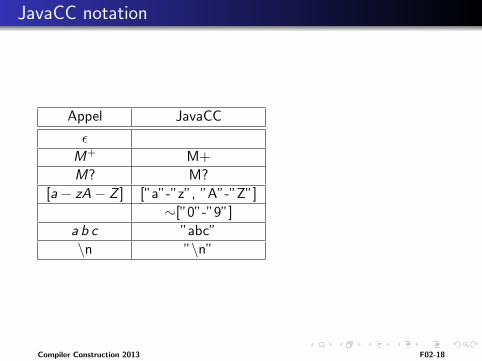
JavaCC notation
Appel JavaCC
ε
M+ M+
M? M?
[a− zA− Z ] [”a”-”z”, ”A”-”Z”]
∼[”0”-”9”]
a b c ”abc”
\n ”\n”
Compiler Construction 2013 F02-18

JavaCC example . . .
/* Skip whitespace */
SKIP : { " " | "\t" | "\n" | "\r" }
/* Reserved words */
TOKEN [IGNORE_CASE]: {
< IF: "if">
| < THEN: "then">
}
/* Identifiers */
TOKEN: {
< ID: (["A"-"Z", "a"-"z"])+ >
}
Compiler Construction 2013 F02-19

. . . JavaCC example
/* Literals */
TOKEN: {
< INT: (["0"-"9"])+ >
}
/* Operators and separators */
TOKEN: {
< ASSIGN: "=" >
| < MULT: "*" >
| < LT: "<" >
| < LE: "<=" >
...
}
Compiler Construction 2013 F02-20

Ambiguous lexical definitions
The scanned text can match tokens in more than one way
Which tokens match ’<=’ ?
Which tokens match ’if’ ?
Compiler Construction 2013 F02-21

Ambiguous lexical definitions
The scanned text can match tokens in more than one way
Which tokens match ’<=’ ?
Which tokens match ’if’ ?
Compiler Construction 2013 F02-21

Extra rules for resolving the ambiguities
Longest match
If one rule can be used to match a token, but there is anotherrule that will match a longer token, the latter rule will bechosen. This way, the scanner will match the longest tokenpossible.
Rule priority
If two rules can be used to match the same sequence ofcharacters, the first one takes priority.
Compiler Construction 2013 F02-22

Extra rules for resolving the ambiguities
Longest match
If one rule can be used to match a token, but there is anotherrule that will match a longer token, the latter rule will bechosen. This way, the scanner will match the longest tokenpossible.
Rule priority
If two rules can be used to match the same sequence ofcharacters, the first one takes priority.
Compiler Construction 2013 F02-22

Implementation of scanners
Finite automata
state
transition
start state
final state
a
1 2 3i f
1 209
09
INT
IF
Compiler Construction 2013 F02-23

More automata
WHITESPACE
ID
Compiler Construction 2013 F02-24

More automata
WHITESPACE
ID
az
az
” ”
\n
\t
1
2
3
4
1 2
Compiler Construction 2013 F02-25

Automaton for the whole language
Combine the automata for individual tokens
merge the start states
re-enumerate the states so they get unique numbers
mark each final state with the token that is matched
Compiler Construction 2013 F02-26

Example 1
Combine IF and INT
Compiler Construction 2013 F02-27

Example 1
1
2 3i
f
409
09
INT
IF
Compiler Construction 2013 F02-28

Example 2
Combine IF and ID
Compiler Construction 2013 F02-29

Example 2
1
2 3i
f
az
az09
ID
IF
4
Compiler Construction 2013 F02-30

Is the automaton deterministic?
Compiler Construction 2013 F02-31

Translating a RE to an NFA
a
MN
M | NM∗
ε
Compiler Construction 2013 F02-32

DFA vs. NFA
Deterministic Finite Automaton (DFA)A finite automaton is deterministic if
all outgoing edges from any given node have disjoint charactersets
there are no ε edges (the empty string)
Can be implemented efficiently
Non-deterministic Finite Automaton (NFA)An NFA may have
two outgoing edges with overlapping character sets
ε-edges
DFA ⊂ NFA
Compiler Construction 2013 F02-33

DFA vs. NFA
Deterministic Finite Automaton (DFA)A finite automaton is deterministic if
all outgoing edges from any given node have disjoint charactersets
there are no ε edges (the empty string)
Can be implemented efficiently
Non-deterministic Finite Automaton (NFA)An NFA may have
two outgoing edges with overlapping character sets
ε-edges
DFA ⊂ NFA
Compiler Construction 2013 F02-33

Each NFA can be translated to a DFA
Simulate the NFA
keep track of a set of current NFA-states
follow ε edges to extend the current set (take the closure)
Construct the corresponding DFA
Each such set of NFA states corresponds to one DFA state
If any of the NFA states are final, the DFA state is also final,and is marked with the corresponding token.
If there is more than one token to choose from, select thetoken that is defined first (rule priority)
(Minimize the DFA for efficiency)
Compiler Construction 2013 F02-34
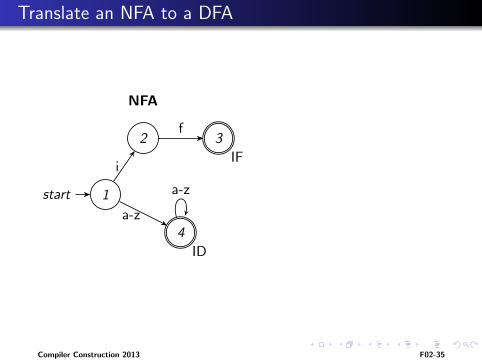
Translate an NFA to a DFA
start 1
2 3
4
i
f
a-z
a-z
IF
ID
NFA
Compiler Construction 2013 F02-35
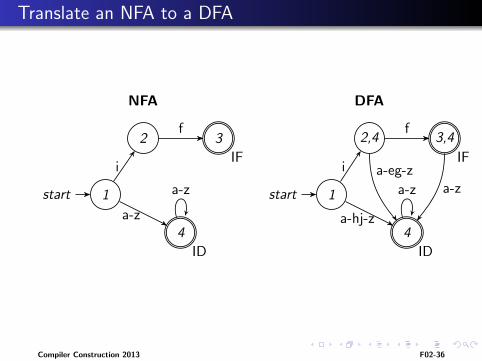
Translate an NFA to a DFA
start 1
2 3
4
i
f
a-z
a-z
IF
ID
NFA
start 1
2,4 3,4
4
i
f
a-eg-za-z
a-hj-z
a-z
IF
ID
DFA
Compiler Construction 2013 F02-36

Construction of a Scanner
Define all tokens as regular expressions
Construct a finite automaton for each token
Combine all these automata to a new automaton (an NFA ingeneral)
Translate to a corresponding DFA
Minimize the DFA
Implement the DFA
Compiler Construction 2013 F02-37

Implementation alternatives for DFAs
Table-driven
Represent the automaton by a table
Additional table to keep track of final states and token kinds
A global variable keeps track of the current state
Switch statements
Each state is implemented as a switch statement
Each case implements a state transition as a jump (to anotherswitch statement).
The current state is represented by the program counter
Compiler Construction 2013 F02-38

Implementation alternatives for DFAs
Table-driven
Represent the automaton by a table
Additional table to keep track of final states and token kinds
A global variable keeps track of the current state
Switch statements
Each state is implemented as a switch statement
Each case implements a state transition as a jump (to anotherswitch statement).
The current state is represented by the program counter
Compiler Construction 2013 F02-38

Error handling
Add a ’dead state’ (state 0), corresponding to erroneous input
Add transitions to the ’dead state’ for all erroneous input
Generate an ’Error token’ when the dead state is reached
Compiler Construction 2013 F02-39

Table-driven implementation
DFA for IF and ID
.. a-e f g-h i j-z .. final kind
true ERROR
1
2,4
3,4
4
Compiler Construction 2013 F02-40

Table-driven implementation
DFA for IF and ID
.. a-e f g-h i j-z .. final kind
0 true ERROR
1 0 4 4 4 2,4 4 0 false
2,4 0 4 3,4 4 4 4 0 true ID
3,4 0 4 4 4 4 4 0 true IF
4 0 4 4 4 4 4 0 true ID
Compiler Construction 2013 F02-41
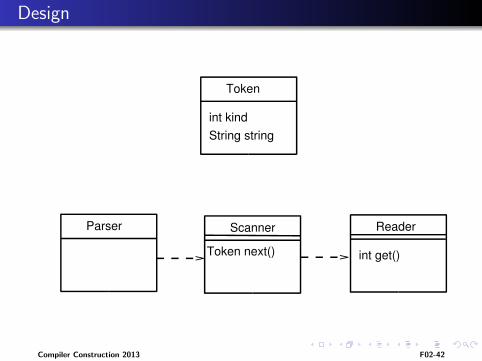
Design
Token
int kindString string
Parser Scanner
Token next()
Reader
int get()
Compiler Construction 2013 F02-42

Scanner (sketch)
class Scanner {
PushbackReader reader;
boolean isFinal [ ];
int edges [ ] [ ];
int kind [ ];
Token next() {
}
}
Compiler Construction 2013 F02-43

Scanner (sketch)
class Scanner { //does not handle:
PushbackReader reader; //longest match
boolean isFinal [ ]; //eof
int edges [ ] [ ]; //whitespace
int kind [ ]; //token strings
Token next() {
int state = 1; //start state
while(!isFinal[state]) {
char ch = reader.read();
state = edges[state][ch];
}
return new Token(kind[state]);
}
}
Compiler Construction 2013 F02-44

Handling End-Of-File (EOF) and non-tokens
EOF
construct an explicit EOF token when the EOF character isread
Non-tokens (Whitespace & Comments)
view as tokens of a special kind
scan them as normal tokens, but don’t create token objectsfor them
loop in next() until a real token has been found
Errors
construct an explicit ERROR token to be returned when novalid token can be found.
Compiler Construction 2013 F02-45

Handling End-Of-File (EOF) and non-tokens
EOF
construct an explicit EOF token when the EOF character isread
Non-tokens (Whitespace & Comments)
view as tokens of a special kind
scan them as normal tokens, but don’t create token objectsfor them
loop in next() until a real token has been found
Errors
construct an explicit ERROR token to be returned when novalid token can be found.
Compiler Construction 2013 F02-45

Handling “longest match”
When a token is matched (a final state reached), don’t stopscanning.
Keep track of the latest matched token in a variable.
Continue scanning until we reach the “dead state”
Restore the input stream. Use PushbackReader to be able todo this.
Return the latest matched token
(or return the ERROR token if there was no latest matchedtoken)
Compiler Construction 2013 F02-46

Scanner with longest match
class Scanner {
...
Token next() {
}
}
Compiler Construction 2013 F02-47

Scanner with longest match
class Scanner { ...
Token next() {
int state = 1, lastFinalState = 0;
int lastFinalStr = "":
StringBuilder builder = new StringBuilder();
while(state!=0) {
char ch = reader.read();
builder.append(ch);
state = edges[state][ch];
if(isFinal[state]) {
lastFinalState = state;
lastFinalStr = builder.toString();
}
}
reader.unread( ... ); //unused characters
return new Token(kind[lastFinalState], lastFinalStr);
}
}Compiler Construction 2013 F02-48
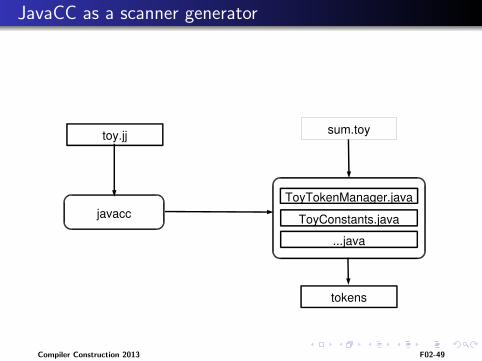
JavaCC as a scanner generator
toy.jj
javacc
sum.toy
ToyTokenManager.javaToyConstants.java
...java
tokens
Compiler Construction 2013 F02-49

Other scanner generators
tool author implementation generates
lex Schmidt, Lesk, 1975 table-driven C code
flex Paxon. 1987 switch statements C code
jlex table-driven Java code
jflex switch statements Java code
Compiler Construction 2013 F02-50

Additional functionality
Lexical actions
extra (Java) code written in the specification
for adapting the generated scanner
e.g., create special token objects, count tokens, keep track ofposition in input text (line and column numbers), etc.
Lexical states (’start states’)
gives the possibility to switch automata during scanning
makes it easier to scan certain tokens, e.g., multi-linecomments
makes it possible to scan certain combined languages, e.g.,HTML
Compiler Construction 2013 F02-51

Additional functionality
Lexical actions
extra (Java) code written in the specification
for adapting the generated scanner
e.g., create special token objects, count tokens, keep track ofposition in input text (line and column numbers), etc.
Lexical states (’start states’)
gives the possibility to switch automata during scanning
makes it easier to scan certain tokens, e.g., multi-linecomments
makes it possible to scan certain combined languages, e.g.,HTML
Compiler Construction 2013 F02-51

Lexcial states, example
Scanning of /* ... */
Compiler Construction 2013 F02-52

Summary questions
What is meant by an ambiguous lexical definition?
Give some typical examples of this and how they may beresolved.
Construct an NFA for a given lexical definition
Construct a DFA for a given NFA
What is the difference between a DFA and an NFA?
Implement a DFA in Java.
How is rule priority handled in the implementation? How islongest match handled? EOF? Whitespace?
Compiler Construction 2013 F02-53

What’s next?
Tomorrow: Seminar 1 (Scanning)
Next week: Parsing and Assignment 1 (Scanning)
Compiler Construction 2013 F02-54
Recommended












![[Lab5]IC Compiler](https://img.pdfslide.tips/doc/110x75/55321dbf5503462d668b4ba7/lab5ic-compiler.jpg)




