
1
Edgar Gabriel
COSC 6385
Computer Architecture
Storage Systems
Edgar Gabriel
Spring 2013
COSC 6385 – Computer Architecture
Edgar Gabriel
I/O problem
• Current processor performance: e.g. Pentium 4
– 3 GHz ~ 6GFLOPS
– Memory Bandwidth: 133 MHz * 4 * 64Bit ~ 4.26 GB/s
• Current network performance:
– Gigabit Ethernet: latency ~ 40 μs, bandwidth=125MB/s
– InfiniBand 4x: latency ~ 4 μs, bandwidth =1GB/s
• Disc performance:
– Latency: 7-12 ms
– Bandwidth: ~20MB/sec – 60 MB/sec

2
COSC 6385 – Computer Architecture
Edgar Gabriel
Basic characteristics of storage
devices • Capacity: amount of data a device can store
• Transfer rate or bandwidth: amount of data at which a device
can read/write in a certain amount of time
• Access time or latency: delay before the first byte is moved
Prefix Abbreviation Base ten Base two
kilo, kibi K, Ki 10^3 2^10=1024
Mega, mebi M, Mi 10^6 2^20
Giga, gibi G, Gi 10^9 2^30
Tera, tebi T, Ti 10^12 2^40
Peta, pebi P, Pi 10^15 2^50
COSC 6385 – Computer Architecture
Edgar Gabriel
UNIX File Access Model (I)
• A File is a sequence of bytes
• When a program opens a file, the file system establishes a
file pointer. The file pointer is an integer indicating the
position in the file, where the next byte will be
written/read.
• Multiple processes can open a file concurrently. Each process
will have its own file pointer.
• No conflicts occur, when multiple processes read the same
file.
• If several processes write at the same location, most UNIX
file systems guarantee sequential consistency. (The data
from one of the processes will be available in the file, but
not a mixture of several processes).

3
COSC 6385 – Computer Architecture
Edgar Gabriel
UNIX File Access Model (II)
• Disk drives read and write data in fixed-sized units (disk sectors)
• File systems allocate space in blocks, which is a fixed number of contiguous disk sectors.
• In UNIX based file systems, the blocks that hold data are listed in an inode. An inode contains the information needed to find all the blocks that belong to a file.
• If a file is too large and an inode can not hold the whole list of blocks, intermediate nodes (indirect blocks) are introduced.
COSC 6385 – Computer Architecture
Edgar Gabriel
Write operations
• Write:
– the file systems copies bytes from the user buffer into system buffer.
– If buffer filled up, system sends data to disk
• System buffering
+ allows file systems to collect full blocks of data before sending to disk
+ File system can send several blocks at once to the disk (delayed write or write behind)
- Data not really saved in the case of a system crash
- For very large write operations, the additional copy from user to system buffer could/should be avoided

4
COSC 6385 – Computer Architecture
Edgar Gabriel
Read operations
• Read:
– File system determines, which blocks contain requested
data
– Read blocks from disk into system buffer
– Copy data from system buffer into user memory
• System buffering:
+ file system always reads a full block (file caching)
+ If application reads data sequentially, prefetching (read
ahead) can improve performance
- Prefetching harmful to the performance, if application
has a random access pattern.
COSC 6385 – Computer Architecture
Edgar Gabriel
File system operations
• Caching and buffering improve performance
– Avoiding repeated access to the same block
– Allowing a file system to smooth out I/O behavior
• Non-blocking I/O gives users control over prefetching
and delayed writing
– Initiate read/write operations as soon as possible
– Wait for the finishing of the read/write operations just
when absolutely necessary.

5
COSC 6385 – Computer Architecture
Edgar Gabriel
Disk striping (I)
• Distribute a large file onto multiple disks
• Stripe factor: number of disks
• Stripe depth: size of each block
COSC 6385 – Computer Architecture
Edgar Gabriel
Disk striping • Requirements for improving disk performance:
– Multiple physical disks
– Separate I/O channels to each disk
– Data transfer to all disks simultaneously
• Problem of simple disk striping:
– Minimum stripe depth (sector size) required for optimal disk performance
• since file size is limited, the number of disks which can be used in parallel is limited as well
– Loss of a single disk makes entire file useless
• Risk to loose a disk is proportional to the number of disks used
• RAID (Redundant Arrays of Independent Disks)

6
COSC 6385 – Computer Architecture
Edgar Gabriel
Concurrent write operations
• How to ensure sequential consistency ?
– File locking
• Prevents parallelism even if processes write to
different locations in the same file (false sharing)
– Better: locking of individual blocks
• Parallel file systems often offer two consistency models
– Sequential consistency
– A relaxed consistency model
• application is responsible for preventing overlapping
write-operations
COSC 6385 – Computer Architecture
Edgar Gabriel
File pointers
• In UNIX: every process has a separate file pointer (individual file pointers)
• Shared file pointers often useful (e.g. reading the next piece of work, writing a parallel log-file)
– On distributed memory machines: slow, since somebody has to coordinate the file pointer
– Can be fast on shared memory machines
– General problems:
• file pointer atomicity
• Non blocking I/O
• Explicit file offset operations: each process tells the file system where to read/write in the file
– no update to file pointers!

7
COSC 6385 – Computer Architecture
Edgar Gabriel
Buffering and caching
• Client buffering: buffering at compute nodes
– Consistency problems (e.g. one node writes, another tries
to read the same data)
• Server buffering: buffering at I/O nodes
– Prevents concatenating several small requests to a single
large one => produces lots of traffic
COSC 6385 – Computer Architecture
Edgar Gabriel
Redundant arrays of independent disks
(RAID) • Central idea:
replicate data over several disks such that no data is lost if a disk fails
• Several RAID levels defined
• RAID 0: disk striping without redundant storage
(“JBOD”= just a bunch of disks)
– No fault tolerance
– Good for high transfer rates
– Good for high request rates
• RAID 1: mirroring
– All data is replicated on two or more disks
– Does not improve write performance and just moderately the read performance

8
COSC 6385 – Computer Architecture
Edgar Gabriel
RAID level 2
• RAID 2: Hamming codes
– Each group of data bits has several check bits appended to it
forming Hamming code words
– Each bit of a Hamming code word is stored on a separate disk
– Very high additional costs: e.g. up to 50% additional capacity
required
• Hardly used today since parity based codes faster and easier
COSC 6385 – Computer Architecture
Edgar Gabriel
RAID level 3 • Parity based protection:
– Based on exclusive OR (XOR)
– Reversible
– Example
01101010 (data byte 1)
XOR 11001001 (data byte 2)
--------------------------------------
10100011 (parity byte)
– Recovery
11001001 (data byte 2)
XOR 10100011 (parity byte)
---------------------------------------
01101010 (recovered data byte 1)

9
COSC 6385 – Computer Architecture
Edgar Gabriel
RAID level 3 (cont.)
• Data divided evenly into N subblocks
(N = number of disks, typically 4 or 5)
• Computing parity bytes generates an additional subblock
• Subblocks written in parallel on N+1 disks
• For best performance data should be of size (N * sector size)
• Problems with RAID level 3:
– All disks are always participating in every operation => contention for applications with high access rates
– If data size is less than N*sector size, system has to read old subblocks to calculate the parity bytes
• RAID level 3 good for high transfer rates
COSC 6385 – Computer Architecture
Edgar Gabriel
RAID level 4
• Parity bytes for N disks calculated and stored
• parity bytes are stored on a separate disk
• Files are not necessarily distributed over N disks
• For read operations:
– Determine disks for the requested blocks
– Read data from these disks
• For write operations
– Retrieve the old data from the sector being overwritten
– Retrieve parity block from the parity disk
– Extract old data from the parity block using XOR operations
– Add the new data to the parity block using XOR
– Store new data
– Store new parity block
• Bottleneck: parity disk is involved in every operation

10
COSC 6385 – Computer Architecture
Edgar Gabriel
RAID level 5
• Same as RAID 4, but parity blocks are distributed on
different disks
Block 1 Block 2 Block 3 Block 4 P(1,2,3,4)
Block 5 Block 6 Block 7 Block 8 P(5,6,7,8)
COSC 6385 – Computer Architecture
Edgar Gabriel
RAID level 6
• Tolerates the loss of more than one disk
• Collection of several techniques
• E.g. P+Q parity: store parity bytes using two different algorithms
and store the two parity blocks on different disks
• E.g. Two dimensional parity
Parity disks
11
COSC 6385 – Computer Architecture
Edgar Gabriel
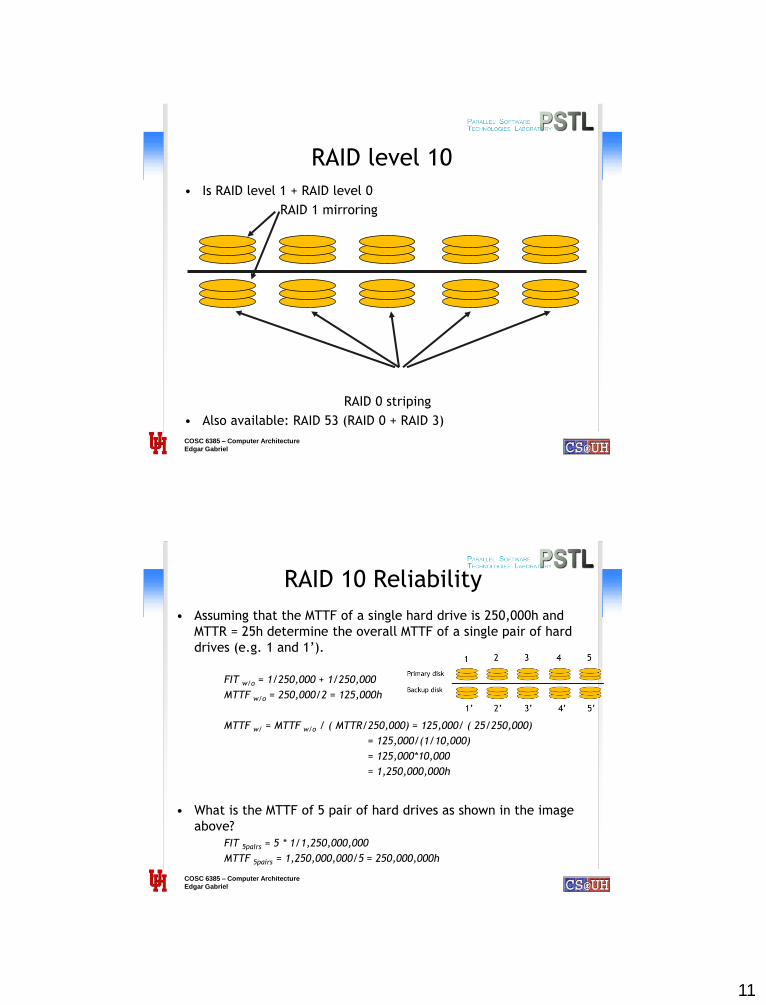
RAID level 10
• Is RAID level 1 + RAID level 0
RAID 1 mirroring
RAID 0 striping
• Also available: RAID 53 (RAID 0 + RAID 3)
COSC 6385 – Computer Architecture
Edgar Gabriel
RAID 10 Reliability
• Assuming that the MTTF of a single hard drive is 250,000h and
MTTR = 25h determine the overall MTTF of a single pair of hard
drives (e.g. 1 and 1’).
FIT w/o = 1/250,000 + 1/250,000
MTTF w/o = 250,000/2 = 125,000h
MTTF w/ = MTTF w/o / ( MTTR/250,000) = 125,000/ ( 25/250,000)
= 125,000/(1/10,000)
= 125,000*10,000
= 1,250,000,000h
• What is the MTTF of 5 pair of hard drives as shown in the image
above?
FIT 5pairs = 5 * 1/1,250,000,000
MTTF 5pairs = 1,250,000,000/5 = 250,000,000h

12
COSC 6385 – Computer Architecture
Edgar Gabriel
RAID 10 vs. RAID 5 • Comparison to a RAID 5 configuration consisting of 5+1 hard drives
• Same data capacity in the overall configuration
FIT 6disks w/o = 6 * 1/250,000
MTTF 6disks w/o = 250,000/6
FIT 5 disks w/o = 5 * 1/250,000
MTTF 5 disks w/o = 250,000/5 = 50,000
MTTF 6 disks RAID5 w/ = MTTF 6dsisk w/o / ( MTTR/(MTTF 5 disks w/o)
= (250,000/6) / (25 / 50,000)
= (250,000/6) / (1/2,000)
= 250,000 * 2,000 / 6
= 250,000 * 1,000 / 3
= 250,000,000 / 3
• RAID 10 has higher MTTF than RAID 5
• Costs of RAID 5 lower than costs of RAID 10 ( 6 drives vs. 10 drives)
Recommended

















