
Escalabilidade Linear com o Banco de Dados NoSQL Apache Cassandra.
Palestrante: Marcio Junior [email protected]

Marcio Junior Vieira
● 16 anos de experiência em informática, vivência em desenvolvimento e análise de sistemas de Gestão empresarial.
● Trabalhando com Software Livre desde 2000 com serviços de consultoria e treinamento.
● Graduado em Tecnologia em Informática(2004) e pós-graduado em Software Livre(2005) ambos pela UFPR.
● Palestrante em diversos Congressos relacionados a Software Livre tais como: CONISLI, SOLISC, FISL, LATINOWARE, SFD, JDBR, Campus Party, Pentaho Day, TDC.
● Organizador Geral do Pentaho Day 2015 e apoio nas edições 2013 e 2014.● CEO da Ambiente Livre.● Data Scientist, Instrutor e Consultor de Big Data com Hadoop, Spark,
Cassandra, MongoDB e Pentaho.

Sobre a Ambiente Livre
● Fundada em 2004 com foco de atuar em consultoria com software livre.
● 2009 ampliou sua soluções para atender ao mercado de gestão empresarial com software livre.
● Tem 14 soluções distintas para geração de negócios com software livre.

Ecosistema da Ambiente Livre

Big Data - Muito se fala...

2005 na apresentação do Papa Bento XVI

2013 na apresentação do Papa Francisco

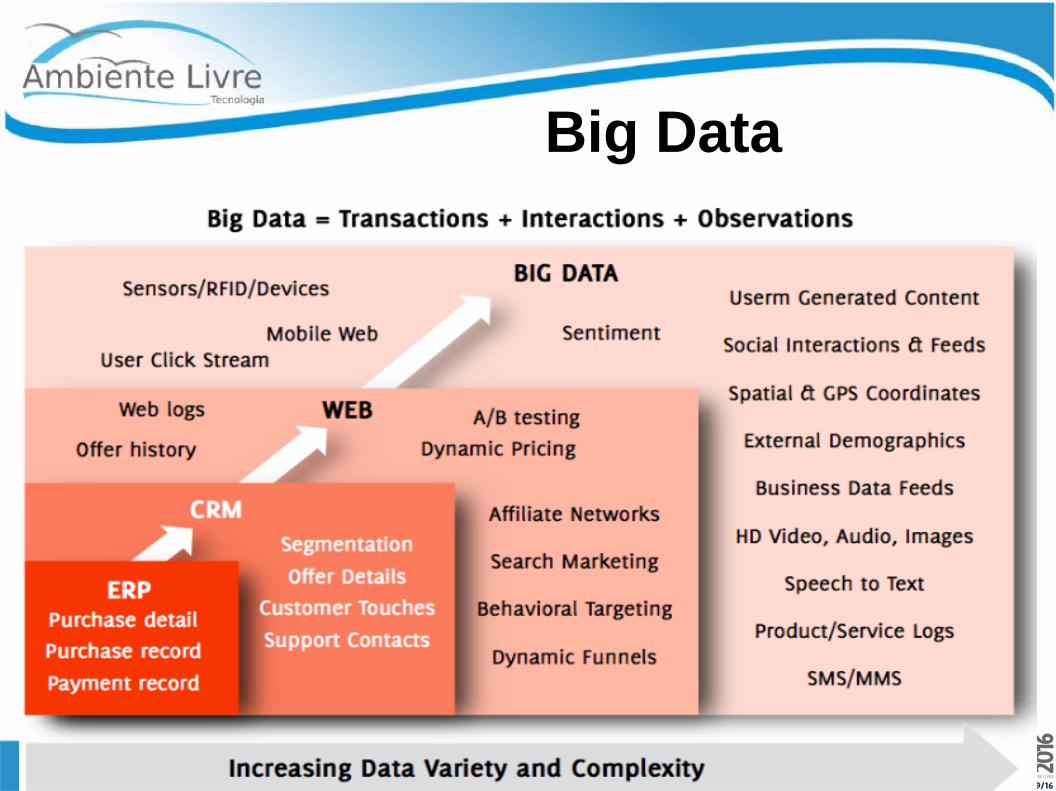
Big Data

IoT- Internet of Things
● Internet das Coisas se aplica a comunicação entre objetos e entre estes e a internet, sejam eles físicos ou virtuais.

Evolução das Coisas

Impacto Econômico - IoT● U$ 4 a 11 trilhões a partir de 2025

A amizade sensor Big Data
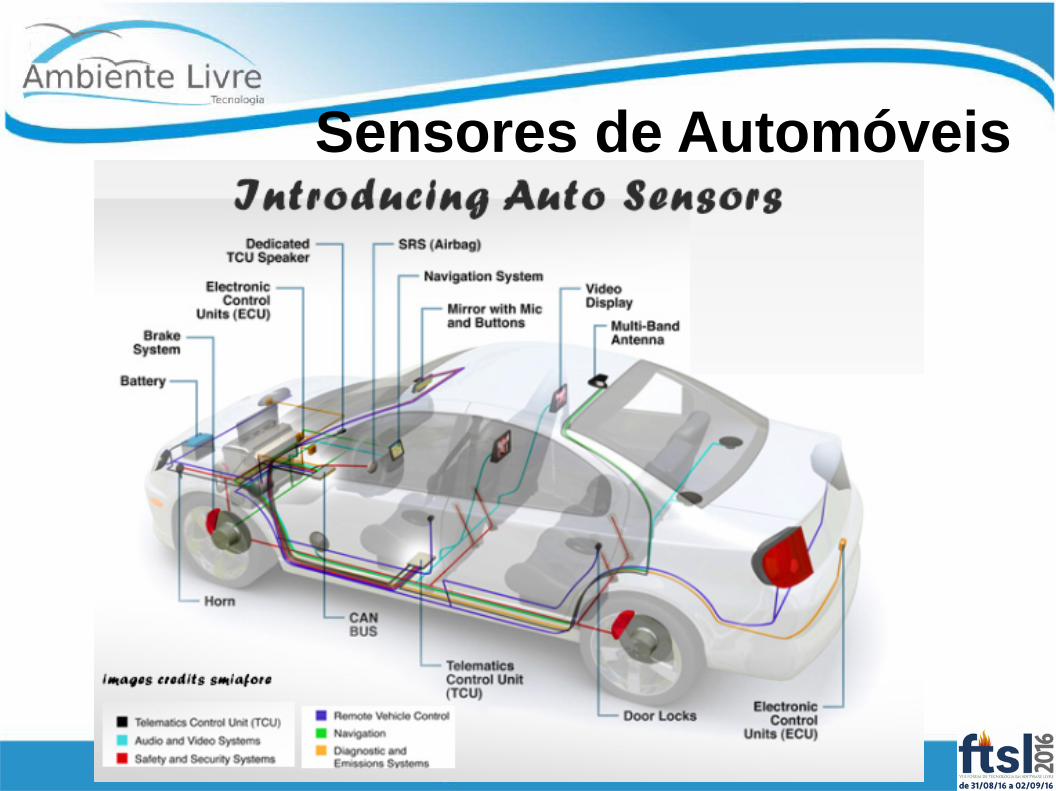
Sensores de Automóveis

Sensores de Voo
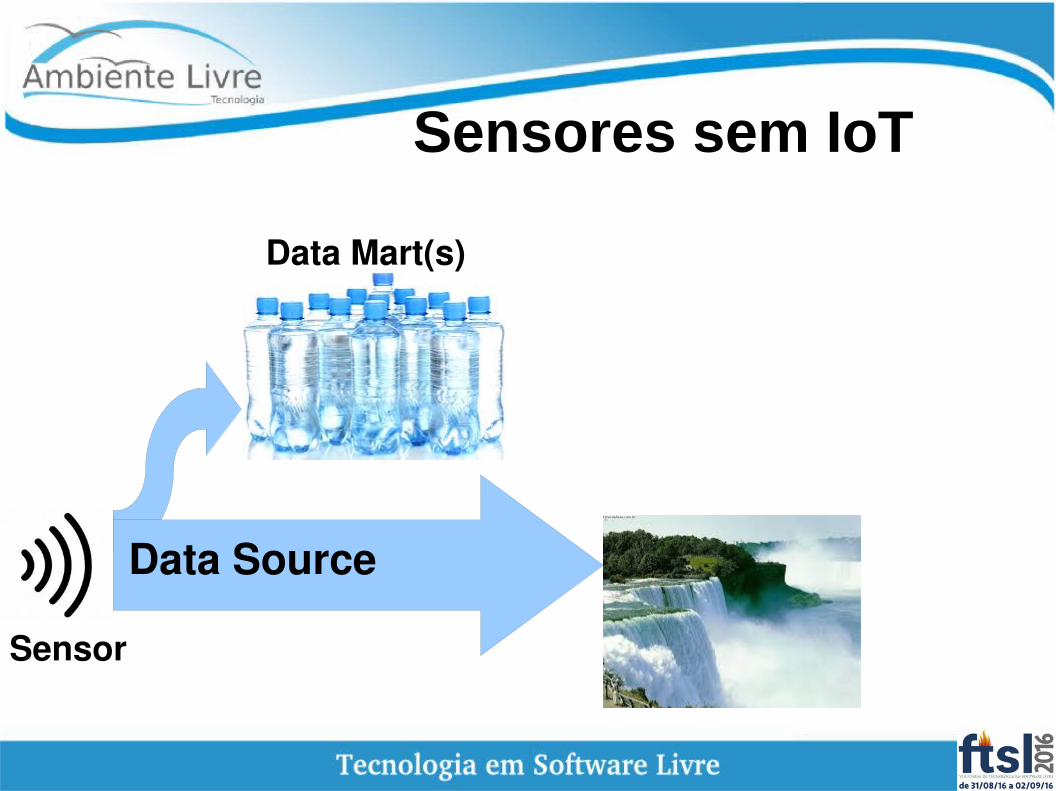
Sensores sem IoT
Data Mart(s)
Data Source
Sensor
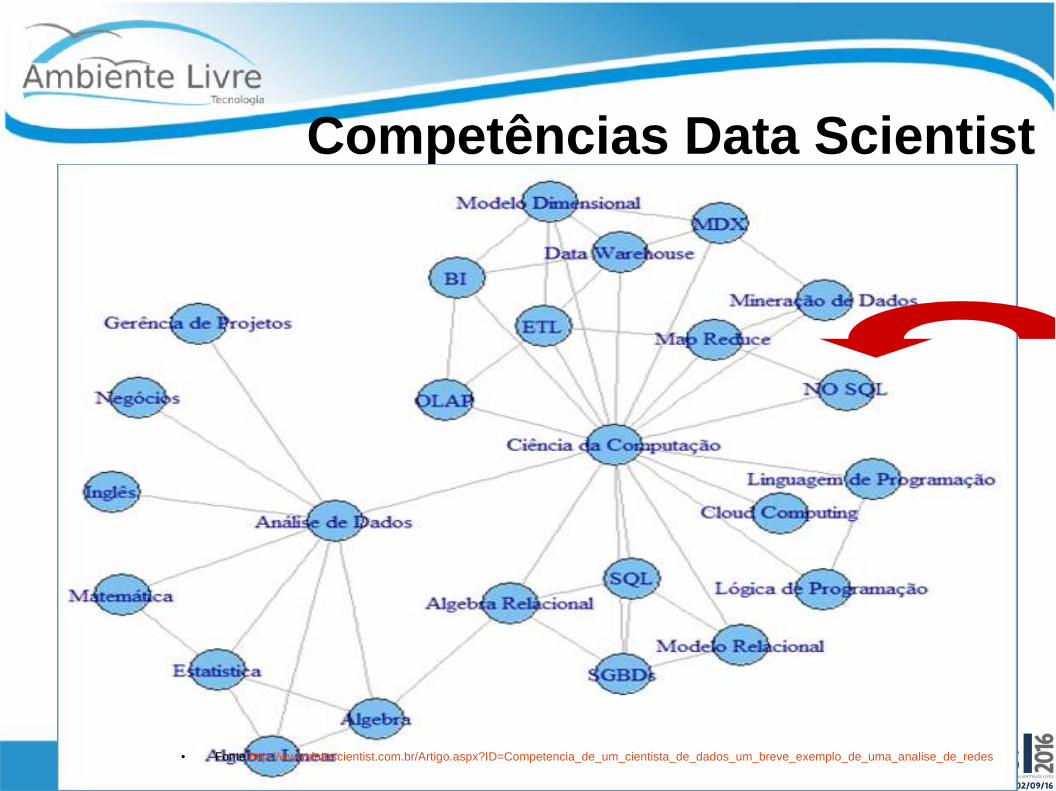
Competências Data Scientist
● Fonte http://www.datascientist.com.br/Artigo.aspx?ID=Competencia_de_um_cientista_de_dados_um_breve_exemplo_de_uma_analise_de_redes

Ferramentas de Big Data

Software Livre

Fundação Apache
● Big Data = Apache = Open Source● Apache é líder em Big Data!● ~31 projetos de Big Data incluindo “Apache
Hadoop” e “Spark” e Cassandra●

Apache Cassandra
● É um tipo de banco nosql que originalmente foi criado pelo Facebook e que atualmente é mantido pela Apache e outras empresas.
● Banco de dados distribuído baseado no modelo BigTable do Google e no sistema de armazenamento Dynamo da Amazon.com.

DataStax
● Principal mantenedora do Cassandra● Fornece Suporte comercial e uma versão
Enterprise do Cassandra● http://www.datastax.com/

Histórico - Versões
Top-level Apache project em 2010● 0.6 – Abril 2010● 1.0 – Outubro 2011● 2.0 – Setembro 2013● 3.0 – Novembro 2015● 3.7 - Julho 2016

NoSQL's
● Gráfos: elementos de dados referem-se a cada n outros em um gráfo/rede
● Chave-Valor: teclas de mapear para valores arbitrários de qualquer tipo de dados
● Documento: conjuntos de documentos (JSON) queryable em todo ou em parte
● Coluna Família: chaves mapeados para conjuntos de n-número de colunas digitadas
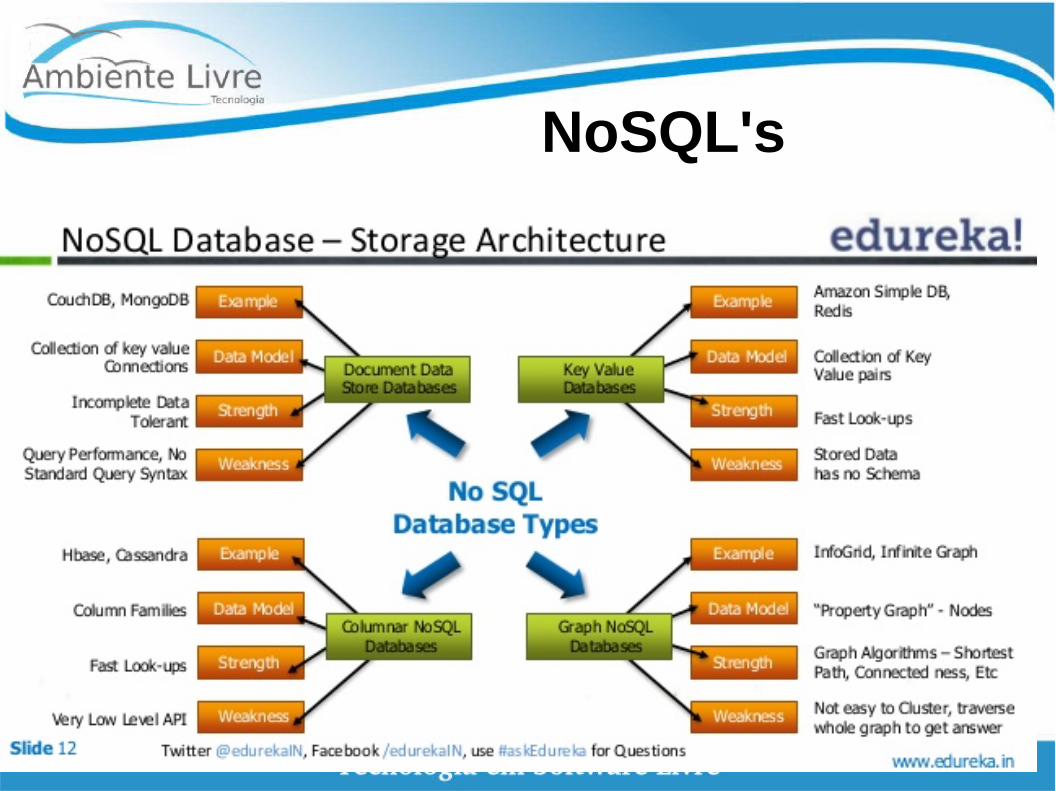
NoSQL's

NoSQL X SQL
● Dificuldade de atingir alta disponibilidade e escalabilidade
● Geralmente não tem Replicação multi master● Mudanças no schema em larga escala são
complicadas e complexos● Não tem suporte a multi datacenter para
distribuição geográfica● Processo de upgrade em escala não é trivial

NoSQL X SQL
● Consistência Estrita = Disponibilidade prejudicada
● Transações = deadlock / não escala● Ad Hoc Queries e Indexação = Devem ser
planejadas antes.

CAP Theorem
● Consistência● Disponibilidade● particionamento

CAP Theorem
● Consistência: ver os dados mais recentes, sem um atraso
● Disponibilidade: O sistema deverá dar uma resposta a todos os pedido
● particionamento: significa a distribuição de seus dados em local diferente.
● O teorema diz que você não pode alcançar os 3, você deve ficar com dois e sacrificar um!

CAP Theorem
● 1- Se você precisa de consistência e disponibilidade. Você deve esquecer de particionamento porque quando você particionar há uma pequena janela entre a gravação e os dados mais recentes.
● 2- Se a disponibilidade e particionamento é o objetivo que você tem que pagar o custo de consistência, como explicado no 1.
● 3- finalmente, se você escolher o particionamento e consistência que você deve sacrificar disponibilidade para lidar com defasagens de nós deferentes para ter dados mais recentes.

Escalabilidade Linear
● A Capacidade pode ser facilmente aumentada simplesmente por adicionar novos nós.
● Exemplo: Se 2 nós pode lidar com 100.000 transações por segundo, 4 nós apoiará 200.000 transações/s e 8 nós vai enfrentar 400.000 transações/s
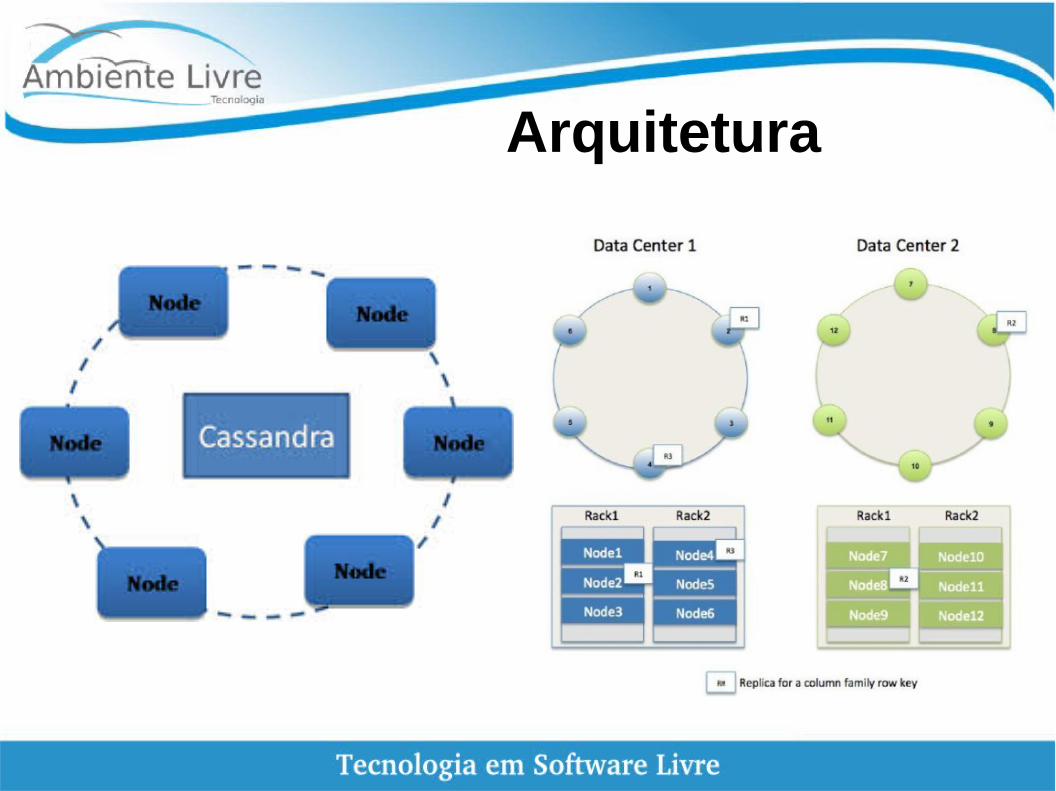
Arquitetura
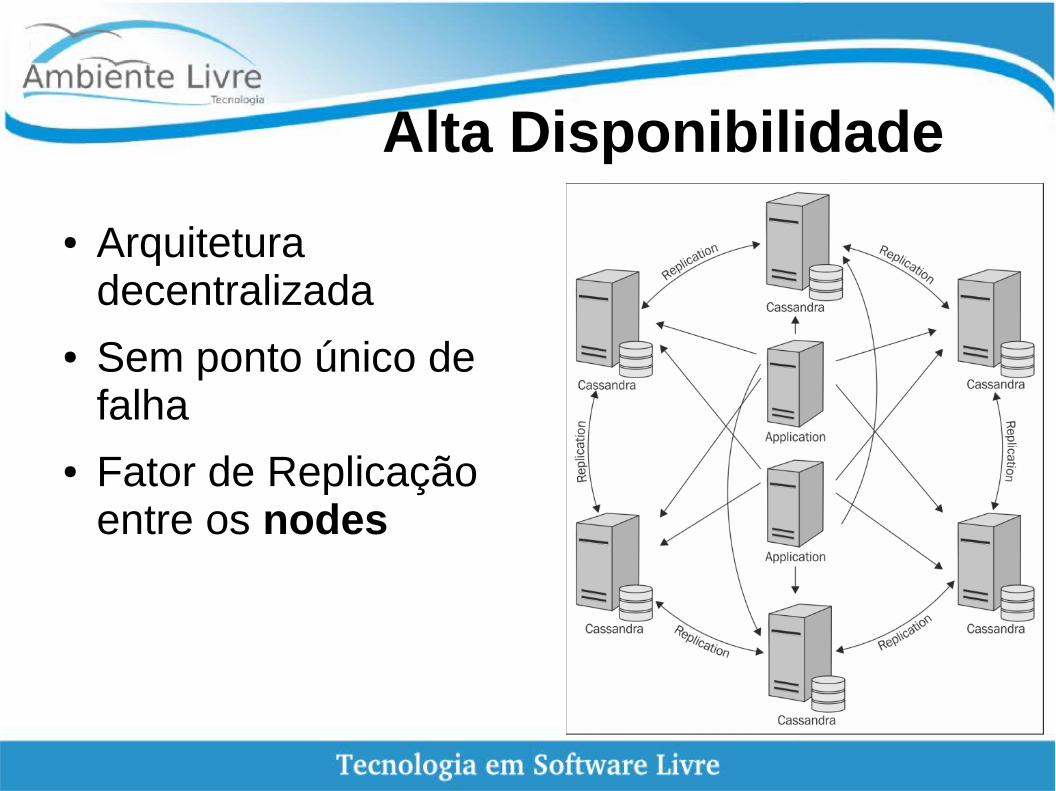
Alta Disponibilidade
● Arquitetura decentralizada
● Sem ponto único de falha
● Fator de Replicaçãoentre os nodes
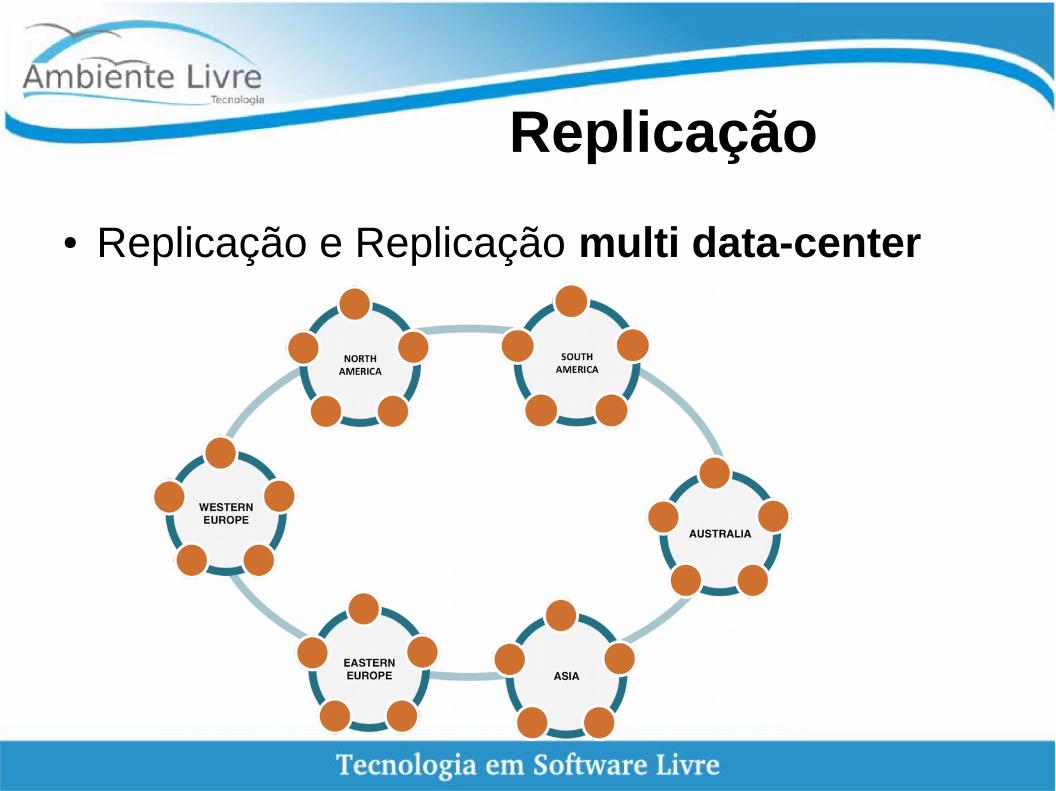
Replicação
● Replicação e Replicação multi data-center
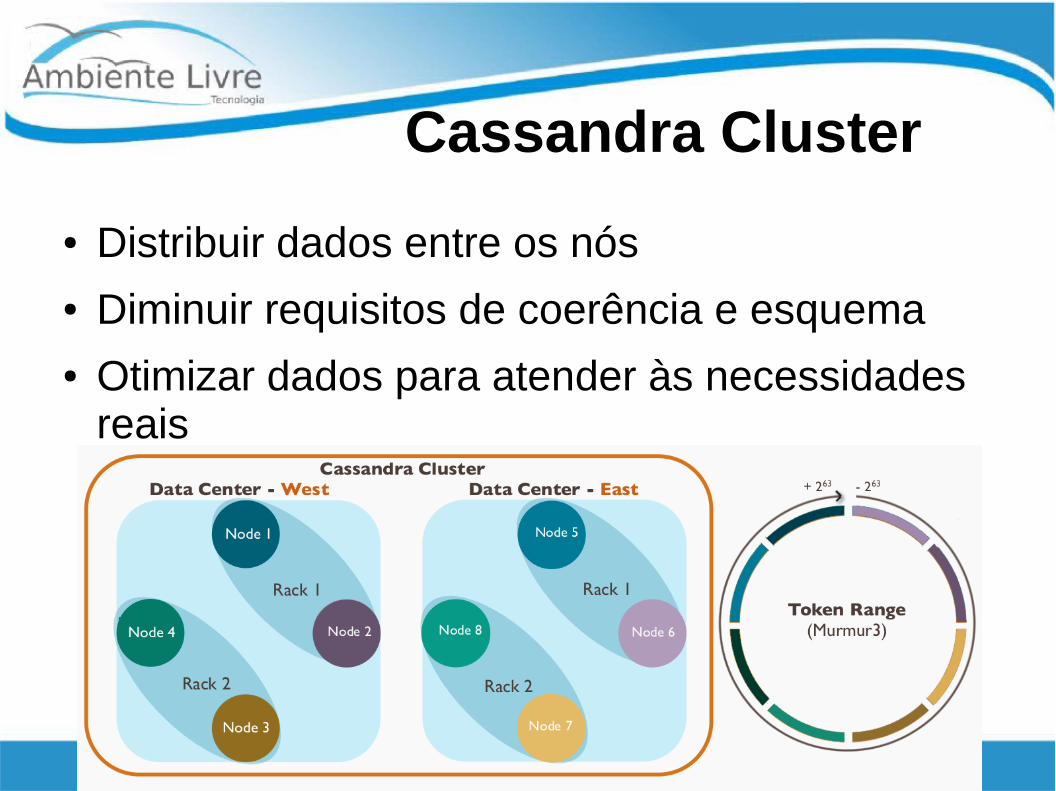
Cassandra Cluster
● Distribuir dados entre os nós● Diminuir requisitos de coerência e esquema● Otimizar dados para atender às necessidades
reais

Outras Características
● Descentralizado● Esquema de Dados flexível● Suporte a MapReduce com Hadoop● Suporte a Spark● Nível de consistência configurável ( tunning )
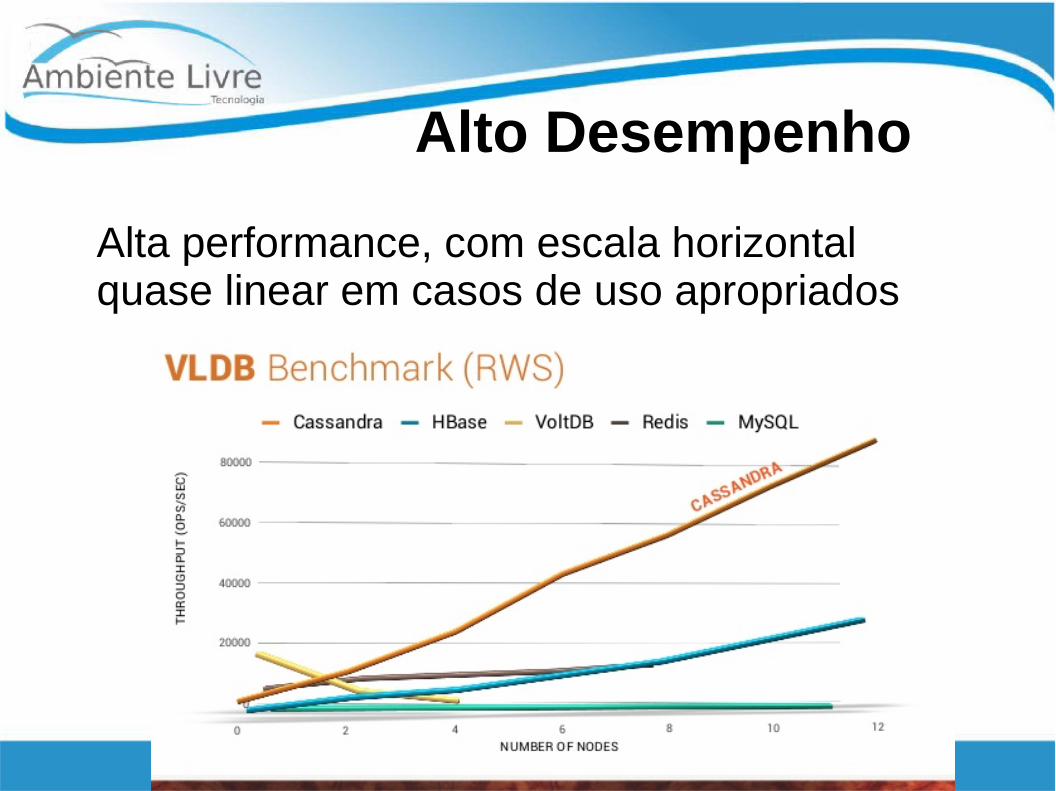
Alto Desempenho
Alta performance, com escala horizontal quase linear em casos de uso apropriados

Modelagem de Dados
Cassandra Query Language (CQL)● Fornece uma, linha-coluna, a abordagem SQL-like familiarizado:
CREATE, ALTER, DROP, SELECT, INSERT, UPDATE, DELETE● Substituiu o complexo
Thrift API orientada para o armazenamento utilizado em versões anteriores
● Fornece definições de esquema claros num contextoflexível esquema (NoSQL)

Características
● Nenhum ponto único de falha● Escreve em Tempo Real ( real-time) com análise de
dados operacional ao vivo● Modelos de dados, facilmente alterados flexíveis● Horizontalmente Escala ( Near-linear ) entre os
servidores de commodities● Replicação de confiança entre data centers distribuídos● Esquema de tabela claramente definido em um
ambiente NoSQL

Quando NÃO é a melhor solução?
● RDBMS tradicional já se sobressai quando você precisa.
● Transações ACID-compliant, com reversão (por exemplo, transferências bancárias)
● Hardware de alta qualidade.

Casos de Uso
● Listas e coleções● Personalização e recomendação motores ● Mensagem/Mensageria ● A detecção de fraudes● Sensor de Dados

Cases● Big Data na Accenture● Mensagem● 5.000-20.000 mensagens por segundo● Multi Data Centers para coleta de dados● Hadoop e Cassandra● http://www.planetcassandra.org/blog/interview/big-data-practice-at-
accenture-helps-customers-deploy-cassandra-for-high-speed-data-ingestion

Cases
● Plataforma de Recomendação, fornecer recomendações para os serviços de e-commerce.
● Os maiores sites de comércio eletrônico no Brasil usam para atender recomendações de compra personalizadas para seus usuários.
● Migração de MySQL para Cassandra● Cluster de 48 Nós● http://www.planetcassandra.org/blog/interview/get-personal-with-chaordic-
bringing-personalization-to-e-commerce-with-48-nodes-of-apache-cassandra-and-hadoop/

Outros Cases
● http://www.planetcassandra.org/apache-cassandra-use-cases/

Cassandra no Brasil

Empresas Usando Cassandra

Cassandra X MongoDB
● MongoDB é orientado a documentos e o Cassandra é column-based.
Vantagens Cassandra:● Altamente escalável;● Volumes de dados massivos;
Desvantagens Cassandra● Maior curva de Aprendizagem
Vantagens MongoDB● Fácil de operar e gerenciar ( baixa curva de aprendizagem )
Desvantagens MongoDB● Pode não apresentar a mesma facilidade de distribuição de dados entre data
centers como o Cassandra.
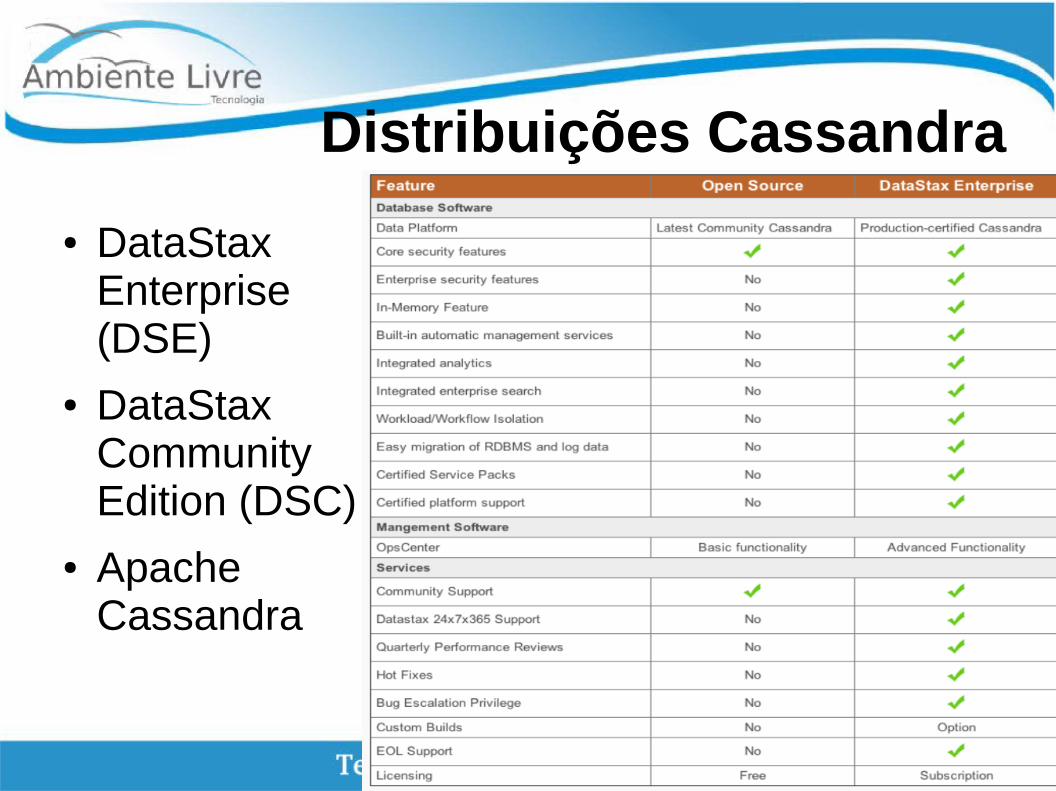
Distribuições Cassandra
● DataStaxEnterprise(DSE)
● DataStax CommunityEdition (DSC)
● Apache Cassandra

Por onde Começar!
● Apache Cassandra Documentation v3.7
http://cassandra.apache.org/doc/latest/● Academia Cassandra
https://academy.datastax.com/● * Formação em Curitiba
De 16 a 18 de Novembro

Referências
● Datastax Documentation http://docs.datastax.com
● Livro: “Cassandra: The Definitive Guide”Eben Hewitt.
● Datastax Academy http://academy.datastax.com ● Academia Chaordic, Florianópolis 2014.● Apache Cassandra Documentation v3.7
http://cassandra.apache.org/doc/latest/
Recommended

















