
Data Science Institute
データの平均値の差を検討する方法-1
2018年8月3日データサイエンス研究所
伊藤嘉朗
(t検定、カイ二乗検定)

Data Science Institute
事例 統計用語・統計手法 ページ
A君の研修成績の評価標準偏差, Z値, 偏差値 3標準正規分布 8
食品の有効成分含有量における標本の平均と母集団の平均との比較
母集団と標本(有意確率、有意水準、Z検定) 10t分布のしくみと正規分布との違い 20(A)1標本t検定のしくみと解釈方法 22(B) 標本平均と母集団の平均の差が拡大した場合 34(C) 標本のバラツキ(標準偏差)が拡大した場合 38(D) 標本サイズが拡大した場合 461標本t検定のまとめ 50
商品パッケージデザインにおける男女別好感度の比較
(A) 2標本t検定のしくみと解釈方法 51(B) 平均値の差が拡大したとき 59(C) データのバラツキが拡大したとき 62(D) 標本サイズが拡大したとき 65
商品説明前後による理解度の比較 データに対応のある場合におけるt検定 67各事例の分析結果の比較 t検定における効果量 79サッカーと野球選手のBMI比較
t検定における分析手法の選択 83サッカー選手間の評価比較サイコロの出る目の妥当性 カイ二乗検定のしくみ 85階層(一般層・富裕層)と商品選択の関連 2×2分割表の検定 95主力ブランド知名度の年度間比較 比率の差の検定への応用 104資格保有者数の年齢階層別比較 m×n分割表の検定 108各事例の分析結果の比較 カイ二乗検定における効果量 109
まとめ検定の考え方、t検定、カイ二乗検定有意確率と効果量
110
本日の内容
Data Science Institute
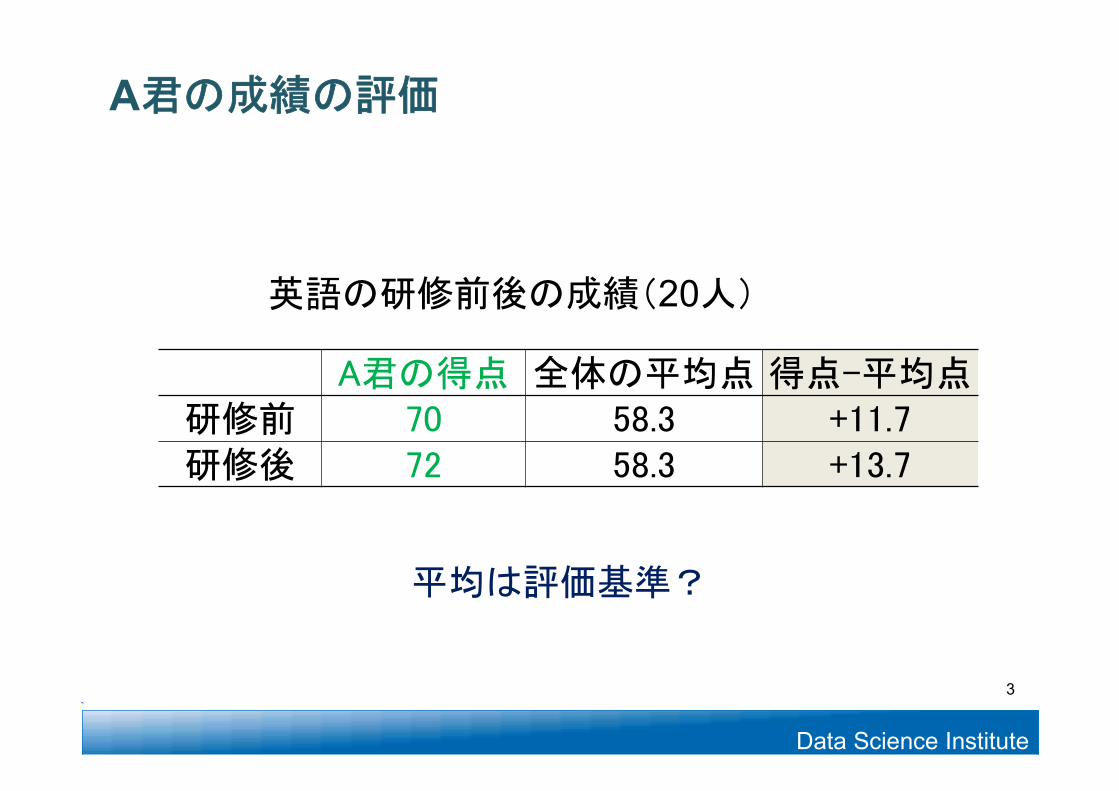
A君の成績の評価
A君の得点 全体の平均点 得点-平均点研修前 70 58.3 +11.7研修後 72 58.3 +13.7
平均は評価基準?
英語の研修前後の成績(20人)
3

Data Science Institute
• <研修前>70、56、89、27、69、57、69
50、33、67、37、49、98、69
68、25、65、67、33、68
• <研修後>72、31、95、36、89、88、89
76、28、47、23、28、96、48
51、20、33、91、27、98
全員の成績
研修後はバラツキ(標準偏差)が大きくなった。4

Data Science Institute
◇平均を基準とした場合研修前(+11.7) < 研修後(+13.7)
成績の評価
・順位研修前(3番) > 研修後(9番)
・バラツキ(標準偏差)研修前<研修後
バラツキ(標準偏差)の大きいデータの平均は信頼できない。
5
Data Science Institute
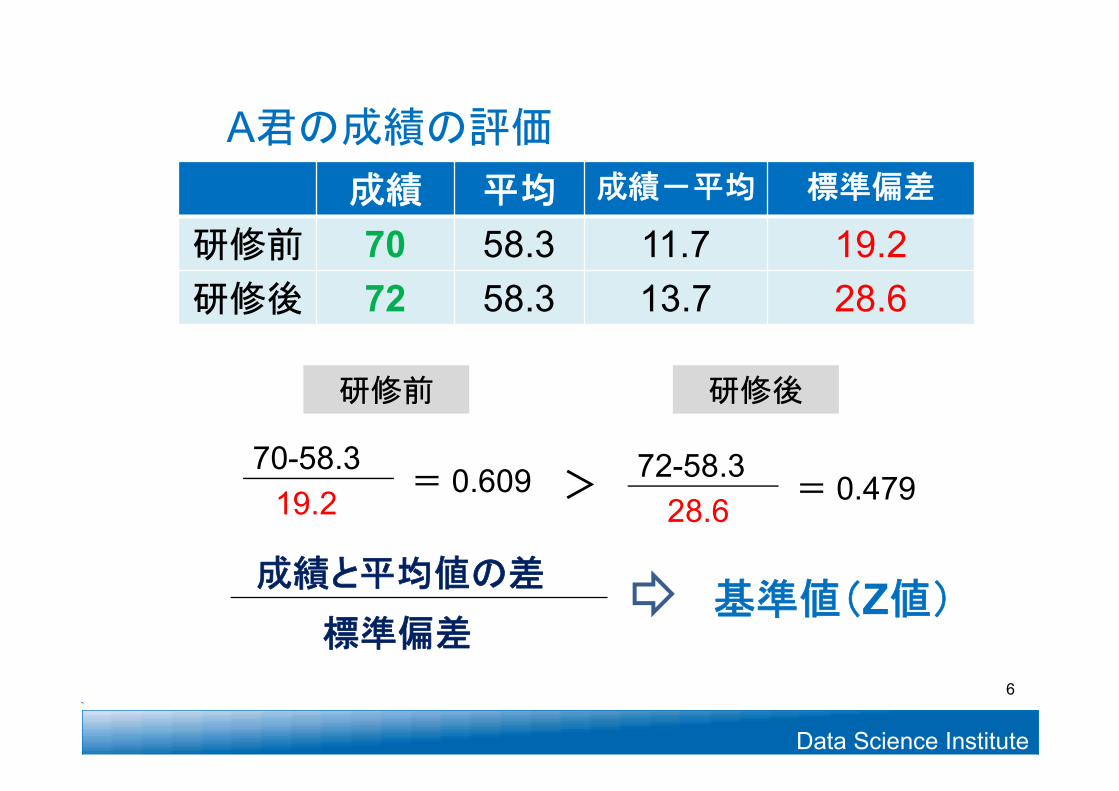
70-58.319.2
72-58.328.6
>
研修前 研修後
成績 平均 成績-平均 標準偏差
研修前 70 58.3 11.7 19.2研修後 72 58.3 13.7 28.6
A君の成績の評価
= 0.609 = 0.479
基準値(Z値)成績と平均値の差
標準偏差
6

Data Science Institute
偏差値
Z値×10+50
研修前の偏差値=0.609×10+50=56.09研修後の偏差値=0.479×10+50=54.79
Z値の比較によりデータの評価・比較が可能
7
Data Science Institute
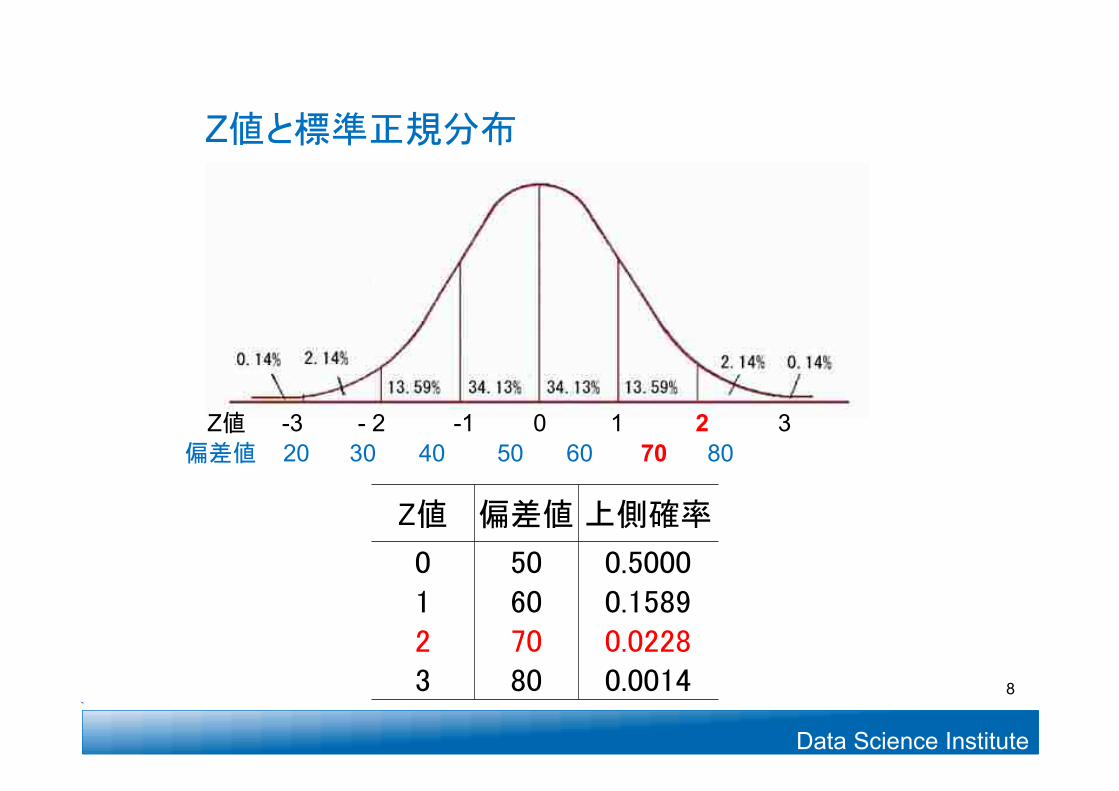
Z値 -3 - 2 -1 0 1 2 3
Z値 偏差値 上側確率
0 50 0.50001 60 0.15892 70 0.02283 80 0.0014
Z値と標準正規分布
偏差値 20 30 40 50 60 70 80
8

Data Science Institute
Z値と標準正規分布
Z= 88-62.412.8
= 2
求める値-平均値
標準偏差
差(違い)
バラツキZ値=
■全国で10万人が参加したある模試A君の成績は、88点、平均点62.4点、標準偏差が12.8点A君の成績は上位何%?
88点以上の割合は約2.28%
9
Data Science Institute
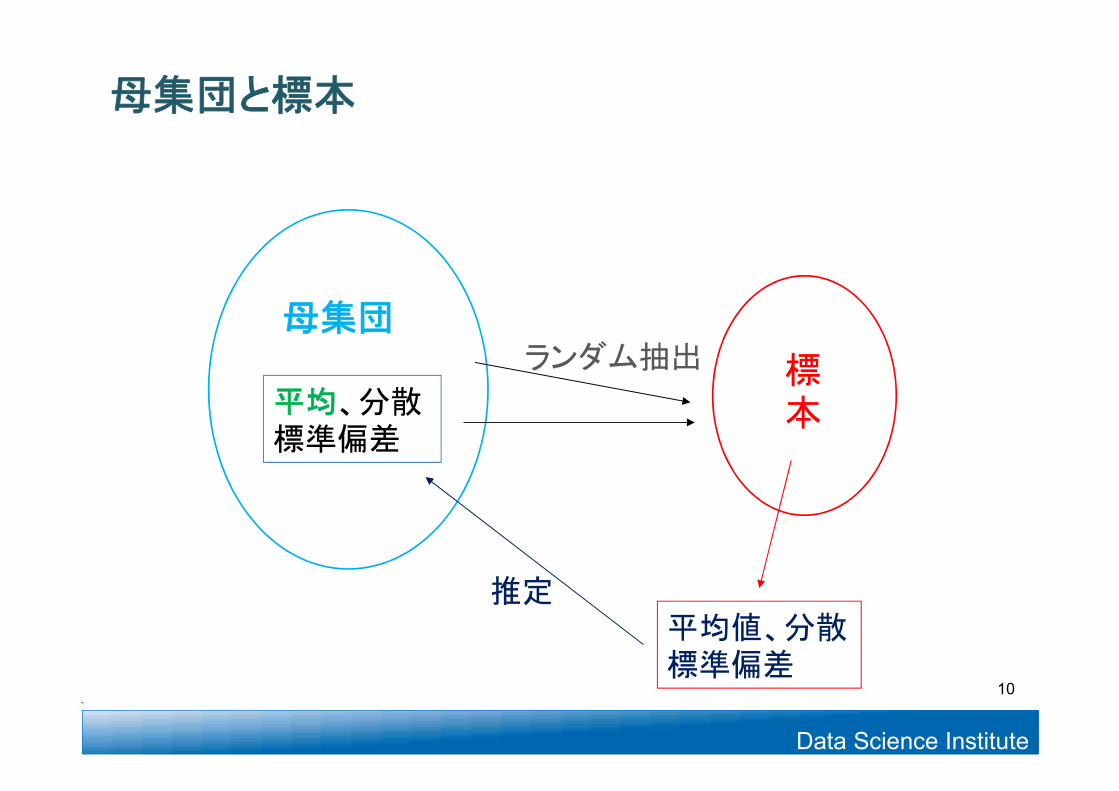
母集団
標本
ランダム抽出
平均値、分散標準偏差
平均、分散標準偏差
推定
10
母集団と標本

Data Science Institute
競合食品メーカー 有効成分含有量平均=60mg、 標準偏差=15mg
(1)市場から一つ購入した : 75mg母平均より多いのか?
違うと判定したときの危険率
検定の主目的 有意確率を求める!
11
食品有効成分含有量における標本平均との比較
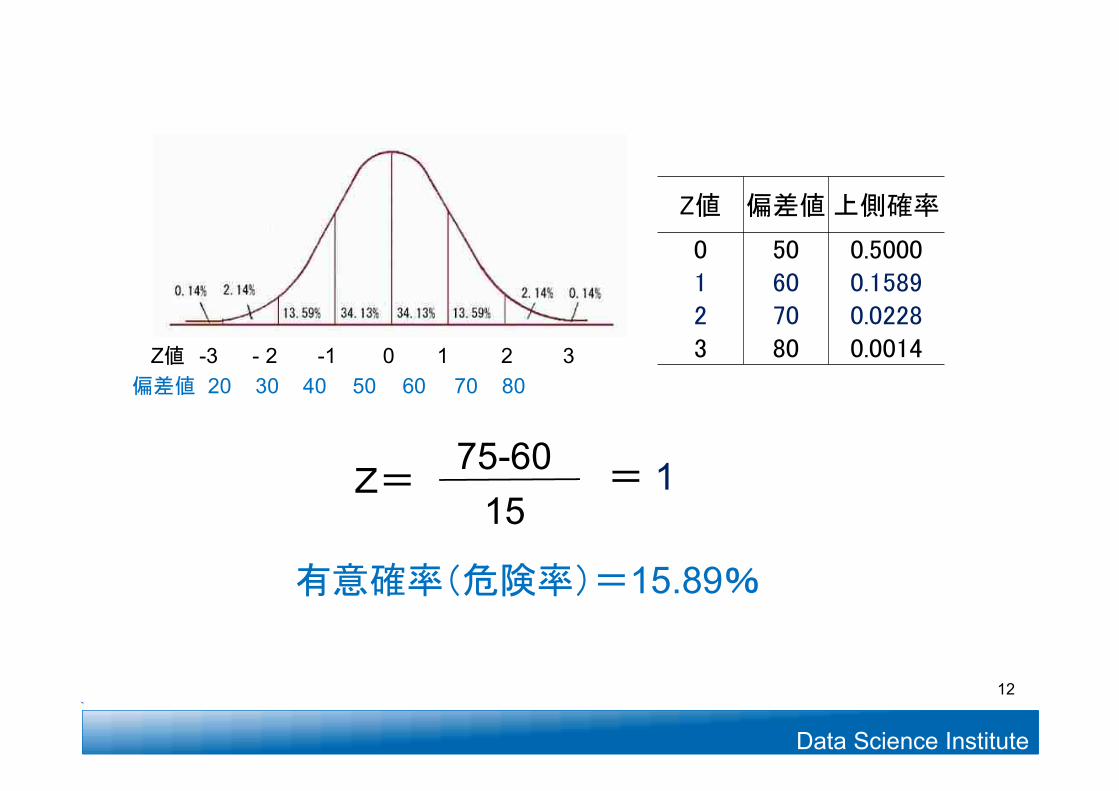
Data Science Institute
Z値 偏差値上側確率
0 50 0.50001 60 0.15892 70 0.02283 80 0.0014Z値 -3 - 2 -1 0 1 2 3
偏差値 20 30 40 50 60 70 80
有意確率(危険率)=15.89%
Z=15
= 175-60
12
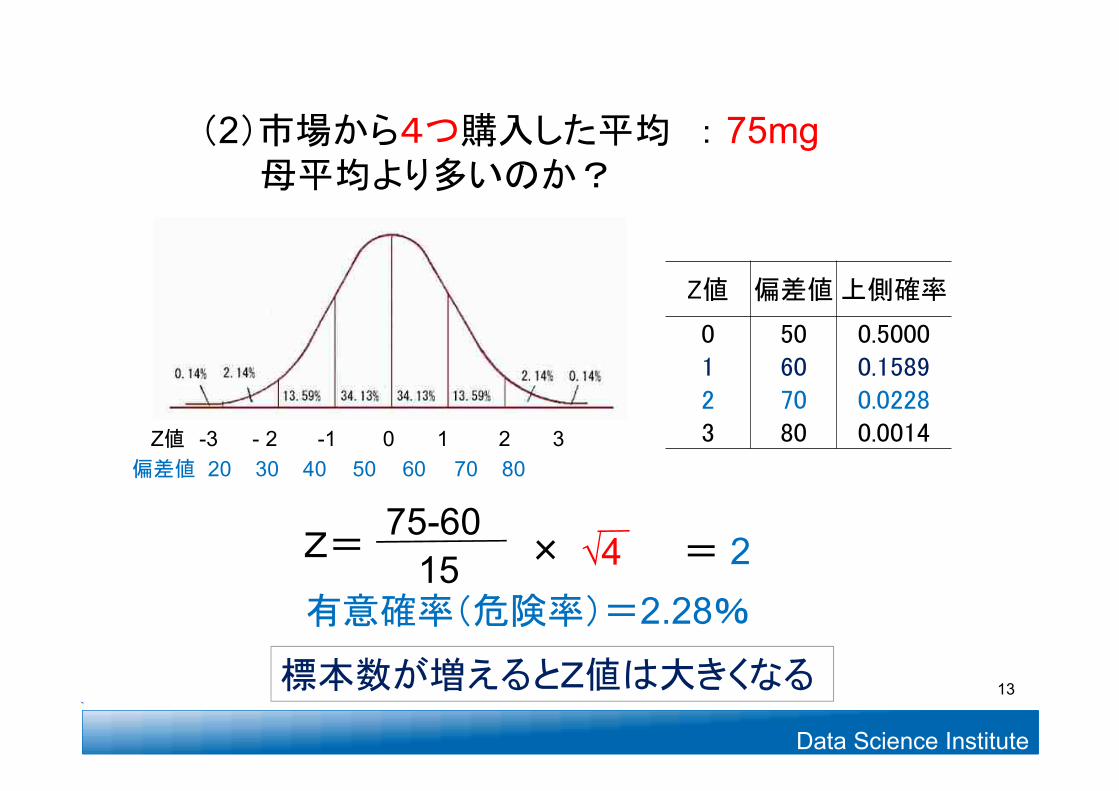
Data Science Institute
Z値 偏差値上側確率
0 50 0.50001 60 0.15892 70 0.02283 80 0.0014Z値 -3 - 2 -1 0 1 2 3
偏差値 20 30 40 50 60 70 80
有意確率(危険率)=2.28%
Z=75-60
15 √4× = 2
(2)市場から4つ購入した平均 : 75mg母平均より多いのか?
標本数が増えるとZ値は大きくなる 13
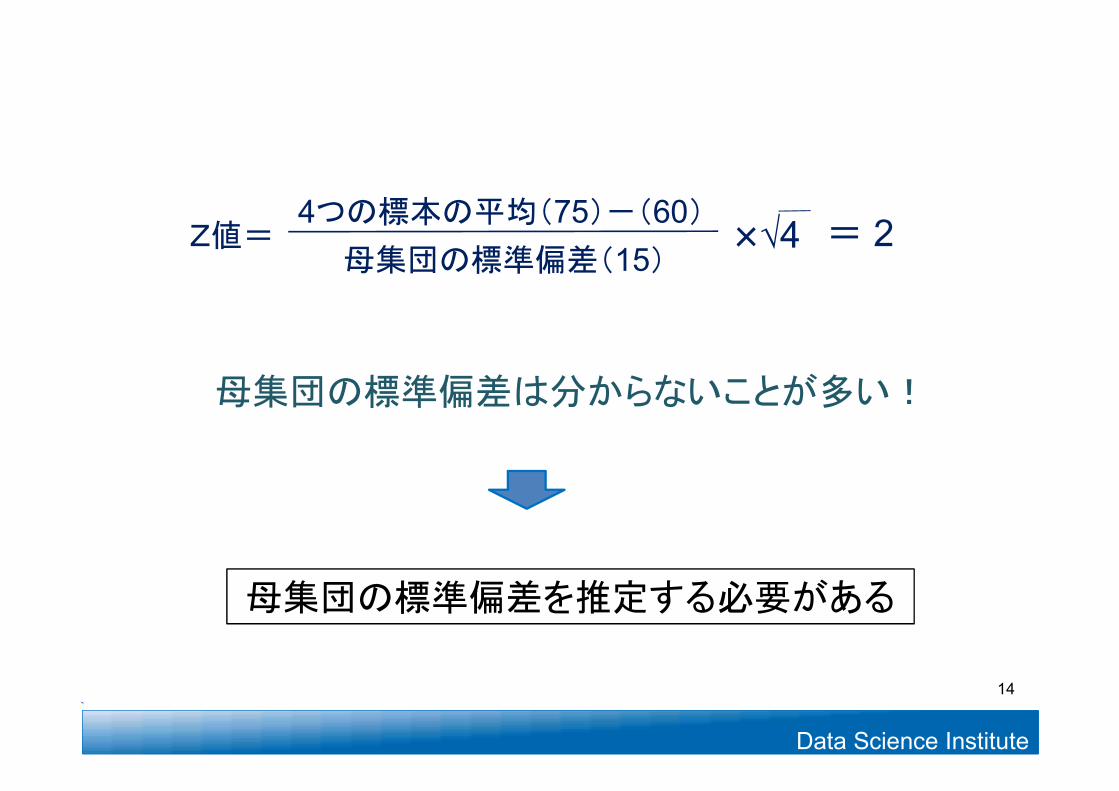
Data Science Institute
母集団の標準偏差(15)√4× = 24つの標本の平均(75)-(60)
Z値=
母集団の標準偏差を推定する必要がある
母集団の標準偏差は分からないことが多い!
14

Data Science Institute
母集団の分散の推定
8 9 9 10 10 10 11 11 11 11 12 12 12 13 13 14
標本数:3 6回抽出
母集団(16個)
標本の分散から母分散を推定!
15
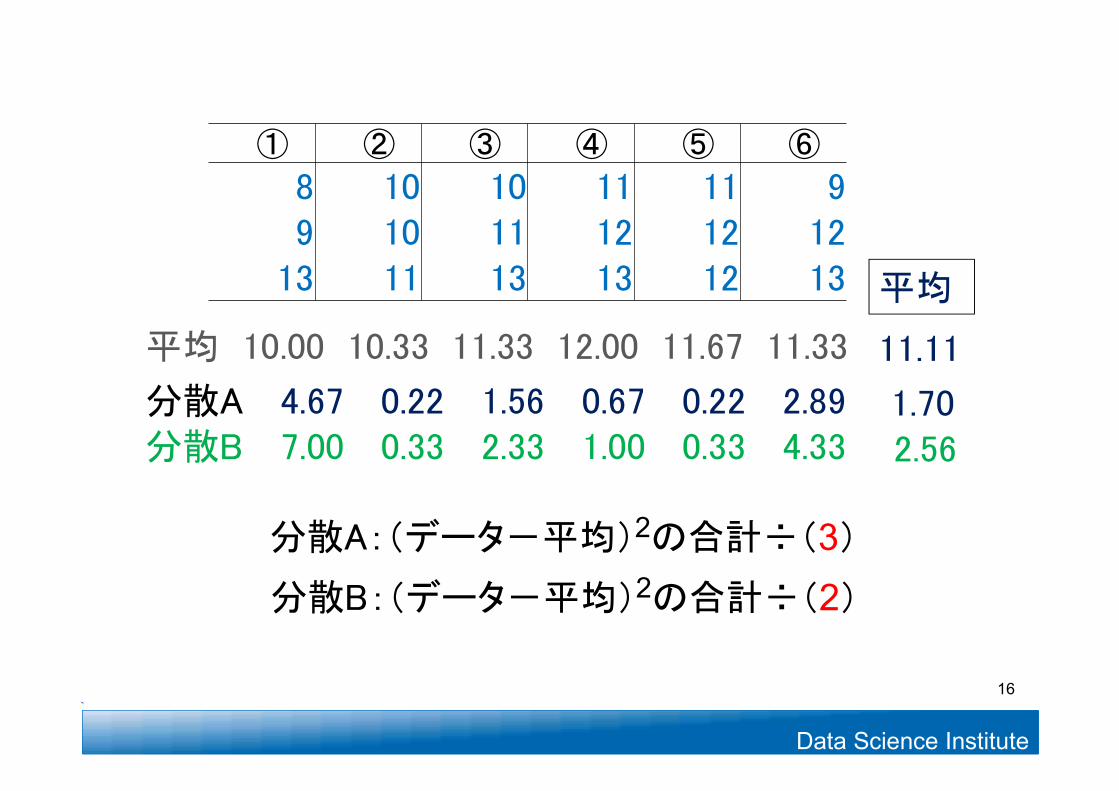
Data Science Institute
① ② ③ ④ ⑤ ⑥
8 10 10 11 11 9 9 10 11 12 12 12 13 11 13 13 12 13
分散A 4.67 0.22 1.56 0.67 0.22 2.89 分散B 7.00 0.33 2.33 1.00 0.33 4.33
平均 10.00 10.33 11.33 12.00 11.67 11.33
分散A:(データ-平均)2の合計÷(3)分散B:(データ-平均)2の合計÷(2)
平均
11.11
1.702.56
16

Data Science Institute
分散の計算
2乗8 - 10 = -2 49 - 10 = -1 1
13 - 10 = 3 9
平均 : ( 8 + 9 + 13 )÷ 3 = 10
計 0 14
分散A : 14 ÷ 3 = 4.67
分散B : 14 ÷ ( 3 – 1 ) = 7.00
17

Data Science Institute
8 9 9 10 10 10 11 11 11 11 12 12 12 13 13 14
平均= =11.0
2 2 2
母集団の平均と分散
分散= = 2.55
分散B(2.56)が母集団の分散(2.55)に近似!
18
Data Science Institute
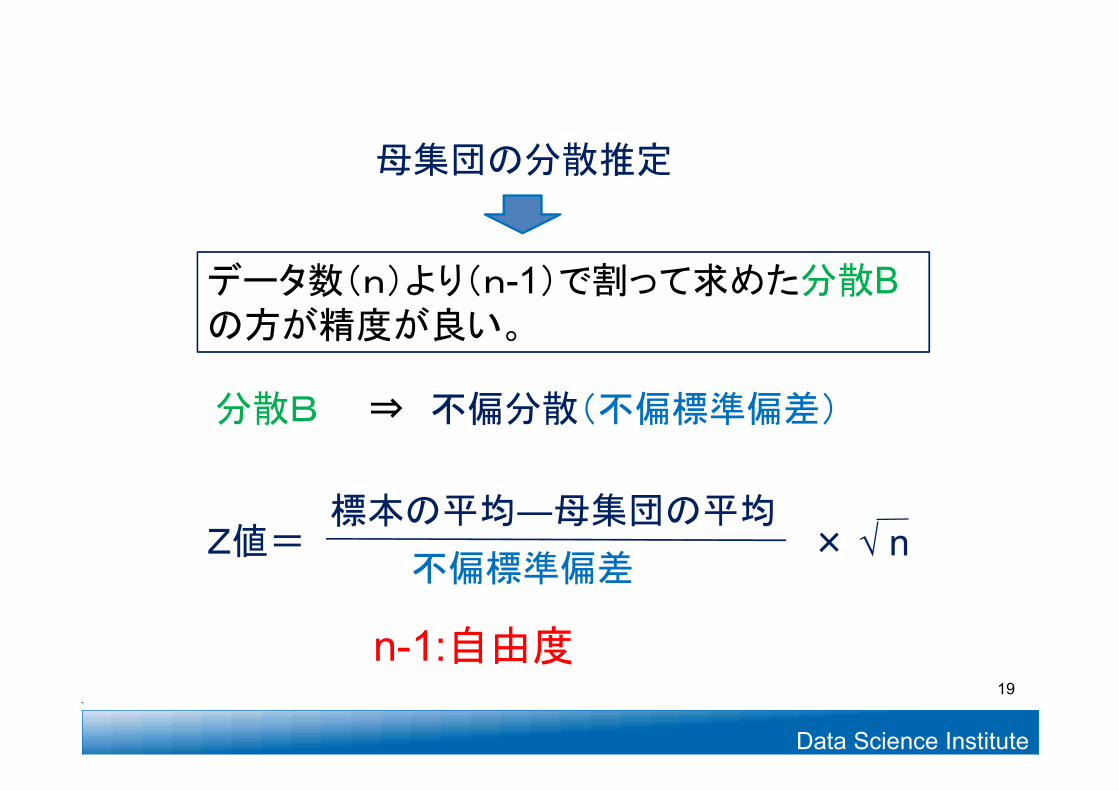
データ数(n)より(n-1)で割って求めた分散Bの方が精度が良い。
n-1:自由度
母集団の分散推定
標本の平均―母集団の平均不偏標準偏差
Z値= × √ n
分散B ⇒ 不偏分散(不偏標準偏差)
19

Data Science Institute
t分布とは1908年、W.S.ゴセット(キネスビールの研究員)が考案。データが少ないときに精度を上げるためにt値を使う。
■全て(データの大小に関係なく) t値を使う。■この検定方法を t検定という。
Z値による検定 正規分布
t値による検定 t分布
Z値による検定は標本数が少ないときに精度が良くない。
20
Data Science Institute
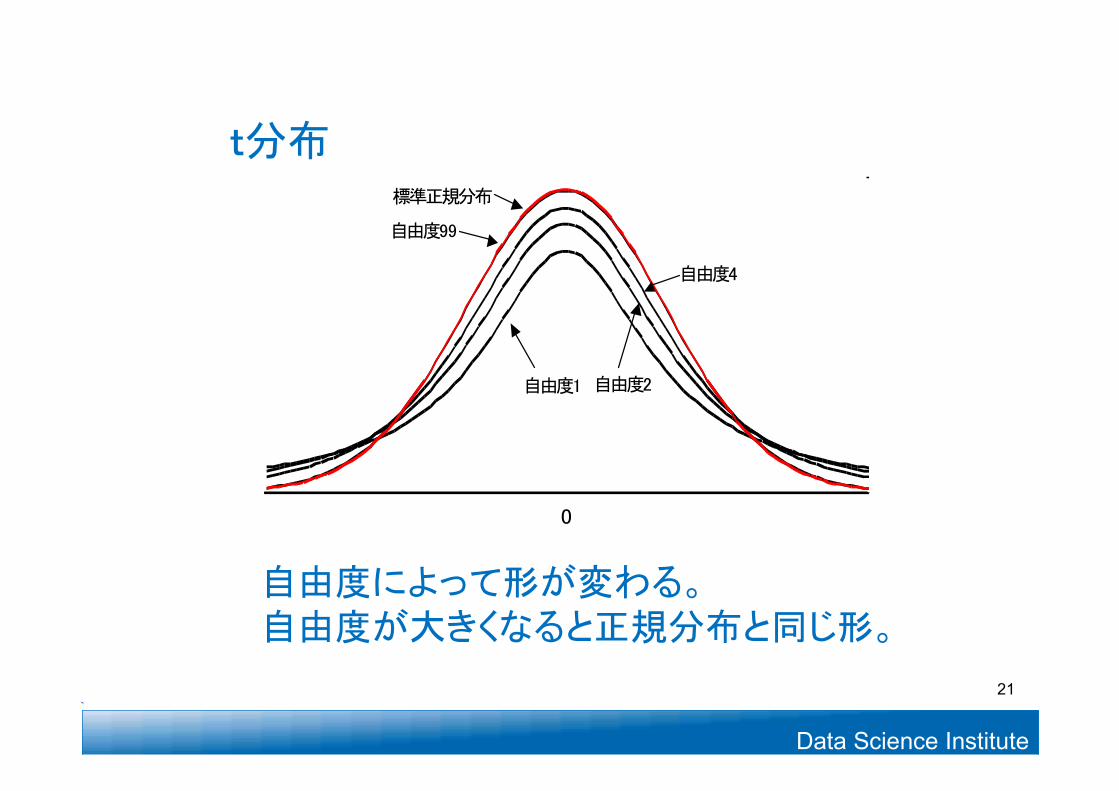
t分布
自由度によって形が変わる。自由度が大きくなると正規分布と同じ形。
0
自由度1 自由度2
自由度4
自由度99
標準正規分布
21

Data Science Institute
ランダムに選んだ製品10個の有効成分含有量母平均:60mg 違いはみられるか?
64 62 58 61 60 59 63 66 62 63
10個の平均値を求めると(64+62+・・・+60+63)÷10 = 61.8
標本平均(61.8)と母平均(60.0)は異なる?
(A)1標本t検定
22

Data Science Institute
(1)データを入力する。
平均と不偏標準偏差を求める(SAS EG )
23
EG
Data Science Institute
(2)「記述統計」-「要約統計量」をクリックする。
24
EG

Data Science Institute
(3)「変数リスト」をから「分析変数」を選択する。
25
EG
Data Science Institute
(4)「統計量」「基本」をクリックし、出力項目を確認する。
26
EG

Data Science Institute
(5)結果が表示される。
不偏標準偏差= 2.394平均= 61.8
27
EG

Data Science Institute
標本の平均-母集団の平均
不偏標準偏差t値 = × √ n
61.8 - 60.02.394
× √ 10
= 2.38
=
28

Data Science Institute
(2)「分析」-「分散分析」-「t検定」をクリックする。
1標本t検定(SAS EG)
(1)データを入力する。
29
EG

Data Science Institute
(3)「1標本に対する検定」を選択する。
30
EG
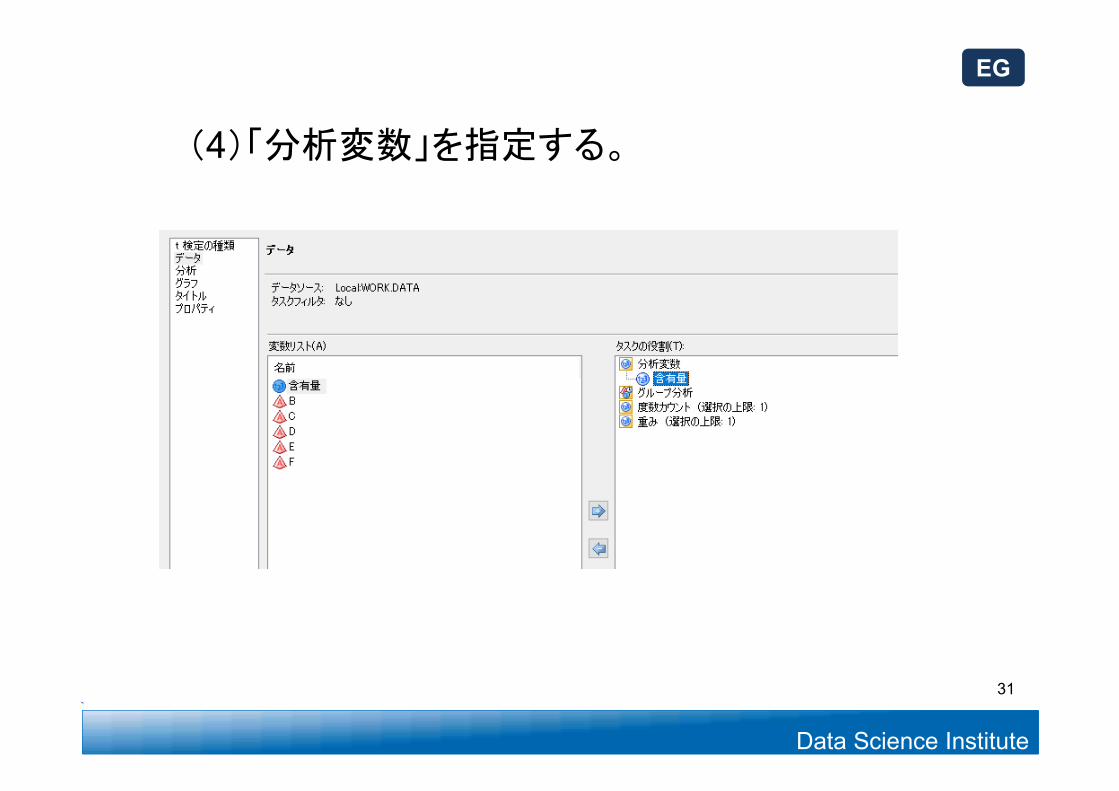
Data Science Institute
(4)「分析変数」を指定する。
31
EG
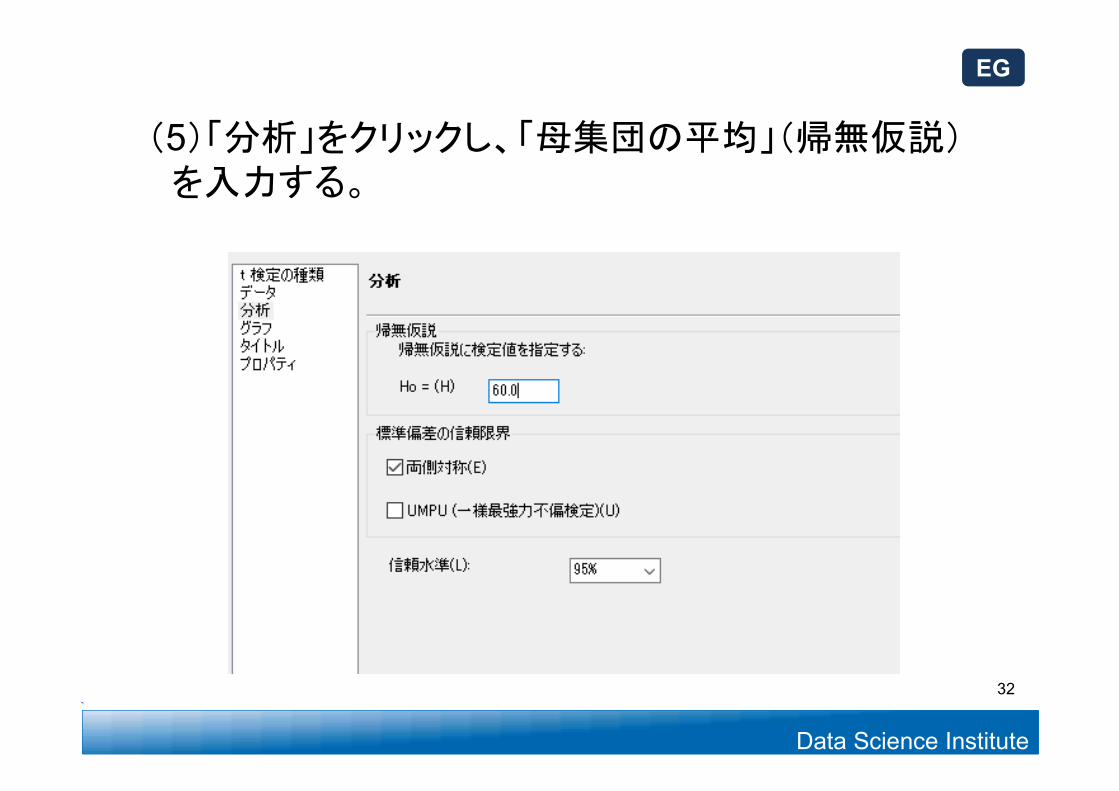
Data Science Institute
(5)「分析」をクリックし、「母集団の平均」(帰無仮説)を入力する。
32
EG

Data Science Institute
有意確率= 0.0414t値 = 2.38
33
EG

Data Science Institute
ランダムに選んだ製品10個の有効成分含有量母平均:59mg 違いはみられるか?
64 62 58 61 60 59 63 66 62 63
10個の平均値を求めると(64+62+・・・+60+63)÷10 = 61.8
標本平均(61.8)と母平均(59.0)は異なる?
(B)標本の平均と母集団の平均の差が拡大した場合
34

Data Science Institute
標本の平均-母集団の平均
標本の不偏標準偏差t値 = × √ n
61.8 - 59.02.394 × √ 10
= 3.70 > 2.38
=
35
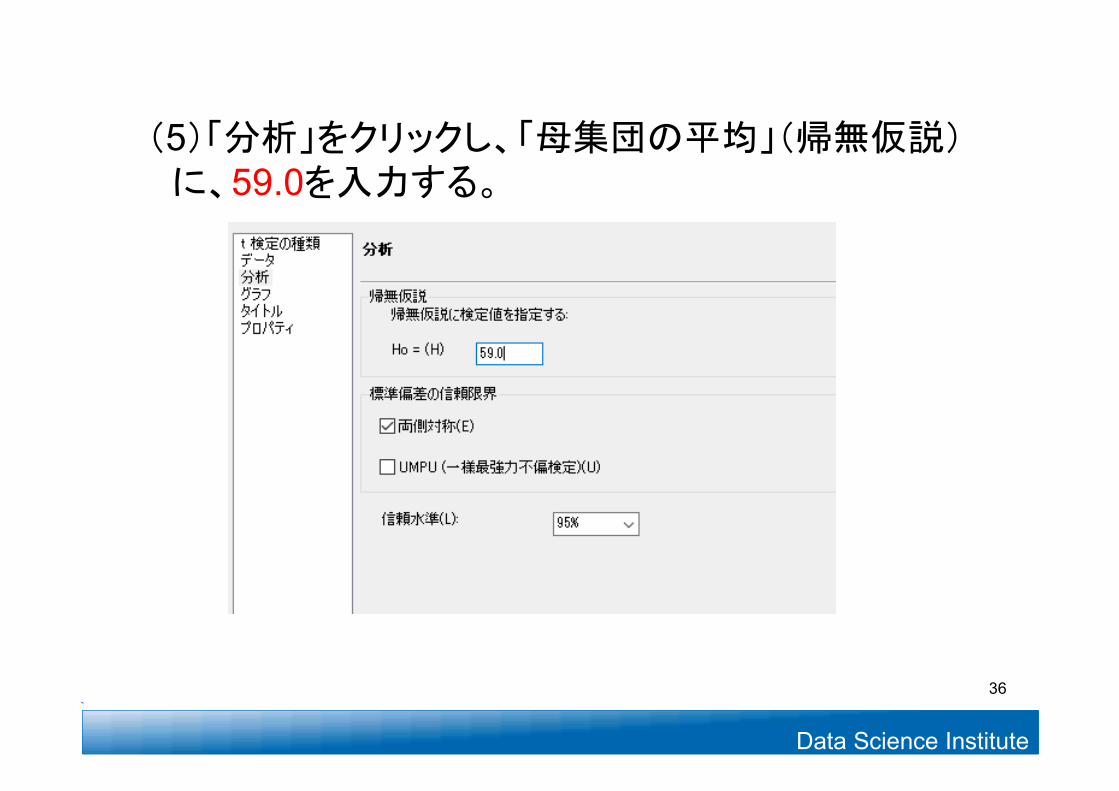
Data Science Institute
(5)「分析」をクリックし、「母集団の平均」(帰無仮説)に、59.0を入力する。
36

Data Science Institute
有意確率= 0.0049 < 0.0414t値 = 3.70 > 2.38
37
EG

Data Science Institute
ランダムに選んだ製品10個の有効成分含有量母平均:60mg 違いはみられるか?
64 62 55 61 60 59 63 66 65 63
10個の平均値を求めると(64+62+・・・+60+63)÷10 = 61.8
標本平均(61.8)と母平均(60.0)は異なる?
64 62 58 61 60 59 63 66 62 63
(C)標本のバラツキ(標準偏差)が拡大した場合
38
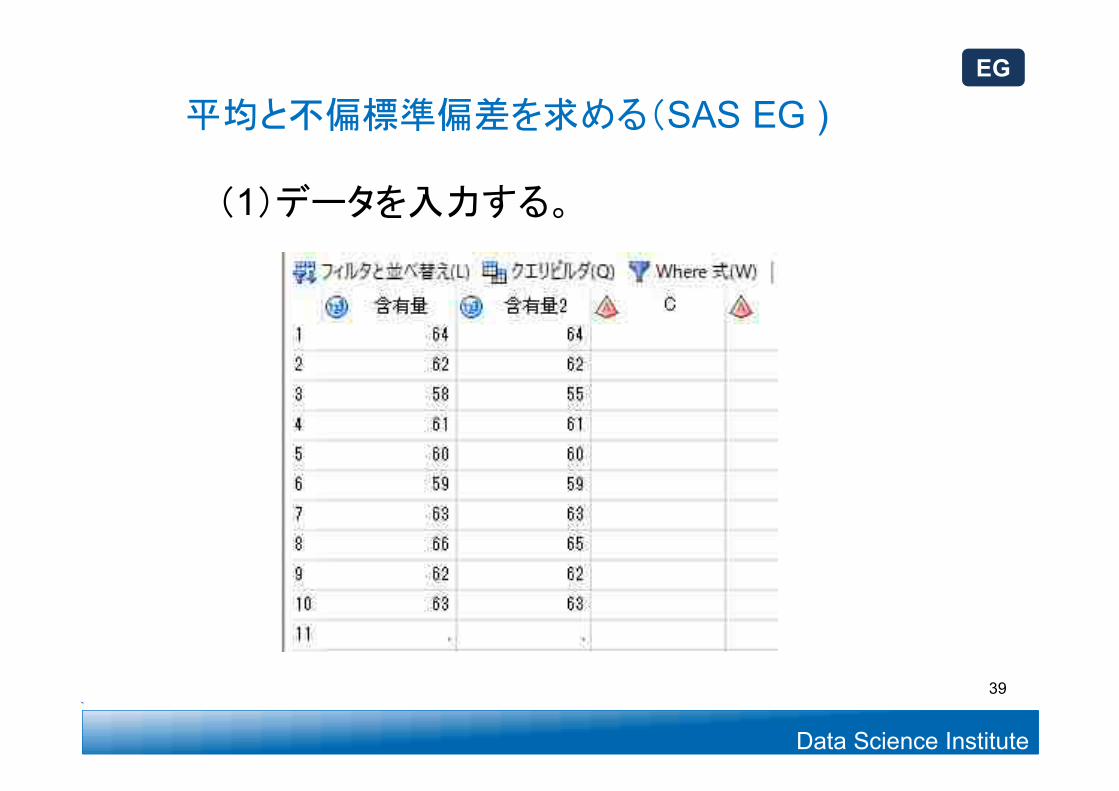
Data Science Institute
(1)データを入力する。
平均と不偏標準偏差を求める(SAS EG )
39
EG
Data Science Institute
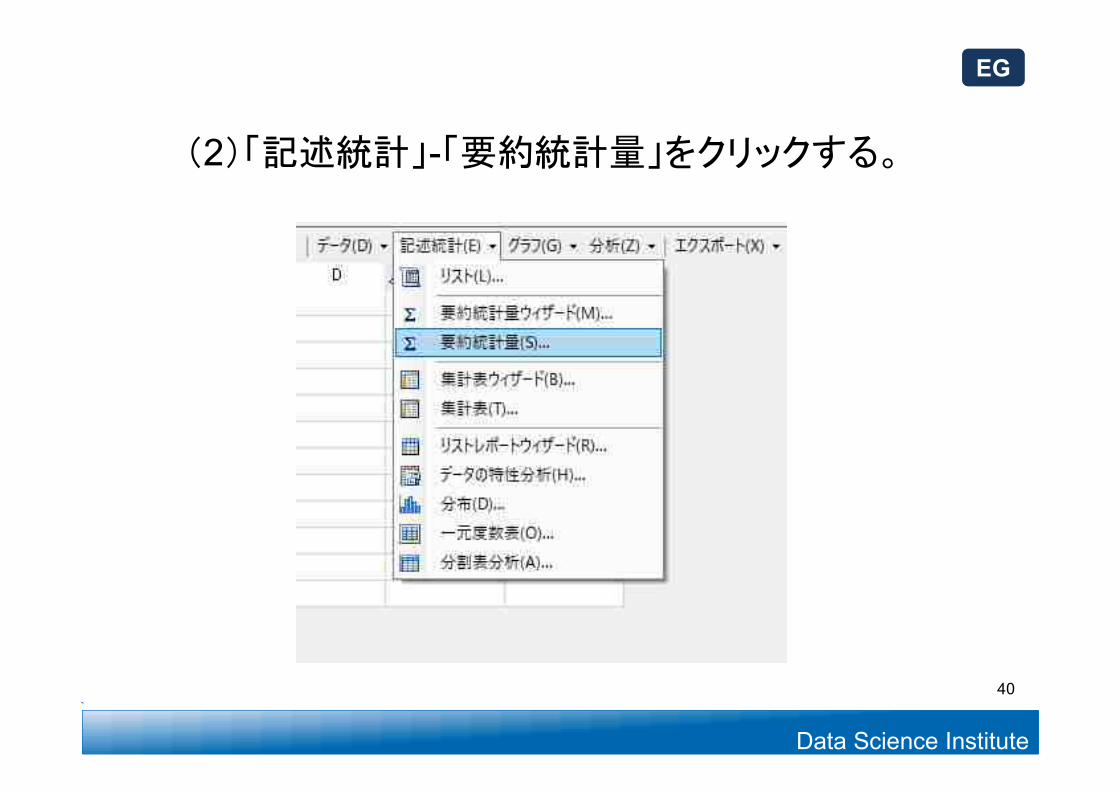
(2)「記述統計」-「要約統計量」をクリックする。
40
EG
Data Science Institute
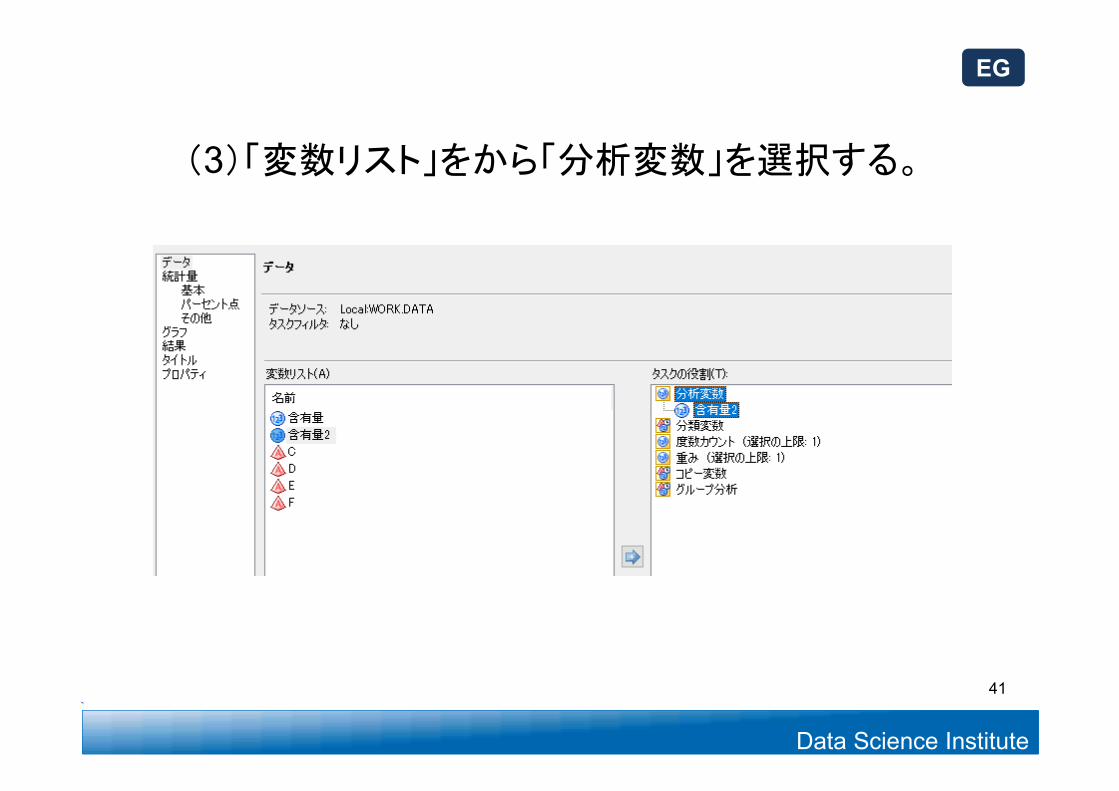
(3)「変数リスト」をから「分析変数」を選択する。
41
EG
Data Science Institute
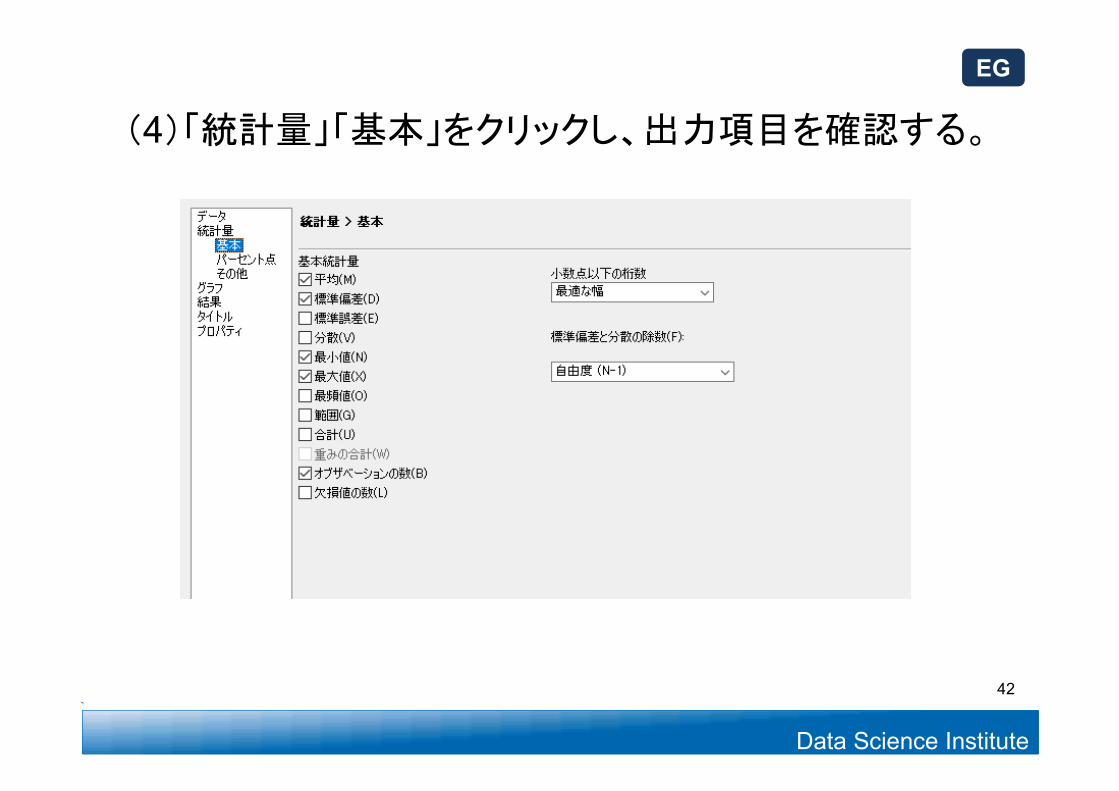
(4)「統計量」「基本」をクリックし、出力項目を確認する。
42
EG

Data Science Institute
不偏標準偏差= 3.225 > 2.394平均= 61.8
43
EG

Data Science Institute
標本の平均-母集団の平均
標本の不偏標準偏差t値 = × √ n
61.8 - 60.03.225 × √ 10
= 1.77 < 2.38
=
44

Data Science Institute
有意確率= 0.1114> 0.0414t値 = 1.77 < 2.38
45
EG

Data Science Institute
ランダムに選んだ製品20個の有効成分含有量母平均:60mg 違いはみられるか?
64 62 58 61 60 59 63 66 62 6364 62 58 61 60 59 63 66 62 63
20個の平均値を求めると(64+62+・・・+60+63)÷10 = 61.8
標本平均(61.8)と母平均(60.0)は異なる?
(D)標本サイズが拡大した場合
46

Data Science Institute
平均と不偏標準偏差を求める(SAS EG )
不偏標準偏差= 2.331平均= 61.8
47
EG

Data Science Institute
標本の平均-母集団の平均
不偏標準偏差t値 = × √ n
61.8 - 60.02.331 × √ 20
= 3.45 > 2.38
=
48

Data Science Institute
有意確率= 0.0027 < 0.0414
t値 = 3.45 > 2.38
49
EG

Data Science Institute
1標本t検定のまとめ
標本の平均-母集団の平均
標本の不偏標準偏差t値 = × √ n
(B)標本の平均と母集団の平均の差が大 ⇒ t値は大(C)標本のバラツキ(不偏分散)が大 ⇒ t値は小(D)標本サイズが大 ⇒ t値は大
t値が大=有意確率(危険率)は小
t値が小=有意確率(危険率)は大
50

Data Science Institute
男女の平均値の差に違いは見られるか?
男性 6 4 5 5 6 5 6 6 4 6 5.3 女性 7 6 7 5 6 5 6 7 6 6 6.1
平均
2標本t検定(2群の平均値の差の検定)
(A) 商品のパッケージの好感度について、男女各10人に10点満点にて調査した。男女間に評価の差は見られるか。
51
商品パッケージの男女別好感度の比較

Data Science Institute
男性の平均-女性の平均√男性の不偏分散+女性の不偏分散
t値=
◇1標本t検定
◇2標本t検定
標本の平均-母集団の平均
標本の不偏標準偏差t値 = × √ n
52
× √ n

Data Science Institute
2標本t検定(SAS EG)
(1)データを入力する。
53
EG
Data Science Institute
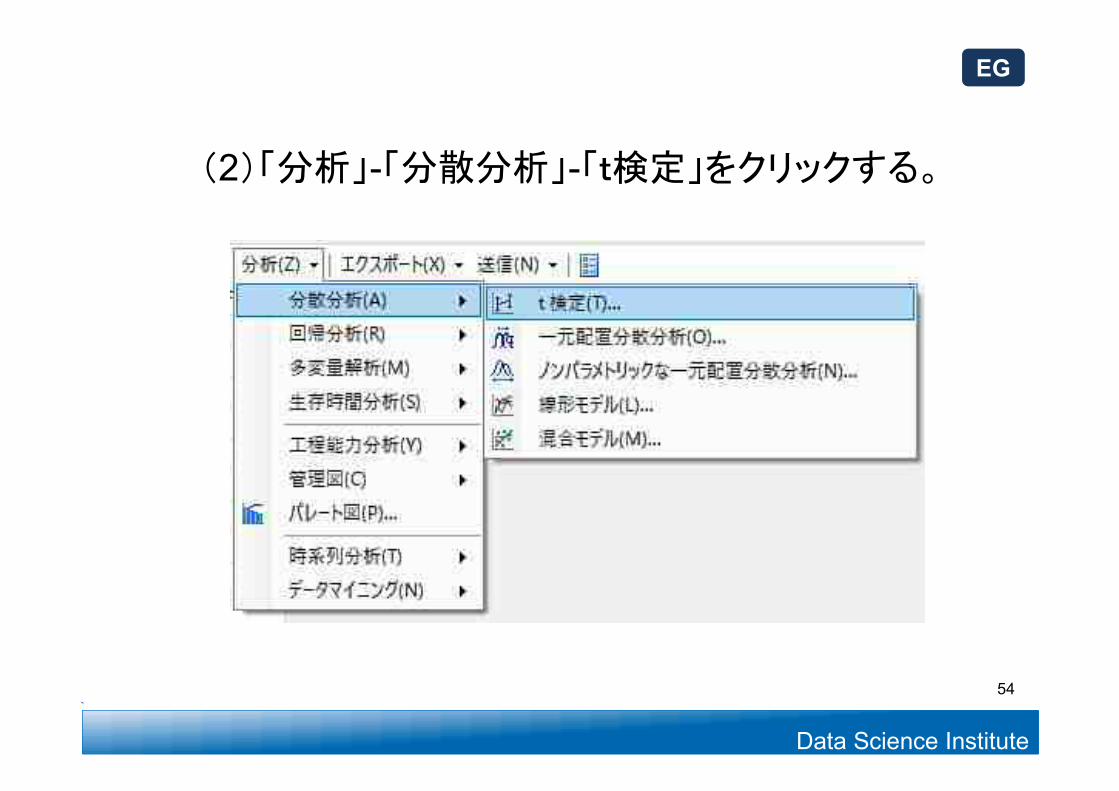
(2)「分析」-「分散分析」-「t検定」をクリックする。
54
EG
Data Science Institute
(3)「2標本に対する検定」を選択する。
55
EG
Data Science Institute
(4)「分類変数」と「分析変数」を指定する。
56
EG

Data Science Institute
◇分散が違うとは言えないとき有意確率=0.0344
◇分散が違うとき有意確率=0.0346
57
EG

Data Science Institute
有意水準5%において、男女間の好感度に違いが見られる。(有意水準5%において、有意である。)
有意確率=0.0346 < 0.05(有意水準)
有意確率(危険率)の判定
<男女別好感度調査 2標本t検定の結果>有意確率(危険率)=0.0346
58

Data Science Institute
男性 6 4 5 5 6 5 6 6 4 6 5.3 女性 7 6 7 6 6 6 6 7 6 6 6.3
平均値
男女の平均値の差に違いは見られるか?
(B)平均値の差が拡大したとき
商品のパッケージの好感度について、男女各10人に10点満点にて調査した。男女間に評価の差は見られるか。
59
Data Science Institute
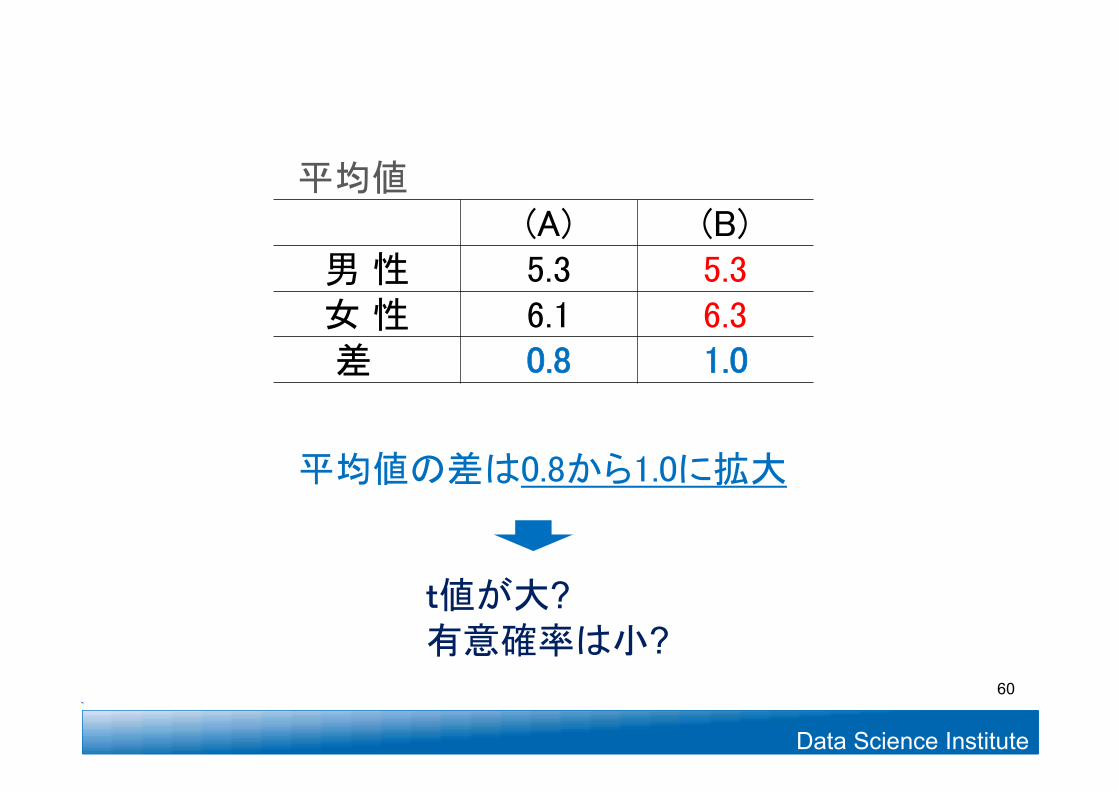
平均値(A) (B)
男 性 5.3 5.3女 性 6.1 6.3差 0.8 1.0
平均値の差は0.8から1.0に拡大
有意確率は小?t値が大?
60

Data Science Institute
t値=3.31 > 2.29
有意確率=0.0049 < 0.0346
61
EG

Data Science Institute
男性 7 3 8 3 7 2 2 6 6 9 5.3女性 7 4 9 3 8 3 5 8 7 9 6.3
平均値
男女の平均値の差に違いは見られるか?
(C)データのバラツキが拡大したとき
商品のパッケージの好感度について、男女各10人に10点満点にて調査した。男女間に評価の差は見られるか。
62
Data Science Institute
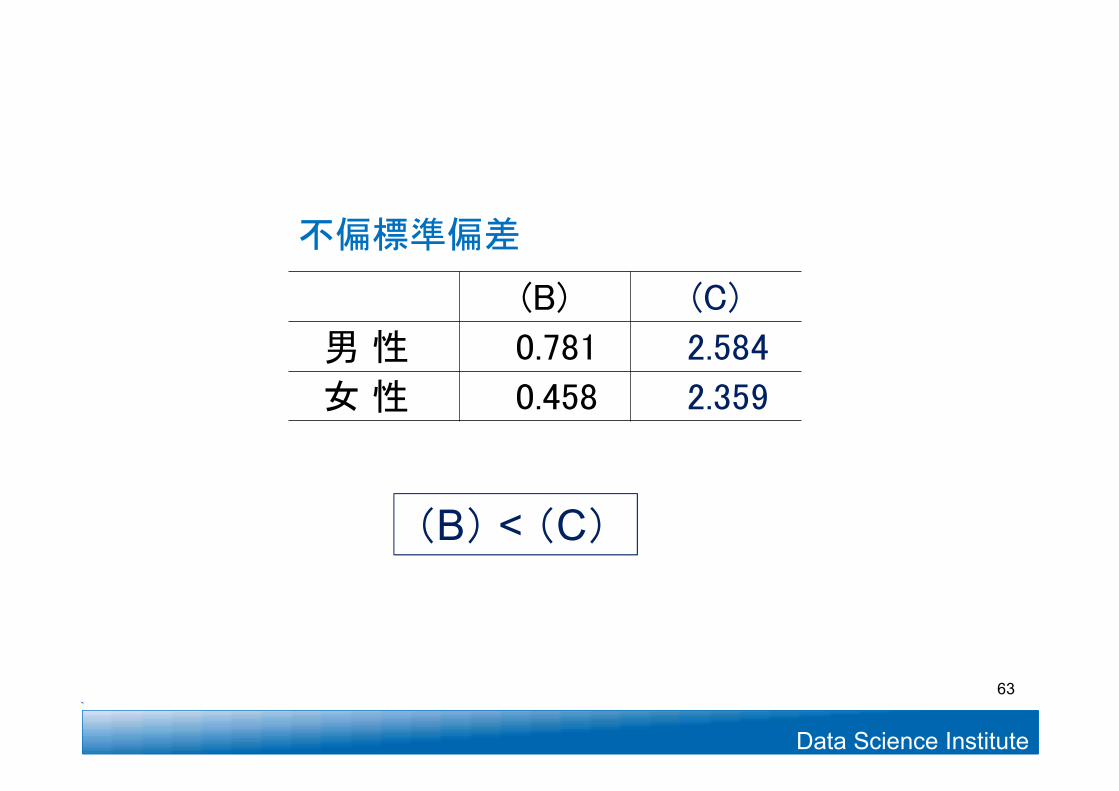
(B) (C)
男 性 0.781 2.584
女 性 0.458 2.359
(B) < (C)
不偏標準偏差
63

Data Science Institute
t値= 0.90 < 3.31
有意確率= 0.3782 > 0.0049
64
EG

Data Science Institute
商品のパッケージの好感度について、男女各20人に10点満点にて調査した。男女間に評価の差は見られるか。
男女の平均値の差に違いは見られるか?
(D)標本サイズが拡大したとき
男女各10人から男女各20人に増加
7 3 8 3 7 2 2 6 6 97 3 8 3 7 2 2 6 6 97 4 9 3 8 3 5 8 7 97 4 9 3 8 3 5 8 7 9
5.3
6.3
男性
女性
65

Data Science Institute
t値= 1.31 > 0.90
有意確率= 0.1971 < 0.3782
66
EG

Data Science Institute
説明前 7 3 8 3 7 2 2 6 6 9 5.3
説明後 7 4 9 3 8 3 5 8 7 9 6.3
平均値
商品の理解度について、10人に商品説明前後に、それぞれ10点満点にて調査した。説明前後による理解度に差は見られるか。
2標本t検定?
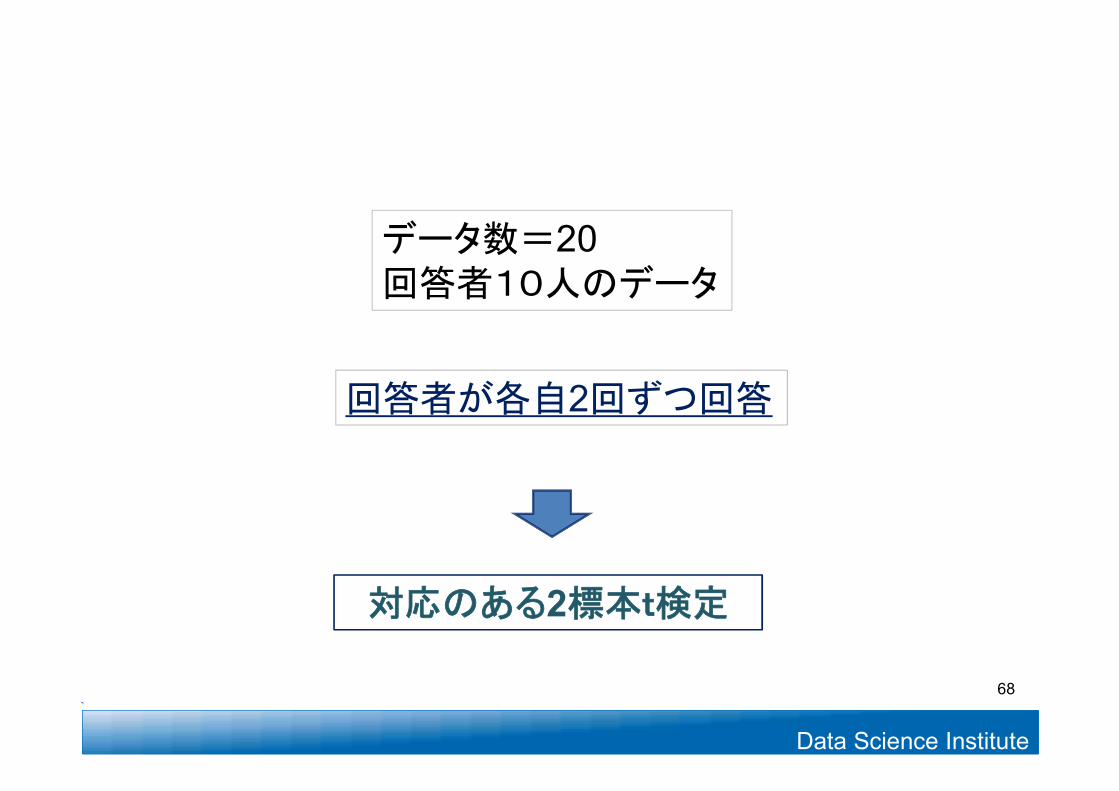
対応のある2標本の検定
67
商品の説明前後による理解度の比較
Data Science Institute
データ数=20回答者10人のデータ
回答者が各自2回ずつ回答
対応のある2標本t検定
68

Data Science Institute
(1)データを入力する。
対応のある2標本t検定(SAS EG)
69
EG
Data Science Institute
(2)「分析」-「分散分析」-「t検定」をクリックする。
70
EG

Data Science Institute
(3)「対応のある検定」を選択する。
71
EG
Data Science Institute
(4)「対応のある変数」を指定する。
72
EG

Data Science Institute
有意確率= 0.0085t値 = 3.35
73
EG

Data Science Institute
対応の有無による有意確率の比較
有意確率は「対応のある場合」の方が小さい!
(C)対応なし (D)対応ありt値 1.31 3.55
有意確率 0.3782 0.0085
74

Data Science Institute
平均値
説明前後の評価の差に着目
説明前 7 3 8 3 7 2 2 6 6 9 5.3 説明後 7 4 9 3 8 3 5 8 7 9 6.3 前後差 0 1 1 0 1 1 3 2 1 0 1.0
1標本t検定75
商品の理解度について、10人に商品説明前後に、それぞれ10点満点にて調査した。説明前後による理解度に差は見られるか。

Data Science Institute
1標本t検定(SAS EG)
(1)データを入力する。
76
EG

Data Science Institute
(2)「分析」-「分散分析」-「t検定」をクリックする。(3)「1標本に対する検定」を選択、「分析変数」を指定する。(4)「分析」をクリックし、「母平均」を入力する。
77
EG

Data Science Institute
対応のある2標本t検定=差に着目した1標本t検定78
EG

Data Science Institute
◇1標本t検定
標本の平均-母集団の平均
標本の不偏標準偏差t値 = × √ n
= 効果量
効果量
× √ n
t値は標本サイズに影響を受ける
79
Data Science Institute
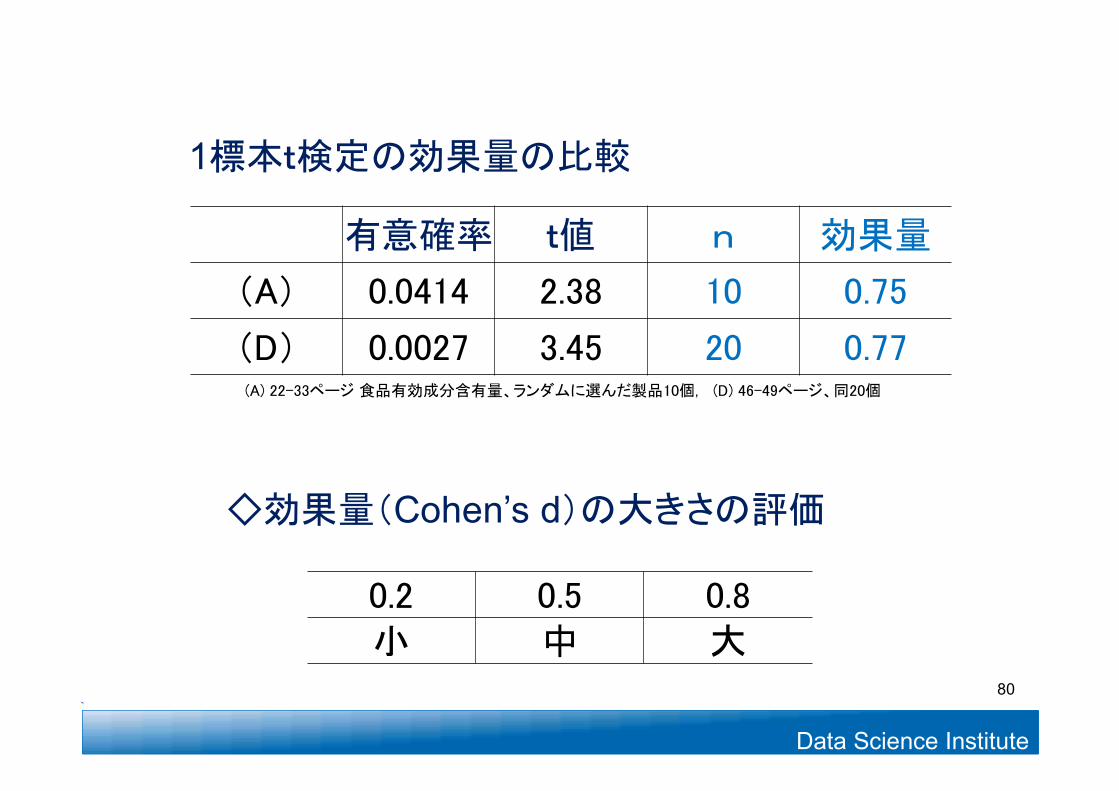
◇効果量(Cohen’s d)の大きさの評価
有意確率 t値 n 効果量
(A) 0.0414 2.38 10 0.75
(D) 0.0027 3.45 20 0.77
1標本t検定の効果量の比較
0.2 0.5 0.8小 中 大
80
(A) 22-33ページ 食品有効成分含有量、ランダムに選んだ製品10個, (D) 46-49ページ、同20個
Data Science Institute
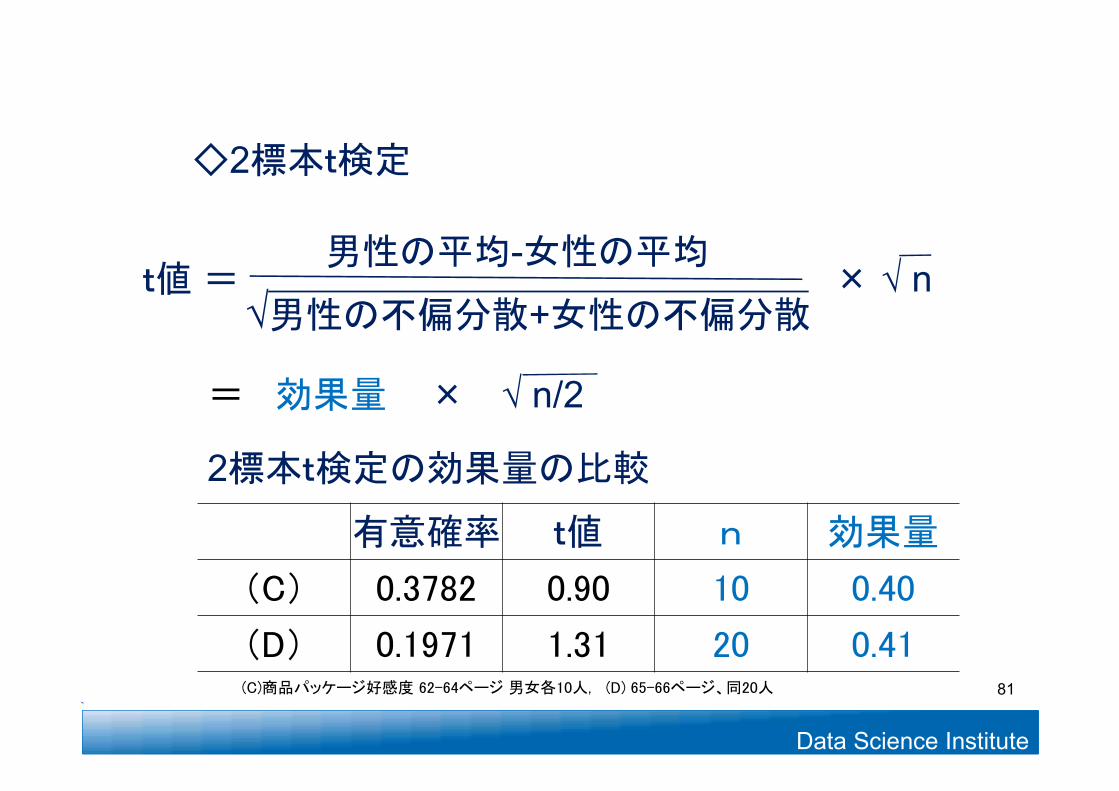
有意確率 t値 n 効果量
(C) 0.3782 0.90 10 0.40
(D) 0.1971 1.31 20 0.41
◇2標本t検定
男性の平均-女性の平均√男性の不偏分散+女性の不偏分散
t値=
= 効果量 × √ n/2
2標本t検定の効果量の比較
81(C)商品パッケージ好感度 62-64ページ 男女各10人, (D) 65-66ページ、同20人
× √ n

Data Science Institute
2)効果量の大きさ
1)有意確率 (危険率)
有意確率が小さい 差が大きい
有意確率と効果量について検討する。
標本数に比例して t値は大きくなる。=標本数に比例して有意確率は小さくなる。
検定結果の検討
82
Data Science Institute
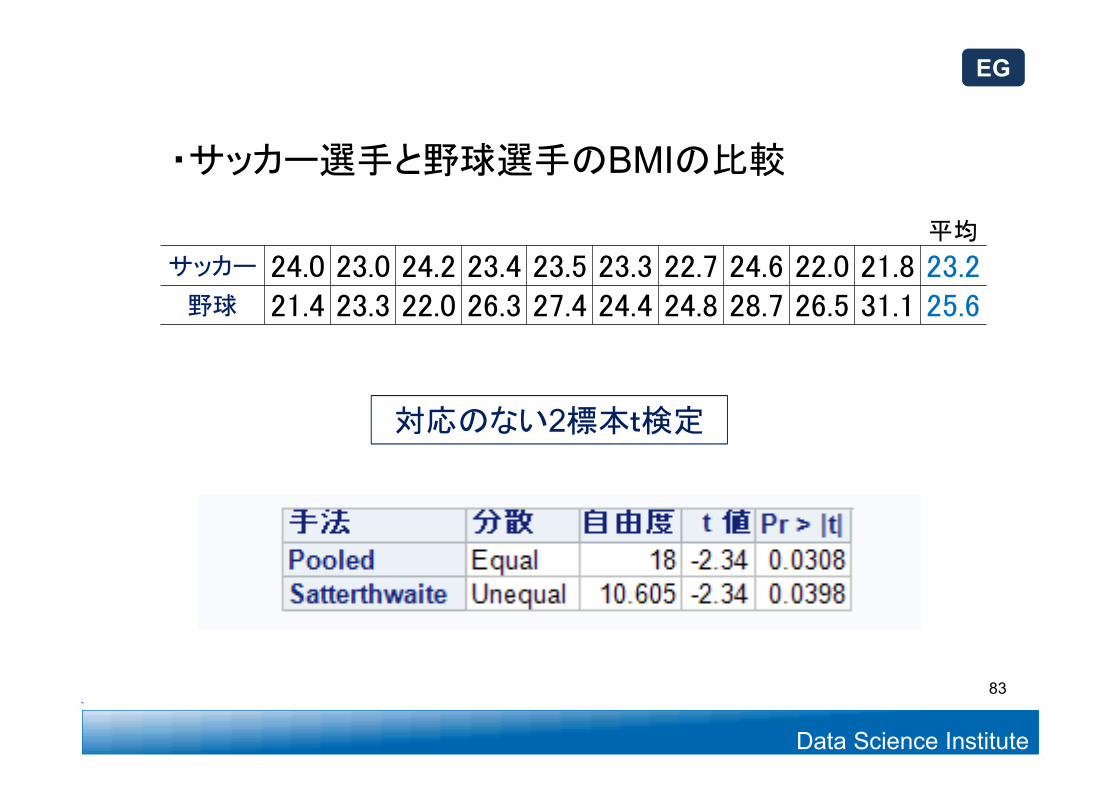
・サッカー選手と野球選手のBMIの比較
平均
サッカー 24.0 23.0 24.2 23.4 23.5 23.3 22.7 24.6 22.0 21.8 23.2 野球 21.4 23.3 22.0 26.3 27.4 24.4 24.8 28.7 26.5 31.1 25.6
対応のない2標本t検定
83
EG

Data Science Institute
・サッカー選手HとKの実績比較(過去10試合)平均
H 7.0 5.5 6.0 5.0 7.0 6.5 6.5 7.0 6.0 5.0 6.2 K 6.5 6.0 5.0 4.5 6.5 6.5 5.0 7.0 4.5 5.0 5.7
対応のある2標本t検定
対応のない2標本t検定
84
EG

Data Science Institute
カイ二乗検定サイコロを60回振ったところ次の様になった。このサイコロは正常に作られているでしょうか。
1の目が出た回数 82の目が出た回数 133の目が出た回数 84の目が出た回数 65の目が出た回数 146の目が出た回数 11合 計 60
正常ではないと判断したときの危険率85
サイコロの出る目の妥当性
Data Science Institute
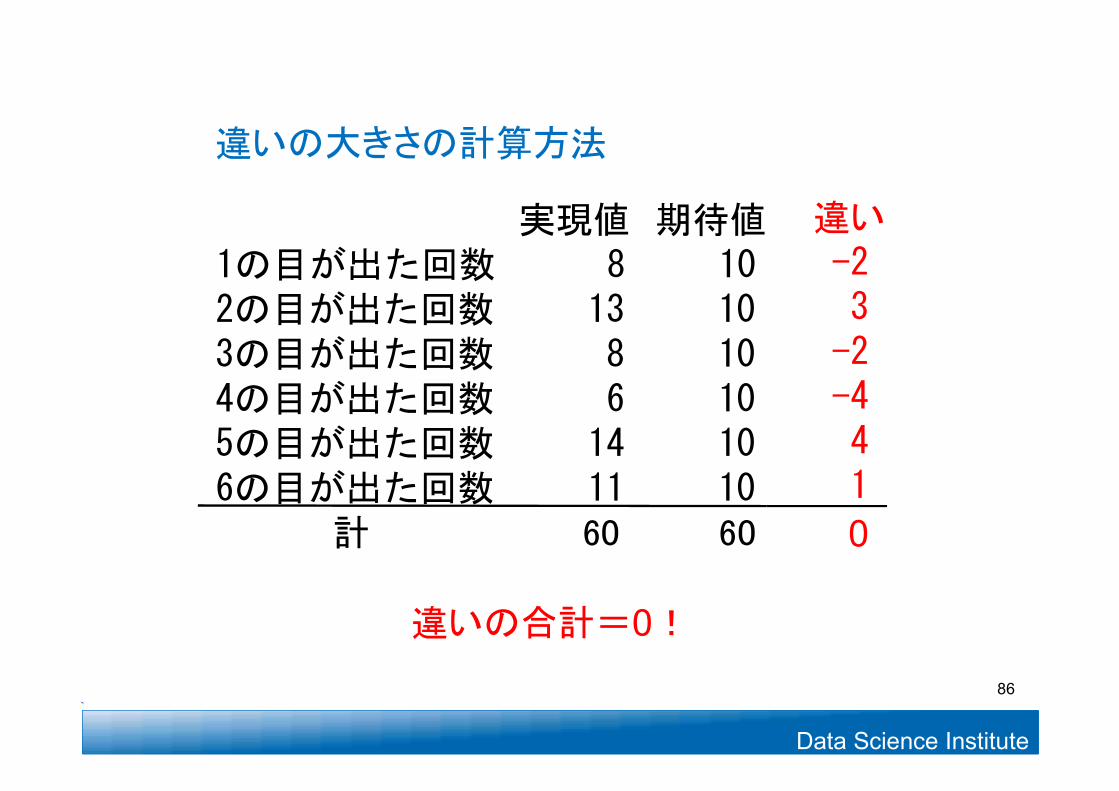
実現値 期待値1の目が出た回数 8 102の目が出た回数 13 103の目が出た回数 8 104の目が出た回数 6 105の目が出た回数 14 106の目が出た回数 11 10
計 60 60
違いの大きさの計算方法
0
違いの合計=0!
違い-23-2-441
86
Data Science Institute
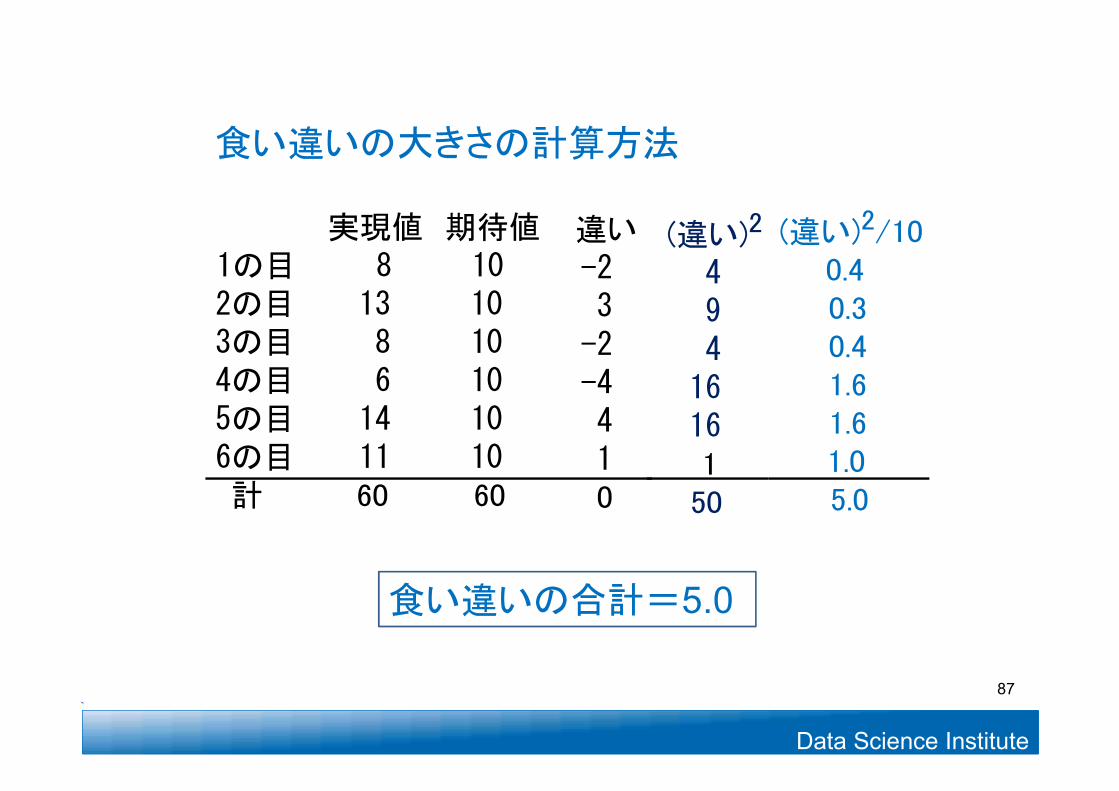
実現値 期待値1の目 8 102の目 13 103の目 8 104の目 6 105の目 14 106の目 11 10 計 60 60
食い違いの大きさの計算方法
食い違いの合計=5.0
違い-23-2-4410
(違い)2
4941616150
(違い)2/100.40.30.41.61.61.05.0
87

Data Science Institute
期待値
食い違いの値をカイ2乗分布を利用して有意確率(危険率)を算出する
食い違い=(実現値-期待値)2
の合計
88
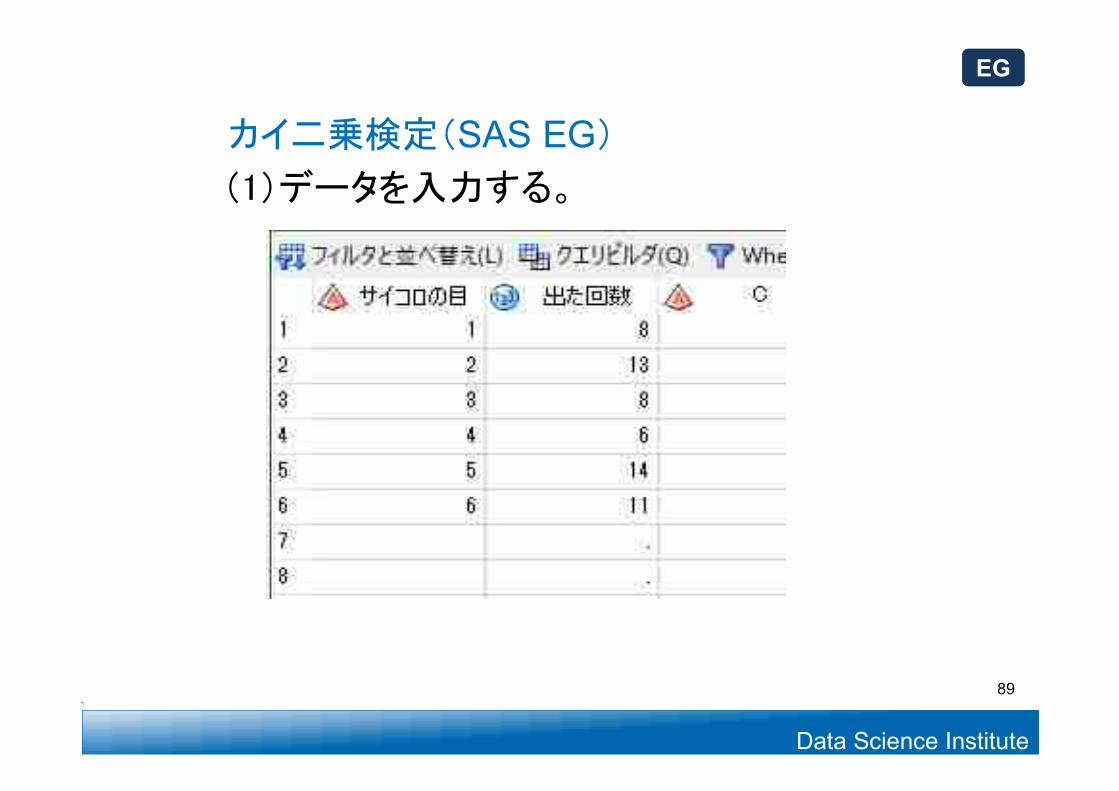
Data Science Institute
(1)データを入力する。
カイ二乗検定(SAS EG)
89
EG
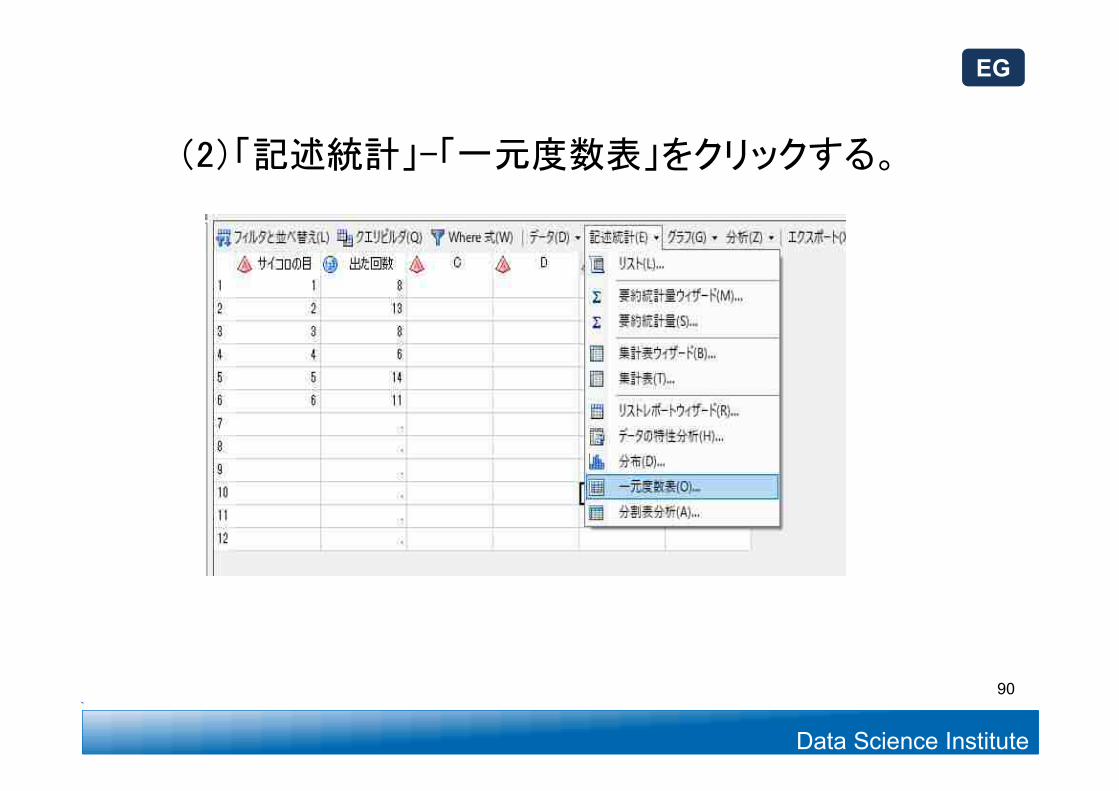
Data Science Institute
(2)「記述統計」-「一元度数表」をクリックする。
90
EG

Data Science Institute
(3)「サイコロの目」を「分析変数」、「出た回数」を「度数カウント」に指定する。
91
EG

Data Science Institute
(4)「統計量」をクリックし、「カイ二乗検定」-「漸近検定」を指定する。
92
EG

Data Science Institute
有意確率=0.415993
EG
Data Science Institute
カイ2乗分布
94

Data Science Institute
主力商品A、B2種類について、一般層と富裕層にA、Bどちらを選択するかについて調査した。違いは見られるか。
(人)
A B 計
一般層 60 40 100
富裕層 30 70 100
計 90 110 200
食い違い ⇒ カイ二乗検定
分割表の検定(カイ2乗検定)
95
階層(一般層・富裕層)と商品選択の関連
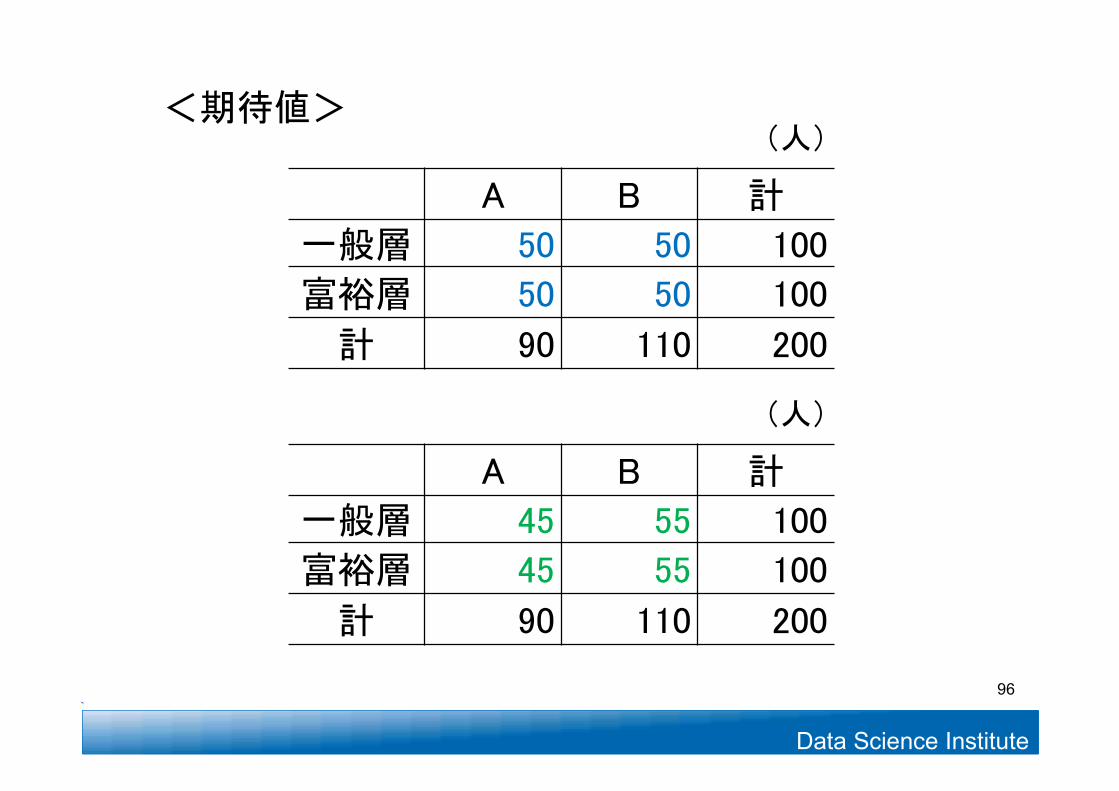
Data Science Institute
<期待値>
(人)
A B 計
一般層 45 55 100
富裕層 45 55 100
計 90 110 200
(人)
A B 計
一般層 50 50 100
富裕層 50 50 100
計 90 110 200
96

Data Science Institute
555540
454560 22
555570
454530 22
18.18 カイ2乗分布
食い違い=(実現値-期待値)2
期待値の合計
97

Data Science Institute
(1)データを入力する。
分割表の検定(SAS EG)
98
EG
Data Science Institute
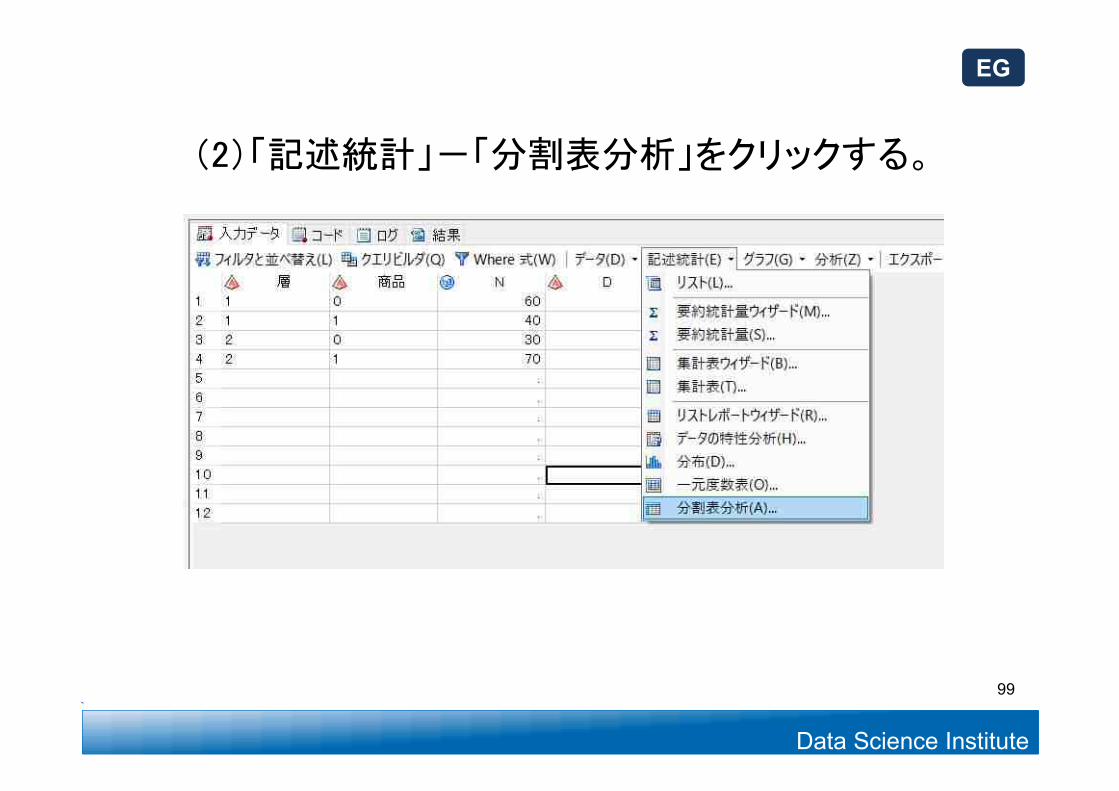
(2)「記述統計」-「分割表分析」をクリックする。
99
EG
Data Science Institute
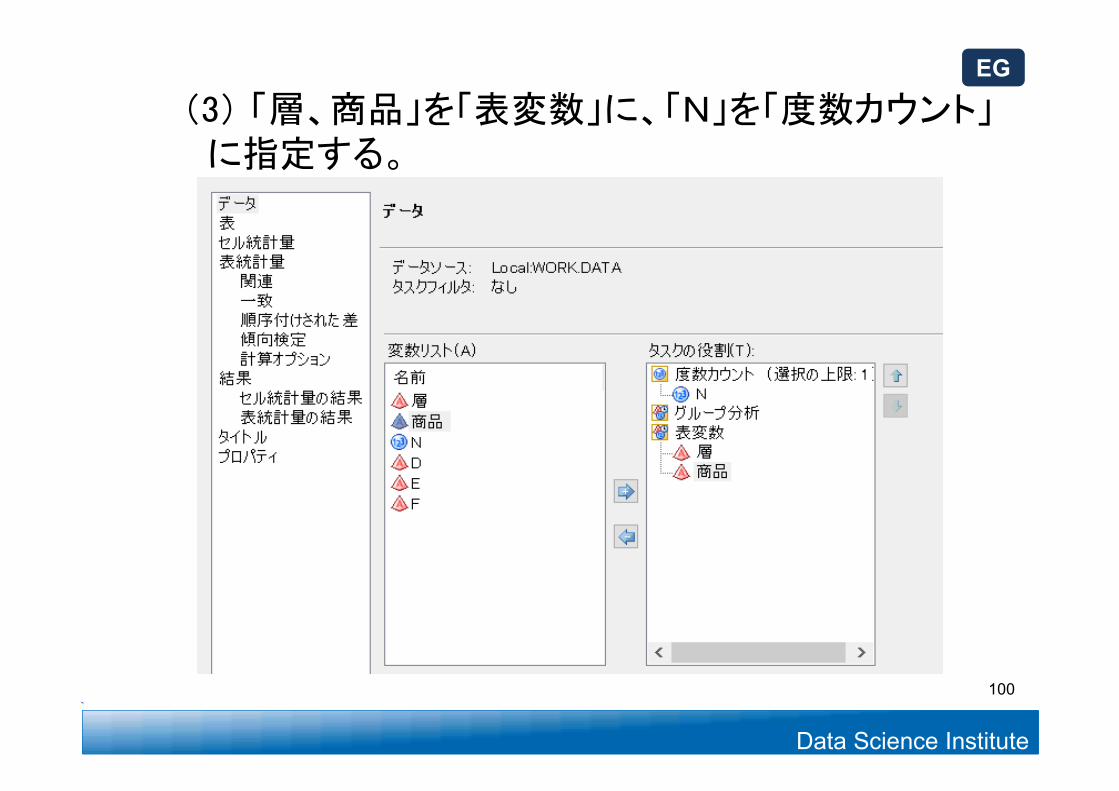
(3) 「層、商品」を「表変数」に、「N」を「度数カウント」に指定する。
100
EG

Data Science Institute
(4)「表」をクリックし、プレビューの表頭に「商品」、表側に「層」を指定する。
101
EG

Data Science Institute
(5)「表統計量」をクリックし、カイ二乗検定を選択し、実行する。
102
EG
Data Science Institute
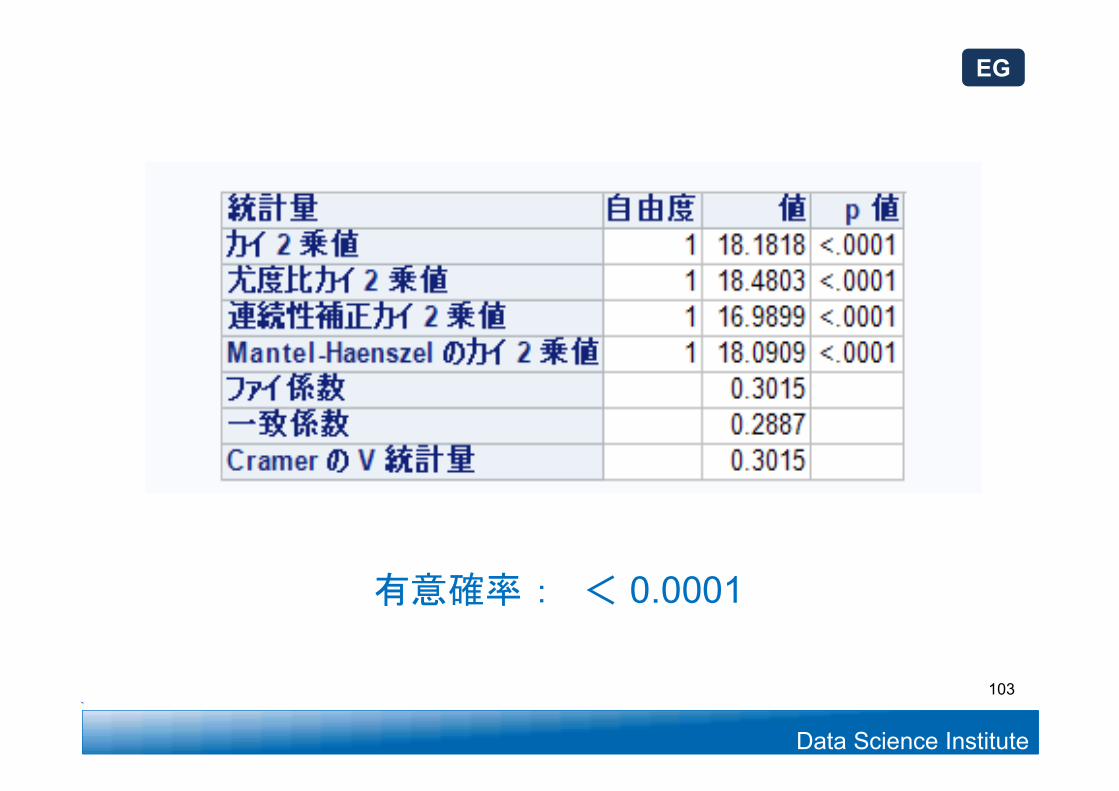
有意確率 : < 0.0001
103
EG
Data Science Institute
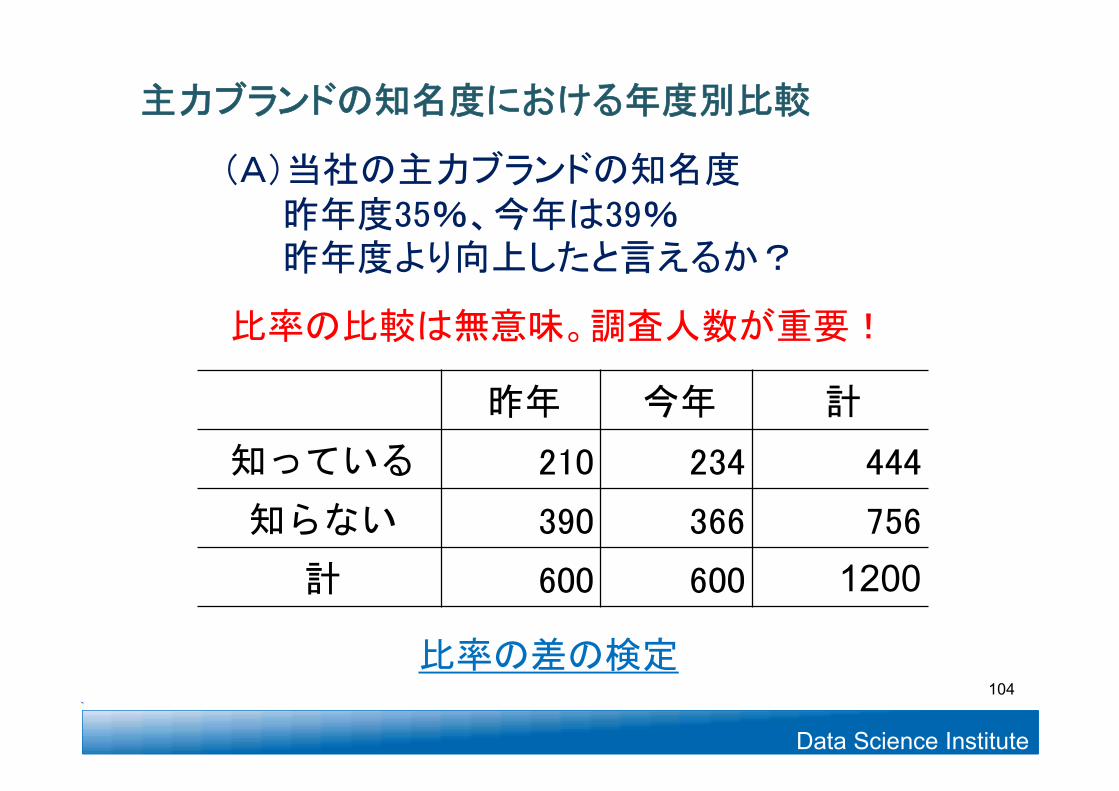
昨年 今年 計
知っている 210 234 444
知らない 390 366 756
計 600 600 1200
比率の比較は無意味。調査人数が重要!
比率の差の検定
(A)当社の主力ブランドの知名度昨年度35%、今年は39%昨年度より向上したと言えるか?
104
主力ブランドの知名度における年度別比較
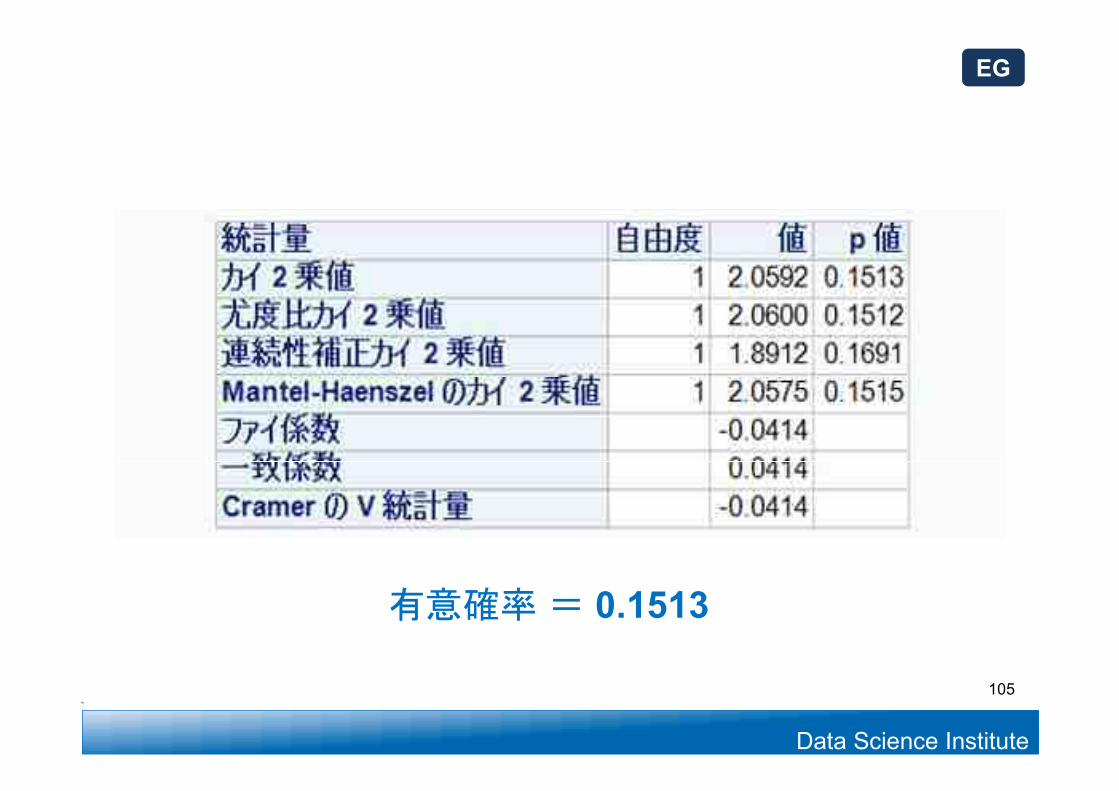
Data Science Institute
有意確率= 0.1513
105
EG
Data Science Institute
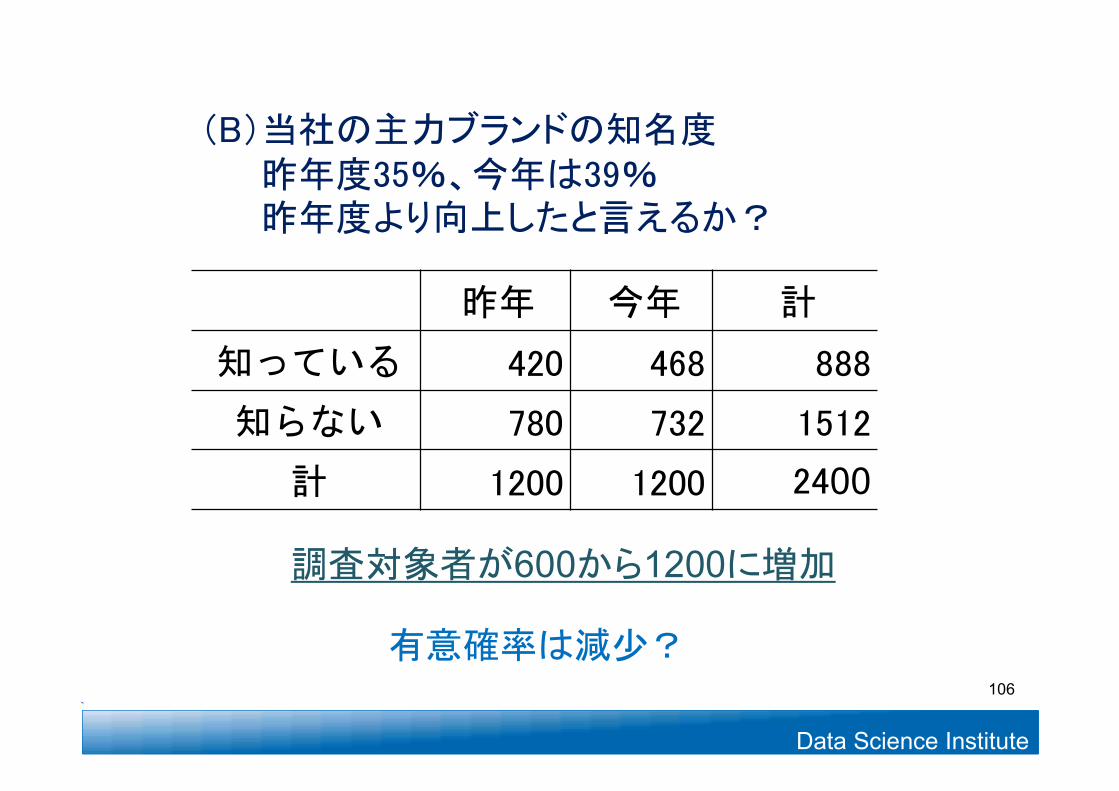
昨年 今年 計
知っている 420 468 888
知らない 780 732 1512
計 1200 1200 2400
調査対象者が600から1200に増加
(B)当社の主力ブランドの知名度昨年度35%、今年は39%昨年度より向上したと言えるか?
有意確率は減少?106
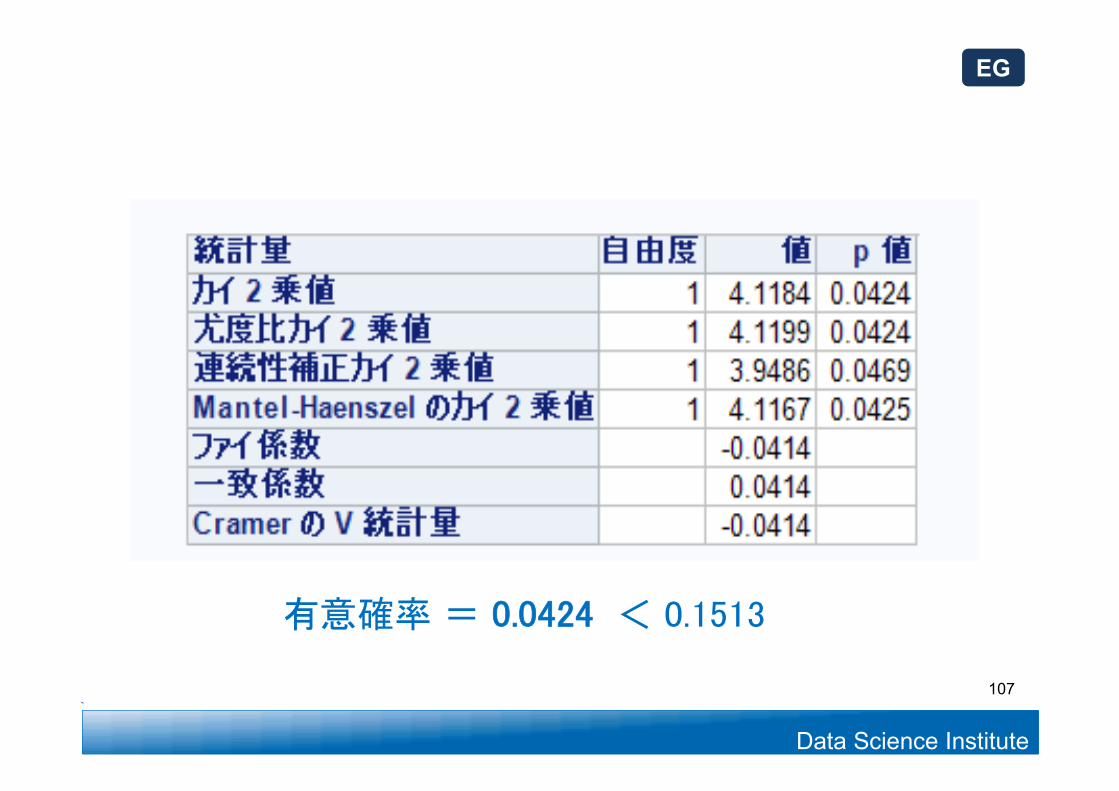
Data Science Institute
有意確率 = 0.0424 < 0.1513
107
EG
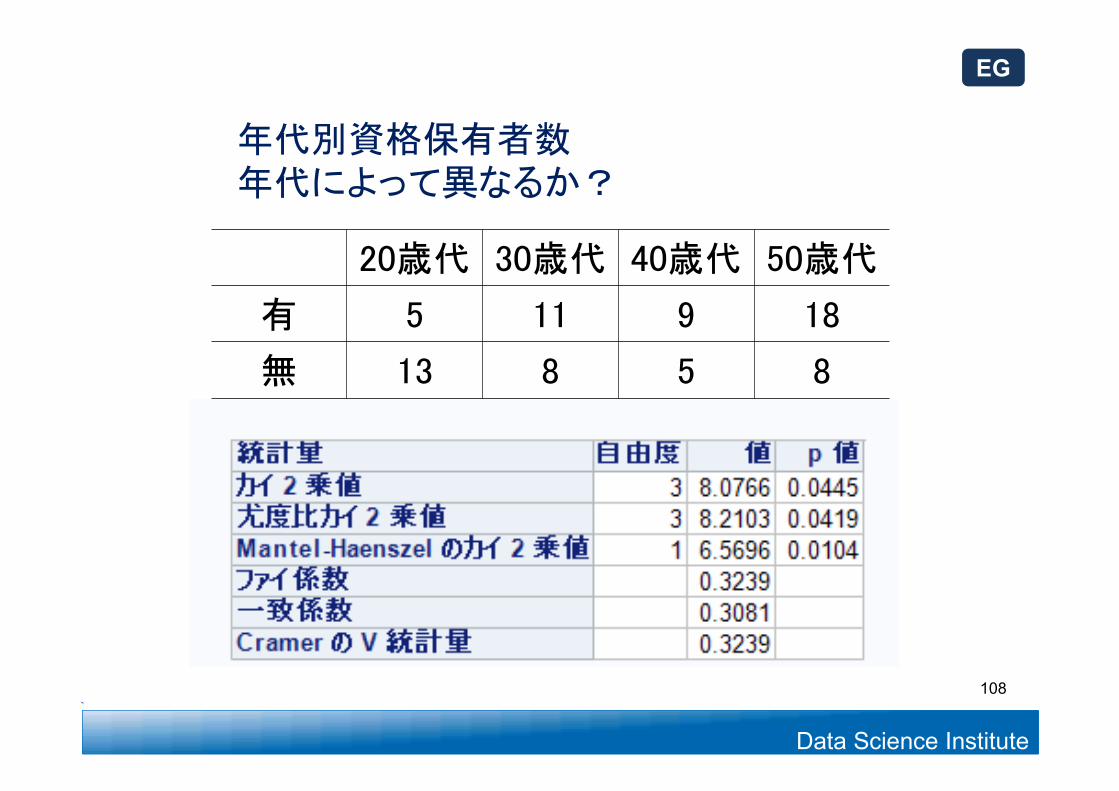
Data Science Institute
年代別資格保有者数年代によって異なるか?
20歳代 30歳代 40歳代 50歳代
有 5 11 9 18
無 13 8 5 8
108
EG
Data Science Institute
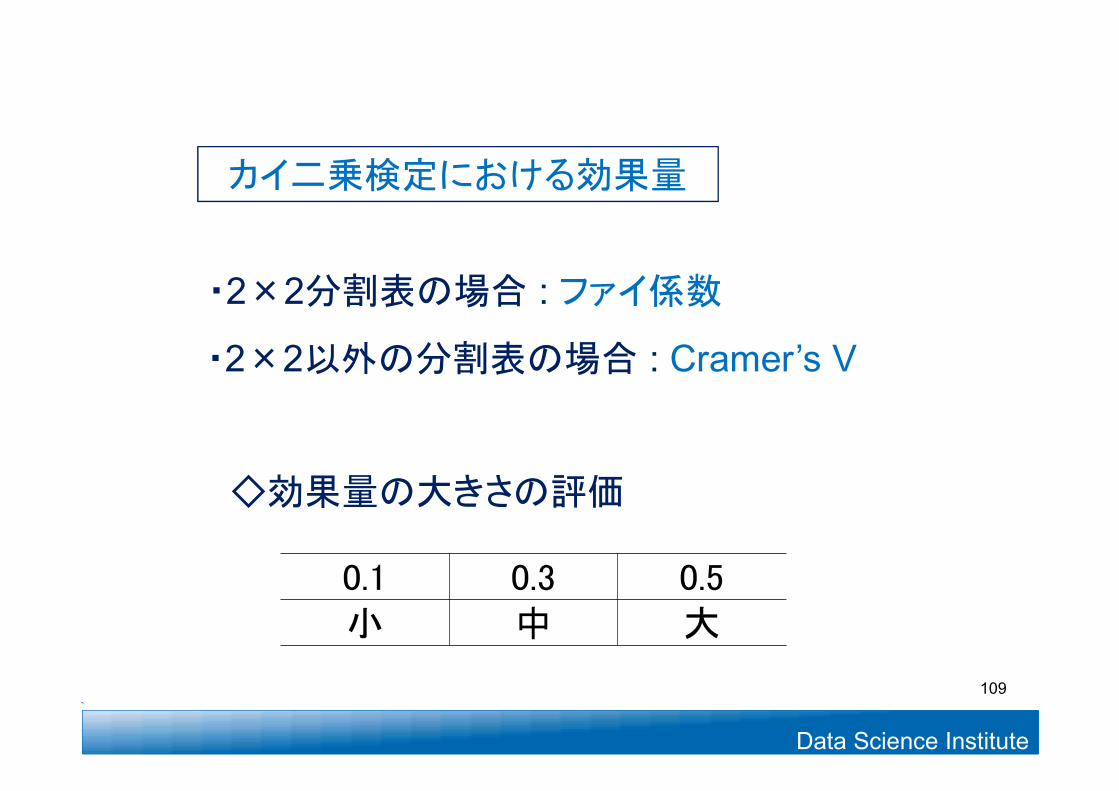
カイ二乗検定における効果量
・2×2分割表の場合 : ファイ係数
・2×2以外の分割表の場合 : Cramer’s V
0.1 0.3 0.5小 中 大
◇効果量の大きさの評価
109

Data Science Institute
まとめ
・統計的検定の考え方有意確率(危険率)、有意水準
・t検定1標本t検定2標本t検定(対応の有無)
・カイ二乗検定(分割表の検定)実現値、期待値
・有意確率と効果量
110
Recommended

















