page 1

page
1. 自己紹介 2. 新事業紹介 3. 回帰分析とは 4. 不動産価格推定の知見 5. まとめ
本日の流れ
2

page
1. 自己紹介
3

page 4

page
公開中のFluentdプラグイン
5
rewrite-tag-filter geoip mysql-replicator munin twitter anonymizer mysql-query
gamobile watch-process twilio sentry feedly

page
執筆書籍
6
サーバ/インフラエンジニア養成読本ログ収集~可視化編 [現場主導のデータ分析環境を構築!] (Software Design plus) 出版社/メーカー: 技術評論社 定価: 本体1,980円+税

page
2. 新事業紹介
7



サービスへの思い• 取引慣習が戦後から変わらないブラックボックスな不動産業界
• この問題を解決すべく、ビッグデータを活用した公平な情報を利用者に提供することで、不動産市場を活性化する
• 建物の中立評価や部屋毎の市場価格とその価格推移履歴を公開
• 適正価格が分かることで、安心したマンション選びを実現する
• 消費者が気軽に住み替えられる循環型社会を実現する




イエシルが提供するもの• ビッグデータを活用した、売買判断に必要な情報を提供!• 部屋ごとの市場価格をリアルタイム査定(特許出願中)!• 価格推移の可視化!• 物件に関する中立なレイティングデータ公開!• 利便性・治安・地盤情報など8項目!• 不動産の売買仲介サービスを提供

イエシルが解決する課題• 値付けの不透明性!• 現在売りに出ている物件だけを見て判断せざるを得ないため、相場より少し高めなのか安めなのか分かりにくい不透明性!
• 中古住宅流通の促進!• マンションの市場価値を知る敷居を下げることでの促進!• 売り時や買い時の判断材料を提供

特許出願中の価格査定システムの概要既知の価格査定システム 特許出願中の価格査定システム
手法取引事例比較法や収益還元法、原価法を用い、物件の価格を1件ごとに算出していた。
そのため、該当マンションにおける相対価値はミクロな形でしか知り得ない。
クロールした部屋情報を所在階ごとにまとめ、部屋ごとに値付けを行う。
その結果、該当マンションにおける相場を含めて、マクロに一望できる形で可視化する
係数 価格算出に用いる係数が少ない(所在階、広さ、方位等)
価格算出に影響する係数群がオープンデータ含め多岐にわたる
過去価格の可視化 現在の価格査定用に作られているため難しい 先進的な時間軸における価格形成モデルを構築
することで、過去価格の変動も可視化できる高級物件の査定
周辺・類似事例も少ない場合には、大きく外れることもある
パンフレット等から収集した新築価格も利用することで、納得感のある値付けを実現
査定モデルの安定性 ○ ○
不動産鑑定士の評価 ○ ○


page
3. 回帰分析とは
18

page
単回帰分析とは
19
x
y y=ax+b
) b: intercept(切片)
線形に1つの変数を用いて値を予測すること。 散布図にプロットし、その点からの距離が最小となるように描ける線を求めることが、単回帰分析の基本

page
単回帰分析とは
20
単回帰分析は右記の散布図とおり、それぞれの点からの距離が最小となるように描ける線を求めることです。 計算には通常、最小二乗法を利用します。

page
単回帰分析とは
21
iPhone 6sの価格査定モデルを作成してみましょう
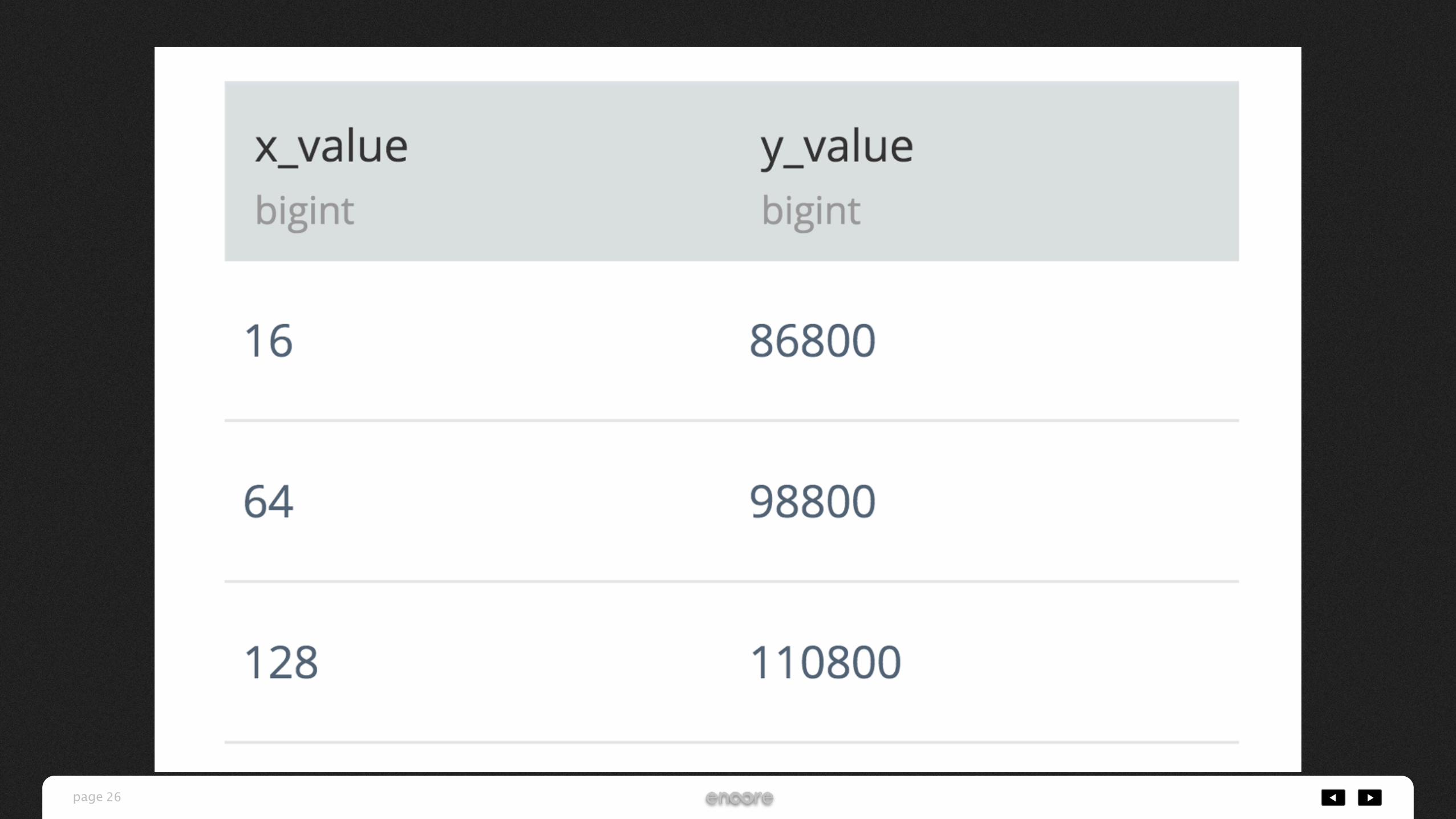
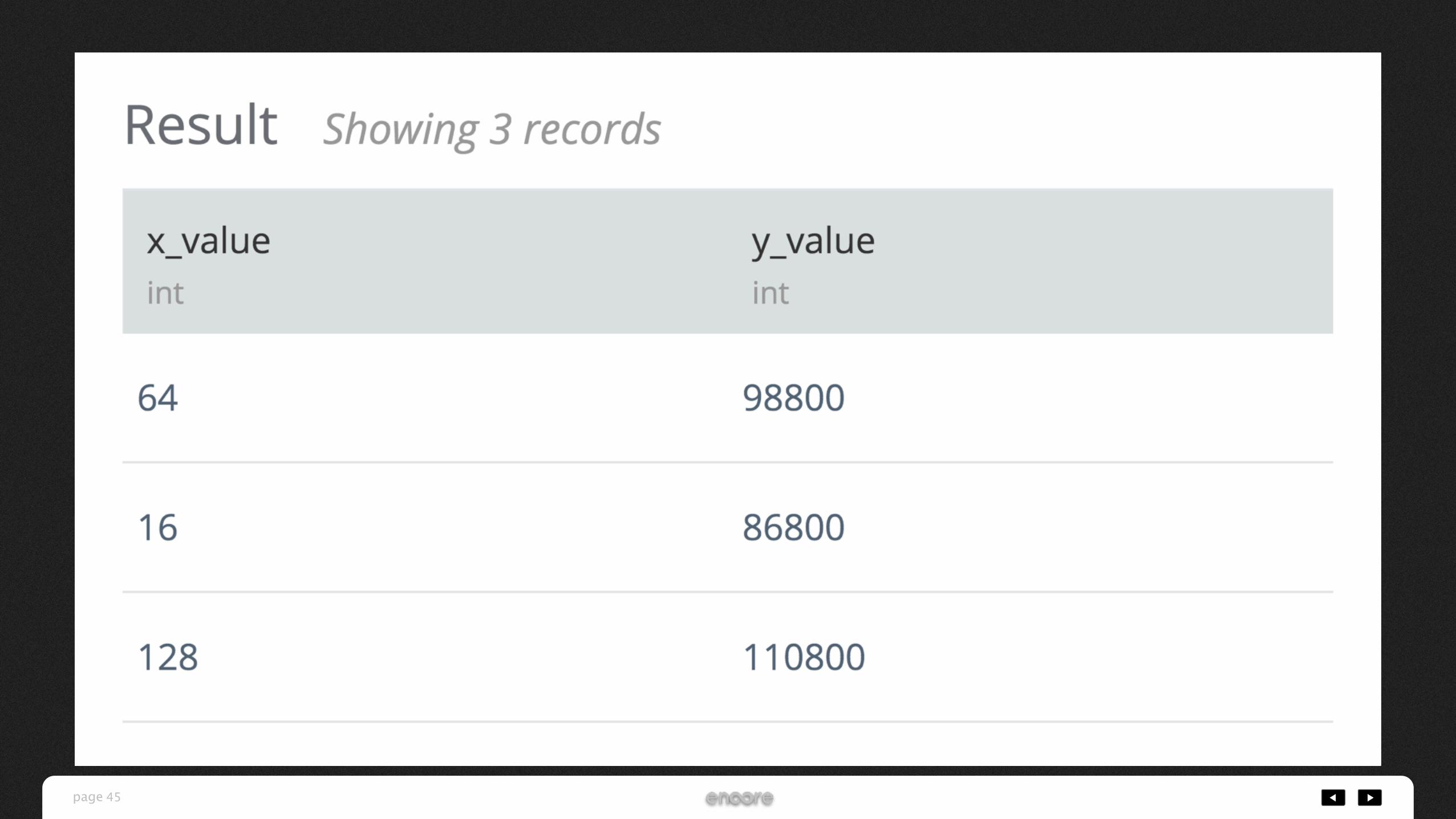
iPhone 6s 16GB:86,800円
iPhone 6s 64GB:98,800円
iPhone 6s 128GB:110,800円
iPhone 6s Plus 16GB:98,800円
iPhone 6s Plus 64GB:110,800円
iPhone 6s Plus 128GB:122,000円

page
まずは散布図にプロットします
22

page 23
128GBモデルがお得

page
SQLで線形回帰モデルを作成します
(PostgreSQL/Presto互換)
24

page 25
-- WITH句を使って、recordsという一時テーブルを用意WITH records AS ( -- size(x), price(y) SELECT * FROM ( VALUES (16, 86800), (64, 98800), (128, 110800) ) AS t (x_value, y_value))
page 26

page 27
-- 先ほどの結果を用いて、最小二乗法の事前計算を行う SELECT SUM(x_value) as sumx, SUM(y_value) as sumy, SUM(x_value*x_value) as sumxx, SUM(y_value*y_value) as sumyy, SUM(x_value*y_value) as sumxy, COUNT(1) as cnt FROM records

page 28

page 29
-- 最小二乗法の事前計算で求めた値を用いて、モデルを求めるSELECT bunshi_a / bunbo as slope, bunshi_b / bunbo as interceptFROM ( SELECT (cnt * sumxx - pow(sumx, 2)) AS bunbo, (cnt * sumxy - sumx * sumy) AS bunshi_a, (sumxx * sumy - sumxy * sumx) AS bunshi_b FROM prepare ) calc

page 30
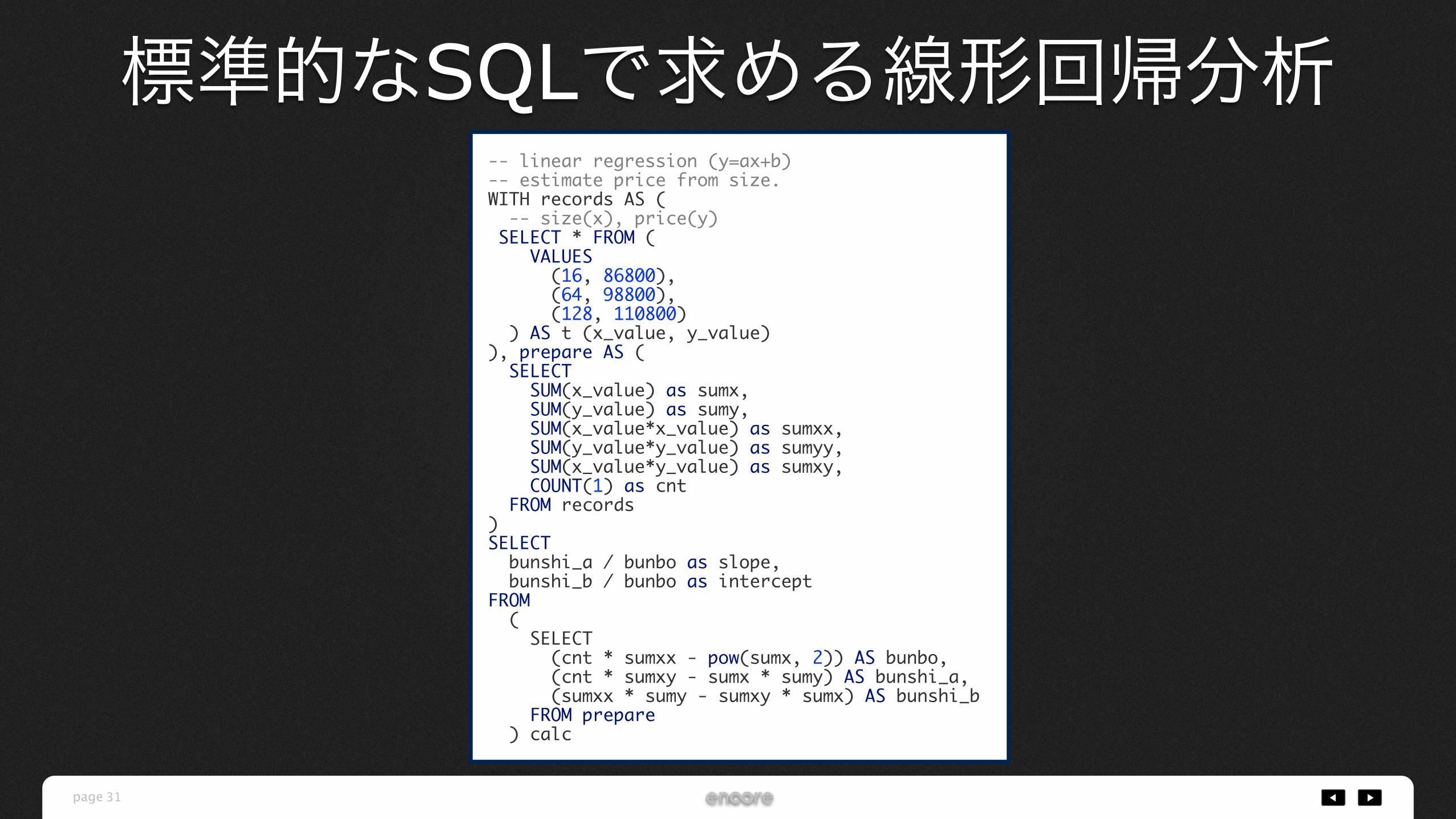
iPhone 6s price estimate model price = 212.83*size + 84043
page 31
-- linear regression (y=ax+b)-- estimate price from size.WITH records AS ( -- size(x), price(y) SELECT * FROM ( VALUES (16, 86800), (64, 98800), (128, 110800) ) AS t (x_value, y_value)), prepare AS ( SELECT SUM(x_value) as sumx, SUM(y_value) as sumy, SUM(x_value*x_value) as sumxx, SUM(y_value*y_value) as sumyy, SUM(x_value*y_value) as sumxy, COUNT(1) as cnt FROM records)SELECT bunshi_a / bunbo as slope, bunshi_b / bunbo as interceptFROM ( SELECT (cnt * sumxx - pow(sumx, 2)) AS bunbo, (cnt * sumxy - sumx * sumy) AS bunshi_a, (sumxx * sumy - sumxy * sumx) AS bunshi_b FROM prepare ) calc
標準的なSQLで求める線形回帰分析

page
price = 212.83*size + 84043
32
iPhone 6sの回帰モデルを用いた価格査定
iPhone 6s 16GB:86,800円
87,448円(誤差0.7%) = 212.83*16 + 84043
iPhone 6s 64GB:98,800円
97,664円(誤差1.1%) = 212.83*64 + 84043
iPhone 6s 128GB:110,800円
111,272円(誤差0.4%) = 212.73*128 + 84043

page 33
線形回帰モデルは、点との距離が最小となるような線
128GBのみ少し値付けが違う

page
Prestoの標準UDFを利用する例
34

page
Prestoでも単回帰分析が出来る
35
Presto v0.104より対応https://prestodb.io/docs/current/functions/aggregate.html
regr_intercept() … 傾きを計算する
regr_slope() … 切片を計算する 驚くほどシンプルに書ける ORACLEと同じ関数名なので分かりやすい

page 36
-- (Presto) y = intercept + x * slope WITH records AS ( SELECT * FROM ( VALUES (16, 86800), (64, 98800), (128, 110800) ) AS t (x_value, y_value))SELECT regr_intercept(y_value, x_value) as intercept, regr_slope(y_value, x_value) as slopeFROM records

page 37
-- (Presto UDF) y = intercept + x * slopeWITH records AS ( SELECT * FROM ( VALUES (16, 86800), (64, 98800), (128, 110800) ) AS t (x_value, y_value))SELECT regr_intercept(y_value, x_value) as intercept, regr_slope(y_value, x_value) as slopeFROM records
-- linear regression (y=ax+b)-- estimate price from size.WITH records AS ( -- size(x), price(y) SELECT * FROM ( VALUES (16, 86800), (64, 98800), (128, 110800) ) AS t (x_value, y_value)), prepare AS ( SELECT SUM(x_value) as sumx, SUM(y_value) as sumy, SUM(x_value*x_value) as sumxx, SUM(y_value*y_value) as sumyy, SUM(x_value*y_value) as sumxy, COUNT(1) as cnt FROM records)SELECT bunshi_a / bunbo as slope, bunshi_b / bunbo as interceptFROM ( SELECT (cnt * sumxx - pow(sumx, 2)) AS bunbo, (cnt * sumxy - sumx * sumy) AS bunshi_a, (sumxx * sumy - sumxy * sumx) AS bunshi_b FROM prepare ) calc
たったこれだけ!

page
精度向上をさらに図るには
38
iPhone6sの価格推定モデルを単回帰分析で作りました
価格 = 212.83*容量 + 84043 単回帰分析で求められた式では、まだ誤差がある
128GBモデルのみ少し値付けが安くなっている
128GBモデルのみ効くダミー変数を追加すると良さそう
説明変数が1つ:単回帰分析
説明変数が2つ以上:重回帰分析

page
重回帰分析をHadoopでしたい!
39
y = a1x1 + a2x2 + a3x3 + a4x4 ・・・+ b

page
そこでHivemallの出番です
40

page
Hivemallを用いた回帰分析
41
hivemallはHiveQLのUDFとしてTreasureDataでも使える
回帰分析 (Regression) で使えるアルゴリズムは次の5種類
Logistic Regression AdaGrad / AdaDelta (with Logistic Loss) Passive Aggressive Regression (PA1, PA2) AROW (Adaptive Regularization of Weight Vectors) Regression Polynomial Regression まず使うならAROWか、AdaGrad / AdaDeltaを使うと良い

page
Hivemall Regressionの使い道
42
ロジスティック回帰 (0/1 or -1/+1) 線形回帰 多項式回帰
Logistic Regression ✓
AdaGrad / AdaDelta (with Logistic Loss)
✓
Passive Aggressive Regression (PA1, PA2) ✓
AROW (Adaptive Regularization of Weight Vectors) Regression ✓
Polynomial Regression ✓過学習を防げるので汎用的

page
AROWeを利用した実例を紹介
43

page 44
-- hivemallを用いた回帰分析WITH records AS ( SELECT 16 as x_value, 86800 as y_value UNION ALL SELECT 64 as x_value, 98800 as y_value UNION ALL SELECT 128 as x_value, 110800 as y_value)SELECT * FROM records
page 45

page 46
SELECT row_number() over () AS rowid, y_value AS target, array_remove(Array( 'bias', CONCAT('size:', x_value), IF(x_value=128, '128GB', NULL) ), NULL) as features FROM records

page 47
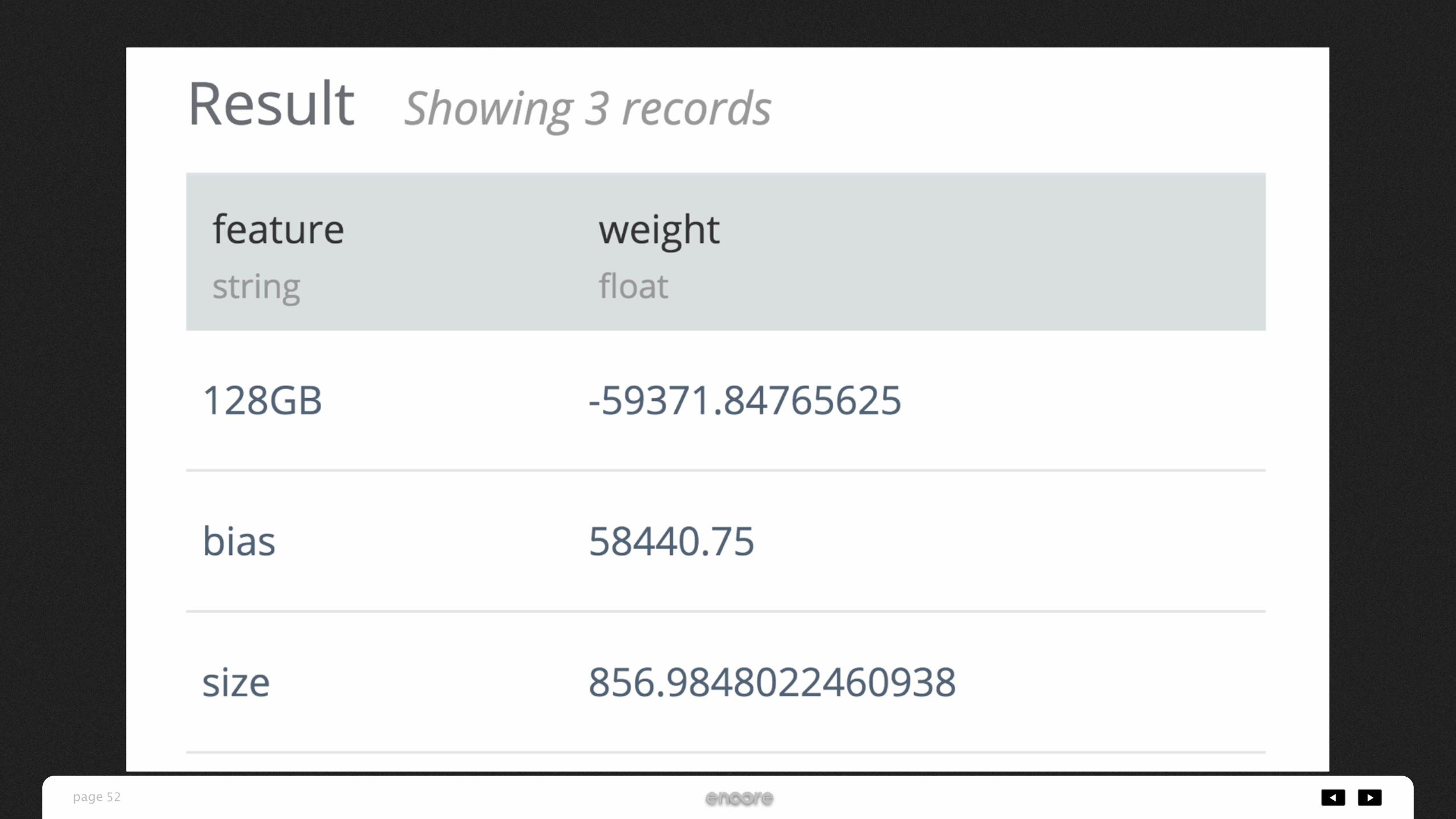
128GBモデルのみに効く質的変数を追加(ダミー変数)

page 48
SELECT arowe_regress(features, target) AS (feature, weight, covar)FROM train
このままですと反復学習数が不足して 精度が出ないためamplifyを使います

page 49
SELECT arowe_regress(features, target) AS (feature, weight, covar)FROM ( select * from ( select amplify(20000, rowid, target, features) AS (rowid, target, features) from train ) t CLUSTER BY rand(1) ) train_amplify

page 50
page 51
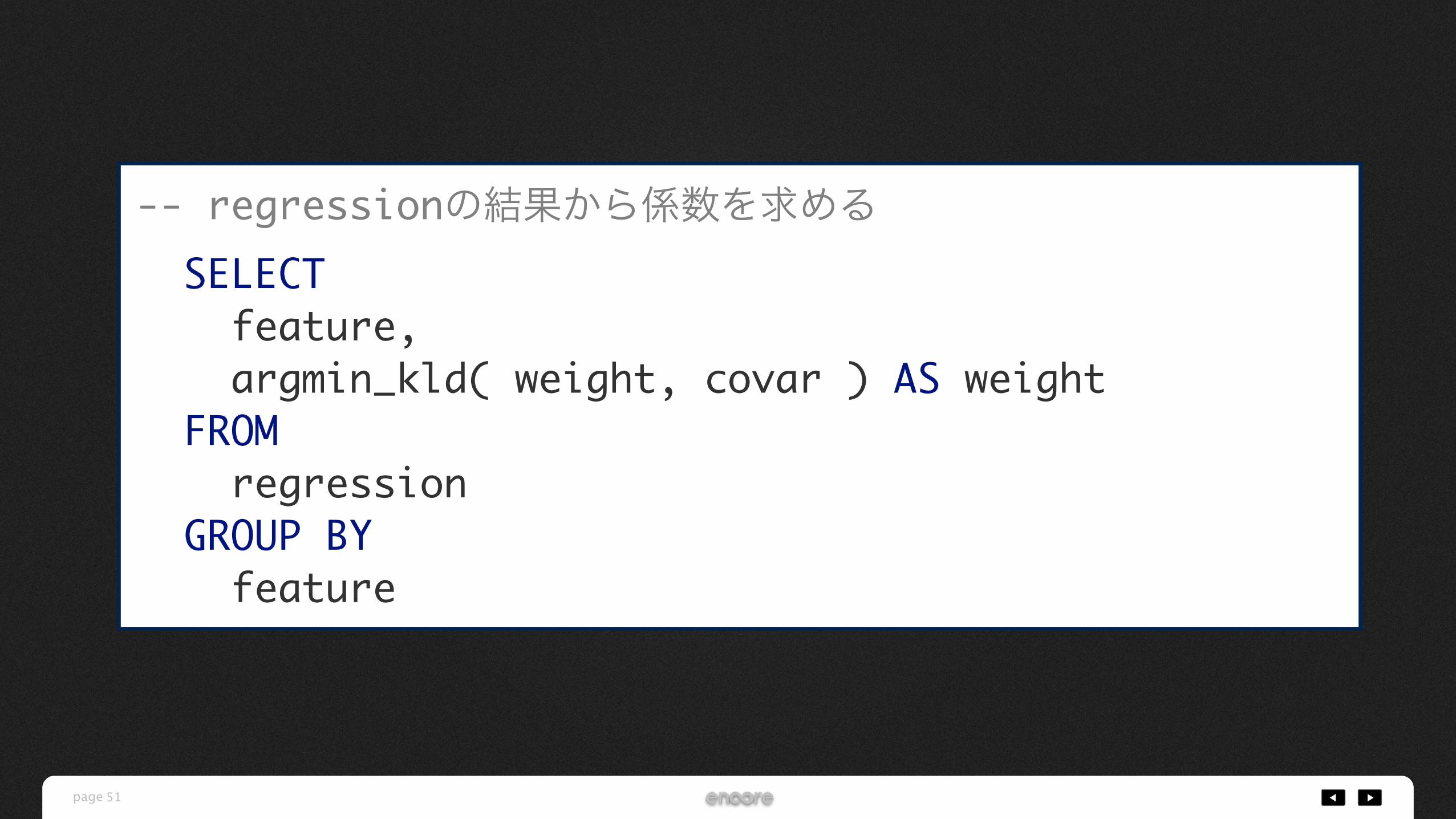
-- regressionの結果から係数を求める SELECT feature, argmin_kld( weight, covar ) AS weight FROM regression GROUP BY feature
page 52
page 53
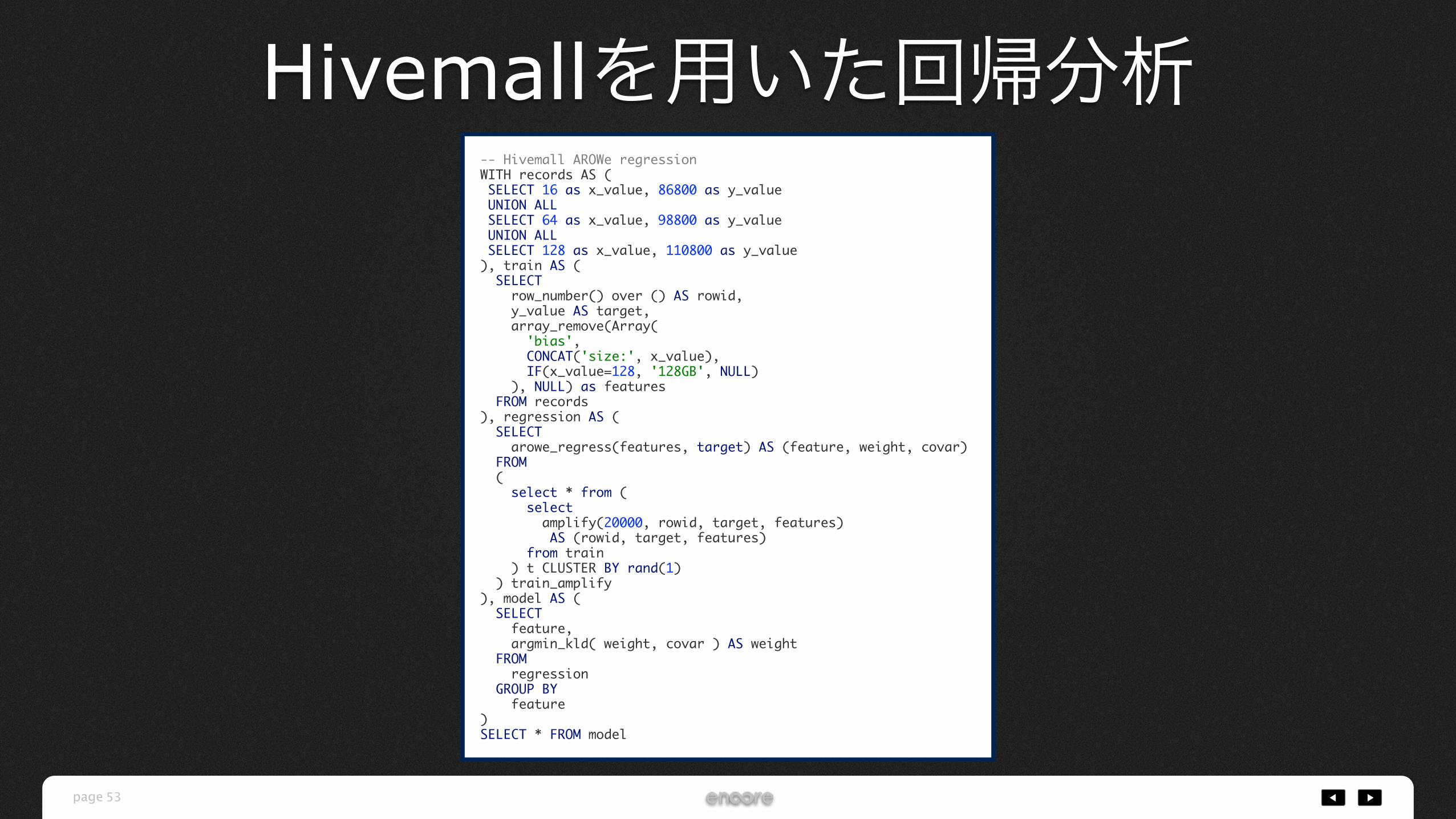
-- Hivemall AROWe regressionWITH records AS ( SELECT 16 as x_value, 86800 as y_value UNION ALL SELECT 64 as x_value, 98800 as y_value UNION ALL SELECT 128 as x_value, 110800 as y_value), train AS ( SELECT row_number() over () AS rowid, y_value AS target, array_remove(Array( 'bias', CONCAT('size:', x_value), IF(x_value=128, '128GB', NULL) ), NULL) as features FROM records), regression AS ( SELECT arowe_regress(features, target) AS (feature, weight, covar) FROM ( select * from ( select amplify(20000, rowid, target, features) AS (rowid, target, features) from train ) t CLUSTER BY rand(1) ) train_amplify), model AS ( SELECT feature, argmin_kld( weight, covar ) AS weight FROM regression GROUP BY feature)SELECT * FROM model
Hivemallを用いた回帰分析

page
AROWe以外の手法も使い精度を比較
54

page 55

page
【結論】 今回の推定対象に採用する手法には PA2a (Passive Aggressive II)との
相性が最も良い
56

page
回帰分析手法ごとの精度
57
iPhone 6s 16 GB
iPhone 6s 64 GB
iPhone 6s 128 GB
実価格 ¥86,800 ¥98,800 ¥110,800
単回帰分析 ¥87,448 (誤差0.7%)
¥97,664 (誤差1.1%)
¥111,272 (誤差0.4%)
重回帰分析(AROWe)
¥80,980 (誤差6.7%)
¥104,373 (誤差5.6%)
¥110,037 (誤差0.7%)
重回帰分析(PA2a)
¥85,820 (誤差1.1%)
¥99,784 (誤差1.0%)
¥111,055 (誤差0.2%)

page
しかしここに 学習データの過学習という問題と、 内挿と外挿の問題が隠れている
ケースもあります。
58

page 59
学習データに無い外挿となる推定の正しさは未知数

page
オンライン学習する際のTips
60
データの種類次第だが、学習回数によって精度が変わる サンプル数が少ない時は反復学習が必要 レコードを重複させる(サンプリング手法の1つ)
綺麗なデータを数倍に重複(増幅)させておくと、 データ密度が高い方にモデルが補正される 結果的に精度が向上する
過学習に注意 学習データと予測データを分けて精度検証を行う

page
4. 不動産価格推定の知見
61

page
中古不動産価格査定の難しさ
62
中古マンションの価格査定 地域によって事例がほとんど存在しない 同じ部屋が市場に何度も出回ることはまず無い 築年数を重ねると値幅が広くなる 建物と部屋の修繕度合いに左右される
賃貸マンションの価格査定 どの地域にも事例が密集して存在する 同じ部屋が市場に何度も出回るので値動きが掴みやすい

page
中古不動産価格査定の難しさ
63
物件の価格は広さだけでは説明出来ません 立地(駅徒歩・眺望・バルコニー面積) 所在建物階数 建物規模・構造 販売会社やブランドのネームバリュー 土地権利
etc…

page
地域によって駅徒歩距離の価値が違う
64

page 65
引用元: http://www.fudousan.or.jp/topics/1011/11_3.html

page
中古不動産価格査定の難しさ
66
購入者は何を評価し、何を評価しないかを考える 車社会の地域なら駅からの距離はあまり気にならない 1人暮らし物件は値段と立地重視で方位は二の次 朝出かけて夜に帰ってくる事が多いですよね? ファミリー向け物件は駅近はそれほど重要では無い
etc…

page
価格推定を行うときの知見
67
データ前処理の重要性 まるっとデータを入れれば綺麗なモデルが作れる事は無い 価格推定は経済原理を元に仮説を立てる力が必要 なるべく内挿となるように分類・集計等の前処理を行う 不足しているデータは欠損値補完をする オープンデータを組み合わせるのも1つの手段 名寄せ処理スゴク大事 自然言語処理やスコアリングなどの各種手法を応用する

page
価格推定を行うときの知見
68
R2決定係数のまやかし
説明変数を増やせば、R2決定係数は1.0に近づきがち 過学習となっているケースもあるのでモデルの精査が大事 学習データの範囲で正と負が逆転するような係数は怪しい
!
予測データから各パーセンタイルでの誤差率を出すと良い 50/60/70/80/90/95 Percentileにて誤差率が○%になる 等
MAEやRMSEの他、MER (Median Error Rate) も有用

page
価格推定を行うときの知見
69
価格査定は割と外挿となる未知の物件価格予測となる 査定モデル次第では価格が0円を割ることもある
量的変数と質的変数(ダミー変数)の使い分け 量的変数のスケーリングも大事
Z-ScoreやMin-Max normalization、対数を取るなど 量的変数であっても駅徒歩と同様に線形に推移しない場合 交差項を用いて、ある程度の範囲のみの係数を用意する いわゆる層別化

page
5. まとめ
70

まとめ• Hadoopで動くHivemallにより、機械学習利用の敷居が下がった
• SQLで機械学習を操れるメリットはかなり大きい
• 学習データ作りが肝なので、データ前処理(正規化)は超大事
• データに関するビジネス的な知識は欠かせない
• モデルを作る際には過学習と境界線問題などに気をつけたい

page
Thanks!
72
ご清聴ありがとうございました。
Recommended

















