
CER
N-T
HES
IS-2
012-
127
07/0
9/20
12
Installation et Configuration
Centralisées et Automatisées
d’une Ferme de Serveur sous SLC6
Institut Supérieur
d’Informatique,
de Modélisation
et de leurs Applications
BP 10125
63173 Aubière Cedex
Stéphane Tourneyre Rapport de Stage de 2eme Année Filière Réseau et Télécommunication 2 Avril – 31 Aout 2012
Tuteur CERN : Niko Neufeld Tuteur ISIMA : Emmanuel Mesnard
Organisation Européenne
pour la Recherche Nucléaire
F-01631 CERN Cedex


Remerciements
Je tiens à remercier :
Niko Neufeld, mon tuteur, pour la confiance qu’il a placé en moi, sa
bonne humeur et sa disponibilité malgré son emploi du temps
chargé.
Loïc Brardra pour le temps qu’il m’a accordé pour répondre à mes
(trop ?) nombreuses questions
L’équipe du LHCb qui m’a permis de mieux comprendre le
fonctionnement du CERN et du LHCb en particulier
Monsieur Menard qui a permis d’ouvrir la brèche et de donner la
chance à des stagiaires de l’ISIMA de pouvoir effectuer leur stage au
sein du CERN

Résumé
Ce rapport a pour but de présenter une étude du changement du système
d’installation et de configuration de serveurs Linux équipés de la distribution
Scientific Linux CERN (SLC) au sein de l’expérience LHCb du CERN. Ces serveurs
servent essentiellement à trier les données en sortie des différents capteurs des
détecteurs de collisions de protons.
Il était prévu d’étudier une solution à base des logiciels Cobbler/Puppet
pour remplacer le logiciel existant, Quattor, pour permettre d’installer et de
configurer de façon automatique. Tout d’abord, ces tests devaient se faire sur
des machines virtuelles puis mettre ces outils en condition réelle avec des
machines sans disque dur, comme celles en production.
À l’heure actuelle, l’utilisation du logiciel pour permettre la configuration
automatise Puppet fonctionne et correspond aux attentes du responsable du
projet, Niko Neufeld. Concernant Cobbler, après différents tests, il ne parvient
pas à combler totalement nos attentes. C’est pourquoi une étude approfondie
doit être continuée soit en trouvant un autre logiciel, soit en adaptant Cobbler.
Pour la partie des machines sans disque dur, elle devrait pouvoir être finie
avant la fin du stage.
Mot clé : installation et configuration automatisée, Cobbler, Puppet,
Quattor, sans disque dur.

Abstract
This report aims to present a study of the change of system installation
and configuration of Linux servers with the distribution of Scientific Linux CERN
(SLC) within the LHCb experiment at CERN. These servers are primarily used to
sort the output data of various sensors detectors proton collisions.
It was planned to explore a solution based software Cobbler / Puppet to
replace the existing software, Quattor, to help install and configure
automatically. First, these tests should be done on virtual machines and then
putting these tools in real conditions with machines without hard disk, such as
those in production.
Currently, the use of software to allow configuration automates Puppet
works and meets the expectations of the project manager, Niko Neufeld. Cobbler
on, after various tests, it fails to meet our expectations fully. Therefore a
thorough study should be continued or finding another software or by adapting
Cobbler.
For the part of the machines without hard disk, it should be done before
the end of the course.
Keyword: automated installation and configuration, Cobbler, Puppet,
Quattor, diskless.

Tables des matières
REMERCIEMENTS ....................................................................................III
RESUME .................................................................................................. IV
ABSTRACT ................................................................................................. V
TABLES DES MATIERES ........................................................................... VI
TABLE DES FIGURES .............................................................................. VII
GLOSSAIRE ............................................................................................. IX
INTRODUCTION ...................................................................................... 11
I. LE CONTEXTE ................................................................................... 12
1) Le CERN ............................................................................................... 12
2) Le LHC ................................................................................................. 13
3) LHCb .................................................................................................... 14
4) L’avenir de l’informatique au CERN ...................................................... 16
5) Le projet .............................................................................................. 17
II. CONFIGURATION AUTOMATISEE AVEC PUPPET ............................ 19
1) Définition de Puppet ............................................................................ 19
2) Principe de Puppet ............................................................................... 20
3) Configuration au LHCb : ....................................................................... 33
III. INSTALLATION AUTOMATISEE AVEC COBBLER ............................. 38
1) Définition de Cobbler ........................................................................... 38
2) Principe de Cobbler .............................................................................. 39
IV. INTERCONNEXION PUPPET – COBBLER ........................................ 49
1) Lien entre Puppet et Cobbler ............................................................... 49
2) Remplacement de Cobbler ? ................................................................. 50
3) Razor ................................................................................................... 50
4) La solution ........................................................................................... 56
V. MACHINE DISKLESS ......................................................................... 60
1) Principe ............................................................................................... 60
2) Problèmes ............................................................................................ 62
3) Diskless avec Cobbler .......................................................................... 63
CONCLUSION .......................................................................................... 64
REFERENCES BIBLIOGRAPHIQUES .......................................................LXVI

Table des figures
FIGURE 1 : LE LHC DANS LE PAYS DE GEX ............................................................................ 13 FIGURE 2 : LE DETECTEUR ET UNE PARTIE DE L'EQUIPE DU LHCB ........................................... 14 FIGURE 3 : SERVEURS FAISANT PARTIE DE LA FERME ............................................................ 15 FIGURE 4 : EXEMPLE DE LANGAGE PAN DE QUATTOR ............................................................. 16 FIGURE 5 : PLANNING PREVISIONNEL .................................................................................. 18 FIGURE 6 : EXEMPLE D'ENTREPRISE UTILISANT PUPPET ......................................................... 20 FIGURE 7 : INSTALLATION DU PACKAGE PUPPET-SERVER ....................................................... 20 FIGURE 8 : INSTALLATION DU PACKAGE CLIENT .................................................................... 20 FIGURE 9 : STRUCTURE DE PUPPET ...................................................................................... 21 FIGURE 10 : FICHIER PUPPET.CONF ..................................................................................... 21 FIGURE 11 : FICHIER NODE.PP ............................................................................................ 22 FIGURE 12 : CHOIX DU MODULE EN FONCTION DU NŒUD ...................................................... 23 FIGURE 13 : PREMIERE CONNEXION D'UN CLIENT VU PAR LE SERVEUR .................................... 24 FIGURE 14 : PREMIERE CONNEXION D’UN CLIENT VU PAR LE CLIENT ....................................... 24 FIGURE 15 : FONCTIONNEMENT DE PUPPET .......................................................................... 25 FIGURE 16 : STRUCTURE D'UNE RESSOURCE ........................................................................ 26 FIGURE 17 : CONFIGURATION DE YUM ................................................................................. 26 FIGURE 18 : STRUCTURE MODULE PUPPET ............................................................................ 27 FIGURE 19 : FICHIER INIT.PP DU MODULE PUPPET ................................................................. 27 FIGURE 20 : FICHIER INSTALL DU MODULE PUPPET ............................................................... 27 FIGURE 21 : FICHIER SERVICE DU MODULE PUPPET ............................................................... 28 FIGURE 22 : UTILISATION DE VARIABLE DANS PUPPET .......................................................... 28 FIGURE 23 : RESULTAT DE LA COMMANDE FACTER ................................................................ 28 FIGURE 24 : CHOIX D'UNE CLASSE EN FONCTION DE L'OS ..................................................... 29 FIGURE 25 : EXEMPLE DE FICHIER TEMPLATE ........................................................................ 29 FIGURE 26 : FICHIER TEMPLATE MACHINE A ......................................................................... 29 FIGURE 27 : FICHIER TEMPLATE MACHINE B ......................................................................... 29 FIGURE 28 : STRUCTURE DE PUPPET AVEC TROIS ENVIRONNEMENTS ...................................... 30 FIGURE 29 : ENVIRONNEMENTS DANS LE FICHIER PUPPET.CONF ............................................ 30 FIGURE 30 : EXECUTION DE PUPPET DANS UN ENVIRONNEMENT PARTICULIER ......................... 30 FIGURE 31 : EXECUTION DE PUPPETMASTER ......................................................................... 31 FIGURE 32 : EXECUTION DE PUPPET CLIENT ......................................................................... 32 FIGURE 33 : EXECUTION DU SCRIPT SITE.PP ........................................................................ 32 FIGURE 34 : EXEMPLE DE MODULE DISPONIBLE SUR LE SITE PUPPET FORGE ........................... 33 FIGURE 35 : LIGNE DE COMMANDE PARAMETRANT LE PROXY .................................................. 35 FIGURE 36 : FICHIER /ETC/BASHRC ..................................................................................... 35 FIGURE 37 : STRUCTURE DU FICHIER NODE.PP ..................................................................... 35 FIGURE 38 : ARBORESCENCE DU MODULE PROXY .................................................................. 36 FIGURE 39 : STRUCTURE DU FICHIER INIT.PP DU MODULE PROXY ........................................... 36 FIGURE 40 : STRUCTURE DU SCRIPT DU MODULE PROXY ....................................................... 37 FIGURE 41 : SEQUENCE DE DEMARRAGE D'UN CLIENT ........................................................... 39 FIGURE 42: CONFIGURATION DHCP DU POSTE CLIENT1 ......................................................... 40 FIGURE 43 : TENTATIVE DE RECUPERATION DU FICHIER PXELINUX.CFG .................................. 40 FIGURE 44 : COBBLER ........................................................................................................ 41 FIGURE 45 : INSTALLATION DE COBBLER ............................................................................. 42 FIGURE 46 : FICHIER SEETINGS DE COBBLER ....................................................................... 43 FIGURE 47 : GESTION DU DHCP PAR COBBLER ...................................................................... 43 FIGURE 48 : CHOIX DU SERVEUR DHCP DANS MODULE.CONF ................................................. 43 FIGURE 49 : TEMPLATE DU FICHIER DHCPD.CONF ................................................................. 44 FIGURE 50 : FICHIER KICKSTART ......................................................................................... 45 FIGURE 51 : IMPORT D'UN REPOSITORY SOUS COBBLER ........................................................ 45 FIGURE 52 : SYNCHRONISATION DES REPOSITORY ............................................................... 46

FIGURE 53 : IMPORTATION DE LA DISTRIBUTION SLC6 DEPUIS LE FICHIER BOOT.ISO .............. 46 FIGURE 54 : STRUCTURE D'UN PROFIL ................................................................................. 46 FIGURE 55 : AJOUT D'UN SYSTEM ........................................................................................ 47 FIGURE 56 : RESULTAT DE LA COMMANDE COBBLER SYNC ..................................................... 47 FIGURE 57 : CLIENT RECUPERANT DES FICHIERS SUR LE SERVEUR PXE .................................. 48 FIGURE 58 : MANAGEMENT CLASSES AU SEIN DE COBBLER .................................................... 49 FIGURE 59 : REPONSE DU SCRIPT EN FONCTION D'UN CLIENT ................................................ 49 FIGURE 60 : CONFIGURATION DU FICHIER PUPPET.CONF ....................................................... 49 FIGURE 61 : SCRIPT EXTERNAL ........................................................................................... 50 FIGURE 62 : RAZOR DISCOVERY .......................................................................................... 51 FIGURE 63 : LISTE DES NŒUDS SUR RAZOR ......................................................................... 52 FIGURE 64 : ATTRIBUT D'UN NODE SUR RAZOR .................................................................... 52 FIGURE 65 : RAZOR TAGGING ............................................................................................. 53 FIGURE 66 : RAZOR POLICY ................................................................................................ 54 FIGURE 67 : RAZOR POLICY ................................................................................................ 54 FIGURE 68 : RAZOR BROKER ............................................................................................... 55 FIGURE 69 : LISTE DES BROKER .......................................................................................... 55 FIGURE 70 : POLITIQUES SUR RAZOR AVEC "BROKER" ........................................................... 55 FIGURE 71 : AJOUT D'UNE MACHINE SUR COBBLER ............................................................... 56 FIGURE 72 : FICHIER SITE.PP .............................................................................................. 57 FIGURE 73 : FICHIER CLIENT1.LBDAQ.CERN.CH.PP ................................................................ 57 FIGURE 74 : FICHIER KICKSTART AVEC SCRIPT PHP .............................................................. 58 FIGURE 75 : SCRIPT PHP POUR CREER LE FICHIER HOSTNAME.PP ........................................... 58 FIGURE 76 : SERVEUR CENTRAL ET CLIENT DISKLESS ........................................................... 60 FIGURE 77 : LISTE DES DOSSIERS DU SERVEUR CENTRAL DISKLESS ...................................... 61 FIGURE 78 : LISTE DES DOSSIERS SPECIFIQUE MACHINE DISKLESS ....................................... 62 FIGURE 79 : DIAGRAMME DE GANT FINAL ............................................................................. 65

Glossaire
Annuaire: Système de stockage de données
Antimatière: Particule en opposition de la matière qui devrait être
en égal quantité en théorie mais qui se révèle en total asymétrie
dans l’univers. Le LHCb devrait réussir à répondre a cette question
Cloud Computing: Concept de déportation sur des serveurs
distants les serveurs ou postes clients locaux
Cobbler: Logiciel d’installation automatisée et centralisée
DHCP: Logiciel fournissant automatiquement une adresse IP aux
machines qui le demande
Diskless: Machine sans disque dur
DNS: Protocole permettant de relier une adresse IP d’une machine à
son nom
HTTP: Langage des sites web. Souvent utilisé pour un logiciel de
serveur web ( exemple : Apache, IIS, WEBrick )
IP: Adresse unique sur un réseau d’une machine permettant la
communication avec les autres machines
Kickstart: Fichier de réponse automatique lors de l’installation des
distributions RedHat/Fedora
Ldap: Protocole utilisé pour l’interrogation et la modification
d’annuaire. Les plus connus sont Active Directory et OpenLDAP
Linux: Système d’exploitation (OS pour Operating System ) très
prisé des laboratoires de recherche de par sa gratuité et son
ouverture. Deux distributions en sont dérivées : RedHat / Fedora et
associé ( CentOS, Scientific Linux) et Debian/Ubuntu
OpenStack: Solution logiciel permettant de gérer un Cloud
Computing
Packages: Archive comprenant les fichiers nécessaires à
l’installation d’un logiciel
Puppet: Logiciel de configuration automatisée et centralisée
Quattor: Logiciel d’installation et de configuration automatisées et
centralisées
Repository: Stockage centralisé de package

Serveur web : machine permettant à des clients d’afficher un site
web via des requêtes HTTP
Template: Utilisation d’un fichier générique pour la création d’un
fichier spécifique grâce à des variables
TFTP: Protocole de serveur de fichier
Virtualbox: logiciel de virtualisation de poste client
Virtualisation: Concept permettant de simuler un système
d’exploitation sur une machine physique
VMware: Solution logiciel de virtualisation
Yum: Gestionnaire de paquets Linux pour les distributions
RedHat/Fedora

Introduction
Page 11
Introduction
Afin de traiter tous les résultats obtenus des nombreux capteurs lors des
collisions au sein du LHC, l’expérience LHCb du CERN a besoin d’une puissance
de calcul phénoménal : une ferme de serveurs de plus de deux mille machines.
Pour administrer toutes ces machines, il est indispensable d’avoir des
outils adaptés et surtout qui permettent une automatisation la plus poussée
possible.
Pour installer et configurer les machines de façon centralisée et
automatisée, les administrateurs système utilisent le logiciel Quattor. Malgré de
nombreux atouts, il n’est plus adapté aux besoins futurs du CERN et en
particulier de l’expérience LHCb. C’est pourquoi il est important d’anticiper et de
trouver une solution équivalente. C’est le sujet de mon stage.
Ce rapport comporte quatre parties :
Avant de changer quoi que ce soit, il est très important de connaitre
l’existant. C’est pourquoi une présentation détaillée du contexte est effectuée
avec les différentes solutions possibles.
Puis une étude du logiciel Puppet qui sert à automatiser et centraliser les
configurations des différents serveurs.
Enfin, je vais mettre en place le logiciel Cobbler pour l’installation des
machines et voir s’il arrive bien à s’interconnecter avec Puppet.
Ceci est une première version du rapport de stage : la version finale
définitive devrait comporter une partie sur les machines sans disque dur.

Le Contexte
Page 12
I. Le Contexte
1) Le CERN
Question : Quel est l’endroit le plus chaud et à la fois le plus froid sur
terre?
Réponse : au LHC du CERN
Avec une température de -271degrés pour pouvoir utiliser des
supraconducteurs et une autre de plus de 10 millions de degrés lors des
collisions des protons, le LHC du CERN nous prouve encore une fois que c’est une
merveille de technologie.
Crée en 1954 à la suite de la 2eme guerre mondiale, l’Organisation
Européenne pour la Recherche Nucléaire (l’acronyme CERN vient du 1er nom
Conseil Européen pour la recherche nucléaire) est le plus grand centre de
physique du monde. Situé sur la frontière entre la France et la Suisse, près de
Genève, c’est la plus grande concentration de physiciens du monde avec plus de
quatorze mille personnes sur le site lors des grandes affluences.
Le CERN a quatre buts principaux :
Recherche fondamentale de physique :
Grâce à l’accélérateur de particules Large Hadron Collider (Grand
Collisionneur de Hadron - LHC), des collisions entre différentes particules
permettent de recréer les instants qui ont succédé au Bigbang et ainsi mieux
connaitre la physique. La conférence sur la découverte du Boson de Higgs du 4
juillet 2012 est le parfait exemple.
Faire avancer la science
Toutes les découvertes du CERN sont publiques et gratuites. C’est ainsi
que le protocole HTTP inventé en 1989 par Tim Berners Lee a permis à Internet
de se démocratiser. Mais aussi le système de grille de calcul qui permet de
répartir des calculs informatiques lourds entre plusieurs dizaines, centaines ou
même milliers de machines.
Former les scientifiques de demain
En permettant à des stagiaires ou des étudiants de pouvoir continuer leurs
apprentissages ici, le CERN s’assure de former les générations futures.

Le Contexte
Page 13
Collaboration entre les différents pays
À sa façon le CERN, collabore pour la paix dans le monde. En effet, les
différents scientifiques travaillent ensemble et mettent de côté leurs différents
pour faire avancer la science.
Le financement du CERN provient essentiellement des douze états
fondateurs (Allemagne, France, Danemark, Italie, Norvège etc....), des douze
autres états membres qui les ont rejoints au fil du temps (Pologne, Bulgarie,
Portugal etc....) mais aussi d’autres états observateurs (Inde, Japon, Turquie
etc...).
2) Le LHC
Basé sur la structure de l’ancien Grand collisionneur de positons et
d’électrons (le LEP), le LHC est le plus puissant accélérateur de particules du
monde et cela devrait encore s’accroitre avec la montée en puissance prévue
pour l’année 2013.
Le principe du LHC est très simple : envoyer des protons dans un anneau
large de vingt-sept kilomètres à une vitesse proche de celle de la lumière et
examiner les collisions des particules au sein de différents détecteurs. Le but est
de confirmer ou non certaines théories et de comprendre la naissance de la
physique fondamentale.
On peut trouver quatre grandes expériences qui correspondent chacune à
un détecteur différent : ATLAS, CMS, ALICE et LHCb.
Figure 1 : Le LHC dans le pays de Gex

Le Contexte
Page 14
3) LHCb
LHCb pour Large Hadron Collider beauty
Le but de l’expérience LHCb est d’étudier la particule de Beauté qui
permettrait d’expliquer pourquoi il y a une dissymétrie entre la matière et
l’antimatière dans l’Univers. L’expérience regroupe près de sept cents physiciens
et autres issus de quinze pays.
Figure 2 : le Détecteur et une partie de l'équipe du LHCb
Le détecteur est en réalité constitué de plusieurs sous détecteurs
permettant chacun de capturer des informations sur une particule (Calorimètre,
Rich etc...) et le flux de données en sortie est très important : 50mo/s pour
chaque collision. Etant donné qu’il y a quatre millions de collisions par seconde, il
est impératif de pouvoir trier ces informations avant que les physiciens puissent
travailler sur les résultats.
Ce tri s’effectue via deux niveaux (le niveau zéro et le niveau un) et
permet de séparer le bruit des données intéressantes.
Le niveau zéro (Level 0 Trigger) est constitué de cartes électroniques
spécialisées qui permettent de passer de quatre millions d’événements à 2
millions.
Le niveau un (HLT pour Hight Level Trigger) est constitué d’une ferme de
plus de deux mille serveurs. La particularité de ces serveurs est d’être diskless
(sans disque) et ils utilisent des stockages réseaux pour fonctionner. Cinquante
de ces serveurs sont utilisés pour gérer jusqu’à vingt-sept nœuds (serveurs
clients)

Le Contexte
Page 15
Figure 3 : Serveurs faisant partie de la ferme
Ce triage permet de passer de quatre Millions d’évènements à deux mille.
Ces données sont traitées par les physiciens ensuite.
À l’heure actuelle, ces serveurs sont sous la distribution Linux SLC 5
(Scientifique Linux CERN version 5) dérivée de RHEL 5 (Red Hat Entreprise Linux
version 5).
Avec une équipe d’administration réduite, il est indispensable d’avoir des
outils permettant une automatisation d’installations et de configurations des
machines Linux. Le choix du CERN et du LHCb en particulier s’est porté sur
Quattor.
Quattor est un logiciel Open Source fonctionnant sous Linux basé sur un
langage descriptif spécifique, le Pan. C’est un langage compilé : avant de
déployer une machine, un fichier XML est créé contenant l’ensemble des
configurations à mettre en place.
Il existe peu d’entités utilisant Quattor : principalement le CERN et la
banque Margan Stanley. De par ce fait, la communauté autour de Quattor n’est
pas très importante.

Le Contexte
Page 16
Figure 4 : Exemple de langage PAN de Quattor
Avantages de Quattor :
Langage facile à prendre en main
Modularité des composants
Code ouvert
Inconvénients :
Communauté restreinte
Gestion des packages (l’installation de packages se fait via un fichier
RPM et il faut gérer manuellement ses dépendances).
Malgré le fait que Quattor soit plutôt bien adapté au système d’information
du CERN, il reste néanmoins perfectible.
4) L’avenir de l’informatique au CERN
Les différentes expériences sont des services informatiques indépendants
les uns des autres, mais aussi du service informatique général du CERN
(généralement appelle IT pour Information Technologique). Malgré leur
indépendance, chacun s’inspire des autres et ainsi tout le monde marche plus ou
moins dans le même sens, ou au moins, essaye les technologies sans forcément
y adhérer.
C’est dans cette optique que le LHCb a commencé une réflexion sur le
changement du système d’information :

Le Contexte
Page 17
Les besoins techniques de l’IT et des expériences sont en constantes
évolution en terme de puissance de calcul sans devoir augmenter le personnel
dédié. La solution retenue est de délocaliser un certain nombre de serveurs dans
un Datacenter à Budapest en Hongrie. La gestion physique sera faite par une
équipe sur place quand la gestion des logiciels (administration des serveurs) sera
toujours effectuée par les équipes du CERN. De plus, cela permet de passer tous
les serveurs en virtualisation ce qui ajoute en flexibilité et réduit les coûts. Ce
système d’infrastructure déportée est ce qu’on appelle de nos jours le “Cloud
computing“.
Malheureusement, en plus des inconvénients précédemment cités, Quattor
gère très mal les machines virtuelles. C’est pourquoi une réflexion s’est portée
sur un outil permettant la configuration mais aussi sur un outil de service
d’infrastructure.
De plus, la migration de SLC à SLC6 à court et moyen terme est un facteur
déclenchant pour le changement d’infrastructure.
Même si les besoins de virtualisation sont moindres voir quasi nuls au sein
du LHCb, il est quand même intéressant de se faire la même réflexion afin de
faire évoluer leur système.
5) Le projet
Le but du projet est de tester un des outils d’installation de serveurs et un
outil de gestion de configuration ainsi que d’étudier leurs intégrations au sein de
la ferme de calculs.
Il est prévu que ces outils soient mis en production suite à ce projet.
a) Le choix des outils
Il n’existe pas des millions d’outils pour gérer un Cloud comme celui du
CERN. De plus, de par sa nature de service public, d’ouverture et de coûts, cet
outil doit être un logiciel libre.
OpenStack est naturellement imposé de par sa pérennité (de nombreux
organisations/entreprises ont choisi OpenStack : la NASA à l’ origine du projet
mais aussi AT&T, Korea Telecom, HP Public Cloud etc...) mais aussi pour sa
modularité (l’ensemble des outils sont interopérable avec les grandes solutions
de virtualisation du marché : VM Ware, HV de Microsoft etc...). OpenStack
commence à s’imposer de plus en plus dans le Cloud.
Concernant la gestion de configuration, étant donné que cela devait
remplacer Quattor, il était judicieux de trouver un logiciel ayant la même
philosophie : déclaratif, etc... Tout en comblant ses inconvénients : gestion des
packages avancée, communautés actives etc...

Le Contexte
Page 18
Tout comme OpenStack, un logiciel s’est plus ou moins imposé, surtout
pour sa complémentarité avec OpenStack : Puppet de PuppetLabs. Il existe
d’autres logiciel comme Chef ou CFEngine mais ils sont soit trop jeunes soit dans
une autre approche que Quattor, mais au cas où Puppet ne convienne pas, il
serait intéressant de les regarder de plus près.
Pour l’installation des serveurs, aucun outil n n’a été privilégié par rapport
à un autre. Il m’incombe de trouver la solution s’intégrant le plus possible avec
Puppet. Mon tuteur m’a conseillé d’étudier en premier le logiciel Cobbler. Si celui-
ci ne convenait pas, je devrais étudier les différentes solutions.
L’ensemble de mes tests se sont effectués soit sur des machines virtuelles
locales sous VirtualBox, soit sur des machines virtuelles RedHat : RedHat
Entreprise Virtualization (c’est un hyperviseur permettant de manager ces
machines virtuelles).
Le plus gros du travail n’est finalement pas la mise en place de ces outils
mais surtout de comprendre leurs fonctionnements.
b) Diagramme de Gantt :
Figure 5 : Planning prévisionnel
Ce planning se décompose en 4 grandes parties avec chacune une partie
découverte du produit, test sur une machine virtuel local et test sur une machine
virtuel de production :
Puppet
Cobbler
Machine Diskless
Résultats Finaux

Configuration automatisée avec Puppet
Page 19
II. Configuration automatisée avec
Puppet
Un dicton dans l’administration système et réseau dit “ Plus tu ruses,
moins tu t’uses”.
1) Définition de Puppet
C’est exactement cela que permet Puppet : ruser pour éviter les tâches
répétitives grâce à un outil d’administration centralisé de parc de machines pour
automatiser, harmoniser et homogénéiser les configurations pour gagner du
temps, de la flexibilité et des performances. Certes au départ cela demande un
travail supplémentaire pour déclarer l’ensemble des machines. Mais une fois ce
travail fait, l’ajout d’une nouvelle machine est plus beaucoup plus rapide et
surtout, on est sûr que chaque machine a la bonne configuration.
L’inconvénient d’un tel système est que lorsque la configuration est bonne,
cela marche très bien mais lors d’une erreur, ce n’est plus une machine mais
potentiellement l’ensemble du parc qui peut être impacté. C’est pourquoi c’est un
outil à magner avec délicatesse.
Ecrit en langage RUBY sous licence GPLv2, la version actuelle est la 2.7 et
est diffusée/écrite par PuppetLabs depuis 2005. Le serveur et le client
fonctionnent avec Linux mais Puppet n’est pas seulement limité au monde linux
(Debian / RedHat) : il existe un client pour les machines MacOs et, fait très
intéressant, Windows. L’ensemble de la documentation et des ressources se
trouvent sur le site officiel de Puppet [1]. De plus, un ouvrage m’a grandement
aidé : ProPuppet [2].
De nombreuses sociétés, dont certaines parmi les plus grandes du monde
internet, utilisent Puppet et en font la promotion ce qui lui garantit une durée de
vie confortable.

Configuration automatisée avec Puppet
Page 20
Figure 6 : Exemple d'entreprise utilisant Puppet
2) Principe de Puppet
Philosophie : Ne pas dire comment, dire quoi faire.
a) Installation de Puppet
Sur une distribution SLC, une ligne de commande permet d’installer le
PuppetMaster ou l’agent avec toutes ses dépendances :
Figure 7 : Installation du package puppet-server
Figure 8 : Installation du package client
Parmi ses dépendances, on retrouve les packages Ruby qui permettent
d’interpréter Puppet mais aussi un package Facter qui fournira les « facts » du
client (expliqué après)

Configuration automatisée avec Puppet
Page 21
b) Structure de Puppet
Figure 9 : Structure de Puppet
Ci-dessus, on trouve la structure de base de Puppet en incorporant un
module Yum.
Les fichiers de configuration se trouvent à la racine de puppet dans
/etc/puppet : puppet.conf, auth.conf et autosign.conf.
Le fichier puppet.conf contient la configuration utilisée par Puppet, que ce
soit le client (partie [agent]), le serveur (partie [master]) ou pour les deux
(partie [main]). C’est ici qu’est spécifié, s’il y a besoin, le nom du serveur,
l’intervalle entre chaque demande du client au serveur, etc..... . Dans notre cas,
la configuration par défaut nous convient.
Figure 10 : Fichier puppet.conf
Le fichier auth.conf permet de spécifier quel client (appelé Nœud) aura
accès à quel module. Dans notre cas, on laisse les paramètres par défaut : tous
les nœuds auront accès à tous les modules.

Configuration automatisée avec Puppet
Page 22
Le fichier autosign.conf gère l’auto signature de certificat pour la 1ere
connexion des clients. Il est possible de laisser ce fichier vide et ainsi, pour
chaque nœud, l’administrateur devra accepter manuellement le certificat. Dans
notre cas, nous allons auto signer toutes les machines ayant un hostname
*.lbdaq.cern.ch.
Les différentes configurations sont appelées Ressource, elles sont
regroupées en Class et sont écrites dans des Manifests (fichiers une extension
.pp)
Les deux principaux manifests sont dans /etc/puppet/manifests : site.pp et
node.pp.
Site.pp : Premier fichier à être lu par le serveur lors d’une demande
de configuration d’un client. Souvent utilisé pour mettre une
configuration de base.
Node.pp : Afin de savoir quelle configuration doit être appliquée tel
Nœud, on utilise le fichier node.pp ou est répertorié l’ensemble des
Noeuds du systeme. Un nœud peut hériter d’un autre nœud.
Figure 11 : Fichier node.pp
Ici notre nœud « virttest1006.lbdaq.cern.ch » va appliquer la classe razor
avec en paramètre « ruby_version » et va hériter du nœud « base » qui
appliquera le module Yum.
Les modules sont des classes qui peuvent être utilisées par les nœuds.
L’avantage d’utiliser les modules est que, en fonction du nœud, on peut appliquer
une configuration particulière en ayant une seule classe : la class razor sera
utilisé avec le paramètres « ruby_version = 1.8.7 ».On peut imaginer un autre
nœud avec un autre paramètre « ruby_version = 1.9.3 ».

Configuration automatisée avec Puppet
Page 23
Figure 12 : Choix du module en fonction du nœud
PS : Il est important de configurer le pare-feu du client et du serveur pour
laisser passer les trames Puppet. Etant donné que les pare-feu des machines du
LHCb sont désactivés par défaut, il n’y a rien à changer. Si on veut garder le
pare feu activé, il faut autoriser le port 8240.
c) Déploiement
Sur un fonctionnement Client/Serveur, un agent installé sur le client
(appelé Nœud) va demander quelle configuration a adopté le serveur maitre
(appelé PuppetMaster). Une possibilité d’utiliser le client seul existe en utilisant
un script mais cela reste marginal et n’est pas approprié à notre besoin. Les
échanges se font grâce à une connexion HTTPS via un échange de clé SSL lors de
la première connexion du client. Cette première connexion demande une
autorisation du client sur le serveur (de façon automatique ou manuelle). Une
fois acceptée, le serveur ne fait plus cette demande.

Configuration automatisée avec Puppet
Page 24
Figure 13 : Première connexion d'un client vu par le serveur
Figure 14 : Première connexion d’un client vu par le client
d) Traitement d’une configuration :
Plutôt que diffuser la configuration du serveur au client, ce sont les clients
qui viennent réclamer cette configuration. Cela peut porter sur un fichier, un
package, un service, etc... et sur son état : présent, absent, version pour les
packages etc... Il est possible de spécifier les intervalles entre les différentes
demandes de chaque client ou alors, passer par une tâche planifiée sur le client
afin de mieux anticiper les possibles montées en charge : avoir deux mille
demandes en même temps est diffèrent d’avoir deux mille clients répartis sur
deux heures pour le serveur.
Configuration automatisée avec Puppet
Page 25
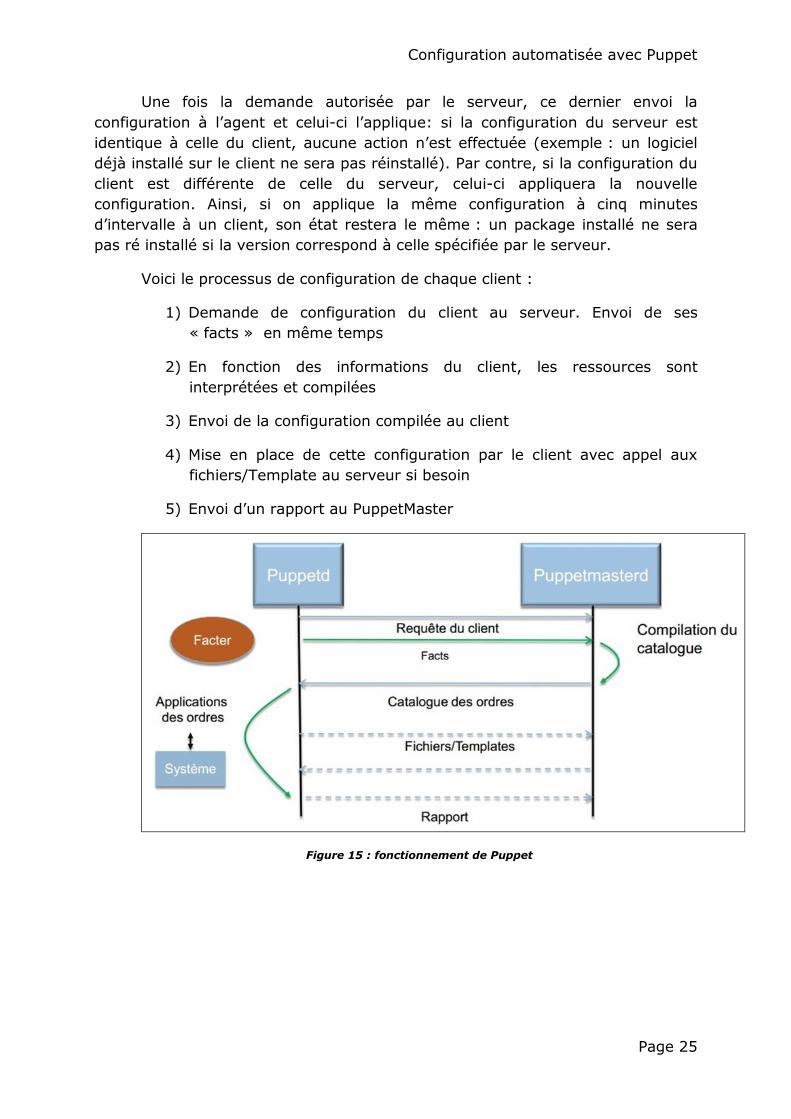
Une fois la demande autorisée par le serveur, ce dernier envoi la
configuration à l’agent et celui-ci l’applique: si la configuration du serveur est
identique à celle du client, aucune action n’est effectuée (exemple : un logiciel
déjà installé sur le client ne sera pas réinstallé). Par contre, si la configuration du
client est différente de celle du serveur, celui-ci appliquera la nouvelle
configuration. Ainsi, si on applique la même configuration à cinq minutes
d’intervalle à un client, son état restera le même : un package installé ne sera
pas ré installé si la version correspond à celle spécifiée par le serveur.
Voici le processus de configuration de chaque client :
1) Demande de configuration du client au serveur. Envoi de ses
« facts » en même temps
2) En fonction des informations du client, les ressources sont
interprétées et compilées
3) Envoi de la configuration compilée au client
4) Mise en place de cette configuration par le client avec appel aux
fichiers/Template au serveur si besoin
5) Envoi d’un rapport au PuppetMaster
Figure 15 : fonctionnement de Puppet

Configuration automatisée avec Puppet
Page 26
e) Langage de configuration
Puppet utilise un langage déclaratif simple pour définir les Ressources. Le
fait que ce soit du déclaratif distingue Puppet des autres logiciels de
configuration. Par exemple, pour installer un package, plutôt que d’indiquer la
marche à suivre, on va seulement déclarer le logiciel que l’on veut installer et
Puppet va, en fonction de l’OS ou de la distribution, installer la bonne version
avec le bon installateur. Ainsi, on peut avoir une seule ressource pour plusieurs
OS. L’administrateur s’occupe seulement du “quoi” et plus du “comment”.
Figure 16 : Structure d'une ressource
Exemple de code de configuration :
Figure 17 : Configuration de Yum
Ici, on souhaite configurer Yum avec un fichier yum.conf et des Repository
spécifiques. Pour le fichier yum.conf, on remplace le fichier/etc/yum.conf par le
fichier se trouvant dans/etc/puppet/module/yum/files/yum.conf
Voici une liste des principaux types de Ressource, qui peuvent être
regroupés en classes, eux même regroupés en modules (qui regroupe les
différentes ressources et fichiers utilisés par les ressources si besoin) :
Fichier
Package

Configuration automatisée avec Puppet
Page 27
Cron (tache planifié)
Exec (exécution d’une ligne de commande)
User (tout ce qui touche un utilisateur)
Group (tout ce qui touche un groupe)
Service
Nagios (pour la configuration du logiciel de monitoring Nagios)
Mount
Host (gère le fichier /etc/hosts)
Router (gère une interface d’un routeur ou un switch)
Etc…
Voici l’exemple d’un module Puppet avec plusieurs types de ressources :
Figure 18 : Structure module Puppet
Figure 19 : Fichier init.pp du module puppet
Le fichier init.pp sera le premier fichier lu lors de l’import du module
puppet. Ce manifests inclus le fichier install.pp (puppet ::install) et le fichier
service.pp (puppet ::service).
Figure 20 : Fichier install du module puppet
Le manifest puppet ::install utilise le type « package » pour installer le
client Puppet. Il n’y a pas besoin de spécifier l’installateur (Yum, Apt …), Puppet
s’occupe d’exécuter le code en fonction de l’OS.

Configuration automatisée avec Puppet
Page 28
Figure 21 : Fichier service du module puppet
Il est possible de spécifier des variables qui seront utilisés dans les
ressources :
Figure 22 : Utilisation de variable dans Puppet
La variable $longthing est utilisée par la ressource file « authorized_keys »
afin de renseigner le fichier ssh. Cette variable peut très bien être déclarée
ailleurs, comme par exemple dans le fichier node.pp. Ainsi, chaque nœud peut
avoir une clé ssh autorisée particulière.
f) Utilisation des facts
Le package de PuppetLabs Facter est un outil d’inventaire system : il
retourne des “facts” ; des variables globales, du client telle que son adresse ip,
son hostname, son os et sa version etc... Ces “facts” peuvent être utilisés par
Puppet afin de servir de variable :
Figure 23 : Résultat de la commande Facter

Configuration automatisée avec Puppet
Page 29
Exemple de code avec operating-system :
Figure 24 : Choix d'une classe en fonction de l'OS
Ici, en fonction de la distribution, on va appliquer la class apache-RedHat
ou apache-Debian.
g) Les fichiers Template
Nous avons vu que nous pouvons copier des fichiers depuis le serveur
Puppet. Ces fichiers sont figés et ne sont pas modifiables par Puppet.
Néanmoins, certains fichiers doivent être différents sur chaque machine, même
si une seule ligne les diffère. Plutôt que d’avoir un fichier par machine, il est
possible d’utiliser les Template.
Ces Template sont des fichiers qu’il y possible de modifier avec des
variables dans des manifests et des « facts ».
Figure 25 : Exemple de fichier Template
Notre exemple de fichier Template permet de créer un fichier sur chaque
nœud avec l’adresse ip du nœud en question.
Si l’IP de la machine A est 10.20.1.15, le fichier sera :
Figure 26 : Fichier Template machine A
Si l’IP de la machine B est 10.20.1.15, le fichier sera :
Figure 27 : Fichier Template machine B
h) Environnement :
Il est possible de séparer des environnements afin que ceux-ci s’adaptent
à nos besoins. Le meilleur exemple est un environnement de production, un de
test et un de développement. Ainsi, les changements de configuration dans
l’environnement de test n’impacte pas les autres environnements.

Configuration automatisée avec Puppet
Page 30
Pour cela, il faut mettre en place une arborescence avec un dossier par
environnement diffèrent.
Figure 28 : Structure de Puppet avec trois environnements
Puis il faut spécifier dans le fichier puppet.conf l’emplacement des
environnements. :
Figure 29 : Environnements dans le fichier puppet.conf
Lors du lancement de l’agent, il faut spécifier l’environnement :
Figure 30 : Exécution de Puppet dans un environnement particulier

Configuration automatisée avec Puppet
Page 31
Le cheminement dans la mise en place d’une nouvelle configuration :
1. Mise en place d’une nouvelle configuration dans l’environnement
« dev ».
2. Si la configuration convient pour une machine, on peut la copier
dans l’environnement « test » afin de faire des tests à plus grande
échelle.
3. Si ces tests sont concluants, on peut mettre en place la mise en
production sur l’ensemble des machines en copiant le contenu de
« test » dans « prod ».
Pour cela, le plus pratique est de mettre en place une solution avec GIT :
en plus de pouvoir gérer les versions des scripts, il pourra nous aider à utiliser
les environnements via des dossiers séparés.
i) Montée en puissance
En ayant un serveur et un client il est évident que nous n’avons pas de
problème de charge. Néanmoins, dans un domaine de production, il n y’a plus un
client mais plusieurs milliers et un seul serveur ne pourrait supporter la charge.
Pour gérer cela, nous avons différentes possibilités :
changer le serveur HTTP utilisé (WEBrick) par un serveur Apache
multiplier les PuppetMaster.
utiliser un ou plusieurs serveurs pour isoler la fonction PuppetCA qui
authentifie les clients
Nous savons que cela est possible et que c’est utilisé par de nombreux
utilisateurs. C’est pourquoi un tel dispositif ne fera pas partie du stage,
sauf si le temps me le permet.
j) Exécution de Puppet
Afin de procéder aux différents tests, nous voulons que les processus
PuppetMaster et Agent ne soient pas utilisés en tant que démon et aussi que la
sortie soit détaillée, nous utilisons la commande suivante :
D’abord le PuppetMaster :
Figure 31 : Exécution de PuppetMaster

Configuration automatisée avec Puppet
Page 32
Figure 32 : Exécution de Puppet Client
Notre client s’est connecté sur le serveur maitre et a exécuté la
configuration spécifiée par le fichier/etc/puppet/site.pp. Etant donné que ce
fichier est vide, la configuration n’a rien changé. Si on voulait lancer le script
directement sur le client sans devoir se connecter d’abord au serveur, on
utiliserait la commande suivante en spécifiant le script à utiliser :
Figure 33 : Exécution du script site.pp
k) Communauté Puppet
L’une des grandes forces de Puppet est sa communauté extrêmement
active.
Par active, il faut comprendre avec une entraide solide, du partage de
codes via des modules à installer ou des conférences comme lors des 13emes
Rencontre Mondiales du Logiciel Libre à Genève du 7 au 12 Juillet 2012
(conférences concernant Puppet faites par la société PuppetLabs mais aussi par
des utilisateurs donnant leur point de vue basé sur une expérience de plusieurs
années de Puppet).
Ces rencontres sur internet ou en vrai permettent de s’enrichir et en
retour, d’aider d’autres personnes.
Le site PuppetForge [3] rassemble les modules de la communauté.

Configuration automatisée avec Puppet
Page 33
Figure 34 : Exemple de module disponible sur le site Puppet Forge
Concernant les modules, il existe même un outil de PuppetLabs pour
faciliter leur mise en place.
L’outil va se connecter sur le site PuppetForge regroupant tous les modules
mis à disposition et va récupérer les fichiers correspondants.
3) Configuration au LHCb :
Pour endommager une machine, une seule personne suffit. Pour
endommager une ferme de serveur, il faut passer par un outil de configuration
automatisé.
Un des buts du stage est de répondre à la question :
Est-ce que Puppet peut configurer les machines de la ferme pour obtenir le
même résultat que Quattor en apportant ses avantages ?
Pour répondre à cela, mon tuteur m’a donné un cahier des charges et en
fonction des résultats, nous aurons une réponse à cette question.
a) Configuration minimum
En fait, un serveur de la ferme n’a pas besoin de beaucoup de
configuration. Cela consiste en une installation de quelques package et de leur
paramétrage, de faire en sorte que l’on puisse se connecter en SSH et de monter
des dossiers.
Liste de packages à installer :
Openldap : implémentation libre du protocole LDAP
Autofs : contrôle les opérations des démons d’automount
Nss-pam-ldapd : permet de fournir des services de correspondance
entre hostname de toute sorte

Configuration automatisée avec Puppet
Page 34
Cyrus-sasl-gssapi : contient les plugins Cyrus SASL supportant
l'authentification GSSAPI. GSSAPI est fréquemment utilisé pour
l'authentification Kerberos (protocole d’authenfication réseau)
Liste des configurations à implémenter :
Clé SSH
Paramétrage du proxy netgw01
Configuration du cache ldap
Configuration Kerberos pour LDAP
Configuration des recherches LDAP
Montage de deux dossiers réseau
Configuration du client NFS
Dans le monde linux, tout est fichier. Donc, on peut mettre en place ces
configurations en modifiant des fichiers ou en utilisant des types de ressources
de Puppet pour y arriver.
La façon la plus simple serait de copier les fichiers depuis une machine en
fonctionnement et les mettre au bon endroit. Mais, pour le faire dans les règles
de l’art, il serait préférable de récupérer les différents paramètres depuis les
fichiers de configuration de Quattor, en déduire les variables et créer des fichiers
génériques en utilisant les variables de Quattor comme des variables sur Puppet.
b) Exemple de configuration :
Configuration des tests :
Un serveur PuppetMaster sous SLC6
Deux clients sous SLC6
Avec un serveur et deux clients, il était simple de comparer la mise en
place d’une configuration.
Vous pourrez trouver ci-dessous un exemple de configuration que j’ai
appliqué.
Paramétrage du proxy Netgw01 :8080 :
Ce proxy permet d’avoir une porte ouverte sur Internet si on passe par lui.
Cela permet de restreindre certains accès si besoin. Pour cela, il existe plusieurs
façons de faire :

Configuration automatisée avec Puppet
Page 35
Via une ligne de commande :
Figure 35 : ligne de commande paramétrant le proxy
Via le fichier /etc/bashrc
Figure 36 : fichier /etc/bashrc
Encore une fois, pour bien prendre en main Puppet, il faut penser
fichier/action générique avec des variables définies à côté. Ainsi, si le proxy vient
à changer, plutôt que changer le fichier, il suffira de changer la variable dans un
fichier. De même, si un deuxième proxy vient à exister, un changement de
variable résout le problème.
C’est pour cela qu’il a été préféré la deuxième méthode. Pour se faire,
plutôt que remplacer le fichier, il est préférable de rajouter une ligne dans le
fichier.
Notre problème est que Puppet ne gère pas l’ajout de texte avec
vérification si le texte est déjà présent et si c’est le cas, ne pas le rajouter.
C’est pourquoi j’ai dû passer par un script qui va « parser »le fichier
/etc/bashrc et rajouter les paramètres en conséquence.
Figure 37 : Structure du fichier node.pp
Le fichier node.pp permet de spécifier la configuration pour chaque nœud.
Dans notre cas, le nœud « client1.lbdaq.cern.ch » n’a pas besoin d’autre
configuration que celle de base (juste le module proxy ici).

Configuration automatisée avec Puppet
Page 36
Pour inclure un module, il suffit de mettre « include ‘nom_du_module’ »
et Puppet ira chercher le module /etc/puppet/module (possibilité de changer le
chemin avec le fichier « puppet.conf »).Bien entendu, il est possible de spécifier
des paramètres sont seront repris dans le module. Cela pourrait, si on le
souhaitait, permettre d’avoir un proxy diffèrent sur certaine machine tout en
gardant des fichiers génériques.
Figure 38 : Arborescence du module proxy
Le fichier « init.pp » est le premier fichier lu lors de l’appel d’un module.
Ce fichier est le « chef d’orchestre » et son rôle est de faire appel aux autres
fichiers du module. Bien entendu, tout le module peut tenir dans ce fichier mais,
encore une fois, il est préférable de séparer le code.
Figure 39 : Structure du fichier init.pp du module proxy
Le fichier « init.pp » est composé de deux ressources :
La première qui va copier un fichier « script_proxy »dans le
dossier/tmp/du client avec certains droits.
La deuxième qui va exécuter ce script.
Vous pouvez remarquer qu’il est possible d’ordonnancer l’exécution de la
configuration. En effet, par défaut, Puppet ne va lire les fichiers que dans l’ordre
que l’on veut. Cela se fait de manière plus ou moins aléatoire : deux exécutions
de la même configuration pourront ne pas avoir le même enchaînement de
Ressource. Pour pallier à cela, il est possible d’utiliser des mots clé : Before,
Require, Notify et Subscribe. Ainsi, la deuxième Ressource sera appelée si et
seulement si la première ressource a déjà été utilisée. Il est logique d’exécuter
un script seulement s’il est bien présent à l’emplacement prévu.

Configuration automatisée avec Puppet
Page 37
Figure 40 : Structure du script du module proxy
Le script va « parser » le fichier /etc/bashrc et agir en fonction : si la ligne
« export http_proxy=netgw01 :8080 » n’existe pas, il va la rajouter.
Ce module est assez simple mais permet d’apercevoir la puissance de
Puppet avec les types de ressources.
Et même quand une fonctionnalité n’est pas native dans Puppet, il existe
certainement un module pour le faire (ce qui n’est pas le cas pour notre module
proxy).
c) Conclusion
La configuration de base des machines de la ferme est très bien gérée par
Puppet. Une fois ce travail achevé et validé par mon tuteur, nous en avons
conclu que Puppet correspondait à nos attentes et qu’il pourra remplacer Quattor
dans un futur proche.
Mais la vraie question est : peut-on optimiser cela ?
La seule réponse est : oui mais avec de l’expérience. En effet, comme dit
plus haut, il n’existe pas qu’une seule manière d’utiliser Puppet. Reste à trouver
la méthode la plus adaptée et la plus fonctionnelle possible.
Quattor comprend la gestion des configurations mais aussi une partie
d’installation automatisée. Puppet remplie la première fonction. Il nous reste à
trouver le logiciel pour la deuxième partie.

Installation automatisée avec Cobbler
Page 38
III. Installation automatisée avec
Cobbler
On sait que Puppet est l’outil que l’on veut pour configurer les différentes
machines. Mais avant de configurer ces serveurs, il faut les installer.
Il existe la méthode « à l’ancienne » : insérer un dvd dans chaque
machine et valider manuellement le paramétrage. Ça fonctionne pour un seul
serveur mais quand il y en a plus de deux mille, à moins de prendre un stagiaire
pendant cinq mois pour cette seule tâche et ne faisant que ça, c’est mission
impossible.
C’est là qu’intervient Cobbler.
1) Définition de Cobbler
Cobbler est un serveur d’installation par réseau d’OS Linux permettant un
paramétrage rapide des environnements d’installations. Il relie et automatise
plusieurs fonctions comme un serveur web, un serveur TFP etc… et ainsi n’a
qu’une seule interface pour gérer une nouvelle machine. Il relie dans le sens où il
peut utiliser des services externes ou bien fournir ces services par lui-même.
Projet de la distribution Fedora, il gère de plus en plus d’autres distributions :
bien entendu Fedora/RedHat et ses dérivés (CentOS et Scientific Linux) mais
aussi Debian/Ubuntu, Suse et FreeBsd. Le serveur ne fonctionne par contre que
pour la famille Fedora/RedHat. La version actuelle est la 2.2.3 et la
documentation et les sources peuvent se trouver sur le site officiel [4].
Avantage :
Rapidité
Simplification et automatisation
Installation de plusieurs clients à la fois
Installation homogène
Abstraction d’un support physique tel que Dvd ou clé USB
Inconvénients :
Utilisation des ressources réseaux

Installation automatisée avec Cobbler
Page 39
2) Principe de Cobbler
Cobbler utilise le protocole PXE (Pre-boot eXecution Environment) qui
permet à un client d’utiliser le réseau pour récupérer une image d’un OS. Cette
image peut être utilisée pour permettre le diagnostic d’un mini OS pour des
clients légers, d’un vrai OS dans le cas de machine diskless où le système
d’exploitation sera entièrement utilisé via le réseau, ou un mini système
d’exploitation qui permet d’installer un OS sur le disque dur local de la machine.
C’est cette dernière possibilité qui nous intéresse.
De nombreuses sociétés utilisent Cobbler (Dell, Sony, LinkShare, TomTom
etc…) et donc, sa pérennité ne peut pas être remise en question.
a) Serveur Pxe
Figure 41 : Séquence de démarrage d'un client
Tout d’abord, le client doit avoir une carte réseau compatible PXE (ce qui
est vrai pour la plupart des machines actuelles) et spécifier qu’il doit démarrer
sur le réseau au lieu d’utiliser le disque dur local. Afin de savoir où le client doit
aller chercher le serveur PXE, on utilise le serveur DHCP (1er composant
indispensable à Cobbler). En effet, la première information que le client va
chercher est une adresse IP. Dans la configuration du serveur DHCP est indiquée
l’adresse du serveur TFT PXE et le nom du fichier d’amorce. Ce fichier d’amorce
se nomme « pxelinux.0 » et c’est ce fichier qui indiquera où récupérer la
configuration PXE en utilisant le format suivant :

Installation automatisée avec Cobbler
Page 40
Figure 42: Configuration DHCP du poste client1
Le client va chercher sa configuration dans un dossier en commençant par
un dossier portant le nom de son adresse MAC (numéro unique), puis cette
adresse convertit en hexadécimal en retranchant un digit à chaque essai pour
finir par le fichier par default. Si malgré cela le client n’a rien trouvé lui
correspondant alors l’installation se solde par un échec.
Figure 43 : Tentative de récupération du fichier pxelinux.cfg
Dans le cas où un fichier de configuration est trouvé, ce fichier est analysé
et exploité : requête PXE au serveur TFTP PXE pour les paramètres de
démarrage.
Si la machine est vierge, on souhaite installer un OS. Si l’OS est déjà
installé, on va booter sur le disque dur local. Tous ces fichiers sont hébergés sur
un serveur TFTP (deuxième composant indispensable à Cobbler).
Ainsi, en fonction de l’adresse MAC, Cobbler pourra indiquer quel OS
installer avec quelle configuration.
C’est à partir de ce moment que la machine peut commencer à s’installer.
Afin d’automatiser cela, un fichier de réponse appelé fichier « Kickstart » est
fourni au client. Ce fichier va automatiquement fournir des réponses que
l’installateur pourrait poser comme le choix de la langue, du clavier, des
packages à installer etc…

Installation automatisée avec Cobbler
Page 41
Une variable sur Cobbler indique si une machine doit être installée ou si
elle doit démarrer sur le disque dur local. Par défaut, cette variable indique qu’un
nouveau system doit être installé. Pour la modifier, on peut le faire
manuellement ou bien une routine est utilisée à la fin du fichier Kickstart dans le
script de post-install. Ainsi, si l’installation doit s’interrompre avant la fin, au
prochain démarrage la machine recommencera le processus d’installation. Si
l’installation s’est bien déroulée, le prochain démarrage se fera sur le disque dur
local.
Figure 44 : Cobbler
Ce schéma montre bien comment Cobbler agit comme un couteau suisse :
utiliser des services externes (DHCP, DNS, HTTP, TFTP) pour des ressources
internes (System, Profile, Distro, Repository, Kickstart). Pour configurer une
nouvelle machine, on va créer un nouveau « System » avec son adresse MAC
(adresse IP en option) que l’on va rattacher à un « Profil » (ex : serveur web),
qui ira puiser ses fichiers de base dans une « Distribution » en utilisant des
« Repository » pour l’installation de packages définis dans un fichier
« Kickstart »(les Mgmt-Class pour Management Class est un peu à part : cela
sera utilisé pour créer un lien avec Puppet).
Notre but est d’avoir une configuration minimum, la plus générique
possible avec juste le package Puppet installé et que ce soit Puppet qui gère
vraiment toute la configuration de la machine.

Installation automatisée avec Cobbler
Page 42
b) Installation de Cobbler
Sur une distribution SLC, une ligne de commande permet d’installer
Cobbler et ses dépendances :
Figure 45 : Installation de Cobbler
Parmi ces dépendances, on retrouve « httpd » (serveur web), « tftp-
server » (serveur tftp), « xinetd » (gère les connexions basé sur Internet).
c) Structure de Cobbler
Liste des dossiers créés durant l’installation de Cobbler :
/etc/cobbler :
Regroupe la configuration propre à Cobbler
/var/www/cobbler
Ensemble des données utiles aux clients pour s’installer
(exemple : distribution, packages etc…)
/var/lib/cobbler
Dossier des données propre à Cobbler
/var/log/cobbler
Journaux de Cobbler

Installation automatisée avec Cobbler
Page 43
d) Configuration de Cobbler
Avant de paramétrer les services externes, on va le faire via Cobbler au
fichier/etc/cobbler/seetings. Exemples :
Adresse du serveur PXE (Serveur hébergeant Cobbler dans notre cas)
Figure 46 : Fichier seetings de Cobbler
Gestion du DHCP par Cobbler
Figure 47 : Gestion du DHCP par Cobbler
Le choix des outils DHCP ou http par exemple se fait dans le fichier
/etc/cobbler/module.conf.
Figure 48 : Choix du serveur DHCP dans module.conf
Cobbler est un outil permettant de centraliser les configurations des autres
services qui lui sont utiles. Ainsi, il n’existe qu’une seule interface pour gérer les
données et les serveurs externes. Pour se faire, des Template existent et Cobbler
va modifier les fichiers de config de ces serveurs grâce au variable fournit par
l’administrateur dans la configuration de Cobbler.

Installation automatisée avec Cobbler
Page 44
Figure 49 : Template du fichier dhcpd.conf
Une fois l’installation terminée et la configuration de Cobbler finit, une
commande (cobbler check) va confirmer que la configuration est conforme et on
saura si on peut commencer l’importation des données.
e) Fichier Kickstart
Un fichier Kickstart est composé de quatre parties :
La configuration de base
Répond aux questions de base : langue, time zone,
partitionnement des disques durs etc...
Liste des packages
Dans notre cas, seul le package Puppet sera installé mais on
peut aussi spécifier des packages simples ou des groupes de
packages, voire d’enlever un package d’un groupe
Script de Pré Install
Liste des commandes à exécuter avant l’installation. Vide
dans notre cas.
Script de Post Install
Liste des commandes à exécuter après l’installation. On va
effacer les listes d’origines des Repository de Yum qui pointent sur
l’extérieur et faire en sorte que Puppet se lance à chaque démarrage
du client. On va aussi utiliser un Template de Cobbler appelé
SNIPPET pour modifier la variable qui désactive l’installation du
client à son prochain démarrage.

Installation automatisée avec Cobbler
Page 45
Figure 50 : Fichier Kickstart
f) Import des Repository
La première chose à faire est d’importer des Repository qui seront utilisés
lors de l’installation des packages pendant l’installation de l’OS. Il est possible
d’utiliser des Repository externe à Cobbler (sur Internet par exemple pour avoir
les dernières versions des packages) mais étant donné que l’on souhaite qu’il n’y
ait aucune donnée venant de l’autre part du serveur Cobbler afin de pouvoir
garantir leur bonne intégrité, nous allons devoir importer leur contenu. Le
Repository le plus important est celui hébergeant Puppet. Malheureusement, le
package Puppet (et certaines de ses dépendances) ne fait pas partie des
packages d’origine des Repository de SLC6. C’est pourquoi j’ai créé un Repository
local spécialement pour cela.
L’importation des données se fait en deux étapes : configuration d’un
Repository et synchronisation des données.
Figure 51 : Import d'un Repository sous Cobbler

Installation automatisée avec Cobbler
Page 46
Par la suite, il est possible de resynchroniser nos Repository locaux avec
les originaux.
Figure 52 : Synchronisation des Repository
Les Repository se trouvent dans le dossier /var/www/cobbler/repo_mirror/
g) Import des OS
Dans ce projet, seul l’OS SLC6 sera utilisé pour l’installation des clients
mais il est possible d’importer plusieurs OS. Il suffit de spécifier le nom que l’on
souhaite donner à cet OS et son emplacement d’origine (Dvd, Fichier ISO etc…)
Figure 53 : Importation de la distribution SLC6 depuis le fichier boot.iso
Les distributions se trouvent dans le dossier /var/www/cobbler/ks_mirror/.
h) Création d’un profil
Lors de l’importation d’une distribution, un profil est automatiquement
créé avec comme seul paramètre la distribution qui lui est lié. Nous devons lui
ajouter les Repository que l’on a créés juste avant, ainsi que l’emplacement du
fichier Kickstart.
Figure 54 : Structure d'un profil
Il est tout à fait possible de créer d’autres profiles que ceux d’origine pour
spécifier d’autres fichiers Kickstart par exemple.
i) Ajout d’un système
Maintenant que tout est mis en place pour permettre l’installation d’une
nouvelle machine, il suffit de la rajouter dans Cobbler.

Installation automatisée avec Cobbler
Page 47
Pour cela, on a besoin de son nom pour l’identifier sur Cobbler, du profil
utilisé, de son adresse MAC et interface réseau, son config réseau (adresse IP,
DNS etc…). Ces informations iront renseigner le fichier de configuration du
serveur DHCP (dhcpd.conf). Une seule interface de configuration : Cobbler.
Figure 55 : Ajout d'un system
j) Installation d’une machine
Avant de lancer une nouvelle installation d’un client, il faut synchroniser
Cobbler pour qu’il puisse modifier les fichiers de configuration et relancer les
services.
Figure 56 : Résultat de la commande cobbler sync
Installation automatisée avec Cobbler
Page 48
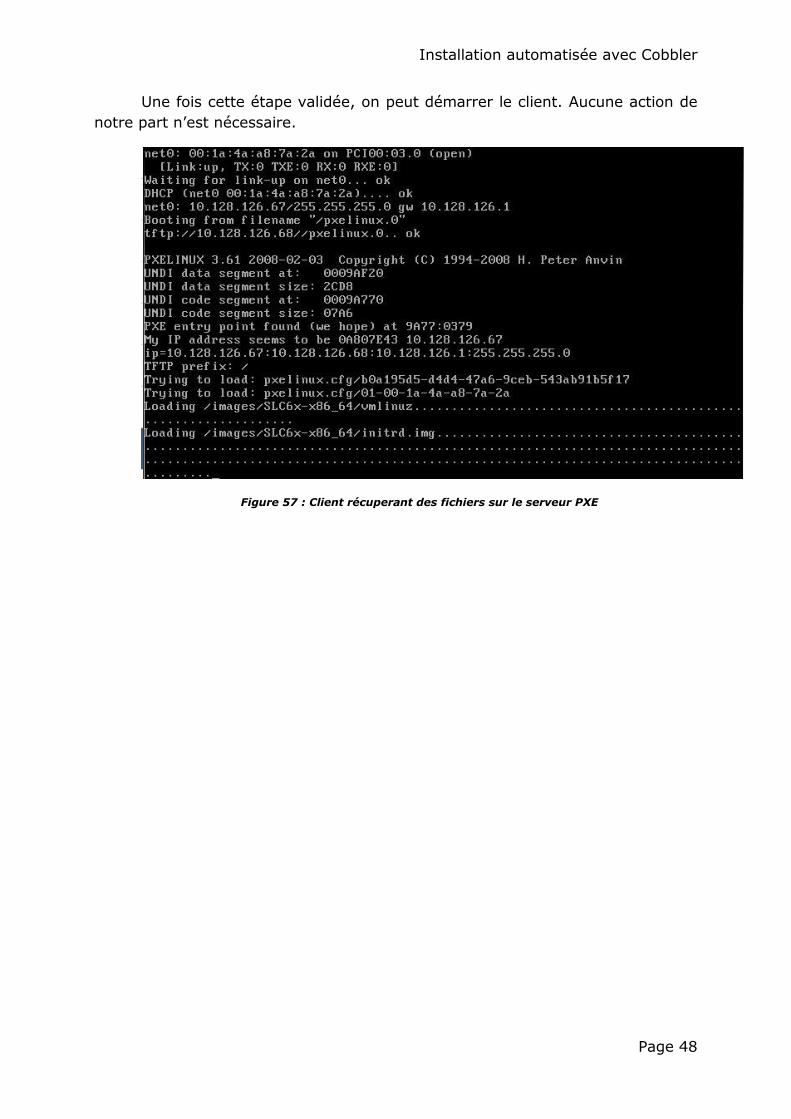
Une fois cette étape validée, on peut démarrer le client. Aucune action de
notre part n’est nécessaire.
Figure 57 : Client récuperant des fichiers sur le serveur PXE

Interconnexion Puppet – Cobbler
Page 49
IV. Interconnexion Puppet – Cobbler
1) Lien entre Puppet et Cobbler
C’est parfait. Cobbler installe les clients et Puppet les configure. Mais
il reste un problème à résoudre : chaque machine est déclarée sous
Cobbler et sous Puppet à la fois. Il y a des outils pour éviter ce double
travail.
Pour pallier à cela, il est possible de configurer Puppet pour que, au lieu
d’utiliser le fichier « node.pp » pour connaitre la configuration à appliquer à
chaque client, il aille chercher ces informations à l’extérieur : c’est la notion de
configuration de node externe (ENC pour External Node Configuration).
Mais cela est un peu plus subtil avec Cobbler qu’avec le fichier
« node.pp » : un paramètre dans Cobbler, que l’on retrouve sur les distributions
les profiles et les systèmes, est appelé « Management Classes » et on peut y
spécifier plusieurs variables. On va y mettre des noms de class de Puppet
(exemple : la class yum ou la class puppet qui se trouve chacune dans un
module).
Figure 58 : Management Classes au sein de Cobbler
Mais comment retourner ces variables en fonction de l’hostname d’un
client et les utiliser dans Puppet ?
Cobbler fournit un script qui retourne ces valeurs via le serveur web.
Figure 59 : Réponse du script en fonction d'un client
Et justement, la notion de node externe peut se paramétrer dans
/etc/puppet/puppet.conf grâce à un script (ici, une copie du script d’origine
renommé dans /etc/puppet/external).
Figure 60 : Configuration du fichier puppet.conf

Interconnexion Puppet – Cobbler
Page 50
Figure 61 : Script external
Ainsi, Puppet peut interroger Cobbler pour connaitre les class à utiliser
pour tel ou tel client. L’interconnexion fonctionne parfaitement mais…
Mais ce n’est pas l’utilisation souhaitée. Ce que nous recherchons, c’est de
définir les distributions, les profiles et les Repository sous Cobbler et tout ce qui
touche les systèmes, de les définir sous Puppet. Dans le meilleur des cas, c’est
Puppet qui va renseigner Cobbler sur les clients et non pas Cobbler qui indique à
Puppet ce qu’il doit faire.
À l’heure actuelle, malgré tous ces atouts, Cobbler ne correspond pas à
l’outil souhaité par le LHCb et par Niko Neufeld en particulier. Mais, il est faut pas
enterrer Cobbler trop vite.
2) Remplacement de Cobbler ?
Quelle est finalement la solution ?
Lors des conférences des Rencontres du Monde du Logiciel Libre le 11
Juillet 2012, PuppetLabs a parlé d’une nouvelle solution qui pourrait nous
convenir : Razor. Etant donné qu’il est développé par PuppetLabs justement, on
est en droit d’espérer une complète imbrication dans Puppet.
3) Razor
« La solution la plus simple est la plus élégante » Luke Kanies, Fondateur
de PuppetLabs

Interconnexion Puppet – Cobbler
Page 51
Razor [5] utilise 4 composants ayant chacun une fonctionnalité bien
définie :
a) Discovery
Figure 62 : Razor Discovery
Alors qu’avec Cobbler chaque machine doit être déclarée manuellement,
Razor intègre un outil permettant de connaitre exactement les composants
matériels et logiciels de chaque nœud avant même leur installation et ainsi si une
machine fait partie d’un lot de même type, Razor saura déjà quel OS installer.
Fonctionnant aussi avec un serveur DHCP et un serveur PXE, le serveur
Razor va fournir une adresse IP via le serveur DHCP. En plus de l’adresse, le
client va récupérer l’adresse du « next-server » qui correspond au serveur PXE
Razor.
Ce serveur PXE va fournir un MicroKernel de 20mo à peu près. Ce
MicroKernel est un système d’exploitation extrêmement simplifié basé sur Linux
et fournissant une certaine fonctionnalité de base au client. Son but est de faire
en sorte que le client puisse faire un inventaire, de contacter le serveur Razor et
s’enregistrer sur celui-ci.
En s’enregistrant, il fournit grâce au logiciel Facter de PuppetLabs des
informations sur son matériel et sa configuration réseau ( Adresse IP, Mac etc…).
Parmi ces informations, on trouve le nombre de processeur, le fabriquant de
l’ordinateur, le nombre de disque dur et bien plus.

Interconnexion Puppet – Cobbler
Page 52
Grace à cela, Razor est capable de découvrir et répertorier des centaines
de nœud automatiquement.
Figure 63 : Liste des nœuds sur Razor
Figure 64 : Attribut d'un node sur Razor

Interconnexion Puppet – Cobbler
Page 53
b) Tagging
Figure 65 : Razor Tagging
Une fois le client et ses informations découverts, il faut utiliser des
modèles permettant une classification et ainsi traiter un ensemble de serveur
plutôt que chaque machine individuellement.
Pour se faire, Razor utilise des règles de « tags » à appliquer sur les
nœuds en fonction de ce que Facter a découvert.
Exemple : on a 50 serveurs avec 25 de la marque Cisco UCS et 25 de la
marque Dell. On souhaite utiliser chaque groupe de serveurs dans un rôle bien
spécifique : les Cisco pour faire une ferme de serveur et les Dell pour faire de la
virtualisation.
On peut connaitre toutes les informations dont on a besoin pour les classer
grâce à la partie Discovery et on peut les grouper en appliquant un « tag »
commun. Exemple : si l’information « constructeur » est ‘Cisco’ alors on applique
le « tag » Cisco. On peut aussi avoir des tags ‘big_server’, ‘medium_server’ et
‘small_server’ en fonction du nombre de processeur. Il est aussi possible de
spécifier plusieurs tag à la fois : [‘Dell’, ‘small_server’].
Par défaut, Razor utilise les tags [‘Nombre_de_CPU’, ’Type_de_CPU’,
’Nombre_de_Carte_Reseau’, ‘Type_de_machine’].

Interconnexion Puppet – Cobbler
Page 54
c) Policy
Figure 66 : Razor Policy
Maintenant, il faut appliquer un modèle commun à chaque tags ou groupe
de tags pour l’installation des systèmes d’exploitation : si les tags sont
[‘web_farm’, ‘small_server’] alors on applique le model « Ubuntu » (du nom de la
distribution Ubuntu). Ces modèles sont déclarés préalablement sur Razor en
important le système d’exploitation.
Ainsi, le système d’exploitation SLC6 sera installé sur les machines ayant
les mêmes « tags » que ceux déclarés.
Figure 67 : Razor Policy
Ci-dessous, on retrouve la liste des politiques déclarés sur Razor avec la
liste des tags associé et le nombre de clients existants.

Interconnexion Puppet – Cobbler
Page 55
d) Brokers
Figure 68 : Razor Broker
On se retrouve avec des machines installées avec le système d’exploitation
souhaité. Mais il n’y a pas de lien encore avec Puppet. Etant donné que Razor et
Puppet viennent de la même entreprise, PuppetLabs, il est très facile d’intégrer
Puppet lors de l’installation des clients. Pour se faire, il faut spécifier via une ligne
de commande un lien entre le serveur Razor et le serveur Puppet : un
« Broker » (agent de change).
Figure 69 : Liste des Broker
Il faut ensuite associer ce « Broker » a une politique existante.
Figure 70 : Politiques sur Razor avec "Broker"

Interconnexion Puppet – Cobbler
Page 56
e) Avantages / Inconvénients
On a un outil permettant l’automatisation à outrance : contrairement à
Cobbler, il n’est plus utile de déclarer chaque machine pour permettre leur
installation : un modèle unique pour un groupe de machine suffit.
Mais Razor n’est pas dénué d’inconvénients :
Pour l’instant, seules les distributions Debian/Ubuntu sont supportées. Il
faut adapter une partie du code de Razor pour le rendre compatibles avec SLC6.
Si certaines parties sont plutôt simples, d’autres sont plus compliquées : Razor
utilise des packages Ruby appelés Gems dont certains n’existent que pour
Debian/Ubuntu. Une réécriture complète de ces Gems est donc indispensable.
De plus, Razor est un outil extrêmement jeune : début Juillet 2012, l’outil
venait tout juste d’être publié par PuppetLabs, soit à peine quelques mois
d’existence contrairement à Cobbler qui existe depuis plus de quatre ans et a de
nombreux clients. Il est donc difficile de trouver de la documentation de
nombreux cas ne sont pas pris en compte ( exemple de SLC6 reconnu comme un
OS SLC et non pas RedHat ).
C’est pourquoi, malgré ses avantages, Razor n’est pas une solution
retenue.
4) La solution
Finalement, pour la solution de lien entre Puppet et le logiciel
d’installation, il est envisagé de revenir à Cobbler avec le développement de
script : séparer la partie matérielle avec Cobbler de la partie logiciel avec Puppet.
a) Partie Matériel
La première partie consiste à déclarer chaque machine sur Cobbler avec
comme information : Hostname, Adresse Mac et Adresse IP. Ces seules
informations sont indispensables pour l’installation du client avec, bien sûr , le
choix d’un Profil existant dans Cobbler.
Figure 71 : Ajout d'une machine sur Cobbler

Interconnexion Puppet – Cobbler
Page 57
b) Partie Logiciel
L’enregistrement sous Puppet est extrêmement simple : cela consiste à
avoir un fichier ayant pour nom l’hostname du nœud avec l’extension
« :pp »dans le dossier /etc/puppet/manifests/nodes/ avec comme contenu
« node hostname ». En paramétrant le fichier /etc/puppet/manifests/site.pp, il
ira directement chercher la définition des nœuds dans ce dossier.
Figure 72 : Fichier site.pp
Figure 73 : Fichier client1.lbdaq.cern.ch.pp
c) Lien entre les deux
Une solution est d’enregistrer chaque machine sur Puppet grâce à Cobbler
et au fichier Kickstart.
A la fin de l’installation avec un fichier Kickstart, il est possible d’exécuter
des commandes. Ces commandes peuvent servir à modifier le champ «Netboot
Enable » des machines sous Cobbler pour éviter que l’installation se fasse en
boucle si elle est réussie. Nous pouvons nous servir de ce modèle en utilisant un
serveur web fonctionnant sous la technologie Web PHP pour créer le fichier
« hostname .pp » dans le serveur Puppet.
En utlisant une addresse web avec l’hostname du client en paramettre, le
serveur va créer le fichier .pp.

Interconnexion Puppet – Cobbler
Page 58
Figure 74 : Fichier Kickstart avec script PHP
Figure 75 : Script PHP pour créer le fichier hostname.pp
Ce fichier .pp pourra être modifié par la suite au besoin et ainsi modifier la
configuration du client.

Interconnexion Puppet – Cobbler
Page 59
Même si cette solution n’est pas parfaite (utilisation d’outil externe avec le
serveur web en PHP plutôt que des outils internes à Cobbler) l’avantage d’un tel
système est de séparer la partie logiciel et la partie matériel. Si une machine a
un problème de carte réseau et qu’elle doit être changée, l’adresse MAC du nœud
changera. Seule la modification sous Cobbler est nécessaire et rien ne change
pour Puppet.

Machine Diskless
Page 60
V. Machine Diskless
Une fois la solution pour interconnecter Puppet et le logiciel d’installation
trouvé, il faut pouvoir la mettre en production.
Seulement, la production, c’est la ferme de serveur. Et cette ferme de
serveur est composée de machines Diskless (sans disque dur local : l’OS est sur
un disque dur d’un serveur central et envoyé au client via le réseau).
1) Principe
Comme indiqué, une machine Diskless ne possède pas de disque dur. Son
espace de stockage est centralisé avec les espaces de stockage des autres clients
sur un serveur central. Au LHCb, un serveur central administre 27 nœuds client
Figure 76 : Serveur Central et Client Diskless
Il existe deux fonctionnements de serveur Diskless :
Chaque client possède son propre espace
Tous les clients partagent le même espace (fichiers communs pour
tous les clients, appelé root ), sauf quelques dossiers sélectionnés
où chaque client possède son propre espace (appelé snapshot).
Le deuxième système est celui sélectionné par le LHCb. Deux raisons à
cela :
Gain de place : l’ensemble des données d’un client font 4,5 Giga et
avec ce système, on a 500 mo de données spécifiques et les
données partagées font 4 Giga. Au lieu d’avoir 27x 4,5 Giga =120
Giga par serveur), on a 27x500mo + 4 Giga= 17,5 Giga.

Machine Diskless
Page 61
Gain d’administration : les fichiers administrés sur les clients sont
souvent des fichiers communs à tous les clients. Ainsi, plutôt que de
modifier 27 fichiers pour l’ensemble des clients, on modifie juste le
fichier commun. Cela représente un gain de vitesse, de ressource
(réseau et machine ) etc…
Figure 77 : Liste des dossiers du serveur central Diskless
Ci-dessus, on peut voir l’arborescence sur le serveur central des dossiers
avec le dossier « root » commun à tous les clients et le dossier snapshot où
chaque client a son propre dossier.
L’ensemble des fichiers spécifiques à chaque client sont déclaré dans le
fichier /diskless/snapshot/files.custom.

Machine Diskless
Page 62
Figure 78 : Liste des dossiers spécifique machine Diskless
2) Problèmes
Ce système de machine Diskless au sein du LHCb fonctionne très bien.
Toutefois, le passage à SLC6 peut être compromis : alors que SLC5 gère très
bien les snapshot, SLC6 n’a plus cette fonctionnalité de base (seule la possibilité
d’avoir des espaces spécifiques existe). Il faut adapter l’OS.
De plus, Cobbler ne gère pas ce système de machine Diskless avec dossier
snapshot : seul celui où les clients ne possèdent que des données spécifique est
possible. Donc même avec SLC5, les snapshots ne sont pas disponible avec
Cobbler
Le premier problème sera résolu par Pierre Schweitzer ( Etudiant ISIMA
ZZ3 promo 12 ) lors de la fin de son stage au CERN. Sa solution passe par la
création d’un nouveau système de fichier permettant une utilisation transparente
des snapshot.
Le deuxième problème ne peut être résolu à moins de revoir en grande
partie le code de Cobbler. Ce n’est pas le but de ce stage.
Mais au lieu de trouver une solution à ce problème, il peut être envisagé
de le contourner. Aujourd’hui les disques durs ne sont plus aussi onéreux
qu’avant. La taille des disques durs a considérablement augmenté alors que les
prix ont chuté. De même, les ressources telles que le réseau ou les processeurs
ont eux aussi gagné en performances.

Machine Diskless
Page 63
De ce fait, il peut être envisagé de changer de système de machine
diskless et faire en sorte que chaque client ait son propre espace.
Un tel choix ne fait pas partie du sujet du stage. C’est pourquoi nous allons
rester sur la solution avec toutes les données qui sont spécifique à chaque
clients.
3) Diskless avec Cobbler
A l’heure actuelle, je n’ai pas pu tester encore les machines Diskless avec
Cobbler.
Cela devrait être fait avant la fin du stage.

Conclusion
Page 64
Conclusion
Un grand changement est en train de s’opérer dans le système
d’information au CERN et plus particulièrement au sein de l’expérience du LHCb :
un changement d’infrastructure ou plus simplement une remise en cause de
certains outils devenus plus ou moins obsolètes.
Les objectifs de ce stage étaient multiples et devaient s’inscrire dans ce
changement :
Confirmer que Puppet est conforme à nos besoins
Trouver un outil d’installation de client adapté
Les mettre en relation de façon satisfaisante
Configurer les machines Diskless
Deux de ces objectifs sont remplis et confirment le potentiel de Puppet. Ce
n’est pas étonnant que des grands noms comme Google ou autres l’utilisent.
En plus d’être simple, Puppet est extrêmement complet surtout très
ouvert. Je pense que c’est un outil qui sera une référence dans ce domaine, si ce
n’est pas déjà fait.
Concernant Cobbler, malgré ses qualités et qu’il soit tout à fait adapté à
nos besoins, son interconnexion avec Puppet nous pose problème…
Comment résoudre cela ?
Garder Cobbler et trouver une autre solution que Puppet ? Il n’existe
pas vraiment d’alternatives possibles…
Garder Puppet et prendre un autre logiciel d’installation de client ?
La solution Razor ne nous convient pas
Adapter l’interconnexion entre Puppet et Cobbler ? C’est peut-être la
dernière solution
Nous allons garder la dernière solution même si d’autres outils auraient
mérité d’être testé comme par exemple Foreman même si les premiers
renseignements nous permettent de penser que l’interconnexion avec Puppet est
exactement la même qu’avec Cobbler.
Concernant les machines Diskless, là aussi il n’y a pas de solution
parfaite : soit la création de nouveau outils ( système de fichier de Pierre
Schweizer ) et l’adaptation de ceux existant ( Cobbler ) , soit une remise en
question du système de machine Diskless du LHCb. Cette décision appartient au
service informatique du LHCb.
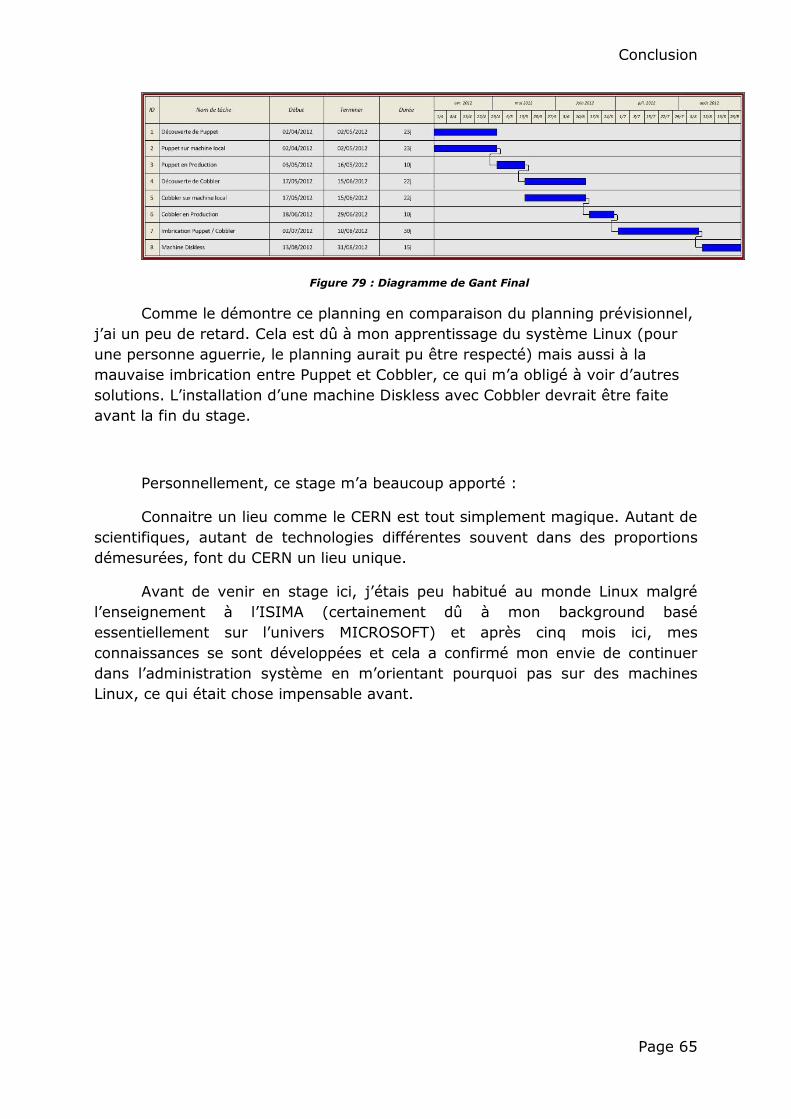
Conclusion
Page 65
Figure 79 : Diagramme de Gant Final
Comme le démontre ce planning en comparaison du planning prévisionnel,
j’ai un peu de retard. Cela est dû à mon apprentissage du système Linux (pour
une personne aguerrie, le planning aurait pu être respecté) mais aussi à la
mauvaise imbrication entre Puppet et Cobbler, ce qui m’a obligé à voir d’autres
solutions. L’installation d’une machine Diskless avec Cobbler devrait être faite
avant la fin du stage.
Personnellement, ce stage m’a beaucoup apporté :
Connaitre un lieu comme le CERN est tout simplement magique. Autant de
scientifiques, autant de technologies différentes souvent dans des proportions
démesurées, font du CERN un lieu unique.
Avant de venir en stage ici, j’étais peu habitué au monde Linux malgré
l’enseignement à l’ISIMA (certainement dû à mon background basé
essentiellement sur l’univers MICROSOFT) et après cinq mois ici, mes
connaissances se sont développées et cela a confirmé mon envie de continuer
dans l’administration système en m’orientant pourquoi pas sur des machines
Linux, ce qui était chose impensable avant.

Références bibliographiques
[1] Documentation Puppet : http://doc.puppetlabs.com
[2] James Turnbull et Jeffrey McCune , “Pro Puppet , Maximize and
customize Puppet’s capabilities for your environment” , 2011 , Edition
Apress
[3] Documentation Communauté Puppet : http://forge.puppetlabs.com
[4] Documentation Cobbler : http://cobbler.github.com
[5] Documentation Razor : https://github.com/puppetlabs/Razor
Recommended

















