
Les Big Dataune Transformation Disruptivedes Systèmes d'Information
Rabat, Morocco, November, 9-10th, 2016
Prof. Karim Baï[email protected], [email protected]
Professeur d'Enseignement SupérieurENSIAS, Université Mohammed V de Rabat, Maroc
Co-responsable du Diplôme Universitaire « Big Data Scientist »Ex-Responsable de l'équipe Alqualsadi sur les Architectures d'Entreprisesdu Laboratoire International Associé CNRS (LIA) : DATANET - Big Data et Réseaux à Large échelle
Chef du Département Génie Logiciel et Chef de Service de Coopération

© Karim Baïna 2016 2/61
Les prédictions des résultats de éléctions présidentielles
2016 aux USA :un anti-pattern pour la Big
Data Analytics
Rabat, Morocco, November, 9-10th, 2016
© Karim Baïna 2016 3/61
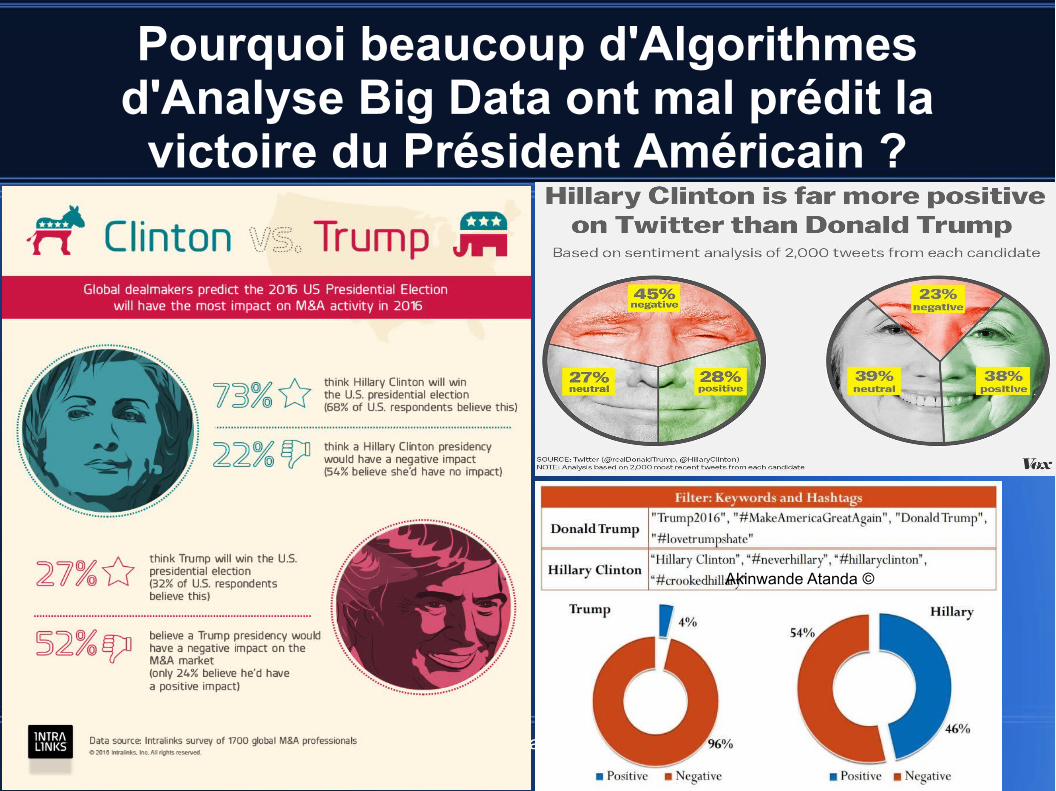
Pourquoi beaucoup d'Algorithmes d'Analyse Big Data ont mal prédit la
victoire du Président Américain ?
Akinwande Atanda ©

© Karim Baïna 2016 4/61
Pourquoi beaucoup d'Algorithmes d'Analyse Big Data ont mal prédit la
victoire du Président Américain ?● Le déni de la réalité : « Denial can be a powerful drug », « the black swan
election »
● la « bulle digitale » avec ses données non représentatives du citoyen lambda, et ses filtres algorithmiques peuvent se transformer en prisme qui fausse la réalité
– Les lecteurs de journaux croient ce qu'ils veulent croire, ainsi que ceux sur Facebook - et jamais les deux ne se rencontreront
● Les médias n'ont pas l'information réelle de la base
– Les médias de la côté est sont sans doute hors de contact avec la population en grande partie rurale qui a voté pour Trump : Coût de la vie, exode rurale, manque d'espoir, etc.
● Les médias était très divisés et fragmentés par rapport aux vérités (manque de Véracité):
● favorable à l'infobésité, désinformation, les mensonges et les canulars
http://fortune.com/2016/11/09/media-trump-failure/ « Here's Why the Media Failed to Predict a Donald Trump Victory »

© Karim Baïna 2016 5/61
Pourquoi beaucoup d'Algorithmes d'Analyse Big Data ont mal prédit la
victoire du Président Américain ?● A ‘Dewey Defeats Truman’ Lesson for the Digital Age
● Erreur de prédiction en 1948 du succès du président Truman
commise par le Chicago Daily Tribune
● Mike Murphy, a Republican strategist, said on MSNBC, “My crystal ball has been shattered into atoms’’ because he predicted the opposite outcome. “Tonight Data died,’’ he added.
● Big Data and the sophisticated modeling could not save American journalism from yet again being behind the story
http://www.nytimes.com/2016/11/09/business/media/media-trump-clinton.html?_r=0

© Karim Baïna 2016 6/61
Pourquoi beaucoup d'Algorithmes d'Analyse Big Data ont mal prédit la
victoire du Président Américain ?● The news media by and large missed what was happening all around
it, and it was the story of a lifetime. The numbers weren’t just a poor guide for election night - they were an off-ramp away from what was actually happening.
● No one predicted a night like this — that Donald J. Trump would pull off a stunning upset over Hillary Clinton and win the presidency.
● The misfire on Tuesday night was about a lot more than a failure in polling. It was a failure to capture the boiling anger of a large portion of the American electorate that feels left behind by a selective recovery, betrayed by trade deals that they see as threats to their jobs and disrespected by establishment Washington, Wall Street and the mainstream media.
http://www.nytimes.com/2016/11/09/business/media/media-trump-clinton.html?_r=0

© Karim Baïna 2016 7/61
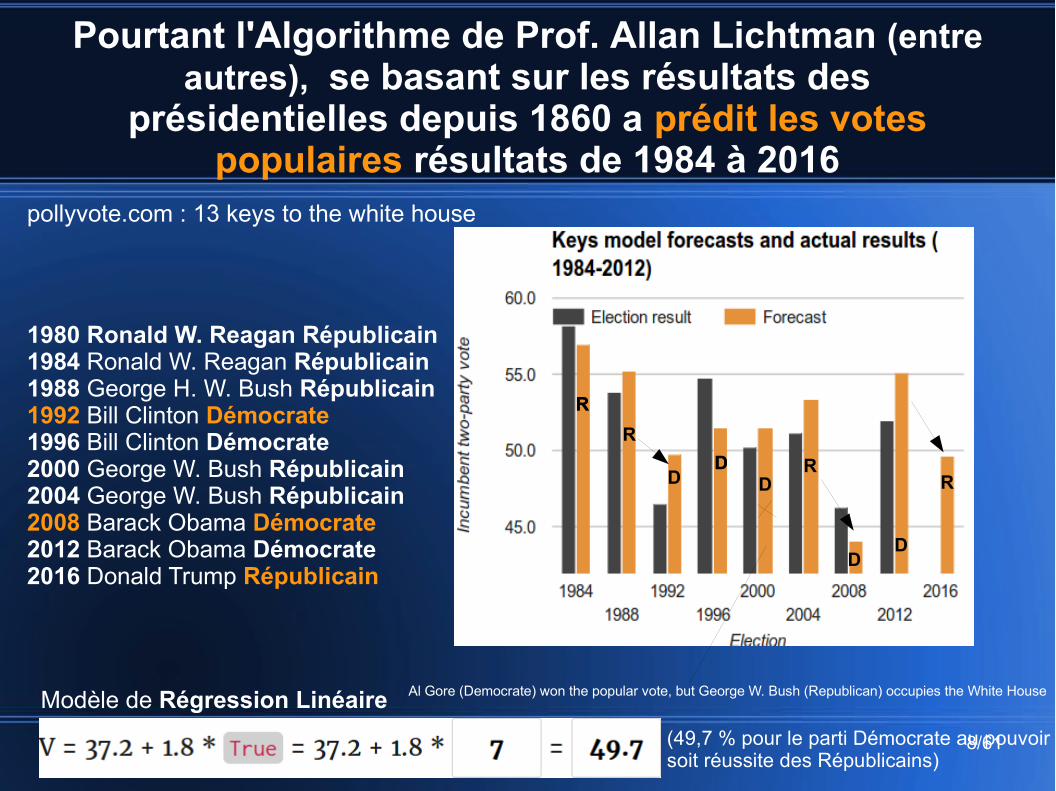
True = 1False = 0
Lorsque cinq clés ou moins sont fausses, le parti au pouvoir (incubent-party) gagne. Lorsque six ou plus sont fausses (ici 6), le parti contestataire (challenging-party) gagne !!
pollyvote.com : 13 keys to the white house
Pourtant l'Algorithme de Prof. Allan Lichtman (entre autres), se basant sur les résultats des présidentielles depuis 1860 a prédit les votes populaires résultats de
1984 à 2016
© Karim Baïna 2016 8/61
Pourtant l'Algorithme de Prof. Allan Lichtman (entre autres), se basant sur les résultats des
présidentielles depuis 1860 a prédit les votes populaires résultats de 1984 à 2016
1980 Ronald W. Reagan Républicain1984 Ronald W. Reagan Républicain1988 George H. W. Bush Républicain1992 Bill Clinton Démocrate1996 Bill Clinton Démocrate2000 George W. Bush Républicain2004 George W. Bush Républicain2008 Barack Obama Démocrate2012 Barack Obama Démocrate2016 Donald Trump Républicain
R
R
R
DDD
DR
DD
R
Al Gore (Democrate) won the popular vote, but George W. Bush (Republican) occupies the White House
(49,7 % pour le parti Démocrate au pouvoirsoit réussite des Républicains)
Modèle de Régression Linéaire
pollyvote.com : 13 keys to the white house

© Karim Baïna 2016 9/61
Pourquoi beaucoup d'Algorithmes d'Analyse Big Data ont mal prédit la
victoire du Président Américain ?● Pourtant l'Algorithme de Prof. Allan Lichtman
● n'applique même pas une analyse Big Data● C'est un algorithme supervisé (régression linéaire)
qui exploite seulement une matrice booléenne de taille 39 * 13 (réponses à 13 questions durant 30 élections )
http://www.nytimes.com/2016/11/09/business/media/media-trump-clinton.html?_r=0

© Karim Baïna 2016 10/61
Plan
● Élections présidentielles 2016 et anti-pattern pour
la Big Data Analytics
● Introduction
● Les Systèmes d'Information
● Les Big Data
● Les Systèmes d'Information pour Les Big Data - Transformation Disruptive
– des Données
– des Technologies
– des Processus
– des Personnes
● Études de Cas et Opportunités de création de la Valeur
Rabat, Morocco, November, 9-10th, 2016

© Karim Baïna 2016 11/61
Introduction
Rabat, Morocco, November, 9-10th, 2016

© Karim Baïna 2016 12/61
Les Systèmes d'Information
Rabat, Morocco, November, 9-10th, 2016

© Karim Baïna 2016 13/61
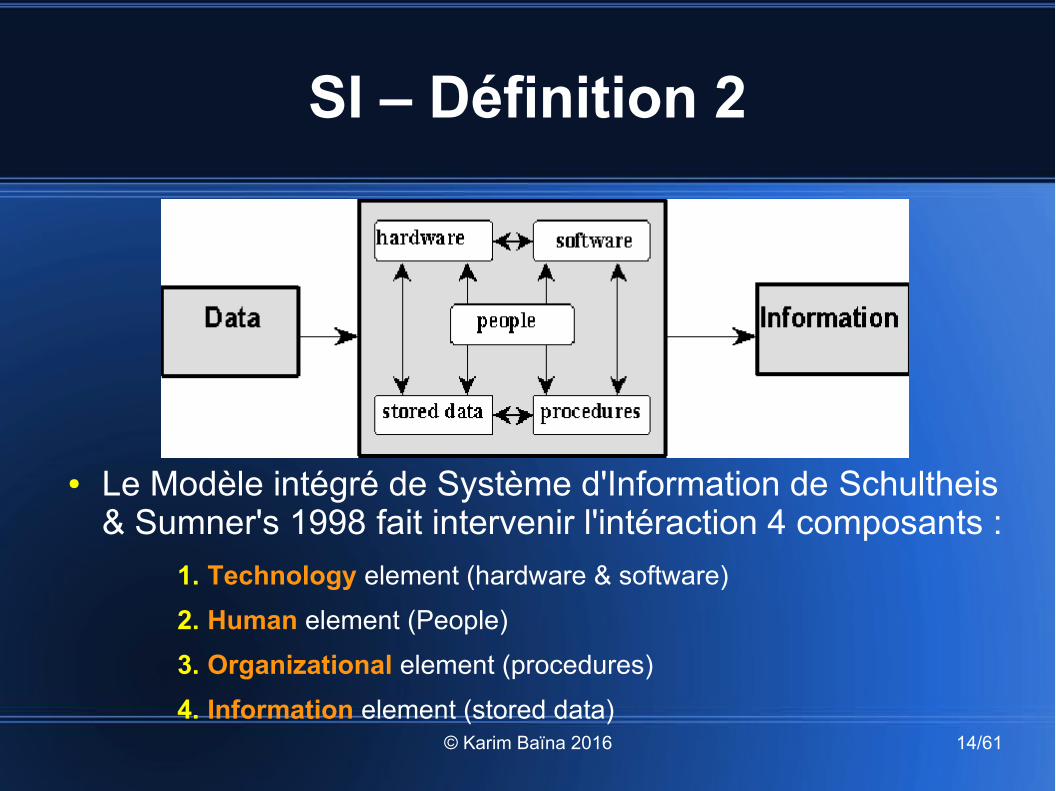
SI – Définition 1
● "Role of information technology within an Information System is to capture, transmit, store, retrieve, manipulate, or display information used in one or more business processes" Alter'1996
© Karim Baïna 2016 14/61
SI – Définition 2
● Le Modèle intégré de Système d'Information de Schultheis & Sumner's 1998 fait intervenir l'intéraction 4 composants :
1. Technology element (hardware & software)
2. Human element (People)
3. Organizational element (procedures)
4. Information element (stored data)

© Karim Baïna 2016 15/61
Les Big Data
Rabat, Morocco, November, 9-10th, 2016

© Karim Baïna 2016 16/61
Big Data 5 V● VOLUME
– de 2013 à 2020, la taille de l'univers digital sera multipliée par 10 de 4.4 à 44 trillion (10^12) GB
– La taille de l'univers digital plus que double chaque 2 ans
● VELOCITY (Fréquence de production de la donnée)
– Une voiture moderne embarque plus de 100 capteurs
– 2,3 Trillion (10^12) GB de données sont générées chaque jours dans le monde
● VARIETY
– 80% des données universelles sont non-structurées (inexploitables par les systèmes traditionnels)
● VERACITY
– Données incertaines, entre 30 % – 80 % followers fictifs sur twitter (selon la popularité du compte)
– La circulation des hoax (canulars), spam, fake post est reprise (retwittée) plus que les démentis.
● VALUE (VA mesurable générée à la société ou à l'entreprise)
– améliorer soins de santé, mieux comprendre & servir clients/citoyens, optimiser processus métiers & booster performance, améliorer sécurité & mieux maîtriser risques à l'international, obtenir de nouveaux avantages compétitifs, et créer de nouveaux modèles business radicaux, etc.
Doug Laney, « 3D Data Management: Controlling Data Volume, Velocity, and Variety. », 2001 research report, META Group (now Gartner)
Samsung 16TB (Technologie SSD)Le plus large HD
© Karim Baïna 2016 17/61
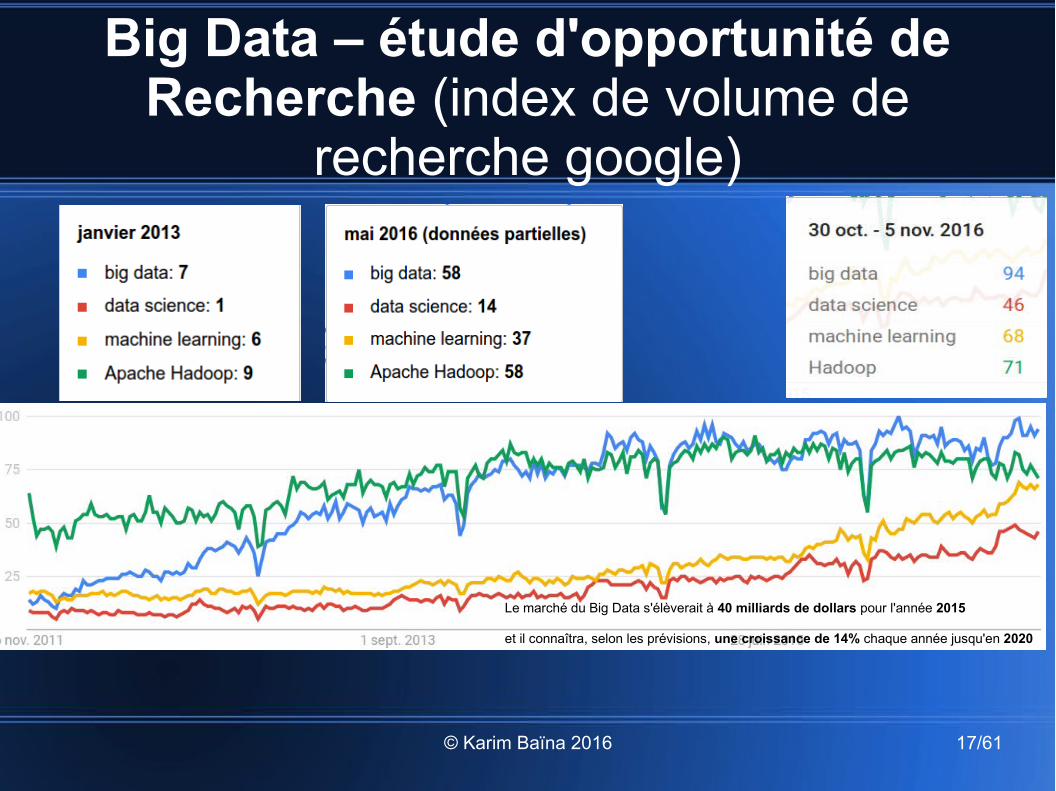
Big Data – étude d'opportunité de Recherche (index de volume de
recherche google)
https://www.google.com/trends/
Le marché du Big Data s'élèverait à 40 milliards de dollars pour l'année 2015
et il connaîtra, selon les prévisions, une croissance de 14% chaque année jusqu'en 2020

© Karim Baïna 2016 18/61
Big Data -Un domaine au carrefour
de plusieurs disciplines et d'expertises
IoT/IoE
Digital Humanities
Social Networking
Information Systems
ComputationalLinguistics

© Karim Baïna 2016 19/61
Big Data -Un domaine au carrefour
de plusieurs disciplines et d'expertises
IoT/IoE
Digital Humanities
Social Networking
Information Systems
Cloud &Grid
Computing
ComputationalLinguistics

© Karim Baïna 2016 20/61
Big Data -Un domaine au carrefour
de plusieurs disciplines et d'expertises
IoT/IoE
Digital Humanities
Social Networking
Information Systems
KM
Data Management
Cloud &Grid
Computing
ComputationalLinguistics

© Karim Baïna 2016 21/61
Big Data -Un domaine au carrefour
de plusieurs disciplines et d'expertises
IoT/IoE
Digital Humanities
Social Networking
Information Systems
Maths &Statistics
& OR
ComputationalLinguistics
KM
Data Management
Cloud &Grid
Computing

© Karim Baïna 2016 22/61
Big Data -Un domaine au carrefour
de plusieurs disciplines et d'expertises
IoT/IoE
Digital Humanities
Social Networking
Software engineering
Information Systems
Maths &Statistics
& RO
ComputationalLinguistics
KM
Data Management
Cloud &Grid
Computing

© Karim Baïna 2016 23/61
Les Systèmes d'Informationpour
Les Big Data
« Transformation disruptive des Données »
Rabat, Morocco, November, 9-10th, 2016
© Karim Baïna 2016 24/61
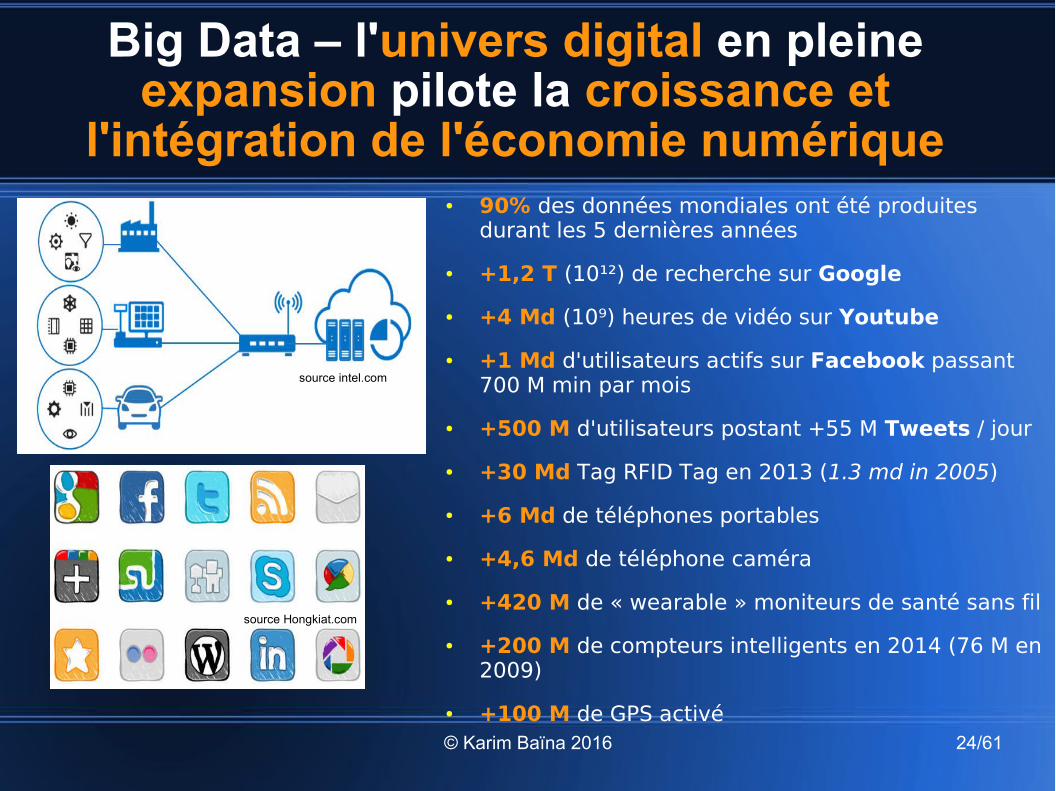
Big Data – l'univers digital en pleine expansion pilote la croissance et
l'intégration de l'économie numérique
source intel.com
source Hongkiat.com
● 90% des données mondiales ont été produites durant les 5 dernières années
● +1,2 T (10¹²) de recherche sur Google
● +4 Md (10⁹) heures de vidéo sur Youtube
● +1 Md d'utilisateurs actifs sur Facebook passant 700 M min par mois
● +500 M d'utilisateurs postant +55 M Tweets / jour
● +30 Md Tag RFID Tag en 2013 (1.3 md in 2005)
● +6 Md de téléphones portables
● +4,6 Md de téléphone caméra
● +420 M de « wearable » moniteurs de santé sans fil
● +200 M de compteurs intelligents en 2014 (76 M en 2009)
● +100 M de GPS activé

© Karim Baïna 2016 25/61
Big Data – Perception du Volume de l'univers digital
Lune
Terre
2/3 6,6x
TeraB (10**12 B) → PetaB (10**15 B) → ExaB (10**18 B) → ZetaB (10**21 B)
© Karim Baïna 2016 26/61
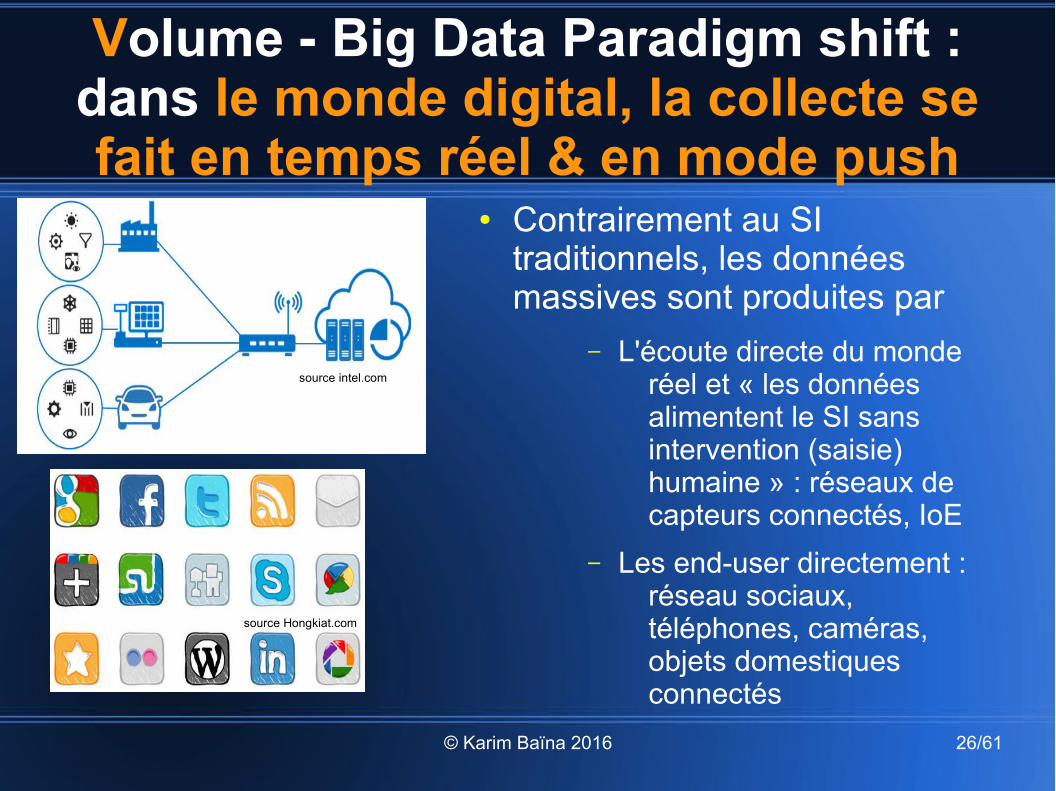
Volume - Big Data Paradigm shift : dans le monde digital, la collecte se fait en temps réel & en mode push
● Contrairement au SI traditionnels, les données massives sont produites par
– L'écoute directe du monde réel et « les données alimentent le SI sans intervention (saisie) humaine » : réseaux de capteurs connectés, IoE
– Les end-user directement : réseau sociaux, téléphones, caméras, objets domestiques connectés
source intel.com
source Hongkiat.com

© Karim Baïna 2016 27/61
Variété - Big Data :multitude des formats de données
OLAP
non-structured
semi-structured
structured
● Contrairement au SI traditionnels, les données massives sont produites par Les SI à l'ère du Big Data sont capables de Croiser
– de multiples sources de données (internes et externes)
– de formats multiples (ou même sans format)
– Avec ou sans contrainte de schéma (ELT ou « schema on read »)
● Le Traitement de la Langue Naturelle fait partie intégrantes des SI à l'ère du Big Data
80 % des données produites sont non- structurées et donc non exploitables par les SI traditionnels

© Karim Baïna 2016 28/61
Les Systèmes d'Informationpour
Les Big Data
« Transformation disruptive des Technologies »
Rabat, Morocco, November, 9-10th, 2016
© Karim Baïna 2016 29/61
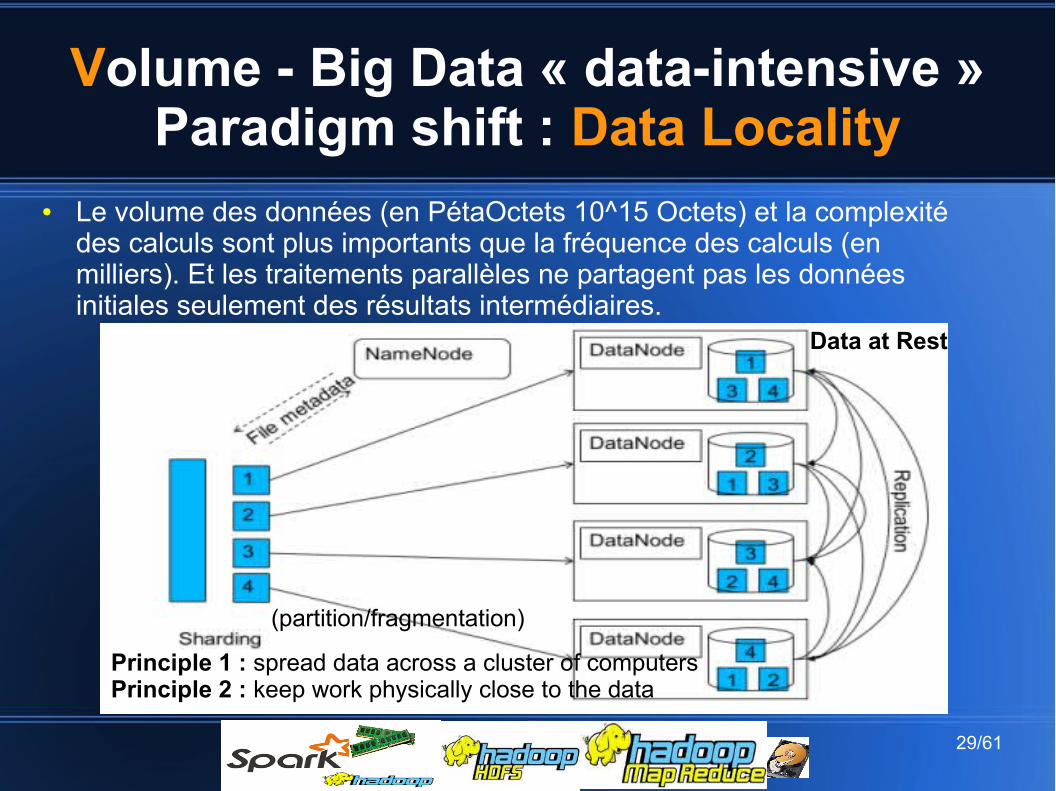
Volume - Big Data « data-intensive » Paradigm shift : Data Locality
Principle 1 : spread data across a cluster of computersPrinciple 2 : keep work physically close to the data
(partition/fragmentation)
● Le volume des données (en PétaOctets 10^15 Octets) et la complexité des calculs sont plus importants que la fréquence des calculs (en milliers). Et les traitements parallèles ne partagent pas les données initiales seulement des résultats intermédiaires.
Data at Rest
© Karim Baïna 2016 30/61
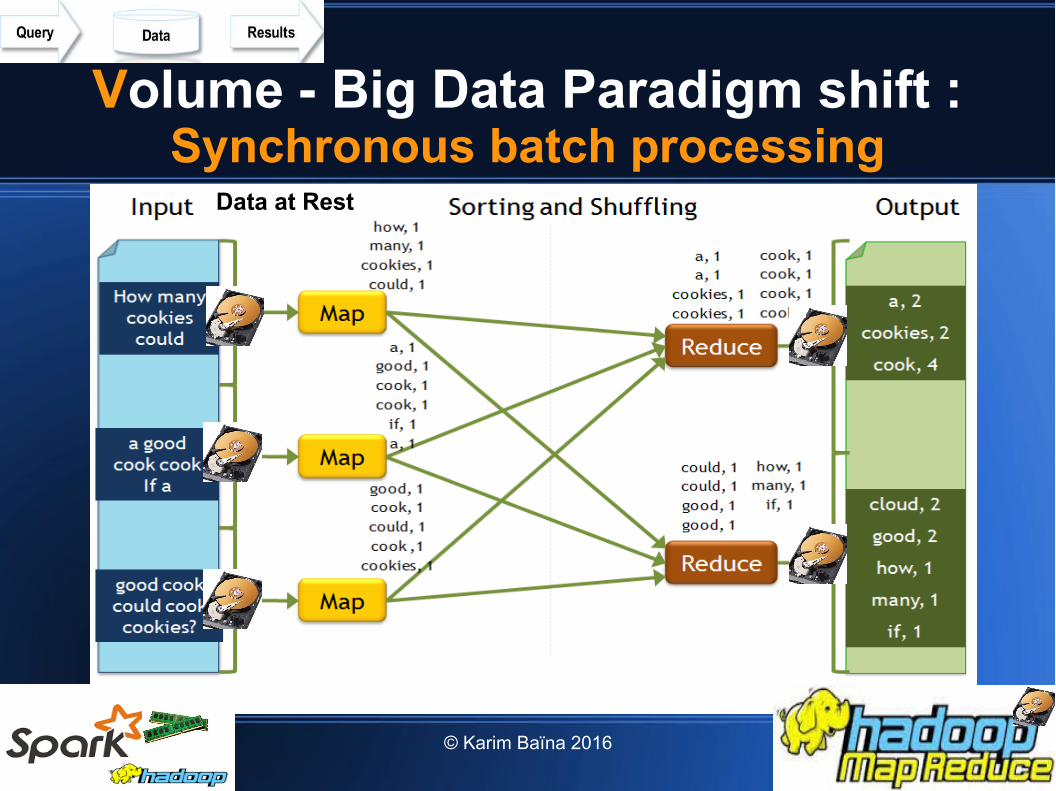
Volume - Big Data Paradigm shift :Synchronous batch processing
Data at Rest

© Karim Baïna 2016 31/61
Variété - Big Data Paradigme shift :Cohabitations de Syntaxe & Sémantique variables de données
● Avant les Big Data : syntaxe et sémantique statique
– Toutes les informations d'une entité ou relation obéissent à un schéma unique (modèle relationnel)
● Avec les Big Data : syntaxe et sémantique ad-hoc
– Il peut y avoir autant de schémas que de faits (modèle NoSQL)

© Karim Baïna 2016 32/61
Variété - Big Data paradigm shift :Schema on Run/Read (aka ELT)
● Avant les Big Data : Schema on Load/Write (aka ETL)– L'Objet & les dimensions d'analyse sont pré-organisées selon l’utilisation envisagée
– Collecte des données de production structurées selon un format initial
– Stockage dans un hyper-cube structuré.
– A chaque fois que les données évoluent, il y a nécessité de mise à niveau du datawarehouse et remise en question de la stratégie d’organisation de l’information (Cycle de vie très long et rigide)
● Avec le Big Data - Schema on Run/Read (aka ELT) :– Collecte des données non ou semi-structurées depuis les sources
– Stockage les données brutes sans structures explicites
– Exploration et Analyse les données « programmatoirement » le programme s'adapte au format et pas l'inverse !!
– Stockage dans une structure cible pour de futures analyses
– Cycle de vie court, flexible et Compatible avec la démarche inductive (zéro hypothèse)
© Karim Baïna 2016 33/61
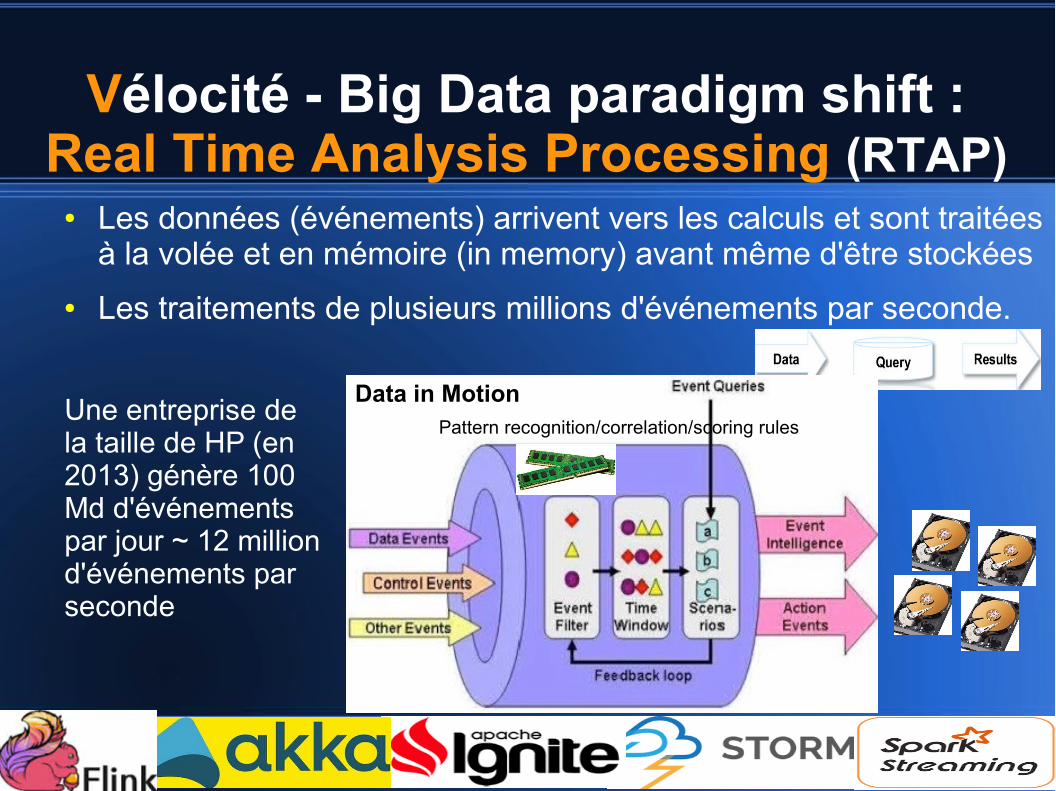
Vélocité - Big Data paradigm shift :Real Time Analysis Processing (RTAP)
● Les données (événements) arrivent vers les calculs et sont traitées à la volée et en mémoire (in memory) avant même d'être stockées
● Les traitements de plusieurs millions d'événements par seconde.
Pattern recognition/correlation/scoring rules
Data in MotionUne entreprise de la taille de HP (en 2013) génère 100 Md d'événements par jour ~ 12 million d'événements par seconde

© Karim Baïna 2016 34/61
Big Data – un écosystème de nouveaux concepts et technologies
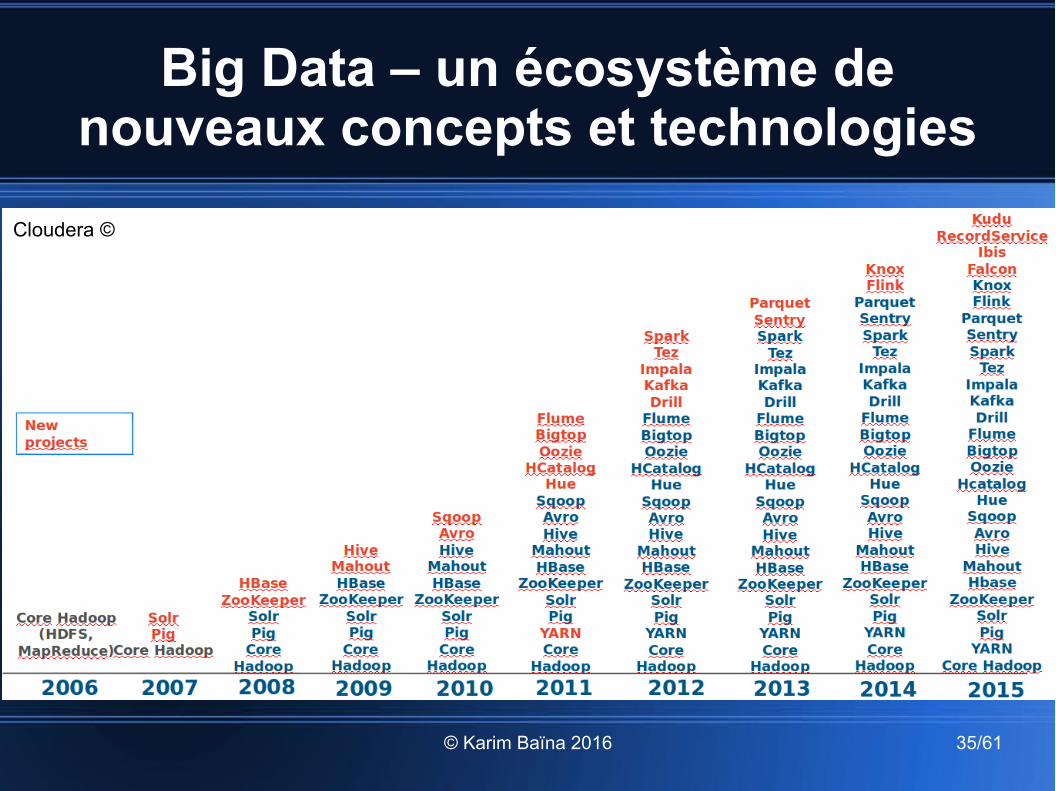
© Karim Baïna 2016 35/61
Big Data – un écosystème de nouveaux concepts et technologies
Cloudera ©

© Karim Baïna 2016 36/61
Les Systèmes d'Informationpour
Les Big Data
« Transformation disruptive des Processus »
Rabat, Morocco, November, 9-10th, 2016

© Karim Baïna 2016 37/61
● Avant les Big Data : réactivité hors contexte– Procédé métier sans état : n'a pas de mémoire
– Procédé métier malvoyant : traitement hors contexte ne prenant que les informations explicites
– Procédé métier réactif : request/response
● Avec les Big Data : proactivité contextuelle– Procédé métier avec état : possède une mémoire du dossier permettant
un traitement personnalisé (recommandation personnalisée)
– Procédé métier voyant et pré-voyant : prend en compte tout le contexte du dossier et des dossiers similaires (recommandation item & sociale)
– Procédé métier proactif : prédictif et préventif (recommandation hybride)
K. Baïna & A. Ismaïli Alaoui 2015
Big Data paradigm shift : Processus métiers enrichis par les Big Data

© Karim Baïna 2016 38/61
Big Data paradigm shift : Démarche inductive d'ingénierie des données● SI Avant les Big Data : Démarche DÉDUCTIVE (expérimentale)
– Le chercheur a une vue théorique du monde naturel, basée sur des concepts et théories acceptés, et cherche à vérifier certaines hypothèses quant aux causes d'un phénomène. Ces hypothèses sont ensuite testées au cours de l'analyse, et c'est par le jeu de leurs acceptations/rejets que se construisent les théories explicatives. Les scientifiques qui pratiquent cette approche sont qualifiés de rationalistes.
● SI Avec les Big Data : Démarche INDUCTIVE/INFERENTIELLE (observationnelle, corrélative, régressive)
– Les données (observations) sont collectées sans formuler préalablement d'hypothèse et les explications sont dérivées de ces données par généralisation des faits observés pour produire un modèle scientifique de la réalité dit prévisionnel.
« patterns »
© Karim Baïna 2016 39/61
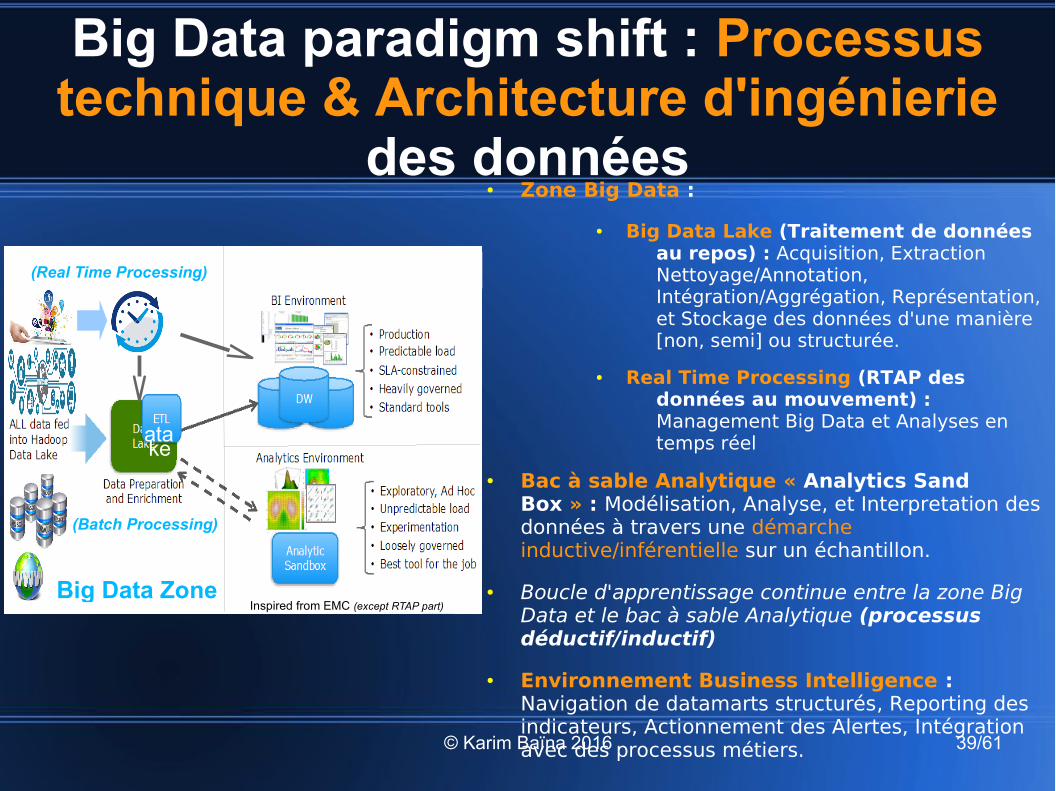
Big Data paradigm shift : Processus technique & Architecture d'ingénierie
des données
(Real Time Processing)
Big Data Zone
atake
(Batch Processing)
● Zone Big Data :
● Big Data Lake (Traitement de données au repos) : Acquisition, Extraction Nettoyage/Annotation, Intégration/Aggrégation, Représentation, et Stockage des données d'une manière [non, semi] ou structurée.
● Real Time Processing (RTAP des données au mouvement) : Management Big Data et Analyses en temps réel
● Bac à sable Analytique « Analytics Sand Box » : Modélisation, Analyse, et Interpretation des données à travers une démarche inductive/inférentielle sur un échantillon.
● Boucle d'apprentissage continue entre la zone Big Data et le bac à sable Analytique (processus déductif/inductif)
● Environnement Business Intelligence : Navigation de datamarts structurés, Reporting des indicateurs, Actionnement des Alertes, Intégration avec des processus métiers.
Inspired from EMC (except RTAP part)

© Karim Baïna 2016 40/61
Les Systèmes d'Informationpour
Les Big Data
« Transformation disruptive des Personnes »
Rabat, Morocco, November, 9-10th, 2016

© Karim Baïna 2016 41/61
Dev Ops Engineer
Builds the cluster
Data AnalystSQL & NoSQL guru
Big Data Developer/Insight Developer
Insight Developer, Productise insight
Data Scientist
Data Manager,Machine learning expert
Data Innovator
Business Analyst,Data Value services
INFRA DATA ENGINEERING DATA SCIENCE DATA INNOVATION
SI pour les Big Data – nouveaux Profils de Personnes
TECHNOLOGIES ALGORITHMES OPPORTUNITES
Digital-citizennews publisher
DistributorE-journalist
Big Data producer

© Karim Baïna 2016 42/61
● Pour devenir Spécialiste de Big Data
– Un Statisticien devra apprendre à manipuler des données distribuées et qui ne tiennent pas en mémoire RAM d'une seule machine
– Un analyste métier ingénieur BI (ou analyste d'affaires - Business Analyst) devra apprendre à écrire et exécuter des algorithmes décisionnels à l'échelle et faire du reporting sur des données stockées en format brute
– Un DBA devra apprendre à manipuler des données non-structurées
– Un ingénieur Génie Logiciel devra apprendre la modélisation statistique et la communication des résultats
© Prof. Bill Howe
SI pour les Big Data – nouveaux Profils de Personnes

© Karim Baïna 2016 43/61
Les Systèmes d'InformationPour
Les Big Data –
études de cas et opportunités de création de la Valeur
Rabat, Morocco, November, 9-10th, 2016

© Karim Baïna 2016 44/61
Valeur - Big Data paradigm shift : 3 P
● PERSONNALISATION
– Prise en compte personnalisée du comportement, pour proposer, suggérer et recommander
● PREDICTION / PREVISION
– Explication de phénomènes, Simulation des tendances et Prévision des conséquences
● PREVENTION
– Proposition de mesures, d’actions anticipatives pour limiter l’impact d’un phénomène

© Karim Baïna 2016 45/61
Valeur - Big Data paradigm shift : 3 P
● PERSONNALISATION
– Analyse de corrélation d'événements complexes pour produire des éléments de connaissances
– Reconnaissance personnalisée et efficace des comportements anormaux pour suggérer/recommander des actions adécquates.
– Identification d'informations actionables parmi des larges masses de données et réduire le taux de faux positifs (Veracité) à des niveaux gérables (actions/interventions sont coûteuses).
● PREDICTION / PREVISION
– Analyse de Prédiction : déduction & explication qu'un événement risque de se produire (Prévision), exactement quand (Prédiction), et prévoir les conséquences.
● PREVENTION
– Analyse de Prévention : proposition d'actions correctives/préventives pour limiter l'impact d'un événement

© Karim Baïna 2016 46/61
● e-Gov et e-citoyen
– Analyser les problèmes du quotidien pour mieux servir le citoyen
● Commerce & Marketing
– Analyser la satisfaction Client et prédire le churn (attrition)
– Détecter les nouveaux usages et besoins et Acquérir de nouveaux clients
– Fructifier les clients acquis grâce aux systèmes de recommandation
● Industrie & Production
– Analyser la qualité des procédés de production
– Réduire les pertes et les redondances
● Sécurité & cyber-sécurité
– Détecter les Fraudes
– Détecter les anomalies liées à la cybersécurité
Baïna & Ismaïli Alaoui 2015
Valeur du Big Data résulte de la richesse des données + la force des algorithmes

© Karim Baïna 2016 47/61
Val
Recommandationde services/produits
Prévision Catastrophes naturelles
...
Prévision des évolutiondes épidémies
Traitement des échanges boursiers
Sécurité territoriale
Mesure de la Perception du citoyen
Mesure de la Satisfaction du client
Anticiper les picsde la circulation
Sécurité du citoyen
Valeur
© Karim Baïna 2016 48/61
Baïna & Ismaïli Alaoui 2015
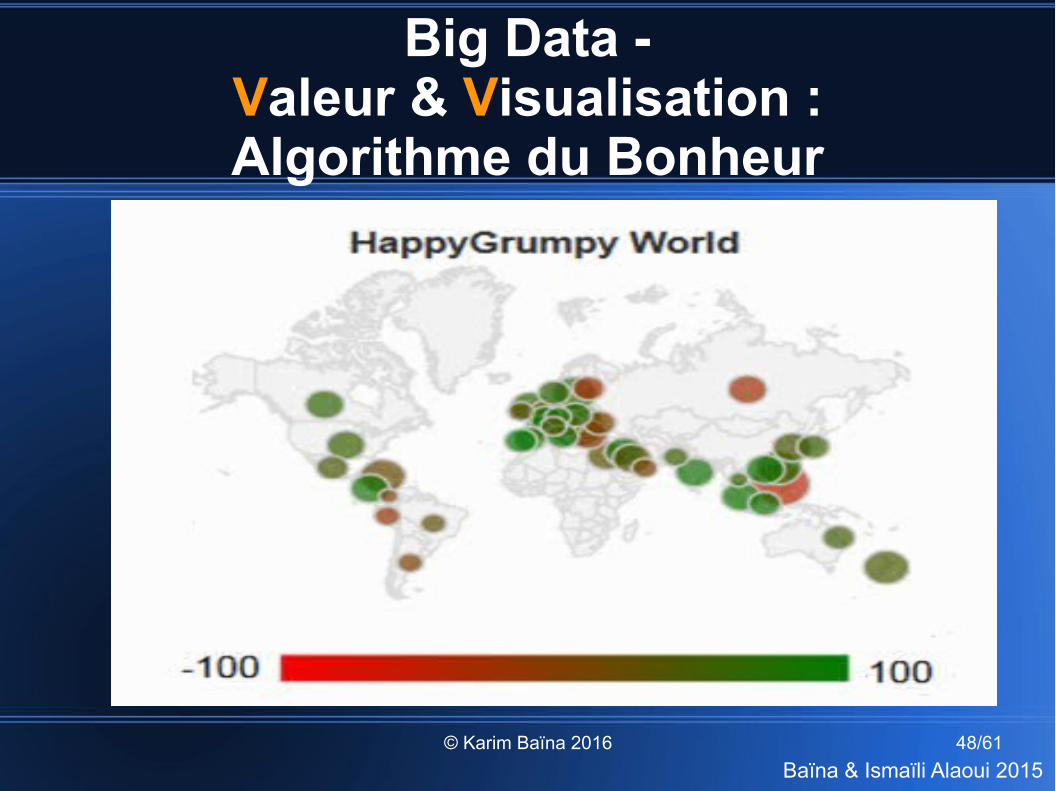
Big Data - Valeur & Visualisation : Algorithme du Bonheur

© Karim Baïna 2016 49/61
Big Data - Valeur & Visualisation : Algorithme du Bonheur
Un échantillonJson de Tweeter
Un dictionnaired'émotion

© Karim Baïna 2016 50/61
Big Data - Valeur & Visualisation : Algorithme du
Bonheur (en 7 mini-requêtes HiveQL)I) Charger Dictionnaire d'émotioncreate table dictionary (word string, rating int)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t';LOAD DATA LOCAL INPATH '/home/hadoop/AFINN.txt' into TABLE dictionary;
II) Charger Tweets depuis stockage flumecreate external table load_tweets(id BIGINT, text STRING, country STRING) ROW FORMAT SERDE 'com.cloudera.hive.serde.JSONSerDe' LOCATION '/user/flume/tweets'Tokeniser les tweetscreate table split_words as select id as id, split(text,' ') as words, country from load_tweets;Applatir les mots des tweetscreate table tweet_word as
select id as id, word, location from split_words LATERAL VIEW explode(words) w as word;
III) Croiser Tweets & Dictionnairecreate table tweet_word_join as
select tweet_word.id, tweet_word.word, country, dictionary.ratingfrom tweet_word LEFT OUTER JOIN dictionary ON(tweet_word.word =dictionary.word);
Calculer moyenne score de chaque Tweetcreate table tweet_rating_avg as
select id, country, AVG(rating) as rating from tweet_word_join GROUP BY id, country order by rating DESC;Calculer moyenne score de chaque Payscreate table location_rating_avg as
select country, AVG(rating) as rating from tweet_rating_avg GROUP BY country order by rating DESC;
-Like

© Karim Baïna 2016 51/61
Big Data - Valeur & Visualisation : Détection
d'Anomalies (AD) – macro ségmentationanomaly
outlier
Cluster 2
Cluster 1
anomaly
Linear regression
K-Means (clustering)1) Générer un Modèle de ce qui est normal pour tous les individus observés :regrouper les données en utilisant de sméthodes supervisées ou non supervisées ex. Classification/Clustering
2) Détecter les anomalies : Trouver des données qui ne confirme pas le schéma/pattern normal
Détecter les observations qui dévient énormément des comportements attendus.
Quand cela se produit, lever l'alerte.
Ex : analyse globales de comportements des utilisateurs/employés/citoyens/clients, matériels, Interactions inter-application, ..
unsupervised algorithm
supervised algorithm
© Karim Baïna 2016 52/61
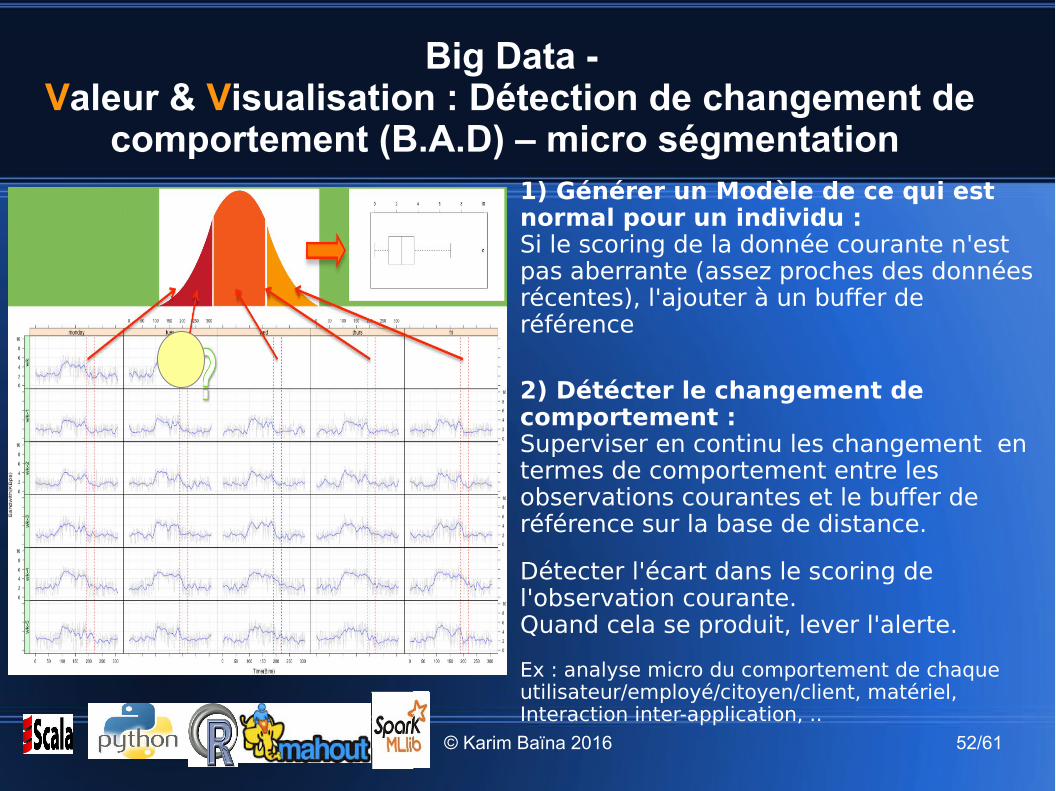
Big Data - Valeur & Visualisation : Détection de changement de
comportement (B.A.D) – micro ségmentation1) Générer un Modèle de ce qui est normal pour un individu :Si le scoring de la donnée courante n'est pas aberrante (assez proches des données récentes), l'ajouter à un buffer de référence
2) Détécter le changement de comportement : Superviser en continu les changement en termes de comportement entre les observations courantes et le buffer de référence sur la base de distance.
Détecter l'écart dans le scoring de l'observation courante. Quand cela se produit, lever l'alerte.
Ex : analyse micro du comportement de chaque utilisateur/employé/citoyen/client, matériel, Interaction inter-application, ..
© Karim Baïna 2016 53/61
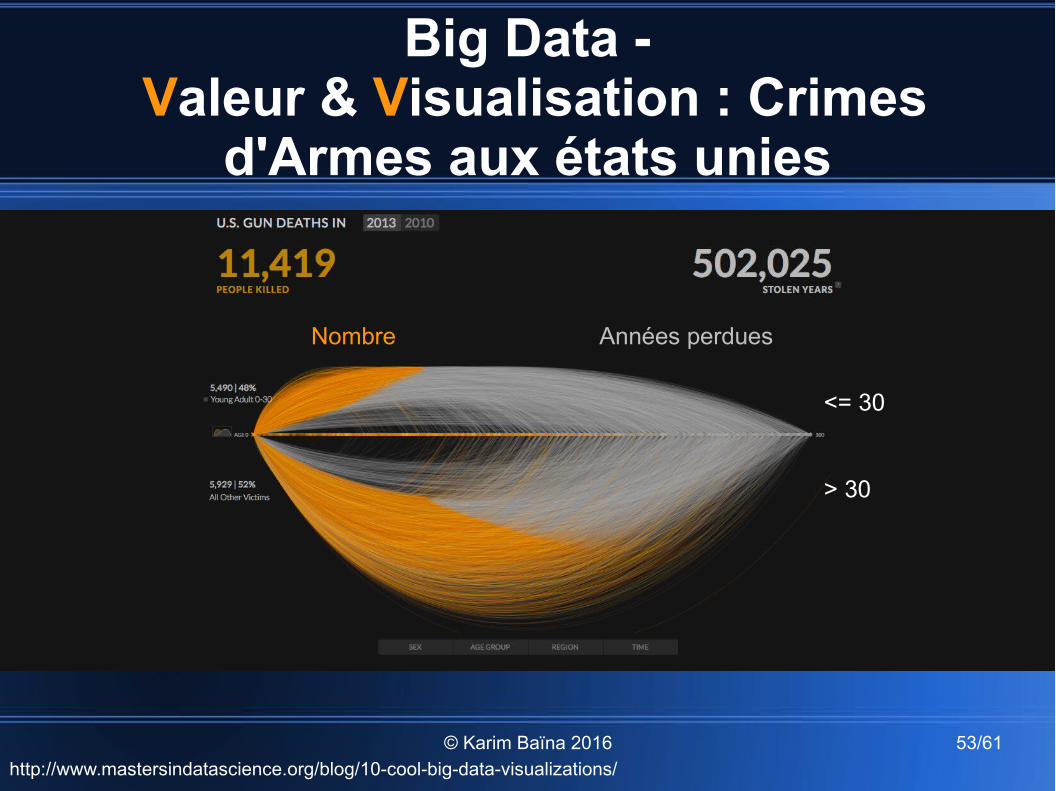
Big Data - Valeur & Visualisation : Crimes
d'Armes aux états unies
http://www.mastersindatascience.org/blog/10-cool-big-data-visualizations/
<= 30
> 30
Nombre Années perdues

© Karim Baïna 2016 54/61
Big Data - Valeur & Visualisation : intensité
séismiques dans le monde
http://www.mastersindatascience.org/blog/10-cool-big-data-visualizations/
© Karim Baïna 2016 55/61
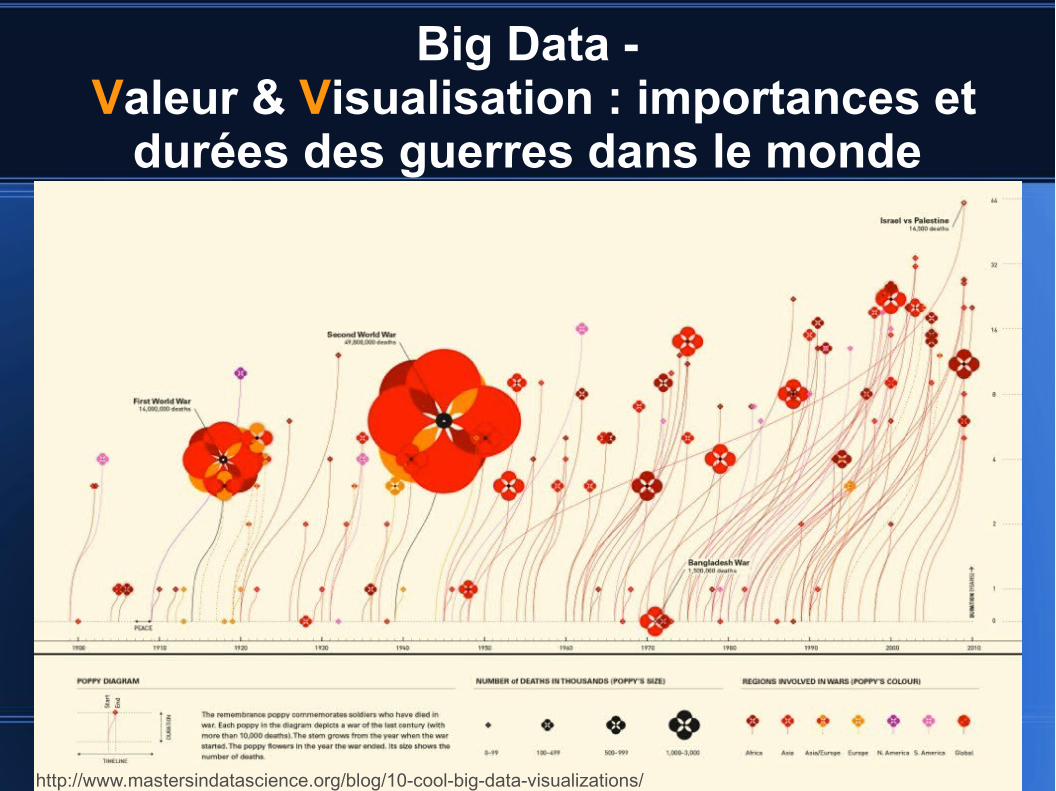
Big Data - Valeur & Visualisation : importances et
durées des guerres dans le monde
http://www.mastersindatascience.org/blog/10-cool-big-data-visualizations/
© Karim Baïna 2016 56/61
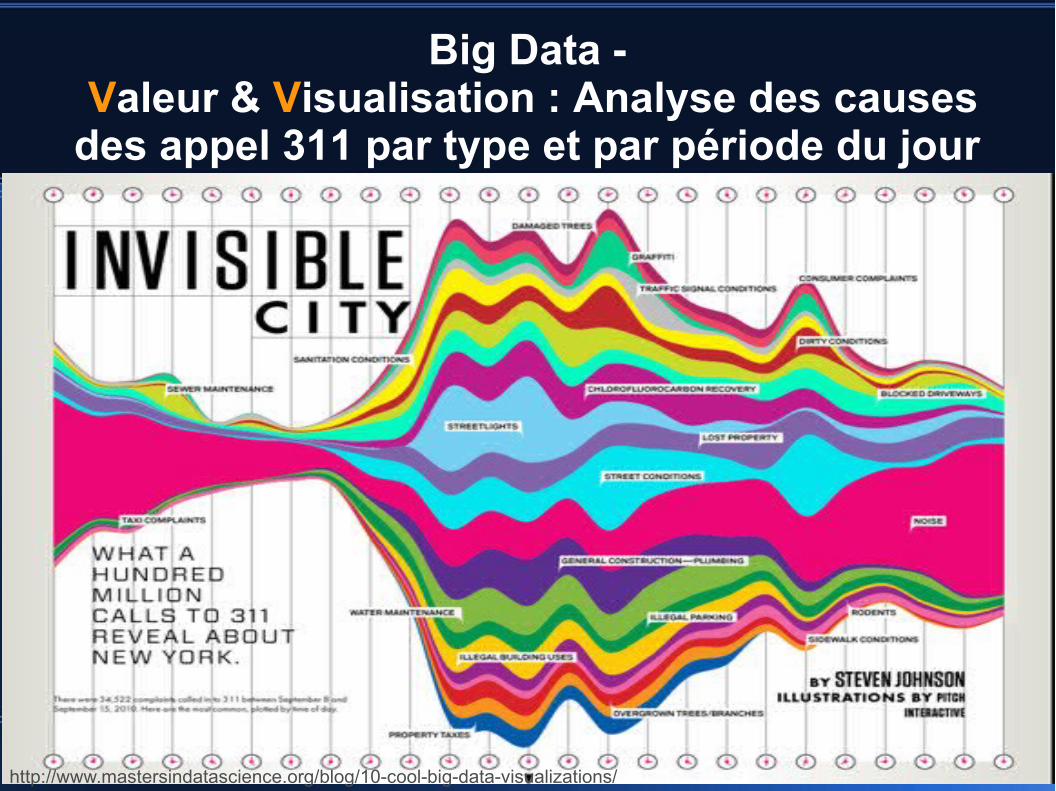
Big Data - Valeur & Visualisation : Analyse des causes des appel 311 par type et par période du jour
http://www.mastersindatascience.org/blog/10-cool-big-data-visualizations/
© Karim Baïna 2016 57/61
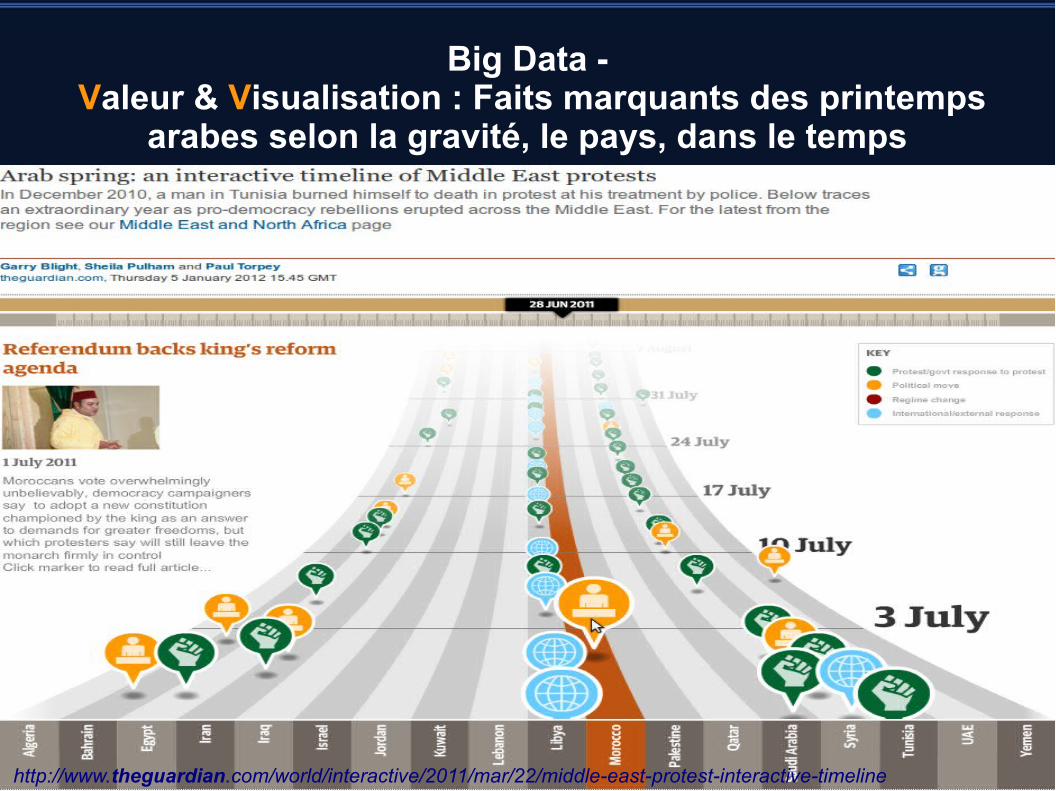
Big Data - Valeur & Visualisation : Faits marquants des printemps
arabes selon la gravité, le pays, dans le temps
http://www.theguardian.com/world/interactive/2011/mar/22/middle-east-protest-interactive-timeline

© Karim Baïna 2016 58/61
Big Data - Valeur & Visualisation : Polarité des opinions sur les
réseaux sociaux par rapport à une féministe Arabe
Not all Arab tweeters agreed with Mona Eltahawy views of feminism in the Arab world
Visualizing Big Data:Social Network Analysisby Michael Lieberman, 2014

© Karim Baïna 2016 59/61
Valeur & Opportunités du Big Data – Améliorer le quotidien du
citoyen Marocain
Améliorer la Sécurité Routière – plus de campagnes et de signalisation dans les régions/véhicules à haut risque
Améliorer la qualité du transport – mieux desservir la demande en période de pic
Améliorer les services sociaux – mieux desservir les régions selon les spécialités manquantes
Réduire le chômage et augmenter l'employabilité – mieux connecter offreurs et demandeurs d'emploi, anticiper les besoins du marché d'emploi
Améliorer l'éducation – mieux servir les régions marginalisées

© Karim Baïna 2016 60/61
Valeur & Opportunités du Big Data – Sans oublier bien évidemment de
Préparer le Maroc de demainÉnergies
Desertec
Développement durable& Économie verte
Développement humain & Économie équitable
Environnement
Logistique
Industrie & Services

© Karim Baïna 2016 61/61
Big Dataas a Disruptive Transformation of Information Systems
Prof. Karim Baïna [email protected], [email protected], @kbaina, www.slideshare.net/kbaina
Professeur d'Enseignement SupérieurENSIAS, Université Mohammed V de Rabat, Maroc
Co-responsable du Diplôme Universitaire « Big Data Scientist »Ex-Responsable de l'équipe Alqualsadi sur les Architectures d'Entreprisesdu Laboratoire International Associé CNRS (LIA) : DATANET - Big Data et Réseaux à Large échelle
Chef du Département Génie Logiciel et Chef de Service de Coopération
Rabat, Morocco, November, 9-10th, 2016
46/46
made with :
Recommended

















