PREDIKSI KELULUSAN MAHASISWA FAKULTAS SAINS
DAN TEKNOLOGI UNIVERSITAS SANATA DHARMA
MENGGUNAKAN METODE KLASIFIKASI NAÏVE BAYES
SKRIPSI
Diajukan Untuk Memenuhi Salah Satu Syarat
Memperoleh Gelar Sarjana Komputer
Program Studi Informatika
Oleh:
Artha Dian Sinaga
165314073
PROGRAM STUDI INFORMATIKA
FAKULTAS SAINS DAN TEKNOLOGI
UNIVERSITAS SANATA DHARMA
YOGYAKARTA
2020
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI
STUDENTS GRADUATION PREDICTION AT THE FACULTY
OF SCIENCE AND TECHNOLOGY OF THE UNIVERSITY OF
SANATA DHARMA USING NAÏVE BAYES CLASSIFICATION
THESIS
Present as Partial Fulfillment of the Requirements
to Obtain Sarjana Komputer Degree
in Informatics Study Program
Created by :
Artha Dian Sinaga
165314073
INFORMATICS STUDY PROGRAM
INFORMATICS DEPARTMENT
FACULTY OF SCIENCE OF TECHNOLOGY
SANATA DHARMA UNIVERSITY
YOGYAKARTA
2020
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI
iii
HALAMAN PERSEMBAHAN
“I can do all this through Him who gives me strength.”
(Philippians 4:13)
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI
vi
ABSTRAK
Kelulusan mahasiswa merupakan salah satu bidang yang termasuk ke
dalam Standar Penjaminan Mutu Internal (SPMI) suatu perguruan tinggi. Salah
satu standar yang ditetapkan oleh perguruan tinggi untuk menghasilkan lulusan
tepat waktu yaitu mahasiswa dapat menempuh kuliah maksimal 8 semester
dengan total beban studi minimal 144 SKS.
Penelitian ini mencoba untuk memprediksi kelulusan mahasiswa agar
pihak akademik dapat meminimalisir mahasiswa yang lulus tidak tepat waktu.
Data yang digunakan dalam penelitian ini adalah data mahasiswa Fakultas Sains
dan Teknologi Universitas Sanata Dharma lulusan tahun 2010 sampai 2018.
Metode yang digunakan adalah metode klasifikasi dengan menerapkan
algoritma naïve bayes. Percobaan dilakukan pada 1630 data menggunakan 3-
Fold Cross Validation dengan hasil akurasi tertinggi sebesar 80.5402%.
Kata kunci: Kelulusan, Naive Bayes, klasifikasi, K-Fold Cross Validation,
Confusion Matrix.
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI
vii
ABSTRACT
Graduation of college students is one of the factors that is included into
college’s internal quality assurance standards (SPMI). One of the standards used
for college in higher education is for the institution to produce students that
graduated on time where they finished their college courses with maximum 8
semesters and minimum 144 credit hours.
The objective of this research was to evaluate and predict college
student’s graduation rate for the academic administration to utilize this
information and minimize the rate of students who were not graduating on time.
The data used for this research derived from 2010-2018 graduation data of
students from the Faculty of Science and Technology of The University of
Sanata Dharma.
The method used was the classification method using the naïve bayes
algorithm. The testing was done on 1630 data using 3-fold cross validation
which resulted in the highest result of 80.5402%.
Key words: Graduation, Naïve Bayes, Clarification, K-Fold Cross Validation,
Confusion Matrix.
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI
viii
KATA PENGANTAR
Puji dan syukur saya ucapkan kepada Tuhan Yesus atas berkat dan
rahmatnya sehingga penulis dapat menyelesaikan skripsi ini dengan baik.
Penulis menyadari bahwa penelitian ini tidak dapat terselesaikan dengan
baik tanpa bimbingan dan dukungan dari berbagai pihak. Oleh karena itu, penulis
ingin menyampaikan ucapan terima kasih kepada semua pihak yang telah
membantu dalam penyusunan skripsi ini terutama kepada:
1. Kedua orang tua, kakak, dan adik tercinta yang senantiasa memberikan
dukungan dan doa kepada penulis.
2. Dr. Cyprianus Kuntoro Adi, S.J. M.A., M.Sc. selaku dosen pembimbing
skripsi saya yang dengan sabar memberikan masukkan dan
membimbing saya dalam penyusunan skripsi.
3. Bapak Robertus Adi Nugroho S.T., M.Eng., selaku Ketua Program
Studi Informatika Universitas Sanata Dharma Yogyakarta.
4. Bapak Sudi Mungkasi, S.Si., M.Math.Sc., Ph.D selaku Dekan Fakultas
Sains dan Teknologi Universitas Sanata Dharma Yogyakarta.
5. Ibu Agnes Maria Polina S.Kom., M.Sc. selaku Dosen Pembimbing
Akademik yang sering memberikan perhatian dan masukkan selama
perkuliahan.
6. Valen, Dodi, Hananto, Caroline, Alfri, Indah, Yiyin, Yuni, Arsa,
Maretha yang membantu dan menemani penyusunan skripsi.
7. Sahabat-sahabat yang saling menguatkan ketika sama-sama merasa
down yaitu Gabby, Meisi, Dila, Jason, dan Chanley.
8. Teman-teman pejuang skripsi yang saling memberikan semangat yaitu
Fica, Retno, Lauren, Clara, Vicky, dan Winda.
9. Teman-teman Informatika angkatan 2016 yang saling menyemangati
dalam menyelesaikan skripsi.
10. Semua pihak yang tidak dapat disebutkan satu-persatu yang telah
membantu penulis dalam menyelesaikan skripsi ini.
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI
ix
DAFTAR ISI
HALAMAN PERSETUJUAN PEMBIMBING ...................................................... i
HALAMAN PENGESAHAN ................................................................................ ii
HALAMAN PERSEMBAHAN ............................................................................ iii
PERNYATAAN KEASLIAN KARYA ................................................................ iv
LEMBAR PERNYATAAN PERSETUJUAN PUBLIKASI ................................ v
ABSTRAK ............................................................................................................. vi
ABSTRACT ............................................................................................................ vii
KATA PENGANTAR ......................................................................................... viii
DAFTAR ISI .......................................................................................................... ix
DAFTAR TABEL ................................................................................................. xii
DAFTAR GAMBAR ........................................................................................... xiii
BAB I PENDAHULUAN ....................................................................................... 1
1.1 Latar Belakang .............................................................................................. 1
1.2 Rumusan Masalah ......................................................................................... 2
1.3 Tujuan ............................................................................................................ 2
1.4 Manfaat .......................................................................................................... 2
1.5 Batasan Masalah ............................................................................................ 2
1.6 Metodologi Penelitian ................................................................................... 3
1.7 Sistematika Penulisan .................................................................................... 3
BAB II LANDASAN TEORI ................................................................................. 5
2.1 Kelulusan Studi Mahasiswa .......................................................................... 5
2.2 Data Mining .................................................................................................. 6
2.2.1 Pengertian Data Mining .......................................................................... 6
2.2.2 Pengelompokkan Data Mining ............................................................... 8
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI
x
2.2.3 Klasifikasi ............................................................................................... 9
2.2.4 Naïve bayes ........................................................................................... 10
2.3 Information Gain ......................................................................................... 11
2.4 Normalisasi Min-Max .................................................................................. 12
2.5 Cross Validation .......................................................................................... 13
2.6 Confusion Matrix ......................................................................................... 13
BAB III METODE PENELITIAN ....................................................................... 15
3.1 Gambaran Umum ........................................................................................ 15
3.1.2 Data ....................................................................................................... 17
3.1.3 Preprocessing ....................................................................................... 19
3.1.3.1 Data Cleaning ................................................................................ 19
3.1.3.2 Data Selection ................................................................................ 20
3.1.3.3 Data Transformation ..................................................................... 21
3.1.4 Modelling Naïve Bayes ......................................................................... 22
3.1.5 Akurasi .................................................................................................. 26
3.2 Peralatan Penelitian ..................................................................................... 27
3.3 Perancangan Interface ................................................................................. 28
BAB IV HASIL DAN ANALISIS ....................................................................... 30
4.1 Preprocessing .............................................................................................. 30
4.1.1 Data Cleaning ....................................................................................... 30
4.1.2 Data Selection ....................................................................................... 30
4.1.3 Data Transformation ............................................................................ 31
4.2 Klasifikasi .................................................................................................... 32
4.3 Uji Data ....................................................................................................... 36
4.3.1 Uji Data Tunggal .................................................................................. 36
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI
xi
4.3.2 Uji Data Kelompok ............................................................................... 37
BAB V PENUTUP ............................................................................................... 39
5.1 Kesimpulan .................................................................................................. 39
5.2 Saran ............................................................................................................ 39
DAFTAR PUSTAKA ........................................................................................... 40
LAMPIRAN .......................................................................................................... 42
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI
xii
DAFTAR TABEL
Tabel 2. 1 Confusion Matrix ................................................................................. 14
Tabel 3. 1 Contoh Data Awal ............................................................................... 17
Tabel 3. 2 Contoh Data Training .......................................................................... 22
Tabel 3. 3 Contoh Data Testing ............................................................................ 22
Tabel 3. 4 Prior Kelas ........................................................................................... 23
Tabel 3. 5 Mean dan Standar Deviasi IPS 2 ......................................................... 23
Tabel 3. 6 Mean dan Standar Deviasi SKS Semester 4 ........................................ 23
Tabel 3. 7 Mean dan Standar Deviasi Lama TA ................................................... 24
Tabel 3. 8 Probabilitas Data Testing No. 9 ........................................................... 24
Tabel 3. 9 Probabilitas Data Testing No.10 .......................................................... 24
Tabel 3. 10 Probabilitas Data Testing No. 11 ....................................................... 24
Tabel 3. 11 Probabilitas Data Testing No. 12 ....................................................... 25
Tabel 3. 12 Posterior Fold Pertama ....................................................................... 25
Tabel 3. 13 Hasil Klasifikasi Fold Pertama .......................................................... 25
Tabel 3. 14 Hasil Klasifikasi Fold Kedua ............................................................. 26
Tabel 3. 15 Hasil Klasifikasi Fold Ketiga ............................................................. 26
Tabel 3.16 Confusion Matrix Fold Pertama.......................................................... 26
Tabel 3. 17 Confusion Matrix Fold Kedua ........................................................... 27
Tabel 3. 18 Confusion Matrix Fold Ketiga ........................................................... 27
Tabel 4. 1 Hasil Perankingan Atribut.................................................................... 30
Tabel 4. 2 Contoh Transformasi Data Awal ......................................................... 31
Tabel 4. 3 Contoh Transformasi Data Akhir......................................................... 31
Tabel 4. 4 Hasil Pengujian Akurasi ...................................................................... 32
Tabel 4. 5 Data Testing Uji Data Tunggal ............................................................ 36
Tabel 4. 6 Data Testing Uji Data Kelompok ........................................................ 37
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI
xiii
DAFTAR GAMBAR
Gambar 2. 1 Knowledge Discovery Database (KDD) ............................................ 6
Gambar 2. 2 3-Fold Cross Validation ................................................................... 13
Gambar 3. 1 Diagram Blok ................................................................................... 15
Gambar 3. 2 Contoh Data Sebelum Proses Data Cleaning ................................... 19
Gambar 3. 3 Contoh Data Sesudah Proses Data Cleaning .................................... 20
Gambar 3. 4 Contoh Data Selection ..................................................................... 20
Gambar 3. 5 Contoh Data Pakai ........................................................................... 21
Gambar 3. 6 Perancangan Interface ...................................................................... 28
Gambar 3. 7 Confusion Matrix Fold Pertama ....................................................... 34
Gambar 3. 8 Confusion Matrix Fold Kedua ......................................................... 35
Gambar 3. 9 Confusion Matrix Fold Ketiga ......................................................... 35
Gambar 3. 10 Akurasi Total .................................................................................. 35
Gambar 4. 1 Akurasi Rata-rata ............................................................................. 34
Gambar 4. 2 Uji Data Tunggal Tepat .................................................................... 36
Gambar 4. 3 Uji Data Tunggal Tidak Tepat ......................................................... 37
Gambar 4. 4 Upload Uji Data Kelompok ............................................................. 38
Gambar 4. 5 Hasil Uji Data Kelompok ................................................................. 38
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI
1
BAB I
PENDAHULUAN
1.1 Latar Belakang
Kelulusan mahasiswa merupakan salah satu bidang yang termasuk ke dalam
Standar Penjaminan Mutu Internal (SPMI) suatu perguruan tinggi. Salah satu
standar yang ditetapkan oleh perguruan tinggi untuk menghasilkan lulusan tepat
waktu yaitu mahasiswa dapat menempuh kuliah maksimal 8 semester dengan total
beban studi minimal 144 SKS.
Dalam proses akreditasi suatu perguruan tinggi, salah satunya di Universitas
Sanata Dharma, ketepatan kelulusan mahasiswa merupakan hal yang penting
karena dapat mempengaruhi penilaian akreditasi. Untuk mengurangi jumlah
mahasiswa yang tidak lulus tepat waktu, perlu adanya suatu sistem yang dapat
digunakan untuk memprediksi kelulusan mahasiswa. Sistem tersebut memerlukan
data atau informasi untuk menentukan mahasiswa tersebut lulus tepat waktu atau
tidak. Jika kelulusan mahasiswa dapat diprediksi sejak awal, maka pihak akademik
dapat menerapkan suatu kebijakan untuk meminimalisir jumlah mahasiswa yang
tidak lulus tepat waktu.
Salah satu cara memanfaatkan data mahasiswa adalah dengan
mengelolahnya menggunakan teknik data mining untuk menghasilkan informasi
yaitu prediksi kelulusan mahasiswa. Teknik data mining yang akan digunakan
adalah metode klasifikasi dengan menggunakan algoritma naïve bayes.
Dalam dunia pendidikan, algoritma naïve bayes telah banyak digunakan
pada beberapa penelitian, salah satunya yang dilakukan oleh Yuda Septian Nugroho
(2014) dengan judul “Data Mining Menggunakan Algoritma Untuk Klasifikasi
Kelulusan Mahasiswa Universitas Dian Nuswantoro”. Pada penelitian tersebut,
atribut yang digunakan adalah NIM, nama, jenjang, program studi, nama provinsi,
jenis kelamin, SKS yang telah ditempuh, IPK, dan tahun kelulusan. Berdasarkan
proses klasifikasi tersebut dengan menggunakan algoritma naïve bayes, dihasilkan
tingkat akurasi sebesar 82,08%.
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI
2
Dari hasil penelitian tersebut, maka penulis juga ingin menggunakan
metode klasifikasi dengan algoritma naïve bayes dalam memprediksi kelulusan
mahasiswa karena penelitian yang telah dilakukan sebelumnya mendapatkan
tingkat akurasi yang tergolong baik.
1.2 Rumusan Masalah
1. Bagaimana metode naïve bayes mampu dengan tepat memprediksi
kelulusan mahasiswa?
2. Berapa hasil akurasi yang didapatkan dengan menggunakan metode
naïve bayes?
1.3 Tujuan
1. Mampu memprediksi kelulusan mahasiswa secara tepat dengan
menggunakan metode naïve bayes.
2. Mengetahui tingkat akurasi metode naïve bayes dalam memprediksi
kelulusan mahasiswa.
1.4 Manfaat
1. Dapat memprediksi mahasiswa yang lulus tepat waktu dan tidak tepat
waktu.
2. Dapat membantu pihak akademik dalam meminimalisir mahasiswa
yang lulus tidak tepat waktu.
1.5 Batasan Masalah
1. Data hanya berasal dari mahasiswa Fakultas Sains dan Teknologi
Universitas Sanata Dharma lulusan tahun 2010 sampai 2018.
2. Data yang digunakan dalam penelitian ini adalah data akademik dan
data pribadi mahasiswa yang meliputi program studi, jenis kelamin,
daerah asal, Indeks Prestasi Semester 1 sampai 4, jumlah SKS yang
telah ditempuh pada saat semester 4, jumlah poin, lama tugas akhir, dan
masa studi.
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI
3
1.6 Metodologi Penelitian
Penelitian ini menggunakan beberapa tahap sebagai berikut:
1. Studi Pustaka
Pada tahap ini, peneliti mempelajari teori-teori yang berkaitan
dengan data mining dan algoritma naïve bayes melalui jurnal, buku, dan
artikel.
2. Pengumpulan data
Data yang diperoleh mempunyai beberapa atribut dan record. Data
tersebut kemudian akan diintegrasikan dan dijadikan sebagai dataset
yang akan diproses lebih lanjut.
3. Pengolahan awal data
Pada tahap ini, data akan diseleksi dan dibersihkan dari noise.
Selanjutnya data akan ditransformasi untuk mendapatkan bentuk atau
format yang valid.
4. Pengujian model
Model yang akan diuji pada tahap ini adalah dengan menggunakan
algoritma naïve bayes dan beberapa metode lainnya.
5. Evaluasi dan validasi hasil
Evaluasi pada model dilakukan pada tahap ini sebagai hasil untuk
mengetahui tingkat akurasi.
1.7 Sistematika Penulisan
Sistematika penulisan pada penelitian ini dibagi menjadi 5 bab, yaitu:
BAB I PENDAHULUAN
Bab ini menjelaskan tentang latar belakang, rumusan masalah, tujuan,
manfaat, batasan masalah, metodologi penelitian, dan sistematika
penulisan.
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI
4
BAB II LANDASAN TEORI
Bab ini berisi mengenai teori-teori yang akan digunakan sebagai dasar
dalam penelitian klasifikasi dengan menggunakan algoritma naïve bayes.
BAB III METODOLOGI PENELITIAN
Bab ini berisi tentang gambaran umum sistem yang akan dibangun, data
yang digunakan dan tahap-tahap prediksi kelulusan dengan menggunakan
metode naïve bayes.
BAB IV IMPLEMENTASI DAN ANALISA HASIL
Bab ini menjelaskan tentang hasil dari perancangan sistem dan pengujian
metode klasifikasi naïve bayes.
BAB V PENUTUP
Bab ini akan menjelaskan tentang hasil kesimpulan dari analisa dan saran-
saran untuk pengembangan lebih lanjut.
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI
5
BAB II
LANDASAN TEORI
Bab ini akan menjelaskan secara singkat teori-teori yang digunakan pada
penelitian, antara lain, kelulusan studi mahasiswa, data mining, k-fold cross
validation dan confusion matrix. Teori-teori tersebut antara lain:
2.1 Kelulusan Studi Mahasiswa
Kriteria kelulusan mahasiswa dari suatu program studi dirumuskan dalam
bentuk Standar Kompetensi Lulusan yang yang terdapat dalam rancangan
kurikulum. Secara khusus, Pasal 1 butir 4 Peraturan Pemerintah No. 19 tahun 2005
tentang Standar Nasional Pendidikan, menyebutkan bahwa “Standar Kompetensi
Lulusan” adalah kualifikasi kemampuan lulusan yang mencakup sikap,
pengetahuan, dan keterampilan.
Pada suatu perguruan tinggi contohnya Universitas Sanata Dharma Fakultas
Sains dan Teknologi, jumlah mahasiswa yang lulus tidak tepat waktu tergolong
lebih banyak daripada mahasiswa yang lulus tepat waktu. Mahasiswa dapat
dikatakan lulus tepat waktu jika mampu menyelesaikan masa studinya tidak lebih
dari 4 tahun, sedangkan mahasiswa yang menyelesaikan masa studinya lebih dari 4
tahun termasuk dalam mahasiswa yang lulus tidak tepat waktu.
Terdapat beberapa faktor yang mempengaruhi lama masa studi mahasiswa,
diantaranya faktor eksternal dan internal. Faktor internal penyebab lamanya masa
studi mahasiswa antara lain: (1) kuliah karena keterpaksaan dan (2) salah memilih
jurusan. Sedangkan faktor eksternal penyebab lamanya masa studi mahasiswa
antara lain: (1) terlalu menikmati kebebasan karena jauh dari orang tua, (2) terlalu
aktif mengikut organisasi kemahasiswaan, (3) menekuni hobi secara berlebihan, (4)
bekerja, dan (5) tidak adanya jaminan mendapatkan pekerjaan setelah lulus
(Wahyu, 2010).
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI
6
Menurut buku panduan akademik Universitas Sanata Dharma yang
mengacu pada peraturan akademik Universitas Sanata Dharma tahun 2010, BAB
VI, Pasal 30, mahasiswa dinyatakan lulus program sarjana apabila:
a. Telah menyelesaikan 144 satuan kredit;
b. Mencapai IPK sekurang-kurangnya 2,00;
c. Proporsi nilai D tidak melebihi 15% dari jumlah satuan kredit program
studi yang bersangkutan.
d. Tidak ada nilai E;
e. Mencapai nilai sekurang-kurangnya C untuk mata kuliah wajib
Universitas yang diatur dengan SK Rektor.
f. Lulus ujian akhir
g. Memenuhi jumlah poin softskills yang ditetapkan Universitas
2.2 Data Mining
2.2.1 Pengertian Data Mining
Data mining merupakan proses yang menggunakan teknik statistik,
matematika, kecerdasan buatan, dan machine learning untuk mengekstraksi
dan mengidentifikasi informasi yang bermanfaat dan pengetahuan yang
terkait dari berbagai database besar (Turban dkk, 2005).
Gambar 2.1 Knowledge Discovery Database (KDD)
Han, Jiawei (2011)
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI
7
Data mining mengacu pada mining knowledge dari data dalam
jumlah besar (Han & Kamber, 2006). Secara umum data mining dikenal
dengan proses Knowledge Discovery from Data (KDD). Proses KDD
sebagai berikut:
1. Pembersihan data (Data Cleaning).
Proses pembersihan data atau data cleaning dilakukan untuk
menghilangkan noise dan data yang tidak konsisten.
2. Integrasi data (Data Integration).
Proses data integrasi adalah proses menggabungkan data dari
sumber data yang berbeda.
3. Seleksi data (Data Selection).
Seleksi data adalah proses memilih data atau atribut yang
relevan untuk atribut ini. Pada tahap ini dilakukan analisis
korelasi atribut data. Atribut – atribut data tersebut dicek apakah
relevan untuk dilakukan penambangan data.
4. Transformasi data (Data Transformation).
Transformasi atau data transformation proses
menggabungkan data ke dalam bank yang sesuai untuk
ditambang.
5. Penambangan data (Data Mining).
Langkah ini adalah langkah paling penting yaitu melakukan
pengaplikasian metode yang tepat untuk pola data.
6. Evaluasi pola (Pattern Evaluation).
Pada langkah ini dilakukan identifikasi pola dalam bentuk
pengetahuan berdasarkan beberapa pengukuran yang penting.
7. Presentasi pengetahuan (Knowledge Presentation).
Pada langkah ini dilakukan proses penyajian pengetahuan
dari hasil penambangan data. hasil klasifikasi data nasabah akan
ditampilkan ke dalam bentuk yang mudah dipahami
user/pengguna.
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI
8
2.2.2 Pengelompokkan Data Mining
Data mining dibagi menjadi beberapa kelompok berdasarkan
tugas yang dapat dilakukan (Larose, 2005), yaitu:
a. Deskripsi
Terkadang peneliti dan analisis secara sederhana ingin
mencoba mencari cara untuk menggambarkan pola dan
kecendrungan yang terdapat dalam data.
b. Estimasi
Estimasi hampir sama dengan klasifikasi, kecuali
variabel target estimasi lebih ke arah numerik dari pada ke
arah kategori.
c. Prediksi
Prediksi hampir sama dengan klasifikasi dan estimasi,
kecuali bahwa dalam prediksi nilai dari hasil akan ada di
masa mendatang.
d. Klasifikasi
Dalam klasifikasi, terdapat target variabel kategori.
Model data mining memeriksa serangkaian record yang
besar, masing-masing record berisi informasi tentang target
variabel serta serangkaian input atau prediktor variabel.
e. Pengklusteran
Clustering merupakan suatu metode untuk mencari dan
mengelompokkan data yang memiliki kemiripan
karakteriktik (similarity) antara satu data dengan data yang
lain. Clustering merupakan salah satu metode data mining
yang bersifat tanpa arahan (unsupervised).
f. Asosiasi
Tugas asosiasi dalam data mining adalah menemukan
atribut yang muncul dalam suatu waktu. Dalam dunia bisnis
lebih umum disebut analisis keranjang belanja.
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI
9
Dalam melakukan proses data mining, terdapat teknik-teknik
dengan 2 pendekatan yang berbeda yaitu supervised learning dan
unsupervised learning. Berikut penjelasan dari supervised learning dan
unsupervised learning (Jiawei, 2011).
a. Supervised learning
Supervised learning merupakan sebuah pendekatan yang
pada umumnya disebut dengan teknik klasifikasi. Pada
supervised learning, pembelajaran model berasal dari label
dan juga data yang digunakan sebagai training.
b. Unsupervised Learning
Unsupervised learning merupakan sebuah pendekatan
yang pada umumnya disebut dengan teknik klaster. Input
yang digunakan pada unsupervised learning tidak diberi
label kelas, biasanya pengguna teknik ini menggunakan
teknik clustering untuk menemukan kelas pada data.
Pada penelitian ini, penulis menggunakan pendekatan
supervised learning dengan menerapkan metode klasifikasi dimana
algoritma yang digunakan adalah algoritma naïve bayes.
2.2.3 Klasifikasi
Klasifikasi adalah proses penemuan model (atau fungsi) yang
menggambarkan dan membedakan kelas data atau konsep yang bertujuan
agar bisa digunakan untuk memprediksi kelas dari objek yang label
kelasnya tidak diketahui.
Klasifikasi data terdiri dari 2 langkah proses. Pertama adalah
learning (fase training), dimana algoritma klasifikasi dibuat untuk
menganalisa data training lalu direpresentasikan dalam bentuk rule
klasifikasi. Proses kedua adalah klasifikasi, dimana data tes digunakan
untuk memperkirakan akurasi dari rule klasifikasi (Kamber & Han, 2006).
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI
10
2.2.4 Naïve Bayes
Naïve bayes merupakan salah satu metode yang digunakan untuk
pengklasifikasian sebuah data dengan berdasarkan teorema bayes dengan
mengasumsikan bahwa suatu data memiliki sifat tidak saling terkait antar
satu dengan yang lain atau disebut independent. Teknik penggunaan naïve
bayes sangat sederhana dan cepat dengan penggunaan probabilistik.
Algoritma ini menggunakan metode probabilitas dan statistik yang
dikemukakan oleh ilmuan Inggris Thomas Bayes yaitu memprediksi
peluang di masa depan berdasarkan pengalaman sebelumnya (Tan &
Kumar, 2006).
Berikut persamaan dari teorema Bayes:
𝑃(𝐻|𝑋) = 𝑃(𝑋|𝐻). 𝑃(𝐻)
𝑃(𝑋) (2.1)
Keterangan :
X : Data dengan class yang belum diketahui
H : Hipotesis data merupakan suatu class spesifik
P(H|X) : Probabilitas hipotesis H berdasar kondisi X (posterior
Probabilitas)
P(H) : Probabilitas hipotesis H (prior probabilitas)
P(X|H) : Probabilitas X berdasarkan kondisi pada hipotesis H
P(X) : Probabilitas X
Atau dengan kata lain dapat ditulis:
𝑃𝑜𝑠𝑡𝑒𝑟𝑖𝑜𝑟 = 𝑝𝑟𝑖𝑜𝑟 𝑥 𝑙𝑖𝑘𝑒𝑙𝑖ℎ𝑜𝑜𝑑
𝑒𝑣𝑖𝑑𝑒𝑛𝑐𝑒
(2.2)
Nilai Evidence selalu tetap untuk setiap kelas pada satu sampel.
Nilai dari posterior tersebut nantinya akan dibandingkan dengan nilai-nilai
posterior kelas lainnya untuk menentukan ke kelas apa suatu sampel akan
diklasifikasikan.
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI
11
Untuk klasifikasi dengan data kontinyu, digunakan rumus densitas
gauss sebagai berikut:
P(𝑋𝑖 = 𝑥𝑖|𝑌 = 𝑌𝑗) =1
√2𝜋𝜎𝑒
−(𝑥𝑖−𝜇)2
2(𝜎)2 (2.3)
Keterangan :
𝑃 : Peluang
𝑋𝑖 : Atribut ke-i
𝑥𝑖 : Nilai atribut ke-i
𝑌 : Kelas yang dicari
𝜇 : mean, menyatakan rata-rata dari seluruh atribut
𝜎 : Standar deviasi
2.3 Information Gain
Information Gain merupakan metode seleksi fitur paling sederhana dengan
melakukan perangkingan atribut dan banyak digunakan dalam aplikasi kategorisasi
teks, analisis data microarray dan analisis data citra. (Chormunge & Jena, 2016).
Information gain digunakan pada tahap preprocessing untuk mengurangi noise
yang disebabkan oleh atribut-atribut yang tidak sesuai.
Untuk menghitung information gain digunakan persamaan (2.4), persamaan
(2.5) dan persamaan (2.6) sebagai berikut (Han et al., 2012):
𝑖𝑛𝑓𝑜(𝐷) = ∑ − 𝑃𝑖𝑚
𝑖=1𝑙𝑜𝑔2(𝑃𝑖) (2.4)
Keterangan:
𝐷 : Jumlah seluruh sampel data
𝑚 : Jumlah nilai yang ada pada kelas klasifikasi
𝑖 : Maksimal nilai yang ada pada kelas klasifikasi
𝑃𝑖 : Jumlah sampel untuk kelas i
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI
12
𝑖𝑛𝑓𝑜𝐴(𝐷) = 𝐸(𝐴) = ∑|𝐷𝑗|
|𝐷|
𝑣
𝑗=1
𝑥 𝑖𝑛𝑓𝑜 (𝐷𝑖) (2.5)
Keterangan:
𝐴 : Atribut
𝑣 : Suatu nilai yang mungkin untuk atribut A
𝑗 : Maksimal nilai yang mungkin untuk atribut A
𝐷 : Jumlah seluruh sampel data
𝐷𝑗 : Jumlah sampel untuk nilai j
𝐷𝑖 : Jumlah sampel untuk nilai i
𝐺𝑎𝑖𝑛(𝐴) = |𝑖𝑛𝑓𝑜(𝐷) − 𝑖𝑛𝑓𝑜𝐴(𝐷)| (2.6)
Keterangan:
𝐴 : Atribut
𝑖𝑛𝑓𝑜(𝐷) : Entropi untuk kelas D
𝑖𝑛𝑓𝑜𝐴(𝐷) : Entropi untuk kelas D pada atribut A
2.4 Normalisasi Min-Max
Tahap preprocessing lainnya ialah normalisasi data. Tujuan normalisasi
data adalah untuk memberikan tiap atribut bobot yang sama. Contohnya data minA
dan maxA adalah nilai minimum dan maksimum atribut. Normalisasi min-max
memetakan nilai, vi, dari A ke v0 i dalam kisaran [minA baru, maks baru] (Han et
al., 2012).Berikut rumus dari normalisasi min-max:
𝑉𝑖 =𝑋 − min(𝑋)
max(𝑋) − min(𝑋)(𝑛𝑒𝑤_𝑚𝑎𝑥𝐴 − 𝑛𝑒𝑤_𝑚𝑖𝑛𝐴) + 𝑛𝑒𝑤_𝑚𝑖𝑛𝐴 (2.7)
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI
13
Keterangan:
𝑋 : Data yang akan di normalisasi
Min(𝑋) : Jumlah minimum data
Max(𝑋) : Jumlah maksimum data
𝑁𝑒𝑤_𝑚𝑖𝑛𝐴 : range minimum data
𝑁𝑒𝑤_𝑚𝑎𝑥𝐴 : range maximum data
2.5 Cross Validation
Pada pendekatan ini, setiap data digunakan dalam jumlah yang sama untuk
pelatihan dan tepat satu kali untuk pengujian. Bentuk umum pendekatan ini disebut
dengan k-fold cross validation, yang memecah set data menjadi k bagian set data
dengan ukuran yang sama. Setiap kali berjalan, satu pecahan berperan sebagai data
set data latih sedangkan pecahan lainnya menjadi set data latih. Prosedur tersebut
dilakukan sebanyak k kali sehingga setiap data kesempatan menjadi data uji tepat
satu kali dan menjadi data latih sebanyak k1 kali. Total error didapatkan dengan
menjumlahkan semua error yang didapatkan dari k kali proses (Prasetyo, 2014).
Gambar 2.2 3-Fold Cross Validation
Ketika pengujian dilakukan sebanyak k kali iterasi, maka rata-rata akurasi
tiap pengujian akan dihitung untuk mendapatkan tingkat akurasi keseluruhan.
Tingkat akurasi dapat dihasilkan dari perhitungan metode confusion matrix.
2.6 Confusion Matrix
Confusion matrix adalah suatu metode yang digunakan untuk melakukan
perhitungan akurasi pada konsep data mining. Evaluasi dengan confusion matrix
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI
14
menghasilkan nilai akurasi, presisi dan recall. Akurasi dalam klasifikasi adalah
persentase ketepatan record data yang diklasifikasikan secara benar setelah
dilakukan pengujian pada hasil klasifikasi (Jiawei, Kamber, & Pei, 2006).
Dalam penelitian ini, pengukuran akurasi dilakukan dengan metode
pengujian confusion matrix yang dapat dilihat pada tabel berikut:
Tabel 2.1 Confusion Matrix
Kategori Nilai Sebenarnya
Nilai Prediksi
Benar Salah
Benar TP FP
Salah FN TN
Keterangan:
TP : Klasifikasi bernilai benar menurut prediksi dan benar menurut nilai
sebenarnya
FP : Klasifikasi bernilai benar menurut prediksi dan salah menurut nilai
Sebenarnya
FN : Klasifikasi bernilai salah menurut prediksi dan benar menurut nilai
sebenarnya
TN : Klasifikasi bernilai salah menurut prediksi dan salah menurut nilai
sebenarnya
Untuk menghitung tingkat akurasi digunakan rumus perhitungan sebagai
berikut:
𝐴𝑘𝑢𝑟𝑎𝑠𝑖 =𝑇𝑃 + 𝑇𝑁
𝑇𝑃 + 𝑇𝑁 + 𝐹𝑃 + 𝐹𝑁 𝑥 100% (2.8)
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI
15
BAB III
METODE PENELITIAN
Bab ini akan menjelaskan tentang gambaran umum sistem, peralatan
penelitian, dan perancangan interface untuk prediksi kelulusan mahasiswa Fakultas
Sains dan Teknologi Universitas Sanata Dharma menggunakan metode klasifikasi
naïve bayes.
3.1 Gambaran Umum
Gambar 3.1 Diagram Blok
Gambar 3.1 diatas merupakan proses sistem dalam mengolah data. Berikut
alur sistem yang dibangun dengan menggunakan algoritma naïve bayes:
1. Sistem membaca file bertipe .xlsx atau .xls yang di-upload melalui
direktori komputer.
2. File yang telah di-upload akan melalui tahap preprocessing untuk
menghilangkan noise. Tahap preprocessing yang digunakan adalah data
cleaning, data selection, dan data transformation.
3. Pada tahap data cleaning, data yang memiliki missing value akan
dihapus dengan melakukan cek terhadap kolom/atribut, jika salah satu
kolom atau lebih memiliki nilai kosong, maka baris data tersebut akan
dihapus dari tabel.
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI
16
4. Pada tahap data selection, dilakukan seleksi atribut dimana atribut akan
diranking menggunakan info gain untuk mendapatkan variasi atribut
paling optimal, dan hasil perankingan akan dimasukkan secara manual
pada program.
5. Pada tahap data transformation, tiap kolom/atribut yang ingin diubah
ke nilai tertentu akan diambil untuk dilakukan transformasi data.
Transformasi data dilakukan pada atribut masa studi dengan membuat
kategori tepat dan tidak tepat, serta dilakukan normalisasi min-max pada
atribut SKS semester 4 untuk mengubah rentang nilai dari 0 sampai 1.
6. Setelah data awal melalui tahap preprocessing, maka sistem akan
menghasilkan dataset atau data yang siap dipakai untuk proses
pembentukan model naïve bayes.
7. Kemudian dataset akan dibagi menjadi data training dan data testing
berdasarkan 3-fold cross validation. Data tersebut memiliki 3 bagian set
dimana 1/3 data akan dijadikan sebagai data testing dan 2/3 data akan
digunakan sebagai data training.
8. Tahap selanjutnya adalah melakukan perhitungan untuk mencari
probabilitas tiap atribut dan probabilitas kelas (prior).
9. Untuk mencari probabilitas atribut, tiap kolom pada data training akan
dihitung mean dan standar deviasinya terlebih dahulu, kemudian
probabilitas dihitung menggunakan rumus densitas gauss atau
persamaan (2.3) berdasarkan nilai data testing.
10. Setelah probabilitas didapatkan, maka probabilitas tiap atribut akan
dikali untuk menghitung likelihood berdasarkan kelas tepat dan tidak
tepat.
11. Selanjutnya rumus naïve bayes pada persamaan (2.2) akan diterapkan
untuk mencari nilai posterior dari kelas tepat dan tidak tepat dengan
memasukkan nilai likelihood, probabilitas kelas/prior, dan nilai
evidence.
12. Setelah nilai posterior tiap kelas didapatkan, maka hasil posterior
tersebut akan dibandingkan untuk dicari nilai tertingginya, jika salah
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI
17
satu kelas memiliki nilai posterior terbesar, maka kelas tersebut akan
menjadi label dari data testing. Pada tahap ini model dari naïve bayes
telah dibentuk.
13. Setelah model naïve bayes telah dibentuk, tahap selanjutnya adalah
membandingkan hasil klasifikasi dengan label testing, kemudian
menguji akurasi dengan menggunakan confusion matrix dengan
menggunakan persamaan (2.8).
14. Selanjutnya akan dilakukan uji data tunggal dengan memasukkan data
baru sebagai data test. Setelah melalui tahap perhitungan model naïve
bayes, maka sistem akan menampilkan hasil prediksi yakni tepat atau
tidak tepat.
3.1.2 Data
Data awal yang digunakan merupakan data mahasiswa Fakultas
Sains dan Teknologi Universitas Sanata Dharma lulusan tahun 2010 sampai
2018 yang diambil dari BAPSI kampus 3 Universitas Sanata Dharma. Dari
data tersebut diperoleh 1630 data record dan terdapat 10 atribut serta 1 kelas
yang digunakan sebagain inputan dalam perhitungan metode klasifikasi
naïve bayes. Atribut-atribut tersebut antara lain program studi, jenis
kelamin, daerah asal, Indeks Prestasi Semester 1, Indeks Prestasi Semester
2, Indeks Prestasi Semester 3, Indeks Prestasi Semester 4, SKS yang telah
ditempuh selama semester 1 sampai 4, poin, lama tugas akhir dan masa
studi.
Berikut merupakan contoh data awal yang belum melalui tahap
preprocessing:
Tabel 3.1 Contoh Data Awal
No. IPS 2 SKS S4 Lama TA Masa studi
1. 1.55 66 2 7
2. 3.47 81 1 4
3. 2.55 81 7 5
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI
18
4. 3.88 81 1 4
5. 3.64 79 1 4
6. 1.95 78 5 6
7. 2.77 83 1 6
8. 3.37 81 2 4
9. 2.32 65 3 5
10. 3.24 77 1 4
11. 2.33 69 2 5
12. 3.17 83 1 4
13. 2.91 2 6
Berikut penjelasan masing-masing atribut yang digunakan pada penelitian
ini:
1. Prodi : Program studi atau disingkat prodi merupakan
kesatuan rencana belajar yang digunakan sebagai
pedoman jalannya pendidikan akademik yang
penyelenggaraannya berdasarkan suatu kurikulum.
Data prodi terdiri dari TM, TE, INF, dan MAT.
2. JK : JK merupakan singkatan dari jenis kelamin yang
terdiri dari laki-laki dan perempuan.
3. Daerah asal : Daerah asal yang digunakan adalah nama asal
provinsi mahasiswa.
4. IPS 1 : Indeks Prestasi mahasiswa pada saat semester 1.
5. IPS 2 : Indeks Prestasi mahasiswa pada saat semester 2.
6. IPS 3 : Indeks Prestasi mahasiswa pada saat semester 3.
7. IPS 4 : Indeks Prestasi mahasiswa pada saat semester 4.
8. SKS S4 : Jumlah SKS yang telah ditempuh pada saat
semester 4.
9. Poin : Jumlah poin kegiatan kemahasiswaan.
10. Lama TA : Lama pengerjaan tugas akhir mahasiswa dalam
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI
19
satuan semester.
11. Masa studi : Jangka waktu penyelesaian studi mahasiswa dalam
satuan tahun.
3.1.3 Preprocessing
Pada tahap ini data akan melalui tahap preprocessing untuk
menghilangkan noise sehingga sistem menghasilkan dataset yang siap
dipakai untuk proses klasifikasi selanjutnya. Jenis Preprocessing yang ada
pada sistem ini adalah data cleaning, data selection, dan data
transformation.
3.1.3.1 Data Cleaning
Proses pembersihan data dilakukan untuk menghilangkan
noise dan data yang tidak konsisten. Jika terdapat nilai kosong pada
salah satu atribut maka baris data tersebut akan dihapus atau
dihilangkan dari tabel. Pada tabel 3.1 terdapat field kosong pada
baris ke-13 yaitu atribut SKS semester 4, maka baris data tersebut
akan dihapus dari tabel.
Gambar 3. 2 Contoh Data Sebelum Proses Data Cleaning
Pada gambar 3.2 diatas, data awal yang telah di-upload
ditampilkan pada tabel dan terdapat field kosong pada baris nomor
13 yaitu atribut SKS semester 4 sehingga sistem mengembalikan
nilai nan.
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI
20
Gambar 3. 3 Contoh Data Sesudah Proses Data Cleaning
Pada gambar 3.3, setelah tombol preprocessing dijalankan,
maka baris nomor 13 akan dihapus dari tabel dan menyisakan 12
data.
3.1.3.2 Data Selection
Pada tahap seleksi data, semua atribut akan diranking
dengan menerapkan metode information gain. Untuk mendapatkan
hasil information gain, penulis menggunakan weka tools versi 3.9
dan jumlah atribut dengan akurasi tertinggi akan digunakan untuk
proses klasifikasi selanjutnya.
Pada tabel 3.1, contoh data awal memiliki tiga atribut
dimana seluruh atribut tersebut digunakan untuk proses klasifikasi.
Jumlah atribut akan dimasukkan secara manual dan menghasilkan
tabel seperti gambar 3.4 berikut:
Gambar 3. 4 Contoh Data Selection
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI
21
3.1.3.3 Data Transformation
Transformasi data adalah proses perubahan data ke dalam
kategori atau nilai tertentu yang sesuai untuk proses data mining.
Pada tahap ini data yang akan ditransformasikan adalah atribut SKS
semester 4 dengan menggunakan normalisasi min-max dan atribut
masa studi dengan mengkategorikan nilai menjadi 1 dan 0.
a. Transformasi kelas masa studi
Pada kelas masa studi terdapat nilai yang terdiri dari
2, 3, 4, 5, 6, 7, 8 dan 9. Nilai-nilai tersebut akan
dikelompokkan menjadi 1 dan 0 atau tepat dan tidak
tepat berdasarkan syarat berikut:
• Masa studi 4 tahun : 0
b. Normalisasi min-max SKS semester 4
Normalisasi min-max digunakan pada atribut SKS
semester 4 karena atribut tersebut memiliki nilai yang
rentangnya cukup jauh dibandingkan dengan atribut
lainnya. Untuk melakukan proses normalisasi data,
dilakukan perhitungan min-max dengan menggunakan
persamaan (2.7).
Setelah melalui tahap data cleaning, data selection,
dan data transformation maka sistem menghasilkan data
pakai sebagai berikut:
Gambar 3. 5 Contoh Data Pakai
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI
22
3.1.4 Modelling Naïve Bayes
Dalam tahap pembentukan model, data yang telah melalui tahap
preprocessing akan dibentuk modelnya terlebih dahulu dengan
menggunakan algoritma naïve bayes. Sebelum masuk ke perhitungan
modelling naïve bayes, data pakai dibagi menjadi 3 bagian terlebih dahulu
dengan menggunakan metode 3-fold cross validation. Selanjutnya 2/3 data
partisi tersebut akan digunakan sebagai data training dan 1/3 lainnya akan
digunakan sebagai data testing. Berikut contoh pembagian data training
dan data testing pada fold pertama:
Tabel 3. 2 Contoh Data Training
No. IPS 2 SKS S4 Lama TA Masa Studi
1. 1.55 0.777777778 2 0
2. 3.47 0.722222222 1 1
3. 2.55 1 7 0
4. 3.88 0.888888889 1 1
5. 3.64 0 1 1
6. 1.95 0.666666667 5 0
7. 2.77 0.222222222 1 0
8. 3.37 1 2 1
Tabel 3. 3 Contoh Data Testing
No. IPS 2 SKS S4 Lama TA Masa Studi
9. 2.32 0.055555556 3 0
10. 3.24 0.888888889 1 1
11. 2.33 0.888888889 2 0
12. 3.17 0.888888889 1 1
Setelah data training dan data testing didapatkan, selanjutnya
adalah mencari prior dan probabilitas tiap atribut. Pada data pakai, atribut
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI
23
yang digunakan adalah IPS 2, SKS semester 4, dan lama tugas akhir dimana
nilai tiap atribut bersifat kontinu, maka untuk mencari probabilitas atribut-
atribut tersebut, digunakan perhitungan mean dan standar deviasi terlebih
dahulu.
Tabel 3. 4 Prior Kelas
Masa studi P(masa studi)
1 4/8
0 4/8
Untuk menghitung mean, digunakan rumus sebagai berikut:
�̅� =𝐽𝑢𝑚𝑙𝑎ℎ 𝑛𝑖𝑙𝑎𝑖
𝐵𝑎𝑛𝑦𝑎𝑘 𝑑𝑎𝑡𝑎 (3.1)
Untuk menghitung standar deviasi, digunakan rumus sebagai
berikut:
𝑆 = √∑ (𝑥𝑖 − 𝑥)2𝑛𝑖=1
𝑛 − 1 (3.2)
Berikut hasil perhitungan mean dan standar deviasi tiap atribut:
Tabel 3. 5 Mean dan Standar Deviasi IPS 2
IPS 2 Tepat Tidak Tepat
Mean 3.59 2.205
Standar Deviasi 1.377717902 1.427983203
Tabel 3. 6 Mean dan Standar Deviasi SKS Semester 4
SKS S4 Tepat Tidak Tepat
Mean 0.861111111 0.666666667
Standar Deviasi 0.435025813 0.452515562
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI
24
Tabel 3. 7 Mean dan Standar Deviasi Lama TA
Lama TA Tepat Tidak Tepat
Mean 1.25 3.75
Standar Deviasi 1.841115391 1.872792819
Jika mean dan standar deviasi telah dihitung, selanjutnya
menggunakan data testing pada tabel 3.5 untuk mencari nilai probabilitas
tiap atribut. Hasil akan dihitung berdasarkan persamaan (2.3) atau
menggunakan rumus densitas gauss dengan memasukkan mean, standar
deviasi, dan nilai data testing. Berikut hasil probabilitas tiap atribut
berdasarkan data testing:
Tabel 3. 8 Probabilitas Data Testing No. 9
Data testing no.9 Tepat Tidak Tepat
IPS 2 0.189334928 0.278470144
SKS S4 0.377385952 0.613584785
lama TA 0.137924966 0.196605123
Tabel 3. 9 Probabilitas Data Testing No.10
Data testing no.10 Tepat Tidak Tepat
IPS 2 0.280372566 0.214838644
SKS S4 0.463987358 0.69365332
lama TA 0.214696645 0.072478771
Tabel 3. 10 Probabilitas Data Testing No. 11
Data testing no.11 Tepat TidakTepat
IPS 2 0.190600971 0.278306316
SKS S4 0.405558222 0.641024052
lama TA 0.199432008 0.137662238
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI
25
Tabel 3. 11 Probabilitas Data Testing No. 12
Data testing no.12 Tepat TidakTepat
IPS 2 0.276419863 0.222341729
SKS S4 0.509170704 0.641024052
lama TA 0.214696645 0.072478771
Setelah nilai probabilitas seluruh atribut terhadap kelas didapatkan,
nilai posterior untuk kelas tepat dan tidak tepat akan dicari berdasarkan data
testing dengan menggunakan persamaan (2.2). Jika salah satu posterior
kelas memiliki nilai paling tinggi, maka kelas pada posterior tersebut adalah
label dari data testing yang diuji. Berikut hasil perhitungan naïve bayes
berdasarkan persamaan (2.2):
Tabel 3. 12 Posterior Fold Pertama
Posterior Tepat Tidak Tepat
Data testing no. 9 0.004927531 0.016796471
Data testing no. 11 0.013964871 0.005400521
Data testing no. 12 0.007708026 0.012279543
Data testing no. 13 0.015108728 0.005165069
Setelah melakukan perhitungan yang sama pada data testing fold
kedua dan ketiga, maka didapatkan hasil klasifikasi sebagai berikut:
Tabel 3. 13 Hasil Klasifikasi Fold Pertama
No. IPS 2 SKS S4 Lama TA Masa Studi Klasifikasi
9. 2.32 0.2814 3 0 0
10. 3.24 0.3533 1 1 1
11. 2.33 0.3054 2 0 0
12. 3.17 0.3892 1 1 1
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI
26
Tabel 3. 14 Hasil Klasifikasi Fold Kedua
No. IPS 2 SKS S4 Lama TA Masa Studi Klasifikasi
5. 3.64 0.3653 1 1 1
6. 1.95 0.3593 5 0 0
7. 2.77 0.3892 1 0 1
8. 3.37 0.3772 2 1 1
Tabel 3. 15 Hasil Klasifikasi Fold Ketiga
No. IPS 2 SKS S4 Lama TA Masa Studi Klasifikasi
1. 1.55 0.2874 2 0 0
2. 3.47 0.3772 1 1 1
3. 2.55 0.3772 7 0 0
4. 3.88 0.3772 1 1 1
3.1.5 Akurasi
Untuk mencari hasil akurasi dari hasil perhitungan naïve bayes,
digunakan perhitungan confusion matrix yakni dengan menjumlahkan data
yang diprediksi benar dan dibagi dengan seluruh data yang diprediksi benar
maupun salah lalu dikali dengan 100%. Pada kasus diatas, pengujian
dilakukan sebanyak 3 kali sehingga menghasilkan akurasi sebagai berikut:
Tabel 3.16 Confusion Matrix Fold Pertama
Masa Studi Tepat Tidak Tepat
Tepat 2 0
Tidak Tepat 0 2
𝐴𝑘𝑢𝑟𝑎𝑠𝑖 = 2 + 2
2 + 0 + 0 + 2𝑥 100% = 100%
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI
27
Tabel 3. 17 Confusion Matrix Fold Kedua
Masa Studi Tepat Tidak Tepat
Tepat 2 0
Tidak Tepat 1 1
𝐴𝑘𝑢𝑟𝑎𝑠𝑖 = 2 + 1
2 + 0 + 1 + 1𝑥 100% = 75%
Tabel 3. 18 Confusion Matrix Fold Ketiga
Masa Studi Tepat Tidak Tepat
Tepat 2 0
Tidak Tepat 0 2
𝐴𝑘𝑢𝑟𝑎𝑠𝑖 = 2 + 2
2 + 0 + 0 + 2𝑥 100% = 100%
Setelah mendapatkan hasil akurasi tiap pengujian, selanjutnya hasil
akurasi tersebut dihitung rata-ratanya untuk mendapatkan tingkat akurasi
keseluruhan. Berikut tingkat akurasi keseluruhan dengan menggunakan
rumus rata-rata:
𝑇𝑖𝑛𝑔𝑘𝑎𝑡 𝐴𝑘𝑢𝑟𝑎𝑠𝑖 =100 + 75 + 100
3= 91,6%
3.2 Peralatan Penelitian
Penelitian ini menggunakan beberapa peralatan untuk membangun sistem,
yaitu sebagai berikut:
1. Perangkat keras
a. Merk : Asus
b. Type : X505Z
c. Processor : AMD Quad Core R5, 3.6 GHz
d. RAM : 8,00 GB
e. HDD : 1 TB
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI
28
2. Perangkat Lunak
a. Windows 10 Home
b. Microsoft Excel 2013
c. Weka Tools 3.9
d. Matlab R2014B
3.3 Perancangan Interface
Gambar 3.6 Perancangan Interface
Pada perancangan interface yang dibuat, terdapat bagian untuk
pembentukan model dan uji data. Untuk membuat model, terdapat tombol upload
pada area 2 untuk membuka file excel dari direktori komputer dan data yang dipilih
akan ditampilkan dalam bentuk tabel pada area 1. Sebelum masuk pada tahap
preprocessing terdapat field pada area 3 untuk memasukkan jumlah atribut yang
akan digunakan. Kemudian tombol preprocessing pada area 5 akan menghasilkan
dataset yang ditampilkan pada area 4. Setelah data hasil preprocessing ditampilkan,
tombol hitung pada area 7 akan menghitung tingkat akurasi dan menampilkannya
pada area 6. Kemudian hasil confusion matrix dari tiap pengujian akan ditampilkan
pada area 8, area 9, dan area 10 .
Untuk melakukan uji data tunggal, data tiap atribut diinputkan satu persatu
terlebih dahulu di area 13. Kemudian ketika tombol klasifikasi pada area 14
dijalankan, maka hasil prediksi masa studi yakni tepat atau tidak tepat akan
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI
29
ditampilkan pada area 15. Ketika tombol hapus pada area 16 dijalankan, maka isi
dari tiap field uji data tunggal akan dihapus.
Untuk melakukan uji data dengan data yang berjumlah banyak, maka
pengguna melakukan upload data terlebih dahulu pada area 17 dan hasil data akan
ditampilkan di area 11. Setelah itu ketika tombol klasifikasi pada area 18
dijalankan, hasil klasifikasi tiap data akan ditampilkan pada area 12.
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI
30
BAB IV
HASIL DAN ANALISIS
Bab ini akan membahas hasil implementasi dari sistem yang telah dibuat
serta menganalisa hasil pengujian yang telah dilakukan.
4.1 Preprocessing
4.1.1 Data Cleaning
Pada tahapan data cleaning, baris data yang memiliki missing value
akan dihapus dari tabel sehingga tidak terdapat data kosong. Dari data yang
berjumlah 1630, terdapat satu data yang mengandung nilai kosong. Karena
jumlah data yang bernilai kosong hanya sebesar 0,06135%, maka baris data
tersebut dihapus dari tabel. Penelitian ini hanya menggunakan data yang
memiliki nilai pada setiap atribut agar tidak terdapat noise pada saat proses
klasifikasi.
4.1.2 Data Selection
Tahap ini akan melakukan seleksi atribut dengan menggunakan
Weka Tools 3.9 dan hasil seleksi atribut didapatkan berdasarkan infomation
gain dengan hasil sebagai berikut:
Tabel 4. 1 Hasil Perankingan Atribut
Ranking Atribut
1 SKS semester 4
2 Lama tugas akhir
3 IPS 2
4 IPS 3
5 IPS 4
6 IPS 1
7 Prodi
8 Poin
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI
31
9 Daerah asal
10 Jenis kelamin
4.1.3 Data Transformation
Pada tahap ini, atribut yang memiliki rentang nilai yang jauh atau
tidak seimbang terhadap atribut lain akan ditransformasi menggunakan
normalisasi min-max. Salah satu atribut yang rentang nilainya cukup jauh
adalah SKS Semester 4 dengan nilai terendah yaitu 18 dan nilai tertinggi
yaitu 185. Kemudian nilai dari atribut masa studi akan diubah menjadi 1 dan
0, dimana nilai 1 merupakan masa studi 4 tahun. Berikut contoh data awal pada tahap transformasi
data:
Tabel 4. 2 Contoh Transformasi Data Awal
No. SKS Semester 4 Masa Studi
1. 66 5
2. 81 4
3. 107 5
Setelah melalui tahap transformasi data, atribut SKS semester 4
dan masa studi akan menghasilkan contoh data akhir seperti pada tabel 4.4
berikut:
Tabel 4. 3 Contoh Transformasi Data Akhir
No. SKS Semester 4 Masa Studi
1. 0.2874 0
2. 0.3772 1
3. 0.5329 0
Keterangan:
a. Masa studi = 1 : Tepat
b. Masa studi = 0 : Tidak Tepat
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI
32
4.2 Klasifikasi
Setelah melalui tahap preprocessing, sistem akan menghasilkan dataset
atau data pakai dengan jumlah keseluruhan yaitu 1629 data. Penelitian ini
menggunakan seluruh atribut yang berjumlah 10 untuk diuji pada proses klasifikasi.
Penulis mencoba melakukan variasi terhadap tiap atribut untuk mencari hasil
akurasi yang optimal dan atribut dengan hasil paling optimal akan digunakan pada
uji data tunggal. Variasi atribut akan diurut berdasarkan hasil ranking atribut pada
tabel 4.3. Pengujian dilakukan menggunakan 3-fold cross validation dengan
membagi data menjadi 3 bagian dimana 2/3 data akan menjadi data training dan
1/3 data akan menjadi data testing. Berikut merupakan hasil variasi dan akurasi
dari tiap atribut:
Tabel 4. 4 Hasil Pengujian Akurasi
Jumlah Atribut Nama Atribut Akurasi
1 SKS semester 4 66.1142%
2 SKS semester 4
lama tugas akhir 80.4788%
3
SKS semester 4
lama tugas akhir
IPS 2
80.5402%
4
SKS semester 4
lama tugas akhir
IPS 2
IPS 3
79.6808%
5
SKS semester 4
lama tugas akhir
IPS 2
IPS 3
IPS 4
78.9441%
6
SKS semester 4
lama tugas akhir
IPS 2
IPS 3
IPS 4
IPS 1
78.0233%
7
SKS semester 4
lama tugas akhir
IPS 2
80.3560%
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI
33
IPS 3
IPS 4
IPS 1
prodi
8
SKS semester 4
lama tugas akhir
IPS 2
IPS 3
IPS 4
IPS 1
Prodi
poin
80.1150%
9
SKS semester 4
lama tugas akhir
IPS 2
IPS 3
IPS 4
IPS 1
Prodi
poin
daerah asal
79.8036%
10
SKS semester 4
lama tugas akhir
IPS 2
IPS 3
IPS 4
IPS 1
Prodi
poin
daerah asal
jenis kelamin
79.9263%
Tabel 4.6 merupakan hasil akurasi dari 10 kali percobaan terhadap variasi
atribut. Setelah penulis melakukan percobaan tersebut, didapatkan hasil akurasi
yang berbeda-beda pada tiap variasi atribut dengan tingkat akurasi tertinggi sebesar
80.5402% dan akurasi terendah sebesar 66.1142%. Tingkat akurasi tertinggi
terdapat pada atribut berjumlah 3 yaitu SKS semester 4, lama tugas akhir, dan IPS
2 sedangkan tingkat akurasi terendah terdapat pada atribut yang berjumlah 1 yaitu
SKS semester 4. Hal ini menunjukkan bahwa atribut SKS semester 4, lama tugas
akhir, dan IPS 2 merupakan variasi atribut paling optimal dan sudah tepat dalam
memprediksi kelulusan mahasiswa karena memiliki tingkat akurasi paling baik.
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI
34
Berdasarkan penelitian ini, jenis atribut yang baik dalam menentukan
kelulusan adalah atribut dengan tipe numerik. Hal ini dapat dilihat dari hasil ranking
atribut dimana atribut bertipe numerik berada diatas atribut bertipe kategorik.
Grafik tingkat akurasi tiap variasi atribut akan ditampilkan pada gambar 4.1 berikut:
Gambar 4. 1 Akurasi Rata-rata
Berikut hasil confusion matrix dengan menggunakan 3 atribut untuk 3-fold
cross validation:
Gambar 3. 7 Confusion Matrix Fold Pertama
𝐴𝑘𝑢𝑟𝑎𝑠𝑖 = 255 + 184
255 + 58 + 46 + 184𝑥100% = 80.8471%
60.00%
65.00%
70.00%
75.00%
80.00%
85.00%
90.00%
0 1 2 3 4 5 6 7 8 9 10 11
Tin
gkat
Aku
rasi
Jumlah Atribut
Akurasi
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI
35
Gambar 3. 8 Confusion Matrix Fold Kedua
𝐴𝑘𝑢𝑟𝑎𝑠𝑖 = 269 + 40
269 + 40 + 51 + 183𝑥100% = 83.2413%
Gambar 3. 9 Confusion Matrix Fold Ketiga
𝐴𝑘𝑢𝑟𝑎𝑠𝑖 = 264 + 64
264 + 64 + 58 + 157𝑥100% = 77.5322%
Gambar 3. 10 Akurasi Total
𝐴𝑘𝑢𝑟𝑎𝑠𝑖 𝑇𝑜𝑡𝑎𝑙 = 80.8471 + 83.2413 + 77.5322
3𝑥100% = 80.5402%
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI
36
4.3 Uji Data
4.3.1 Uji Data Tunggal
Pada tahap uji data tunggal, sistem akan menentukan hasil klasifikasi
berdasarkan data yang dimasukkan oleh pengguna. Untuk melakukan validasi,
penulis menggunakan model yang telah dibentuk dari pengujian pertama atau
fold pertama. Data training yang digunakan adalah 2/3 dari jumlah data dan
data testing yang digunakan adalah 1/3 dari jumlah data dimana data testing
berada pada set bawah. Inputan yang digunakan dalam proses klasifikasi hanya
atribut dengan tingkat akurasi tertinggi yaitu SKS semester 4, lama tugas akhir,
dan IPS 2. Berikut merupakan dua dari data testing yang akan diuji:
Tabel 4. 5 Data Testing Uji Data Tunggal
No. IPS 2 SKS S4 Lama TA Masa Studi
1. 3.17 81 1 1
2. 3.00 78 3 0
a. Data 1
Gambar 4. 2 Uji Data Tunggal Tepat
Pada gambar 4.2 diatas, data diklasifikasikan sebagai label tepat. Hasil
klasifikasi tersebut sesuai dengan label baris pertama pada tabel 4.5
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI
37
b. Data 2
Gambar 4. 3 Uji Data Tunggal Tidak Tepat
Pada gambar 4.3 diatas, data diklasifikasikan sebagai label tidak tepat.
Hasil klasifikasi tersebut sesuai dengan label baris kedua pada tabel 4.5
4.3.2 Uji Data Kelompok
Pada tahap ini sistem akan melakukan klasifikasi terhadap data
dalam jumlah banyak. Data yang di-upload adalah data bertipe .xls atau
.xlsx dengan label yang belum diketahui. Ketika tombol klasifikasi
dijalankan, maka masing-masing data uji akan ditampilkan kembali beserta
label hasil klasifikasi. Pada uji data kelompok, penulis kembali melakukan
validasi dengan cara yang sama pada tahap uji data tunggal. Berikut
merupakan tiga dari data testing yang akan diuji:
Tabel 4. 6 Data Testing Uji Data Kelompok
No. IPS 2 SKS S4 Lama TA Masa Studi
1. 3.17 81 1 1
2. 3.00 78 3 0
3. 3.79 85 2 1
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI
38
a. Data
Data yang dijadikan input pada uji data kelompok dapat
memiliki jumlah atribut yang lebih dari tiga, maka sistem memilih
dan melakukan ranking terlebih dahulu terhadap data dengan
memilih atribut SKS semester 4, lama tugas akhir, dan IPS 2.
Gambar 4.4 berikut merupakan tampilan uji data kelompok yang
datanya telah di-upload pada sistem:
Gambar 4. 4 Upload Uji Data Kelompok
Setelah data di-upload dan tombol klasifikasi dijalankan,
sistem akan menampilkan kembali data ke tabel beserta label hasil
klasifikasi pada tiap data uji seperti pada gambar 4.5 berikut:
Gambar 4. 5 Hasil Uji Data Kelompok
Pada gambar 4.5, label hasil klasifikasi akan ditampilkan di kolom 11, hasil
tersebut telah sesuai dengan data testing yang digunakan pada tabel 4.6.
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI
39
BAB V
PENUTUP
5.1 Kesimpulan
Berdasarkan hasil penelitian yang telah dilakukan penulis dengan judul
prediksi kelulusan mahasiswa Fakultas Sains dan Teknologi Universitas Sanata
Dharma menggunakan metode klasifikasi naïve bayes, didapatkan kesimpulan
sebagai berikut:
1. Metode klasifikasi dengan menggunakan algoritma naïve bayes sudah
cukup tepat dalam memprediksi kelulusan mahasiswa.
2. Tingkat akurasi tertinggi terdapat pada 3 atribut yaitu SKS semester 4,
lama tugas akhir, dan Indeks Prestasi Semester 2 dengan hasil akurasi
sebesar 80.5402%. Hal ini menunjukkan bahwa atribut-atribut tersebut
dapat digunakan dalam menentukan pengklasifikasian.
5.2 Saran
Saran yang diberikan untuk penelitian selanjutnya adalah:
1. Sistem untuk memprediksi kelulusan mahasiswa dapat dikembangkan
menggunakan metode yang berbeda.
2. Penelitian selanjutnya dapat menambahkan atribut-atribut lain yang
lebih mempengaruhi kelulusan mahasiswa.
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI
40
DAFTAR PUSTAKA
Anggreani, D., Herman, & Astuti, W. (2018). Kinerja Metode Naive Bayes dalam
Prediksi Lama Studi Mahasiswa Fakultas Ilmu Komputer. Seminar Ilmu
Komputer dan Teknologi Informasi, Vol.3 No.2.
Bustami. (2013). Penerapan Algoritma Untuk Mengklasifikasi Data Nasabah
Asuransi. Jurnal Penelitian Teknik Informatika, Vol.3, No.2.
Chormunge, S., & S., J. (2016). Efficient Feature Subset Selection Algorithm for
High Dimensional Data. International Journal of Electrical and Computer
Engineering (IJECE), Vol. 6, 1880-1888.
Kamber, M., & Han, J. (2006). Data Mining Concept and Techniques. San
Fransisco: Morgan Kauffman.
Larose, Daniel T. (2005). Discovering Knowledge in Data: An Introduction to
Data Mining. John Willey & Sons. Inc.
Nugroho, Y. S. (2014). Data Mining Menggunakan Algoritma Untuk Klasifikasi
Kelulusan Mahasiswa Universitas Dian Nuswantoro. Skripsi.
Santoso, B. (2007). Data Mining Teknik Pemanfaatan Data untuk Keperluan
Bisnis (1st ed.). Yogyakarta, Indonesia.
Tim Dosen Teknik Informatika. (2015). Panduan Akademik 2016/2017 Program
Studi Teknik Informatika. Yogyakarta: Universitas Sanata Dharma.
Turban, E., Aronson, J., & Liang, T. (2005). Decision Support System and
Intelligent Systems - 7th ed. Pearson Education, Inc. In Sistem Pendukung
Keputusan dan Sistem Cerdas (D. Prabantini, Trans.). Yogyakarta: ANDI.
Universitas Sanata Dharma. (2008). Manual Mutu Lulusan. Yogyakarta: Lembaga
Penjaminan Mutu Universitas Sanata Dharma.
Wahyu. (2010). Penyebab Lama Kuliah (Online). Dipetik July 1, 2020, dari
(http://blog.umy.ac.id/anharwahyu/2010/12/07/penyebab-lama-kuliah)
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI
41
Widaningsih, S. (2019). Perbandingan Metode Data Mining untuk Prediksi Nilai
dan Waktu Kelulusan Mahasiswa Prodi Teknik Informatika dengan
Algoritma C4.5, Naive Bayes, KNN, dan SVM. Jurnal Tekno Insentif,
Vol.13, No.1, 16-25.
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI
42
LAMPIRAN
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI
43
A. Lampiran Percobaan Menggunakan Weka Tools 3.9
1. Information Gain
B. Lampiran Program
1. Preprocessing
clear; clc; [num, text, data] = xlsread('DATA AWAL.xlsx');
revenue = data(:,11); [m,n] = size(revenue);
% transformasi kelas lama studi data2 = cell2mat(data(:,11));
for i=1:m if (data2(i)
44
2. Main
3. Tigafold
clear; clc; [num,text,data] = xlsread('dataset.xls'); jumlahAtribut = 3; revenue = data(:,11); [m,~] = size(revenue);
rangking = [8, 10, 5, 6, 7, 4, 1, 9, 3, 2]; kategorikal = [1,2,3]; nonKategorikal = [4,5,6,7,8,9,10];
j = 0; k = 0;
atributKategorikal = 0; atributNonKategorikal = 0;
for i = 1:jumlahAtribut if ismember(rangking(i),kategorikal) j=j+1; atributKategorikal(j) = rangking(i); elseif ismember(rangking(i), nonKategorikal) k=k+1; atributNonKategorikal(k) = rangking(i); end end
tigafold;
ukurandata = size(data,2); X = data(:,1:ukurandata-1); Y = data(:,ukurandata); jmlhdata = size(X);
range = jmlhdata(1)/3;
data1 = X(1:range,:); data2 = X(range+1:range*2,:); data3 = X(range*2+1:jmlhdata(1),:);
dataTr1 = [data2;data3]; dataTs1 = data1;
dataTr2 = [data1;data3]; dataTs2 = data2;
dataTr3 = [data1;data2]; dataTs3 = data3;
atributKategorikal(j) = rangking(i); elseif ismember(rangking(i), nonKategorikal) k=k+1; atributNonKategorikal(k) = rangking(i); end end
tigafold;
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI
45
like1 = Y(1:range); like2 = Y(range+1:range*2); like3 = Y(range*2+1:jmlhdata(1));
labelTr1 = [like2; like3]; labelTs1 = like1;
labelTr2 = [like1; like3]; labelTs2 = like2;
labelTr3 = [like1; like2]; labelTs3 = like3;
a = atributKategorikal; b = atributNonKategorikal;
for i=1:size(dataTs1, 1) if (a == 0) naiveKat = [1;1]; naiveNum = naiveNumerikal(dataTr1(:,b),
labelTr1, dataTs1(i,b)); hasil(i,1) = naiveBayes (naiveKat,
naiveNum, labelTr1); elseif (b==0) naiveNum = [1;1]; naiveKat =
naiveKategorikal(dataTr1(:,kategorikal),
labelTr1, dataTs1(i,kategorikal), a); hasil(i,1) = naiveBayes (naiveKat,
naiveNum, labelTr1); else naiveKat =
naiveKategorikal(dataTr1(:,kategorikal),
labelTr1, dataTs1(i,kategorikal), a); naiveNum = naiveNumerikal(dataTr1(:,b),
labelTr1, dataTs1(i,b)); hasil(i,1) = naiveBayes (naiveKat, naiveNum,
labelTr1); end end labelTs1 = cell2mat(labelTs1); confmat1 = confusionmat(hasil,labelTs1); output1 =
(sum(diag(confmat1))/sum(sum(confmat1)))*100;
for i = 1:size(dataTs2, 1) if (a == 0) naiveKat = [1;1]; naiveNum = naiveNumerikal(dataTr2(:,b),
labelTr2, dataTs2(i,b)); hasil(i,1) = naiveBayes (naiveKat,
naiveNum, labelTr2); elseif (b==0) naiveNum = [1;1]; naiveKat =
naiveKategorikal(dataTr2(:,kategorikal),
labelTr2, dataTs2(i,kategorikal), a); hasil(i,1) = naiveBayes (naiveKat,
naiveNum, labelTr2);
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI
46
elseif (b==0) naiveNum = [1;1]; naiveKat =
naiveKategorikal(dataTr2(:,kategorikal),
labelTr2, dataTs2(i,kategorikal), a); hasil(i,1) = naiveBayes (naiveKat,
naiveNum, labelTr2); else naiveKat =
naiveKategorikal(dataTr2(:,kategorikal),
labelTr2, dataTs2(i,kategorikal), a); naiveNum = naiveNumerikal(dataTr2(:,b),
labelTr2, dataTs2(i,b)); hasil(i,1) = naiveBayes (naiveKat, naiveNum,
labelTr2); end end labelTs2 = cell2mat(labelTs2); confmat2 = confusionmat(hasil,labelTs2); output2 =
(sum(diag(confmat2))/sum(sum(confmat2)))*100;
for i = 1:size(dataTs3, 1) if (a == 0) naiveKat = [1;1]; naiveNum = naiveNumerikal(dataTr3(:,b),
labelTr3, dataTs3(i,b)); hasil(i,1) = naiveBayes (naiveKat, naiveNum,
labelTr3); elseif (b==0) naiveNum = [1;1]; naiveKat =
naiveKategorikal(dataTr3(:,kategorikal),
labelTr3, dataTs3(i,kategorikal), a); hasil(i,1) = naiveBayes (naiveKat,
naiveNum, labelTr3); else naiveKat =
naiveKategorikal(dataTr3(:,kategorikal),
labelTr3, dataTs3(i,kategorikal), a); naiveNum = naiveNumerikal(dataTr3(:,b),
labelTr3, dataTs3(i,b)); hasil(i,1) = naiveBayes (naiveKat, naiveNum,
labelTr3); end end labelTs3 = cell2mat(labelTs3); confmat3 = confusionmat(hasil,labelTs3); output3 =
(sum(diag(confmat3))/sum(sum(confmat3)))*100;
akurasi = (output1 + output2 + output3)/3
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI
47
4. NaïveKategorikal
function output = naiveKategorikal (B, labelTr,
testData, atributKategorikal)
labelTr = cell2mat(labelTr(:,:)); Tepat = find(labelTr(:) == 1); TidakTepat = find(labelTr(:) == 0); [m,~] = size(B);
%berdasar prodi if(ismember(1,atributKategorikal)) prodi = zeros(4,2); for i=1:m if(isequal(B{i,1},
'TM')&&isequal(labelTr(i,1), 1)) prodi(1,1) = prodi(1,1) + 1; elseif(isequal(B{i,1},
'TM')&&isequal(labelTr(i,1), 0)) prodi(1,2) = prodi(1,2) + 1; elseif(isequal(B{i,1},
'INF')&&isequal(labelTr(i,1), 1)) prodi(2,1) = prodi(2,1) + 1; elseif(isequal(B{i,1},
'INF')&&isequal(labelTr(i,1), 0)) prodi(2,2) = prodi(2,2) + 1; elseif(isequal(B{i,1},
'MAT')&&isequal(labelTr(i,1), 1)) prodi(3,1) = prodi(3,1) + 1; elseif(isequal(B{i,1},
'MAT')&&isequal(labelTr(i,1), 0)) prodi(3,2) = prodi(3,2) + 1; elseif(isequal(B{i,1},
'TE')&&isequal(labelTr(i,1), 1)) prodi(4,1) = prodi(4,1) + 1; elseif(isequal(B{i,1},
'TE')&&isequal(labelTr(i,1), 0)) prodi(4,2) = prodi(4,2) + 1; end end %model prodiM = [prodi(:,1)/length(Tepat)
prodi(:,2)/length(TidakTepat)]; end
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI
48
%berdasar jenis kelamin if(ismember(2,atributKategorikal)) jk = zeros(2,2); for i=1:m if(isequal(B{i,2},
'L')&&isequal(labelTr(i,1), 1)) jk(1,1) = jk(1,1) + 1; elseif(isequal(B{i,2},
'L')&&isequal(labelTr(i,1), 0)) jk(1,2) = jk(1,2) + 1; elseif(isequal(B{i,2},
'P')&&isequal(labelTr(i,1), 1)) jk(2,1) = jk(2,1) + 1; elseif(isequal(B{i,2},
'P')&&isequal(labelTr(i,1), 0)) jk(2,2) = jk(2,2) + 1; end end %model jkM = [jk(:,1)/length(Tepat)
jk(:,2)/length(TidakTepat)]; end
%berdasar daerah asal if(ismember(3,atributKategorikal)) daerah = zeros(30,2); for i=1:m if(isequal(B{i,3}, 'Sumatera
Utara')&&isequal(labelTr(i,1), 1)) daerah(1,1) = daerah(1,1) + 1; elseif(isequal(B{i,3}, 'Sumatera
Utara')&&isequal(labelTr(i,1), 0)) daerah(1,2) = daerah(1,2) + 1; elseif(isequal(B{i,3}, 'Sumatera
Selatan')&&isequal(labelTr(i,1), 1)) daerah(2,1) = daerah(2,1) + 1; elseif(isequal(B{i,3}, 'Sumatera
Selatan')&&isequal(labelTr(i,1), 0)) daerah(2,2) = daerah(2,2) + 1; elseif(isequal(B{i,3}, 'Sumatera
Barat')&&isequal(labelTr(i,1), 1)) daerah(3,1) = daerah(3,1) + 1; elseif(isequal(B{i,3}, 'Sumatera
Barat')&&isequal(labelTr(i,1), 0)) daerah(3,2) = daerah(3,2) + 1; elseif(isequal(B{i,3}, 'Sulawesi
Utara')&&isequal(labelTr(i,1), 1)) daerah(4,1) = daerah(4,1) + 1; elseif(isequal(B{i,3}, 'Sulawesi
Utara')&&isequal(labelTr(i,1), 0)) daerah(4,2) = daerah(4,2) + 1; elseif(isequal(B{i,3}, 'Sulawesi
Tenggara')&&isequal(labelTr(i,1), 1)) daerah(5,1) = daerah(5,1) + 1;
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI
49
elseif(isequal(B{i,3}, 'Sulawesi Tenggara')&&isequal(labelTr(i,1), 0)) daerah(5,2) = daerah(5,2) + 1; elseif(isequal(B{i,3}, 'Sulawesi
Tengah')&&isequal(labelTr(i,1), 1)) daerah(6,1) = daerah(7,1) + 1; elseif(isequal(B{i,3}, 'Sulawesi
Tengah')&&isequal(labelTr(i,1), 0)) daerah(6,2) = daerah(7,2) + 1; elseif(isequal(B{i,3}, 'Sulawesi
Selatan')&&isequal(labelTr(i,1), 1)) daerah(7,1) = daerah(7,1) + 1; elseif(isequal(B{i,3}, 'Sulawesi
Selatan')&&isequal(labelTr(i,1), 0)) daerah(7,2) = daerah(7,2) + 1; elseif(isequal(B{i,3},
'Riau')&&isequal(labelTr(i,1), 1)) daerah(8,1) = daerah(8,1) + 1; elseif(isequal(B{i,3},
'Riau')&&isequal(labelTr(i,1), 0)) daerah(8,2) = daerah(8,2) + 1; elseif(isequal(B{i,3}, 'Papua
Barat')&&isequal(labelTr(i,1), 1)) daerah(9,1) = daerah(9,1) + 1; elseif(isequal(B{i,3}, 'Papua
Barat')&&isequal(labelTr(i,1), 0)) daerah(9,2) = daerah(9,2) + 1; elseif(isequal(B{i,3}, 'Nusa Tenggara
Timur')&&isequal(labelTr(i,1), 1)) daerah(10,1) = daerah(10,1) + 1; elseif(isequal(B{i,3}, 'Nusa Tenggara
Timur')&&isequal(labelTr(i,1), 0)) daerah(10,2) = daerah(10,2) + 1; elseif(isequal(B{i,3}, 'Nusa Tenggara
Barat')&&isequal(labelTr(i,1), 1)) daerah(11,1) = daerah(11,1) + 1; elseif(isequal(B{i,3}, 'Nusa Tenggara
Barat')&&isequal(labelTr(i,1), 0)) daerah(11,2) = daerah(11,2) + 1; elseif(isequal(B{i,3},
'Maluku')&&isequal(labelTr(i,1), 1)) daerah(12,1) = daerah(12,1) + 1; elseif(isequal(B{i,3},
'Maluku')&&isequal(labelTr(i,1), 0)) daerah(12,2) = daerah(12,2) + 1; elseif(isequal(B{i,3}, 'Luar Negeri
(Abroad)')&&isequal(labelTr(i,1), 1)) daerah(13,1) = daerah(13,1) + 1; elseif(isequal(B{i,3}, 'Luar Negeri
(Abroad)')&&isequal(labelTr(i,1), 0)) daerah(13,2) = daerah(13,2) + 1; elseif(isequal(B{i,3},
'Lampung')&&isequal(labelTr(i,1), 1)) daerah(14,1) = daerah(14,1) + 1; elseif(isequal(B{i,3},
'Lampung')&&isequal(labelTr(i,1), 0)) daerah(14,2) = daerah(14,2) + 1;
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI
50
elseif(isequal(B{i,3}, 'Kepulauan
Riau')&&isequal(labelTr(i,1), 1)) daerah(15,1) = daerah(15,1) + 1; elseif(isequal(B{i,3}, 'Kepulauan
Riau')&&isequal(labelTr(i,1), 0)) daerah(15,2) = daerah(15,2) + 1; elseif(isequal(B{i,3}, 'Kalimantan
Timur')&&isequal(labelTr(i,1), 1)) daerah(16,1) = daerah(16,1) + 1; elseif(isequal(B{i,3}, 'Kalimantan
Timur')&&isequal(labelTr(i,1), 0)) daerah(16,2) = daerah(16,2) + 1; elseif(isequal(B{i,3}, 'Kalimantan
Tengah')&&isequal(labelTr(i,1), 1)) daerah(17,1) = daerah(17,1) + 1; elseif(isequal(B{i,3}, 'Kalimantan
Tengah')&&isequal(labelTr(i,1), 0)) daerah(17,2) = daerah(17,2) + 1; elseif(isequal(B{i,3}, 'Kalimantan
Selatan')&&isequal(labelTr(i,1), 1)) daerah(18,1) = daerah(18,1) + 1; elseif(isequal(B{i,3}, 'Kalimantan
Selatan')&&isequal(labelTr(i,1), 0)) daerah(18,2) = daerah(18,2) + 1; elseif(isequal(B{i,3}, 'Kalimantan
Barat')&&isequal(labelTr(i,1), 1)) daerah(19,1) = daerah(19,1) + 1; elseif(isequal(B{i,3}, 'Kalimantan
Barat')&&isequal(labelTr(i,1), 0)) daerah(19,2) = daerah(19,2) + 1; elseif(isequal(B{i,3}, 'Jawa
Timur')&&isequal(labelTr(i,1), 1)) daerah(20,1) = daerah(20,1) + 1; elseif(isequal(B{i,3}, 'Jawa
Timur')&&isequal(labelTr(i,1), 0)) daerah(20,2) = daerah(20,2) + 1; elseif(isequal(B{i,3}, 'Jawa
Tengah')&&isequal(labelTr(i,1), 1)) daerah(21,1) = daerah(21,1) + 1; elseif(isequal(B{i,3}, 'Jawa
Tengah')&&isequal(labelTr(i,1), 0)) daerah(21,2) = daerah(21,2) + 1; elseif(isequal(B{i,3}, 'Jawa
Barat')&&isequal(labelTr(i,1), 1)) daerah(22,1) = daerah(22,1) + 1; elseif(isequal(B{i,3}, 'Jawa
Barat')&&isequal(labelTr(i,1), 0)) daerah(22,2) = daerah(22,2) + 1; elseif(isequal(B{i,3},
'Jambi')&&isequal(labelTr(i,1), 1)) daerah(23,1) = daerah(23,1) + 1; elseif(isequal(B{i,3},
'Jambi')&&isequal(labelTr(i,1), 0)) daerah(23,2) = daerah(23,2) + 1;
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI
51
elseif(isequal(B{i,3}, 'Irian Jaya/ Papua')&&isequal(labelTr(i,1), 1)) daerah(24,1) = daerah(24,1) + 1; elseif(isequal(B{i,3}, 'Irian Jaya/
Papua')&&isequal(labelTr(i,1), 0)) daerah(24,2) = daerah(24,2) + 1; elseif(isequal(B{i,3}, 'Daerah Khusus
Ibukota Jakarta')&&isequal(labelTr(i,1), 1)) daerah(25,1) = daerah(25,1) + 1; elseif(isequal(B{i,3}, 'Daerah Khusus
Ibukota Jakarta')&&isequal(labelTr(i,1), 0)) daerah(25,2) = daerah(25,2) + 1; elseif(isequal(B{i,3}, 'Daerah Istimewa
Yogyakarta')&&isequal(labelTr(i,1), 1)) daerah(26,1) = daerah(26,1) + 1; elseif(isequal(B{i,3}, 'Daerah Istimewa
Yogyakarta')&&isequal(labelTr(i,1), 0)) daerah(26,2) = daerah(26,2) + 1; elseif(isequal(B{i,3},
'Bengkulu')&&isequal(labelTr(i,1), 1)) daerah(27,1) = daerah(27,1) + 1; elseif(isequal(B{i,3},
'Bengkulu')&&isequal(labelTr(i,1), 0)) daerah(27,2) = daerah(27,2) + 1; elseif(isequal(B{i,3},
'Banten')&&isequal(labelTr(i,1), 1)) daerah(28,1) = daerah(28,1) + 1; elseif(isequal(B{i,3},
'Banten')&&isequal(labelTr(i,1), 0)) daerah(28,2) = daerah(28,2) + 1; elseif(isequal(B{i,3}, 'Bangka
Belitung')&&isequal(labelTr(i,1), 1)) daerah(29,1) = daerah(29,1) + 1; elseif(isequal(B{i,3}, 'Bangka
Belitung')&&isequal(labelTr(i,1), 0)) daerah(29,2) = daerah(29,2) + 1; elseif(isequal(B{i,3},
'Bali')&&isequal(labelTr(i,1), 1)) daerah(30,1) = daerah(30,1) + 1; elseif(isequal(B{i,3},
'Bali')&&isequal(labelTr(i,1), 0)) daerah(30,2) = daerah(30,2) + 1;
end end
%model daerahM =[daerah(:,1)/length(Tepat)
daerah(:,2)/length(TidakTepat)]; end
%Testing data = zeros(1,length(atributKategorikal)); output1 = 1; output2 = 1;
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI
52
%prodi if(ismember(1,atributKategorikal)) switch testData{1,1} case 'TM' data(1,1) = 1; case 'INF' data(1,1) = 2; case 'MAT' data(1,1) = 3; case 'TE' data(1,1) = 4; end output1 = output1 * prodiM(data(1,1),1); output2 = output2 * prodiM(data(1,1),2); end
%JenisKelamin if(ismember(2,atributKategorikal)) switch testData{1,2} case 'L' data(1,2) = 1; case 'P' data(1,2) = 2; end output1 = output1 * jkM(data(1,2),1); output2 = output2 * jkM(data(1,2),2); end
%AsalDaerah if(ismember(3,atributKategorikal)) switch testData{1,3} case 'Sumatera Utara' data(1,3) = 1; case 'Sumatera Selatan' data(1,3) = 2; case 'Sumatera Barat' data(1,3) = 3; case 'Sulawesi Utara' data(1,3) = 4; case 'Sulawesi Tenggara' data(1,3) = 5; case 'Sulawesi Tengah' data(1,3) = 6; case 'Sulawesi Selatan' data(1,3) = 7; case 'Riau' data(1,3) = 8; case 'Papua Barat' data(1,3) = 9; case 'Nusa Tenggara Timur' data(1,3) = 10;
case 'Nusa Tenggara Barat' data(1,3) = 11; case 'Maluku' data(1,3) = 12;
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI
53
case 'Luar Negeri (Abroad)' data(1,3) = 13; case 'Lampung' data(1,3) = 14; case 'Kepulauan Riau' data(1,3) = 15; case 'Kalimantan Timur' data(1,3) = 16; case 'Kalimantan Tengah' data(1,3) = 17; case 'Kalimantan Selatan' data(1,3) = 18; case 'Kalimantan Barat' data(1,3) = 19; case 'Jawa Timur' data(1,3) = 20; case 'Jawa Tengah' data(1,3) = 21; case 'Jawa Barat' data(1,3) = 22; case 'Jambi' data(1,3) = 23; case 'Irian Jaya/ Papua' data(1,3) = 24; case 'Daerah Khusus Ibukota
Jakarta' data(1,3) = 25; case 'Daerah Istimewa Yogyakarta' data(1,3) = 26; case 'Bengkulu' data(1,3) = 27; case 'Banten' data(1,3) = 28; case 'Bangka Belitung' data(1,3) = 29; case 'Bali' data(1,3) = 30;
end output1 = output1 * daerahM(data(1,3),1); output2 = output2 * daerahM(data(1,3),2); end
output = [output1; output2];
end
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI
54
5. NaiveNumerikal
6. NaiveBayes
function output = naiveNumerikal (B,
labelTr,testData)
%------------------------------Numerik----------
-------------------------% labelTr = cell2mat(labelTr(:,:)); %likelihood kelas = [1,0];
dataTr = cell2mat(B (:,:)); % labelTr = labelTr(:,4:end); for i = 1:length(kelas(1,:)) mn(i,:) = mean(dataTr(labelTr ==
kelas(1,i),:)); st_dev(i,:) = std(dataTr(labelTr ==
kelas(1,i),:)); end
%posterior Uji = cell2mat(testData(1,:)); for j = 1:size(kelas,2) likelihood = normpdf(Uji,
mn(j,:),st_dev(j,:)); posterior(j) = prod(likelihood); end
output = posterior;
end
function output = naiveBayes (naiveKat,
naiveNum, labelTr)
labelTr = cell2mat(labelTr(:,:)); Tepat = find(labelTr(:) == 1); TidakTepat = find(labelTr(:) ==
Recommended





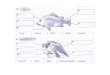
![]urnal Sains Teknologi - repository.unsada.ac.id](https://img.pdfslide.tips/doc/110x75/6174ae61c9c85551b70658c4/urnal-sains-teknologi-.jpg)










