
SCIPA: Servicii software semantice de Colaborare şi Interoperabilitate pentru
realizarea Proceselor Adaptive de business
Contract nr. 12118/01.10.2008 Autoritatea contractantă: CNMP
Etapa 3: Dezvoltarea componentelor semantice ale platformei
Raportul Stiintific si Tehnic in extenso
Universitatea Politehnica Bucuresti
Universitatea de Vest Timişoara
Academia de Studii Economice Bucureşti
Universitatea din Craiova
Pagina Web: http://aimas.cs.pub.ro/scipa/

PROGRAMUL 4 “PARTENERIATE IN DOMENIILE PRIORITARE” 2007-2013
SCIPA – Etapa 3: Dezvoltarea componentelor semantice ale platformei
2
CUPRINS
A. Obiective generale ale proiectului
B. Obiectivele etapei de executie
C. Rezumatul etapei
D. Descrierea stiintifica si tehnica
Partea I: Dezvoltarea ontologiilor procesului de business
Autori – Academia de Studii Economice Bucureşti Prof. dr. Ion Smeureanu – responsabil ştiinţific Prof. dr. Ion Gh. Roşca Prof. dr. Marian Dârdală Conf. dr. Titus-Felix Furtună Conf. dr. Adriana Reveiu Prep. drd. Andreea Dioşteanu
Partea a II-a: Modele de cooperare bazate pe agenti software
Autori – Universitatea Politehnica din Bucureşti Prof. dr. ing. Adina Magda Florea – responsabil ştiinţific Prof. dr. ing. Eugenia Kalisz S.l. dr. ing. Alexandru Boicea As. drd. ing. Andrei Mogos As. drd. ing. Andreea Urzică
Partea a III-a: Modele de compunere si descompunere a serviciilor semantice
Autori – Universitatea Politehnica din Bucureşti Prof. dr. ing. Adina Magda Florea – responsabil ştiinţific As. drd. ing. Andrei Mogos Drd. ing. Andreea Urzică
Partea a IV-a: Modele de incredere, reputatie si norme in sisteme de agenti pentru procese de e-business
Autori – Universitatea din Craiova Prof. dr. ing. Costin Bădică – responsabil ştiinţific Conf. dr. ing. Amalia Bădică As. Dr. Elvira Popescu Drd. ing. Sorin Ilie Drd. ing. Mihnea Scafes Autori – Universitatea Politehnica din Bucureşti Prof. dr. ing. Adina Magda Florea – responsabil ştiinţific Prof. dr. ing. Eugenia Kalisz As. drd. ing. Andrei Mogos Drd. ing. Andreea Urzică
Partea a V-a: Translator din BPEL in Event Calculus in scopul verificarii serviciilor business web
Autori – Universitatea de Vest din Timişoara Prof. dr. Viorel Negru – responsabil ştiinţific Prof. dr. Dana Petcu Prep. drd. Ovidiu Aritoni Prep. drd. Ciprian Pungilă

PROGRAMUL 4 “PARTENERIATE IN DOMENIILE PRIORITARE” 2007-2013
SCIPA – Etapa 3: Dezvoltarea componentelor semantice ale platformei
3
A. Obiective generale ale proiectului In cele ce urmeaza sunt prezentate obiectivele generale ale proiectului modificate pentru a reflecta reducerea substantiala de buget efectuata in anii 2008, 2009 si 2010 fata de bugetul aprobat initial (26,25% finantare - de la bugetul de stat - fata de finantarea aprobata initial pentru anii 2008, 2009 si 2010).
Proiectul de fata are ca obiectiv principal studiul, proiectarea si realizarea unei unei solutii software integrate care sa permita:
interoperabilitatea serviciilor software semantice oferite de intreprinderi,
adaptabilitatea proceselor de afaceri
descoperirea si compunerea a noi servicii
un model de colaborare flexibil
Obiectivele specifice sunt:
O1: Dezvoltarea unui model al proceselor de business sustinut de servicii software capabil sa realizeze:
Adaptarea in functie de context si mediul specific
Realizarea colaborarii
Adnotarea semantica a componentelor
O2: Dezvoltarea de agenti inteligenti capabili sa compuna autonom servicii Web generand astfel servicii compuse
O4: Realizarea modelului de colaborare pe baza unei colectivitati de agenti cognitivi
O5: Dezvoltarea solutiei software
O6: Validarea solutiei prin doua aplicatii particulare
B. Obiectivele etapei de executie
O2: Dezvoltarea de agenti inteligenti capabili sa compuna autonom servicii Web generand astfel servicii compuse
O4: Realizarea modelului de colaborare pe baza unei colectivitati de agenti cognitivi

PROGRAMUL 4 “PARTENERIATE IN DOMENIILE PRIORITARE” 2007-2013
SCIPA – Etapa 3: Dezvoltarea componentelor semantice ale platformei
4
C. Descrierea stiintifica si tehnica
Partea I
Dezvoltarea ontologiilor procesului de business Autori – Academia de Studii Economice Bucureşti
Prof. dr. Ion Smeureanu – responsabil ştiinţific
Prof. dr. Ion Gh. Roşca
Prof. dr. Marian Dârdală Conf. dr. Titus-Felix Furtună
Conf. dr. Adriana Reveiu Prep. drd. Andreea Dioşteanu

PROGRAMUL 4 “PARTENERIATE IN DOMENIILE PRIORITARE” 2007-2013
SCIPA – Etapa 3: Dezvoltarea componentelor semantice ale platformei
5
CUPRINS
1 6 Utilizarea ontologiilor în aria de business1.1 ......................................................................... 6 Motivarea utilizării ontologiilor în afaceri1.2 ................................................................................. 8 Scopul ontologiilor din aria business1.3 ................................................................ 9 Ontologiile de business în modelarea afacerilor1.4 ....................................................................... 18 Exemple de ontologii existente în prezent
1.4.1 ................................................................................. 18 Ontologia Edinburg Enterprise1.4.2 ......................................................................... 18 TOVE (Toronto Virtual Enterprise)1.4.3 .................................................................... 19 FEF (Financial Exchange Framework)
1.5 ............................................................................................................................... 19
Maparea modelului de business peste modelul lingvistic bazat pe ontologii şi semantici web
1.5.1 ......................................................................................... 21 Standardizarea semantică1.5.2 ....................................................................................... 22 Ontologii şi SemanticWeb1.5.3 ..................................................................................................... 24 Modelarea datelor
1.6 ........................................... 26 Proiectarea şi dezvoltarea ontologiilor procesului de afaceri1.6.1 .................. 26 Scurtă trecere în revistă a metodologiilor de construcţie a ontologiilor1.6.2 ................................... 27 Metodologia propusă pentru crearea ontologiilor de afaceri
2 32 Modelarea aplicaţiei de management al lanţului de aprovizionare2.1
..................................................................................................................................... 32 Specificarea de nivel înalt a cerinţelor de funcţionalitate şi interoperabilitate ale
platformei2.2
......................................................................................................................... 38 Dezvoltarea unei aplicaţii de management al lanţului de aprovizionare folosind
platforma propusă3 45 Evaluarea riscului în mediile de programare bazate pe agenţi inteligenţi
3.1 .................................. 45 Fiabilitatea sistemelor distribuite bazate pe agenţi şi servicii web3.1.1 .................. 45 Aspecte generale privind metricile de evaluare a fiabilităţii sistemelor3.1.2 ........................................... 47 Fiabilitatea în sistemele de compunere de servicii web
3.2 .......................................................... 51 Riscul în managementul lanţului de aprovizionareAnexa 1- Codul asociat ontologiei clientului 62 Anexa 2- Compunerea simplă AE - cod sursă 63

PROGRAMUL 4 “PARTENERIATE IN DOMENIILE PRIORITARE” 2007-2013
SCIPA – Etapa 3: Dezvoltarea componentelor semantice ale platformei
6
1 Utilizarea ontologiilor în aria de business
1.1 Motivarea utilizării ontologiilor în afaceri
Competiţia pune presiune pe firme pentru a obţine profit prin cele două metode
principale: cucerirea de noi pieţe (prin extindere geografică sau prin introducerea de noi
produse) şi prin reducerea costurilor. Schema de mai jos ilustrează acest aspect.
Fig.1 Influenţele mediului exterior asupra companiei
[Hod03] explică faptul că “în această căutare a inovaţiei, frontierele ştiinţei şi ale
tehnologiei avansează, ducând spre noi câmpuri de cunoaştere şi cercetare”. De asemenea,
conform aceleiaşi lucrări “în general, serviciile sunt mai diversificate decât producţia de
bunuri, această diversitate crescând odata cu creşterea sectorului de servicii în sine”.
a) Schimbările tehnologice şi apariţia afacerilor electronice
Dacă se analizează statisticile în domeniu, se poate observa că investiţiile în echipamente
IT şi software au crescut în mod constant în ultimele decenii. În acelaşi timp, costurile de
hardware, software şi servicii au scăzut drastic, în timp ce performanţele lor au explodat.
Bineînţeles, acest lucru are un important impact asupra firmelor de orice dimensiune, pe
măsură ce adoptă şi se bazează pe IT. În special, răspândirea Internetului şi adoptarea de e-
business şi e-commerce a schimbat în mod drastic felul în care companile fac afaceri. E-
commerce nu se referă doar la cumpărarea şi vânzarea de bunuri, ci şi la a oferii servicii şi a
colabora cu partenerii.
În ceea ce priveşte efectele inovaţiilor IT, e-commerce şi e-business, impactul lor a fost de
multiplicarea configuraţiilor de afaceri posibile şi deci a alegerilor ce trebuie făcute de
manageri. În contrast cu modul tradiţional de organizare a unei industrii, unde modele de

PROGRAMUL 4 “PARTENERIATE IN DOMENIILE PRIORITARE” 2007-2013
SCIPA – Etapa 3: Dezvoltarea componentelor semantice ale platformei
7
afaceri arătau la fel, gama de modele noi posibile, în era tehnologiei şi a comunicaţiei au
crescut puternic.
Se pot evidenţia patru impacte majore ale dezvoltării tehnologiei. În primul rând, preţurile
accesibile ale tehnologiei au redus costurile de tranzacţie şi coordonare. Cu alte cuvinte,
costurile de colaborarea cu parteneri (de exemplu externalizările) şi integrarea clienţilor în
procesele companiei (de exemplu personalizările, serviciile cu clienţii) nu sunt mai restrictive.
Aceasta a facilitat crearea de noi forme de organizaţii legate între ele prin reţele. Consecinţele
asupra managementului sunt constituite de noile configuraţii posibile de afaceri şi de
varietatea lor. În al doilea rând, creşterea IT, e-commerce şi e-business, au făcut posibilă
apariţia unor produse şi servicii complet noi, din care multe au o componentă importantă
informaţia şi care sunt utilizate în mod frecvent în colaborare de mai multe companii. În al
treilea rând, IT-ul a creat moduri noi şi inovatoare de a ajunge la clienţi, şi printr-o
multitudine de canale. De asemenea, Internetul a facilitat desfăşurarea afacerilor la nivel
global şi deservirea clienţilor în locurile ultraperiferice ale planetei. În final, datorită
Internetului şi a Web-ului, o serie de noi mecanisme de stabilire a preţurilor şi a veniturilor şi-
au găsit locul în practicarea afacerilor.
Lista impactului IT-ului asupra afacerilor poate fi prelungită, dar principalul lucru care
trebuie păstrat din cele de mai sus este că aceste evoluţii aduc o importantă creştere în
alegerile şi deciziile cu care managerii se confruntă în termenii noilor modele de afaceri.
Aceasta explică creşterea cercetărilor în modele de afaceri în general şi în modele de afaceri
cu o puternică componentă de tehnologie de comunicaţie (de exemplu e-commerce).
b) Complexitatea
O altă caracteristică a peisajului de afaceri de azi este de complexitatea acestuia. Potrivit
lui [Hod03] capitalismul natural duce la mai multă complexitate datorită unor puternice forţe
economice. El menţionează că „forme organizatorice noi şi variate vor fi create pentru a creşte
productivitatea şi pentru a administra o expansiune a numărului de produse şi procese”. Într-
adevăr, descompunerea companiei integrate şi formarea de reţele de afaceri, după cum este
descris mai sus, a contribuit la complexitate, pentru că este un mecanism care generează
diversitatea [And01]. Conceptul de model de afaceri poate fi unul dintre instrumentele care
ajută la combaterea a cel puţin unor aspecte legate de complexitate prin evidenţierea
problemelor importante şi subliniind relaţiile dintre ele. Ca de fiecare conceptualizare şi
modelare, conceptul de model de afaceri are ca obiectiv reprezintarea realităţii într-um mod
structurat, simplificat şi uşor de înţeles.

PROGRAMUL 4 “PARTENERIATE IN DOMENIILE PRIORITARE” 2007-2013
SCIPA – Etapa 3: Dezvoltarea componentelor semantice ale platformei
8
c) Nesiguranţa
Este larg acceptat faptul că unul dintre efectele revoluţiei tehnologice în comunicare din
anii 1990, împreună cu forţele globalizării şi liberalizării, a fost creşterea riscului de mediu şi
incertitudinea la care organizaţiile au trebuit să facă faţă [And01]. Problema cu incertitudinea
este că ea creşte riscul de mediu cu care se confruntă cu o companie, deoarece viitorul devine
imprevizibil. Specialiştii în domeniu vorbesc de patru niveluri de incertitudine cu care se
confruntă managerii. La primul nivel există o singură viziune a viitorului, la cel de-al doilea
nivel una din cele câteva posibilităţi va avea loc, la cel de-al treia nivel există o serie de
evenimente posibile şi la cel de-al patrulea nivel, găsim ambiguitatea generală în ceea ce
priveşte viitorul.
Gestionarea incertitudinii este probabil una dintre cele mai importante provocări cu care
se confruntă astăzi managerii. Furnizarea specificărilor conceptualizării de modele de afaceri
ar putea îmbunătăţi scenariile abordabile şi să ducă la simulare. Aceasta ar ajuta managerii să
fie mai bine pregatiţi pentru viitor .
1.2 Scopul ontologiilor din aria business
Scopul ontologiilor din aria business este de a facilita comunicaţia între oameni prin
evaluarea modelelor de business. Ca rezultat al folosirii ontologiilor apar şi alte beneficii
precum reutilizarea datelor, o căutare mai avansata în baza de date, o verificare automată a
consistenţei datelor, asistenţă în procesele de specificaţie, reducerea costurilor de mentenanţă
şi creşterea vitezei de obtinere a informaţiei şi acurateţea acesteia.
Printr-o ontologie de business se combină managementul afacerilor cu modelul conceptual
tehnic al ontologiei. Cu alte cuvinte, scopul lor este de a aplica descrierile complete şi
riguroase ale ontologiilor asupra conceptelor de afaceri.
Crearea unui model de ontologie va furniza baza pentru noi metode şi instrumente în
gestionarea afacerilor la nivel de management, în startegiile de business, în automatizarea
comparărilor modelelor de afaceri. Această abordare mai formală va înlătura eventualele
ambiguităţi şi va permite folosirea unui raţionament bazat pe ontologie, cu un limbaj logic
care să verifice consistenţa şi gradul de eficienţă al modelului de afacere şi care să completeze
modelul cu constrângeri de integritate şi reguli de deducţie.
Rolurile ontologiilor din aria business sunt structurate pe mai multe nivele de
abstractizare. Acestea variază de la ontologii ce reprezintă un cumul de alte ontologii, până la
ontologii ce descriu lucruri şi proprietăţile lor. Se pot distinge următoarele trei nivele:

PROGRAMUL 4 “PARTENERIATE IN DOMENIILE PRIORITARE” 2007-2013
SCIPA – Etapa 3: Dezvoltarea componentelor semantice ale platformei
9
N1: date operaţionale. Ontologia cuprinde date operaţionale. Informaţia de la acest
nivel este clasificată folosind termenii unui vocabular definit la nivelul doi.
N2: ontologia. Ontologia specifică termenii generali şi definiţiile pentru conceptele
importante dintr-un anumit domeniu. La acest nivel este creat vocabularul pentru limbajul
folosit la nivelul unu.
N3: limbajul de reprezentare al ontologiei. Ontologia joacă un rol important când
informaţia este folosită de autori pentru a scrie ontologii de nivelul doi.
Ontologiile oferă o înţelegere a structurii informaţiei, separă informaţiile dintr-un
domeniu de datele operaţionale, prezintă teoriile dintr-un domeniu în mod explicit
reprezentând un mod eficient de comunicare între programele ce le utilizează. Ţinta
industriei ce evoluează spre aplicaţii orientate pe servicii este de a facilita inetroperabiliate
standardizată la nivel semantic între procesele software ale partenerilor de afaceri pe întregul
lanţ valoric
De asemenea, una din facilităţile folosirii ontologiilor este regăsirea informaţiei într-un
limbaj mai apropiat de cel natural. Astfel, la întrebări formulate ca în vorbirea directă, se
pot răspunsuri pertinente. Utilizând ontologiile în motoarele de căutare se obţin rezultate
logice şi riguros construite. Folosind o ontologie de business într-un astfel de motor, se obţin
rezultate mult mai precise în acest domeniu, răsunsul fiind concis şi exact, detaliind aspectele
economice şi financiare, şi excluzând datele mai puţin legate de domeniul afacerilor. Pe acest
aspect se va concentra şi aplicaţia prezentată în capitolul următor.
1.3 Ontologiile de business în modelarea afacerilor
Există o mare varietate de ontologii pentru afaceri, fiecare cu particularităţile ei. În funcţie de
subdomeniul pe care sunt specializate pot fi ontologii financiare, de management, pentru
producţie, pentru piaţă şi desfacere, pentru comerţ electronic, etc.
Din punct de vedere al designului, ontologiile trebuie să urmărească anumite criterii:
Claritate: sensul descrierilor trebuie să fie comunicat fără ambiguităţi şi trebuie să fie
furnizate toate condiţiile necesare şi suficiente.
Coerenţă: consistenţa internă trebuie menţinută, cel puţin axiomele, din moment ce
acestea determină competenţa unei ontologii
Extindere: trebuie să permită extinderea termenilor deja existenţi fără a necesita o
verificare foarte amănunţită
Conform [Ost04], “există patru piloni esenţiali într-o ontologie: produsul, interfaţa cu clientul,
infrastructura şi finanţele”.
Produsul: Cu ce afaceri se ocupă compania, produsele şi valoarea propusă oferite pe piaţă.
Interfaţa cu clienţii: Care sunt clienţii ţintă ai companiei, cum le oferă produse şi servicii, şi
cum se construieşte o relaţie puternică cu ei.

PROGRAMUL 4 “PARTENERIATE IN DOMENIILE PRIORITARE” 2007-2013
SCIPA – Etapa 3: Dezvoltarea componentelor semantice ale platformei
10
Infrastructura managementului: Cum tratează compania problemele legate de logistică şi
infrastructură în mod eficient, cu cine, şi ca ce fel de întreprindere în reţea.
Aspecte financiare: Care este modelul de venituri, structura costurilor şi modelul de
durabilitate al afacerii.
Dezvoltând pe această schemă, pentru modelarea proceselor de afaceri, acum sunt
folosite nouă elemente: nume, valoare propusă, consumator vizat, canal de distribuţie, relaţie,
valoare de configurare, capacitate, parteneriat, structura costului şi model de venit. Valoarea
propusă este un ansamblu de produse şi servicii care pot fi vândute. Consumatorul vizat este
segmentul de clienţi căreia se adreseaza firma. Canalul de distribuţie se referă la modul în
care se face legătura cu clientul. Relaţia descrie tipul de legatură pe care compania o stabileşte
cu clientul. Valoarea de configurare constă în ansamblul de activităţi şi resurse ce sunt
necesare pentru a crea ceva cu valoare pentru client. Capacitatea este abilitatea de a executa
un tipar repetabil de acţiuni care sunt necesare pentru a crea produse ce pot fi vândute.
Parteneriatul este un aranjament voluntar între companie şi o altă firmă în scopul de a crea
bunuri şi servicii. Structura costului constituie reprezentarea în bani a tuturor eforturilor
depuse în modelul de afacere. Modelul de venit descrie felul în care compania face bani prin
varietatea de fluxuri de venituri. Aceste elemente şi relaţiile dintre ele sunt reprezentate în
schema de mai jos.
Fig.2 Modelul de venit
Ansamblul elementelor descrise mai sus formează într-adevăr un model: este
independent de orice firmă şi poate descrie modelul de afacere al oricărei companii. Mai mult,
reprezintă o sinteză a modelelor de afaceri, îndeplinind cerinţa primară a ontologiilor de a fi o
descriere generală a unei comunităţi de utilizatori. Modelul poate dezvoltat şi detaliat în
funcţie de specificul fiecărui subdomeniu.
Practic, cele nouă elemente ale ontologiei acoperă toate blocurile de modele de afaceri
menţionate de către cel puţin doi autori. Modelul exclude elemente legate de peisajul
competitiv, implementare, capital şi piaţă, considerându-le legate de modelul de afaceri , dar
nu ca o parte din aceasta. [ATu03] menţionează profitul, care situează compania într-o
configuraţie valoarică vis-a-vis de furnizorii, clienţii, rivali, nou-veniţii potenţiali,

PROGRAMUL 4 “PARTENERIATE IN DOMENIILE PRIORITARE” 2007-2013
SCIPA – Etapa 3: Dezvoltarea componentelor semantice ale platformei
11
complementarii şi suplinitorii săi. În această abordare acest element este văzutmai degrabă ca
parte a strategiei de poziţionare a firmei în peisajul competitiv şi în consecinţă de proiectare a
modelului de afaceri a companiei.
Ontologia bazată pe modelul de afaceri este un set de elemente şi relaţiile acestora
care au ca scop descrierea logica unei firme în câştigarea banilor. Aşa cum este subliniat mai
sus, ontologia bazată pe modelul de afaceri conţine nouă elemente, caracterizate în tabelul de
mai jos. Fiecare element din modelul de afaceri poate fi descompus într-un set de subelemente
definite. Acest lucru permite studierea modelelor de afaceri pe diferite niveluri mai mult sau
mai puţin în detaliu şi în funcţie de nevoile specifice.
Mai jos sunt descrise în detaliu elementele ontologiei
A) Produsul
Tradiţional, companiile se concentrau pe poziţionarea pe poziţia potrivită în lanţ valoric,
cu produsele potrivite, pe segmentele de piaţă potrivite şi cu serviciile cu valoare adăugată.
Dar prin globalizare, pieţele în schimbare rapidă şi noile tehnologii lucrurile au devenit mai
complexe şi mai complicate. Companiile se organizează din ce în ce mai mult în reţele şi
oferă pachete de produse şi servicii ca un grup. Azi, arta de a crea şi a produce în cooperare cu
alţii este, în mod clar, centrul sarcinilor strategice. Aşa cum s-a arătat anterior, aceasta este în
esenţă consecinţa reducerii costurilor IT şi a creşterii conectivităţii actorilor, care a a deschis
noi posibilităţi pentru crearea de informaţii, bunuri şi servicii în cooperare, noi informaţiile pe
bază de servicii cu valoare adăugată sau bunuri fizice bogate in informaţii.
O companie care şi-a dat seama de aceasta foarte repede a fost Federal Express. În 1994
ea a extins valoarea propusă prin oferirea de servicii suplimentare prin lansarea unui nou
website. FedEx a fost primul care a oferit un sistem online de urmărire a pachetelor, care a
permis clienţilor să ştie unde se află pachetul lor până la livrare. În timp ce acest lucru nu a
schimbat profund industria navală, alte sectoare, cum ar fi muzica şi industria de film riscă să
fie complet transformate, deoarece produsele lor pot fi în întregime digitalizate. În general,
companiile care nu sunt capabile să inoveze constant, riscă să cădă în capcana comodităţii,
deoarece produsele de succes sunt rapid copiate de o concurenţă tot mai globală. Desigur,
inovarea nu este o garanţie a succesului, dar studii recente arată că cele ce activează in pieţele
superioare sunt în esenţă, companiile care sunt capabile să inoveze şi să transforme în mod
constant valoarea lor propusă [KMa02]. În modelul de ontologie de business, acest lucru este
exprimat prin produsul de inovare, care este unul dintre principalii patru piloni ai unui model
de afaceri. Produsul este compus din elementul valoarea propusă, care poate fi descompus în
ofertele sale elementare (vezi figura de mai jos).

PROGRAMUL 4 “PARTENERIATE IN DOMENIILE PRIORITARE” 2007-2013
SCIPA – Etapa 3: Dezvoltarea componentelor semantice ale platformei
12
Fig.3 Elementele componente ale produsului
Valoarea Propusă este primul din cele nouă elemente ale ontologiei bazate pe modelul de
afaceri şi poate fi înţeleasă ca declaraţiile de prestaţii care sunt livrate de firmă clientelei sale
externe [BTu00]. Poate fi descrisă ca definirea modului în care sunt ambalate şi oferite
elementele de valoare, cum ar fi produse şi servicii complementare care adaugă valoare,
pentru a îndeplini nevoile clienţilor. Pentru a înţelege mai bine valoarea şi a construi pachete
de produse şi servicii noi şi inovatoare, [Ost04], propune o abordare conceptuală subliniată de
elementul valoarea propusă.
Oferta. În timp ce elementul valoarea propusă oferă o vedere sintetizată asupra grupului de
valori pe care compania le oferă unui segment de clienţi ea poate fi descompusă într-un set de
elementar oferte. Prin descrierea diferitelor componente ale valorii propuse, o firmă poate
observa mai bine unde se situează în comparaţie cu concurenţii săi. Aceasta va permite
companiei inoveze şi să se diferenţieze pentru a ajunge într-o poziţie competitivă. O ofertă
elementară descrie o parte din pachetul de bunurile şi serviciile firmei. Ea ilustrează un
anumit produs, serviciu, sau chiar caracteristicile produsului sau serviciului şi subliniază
presupusa sa valoarea pentru client. Un set de oferte elementare, formează împreună o valoare
propusă.
B) Interfaţa cu clientul Cel de-al doilea pilon al ontologiei bazată pe modelul de afaceri este relaţia cu
clientul. Aceasta find fără îndoială, esenţială pentru companii. Elementul relaţia cu clienţii se
referă la felul în care o firmă activează pr piaţă, cum ajunge de fapt la clienţii săi şi la modul
în care interacţionează cu ei. Tehnologia de comunicaţie a avut o foarte puternică influenţă în
modul de organizare a companiilor în relaţia cu clienţii. Utilizarea de baze de date pentru
gestionarea informaţiilor legate de clienţi, introducerea de scanere în supermarket, oferta de
numere de apel gratuit conectate la centrele de informare sau utilizarea de noi canale de
distribuţie şi comunicare sunt doar câteva dintre numeroasele aplicaţii care au transformat
relaţiile cu clienţii. Mai ales Internetul a marit gama de posibilităţi de interacţiune cu clienţii.
Data Warehousing, data mining şi business intelligence, de exemplu, sunt tehnologii care au
permis managerilor să studieze comportamentul de cumpărare ale clienţilor lor şi să

PROGRAMUL 4 “PARTENERIATE IN DOMENIILE PRIORITARE” 2007-2013
SCIPA – Etapa 3: Dezvoltarea componentelor semantice ale platformei
13
îmbunătăţească relaţiile cu aceştia. Interfaţa cu clientul acoperă toate aspectele legate de
client. Aceasta cuprinde alegerea unei firme referitoare la clienţii ţintă, canalele prin care este
în legătură cu ei şi cu tipul de relaţii de compania doreşte să se stabilească cu clienţii săi.
Interfaţa cu clienţii descrie cum şi cui furnizează valoarea propusă, reprezentată de pachetul
de produse şi servicii oferite de firmă (vezi figura de mai jos).
Fig.4 Pachetul de produse şi servicii oferite de firmă
Clientul ţintă este cel de-al doilea element al ontologie bazate pe modelul de afaceri.
Esenţa selectării unui grup ţintă de clienţi este segmentarea. Segmentarea eficientă permite
unei companii să aloce resurse de investiţii pentru clienţii care vor fi cei mai atraşi de valoarea
sa propusă. Cea mai generală deosebire între de clienţii ţintă există între afaceri şi / sau
clienţii individuali, denumite business-to-business (B2B) si business-to-consumer (B2C).
Definiţia clientul vizat va ajuta firmele să stabilească prin intermediul căror canale doreşte să
ajungă la clienţii săi în mod eficient. De fapt, tehnologia ajută companiile să facă alegeri
strategice pentru ţinta lor de piaţă, la orice nivel între "masă" şi "unul câte unul” prin
echilibrarea veniturilor cu costul. Tehnicile de segmentare a datelor, precum data mining,
segmentare multidimensională, şi împărţire pe clustere cu reţele neuronale artificiale poate
duce la un marketing mai eficient şi la sporirea.
Odată cu extinderea prin intermediul tehnologiei de comunicare, cum ar fi Internetul,
companiile ţintesc din ce în ce mai mult, nu doar grupuri care sunt localizabile din punct de
vedere geografic, ci şi comunităţi online dispersate pe scară largă cu caracteristici comune
împărţite în comunităţi de tranzacţie, interes, fantezie şi relaţie.

PROGRAMUL 4 “PARTENERIATE IN DOMENIILE PRIORITARE” 2007-2013
SCIPA – Etapa 3: Dezvoltarea componentelor semantice ale platformei
14
Fig.5 Modelul valorii propuse
Elementul criteriu. Pentru a detecta segmentarea clienţilor, companiile împart de obicei un
segment de clienţi ţintă într-un set de caracteristici denumite criterii. Acestea pot fi de natură
geografică sau socio-demografică.
Canalul de distribuţie este cel de-al treilea element al ontologiei bazate pe modelul de
afaceri. Acesta reprezintă conexiunea între valoarea propusă de o firmă şi clienţii ei ţintă. Un
canal de distribuţie permite unei companii să ofere valoare clienţilor săi, fie direct, de
exemplu, printr-o metodă de vânzare sau printr-un un site, sau indirect, prin intermediul
intermediarilor, ca de exemplu revânzători sau brokeri.
Un canale de distribuţie descrie modul în care o companie intră în contact cu clienţii săi.
Scopul lui este de a face cantitatea potrivită de produse sau servicii disponibile la locul
potrivit, la timpul potrivit pentru oamenii potriviţi [PBe01] – supuse constrângerilor de cost,
de investiţii, precum şi de flexibilitate. Tehnologia, şi în special Internetul, are un mare
potenţial să completeze canalele de distribuţie existente în afaceri. Cu toate acestea vânzarea
prin mai multe canale simultan, eventual va cauza conflicte, atunci când acestea concurează
pentru a ajunge la acelaşi grup de clienţi.
Fig.6 Canalul de distribuţie

PROGRAMUL 4 “PARTENERIATE IN DOMENIILE PRIORITARE” 2007-2013
SCIPA – Etapa 3: Dezvoltarea componentelor semantice ale platformei
15
Link-ul. În timp ce canalul de distribuţie oferă o sinteză a modului în care o companie ajunge
la clienţi el poate fi descompus în mai multe link-uri de la canal. Acest lucru se face deoarece
canalele nu sunt blocuri de construire de bază ale unui sistem de comercializare. Un link l
unui canal descrie o parte a unui canal şi ilustreaza sarcini specifice de marketing. Un set de
linkuri de canal reprezintă un canal. Link-uri de canal din diferite canale pot uneori fi
interdependente, în scopul de a exploata sinergiile dintre canale. În plus faţă de rolul
tradiţional de a livra valoare pur şi simplu, canalele moderne şi link-urile lor au din ce în ce
mai au un potenţial pentru crearea de valoare şi astfel contribuie la valoarea propusă a unei
firme. Prin urmare, elementul link moşteneşte caracteristicile elementul ofertă, deoarece poate
face parte simultan din canalul de distribuţie şi din elementele creatoare valoare a firmei.
Relaţiile. Cel de-al patrulea element al modelului de afaceri ontologiilor se referă la relaţiile
pe care o companie le construieşte cu clienţii săi. Toate interacţiunile între o firmă şi clienţii
săi afectează puterea relaţiei pe care compania o are cu clienţii săi. Dar, cum interacţiunile vin
la un anumit cost, firmele trebuie să definească cu atenţie ce fel de relaţie vrea să stabilească
cu ce fel de clienţi. Profiturile din relaţia cu clienţii sunt esenţa tuturor întreprinderilor.
Companiile trebuie să analizeze datele clientului cu scopul de a evalua tipul de client pe care
vrea să îl dobândească, şi să stabilească profitabilitatea cheltuielilor şi eforturilor pentru aceşti
clienţi Apoi, firmele trebuie să definească diferitele mecanisme pe care vor să le utilizeze
pentru a crea şi menţine o relaţie cu clientul. Acest lucru înseamnă utilizarea de mecanisme
pentru a optimiza dobândirea, păstrarea, şi vânzarea de produse adiţionale la clienţii unei
firme, precum şi maximizarea valorii relaţiilor cu clienţii companiei pe tot parcursul ciclului
său de viaţă [BGe01].
Mecanismul relaţiei este parte a unei relaţii. Este un mecanism specific care are o funcţie în
clădirea relaţiei cu clienţii unei companii. El contribuie la personalizare, incredere şi brand
building.
C) Infrastructura managementului
Principalul scop al modelelor de business este de a oferi utilizatorilor precum managerii,
consultanţii sau designerii IS/IT un mod simplu de a analiza şi compara descrierea modelului
de afacere al firmei lor. Infrastructura managementului este pilonul care arată cum creează o
companie valoare. El descrie ce abilităţi sunt necesare pentru a furniza valoarea propusă şi
pentru a menţine interfaţa cu clienţii. Infrastructura managementului subliniază valoarea
reţelei care generează valoare economică prin intermediul schimbărilor complexe şi dinamice
între una sau mai multe întreprinderi, clienţi, furnizori, parteneri strategici şi comunitatea. Cu
alte cuvinte, acest pilon specifică capabilităţile modelului de afaceri şi resursele, proprietarii
acestora şi furnizorii, precum şi cine execută activitatea şi modul în care acestea se leagă între
ele.

PROGRAMUL 4 “PARTENERIATE IN DOMENIILE PRIORITARE” 2007-2013
SCIPA – Etapa 3: Dezvoltarea componentelor semantice ale platformei
16
Fig.7 Infrastructura managementului
Capacitatea. Elementul capacitate este cel de-al cincilea element al ontologiei bazată pe
modelul de afaceri. [Wal00] descrie capabilităţile ca modele de acţiune repeatabile în
utilizarea de active pentru a crea, produce, şi / sau oferi produse şi servicii piaţă Astfel, o
firmă trebuie să dispună de un set de capacităţi în scopul de a furniza valoarea sa propusă.
Aceste capacităţi depind de activele sau resursele firmei [BTu00]. Din ce în ce mai mult, ele
sunt externalizate, încrediţate partenerilor, în timp ce utilizează tehnologii de e-business,
pentru a menţine restricţiile integrării necesare pentru ca o firmă să funcţioneze eficient.
Capabilităţile de bază ajută companiile să eficientizeze organizarea şi construieşte avantaje
competitive.
Valoarea de configurare este cel de-al şaselea element al ontologiei bazate pe modelul de
afaceri. La fel cum am menţionat mai sus, principalul scop al unei companii este crearea de
valoare pentru care peclienţii sunt dispuşi să plătească. Această valoare este rezultatul unei
configuraţii din interiorul şi din afara proceselor şi activităţilor. Valoarea de configurare arată
toate activităţile necesare şi legăturile între ele, în scopul de a crea valoare pentru client.
Pentru a defini procesul de creare de valoare într-un model de afacere, se foloseşte lanţului de
valoare şi extinderea acestuia, cu valoarea magazinelor şi valoarea reţelei. Primul descrie
procesul de creare de valoare al furnizorilor de servicii (de exemplu consultanţi), iar acestea
din urmă descrie activităţile de brokeraj şi intermediere (de exemplu, băncile şi companii de
telecomunicaţii).
Al şaptea element al ontologiei bazată pe modelul de afaceri este parteneriatul.
Reţeaua de parteneri a companiei evidenţiază care părţi din configurarea activităţii sunt
distribuite între partenerii firmei. Apariţia unei reţele de firme în care piaţa şi mecanisme de
guvernare ierarhică coexistă a îmbunătăţit în mod semnificativ gama de organizări posibile şi
aranjamente pentru crearea de valoare (Hamel). În general, parteneriatele şi alianţele au
devenit o componentă esenţială în strategiile puse în aplicare de cele mai multe companii.
Deşi au fost utilizate de către unele firme de zeci de ani, astăzi, parteneriatele şi alianţele si-au
schimbat natura. S-au făcut loc la alianţe strategice care au ca scop crearea şi consolidarea

PROGRAMUL 4 “PARTENERIATE IN DOMENIILE PRIORITARE” 2007-2013
SCIPA – Etapa 3: Dezvoltarea componentelor semantice ale platformei
17
poziţiilor concurenţiale ale firmelor implicate, într-un mediu extrem de competitiv. Timp de
decenii deja literatura de gestionare a subliniat importanţa parteneriatul şi alianţelor şi a
produs un mare corp de literatura de la care am avea două definiţii. Se definesc alianţele ca
orice cooperare iniţiată în mod voluntar ca un acord de între firme care implică schimbul,
partajarea sau co-dezvoltare, şi poate include contribuţii de către parteneri la capital,
tehnologie sau active. Se adaugă unele elemente de definirea a alianţelor ca legături formate
între două - sau mai multe - societăţi independente care aleg să realizeze un proiect sau
activitate specifică în comun, coordonându-şi a competenţele şi resursele necesare, mai
degrabă decât să exercite proiectul sau activitatea de unele singure.
D) Aspecte financiare
Aspectele financiare reprezintă ultimul pilon din schema prezentată. Este transversală
deoarece toţi ceilalţi piloni il influenţează. Acest bloc este rezultatul restului de configurare a
modelului de afaceri. Aspectele financiare sunt compuse din veniturile companiei, de modelul
şi de structura costurilor. Împreună ele determină logica de a obţine profit sau pierdere, şi prin
urmare, capacitatea sa de a supravieţui în mediile cu concurenţă.
Fig.8 Aspecte financiare
Modelul de venit este cel de al optulea element al ontologiilorbazate pe modelul de afaceri şi
măsoară capacitatea uneifirme de a traduce valoarea pe care o oferă clienţilor săi în bani şi
fluxuri de intrare de venituri. Modelul de venituri al unei firme poate fi compus din diferite
fluxuri de venituri care pot avea diferite mecanisme de stabilire a preţurilor.
Structura costului. Acest element măsoară toate costurile suportate de firmă, în scopul de a
crea, comercializa şi transporta valoare clienţilor săi. Ea pune un preţ pe toate resursele,
bunurile, activităţile, relaţiile cu partenerii şi schimburi valutare care costă societatea o
anumită cantitate de bani. Pe măsură ce firma se axează pe competenţele sale de bază şi
activităţi şi se bazează pe reţelele de parteneriate în alte competenţe şi activităţi auxiliare,
există un important potenţial de economii în procesul de creare de valoare.

PROGRAMUL 4 “PARTENERIATE IN DOMENIILE PRIORITARE” 2007-2013
SCIPA – Etapa 3: Dezvoltarea componentelor semantice ale platformei
18
1.4 Exemple de ontologii existente în prezent
Concret, efortul de a defini ontologiile de afaceri a luat două direcţii diferite. În primul
rând, există ontologiile care aparţin categoriei numită ontologii de întreprindere care descriu
concepte legate de natură şi structura activităţii întreprinderii. În al doilea rând, există
ontologii legate de tranzacţii, în esenţă utilizate în e-business, şi care au ca scop specificarea
informaţiilor în tranzacţiile electronice de afaceri, în scopul îmbunătăţirii şi automatizării
acestor tranzacţii [Fen01].
1.4.1 Ontologia Edinburg Enterprise
Activitatea Grupului de la Edinburgh are scopul de a propune o ontologie întreprindere,
de exemplu, un set de concepte definite cu atenţie utilizate pe scară largă pentru descriera
întreprinderilor în general, şi care pot servi ca o bază stabilă pentru specificarea cerinţelor de
software Grupul a dezvoltat instrumente pentru modelarea întreprinderilor şi proceselor.
Ontologia Enterprise este propusă ca o modalitate de comunicare, de integrare şi reprezentare
într-un mod unic, diferitele aspecte ale unei întreprinderi. Ontologia Enterprise este
reprezentată într-un mod informal, (versiunea text) şi într-un mod de semi-formale
(Ontolingua). În primul rând, ontologiile prezintă definiţii în limbaj natural pentru toţi
termenii, începând cu conceptele fundamentale, cum ar fi o entitate, o relaţie sau un actor (de
exemplu, meta-ontologie). Acestea sunt apoi folosite pentru a defini principalul calup de
termeni, care sunt împărţiţi în patru zone, şi anume: Activităţi, Organizare, Strategie şi
Marketing.
1.4.2 TOVE (Toronto Virtual Enterprise)
TOVE are ca scop furnizarea unui model care suportă proiectarea întreprinderilor
bazate pe modelare, analiză şi operaţii. Acest proiect a definit în mod formal un set de
concepte suficient de generale pentru a permite utilizarea lor în diverse aplicaţii. Conceptele,
în mod similar cu Ontologia Enterprise, sunt grupate în secţiuni tematice şi fiecare concept,
proprietate şi relaţie sunt definite. Cu toate acestea, spre deosebire de Ontologia Enterprise
care este semi-formală, TOVE este riguros formală. Cu alte cuvinte, are termeni meticulos
definiţi, cu semantica formală, teoreme şi demonstraţii a unor proprietăţi precum corectitudine
şi completitudine. Practic, modelul de date generic pentru întreprindere are următoarele
caracteristici:
• oferă o terminologie partajată pentru întreprindere pe care fiecare agent o poate
înţelege şi utiliza
• defineşte sensul fiecărui termen (de exemplu, semantica) într-un mod cât mai precis şi
lipsit de ambiguitate

PROGRAMUL 4 “PARTENERIATE IN DOMENIILE PRIORITARE” 2007-2013
SCIPA – Etapa 3: Dezvoltarea componentelor semantice ale platformei
19
• implementează semantica într-un set de axiome, care va permite TOVE să deducă
automat răspunsul la multe întrebări de "bun simţ" despre întreprindere
• defineşte o simbolică pentru ilustrarea unui termen sau concept construit într-un
context grafic.
1.4.3 FEF (Financial Exchange Framework)
FEF sprijină conceptual modelul financiar propus de teoria schimburilor financiare FET
(Financial Exchange Theory). Aceasta din urmă oferă o bază pentru definirea de entităţi
financiare, cum ar fi produse financiare internaţionale, tranzacţii financiare, servicii financiare
şi monitorizarea poziţiei. Componentele financiare, corespondează cu funcţiile generice de pe
pieţele financiare internaţionale, şi sunt puse împreună în urma unui set de reguli simplu
pentru a crea toate entităţile financiare de mai sus.
FEF conţine în definiţia sa clase, relaţii şi constrângeri; entităţile efective ale pieţei
financiare internaţionale sunt înregistrate ca instanţe. Structura şi natura tuturor entităţilor
financiare, astfel, poate fi văzută şi comparată. FEF a fost creată folosind instrumentul de
definire a ontologiilor, "PROTEGE" şi a fost iniţiată de Universitatea Stanford şi a fost creată
pe baza modelului de piaţă „I - Format” al Ifip pentru I-format este singura definiţie de date
care acoperă toate datele de sprijin ale sistemului financiar:
produse, tranzacţii şi servicii financiare, şi poziţii pentru toate tipurile de procese
bancare internaţionale.
definiţii de bază pentru unităţi, părţi, acorduri şi contabilităţi de afaceri.
definiţii de afaceri, cum ar fi trezoreria, pieţa de capital, comerţ, vânzare cu de-
amănuntul, investiţii private etc.
În totalitate compatibil şi complementar cu standardele B2B (Business to Business), I-
format lucrează middleware-ul existent, ETL, OLAP şi medii de raportare prin asigurarea
unui format de publicare comun şi uşor de înţeles. În plus, acesta oferă o soluţie integrată de
raportare şi analiză a datelor financiare, de pe toate pieţele financiare.
FEF, este o initiativa a Ifip (International Financial Information Publishing Ltd) şi a fost
creată pe baza modelului de piaţă „I - Format” al Ifip pentru publicaţii legate de întreprindere
şi pentru prelucrare a datelor financiare. FEF conţine doar acele componente şi atribute
necesare pentru a descrie FET.
1.5 Maparea modelului de business peste modelul lingvistic bazat
pe ontologii şi semantici web
Pasul următor constituirii unui model abstract al întreprinderi este un moment crucial şi
este reprezentat de faza de implementare a acestuia. Procesul de implementare presupune

PROGRAMUL 4 “PARTENERIATE IN DOMENIILE PRIORITARE” 2007-2013
SCIPA – Etapa 3: Dezvoltarea componentelor semantice ale platformei
20
selecţia tehnologiilor care asigură scalabilitate, flexibilitate şi, disponibilitate la asimilarea
standardelor ce privesc automatizarea colaborării B2B la nivel sintactic şi semantic. Conform
[Cre05], “faza de implementare presupune:
adaptarea modelului la eventualele elementele de implementare specifice tehnologiilor
utilizate;
respectarea întocmai a delimitării responsabilităţilor între diversele componente;
identificarea şi adoptarea standardelor larg acceptate la nivelul industriei pentru
definirea mesajelor schimbate între componente. “
Figura următoare ilustrează aspectele tehnice ale implementării modelului întreprinderii
pe straturi, prin care se încearcă decuplarea totală a componentelor şi delimitarea clară a
responsabilităţilor fiecărui strat. În mod evident, printr-o organizare multistrat se va asigura o
uşoară mentenanţă a sistemului în ansamblu. Modelul întreprinderii este construit pornind de
la o arhitectură orientată pe servicii (SOA).
Fig. 9 Modelul întreprinderii
Scopul primordial al acestei arhitecturi este capacitatea de colaborare între servicii,
indiferent de platforma de dezvoltare adoptată.
Serviciile Web reprezintă termenul general adoptat în ultima vreme pentru a descrie
modulele funcţional independente ce comunică prin mesaje standardizate. Termenul este
folosit în diverse contexte: integrare B2B, EAI, servicii de bază (o implementare Remote
Procedure Call - RPC) şi vine cu o suită de protocoale bazate pe XML . Tehnologiile utilizate
în implementarea acestei arhitecturi nu rezolvă decât aspectele sintactice legate de mesajele
schimbate între servicii.
Astăzi, ţinta mult râvnită a industriei ce evoluează în jurul conceptului SOA este
facilitarea inetroperabiliăţii standardizate la nivel semantic între procesele software ale
partenerilor de afaceri pe întregul lanţ valoric. Conform lui Creţu, “miza standardizării
structurale a mesajelor şi documentelor ce se transferă în mod electronic între parteneri este

PROGRAMUL 4 “PARTENERIATE IN DOMENIILE PRIORITARE” 2007-2013
SCIPA – Etapa 3: Dezvoltarea componentelor semantice ale platformei
21
uriaşă. Dacă ne gândim numai la efectul plug-and-paly pe care l-ar genera în lumea e-
business, ne putem închipui deja o reţea mondială de furnizori – producători – parteneri –
consumatori extrem de dinamică şi flexibilă, în care fiecare companie şi-ar putea selecta
partenerii de afaceri cu un click de mouse iar consumatorii ar obţine instantaneu, direct de la
producători, toate informaţiile referitoare la fiecare componentă a produsului cumpărat”.
1.5.1 Standardizarea semantică
Problema principală în ceea ce priveşte construirea modulelor software care să
coopereze între ele, asigurând colaborare funcţională şi informaţională, constă în identificarea
unui limbaj comun. Analizând infrastructura informaţională a companiilor globale, analiştii
Commerce One (una din cele mai mari reţele de comerţ pe Internet şi actor mondial pe piaţa
EAI) au descoperit că eforturi de integrare a aplicaţiilor se exercită la toate nivelurile
întreprinderii, doar că echipele implicate în proces nu comunică între ele şi se concentrează
asupra rezolvării problemelor specifice pentru care s-au constituit. Ca urmare se creează o
reţea extrem de încâlcită de informaţii din cele mai diverse ce tranzitează reţelele între
procesele-interfaţă, pe baza mai multor protocoale personalizate, generând un adevărat “efect
spagetti”. Pentru a elimina efectele nedorite ale acestui fenomen, este necesară o nouă direcţie
de abordare a relaţiilor B2B:eforturile de integrare informaţională de tip point-to-point (P2P)
ar trebui să se transforme în eforturi de realizare a unui limbaj e-business comun, standardizat
cel puţin la nivelul industriei atât sintactic cât şi semantic.
Astfel, relaţii de colaborare la nivel de procese software ar putea aduce un spor real de
flexibilitate în abordarea relaţiilor de afaceri între parteneri. Scenariul tipic de cooperare B2B,
reprezentativ, de altfel, pentru orice gen de colaborare inter-procese software eterogene,
presupune:
clientul introduce comanda în propriul sistem computerizat, utilizând propriile
simboluri şi formate;
software-ul specializat translatează comanda în mesaj standardizat care descrie
formatul şi conţinutul comenzi;
comanda este transmisă electronic către sistemul producătorului;
software-ul specializat transformă mesajul în formatul producătorului;
mesajul electronic este trimis direct către sistemul secţiei de fabricaţie pentru a fi
inclus în programul de fabricaţie.
Istoric vorbind, EDI(Electronic Data Interchange) a fost tehnologia de pionierat în acest
domeniu. Deşi costurile sale erau destul de ridicate, putem spune că şi-a îndeplinit, în mare
măsură, scopul pentru care a fost construit: marile companii au renunţat într-o măsură
apreciabilă la hîrtie, fax şi e-mail pentru a schimba documente. O dată implementate,

PROGRAMUL 4 “PARTENERIATE IN DOMENIILE PRIORITARE” 2007-2013
SCIPA – Etapa 3: Dezvoltarea componentelor semantice ale platformei
22
sistemele EDI au generat avantaje majore, consemnate de literatură astfel: reducerea timpului
necesar procesării unei comenzi (de la trimitere până la intrarea în fabricaţie) la mai puţin de o
zi. Asemenea rezultate spectaculoase au determinat marile companii să îşi oblige furnizorii la
adoptarea sistemelor de transfer electronic de documente. Deşi pot fi identificate nenumărate
poveşti de succes EDI, există şi câteva probleme fundamentale de concepţie care au redus
drastic rata de adopţie mai ales la nivelul micilor companii:
costuri ridicate de implementare (pentru reţeaua privată şi software-ul aferent);
protocol de comunicaţie personalizat nestandardizat la nivel global;
trebuia definit formatul mesajului cu fiecare partener.
În esenţă, eşecul EDI de a deveni infrastructura globală e-business are la bază lipsa de
standardizare semantică, furnizorii regăsindu-se în situaţia de a gestiona mai multe baze de
reguli în paralel, câte una pentru fiecare companie-client.
Astăzi, deşi se vorbeşte încă de reabilitarea EDI prin XML/EDI sau EDI IIgen, prin
colaborare B2B înţelegem cu totul altceva: standarde privind structura şi semantica mesajelor,
dicţionare/taxonomii pentru definirea limbajului universal e-business şi depozite globale de
procese economice automatizate, public accesibile.
1.5.2 Ontologii şi SemanticWeb
SemanticWeb nu este altceva decât o reeditare a mai vechilor teorii (anii ‘60) privind
reprezentarea cunoaşterii prin intermediul reţelelor semantice. Aşadar, SemanticWeb îşi are
rădăcinile în domeniul tehnologiilor de inteligenţă artificială (IA). Având în vedere
imposibiliteatea de a dezvolta deocamdată agenţii inteligenţi promişi, dar şi din necesitatea
stringentă a colaborării în ciberspaţiul global, strategiile de cercetare IA s-au orientat în ultima
perioadă spre o ramură ceva mai realistă din punct de vedere pragmatic: ontologiiel. Ierarhia
este o parte foarte importantă a formalismului. Scopul declarat al ontologiilor este acela de a
oferi posibilitatea definirii unui vocabular pentru un anumit domeniu, o formă canonică a
cunoştinţelor şi de a le disponibiliza spre utilizare între sisteme eterogene. Un efort susţinut în
această direcţie, şi care pare să dea rezultate deja, este constituit de stiva de protocoale
Semantic Web dezvoltată şi promovată sub supravegherea cunoscutului consorţiu de
standardizare web, W3C.
Toate ontologiile au la bază un vocabular alături de unele specificaţii legate de
înţelesul/semantica terminologiei conţinute. Gruber afirmă că ontologiile pot fi utilizate cu
scopul de a obţine partajarea şi reutilizarea cunoştinţelor. Din raţiuni pragmatice o ontologie
este scrisă ca un set de definiţii ale unui vocabular formal. Deşi acesta nu e singurul mod de
reprezentare a unei conceptualizări, este totuşi recunoscut în lumea IA pentru câteva
proprietăţi interesante privind partajarea cunoştinţelor: semantică independentă de cititor sau
context. Spunem astfel că un angajament ontologic reprezintă o înţelegere de a utiliza un

PROGRAMUL 4 “PARTENERIATE IN DOMENIILE PRIORITARE” 2007-2013
SCIPA – Etapa 3: Dezvoltarea componentelor semantice ale platformei
23
anumit vocabular (întrebări şi afirmaţii) într-un mod consistent (dar nu complet).
SemanticWeb (SW) este tehnologia promovată de W3C pentru construirea ontologiilor.
Esenţa conceptului semanticWeb constă în îmbogăţirea HTML cu un set de taguri
standardizate care să exprime semantica paginii, generând astfel un conţinut Web mult mai
bine formalizat pentru a fi înţeles de agenţi inteligenţi. Astfel, paginile Web trebuie să conţină
metadate explicite prin care să se autodescrie. Ideea a pornit de la Tim Berners-Lee,
inventatorul World Wide Web. Nemulţumit de discrepanţa între stadiul Internet-ului astăzi şi
viziunea iniţială asupra reţelei globale, precum şi de capacităţile limitate ale motoarelor de
căutare, acesta a imaginat o altă modalitate de descriere a paginilor HTML. Schema din figura
de mai jos reprezintă viziunea tehnologică a renumitului inventator asupra conceptului
SemanticWeb.
Fig.10 Schema web-ului semantic
Schema trebuie interpretată astfel: cunoştinţe de diferite tipuri sunt separate; Unicode şi
URI sunt standardele tehnice de reprezentare/localizare a datelor; XML poate fi utilizat
pentru a-i spune computerului ce obiecte sunt reprezentate de o anumită secvenţă UNICODE;
RDF ne spune că acele obiecte sunt legate în variate feluri; ontologiile dau un context pentru
tipul (tipologia) obiectelor şi a relaţiilor; avem apoi nevoie de motoare de inferenţe pentru a
face deducţii context-sensitive asupra bazei de cunoştinţe; în teoriile ce promovează utilizarea
logicii pentru reprezentarea cunoaşterii fiecare deducţie trebuie demonstrată; încredere –
metoda utilizată pt demonstraţie trebuie acceptată de către participanţi.
Resource Description Framework (RDF) a fost prima specificaţie, cu sintaxa bazată pe
XML, special concepută pentru a construi un model semantic. În esenţă, RDF este nimic
altceva decât un model abstract de date (bazat pe entităţi/obiecte şi relaţii) necesar pentru a
declara propoziţii simple despre obiecte. Conceptele fundamentale RDF sunt resurse (obiecte
din lumea reală ce vor fi descrise, identificate prin URL), proprietăţi (un tip special de resurse
ce descriu relaţiile între resurse) şi propoziţii (descriu proprietăţile resurselor).

PROGRAMUL 4 “PARTENERIATE IN DOMENIILE PRIORITARE” 2007-2013
SCIPA – Etapa 3: Dezvoltarea componentelor semantice ale platformei
24
Propoziţiile sunt declarate după un formalism numit triplet, conform unui şablon
subiect-predicat-obiect, unde: subiectul reprezintă resursa descrisă; predicatul este aspectul
descris despre acel subiect; obiectul este valoarea acelei aserţiuni sau obiectul relaţiei
De la această primă fază însă, astăzi SW a evoluat către un real formalism de
reprezentare a cunoştinţelor bazat pe o combinaţie de logica predicatelor şi reţele semantice.
După cum majoritatea teoriilor de reprezentare a cunoaşterii recunosc utilitatea ierarhiilor de
tip IS-PART-OF şi IS-A pentru a exprima relaţii de dependenţă, SW a fost îmbogăţit cu RDF
Schema: limbajul bazat pe RDF care furnizează primitivele de modelare necesare (clase,
proprietăţi, relaţii de subclase şi subproprietăţi, restricţii de domeniu sau de scop). RDF
Schema este considerat un limbaj- fundament pentru a construi ontologii, având în vedere mai
ales faptul că furnizeazădouă primitive de modelare, denumite proprietăţi utilitare, pentru a
construi conţinut pe baza altuia existent deja la o altă adresă în reţea.
Expresivitatea RDF Schema este limitată la predicate binare şi la ierarhii de clase şi de
proprietăţi, cu definiţii de domeniu şi de scop. Ca urmare, un număr de grupuri de cercetare
atât din SUA cât şi Europa au identificat necesitatea unui limbaj mult mai puternic pentru
crearea de ontologii. Aşa a apărut DAML+OIL ca rezultat cumulat al eforturilor celor două
grupări (DAML–ONT al americanilor şi OIL al europenilor). La rândul lui, DAML+OIL a
devenit baza de construcţie
a limbajului OWL (de către W3C Web Ontology Working Group) pe care W3C l-a
propus spre standardizare şi adoptare globală. Limbajul oferă câteva caracteristici cheie: este
construit deasupra protocolului RDF şi, ca urmare, beneficiază de popularitatea acestuia;
furnizează o sintaxă riguroasă, o semantică formală şi un suport robust de raţionament. In
esenţă, OWL este o extensie RDF cu scopul de a acoperi câteva caracteristici lipsă ale celui
din urmă: restricţii localizate la nivelul unei anumite clase clase disjuncte(mascul/femelă);
combinaţii logice de clase (reuniune, intersecţie, complement); restricţii de cardinalitate în
sensul de a exprima “cel puţin una” sau “exact n”. OWL este construit pornind de la RDF (în
scopul compatibilităţii), este utilizată sintaxa RDF iar conceptele fundamentale sunt
specializări RDF.
1.5.3 Modelarea datelor
Întrucât modelul de afaceri este relativ informal şi descriptiv, această secţiune tratează
modelarea ontologiei. Sub această denumire se înţelege o abordare riguroasă a definirii
modelelor de afaceri. În alţi termeni, aceasta înseamnă definirea exactă şi minuţioasă a
termenilor, conceptelor, componentelor şi relaţiilor modelului de afaceri.
Pentru a accesa baza de date a ontologiilor au fost definite modele de date cu diagrame
vizuale şi unelte de design. Structura acestora diferă de la modele binare (ex. DOGMA) la
modele bazate pe relaţii extinse între entităţi (ex. MADS). Calea de mijloc este dată de
descrierile logice şi schemele conceptuale din modelele frame-based precum KAON şi

PROGRAMUL 4 “PARTENERIATE IN DOMENIILE PRIORITARE” 2007-2013
SCIPA – Etapa 3: Dezvoltarea componentelor semantice ale platformei
25
PROTEGE. Acestea suportă un mecanism de raţionare limitat. Mai jos sunt comparate cele
două extreme ale tipurilor de modelare (bazele de date şi descrierile logice), din punct de
vedere al conceptelor pe care se bazează.
Modelarea datelor: Se poate spuneca modelele conceptuale sunt mai bune la proiectarea
conceptelor primare pentru că ele pot descrie structuri mai complexe, mai apropiate de lumea
reală şi pentru că pot suporta diagrame vizuale şi unelte de design. Unele dintre ele pot
suporta şi câteva construcţii derivate ale căror instanţe pot fi automat deduse. Dar contrar
modelelor bazate pe o descriere logică, ele nu pot suporta construcţii pe care designerii le
definesc după o formulă logică, nu ştiu unde se încadreză în ierarhia generală sau nu sunt
conştiente de existenţa acestei ierarhii. Pe de altă parte, majoritatea descrierilor logice se
bazează pe structuri binare simple, oferind însă utilizatorilor facilităţile raţionării logice. Ele
permit utilizatorilor să definească construcţii noi precise, după o formulă logică, oricât de
complexe. Constrângerile pot fi deasemenea după formule logice (de tip incluziune sau
echivalenţă). Mecanismul de deducţie verifică automat consistenţa noilor definiţii şi
constrângeri, stabileşte unde să insereze noile construcţii în ierarhia de ansamblu şi crează
instanţele lor.
Instanţele: Sistemele bazate pe descrierea logică aderă în mod natural la conceptul de
„lume deschisă”, ce presupune că datele existente formează subsetul deja ştiut al datelor
valide, şi că mai multă informaţie poate fi dedusă prin raţionări sofisticate. Pe de altă parte,
bazele de date urmează conceptul de „lume închisă” susţinând că doar informaţia deja
existentă din baza de date (sau derivabilă prin reguli definite în mod explicit) este validă. Deci
ele nu au nevoie de raţionări pentru a deduce informaţii adiţionale.
Constrângerile: Validarea consistenţei unui set de constrângeri şi verificarea corelaţiei
dintre constrângeri şi schemă, sunt sarcini care pot fi făcute automat de către raţionări puse la
dispoziţie de către descrierile logice. Pe de altă parte, bazele de date au o abordare normativă
şi nu este posibilă definirea unei scheme ce nu urmează constrângerile modelului de metadate.
Cum bazele de date nu au facilităţi de raţionare, ele nu pot verifica setul de contrângeri de
integritate, şi de obicei nu au un integrat un limbaj pentru a defini constrângeri de integritate.
Un exemplu de astfel de constrângere este „dacă prin canalul de distribuţie este livrată o
valoare propusă şi ajunge la un grup de clienţi, atunci această valoare are ca ţintă acest grup
de clienţi”.
Interogarea instanţelor: Bazele de date si descrierile logice oferă funcţionalităţi
complementare pentru cereri către instanţe. Sistemele de baze de date oferă de obicei un
limbaj de interogări puternic, susţinut de unelte de optimizare a interogărilor eficiente.
Sistemele de descriere logică suportă un set de funcţii simple pentru a accesa instanţele si
derivatele lor obţinute prin motoarele lor de deducţie. În concluzie, cum doar limbajele logice
suportă definirea constrângerilor de integritate şi regulile de derivare care sunt pe deplin
integrate în descrierea ontologiilor, un sistem logic de descriere pare adecvat pentru definirea

PROGRAMUL 4 “PARTENERIATE IN DOMENIILE PRIORITARE” 2007-2013
SCIPA – Etapa 3: Dezvoltarea componentelor semantice ale platformei
26
unei noi versiuni de model de business. Ca interfaţă cu utilizatorul în definirea şi editarea
modelului de afacere este foarte des utilizat PROTEGE, iar pentru definirea constrângerilor de
integritate şi regulilor de derivare, sunt utilizate prioritar OWL şi RACER.
1.6 Proiectarea şi dezvoltarea ontologiilor procesului de afaceri
1.6.1 Scurtă trecere în revistă a metodologiilor de construcţie a
ontologiilor
Procesul de dezvoltare a ontologiilor este strâns legat de fluxul de extragere a
cunoştinţelor, astfel devenind un proces iterativ. Există multe metodologii propuse pentru
crearea ontologiilor al căror scop este acela de a atinge diverse nivele de aplicabilitate şi de a
folosi tehnici centralizate sau descentralizate. Metodologiile sunt de asemenea dependente de
dezvoltator.
În general, procesul de implementare a ontologiilor este “open-source” şi bazat pe
implicarea comunităţii, dar există şi ontologii dezvoltate de un grup restrâns de cercetători
pentru anumite scopuri. Mai mult, tendinţele actuale pentru dezvoltarea ontologiilor sunt
caracterizate de un nivel ridicat de automatizare. Astfel, putem vorbi despre metodologii de
construcţie automate sau semiautomate. Aceste metodologii sunt bazate pe: “data mining”,
“text mining” sau colaborarea dintre utilizatori.
Ontologiile pot fi considerate o formă structurată de cunoştinţe. [GFR08] prezintă o
metodă semiautomată de obţinere a cunoştinţelor din texte. Această abordare este bazată pe
trei module: extragerea, izolarea conceptelor şi detectarea inconsistenţelor.
Primul modul este bazat pe utilizarea categoriilor gramaticale de cuvinte, o constucţie
incrementală a bazelor de cunoştiinţe pentru relaţiile semantice şi pentru concepte în vederea
realizării inferenţelor. Extragerea cunoştinţelor este implementată prin utilizarea a trei tipuri
de procese: gruparea în funcţie de categoria gramaticală (POS tagging), identificarea
conceptelor şi inferenţe.
Procesul de inferenţă este capabil să inducă relaţii şi concepte pe baza categoriei
gramaticale. Acest lucru se realizează prin aplicarea unui set de reguli (MCRDR) dezvoltat
automat din entităţile de cunoştinţe extrase dintr-o frază. Principalul obiectiv al modulului de
inferenţă este acela de a modela relaţiile semantice dintre concepte.
Al doilea modul încearcă să interconecteze toate elementele dispersate din cadrul
ontologiei, obţinute pe baza modulului anterior, folosind UMLS. Cel de-al treilea modul
detectează inconsistenţele dintre relaţii bazându-se pe proprietăţile relaţiilor semantice ale
modelului ontologic. În vederea îmbunătăţirii procesului de verificare a consistenţei, autorii
utilizează OWL.

PROGRAMUL 4 “PARTENERIATE IN DOMENIILE PRIORITARE” 2007-2013
SCIPA – Etapa 3: Dezvoltarea componentelor semantice ale platformei
27
O altă abordare pentru construcţia ontologiilor este realizată de [Lin07]. Datorită
faptului că procesul de extragere şi reprezentare colaborativă a cunoştinţelor este unul dificil,
autorii implementează o evaluare convergentă şi iterativă utilizând tehnica sondajului. Diferite
situaţii contradictorii, la nivel de ontologie, sunt considerate şi tratate prin crearea de itemi
corespunzători în cadrul chestionarelor. Autorii propun un anumit format de chestionar pentru
calcularea nivelulului de cunoştinţe ale utilizatorilor, folosind metoda Delphi.
Mai mult, această abordare poate elimina zgomotul şi previne apariţia subiectivismului
şi divergenţa ontologiei.
[LGW09] prezintă în lucrarea lor, un cadru general de dezvoltare a ontologiilor bazat pe
învăţare, inclusiv suport automat pentru extragerea datelor din documente, clasificare, filtrare
şi obţinere informaţiilor relevante în vederea îmbunătăţirii ontologiei. Procesul de construcţie
a ontologiei este bazat pe crawling specializat. Acest tip de crawling permite extragerea
informaţiilor solicitate dintr-un anumit domeniu de interes. Crawler-ele sunt rulate pe site-uri
specializate precum biblioteci digitale sau motoare de căutare. Lucrarea prezintă un proces de
evaluare bazat pe filtrare de tip SVM (Suport Vector Machine) care selectează automat
documentele care oferă un nivel mai scăzut de relevanţă pentru criteriul solicitat.
Documentele rămase sunt utilizate în procesul de extragere al cunoştinţelor. Cu toate că
achiziţionarea automată este destul de relevantă, peste 77.5%, această clasificare poate fi
utilizată în mod semiautomat pe viitor pentu a permite experţilor o filtrare mai avansată.
1.6.2 Metodologia propusă pentru crearea ontologiilor de afaceri
Această lucrare propune o metodologie iterativă de dezvoltare a ontologiei într-o
manieră semiautomată. Această metodologie este în conformitate cu abordările prezentate
anterior. Metodologia propusă de autorii acestei lucrări constă în faptul că frazele procesate
sunt parsate, iar termenii sunt comparaţi în cadrul aceleeaşi categorii gramaticale, proces
cunoscut sub numele de “POS tagging”.
Totuşi, în viziunea noastră este mai bine să se aplice un algoritm de evaluare a
similarităţii semantice faţă de un modul automat bazat pe reguli, concentrat în principal pe
trăsăturile gramaticale şi sintactice şi mai puţin pe sens.
Abordarea iterativă şi colaborativă este aplicată mai ales în faza de îmbunătăţire şi are
ca avantaj principal o calitate sporită a ontologiei rezultate. Totuşi, abordarea prezentată de
această lucrare nu se bazează pe tehnica sondajului, ci mai degrabă pe evaluarea realizată de
agenţii inteligenţi şi pe experienţele lor anterioare.
Algoritmul de similaritate semantică interoghează baza de date WordNet în vederea
clasificării termenilor sub un sumator bazat pe relaţiile contextuale şi semantice din baza de
date. Calculul similarităţii este de asemenea bazat pe clasificare, dar nu în totaliatate pe SVM.
Principalul dezavantaj al metodelor tip SVM derivă din faptul că fiecare cuvânt nu are un sens
unic neambiguu. Dacă se consideră omonimele, acestea au sensuri diferite dar aceeaşi formă.

PROGRAMUL 4 “PARTENERIATE IN DOMENIILE PRIORITARE” 2007-2013
SCIPA – Etapa 3: Dezvoltarea componentelor semantice ale platformei
28
Mai mult, un cuvânt poate avea o serie de sinonime. În aceste situaţii, reprezentarea
vectorială a diferitelor texte poate să semene, dar subiectul sensului semantic poate să difere
mult, astfel obţinându-se inconsistenţe în metricile de evaluare a similarităţii. În plus, lipsa
termenilor comuni din două documente nu înseamnă neapărat că aceste documente nu sunt
similare. Procesul de obţinere a informaţiilor care se bazează numai pe modele clasice precum
algoritmul probabilistic de clasificare bayesian, spaţiul vectorial sau algoritmul boolean
constau în maparea lexicografică a termenilor. Totuşi, doi termeni pot fi similari din punct de
vedere semantic (ex: pot fi sinonime) chiar dacă sunt diferiţi din punct de vedere lexicografic.
Astfel, extragerea folosind metodele clasice va eşua să extragă documente cu termeni
similari.. În abordarea propusă vom folosi web crawlingul ca sursă principală de obţinere a
datelor. Principalii paşi pe care îi urmăm în cadrul procesului de construcţie a ontologiei sunt
prezentaţi mai jos şi pot fi grupaţi pe categorii:
PASUL 1: Construcţia ontologiei
A. Definirea şi înţelegerea mediului ontologiei
Această secţiune necesită o abordare sus – jos, de la general la particular.
1. ÎNŢELEGEREA DOMENIULUI – zona de interes pentru dezvoltarea
ontologiei specifice.
2. ÎNŢELEGEREA SECTORULUI – parte a domeniului pe care o modelează
ontologia.
3. ÎNŢELEGEREA DATELOR – datele disponibile, logica de afaceri şi modul în
care aceste date pot fi procesate într-o abordare semiautomată.
B. Clasificarea datelor
4. CLASIFICAREA DOCUMENTELOR BAZATĂ PE SARCINI – pe baza datelor
disponibile se identifică sarcinile şi se încearcă stabilirea de legături între date şi sarcini. Acest
lucru se poate realiza prin aplicarea unui algoritm de clasificare a documentelor. Secţiunea
următoare va insista asupra acestui algoritm.
C. Aplicarea similarităţii semantice pentru ontologia existentă
5. Îmbogăţirea ontologiei prin adăugarea unor relaţii semantice suplimentare pe baza
unui algoritm de similaritate semantică prezentat în secţiunea următoare.

PROGRAMUL 4 “PARTENERIATE IN DOMENIILE PRIORITARE” 2007-2013
SCIPA – Etapa 3: Dezvoltarea componentelor semantice ale platformei
29
Paşii B şi C reprezintă procesul efectiv de extragere a informaţiilor. Extragerea
informaţiilor va fi implementată prin utilizarea unei metode hibride de măsurare a similarităţii
semantice.
Această metodă este o combinaţie din următoarele:
numărarea muchiilor – utilizarea unei funcţii care măsoară lungimea drumului
între concepte în cadrul unei reţele semantice
măsurarea conţinutului informaţional – aceasta se referă la măsurarea diferenţei în
conţinut informaţional între doi termeni în funcţie de probabilitatea lor de apariţie.
Această clasă de metode garantează faptul că volumul conţinutului informaţional
al fiecărui termen este mai puţin semnificativ decât conţinutul informaţional al
termenilor sumatori.
PASUL 2: Rafinarea Ontologiei
6. Rafinarea este realizată sub supravegherea unui expert în domeniul ontologiei.
Agenţii inteligenţi iterează paşii anteriori pentru a îmbunătăţii calitatea ontologiei rezultate
7. Agenţii inteligenţi supraveghează de asemenea întreg procesul şi înregistrează
experienţele anterioare într-o bază de cunoştinţe.
Primele faze trebuiesc monitorizate de experţi umani astfel încât să se obţină o calitate
mai bună a ontologiei. Mai mult, aceste faze necesită un nivel ridicat de intervenţie umană.
Fazele 4, 5 şi 6 pot fi implementate într-o manieră automată, dar care trebuie supravegheată
de experţi.
1.6.3 Algoritmul de similaritate semantică
În vederea grupării termenilor bazaţi pe sensul semantic şi context folosim agenţi
inteligenţi. Agenţii sunt instruiţi şi apoi învaţă continuu pe baza experienţelor anterioare.
Agenţii interoghează baza WordNet şi încearcă să grupeze termenii din documente în synset-
uri pe baza analizei relaţiilor semantice. După accea, când se reiterează, se adaugă termenii
suplimentari şi relaţiile semantice la ontologia iniţială.
Pentru a măsura similaritatea semantică dintre două synset-uri, cele mai potrivite relaţii
care sunt utilizate în ierarhia semantică sunt hiponimie/hipernimie. Prin utilizarea acestui tip
de relaţii se foloseşte tehnica de “cel mai mic sumator comun”.
Totuşi datorită limitării relaţiei de tip “este o” în cadrul ierarhiilor algortimul
funcţionează numai între aceleaşi tipuri de părţi de vorbire.
Aşa cum este precizat în lucrarea lui [Liu09], dacă vom considera un set de concepte
mai generale direct legate de un concept X dat în cadrul acestui synset şi o funcţie care
returnează părinţii unui concept dat X. În cazul unei moşteniri singulare, funcţia întoarce
întotdeauna un singur termen. În situaţia unei moşteniri multiple doi părinţi distincţi pot fi

PROGRAMUL 4 “PARTENERIATE IN DOMENIILE PRIORITARE” 2007-2013
SCIPA – Etapa 3: Dezvoltarea componentelor semantice ale platformei
30
foarte diferiţi dar să reprezinte limita minimă superioară (cel mai mic sumator comun). Aceste
două noduri pot avea valori informaţionale diferite, astfel funcţia Parents(X) poate să întoarcă
mai mult de un termen. Pentru a determina funcţia de măsurare a similarităţii, trebuie să luăm
în considerare drumul dintre concepte:
(1)
în care:
XA - conceptul A
XB - conceptul B
Setul de părinţi ai unui concept este reprezentat de elementele care sunt unite prin cel
puţin o cale de conceptul luat în calcul. Conţinutul informaţional este invers proporţional cu
frecvenţa din dicţionar. Frecvenţa conceptelor defineşte numărul de apariţii a unui concept şi
a tuturor descendenţilor lui. Pornind de la frecvenţe se determină probabilitatea de apariţie a
unei instanţe a conceptului.
(2)
în care:
F(x) = frecvenţa de apariţie a conceptului X
N = numărul total de concepte din synset
Pe baza acestei probabilităţi se determină conţinutul informaţional al conceptului X
după formula:
CI(X) = - log2 (P(X)) (3)
în care:
CI(X) = conţinutul informaţional (CI) al conceptului X
P(x) = frecvenţa de apariţie a conceptului X
N = numărul total de concepte din synset
Prin folosirea conţinutului informaţional putem calcula similaritatea semantică sub
formă de distanţă. Similaritatea semantică este legată de nivelul de informaţie partajată.
Nivelul de informaţie partajată se poate calcula după formula următoare:
(4)
în care:
S(X1, X2) = nivelul de informaţie partajată între conceptele X1 şi X2
X1, X2 = conceptele 1 şi 2

PROGRAMUL 4 “PARTENERIATE IN DOMENIILE PRIORITARE” 2007-2013
SCIPA – Etapa 3: Dezvoltarea componentelor semantice ale platformei
31
În vederea calculării similarităţii semantice se pot folosi o serie de formule propuse de
Conrath, Lin, Resnik. În cazul algoritmului utilizat în această lucrare se foloseşte formula lui
Lin. Am ales această formulă deoarece ia în considerare în întregime conţinutul informaţional:
(5)
în care:
SimLin(X1,X2) = nivelul de similaritate dintre conceptele 1 şi 2 ( formula Lin )
S(X1, X2) = nivelul de informaţie partajată între conceptele 1 şi 2
X1, X2 = conceptele 1şi 2
IC(X) = conţinutul informaţional (IC) al conceptului X

PROGRAMUL 4 “PARTENERIATE IN DOMENIILE PRIORITARE” 2007-2013
SCIPA – Etapa 3: Dezvoltarea componentelor semantice ale platformei
32
2 Modelarea aplicaţiei de management al lanţului de
aprovizionare
2.1 Specificarea de nivel înalt a cerinţelor de funcţionalitate şi
interoperabilitate ale platformei
Această secţiune prezintă o imagine de ansamblu asupra arhitecturii framework-ului şi
de asemenea despre procesul de dezvoltare a agenţilor şi ontologiei de test.
Platforma propusă reprezintă un mediu general de dezvoltare pentru sistemele de afaceri
distribuite bazate pe agenţi care asigură interoperabilitatea şi colaborarea la nivel de
întreprindere şi de asemenea reprezintă un instrument ce asigură dinamica cunoştinţelor
[SDC10]
Soluţia care urmează a fi dezvoltată foloseşte următoarele tehnologii:
web semantic şi ontologii
sisteme multi agent
servicii web semantice
Arhitectura sistemului propus va avea următoarele module [DCo09]:
componenta de proiectare a ontologiilor care oferă interfaţă cu utilizatorul
modulul de regăsire al serviciilor web bazat pe agenţi
baza de cunoştinţe
modul de compunere a serviciilor semantice web
interfaţă cu utlizatorul pentru afişarea rezultatelor
Mai jos, este prezentată o descriere a fiecărei componente a frameworkului în termeni
generali.
1. Componenta de proiectare a ontologiei
Utilizând această componentă, utilizatorii vor putea pe de-o parte să-şi proiecteze
ontologia folosind
elemente grafice intuitive, iar pe de altă parte ontologia poate fi imbogăţită într-o
manieră semi-automată prin aplicarea metodologiei propuse la secţiunea anterioară.
În cazul abordării semi-automate, utilizatorul vor selecta un document pe care doreşte
să îl modeleze ca ontologie. Documentul este la început clasificat folosind algoritmul
Bayesian, în conformitate cu nişte trasături identificate în procesul de învăţare.
După aceea se aplică algoritmul de similaritate semantică pentru a extrage din baza de
cunoştinţe componente care servesc la anotarea semantică a documentului. Aceste
componente poartă denumirea de UIMA Pear.

PROGRAMUL 4 “PARTENERIATE IN DOMENIILE PRIORITARE” 2007-2013
SCIPA – Etapa 3: Dezvoltarea componentelor semantice ale platformei
33
Pentru realizarea într-o manieră semi-automată a ontologiei, componentele sunt
instalate, se extrag aşa numiţii “analysis engine” (AE) individuali. Componentele AE
individuale se compun pe baza unui set de reguli şi dau naştere unui AAE. Pe baza acestor
anotatori se identifică principalii termeni din document. Aceşti termeni sunt apoi proiectaţi
folosind sistemul de reguli şi o gramatică proprie dezvoltată cu ANTLR la nivel de ontologie.
În anexa 2 se afla codul metodei care realizează compunerea simplă a acestor elemente.
Compunerea pe baza unui set de reguli avansat este în lucru. În bază, sunt stocate pentru
fiecare ontologie regulile utilizate şi componentele astfel încât, pentru a eficientiza algoritmul,
sa aplicăm “ontology matching” şi elementele mapate să asiguram componentele identificate
deja anterior, fructificând astfel experienţa sistemului.
2. Modulul de regăsire al serviciilor web bazat pe agenţi
Acest modul de regăsire bazat pe agenţi interogheză un fel de serviciu de tip “pagini
aurii”, DF, care permite agenţilor să publice unul sau mai multe servicii astfel încât ceilalţi
agenţi să le găsească şi să le exploateze.
Agenţii interacţionează cu DF prin schimbarea mesajelor de tip ACLfolosind un limbaj
apropiat (limbajul SL0) şi o ontlogie apropiată, conform specificaţiilor FIPA.
Pentru implementarea agenţilor am folosit Jade. În Jade, interogarea agentului DF este
tratată folosind clasa jade.domain.DFService, prin intermediul căreia se pot publica şi căuta
servicii.
Un agent care doreşte să publice unul sau mai multe servicii, trebuie să transmită la DF
o descriere ce include ID-ul său, o listă cu limbajele şi ontologiile pe care ceilalţi agenţi
trebuie să le cunoască pentru a putea comunica şi o listă ce conţine serviciile publicate. Pentru
fiecare serviciu publicat, este generată o descriere care cuprinde tipul serviciului, numele,
limbajele şi ontologiile necesare pentru a putea exploata serviciul respectiv, precum şi setul de
proprietăţi din cadrul serviciului. Clasele DFAgentDescription, ServiceDescription şi
Property, incluse în pachetul jade.domain.FIPAAgentManagement, reprezintă cele trei
abstarctizări menţionate.
Agenţii care publică servicii caută partenerii cei mai potriviţi de comunicare luând în
considerare logica de afaceri modelată cu ajutorul ontologiei şi parametrii de intrare şi ieşire
ale metodelorimplementate de serviciile web expuse. Pentru a reliza regăsirea semantică a
serviciilor care se potrivesc, se va aplica algoritmul de similaritate semantică.
Prima dată, fişierul de descriere a serviciului web va fi clasificat cu ajutorul
algoritmului Naïve Bayes, şi vor fi grupate în clustere în conformitate cu regulile de afaceri şi
experienţele aleatoare. Agenţii utilizează mecanisme de inferenţă pentru a clasifica corect
serviciile web semantice şi sinctactice. Dacă agenţii folosesc, servicii web semantice,

PROGRAMUL 4 “PARTENERIATE IN DOMENIILE PRIORITARE” 2007-2013
SCIPA – Etapa 3: Dezvoltarea componentelor semantice ale platformei
34
algoritmul de similaritate semantică va avea rezultate mai bune datorită informaţiilor
suplimentare oferite de fişierul de descriere.
După ce documentele au fost grupate în cluster, sunt parsate şi se aplică o versiune uşor
modificată a algoritmului de similaritate prezentat în secţiunea anterioară.
Documentul parsat va fi salvat într-o baza de date care are schema din figura 11,
reducănd-se astfel timpul de acces la document.
Fig. 11 Schema bazei de date pentru stocarea serviciilor semantice web
Paşii urmaţi pentru identificare serviciilor potrivte:
Pasul 1: Pentru fiecare document care reprezintă un fişier de descriere a serviciului
web, se înlatură cuvintele nesemnificative precum:prepoziţii, articole, conjuncţii.
Pasul 2: Se determină rădăcina cuvântului prin aplicarea algoritmului Porter, impus ca
standard pentru acest proces. Se identifică apoi categoria gramaticală pentru fiecare cuvânt
astfel încât comparaţia să se realizeze în cadrul aceleiaşi categorii gramaticale.
Pasul 3: Se realizează dezambiguizarea termenilor folosind algoritmul prezentat în
secţiunea anterioară şi se calculează nivelul de similaritate semantică pentru perechi de
cuvinte. Acest algoritm este aplicat pentru numele parametrilor atât de intrare cât şi de ieşire
ale fiecărei metode din serviciu.
Pasul 4: Pentru fiecare pereche de fişiere ce descriu servicii web, se crează o matrice
semantică M [m, n] (serviciul A are m operaţii în timp ce serviciul B are N operaţii). Acest
pas este diferit de algoritmul iniţial. Matricea calculează două câte două similarităţi pentru

PROGRAMUL 4 “PARTENERIATE IN DOMENIILE PRIORITARE” 2007-2013
SCIPA – Etapa 3: Dezvoltarea componentelor semantice ale platformei
35
operaţii, nu pentru cuvinte. Parametrii de intrarea ai unei metode sunt comparaţi cu parametrii
de ieşire.
M [i, j] reprezintă nivelul de similaritate semnatică dintre operaţia de la poziţia i în
cadrul serviciului A şi operaţia de pe poziţia j din cadrul serviciului B. Nivelul de similaritatea
calculat prin aplicarea algoritmului ungar în grafuri bipartite, este stocat în tabela
SimilarityMeasures.
M[i,j]=Sim(OpAi,OpBj)= +
, i=1..m, j=1..n, p=1..k, q=1..v, r=1..l, s=1..u
(6)
în care:
OpAi – Operaţia i din web service-ul A
OpBj – Operaţia j din web service-ul B
Iip–numele celui de al al p-lea parametru de intrare din operaţia i in web service-ul A
Ijs– numele celui de al al s-lea parametru de intrare din operaţia j in web service-ul B
Oir– numele celui de al al r-lea parametru de ieşire din operaţia i in web service-ul A
Ojq– numele celui de al al q-lea parametru de ieşire din operaţia j in web service-ul B
k- numărul parametrilor de intrare ai operaţiei i in web service-ul A
u- numărul parametrilor de intrare ai operaţiei j in web service-ul B
l- numărul parametrilor de ieşire ai operaţiei i in web service-ul A
v- numărul parametrilor de ieşire ai operaţiei j in web service-ul B
Similaritatea este calculată aplicând formula lui Lin (5) prezentată în secţiunea
anterioară:
Sim(Iip,Ojq)= SimLin(Iip,Ojq) = (7)
în care:
SimLin(Iip,Ojq)- nivelul de similaritate dintre conceptele Iip şi Ojq calculat cu formula
lui Lin
S(Iip,Ojq)) = nivelul de informaţie comună dintre conceptele Iip and Ojq
Iip– numele celui de al al p-lea parametru de intrare din operaţia i in web service-ul A
Ojq – numele celui de al al q-lea parametru de ieşire din operaţia j in web service-ul B
IC(X)- conţinutul informaţional (IC) al conceptului X
Pasul 5: În baza de cunoştinţe asociată fiecărui agent, sunt stocate nivelel optime de
similaritate ale experienţelor anterioare pentru fiecrae clasă de documente, astfel pe baza
modulului de inferenţă, fiecare agent poate stabiliun prag de similaritate. Serviciile web care
se portivesc sunt considerate cele care au nivelul de similaritate mai mare decât valoarea prag.
3. Baza de cunoştinţe

PROGRAMUL 4 “PARTENERIATE IN DOMENIILE PRIORITARE” 2007-2013
SCIPA – Etapa 3: Dezvoltarea componentelor semantice ale platformei
36
Baza de cunoştinţe stocheaza, ontologii, reguli structurate de proiecţie a ontologiilor,
componentele de anotare asociate, atât simple cât şi agregate şi date referitoare la experienţele
anterioare, precum nivelul de similaritare prag pentru fiecare grup de descrieri ale serviciilor
web. Astfel, se facilitează şi îmbunătăţeşte procesul decizional.
4. Modulul de compunere a serviciilor web semantice
Modulul acesta are rolul de a realiza compunerea automată a serviciilor web. După ce
au fost identificaţi agenţii cei mai potriviţi care publică serviciile solicitate, acest modul le
combină astfel încât să se obţină rezultatul solicitat sau să finalizeze tranzacţia atunci când ne
referim la aplicaţii de management al lanţului de aprovizionare. Compoziţia este realizată
ţinând cont nivelele de similaritate dintre perechile de parametri de intrare-ieşire. Aceasta se
referă la faptul că parametrul de ieşire a unei metode care apare într-un anumit serviciu web
poate fi parametru de intrare pentru metodele aparţinând altui serviciu.
5. Interfaţa cu utilizatorul pentru afişarea rezultatelor
Interfaţa va trebui să afişeze într-o manieră facilă pentru utilizator rezultatele
compunerii serviciilor web. Interfaţa va fi de tip web astfel încât să se faciliteze accesul unei
clase cât mai largi de utilizatori şi de asemenea să fi cât mai uşor portată, întreţinută şi
accesibilă. Framework-ul trebuie să conţină o librărie de controale pentru utilizatori uşor de
manipulat atunci când se dezvoltă aplicaţii de afaceri.
Arhitectura platformei software este prezentatată în figurile 12 şi 13. Fig. 12 ilustrează
modulele principale ale platformei propuse, în timp ce figura 13 prezintă mai detaliat fiecare
componentă.
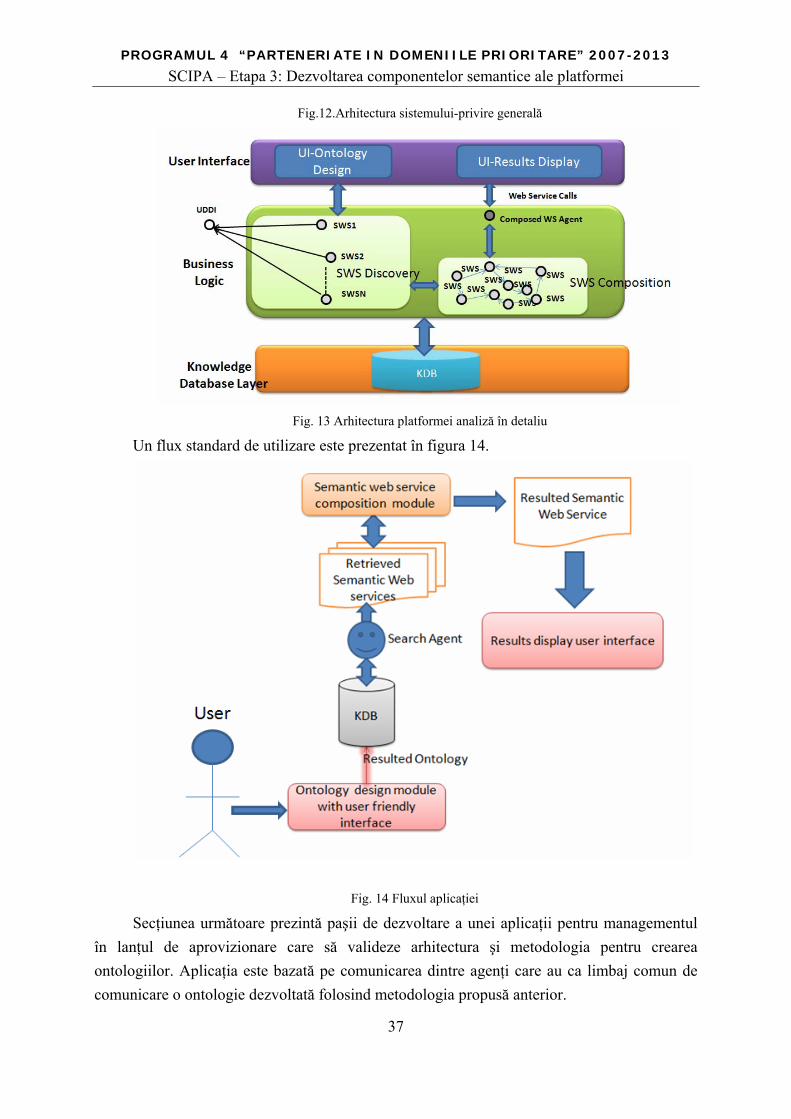
PROGRAMUL 4 “PARTENERIATE IN DOMENIILE PRIORITARE” 2007-2013
SCIPA – Etapa 3: Dezvoltarea componentelor semantice ale platformei
37
Fig.12.Arhitectura sistemului-privire generală
Fig. 13 Arhitectura platformei analiză în detaliu
Un flux standard de utilizare este prezentat în figura 14.
Fig. 14 Fluxul aplicaţiei
Secţiunea următoare prezintă paşii de dezvoltare a unei aplicaţii pentru managementul
în lanţul de aprovizionare care să valideze arhitectura şi metodologia pentru crearea
ontologiilor. Aplicaţia este bazată pe comunicarea dintre agenţi care au ca limbaj comun de
comunicare o ontologie dezvoltată folosind metodologia propusă anterior.

PROGRAMUL 4 “PARTENERIATE IN DOMENIILE PRIORITARE” 2007-2013
SCIPA – Etapa 3: Dezvoltarea componentelor semantice ale platformei
38
2.2 Dezvoltarea unei aplicaţii de management al lanţului de
aprovizionare folosind platforma propusă
[FBT00] defineşte “lanţul de aprovizionare” drept reţea de furnizori, fabrici, depozite,
centre de distribuţie şi puncte de desfacere prin intermediul căreia sunt ahiziţionate materiile
prime, sunt transformate şi apoi livrate consumatorilor. Managementul “lanţului de
aprovizionare” este reprezentat pe de trei nivele: strategic, tactic şi operaţional-decizional care
optimizează performanţa lanţului de aprovizionare. Nivelul strategic defineşte reţeaua lanţului
de aprovizionare, respectiv procesul de selecţie al furnizorilor, rutele de transport, facilităţile
de producţie, nivelele de producţie, depozitele, etc. Nivelul tactic se referă la planificarea şi
programarea activităţilor din cadrul lanţului astfel încât să satisfacă cererea. Nivelul
operaţional are rolul de a executa planurile. Toate aceste nivele înpreună cu proprietăţile
asociate lor sunt distribuite de-a lungul lanţului de aprovizionare.
În vederea îmbunatăţirii performanţei, funcţiile lanţului de aprovizionare trebuie să
opereze într-o manieră organizată şi controlată. Totuşi, sunt anumite probleme care afectează
fluxul lanţului de aprovizionare, majoritatea dintre ele greu de prezis sau de depistat într-o
fază incipientă fără a analiza şi fructifica experienţele anterioare într-o manieră organizată.
Spre exemplu, să presupunem ca modelăm activitatea unei firme de construcţii care are
nevoie de anumite materiale. Sunt mai mulţi furnizori, iar constructorul trebuie să facă
alegerea corectă. Pentru aceasta el trebuie să ţină cont de urmatoarele aspecte: preţ, calitate,
costuri de transport, riscuri de natură geografică, experienţele anterioare în relaţiile cu anumiţi
furnizori, risul de faliment al firmelor furnizoare, etc. Toate aceste informaţii reprezintă
valoare adăugată pentru tranzacţie şi sunt transformate în cunoştinţe şi stocate în baza de
cunoştinţe.
În ultimii ani, au fost dezvoltate multe arhitecturi pentru managementul “lanţului de
aprovizionare” la nivel tactic şi operaţional. Conform noului trend, lanţul de aprovizionare
este privit sub forma unui set de agenţi software inteligenţi, fiecare dintre ei fiind responsabil
pentru coordonarea unei sau mai multor activităţi în cadrul lanţului de administrare, şi fiecare
interacţionând cu alţi agenţi în vederea planificării şi execuţiei responsabilităţilor [SDD09].
În [PKr07] autorii vorbesc despre elementele care au fost luate în considerare când
procesele de afaceri încep să se extindă. Acest articol subliniază faptul că dezvoltarea
activităţii în deomeniul afacerilor implică colaborarea dintre întreprinderi şi necesită utilizarea
tehnologiilor şi elementelor de afaceri complexe. Este foarte important ca partenerii de afaceri
să cadă de acord încă de la începutul colaborării cu privire la documentele care urmează să fie
utlilizate (ordine de cumpărare, facturi, etc.) şi de asemenea trebuie să specifice în mod
explicit standardele utilizate pentru comunicare. Nevoia de utilizare a standardelor de

PROGRAMUL 4 “PARTENERIATE IN DOMENIILE PRIORITARE” 2007-2013
SCIPA – Etapa 3: Dezvoltarea componentelor semantice ale platformei
39
comunicare ia naştere din faptul că aşa numită „compunere slabă” („loose coupling”) a
serviciilor web expuse de sisteme necesită protocale de comunicare în mediul de afaceri.
Aceste protocoale sunt orientate pe mesaj: specifică fluxul mesajelor care reprezintă de fapt
activităţi din cadrul fluxului de afaceri dintre parteneri (fără a fi nevoie de mecanisme de
implementare specifice). Privite ca un tot unitar, protocoalele procesului de afaceri, formatele
de date asociate, standardele de transmitere a mesajelor, asigură mediul necesar pentru
comunicarea automată dintre sisteme diferite aparţinând partenerilor de afaceri din cadrul
lanţului.
În framework-ul pe care îl propunem, fiecare sistem care expune servicii web este
reprezentat de agenţi inteligenţi, iar comunicarea dintre ei este realizată prin utilizarea
ontologiilor dezvoltate folosind metodologia propusă anterior, dar şi a algoritmului de
măsurare a similarităţii semantice, care determină nivelul de similaritate dintre ontologii şi
ajută la regăsirea seamntică a serviciilor web şi componentelor utilizate pentru anotarea
documentelor de afaceri.
Un agent este un proces software autonom, care are ca scop realizarea unui obiectiv
specific şi care operează asincron, comunicând şi coordonând relaţiile cu alţi agenţi. În
secţiunea următoare vom prezenta într-o manieră mai detaliată modul în care aceşti agenţi
comunică şi cum îşi aleg partenerii de afaceri.
Aplicaţia care a fost dezvoltată pentru a valida interacţiunea dintre agenţi, dar şi
metodologia de construcţie a ontologiilor se referă la modelarea lanţului de aprovizionare
pentru o companie de construcţii.
Problema care urmează a fi modelată este următoarea: “o companie de construcţii
doreşte să cumpere cărămidăde la furnizorii de materiale de construcţii. Compania de
construcţii este reprezentată de un agent numit “Customer”.
Framework-ul propus facilitează implementarea sistemelor multi agent pentru lanţuri
de aprovizionare, deoarece permite consumatorilor să identifice furnizori care să satisfacă
nevoile lor de afaceri. Toti participanţii din cadrul lanţului de aprovizionare sunt modelaţi prin
intermediul agenţilor.
Aşa cum am precizat şi mai înainte în cadrul acestui raport, principalele categorii de
actori din domeniul lanţului de aprovizionare sunt următoarele: furnizori, fabrici, depozite,
centre de distribuţie şi puncte de desfacere prin intermediul cărora sunt achiziţionate,
transformate şi livrate materiile prime.
Deşi crearea unui tip specializat de agent pentru fiecare categorie de actori aşa cum
este prezentat în [LWa08] implică multiple beneficii, considerăm că acest tip de abordare
limiteză flexibilitatea şi capacitatea totală a sistemului de a modela entităţi din mediul real de
afaceri. Ţinând cont de faptul ca un participant din cadrul lanţului de aprovizionare, poate
aparţine mai multor categorii dintre cele menţionate mai sus şi de asemenea poate oferi o

PROGRAMUL 4 “PARTENERIATE IN DOMENIILE PRIORITARE” 2007-2013
SCIPA – Etapa 3: Dezvoltarea componentelor semantice ale platformei
40
gamă variată de servicii şi produs, a fost mai bine să implementăm un agent generic de tip
“trader”.
Similar mediului de afaceri real pe care îl reprezintă pe internet, fiecare agent are
parametri de intrare şi parametri de ieşire. Parametrii de ieşire sunt reprezentaţi de serviciile şi
produsele pe care agenţii le oferă, nivelul de preţ şi caracteristicile tehnice. Parametri de
intrare constau în materia primă, serviciile solicitate sau subansamblele necesare în vederea
producerii unui tip specific de produs sau să asigure un anumit tip de serviciu.
În vederea selecţiei celui mai bun furnizor, pentru fiecare intrare, trebuiesc definite
atât reguli obligatorii precum (ex: distanţa maximă dintre consumator şi frunizor), precum şi o
funcţie de evaluare. Aceste elemente sunt aplicate la nivelul fiecărui agent astfel încât să se
poată calcula un scor pentru fiecare ofertă (ex: pe baza preţului şi a caracteristicilor tehnice).
Rezultatele funcţiei precum şi parametrii acesteia sunt stocate în baza de cunoştinţe. Funcţia
de mai jos reprezintă un şablon parametrizat de funcţie. Pe baza experienţelor anterioare, prin
aplicarea inferenţei, fiecrae agent poate include alţi parametri şi de asemanea poate asocia
diverse nivele de ponderi. Sistemul de ponderi, este astfel customizat şi actualizat la nivel de
agent şi depinde de contextul de afaceri. În aplicaţia de test, utilizatorii pot interveni si
modifica manual ponderile.
(8)
în care:
m - numărul de furnizori
n - numărul de trăsături tehnice
- numărul valorilor posibile pentru caracteristica j
- importanţă caracteristicii j pentru agentul l
- valorilor posibile pentru caracteristica j
- funcţie ce evaluează optimalitatea
caracteristicii j pentru agentul l
Riscul poate fi de asemanea luat în calcul ţinând cont de poziţia geografică a
furnizorului, reţelele de transport disponibile, reiscul de faliment, etc. În secţiunea următoare
prezentăm un model care evaluează riscul de faliment al furnizorului. Dacă o regulă
obligatorie nu este îndeplinită, oferta este automat respinsă şi nu va mai fi luată în considerare
în procesul de evaluare. Pe baza experienţelor anterioare sau a datelor introduse de utilizator,
fiecare agent menţine o listă de furnizori “de încredere”, dar şi o listă de furnizori care
trebuiesc evitaţi.

PROGRAMUL 4 “PARTENERIATE IN DOMENIILE PRIORITARE” 2007-2013
SCIPA – Etapa 3: Dezvoltarea componentelor semantice ale platformei
41
Importanţa parametrilor menţionaţi anterior poate fi definită anterior şi prin utilizarea
interfeţei web dedicate furnizorilor.
Un flux posibil de comunicare dintre agenţi este prezentat în figura 15 de mai jos:
Fig 15. Fluxul de comunicaţie dintre agenţi
Agenţii pot efectua diverse roluri în cadrul lanţului de aprovizionare. În figura de mai
sus, agentul numit “Trader 1” este un frunizor pentru agentul “customer”, de la care primeşte
o cerere pentru un produs sau serviciu. Dacă “Trader 1” nu poate să soluţioneze cererea,
poate solicita servicii adiţionale sau subansamble de la alţi agenţi, devenind astfel la rândul
său un agent de tip “customer” . “Trader 2,3 şi 4” reprezintă posibili furnizori pentru “Trader
1” , dar la rândul lor pot deveni consumatori pentru alţi agenţi. Dacă un agent “trader” nu
poate satisface cererea de servicii sau produse în condiţiile solicitate, returnează o ofertă
“void”.
Limbajul OWL pentru ontologii, este folosit pentru a descrie produse şi servicii precum
şi caracteristicile tehnice ale acestora. Toate configurările se fac utilizând interfaţa web a
agentului de tip “trader”.
Cu toate că poziţia geografică este considerată un aspect important [Men04] multe
dintre framework-urile existente nu ţin cont de acest aspect sau eşuează în fructificarea pe
deplin a potenţialului acestui criteriu. Noi considerăm locaţia un element important în selecţia
potenţialilor parteneri de afaceri în cadrul lanţului de aprovizionare atât prin impactul pe care
îl are asupra costurilor de transport, dar şi prin risc-uril impuse. De asemenea, poziţionarea
geogarfică poate reprezenta un criteriu de restrângere a spaţiului de căutarea aşa cum îl
reprezintă şi riscul de faliment al furnizorilor. Coordonatele GPS, sunt stocate în ontologiile
tuturor agenţilor implicaţi în flux. Alături de coordonate sunt specificate şi formele geografice
(sub forma de poligoane) folosind limbajul specific GML (Geographic Markup Language),
format standard definit de OGC (Open Geospatial Consortium) [OGC09].
Agentul consumator, va interoga agentul DF (Domain Facilitator) astfel încât să poată
identifica cea mai apropiată companie furnizoare. Cererea, constă în specificarea tipului
agenţilor solicitaţi (în cazul nostru furnizorii de materiale de construcţii), tipul ontologiei (în

PROGRAMUL 4 “PARTENERIATE IN DOMENIILE PRIORITARE” 2007-2013
SCIPA – Etapa 3: Dezvoltarea componentelor semantice ale platformei
42
cazul nostru ontologia creată pentru această platformă şi al cărei template este prezentat in
anexa 1) şi limbajul utilizat.
Ontologia agentului consumator are următoarele informaţii:
Domain- conţine informaţii referitoare la domeniul de activitate al agentului
consumator;
TradedThing-conţine informaţii referitoare la cererea companiei: tipul de produs şi
caracteristicile tehnice. Pentru o companie care solicită cărămidă, o caracteristică tehnică
poate fi temperatura maximă suportată;
Area- conţine informaţii referitoare la poziţia geografică a companiei, fiind dată de
coordonatele GPS. Aria reprezintă suprafaţa acoperită de firma de construcţii (filiale dacă
există şi sediul central).
Pe de altă parte, sunt furnizorii de materiale de construcţii, care utilizează aceeaşi
ontologie:
Domain – conţine informaţii referitoare la activitatea lor
TradedThing – informaţii referitoare la gama de servicii şi produse pe care o oferă
împreună cu caracteristicile tehnice asociate
Area – informaţii referitoare la poziţia punctelor de desfacere. Informaţia este descrisă
prin utilizarea instanţelor şi a proprietăţilor. Punctele de desfacere sunt date sub formă de
figuri geometrice definite prin intermediul coordonatelor GPS.
În vederea identificării celei mai bune oferte trebuiesc parcurşi următorii paşi.
Comunicarea dintre agenţi este bazată pe OWL şi mesaje ACLcompatibile cu standardul
FIPA [FIPA]
Pasul 1: toţi agenţii de afaceri (BA) sunt înregistraţi la agentul DF (Domain
Facilitator).Agenţii de afaceri vor avea informaţii despre servicii dintr-un anumit domeniu de
afaceri. Un agent de tip “trader”, interoghează prima dată agentul DF pentru a obţina lista
agenţilor de afaceri disponibili, apoi îşi înregistrează serviciile şi produsele cu cele
corespunzătoare cererii.
Platforma software este implementată într-o manieră distribuită astfel încât permite
existenţa mai multor agenţi DF care ruleză pe maşini diferite.Comunicarea dintre
componentele distribuite se realizează prin utilizarea serviciilor web pentru a asigura
interoperabilitatea la nivelul mediilor de dezvoltare eterogene. Agentul care reprezintă
serviciile web (WSA) coordonează proceul de traducere al mesajelor din ACL şi apelurilor de
servicii web şi actualizează constant lista agenţilor DF aflaţi pe alte maşini.
Pasul 2: Datorită faptului că lanţul de aprovizionare este un sistem orientat pe cererea
consumatorului. Fluxul începe cu cererea primită. Agentul consumator, interoghează prima
dată agentul DF şi agenţii de afaceri de pe toate maşinile conform listei create de agentul DF
în funcţie de conţinutul cererii.

PROGRAMUL 4 “PARTENERIATE IN DOMENIILE PRIORITARE” 2007-2013
SCIPA – Etapa 3: Dezvoltarea componentelor semantice ale platformei
43
Pasul 3: Agentul consumator îşi transmite cererea la agenţii vânzători descoperiţi la
pasul anterior. În cadrul cererii se specifică de asemenea adresa dorită pentru livrareutilizând
coordonatele GPS, produsele solicitate, caracteristicile lor tehnice, cantitatea şi data maximă
de livrare.
Pasul 4: Fiecare agent furnizor contactat analizează cererea consumatorului şi
răspunde în caz de similaritate. Prima dată se compară poziţia geografică a consumatorului cu
punctele de vânzare acoperite. Apoi, agentul vânzător compară produsele sau serviciile
solicitate cu datele sale. Match-ingule dintre cerere şi ofertă se face prin compararea
ontologiior celor doi create aplicând metodologia propusă. Nivelul de similaritate este
determinat cu ajutorul algoritmului de similaritate semantică.
Utilizarea limbajului OWL s-a dovedit a fi o soluţie bună deoarece rezolvă problema
heterogenităţii datelor. Inferenţa a fost implementată cu ajutorul Jena [Jena] şi serveşte la o
mai bună înţelegere a cererii consumatorului. Dacă agentul vânzător nu poate să asigure pe
cont propriu produsul sau serviciul solicitat, va trebui să identifice la rândul sau furnizori,
astfel devenind la rândul său consumator, iar procesul se repetă începând cu pasul 2.
Reasoner reasoner = ReasonerRegistry.getOWLReasoner();
reasoner = reasoner.bindSchema(GenerateOntology());
InfModel infmodel = ModelFactory.createInfModel(reasoner,ontologyModel);
Resource resource= infmodel.getResource(NS + "TradedThing");
Pasul 5: Agentul consumator continuă să comunice şi să negocieze cu agenţii care i-au
raspuns pozitiv. Evaluarea ofertei ia în considerare atât regulile obligatorii, riscul de faliment,
dar şi funcţia de evaluare prezentată mai sus. Mai mulţi agenţi vânzătoripot fi selectaţi dacă
este nevoie pentru a satisface cererea din punct de vedere al cantităţii. În situaţia în care
agentul nu este consumatorul iniţial, ci un consumator intermediar care doreşte să
achiziţioneze subansamble sau alte materiale,algoritmul continuă cu selecţia celei mai bune
oferte de la pasul recursiv anterior. Algoritmul se finalizează în momentul în care a fost
selectată cea mai bună ofertă. Evaluarea este facuta de către clientul iniţial. Aşa cum este
prezntat mai sus, algoritmul este implementat într-o manieră recursivă care permite fiecărui
agent vânzător să devină la rândul său consumator.
Această abordare asigură un nivel ridicat de flexibilitate în generarea lanţului de
aprovizionare. Agenţii consumatori pot lua în considerare un set de reguli peredefintie atunci
când aleg furnizorii aşa cum este prezentat în figura de mai jos:
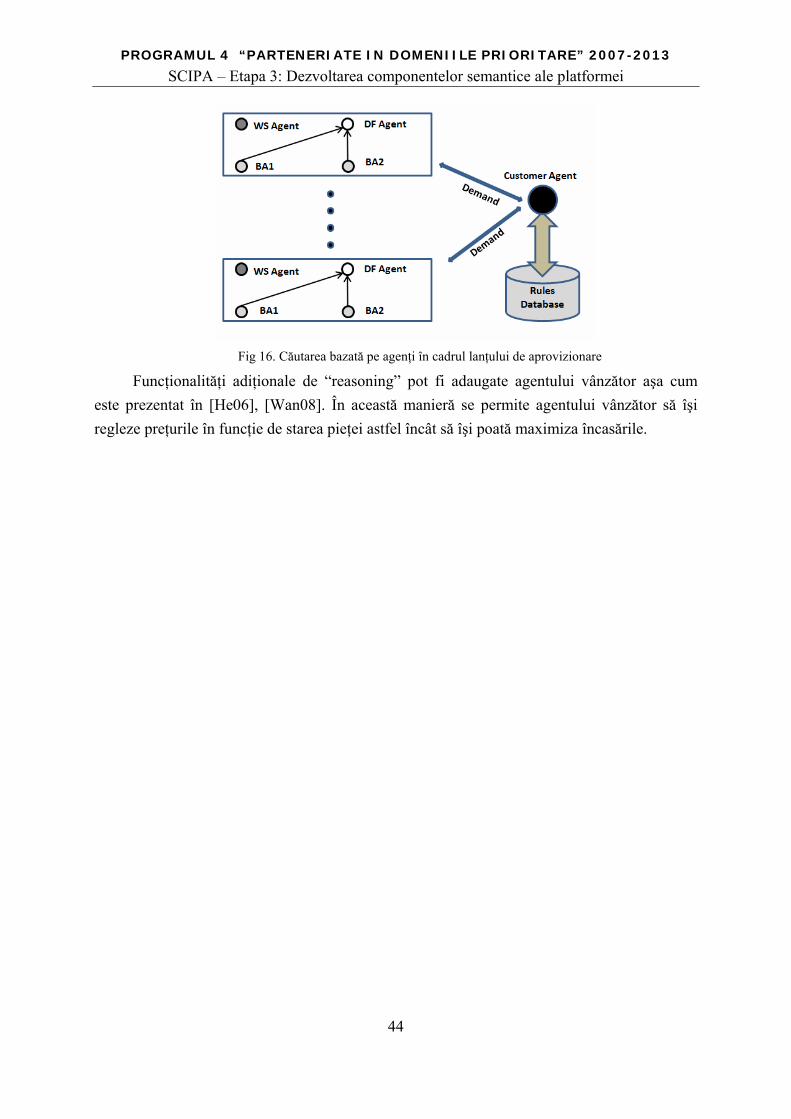
PROGRAMUL 4 “PARTENERIATE IN DOMENIILE PRIORITARE” 2007-2013
SCIPA – Etapa 3: Dezvoltarea componentelor semantice ale platformei
44
Fig 16. Căutarea bazată pe agenţi în cadrul lanţului de aprovizionare
Funcţionalităţi adiţionale de “reasoning” pot fi adaugate agentului vânzător aşa cum
este prezentat în [He06], [Wan08]. În această manieră se permite agentului vânzător să îşi
regleze preţurile în funcţie de starea pieţei astfel încât să îşi poată maximiza încasările.

PROGRAMUL 4 “PARTENERIATE IN DOMENIILE PRIORITARE” 2007-2013
SCIPA – Etapa 3: Dezvoltarea componentelor semantice ale platformei
45
3 Evaluarea riscului în mediile de programare bazate pe
agenţi inteligenţi
În această secţiune urmarim să propunem marimi de evaluare a fiabilitaţii sistemelor
distribuite bazate pe agenţi inteligenţi şi pe interacţiune dintre servicii web. Pentru aceasta am
facut o analiză asupra diverselor modalităţi de calcul a fiablităţii. Riscul de eşec al unui astfel
de sistem este în relaţie negativă cu fiabilitatea.
3.1 Fiabilitatea sistemelor distribuite bazate pe agenţi şi servicii
web
3.1.1 Aspecte generale privind metricile de evaluare a fiabilităţii
sistemelor
Definiţiile date în literatură pentru fiabilitate diferă în funcţie de diverşi cercetători şi
de sistemele care uremază a fi evaluate. Cu toate acestea există o definiţie unanim acceptată
de toţi cercetătorii: “Fiabilitatea reprezintă probabilitatea de succes ca un sistem să realizeze
funcţionalităţile pentru care a fost dezvoltat în condiţiile limitărilor impuse în faza de
proiectare.” Mai explicit, această definiţie se referă la faptul că fiabilitatea este probabilitatea
ca un produs sau o parte să funcţioneze corect pentru o anumită perioadă de timp sub anumite
condiţii fără a avea eşecuri. Din punct de vedere matematic, fiabilitatea se poate exprima ca o
funcţie de probabilitate dependentă de timp. este probabilitatea ca un sistem să
funcţioneze cu succes de la început până în momentul t.
(9)
în care:
–reprezintă timpul de eşec;
Exprimată sub forma densităţii de probabilitate, funcţia de fiabilitate este următoarea:
(10)
în care:
f(t) –funcţia de densitate pentru momentul de eşec T;
f(t)= - (11)
În cele mai multe cazuri, spre exemplu analiza fiabilităţii unui serviciu web, evaluarea
bazată pe timpul de esec nu este cea mia bună opţiune. O măsură mai consistentă poate fi dată
de evaluarea numărului de eşecuri raportat la numărul total de apeluri. În ambele abordări R(t)
ia valori în intervalul [0,1].

PROGRAMUL 4 “PARTENERIATE IN DOMENIILE PRIORITARE” 2007-2013
SCIPA – Etapa 3: Dezvoltarea componentelor semantice ale platformei
46
Ca o alternativă la funcţia clasică de evaluare a fiabilităţii, [Pha05] a dezvoltate o nouă
funcţie matematică numită: “sistemabilitate” , luând în considerare nivelul de incertitudine a
mediilor operaţionale care afecteză funcţia de predicţie a fiabilităţii sistemelor.
Sistemabilitatea este definită ca probabilitatea unui sistem de a executa funcţiile pentru o
anumită sarcină în medii operaţionale aleatoare. Matematic acest lucru se exprimă astfel:
(12)
în care:
– funcţia care masoară rata de hazard;
–factor de mediu;
– funcţie de disribuţie cumulativă pentru η;
Fiabilitatea este una dintre cele mai importante caracteristici solicitate de clienţi de la
dezvoltatorii de sisteme software. Au fost identificaţi peste treizeci de factori care
influenţează fiabilitatea unei aplicaţii. Dintre aceştia amintim: dificultatea de programare
(PDIF), nivelul tehnologiilor de programare (TLVL), procentul de cod refolosit (PORC)
[Pha06].
Fiabilitate a este cel mai des luată în calcul atunci când se evaluează calitatea serviciilor
(Quality of Service - QoS) asociată unei aplicaţii. Alte aspecte care sunt laute în considerare
când se evaluează QoS sunt: disponibilitatea, accesibilitatea, integritatea, performanţa şi
securitatea [CPE05].
Datorită importanţei acestei teme, ISO şi International Electrotechnical Commission
(IEC) au adoptat în 1991standrdul de calitate ISO/IEC 9126. Standardul specifică stributele
de calitate împărţite în şase grupe: funcţionalitate, fiabilitate, utilizabilitate, eficienţă,
mentenanţă şi portabilitate. Evaluarea fiabilităţi poate lua în considerare metrici precum:
metrica de maturitate, metrica de toleranţă la erori, metrica de recuperare şi metrici de
conformitate. Cei mai comuni indicatori de fiabilitate sunt [Pha06]:
Timpul mediu de eşec al sistemului (SMTTF)
SMTTF este cel mai des utilizat, dar şi cel mai incorect folosit. A fost eronat interpretat
drept “timpul minim de viaţă garantat”.
(13)
în care:
– funcţia de densitate pentru timpul de eşec T;
Mentenanţa
Mentenanţa este definită ca probabilitatea unui sistem care a eşuat să fie recuperat la
condiţiile specificate într-o perioadă de timp dată atunci când recuperarea se face după
proceduri şi resurse anterior specificate.

PROGRAMUL 4 “PARTENERIATE IN DOMENIILE PRIORITARE” 2007-2013
SCIPA – Etapa 3: Dezvoltarea componentelor semantice ale platformei
47
Cu alte cuvinte, mentenanţa este probabilitatea de a izola şi repara o eroare a sistemului
într-un anumit timp. Funcţia analizează timpul de înlăturare, înlocuire, rescriere a
componentei care a eşuat. De asemenea, se iau în calcul şi abilităţile necesare, echipamnetul
de suport necesar, documentarea:
(14)
în care:
–funcţia de densitate pentru timpul de refacere T;
Disponibilitatea
Fiabilitate este o masură ce necesită execuţia cu succes a sarcinilor pe parcursul unui
interval de timp la nivel de sistem complet. Pe parcursul acestei perioadenu sunt permise
schimbări sau corecţii. Disponibilitatea este o măsură ce permite unui sistem să fie corectat
atunci când apar eşecuri.
(15)
în care:
– perioada de timp în care sistemul funcţionează;
-perioada de timp în care sistemul nu funcţionează ;
3.1.2 Fiabilitatea în sistemele de compunere de servicii web
În timp ce serviciile web individuale sunt utilizate pentru realizarea sarcinilor
independente, este nevoie din ce în ce mai mare de a integra serviciile în fluxuri mai
complexe. Acest aspect este aplicat şi la nivelul aplicaţiei de management a lanţului de
aprovizionare. Tranzacţia este realizată prin compunerea serviciilor web individuale expuse
de agenţii participanţi la procesul de afaceri. Aplicaţiile bazate pe compunerea de servicii,
oferă posibilitatea reconfigurării rapide astfel încât să se poată adapta şi să poată beneficia zât
mai uşor de toate schimbările de pe piaţă. Comparativ cu abordările tradiţionale, compunerea
de servici permite modificarea funcţionalităţii aplicaţiei prin simpla modificare a serviciilor
web implicate, fără a fi nevoie de a rescrie codul aplicaţiei, reducând astfel ciclul de
dezvoltare al produselor software. În plus faţă de reducerea timpului de dezvoltare, sunt
reduse şi costurile de dezvoltare asociate [HNa07].
Aplicaţiile complexe pot fi vazute ca o colecţie de servicii web independente oferite de
diverse companii, în cazul nostru expuse de agenţi situaţi pe platforme diferite.
Interoperabilitatea devine astfel un aspect important, deoarece înteprinderile tradiţionale
complet integarate sunt înlocuite de reţele de afaceri în care fiecare companie este
specializată într-un anumit domeniu.
Abordările curente de compunere a serviciilor web pot fi clasificate astfel:

PROGRAMUL 4 “PARTENERIATE IN DOMENIILE PRIORITARE” 2007-2013
SCIPA – Etapa 3: Dezvoltarea componentelor semantice ale platformei
48
Manuală- este considerată consumatoare de timp şi în acelaşi timp cu un nivel ridicat
de erori. Persoana care realizează compunerea trebuie să cunoască foarte bine domeniul
[MRP10].
Semi-automată – utilizatorul este implicat în procesul de validare a fluxului generat, în
diverse etape ale procesului de compunere. Această abordare asigură de cele mai multe ori un
nivel ridicat de QoS.
Automată – implicarea utilizatorului este minima, iar sistemul trebuie să asigure
validarea fluxului.
Modelele existente de evaluare a fiabilităţii sistemelor au fost dezvoltate pentru aplicaţii
statice. Date fiind diferenţele dintre aplicaţiile monolitice şi cele bazate pe servicii web, multe
tehnologii, tehnici şi modele dezvoltate pentru aplicaţiile tradiţionale nu mai sunt valide. prin
urmare, nici modelele de evaluare a fiabilităţii nu mai sunt în concordanţă cu specificul
aplicaţiilor.
Există mai multe abordari în realizarea compunerii de servicii: metode bazate pe
inteligenţăartificială, reţele Petri, metode abstracte modelate prin funcţii matematice, etc, însă
toatea aceste metode au în comun faptul că mai multe servicii pot realiza funcţionalităţile
indeividuale necesare alcătuirii fluxului. În general, selecţia serviciilor participante se
realizează după criterii precum: cost, performanţă, reputaţie sau o combinaţie a acestor
atribute [YPi09], [JMR10]
În vederea creşterii fiabilităţii întregului lanţ de servicii web, propunem să le
considerăm ca fiind construite din servicii abstracte. În pasul de descoperire, pe lângă selecţia
serviciului web, care oferă cele mai bune caracteristici, reţinem de asemenea toate serviciile
care oferă funcţionalitatea solicitată. Dacă pentru un anumit motiv cel mai serviciu web nu
este disponibil la momentul execuţiei, un altul îl va înlocui.
Definim serviciu web abstract drept un grup de servicii web care asigură o
funcţionalitate specifică. Considerăm că serviciul abstract eşuează numai dacă toate serviciile
din grup eşuează. Astfel se calculează fiabilitatea unui serviciu abstract după următoarea
formulă:
(16)
în care:
numărul serviciilor web care asigură funcţionalitatea solicitată. Dacă atunci
este mai aproape de 1 decât fiabilitatea oricărui alt serviciu din grup.Cu alte cuvinte,
.
Fiabilitatea totală a unui sistem depinde de fiabilitatea subsistemelor sale, care este la
rândul ei influenţată de fiablitatea componentelor şi fiabilitatea conexiunii dintre componente.
Nivelul aşteptat de QoS este un criteriu important în momentul în care se construieşte un lanţ

PROGRAMUL 4 “PARTENERIATE IN DOMENIILE PRIORITARE” 2007-2013
SCIPA – Etapa 3: Dezvoltarea componentelor semantice ale platformei
49
de servicii web. Este cel mai des utilizată când mai multe servicii web răspund la cerinţe. În
vederea selectării unuia dintre ele, se ia în calcul valoarea QoS.Există mai multe abordări
pentru selecţia serviciilor astfel încât per total să se asigure cel mai ridicat nivel QoS. [Li10]
propune un algoritm de înlănţuire a serviciilor web în care metoda de optimizare este bazată
pe Multi-objective Chaos Ant Colony Optimization - MCACO care oferă rezultate mai bune
faţă de metodele anterioare bazate pe
Multi-objective Genetic Algorithms - MOGA [Liu05]. Unele dintre abordări propun
extinderea standardelor prin încorporarea informaţiilor legate de fiabilitate. O astfel de
abordare este o extensie a Web Service Description Language – WSDL şi se numeşte Q-
WSDL (QoS enabled WSDL) prezentată în [BAm10]. Această abordare adaugă informaţii
legate de QoS la limbajul standrd de descriere al serviciilor web.
Prezicerea fiabilităţii în compunere de servicii se poate realiza:
În etapa de proiectare – predicţie statică. Fiabilitatea este calculată la momentul
proiectării şi tot atunci sunt alese şi cele mai bune servicii. Această abordare asigură o
performanţă mai bună deoarece nu încetineşte faza de execuţie. Se pot utiliza algoritmi
complexi de evaluare a fiabilităţii.
La momentul execuţiei – predicţie dinamică. Predicţia fiabilităţii şi selecţia serviciilor
sunt realizate la momentul execuţiei. Avantajul faţă de etapa anterioară este realizat de faptul
că nu se modifică dacă seriviciile web implicate se modifică în timp. Dezavantajul este legat
de prelungirea timpului de execuţie ceea ce rezultă în necesitatea de a utiliza algoritmi de
evaluare mai puţin complexi.
În viziunea noastră, o evaluare mixtă ar trebui realizată. Fiabilitatea este evaluată prima
dată la momentul proiectării, atunci când se realizează lanţul de servicii web. Astfel se alege
cel mai fiabil lanţ. Prin stocarea tuturor serviciilor care pot realiza suncţionalitatea solicitată,
ni se permite schimbarea la momentul execuţiei a serviciilor care nu mai sunt disponibile.
Astfel este îmbunătăţită fiabilitatea, fără a încetini execuţia. Pe baza valorii fiabilităţii fiecărui
serviciu web, valoarea agregată a fiabilităţii poate fi calculată aşa cum este prezentat în
[HNa07] şi [BAm10]. Formulele au fost definite pentru servicii web, dar pot fi de asemenea
utilizate pentru servicii abstarcte:
1. – Fiabilitatea unei secvenţe:
(17)
în care reprezintă numărul de blocuri din secvenţă.Blocurile pot fi fie servicii web
individuale sau lanţuri de servicii web compuse din mai multe servicii.
2. – Fiabilitatea blocurilor alternative:

PROGRAMUL 4 “PARTENERIATE IN DOMENIILE PRIORITARE” 2007-2013
SCIPA – Etapa 3: Dezvoltarea componentelor semantice ale platformei
50
(18)
în care m este numărul de ramuri, este fiabilitatea condiţiei de test şi
probabilitatea ca ramura i să fie selectată. Astfel . Pentru un loc alternativ carea re
doar două ramuri, formula poate fi rescrisă astfel:
(19)
3. – Fiabilitatea blocurilor repetitive
(20)
în care fiabilitatea condiţiei de repetiţie, este fiabilitatea blocului
care se repetă şi LoopCount reprezintă numărul de repetări ale unui bloc
Pentru a exemplifica se consideră următoarea situaţie din cardul unui lanţ de
aprovizionare prezentată în figura de mai jos:
Fig.17 Exemplu de lanţ de servicii web pentru aplicaţie de modelarea lanţului de aprovizionare
Figura 17 prezintă un lanţ simplu de servicii web care genereză facturi pe baza adresei
de livrarea a produsleo. Primele două servicii web sunt de la furnizori externi, în timp ce
serviciul de facturare este deţinut de companie. Pentru fiecare serviciu abstarct, serviciile care
se potrivesc sunt stocate împreună cu nivelul lor de fiabilitate. Dacă s-ar fi stocat doar un
singur serviciu, iar sistemul nu ar mai fi avut posibilitatea să se recupereze în cazul unei erori,
valoarea funcţiei de fiabilitate ar fi următoarea: .
În abordarea noastră, pe baza faptului ca multe servicii chiar externe platformi pot
asigura traducerea dintre coordonatele GPS şi adresă, fiabilitatea este calculată astfel:
.
Dezavantajul abordării propuse este legat de faptul că în anumite situaţii poate fi un
singur serviciu web care să satisfacă cererea. În această situaţie, sistemul poate verifica lista
de servicii web adăugate după ce lanţul de servicii a fost proiectat, pentru a vedea dacă se
poate gasi un serviciu web. Daca nu este identificat nici un serviciu web, execuţia sistemului
va eşua.

PROGRAMUL 4 “PARTENERIATE IN DOMENIILE PRIORITARE” 2007-2013
SCIPA – Etapa 3: Dezvoltarea componentelor semantice ale platformei
51
3.2 Riscul în managementul lanţului de aprovizionare
În scopul clasificării furnizorilor identificaţi, în două categorii: siguri şi nesiguri, a fost
dezvoltat un model de clasificare binară, bazat pe reţea neuronală de tip wavelet.
Datorită competitivităţii schimburilor economice, fiecare firmă poate apare atât ca
producător, , urmărind atât maximizarea profitului, cât şi în calitate de consumator care
urmăreşte maximizarea utilităţii consumului [RAn10].
Mai jos se prezintă principalele etape ale aplicării modelului.
Etapa 1: Etapa de colectare a datelor
În cadrul acestei etape se crează setul de antrenament pentru etapele următoare. Setul de
antrenare este format din 45 de companii care sunt grupate în profitabile (32 de companii) şi
neprofitabile(13 companii). Pentru aceste companii se iau in calcul 10 indicatori financiari din
care se vor selecta cei mai relevanţi pentru algoritmul binar de clasificare. Calculele sunt
efectuate în MATLAB 7.9.0 şi am luat în considerare mai multe surse de date: [BVB10],
[ANAF10], [Mfin10], [LFi10], [KTD10].
Etapa 2: Etapa de “data mining” şi selecţie a indicatorilor
Pe parcursul acestei etape se identifică lista de indicatori financiari care vor fi luaţi în
calcul pentru prezicerea falimentului. De asemenea, pe parcursul acestei etape calculăm şi
valorile acestor indicatori. Selecţia variabilelor se realizează în trei paşi:
Pasul 1: analiza literaturii de specialitate: s-au obţinut cincizeci de variabile
reprezentând caracteristici precum: profitabilitate, nivelul de lichidităţi, stabilitatea, creşterea,
etc., a se vedea Tabelul 1 Tabel 1. Indicatorii utilizaţi pentru analiza financiară [Del10], [DSc10] completaţi cu alţi indicatori
Categoria Indicatorul
Profitabilitate Venitul brut raportat la volumul vânzărilor
Câştigurile fără dobândă şi taxe raportate la total active
Randamentul activelor totale
Randamentul capitalului
Cheltuieli financiare raportate la pasive
Cheltuieli financiare raportate la vânzări
Costul vânzărilor * Costul ratei de creştere a vânzărilor
Venitul net total raportat la dobânzi
Profit marginal
Costul vânzărilor raportat la vânzările nete
Cheltuielile financiare şi profitul normal raportat la total
active
Rata de creştere acheltuielilor financiare raportată la

PROGRAMUL 4 “PARTENERIATE IN DOMENIILE PRIORITARE” 2007-2013
SCIPA – Etapa 3: Dezvoltarea componentelor semantice ale platformei
52
active
Rata de creştere a cheltuielilor non-operaţionale
raportată la active
Profitul net raportat la capital
Câştiguri pe acţiune
Activitatea Datorii la cifra de afaceri
Rata de creştere a inventarului raportată la vânzări
Cifra de afaceri a activelor curente
Cifra de afaceri a activelor fixe
Cifra de afaceri a inventarului
Cifra de afaceri a activelor totale
Cifra de afaceri a activelor totale *
rata de creştere a vânzărilor
Lichiditatea Rata de solvabilitate
Coeficientul Window
Fluxul de lichidităţi la totalul pasivelor
Stabilitatea Rata de îndatorare
Rata de îndatorare pe termen lung
Quick ratio
Valoarea netă la total active
Numerar şi echivalente de numerar pentru datoriile
curente
Creşterea Rata de creştere a afacerii primare
Rata de creştere a activelor totale
Rata de creştere a vânzărilor
Rata de schimb a activelor totale
Rata de creştere a activelor totale
Rata de creştere a dobânzii
Venit minim de subzistenţă la total active
Trend Creşterea cheltuielilor financiare
Ratele de structura Proporţia activelor fixe
Proporţia activelor curente
Proporţia capitalului în active fixe
Proporţia pasivelor
Pasivele Rata curentă
Rata active-pasive
Ratafluxului de numerar la pasivele curente
Capital la ratade îndatorare

PROGRAMUL 4 “PARTENERIATE IN DOMENIILE PRIORITARE” 2007-2013
SCIPA – Etapa 3: Dezvoltarea componentelor semantice ale platformei
53
Rata pasivelor la ctive tangibile nete
Rata de acoperiere a dobânzii
Rata pasivelor la valoarea de piaţă a capitalului
Pasul 2: dintre aceşti indicatori au fost selectaţi opt, cei care au fost disponibili pe
internet;
În vederea obţinerii acestor date a fost dezvoltată o aplicaţie de web crawling. Aplicaţia
primeşte ca parametru de intrare codul fiscal al companiei şi crawlează site-urile amintite mai
sus.
Modulul de crawlere, nu caută doar date pe internet, dar are şi rolul de a calcula
indicatorii financiari pentru care au fost gasite datele necesare.
Pentru setul de antrenament format din patruzeci şi cinci de companii aplicaţia a fost
capabilă să identifice date doar pentru opt indicatori care vor fi detaliaţi. Figura18 prezintă un
ecran din aplicaţia de crawlere, în cazul în care s-a introdus un cod fiscal specific.
Fig. 18 Captură de ecran din aplicaţia de crwlere când se efectuează o căutare specifică
Dacă nu se introduce nici un cod fiscal, aplicaţia obţine date pentru companiile din
setul de antrenament. Rezultatele sunt prezentate mai jos:
Fig 19. Captură de ecran din aplicaţia de crwlere când nu se introduce un cod fiscal
Următoarele opt variabile au fost cele care au putut fi calculate pe baza datelor cel mai
des regăsite de către modulul de web crawling:
X1 – rata de îndatorare (DR);
X2 - Quick assets to total assets (QA2TA);
X3 – randamentul capitalului (ROE);

PROGRAMUL 4 “PARTENERIATE IN DOMENIILE PRIORITARE” 2007-2013
SCIPA – Etapa 3: Dezvoltarea componentelor semantice ale platformei
54
X4 –profit net raportat la capital (NPE);
X5 – Cheltuieli financiare raportate la vânzări (FE2S) ;
X6 – câştiguri pe acţiune (EPS);
X7 – cifra de afaceri a activelor curente (CAT);
X8 - Profit marginal (PM);
Pasul 3: Utilizând selecţia caracteristicilor pentru un anumit nivel de relevanţă, se reţine
un număr de trei variabile care vor fi utilizate în modelul propus.
Autorii în lucrarea [GEl03] au identificat avantajelealgoritmului de selecţie a
caracteristicilor:
1 facilitează vizualizarea datelor şi întelegerea datelor;
2 reducerea cerinţelor de măsurare şi stocare;
3 reducerea timpului de antrenamnet şi utilizare;
4 reducerea dimensionalităţii în vederea îmbunătăţirii perfomanţei predicţiei;
Algoritmul de selecţie a caracteristicilor este potrivit pentru antrenarea reţelelor
neuronale de tip wavelet. În vederea determinării caracteristicilor celor mai importante, am
antrenat o reţea neuronală folosind toate cele opt caracteristici prezentate la pasul anterior.
Acest procedeu este ilustrat in figura 20. Reţeaua este formată din trei straturi: stratul de
intrare, stratul ascuns şi stratul de rezultat. Toate nodurile fiecărui strat sunt complet conectate
cu nodurile din stratul următor. Stratul de intrare are opt noduri corespunzătoare
caracteristicilor luate în calcul. Stratul ascun are m noduri, iar stratul rezultat are un singur
nod, reprezentând clasificarea. Reţeaua este antrenată utilizând firmele luate în calcul pentru a
determina ponderile dintre noduri. Se consideră wij ponderea unei conexiuni dintre nodul de
intrare i şi nodul ascuns j (i = 1... ; j=1... ), iar ponderea asociată conexiunii dintre
nodul ascuns j şi nodul rezultat. În cazul nostru, numărul nodurilor de intrare, este egal cu
opt, şi reprezintă numărul variabilelor luate în considerare.
Fig. 20 Alegerea celor mai importante caracteristici pe baza influenţei lor din cadrul reţelei neuronale
Cele mai importante caracteristici sunt cele pentru care input-ula are cea mai mare
influenţă absolută asupra outputului. Se poate calcula impactul nodului de input i asupra

PROGRAMUL 4 “PARTENERIATE IN DOMENIILE PRIORITARE” 2007-2013
SCIPA – Etapa 3: Dezvoltarea componentelor semantice ale platformei
55
outputului nodului ascuns j folosind următoarea formulă în care împărţim ponderea nodului
ascuns asupra outputului cu relevanţa conexiunii dintre i şi j asupra tuturor inputurilor
conectate cu j:
(21)
Pentru fiecare nod de input calculăm indicatorul de importanţă:
(12)
(1) şi (2) pot fi combinate într-o singură formulă:
(23)
Pe baza indicatorului de importanţă, au fost selectate următoarele trei variabile:
X1 – rata de îndatorare; (stabilitate)
X7 - cifra de afaceri a activelor curente; (activitate)
X8 - profit marginal; (profitabilitate)
Rata de îndatorare (DR) este calculată astfel:
(24)
în care: TL=pasive totale; TA=active totale
DR indică proporţia datoriilor companiei raportată la activele sale. Aparţine categoriei
solvabilitate şi stabilitate.
Solvabilitate poate indica drept cauza eşecului politica financiară. Solvabilitatea oferă
de asemenea informaţii asupra riscului potenţial al companiei cu privire la volumul de
îndatorare şi se află în relaţie negativă cu ricul de apariţie al falimetului
Cifra de afaceri aactivelor curente (CAT), această rată este determinată prin
împărţirea volumului vânzărilor la activele curente şi este o rată a eficienţei. O eficienţă mai
mare poate fi tradusă printr-o profitabilitate mai mare, lichiditate mai bunăşi în final risc
diminuat [ERD09]
(25)
în care TS=volumul total al vânzărilor; CA-active curente
Profit marginal (PM) calculat sub forma raportului dintre profitul net şi vânzări sau ca
raport dintre venit net şi venit total. Un nivel ridicat al acestei rate indică o rată mare de
acoperire a costurilor de producţie şi prin urmare un risc mai mic.
(26)
în care: NP= profit net; TS=vânzări totale
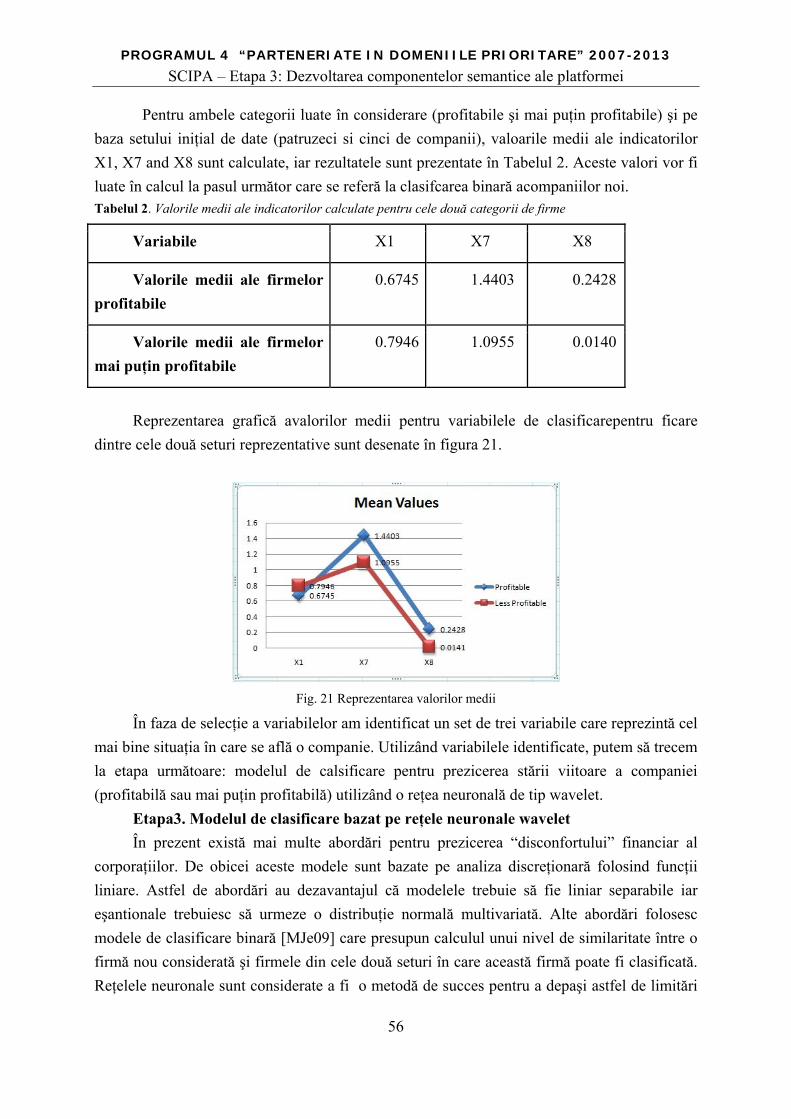
PROGRAMUL 4 “PARTENERIATE IN DOMENIILE PRIORITARE” 2007-2013
SCIPA – Etapa 3: Dezvoltarea componentelor semantice ale platformei
56
Pentru ambele categorii luate în considerare (profitabile şi mai puţin profitabile) şi pe
baza setului iniţial de date (patruzeci si cinci de companii), valoarile medii ale indicatorilor
X1, X7 and X8 sunt calculate, iar rezultatele sunt prezentate în Tabelul 2. Aceste valori vor fi
luate în calcul la pasul următor care se referă la clasifcarea binară acompaniilor noi. Tabelul 2. Valorile medii ale indicatorilor calculate pentru cele două categorii de firme
Variabile X1 X7 X8
Valorile medii ale firmelor
profitabile
0.6745 1.4403 0.2428
Valorile medii ale firmelor
mai puţin profitabile
0.7946 1.0955 0.0140
Reprezentarea grafică avalorilor medii pentru variabilele de clasificarepentru ficare
dintre cele două seturi reprezentative sunt desenate în figura 21.
Fig. 21 Reprezentarea valorilor medii
În faza de selecţie a variabilelor am identificat un set de trei variabile care reprezintă cel
mai bine situaţia în care se află o companie. Utilizând variabilele identificate, putem să trecem
la etapa următoare: modelul de calsificare pentru prezicerea stării viitoare a companiei
(profitabilă sau mai puţin profitabilă) utilizând o reţea neuronală de tip wavelet.
Etapa3. Modelul de clasificare bazat pe reţele neuronale wavelet
În prezent există mai multe abordări pentru prezicerea “disconfortului” financiar al
corporaţiilor. De obicei aceste modele sunt bazate pe analiza discreţionară folosind funcţii
liniare. Astfel de abordări au dezavantajul că modelele trebuie să fie liniar separabile iar
eşantionale trebuiesc să urmeze o distribuţie normală multivariată. Alte abordări folosesc
modele de clasificare binară [MJe09] care presupun calculul unui nivel de similaritate între o
firmă nou considerată şi firmele din cele două seturi în care această firmă poate fi clasificată.
Reţelele neuronale sunt considerate a fi o metodă de succes pentru a depaşi astfel de limitări

PROGRAMUL 4 “PARTENERIATE IN DOMENIILE PRIORITARE” 2007-2013
SCIPA – Etapa 3: Dezvoltarea componentelor semantice ale platformei
57
[CRK09]. Sunt construite din din mai multe elemente de procesare numite neuroni. Ponderile
asociate conexiunilor dintre neuroni modelează caracteristicile de input-output. Reţelele
neuronale wavelet reprezintă o abordare care nu depinde de un set de condiţii iniţiale folosite
în momentul în care se defineşte sructura reţelei neuronale. Figura 18 prezintă o reprezentare
a unei funcţii wavelet folosind Wolfram Mathematica.
O funcţie individuală wavelet este definită de următoarea formulă:
(27)
Există mai multe metode de antrenare a reţelelor neuronale wavelet inclusiv evoluţia
diferenţială şi pragul de acceptanţă [CRK09]. În vederea antrenării reţelei am folosit următorii
paşi.
Fig 22 Reprezentarea funcţiei wavelet folosind Mathematica
Pasul 1: Asignam prima dată valori aleatoare conexiunilor dintre nodurile de intrae şi
nodurile ascunse şi dintre nodurile ascunse şi nodul rezultat, .
Pasul 2: Rezultatul unui eşantion , k = 1, . . ., np, unde np este numărul de eşantioane,
este calculat pe baza formulei:
(28)
în care k = 1,. . .,np, nin = numărul nodurilor input şi nhn = numărul nodurilor ascunse.
Pasul 3: Reducere erorii de predicţie pe baza datelor din setul de antrenament prin
ajustarea ponderilor
şi a valorilor pentru a, b. Eroarea este compusă după cum urmează:
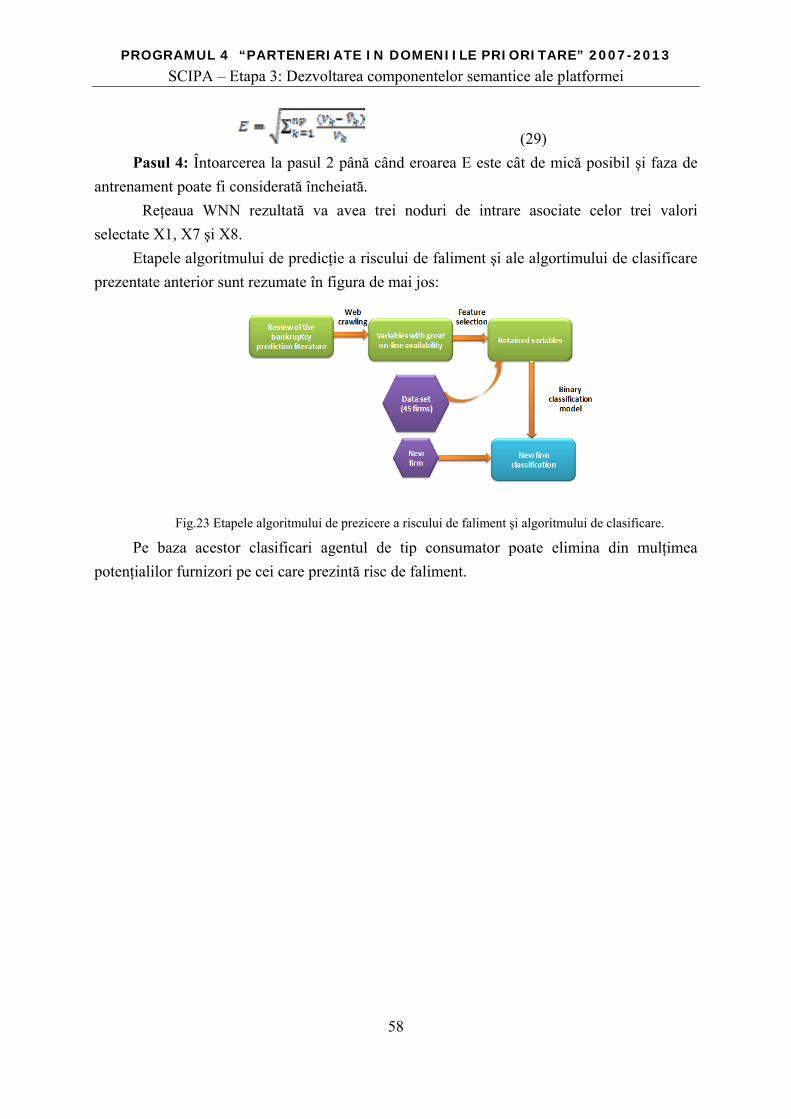
PROGRAMUL 4 “PARTENERIATE IN DOMENIILE PRIORITARE” 2007-2013
SCIPA – Etapa 3: Dezvoltarea componentelor semantice ale platformei
58
(29)
Pasul 4: Întoarcerea la pasul 2 până când eroarea E este cât de mică posibil şi faza de
antrenament poate fi considerată încheiată.
Reţeaua WNN rezultată va avea trei noduri de intrare asociate celor trei valori
selectate X1, X7 şi X8.
Etapele algoritmului de predicţie a riscului de faliment şi ale algortimului de clasificare
prezentate anterior sunt rezumate în figura de mai jos:
Fig.23 Etapele algoritmului de prezicere a riscului de faliment şi algoritmului de clasificare.
Pe baza acestor clasificari agentul de tip consumator poate elimina din mulţimea
potenţialilor furnizori pe cei care prezintă risc de faliment.

PROGRAMUL 4 “PARTENERIATE IN DOMENIILE PRIORITARE” 2007-2013
SCIPA – Etapa 3: Dezvoltarea componentelor semantice ale platformei
59
Bibliografie [ANAF10] National Agency for Fiscal Administration, www.anaf.ro.
[And01] P. Andriani, Diversity, Knowledge and Complexity Theory: Some Introductory Issues, International Journal of
Innovation Management, vol 5, nr 2, p 257-274, 2001
[ATu03] A. Afuah, and C. Tucci , Internet Business Models and Strategies, Editura McGraw Hill, Boston, 2003
[BAm10] P.Bocciarelli, A. D’Ambrogio, A model-driven method for describing and predicting the reliability of composite services, Software & Systems Modeling, http://www.springerlink.com/index/10.1007/s10270-010-0150-3
[BGe01] R. Blattberg, G. Getz, et al.,Customer Equity, Boston, Harvard Business School Press, 2001
[BTu00] S. Bagchi, and B. Tulskie, e-business Models: Integrating Learning from Strategy Development Experiences and
Empirical Research, 20th Annual InternationalConference of the Strategic Management Society, Vancouver, 2000
[BVB10] Bucharest Stock Exchange, www.bvb.ro [CPE05] G.Canfora, M. Di Penta, R. Esposito, An approach for QoS-aware service composition based on genetic algorithms, Genetic And Evolutionary Computation Conference p.1069-1075, 2005 [Cre05] L.G Creţu, Information Technology for Organization (Re)Design (4), Revista “Informatica Economică”, vol 34, nr.2, p.90 – 98, 2005 [CRK09] N.Chauhan, V.Ravi, D.Karthik, Differential evolution trained wavelet neural networks: Application to bankruptcy prediction in banks, Expert Systems with Applications, nr 36, p 7659-7665, 2009 [DCo09] A. Dioşteanu, L. Cotfas, Agent Based Knowledge Management Solution using Ontology, Semantic Web Services and GIS, Informatica Economic Journal, Vol. 13, No.4, pp. 90-98, 2009 [Del10] C.Delcea, Pattern recognition in Financial Distress with Prior Grey Selection of Variables, IBIMA Conference, Istanbul, p 120-130, 2010 [DSc10] C.Delcea, E.Scarlat, Finding Companies’ Bankruptcy Causes using a Hybrid Grey-Fuzzy Model, Economic computation and economic cybernetics studies and research, nr 44, p 77-94, 2010 [ERD09] H.Etemadi, A. Rostamy, H. Dehkordi, A genetic programming model for bankruptcy prediction: Empirical evidence from Iran, Expert Systems with Applications, nr 36, 3199–3207, 2009 [FBT00] M.Fox, M. Barbuceanu, R. Teigen, Agent-Oriented Supply-Chain Management, The International Journal of Flexible Manufacturing Systems, Vol. 12, No. 2-3, April, p.165-188, 2000
[Fen01] D. Fensel, Ontologies: Silver Bullet for Knowledge Management and Electronic Commerce, Editura Springer-
Verlag, Heidelberg, 2001
[FIPA] Foundation for Intelligent Physical Agents. http://www.fipa.org.
[GEl03] I.Guyon, A. Elisseeff, An Introduction to Variables and Feature Selection, Journal of Machine Learning Research, nr.3, p. 1157-1182, 2003 [GFR08] R. Valencia-Garcia, et al. A knowledge acquisition methodology to ontology construction for information retrieval from medical documents, Expert Systems, vol. 25, Nr 3, p 314-334, 2008
[He06] M. He, et al. Designing a successful trading agent for supply chain management, Proc. of the 5th International Joint Conference on Autonomous Agents and Multi-agent Systems, 2006, Japan, p. 1159 - 1166, 2006

PROGRAMUL 4 “PARTENERIATE IN DOMENIILE PRIORITARE” 2007-2013
SCIPA – Etapa 3: Dezvoltarea componentelor semantice ale platformei
60
[HNa07] Z.Hangjung, D.Nazareth, Measuring reliability of applications composed of web services, System Sciences, p. 1-10, 2007 [Hod03] G. M. Hodgson, Capitalism, complexity, and inequality, Journal of Economic Issues, vol 37, nr 2, p 471-478, 2003.
[Jena] Jena Semantic Web Framework, disponibil la http://jena.sourceforge.net. [JMR10] E. H. Joyce, M. Manouvrier, M. Rukoz, TQoS: Transac-tional and QoS-Aware Selection Algorithm for Automatic Web Service Composition, IEEE Transactions on Services Computing, vol 3, no. 1, 2010.
[KMa02] W. C. Kim, and R. Mauborgne , Charting Your Company's Future, Harvard Business Review, 2002
[KTD10] KTD Invest, www.ktd.ro [LFi10] Romanian Companies Database, www.listafirme.ro [LGW09] H. P Luong, S. Gauch, and Q. Wang, Ontology-based Focused Crawling, Proc. IEEE International Conference on Information, Process, and Knowledge Management, pp 123-128, 2009 [Li10] W.Li,A Web Service Composition Algorithm Based on Global QoS Optimizing with MOCACO, Algorithms and Architectures for Parallel Processing p. 218-224,2010 [Lin07] H. N. Lin, et. al, An Iterative, Collaborative Ontology Construction Scheme, Proc. of the 2nd Conference on Innovative Computing, Information and Control, Japan, pp 150-154, 2007 [Liu05] S.Liu, A Dynamic Web Service Selection Strategy with QoS Global Optimization Based on Multi-objective Genetic Algorithm. In: Zhuge, H., Fox, G.C. (eds.) GCC 2005. LNCS, vol. 3795, p 84–89. Springer, Heidelberg,2005
[Liu09] M. Liu, et al., An weighted ontology-based semantic similarity algorithm for web service, Experts Sysems with Applications , vol. 36, pp 12480-12490, 2009 [LWa08] L. Lu, and G. Wang, A study on multi-agent supply chain framework based on network economy,”Computers & Industrial Engineering, Vol. 54, Issue 2, March 2008, p.288-300, 2008 [Men04] D. Menasce, Composing web services: A QoS view, IEEE Internet Computing, Vol. 8, Issue 6, p.88–90, 2004 [Mfin10] Public Finance Ministery, www.mfinante.ro [MJe09] J.Min, C.Jeong, A binary classification method for bankruptcy prediction, Expert Systems with Applications, nr 36, p. 5256–5263, 2009 [MRP10] R.Mohanty,V. Ravi, M.R. Patra, Web-services classification using intelligent techniques, Expert Systems with Applications Vol.37, no. 7, p 5484-5490, 2010 [OGC09] Geography Markup Language, disponibil la http://www.opengeospatial.org
[Ost04] A.Osterwalder, The Business Model Ontology - a proposition in a design science approach, Ph.D. thesis, In Institut
d'Informatique et Organisation, University of Lausanne, Ecole des Hautes Etudes Commerciales HEC, Lausanne,
Switzerland, 2004
[Pha05] H. Pham, A new generalized systemability model, International Journal of Performability Engineering, vol 1, no. 2, p. 145-155, 2005 [Pha06] H.Pham, System software reliability, Springer, 2006
[PBe01] L. Pitt, P. Berthon, et al. Pricing Strategy and the Net , Business Horizons, vol 44, nr 2, pag 45-54, 2001
[PKr07] M. Papazoglou, B. Kratz, Web services technology in support of business transactions, Service Oriented Computing and Applications, Vol. 1, No. 1, London: Springer, p 51-63, 2007 [RAn10]M. H. Rezvani, M.Analoui, An economic model for multi-service overlay multicast networks based on walrasian general equilibrium, Economic computation and economic cybernetics studies and research, 44, p 139-161,2010.

PROGRAMUL 4 “PARTENERIATE IN DOMENIILE PRIORITARE” 2007-2013
SCIPA – Etapa 3: Dezvoltarea componentelor semantice ale platformei
61
[SDC10] I. Smeureanu, A. Dioşteanu, L. Cotfas, Knowlegde Dynamics in Semantic Web Service Composition for Supply Chain Management Applications, Journal of Applied Quantitative Methods, Vol. 5, Issue.1, pp. 1, 2010 [SDD09] I. Smeureanu, A. Dioşteanu, A. Dardală, Semantic Networks for Modeling Supply Chain Business Flow, Proc. CSCS-17, 17th International Conference on Control Systems and Computer Science, Vol 2, p 547-554, 2009
[Wal00] J.Wallin, Operationalizing Competences, International Conference on Competence-Based Management, Helsinki,
2000
[Wan08] M. Wang, et al., On-demand e-supply chain integration: A multi-agent constraint-based approach, Expert Systems with Applications, Vol. 34, Issue 4, p.2683-2692, 2008 [YPi09] J.Yan, J. Piao, Towards QoS-Based Web Services Discovery, Lecture Notes In Computer Science,p 200–210, 2009

PROGRAMUL 4 “PARTENERIATE IN DOMENIILE PRIORITARE” 2007-2013
SCIPA – Etapa 3: Dezvoltarea componentelor semantice ale platformei
62
Anexa 1- Codul asociat ontologiei clientului <rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#" xmlns:owl="http://www.w3.org/2002/07/owl#" xmlns:xsd="http://www.w3.org/2001/XMLSchema#" xmlns:j.0="http://constructionfirm.com/" xmlns:rdfs="http://www.w3.org/2000/01/rdf-schema#" > <rdf:Description rdf:about="http://constructionfirm.com/maxTemperature"> <rdfs:range rdf:resource="http://www.w3.org/2001/XMLSchema#unsignedInt"/> <rdfs:domain rdf:resource="http://constructionfirm.com/Brick"/> <rdf:type rdf:resource="http://www.w3.org/2002/07/owl#DatatypeProperty"/> </rdf:Description> <rdf:Description rdf:about="http://constructionfirm.com/geogrphiCoordinates"> <rdfs:range rdf:resource="http://www.w3.org/2001/XMLSchema#string"/> <rdfs:domain rdf:resource="http://constructionfirm.com/Area"/> <rdf:type rdf:resource="http://www.w3.org/2002/07/owl#DatatypeProperty"/> </rdf:Description> <rdf:Description rdf:nodeID="A0"> <owl:cardinality rdf:datatype="http://www.w3.org/2001/XMLSchema#int">1</owl: cardinality> <owl:onProperty rdf:resource="http://constructionfirm.com/maxTemperature"/> <rdf:type rdf:resource="http://www.w3.org/2002/07/owl#Restriction"/> </rdf:Description> <rdf:Description rdf:about="http://constructionfirm.com/Domain"> <rdfs:label xml:lang="EN">Domain</rdfs:label> <rdf:type rdf:resource="http://www.w3.org/2002/07/owl#Class"/> </rdf:Description> <rdf:Description rdf:about="http://constructionfirm.com/Area"> <rdfs:label xml:lang="EN">Area</rdfs:label> <rdfs:subClassOf rdf:resource="http://constructionfirm.com/Brick"/> <rdf:type rdf:resource="http://www.w3.org/2002/07/owl#Class"/> </rdf:Description> <rdf:Description rdf:about="http://constructionfirm.com/requestedThing"> <rdfs:label xml:lang="EN">TradedThing</rdfs:label> <rdf:type rdf:resource="http://www.w3.org/2002/07/owl#Class"/> </rdf:Description> <rdf:Description rdf:about="http://constructionfirm.com/RequestedBrick"> <j.0:maxTemperature>150</j.0:maxTemperature> <rdf:type rdf:resource="http://constructionfirm.com/Brick"/> </rdf:Description> <rdf:Description rdf:about="http://constructionfirm.com/Brick"> <rdfs:label xml:lang="EN">Brick</rdfs:label> <rdfs:subClassOf rdf:resource="http://constructionfirm.com/requestedThing"/> <rdf:type rdf:resource="http://www.w3.org/2002/07/owl#Class"/> </rdf:Description> </rdf:RDF>

PROGRAMUL 4 “PARTENERIATE IN DOMENIILE PRIORITARE” 2007-2013
SCIPA – Etapa 3: Dezvoltarea componentelor semantice ale platformei
63
Anexa 2- Compunerea simplă AE - cod sursă public static PackageBrowser InstallPear(File installDir, File pearFile) { boolean doVerification = true; PackageBrowser instPear = PackageInstaller.installPackage(installDir, pearFile, doVerification); return instPear; } public static String PearInstallerTest(Vector<PackageBrowser> packageArray, String installDir, String ontoURI) throws TransformerConfigurationException, TransformerException { String xmlRes=""; try { Vector<AnalysisEngineDescription> analysisEngineDescVect=new Vector<AnalysisEngineDescription>(); String classpath=""; String datapath=""; Vector<String> pearDescPath=new Vector<String>(); Vector<String> mainComponentDescriptor=new Vector<String>(); Vector<String> mainComponentDescriptorID=new Vector<String>(); ResourceManager resourceMgr = UIMAFramework.newDefaultResourceManager(); for(int c=0; c<packageArray.size(); c++) { classpath+= packageArray.get(c).buildComponentClassPath()+";"; // PEAR package datapath datapath += packageArray.get(c).getComponentDataPath()+";"; // PEAR package main component descriptor mainComponentDescriptor.add(packageArray.get(c).getInstallationDescriptor().getMainComponentDesc()); // PEAR package component ID mainComponentDescriptorID.add(packageArray.get(c).getInstallationDescriptor().getMainComponentId()); // PEAR package pear descriptor pearDescPath.add(packageArray.get(c).getComponentPearDescPath()); //get AnalysisEngine from pear AnalysisEngineDescription ae_desc = UIMAFramework.getXMLParser().parseAnalysisEngineDescription(new XMLInputSource(packageArray.get(c).getInstallationDescriptor().getMainComponentDesc())); // Do full validation ae_desc.doFullValidation(resourceMgr); analysisEngineDescVect.add(ae_desc); } // Create an aggregate engine descriptor System.out.println("Starting the AED creation...."); AnalysisEngineDescription aggDesc = new AnalysisEngineDescription_impl();

PROGRAMUL 4 “PARTENERIATE IN DOMENIILE PRIORITARE” 2007-2013
SCIPA – Etapa 3: Dezvoltarea componentelor semantice ale platformei
64
FixedFlow_impl flow = new FixedFlow_impl(); Capability_impl cap; Vector<Capability> aggregateCapArray=new Vector<Capability>(); Capability[] capVector; Vector<String> flowVector=new Vector<String>(); for(int k=0; k<analysisEngineDescVect.size(); k++) { String key="AE"+k; aggDesc.getDelegateAnalysisEngineSpecifiersWithImports().put(key, analysisEngineDescVect.get(k)); flowVector.add(key); capVector= analysisEngineDescVect.get(k).getAnalysisEngineMetaData().getCapabilities(); for(int i=0; i<capVector.length;i++) { TypeOrFeature[]typeFeature= capVector[i].getOutputs(); for(int j=0;j<typeFeature.length;j++) { cap=new Capability_impl(); System.out.println("Type feature "+typeFeature[j].getName()); cap.addOutputType(typeFeature[j].getName(), true); aggregateCapArray.add(cap); } } } String[] flowArray=new String[flowVector.size()]; flowArray=flowVector.toArray(flowArray); flow.setFixedFlow(flowArray); aggDesc.getAnalysisEngineMetaData().setFlowConstraints(flow); Capability[] capArray = new Capability[aggregateCapArray.size()] ; capArray=aggregateCapArray.toArray(capArray); aggDesc.getAnalysisEngineMetaData().setCapabilities(capArray); // Create the aggregate engine using the resource manager DatabaseConnectionHelper.GetConnection(null); AnalysisEngine ae = UIMAFramework.produceAnalysisEngine(aggDesc, resourceMgr, null); System.out.println("test_string_1"); String commonName="AggregatedAEforONT_"; //obtain the name of the aggregated pear under the format AggregatedAEforONT_OntoID if(!DatabaseConnectionHelper.con.isClosed()) { System.out.println("Teste!"); PreparedStatement stmt = DatabaseConnectionHelper.con.prepareStatement("SELECT IdOntology from ontologydata where OntologyURI=?"); System.out.println("Ontology URI: "+ ontoURI);

PROGRAMUL 4 “PARTENERIATE IN DOMENIILE PRIORITARE” 2007-2013
SCIPA – Etapa 3: Dezvoltarea componentelor semantice ale platformei
65
stmt.setString(1,ontoURI); ResultSet rs=null; =stmt.executeQuery(); rs if(rs.next()) { if(rs!=null && rs.getInt(1)!=0) { commonName+=rs.getInt(1); System.out.println("commonName="+commonName); } else commonName=""; } else System.out.println("Problems with iteration in the resultset!"); } else { System.out.println("There was a problem when opening the connection!"); } if(commonName!="") { File f=new File(installDir+"\\"+commonName+".xml"); FileOutputStream fos= new FileOutputStream(f); xmlRes=""; if(f.exists()) { aggDesc.toXML(fos); fos.close(); StringBuffer fileData new StringBuffer(1000); = BufferedReader reader = new BufferedReader(new FileReader(f.getAbsolutePath())); char[] buf = new char[1024]; int numRead=0; while((numRead=reader.read(buf)) != -1){ String readData = String.valueOf(buf, 0, numRead); fileData.append(readData); buf = new char[1024]; } reader.close(); xmlRes=fileData.toString(); System.out.println("String Aggregated:\n "+xmlRes); System.out.println("Data successfully written!!"); //store the aggregated AE into the DB CallableStatement cs=DatabaseConnectionHelper.con.prepareCall("{call spRegisterAggregatedPear(?,?)}"); cs.setString("OntoURI", ontoURI); cs.setString("componentPath", f.getAbsolutePath()); cs.execute(); }

PROGRAMUL 4 “PARTENERIATE IN DOMENIILE PRIORITARE” 2007-2013
SCIPA – Etapa 3: Dezvoltarea componentelor semantice ale platformei
66
else System.out.println("FileNotExists!!!!!!"); } else throw new Exception("Problems occured when trying to retrive IdOntology!"); } catch (PackageInstallerException ex) { // catch PackageInstallerException - PEAR installation failed ex.printStackTrace(); System.out.println("PEAR installation failed"); } catch (IOException ex) { ex.printStackTrace(); System.out.println("Error retrieving installed PEAR settings"); } catch(InvalidXMLException ex) { ex.printStackTrace(); System.out.println("AE descriptor XML not valid!!!!"); } catch(ResourceInitializationException ex) { ex.printStackTrace(); System.out.println("Could not initialize resource"); } catch( Exception ex ) { ex.printStackTrace(); } return xmlRes; } public static String createComposedPearDescriptor( String installDirString, String sourceFileURLsString,String ontoURI ) { String outputSting=""; File installDir; Vector<File> sourceFile=new Vector<File>(); String pearFolder="D:\\TempFolder"; String[] sourceFileURLStringVector=sourceFileURLsString.split(","); for(int j=0;j<sourceFileURLStringVector.length;j++) { System.out.println("Download from URL.... "+sourceFileURLStringVector[j]); String[] temp=sourceFileURLStringVector[j].split("/"); String fileName=temp[temp.length-1]; System.out.println("The file name: "+fileName); System.out.println("Pear folder... " +pearFolder+fileName); sourceFile.add(downloadPear(sourceFileURLStringVector[j], pearFolder+fileName));

PROGRAMUL 4 “PARTENERIATE IN DOMENIILE PRIORITARE” 2007-2013
SCIPA – Etapa 3: Dezvoltarea componentelor semantice ale platformei
67
System.out.println("Download..."); } Vector<PackageBrowser> packageVector=new Vector<PackageBrowser>(); for (int i=0; i<sourceFileURLStringVector.length;i++) { installDir=new File(installDirString+"_"+i); if(!installDir.exists()) { installDir.mkdir(); System.out.println("Directory created... "+installDir.getName()); } packageVector.add(InstallPear(installDir, sourceFile.get(i))); } try { outputSting=PearInstallerTest(packageVector,installDirString,ontoURI); } catch(TransformerConfigurationException ex) { System.out.println(ex.getMessage()); } catch(TransformerException ex) { System.out.println(ex.getMessage()); } return outputSting; }

PROGRAMUL 4 “PARTENERIATE IN DOMENIILE PRIORITARE” 2007-2013
SCIPA – Etapa 3: Dezvoltarea componentelor semantice ale platformei
68
Partea a II-a
Modele de cooperare bazate pe agenti software
Autori – Universitatea Politehnica din Bucureşti
Prof. dr. ing. Adina Magda Florea – responsabil ştiinţific
Prof. dr. ing. Eugenia Kalisz
S.l. dr. ing. Alexandru Boicea
As. drd. ing. Andrei Mogos As. drd. ing. Andreea Urzica
CUPRINS
1 Cooperare bazata pe costuri in cazul agentilor motivati individual 71
1.1 Motivarea necesitatii cooperarii 71
1.1.1 Modelul de Rationament 71
1.1.2 Rationamentul Agentului 73
1.2 Structura de Control a Agentului 74
1.3 Reguli de Negociere bazate pe Cost 76
1.3.1. Reguli de Generare Cereri 76
1.3.2. Reguli de Evaluare a Cererilor Primite 77
1.3.3. Reguli de Evaluare a Raspunsurilor 78
1.4 Concluzii 78
2 Un model de învăţare bazat pe negociere pentru medii deschise multi-agent 80
2.1 Negocierea in sistemele multi-agent 80
2.2 Modelul de Negociere 81
2.2.1 Primitive de Negociere 82
2.3 Invatarea strategiei de negociere 84
2.4 Concluzii 89

PROGRAMUL 4 “PARTENERIATE IN DOMENIILE PRIORITARE” 2007-2013
SCIPA – Etapa 3: Dezvoltarea componentelor semantice ale platformei
69
1 Cooperare bazata pe costuri in cazul agentilor motivati individual
1.1 Motivarea necesitatii cooperarii
Intr-un sistem multi-agent, un agent exista si isi desfasoara activitatea intr-o societate
in care alti agenti ies si actioneaza. Prin urmare, coordonarea dintre agenti este esentiala
pentru atingerea obiectivelor si actionarea intr-o maniera coerenta, atat in cazul sistemelor
competitive, cat si a celor cooperative. Atunci cand agentii din sistem sunt motivati
individual, coordonarea si cooperarea nu pot fi luate ca atare. Cooperarea trebuie sa fie
planificata si atinsa prin comunicare si negociere.
In continuare se prezinta modelul si functionarea unui sistem multi-agent in care
agentii motivati individual urmaresc indeplinirea dorintelor lor non-contradictorii, in acelasi
timp cu indeplinirea propriilor obligatii si norme, atingerea unui castig maxim si stabilirea de
relatii bune cu ceilalti agenti din sistem. Se prezinta reprezentarea agentului in ceea ce
priveste modelul mental al acestora, atributele si modul de rationament al acestora, descrierea
functionarii sistemului, si procesul de negociere pentru atingerea acordului.
1.1.1 Modelul de Rationament
Intr-un sistem multi-agent, pentru a coopera eficient si a fi capabil sa negocieze
aceasta cooperare, un agent are nevoie de capacitatea de a reprezenta si rationa pe baza unui
model mental al comportamentului sau, si sa-si dezvolte si rationa modele celorlalti agenti din
sistem. Starea mentala a unui agent se caracterizeaza prin folosirea unor notiuni precum
credinte, dorinte, intentii, obiective, preferinte si obligatie, fiind o extindere a modelului BDI
[6] si a BDIG [4].
Convingerile sunt informatiile pe care agentul le are asupra mediului sau: ele includ
convingerile cu privire la lume si convingerile cu privire la starile mentale ale altor agenti.
Convingerile pot fi adevarate sau false; ele vor fi actualizate dupa observarea lumii si dupa
cumunicare cu alti agenti. Dorintele sunt acele lucruri pe care agentul ar dori sa le vada
realizate – dorintele nu trebuie sa fie consecvente si nu ne putem astepta ca un agent sa
actioneze asupra tuturor dorintelor. Intentiile sunt acele lucruri pe care agentul este fie
angajat sa le faca (intentia-sa) sau angajat sa le aduca (intentia-de-a). Primul tip de intentie
este reprezentat de acelea pe care agentul este capabil sa le atinga, in timp ce a doua categorie
le include pe acelea care nu sunt neaparat in propria raza de actiune, si pentru care agentul
trebuie sa coopereze cu alti agenti pentru a le indeplini.
Obligatiile sunt acele lucruri pe care agentul trebuie sa le respecte, iar preferintele sunt
valorile pe care un agent le asociaza cu propriile dorinte. Obiectivele agentului sunt selectate
ca un subset consistent al dorintelor agentului, in functie de preferintele sale mai mari si care
respecta obligatiile. Un agent “rebel” poate selecta obiectivele doar din setul de dorinte cele

PROGRAMUL 4 “PARTENERIATE IN DOMENIILE PRIORITARE” 2007-2013
SCIPA – Etapa 3: Dezvoltarea componentelor semantice ale platformei
70
].
mai preferate (mentinand in acelasi timp consistenta obiectivelor sale), astfel neincercand sa
isi indeplineasca propriile obligatii.
Fara a intra in detalii formale, modelul contine cateva operatori modali (unde w este o
wff in logica predicatelor de ordin intai), si anume: Beliw - agentul i crede w, Desiw - i
doreste w, Intiw - i intentioneaza w, Prefi (w,v) - i prefera w cu valoarea (preferinta) v, si Obiw
- i are obligatia w. Setul Pred al tuturor predicatelor posibile ce pot fi folosite pentru
descrierea conceptualizarii include trei predicate speciale: Abiw - agentul i are abilitatea w,
Consi (w,v) - i consuma v pentru executarea actiunii w (unde w este o intentie), si Gaini (w,v) -
i castiga v daca w este atins (w este un obiectiv). Semantica modelului este bazat in mare parte
pe structuri minimale [1
Comunicarea dintre agenti este efectuata prin intermediului unui set de mesaje (M) ce
contine:
Request(w, DeadLine, Payment) – cererea de a efectua w intr-un anumit interval de timp
DeadLine cu cosutul Payment pentru w
ModifyRequest(w, DeadLine, Payment) – raspunsul cu o cerere modificata (w va fi
efectuat dar cu valori diferite pentru DeadLine si Payment spre deosebire de cele initial
propuse)
Accept(w, DeadLine, Payment) – acceptarea cererii w cu DeadLine si Payment ca o
recompensa
Reject(w, Justification) – refuzarea cererii w cu o justificate Justification pentru refuz
Declare(w) – declararea ca w este o convingere
DealLine, Payment si Justification pot fi omise. Mesajele sunt transmise folosind:
Send: T x Ag x Ag M (cu Ag setul de agenti si T o multime de momente de timp
ordonata nemarginita in ambele directii) ce indica mesajele trimise la timpul tT de catre
expeditor catre receptor
Receive: T x Ag x Ag M ce indica mesajul receptionat la timpul tT de catre receptor
din partea expeditorului.
Exista, de asemenea, un set de norme general acceptate, care indica actiunile permise
in sistemele multi-agent.

PROGRAMUL 4 “PARTENERIATE IN DOMENIILE PRIORITARE” 2007-2013
SCIPA – Etapa 3: Dezvoltarea componentelor semantice ale platformei
71
Mental State Description of self mental state:
beliefs, desires, intentions, goals, preferences, obligations
Description of the mental states of other agents Description of the cooperation profile of other agents
Features Abilities, Consume, Gain
Messages request, modrequest, accept, reject, declare
NORMS
Inference Rules Inference Rules for updating the Mental State Inference Rules for Goal Selection Inference Rules for plan generation Inference Rules for evaluating the cooperation profile Inference Rules for negotiation
(a) Request generation & selection (b) Incoming request evaluation & answer generation (c) Answer evaluation & reply generation
Figura 1. Structura agentului.
1.1.2 Rationamentul Agentului
Un agent are cateva capabilitati de rationament ce includ rationamente despre starea
lumii, despre cum sa selecteze si sa isi atinga obiectivele si cu privire la modul de desfasurare
a negocierii. Negocierea se bazeaza in principal pe castigul pe care agentul il va avea prin
indeplinirea obiectivelor sale, dar criteriile de negociere vor cuprinde, de asemenea, profilul
de cooperare al agentilor cu care agentul a lucrat anterior si credintele sale despre starile
mentale ale acestora, incluzand de exemplu convingeri despre obligatiile pe care alti agenti
trebuie sa le respecte. Rationamentul din spatele negocierii este prezentat in sectiunea 4.
Dupa cum s-a precizat anterior, agentul are un set de reguli de inferenta (IR) pentru
selectarea setului curent de obiective al acestuia, o multime de IR pentru actualizarea starii
mentale (convingeri modificabile despre sine si despre alti agenti, dorinte in schimbare, etc.)
si IR pentru generarea de planuri pentru planurile de constructie in vederea atingerii
obiectivelor selectate. Actiunile in plan sunt indexate conform timpului T ce permite asocierea
unui termen limita pentru fiecare actiune. Dupa dezvoltarea unui plan agentul analizeaza
intentiile necesare pentru desfasurarea planului si identifica intentiile-sa si intentiile-de-a prin
investigarea propriilor abilitati. Pentru realizarea intentiilor-de-a agentul trebuie sa negocieze
indeplinirea acestora cu alti agenti din sistem. Pentru efectuarea unei negocieri corecte si
eficiente, agentul este de asemenea dotat cu un set de negociere IR (Fig. 1) si un set de IR
pentru evaluarea profilului de cooperare a altor agenti. Profilul de cooperare poate fi, de
asemenea, considerat ca o parte din convingerile agentului cu privire la alti agenti din sistem.

PROGRAMUL 4 “PARTENERIATE IN DOMENIILE PRIORITARE” 2007-2013
SCIPA – Etapa 3: Dezvoltarea componentelor semantice ale platformei
72
1.2 Structura de Control a Agentului Structura de control a agentului este in principal formata din doua faze. Prima faza
este dedicata controlului activitatilor agentului, care nu depind de alti agenti, in timp ce a doua
faza este dedicata in mod special negocierii si ajungerii la un acord. Prima faza cuprinde
selectarea obiectivului, generarea planului pentru obiectivele selectate si analiza intentiilor
conform planului general. Fiecare obiectiv are un castig asociat, dupa cum s-a precizat
anterior. Daca nu se specifica altfel, obiectivul este impartit in mod egal si asociat intentiilor
care vor conduce la realizarea obiectivului. Acest castig asociat la intentii va fi folosit de catre
agent in timpul efectuarii negocierilor.
Analiza planurilor generate se refera la doua aspecte: analiza daca actiunile
intentionate in cadrul planului incalca normele si cea daca actiunile se afla in gama actuala de
abilitati ale agentului. Fiecare analiza poate conduce la o revizuire a planului de generare sau
a selectiei obiectivului. Ca o consecinta a analizarii celui de-al doilea aspect agentul identifica
intentia-sa (ce actiuni sunt in intervalul propriilor abilitati) si pe cele de tip intentia-de-a.
Intentiile-de-a sunt ulterior analizate pentru identificarea agentilor care, conform
convingerilor agentului, sunt capabile sa le indeplineasca. Daca exista cel putin o intentie-de-a
care nu poate fi indeplinita de catre un alt agent (sau cel putin nu conform cunostintelor
agentului) agentul va revizui obiectivele sale sau planurile (daca exista un plan alternativ) sau
se va adresa unui facilitator la cerere (a se vedea arhitectura din [2]) ce poate sa ii recomande
un agent avand abilitatile necesare. Prima faza a controlului agentului este sumarizata in cele
ce urmeaza.
Faza I pentru agentul A
1. Select goals {Goals} as a noncontradictory subset of {DesA} considering {PrefA}
2. Generate plans for selected goals {PlansGoalA}
3. Analyze actions in {PlansGoalsA} from the point of view of norm compliance
4. if actions violate norms
5. then revise {PlansGoalsA} or {GoalsA}
6. Analyze action on {PlansGoalsA} from the point of view of agent’s abilities {AbA}
7. if there are intentions-that
8. then search description of other agents and identofy the agents {i} with {Abi} able to do
intentions-that
- if no such agents exist
- then address facilitator or revise {PlansGoalsA} or {GoalsA}
9. Perform all intentions-to

PROGRAMUL 4 “PARTENERIATE IN DOMENIILE PRIORITARE” 2007-2013
SCIPA – Etapa 3: Dezvoltarea componentelor semantice ale platformei
73
Cea de-a doua faza este dedicata negocierii, in cazul in care agentul a identificat
indentii-de-a necesare pentru atingerea propriului obiectiv. In pasul 6 al fazei I, agentul a
construit, pentru fiecare intentie-de-a, o lista cu agentii ce pot efectua respectivele actiuni. In
faza II agentul incearca ajungerea la un consens cu respectivii agenti in efectuarea acestor
actiuni. Negocierea poate fi efectuata de ambele parti sau de mai multe. In cazul negocierii
intre mai multe parti regulile de inferenta corespunzatoare vor spune agentului care sunt acei
agenti cu care se negociaza dintre aceia care au abilitatea de a efectua propriile intentii-de-a.
Un sumar al pasilor corespunzatori fazei II este prezentat mai jos.
Faza II pentru agentul A
1. Generate requests for agents in {i} to do intentions-that
2. Select requests {Reqi} to be sent
3. Send requests {Reqi}
4. Read answers to {Reqi}
5. Evaluate answers, accept them or generate counterproposals
6. Evaluate incoming requests {ReqA} and generate answers
7. Update mental model (including the cooperation profile)
8. Send answers to {ReqA} (accept or counterproposals)
Primul si al doilea pas vor aplica negocierea IR pentru a genera si selecta cererea
corespunzatoare si agentul/agentii asociati carora li se vor trimite cererile. Pasul 5 este dedicat
evaluarii raspunsurilor la aceste cereri si, in cazul receptionarii unei contrapropuneri (de
exemplu, cererea anterior trimisa va fi efetuata de un alt agent cu alte valori pentru DeadLine
si/sau Payment) noile conditii pot fi fie acceptate, rejectate cu o justificare, sau o contra-
propunere este generata cu modificari aduse valorilor propuse pentru DeadLine si Payment.
Pasul 6 este dedicat procesarii cererilor provenind de la alti agenti ce au nevioe de asistenta.
Agentul ce primeste cererea poate fie sa o acceptate si in consecinta va trimite un mesaj de
acceptare, sa o rejecteze cu sau fara o justificare, sau sa genereze o contra-propunere. Dupa
fiecare runda de negociere modelul de rationament este actualizat. Aceasta inseamna
convingerile, intentiile si chiar obiectivele (in cazul in care agentul se angajeaza sa efectueze
actiuni ce ar putea contrazice setul curent de obiective) si profilele de cooperare ale agentilor
cu care agentul curent a schimbat mesaje. Principalele aspecte ce definesc profilul de
cooperare al unui agent din punctul de vedere al altui agent sunt prezentate in Fig. 2.

PROGRAMUL 4 “PARTENERIATE IN DOMENIILE PRIORITARE” 2007-2013
SCIPA – Etapa 3: Dezvoltarea componentelor semantice ale platformei
74
No. of requests accepted by x (No_req)
A’s gain obtained from x’s previous actions (My_gain)
x’s credit as given by A (Given_credit)
No. of x’s requests rejected by A (No_reject)
No. of x’s abilities that may lead to A’s goal fulfillment (No_abil)
A’s credit as given by x (My_credit)
Figura 2. Descrierea lui A despre profilul de cooperare al altui agent x.
1.3 Reguli de Negociere bazate pe Cost Regulile de negociere pot fi impartite in trei parti: (a) reguli pentru generarea si
selectarea unei cereri initiale pentru executarea unei actiuni; (b) reguli pentru evaluarea
cererilor emise de alti agenti si generarea raspunsurilor adecvate, mai precis acceptare,
rejectare sau contra-propuneri; (c) reguli pentru evaluarea raspunsurilor obtinute pentru o
anumita cerere, pentru generarea de contrapropuneri, daca sunt necesare, si a raspunde la
intrebari (a se vedea si Fig. 1).
1.3.1. Reguli de Generare Cereri
Generarea cererilor consta in contruirea, pentru fiecare intentie-de-a, a unui mesaj
avand continutul:
(Action, DeadLine, Payment)
fiecare astfel de mesaj avand asociata o lista ListOfAgents de agenti capabili de
efectuarea actiunii. Valorile corespunzatoare pentru DeadLine si ListOfAgents sunt obtinute
in faza I (pasul 2, respectiv 6), in timp ce Payment si agentul/agentii particulari carora li se
trimite mesajul sunt fixati prin reguli de inferenta. Pentru determinarea valorii Payment,
agentul calculeaza initial valoarea maxima pe care e dispus sa o plateasca pentru Action,
insemnand ca prin calculul acestei valori nu va obtine nici un castig pentru Action. Fie N
intentia-de-a a agentului A si gN castigul asociat lui N, obtinut din GainA(w,v) al obiectivului
GoalAw ce a generat necesitatea pentru N (in timpul planificarii) si Pmax=gN. Atunci cele
doua posibile reguli pentru actualizarea valorii Payment si selectarea agentului x de catre
agentul A sunt prezentate mai jos.

PROGRAMUL 4 “PARTENERIATE IN DOMENIILE PRIORITARE” 2007-2013
SCIPA – Etapa 3: Dezvoltarea componentelor semantice ale platformei
75
if Action = N and MaxPayment.N = Pmax
and x isin ListOfAgents and No_req.x > 0
and My_gain.x > 0 and Given_credit.x > 0
then Rank.x = 4 and Payment.N = Pmax/2
if Action = N and x isin ListOfAgents
and No_reject.x > 0 and No_req.x = 0
and Given_credit.x = 0
then Rank.x = 2 and Payment.N = 0
Agentii sunt ordonati conform acestor reguli si agentul avand tangul maxim este cel
selectat pentru trimiterea cererilor. De exemplu, daca agentul y este selectat, atunci
Send(t, A, y) = Request(N, DeadLine, Payment)
1.3.2. Reguli de Evaluare a Cererilor Primite
Atunci cand un agent A primeste o cerere provenind din partea unui agent x, A
determina prima data daca actiunea ceruta se afla in raza sa de abilitati si daca nu contravine
normelor. In cazul in care una dintre aceste conditii este adevarata, A rejecteaza cererea lui x
prin emiterea unui mesaj
Send(t, A, x) = Reject(Action, Justification)
cu Justification {NotAbility, NotConfNorms}. Altfel, agentul verifica daca cererea
nu contravine propriilor obiective sau obligatii. Un agent care se conforma va rejecta orice
cerere ce ar putea conduce la o contradictie cu propriile obligatii. In cazul unei contradictii cu
obiectivele agentul va investiga profilul de cooperare al agentului x pentru a vedea daca are
sens renuntarea la unul dintre propriile obiective pentru satisfacerea cererii lui x. Un agent
care nu se conforma ce primeste o cerere N din partea lui x aflata in contradictie cu obligatiile
sale poate determina cat ar costa executia lui N (ConsA( N, v)) si, daca valoarea Payment in
Receive(t, A, x) = Request(N, DeadLine, Payment) este mai mare decat ceea ce consuma
pentru N, ar putea accepta cererea si revizui propriile obligatii pentru a mentine propria stare
fara contradictii. In acest caz este necesar un plan de revizie, precum si in cazul in care N
contrazice unul dintre obiectivele lui A.
Sa presupunem ca actiunea ceruta nu contravine nici obiectivele si nici obligatiile lui
A. In acest caz agentul A va investiga planul generat si va compara valoarea oferita pentru
Payment cu cat consuma el pentru N. Daca Payment este mai mare si limita de timp DeadLine
poate fi satisfacuta, atunci A va emite Send(t1, A, x) = Accept(N, DeadLine, Payment). In
acest moment A va adopta N ca una din propriile intentii. Daca valoarea Payment este mai
mica decat ceea ce consuma, agentul poate aplica regula (with Cost = v, ConsA(N, v)):

PROGRAMUL 4 “PARTENERIATE IN DOMENIILE PRIORITARE” 2007-2013
SCIPA – Etapa 3: Dezvoltarea componentelor semantice ale platformei
76
if Action = N and Consume.N = Cost
and Cost > Payment and No_req.x > 0
and My_gain.x > 0 and My_credit.x > 0
then Rank.x = 4
si sa actualizeze profilul de cooperare al agentului x cu Given_credit.x = Cost -
Payment
Ulterior agentul A emite un mesaj de acceptare pentru oricare agent ce a fost clasificat
superior decat o anumita valoare pentru cererea sa. Altfel, agentul A poate genera o contra-
propunere
Send(t1, A, x) = ModifyRequest(N, DeadLine, Payment1)
cu Payment1 Cost. Daca limita de timp nu poate fi atinsa agentul A va emite fie un
mesaj
Send(t1, A, x) = Reject(N, NotDeadLine}
sau o contra-propunere
Send(t1, A, x) = ModifyRequest(N, DeadLine1, Payment)
cu noua limita de timp DeadLine1, in functie de cum N poate fi atinsa prin comparatie
cu propriile planurile generate curent.
1.3.3. Reguli de Evaluare a Raspunsurilor
Un mesaj de acceptare Accept(N, DeadLine, Payment) din partea lui x pentru o cerere
a lui A va duce la terminarea negocierii, A considerand ca x va executa actiunea N in
intervalul de timp DeadLine. A va actualiza corespunzator profilul de cooperare al lui x. Un
mesaj de rejectare va avea acelasi efect, incluzand actualizarea profilului de cooperare, dar
poate conduce de asemenea la revizuirea convingerilor lui A legate de x, de exemplu daca
actiunea ceruta N nu este una dintre abilitatile lui x (Justification = NotAbility in mesajul de
rejectare). O contra-propunere la actiunea ceruta va fi tratata intr-o maniera similara celei
descrise pentru cererile primite, folosind ca si criteriu castigul si profilul de cooperare al lui x
pe care A l-a dezvoltat pana la momentul curent.
1.4 Concluzii Modelul mental al agentilor are la baza lucrari precum [6,4] dar aduce preferinte,
abilitati, obligatii si norme. Structura de control a agentilor din sistem respecta definita din
paradigma de programare orientata pe agenti descrisa in [7]. Adaugarea costurilor (castig si
consum) la modelele mentale leaga diversele modele existente bazate pe paradigma BDI si
alte modele alternative ce au la baza teorii economice, precum in [3]. Exista o serie de lucrari
asupra negocierii, pornind de la cele teoretice pana la unele mai practice. Lucrarea de fata se
concentreaza pe aspectele practice ale negocierii, omitand modelul formal de dedesubt.

PROGRAMUL 4 “PARTENERIATE IN DOMENIILE PRIORITARE” 2007-2013
SCIPA – Etapa 3: Dezvoltarea componentelor semantice ale platformei
77
Abordarea propusa poate fi comparata cu lucrari precum [5,8] dar are avantajul unui criteriu
de negociere flexibil si a unor strategii definite de reguli de negociere.
Am prezentat un model de agenti motivati individual intr-un sistem multi-agent
cognitiv in care agentii sunt dotati, pe langa notiuni mentale de BDI (convingeri-dorinte-
intentii) cu obiective, preferinte si norme. Comportamentul agentilor este motivat in mare
parte de castigul pe care il pot obtine din indeplinirea obiectivelor lor preferate si de
necesitatea cooperarii cu alti agenti pentru atingerea acestor obiective. In timpul cooperarii cu
alti membrii ai societatii de agenti un agent dezvolta profile de cooperare, ce sunt rafinate
treptat si folosite pentru controlul propriului comportament in timpul negocierii. In timpul
cooperarii si negocierii convingerile agentului asupra celorlalti agenti se actualizeaza astfel
incat agentul ajunge sa cunoasca mai multe despre ceilalti.
Sub diverse presupuneri asupra proprietatilor agentilor si criteriului/criteriilor de
negociere, sistemul poate modela cateva tipuri de agenti. Agentii pot fi conformi, avand astfel
capabilitatea de a-si onora toate obligatiile, sau pot fi modelati sa renunte la propriile obligatii
in cazul in care castigul propus este destul de stimulant. Agentii pot ceda credite altor agenti
daca istoria de cooperare justifica o asemenea actiune sau daca abilitatile celorlalti agenti sutn
importante pentru atingerea propriului obiectiv. Alte definitii ale regulilor de negociere pot
modela agenti mai increzatori ce intotdeauna cedeaza credit celorlalti, indiferent de propriul
castig.
Mai multe extensii ale modelului sunt curent considerate pentru dezvoltari ulterioare.
O posibila astfel de extensie este legata de adaugarea de conventii pentru monitorizarea
viabilitatii angajamentelor agentilor (intentii acceptate in timpul negocierii), urmate de
directiile prezentate in [5].
O alta extensie consta in integrarea modelului curent in arhitectura recursiva propusa
in [2] astfel incat sa dezvoltam agentii motivate individual in care un agent poate fi vazut ca o
colectie de agenti, si de a adauga roluri pentru modelarea diverselor grade de cooperare (de la
agenti complet motivati individual pana la agenti complet cooperanti). Desi modelul prezentat
pare sa fie capabil cu precadere sa se adreseze agentilor motivati individual, consideram ca un
comportament bazat pe costuri si istoria si experienta de cooperare poate furniza un cadrul de
lucru pentru implementarea unei game largi de profile de cooperare in sisteme multi-agent.
Bibliografie
[1] B.F. Chellas. “Modal Logic: An Introduction”, Cambridge University Press, Cambridge, UK, 1980. [2] A. Florea. “Intelligent Agents Technology in Virtual Enterprise Design”, In Preprints of ISoCE’98,
The First International Symposium on Concurrent Enterprising, Sinaia, pp.107 - 117, 4-6 Junie, 1998. [3] S. Kraus. “Negotiation and Cooperation in Multi-agent Environments”, Artificial Intelligence, vol.
94, no. 1-2, pp. 79-97, 1997. [4] S. Kraus, K. Sycara, and A. Evenchik. “Reaching Agreements Through Argumentation: a logical
model and implementation”, Artificial Intelligence, vol. 104, no.1-2, pp. 1-69, 1998.

PROGRAMUL 4 “PARTENERIATE IN DOMENIILE PRIORITARE” 2007-2013
SCIPA – Etapa 3: Dezvoltarea componentelor semantice ale platformei
78
[5] T. Norman, N. Jennings, P. Faratin, and A. Mamdani. “Designing and Implementing a Multi-agent Architecture for Business Process Management”. In Intelligent Agents III: Agent Theories, Architectures, and Languages, J.P. Muller, M.J. Wooldridge, and N.R. Jennings, Eds. Springer Verlag, pp.261-275, 1997.
[6] A.S. Rao and M.P. “Georgeff. Modeling Rational Agents Within a BDI-architecture”. In R. Fikes and E. Sandwall, editors, Proc. of Knowledge Representation and Reasoning (KR&R-91), Morgan Kaufman, pp.473-484, 1991.
[7] Y. Shoham. “Agent-oriented programming”, Artificial Intelligence, vol. 60, no. 1, p.51-92, 1993. [8] C. Sierra, P. Faratin, N. Jennings. “A Service-oriented Negotiation Model between Autonomous
Agents”. Preprint submitted to Elsevier Science, pp.24, 1998.
2 Un model de învăţare bazat pe negociere pentru medii deschise multi-agent 2.1 Negocierea in sistemele multi-agent
Negocierea este esenţială în scenarii in care în care agenţi autonomi au conflict de interese şi
dorinţa de a coopera. Negociere automată între agenti inteligenti a devenit astfel tot mai
importanta în aplicaţii care necesită luarea de decizii asistate de calculator, cum ar fi e-
commerce, alocarea distribuita a resurselor, sau întreprinderi virtuale. Mediile unor astfel de
aplicatii sunt în mod inerent deschise deoarece ele sunt populate cu agenţi de auto-interes
proiectati şi / sau deţinuti de persoane diferite şi nu există informaţii complete despre
preferinţele sau despre procesul de luare a deciziilor al agenţilor participanti. Pentru a fi cu
adevărat autonom şi a obţine performanţă atunci când efectuează o negociere, un agent ar
trebui să fie capabil să anticipeze atât rezultatul negocierii cat şi cel mai bun potential
partener cu care sa înceapa o negociere. Abordarile bazate pe invatare automata cum ar fi
invatarea bazata pe recompensa pot contribui la adaptarea strategiei agentului în timpul
negocierii şi comercializarea, obţinerea unor rezultate mai bune şi a unor retributii crescute.
Propunem un cadru de negociere care include obiecte de negociere care cuprind mai multe
aspecte ale elementului negociat, şi seturi diferite ale primitivelor de negociere pentru agenţi
cognitivi şi, în special, a agenţilor BDI. În contextul unui mediu deschis, un mecanism pentru
a învăţa cum să negocieze este necesar, dar învăţarea ar trebui să aibă loc fără o cunoaştere
prealabilă a mediului şi a agenţiilor din ea. În acest scop, propunem o abordare a învăţarii care
ii permite negociatorului sa invete care primitiva de negociere sa fie folosita intr-un anumit
stadiu de negociere; abordarea este bazata pe o metoda de invatare de tip Q-learning (invatare
prin recompensa de tip Q).
Lucrarea este structurată după cum urmează. Secţiunea 2 prezintă modelul de negociere al
agenţilor auto-interesaţi într-un mediu deschis, Secţiunea 3 prezintă primitivele de negociere
şi protocolul, Secţiunea 4 descrie modelul de invatare a negocierii şi reprezentarea asociata a
starilor negocierii, Secţiunea 5 se ocupă cu lucrările inrudite, în timp ce secţiunea 6 este
dedicată concluzilor şi lucrarilor viitoare.

PROGRAMUL 4 “PARTENERIATE IN DOMENIILE PRIORITARE” 2007-2013
SCIPA – Etapa 3: Dezvoltarea componentelor semantice ale platformei
79
2.2 Modelul de Negociere
Modelul de negociere pe care il propunem cuprinde un set de agenţi cognitivi motivati
individual care sunt capabili sa rationeze cu privire la diferite probleme in ceea ce priveste
obiectul care urmează să fie negociat. Un model de agenti BDI (Beliefs,Desires,Intentions) [1]
este în continuare necesar pentru a sprijini setul extins de primitive definit în cele ce urmeaz.
Într-un model BDI agenţii sunt dotati cu convingeri despre mediul înconjurător şi despre alţi
agenţi din mediu, intenţiile de a executa acţiunile structurate în planuri, şi dorinţe, care
reprezintă rezultatele pe care agenţii doresc să le obţină. Un subset consistent de dorinte
formeaza obiectivele agentului spre acele planuri care urmeaza să fie dezvoltate.
Mediul agentului este deschis, agenţii fiind capabili sa intre si sa iasa din mediu în timpul
vieţii lor. Un facilitator se presupune ca e prezent şi e conştient / informat cu privire la
identitatile agenţilor şi abilităţile lor. Nici un detaliu suplimentar despre interactiunile agenţi-
facilitator nu sunt date, insa o serie de scheme ale acestor interacţiunii pot fi găsite în [2].
Aspectele diferite care trebuiesc tratate într-o negociere sunt grupate într-un obiect de
negociere. Un obiect de negociere (NO) este gama de probleme asupra trebuie sa se realizeze
acorduri, asa cum sunt definite în [3]. Obiectul de negociere poate fi: un articol pe care
agentul A vrea să-l cumpere de la B; o acţiune pe care agentul negociatorul A ii cere agentului
B sa o efectueze pentru el; un serviciu pe care agentul A ii cere lui B, de exemplu, realizare
unui bazin de inot, o oferta a unui serviciu pe care agentul A este dispus sa il efectueze pentru
B, cu conditia ca B sa fie de acord cu conditiile agentului A, de exemplu o companie de
comunicare oferindu-i unui client potential un serviciu competitiv de apeluri la distanta.
Un obiect de negociere are un număr de atribute, cum ar fi preţul, termenul limită sau
planificarea, calitatea, sancţiuni, etc, fiecare atribut având un nume, o valoare, un tip, şi un
simbol care indică dacă atributul poate fi modificat sau nu. În timpul negocierii, valorile unor
atribute pot fi modificate sau unele atribute suplimentare pot fi adăugate obiectului de
negociere, de exemplu, un număr de minute gratuite pentru convorbirile la distanta în
serviciul de comunicare oferite de o companie. Un obiect de negociere are astfel o serie de
atribute care pot fi negociate, şi altele care nu pot fi modificate în timpul negocierii. O astfel
de structură pentru un obiect de negociere permite capturarea unei game largi de situaţii,
pentru a specifica în mod corespunzător modificări în timpul negocierilor, şi pentru a estima
utilitatea unei modificari NO în timpul negocierii. Se presupune că agenţii implicaţi într-o
negociere au acces la o înţelegere comună a semanticii unei NO.
Un cadru de negociere (NF) specifica cadrul pentru negocierea unui obiect de negociere
particular. Un cadru de negociere conţine numele cadrului, setul de primitive de negociere
permis în acel cadru de lucru, protocolul de negociere care trebuie urmat, un suport pentru
obiectul negociat şi un substituent pentru agentul (ii), cu care va negocia - fie negociere cu un

PROGRAMUL 4 “PARTENERIATE IN DOMENIILE PRIORITARE” 2007-2013
SCIPA – Etapa 3: Dezvoltarea componentelor semantice ale platformei
80
singur partener sau cu mai multi. Atunci când doreste să înceapă o negociere, un agent preia
un cadru de negociere, care este cel mai potrivit pentru negocierea obiectului, adaugă NO-ul
la acest cadru, şi adaugă lista de cunostinte sau doar un agent la acest cadru. Un agent poate
avea o bibliotecă de cadre negociate sau il poate interoga pe facilitator pentru noi cadre
negociate. În scopul utilizarii sau a înţelegerii unui NF, un agent trebuie să înţeleagă
primitivele negocierii cadrului, care funcţioneaza ca ontologie a negocierii, şi să poată să
urmeze protocolul specificat în acel NF. Cadrul de negociere modeleaza procesul de
negociere prin separarea semantică a protocolului de negociere de partea semantica a
obiectului de negociere.
2.2.1 Primitive de Negociere
Primitivele de negociere pe care le propunem în modelul nostru pot fi împărţite într-un set de
primitive de negociere de bază şi un altul extins. Primitivele de negociere de bază cuprind un
set de primitive care sunt, într-o formă sau alta, destul de frecvente în negocierea euristica
(conform clasificării de tehnici de negociere din [3]). Aceste primitive sunt:
Propose NO- cererea unui obiect de negociere
Accept NO- acceptarea cererii pentru NO
Reject NO - respingerea cererii pentru NO
ModifReq NO NO’ - modificarea cererii prin modificarea unor valori de atribute şi /
sau prin adăugarea de atribute NO-ului pentru a obtine NO’.
De exemplu, negociatorul A emite o cerere pentru un element, o acţiune, sau un serviciu care
trebuie asigurat, sau de serviciu care urmează să fie oferite, cererea fiind directionata, să
spunem, catre agentul B. Agentul B poate accepta cererea, poate să o respingă, şi poate
modifica cererea prin shimbarea valorii unui atribut de NO sau prin adăugarea unui nou
atribut. Negociere poate continua prin efectuarea de mai multe etape consecutive în care unul
sau alt agent modifică NO, un contract de succes a fost încheiat sau negocierea a esuat.
În cazul agenţilor BDI, vom extinde setul de negociere stabilit printr-un set de primitive de
negociere care reprezintă argumente că negociatorul, iar în unele cazuri agentul de legatura
poate să utilizeze în timpul negocieri. Fiecare tip de argument defineşte precondiţiile pentru
utilizarea acestuia. În cazul în care precondiţiile sunt îndeplinite, atunci agentul poate utiliza
argumentul. Printre tipurile de argument posibile menţionate în literatura [3, 4], am selectat
pentru setul de primitive de negociere extins următoarele argumente şi primitive de negociere
asociate:
Appeal to past promise (Apel la promisiunea trecuta) - negociatorul A reaminteşte
agentului B de o promisiune trecuta în ceea ce priveşte NO, de exemplu, agentul B a
promis agentului A sa efectueze sau sa ofere NO într-o negociere anterioară.

PROGRAMUL 4 “PARTENERIATE IN DOMENIILE PRIORITARE” 2007-2013
SCIPA – Etapa 3: Dezvoltarea componentelor semantice ale platformei
81
Precondiţii: A trebuie să verifice dacă o promisiune de NO (rasplata viitoare) a fost
primita în trecut într-o negociere încheiata cu succes. Negotiation primitive:
Remember NO ;( Negociere primitiva: Amintiţi-vă NO;)
Promise of a future reward - Promisiunea unei rasplate viitoare - Negociatorul A
promite să facă un NO pentru alt agent A la un moment dat în viitor. Precondiţii: A
trebuie să găsească o singura dorinţa a agentului B pentru un interval de timp viitor,
dacă este posibil, o dorinta care poate fi satisfăcuta printr-o acţiune (serviciu) pe
care A o poate efectua în timp ce B nu poate. Negotiation primitive: Promise NO
;(Negociere Primitiva: Promisiunea NO;).
Appeal to self interest – (Apel pentru interes propriu) – Agentul A este de părere că
încheierea contractului de NO este în interesul superior al lui B şi încearcă să-l
convingă pe B de acest lucru. Precondiţii: A trebuie să găsească (sau sa deduca), una
dintre dorintele lui B care este îndeplinită în cazul în care B are NO (de exemplu, A
crede că, clienţii vor dori servicii convenabile de comunicare) sau, alternativ, A
trebuie să găsească un alt obiect de negociere NO’, care este oferit în prealabil pe
piaţă (de exemplu, un alt serviciu de comunicare) şi se crede ca NO este mai bună
decât NO’. Negotiation primitive: CompareD NO Desire or CompareO NO NO’;
Threat - Amenintare - negociatorul face ameninţarea de a refuza sa faca / sa ofere
ceva lui B (de exemplu A il ameninţă pe B că va întrerupe furnizarea de energie
electrică în cazul în care B nu achita factura), sau ameninţă că va face ceva pentru a
contrazice dorinţele lui B. Precondiţii: A trebuie să găsească una dintre dorintele lui
B direct îndeplinite de către un NO pe care A o poate oferi sau A trebuie să găsească
o acţiune care este în contradicţie cu ceea ce crede ca este una din dorintele lui B.
Negotiation primitive: TreatForbid NO or ThreatDo NO.
Protocolul de negociere poate fi descris intuitiv prin utilizarea unui arbore aşa cum se arată în
Figura 1 (reprezentat pentru setul de negociere de baza), unde A este negociator şi B este
agentul cu care A negociază. Nodurile din arbore reprezintă starile în care unul sau altul
dintre agenţii de negociere trebuie să emită o negociere primitiva: starile SA corespund
deciziilor negociatorului, în timp ce SB starile agentului cu care A negociază. Starile dublu
incercuite sunt stari terminale, atunci când negocierea se termină. Tranzitiile de la o stare la
alta sunt etichetate cu primitivele negocierii posibile. Arborele de negociere este construit din
punct de vedere al negociatorului, şi anume, starile SA sunt stari în care agentul A are
controlul asupra primitivelor pe care le emite, în timp din starile SB este B cel care va
răspunde, prin urmare A nu are nici un control . Modelul descris este similar cu un arbore
dintr-un joc de noroc, cu noduri SB care corespund nodurilor şansă.

PROGRAMUL 4 “PARTENERIATE IN DOMENIILE PRIORITARE” 2007-2013
SCIPA – Etapa 3: Dezvoltarea componentelor semantice ale platformei
82
pA1=Accept pA
2=Reject pA3=ModifReq
pB1=Accept
. . . . . . . . . . . . . .
pB2=Reject
pA=Propose
pB3=ModifReq
SA
13
SA
SB
SA
11 SA
12
SB
13SB
11 SB
12
Figure 1: Arbore de negociere cu stari SA si SB alternative
O modalitate alternativă pentru specificarea protocolului de negociere consta in utilizarea unei
Definite Clause Grammar cum este descris în [5] şi [6]. Această a doua modalitate de a
specifica protocolul de negociere este utila pentru o reprezentare compactă a protocolului în
cadrul negocierii şi pentru o definiţie executabil formala a pasilor negocierii posibili să fie
urmati de un agent.
2.3 Invatarea strategiei de negociere
Secţiunea anterioară a arătat că un agent poate avea mai multe posibilităţi / primitive de
negociere pentru a efectua o negociere spre succesul (sau insuccesul) contractului. Este
modelul de lucrae a deciziei in cazul agentului cea care dictează care este strategia de
negociere ce va fi utilizata [3]. Strategiile euristice sunt destul de puternice în acest caz, dar
ele sunt dependente de domeniu, destul de greu să ne dam seama, şi consumatoare de timp.
Propunem o abordare de consolidare a invatarii care ar putea permite negociatorului sa invete
ce primitive de negociere sa foloseasca intr- un anumit stadiu al negocierii.
Invăţare de armare este sarcina cu care se confruntă un agent care învaţă un comportament
adecvat prin interacţiuni cu un mediu dinamic, prin recompensa si pedeapsa, care poate fi
considerat un semnal de armare primit de agent din partea mediului [7]. În modelul nostru,
agentul încearcă să înveţe o aproximare a unei politici optime prin utilizarea unui algoritm de
invatare-Q [8]. Un algoritm de învăţare Q-learning (algoritm Q-învăţare) este un model de
învăţare în care agentul foloseşte functia Q(a,s)) - valoarea de a face o acţiune a în starea s. O
politică este o mapare a starilor in acţiunile care maximizează unele măsuri pe termen lung de
recompensa, în cazul nostru de utilitate pentru starile în care agentul se confruntă cu o decizie
în ceea ce priveşte negocierea primitivă care urmeaza a fi emisa. Utilităţile starilor sunt legate

PROGRAMUL 4 “PARTENERIATE IN DOMENIILE PRIORITARE” 2007-2013
SCIPA – Etapa 3: Dezvoltarea componentelor semantice ale platformei
83
de valorile Q(a,s) ca U(s) = maxaQ(a,s). Într-un algoritm Q-învăţare avem următoarea
definiţie a funcţiei Q:
Ss'
a' Q(s',a')T(s,a,s')R(s)Q(s,a) max (1)
unde S este un set de stari, A este un set de acţiuni, R este funcţia recompensa R: S x A R,
a este actiunea care are loc în starea actuală s, s 'este starea următoare, a’ este acţiunea luata
în starea s’ şi T (s, a, s ') este funcţia de tranziţie a starii definită peste distribuţia de
probabilitate a tranziţiei de stare, potrivit unui Proces Markov de Decizie (MDP). Cu toate
acestea, un agent folosind un Q-algoritm de invatare nu trebuie să înveţe un model al mediului
deoarece actualizările Q pot fi calculate folosind Q-regula de învăţare, unde este rata de
învăţare:
Q(s,a) Q(s,a) + (R(s) + maxa’Q(s’,a’)-Q(s,a)) (2)
Q-regula de învăţare are un caracter anticipativ, deoarece utilizează stari şi acţiuni viitoare
pentru calcul Q (a,s), şi anume valoarea de a face acţiunea a în starea actuală s.
Pentru a aplica algoritmul de Q-learning pentru negociere se realizeaza o modificare a
arborelui de negociere, aşa cum se arată în figura 2. De data aceasta, nodurile din arbore
reprezintă o stare care corespunde la două etape ale procesului de negociere, un pas asociat
unei primitive emisa de către agentul A şi un alt pas asociat cu răspunsul agentului B. În acest
fel, un SAk şi o stare succesiva SB
k care urmeaza sunt unite în aceeaşi stare. Tranziţiile sunt
etichetate de data aceasta cu o secvenţă de doua primite de negociere, una emisa de agentul A
în SAk şi a doua care corespunde răspunsului lui B în SB
k. Să facem următoarea notaţie:
kBij
Aik ppa )( (3)
unde pAi este una din primitivele negocierii permise în stare SA
k (în cazul în care i variaza
peste toate aceste primitive) şi <pijB> este unul dintre răspunsurile permise ale lui B în starea
SBk atunci când primeste pA
i. Numim ak o acţiune compusa în procesul de negociere.
Folosind acesta nou reprezentare, putem vedea spaţiul de stari ca o MDP în care agentul A ar
emite o actiune de negociere compusa ak în starea SAk şi ar merge non-determinist într-una
dintre urmatoarele stari posibile, SAk+1, pentru fiecare actiune ak având acelaşi pA
i. Astfel,
non-determinismul este generat de lipsa de cunoaştere a răspunsului exact dat de către agentul
B pentru o anumita negociere primitiva pAi emisa de către A.
Regula noastra de invatare Q este acum obţinuta prin substituirea s si a în ecuaţia (2), cu
starile corespunzătoare şi acţiunile combinate definite mai sus, după cum urmează:
)),(),(max)((),(),( 111
kAkk
Ak
a
Akk
Akk
Ak aSQaSQSRaSQaSQ
k
(4)

PROGRAMUL 4 “PARTENERIATE IN DOMENIILE PRIORITARE” 2007-2013
SCIPA – Etapa 3: Dezvoltarea componentelor semantice ale platformei
84
Atunci când negociază cu un agent, relaţiile de actualizare (4) nu sunt aplicate pentru k=0,
primul nivel în arbore, deoarece acest nivel corespunde întotdeauna unei propuneri. Atunci
când se considera cazul unei negocieri intre mai multe parti, nivelul k = 0 este, de asemenea,
luat în considerare în Q-invatare, deoarece agentul trebuie să înveţe la care agentul ar face cel
mai bine o anumita propunere.
pA3=ModifReq
pB1=Accept pA
1=Accept pB=ok
pA =Propose pB
1=Accept
SA
AB R
B
pA =Propose pB
2=Reject
pA =ProposepB
3=ModifReq
N AB
RB
pA3=ModifReq
pB3=ModifReq
AA
RA
pA2=Reject
pB=ok pA
3=ModifReqpB
2= Reject
N
. . . . . . . . . . . . . .
Figure 2: Arborele de negociere cu starile SA si SB comprimate
În scopul de a aplica în mod eficient algoritmul Q-learning trebuie sa fie proiectata o
clusterizare de stari. În modelul nostru propus am considerat echivalenţa de stari prezentata în
Figura 3 şi vom sancţiona mai multe runde de negocieri prin recompensele asociate obţinute
în starile corespunzătoare; o stare finală de acceptare, de exemplu, va avea o utilitate mai mică
dacă se obţine după mai multe ModifReq decât în cazul în care acordul ar fi fost atins dintr-un
pas. În Figura 3, SI este starea în care începe negocierea (fostă SA), SN este starea de negociere
generica (atinsa de către una sau mai multe perechi ale ModifReq). Numărul de mesaje
ModifReq schimbate în procesul de negociere este fie par fie impar, în funcţie de expeditorul
mesajului final - agentul sau agentul B.
O negociere se încheie în două situaţii:
Agent A a primit de la B un mesaj de Acceptare / Respingere, ajungând in starea SAB sau
SRB
Agentul A trimite un mesaj de încheiere (Acceptare / Respingere) şi B confirma recepţia,
prin intermediul unui mesaj ok, ajungând in starea SAA sau SRA.

PROGRAMUL 4 “PARTENERIATE IN DOMENIILE PRIORITARE” 2007-2013
SCIPA – Etapa 3: Dezvoltarea componentelor semantice ale platformei
85
Figure 3: Tranzitii de stare in timpul procesului de negociere
Primitive: P – Propose, Mx, Ax, Rx – ModifReq/Accept/Reject trimise de agentul x (A or B),
ok – trimis de agentul B
Fiecare dintre cei doi agenti de negociere ar putea folosi o politica de "time-out", suspendand
procesul de negociere după un anumit număr de iteraţii. Această situaţie poate fi considerată
ca un caz special de Respingere şi, în consecinţă, nu este tratată în mod explicit. Starile finale
ale negocierii (SAB, SAA - de succes, SRB, SRA– de esuare), pot fi atinse fie direct din starea
iniţială SI, sau după mai multe tranziţii de stare prin intermediul starii de negociere SN.
O recompensă într-o stare finală de acceptare este +1 şi într-o stare finală de respingere este -
1. Orice stare intermediară în care o modificare a obiectului de negociere este propusa
primeşte 1/k din recompensa, în care k se presupune a fi numărul maxim de runde de
negociere. Două modificări succesive, astfel, corespund cu -2/k. Recompensele asociate
fiecărei stari sunt, de asemenea, prezentate în Figura 3. Tabelul 1 prezintă recompensele,
utilitatile şi acţiunile pentru a ajunge la o stare finală reprezentata in Figura 3.
Modelul din figura 3 poate fi extins prin luarea în considerare a unui set extins de primitive de
argumentare ale negocierii ca instanţe ale ModifReq, (Appeal to past promise, Promise of a
future reward, Appeal to self interest, Threat) (Recurs la promisiunea din trecut, Promisiunea
de o rasplata viitoare, Apel la interes propriu, Amenintare). În acest caz, dacă setul de
negociere conţine N tipuri de mesaje, apoi perechile {MA, MB} în procesul de negocieri vor
avea N2 variante. Deşi numărul de stari grupate creşte în acest caz, algoritmul Q de invatare
poate rezolva în mod eficient această situaţie.
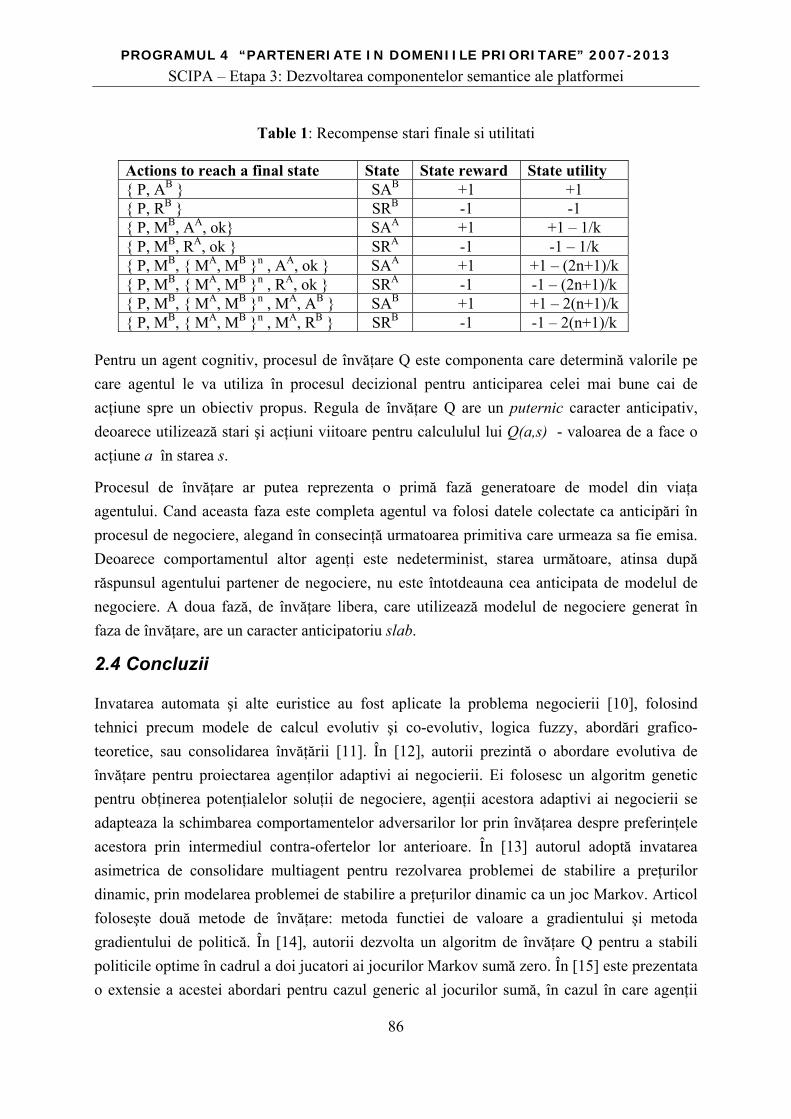
PROGRAMUL 4 “PARTENERIATE IN DOMENIILE PRIORITARE” 2007-2013
SCIPA – Etapa 3: Dezvoltarea componentelor semantice ale platformei
86
Table 1: Recompense stari finale si utilitati
Actions to reach a final state State State reward State utility { P, AB } SAB +1 +1 { P, RB } SRB -1 -1 { P, MB, AA, ok} SAA +1 +1 – 1/k { P, MB, RA, ok } SRA -1 -1 – 1/k { P, MB, { MA, MB }n , AA, ok } SAA +1 +1 – (2n+1)/k { P, MB, { MA, MB }n , RA, ok } SRA -1 -1 – (2n+1)/k { P, MB, { MA, MB }n , MA, AB } SAB +1 +1 – 2(n+1)/k { P, MB, { MA, MB }n , MA, RB } SRB -1 -1 – 2(n+1)/k
Pentru un agent cognitiv, procesul de învăţare Q este componenta care determină valorile pe
care agentul le va utiliza în procesul decizional pentru anticiparea celei mai bune cai de
acţiune spre un obiectiv propus. Regula de învăţare Q are un puternic caracter anticipativ,
deoarece utilizează stari şi acţiuni viitoare pentru calcululul lui Q(a,s) - valoarea de a face o
acţiune a în starea s.
Procesul de învăţare ar putea reprezenta o primă fază generatoare de model din viaţa
agentului. Cand aceasta faza este completa agentul va folosi datele colectate ca anticipări în
procesul de negociere, alegand în consecinţă urmatoarea primitiva care urmeaza sa fie emisa.
Deoarece comportamentul altor agenţi este nedeterminist, starea următoare, atinsa după
răspunsul agentului partener de negociere, nu este întotdeauna cea anticipata de modelul de
negociere. A doua fază, de învăţare libera, care utilizează modelul de negociere generat în
faza de învăţare, are un caracter anticipatoriu slab.
2.4 Concluzii
Invatarea automata şi alte euristice au fost aplicate la problema negocierii [10], folosind
tehnici precum modele de calcul evolutiv şi co-evolutiv, logica fuzzy, abordări grafico-
teoretice, sau consolidarea învăţării [11]. În [12], autorii prezintă o abordare evolutiva de
învăţare pentru proiectarea agenţilor adaptivi ai negocierii. Ei folosesc un algoritm genetic
pentru obţinerea potenţialelor soluţii de negociere, agenţii acestora adaptivi ai negocierii se
adapteaza la schimbarea comportamentelor adversarilor lor prin învăţarea despre preferinţele
acestora prin intermediul contra-ofertelor lor anterioare. În [13] autorul adoptă invatarea
asimetrica de consolidare multiagent pentru rezolvarea problemei de stabilire a preţurilor
dinamic, prin modelarea problemei de stabilire a preţurilor dinamic ca un joc Markov. Articol
foloseşte două metode de învăţare: metoda functiei de valoare a gradientului şi metoda
gradientului de politică. În [14], autorii dezvolta un algoritm de învăţare Q pentru a stabili
politicile optime în cadrul a doi jucatori ai jocurilor Markov sumă zero. În [15] este prezentata
o extensie a acestei abordari pentru cazul generic al jocurilor sumă, în cazul în care agenţii

PROGRAMUL 4 “PARTENERIATE IN DOMENIILE PRIORITARE” 2007-2013
SCIPA – Etapa 3: Dezvoltarea componentelor semantice ale platformei
87
determină mai întâi un mixt de strategie de profil de echilibru Nash pentru joc şi apoi
utilizeaza acest profil pentru algoritmul de invatare Q pentru a determina o politică optimă. În
[16], negocierea este modelata ca un set de două procese Markov decizionale non-stationare şi
un algoritm de iterare a valorii este folosit pentru a învăţa o politică optimă de negociere.
Spre deosebire de abordările anterioare, modelul nostru nu are nevoie sa construiasca un
model al mediului şi propune o reprezentare în care negocierea este vazuta ca un singur MDP
asupra starilor de negociere fuzionate. În plus, abordarea noastră poate include diferite tipuri
primitive de negociere şi să le trateze în mod uniform şi poate fi extinsă la negociere intre mai
multe parti.
Am elaborat un model al unui proces de negociere, care surprinde o mare varietate de situatii
şi obiecte posibile de negociere şi care combină o negociere euristica cu una bazata pe
argumentare. Ne-am definit un set de primitive de negociere şi un protocol de negociere care
cuprinde mai multe opţiuni posibile de proiectare care pot fi selectate în funcţie de domeniul
unei anumite probleme. Primitive propuse de negociere combina facilităţi de modificare a
obiectului negociat cu posibilitatea de a specifica diferite tipuri de argumente care implică
aceste obiecte foarte negociate; este prima astfel de abordare dupa cunoştinţele noastre. Am
prezentat structuri pentru specificarea obiectului de negociere şi a cadrului de negociere care
permit separarea obiectul negociat de protocolul de negociere.
Agenţii pot fi dotati cu diferite primitive de negociere, dar acestea trebuie să aibă un proces
decizional care va permite apoi să aleagă pe cel mai bun la un moment dat. Am modelat
procesul de negociere ca Proces Decizional Markov şi am propus un algoritm de invatare Q
care foloseste recompense de stari fuzionate în spaţiul starii negociate pentru a invata cum
să negocieze. Algoritmul de invatare Q poate fi, de asemenea, utilizat de către negociator
pentru a alege între mai mulţi agenţi din lista de cunoştinţe a agentului pe cel cu care să
negocieze, în cazul de negociere intre mai multe parti.
Folosind regula de invatare Q agenţii nu trebuie să modeleze mediul sau pe alti agenti cu care
ei negociaza; prin urmare, abordarea noastră propusă este potrivita pentru medii deschise şi de
învăţare on-line. Desi agentii folosind o abordare de invatare Q nu modeleaza mediul, ei
contin un model anticipativ al lor din punct de vedere al valorilor Q pe care le-au calculat in
timpul invatarii. Aceste valori le permit să aleagă presupusul primitiva de negociere corecta la
un anumit moment in proces, in functie de predictia modelului de negociere a ceea ce se va
intampla la un moment din urma.
Bibliografie [1] A.S.Rao, M.P.Georgeff, “Modeling Rational Agents Within a BDI-architecture”, edited by
R.Fikes and E.Sandwall, Morgan Kaufman, Proc. of Knowledge Representation and Reasoning (KR&R-91), 1991, pp. 473-484.

PROGRAMUL 4 “PARTENERIATE IN DOMENIILE PRIORITARE” 2007-2013
SCIPA – Etapa 3: Dezvoltarea componentelor semantice ale platformei
88
[2] A.Florea, E.Kalisz, “Anticipatory Attributes of Agent Behaviour in MAS”, CP627, Computing Anticipatory Systems: CASYS 2001 - Fifth International Conference, edited by D.M.Dubois, American Institute of Physics 0-7354-0081-4/02, p.359-364.
[3] N.R.Jennings, e.a., “Automated negotiation: prospects, methods, and challenges”, Int. J. of Group Decision and Negotiation 10 (2), 2001, pp.199-215.
[4] S.Kraus, K.Sycara, A.Evenchik, “Reaching agreements through arumentation: a logical model and implementation”, Artificial Intelligence, Elsevier Science, 104, 1998, pp. 1-69.
[5] Y.Labrou, T.Finin, “Semantics and conversations for an agent communication language”, In Readings in Agents, M. Huhns and M. Singh, editors, Morgan Kaufmann, San Francisco, 1998, pp.235-242.
[6] A.Florea. “Using Utility Values in Argument-based Negotiation”, In Proc. of IC-AI'02, the 2002 International Conference on Artificial Intelligence, Las Vegas, Nevada, USA, 24-27 June 2002, CSREA Press, p.1021-1026.
[7] Kaelbling, L.P., M.L. Littman, and A.W. Moore, “Reinforcement learning: a survey”, Journal of Artificial Intelligence Research, 4, 1996, pp. 237-285.
[8] Watkins, C.J. and P. Dayan, “Q-learning”, Machine Learning, 8(3), 1992, pp. 279-292. [9] D.M.Dubois, "Review of Incursive, Hyperincursive and Anticipatory Systems – Foundation of
Anticipation in Electromagnetism,” in Computing Anticipatory Systems: CASYS'99 – Third International Conference, edited by Daniel M. Dubois, AIP Conference Proceedings 517, American Institute of Physics, Melville, NY, 2000, pp. 3-30.
[10] D.Zeng, K.Sycara, “Benefits of learning in negotiation”, in Proc of the 14th National Conference on Artificial Intelligence and 9th Innovative Applications of Artificial Intelligence Conference (AAAI- 97/IAAI-97), AAAI Press, 1997, pp. 36-42.
[11] Y.Shoham, R.Powers, T.Grenager, “Multi-agent reinforcement learning: a critical survey”, Technical report, Stanford University, 2003.
[12] R.Y.K.Lau, e.a., “An evolutionary learning approach for adaptive negotiation agents”, International Journal of Intelligent Systems, 21(1), 2006, pp.41-72.
[13] V.Könönen, “Dynamic pricing based on asymmetric multiagent reinforcement learning”, International Journal of Intelligent Systems, 21(1), 2006, pp.73-98.
[14] M.L.Littman. Markov games as a framework for multi-agent reinforcement learning. Proc. of the 11th Int. Conference on Machine Learning (ML-94), 1994.
[15] J.Hu, M.P. Wellman. Multiagent reinforcement learning: Theoretical framework and an algorithm. Proc. of the 15th Int. Conf. on Machine Learning (ML-98), 1998.
[16] V.Narayanan, N.R.Jennings, “An adaptive bilateral negotiation model for e-commerce settings”, in 7th Int. IEEE Conf. on E-Commerce Technology, Munich, Germany, 2005, pp. 34-39.

PROGRAMUL 4 “PARTENERIATE IN DOMENIILE PRIORITARE” 2007-2013
SCIPA – Etapa 3: Dezvoltarea componentelor semantice ale platformei
89
Partea a III-a
Modele de compunere si descompunere a serviciilor semantice
Autori – Universitatea Politehnica din Bucureşti
Prof. dr. ing. Adina Magda Florea – responsabil ştiinţific
As. drd. ing. Andrei Mogos As. drd. ing. Andreea Urzica

PROGRAMUL 4 “PARTENERIATE IN DOMENIILE PRIORITARE” 2007-2013
SCIPA – Etapa 3: Dezvoltarea componentelor semantice ale platformei
90
1 Introducere
Atat serviciile Web cat si Web-ul semantic reprezinta doua tehnologii importante in
domeniul cercetarilor din stiinta calculatoarelor. In [12], este data urmatoarea definitie pentru
un serviciu web: “Un serviciu Web este un system software proiectat pentru a sprijini
interactiunea calculator - calculator intr-o retea”. Web-ul semantic reprezinta web-ul ce poate
fi procesat si interpretat de calculator. Dupa cum se mentioneaza in [1], “Web-ul semantic nu
este un alt Web, ci o extensie a Web-ului current, in care informatiile sunt furnizate cu
semnificatie bine definite, care permit o cooperare mai buna intre oameni si calculatoare”.
Serviciile web semantice pun la un loc cele doua tehnologii prezentate mai sus:
servicii web si web-ul semantic. Serviciile web semantice sunt serviciile web ce au o
decscriere web demantica formala. Folosirea acestui tip de descrieri semantice fac posibila
realizarea automata a unor operatii importante peste serviciile web automatizarea:
descoperirea, selectia, compunerea, precum si invocarea serviciilor [7].
Compunerea serviciilor web semantice reprezinta o problema actuala si foarte
importanta in domeniul de cercetare al serviciilor web. Exista o serie de metode semiautomate
pentru aceasta problema [11], dar marea majoritate a rezultatelor se refera la abordari
automate. O parte dintre metodele principale folosite pentru compunerea automata a
serviciilor web sunt: planificare bazata pe inteligenta artificiala [6], [4], [8], sisteme multi-
agent [5], limbaje logice [9], reguli [10].
Prezentam o abordare de compunere a serviciilor web semantice bazata pe potrivire de
sabloane. Dandu-se o descriere semantica, sub forma unei liste de descrieri semantice ce
corespund unui numar de servicii web semantice dintr-o biblioteca de servicii web semantice,
se doreste crearea unui serviciu web semantic nou, care sa corespunda descrieriii semantice
initiale, prin folosirea serviciilor web semantice din biblioteca data; acest obiectiv este realizat
pe baza descompunerii descrierii semantice initiale. In continuare vor fi analizate cateva
structuri posibile ale descrierii semantice initiale si va fi prezentat un algoritm de
descompunere, precum si un sistem software pentru rezolvarea problemei. Ideea de baza
consta in determinarea sabloanelor similare in descrierea semantica initiala si folosirea lor
pentru a facilita o rezolvare eficienta a problemei.
2. Descrierea problemei
Sa consideram descrierea semantica SD pentru un serviciu semantic S si o biblioteca
de servicii semantice, numita biblioteca SWS. Descrierea semantica SD are urmatoarea forma:
, in care sunt descrieri semantice ce corespund unor
servicii web din biblioteca SWS. Serviciile web semantice din biblioteca SWS vor fi numite
1 2 ... nSD SD SD SD 1 2, , ..., nSD SD SD

PROGRAMUL 4 “PARTENERIATE IN DOMENIILE PRIORITARE” 2007-2013
SCIPA – Etapa 3: Dezvoltarea componentelor semantice ale platformei
91
servicii web semantice elementare si descrierile lor semantice vor fi numite descrieri
semantice elementare. Se doreste constructia unui serviciu web semantic S care sa corespunda
descrierii semantice SD folosind servicii web semantice din biblioteca SWS. Serviciul web
semantic S va corespunde rezultatului compunerii unor servicii web semantice elementare.
Consideram ca biblioteca SWS poate contine un numar de servicii semantice web
elementare care corespund aceleiasi descrieri web semantice elementare. Fiecare serviciu web
semantic elementar are asociat un coeficient de calitate. Nu ne va interesa cum poate fi
modificat acest coeficient (crescut / scazut). Acest coeficient a fost introdus numai pentru a
ajuta sistemul software sa faca alegerea unui serviciu web semantic (cel ce are coeficientul de
calitate cel mai mare) dintre serviciile web semantice ce au aceeasi descriere semantica.
3. Algoritmi de potrivire de sabloane
Potrivirea sirurilor (sau potrivirea sabloanelor) repreinta urmatoarea problema [3]:
dandu-se un sir (in mod general, numit sablon) si un text, trebuie sa se determine o aparitie,
sau mai general, toate aparitiile sirului in text; lungimea sablonului este m si lungimea textului
este n. Sablonul si textul folosesc acelasi alfabet finit a carui dimensiune este a.
Exista o serie de algoritmi pentru rezolvarea acestei probleme [3], de exemplu,
algoritmii: Karp-Rabin, Shift Or, Knuth-Morris-Pratt, Galil-Giancarlo, Colussi, Boyer-Moore,
Horspool, Quick Search, Two Way, Optimal Mismatch, Maximal shift, Alpha Skip Search.
Dupa cum se arata in [3], “algoritmul Boyer-Moore este considerat cel mai eficient
algoritm de potrivire de siruri in aplicatii uzuale”. Prima data, algoritmul Boyer-Moore a fost
prezentat in [2].
In continuare este prezentata o scurta descriere a algoritmului Boyer-Moore, asa cum
este descris in [3]: algoritmul aliniaza marginea din stanga a sablonului cu marginea din
stanga a textului si compara caracterele din sablon cu caracterele din text de la dreapta la
stanga. In momentul in care algoritmul determina o nepotrivire sau o potrivire completa in
text, sablonul va fi deplasat la dreapta folosind doua functii: good-suffix shift si bad-character
shift. Algoritmul Boyer-Moore consta din doua faze: faza de preprocesare si faza de cautare.
In timpul fazei de preprocesare cele doua functii sunt precalculate in timp O(m+a). Faza de
cautare are complexitatea O(mn), dar algoritmul realizeaza cel mult 3n comparatii de
caractere pentru un sablon neperiodic. Performanta cea mai buna a algoritmului este O(n/m).
4. Metoda de descompunere
In aceasta sectiune este prezentata metoda de descompunere ce va fi folosita de
sistemul software pentru a obtine serviciul web semantic S care corespunde descrierii
semantice initiale SD. Sunt analizate cateva structuri posibile ale descrierii semantice SD si

PROGRAMUL 4 “PARTENERIATE IN DOMENIILE PRIORITARE” 2007-2013
SCIPA – Etapa 3: Dezvoltarea componentelor semantice ale platformei
92
este propusa o solutie pentru fiecare situatie. In final este prezentat algoritmul mrincipal ce
descrie metoda de descompunere a descrierii semantice.
Situatii posibile
a) Descrierea semantica initiala contine fiecare descriere semantica o singura data, ce
corespunde unui serviciu web semantic elementar. Descrierea formala pentru descrierea
semantica SD va fi urmatoarea:
jin SDSDincatastfelnjiSDSDSDSD },...,2,1{, , ... 21 (1)
In aceasta situatie, descrierea semantica SD este descompusa in urmatoarele descrieri
semantice: . Pentru fiecare din aceste descrieri semantice, sistemul va cauta
in biblioteca SWS un serviciu web semantic elementar corespunzator. Numim algoritmul
pentru acest tip de descompunere DecompositionMethod1. Dupa procesul de descompunere,
in timpul procesului de cautare, sistemul va trebui sa realizeze n cautari in biblioteca SWS.
1 2, , ..., nSD SD SD
In cele ce urmeaza este prezentat un exemplu simplu, in care fiecare descriere
semantica elementara este reprezentata printr-un caracter:
- fie SD a b c d
- rezultatul descompunerii: , , ,a b c d
b) Descrierea semantica initiala SD contine descrieri semantice elementare cu multiple aparitii
in SD, dar nu exista secvente de descrieri semantice elementare cu multiple aparitii in SD.
Descrierea formala a descrierii semantice SD este urmatoarea:
2121......
, }, ..., ,2 ,1{ , , ,
} ..., ,2 ,1{, , ...
121221212121
21
jjii
jin
SDSDSDSDincatastfel
jjiijjiicunjjiidar
SDSDincatastfelnjiSDSDSDSD
(2)
In aceasta situatie, descrierea semantica SD este descompusa in urmatoarele descrieri
semantice: , cu k1 2, , ...,
ki i iSD SD SD n in care aceste descrieri semantice sunt toate descrieri
semantice diferite din SD. Vom numi algoritmul care corespunde acestui tip de descompunere
DecompositionMethod2.
Dupa procesul de descompunere, in timpul procesului de cautare, in momentul gasirii
unui serviciu web semantic elementar din biblioteca SWS, acest serviciu este introdus in
biblioteca Auxiliary SWS. In acest caz, sistemul trebuie sa realizeze k cautari in biblioteca
SWS.

PROGRAMUL 4 “PARTENERIATE IN DOMENIILE PRIORITARE” 2007-2013
SCIPA – Etapa 3: Dezvoltarea componentelor semantice ale platformei
93
ca elementara este reprezentata printr-un caracter:
- fie
la SD contine secvente de descrieri semantice elementare cu
ultiple aparitii in SD. Descrierea formala pentru descrierea semantica SD este urmatoarea:
In cele ce urmeaza vom prezenta un exemplu simplu, in care fiecare descriere
semanti
SD a b c a d c e
- rezultul descompunerii este: , , , ,a b c d e
c) Descrierea semantica initia
m
} ..., ,2 ,1{,,, , ... 212121 n njjiiSDSDSDSD
2121......
, 12122121
jjii SDSDSDSDincatastfel
jjiijjiicu
(3)
In aceasta situatie, descrierea semantica SD este descompusa in urmatoarele descrieri
semantice: cu in
care ac
1 2 1 2 1 2 r
este secvente de descrieri semantice reprezinta toate secventele diferite de descrieri
semantice fa em
avea secvente cu cel putin o descriere semantica elementara. In acest caz, sistemul trebuie sa
efectueze cel mult ...p q r
( ... ), ( ... ), ... ( ... )p qi i i j j j l l lSD SD SD SD SD SD SD SD SD
ra a avea indici comuni din SD. In aceasta descom
...p q r n
punere consideram ca put
cautari in biblioteca SWS. Vom numi algoritmul care
corespunde acestui tip de descompunere DecompositionMethod3.
Dupa procesul de descompunere, in timpul procesului de cautare, cand se construieste
pe baza serviciilor web semantice elementare din biblioteca SWS, un serviciu web din
descom
zentata printr-un caracter:
ie
unere
urmatoarea:
: Type = getDecompositionType(SD)
puneri, acel serviciu este introdus in biblioteca Auxiliary SWS. Se observa ca pot fi
servicii web semantice in biblioteca Auxiliary SWS care corespund secventelor de lungime 1.
De asemenea observam, ca in aceasta situatie, vor fi create servicii semantice noi prin
compunerea serviciilor web semantice elementare care corespund descrierilor semantice
elementare din unele secvente.
In cele ce urmeaza este prezentat un exemplu simplu, in care fiecare descriere
semantica elementara este repre
- f a b c a b a d e a b c a b f d e
- rezultatul descompunerii este: ( ), , ( ),a b c a b a d e f
SD
Metoda principala de descomp
Metoda principala de descompunere este
1: DecompositionMethod(SD) {
2

PROGRAMUL 4 “PARTENERIATE IN DOMENIILE PRIORITARE” 2007-2013
SCIPA – Etapa 3: Dezvoltarea componentelor semantice ale platformei
94
sitionMethod(SD, Type)
ecompositionMethod(D)
p, AuxDecomp) }}
ompositionType’ analizeaza descrierea semantica SD pentru a
etermina metoda de descompunere care corespunde situatiei curente:
Decom
r un proces recursiv de descompunere (a se observa
re
ftware este prezentata in Figura 1.
Figure 1. Arhitectura sistemului
Main Agent receptioneaza o descriere sem arce descrierea completa
D a serviciul web semantic ce corespunde descri Aceasta descriere completa
ntine
3: Decomp = applyDecompo
4: for-each D in Decomp {
5: if length(D) > 1 {
6: AuxDecomp = D
7: update(Decom
8: return Decomp }
Functia ‘getDec
d
positionMethod1, DecompositionMethod2 sau DecompositionMethod3. Dupa aceasta,
metoda de descompunere selectata este aplicata pentru descompunerea descrierii semantice
SD folosind functia ‘applyDecompositionMethod’. Algoritmul Boyer-Moore este folosit
pentru toate problemele de determinare a potrivirilor de sabloane, care trebuie rezolvate in
timpul procesului de descompunere.
Dupa cum se poate observa, in cazul situatiei c) unde este aplicata metoda
DecompositionMethod3, este necesa
liniile 5-7 din algoritm).
5. Sistemul softwa
Structura sistemului so
antica SD si into
erii semantice.C
co toate informatiile necesare pentru accesa acel serviciu web semantic. Decomposition
Agent foloseste algoritmul prezentat in sectiunea anterioara si descompune descrierea
semantica SD receptionata de la Main Agent. Composition Agent compune toate serviciile
Main Agent
Auxiliary
SWS Library
Decomposition SWS Library Agent
Composition Agent
Patte hing Agent
rn Matc
Searching Agent
SD
CD

PROGRAMUL 4 “PARTENERIATE IN DOMENIILE PRIORITARE” 2007-2013
SCIPA – Etapa 3: Dezvoltarea componentelor semantice ale platformei
95
ntat o metoda de compunere pentru servicii web semantice bazata pe
determinarea potrivirilor sabloanelor. Scopul acestei metode consta in determinarea unui nou
mantic poate insemna un task dificil din punctul de vedere al
resurse
tarile viitoare se vor analiza
proprie
m and Hendler, James and Lassila, Ora. The Semantic Web, Scientific American, May 2001 Stephen and Moore, J Strother. A fast string searching algorithm, Communications of the
ACM, vol. 20, 1977, pages 762-772 v-
web semantice corespunzatoare unei descompuneri in scopul crearii unui nou serviciu web
semantic compus. In final, acest agent va transmite catre Main Agent descrierea completa a
serviciului web semantic care corespunde descrierii semantice SD. Composition Agent va
introduce in biblioteca Auxiliary SWS serviciile web pe care le creeaza in timpul procesului
de compunere. Searching Agent realizeaza cautarea serviciilor web semantice in cele doua
biblioteci de servicii web semantice, astfel ajutand Composition Agent in timpul procesului
de compunere. Pattern Matching Agent foloseste algoritmul Boyer-Moore pentru rezolvarea
tuturor problemelor de determinare a potrivirilor sabloanelor trimise de Decomposition Agent,
Composition Agent si de the Searching Agent.
6. Concluzii
Am preze
serviciu semantic compus, care corespunde unei descrieri semantice, folosind servicii web
elementare dintr-o biblioteca.
In cazul in care biblioteca de servicii web contine multe servicii web semantice,
cautarea unui serviciu web se
lor de calcul necesare. Avantajul principal al metodei propuse consta in minimizarea
numarului de cautari, analizand structura descrierii semantice initiale. Metoda este foarte
folositoare in cazul in care o parte din descrierile semantice elementare care fac parte din
descrierea semantica initiala SD au multiple aparitii in SD. Performantele cele mai bune sunt
obtinute in cazul in care numarul acestor aparitii este ridicat.
Descrierea semantica initiala folosita in aceasta lucrare este reprezentata sub forma
unei liste de descrieri semantice elementare. In dezvol
tatile unei descrieri semantice mai generale, in scopul de a crea o metoda care sa
acopere un numar mai mare de cazuri de compunere a serviciilor web semantice.
Bibliografie
1. Berners-Lee, Ti2. Boyer, Robert
3. Charras, Christian and Lecroq, Thierry. Exact String Matching Algorithms, http://www-igm.unimlv.fr/~lecroq/string/ offmann, Jörg and Bertoli, Piergiorg4. H io and Pistore, Marco. Web Service Composition as Planning, Revisited:
(AAAI-07), 22-26 July 2007, Vancouver, British Columbia, Canada, vol. 2, pages
5. K
In Between Background Theories and Initial State Uncertainty, in Proceedings of the 22nd Conference on Artificial Intelligence 1013-1018 umar, Sandeep and Mishra, Ravi Bhusan. Multi-Agent Based Semantic Web Service Composition Models, in
Journal of Computer Science, Infocomp, 2008, vol. 7, iss. 3, pages 42-51

PROGRAMUL 4 “PARTENERIATE IN DOMENIILE PRIORITARE” 2007-2013
SCIPA – Etapa 3: Dezvoltarea componentelor semantice ale platformei
96
06, Athens, GA, USA, pages 385-
7. edings of the 22 Conference on Artificial Intelligence (AAAI-07), 22-26 July 2007, Vancouver,
8. ference (ESWC 2008), Tenerife, Canary Islands, Spain,
9. nal Conference on Knowledge Representation and Reasoning (KR 2002), 22-
10.ngs of OWL-S: Experiences and Directions Workshop in
11. Descriptions, in Proceedings of Web Services: Modeling, Architecture and Infrastructure
12.
6. Lécué, Freddy and Léger, Alain. A formal model for semantic Web service composition, in Proceedings of the 5th International Semantic Web Conference (ISWC 2006), November 20398 Lécué, Freddy and Delteil, Alexandre. Making the Difference in Semantic Web Service Composition, in Proce nd
British Columbia, Canada, vol. 2, pages 1383-1388 Lin, Naiwen and Kuter, Ugur and Sirin, Evren. Web Service Composition with User Preferences, in Proceedings of the 5th European Semantic Web Con1-5 June 2008, pages 629-643 McIlraith, Sheila and Son, Tran Cao. Adapting Golog for Composition of Semantic Web Services, in Proceedings of the 8th Internatio25 April 2002, Toulouse, France, pages 482-493 Meditskos, Georgios and Bassiliades, Nick. A Semantic Web Service Discovery and Composition Prototype Framework Using Production Rules, in Proceediconjunction with the 4th European Semantic Web Conference (ESWC 2007), 3-7 June 2007, Innsbruck, Austria Sirin, Evren and Hendler, James and Parsia, Bijan. Semi-automatic Composition of Web Services using SemanticWorkshop in conjunction with the 5th International Conference on Enterprise Information Systems (ICEIS 2003), 23-26 April 2003, Angers, France Web Service Architecture W3C Working Group: “Web Services Architecture”, February 2004, http://www.w3.org/TR/ws-arch/

PROGRAMUL 4 “PARTENERIATE IN DOMENIILE PRIORITARE” 2007-2013
SCIPA – Etapa 3: Dezvoltarea componentelor semantice ale platformei
97
Partea a IV-a
Modele de incredere, reputatie si norme in sisteme de agenti pentru procese de e-business
Autori – Universitatea din Craiova
Prof. dr. ing. Costin Bădică – responsabil ştiinţific
Conf. dr. ing. Amalia Bădică
As. Dr. Elvira Popescu
Drd. ing. Sorin Ilie Drd. ing. Mihnea Scafes
Autori – Universitatea Politehnica din Bucureşti
Prof. dr. ing. Adina Magda Florea – responsabil ştiinţific
Prof. dr. ing. Eugenia Kalisz
As. drd. ing. Andrei Mogos Drd. ing. Andreea Urzică

PROGRAMUL 4 “PARTENERIATE IN DOMENIILE PRIORITARE” 2007-2013
SCIPA – Etapa 3: Dezvoltarea componentelor semantice ale platformei
98
1 Model de reputatie imbunatatit cu factor de iertare pentru agentii e-business
1.1 INTRODUCERE Reputatia este unul dintre conceptele ce stau la baza selectarii partenerilor in tranzactiile de
afaceri electronice. Participantii din cadrul unei piete electronice globale, de obicei
cumparatori si vanzatori, sunt reprezentati cu ajutorul agentilor software. Similar societatii
umane, un agent va fi de acord sa se angajeze intr-o noua relatie de afaceri guvernata de o
multime de termeni si conditii contractuale numai cu parteneri de afaceri cu reputatie buna.
Acest lucru inseamna ca, daca un agent are o buna reputatie in interiorul unei societati de
agenti, este foarte probabil ca alti agenti vor decide sa-l selecteze in realizarea unor noi
tranzactii de afaceri.
In stransa legatura cu reputatia este conceptul de incredere. Afacerile electronice de succes se
bazeaza de obicei pe crearea unor relatii de incredere consistenta si durabila cu potentialii
clienti de-a lungul unei perioade semnificative de timp. Increderea este un concept complex,
care are o multitudine de fatete (Srinivasan, 2004). Desi nu exista un consens unanim cu
privire la definirea sa, increderea poate fi privita ca o masura subiectiva a credintei unui agent
in capabilitatile, onestitatea si siguranta altui agent, bazata pe experientele directe proprii
(relatii de tipul unu-la-unu), pe cand reputatia este considerata a fi o masura obiectiva a
credintei unui agent in capabilitatile, onestitatea si siguranta altui agent, bazata pe
recomandarile primite de la alti agenti (relatii de tipul unu-la-multi) (Badica et al., 2006).
In continuare, pentru a clarifica terminologia, daca se dau doi agenti a si b, vom considera
reputatia agentului a pentru agentul b ca masura gradului credintei lui b in capabilitatea,
onestitatea si siguranta agentului a. Vom nota aceasta valoare cu Rb,a. De obicei, intr-o
asemenea relatie se spune ca agentul a are rolul credibil, iar agentul b are rolul increzator
(Jøsang, Ismail, & Boyd, 2007). Se observa ca, prin prisma aceasta, parametrii a si b pot sa
reprezinte atat agenti singulari, cat si grupuri de agenti.
Distinctia intre rolurile credibil – increzator intr-o relatie de afaceri evidentiaza cele doua
fatete ale dihotomiei incredere – reputatie. Conform fatetei reputatie, putem vorbi despre
reputatia agentului a asa cum este vazuta de agentul b, pe cand conform fatetei incredere,
putem vorbi despre increderea dezvoltata de agentul b in agentul a. In cadrul acestui raport
vom discuta despre conceptul de reputatie, intrucat consideram ca acest concept este mai
adecvat domeniului afacerilor electronice. Intuitiv, reputatia poate fi utilizata pentru a
caracteriza din punct de vedere calitativ o anumita afacere, intrucat acest termen este strans

PROGRAMUL 4 “PARTENERIATE IN DOMENIILE PRIORITARE” 2007-2013
SCIPA – Etapa 3: Dezvoltarea componentelor semantice ale platformei
99
legat de concepte de marketing frecvent intalnite cum sunt marca si imagine (Jøsang, Keser,
& Dimitrakos, 2005).
In mod traditional, reputatia este evaluata prin colectarea feedback-ului in urma interactiunilor
anterioare intre partenerii de afaceri (Badica et al., 2006; Ganzha et al., 2006). Exista multe
abordari pentru modelarea si evaluarea reputatiei in sistemele de agenti, pornind de la metode
simple de evaluare si pana la modele matematice complexe bazate pe grafuri sau modele
sofisticate bazate pe logica sau incertitudini, conform urmatoarelor lucrari de referinta:
(Sabater & Sierra, 2005; Wang & Lin, 2008; Jøsang, Ismail, & Boyd, 2007).
In abordarea noastra, am modelat afacerea electronica printr-un mediu semi-competitiv in
care agentii trebuie sa decida daca se angajeaza sau nu intr-o tranzactie de afaceri cu un
anumit partener (Foued et al., 2009). Deciziile se iau pe baza reputatiei potentialilor parteneri,
deci, cu cat este mai mare reputatia unui partener, cu atat este mai mare beneficiul agentului
prin angajarea intr-o tranzactie cu acel partener.
In modelul dezvoltat, consideram ca agentii sunt grupati in “societati”. Vom avea in vedere
doua astfel de societati: o societate vanzator si o societate cumparator. Relativ la aceste
societati, conform propunerii initiale a lui (Foued et al., 2009), in functie de sursele de
informatie care pot fi utilizate in calculul reputatiei, se definesc patru tipuri de reputatie: (i)
reputatia directa a unui anumit vanzator pentru un anumit client cumparator; (ii) reputatia
directa a unui anumit cumparator pentru un anumit vanzator; (iii) reputatia unui anumit
vanzator pentru societatea cumparatorilor; (iv) reputatia societatii vanzatorilor pentru un
anumit cumparator.
Reputatiile directe (primele doua tipuri) sunt imbogatite cu un model continand un factor de
iertare (Henderson, 1996) care, in principiu, propune aplicarea filosofiei “reconcilierii”.
Aceasta inseamna ca, odata cu trecerea timpului, fiecare agent ar trebui sa uite greselile facute
de un partener in timpul tranzactiilor anterioare. In plus, modelul nostru cu factor de iertare
introduce o perspectiva optimista asupra realitatii. Prin urmare, un agent ar trebui sa acorde
intotdeauna credit partenerului sau, adica initial sau dupa o perioada suficienta de timp fara
nici o interactiune, reputatia partenerului ar trebui sa aiba sau sa creasca la valoarea maxima
posibil.
In prezentul raport, vom introduce modelul computational conceput de noi pentru reputatie,
vom arata cum poate fi imbunatatit acest model cu un factor de iertare si con-resistance, vom
schita proiectarea unui sistem multi-agent pe care l-am folosit in experimente si vom discuta
rezultatele experimentale obtinute.

PROGRAMUL 4 “PARTENERIATE IN DOMENIILE PRIORITARE” 2007-2013
SCIPA – Etapa 3: Dezvoltarea componentelor semantice ale platformei
100
1.2 MODEL DE REPUTATIE CU IERTARE
1.2.1 Tipuri de reputatie
Tranzactiile din cadrul afacerilor electronice se modeleaza prin “contracte semnate”. In urma
unui proces de negociere, intre un agent cumparator si un agent vanzator se incheie un
contract. Cumparatorul trimite un apel pentru propuneri catre fiecare membru al societatii
vanzatorilor. Unii vanzatori sunt capabili sa satisfaca termenii si conditiile apelului si decid sa
coopereze, trimitand o propunere. Cumparatorul va selecta un vanzator preferat (care isi
maximizeaza propria utilitate) si aceasta selectie va defini un “contract semnat” intre
cumparator si vanzatorul selectat. In continuare, vom generaliza aceasta abordare la un
contract generic, referitor la oferirea unui anumit serviciu unui agent solicitant de catre un
agent furnizor.
Un contract intre doi agenti specifica multimea de termeni ai serviciului pe care agentul
furnizor este de acord sa il ofere agentului solicitant, prin urmare putem spune ca avem
contracte semnate cu mai multe clauze. De exemplu, daca agentul furnizor este un vanzator si
agentul solicitant este un cumparator, atunci contractul va specifica termenii vanzarii, putand
sa includa aspecte legate de: timpul de livrare, livrarea produsului corespunzator etc. Daca S
este multimea de termeni si fiecare termen k are o pondere stabilita wk care masoara
importanta termenului respectiv pentru solicitant, atunci solicitantul poate evalua contractul
cu ajutorul formulei: C = kS wk tk , unde tk = 1 daca agentul solicitant este multumit de
termenul k al serviciului livrat, iar in caz contrar tk = 0. Se observa ca, intrucat ponderile
termenilor serviciului satisfac conditia wk 0 si kS wk = 1, atunci 0 C 1.
In dezvoltarea modelului nostru vom considera doua societati de agenti: societatea
cumparatorilor B = {b1, b2, …, bm} si societatea vanzatorilor S = {s1, s2, …, sn}, unde m este
numarul de cumparatori si n este numarul de vanzatori. Agentii cumparatori cauta sa realizeze
angajamente in tranzactii de afaceri electronice cu agentii vanzatori. O tranzactie presupune
semnarea si derularea unui contract intre doi agenti. Pe baza gruparii agentilor in societati,
conform propunerii facute de (Foued et al., 2009), putem defini patru tipuri de masuri pentru
reputatie.
Reputatia directa se defineste intre un agent cumparator si un agent vanzator pe baza
rezultatelor contractelor anterioare dintre ei. Daca |B| = m si |S| = n, atunci putem defini 2mn
reputatii intre bi si sj (se observa ca relatia reputatiei nu este simetrica). Valoarea reputatiei
directe se actualizeaza dupa derularea fiecarui contract cu formula R = C + (1 - )R , unde
R si R sunt noua, respectiv vechea valoare a reputatiei directe, iar C este valoarea ultimului

PROGRAMUL 4 “PARTENERIATE IN DOMENIILE PRIORITARE” 2007-2013
SCIPA – Etapa 3: Dezvoltarea componentelor semantice ale platformei
101
contract derulat intre agenti. Parametrul 0 < < 1 controleaza importanta relativa a valorii
contractului curent in valoarea actualizata a reputatiei directe. Se observa cu usurinta ca daca
R > 0 atunci R > 0, prin urmare, daca valoarea initiala a reputatiei directe este diferita de zero,
atunci reputatia directa va fi intotdeauna strict pozitiva. Dar, conform abordarii optimiste
asupra lumii, valorile initiale pentru toate reputatiile directe sunt setate la 1, rezultand astfel ca
in modelul nostru valorile reputatiei directe sunt intotdeauna strict pozitive.
Se iau in considerare atat reputatia directa a unui anumit vanzator pentru un anumit
cumparator, cat si reputatia directa a unui anumit cumparator pentru un anumit vanzator,
deoarece un contract semnat intre un cumparator si un vanzator defineste o multime de
angajamente pentru vanzator si o multime de angajamente pentru cumparator. De exemplu,
vanzatorul se angajeaza sa livreze un produs cu anumite caracteristici specificate, la un
anumit pret si respectand un termen limita, iar cumparatorul se angajeaza sa accepte si sa
plateasca pentru produsul primit in timp util si care respecta caracteristicile convenite.
Reputatia unui anumit vanzator pentru societatea cumparatorilor se defineste intre societatea
cumparatorilor si fiecare membru al societatii vanzatorilor si defineste imaginea vanzatorului
in fata intregii societati a cumparatorilor. Aceasta reputatie este influentata de reputatia directa
a respectivului vanzator fata de fiecare cumparator. Daca |S| = n atunci putem defini n
reputatii intre multimea de cumparatori B si vanzatorul sj. Reputatia unui anumit vanzator
pentru societatea cumparatorilor se calculeaza ca media reputatiilor directe ale vanzatorului sj
fata de fiecare membru bi al societatii vanzatorilor, adica RB,j = (iB Ri,j) / m, unde Ri,j este
reputatia directa a vanzatorului sj pentru cumparatorul bi.
Reputatia societatii vanzatorilor pentru un anumit cumparator se defineste intre fiecare
membru al societatii cumparatorilor si societatea vanzatorilor. Aceasta reputatie este
influentata de reputatia directa a fiecarui vanzator in fata respectivului cumparator. Daca |B| =
m atunci putem defini m reputatii intre bi si S. Reputatia societatii vanzatorilor fata de un
anumit cumparator se calculeaza ca medie a reputatiilor fiecarui vanzator sj fata de
cumparatorul bi, adica Ri,S = (jS Ri,j) / n, unde Ri,j este reputatia directa a vanzatorului sj
pentru cumparatorul bi.
1.2.2 Factorul de iertare
Reputatia este cumulativa si dinamica, deci depinde de timp. Pe masura trecerii timpului,
reputatia se actualizeaza in doua moduri: (i) ori de cate ori se incheie si se deruleaza un nou
contract intre un agent vanzator si un agent cumparator, reputatia se actualizeaza, reflectand
starea rezultatelor contractului; (ii) ori de cate ori a trecut o perioada de relaxare suficient de
mare t fara niciun contract semnat, reputatia se actualizeaza printr-o usoara crestere.

PROGRAMUL 4 “PARTENERIATE IN DOMENIILE PRIORITARE” 2007-2013
SCIPA – Etapa 3: Dezvoltarea componentelor semantice ale platformei
102
Factorul de iertare actioneaza prin declansarea actualizarii reputatiei directe conform ecuatiei
urmatoare: R(t+t) = min{(1+)R(t),1}. t si > 0 sunt parametrii modelului reputatiei cu
iertare. Parametrul controleaza gradul in care creste reputatia, iar t controleaza viteza cu
care este crescuta reputatia. Se observa ca, in conformitate cu aceasta ecuatie, valoarea
reputatiei va fi intotdeauna apropiata de 1. Daca nu se semneaza contracte pentru o perioada
suficient de lunga de timp, atunci valoarea reputatiei va converge spre 1, reflectand astfel
viziunea optimista asupra realitatii.
Perechea de parametri (t,) caracterizeaza un anumit agent increzator si se poate considera
ca defineste profilul de iertare al agentului increzator. De exemplu, cu cat este mai mare
valoarea lui si mai mica valoarea lui t, atunci cu atat mai mare este capacitatea agentului
increzator de a ierta, adica acel agent increzator este capabil sa ierte mai repede. In cazul in
care partea increzatoare are rolul de cumparator, putem defini profilul de iertare al
cumparatorului.
Se observa ca, in principiu, iertarea inseamna ca agentul increzator va creste reputatia
agentului credibil cu un increment dat R(t). Incrementul reputatiei este proportional cu
valoarea curenta a reputatiei R(t). Acest lucru poate fi interpretat astfel: daca un agent are mai
multa incredere intr-un partener (adica partenerul are o valoare mai mare pentru reputatia
R(t)), atunci el este de asemenea capabil sa ierte mai repede greselile partenerului (deoarece
valoarea incrementului reputatiei R(t) este mai mare). Mai mult, deoarece R(t) > 0, rezulta ca
incrementul reputatiei R(t) este strict pozitiv, determinand astfel o crestere stricta a reputatiei
agentului credibil.
1.2.3 Adaugarea Con-Rezistentei
Similar societatii umane, un agent va decide sa incheie un nou contract cu un alt agent daca si
numai daca agentul care furnizeaza serviciul cerut are o buna reputatie, castigata in urma unor
interactiuni reusite de-a lungul unei perioade semnificative de timp. Conform (Salehi-Abari &
White, 2009), un om de incredere, sau con-om, este cineva care are avantaj in fata celorlati
dupa ce le-a castigat increderea construindu-si o buna reputatie si apoi exploatand-o in scopuri
proprii private. Acest sablon comportamental este cunoscut sub numele de siretlicul
increderii. Modelul reputatiei cu factor de iertare introdus de noi poate fi imbunatatit cu
caracteristica con-rezistenta, inspirata de (Salehi-Abari & White, 2009).
Relativ la siretlicul increderii, pentru includerea sa intr-un model de reputatie trebuie avute in
vedere doua aspecte. Mai intai, ori de cate ori se detecteaza un siretlic de incredere, reputatia

PROGRAMUL 4 “PARTENERIATE IN DOMENIILE PRIORITARE” 2007-2013
SCIPA – Etapa 3: Dezvoltarea componentelor semantice ale platformei
103
agentului con-on ar trebui redusa mai mult decat inainte. In principiu, acest lucru se poate
realiza prin cresterea valorii parametrului care controleaza importanta relativa a valorii
contractului curent in valoarea actualizata a reputatiei directe la o noua valoare >.
Presupunand ca se detecteaza un siretlic de incredere, aceasta inseamna ca valoarea
contractului curent C este mica, in timp ce agentul are o reputatie mare R > C. Deci, prin
actualizarea reputatiei directe cu formula R = 'C + (1 - )R, se va ajunge la o valoare strict
mai mica decat C + (1 - )R (adica decat valoarea care ar fi putut fi obtinuta prin ignorarea
detectarii siretlicului de incredere).
In al doilea rand, dupa fiecare urmatoare interactiune reusita sau dupa o perioada de relaxare
urmatoare unei detectii a unui siretlic de incredere, reputatia agentului con-om trebuie crecuta
cu mai multa precautie. Deci, ori de cate ori se obtine o interactiune reusita dupa un
eveniment de detectare a unui siretlic de incredere, reputatia va fi crescuta cu un increment
mai mic. In acest caz, con-omul are o reputatie scazuta, dar valoarea contractului curent C
este mare, adica C > R. Acest efect se poate obtine prin scaderea valorii parametrului care
controleaza importanta relativa a contractului curent C in valoarea actualizata a reputatiei
directe la o noua valoare <. In final, ori de cate ori urmeaza o perioada de relaxare dupa
detectarea unui siretlic de incredere, iertarea ar trebui sa fie mai lenta. Acest efect se poate
obtine prin actualizarea profilului de iertare al agentului increzator (t,) la (t',') astfel
incat ' si t't si cel putin o inegalitate sa fie stricta.
Facem observatia ca pedepsele ar trebui sa fie mai mari dupa fiecare greseala, pentru a
descuraja agentul con-om sa mai utilizeze siretlicuri de incredere. De asemenea, pedepsele pot
fi scazute conform modelului cu factor de iertare. Aceste posibile extensii ale modelului
nostru vor fi tratate intr-o dezvoltare viitoare.
1.3 PROIECTARE SI IMPLEMENTARE
In cadrul acestui proiect, am conceput si implementat un sistem multi-agent in care am
incorporat modelul de reputatie descris anterior, utilizand platforma multi-agent JADE
(Bellifemine, Caire, & Greenwood, 2007). Sistemul reprezinta o piata virtuala distribuita, in
care se pot intalni agenti software reprezentand cumparatori si vanzatori, pot negocia si
incheia contracte de afaceri electronice cu clauze multiple.
Arhitectura sistemului este prezentata in Figura 1. Conform modelului nostru, in sistem se pot
regasi doua grupuri de agenti: grupul SellerSociety si grupul BuyerSociety.

PROGRAMUL 4 “PARTENERIATE IN DOMENIILE PRIORITARE” 2007-2013
SCIPA – Etapa 3: Dezvoltarea componentelor semantice ale platformei
104
Figura 1.Arhitectura sistemului
In cadrul modelului nostru operational, am evaluat experimental trei dintre tipurile de
reputatie, astfel: (i) reputatia directa a unui anumit vanzator pentru un anumit cumparator, (ii)
reputatia unui anumit vanzator pentru societatea cumparatorilor si (iii) reputatia societatii
vanzatorilor pentru un anumit cumparator. Acest lucru inseamna ca in modelul nostru am
inregistrat modalitatera de evaluare de catre cumparatori a vanzatorilor, pe baza contractelor
incheiate intre ei. Sistemul poate fi extins prin adaugarea unei noi functionalitati, pentru a
permite vanzatorilor sa evalueze reputatia cumparatorilor, utilizand aceleasi principii de
modelare si fara a afecta arhitectura curenta a sistemului din Figura 1.
Grupul agentilor BuyerSociety contine urmatoarele tipuri de agenti software: Buyer,
BuyerManager si InterpreterB:
Agentul Buyer este de fapt agentul care reprezinta un cumparator intr-o aplicatie de e-
business. In sistem pot fi introdusi mai multi agenti de acest tip, fiecare din ei
reprezentand un cumparator diferit, care poate sa selecteze vanzatori cu care sa
interactioneze. Pentru rularea sistemului este necesar cel putin un agent Buyer.
Agentul BuyerManager are rolul de manager al societatii de cumparatori. Fiecare agent
Buyer care se alatura sistemului va trebui sa raporteze rezultatele sale agentului
BuyerManager. In sistem poate fiinta un singur agent BuyerManager. Conform figurii 1,
fiecare agent Buyer trimite agentului BuyerManager rezultatul fiecarui contract derulat cu
un agent Seller. Rezultatele sunt memorate de catre agentul BuyerAgent intr-o baza de
date. Executia sistemului este condusa de catre grupul de agenti BuyerSociety si deci

PROGRAMUL 4 “PARTENERIATE IN DOMENIILE PRIORITARE” 2007-2013
SCIPA – Etapa 3: Dezvoltarea componentelor semantice ale platformei
105
agentul BuyerManager este responsabil cu detectarea sfarsitului executiei, adica a
finalizarii unui numar prestabilit de contracte.
Agentul InterpreterB actioneaza ca interpretor al informatiei capturate in timpul executiei
sistemului din partea cumparatorilor. Principalul sau scop este sa interpreteze si sa
analizeze aceasta informatie, pentru a genera in mod dinamic un raport care afiseaza
rezultatele executiei cu privire la reputatiile calculate din partea cumparatorilor. In acest
scop, agentul InterpreterB utilizeaza o componenta non-agent software numita AnalyzerB.
Grupul agentilor SellerSociety contine urmatoarele tipuri de agenti software: Seller,
SellerManager si InterpreterS:
Agentul Seller este agentul care actioneaza ca vanzator intr-o aplicatie de e-business. Pot
exista mai multi agenti de acest tip in sistem, fiecare dintre ei reprezentand un vanzator
diferit, pe care cumparatorii il pot selecta pentru incheierea de contracte. Pentru executia
sistemului este necesar cel putin un agent Seller.
Agentul SellerManager are rolul de manager al societatii vanzatorilor. Fiecare agent
Seller care intra in sistem va trebui sa raporteze rezultatele sale catre agentul
SellerManager. Este permis un singur agent SellerManager in sistem. Conform figurii 1,
fiecare agent Seller trimite catre SellerManager rezultatul fiecarui contract derulat cu un
agent Buyer. Multimea de rezultate finale este memorata de catre agentul SellerManager
intr-o baza de date.
Agentul InterpreterS actioneaza ca interpretor al informatiei capturate in timpul executiei
sistemului de partea vanzatorilor. Principalul sau scop este de a interpreta si analiza
aceasta informatie, pentru a genera in mod dinamic o multime de rapoarte care afiseaza
statistici ale executiei referitoare la rezultatele contractelor incheiate si vanzarilor
efectuate. Pentru aceasta, InterpreterS utilizeaza o componenta non-agent software numita
AnalyzerS. Executia sistemului este condusa de agentii cumparatori, deci sfarsitul
executiei sistemuluieste recunoscut mai intai de catre agentul BuyerManager agent si dupa
aceea ceilalti agenti sunt instiintati cu privire la finalizarea executiei (vezi figura 1).
Executia sistemului este organizata pe sesiuni de executie. In timpul unei sesiuni, fiecare
agent cumparator bi are un anumit numar de contracte ci de incheiat inainte de terminarea
executiei. Intre doua incheieri consecutive de contracte pentru un cumparator exista un
interval de timp . Acest interval reprezinta timpul necesar pentru derularea unui anumit
contract. Prin urmare, timpul de executie pentru fiecare agent cumparator bi in timpul unei
sesiuni este egal cu ci. Daca fiecare cumparator bi isi incepe activitatea la momentul de timp
Ti, atunci timpul total de executie al unei sesiuni va fi max1im {Ti+ci} - min1im{Ti}, unde
m este numarul total de cumparatori care participa in sistem.

PROGRAMUL 4 “PARTENERIATE IN DOMENIILE PRIORITARE” 2007-2013
SCIPA – Etapa 3: Dezvoltarea componentelor semantice ale platformei
106
Presupunem ca avem o multime finita C de bunuri care sunt tranzactionate in timpul unei
sesiuni de executie. Pentru fiecare bun c C, vanzatorul sj este capabil sa furnizeze o
cantitate qc,j. Se observa ca, daca qc,j = 0, atunci bunul c nu este disponibil pentru vanzare la
vanzatorul sj in timpul sesiunii de executie curente.
O sesiune de executie cuprinde trei faze: (i) initializare, (ii) tranzactii si (iii) post-procesare.
In timpul fazei de initializare, se creeaza si se initializeaza agentii. Primul pas il reprezinta
crearea agentilor din grupul SellerSociety. Atunci cand un agent Seller apare online, el se va
inregistra la Directory Facilitator din JADE, cunoscut si ca agentul DF (Bellifemine, Caire,
& Caire, Greenwood, 2007) si apoi initializeaza bunurile pe care este capabil sa le vanda,
adica propriul sau catalog de produse si cantitatile corespondente. Dupa aceea, se creeaza
agentii din grupul BuyerSociety. Atunci cand un nou agent Buyer apare online, el preia mai
intai lista de agenti Seller care sunt disponibili la momentul respectiv in sistem prin
interogarea agentului DF. In pasul urmator, acesta trimite lista agentilor Seller disponibili
catre agentul BuyerManager si apoi informeaza agentul BuyerManager ca va incepe sesiunea
de executie – adica procesul de incheiere de contracte cu agentii Seller.
Agentii InterpreterB si InterpreterS realizeaza analiza si interpretarile datelor achizitionate in
timpul executiei si apoi afiseaza rezultatele in timpul fazei de post-procesare. De asemenea,
agentii SellerManager si BuyerManager sunt utilizati pentru memorarea tuturor informatiilor
achizitionate in timpul executiei intr-o baza de date centrala. Pentru a-si atinge scopul, acesti
agenti sunt actualizati continuu de catre agentii Seller si Buyer, ori de cate ori se genereaza
noi informatii in timpul executiei, pana la incheierea sesiunii de executie.
In continuare vom prezenta detaliile interactiunilor dintre agenti in timpul fazei de
tranzactionare a unei sesiuni de executie (vezi figura 2). Aceste interactiuni cuprind atat
protocoalele de interactiune, cat si mesajele schimbate intre agenti. Executia este dirijata de
catre agentii Buyer, care contacteaza continuu agentii Seller in vederea incheierii de noi
contracte.
Conform diagramei de interactiune prezentate in figura 2, ori de cate ori un agent Buyer
incepe executia, el va notifica mai intai agentul BuyerManager cu mesajul start_sim,
mentionand si numarul total de contracte maxContr pe care le are de incheiat in timpul
sesiunii curente. Dupa aceea, agentul Buyer genereaza aleator un bun comType care va fi
tranzactionat in cadrul contractului curent si intreaba agentii Seller daca pot furniza acel bun
prin intermediul mesajului do-have(comType). Agentii Seller raspund fie cu mesajul do-have-

PROGRAMUL 4 “PARTENERIATE IN DOMENIILE PRIORITARE” 2007-2013
SCIPA – Etapa 3: Dezvoltarea componentelor semantice ale platformei
107
yes(comType), fie cu mesajul do-have-no(comType), in functie de posibilitatea de a furniza
sau nu bunul comType.
In pasul urmator, agentul Buyer selecteaza un agent Seller cu cea mai mare reputatie dintre cei
care au raspuns pozitiv la cererea sa, prin mesajul buy(comType) – acesta este momentul in
care consideram ca se incheie un contract pentru vanzarea bunului comType de catre agentul
selectat Seller catre agentul curent Buyer. Derularea acestui contract este modelata prin
schimbul de mesaje sold(comType, status) si respectiv refused(probType) sau not-
refused(probType). Parametrul status reprezinta problemele care pot sa apara in cadrul unui
contract pe partea vanzatorului, adica probleme de livrare sau calitate scazuta a produselor
vandute. In cadrul modelului nostru, consideram ca fiecare din aceste probleme poate sa apara
independent, cu o anumita probabilitate. Parametrul probType reprezinta problemele care pot
sa apara pe partea cumparatorului, cum ar fi intarzierea platii de catre cumparator pentru
produsul achizitionat.
In continuare, agentul Seller trimite rezultatele tranzactiei curente catre agentul
SellerManager folosind mesajele refusedInfo(buyer, seller, yes_no, probType) si
sold(comType, status, buyer), iar agentul Buyer informeaza agentul BuyerManager ca a fost
finalizat un nou contract, prin intermediul mesajului end-contr(contrNo, seller, r). Parametrul
contrNo reprezinta numarul contractului, parametrul seller reprezinta partenerul Seller din
contract, iar parametrul r reprezinta reputatia directa actualizata avanzatorului Seller. Atunci
cand se finalizeaza si ultimul contract, adica atunci cand conditia contrNo = maxContr devine
adevarata, agentul Buyer anunta agentul BuyerManager cu mesajul end-sim ca a ajuns la
sfarsitul sesiunii de executie. Atunci agentul BuyerManager detecteaza sfarsitul sesiunii de
executie pentru toti agentii Buyer, adica evalueaza conditia noRegBuyers = noTermBuyers ca
fiind adevarata (numarul de cumparatori inregistrati este egal cu numarul de cumparatori
finalizati) si anunta pe InterpreterB si SellerManager. In final, agentul SellerManager pe
InterpreterS, iar ambii agenti InterpreterB si InterpreterS pot incepe interpretarea si analiza
datelor achizitionate pe parcursul executiei, in timpul fazei de post-procesare.

PROGRAMUL 4 “PARTENERIATE IN DOMENIILE PRIORITARE” 2007-2013
SCIPA – Etapa 3: Dezvoltarea componentelor semantice ale platformei
108
Figura 2. Interactiunile agentilor in timpul unei sesiuni de executie
1.4 REZULTATE EXPERIMENTALE 1.4.1 Scenariu experimental
Am realizat o serie de experimente cu sistemul mult-agent descris care utilizeaza reputatie cu
factor de iertare. Vom prezenta rezultatele obtinute cu un scenariu simplu de comert
electronic constand in 8 agenti cumparatori: dan, sorin, ana, radu, alex, george, john, mike si
9 agenti vanzatori: cel, emag, magic, mcomp1, ..., mcomp6. Acest scenariu se refera la
comercializarea de componente de PC si PC-uri. In particular, am considerat urmatoarea
multime de bunuri: C = {laptop, imprimanta, tastatura, cpu, monitor}. Bunurile disponibile la
fiecare vanzator sunt prezentate in tabelul 1.
In acest scenariu, un cumparator evalueaza rezultatul unui contract pe baza unei multimi S de
patru criterii: probleme de livrare, probleme de calitate, probleme legate de pret si alte
probleme. Ponderile acestor criterii au fost stabilite astfel: w1 = 0.2, w2 = 0.4, w3 = 0.3 si w4 =
0.1. Parametrul care controleaza importanta contractului curent pentru actualizarea reputatiei
directe a fost setat la = 0.5. Numarul de contracte incheiate de fiecare cumparatora fost setat
la ci = 10.
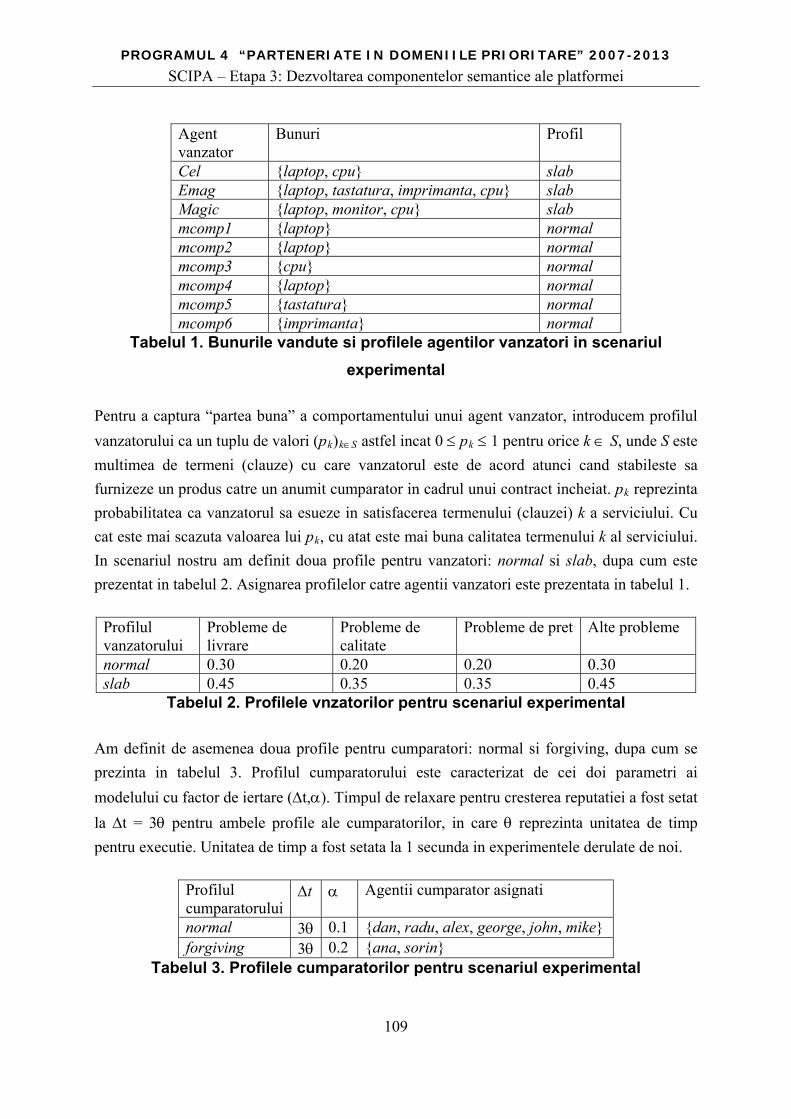
PROGRAMUL 4 “PARTENERIATE IN DOMENIILE PRIORITARE” 2007-2013
SCIPA – Etapa 3: Dezvoltarea componentelor semantice ale platformei
109
Agent vanzator
Bunuri Profil
Cel {laptop, cpu} slab Emag {laptop, tastatura, imprimanta, cpu} slab Magic {laptop, monitor, cpu} slab mcomp1 {laptop} normal mcomp2 {laptop} normal mcomp3 {cpu} normal mcomp4 {laptop} normal mcomp5 {tastatura} normal mcomp6 {imprimanta} normal
Tabelul 1. Bunurile vandute si profilele agentilor vanzatori in scenariul
experimental
Pentru a captura “partea buna” a comportamentului unui agent vanzator, introducem profilul
vanzatorului ca un tuplu de valori (pk)kS astfel incat 0 pk 1 pentru orice k S, unde S este
multimea de termeni (clauze) cu care vanzatorul este de acord atunci cand stabileste sa
furnizeze un produs catre un anumit cumparator in cadrul unui contract incheiat. pk reprezinta
probabilitatea ca vanzatorul sa esueze in satisfacerea termenului (clauzei) k a serviciului. Cu
cat este mai scazuta valoarea lui pk, cu atat este mai buna calitatea termenului k al serviciului.
In scenariul nostru am definit doua profile pentru vanzatori: normal si slab, dupa cum este
prezentat in tabelul 2. Asignarea profilelor catre agentii vanzatori este prezentata in tabelul 1.
Profilul vanzatorului
Probleme de livrare
Probleme de calitate
Probleme de pret Alte probleme
normal 0.30 0.20 0.20 0.30 slab 0.45 0.35 0.35 0.45
Tabelul 2. Profilele vnzatorilor pentru scenariul experimental
Am definit de asemenea doua profile pentru cumparatori: normal si forgiving, dupa cum se
prezinta in tabelul 3. Profilul cumparatorului este caracterizat de cei doi parametri ai
modelului cu factor de iertare (t,). Timpul de relaxare pentru cresterea reputatiei a fost setat
la t = 3 pentru ambele profile ale cumparatorilor, in care reprezinta unitatea de timp
pentru executie. Unitatea de timp a fost setata la 1 secunda in experimentele derulate de noi.
Profilul cumparatorului
t Agentii cumparator asignati
normal 3 0.1 {dan, radu, alex, george, john, mike} forgiving 3 0.2 {ana, sorin}
Tabelul 3. Profilele cumparatorilor pentru scenariul experimental
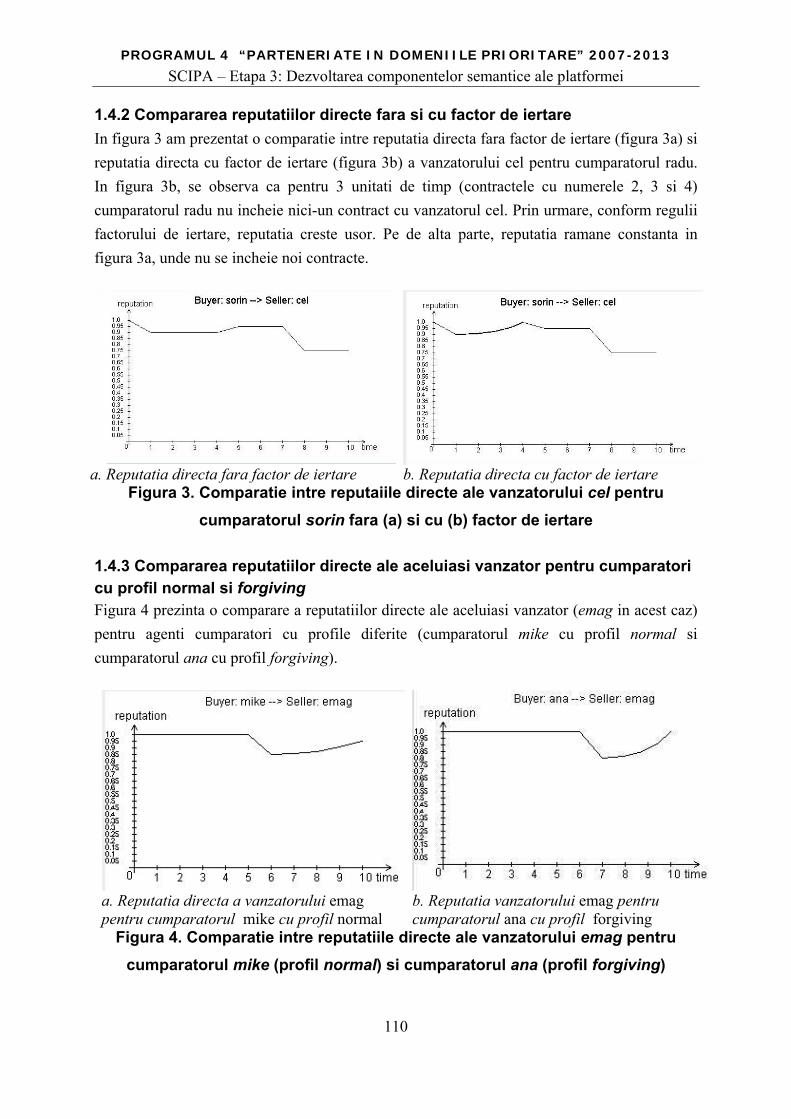
PROGRAMUL 4 “PARTENERIATE IN DOMENIILE PRIORITARE” 2007-2013
SCIPA – Etapa 3: Dezvoltarea componentelor semantice ale platformei
110
1.4.2 Compararea reputatiilor directe fara si cu factor de iertare
In figura 3 am prezentat o comparatie intre reputatia directa fara factor de iertare (figura 3a) si
reputatia directa cu factor de iertare (figura 3b) a vanzatorului cel pentru cumparatorul radu.
In figura 3b, se observa ca pentru 3 unitati de timp (contractele cu numerele 2, 3 si 4)
cumparatorul radu nu incheie nici-un contract cu vanzatorul cel. Prin urmare, conform regulii
factorului de iertare, reputatia creste usor. Pe de alta parte, reputatia ramane constanta in
figura 3a, unde nu se incheie noi contracte.
a. Reputatia directa fara factor de iertare b. Reputatia directa cu factor de iertare Figura 3. Comparatie intre reputaiile directe ale vanzatorului cel pentru
cumparatorul sorin fara (a) si cu (b) factor de iertare
1.4.3 Compararea reputatiilor directe ale aceluiasi vanzator pentru cumparatori cu profil normal si forgiving Figura 4 prezinta o comparare a reputatiilor directe ale aceluiasi vanzator (emag in acest caz)
pentru agenti cumparatori cu profile diferite (cumparatorul mike cu profil normal si
cumparatorul ana cu profil forgiving).
a. Reputatia directa a vanzatorului emag pentru cumparatorul mike cu profil normal
b. Reputatia vanzatorului emag pentru cumparatorul ana cu profil forgiving
Figura 4. Comparatie intre reputatiile directe ale vanzatorului emag pentru
cumparatorul mike (profil normal) si cumparatorul ana (profil forgiving)
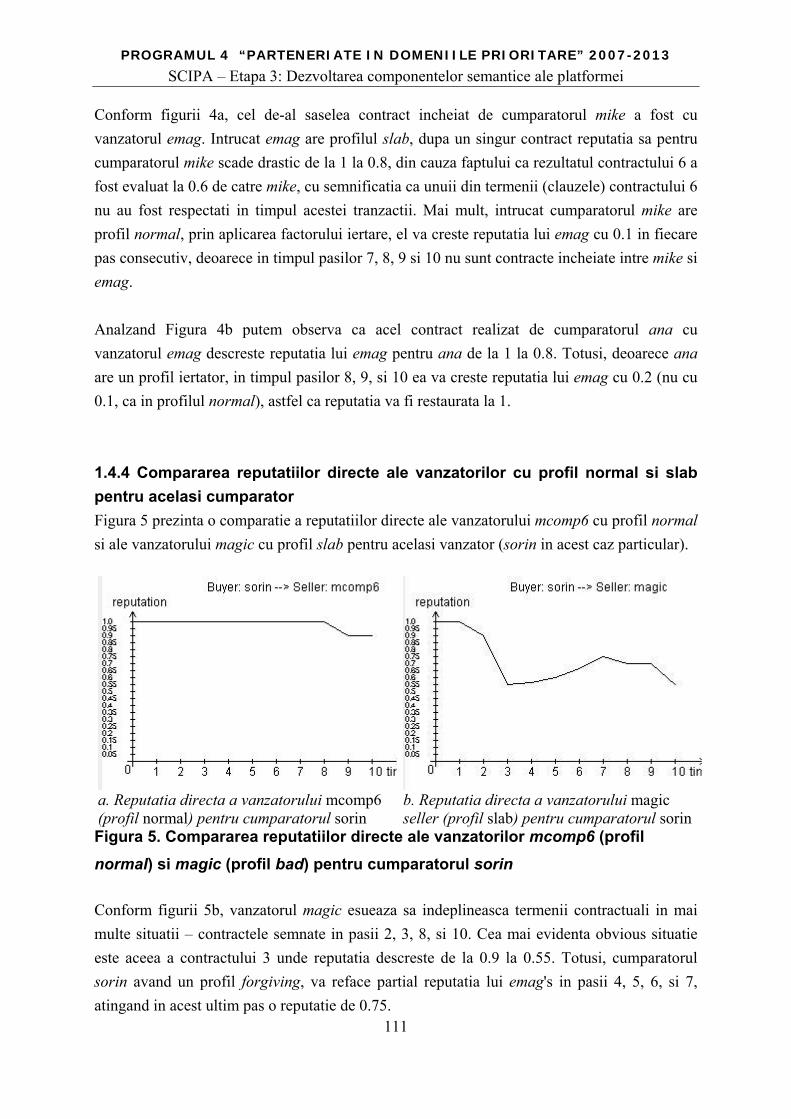
PROGRAMUL 4 “PARTENERIATE IN DOMENIILE PRIORITARE” 2007-2013
SCIPA – Etapa 3: Dezvoltarea componentelor semantice ale platformei
111
Conform figurii 4a, cel de-al saselea contract incheiat de cumparatorul mike a fost cu
vanzatorul emag. Intrucat emag are profilul slab, dupa un singur contract reputatia sa pentru
cumparatorul mike scade drastic de la 1 la 0.8, din cauza faptului ca rezultatul contractului 6 a
fost evaluat la 0.6 de catre mike, cu semnificatia ca unuii din termenii (clauzele) contractului 6
nu au fost respectati in timpul acestei tranzactii. Mai mult, intrucat cumparatorul mike are
profil normal, prin aplicarea factorului iertare, el va creste reputatia lui emag cu 0.1 in fiecare
pas consecutiv, deoarece in timpul pasilor 7, 8, 9 si 10 nu sunt contracte incheiate intre mike si
emag.
Analzand Figura 4b putem observa ca acel contract realizat de cumparatorul ana cu
vanzatorul emag descreste reputatia lui emag pentru ana de la 1 la 0.8. Totusi, deoarece ana
are un profil iertator, in timpul pasilor 8, 9, si 10 ea va creste reputatia lui emag cu 0.2 (nu cu
0.1, ca in profilul normal), astfel ca reputatia va fi restaurata la 1.
1.4.4 Compararea reputatiilor directe ale vanzatorilor cu profil normal si slab
pentru acelasi cumparator
Figura 5 prezinta o comparatie a reputatiilor directe ale vanzatorului mcomp6 cu profil normal
si ale vanzatorului magic cu profil slab pentru acelasi vanzator (sorin in acest caz particular).
a. Reputatia directa a vanzatorului mcomp6 (profil normal) pentru cumparatorul sorin
b. Reputatia directa a vanzatorului magic seller (profil slab) pentru cumparatorul sorin
Figura 5. Compararea reputatiilor directe ale vanzatorilor mcomp6 (profil
normal) si magic (profil bad) pentru cumparatorul sorin
Conform figurii 5b, vanzatorul magic esueaza sa indeplineasca termenii contractuali in mai
multe situatii – contractele semnate in pasii 2, 3, 8, si 10. Cea mai evidenta obvious situatie
este aceea a contractului 3 unde reputatia descreste de la 0.9 la 0.55. Totusi, cumparatorul
sorin avand un profil forgiving, va reface partial reputatia lui emag's in pasii 4, 5, 6, si 7,
atingand in acest ultim pas o reputatie de 0.75.
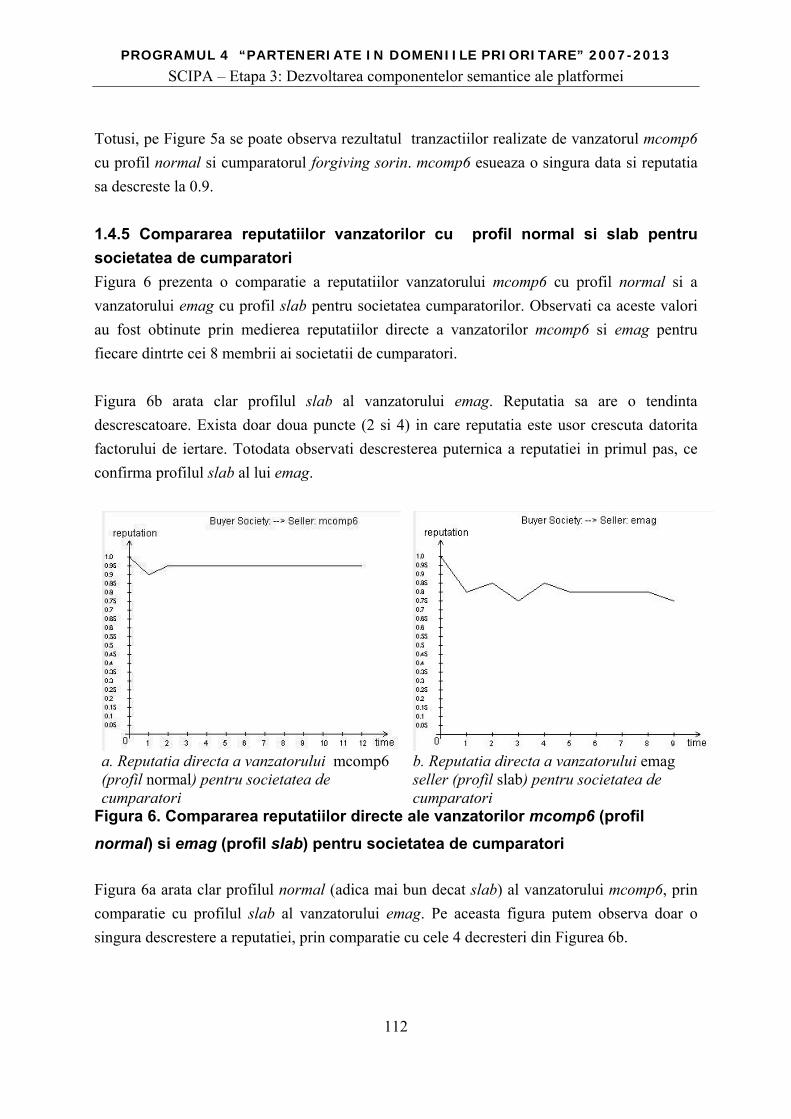
PROGRAMUL 4 “PARTENERIATE IN DOMENIILE PRIORITARE” 2007-2013
SCIPA – Etapa 3: Dezvoltarea componentelor semantice ale platformei
112
Totusi, pe Figure 5a se poate observa rezultatul tranzactiilor realizate de vanzatorul mcomp6
cu profil normal si cumparatorul forgiving sorin. mcomp6 esueaza o singura data si reputatia
sa descreste la 0.9.
1.4.5 Compararea reputatiilor vanzatorilor cu profil normal si slab pentru
societatea de cumparatori
Figura 6 prezenta o comparatie a reputatiilor vanzatorului mcomp6 cu profil normal si a
vanzatorului emag cu profil slab pentru societatea cumparatorilor. Observati ca aceste valori
au fost obtinute prin medierea reputatiilor directe a vanzatorilor mcomp6 si emag pentru
fiecare dintrte cei 8 membrii ai societatii de cumparatori.
Figura 6b arata clar profilul slab al vanzatorului emag. Reputatia sa are o tendinta
descrescatoare. Exista doar doua puncte (2 si 4) in care reputatia este usor crescuta datorita
factorului de iertare. Totodata observati descresterea puternica a reputatiei in primul pas, ce
confirma profilul slab al lui emag.
a. Reputatia directa a vanzatorului mcomp6 (profil normal) pentru societatea de cumparatori
b. Reputatia directa a vanzatorului emag seller (profil slab) pentru societatea de cumparatori
Figura 6. Compararea reputatiilor directe ale vanzatorilor mcomp6 (profil
normal) si emag (profil slab) pentru societatea de cumparatori
Figura 6a arata clar profilul normal (adica mai bun decat slab) al vanzatorului mcomp6, prin
comparatie cu profilul slab al vanzatorului emag. Pe aceasta figura putem observa doar o
singura descrestere a reputatiei, prin comparatie cu cele 4 decresteri din Figurea 6b.
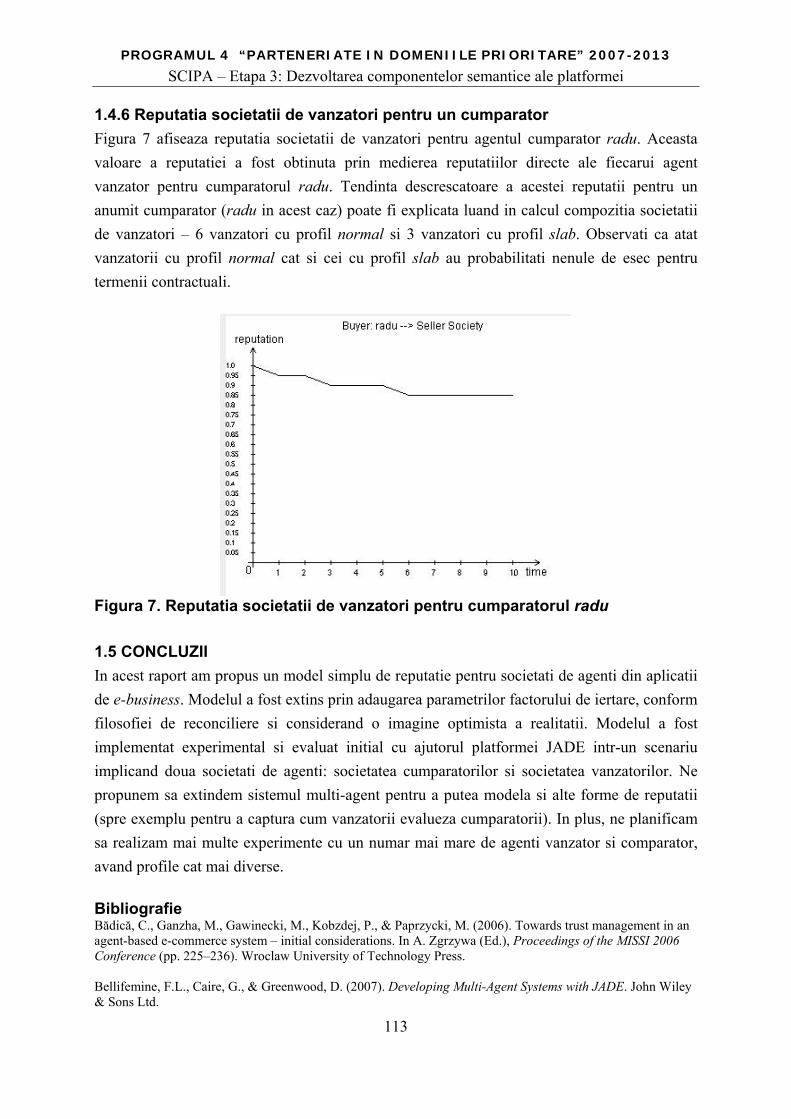
PROGRAMUL 4 “PARTENERIATE IN DOMENIILE PRIORITARE” 2007-2013
SCIPA – Etapa 3: Dezvoltarea componentelor semantice ale platformei
113
1.4.6 Reputatia societatii de vanzatori pentru un cumparator
Figura 7 afiseaza reputatia societatii de vanzatori pentru agentul cumparator radu. Aceasta
valoare a reputatiei a fost obtinuta prin medierea reputatiilor directe ale fiecarui agent
vanzator pentru cumparatorul radu. Tendinta descrescatoare a acestei reputatii pentru un
anumit cumparator (radu in acest caz) poate fi explicata luand in calcul compozitia societatii
de vanzatori – 6 vanzatori cu profil normal si 3 vanzatori cu profil slab. Observati ca atat
vanzatorii cu profil normal cat si cei cu profil slab au probabilitati nenule de esec pentru
termenii contractuali.
Figura 7. Reputatia societatii de vanzatori pentru cumparatorul radu
1.5 CONCLUZII
In acest raport am propus un model simplu de reputatie pentru societati de agenti din aplicatii
de e-business. Modelul a fost extins prin adaugarea parametrilor factorului de iertare, conform
filosofiei de reconciliere si considerand o imagine optimista a realitatii. Modelul a fost
implementat experimental si evaluat initial cu ajutorul platformei JADE intr-un scenariu
implicand doua societati de agenti: societatea cumparatorilor si societatea vanzatorilor. Ne
propunem sa extindem sistemul multi-agent pentru a putea modela si alte forme de reputatii
(spre exemplu pentru a captura cum vanzatorii evalueza cumparatorii). In plus, ne planificam
sa realizam mai multe experimente cu un numar mai mare de agenti vanzator si comparator,
avand profile cat mai diverse.
Bibliografie Bădică, C., Ganzha, M., Gawinecki, M., Kobzdej, P., & Paprzycki, M. (2006). Towards trust management in an agent-based e-commerce system – initial considerations. In A. Zgrzywa (Ed.), Proceedings of the MISSI 2006 Conference (pp. 225–236). Wroclaw University of Technology Press. Bellifemine, F.L., Caire, G., & Greenwood, D. (2007). Developing Multi-Agent Systems with JADE. John Wiley & Sons Ltd.

PROGRAMUL 4 “PARTENERIATE IN DOMENIILE PRIORITARE” 2007-2013
SCIPA – Etapa 3: Dezvoltarea componentelor semantice ale platformei
114
Foued, B., Ait-Kadi, D., Mellouli, S., & Ruiz, A. (2009). A reputation-based model for semicompetitive multi-agent systems. International Journal of Intelligent Information and Database Systems, 3, 146–162. Ganzha, M., Gawinecki, M., Kobzdej, P., Paprzycki, M., Bădică, C. (2006). Functionalizing trust in a model agent based e-commerce system. In M. Bohanec et. al. (Eds.), Proceedings of the 2006 Information Society Multiconference (pp. 22–26). Josef Stefan Institute Press. Henderson, M. (1996). The Forgiveness Factor – Stories of Hope in a World of Conflict. Grosvenor Books USA. Huynh, T.D., Jennings, N.R., & Shadbolt, N.R. (2006). An integrated trust and reputation model for open multi-agent systems. Autonomous Agents and Multi-Agent Systems 13(2), 119–154. Jøsang, A., Keser, C., & Dimitrakos, T. (2005). Can we manage trust? In P. Herrmann, V. Issarny, & S. Shiu, S. (Eds.), Trust Management, Third International Conference, iTrust’2005 (pp. 93–107). Lecture Notes in Computer Science, 3477, Springer. Jøsang, A., Ismail, R., & Boyd, C. (2007). A survey of trust and reputation systems for online service provision. Decision Support Systems, 43, 618–644. Sabater, J. & Sierra, C. (2001). Regret: A reputation model for gregarious societies. In Regret: A reputation model for gregarious societies, (pp. 61–69). Montreal, Canada. Sabater, J. & Sierra, C. (2005). Review on computational trust and reputation models. Artificial Intelligence Review, 24, 33–60. Salehi-Abari, A. & White, T. (2009). Towards con-resistant trust models for distributed agent systems. In Proceedings of the 21st International Joint Conference on Artificial Intelligence, IJCAI 2009 (pp. 272–277). Morgan Kaufmann Publishers Inc. Sathiyamoorthy, E., Iyenger, N., & Ramachandran, V. (2010). Agent based trust management framework in distributed e-business environment. International Journal of Computer Science & Information Technology, 2, 14–28. Scarlat, E. & Maries, I. (2009). Towards an increase of collective intelligence within organizations using trust and reputation models. In N.T. Nguyen, R. Kowalczyk, & S.M. Chen (Eds.), First International Conference on Computational Collective Intelligence. Semantic Web, Social Networks and Multiagent Systems, ICCCI 2009 (pp. 140–151). Lecture Notes in Computer Science, 5796, Springer. Srinivasan, S. (2004). Role of trust in e-business success. Information Management & Computer Security, 12(1), 66–72. Wang, Y. & Lin, K.J. (2008). Reputation-oriented trustworthy computing in e-commerce environments. IEEE Internet Computing, 12, 55–59. Yu, B. & Singh, M.P. (2000). A social mechanism of reputation management in electronic communities. In Cooperative Information Agents IV - The Future of Information Agents in Cyberspace, CIA 2000 (pp. 154–165). Lecture Notes in Computer Science, 1860, Springer. Zacharia, G. & Maes, P. (2000). Trust management through reputation mechanisms. Applied Artificial Intelligence, 14(9), 881–908.

PROGRAMUL 4 “PARTENERIATE IN DOMENIILE PRIORITARE” 2007-2013
SCIPA – Etapa 3: Dezvoltarea componentelor semantice ale platformei
115
2 Un model de piata bazat pe schimburi intre agenti software
2.1 Introducere Conceptul de organizatie a fost acceptat da catre comunitatea cercetatorilor in sistememe
multiagent atat drept un bun instrument pentru controlul autonomiei agentilor cat si un
mecanism de asigurare a unui comportament global coerent in cazul sistemelor deschise.
Printre mecanismele de control folosite in organizatiile multiagent, in special de organizatiile
mari, sistemele normative reprezinta actuala provocare in cadrul comunitatii de cercerare.
Impunerea normelor in societatile multiagent poate conduce la dezvoltarea de organizatii
flexibile, in care agentii nu sunt nici complet autonomi, intrucat trebuie sa respecte normele,
nici total restrictionati printr-un comportament prestabilit.
Modelele de Incredere si Reputatie sunt deja cunoscute ca fiind probleme cheie in proiectarea
sistemelor multiagent . Astfel de modele reusesc sa sintetizeze informatia necesara unui agent
pentru o selectie sigura si eficienta a partenerilor de interactiune in cazul situatiilor incerte.
Aceasta lucrare isi propune sa construiasca o conexiune intre modelele normative pe de o
parte si modelele de incredere si reputatie pe de alta parte, pentru a simula mai bine
functionarea comunitatilor din lumea reala. Mecanismele propuse pentru calculul increderii si
reputatiei agentilor cu scopuri individuale, ce vor sa stabileasca relatii de colaborare pentru a-
si atinge scopurile, au fost inspirate din jocul de societate premiat “Settlers of Catan”. Settlers
of Catan este un joc de societate cu mai multi jucatori proiectat de Klaus Teuber [9].
Principiile motoare ale acestui joc au fost considerate drept un relevant caz de interactiune
intre agenti ce doresc sa colectioneze diverse cantitati de resurse prin schimburi de tip troc.
Mecanica jocului este simpla in timp ce dinamica suficient de complexa: jucatorii “produc”
resurse prin aruncarea zarurilor si pot efectua schimburi de resurse intre ei sau cu banca
pentru a realiza combinatia de resurse necesara finalizarii unui produs.
Chiar si in ziua de astazi exista numeroase situatii in viata reala in care sunt necesare
schimburi prin troc, spre exemplu, schimbul de cunostinte sau de servicii. Lucrarea de fata
prezinte un scenariu in care agentii fac schimb de bunuri doar prin troc si propune un
mecanism care subliniaza strategiile pe care agentii le pot utiliza pentru a-si maximiza
profitul. Modelul foloseste conceptele de incredere si reputatie in contextul unui sistem
normativ. Acest model poate fi adaptat si aplicat in aplicatii de comert electronic care
faciliteaza schimburile intre colectionari.
Reputatia este un concept ce are atat rol informativ cat si punitiv in cadrul unui grup social. In
modelul de fata, plasarea agentilor in clase de reputatie are doar un rol punitiv si nu ajuta la
dezvoltarea de strategii de fraudare (spre exemplu, alegerea intentionata a unei clase de
reputatie scazuta).

PROGRAMUL 4 “PARTENERIATE IN DOMENIILE PRIORITARE” 2007-2013
SCIPA – Etapa 3: Dezvoltarea componentelor semantice ale platformei
116
Modelul descris foloseste o autoritate centrala pentru inpunerea normelor, sanctionand
violarea normelor prin ajustarea valorii reputatiei. In acelasi timp, fiecare individ isi evalueaza
partenerul folosind o scala de valori personala pentru stabilirea nivelului de incredere.
Autoritatea Centrala are puterea sa altereze reputatia unui agent, influentandu-i astfel castigul,
dar responsabilitatea detectarii si raportarii cazurilor de violare a normelor este lasata in
seama agentilor. Ideea dependentei dintre sanctionarea incalcarilor si motivatia agentilor de a
le raporta se regaseste si in lucrarea [3]. Autorii lucrarii [3] propun ca ambele parti implicate
intr-o obligatie cu un deadline sa se poata exprima in cazul unei incalcari de norme. Unele
lucrari sustin ideea responsabilizarii sistemului pentru (ex: o organizatie electronica [11] sau o
institutie electronica [4]) pentru detectarea incalcarilor si impunerea normelor care sunt
proiectate in mediu (in unele cazuri chiar regimentate in asa fel incat incalcarile sa nu fie
posibile) [3]. Folosirea plangerilor poate fi gasita si in lucrarea [2], lucrare ce incearca
gestionarea increderii in sisteme peer-to-peer. Pentru a permite unui agent sa obtina toate
plangerile referitoare la un alt agent anume, intr-o maniera total descentralizata, autorii
folosesc un sistem de stocare replicat, prezentat in [1]. Un punct important in [2] este
reprezentat de incercarea de a face fata situatiilor in care agenti rau intentionati care plaseaza
plangeri nefondate la adresa partenerilor lor. Spre deosebire de abordarea noastra, autorii
lucrarii [2] folosesc valori binare ale increderii, ceea ce nu permite nici o negociere cu privire
la clauzele contractuale. In loc sa fie exclusi din comunitate, asa cum se intampla in [6], in
sistemul din prezenta lucrare agentii ce nu se conformeaza normelor sunt liberi sa stea, doar
ca nivelul scazut al increderii si reputatiei dobandite ii va impiedica sa obtina recompensa
dependenta de clasamentul final.
2.2 Sistemul de agenti
Comunitatea de agenti prezentata aici consta in agenti cu drepturi si responsabilitati egale,
care au luat toti cunostinta de acelasi set de norme si recunosc aceeasi Autoritate Centrala
(notata AC de aici inainte) ce detine informatii despre toti agentii din sistem (valoarea
reputatiei si capabilitatile de productie pentru fiecare agent). Autoritatea centrala recalculeaza
periodic valorile reputatiei, publicandu-le pe un sistem de tip „black-board” pentru a putea fi
consultate de toti agentii cu nici un cost. Cand intra in sistem, fiecare agent producator se
inregistreaza la AC si isi alege un produs pe care sa il dezvolte. Produsul este considerat a fi
finalizat atunci cand agentul a adunat toate resursele specificate in componenta produsului.
Un agent are o anumita reputatie si apartine clasei de reputatie corespunzatoare, asa cum este
descris in Sectiunea 4.1. In plus, fiecare agent retine cate o valoare a increderii pe care o are in
fiecare dintre partenerii sai, mai vechi, sau actuali, asa cum este explicat in Sectiunea 4.2.
Periodic, pe mansura ce agentii intra sau parasesc sistemul, sunt calculate niste clasamente.
Aceste clasamente iau in considerare: timpul consumat, procentajul realizat din produsul

PROGRAMUL 4 “PARTENERIATE IN DOMENIILE PRIORITARE” 2007-2013
SCIPA – Etapa 3: Dezvoltarea componentelor semantice ale platformei
117
primit ca scop, reputatia castigata si numarul de resurse la care agentul are acces direct. Locul
pe care se claseaza un agent determina recompensa pe care o va primi, agentii fiind astfel
motivati sa adopte strategii eficiente (ex: cum sa isi creasca viteza de productie fara a pierde
din reputatie). Motorul motivational intern al unui agent este acela de a ajunge pe un loc cat
mai inalt in clasamentele periodice.
Fie m o multime de tipuri de resurse din sistem. Fiecare agent are acces direct la un numar de
i tipuri de resurse (1 < i < m, i diferit pentru fiecare agent), numite resurse interne de aici
inainte. Intrucat este foarte mica probabilitatea ca un agent sa isi atinga produsul stabilit drept
scop folosindu-se exclusiv de resursele interne, el trebuie sa le obtina pe celelalte prin
schimburi cu alti alti agenti. Vom numi resursele obtinute prin troc, schimbate la rate
negociate, resurse externe.
Pentru fiecare tip de resursa interna, un agent are asociata o rata de exploatare specifica. Rata
de exploatare arata numarul de unitati din acel tip primit de un agent la fiecare tur.
Figura 1 Gestionarea resurselor individuale
Figura 1 ilustreaza felul in care fiecare agent isi gestioneaza resursele interne si externe.
Segmentul mai intunecat semnifica procentul de resurse acumulate din necesarul total. Fie r
multimea tipurilor de produse. Dezvoltarea unui produs consta doar in adunarea numarului de
unitati din fiecare tip de resursa componenta. Pentru fiecare pereche produs, tip de resursa
exista asociata cantitatea necesara.
2.3 Modelul
Mecanismul de sincronizare folosit de modelul prezentat aici se bazeaza pe ture. Fiecare tur
consta in doi pasi. In primul pas, un agent poate fie plasa o oferta catre un alt agent, fie trimite
un mesaj de informare catre AC prin care sa inregistreze o incalcare a normelor. Dupa ce a
primit toate ofertele, un agent le poate accepta sau refuza in functie de propriile sale interese
si de informatiile despre reputatie.
In cel de-al doilea pas, un agent poate raspunde pozitiv la o cerere de colaborare, ceea ce duce
la un schimb instantaneu resurse. Tot in acest pas AC va raspunde cu un mesaj de confirmare
la instiintarile de violare a normelor pe care le-a primit in primul pas.
Lista agentilor existenti in sistem, capabilitatile lor de productie precum si valorile actualizate
ale reputatiei sunt accesibile tuturor, in orice moment, fara nici un cost.

PROGRAMUL 4 “PARTENERIATE IN DOMENIILE PRIORITARE” 2007-2013
SCIPA – Etapa 3: Dezvoltarea componentelor semantice ale platformei
118
2.3.1 Reputatia
In aceasta lucrare Reputatia este considerata drept o masura globala a comportamentului
agentului, o informatie centralizata, disponibila oricarui participant din sistem, adunata din
surse multiple si folosita ca valoare de referinta. Reputatia asociata unui agent este
reprezentata printr-o valoare intreaga, direct proportionala cu nivelul reputatiei, situata intre o
valoare minima, -RpBound, si una maxima, RpBound. Functia Rp este cea care asociaza
fiecarui agent valoarea curenta a reputatiei sale.
, unde Z reprezinta multimea numerelor intregi.
La intrarea in sistem, valoarea reputatiei unui agent este initializata la 0. Dupa un anumit
numar de ture (numit de aici inainte perioada de evolutie), Autoritatea Centrala recalculeaza
valorile reputatiei prin aplicarea urmatorului set de reguli:
daca numarul_tranzactiilor(a) > 0 atunci
daca numarul_de_incalcari_raportate == 0 atunci
daca reputatie(a) < RpBound atunci reputatie(a) +=1
altfel
daca reputatie(a) > (-1*RpBound) atunci
reputatie(a)-=1
altfel reputatie(a) = reputatie(a)
unde numarul_tranzactiilor(x) intoarce un intreg reprezentand numarul tranzactiilor in care
agentul x a participat in decursul ultimei perioade de evolutie, iar reputatie(x) reprezinta
valoarea reputatiei pe care a obtinut-o agentul x de cand a intrat in sistem si pana in prezent.
Am ales o scala discreta pentru reprezentarea reputatiei pentru a pastra modelul cat mai
simplu si ilustrativ in acelasi timp. Exista alte modele, [5], [8], care considera evaluarea
performantei unui agent printr-o valoare binara (bun/rau). Noi am extins aceasta scala si am
stabilit trei clase de reputatie.
In functie de valoarea reputatiei fiecaruia, agentii sunt impartiti pe trei clase de reputatie:
Trustworthy, Neutral, Untrustworthy, asa cum se arata in Figura 2. Pe axa R se situeaza
nivelele de reputatie. R
Figura 2 Clasele de reputatie si ratele de schimb
1:3
1:1
1:1
1:1
Neutral
Trustworthy
Untrustworthy
RpBound
0
RpBound / 3 1:2
1:2- RpBound / 3
- RpBound

PROGRAMUL 4 “PARTENERIATE IN DOMENIILE PRIORITARE” 2007-2013
SCIPA – Etapa 3: Dezvoltarea componentelor semantice ale platformei
119
Modelul de reputatie prezentat in aceasta lucrare poate fi cu usurinta extins pentru a lua in
considerare si diverse alte functii precum: diversitatea (diminuand ponderea unei opinii
primite de prea multe ori de la aceeasi sursa), variabilitatea in valorile de evaluare [7] sau
validitatea (excluzand valorile ce sunt prea departe de seria celolalte valori primite) si a oferi
astfel o valoare a reputatiei mult mai realista.
Reputatia poate fi privita ca fiind un capital social, intrucat influenteaza interactiunile de
schimb prin alterarea incredereii intr-un potential partener, modificand astfel ratele de schimb.
Valoare acelorasi bunuri depinde de reputatia vanzatorului. Acest principiu motiveaza agentii
sa obtina o reputatie cat mai mare, respectandu-si angajamentele.
2.3.2 Increderea
In aceasta lucrare Increderea este considerata a fi o opinie subiectiva a unui agent asupra
comportamentului partenerilor sai de tranzactii, bazata pe interactiuni directe.
Valoarea prin care se arata cat de mult are incredere agentul A1 in agentul A2 este
reprezentata printr-un intreg, folosindu-se aceeasi grila ca si reprezentarea reputatiei. Fiecare
agent pastreaza o tabela actualizata a valorilor increderii pentru fiecare dintre agentii cu care a
interactionat. La inceputul simularii agentii nu au nici o inregistrare in aceasta tabela. Atunci
cand trebuie sa decida daca sa interactioneze sau nu cu un agent necunoscut, agentii folosesc
valoarea reputatiei acelui agent (valoare care este publicata gratuit de catre AC) ca si valoare a
increderii.
Dupa un numar fixat de ture (perioada de evolutie), fiecare agent recalculeaza increderea
pentru fiecare fost colaborator al sau conform urmatorului set de reguli: daca numarul_interactiunilor(a1, a2) > 0 atunci
daca incalcari_norme == 0 atunci
daca incredere(a1, a2)< RpBound atunci incredere(a1,a2)+=1
altfel
daca incredere (a1, a2) > (-1 * RpBound) atunci
incredere (a1, a2) -=1
altfel incredere (a1, a2) = incredere (a1, a2)
unde numarul_interactiunilor(x, y) intoarce un intreg reprezentand numarul interactiunilor
dintre agentul x si agentul y in timpul ultimei perioade de evolutie iar incredere(x,y)
reprezinta increderea pe care o are agentul x in agentul y.
2.3.3 Norme
Consideram setul de norme folosit de acest model ca fiind „imposive” conform clasificarii din
lucrarea [10], adica norme ce forteaza o entitate sa faca o actiune sau sa ajunga intr-o anume
stare. Pentru a simplifica scenariul am ales o singura regula generala: Agentii trebuie sa

PROGRAMUL 4 “PARTENERIATE IN DOMENIILE PRIORITARE” 2007-2013
SCIPA – Etapa 3: Dezvoltarea componentelor semantice ale platformei
120
respecte ratele de schimb afisate in Figura 2, conform clasei de reputatie in care se afla. Rata
de schimb intre un agent apartinand clasei Trustworthy si un agent apartinand clasei
Untrustworthy este de 1:3 (pentru fiecare unitate pe care o da agentul din clasa superioara
primeste 3 unitati de la celalalt agent), 1:2 pentru agenti apartinand claselor adiacente si 1:1
intre agenti apartinand aceleiasi clase.
Atat Autoritatea Centrala cat si agentii producatori sunt responsabili pentru impunerea
normelor in felul urmator: un agent poate plasa o plangere la AC ori de cate ori intalneste
nerespectarea unui contract, adica daca nu i s-a livrat numarul de unitati promis din tipul
stabilit. Un agent poate observa violarea unei norme doar daca aceasta a aparut in timpul
uneia dintre interactiunile sale cu un alt agent.
2.3.4 Rezultatele implementarii
Pe baza a diversi parametri ce contribuie la evaluarea realizarilor unui agent, pe parcursul
simularii se efectueaza periodic clasamente. Recompensa urmarita de un agent este invers
proportionala cu locul obtinut in clasament. Parametri luati in considerare in masurarea
calitatilor unui agent pot fi: timpul consumat in realizarea produsului, valoarea finala a
reputatiei sale, sau capitalul initial (cate dintre tipurile de resurse interne ale agentului intrau
in compozitia produsului definit drept scop).
Am dezvoltat un sistem de testare cu scopul de a regla valorile de intrare ale sistemului
multiagent prin modificarea diversilor parametri: numarul de agenti, numarul de resurse,
numarul de produse, ingredientele produselor si cantitatile asociate, ratele de productie a
resurselor pentru fiecare agent precum si diversele valori de prag si de probabilitate care
influenteaza generatorul de date sau comportamentul agentului. Am desfasurat mai multe
experimente cu multimi intre 40 si 100 de agenti. Am variat perioada de evolutie de la 100 la
20 de runde si am observat ca pe masura ce perioada de Figura 3. Valorile reputatiei in functie de incalcarea normelor
evolutie este mai mica, cu atat este mai mare valoarea de reputatie atinsa in media de catre
agenti, intrucat acestia au mai multe oportunitati de a-si reface reputatia si mai putine sanse de
a incalca o norma in acea perioada. Un exemplu de evolutie a valorilor reputatiei alaturi de
numarul total de incalcari ale normelor per agent este ilustrat in Figura 3.

PROGRAMUL 4 “PARTENERIATE IN DOMENIILE PRIORITARE” 2007-2013
SCIPA – Etapa 3: Dezvoltarea componentelor semantice ale platformei
121
In Figura 4 agentii sunt aliniati pe abscisa dupa locul obtinut in clasamentul in functie de
timpul consumat (agentul numerotat cu 1 este cel care a terminat primul produsul asignat).
Graficul prezinta modul in care numarul de incalcari ale normelor si numarul de resurse
interne influenteaza viteza de dezvoltare a produsului.
Figura 4. Incalcarea normelor si capitalul initial in functie de clasamentul de timp
Procentul ramas de indeplinit consta in cantitatea de resurse externe ce trebuie adunate prin
schimburi de la alti agenti. Curba de tendinta arata ca agentii care au mai multe resurse ce
trebuie obtinute din exterior petrec mai mult timp in realizarea produsului. Analizand
distributia numarului de incalcari ale normelor se observa un numar mic de agenti foarte de
neincredere. Sistemul poate fi considerat bine echilibrat per ansamblu pentru ca acesti agenti
foarte de ne incredere (cu o valoare foarte mica a reputatiei), desi rar ocupa ultimele locuri in
clasamentul dupa timpul consumat, nu ajung niciodata pe primele locuri.
2.4 Strategii
Dat fiind un set de norme, agentii ar trebui sa dezvolte si sa foloseasca un set de strategii
pentru selectarea partenerilor de interactiune. Un agent poate decide daca sa informeze sau nu
Autoritatea Centrala in urma observarii unei incalcari a normelor. Actiunea rezultata in urma
acestui proces de decizie poate varia in functie de nivelul de dezvoltare in care se afla
produsul de realizat. Intrucat comunicarea cu AC costa un tur, agentul poate alege sa nu
raporteze frauda. Agentul producator va fi interesat sa informeze AC la observarea unei
nereguli in special in primele stagii de dezvoltare, deoarece amenzile primite de ceilalti agenti
ii pot pune in clase inferioare de reputatie, scazand astfel costurile tranzactiilor. Tranzactiile
cu agenti din clase inferioare de reputatie sunt mai profitabile dar si mai riscante. Cand se alfa
la ultimele etape ale dezvoltarii produsului sau, interesul unui agent de a informa Autoritatea
Centrala despre o neregula poate scadea pentru ca incearca sa termine produsul cat mai repede
si nu isi permite sa piarda un tur. Astfel, contributia agentilor la acuratetea valorilor reputatiei
scade spre finalul dezvoltarii produselor lor. Acestea sunt decizii gestionate intern de catre
fiecare individ. Dupa ce si-a finalizat produsul, interesul unui individ de a informa AC despre
nereguli poate creste deoarece este in favoarea lui ca ceilalti agenti sa termine cat mai tarziu
posibil; asadar, un astfel de agent va raporta o plangere de cate ori observa o frauda.
Un agent incalca o norma cand nu furnizeaza toate unitatile promise din resursa stabilita
conform contractului. Tindem sa credem ca acest comportament va aparea mai frecvent cand

PROGRAMUL 4 “PARTENERIATE IN DOMENIILE PRIORITARE” 2007-2013
SCIPA – Etapa 3: Dezvoltarea componentelor semantice ale platformei
122
un agent este foarte aproape de finalizarea produsului sau si de aceea pretuieste mai mult
timpul decat reputatia. Dat fiind mecanismul de sincronizare propus de acest model,
consideram ca acest tip de incalcare a normelor are loc cu premeditare intrucat agentii pot
evalua toate ofertele, si calcula unde urmeaza a-si investi resursele in turul curent inainte de a-
si lua un angajament. Cand evalueaza ofertele primite sau inspecteaza lista de agenti ce ofera
o anume resursa, agentul A1 calculeaza clasa de reputatie pentru fiecare dintre acesti agenti
folosing urmatoarele doua reguli:
1. Daca nu exista o colaborare anterioara cu agentul analizat, A2, agentul evaluator, A1
considera increderea sa in A2 ca fiind egala cu reputatia lui A2, furnizata de
Autoritatea Centrala.
2. Daca agentul evaluator, A1, are deja o inregistrare referitoare la agentul analizat, A2,
atuncu clasa de reputatie a lui A2 este data de media dintre reputatia public disponiblia
si increderea pe care A1 o are fata de A2.
Prima regula exprima influenta reputatiei acumulate in initializarea unei relatii. Cea de-a doua
regula arata cum experienta personala influenteaza perceptia asupra reputatiei cuiva.
Motivatia pentru cea de-a doua regula vine din nevoia de a compensa eventualele anomalii in
calculul global al reputatiei. Pot exista cazuri in care un agent rau intentionat, agentul D, vrea
sa denigreze reputatia unui agent ce se conformeaza normelor sistemului, agentul A, si trimite
numeroase plangeri nefondate despre A Autoritatii Centrale. Daca agentul B a mai
interactionat in trecut cu agentul A si valoarea increderii sale in agentul A este mare, folosirea
mediei intre incredere si reputatie va duce la o valoare mai apropiata de adevar.
Toti agentii ar dori sa scada pozitia celorlalti participant pe grila de reputatie, pentru aceasta
chiar atunci cand reputatia afisata public are o valoare mare, ei pot minti in privinta valorii
increderii contabilizate intern. Aceasta situatie este tratata prin impunerea unui acord care
trebuie aprobat de catre ambele parti in cazul oricarei tranzactii. Contractul nu este stabilit
pana cand cele doua parti nu cad de acord in privinta clasei de reputatie in care fiecare isi
incadreaza partenerul. Aici negocierea joaca un rol esential. Nivelu reputatiei afisat public
poate fi folosit intotdeauna ca valoare de referinta in timpul negocierilor si este interesul
ambelor parti sa incerce sa isi plaseze partenerul cat mai corect pe grila de reputatie pentru a
obtine un acord.
In vederea unor dezvoltari viitoare, nivelul pe care fiecare agent isi plaseaza partenerul in
grila de reputatie ar trebui determinat intr-un mod mai realist, folosind media ponderata intre
incredere si reputatie. Ponderile folosite ar trebui sa fie invers proportionale intre ele si
corelate cu numarul de interactiuni anterioare. In acest fel, Agentul A va acorda o mai mare
importanta reputatiei agentului B atunci cand nu a interactionat niciodata sau de foarte putine
ori cu el in trecut si va actiona mai mult conform propriilor sale evaluari in privinta gradului
de incredere al agentului B atunci cand exista experienta mai multor interactiuni.

PROGRAMUL 4 “PARTENERIATE IN DOMENIILE PRIORITARE” 2007-2013
SCIPA – Etapa 3: Dezvoltarea componentelor semantice ale platformei
123
2.5 Concluzii
Aceasta lucrare propune un model de evaluare a increderii si reputatiei in sisteme multiagent
luand in considerare si impunerea setului de norme asociat sistemului multiagent.
Modelul propus foloseste interactiuni de schimb non-monetare. Procesul de selectare a
partenerului pentru schimbul de bunuri ia in seama atat reputatia obtinuta de catre candidat (o
masura globala) cat si valoarea subiectiva a increderii in candidatul respectiv (valoare stabilita
in urma altor interactiuni directe). Valorile de incredere pe care agentii si le asociaza unii
altora sunt calculate conform unui set de norme specifice sistemului. Modelul adreseaza
problema penalizarilor prin plasarea agentilor in diferite clase de reputatie, in conditiile in
care apartenenta la clase diferite implica modificarea costurilor pentru aceasi bunuri.
Articolul studiaza modul in care normele sunt impuse prin utilizarea unei Autoritati Centrale.
Intrucat folosirea unei autoritati centrale implica doua neajunsuri importante, si anume, supra-
incarcarea retelei de comunicatie intre agenti si existenta unui singur punct de ce poate
compromite intregul sistem, studiem in continuare noi metode in vederea implementarii unei
solutii descentralizate rezistenta la fraude. Ca si obiective viitoare ne propunem sa investigam
cum poate fi tratata posibilitatea ca un agent sa depuna o evaluare injusta si sa adaugam un
sistem paralel de reputatie: reputatia evaluatorilor.
Bibliografie
1. Aberer, K.: P-Grid: A self-organizing access structure for P2P information systems. In: Cooperative Information Systems, pp. 179—194, Springer, (2001)
2. Aberer, K. and Despotovic, Z.: Managing trust in a peer-2-peer information system. In: CIKM ’01: Proceedings of the tenth international Conference on Information and Knowledge Management, pp 310—317, New York, ACM Press, (2001)
3. Cardoso, H.L. and Oliveira, E.: Directed Deadline Obligations in Agent-based Business Contracts. In: Proceedings of the 8th International Joint Conference on Autonomous Agents and Multiagent Systems, (2009)
4. Esteva, M. and Rodriguez-Aguilar, J.A. and Sierra, C. and Garcia, P. and Arcos, J.L.: On the formal specifications of electronic institutions. In: Lecture Notes in Computer Science. Springer Verlag, (2001)
5. Mui, L., Mohtashemi, M. & Halberstadt, A. : A computational model of trust and reputation for e-business. In: 35th Hawaii International Conference on System Science (HICSS 35 CDROM). IEEE Computer Society (online publication), (2002)
6. de Pinninck, A.P. and Sierra, C. and Schorlemmer, M.: Friends No More: Norm Enforcement in Multi-Agent Systems. In: Proceedings of the 6th international joint conference on Autonomous agents and multiagent systems. ACM New York, (2007)
7. Sabater, J. & Sierra, C.: REGRET: a reputation model for gregarious societies. In: Castelfranchi, C. & Johnson, L. (eds.), Proceedings of the 1st International Joint Conference on Autonomous Agents and Multi-Agent Systems, pp. 475–482, (2002)
8. Sen, S. & Sajja, N.: Robustness of reputation-based trust: Boolean case. In: Castelfranchi, C. & Johnson, L. (eds.), Proceedings of the First International Joint Conference on Autonomous Agents and Multi-Agent Systems, Vol. 1, pp. 288–293, (2002)
9. Catan Official Site, http://www.catan.com/en/download/?SoC_rv_Rules_091907.pdf, (last accessed 2009). 10. Vazquez-Salceda, J. and Aldewereld, H. and Dignum, F.: Implementing Norms in Multiagent Systems, In: Proceedings
of the 2nd German conference, MATES 2004 Multiagent system technologies, Springer Verlag, (2004) 11. Vazquez-Salceda, J. and Dignum, F.: Modelling electronic organizations. In: Multi-Agent Systems and Applications III,
pp. 1070--1085 (2003)

PROGRAMUL 4 “PARTENERIATE IN DOMENIILE PRIORITARE” 2007-2013
SCIPA – Etapa 3: Dezvoltarea componentelor semantice ale platformei
124
Partea a V-a
Translator din BPEL in Event Calculus in scopul verificarii serviciilor business web
Autori – Universitatea de Vest din Timişoara
Prof. dr. Viorel Negru – responsabil ştiinţific
Prof. dr. Dana Petcu
Prep. drd. Ovidiu Aritoni Prep. drd. Ciprian Pungilă

PROGRAMUL 4 “PARTENERIATE IN DOMENIILE PRIORITARE” 2007-2013
SCIPA – Etapa 3: Dezvoltarea componentelor semantice ale platformei
125
1 Introducere
Complexitatea serviciilor web creste de la an la an si implica din ce in ce mai multe
interactiuni cu obiecte business din cadrul unor procese complexe distribuite. Pentru a ne
putea folosi de serviciile business web la capacitatea lor maxima avem nevoie de o executie
corecta si fiabila a acestora. Prin analiza si urmarirea acestora, vom putea ca sa le intelegem si
sa le controlam mai bine. In cadrul acestui raport vom acoperi tehnicile folosite in aplicatia
BPEL Validator cu care vom face o verificare a serviciilor business web.
Arhitecturile orientate spre servicii (SOA) sunt tot mai populare in cadrul proceselor business.
Aceste au devenit o arhitectura esentiala pentru BPM (Business Process Management). SOA
permite ca o aplicatie sa fie con- siderata ca compunere de servicii, sisteme de management
de workflow-uri (WfMSs -Workflow Management Systems) si alte aplicatii mai vechi. Astfel,
un proces business devine un set de servicii compuse care poate fi partajat pe mai multe
unitati business, organizatii sau parteneri. Desi exista produse care sa faciliteze modelarea,
analiza si simularea proce- selor business, cuplarea BPM si SOA este mai buna deoarece
aceasta poate fi direct implementata (ex. folosind WSBPEL). Din pacate, exista si neajunsuri:
posibilitatea de adaptare si de gestionare automata a proceselor. Verificarea automata a
proceselor poate fi facuta static (in momentul con- ceperii acestora) sau dinamic (in timpul
rularii acestora). Pe baza modelului procesului se poate construi un automat finit care sa
permita o evaluare a acestuia. Pentru ca procesul sa fie verificat in tipul rularii acestuia, acesta
trebuie sa permita audit. Pe datele obtinute in urma rularii procesului se pot aplica diverse
tehnici de data mining care sa extraga comportamentul acestora in timpul rularii (vor putea fi
observate erori sau strangulari). Scopul acestui raport este de a studia anumite tehnici de
verificare a ser- viciilor web. Avand log-ul unui serviciu web, noi vom verifica daca apar dis-
crepante intre modelul procesului si instanta executata. Vom folosi Event Calculus pentru a
rationa asupra log-urilor de evenimente a unui process business pentru a-i verifica consistenta.
Acest raport este un rezultat al aplicatiei BPEL Validator, aplicatie care reprezinta un inceput
in validarea automata a serviciilor web.
2 Arhitectura generala a BPEL Validator
Arhitectura generala a BPEL Validator e dupa cum urmeaza: O parte din aplicatie se va folosi
de fisierele BPEL (Business Process Execu- tion Language) si WSDL (Web Service
Definition Language) pentru a mapa structurile BPEL si a le converti in formule Event
Calculus. O a doua parte din cadrul aplicatiei se va folosi de log-urile generate de instanta
BPEL din cadrul BPWS4J pentru a extrage evenimentele Event Calculus. Avand atat

PROGRAMUL 4 “PARTENERIATE IN DOMENIILE PRIORITARE” 2007-2013
SCIPA – Etapa 3: Dezvoltarea componentelor semantice ale platformei
126
formulele cat si evenimentele putem deduce devieri de comportament in cadrul serviciului.
Din pacate, la momentul respectiv nu exista un validator automatizat pentru Event Calculus.
O metoda alternativa validarii folosind Event Calculus este cea folosind Spike (Theorem
Prover). Acesta a fost folosit in mod similar cu Event Calculus.
3 Event Calculus Se defineste Event Calculus ca fiind un limbaj logic care permite o reprezentare si un
rationament asupra actiunilor si efectelor acestora. Componentele de baza in Event Calculus
sunt fluentii si actiunile. In Event Calculus putem specifica valoare fluentilor la un anumit
timp, actiunile care iau parte la anumite puncte in timp si efectele actiunilor.
3.1 Convertirea fisierelor BPEL
Business Process Execution Language (BPEL) este un limbaj standard executabil OASIS
pentru specificarea actiunilor din cadrul proceselor business din cadrul serviciilor web. BPEL
poate exporta si importa informatiile folosind in mod exclusiv interfetele serviciilor web.
Convertirea a presupus identificarea elementelor esentiale si convertirea acestora in Event
Calculus.
Exemple de transformari:
BPEL receive:
<receive name=”receiveRequest” partner=”UI” portType=”sns:CRSUI”
operation=”CarRequest” variable=”Req” createInstance=”yes”>
<source linkName=”receive-to-auth”/>
<correlations> ... </correlations>
</receive>
Event Calculus receive:
Happens(invoke rc(UI,CarRequest(oID1)),t1, ¬(t1,t1)^
Initiates(invoke rc(UI,CarRequest(oID1)),equalTo(Req.Loc,vReq.Loc),t1)^
Initiates(invoke rc(UI,CarRequest(oID1)),equalTo(Req.CId, vReq.CId),t1)
BPEL assign:
<assign name=”a1”>
<copy>
<from variable=”Req” part=”Loc”/>
<to variable=”Q” part=”Loc”/> </copy>
</assign>

PROGRAMUL 4 “PARTENERIATE IN DOMENIILE PRIORITARE” 2007-2013
SCIPA – Etapa 3: Dezvoltarea componentelor semantice ale platformei
127
Event Calculus assign:
((9t2) (t1 < t2) ^ Happens(assign(a1,aID),t2,¬(t2,t2)) ^ (t3) (t2 < t3) ^
Initiates(assign(a1,aID),equalTo(Q.Loc, vReq.loc),t3)
BPEL invoke:
<invoke name=”findCar” partner=”IS” portType=”crns:CRSIS” operation=”FindAvailable”
inputVariable=”Q” outputVariable=”Res”> ... </invoke>
Event Calculus invoke:
(9t4) Happens(invoke ic(IS,FindAvailable(oID2,vQ)),t4,¬(t3,t4)) ^
(9t5)Happens(invoke ir(IS,FindAvailable(oID2,vQ)),t5, ¬(t4,t5)) ^
Initiates(invoke ir(IS,FindAvailable(oID2,vQ)), equalTo(Res,vRes), t5))
3.2 Convertirea fisierelor log
Fisierele BPEL si WSDL folosite pentru a general formulele Event Calculus sunt folosite in
cadrul BPWS4J[?]. BPWS4J este o platforma dezvoltata in cadrul IBMcare este folosita
pentru crearea si rularea proceselor BPEL4WS.
Log4j va fi folosit pentru generarea de log-uri. Formatul acestora va depinde de modul in care
acesta este configurat si de engine-ul care va executa procesele de business.
Ex1 :
2006-03-13 10:40:39,634 [Thread-35] INFO bpws.runtime - Outgoing res-
ponse: [WSIFResponse:serviceID = http://tempuri.org/services/Custom-
erRegCustomerRegServicefb0b0-fbc5965758–8000operationName =
isFault = false outgoingMessage = org.apache.wsif.base.WSIFDefau-
ltMessage@1df3d59 name:null parts[0]:[JROMBoolean: : true]
faultMessage = null contextMessage = null]
2006-03-13 10:40:39,634 [Thread-35] DEBUG bpws.runtime.bus - Response
for external invoke is[WSIFResponse:serviceID=http://tempuri.org/se-
rvices /CustomerRegCustomerRegServicefb0b0-fbc5965758–8000
operationName = authenticate isFault = false outgoingMessage =
org.apache.wsif.base.WSIFDefaultMessage@1df3d59 name:null parts[0]:
[JROMBoolean: : true]faultMessage = null contextMessage = null]
2006-03-13 10:40:39,634 [Thread-35] DEBUG bpws.runtime.bus - Waiting
for request
Ex2 :
19 Mar 2008 16:26:55,480 [http-8080-Processor25] INFO bpws.runtime -
Outgoing response: [WSIFResponse:

PROGRAMUL 4 “PARTENERIATE IN DOMENIILE PRIORITARE” 2007-2013
SCIPA – Etapa 3: Dezvoltarea componentelor semantice ale platformei
128
serviceID = ’http://loans.org/wsdl/loan-approvalloanapprovalServiceBP’
operationName = ’approve’
isFault = ’false’
outgoingMessage = ’org.apache.wsif.base.WSIFDefaultMessage@1684e26
name:null parts[0]:[JROMString: accept: yes]’
faultMessage = ’null’
contextMessage = ’null’]
19 Mar 2008 16:42:43,042 [http-8080-Processor23] INFO bpws.runtime -
Incoming request: [WSIFRequest:
serviceID = ’http://loans.org/wsdl/loan-approvalloanapprovalServiceBP’
operationName = ’approve’
incomingMessage = ’org.apache.wsif.base.WSIFDefaultMessage@771eb1
name:null parts[0]:[JROMInt: amount: 100] parts[1]:[JROMString: name:
Doe] parts[2]:[JROMString: firstName: John]’
contextMessage = ’org.apache.wsif.base.WSIFDefaultMessage@801059 name:null
parts[0]:http://tempuri.org/services/loanapproverloanApprovalPT
parts[1]:customer
parts[2]:http://xml.apache.org/axis/v1’]
O forma formalizata in Event Calculus a log-ului dupa prelucarea de data mining ar putea fi:
L1 : Happens(rc.CSS.Enter(v1, l1), 1)
L2 : Happens(rc.U IS.RelKey(v1, c1, l1), 5)
L3 : Happens(ic.CIS.Available(v1, l1), 9)
L4 : Happens(rc.U IS.RetKey(v1, l1), 15)
L5 : Happens(rc.CSS.Enter(v2, l2), 18)
L6 : Happens(rc.U IS.RetKey(v2, l2), 23)
L7 : Happens(ic.CIS.Available(v2, l2), 26)
L8 : Happens(rc.CSS.Enter(v1, l1), 27)
L9 : Happens(rc.U IS.RelKey(v2, c2, l2), 29)
L10 : Happens(ic.CIS.Available(v2, l2), 34
L11 : Happens(rc.U IS.CarRequest(c1, l2), 49)
L12 : Happens(ic.CIS.F indAvailable(l2, veh), 50)
L13 : Happens(ir.CIS.F indAvailable(l2, veh), 51)
L14 : Initiates(ir.CIS.F indAvailable(l2, v2), 51)
L15 : Happens(re.U IS.CarHire(c1, l2, v2), 52)
L16 : Happens(rc.U IS.RetKey(v2, l2), 54)

PROGRAMUL 4 “PARTENERIATE IN DOMENIILE PRIORITARE” 2007-2013
SCIPA – Etapa 3: Dezvoltarea componentelor semantice ale platformei
129
4 Concluzii
Posibile directii de studiu ar fi extinderea modelelor la WS-Policy si WS- Agreement. O alta
directie ar fi monitorizarea in timp real a serviciilor si cum ar functiona sistemul de detectie,
raportare si recuperare in urma unei erori.
Bibliografie [1] Mohsen Rouached, Walid Gaaloul, Wil M. P. van der Aalst, Sami Bhiri, Claude Godart. Web Service Mining and Verification of Properties: An approach based on Event Calculus. Lecture Notes in Computer Science. 2006
[2] Mohsen Rouached. Une approche rigoureuse pour l’ingenierie de compositions de services Web. PhD thesis, Universite Henri Poincare Nancy 1. 2008
[3] http://en.wikipedia.org/wiki/Event_calculus
[4] http://en.wikipedia.org/wiki/Business_Process_Execution_
Language
[5] http://www.alphaworks.ibm.com/tech/bpws4j
[6] http://logging.apache.org/log4j/
Recommended

















