
Spark와 HDP, 완벽한 조합 (Hortonworks Data Platform)
최종욱 기술이사, Hortonworks Korea
© Hortonworks Inc. 2011 – 2015. All Rights Reserved

왜 오픈 엔터프라이즈 Hadoop인가?
빅데이터 시대의 분산 저장/분석 플랫폼
© Hortonworks Inc. 2011 – 2015. All Rights Reserved
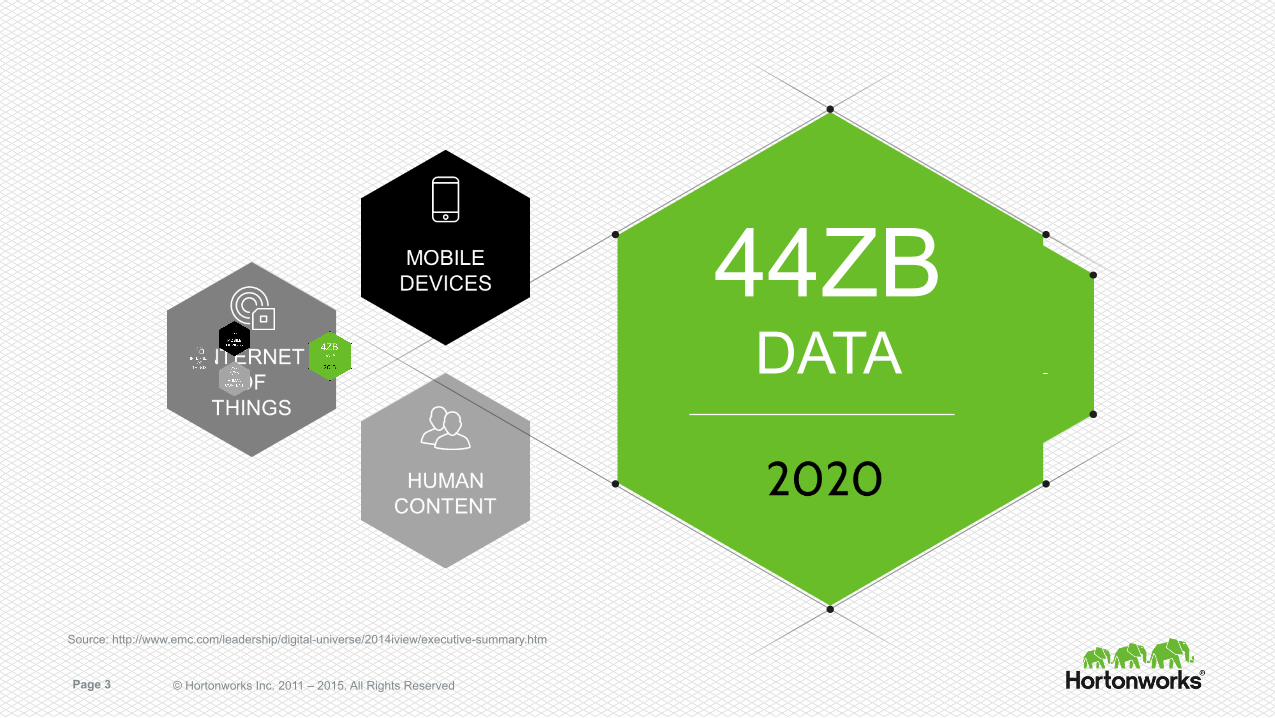
4ZB DATA
MOBILE
DEVICES
HUMAN
CONTENT
INTERNET
OF THINGS
44ZB DATA
Page 3 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
Source: http://www.emc.com/leadership/digital-universe/2014iview/executive-summary.htm

위기
기존의 데이터 아키텍처는 데이터를 접근 불가능하게, 불완전하게, 무관하게, 그리고 비싸게 만듭니다
Page 4 © Hortonworks Inc. 2011 – 2015. All Rights Reserved

기회 Apache™ Hadoop® 은 여러분의 사업을 변화시켜, 어떤 고급 분석 응용 프로그램도 빅데이터에 접근 가능하게 만듭니다
Page 5 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
Page 6 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
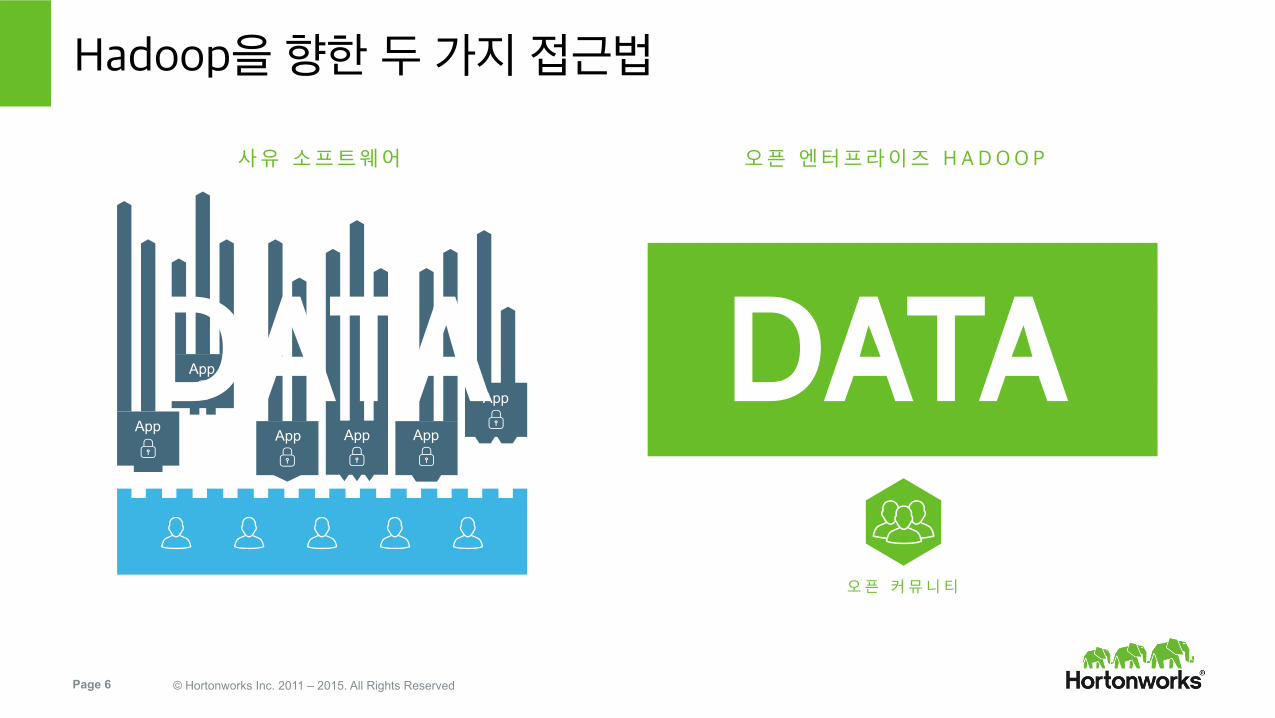
Hadoop을 향한 두 가지 접근법
사유 소프트웨어
App App App App
App
App
Page 6 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
오픈 엔터프라이즈 H ADOO P
오 픈 커 뮤 니 티

오픈 엔터프라이즈 Hadoop
개방성
호환성
집중성
준비성
Page 7 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
Page 8 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
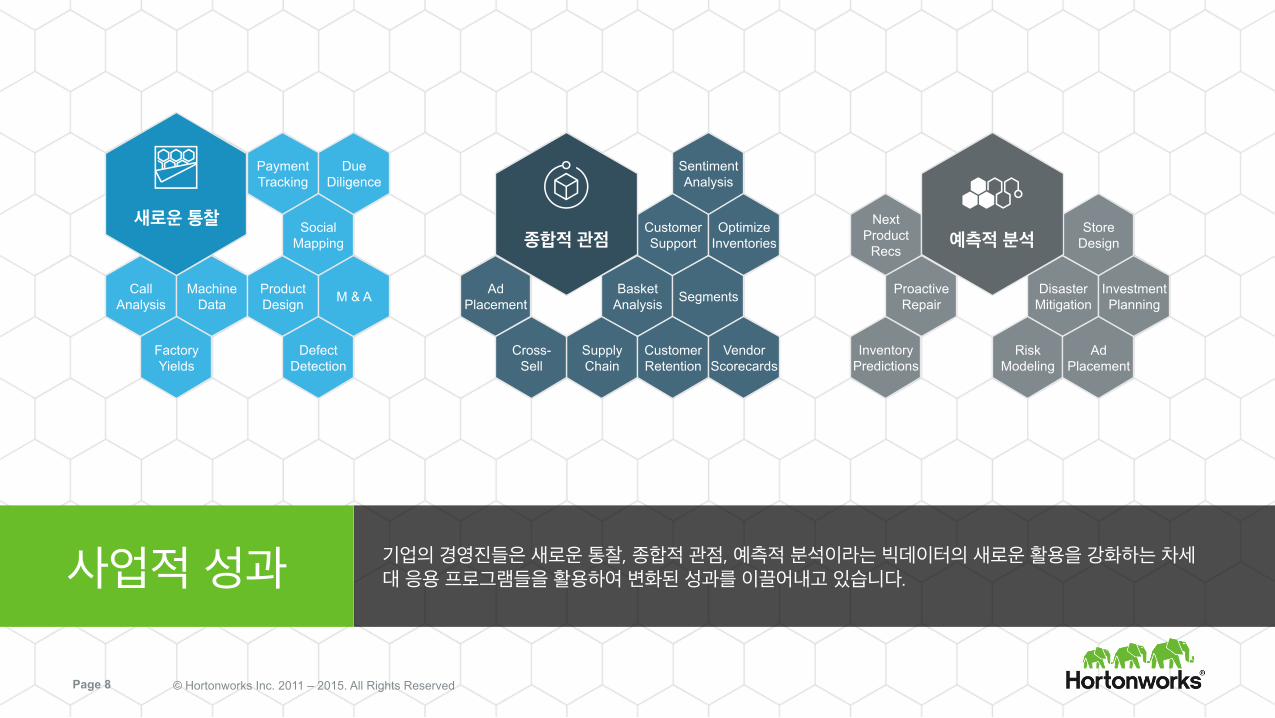
Payment Tracking
Call Analysis
Machine Data
Product Design
Social Mapping
Factory Yields
Defect Detection
Due Diligence
M & A Proactive Repair
Disaster Mitigation
Investment Planning
Next Product
Recs
Store Design
Risk Modeling
Ad Placement
Inventory Predictions
Sentiment Analysis
Ad Placement
Basket Analysis Segments
Customer Support
Supply Chain
Cross- Sell
Customer Retention
Vendor Scorecards
Optimize Inventories
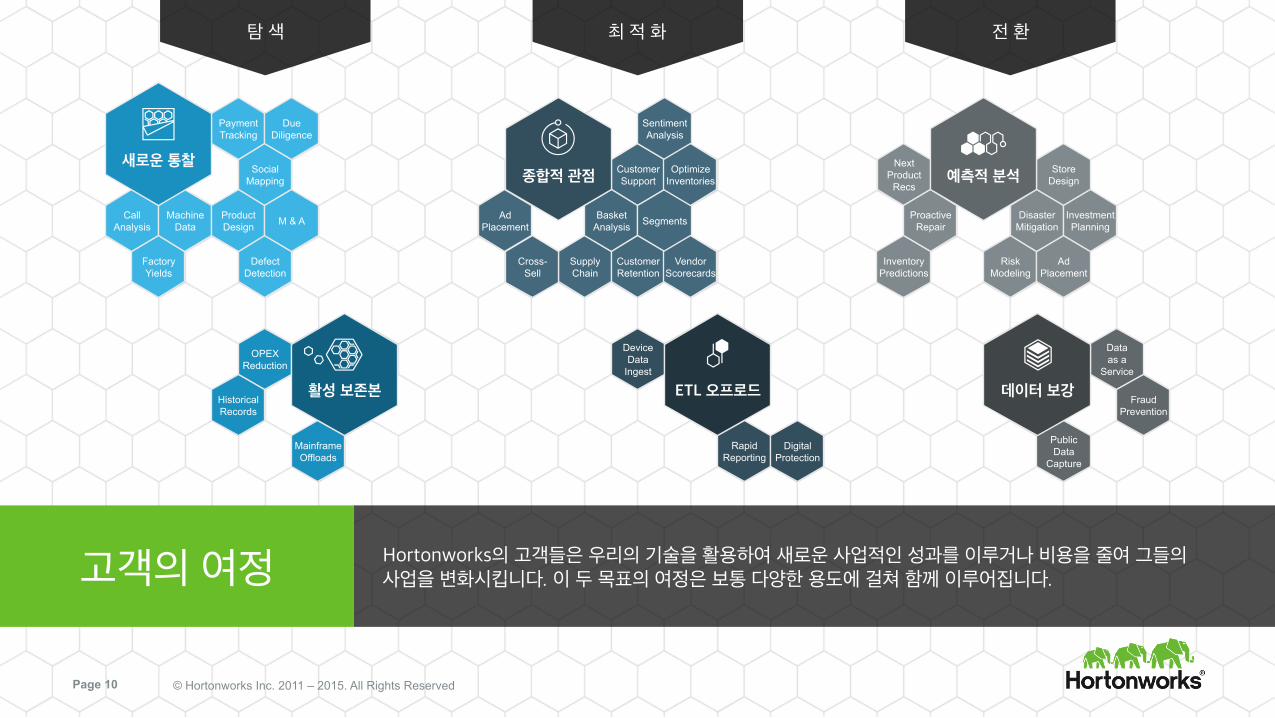
기업의 경영진들은 새로운 통찰, 종합적 관점, 예측적 분석이라는 빅데이터의 새로운 활용을 강화하는 차세대 응용 프로그램들을 활용하여 변화된 성과를 이끌어내고 있습니다. 사업적 성과
새로운 통찰 종합적 관점 예측적 분석
Page 9 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
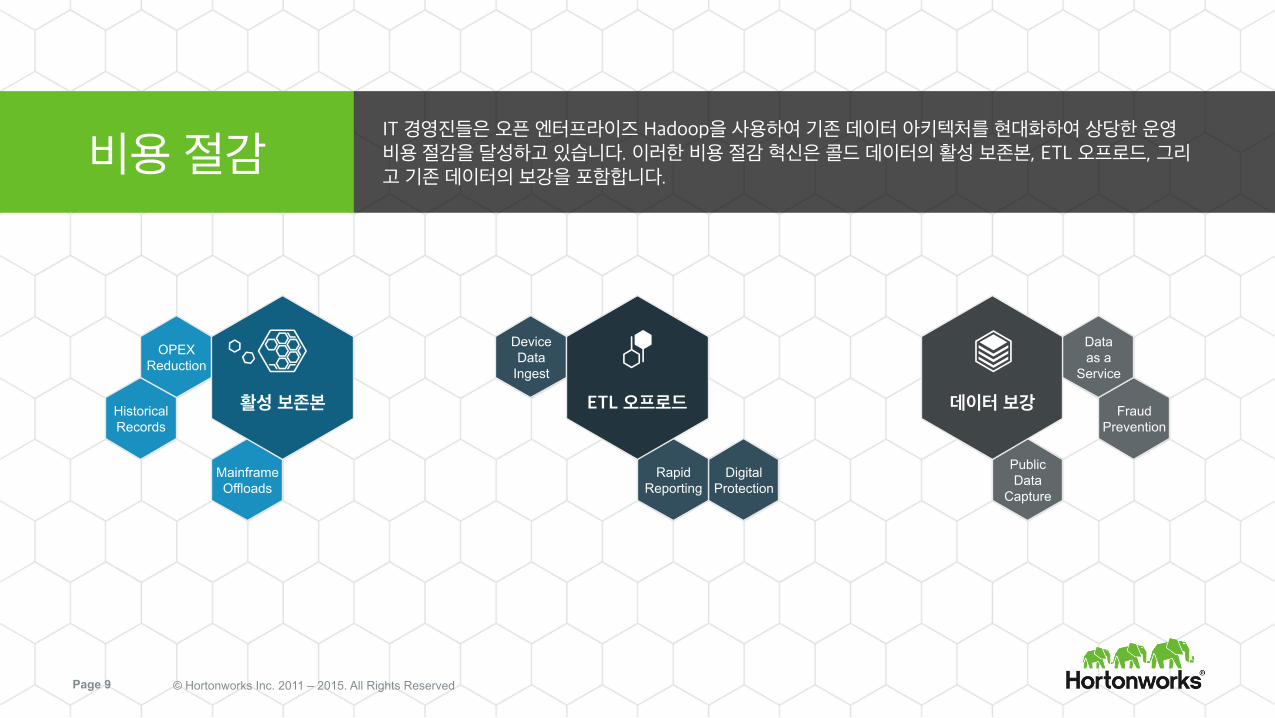
Historical Records
OPEX Reduction
Mainframe Offloads
Fraud Prevention
Data as a
Service
Public Data
Capture
비용 절감 IT 경영진들은 오픈 엔터프라이즈 Hadoop을 사용하여 기존 데이터 아키텍처를 현대화하여 상당한 운영 비용 절감을 달성하고 있습니다. 이러한 비용 절감 혁신은 콜드 데이터의 활성 보존본, ETL 오프로드, 그리고 기존 데이터의 보강을 포함합니다.
Digital Protection
Device Data
Ingest
Rapid Reporting
활성 보존본 ETL 오프로드 데이터 보강
Page 10 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
Hortonworks의 고객들은 우리의 기술을 활용하여 새로운 사업적인 성과를 이루거나 비용을 줄여 그들의 사업을 변화시킵니다. 이 두 목표의 여정은 보통 다양한 용도에 걸쳐 함께 이루어집니다. 고객의 여정
Social Mapping
Payment Tracking
Factory Yields
Defect Detection
Call Analysis
Machine Data
Product Design M & A
Due Diligence
Next Product
Recs
Store Design
Risk Modeling
Ad Placement
Proactive Repair
Disaster Mitigation
Investment Planning
Inventory Predictions
Customer Support
Sentiment Analysis
Supply Chain
Ad Placement
Basket Analysis Segments
Cross- Sell
Customer Retention
Vendor Scorecards
Optimize Inventories
OPEX Reduction
Mainframe Offloads
Historical Records
Data as a
Service
Public Data
Capture
Fraud Prevention
Device Data
Ingest
Rapid Reporting
Digital Protection
새로운 통찰 종합적 관점 예측적 분석
활성 보존본 ETL 오프로드 데이터 보강
탐 색 최 적 화 전 환

왜 Hortonworks인가?
오픈 엔터프라이즈 Hadoop의 리더
© Hortonworks Inc. 2011 – 2015. All Rights Reserved
Page 12 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
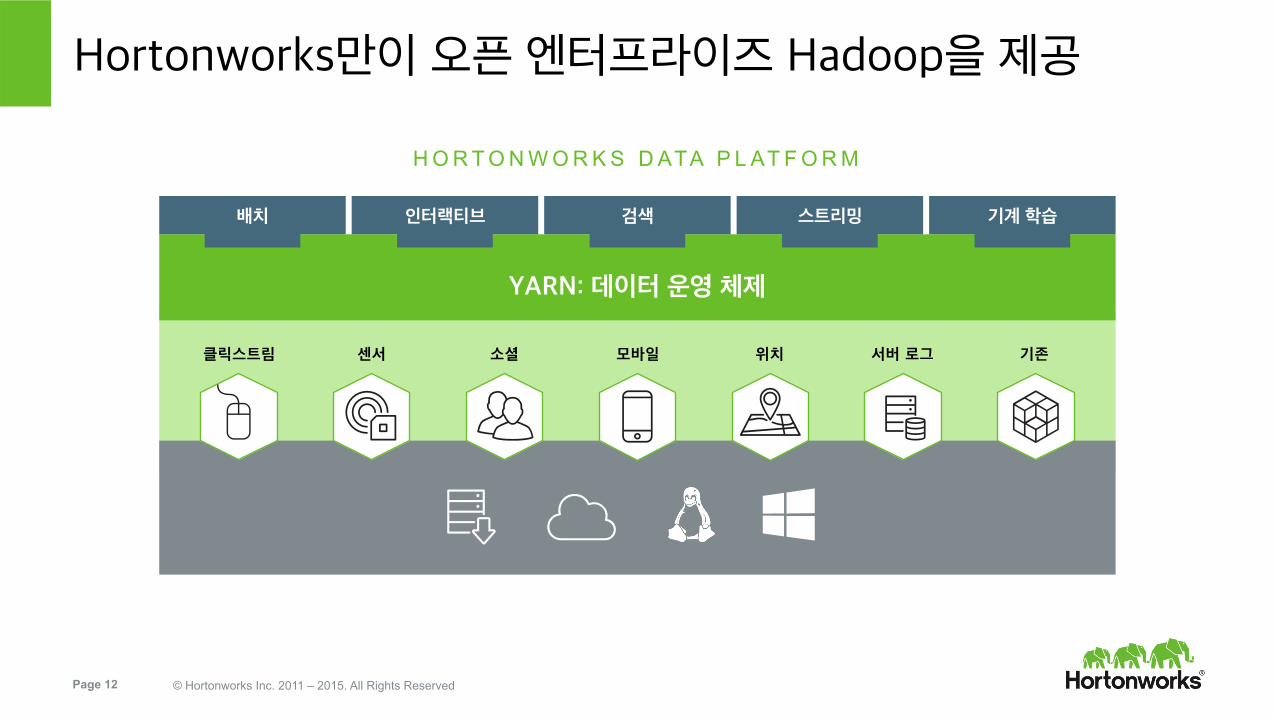
Hortonworks만이 오픈 엔터프라이즈 Hadoop을 제공
H O R T O N W O R K S D ATA P L AT F O R M
YARN: 데이터 운영 체제
클릭스트림 센서 소셜 모바일 위치 서버 로그
배치 인터랙티브 검색 스트리밍 기계 학습
기존

Page 13 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
Hortonworks는 Apache 커뮤니티에 큰 영향력을 행사
커미터들을 고용 Apache Hadoop™ 프로젝트 커미터의 1/3, 다른 중요한 프로젝트에서도 다수 고용
우리의 커미터들이 혁신을 주도
오픈 엔터프라이즈 Hadoop을 확장
Hadoop 로드맵에 영향력을 행사
우리의 리더를 통해서 중요한 요구사항들을 커뮤니티에 주고 받음
A PA C H E H A D O O P C O M M I T T E R S
Page 14 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
STO
RA
GE
STO
RA
GE
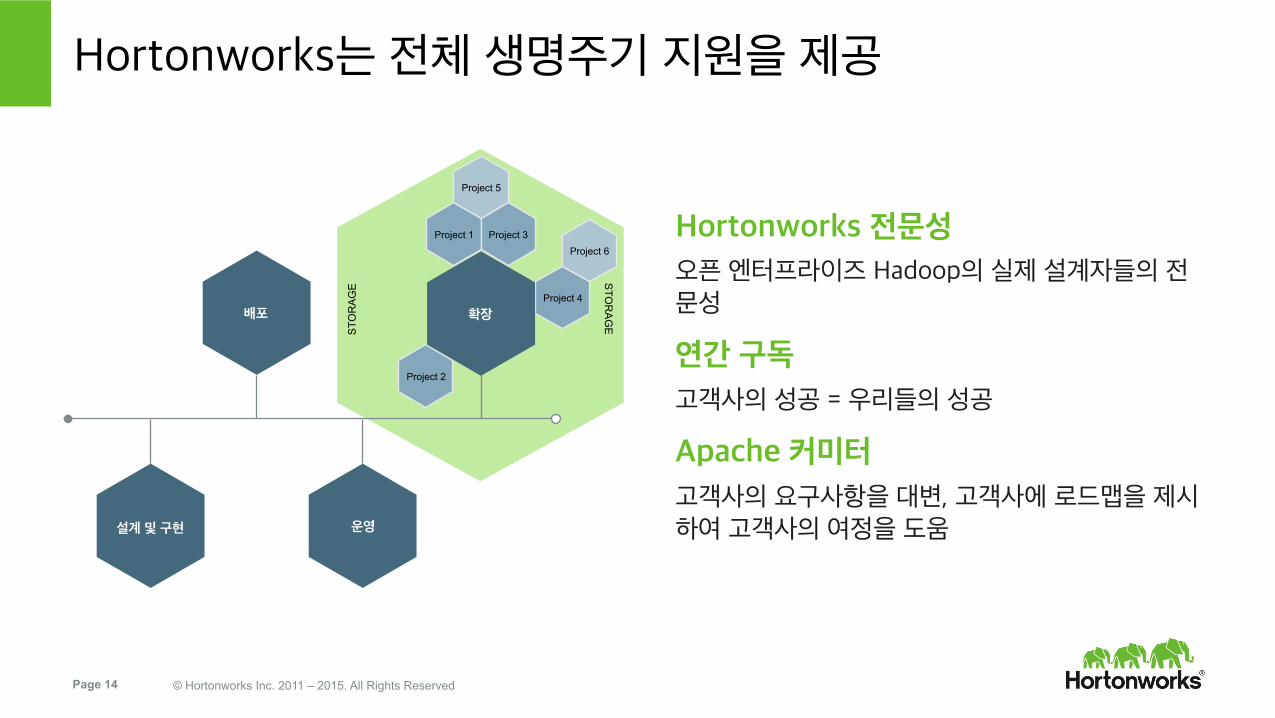
Hortonworks는 전체 생명주기 지원을 제공
Hortonworks 전문성 오픈 엔터프라이즈 Hadoop의 실제 설계자들의 전문성
연간 구독
고객사의 성공 = 우리들의 성공
Apache 커미터
고객사의 요구사항을 대변, 고객사에 로드맵을 제시하여 고객사의 여정을 도움 설계 및 구현
배포
운영
Project 1
Project 5
Project 4
Project 3
Project 2
Project 6
확장
Page 15 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
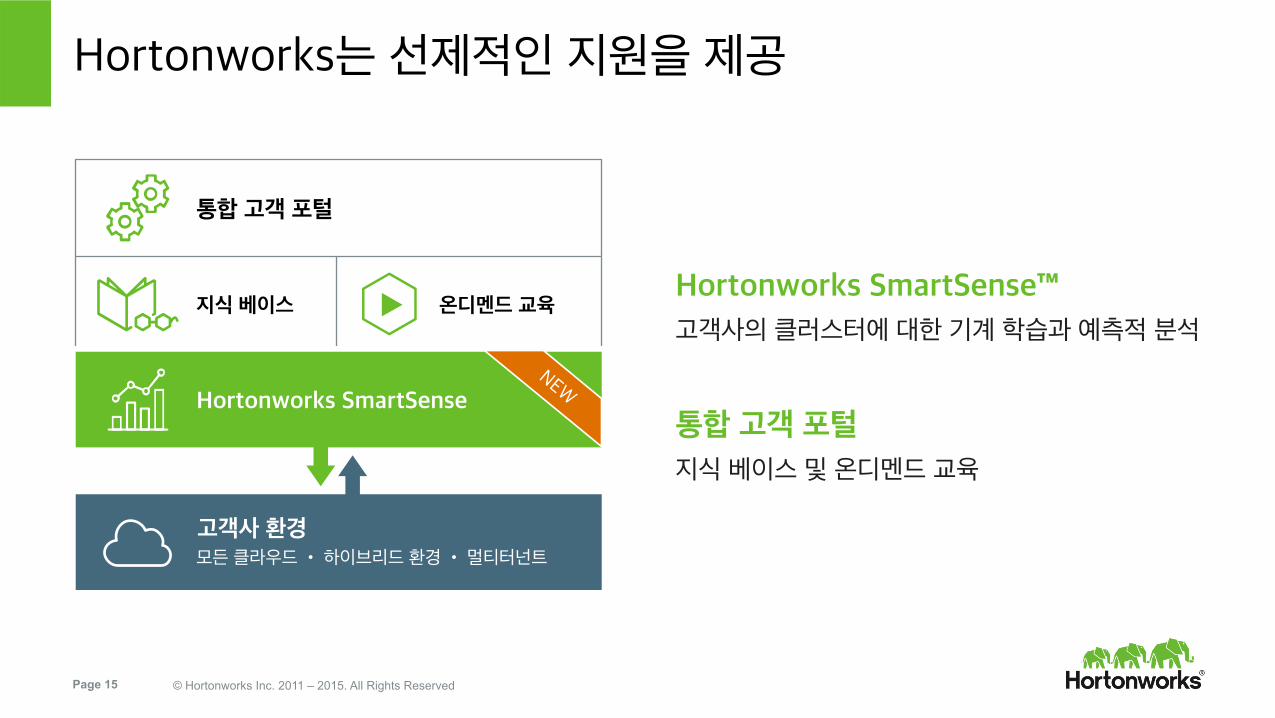
Hortonworks는 선제적인 지원을 제공
Hortonworks SmartSense™ 고객사의 클러스터에 대한 기계 학습과 예측적 분석
통합 고객 포털
지식 베이스 및 온디멘드 교육
지식 베이스
통합 고객 포털
온디멘드 교육
고객사 환경 모든 클라우드 • 하이브리드 환경 • 멀티터넌트
Hortonworks SmartSense
Page 16 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
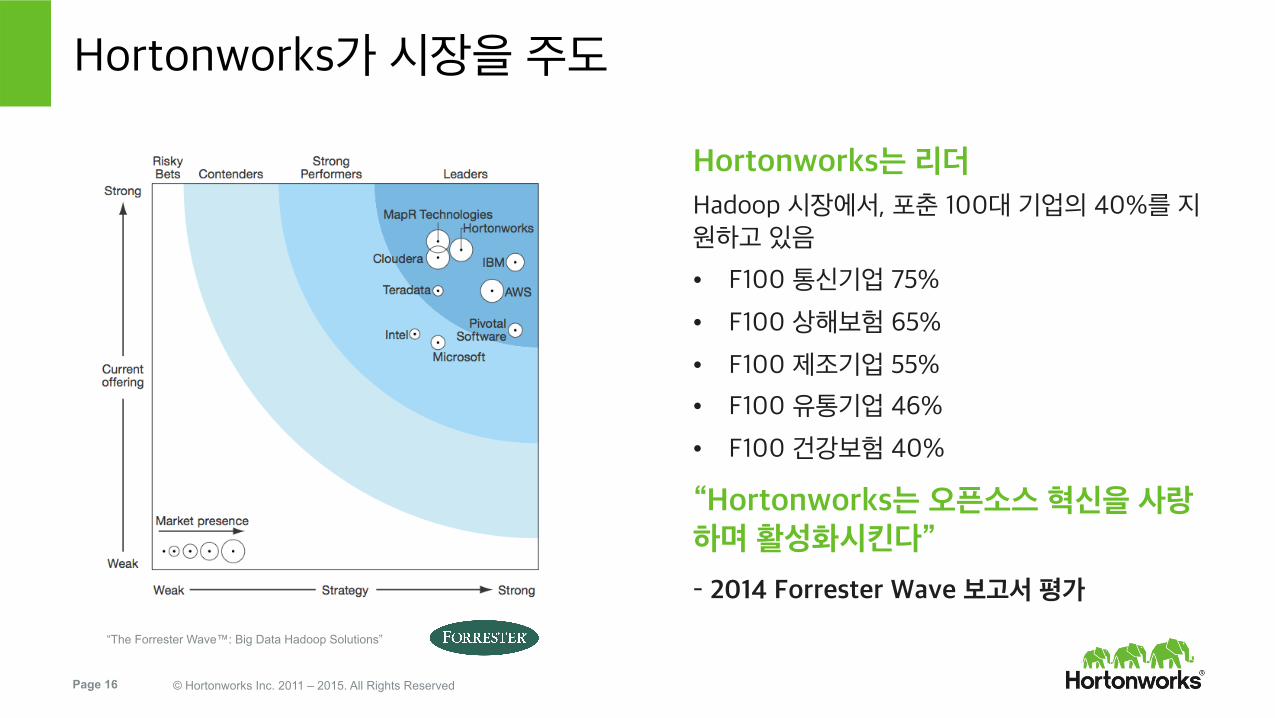
Hortonworks가 시장을 주도
Hortonworks는 리더 Hadoop 시장에서, 포춘 100대 기업의 40%를 지원하고 있음
• F100 통신기업 75%
• F100 상해보험 65%
• F100 제조기업 55%
• F100 유통기업 46%
• F100 건강보험 40%
“Hortonworks는 오픈소스 혁신을 사랑하며 활성화시킨다”
– 2014 Forrester Wave 보고서 평가
“The Forrester Wave™: Big Data Hadoop Solutions”

Page 17 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
Hortonworks 소개
고객 확장세 • 556개 고객사 (2015년 8월 5일 기준)
• 2015년 2분기 119개 신규 고객사
• NASDAQ에 상장됨: HDP
Hortonworks Data Platform • 모든 응용과 모든 데이터를 위해 완전한 오픈 멀티터넌트 플랫폼
• 보안, 운영, 거버넌스를 위해 일관된 기업 서비스
고객 성공의 동반자 • 오픈소스 커뮤니티의 리더이며, 기업이 필요로 하는 혁신에 집중
• 비교 불허의 Hadoop 기술지원 구독
2011년 설립
Yahoo!의 최초 24명의 Hadoop 설계자, 개발자, 운영자
740+ 임직원
1350+ 생태계 협력사

Page 18 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
Hortonworks가 최고 IT 필수품으로 평가됨
최고의 IT 필수품 빅데이터, 웨어하우징, 분석 용도중에서
Hortonworks는 상위에 평가됨
모든 다른 Hadoop 배포판은 하위에 평가됨
개방성, 완전성, 집중형 아키텍처
특별한 기능으로 인용됨
2015년 6월 지출 목적 Shared Accounts of Hortonworks (A, I) (All Cut, n=35)
Hortonworks, Big Data #1
Microsoft, Hosting #2
MongoDB, Warehousing #3
Tableau, Big Data #4
최고 벤더 20
Source: https://hortonworks.com/blog/cio-survey-hortonworks-data-platform-now-a-top-it-imperative/

Spark와 HDP, 완벽한 조합
Spark on YARN, 그리고 그 이상
© Hortonworks Inc. 2011 – 2015. All Rights Reserved

Page 20 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
우아한 개발자 API DataFrames, 기계 학습, 그리고 SQL
인터랙티브 데이터 과학 모든 응용 프로그램들은 대용량인 동시에 정밀한 예측이 필요
기계 학습을 대중화 Hive가 Hadoop에서 SQL을 했듯이 Spark가 Hadoop에서 기계 학습을 수행
커뮤니티 개발자, 고객, 그리고 파트너의 폭 넓은 관심
데이터 운영 체제의 가치를 현실화 Hadoop 도구 상자의 주요한 도구
Hortonworks가 Spark를 사랑하는 이유
Storage
YARN: Data Operating System
Governance Security
Operations
Resource Management

Page 21 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
리소스 관리 YARN이 예측 가능한 SLA 안에서 멀티터넌트, 다양한 워크로드를 제공
계층적 메모리 저장소 오프-힙 RDD 캐시를 위한 HDFS 인메모리 티어
SQL에는 SparkSQL와 Hive 최신 메타스토어와 상호작용, HS2; 최적화된 ORC 지원
Spark와 NoSQL RDDs for predicate pushdown을 통한 HBase와 깊은 통합
알고리즘에서 용례로 – 흩어진 점들을 연결 고수준 기계 학습 추상화 – 검증, 튜닝, 파이프라인 조립… 예: 위치
사용 편의성 인터랙티브 노트북 용으로 Apache Zeppelin을 사용
Spark와 Hadoop – 어떻게 나아질 수 있을까?
Storage
YARN: Data Operating System
Governance Security
Operations
Resource Management

Page 22 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
메타데이터 및 거버넌스 메타데이터를 위한 Apache Atlas, Spark 파이프라인을 위한 Apache Falcon 지원
보안 및 운영 Apache Ranger로 관리되는 인증, Apache Ambari를 통한 배포 및 관리
어느 곳에서 배포 가능 Linux, Windows, 온프레미스 또는 클라우드
셀프 서비스된 클라우드 상의 Spark Cloudbreak와 Ambari를 통해 데이터 과학 클러스터를 쉽게 실행 - Azure, AWS, GCP, OpenStack, Docker를 모두 지원
Spark와 Hadoop – 어떻게 나아질 수 있을까?
Storage
YARN: Data Operating System
Governance Security
Operations
Resource Management

Page 23 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
실제 세계의 용례에 대해 이야기합시다!

Page 24 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
CDO (최고 데이터 관리자) 요구 안정성을 높이고 불리한 상황을 줄임
운전 위반이 발생하기 전에 대응하고 예방적인 행동을 취함
개발 팀의 응답 프로그램에 날씨 데이터와 운전 기사 프로필을 추가
예측 모델 특징을 위해 데이터를 탐색
예측 모델을 훈련 및 생성
운전 위반 사항을 실시간으로 예측하도록 모델을 본래 응용 프로그램에 추가
트럭 운행 용례: 실시간, 예측적 응용

Page 25 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
데이터 과학: 클라우드에서 데이터 탐색 및 모델 생성
클릭-스루 데모 클라우드에서 데이터 과학 환경을 배포
데이터 과학 노트북을 사용하여 데이터를 탐색
예측적 모델을 생성하기 위해 알고리즘을 실행
Cloudbreak 1. 클라우드 선택 2. Spark blueprint
선택 3. HDP 실행
Microsoft Azure

Page 26 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
Login to launch.hortonworks.com which is a self-service portal for launching HDP clusters to the cloud (cloudbreak.sequenceiq.com)
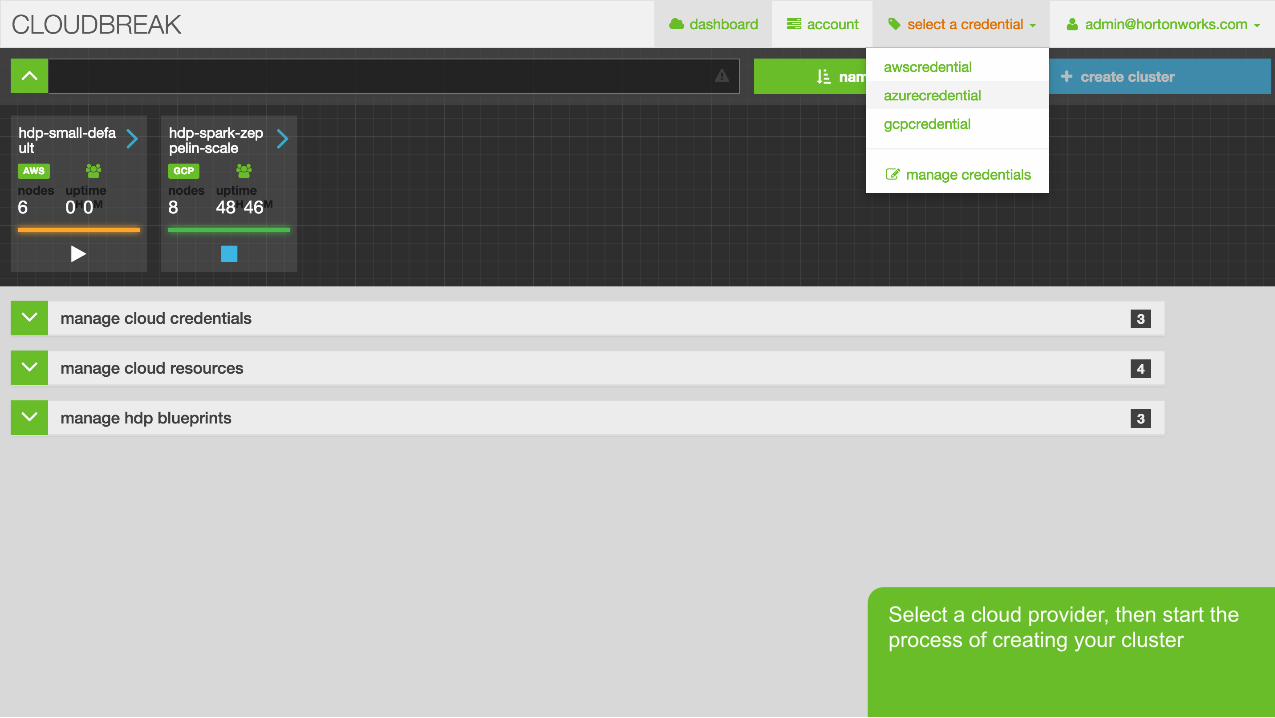
Page 27 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
Select a cloud provider, then start the process of creating your cluster
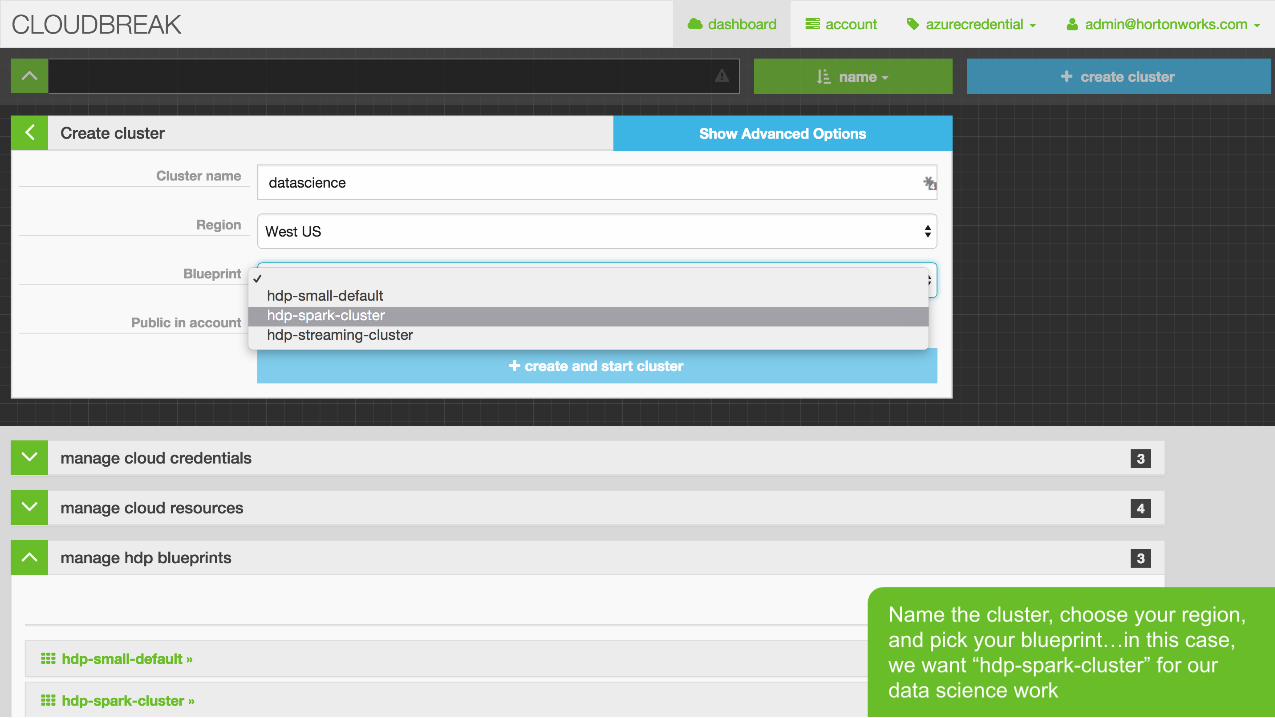
Page 28 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
Name the cluster, choose your region, and pick your blueprint…in this case, we want “hdp-spark-cluster” for our data science work
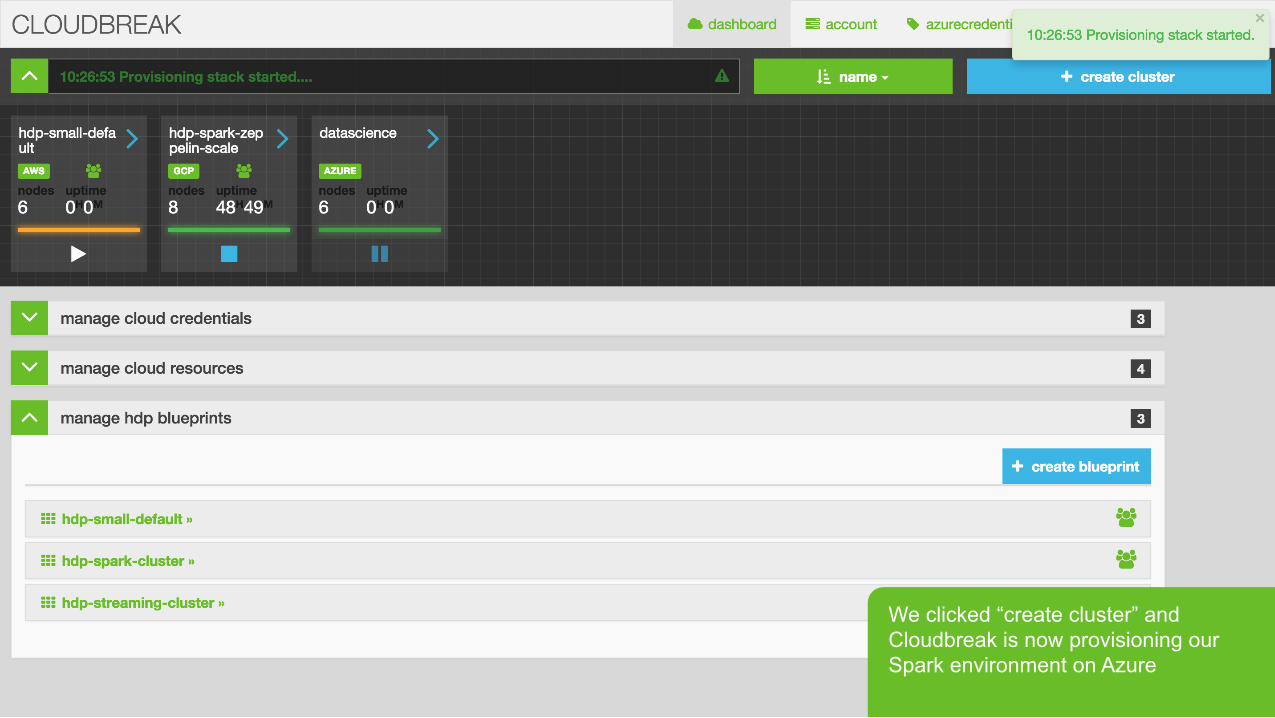
Page 29 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
We clicked “create cluster” and Cloudbreak is now provisioning our Spark environment on Azure
Page 30 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
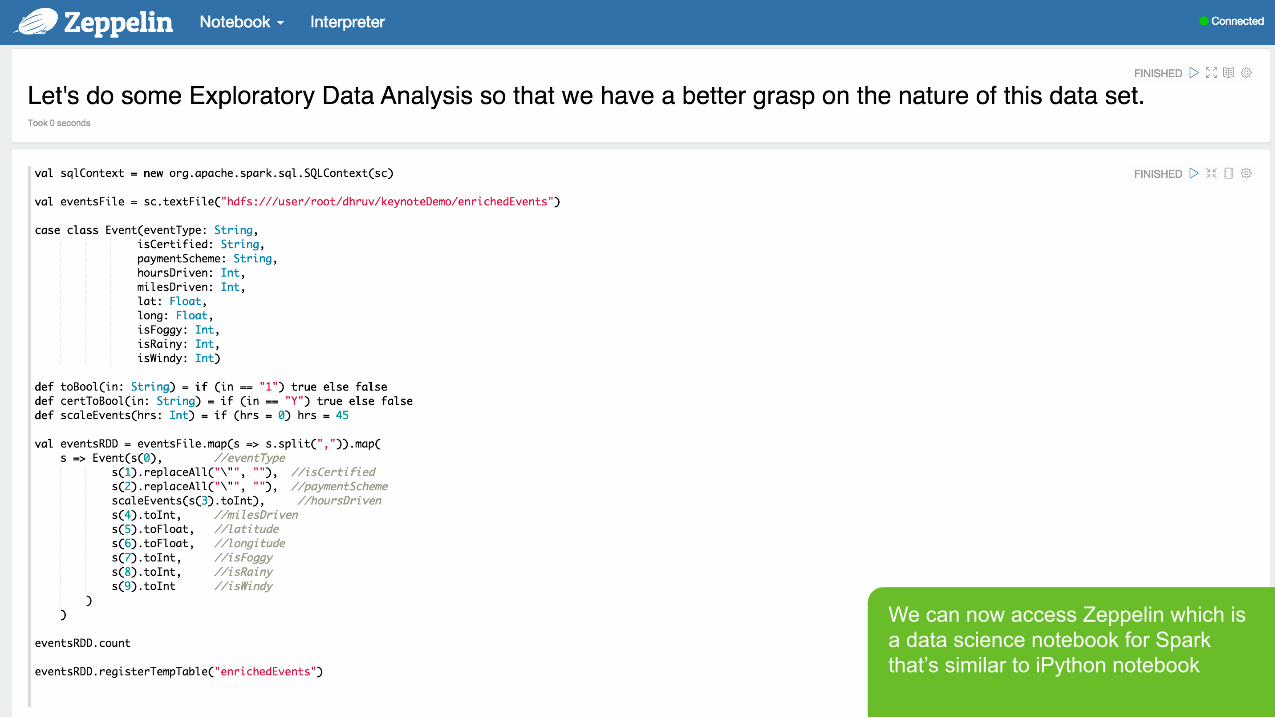
We can now access Zeppelin which is a data science notebook for Spark that’s similar to iPython notebook
Page 31 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
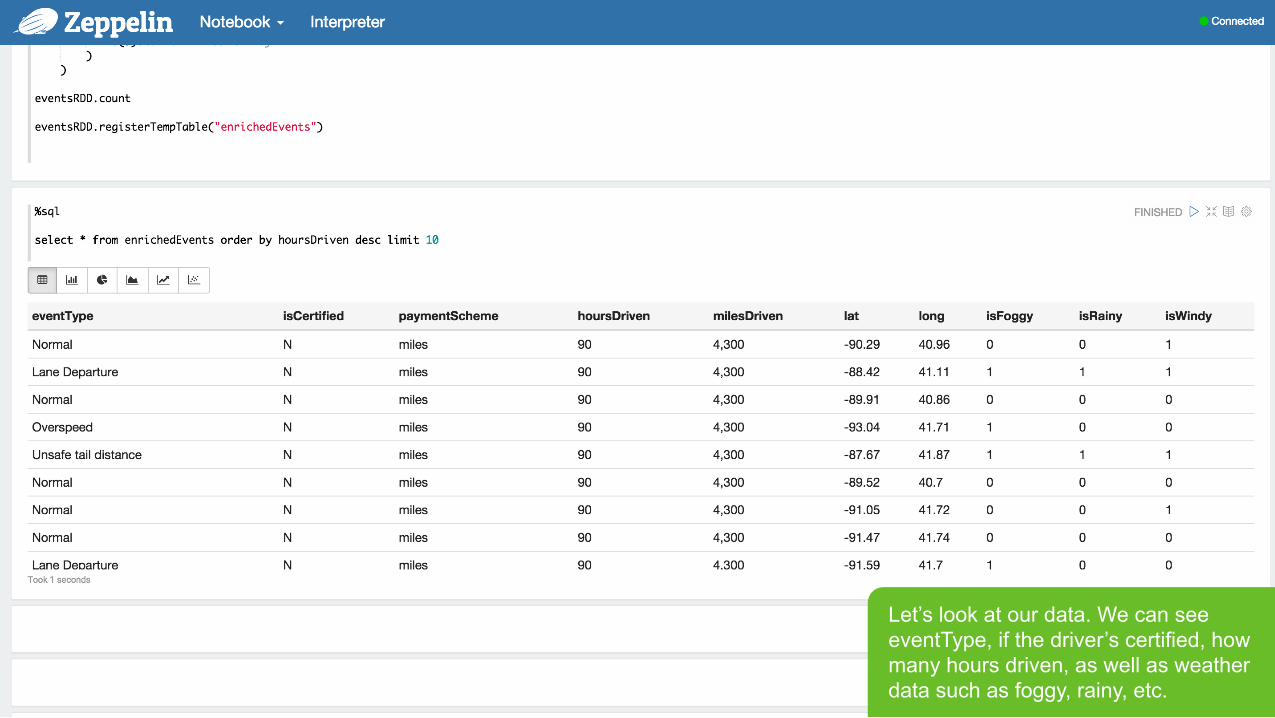
Let’s look at our data. We can see eventType, if the driver’s certified, how many hours driven, as well as weather data such as foggy, rainy, etc.
Page 32 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
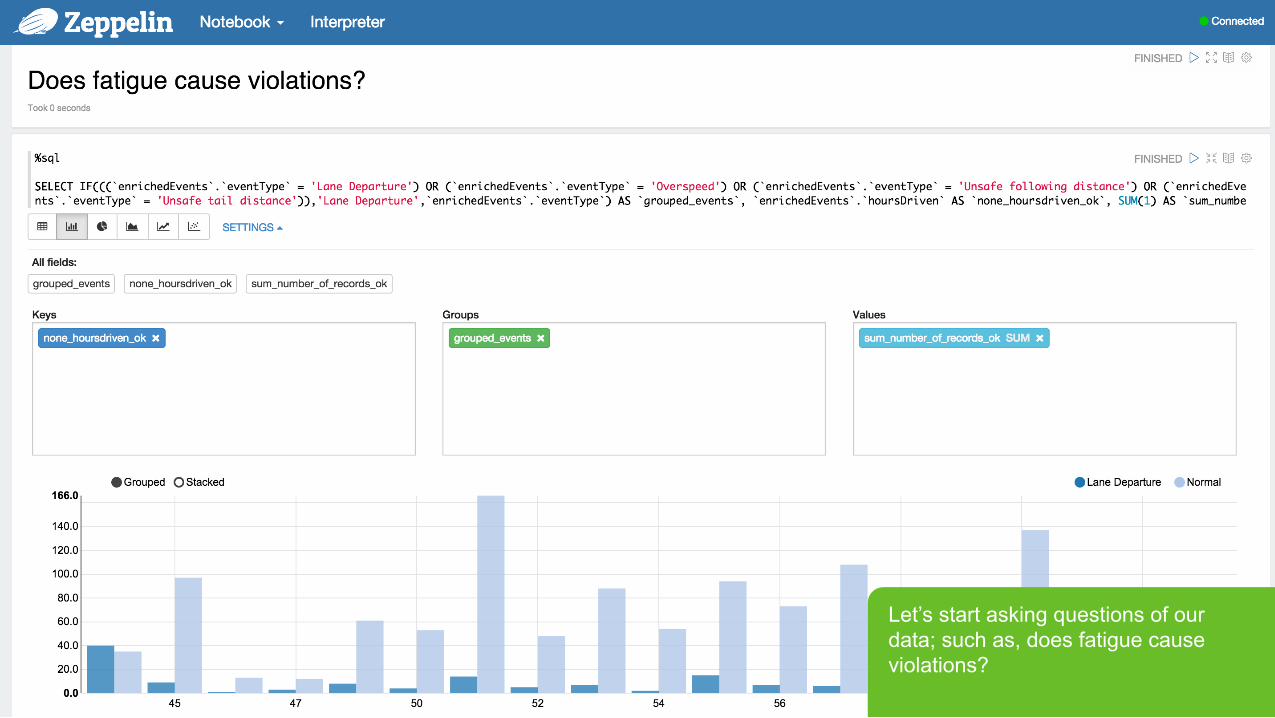
Let’s start asking questions of our data; such as, does fatigue cause violations?
Page 33 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
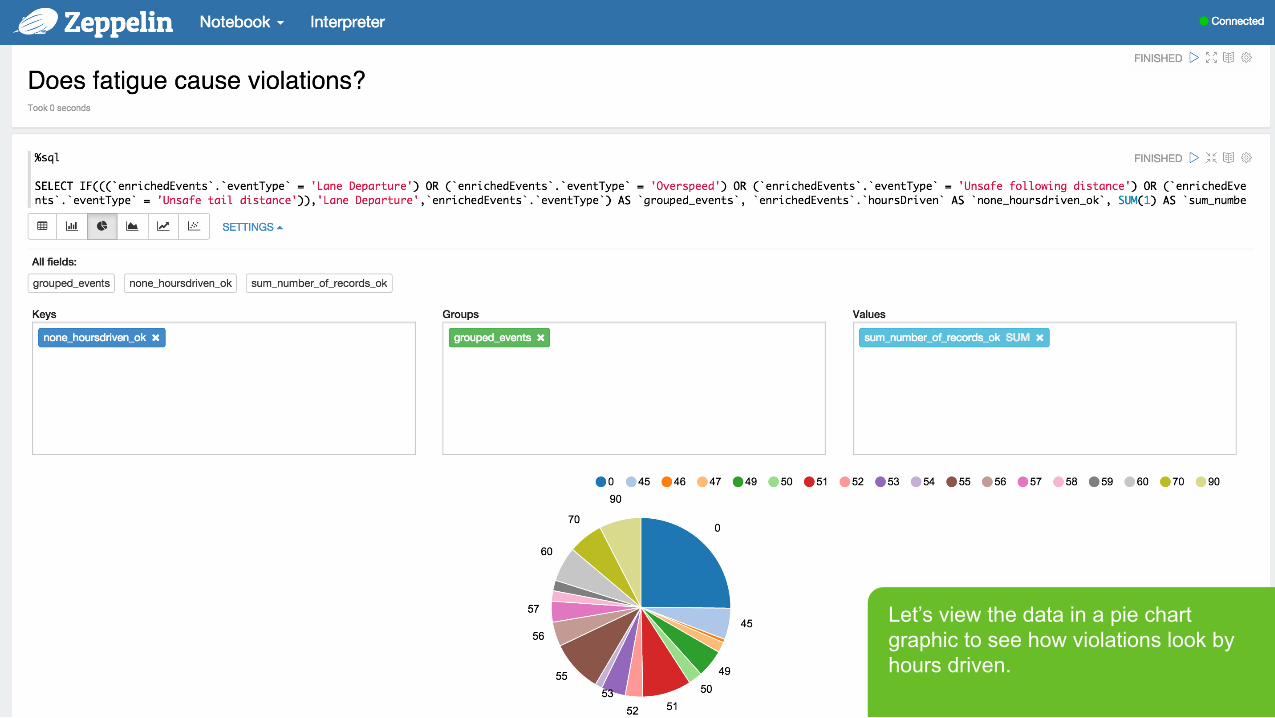
Let’s view the data in a pie chart graphic to see how violations look by hours driven.
Page 34 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
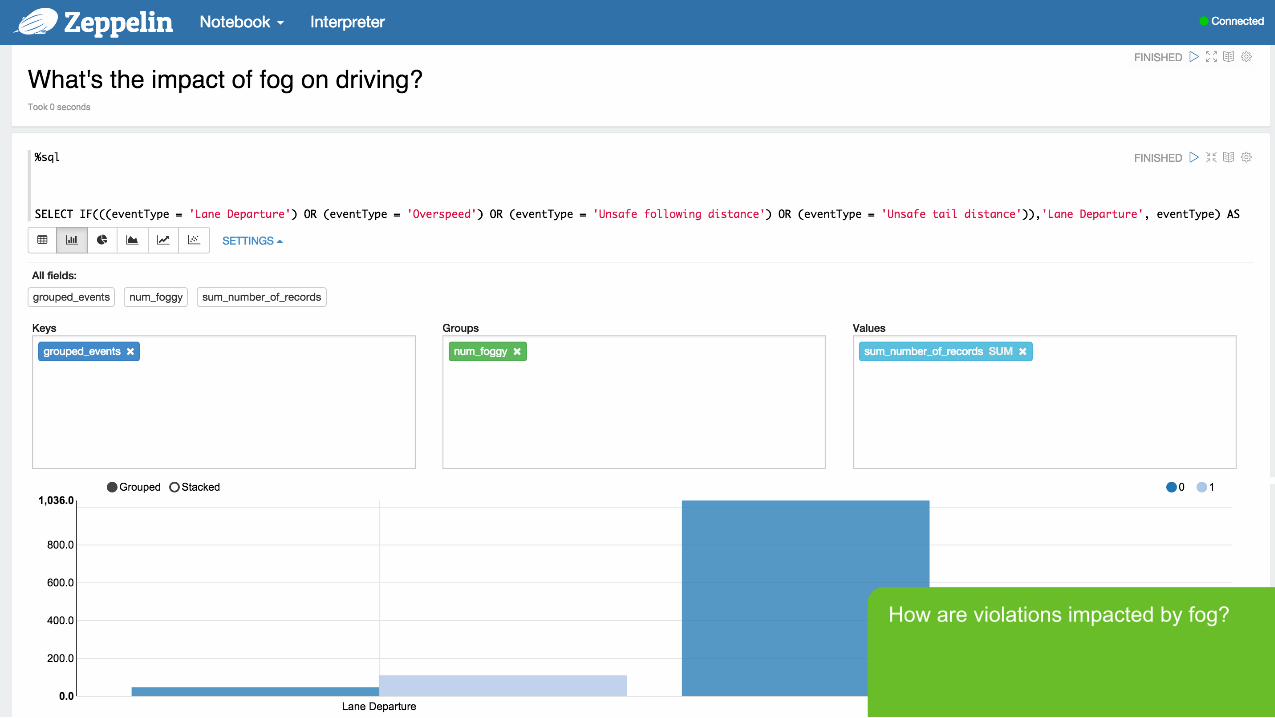
How are violations impacted by fog?
Page 35 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
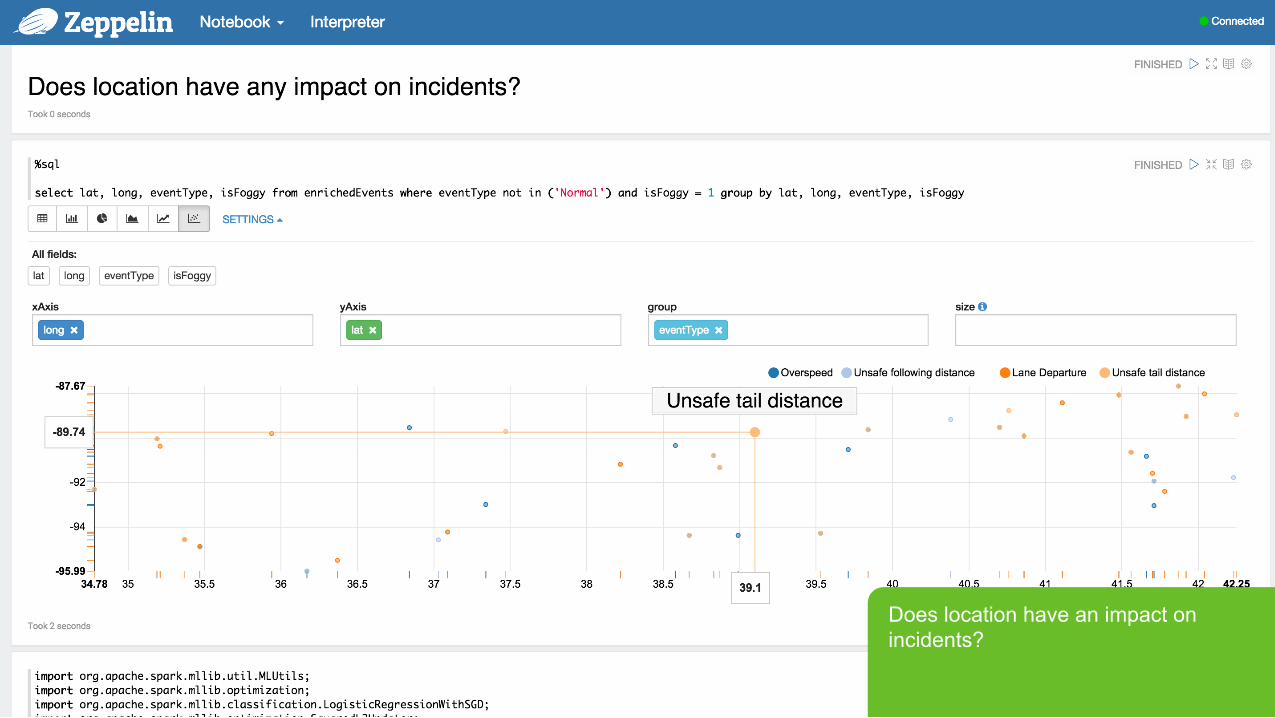
Does location have an impact on incidents?
Page 36 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
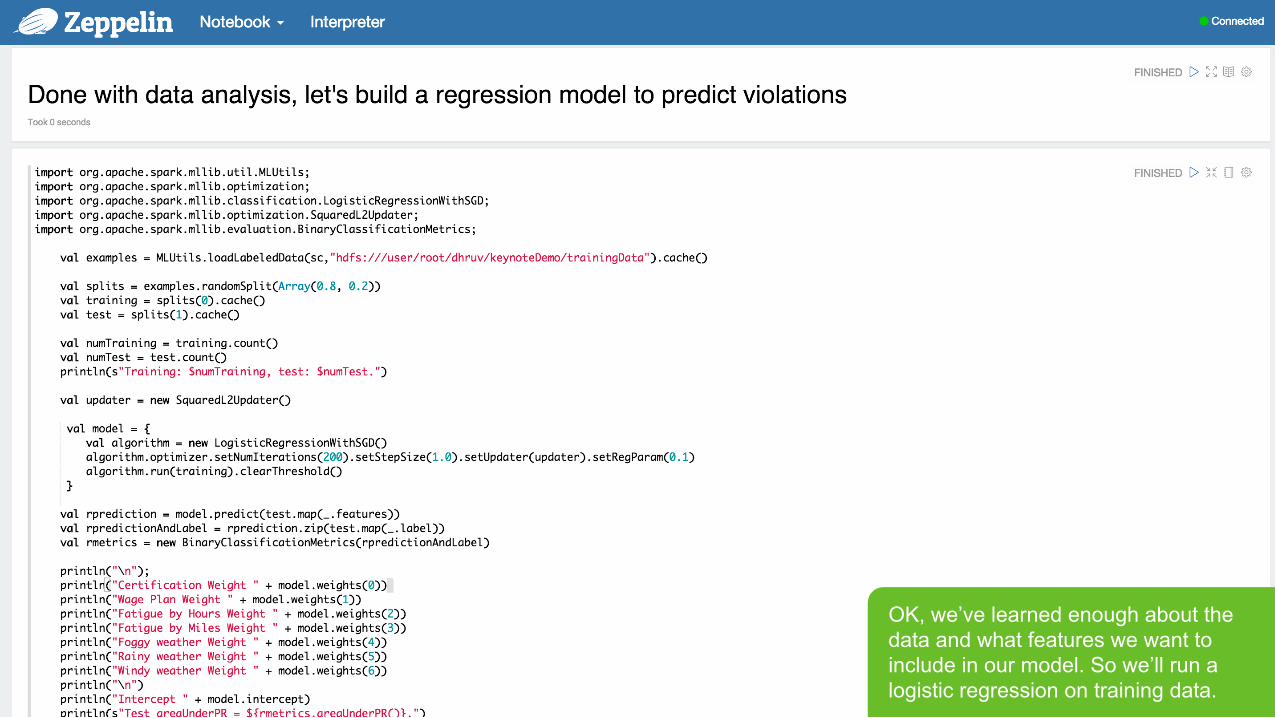
OK, we’ve learned enough about the data and what features we want to include in our model. So we’ll run a logistic regression on training data.
Page 37 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
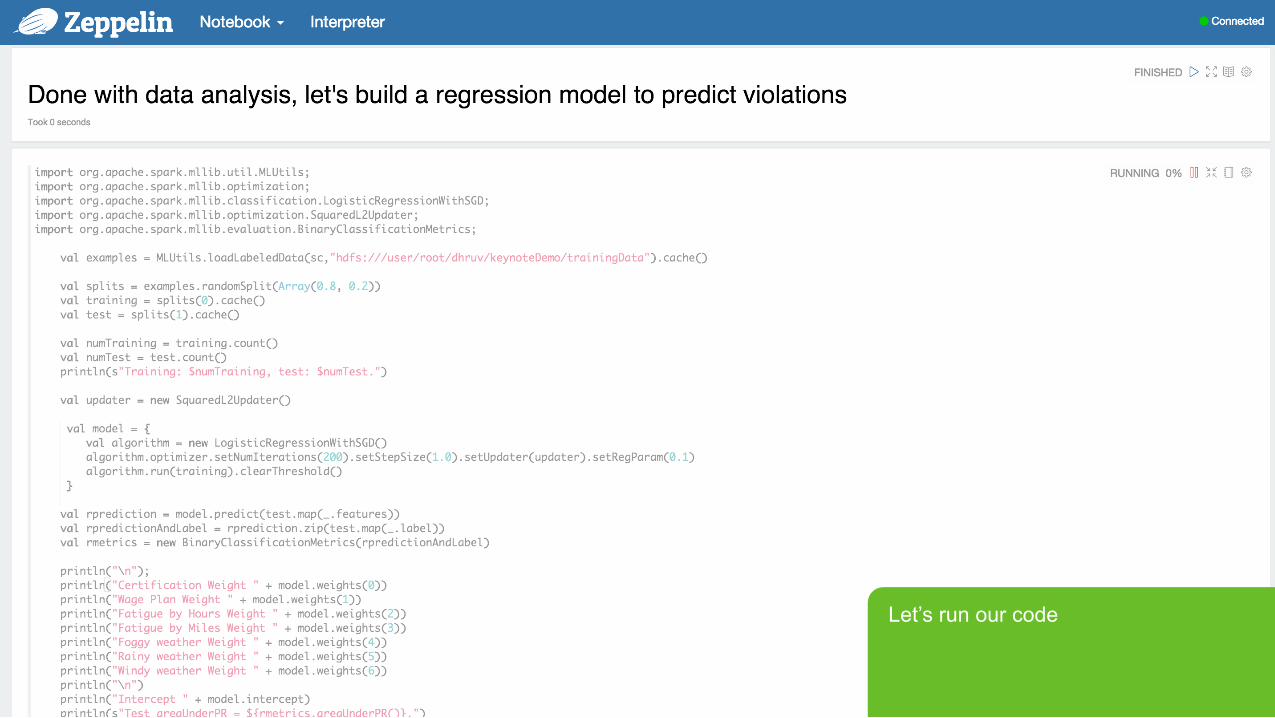
Let’s run our code
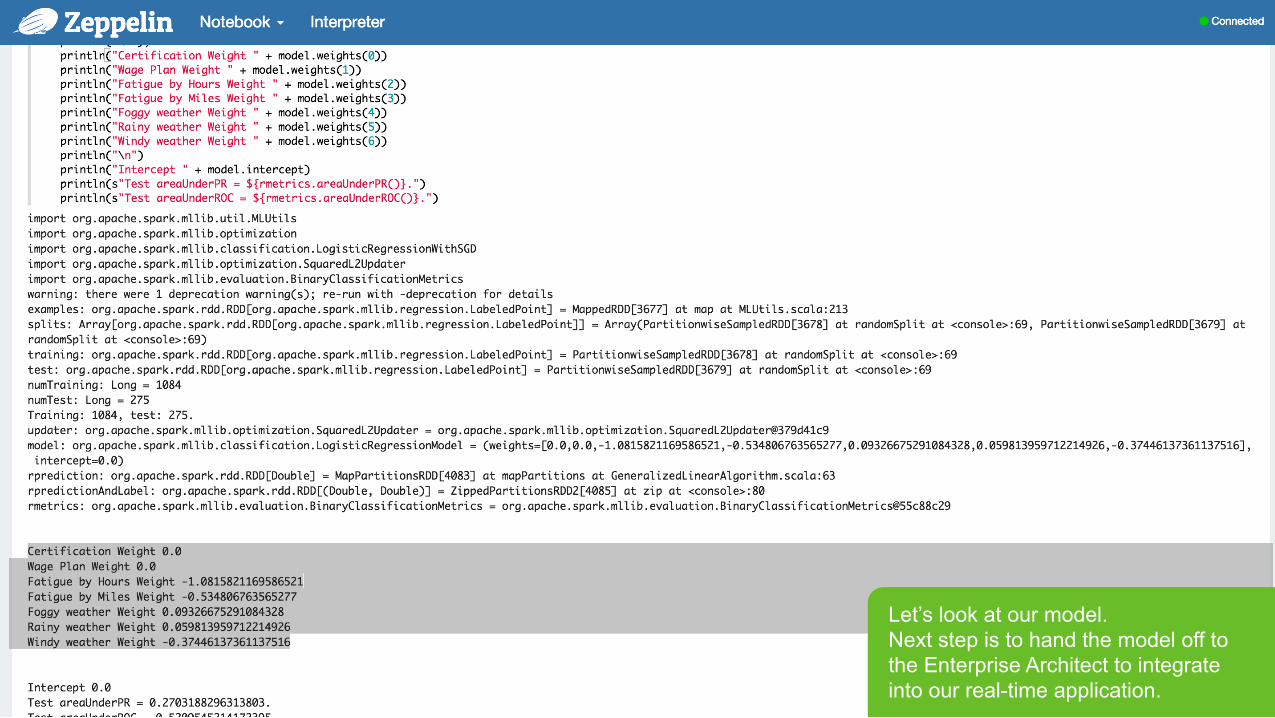
Page 38 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
Let’s look at our model. Next step is to hand the model off to the Enterprise Architect to integrate into our real-time application.
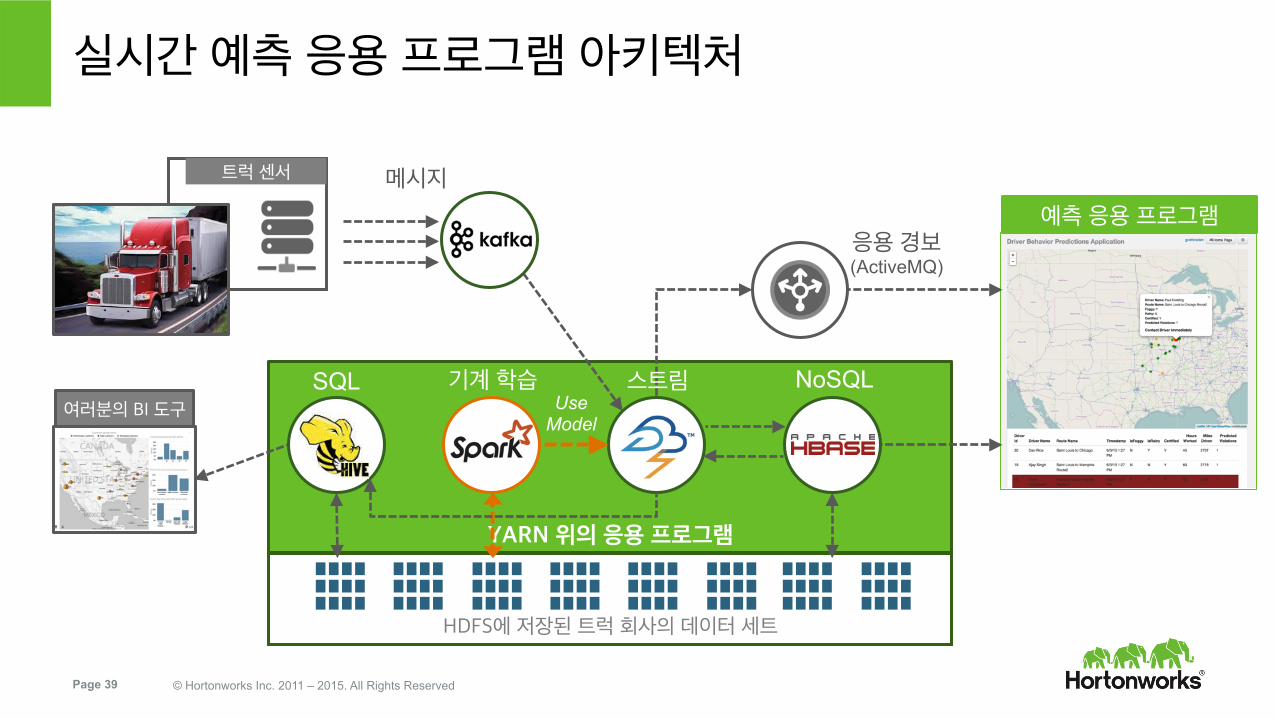
Page 39 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
YARN 위의 응용 프로그램
HDFS에 저장된 트럭 회사의 데이터 세트
실시간 예측 응용 프로그램 아키텍처
여러분의 BI 도구
예측 응용 프로그램
트럭 센서
응용 경보 (ActiveMQ)
메시지
SQL 스트림 NoSQL 기계 학습 Use
Model

Storm에 Spark 기계 학습을 통합
실시간 예측을 위한 아키텍처
© Hortonworks Inc. 2011 – 2015. All Rights Reserved
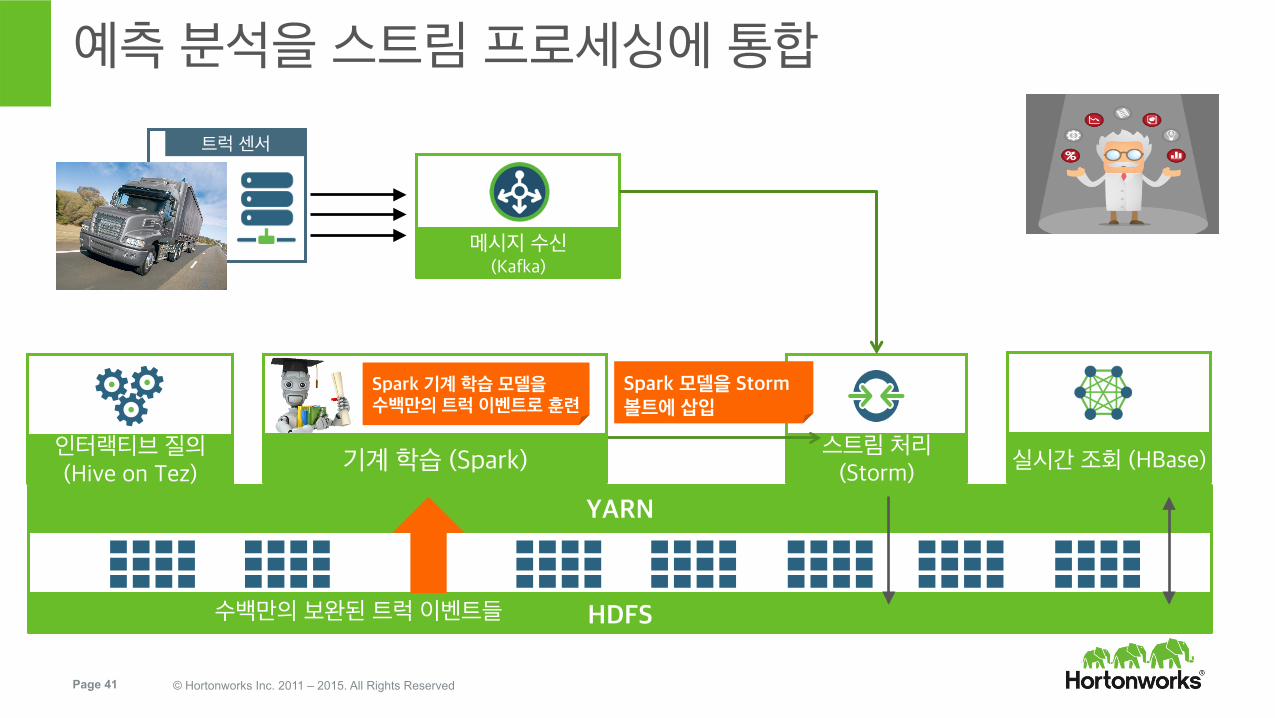
Page 41 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
트럭 센서
HDFS
YARN
예측 분석을 스트림 프로세싱에 통합
스트림 처리 (Storm)
메시지 수신 (Kafka)
인터랙티브 질의 (Hive on Tez)
실시간 조회 (HBase)
수백만의 보완된 트럭 이벤트들
Predic'on Bolt
Spark 모델을 Storm 볼트에 삽입
기계 학습 (Spark)
Spark 기계 학습 모델을 수백만의 트럭 이벤트로 훈련
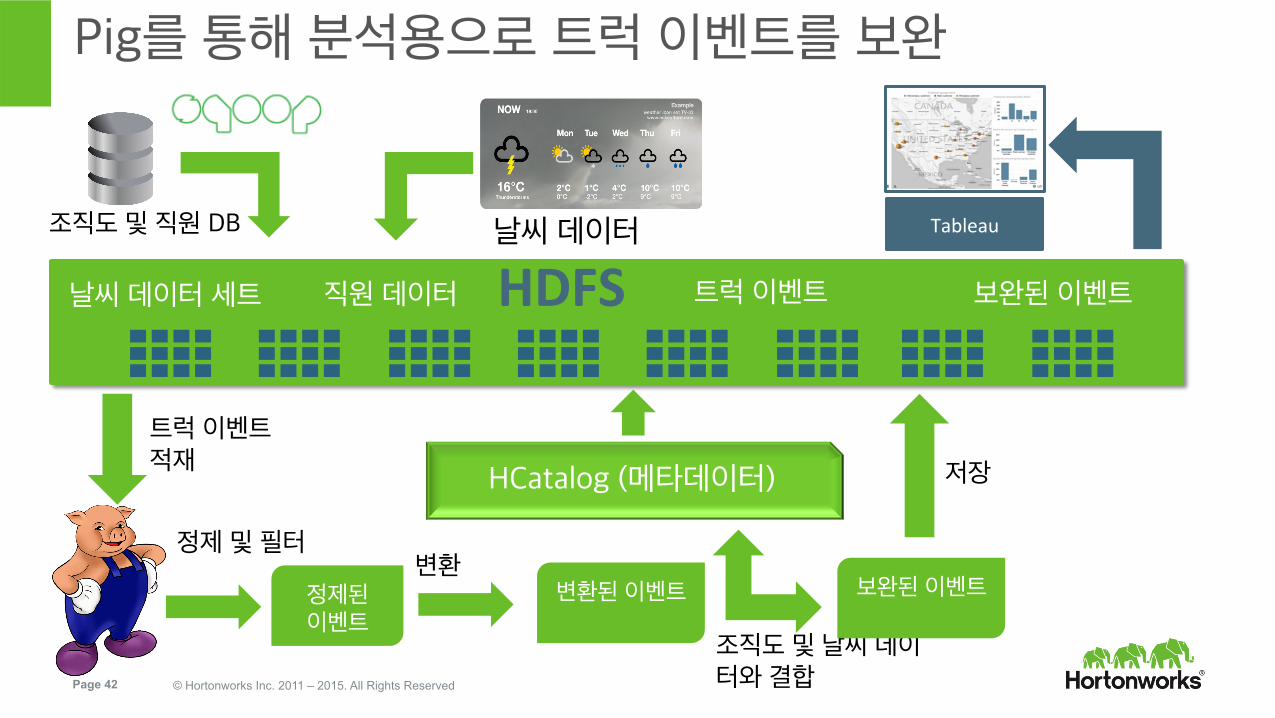
Page 42 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
Pig를 통해 분석용으로 트럭 이벤트를 보완
HDFS 트럭 이벤트 날씨 데이터 세트
날씨 데이터
HCatalog (메타데이터)
직원 데이터
조직도 및 직원 DB
트럭 이벤트 적재
정제 및 필터
정제된 이벤트
변환된 이벤트 변환
조직도 및 날씨 데이터와 결합
보완된 이벤트
보완된 이벤트
저장
Tableau
Page 43 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
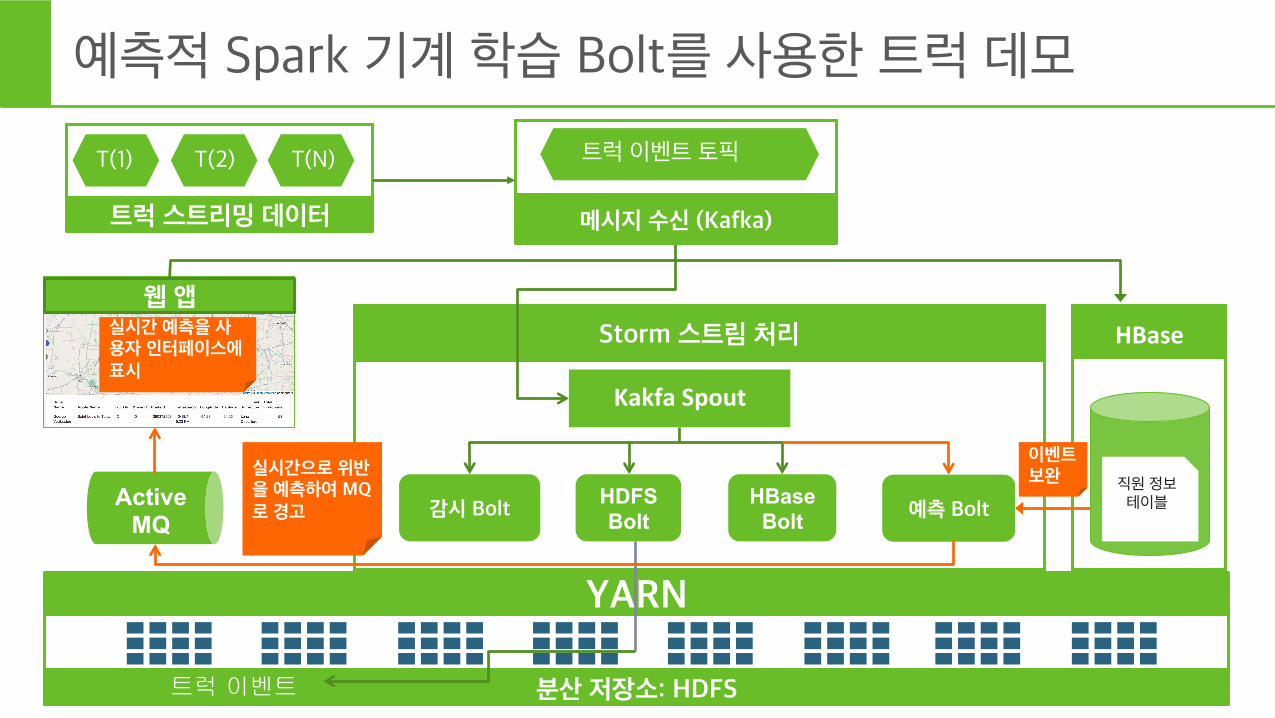
예측적 Spark 기계 학습 Bolt를 사용한 트럭 데모
분산 저장소: HDFS
YARN
Storm 스트림 처리
Kakfa Spout
HBase
직원 정보 테이블 HBase
Bolt HDFS Bolt
트럭 이벤트
Active MQ
감시 Bolt
웹 앱
트럭 스트리밍 데이터
T(1) T(2) T(N)
메시지 수신 (Kafka)
트럭 이벤트 토픽
예측 Bolt
이벤트 보완 실시간으로 위반
을 예측하여 MQ로 경고
실시간 예측을 사용자 인터페이스에 표시
Page 44 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
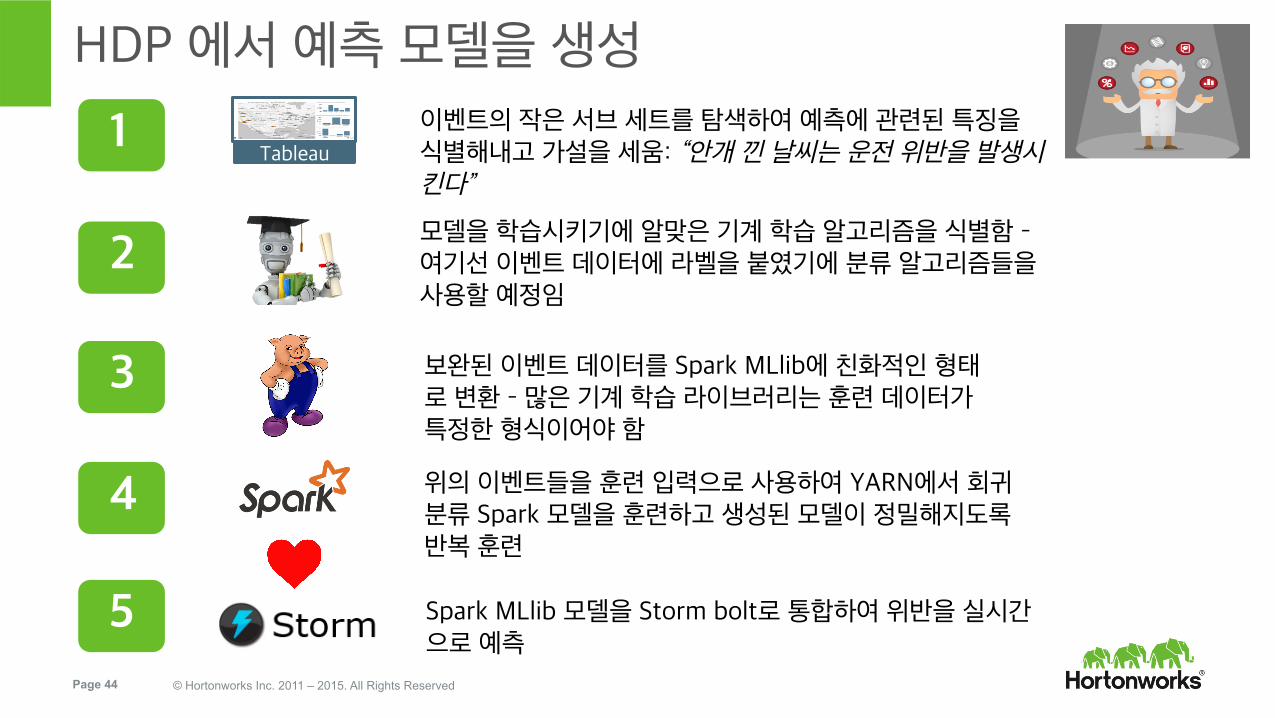
HDP 에서 예측 모델을 생성
Tableau
이벤트의 작은 서브 세트를 탐색하여 예측에 관련된 특징을 식별해내고 가설을 세움: “안개 낀 날씨는 운전 위반을 발생시킨다”
1
모델을 학습시키기에 알맞은 기계 학습 알고리즘을 식별함 – 여기선 이벤트 데이터에 라벨을 붙였기에 분류 알고리즘들을 사용할 예정임
2
보완된 이벤트 데이터를 Spark MLlib에 친화적인 형태로 변환 – 많은 기계 학습 라이브러리는 훈련 데이터가 특정한 형식이어야 함
3
위의 이벤트들을 훈련 입력으로 사용하여 YARN에서 회귀 분류 Spark 모델을 훈련하고 생성된 모델이 정밀해지도록 반복 훈련
4
Spark MLlib 모델을 Storm bolt로 통합하여 위반을 실시간으로 예측
5
Page 45 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
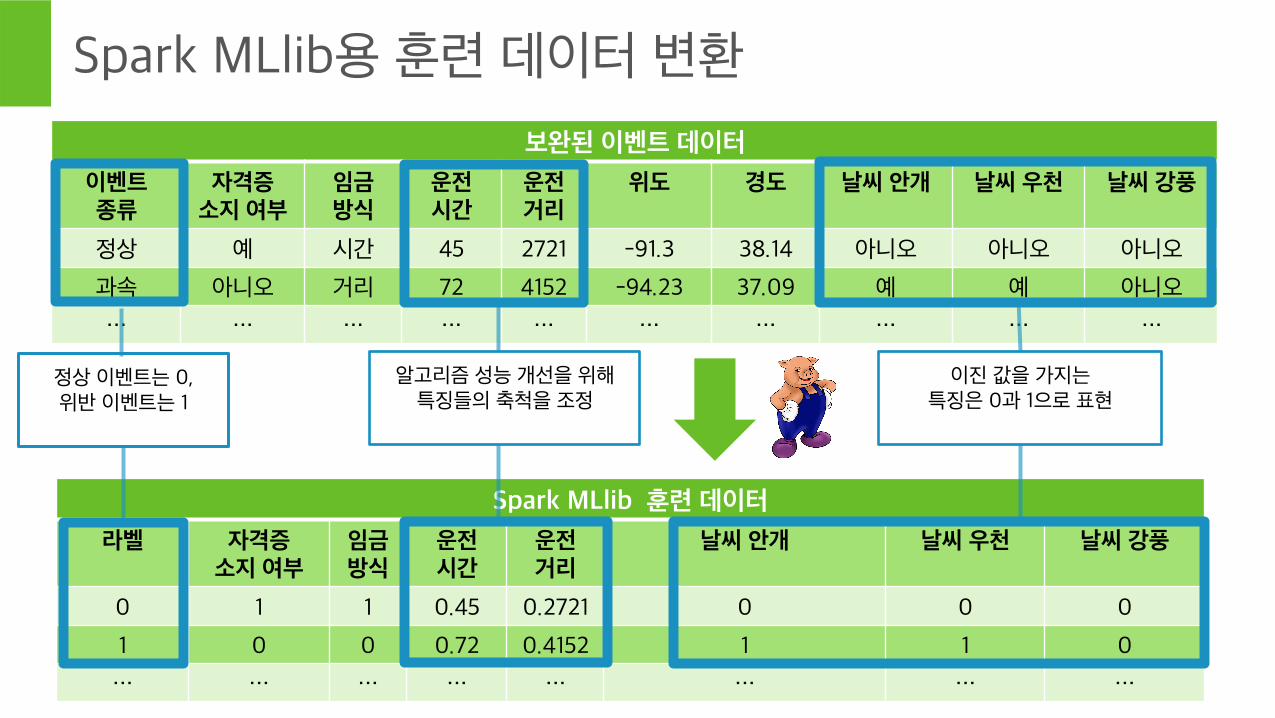
Spark MLlib용 훈련 데이터 변환
보완된 이벤트 데이터
이벤트 종류
자격증 소지 여부
임금 방식
운전 시간
운전 거리
위도 경도 날씨 안개 날씨 우천 날씨 강풍
정상 예 시간 45 2721 -91.3 38.14 아니오 아니오 아니오
과속 아니오 거리 72 4152 -94.23 37.09 예 예 아니오
… … … … … … … … … …
Spark MLlib 훈련 데이터
라벨 자격증 소지 여부
임금 방식
운전 시간
운전 거리
날씨 안개 날씨 우천 날씨 강풍
0 1 1 0.45 0.2721 0 0 0
1 0 0 0.72 0.4152 1 1 0
… … … … … … … …
정상 이벤트는 0, 위반 이벤트는 1
알고리즘 성능 개선을 위해 특징들의 축척을 조정
이진 값을 가지는 특징은 0과 1으로 표현

Page 46 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
Spark 기계 학습을 YARN에서 실행
1
spark-submit --class org.apache.spark.examples.mllib.BinaryClassification --master yarn-cluster --num-executors 3 --driver-memory 512m --executor-memory 512m --executor-cores 1 truckml.jar --algorithm LR --regType L2 --regParam 1.0 /user/root/truck_training --numIterations 100
spark-submit 스크립트를 실행하여 Spark job을 YARN 위에 구동
HDFS 상의 훈련 데이터 위치
2 YARN 리소스 관리자 UI에서 Spark job의 진행을 감시
Page 47 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
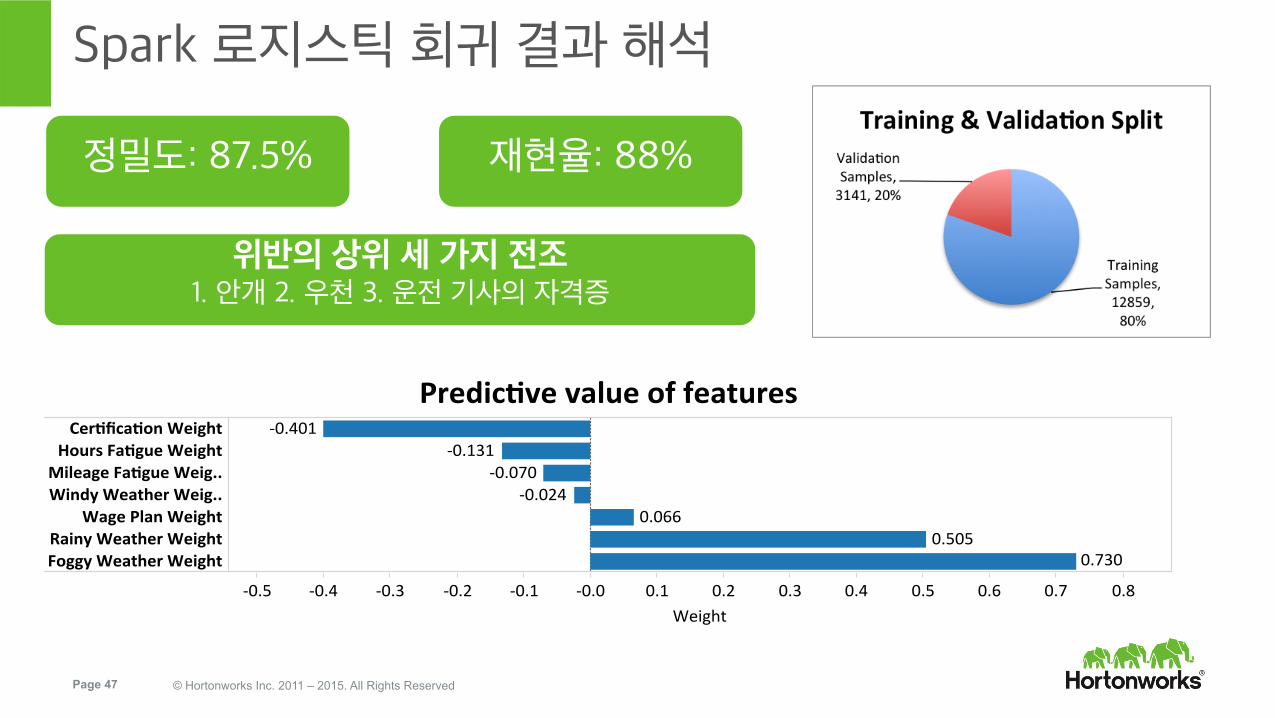
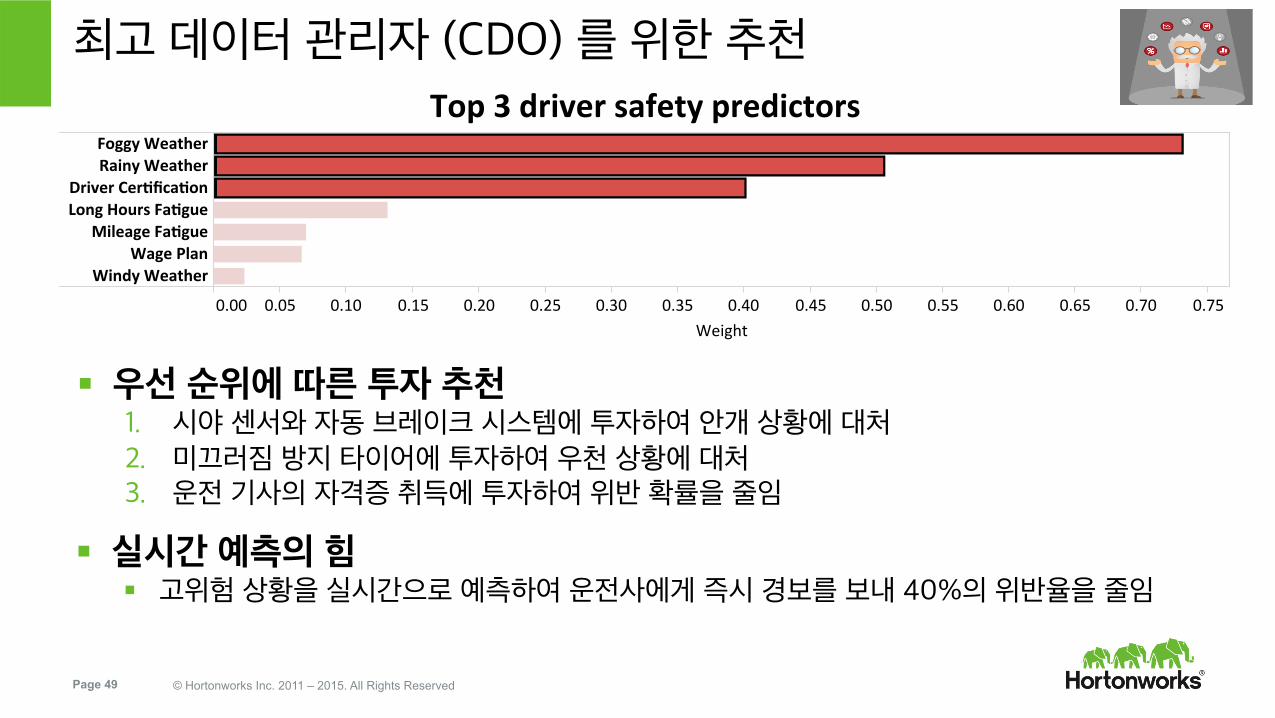
Spark 로지스틱 회귀 결과 해석
정밀도: 87.5% 재현율: 88%
위반의 상위 세 가지 전조 1. 안개 2. 우천 3. 운전 기사의 자격증
Page 48 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
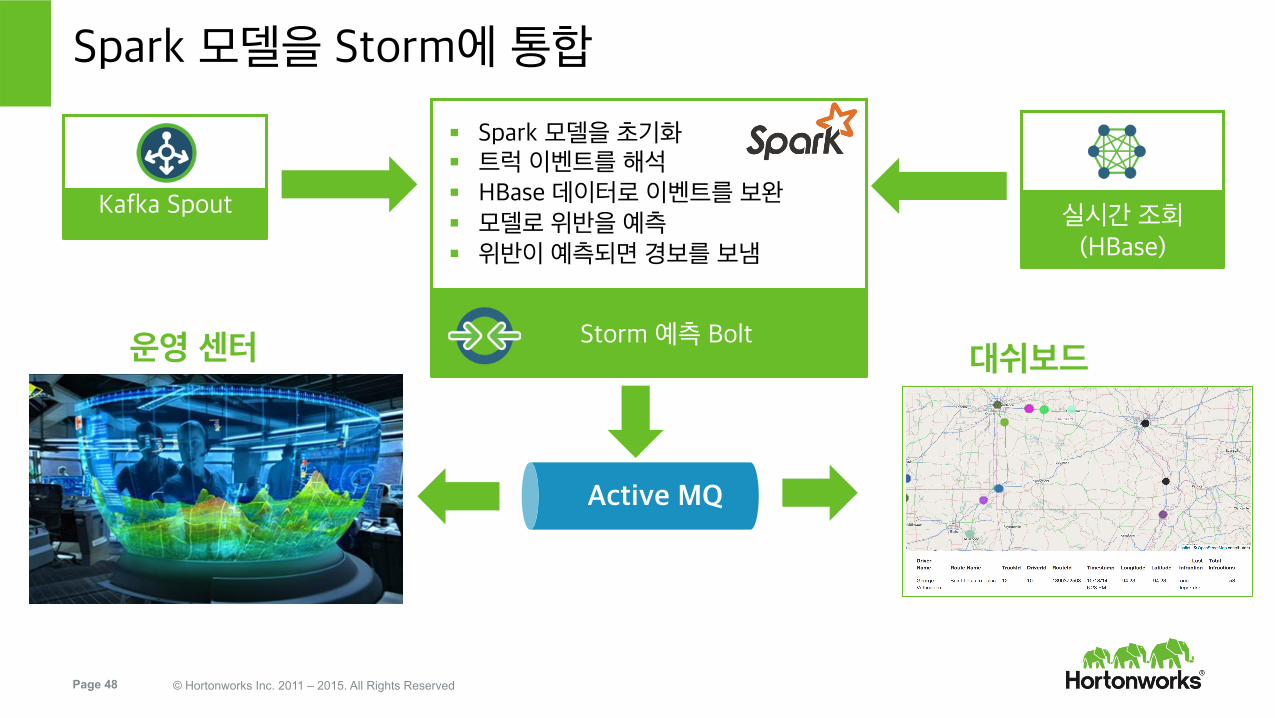
Spark 모델을 Storm에 통합
Kafka Spout
Storm 예측 Bolt
§ Spark 모델을 초기화 § 트럭 이벤트를 해석 § HBase 데이터로 이벤트를 보완 § 모델로 위반을 예측 § 위반이 예측되면 경보를 보냄
실시간 조회 (HBase)
Active MQ
운영 센터 대쉬보드
Page 49 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
최고 데이터 관리자 (CDO) 를 위한 추천
§ 우선 순위에 따른 투자 추천 1. 시야 센서와 자동 브레이크 시스템에 투자하여 안개 상황에 대처 2. 미끄러짐 방지 타이어에 투자하여 우천 상황에 대처 3. 운전 기사의 자격증 취득에 투자하여 위반 확률을 줄임
§ 실시간 예측의 힘 § 고위험 상황을 실시간으로 예측하여 운전사에게 즉시 경보를 보내 40%의 위반율을 줄임

Page 50 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
HDP에서 대용량 기계 학습의 가치 § 시장 및 가치 진입 시간을 가속
§ 다양한 기계 학습 알고리즘을 TB의 훈련 데이터에 대해 합리적인 시간 범위 내에서 수행
§ 가설을 신뢰성을 갖고 TB의 훈련 데이터로 검증 § 우리는 안개가 안전성에 영향을 끼치는 반면 임금 계산 방식이 영향을 끼치지
않음을 검증했으나, BI 도구들은 다른 결과를 내었음
§ 예측 모델을 데이터 주도 응용 프로그램에 쉽게 통합 § 예측 모델을 Storm이나 여러분 회사 내의 다른 어떤 응용 프로그램에
라도 구동
§ 위의 모든 내용을 멀티터넌트 YARN 클러스터에 구동 § YARN에서 대규모 기계 학습은 HDP 클러스터의 다른 작업들을 존중

Page 51 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
Storm Bolt에서 Spark를 호출
§ 로지스틱 회귀 모델의 출력은 가중치들과 하나의 절편: val algorithm = new LogisticRegressionWithSGD() val model = algorithm.run(training).clearThreshold() println(model.weights) println(model.intercept) Weights[-0.40819922025591465,0.06392530395655666,-0.1346227352186122,-0.07188217286407801,0.7277326276521062,0.508779221680863,-0.024689093098281954] Intercept 0.0
§ 해당 모델은 예측을 만들기 위해 위의 가중치와 함께 Storm bolt에서 재생성될 수 있음 import org.apache.spark.mllib.classification.LogisticRegressionModel; import org.apache.spark.mllib.linalg.Vectors; ……….. Vector weights = (Vectors.dense(new double[] <array of weights like above>) LogisticRegressionModel model = new LogisticRegressionModel(weights, 0.0); double prediction = model.predict(<input features>)

Page 52 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
감사합니다
Page 52 © Hortonworks Inc. 2011 – 2015. All Rights Reserved

Page 53 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
This presentation contains forward-looking statements involving risks and uncertainties. Such forward-looking statements in this presentation generally relate to future events, our ability to increase the number of support subscription customers, the growth in usage of the Hadoop framework, our ability to innovate and develop the various open source projects that will enhance the capabilities of the Hortonworks Data Platform, anticipated customer benefits and general business outlook. In some cases, you can identify forward-looking statements because they contain words such as “may,” “will,” “should,” “expects,” “plans,” “anticipates,” “could,” “intends,” “target,” “projects,” “contemplates,” “believes,” “estimates,” “predicts,” “potential” or “continue” or similar terms or expressions that concern our expectations, strategy, plans or intentions. You should not rely upon forward-looking statements as predictions of future events. We have based the forward-looking statements contained in this presentation primarily on our current expectations and projections about future events and trends that we believe may affect our business, financial condition and prospects. We cannot assure you that the results, events and circumstances reflected in the forward-looking statements will be achieved or occur, and actual results, events, or circumstances could differ materially from those described in the forward-looking statements. The forward-looking statements made in this prospectus relate only to events as of the date on which the statements are made and we undertake no obligation to update any of the information in this presentation. Trademarks Hortonworks is a trademark of Hortonworks, Inc. in the United States and other jurisdictions. Other names used herein may be trademarks of their respective owners.
Page 53 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
Recommended


![solid08 [호환 모드] - kycyber.konyang.ac.krkycyber.konyang.ac.kr/contents/private/20122/60133A01/4/3/조합... · 내압을받는박판압력용기에서의응력을해석하고,](https://img.pdfslide.tips/doc/110x75/5a7a87987f8b9a2d788c61e5/solid08-.jpg)














