
Universidad de Murcia 1
Algoritmos matriciales por bloques
Multiplicación de matrices. BLAS
Domingo GiménezDepartamento de Informática y Sistemas
Universidad de Murcia, Spaindis.um.es/~domingo

Universidad de Murcia 2
Contenido Jerarquía de librerías Obteniendo información Algoritmos por bloques BLAS
Universidad de Murcia 3
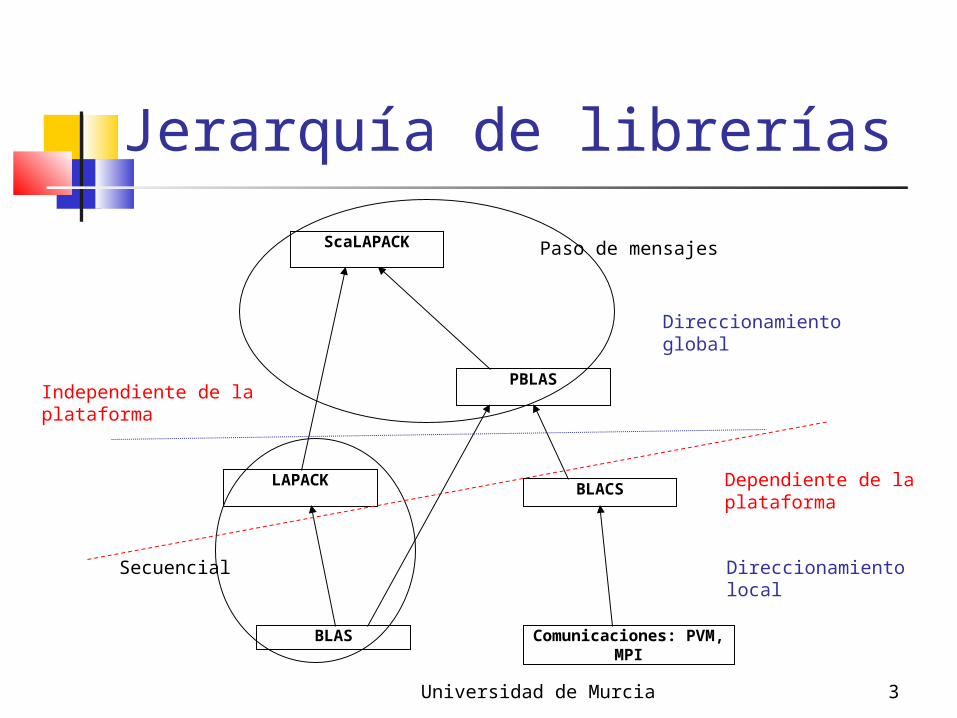
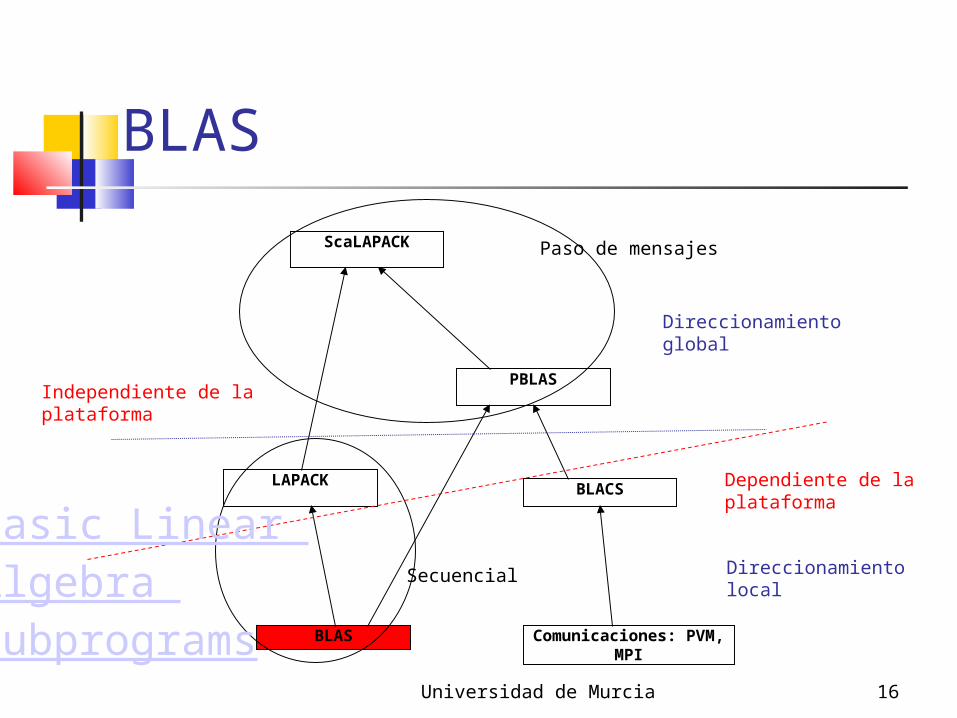
Jerarquía de librerías
ScaLAPACK
LAPACK
BLAS
PBLAS
BLACS
Comunicaciones: PVM, MPI
Secuencial
Paso de mensajes
Dependiente de laplataforma
Independiente de laplataforma
Direccionamientolocal
Direccionamientoglobal
Universidad de Murcia 4
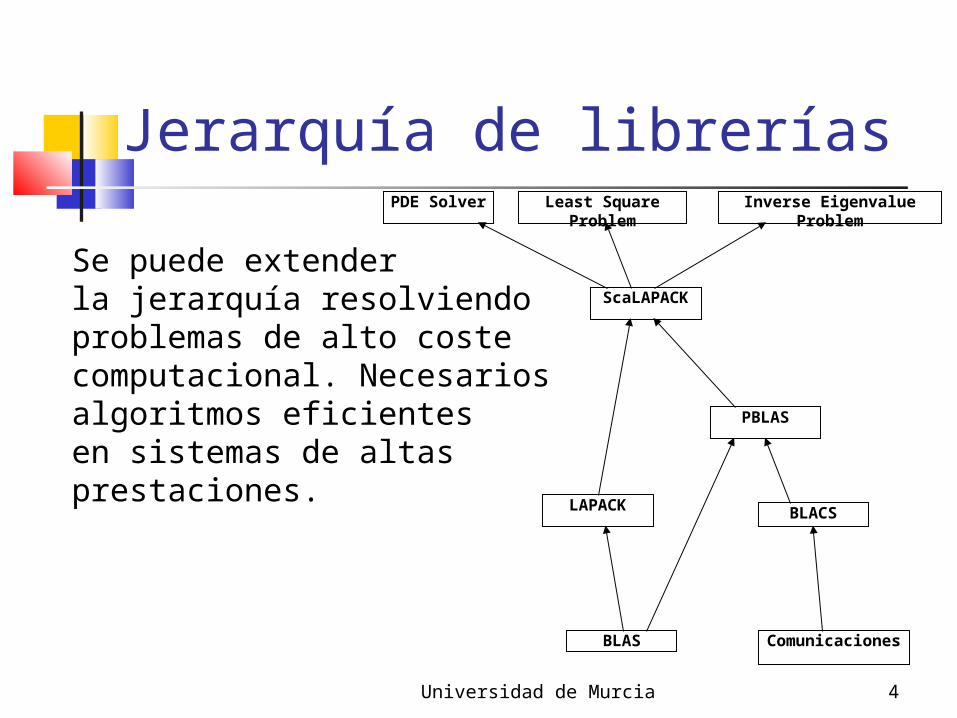
Jerarquía de librerías
ScaLAPACK
LAPACK
BLAS
PBLAS
BLACS
Comunicaciones
Inverse Eigenvalue ProblemLeast Square ProblemPDE Solver
Se puede extenderla jerarquía resolviendoproblemas de alto costecomputacional. Necesariosalgoritmos eficientesen sistemas de altasprestaciones.

Universidad de Murcia 5
Obteniendo información
www.netlib.org/liblist.html www.netlib.org/utk/people/JackDon
garra/la-sw.html

Universidad de Murcia 6
Algoritmos por bloques En vez de realizar operaciones elemento
a elemento realizarlas con bloques de elementos: menos accesos a memoria para el mismo volumen de computación menor tiempo de ejecución.
Técnica utilizada desde los años 80. Se utiliza en LAPACK para obtener rutinas eficientes independientemente del sistema donde se ejecuten.
Universidad de Murcia 7
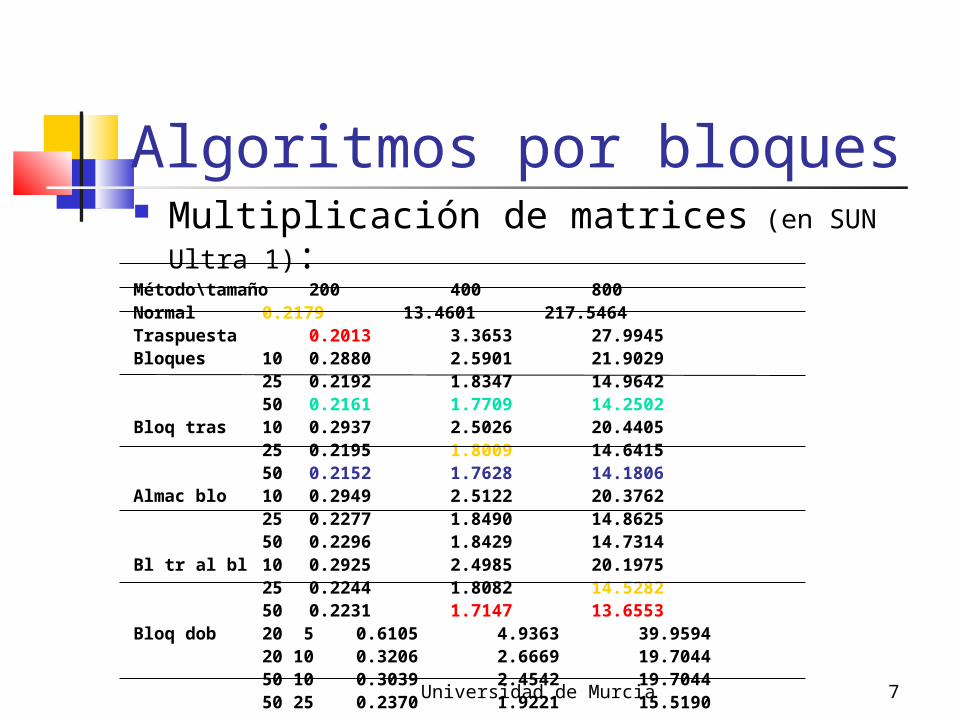
Algoritmos por bloques Multiplicación de matrices (en SUN Ultra 1):Método\tamaño 200 400 800Normal 0.2179 13.4601 217.5464Traspuesta 0.2013 3.3653 27.9945Bloques 10 0.2880 2.5901 21.9029
25 0.2192 1.8347 14.964250 0.2161 1.7709 14.2502
Bloq tras 10 0.2937 2.5026 20.440525 0.2195 1.8009 14.641550 0.2152 1.7628 14.1806
Almac blo 10 0.2949 2.5122 20.376225 0.2277 1.8490 14.862550 0.2296 1.8429 14.7314
Bl tr al bl 10 0.2925 2.4985 20.197525 0.2244 1.8082 14.528250 0.2231 1.7147 13.6553
Bloq dob 20 5 0.6105 4.9363 39.959420 10 0.3206 2.6669 19.704450 10 0.3039 2.4542 19.704450 25 0.2370 1.9221 15.5190

Universidad de Murcia 8
Algoritmos por bloques Las prestaciones de los distintos
algoritmos varían con: Tamaño del problema Parámetros del algoritmo Sistema en que se ejecuta Forma de la matriz …

Universidad de Murcia 9
Algoritmos por bloques Necesario:
Aprender a usar librerías eficientes Aprender a desarrollar algoritmos por
bloques Desarrollar técnicas de autooptimización,
que seleccionen el algoritmo y los parámetros a usar, para obtener buenas prestaciones independiente de:
El sistema donde se ejecuta Las condiciones actuales del sistema Los conocimientos del usuario

Universidad de Murcia 10
Algoritmos por bloquesmult(a,fa,ca,lda,b,fb,cb,ldb,c,fc,cc,ldc)double *a; int fa,ca,lda; double *b; int fb,cb,ldb; double *c; int
fc,cc,ldc;{
int i,j,k; double s;
for(i=0;i<fa;i++) for(j=0;j<cb;j++) { s=0.; for(k=0;k<ca;k++) s+=a[i*lda+k]*b[k*ldb+j]; c[i*ldc+j]=s; }}
Algoritmo sin bloques (normal).Acceso elemento a elemento.Problemas pequeños buenasprestaciones pues caben enmemoria de niveles bajos dela jerarquía.Problemas grandes peores prestaciones.

Universidad de Murcia 11
Algoritmos por bloquesmultbloques(a,fa,ca,lda,b,fb,cb,ldb,c,fc,cc,ldc,tb)double *a; int fa,ca,lda; double *b; int fb,cb,ldb; double *c; int fc,cc,ldc,
tb;{ int i,j,k; double *s; s=(double *) malloc(sizeof(double)* tb * tb);
for(i=0;i<fa;i=i+ tb) for(j=0;j<cb;j=j+ tb) { ceros(s, tb, tb, tb); for(k=0;k<ca;k=k+ tb)
multsumar(&a[i*lda+k], tb, tb,lda,&b[k*ldb+j], tb, tb,ldb,s, tb, tb, tb);
copiar(s, tb, tb, tb,&c[i*ldc+j], tb, tb,ldc); } free(s);}
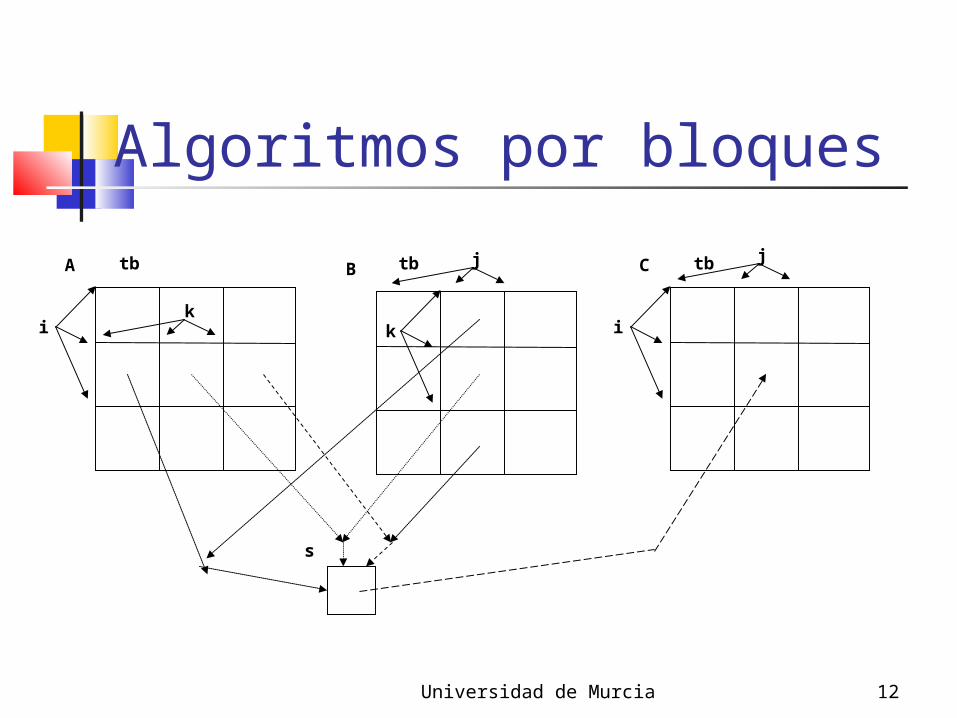
Algoritmo por bloques.Acceso y operaciones porbloques .Buenas prestaciones independiente del tamaño.El tamaño de bloque es parámetro a determinar.
Universidad de Murcia 12
Algoritmos por bloques
A
ik
tb B
k
jtb C
i
tb j
s

Universidad de Murcia 13
Algoritmos por bloquesmultbloquesgrandes(a,fa,ca,lda,b,fb,cb,ldb,c,fc,cc,ldc,tb,tbp)double *a; int fa,ca,lda; double *b; int fb,cb,ldb; double *c; int fc,cc,ldc,
tb, tbp;{ int i,j,k; double *s; s=(double *) malloc(sizeof(double)* tb * tb);
for(i=0;i<fa;i=i+ tb) for(j=0;j<cb;j=j+ tb) { ceros(s, tb, tb, tb); for(k=0;k<ca;k=k+ tb) multsumarbloques(&a[i*lda+k], tb, tb,lda,&b[k*ldb+j], tb, tb,ldb,s, tb, tb,
tb, tbp); copiar(s, tb, tb, tb,&c[i*ldc+j], tb, tb,ldc); } free(s);}
Algoritmo por bloques dobles.La operación sobre bloquesno es la multiplicacióndirecta, sino por bloques.Tenemos dos tamañosde bloque.

Universidad de Murcia 14
Algoritmos por bloquesAlmacenamiento por bloques:
matriz
0 1 2 3
4 5 6 7
8 9 10 11
12 13 14 15
almacenamiento
0 1 4 5
2 3 6 7
8 9 12 13
10 11 14 15
posible acceso más rápido a los datos dentro de las operacionespor bloques

Universidad de Murcia 15
Algoritmos por bloques Trasposición de la matriz B y multiplicación:
mult(a,fa,ca,lda,b,fb,cb,ldb,c,fc,cc,ldc)double *a; int fa,ca,lda; double *b; int fb,cb,ldb; double *c; int
fc,cc,ldc;{
int i,j,k; double s;
for(i=0;i<fa;i++) for(j=0;j<cb;j++) { s=0.; for(k=0;k<ca;k++) s+=a[i*lda+k]*b[j*ldb+k]; c[i*ldc+j]=s; }}
Universidad de Murcia 16
BLAS
ScaLAPACK
LAPACK
BLAS
PBLAS
BLACS
Comunicaciones: PVM, MPI
Paso de mensajes
Secuencial
Dependiente de laplataforma
Independiente de laplataforma
Direccionamientolocal
Direccionamientoglobal
Basic Linear Algebra Subprograms

Universidad de Murcia 17
BLAS Conjunto de rutinas para realizar
operaciones básicas sobre vectores y matrices
Publications/references for the BLAS?
1. C. L. Lawson, R. J. Hanson, D. Kincaid, and F. T. Krogh, Basic Linear Algebra Subprograms for FORTRAN usage, ACM Trans. Math. Soft., 5 (1979), pp. 308--323.
2. J. J. Dongarra, J. Du Croz, S. Hammarling, and R. J. Hanson, An extended set of FORTRAN Basic Linear Algebra Subprograms, ACM Trans. Math. Soft., 14 (1988), pp. 1--17.
3. J. J. Dongarra, J. Du Croz, I. S. Duff, and S. Hammarling, A set of Level 3 Basic Linear Algebra Subprograms, ACM Trans. Math. Soft., 16 (1990), pp. 1--17.

Universidad de Murcia 18
BLAS Hay tres niveles según el coste
computacional: tipo coste accesos operaciones computacional memoria
BLAS1 vector-vector n n
BLAS2 matriz-vector n2 n2
BLAS3 matriz-matriz n3 n2

Universidad de Murcia 19
BLAS 1

Universidad de Murcia 20
BLAS 1
Ejemplo ddot.fCalcula el producto escalar de dos
vectoresSe puede usar en el bucle más
interno de la multiplicación de matrices, dando lugar a una versión con BLAS 1
Se compila con (depende del sistema)cc –O3 mb1.c –lblas -lm

Universidad de Murcia 21
BLAS Formato de las funciones (niveles 2 y 3):
XYYZZZ X: Tipo de datos:
S : REALD : DOUBLE PRECISIONC : COMPLEXZ : DOUBLE COMPLEX
YY: Tipo de matriz:
GE, GB, HE, HP, HB, SY, SP, TR, TP, TB
ZZZ: Operación: MV: productor matriz vectorMM: producto matriz matrizSV: sistema de ecuaciones ...

Universidad de Murcia 22
BLAS 2

Universidad de Murcia 23
BLAS 2

Universidad de Murcia 24
BLAS 2
Ejemplo dgemv.fCalcula el producto de una matriz
por un vectorSe puede usar en el segundo bucle
en la multiplicación de matrices, dando lugar a una versión con BLAS 2
Se compila concc –O3 mb2.c –lblas -lm

Universidad de Murcia 25
BLAS 3

Universidad de Murcia 26
BLAS 3
Ejemplo dgemm.fCalcula el producto de una matriz
por un vectorSe puede hacer la multiplicación de
matrices llamando directamente a la rutina correspondiente de BLAS
Se compila conicc –O3 mb3.c –lgslcblas -lm
Universidad de Murcia 27
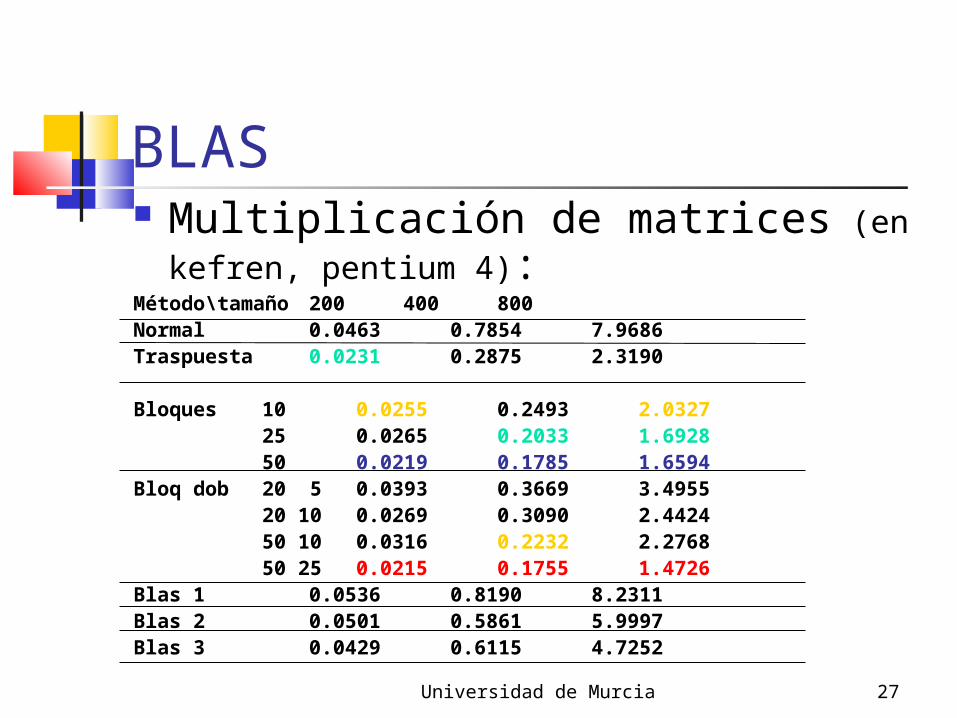
BLAS Multiplicación de matrices (en kefren,
pentium 4):Método\tamaño 200 400 800Normal 0.0463 0.7854 7.9686Traspuesta 0.0231 0.2875 2.3190
Bloques 10 0.0255 0.2493 2.032725 0.0265 0.2033 1.692850 0.0219 0.1785 1.6594
Bloq dob 20 5 0.0393 0.3669 3.495520 10 0.0269 0.3090 2.442450 10 0.0316 0.2232 2.276850 25 0.0215 0.1755 1.4726
Blas 1 0.0536 0.8190 8.2311Blas 2 0.0501 0.5861 5.9997Blas 3 0.0429 0.6115 4.7252

Universidad de Murcia 28
BLAS - Práctica Probar las prestaciones de:
La multiplicación de matrices por bloques y sin bloques
Variando el tamaño de las matrices Y determinar el tamaño de bloque
óptimo Comparar con las prestaciones
obtenidas usando BLAS en sus tres niveles
Recommended

















