
UNIVERSIDADE REGIONAL DE BLUMENAU
CENTRO DE CIÊNCIAS EXATAS E NATURAIS
CURSO DE CIÊNCIA DA COMPUTAÇÃO – BACHARELADO
VISÃO COMPUTACIONAL PARA RECONHECIMENTO DE
FACES APLICADO NA IDENTIFICAÇÃO E
AUTENTICAÇÃO DE USUÁRIOS NA WEB
MÁRCIO KOCH
BLUMENAU
2012
2012/1-21

MÁRCIO KOCH
VISÃO COMPUTACIONAL PARA RECONHECIMENTO DE
FACES APLICADO NA IDENTIFICAÇÃO E
AUTENTICAÇÃO DE USUÁRIOS NA WEB
Trabalho de Conclusão de Curso submetido à
Universidade Regional de Blumenau para a
obtenção dos créditos na disciplina Trabalho
de Conclusão de Curso II do curso de Ciência
da Computação — Bacharelado.
Prof. Jacques Robert Heckmann, Mestre - Orientador
BLUMENAU
2012
2012/1-21

VISÃO COMPUTACIONAL PARA RECONHECIMENTO DE
FACES APLICADO NA IDENTIFICAÇÃO E
AUTENTICAÇÃO DE USUÁRIOS NA WEB
Por
MÁRCIO KOCH
Trabalho aprovado para obtenção dos créditos
na disciplina de Trabalho de Conclusão de
Curso II, pela banca examinadora formada
por:
______________________________________________________
Presidente: Prof. Jacques Robert Heckmann, Mestre – Orientador, FURB
______________________________________________________
Membro: Prof. Dalton Solano dos Reis, Mestre – FURB
______________________________________________________
Membro: Prof. Cláudio Loesch, Doutor – FURB
Blumenau, 11 de julho de 2012

Dedico este trabalho a minha família,
principalmente ao meu Filho Mateus e a minha
esposa Ana Cristina pela paciência e
compreensão em todas as horas que passei na
frente do computador e em sala de aula para
concluir esse trabalho e a faculdade. Aos
amigos, especialmente aqueles que me
ajudaram diretamente na realização deste.

AGRADECIMENTOS
A Deus, pelo seu imenso amor e graça.
À minha família, que mesmo longe, sempre esteve presente.
Aos meus amigos, pelos empurrões, cobranças e fotos de suas faces para utilizar neste
trabalho.
Ao meu orientador, Jacques Robert Heckmann, pelo apoio e por ter acreditado na
conclusão deste trabalho.
Ao professor Cláudio Loesch, pelas inúmeras explicações relacionadas aos métodos
estatísticos multivariados.

Eu testemunhei a capacidade e a coragem
deles e embora sejamos de mundos distintos,
como nós, eles são mais, do que os olhos
podem ver.
Optimus Prime (Transformers)

RESUMO
Este trabalho apresenta a especificação e a implementação de como efetuar a identificação e a
autenticação de usuários através do reconhecimento facial em aplicativos, especificamente os
via web. A face do usuário é detectada e capturada a partir de um applet Java carregado no
navegador de internet. As imagens das faces são processadas e transferidas via socket para um
servidor onde são extraídas suas informações. Em um novo cadastro as informações são
armazenados em uma base de dados Oracle. No caso de uma identificação, são comparados os
dados da face apresentada com os dados das faces conhecidas já armazenadas no banco de
dados, sendo o usuário reconhecido, os seus dados são retornados para o applet que
redireciona para uma página de boas vindas. Praticamente todo o processamento, detecção e
identificação das imagens das faces foi efetuado utilizando a API JavaCV que é uma extensão
em Java para a API OpenCV. A técnica aplicada para a extração das características e
reconhecimento das faces foi a PCA.
Palavras-chave: Reconhecimento facial. Visão computacional. Processamento de imagens.
Autenticação na web. PCA. Análise de componentes principais.

ABSTRACT
This paper presents the specification and implementation of how to perform identification and
authentication of users through facial recognition applications, specifically web. The user
faces are detected and captured from a Java applet loaded in the browser. Images of faces are
processed and transferred via socket to a server where your information is extracted. In a new
account information is stored in an Oracle database. In the case of identification, are
compared against the data presented with data of known faces already stored in the database,
the user is recognized, your data is returned to the applet that redirects to a welcome page.
Virtually all processing, detection and identification of images of faces was performed using
the API JavaCV which is an extension to the Java API OpenCV. The technique used for
feature extraction and recognition of faces was the PCA.
Keywords: Face recognition. Computer vision. Image processing. Authentication on the web.
PCA. Principal component analysis.

LISTA DE ILUSTRAÇÕES
Figura 1 – Exemplo de: (a) íris, (b) geometria da mão, (c) impressão digital, (d)
reconhecimento da face, (e) voz e (f) retina .......................................................... 20
Figura 2 - Webcam Minoru possui duas câmeras lado a lado .................................................. 21
Figura 3 - Câmera digital detecta a face e sorriso para captura da foto ................................... 22
Figura 4 - A câmera detecta, notifica e não bate foto no momento que a pessoa pisca ........... 22
Figura 5 - O estabilizador digital de imagem reduz o embaçamento causado por trepidação na
câmera .................................................................................................................... 22
Figura 6 - Representação de imagem digital: (a) imagem normal e (b) área da imagem
aumentada .............................................................................................................. 24
Quadro 1- Coordenadas da vizinhança-de-4 de p ..................................................................... 24
Quadro 2 - Coordenadas da vizinhança-de-8 de p .................................................................... 25
Figura 7 - Redimensionamento de uma imagem através do algoritmo de intercalação ........... 26
Figura 8 - Imagem colorida (a) e a mesma imagem em tons de cinza (b)................................ 27
Quadro 3 - Equação para calcular um elemento do histograma ............................................... 28
Figura 9 - Exemplo de um histograma com oito níveis de cinza para a imagem ..................... 29
Figura 10 - Uma função de transformação de níveis de cinza.................................................. 30
Quadro 4 - Equação discreta da distribuição de probabilidade CDF ....................................... 31
Quadro 5 - Cálculo do primeiro valor da Tabela 1 ................................................................... 31
Quadro 6 - Cálculo do segundo valor da Tabela 1 ................................................................... 31
Quadro 7 - Cálculo dos demais valores da Tabela 1 ................................................................ 31
Figura 11 - Função de transformação utilizada para a equalização .......................................... 31
Quadro 8 - Cálculo dos demais valores da Tabela 1 ................................................................ 32
Figura 12- Histograma equalizado ........................................................................................... 33
Figura 13 - Equalização de histograma em uma imagem de baixo contraste........................... 33
Quadro 9 - Estrutura de um reconhecedor de padrões .............................................................. 34
Quadro 10 - Representação de um vetor de padrões ................................................................ 35
Figura 14 – Exemplo de separação de padrões com duas medidas realizadas em três faces ... 36
Quadro 11 - Equação da distância euclidiana entre dois vetores ............................................. 37
Quadro 12 - Equação da distância de mahalanobis .................................................................. 37
Figura 15 - Problema da dimensionalidade .............................................................................. 39
Figura 16 – (a) Imagem original e (b) imagem com a interpretação física original alterada ... 41

Quadro 13 - Equação para criar um vetor coluna a partir de uma matriz A ............................. 42
Figura 17 - Padrão criado a partir de uma imagem .................................................................. 42
Quadro 14 - Matriz X de padrões de treinamento .................................................................... 43
Quadro 15 – Criação da matriz de covariância a partir da matriz de padrões de treinamento
X ............................................................................................................................ 43
Quadro 16 – Equação para calcular os valores da matriz de covariância ........................... 43
Quadro 17 – Matriz H para mudança de base da matriz de covariância ............................ 44
Quadro 18 – Obtenção do auto-vetor e auto-valor a partir da matriz de covariância 44
Quadro 19 – Operação para a mudança de base da matriz de covariância ......................... 44
Figura 18 - Processo para assinatura de um arquivo JAR ........................................................ 50
Figura 19 – Passos para a assinatura de um applet................................................................... 51
Quadro 20 - Comando para criar um arquivo JAR ................................................................... 51
Quadro 21 - Opções do comando keytool ........................................................................... 52
Quadro 22 – Opções do comando jarsigner ...................................................................... 53
Quadro 23 – Opções do comando keytool para exportar o certificado com a chave pública
............................................................................................................................... 54
Figura 20 - Passos que deverão ser efetuados pelo usuário do applet ...................................... 54
Quadro 24 – Tag para adicionar um applet em uma página HTML ........................................ 54
Quadro 25 – Opções do comando para importar um certificado .............................................. 54
Figura 21 - Arquivos .policy e .keystore no diretório home do usuário ......................... 55
Quadro 26 - Exemplo dos dados contidos em um arquivo .policy ..................................... 55
Figura 22 - (a) Tela cadastrar usuário, (b) tela selecionar foto e (c) foto selecionada ............. 56
Figura 23 - Resultados da segmentação baseada em bordas em três níveis: (a) ruim, (b)
regular e (c) bom .................................................................................................... 57
Figura 24 - Resultados da segmentação em cor da pele em três níveis: (a) ruim, (b) regular e
(c) bom ................................................................................................................... 58
Figura 25 – Processo distribuído pelo ambiente para autenticação através de reconhecimento
facial ...................................................................................................................... 60
Figura 26 – Diagrama de casos de uso da ferramenta .............................................................. 62
Figura 27 - Diagrama de atividades do acesso à tela de login .................................................. 63
Figura 28 - Diagrama de atividades para cadastrar usuário ...................................................... 64
Figura 29 - Diagrama de atividades para autenticação através da face .................................... 65
Figura 30 - Diagrama de sequência do reconhecimento de usuário através da face ................ 66

Figura 31 - Diagrama de classes do applet ............................................................................... 68
Figura 32 - Diagrama de classes dos componentes das abas novo usuário e login do applet .. 69
Figura 33 - Diagrama de classes da classe FaceProcessor - principal classe de
processamento de imagem ..................................................................................... 70
Figura 34 - Diagrama da classe de usuário e seus relacionamentos ......................................... 71
Figura 35 - Diagrama das classes para processamento PCA .................................................... 72
Figura 36 - Diagrama das classes de socket no aplicativo servidor.......................................... 73
Quadro 27 – Classe WebcamApplet que especializa a classe JApplet ............................ 75
Figura 37 - Exportar pacotes para um arquivo JAR utilizando o Eclipse ................................ 75
Figura 38 - Aviso de segurança exibido pelo Java através do navegador Google Chrome ..... 76
Figura 39 - Erro exibido pelo Java através do navegador Google Chrome .............................. 77
Figura 40 - Detalhes da exceção gerada pelo Java ................................................................... 77
Quadro 28 - Código fonte do método init() do applet ....................................................... 78
Quadro 29 - Arquivos que serão compactados e baixados para a máquina do usuário
automaticamente pelo applet ................................................................................. 78
Quadro 30 - Código fonte do método loadWebcam() ......................................................... 79
Quadro 31 - Código fonte do método start() da webcam .................................................. 80
Quadro 32 - Código fonte do método grabAndPaint() .................................................... 81
Quadro 33 - Código fonte do método para atribuição e sua pintura da imagem no painel do
applet ..................................................................................................................... 81
Figura 41 - Exemplo de detecção de faces, a maior face é pintada em verde .......................... 83
Quadro 34 – Método detectFaces() para detectar as faces em uma imagem .................. 84
Quadro 35 - Código fonte do método getImageWithDetectedFace() ....................... 85
Quadro 36 - Código fonte do método getBigFaceRect() ............................................... 85
Figura 42- Processo executado pelo algoritmo de detecção facial: (a) imagem original, (b)
imagem em tons de cinza, (c) imagem com resolução reduzida em 50%, (d)
imagem com histograma equalizado e (e) imagem com a face detectada ............. 86
Quadro 37 - Método getBigFace() retorna a imagem da maior face detectada ................ 87
Figura 43 - Resultado do método getBigFace(): (a) imagem original, (b) imagem
rotacionada, (c) imagem redimensionada e (d) imagem com histograma
equalizado .............................................................................................................. 88
Figura 44 - Imagem de face com inclinação baseada na linha horizontal entre o centro dos
olhos ....................................................................................................................... 89

Quadro 38 - Código fonte do método rotateFaceByEyes() ........................................... 90
Quadro 39 - Código fonte do método detectEyes() ......................................................... 91
Quadro 40 - Código fonte do método getEyesSliceFromImage ................................... 91
Quadro 41 - Método rotateImage() rotaciona a face baseado no ângulo passado .......... 93
Quadro 42 – Equação para cálculo dos pixels da imagem de destino ...................................... 93
Figura 45 – Exemplo de uma imagem da face rotacionada, (a) imagem original, (b) olhos não
alinhados horizontalmente, (c) face rotacionada em um editor de imagens, (d) face
rotacionada pelo método rotateImage()e (e) olhos alinhados horizontalmente
............................................................................................................................... 94
Quadro 43 - Código fonte do método processUser() ....................................................... 95
Quadro 44 - Código fonte do método autoRecognizedUser() ...................................... 96
Quadro 45 - Código fonte do construtor da classe FaceClientSocket que abre uma
conexão com o aplicativo servidor ........................................................................ 96
Quadro 46 - Código fonte do método send() ....................................................................... 97
Quadro 47 - Código fonte do método sendUserData() .................................................... 97
Quadro 48 - Código fonte do método sendFaces() ........................................................... 98
Quadro 49 - Código fonte do método sendFace() .............................................................. 98
Quadro 50 - Código fonte do método processUserOnServer() ................................... 99
Quadro 51 - Código fonte da classe ServerSystemManager ......................................... 100
Quadro 52 - Código fonte da classe FaceServerSocket ................................................ 100
Quadro 53 - Código fonte do método run() da classe FaceServerClientSocket ... 101
Quadro 54 - Código fonte do método readPacked() ....................................................... 102
Quadro 55 - Código fonte do método executeCommand() ............................................. 103
Quadro 56 - Código fonte do método processUser() da classe
FaceServerClientSocket ........................................................................ 104
Quadro 57 - Código fonte do método processNewUser() ............................................. 105
Figura 46 - (a) imagem média, (b) 59 eigenfaces (auto-vetores) calculados de forma ordenada
da esquerda para a direita e de cima para baixo .................................................. 107
Quadro 58 - Código fonte do método transformPCA() .................................................. 108
Quadro 59 - Código fonte do método recognizeFace() ................................................ 110
Quadro 60 - Código fonte do método findNearestNeighbor() ................................. 111
Figura 47 - Tela de entrada da ferramenta .............................................................................. 112

Figura 48 - Tela principal da ferramenta ................................................................................ 113
Figura 49 - Tela para cadastro de um novo usuário ............................................................... 115
Figura 50 - Tela de cadastro após submissão ao aplicativo servidor ..................................... 116
Figura 51 - Autenticação do usuário através da face com usuário reconhecido..................... 117
Figura 52 - Usuário autenticado e redirecionado para a página principal .............................. 118
Figura 53 - Opção Reconhecer automaticamente a face do usuário marcada ......... 119
Figura 54 - Autenticação convencional através de um usuário e uma senha ......................... 120
Figura 55 - Amostra de imagens coletadas a campo para constituir a população da base de
dados .................................................................................................................... 122
Figura 56 - A detecção facial atingiu 100% de sucesso nas faces apresentadas em pose frontal
e sem oclusões significativas ............................................................................... 123
Figura 57 - Problemas na detecção dos olhos, (a) confusão dos olhos com as sombrancelhas e
(b) confusão dos olhos com as narinas ................................................................ 123
Figura 58 - Amostras de faces normalizadas .......................................................................... 124
Figura 59 - Resultados obtidos pela ferramenta com três imagens por pessoa, comparado com
os resultados de Campos (2001, p. 93) ................................................................ 125
Figura 60 - Visualização do problema da dimensionalidade obtido pela ferramenta ............ 127
Quadro 61 - Descrição do ator Usuário .............................................................................. 134
Quadro 62 - Descrição do UC01 - Cadastrar usuário ............................................ 135
Quadro 63 - Descrição do UC02 - Autenticar usuário através da face ... 137
Quadro 64 - Descrição do UC03 - Reconhecer usuário automaticamente ... 137
Quadro 65 - Descrição do UC04 - Autenticar usuário através de usuário
e senha ............................................................................................................ 138

LISTA DE TABELAS
Tabela 1 - Exemplo de histograma ........................................................................................... 29
Tabela 2 - Histograma equalizado ............................................................................................ 32
Tabela 3 - Classes de resultados para as três abordagens empregadas ..................................... 57
Tabela 4 - Desempenho do classificador para reconhecimento de olhos e de faces quando
treinado com três imagens por pessoa ................................................................... 58
Tabela 5 - Desempenho do classificador para reconhecimento de olhos e de faces quando
treinado com cinco imagens por pessoa ................................................................ 58
Tabela 6 - Resultados obtidos pela ferramenta com três imagens por pessoa, comparado com
Campos (2001, p. 93)........................................................................................... 125
Tabela 7 - Resultados obtidos com cinco imagens por pessoa, comparado com Campos (2001,
p. 93) .................................................................................................................... 125
Tabela 8 - Resultados obtidos pela ferramenta com cinco imagens por pessoa usadas para
treinamento, variando a quantidade de auto-vetores (eigenfaces) ....................... 126

LISTA DE SIGLAS
API - Application Programming Interface
DLL - Dynamic Link Library
HTML - Hyper Text Markup Language
JAR - Java ARchive
Java EE - Java Enterprise Edition
JDK - Java Development Kit
JRE - Java Runtime Environment
JVM - Java Virtual Machine
OpenCV- Open source Computer Vision library
PCA - Principal Component Analysis
ROI - Region Of Interest
UML - Unified Modeling Language
XML - eXtensible Markup Language

SUMÁRIO
1 INTRODUÇÃO .................................................................................................................. 17
1.1 OBJETIVOS DO TRABALHO ........................................................................................ 17
2 FUNDAMENTAÇÃO TEÓRICA .................................................................................... 19
2.1 IDENTIFICAÇÃO BIOMÉTRICA .................................................................................. 19
2.2 AQUISIÇÃO DE IMAGENS............................................................................................ 21
2.3 PROCESSAMENTO DE IMAGENS ............................................................................... 23
2.3.1 Representação de imagens digitais.................................................................................. 23
2.3.2 Relacionamento básico entre pixels ................................................................................ 24
2.3.2.1 Vizinhos de um pixel .................................................................................................... 24
2.3.2.2 Conectividade entre pixels ............................................................................................ 25
2.3.2.3 Rotulação de componentes conexos ............................................................................. 25
2.3.2.4 Redimensionamento ..................................................................................................... 26
2.3.2.5 Imagens em tons de cinza ............................................................................................. 26
2.3.2.6 Histograma .................................................................................................................... 27
2.3.2.7 Equalização de histograma ........................................................................................... 29
2.4 RECONHECIMENTO DE PADRÕES ............................................................................ 34
2.5 MÉTODO DOS K-VIZINHOS MAIS PRÓXIMOS ........................................................ 36
2.6 GENERALIZAÇÃO ......................................................................................................... 38
2.7 PROBLEMA DA DIMENSIONALIDADE ..................................................................... 38
2.8 REDUÇÃO DA DIMENSIONALIDADE ........................................................................ 40
2.9 ANÁLISE DE COMPONENTES PRINCIPAIS .............................................................. 41
2.10 OPENCV ........................................................................................................................... 45
2.10.1 JAVACV .................................................................................................................. 47
2.11 APPLET JAVA .................................................................................................................. 49
2.11.1 Assinatura de applet Java ......................................................................................... 49
2.12 TRABALHOS CORRELATOS ........................................................................................ 55
2.12.1 Reconhecimento facial 2D para sistemas de autenticação em dispositivos móveis 56
2.12.2 Reconhecimento de Faces em Imagens: Projeto Beholder ...................................... 57
2.12.3 Técnicas de seleção de características com aplicação em reconhecimento de faces58
3 DESENVOLVIMENTO DO PROTÓTIPO .................................................................... 59
3.1 REQUISITOS PRINCIPAIS DO PROBLEMA A SER TRABALHADO ....................... 59

3.2 ESPECIFICAÇÃO ............................................................................................................ 60
3.2.1 Processo geral do funcionamento da ferramenta ............................................................ 60
3.2.2 Diagrama de casos de uso ............................................................................................... 61
3.2.3 Diagramas de atividades ................................................................................................. 62
3.2.4 Diagramas de sequência .................................................................................................. 65
3.2.5 Diagramas de classes....................................................................................................... 66
3.3 IMPLEMENTAÇÃO ........................................................................................................ 73
3.3.1 Técnicas e ferramentas utilizadas.................................................................................... 74
3.3.1.1 Applet no lado do usuário ............................................................................................. 74
3.3.1.2 Detecção facial .............................................................................................................. 81
3.3.1.3 Captura da face ............................................................................................................. 86
3.3.1.4 Envio das informações para o aplicativo servidor ........................................................ 95
3.3.1.5 Recebimento das informações pelo aplicativo servidor ............................................... 99
3.3.1.6 Processando um novo usuário .................................................................................... 104
3.3.1.7 Reconhecimento através da face ................................................................................. 109
3.3.1.8 Reconhecimento através de um usuário e uma senha ................................................. 111
3.3.2 Operacionalidade da implementação ............................................................................ 112
3.3.2.1 Acesso à ferramenta .................................................................................................... 112
3.3.2.2 Cadastrar um novo usuário ......................................................................................... 113
3.3.2.3 Autenticar usuário através da face .............................................................................. 116
3.3.2.3.1 Reconhecer usuário através da face automaticamente ........................................... 118
3.3.2.4 Autenticar usuário através de um usuário e uma senha .............................................. 119
3.4 RESULTADOS E DISCUSSÃO .................................................................................... 121
3.4.1 Base de dados ................................................................................................................ 121
3.4.2 Detecção da face ........................................................................................................... 122
3.4.3 Normalização da face .................................................................................................... 123
3.4.4 Reconhecimento da face ............................................................................................... 124
4 CONCLUSÕES ................................................................................................................ 128
4.1 EXTENSÕES .................................................................................................................. 129
REFERÊNCIAS BIBLIOGRÁFICAS ............................................................................... 131
APÊNDICE A – Detalhamento do ator e casos de uso especificados .............................. 134

17
1 INTRODUÇÃO
Do ponto de vista humano a forma mais comum para identificar uma pessoa é
através de sua face. Simplesmente olha-se para o rosto de uma pessoa, seja pessoalmente ou
através de uma foto, e a identifica-se como conhecida ou não (PAMPLONA SOBRINHO,
2010, p. 13).
A identificação de pessoas é um assunto muito explorado pela computação nos dias
atuais, nas mais diversas áreas, tais como criminalística, jogos e segurança.
Visão computacional, área da computação cujo propósito é possibilitar um
computador a entender um ambiente através das informações visuais disponíveis (SHIRAI,
1987, p. 1), é aplicada em diversas atividades, destacando-se a robótica e reconhecimento de
criminosos e a identificação de usuários para acesso as empresas. Segundo Afonso (2009, p.
1), o banco Bradesco utiliza autenticação de usuários para efetuar transações em caixas
eletrônicos através da leitura das veias da palma da mão.
Atualmente há uma deficiência do uso deste tipo de recurso para identificação de
pessoas na web, na qual a forma mais comum para identificar e autenticar pessoas ainda é
através de um nome de usuário e uma senha. Devido ao esquecimento, à perda ou à confusão
por possuir usuários e senhas diferentes para cada site, uma série de transtornos e falhas de
segurança são provocados para estas pessoas.
Diante do exposto, a proposta deste trabalho é o emprego da visão computacional
para o reconhecimento de pessoas através de sua face e a aplicação desta técnica na
identificação e autenticação destas pessoas em um protótipo de sistema web. Com esta forma
de identificação e autenticação pretende-se facilitar o acesso aos sistemas web e proporcionar
uma possível solução para os transtornos descritos anteriormente.
1.1 OBJETIVOS DO TRABALHO
O objetivo deste trabalho é desenvolver um protótipo capaz de efetuar o
reconhecimento de faces para a identificação e autenticação de usuários em aplicativos,
especificamente os via web, utilizando técnicas de processamento de imagens digitais, visão
computacional, applet Java para interface com o usuário dentro do navegador de internet,

18
socket para transmissão dos dados e banco de dados para armazenar as informações das faces.
Os objetivos específicos do trabalho são:
a) utilizar técnicas de processamento de imagens para ajustar a qualidade das
imagens obtidas (i.e. converter em tons de cinza e equalização do histograma);
b) detectar as faces nas imagens obtidas;
c) normalizar a pose das faces encontradas (i.e. padronizar as dimensões e a
inclinação das faces);
d) extrair as características das faces utilizando a Análise de Componentes
Principais;
e) utilizar métricas de comparação de distância para comparar as faces de entrada
com as faces conhecidas;
f) efetuar o reconhecimento mínimo de 96% das faces submetidas à identificação e
autenticação, em uma base de dados de mais de 200 indivíduos;
g) disponibilizar um protótipo de aplicativo web que possibilite o cadastramento
dos usuários, a aquisição de suas imagens e que possibilite a identificação e
autenticação dos usuários cadastrados;
h) utilizar applet para a interface entre o usuário e o navegador de internet;
i) efetuar a transmissão das imagens das faces e dados do usuário a partir do applet
para o servidor via socket;
j) armazenamento e recuperação das imagens das faces, seus dados e dados do
usuário em banco de dados Oracle.

19
2 FUNDAMENTAÇÃO TEÓRICA
A seguir, na seção 2.1, são apresentados alguns conceitos sobre identificação
biométrica. A seção 2.2 comenta sobre a aquisição de imagens e suas características atuais. A
seção 2.3 detalha as principais técnicas de processamento de imagens, como relacionamento,
vizinhos, conectividade e rotulação de componentes conexos dos pixels, bem como explica
sobre imagens em tons de cinza, histograma e equalização de histograma. Na seção 2.4
explicam-se conceitos básicos de reconhecimento de padrões. A seção 2.5 aborda o método
dos k-vizinhos mais próximos. A seção 2.5 explica sobre a importância na capacidade de
generalização de um classificador de padrões. Na seção 2.7 é dada uma visão de como é
importante encontrar a dimensionalidade ideal para resolver um problema de reconhecimento
de padrões. A seção 2.8 aborda os conceitos para controlar a dimensionalidade do espaço de
características. Na seção 2.9 é explicada e aprofundada a transformada da análise de
componentes principais, que permite extrair as características principais dos padrões
reduzindo a dimensionalidade das características. Na seção 2.10 é explicado sobre a API
OpenCV, que é uma poderosa API, própria para visão computacional e seu wrapper para
Java, a API da Google, JavaCV. Explica também de forma sucinta as funções e classes usadas
mais importantes no desenvolvimento deste trabalho. Na seção 2.11 são explicadas de forma
básica as principais vantagens e desvantagens do uso de applet. É descrito também com mais
detalhes como efetuar a assinatura digital de arquivos JAR para que um applet possa sair da
sandbox e acessar dispositivos na máquina do usuário, como por exemplo, a webcam. Por fim
na seção 2.12 são apresentados três trabalhos correlatos sobre reconhecimento de faces.
2.1 IDENTIFICAÇÃO BIOMÉTRICA
A palavra biometria é proveniente do grego bios (vida) metron (medida). Ela estuda
através da estatística as qualidades comportamentais e físicas do ser humano. Atualmente a
biometria é amplamente empregada como um instrumento de controle de segurança, onde o
termo refere-se ao uso do corpo humano em mecanismos de identificação. De acordo com
Pamplona Sobrinho (2010, p. 15), seres humanos utilizam esta forma de reconhecimento,
mesmo que inconscientemente, através de características como a voz, a face e a forma de

20
andar para distinguir seus semelhantes fisicamente. No caso da identificação biométrica,
delega-se a função de diferenciar as pessoas a uma máquina.
Os aparelhos de identificação biométricos capturam amostras do ser humano, como a
íris, retina, dedo, rosto, veias da mão, voz e até odores do corpo. As amostras são
transformadas em um padrão e podem ser utilizadas para futuras identificações (MUNIZ,
2007). Entre os propósitos mais comuns deste tipo de identificação, pode-se enumerar:
controle de ponto, identificação criminal e regulamentação de acesso. Porém, algumas
abordagens possuem o inconveniente por serem um tanto invasivas exigindo certas condições
ao usuário. No caso dos sistemas de reconhecimento pela íris, o usuário deve permanecer
parado em uma posição definida, com os olhos abertos enquanto uma fonte de luz ilumina os
olhos e um scanner ou uma câmera efetua a captura da imagem. O caráter invasivo acentua-se
em sistemas que empregam o uso de imagens do fundo da retina, sendo preciso à utilização de
colírio para dilatação da pupila do usuário antes da aquisição da imagem. Já um sistema de
reconhecimento baseado em imagens da face apresenta um nível invasivo menos acentuado
(CAMPOS, 2001, p. 1). Na Figura 1 é possível visualizar alguns exemplos de identificação
por biometria.
Fonte: SmartSec (2012).
Figura 1 – Exemplo de: (a) íris, (b) geometria da mão, (c) impressão digital, (d) reconhecimento da
face, (e) voz e (f) retina

21
2.2 AQUISIÇÃO DE IMAGENS
Os principais dispositivos para aquisição de imagens para computador são as
câmeras digitais, de vídeo, webcam e scanners. Estes dispositivos estão em constante
aperfeiçoamento. Por exemplo, é o caso da webcam Minoru que filma e transmite vídeos em
3D. Esta webcam usa técnicas de estereoscopia1 e anáglifo
2 para gerar o efeito 3D. Ela pode
ser empregada na robótica como uma nova opção de sensor 3D. Pesquisadores do Nagoya
Institute of Technology realizaram alguns trabalhos no campo da visão computacional
utilizando a Minoru juntamente com a Application Programming Interfaces (API) Open
source Computer Vision library (OpenCV3) (MINORU, 2008).
Fonte: Amazon.com (2011).
Figura 2 - Webcam Minoru possui duas câmeras lado a lado
As câmeras digitais também estão cada vez mais modernas e utilizam técnicas de
visão computacional para detecção da face para posicionar o foco da câmera, bater a foto
apenas se a pessoa sorrir (Figura 3), detectar olhos fechados, se a pessoa piscou (Figura 4) e
redução de embaçamento causado por trepidação na câmera permitindo capturar imagens
claras e nítidas de objetos em movimento (Figura 5).
1Estereoscopia é uma técnica fotográfica pela qual se obtém uma sensação de relevo dada pela fusão numa única
imagem de duas fotografias do mesmo objeto tiradas de pontos diferentes (ESTEREOSCOPIA, 2011).
2Anáglifo é uma imagem impressa com cores complementares, que, vistas através de óculos coloridos, dão a
sensação de relevo (3D) (ANÁGLIFO, 2011).
3OpenCV é uma biblioteca multiplataforma, totalmente livre ao uso acadêmico e comercial, para o
desenvolvimento de aplicativos na área de visão computacional (OPENCV, 2011).

22
Fonte: Fujifilm (2012).
Figura 3 - Câmera digital detecta a face e sorriso para captura da foto
Fonte: Fujifilm (2012).
Figura 4 - A câmera detecta, notifica e não bate foto no momento que a pessoa pisca
Fonte: Fujifilm (2012). Figura 5 - O estabilizador digital de imagem reduz o embaçamento causado por trepidação na câmera
Outra forma para obtenção de imagens e vídeo será através dos navegadores web que
suportarem o HTML5, que proverá acesso aos dispositivos de multimídia locais (câmeras de
vídeo, webcams, microfones) do usuário (WHATWG, 2011). A especificação do HTML5
ainda está em desenvolvimento, mas os principais navegadores do mercado como o Internet

23
Explorer, Chrome, FireFox e Safari já suportam a maioria das especificações do HTML5 já
concluídas.
2.3 PROCESSAMENTO DE IMAGENS
O processamento de imagens é uma etapa fundamental para aplicar técnicas de visão
computacional. Processar uma imagem muito grande, com muitos detalhes de cores pode ser
muito caro computacionalmente. Cada problema que se queira resolver pode exigir técnicas
de processamento de imagens diferentes, como trabalhar apenas da área de interesse de uma
imagem, convertê-la para tons de cinza, reduzir seu tamanho entre outras. A seguir serão
abordados estes temas com maiores detalhes.
2.3.1 Representação de imagens digitais
Uma imagem refere-se à função bidimensional de intensidade da luz f(x, y), onde x e
y representam as coordenadas espaciais e o valor de f em qualquer ponto (x,y) é proporcional
ao brilho (ou níveis de cinza) da imagem naquele ponto. Uma imagem digital pode ser
considerada uma matriz cujos índices de linha e coluna identifica um ponto na imagem, e o
valor do elemento nesta posição da matriz identifica o nível de cinza daquele ponto. Os
elementos desta matriz são chamados de pixels. Cada pixel possui uma cor produzida por uma
combinação de cores primárias: vermelho, verde e azul (Red, Green e Blue - RGB). O brilho
de cada uma destas cores pode variar em uma escala de 0 a 255 (GONZALEZ; WOODS,
2000, p. 174). A Figura 6 mostra uma área da imagem com o zoom aumentado de forma que
seja possível visualizar os pixels da imagem.

24
Fonte: adaptado de Blog do Rost (2011).
Figura 6 - Representação de imagem digital: (a) imagem normal e (b) área da imagem aumentada
2.3.2 Relacionamento básico entre pixels
Serão descritos nesta seção alguns relacionamentos básicos entre pixels de uma
imagem. Estes relacionamentos são utilizados em diversas técnicas de processamento de
imagens.
2.3.2.1 Vizinhos de um pixel
Segundo Gonzales e Woods (2000, p. 26), um pixel denominado p nas coordenadas
(x,y) possui quatro vizinhos horizontais e verticais, cujas coordenadas podem ser vistas no
Quadro 1.
Fonte: Gonzales e Woods (2000, p. 26).
Quadro 1- Coordenadas da vizinhança-de-4 de p
Este conjunto de pixels é chamado de vizinhança-de-4 de p. Cada pixel está a uma
unidade de distância de p. Quando p estiver na borda da imagem, alguns de seus vizinhos
ficarão fora da imagem.
Os quatro vizinhos diagonais de p mais os vizinhos das coordenadas do Quadro 1
formam a vizinhança-de-8 de p, cujas coordenadas podem ser vistas no Quadro 2. Como já
(x + 1, y), (x − 1, y), (x, y + 1), (x, y − 1)

25
mencionado anteriormente, quando p estiver na borda da imagem, alguns vizinhos cairão fora
da imagem.
Fonte: Gonzales e Woods (2000, p. 26).
Quadro 2 - Coordenadas da vizinhança-de-8 de p
2.3.2.2 Conectividade entre pixels
Gonzales e Woods (2000, p. 27) explicam que a conectividade entre pixels é
importante para detecção das bordas de objetos e componentes de regiões em uma imagem.
Para que dois pixels estejam conectados é preciso que eles sejam vizinhos-de-4 ou vizinhos-
de-8 e seus níveis de cinza sejam similares. Por exemplo, em uma imagem binária com
valores 0 e 1, dois pixels podem ser vizinhos-de-4, mas somente estarão conectados se
possuírem o mesmo valor. Facon (1993, p.51) enunciou outra definição para um conjunto
conexo, dizendo que se dois pontos de um conjunto podem ser ligados por uma curva
completamente contida nesse conjunto, então eles são conexos.
2.3.2.3 Rotulação de componentes conexos
Gonzales e Woods (2000, p. 28) apresentam um algoritmo para rotulação de
componentes conexos em uma imagem binária. Sendo a imagem percorrida pixel a pixel, de
cima para baixo e da direita para a esquerda. Considerando a vizinhança-de-4, seja p o pixel
em qualquer passo do processo de varredura e r e t os vizinhos superior e esquerdo de p. Ao
chegar ao ponto p, r e t já terão sido descobertos pela sequência obedecida. Inicialmente
verifica-se se o valor de p é 0. Caso seja, avança para a próxima posição. Se o valor de p for 1,
devem ser verificados os valores de r e t, sendo ambos 0, atribui-se um novo rótulo a p. Neste
caso, ou é a primeira vez que o componente conexo aparece, ou trata-se de um pixel em uma
ponta de um componente já encontrado. Se apenas um dos vizinhos for 1, p recebe seu rótulo,
Caso ambos sejam 1 e possuírem o mesmo rótulo, atribui-se o mesmo rótulo a p. Se forem 1,
porém possuírem rótulos diferentes, atribua um dos rótulos a p e marque que os dois rótulos
são equivalentes. Neste caso, r e t fazem parte do mesmo componente conexo, devido a
estarem ligados por p. Prosseguindo desta maneira, no final da varredura todos os pontos com
(x + 1, y + 1), (x + 1, y - 1), (x - 1, y + 1), (x - 1, y − 1)

26
valor 1 terão sido rotulados. Ao final os pares de rótulos equivalentes devem ser ordenados
em classes de equivalência, atribuindo-se um rótulo diferente para cada classe e percorrendo-
se a imagem para trocar os rótulos pelos que foram atribuídos a sua classe de equivalência.
O mesmo processo pode ser efetuado para rotular os componentes conexos
considerando a vizinhança-de-8, sendo que, neste caso, consideram-se também os dois
vizinhos diagonais superiores de p.
2.3.2.4 Redimensionamento
Reaes (2006, p. 7) explica que imagens muito grandes ou com resolução muito alta
podem ser reduzidas sem perder eficiência na detecção. Existem diversos algoritmos para
redimensionamento de imagens. Entre eles, podem-se citar dois: intercalação e médias. O
algoritmo de intercalação (Figura 7), por exemplo, consiste em substituir um conjunto de
pixels pelo primeiro pixel do conjunto. Define-se uma taxa de redução t, a largura e a altura
da nova imagem com tamanho reduzido. A Figura 7 demonstra o redimensionamento de uma
imagem de 4x6 pixels com taxa de redução de 50%, resultando uma imagem de 2x3 pixels.
Fonte: Reaes (2006, p. 9).
Figura 7 - Redimensionamento de uma imagem através do algoritmo de intercalação
2.3.2.5 Imagens em tons de cinza
Como já discutido na seção 2.3.1 uma imagem digital é composta por três
componentes primárias chamadas de sistema RGB. Em uma imagem em tons de cinza, as
componentes das cores primárias de cada ponto possuem o mesmo valor. Desta forma é
possível representar a cor através de apenas uma componente.
Uma imagem de 8 bits pode ter até 256 tons de cinza. Cada pixel em uma imagem

27
em tons de cinza possui um valor de brilho que varia de 0 (preto) a 255 (branco). Nas imagens
de 16 bits e 32 bits o número de tons de cinza é bem maior do que nas imagens de 8 bits,
consequentemente seu tamanho também aumenta. Os valores de níveis de cinza também
podem ser medidos como porcentagens de cobertura de tinta preta onde 0% é branco e 100%
é preto (ADOBE SYSTEMS INCORPORATED, 2005).
Para transformar uma imagem colorida para níveis de cinza deve-se primeiro obter as
primitivas vermelho, verde e azul (da escala RGB) de cada pixel. Em seguida o pixel é
substituído4 por 30% do vermelho mais 59% do verde mais 11% do azul (NÍVEL, 2011). A
Figura 8 mostra uma imagem colorida (a) e a mesma imagem em tons de cinza (b).
Fonte: adaptado de Blog do Rost (2011).
Figura 8 - Imagem colorida (a) e a mesma imagem em tons de cinza (b)
A ideia é que com apenas um componente na banda de cores o custo computacional
para processar uma imagem é menor. Reaes (2006, p. 6) diz que na escala RGB são
necessárias três matrizes para representar uma imagem, uma para cada componente. Já para as
imagens em tons de cinza, apenas uma matriz é necessária.
2.3.2.6 Histograma
Segundo Marques Filho e Vieira Neto (1999, p. 55), o histograma de uma imagem é
um conjunto de números indicando o percentual de pixels desta imagem para cada um de seus
níveis de cinza. Geralmente estes valores são apresentados através de um gráfico de colunas
que mostra a quantidade ou percentual de pixels de cada nível de cinza da imagem. Gonzales
4 Tais porcentagens estão relacionadas à própria sensibilidade visual do olho humano convencional para as cores
primárias.

28
e Woods (2000, p. 124) apresentam que apesar do histograma não fornecer nada específico
sobre o conteúdo de uma imagem, provê informações úteis sobre a possibilidade para realce
(pixels mais claros) e contraste (pixels mais escuros).
Cada elemento deste conjunto de números é calculado conforme o Quadro 3.
Fonte: Marques Filho e Vieira Neto (1999, p. 55).
Quadro 3 - Equação para calcular um elemento do histograma
Para calcular o histograma de uma imagem monocromática, inicia-se com zero todos
os elementos de um vetor de L elementos, sendo L o número de tons de cinza possíveis.
Percorre-se a imagem, pixel a pixel, incrementando a posição do vetor cujo índice
corresponde ao tom de cinza do pixel visitado. Após ter percorrido toda a imagem, cada
elemento terá a quantidade de pixels com o nível de cinza que o índice do elemento
corresponde. Para normalizar estes valores, basta dividir cada um deles pelo total de pixels na
imagem. Como exemplo, os dados da Tabela 1 são de uma imagem de 128 x 128 pixels, com
oito níveis de cinza. A primeira coluna apresenta o nível de cinza, na segunda coluna é
apresentado o número de pixels de um tom de cinza e na terceira coluna estão as respectivas
probabilidades de .
𝑝𝑟 𝑟𝑘) = 𝑛𝑘
𝑛
Onde:
- 0 ≤ 𝑟𝑘 ≤ 1;
- k = 0, 1, ..., L-1, onde L é o número de níveis de cinza da imagem
digitalizada;
- n = número total de pixels na imagem;
- 𝑝𝑟 𝑟𝑘 = probabilidade do k-ésimo nível de cinza;
- 𝑛𝑘 = número de pixels cujo nível de cinza corresponde a k.

29
Tabela 1 - Exemplo de histograma
Nível de cinza ( )
0 1120 0,068
1/7 3214 0,196
2/7 4850 0,296
3/7 3425 0,209
4/7 1995 0,122
5/7 784 0,048
6/7 541 0,033
1 455 0,028
Total 16384 1
Fonte: Marques Filho e Vieira Neto (1999, p. 56).
Cada fornece a probabilidade de um pixel da imagem possuir nível de cinza
. Um histograma nada mais é que uma função de distribuição de probabilidade. É possível
verificar que na Tabela 1 a soma dos valores de é 1. A Figura 9 mostra a representação
gráfica deste histograma.
Fonte: Marques Filho e Vieira Neto (1999, p. 56).
Figura 9 - Exemplo de um histograma com oito níveis de cinza para a imagem
Marques Filho e Vieira Neto (1999, p. 57), explicam que também é possível aplicar o
conceito de histograma em imagens coloridas. A imagem deve ser decomposta (por exemplo,
em seus componentes R, G e B) e calculado o histograma correspondente para cada
componente obtida.
2.3.2.7 Equalização de histograma
Marques Filho e Vieira Neto (1999, p. 61) explicam que a equalização de histograma

30
é uma técnica que visa redistribuir os valores de tons de cinza em uma imagem de forma que
seja obtido um histograma mais uniforme, ou seja, o número (percentual) de pixels de
qualquer nível de cinza deve ser praticamente igual.
Gonzalez e Woods (2000, p. 124) representam os níveis de cinza a serem realçados
com uma variável r e assumindo que os valores dos pixels são contínuos e foram
normalizados com valores entre [0,1], sendo r = 0 representando o preto e r = 1
representando o branco. Considerando uma formulação discreta e permitindo valores de pixel
entre [0, L–1].
Para todo r no intervalo [0, 1] é obtido através da função de transformação
um novo valor de nível de cinza para r em s. Esta função de transformação satisfaz as
seguintes condições:
a) é univariada e monotonicamente5 crescente no intervalo 0 ≤ r ≤ 1;
b) 0 ≤ ≤ 1 para 0 ≤ r ≤ 1.
A ordem de preto para o branco na escala de cinza é preservada pela primeira
condição acima e um mapeamento consistente com o intervalo permitido de valores de pixels
é garantido pela segunda condição. Na Figura 10 é exibida uma função de transformação que
satisfaz estas condições.
Fonte: Gonzalez e Woods (2000, p. 125).
Figura 10 - Uma função de transformação de níveis de cinza
Uma função de transformação normalmente utilizada é a função de distribuição
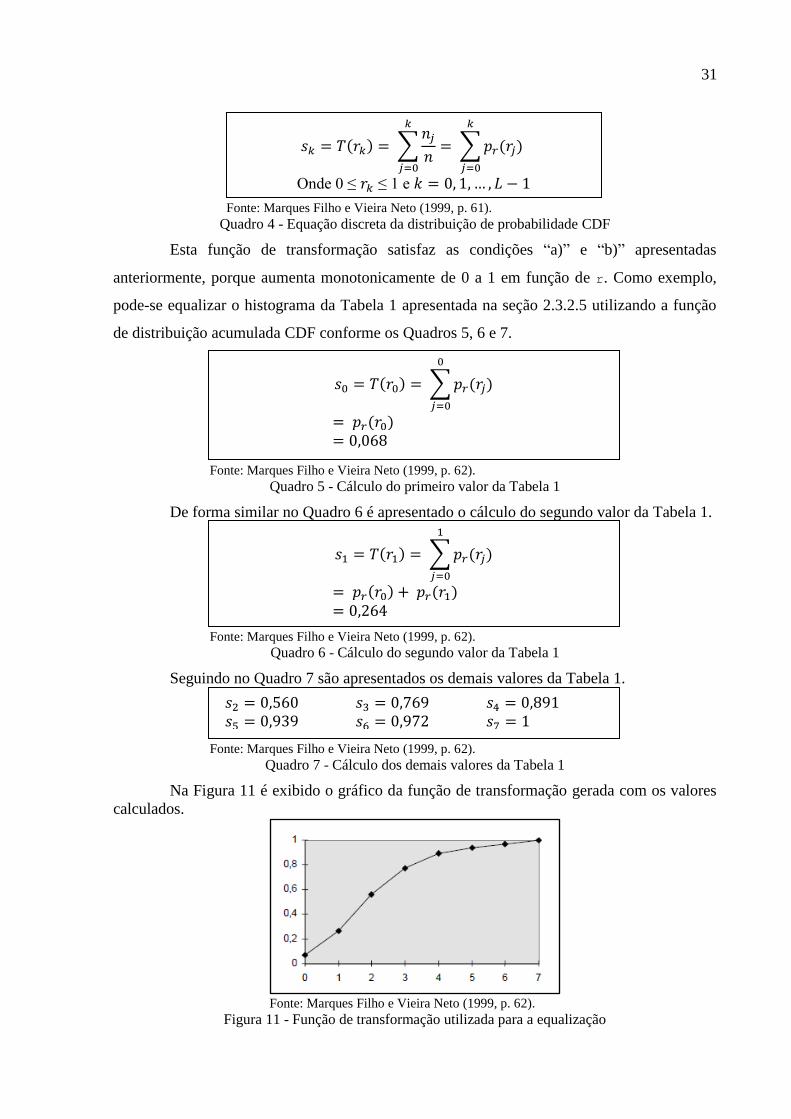
acumulada (Cumulative Distribution Funcion - CDF). Esta função é apresentada no Quadro 4.
5 Monotonicamente refere-se a crescer com uma variação constante.
31
Fonte: Marques Filho e Vieira Neto (1999, p. 61).
Quadro 4 - Equação discreta da distribuição de probabilidade CDF
Esta função de transformação satisfaz as condições “a)” e “b)” apresentadas
anteriormente, porque aumenta monotonicamente de 0 a 1 em função de r. Como exemplo,
pode-se equalizar o histograma da Tabela 1 apresentada na seção 2.3.2.5 utilizando a função
de distribuição acumulada CDF conforme os Quadros 5, 6 e 7.
Fonte: Marques Filho e Vieira Neto (1999, p. 62).
Quadro 5 - Cálculo do primeiro valor da Tabela 1
De forma similar no Quadro 6 é apresentado o cálculo do segundo valor da Tabela 1.
Fonte: Marques Filho e Vieira Neto (1999, p. 62).
Quadro 6 - Cálculo do segundo valor da Tabela 1
Seguindo no Quadro 7 são apresentados os demais valores da Tabela 1.
Fonte: Marques Filho e Vieira Neto (1999, p. 62).
Quadro 7 - Cálculo dos demais valores da Tabela 1
Na Figura 11 é exibido o gráfico da função de transformação gerada com os valores
calculados.
Fonte: Marques Filho e Vieira Neto (1999, p. 62).
Figura 11 - Função de transformação utilizada para a equalização
𝑠𝑘 𝑇 𝑟𝑘 𝑛𝑗
𝑛
𝑘
𝑗=0
𝑝𝑟 𝑟𝑗
𝑘
𝑗=0
Onde 0 ≤ 𝑟𝑘 ≤ 1 e 𝑘 0, 1, … , 𝐿 − 1
𝑠0 𝑇 𝑟0 𝑝𝑟 𝑟𝑗
0
𝑗=0
𝑝𝑟 𝑟0 0,068
𝑠1 𝑇 𝑟1 𝑝𝑟 𝑟𝑗
1
𝑗=0
𝑝𝑟 𝑟0 + 𝑝𝑟 𝑟1 0,264
𝑠2 0,560 𝑠3 0,769 𝑠4 0,891 𝑠5 0,939 𝑠6 0,972 𝑠7 1

32
Como a imagem possui apenas oito níveis de cinza, os valores de devem ser
arredondados para um valor múltiplo de 1/7 mais próximo, como pode ser visto no Quadro 8.
Fonte: Marques Filho e Vieira Neto (1999, p. 62).
Quadro 8 - Cálculo dos demais valores da Tabela 1
Depois de concluído o mapeamento, é possível verificar que o nível 0 0 foi
mapeado para 0 0. A raia correspondente não sofreu alteração. Os 3214 pixels do tom de
cinza 1/7 foram mapeados para 1 2 7. Da mesma forma, os pixels com tom de cinza 2/7
foram modificados para 4/7. Os com 3 7 passaram a 5/7 e os de 4/7 mapearam para 6/7.
As raias dos pixels com tons de cinza 5/7, 6/7 e 1 foram somadas em uma única raia, com tons
de cinza máximo 1.
A Tabela 2 apresenta os valores agrupados e a Figura 12 o histograma após a
equalização. O histograma equalizado não está perfeitamente plano, no entanto apresenta
melhor distribuição dos pixels ao longo da escala de cinza comparado ao original.
Tabela 2 - Histograma equalizado
Nível de cinza ( )
0 1120 0,068
1/7 0 0,000
2/7 3214 0,196
3/7 0 0,000
4/7 4850 0,296
5/7 3425 0,296
6/7 1995 0,122
1 1780 0,109
Total 16384 1
Fonte: Marques Filho e Vieira Neto (1999, p. 63).
𝑠0 ≈ 0 𝑠1 ≈ 2 7 𝑠2 ≈ 4 7 𝑠3 ≈ 5 7
𝑠4 ≈ 6 7 𝑠5 ≈ 1 𝑠6 ≈ 1 𝑠7 ≈ 1

33
Fonte: Marques Filho e Vieira Neto (1999, p. 64).
Figura 12- Histograma equalizado
Na Figura 13 pode-se ver um exemplo da equalização do histograma para aumentar o
contraste de uma imagem 446 x 297 com 256 tons de cinza. A imagem original é apresentada
em (a), sendo (b) o gráfico do seu histograma. Em (c) pode ser visto a mesma imagem com o
seu histograma equalizado e em (d) o gráfico da equalização.
Fonte: Marques Filho e Vieira Neto (1999, p. 64).
Figura 13 - Equalização de histograma em uma imagem de baixo contraste

34
2.4 RECONHECIMENTO DE PADRÕES
Segundo Marques (2005, p. 3), a percepção humana identifica a todo momento
objetos, sons e cheiros através dos sinais captados pelos órgãos sensoriais. Estas operações
são realizadas quase que automaticamente e sem grandes dificuldades. Porém, o mesmo não é
nada trivial para um computador, a menos que se restrinjam as hipóteses a atingir.
O autor afirma que é mais simples escolher dentre um conjunto limitado de
hipóteses, qual delas se adapta melhor às observações feitas do que olhar para um objeto
genérico e identificá-lo. Este problema de decisão pode ser resolvido por métodos
matemáticos gerais se for suficientemente bem definido. O objetivo do reconhecimento de
padrões é resolver este tipo de problema de decisão.
A estrutura clássica de um sistema de reconhecimento de padrões constitui-se por
dois blocos, um de extração de características, chamadas de padrões e um classificador. O
primeiro bloco seleciona através dos sensores apenas as informações mais relevantes para a
decisão, chamadas de características. O classificador utiliza as características para escolher a
hipótese ou classe que melhor soluciona o problema definido. O Quadro 9 apresenta a
estrutura de um reconhecedor de padrões.
Fonte: Marques (2005, p. 3).
Quadro 9 - Estrutura de um reconhecedor de padrões
Gonzalez e Woods (2000, p. 409) apresentam um padrão como uma descrição
quantitativa ou estrutural de um objeto ou outra entidade de interesse em uma imagem. Um
padrão é formado por um ou mais descritores (também denotados de características), ou seja,
é um arranjo de descritores. Uma classe de padrões é uma família que compartilha
propriedades em comum. Estas classes são denotadas como ω1, ω2, ..., ωm, onde m é o número
de classes. Os principais arranjos de padrões para descrições quantitativas são os vetores. O
Quadro 10 apresenta uma representação de vetor de padrões para x.
Dados Extração
de características
Características Classificador
Decisão

35
Fonte: Gonzales e Woods (2000, p. 409).
Quadro 10 - Representação de um vetor de padrões
Cada elemento representa o i-ésimo descritor e n é o número de tais descritores. Os vetores
de padrões são representados por colunas, em uma matriz n x 1. Um vetor de padrões também
pode ser representado por uma forma equivalente para x = ( 1, 2, … , )T, onde T indica a
matriz transposta.
A natureza dos componentes de um vetor de padrões x depende da técnica de medida
usada na descrição do próprio padrão físico. Como exemplo, podem-se descrever três faces de
pessoas (João, Maria e Juninho) medindo a largura e comprimento de suas faces. Pode-se
representá-los com vetores bidimensionais da forma x = ( 1, 2). Em que 1 e 2 representam
a largura e o comprimento das faces respectivamente. As três classes de padrões são
representadas por 1, 2 3 respectivamente, correspondendo às faces de João, Maria e
Juninho, respectivamente.
Como o comprimento e a largura das faces variam de pessoa para pessoa, do mesmo
modo os vetores de padrões que representarão estas faces também variarão, não apenas entre
as diferentes classes, mas também dentro de cada classe. Neste caso foi selecionado um
conjunto com duas medidas. Um vetor de padrões representa fisicamente cada uma das
amostras físicas. Cada face, neste caso, torna-se um ponto no espaço euclidiano
bidimensional. Pode-se notar que o comprimento e a largura de uma das faces a separou
adequadamente (Juninho) das outras duas faces. E não separou adequadamente as classes de
João e Maria, isto ilustra o problema clássico de seleção de características. Através da Figura
14 pode-se observar o exemplo mencionando anteriormente, apresentando diversas amostras
da face de cada indivíduo.
x =
𝑥1𝑥2
⋮𝑥𝑛

36
Fonte: adaptado de Gonzales e Woods (2000, p. 410).
Figura 14 – Exemplo de separação de padrões com duas medidas realizadas em três faces
Pode-se complementar com a explicação de Campos (2001, p. 11), onde explica que
dado um conjunto de c classes, ω1, ω2, ..., ωc e um padrão desconhecido x, um reconhecedor
de padrões auxilia através do pré-processamento, extração e seleção de características,
associando x ao rótulo i de uma classe ωi. Para classificação de faces, uma imagem de face é o
objeto (ou padrão x) e as classes são suas identificações (ωi).
É possível obter uma representação compacta dos padrões e uma estratégia de
decisão simples, com um problema de reconhecimento de padrões bem definido e restrito. Isto
é obtido quando o espaço entre as características de uma classe é pequeno e o espaço entre as
classes é grande.
2.5 MÉTODO DOS K-VIZINHOS MAIS PRÓXIMOS
A classificação de um padrão x consiste em calcular os k padrões de treino
mais próximos e determinar qual a classe mais votada. A classificação de x é determinada
pela classe mais votada. Este método de decisão é chamado de método dos k-vizinhos mais

37
próximos devido a basear-se nos k padrões de treino mais próximos de x (MARQUES, 2005,
p. 101).
Campos (2001, p. 19) explica como é realizada a classificação de um padrão de teste
desconhecido x através do método dos k-vizinhos mais próximos:
a) calcula-se a distância entre x e todos os seus padrões de treinamento;
b) obtém-se as classes cujos k padrões estão mais próximas de x;
c) o padrão de teste é classificado para a classe com maior frequência entre os k
padrões mais próximos de x.
Para implementar esse classificador as duas distâncias mais frequentemente
utilizadas são a euclidiana e a de mahalanobis. A distância euclidiana entre dois vetores é
definida no Quadro 11.
Fonte: Campos (2001, p. 20).
Quadro 11 - Equação da distância euclidiana entre dois vetores
A distância de mahalanobis entre um padrão x e o protótipo 𝜎 de uma classe é
apresentada no Quadro 12, em que é a matriz de covariância dos padrões da classe de 𝜎.
Fonte: Campos (2001, p. 20).
Quadro 12 - Equação da distância de mahalanobis
Um classificador muito comum é adotar k = 1 no classificador dos k vizinhos mais
próximos, obtendo o vizinho mais próximo. Este classificador geralmente possui uma taxa de
erro maior que k > 1. A principal vantagem deste método é a superfície de decisão que ele cria
adaptando-se à forma em que os dados são distribuídos. Isto possibilita boas taxas de acerto
para conjuntos de treinamento grandes ou representativos.
Utilizar k > 1 reduz a taxa de erros provocada por ruídos nos padrões de treinamento.
Por exemplo, para um padrão de treinamento da classe , que se encontra em uma região
do espaço de características da classe devido à ação de ruídos, não prejudicará o
desempenho do classificador devido à verificação dos seus vizinhos, fazendo com que um
padrão de teste que está localizado próximo de seja classificado como um padrão de .
A principal desvantagem do classificador dos k vizinhos mais próximos é a
complexidade na fase de testes, onde ao efetuar-se uma busca sem ordenação pelos vizinhos
mais próximos o desempenho pode não ser eficiente devido à quantidade de operações serem
na ordem O(n).
𝑑𝐸 𝑥𝑖, 𝑥𝑗 𝑥𝑖 − 𝑥𝑗 𝑥𝑖 − 𝑥𝑗 𝑡. 𝑥𝑖 − 𝑥𝑗
𝑑𝑀 𝑥,𝜎 𝑥𝑖 − 𝜎 𝑡. Σ−1 𝑥𝑖 − 𝜎

38
2.6 GENERALIZAÇÃO
Campos (2001, p. 23) explica que um classificador deve ser treinado usando
exemplos de treinamento para estimar a distribuição das classes. Os resultados dependem
diretamente da quantidade de exemplos de treinamento e da qualidade destes exemplos. O
objetivo de um sistema de reconhecimento é conseguir reconhecer futuros exemplos de testes
mesmo que eles não sejam os mesmos utilizados durante o treinamento.
Ocorrem problemas de generalização quando um classificador se especializa demais
em seus padrões de treinamento, ou quando utiliza mais informações (características) do que
o necessário.
2.7 PROBLEMA DA DIMENSIONALIDADE
Conforme Campos (2001, pag. 23), o problema da dimensionalidade refere-se às
dimensões adotadas para o espaço das características para o reconhecimento de padrões. O
número de elementos de treinamento requeridos para que um classificador tenha um bom
desempenho é uma função monotonicamente crescente da dimensão do espaço de
características. Em problemas práticos a adição de características pode prejudicar a
classificação sem a adição de exemplos de treinamento suficientes. Isto é conhecido como o
problema da dimensionalidade e pode ocorrer com qualquer classificador.
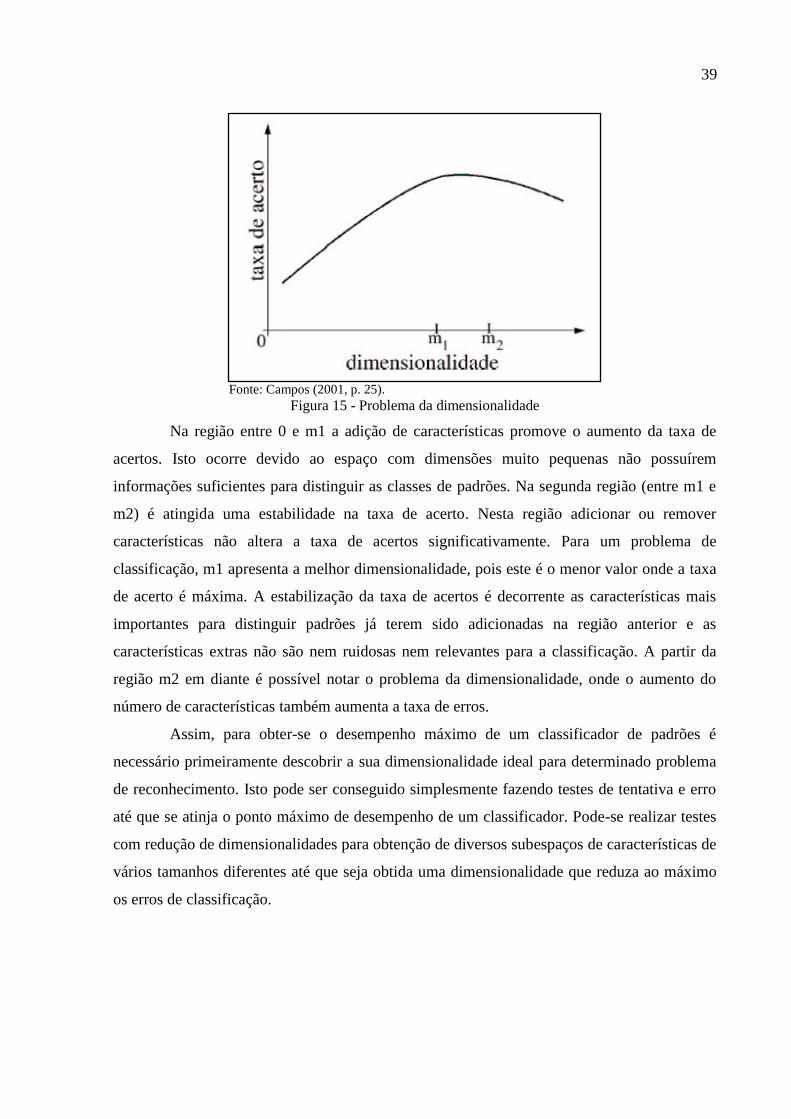
A curva apresentada na Figura 15 ilustra o problema da dimensionalidade, a qual
apresenta três regiões no eixo da dimensionalidade com significados diferentes.
39
Fonte: Campos (2001, p. 25).
Figura 15 - Problema da dimensionalidade
Na região entre 0 e m1 a adição de características promove o aumento da taxa de
acertos. Isto ocorre devido ao espaço com dimensões muito pequenas não possuírem
informações suficientes para distinguir as classes de padrões. Na segunda região (entre m1 e
m2) é atingida uma estabilidade na taxa de acerto. Nesta região adicionar ou remover
características não altera a taxa de acertos significativamente. Para um problema de
classificação, m1 apresenta a melhor dimensionalidade, pois este é o menor valor onde a taxa
de acerto é máxima. A estabilização da taxa de acertos é decorrente as características mais
importantes para distinguir padrões já terem sido adicionadas na região anterior e as
características extras não são nem ruidosas nem relevantes para a classificação. A partir da
região m2 em diante é possível notar o problema da dimensionalidade, onde o aumento do
número de características também aumenta a taxa de erros.
Assim, para obter-se o desempenho máximo de um classificador de padrões é
necessário primeiramente descobrir a sua dimensionalidade ideal para determinado problema
de reconhecimento. Isto pode ser conseguido simplesmente fazendo testes de tentativa e erro
até que se atinja o ponto máximo de desempenho de um classificador. Pode-se realizar testes
com redução de dimensionalidades para obtenção de diversos subespaços de características de
vários tamanhos diferentes até que seja obtida uma dimensionalidade que reduza ao máximo
os erros de classificação.

40
2.8 REDUÇÃO DA DIMENSIONALIDADE
O termo dimensionalidade é o número de características de uma representação de
padrões, ou seja, é a dimensão do espaço de características N. A dimensionalidade deve ser a
menor possível devido ao custo de medição e precisão do classificador. Quando o espaço de
características possuir apenas as características principais, o classificador será mais rápido e
ocupará menos memória.
Devido à dimensionalidade das imagens digitais ser muito elevada, é fundamental a
sua redução na visão computacional. O espaço de imagens possui características que podem
ser eliminadas sem impedir que objetos sejam reconhecidos. Uma imagem de largura w e
altura h (em pixels) é um padrão no espaço de imagens possuindo uma dimensionalidade N =
h x w. Este valor pode ser muito elevado quando as imagens são obtidas através de scanners
ou de câmeras. Alterações na rotação, translação e escala dos objetos contidos nessas imagens
fará com que ocorram grandes erros de classificação. Devido a isso é necessário o emprego de
algoritmos de redução de dimensionalidade que propiciem a obtenção de representações dos
padrões obtidos das imagens de forma robusta a essas alterações.
Campos (2001, p. 28), explica ser possível através do teorema do “patinho feio”,
fazer dois padrões arbitrários ficarem similares se eles forem codificados com um número
suficientemente grande de características similares.
A redução da dimensionalidade pode ser efetuada através de duas abordagens
principais: a extração de características e a seleção de características. A extração de
características cria novas características através de transformações ou combinações sobre as
características originais. Os algoritmos de seleção selecionam através de um critério definido,
o melhor subconjunto de características do conjunto de características original. Normalmente
primeiro aplica-se o algoritmo de extração de características sobre os dados de entrada e
depois aplica-se o algoritmo de seleção para eliminar os atributos irrelevantes efetuando a
redução da dimensionalidade.
A seleção de características normalmente reduz o custo para a medição dos dados e
mantém sua interpretação física original. Porém as características extraídas através dos
algoritmos de extração de características, devido a serem transformadas ou combinadas e
proverem uma habilidade de discriminação melhor do que o subconjunto das características
originais, podem perder seu significado físico. A Figura 16 apresenta uma imagem original (a)

41
e uma nova imagem gerada (b) através de transformações das características originais, porém
sua interpretação original foi alterada devido às transformações realizadas.
Figura 16 – (a) Imagem original e (b) imagem com a interpretação física original alterada
2.9 ANÁLISE DE COMPONENTES PRINCIPAIS
Segundo Lopes (2001, p. 28), para um conjunto de técnicas para análise de dados,
onde parâmetros são estimados de uma mesma unidade experimental, é denominada análise
multivariada. A análise de componentes principais (Principal Component Analisys - PCA) é
um método estatístico multivariado usado para modelar a dependência entre variáveis.
A PCA foi desenvolvida por Pearson em 1901. Ele descreveu que o grupo de
componentes ou combinações lineares era gerado de um conjunto de variáveis originais, com
variâncias mínimas não explicadas. As combinações lineares geram um plano onde o ajuste
da nuvem de pontos será o melhor devido a ser mínima a soma das distâncias de cada ponto
no plano. Hotteling em 1933, reformulou esta teoria extraindo variáveis do desempenho de
estudantes em testes que resolviam problemas aritméticos e a velocidade em que liam textos.
O objetivo de Hotteling era identificar as variáveis que mais influenciavam no desempenho
das notas obtidas pelos alunos. Na época, verificou-se que alguns alunos apresentavam
melhores notas do que outros e que consequentemente deveriam ter algum componente
psicológico mais desenvolvido do que outros estudantes. A análise de componentes
principais, denominada por Hotelling, é a teoria que encontra estes componentes e que
maximiza a variância dos dados originais.
Campos (2001, p. 34) explica que PCA, também conhecida como transformada de
Hotelling, é considerado o melhor extrator de características linear conhecido e é amplamente
utilizada em reconhecimento de padrões e reconhecimento de faces. A PCA trata imagens

42
como padrões em um espaço linear com o objetivo de efetuar reconhecimento estatístico.
Uma imagem pode ser representada por uma matriz de h linhas por w colunas
formando um padrão de h x w características ou um vetor no espaço (h x w)-dimensional,
denominado de espaço de imagens. É possível construir a representação de uma imagem em
um vetor, através da leitura coluna a coluna da imagem, colocando cada valor de pixel da
imagem em um vetor coluna x. Desta forma a dimensionalidade de espaço de imagens N é
dada por N = h x w. Uma imagem representada por uma matriz A de m linhas por n colunas
pode ser construída conforme o Quadro 13.
Fonte: Campos (2001, p. 34).
Quadro 13 - Equação para criar um vetor coluna a partir de uma matriz A
Didaticamente pode-se ilustrar o processo de criação de um padrão X a partir de uma
imagem de face, como é apresentado na Figura 17. Este padrão X é um vetor coluna
transposto (matriz com apenas uma linha e várias colunas, ou seja, um vetor linha).
Fonte: Campos (2001, p. 34).
Figura 17 - Padrão criado a partir de uma imagem
No reconhecimento de padrões é desejável que a representação das classes e seus
respectivos padrões sejam diferentes entre si e compactos. Isto implica em não existir
redundância entre as diferentes características (também chamados de descritores, vide seção
2.4) dos padrões analisados, ou seja, não deve haver covariância entre os vetores da base de
espaço de características. No reconhecimento de faces existe muita redundância das
características devido ao correlacionamento entre os pixels da imagem, pois todas as faces
possuem, testa, olhos, bochecha, nariz, boca, queixo, etc., tornando os vetores que
representam as características das faces altamente correlacionados.
É possível verificar a existência de covariância entre as características através de
uma matriz de covariância obtida a partir de uma matriz de padrões X. A matriz de padrões
possui um padrão de treinamento em cada coluna. Para |T| padrões de treinamento tem-se X1,
X2, ..., X|T|. O Quadro 14 apresenta uma matriz de padrões X.
𝑥𝑙 𝐴𝑗,𝑘
Para 𝑗 1, 2, 3, … , ℎ, 𝑘 1, 2, 3, … ,𝑤 𝑒 𝑙 𝑗 + 𝑘 − 1 . ℎ

43
Fonte: Campos (2001, p. 35).
Quadro 14 - Matriz X de padrões de treinamento
A matriz de covariância de X pode ser obtida a partir da matriz de padrões X
como apresentado no Quadro 15.
Fonte: Campos (2001, p. 35).
Quadro 15 – Criação da matriz de covariância a partir da matriz de padrões de treinamento X
Onde é a matriz N x |T| com a mesma dimensão de X e o valor de suas colunas é
calculado a partir da matriz de padrões X conforme apresentado no Quadro 16.
Fonte: adaptado de Campos (2001, p. 35).
Quadro 16 – Equação para calcular os valores da matriz de covariância
Sendo ∑ , a variância da característica , os elementos na diagonal da matriz de
covariância representam a variância das características e os elementos fora da diagonal
representam as covariâncias, isto é, ∑ , para ≠ 0, representa a covariância entre a
característica e . Caso estas duas características sejam estatisticamente independentes, a
covariância é nula, ou seja, ∑ , = 0.
Para representar os padrões em um espaço onde não exista covariância entre as
características diferentes é preciso que o espaço vetorial possua uma matriz de covariância
com base diagonal. Para isto utiliza-se uma transformada que diagonalize a matriz de
covariância da base atual do espaço de imagens. Com a diagonalização da matriz de
covariância é maximizada a variância das variáveis (características) e a variância entre uma
variável e outra será nula.
De acordo com Campos (2001, p.36), devido ao processo de criação da matriz de
covariância é possível torná-la diagonalizável. A matriz de covariância dos padrões de
treinamento pode ser diagonalizada através de uma mudança de base do espaço de
características como apresentado no Quadro 17. Obtém-se ei da decomposição apresentada no
Quadro 18.
𝑋 [𝑥1, 𝑥2, … , 𝑥|𝑇|]
Σ𝑋 𝑋 − 𝜇 . 𝑋 − 𝜇 𝑡
𝜇𝑙,𝑖 1
|𝑇|. 𝑋𝑙,𝑗
|𝑇|
𝑗=1
onde 𝑙 1, 2, 3, … ,𝑁 𝑒 𝑖 1, 2, 3, … , |𝑇|.

44
Fonte: Campos (2001, p. 36).
Quadro 17 – Matriz H para mudança de base da matriz de covariância
Fonte: Campos (2001, p. 36).
Quadro 18 – Obtenção do auto-vetor e auto-valor a partir da matriz de covariância
Sendo ei o i-ésimo auto-vetor de , m o número total de auto-vetores e o i-ésimo
auto-valor de . Em trabalhos em que a PCA é empregada para o reconhecimento de faces,
ou seja, quando os padrões de treinamento são imagens de faces, os auto-vetores são
denominados eigenfaces. Isto porque quando estes auto-vetores são visualizados como
imagens, possuem a aparência de faces.
As variáveis dos padrões apresentados a partir desta nova base do espaço de
características não são correlacionadas entre si. A mudança de base para este comportamento
pode ser visualizada través do Quadro 19.
Fonte: Campos (2001, p. 36).
Quadro 19 – Operação para a mudança de base da matriz de covariância
Sendo i = 1, 2, 3, .... |T|, e a representação do padrão no novo espaço de
características. O efeito desta mudança de base pode ser ilustrado, criando-se uma matriz Y
contendo os padrões (semelhante como é criada a matriz X no Quadro 14). Desta forma
pode-se verificar que a matriz de covariância de Y, , será diagonal.
Os auto-valores refletem diretamente a importância dos auto-vetores. Na PCA os
auto-valores da matriz de covariância são iguais à variância das características transformadas.
Isto significa que se um auto-vetor possui um auto-valor grande, ele fica em uma direção em
que existe uma grande variância dos padrões. De maneira geral, é mais fácil distinguir um
padrão que usa uma base em que seus vetores apontam para a direção com maior variância
dos dados e não correlacionam-se entre si.
A quantidade de auto-vetores obtidos é no máximo igual ao número de pixels da
imagem, ou seja, N. No entanto, tendo a matriz H sido construída somente com os auto-
vetores contendo os maiores auto-valores, a variância total dos padrões de entrada não sofre
grandes alterações. Portanto é possível obter redução de dimensionalidade usando apenas os
primeiros auto-vetores com os maiores auto-valores na construção da matriz H. Desta forma a
dimensionalidade dos vetores yi possuem m dimensões, reduzindo a dimensionalidade para N
– m dimensões.
𝐻 [𝑒1, 𝑒2, 𝑒3, … , 𝑒𝑚]
𝜆𝑖𝑒𝑖 Σ𝑋𝑒𝑖
𝑦𝑖 Η𝑡.𝑋𝑖

45
Loesch e Hoeltgebaum (2012, p. 68) explicam que a Análise das Componentes
Principais (ACP), envolve um procedimento matemático que transforma um conjunto de
variáveis possivelmente correlacionadas em um número menor de variáveis não
correlacionadas, denominadas de componentes principais. A primeira componente principal
possui a maior informação possível da variabilidade total dos dados e cada componente
principal sucessiva contém parte das informações (menor que a componente principal
anterior) restantes, tão grande quanto possível. Para efetuar este procedimento decompõe-se a
matriz de covariância dos dados, usualmente normalizados através de seus auto-vetores e
auto-valores correspondentes.
Visualizando-se um conjunto de dados multivariados em um espaço de dados de alta
dimensão (uma dimensão para cada variável, ou característica) como sendo um conjunto de
pontos, a ACP fornece ao usuário uma imagem de uma dimensão inferior, uma “sombra”
projetada dos objetos, visualizada a partir de um ponto de vista mais informativo. Como
exemplo, suponha que há uma imagem de um cavalo em um espaço tridimensional (dentro de
um cubo), e busca-se saber qual é o objeto neste espaço. Uma solução seria através da sua
sombra projetada. Se colocar uma luz sobre o alto do objeto, através da sombra projetada no
chão, não será possível determinar de qual objeto se trata. Caso a luz seja movida para traz do
objeto, a sombra projetada na frente dele, também não o demonstrará com clareza. Já
movendo a luz na lateral do objeto, a sombra projetada na outra lateral terá a forma do corpo
de um cavalo, o que permite identificá-lo. Neste exemplo simples, permitiu-se reconhecer um
objeto localizado em um espaço em três dimensões através do uso de apenas duas dimensões,
reduzindo a dimensionalidade.
2.10 OPENCV
Conforme Bradski e Kaehler (2008, p. 1), a Open source Computer Vision library
(OpenCV) é uma biblioteca de código fonte aberto desenhada para eficiência computacional e
com forte foco em aplicações de tempo real. A biblioteca foi escrita em C otimizado e com
utilização de múltiplos processadores.
É uma biblioteca multiplataforma de uso desenvolvida pela empresa Intel em 2000,
livre tanto no meio acadêmico como no comercial para o desenvolvimento de aplicativos na
área de visão computacional. A OpenCV possui módulos para processamento de imagens e

46
vídeo, estrutura de dados, álgebra linear e interface gráfica do usuário (Graphic User
Interface - GUI) básica com sistema de janelas independentes. Também possui controle de
mouse e teclado, além de mais de 350 algoritmos de visão computacional como filtros de
imagens, calibração de câmera, reconhecimento de objetos, análise estrutural entre outros
(OPENCV, 2011).
Esta biblioteca foi desenvolvida nas linguagens de programação C e C++, porém
também dá suporte para outras linguagens de programação como Java, Pyton e Visual Basic.
A versão 1.0 foi lançada no final de 2006, a versão 2.0 foi lançada em setembro de 2009 e
atualmente encontra-se na versão 2.4.2.
As plataformas compatíveis com a OpenCV são:
a) MS Windows (95/98/NT/2000/XP,7);
b) POSIX (Linux/BSD/UNIX-like OSes);
c) Linux;
d) OS X;
e) MAC OS Básico.
A biblioteca pode ser empregada nas seguintes áreas de aplicação:
a) Humano-Computador Interface (HCI);
b) identificação de objetos;
c) sistema de reconhecimento facial;
d) reconhecimento de movimentos;
e) gravação de vídeos;
f) robôs móveis;
g) reconstrução 3D;
h) realidade virtual;
i) realidade aumentada;
j) realidade misturada.
A biblioteca OpenCV é estrutura nos seguintes módulos:
a) cv: módulo das principais funcionalidades e algoritmos de visão computacional;
b) cvaux: módulo com algoritmos de visão, está em fase experimental;
c) cxcore: módulo de estrutura de dados e álgebra linear;
d) highgui: módulo de controle de interface e dispositivos de entrada;
e) ml: módulo de machine learning, é um tipo de máquina de aprendizagem;
f) ed: manual de estrutura de dados e operações.

47
2.10.1 JAVACV
O Java interface para openCV (JavaCV) é uma biblioteca wrapper6 Java para a
biblioteca OpenCV feita em C. Desenvolvida pela Google, ela segue a General Public
License (GPL) versão 2. O JavaCV suporta aceleração de hardware, exibição de imagem em
tela, executa código de forma paralela em processadores de múltiplos núcleos. Naturalmente
suporta as funcionalidades da biblioteca OpenCV. Os requisitos básicos para instalar e usar a
biblioteca JavaCV são possuir instalado a JDK, com versão superior ou igual a 6, e a
biblioteca OpenCV 2.4.0.
Os principais métodos e recursos da biblioteca OpenCV utilizados nesse trabalho são:
a) IplImage: estrutura que armazena uma imagem digital;
b) OpenCVFrameGrabber: classe que provê recursos para acesso a dispositivos, como
câmera de vídeo. O método grab(), por exemplo, retorna o frame corrente da
câmera representado em um objeto IplImage;
c) CvMat: classe que representa uma matriz de dados;
d) cvCreateMat: cria uma instância de uma matriz; recebe como parâmetros a
quantidade de linhas, colunas e o seu tipo;
e) cvEigenDecomposite: possui como principais parâmetros de entrada uma vetor
de IplImages com as imagens de entrada, no caso as faces para treinamento, a
quantidade de auto-vetores a serem criados, um objeto vetor do tipo IplImage para
receber os auto-vetores, um objeto IplImage para armazenar a imagem média
calculada e um vetor de pontos flutuantes para armazenar os coeficientes dos auto-
valores;
f) CvSize: classe que representa uma altura e uma largura;
g) CvTermCriteria: tipo para critérios de terminação usado em algoritmos
iterativos; passa-se como parâmetro o número máximo de iterações de uma
operação iterativa;
h) cvCreateImage: cria uma estrutura para armazenar os dados de uma imagem;
i) cvCalcEigenObjects: calcula os objetos auto-vetores, auto-valores e a imagem
média a partir das imagens de treino (entrada);
j) cvNormalize: normaliza os auto-valores;
6 Em programação, wrapper é uma classe empacotadora que dá acesso à outra classe, geralmente mais complexa
e de mais baixo nível.

48
k) cvSaveImage: salva uma imagem do tipo IplImage no disco;
l) CvRect: classe com estrutura de retângulo, x, y, width e height;
m) cvRect: cria uma instância de um objeto CvRect;
n) cvSetImageROI: marca em uma imagem a região de interesse;
o) cvCopy: copia os dados de uma imagem para outra;
p) cvResetImageROI: desmarca a região de interesse marcada pelo método
cvSetImageROI;
q) cvReleaseImage: libera a memória alocada para uma imagem do tipo IplImage;
r) CvSeq: classe com crescimento dinâmico que armazena uma sequência de
elementos. Exemplo, o retorno da função cvHaarDetectObjects ;
s) cvGetSeqElem: função que retorna um elemento de um objeto do tipo CvSeq
armazenado no índice também passado como parâmetro para a função;
t) CvHaarClassifierCascade: representa um classificador em cascata que utiliza a
transformada de Haar7; os coeficientes de treinamento são carregados a partir de
um arquivo XML;
u) CvMemStorage: é uma estrutura de armazenamento de memória de baixo nível
utilizada para armazenar dinamicamente estruturas de dados de crescimento, tais
como sequências, contornos, gráficos, etc.; é organizada como uma lista de blocos
de memória de tamanho igual;
v) cvCvtColor: converte a escala de cores de uma imagem, por exemplo, transformar
uma imagem colorida para níveis de cinza;
w) cvResize: redimensiona uma imagem resultando em outra imagem
redimensionada;
x) cvEqualizeHist: equaliza o histograma de uma imagem passada como
parâmetro, resultando em outra imagem com o histograma equalizado;
y) cvHaarDetectObjects: detecta objetos em uma imagem, conforme as
configurações passadas em um objeto classificador do tipo
CvHaarClassifierCascade;
z) cvGetQuadrangleSubPix: Extrai os pixels de uma imagem fonte para uma
imagem de destino, onde os valores de pixels de não inteiros são recuperados
usando interpolação bilinear; quando a função precisa de pixels fora da imagem,
7 A Transformada de Haar é um transformada matemática discreta usada no processamento e análise de sinais,
na compressão de dados e em outras aplicações de engenharia e ciência da computação. Ela foi proposta em
1909 pelo matemático húngaro Alfred Haar (TRANSFORMADA DE HAAR, 2012).

49
ele usa o modo de replicação fronteira para reconstruir os valores; função utilizada
para rotacionar uma imagem sem deixar áreas da imagem sem pixels nas laterais.
2.11 APPLET JAVA
Applet é um programa Java que pode ser embarcado em páginas HTML e rodar em
navegadores web que suportam Java, como Chrome, Internet Explorer e Mozilla FireFox. É
utilizado para tornar as páginas web mais dinâmicas e divertidas (ROSE INDIA
TECHNOLOGIES PVT. LTD, 2007). Ainda segundo esta definição, devido aos applets
serem projetados para executar remotamente em um navegador, eles têm restrições, como não
poder acessar recursos do sistema do computador local.
As vantagens dos applets são (ROSE INDIA TECHNOLOGIES PVT. LTD, 2007):
a) são multi-plataforma, podendo ser executados em Windows, Linux e Mac OS,
entre outros;
b) funcionam em qualquer versão da extensão Java;
c) são executados em um contexto isolado, então o usuário final não precisa confiar
no seu código, fazendo com que ele funcione sem confirmação de segurança;
d) são suportados pela maioria dos navegadores web;
e) são mantidos em cache pela maioria dos navegadores web;
f) poder ter acesso completo à máquina se o usuário permitir.
As desvantagens dos applets são (ROSE INDIA TECHNOLOGIES PVT. LTD,
2007):
a) é necessário uma extensão do Java para executá-los;
b) necessita da Java Virtual Machine (JVM), então toma um tempo significativo na
primeira utilização;
c) é difícil construir boas telas em applet, se comparadas à tecnologia HTML.
2.11.1 Assinatura de applet Java
Em Jaco Web Security (2010, p. 1) é explicado que o modelo de segurança
implementado pela plataforma Java é centrada sobre o conceito de sandbox (caixa de areia).

50
De acordo com este conceito, um código remoto (applet) não é confiável e o seu acesso a
recursos é limitado apenas à área do sandbox, uma área do servidor web dedicada àquele
applet. A ideia de sandbox foi desenvolvida para garantir que mesmo que um applet com
código malicioso seja baixado para a máquina do usuário, ele não consiga danificar a máquina
local (apagar um arquivo por exemplo) devido a estar limitado a uma área de acesso.
Entretanto, existem applets confiáveis que precisam sair do sandbox para fornecer
determinado serviço, como por exemplo, acessar a webcam do usuário. Uma das maneiras de
resolver isto é assinando o applet que disponibiliza este serviço.
Uma assinatura digital é utilizada quando se necessita da certeza da origem de uma
mensagem como se fosse uma assinatura escrita no papel. Para assinar um applet, o
desenvolvedor empacota todo o código Java e arquivos relacionados dentro de um arquivo
JAR, que é um formato de arquivo de compactação de propósito geral, usado para compactar
os componentes de uma aplicação Java. A plataforma Java assina e verifica arquivos JAR
usando um par de chaves (chave pública e privada). A chave privada funciona como uma
“caneta” eletrônica que assina o arquivo. Como o próprio nome sugere esta chave só é
conhecida pelo assinante do applet. O processo de verificação da assinatura pode ser feito por
qualquer pessoa que possua a chave pública correspondente à chave que assinou o arquivo.
Na Figura 18 é possível verificar o processo para a assinatura de um arquivo JAR.
Fonte: Jaco Web Security (2010, p. 1).
Figura 18 - Processo para assinatura de um arquivo JAR
A chave pública é distribuída dentro de um certificado que é uma declaração
assinada por uma entidade idônea, chamada autoridade de certificação (Certification
Authority - CA), que confirma que a chave pública que está no mesmo é confiável. Existem
várias autoridades de certificação, por exemplo, a VeriSign, Thawte, Entrust e Certisign
(empresa brasileira). Toda CA requer um emissor para validar a sua identidade, até mesmo a
de mais alto nível. Para estes casos, existem os certificados auto-assinados (self-signed), onde
o emissor do certificado é o próprio sujeito.
Algumas ferramentas são necessárias para efetuar a assinatura de um applet seguindo

51
o padrão Java. Estas ferramentas já vêm com a instalação da JDK e são:
a) Jar: ferramenta para criação de arquivos JAR;
b) Keytool: ferramenta para gerenciamento de chaves e certificados digitais;
c) Jarsigner: ferramenta para assinatura e verificação de arquivos;
d) Policytool: ferramenta para criação e gerenciamento do arquivo .policy.
Na Figura 19 são apresentados os passos de um processo completo para efetuar a
assinatura de um applet adicionado em um arquivo JAR.
Fonte: Jaco Web Security (2010, p. 1).
Figura 19 – Passos para a assinatura de um applet
Deve ser criado o arquivo JAR contendo o arquivo .class do applet e todas as
classes que proverão serviços fora da sandbox. No Quadro 20 pode-se verificar um exemplo
de criação de um arquivo JAR chamado MeuJar.jar a partir do arquivo de classe Java
MeuApplet.class utilizando a ferramenta8 jar disponível na SDK Java.
Fonte: Jaco Web Security (2010, p. 1).
Quadro 20 - Comando para criar um arquivo JAR
Para criar um par de chaves públicas pode-se utilizar a ferramenta keytool da JDK.
No Quadro 21 são apresentadas as opções do comando, onde:
a) alias: é o nome pelo qual as chaves serão reconhecidas e armazenadas em um
arquivo banco de chaves keystore (.keystore);
b) keyalg: algoritmo de criptografia utilizado para a criação das chaves. Este
argumento é opcional, se nada for especificado o algoritmo utilizado será o
Digital Signature Algorithm (DSA);
8 Executado via linha de comando em um console Disk Operating System (DOS) para Windows.
jar cvf MeuJar.jar MeuApplet.class

52
c) keysize: tamanho da chave que será gerada. O algoritmo DSA suporta
tamanhos de 512 a 1024 bits, sendo o tamanho necessariamente múltiplo de 64.
Para qualquer algoritmo o tamanho padrão é 1024;
d) sigalg: algoritmo de criptografia utilizado para assinar o JAR. Este argumento é
opcional, se nada for especificado o algoritmo utilizado será o DAS;
e) dname, nome da entidade que gerará o par de chaves. Exemplo, CN=TCC,
OU=BCC, O=FURB, L=Blumenau, S=Santa Catarina, C=BR. Onde, CN = nome
comum, OU = unidade organizacional (departamento, divisão), O = nome da
organização, L = nome da localidade (cidade), S = estado, C = código do país;
f) keypass: senha utilizada para a proteção da chave no keystore;
g) validity: número de dias que o certificado deve ser válido;
h) storetype: permite definir a forma de armazenamento e o formato dos dados do
keystore. Por padrão o formato é Java Key Store (JKS) que é um tipo proprietário
da implementação de keystore fornecido pela Oracle;
i) keystore: keystore onde as chaves serão armazenadas. Se nada for especificado
serão armazenadas no user.home\.keystore, em geral c:\windows\.keystore, se o
arquivo não existir ele será criado;
j) storepass: senha protetora do keystore;
k) v: mostra o certificado em forma legível.
Fonte: Jaco Web Security (2010, p. 1).
Quadro 21 - Opções do comando keytool
Quando as chaves são geradas, um certificado auto assinado é criado. Caso deseja-se
trocar este certificado por um reconhecido por uma CA, deve-se fazer um pedido de
certificado de assinatura (Certificate Signing Request - CSR). O resultado desta solicitação
deve ser importado para o keystore.
O arquivo JAR deve ser assinado com a chave privada, para isto pode ser utilizada a
ferramenta jarsigner disponível na JDK. O Quadro 22 exibe as opções do comando, onde:
a) keystore: URL do keystore onde a chave está armazenada. Se nada for
especificado serão armazenadas no user.home\.keystore, em geral
c:\windows\.keystore;
keytool -genkey {-alias alias} {-keyalg keyalg} {-keysize keysize} {-
sigalg sigalg} {-dname dname} {-keypass keypass} {-validity valDays} {-
storetype storetype} {-keystore keystore} {-storepass storepass} {-v}

53
b) storetype: especifica o tipo do keystore que será instanciado. O tipo padrão do
keystore é especificado pelo valor da propriedade de keystore.type, no arquivo de
propriedades de segurança;
c) storepass: senha protetora do keystore. Caso a senha não seja informada, o
programa perguntará antes de assinar;
d) keypass: senha protetora da chave privada. Se não for informada, o programa
perguntará antes de assinar;
e) sigfile: especifica o nome a ser usado nos arquivos .SF (arquivo de assinatura)
e .DSA (bloco de assinatura). Caso nada seja informado, o nome será composto
pelos 8 primeiros caracteres do alias especificado;
f) signedjar: especifica o nome e o local de armazenamento do arquivo JAR
assinado. Por padrão, o arquivo assinado irá sobrescrever o não assinado;
g) verbose: indica o modo verbose9, que faz aparecer mais informações na tela
durante o processo de assinatura.
Fonte: Jaco Web Security (2010, p. 1).
Quadro 22 – Opções do comando jarsigner
Para distribuir a chave pública é necessário um certificado autenticando a mesma.
Para isto é necessário exportar o certificado que está no keystore usando a ferramenta
keytool do JDK. O Quadro 23 exibe as opções do comando para exportar a chave pública em
um certificado, onde:
a) alias: nome com o qual a chave foi guardada no keystore;
b) file: local e nome com o qual o certificado será exportado;
c) storetype: especifica o tipo do keystore que será instanciado. O tipo padrão do
keystore é especificado pelo valor da propriedade de keystore.type, no arquivo de
propriedades de segurança;
d) keystore: local do keystore onde o certificado está armazenado. Se nada for
especificado serão exportadas do user.home\.keystore em geral
c:\windows\.keystore;
e) storepass: senha protetora do keystore. Se não for informada o programa
perguntará antes de exportar;
9 Exibe as informações em modo detalhado.
jarsigner {-keystore url} {-storetype storetype} {-storepass
storepass} {-keypass keypass} {-sigfile sigfile} {-signedjar
signedjar} {-verbose}

54
f) rfc: exporta o certificado na forma definida pelo padrão pRivacy enhancement
For eleCtronic mail (RFC) 1421. Quando exportado desta forma este começa
com “-------Begin” e termina por “------End”;
g) v: indica o modo verbose, que faz aparecer mais informações na tela enquanto
exporta o certificado.
Fonte: Jaco Web Security (2010, p. 1).
Quadro 23 – Opções do comando keytool para exportar o certificado com a chave pública
Após o certificado ser exportado, ele pode ser distribuído para os usuários do applet.
Estes deverão executar os procedimentos conforme exposto na Figura 20.
Fonte: Jaco Web Security (2010, p. 1).
Figura 20 - Passos que deverão ser efetuados pelo usuário do applet
Para adicionar um applet dentro de uma página HTML, deve ser adicionada uma tag
semelhante à exibida no Quadro 24.
Fonte: Jaco Web Security (2010, p. 1).
Quadro 24 – Tag para adicionar um applet em uma página HTML
O usuário deve importar o certificado contendo a chave pública do applet para um
keystore de seu disco local. Isto pode ser feito utilizando a ferramenta keytool já mencionada
acima. O Quadro 25 exibe as opções do comando para importar um certificado, onde:
a) alias: nome com o qual o certificado será importado;
b) file: local e nome do certificado.
Fonte: Jaco Web Security (2010, p. 1).
Quadro 25 – Opções do comando para importar um certificado
Deve-se efetuar também as configurações do arquivo de política .policy no disco
local do usuário do applet. Este arquivo informa quais permissões serão atribuídas para o
applet. O arquivo .policy é um arquivo texto normal, podendo ser gerado através da
ferramenta policytool fornecidas com a JDK Java, ou ainda pode ser fornecido pelo
keytool -export {-alias alias} {-file cert_file} {-storetype
storetype} {-keystore keystore} {-storepass storepass} {-rfc} {-v}
<applet code="Applet.class" ARCHIVE="arquivoAssinado.jar"
wdth=500 height=50>
</applet>
keytool -import {-alias alias} {-file file}

55
desenvolvedor do applet com as devidas permissões necessárias. Na Figura 21 é possível
visualizar um arquivo .policy e um arquivo .keystore no diretório home do usuário.
Figura 21 - Arquivos .policy e .keystore no diretório home do usuário
O Quadro 26 exibe os dados do arquivo .policy utilizado neste trabalho de
monografia como exemplo.
Quadro 26 - Exemplo dos dados contidos em um arquivo .policy
2.12 TRABALHOS CORRELATOS
Existem alguns trabalhos relacionados ao reconhecimento de faces, podendo-se citar
o “Reconhecimento facial 2D para sistemas de autenticação em dispositivos móveis” de
Pamplona Sobrinho (2010), feito para autorizar um usuário a acessar o celular iPhone pelo
reconhecimento da face. Outro que pode ser destacado é o de Reaes (2006), “Reconhecimento
/* AUTOMATICALLY GENERATED ON Sat Jan 14 09:40:01 BRST 2012*/
/* DO NOT EDIT */
keystore "file:/C:/Users/marcio.koch/.keystore", "jks";
grant signedBy "TCC", codeBase "http://notedellmk:8080/TCC/*" {
permission java.io.FilePermission "<<ALL FILES>>", "read,
write, execute, delete";
permission java.net.SocketPermission "*", "accept, connect,
listen, resolve";
permission java.util.PropertyPermission "*", "read, write";
permission java.lang.RuntimePermission "*";
permission java.awt.AWTPermission
"showWindowWithoutWarningBanner";
permission java.security.AllPermission;
};

56
de Faces em Imagens: Projeto Beholder”, no qual aborda técnicas de reconhecimento de faces
frontais em fotos 3x4. Já o “Técnicas de seleção de características com aplicação em
reconhecimento de faces” feito por Campos (2001), emprega o método de redução de
dimensionalidade com PCA, principalmente ao tratar-se da seleção de características.
2.12.1 Reconhecimento facial 2D para sistemas de autenticação em dispositivos móveis
Com o trabalho “Reconhecimento facial 2D para sistemas de autenticação em
dispositivos móveis”, Pamplona Sobrinho (2010) descreve o reconhecimento de faces e sua
aplicação para a identificação de usuários no dispositivo móvel iPhone, aplicando a técnica da
PCA que está entre as que possibilitam obter os melhores resultados para o reconhecimento
de faces frontais. O autor utiliza a API OpenCV que já provê métodos, como o
opencvFaceDetect, para detecção de faces. Destaca-se por efetuar todas as etapas do
reconhecimento facial utilizando apenas a capacidade de processamento do dispositivo, sem
qualquer auxílio externo. Segundo Pamplona Sobrinho (2010, p. 49), o sistema proposto é
capaz de reconhecer 100% das imagens do mesmo indivíduo utilizado no treino e também
capaz de identificar 100% dos casos de tentativas de fraude. A Figura 22 demonstra em: (a)
tela para cadastrar usuários, (b) tela para selecionar uma foto e (c) a foto selecionada.
Fonte: Pamplona Sobrinho (2010, p. 44).
Figura 22 - (a) Tela cadastrar usuário, (b) tela selecionar foto e (c) foto selecionada

57
2.12.2 Reconhecimento de Faces em Imagens: Projeto Beholder
Neste projeto Reaes (2006), visa implementar um sistema visual de cadastro e busca
de pessoas, onde no cadastro em que possuir uma foto da pessoa a ser cadastrada, alguns
campos como cor dos olhos, cor da pele, gênero, largura do queixo, distância entre os olhos
são preenchidos automaticamente.
A operação de busca pode ser feita pelo preenchimento de campos como
convencionalmente ou através de uma imagem de rosto como entrada. Este sistema pode ser
utilizado em delegacias, para cadastro e busca de criminosos. Atualmente o autor explica que
a busca é manual folheando álbum por álbum de fotografias de criminosos até encontrar o
suspeito ou não. Com este projeto basta a testemunha informar características da pessoa
procurada para obter a listagem de todas que sigam o padrão descrito.
As técnicas abordadas por Reaes (2006) foram reconhecimento de faces frontais em
fotos 3x4. Ele implementa três técnicas de segmentação de faces: baseada em bordas, outra
baseada na cor da pele e uma técnica híbrida combinando as duas técnicas. Relata também
que os resultados foram satisfatórios, conforme apresentado na Tabela 3.
Tabela 3 - Classes de resultados para as três abordagens empregadas
Baseado em bordas Baseado em cor de pele Segmentação híbrida
RUIM 16,6% 23,3% 6,9%
REGULAR 9,7% 13,2% 9,5%
BOM 73,7% 60,5% 83,6% Fonte: Reaes (2006, p. 19).
A Figura 23 e a Figura 24 mostram exemplos dessas classes respectivamente para os
algoritmos de segmentação baseado em bordas e baseado em cor de pele.
Fonte: Reaes (2006, p. 17).
Figura 23 - Resultados da segmentação baseada em bordas em três níveis: (a) ruim, (b) regular e (c)
bom

58
Fonte: Reaes (2006, p. 17).
Figura 24 - Resultados da segmentação em cor da pele em três níveis: (a) ruim, (b) regular e (c) bom
2.12.3 Técnicas de seleção de características com aplicação em reconhecimento de faces
Campos (2001) emprega os métodos de redução de dimensionalidade com PCA,
principalmente ao tratar-se da seleção de características. Também propôs um esquema de
reconhecimento de pessoas a partir de uma sequência de vídeos utilizando somente regiões
que caracterizam as faces (olhos, nariz e a boca). Elaborou também uma nova função critério
para seleção de características com um método eficiente de busca. Segundo Campos (2001, p.
98), a maioria das funções critério calculam apenas a distância entre dois conjuntos nebulosos.
A função critério desenvolvida em seu trabalho pode efetuar o cálculo da distância entre mais
de dois conjuntos nebulosos para realizar seleção de características. Os resultados obtidos
com os experimentos mostram um bom potencial, conforme Tabela 4 e Tabela 5.
Tabela 4 - Desempenho do classificador para reconhecimento de olhos e de faces quando treinado com
três imagens por pessoa
# Auto-vetores Olhos % Faces %
3 25,00 31,25
4 25,00 37,50
5 50,00 37,50
10 56,25 43,75
13 62,50 43,75
15 62,50 43,75
24 62,50 43,75
48 62,50 43,75 Fonte: Campos (2001, p. 93).
Tabela 5 - Desempenho do classificador para reconhecimento de olhos e de faces quando treinado com
cinco imagens por pessoa
# Auto-vetores Olhos % Faces %
3 40,00 46,67
15 73,33 66,67 Fonte: Campos (2001, p. 93).

59
3 DESENVOLVIMENTO DO PROTÓTIPO
Neste capítulo são detalhadas as etapas do desenvolvimento da ferramenta. São
apresentados os principais requisitos, a especificação, a implementação e por fim são listados
resultados e discussão.
3.1 REQUISITOS PRINCIPAIS DO PROBLEMA A SER TRABALHADO
O protótipo de aplicativo para reconhecimento de faces aplicado na identificação e
autenticação de usuários na web foi desenvolvido atendendo aos seguintes requisitos:
a) permitir o cadastro de usuários (Requisito Funcional - RF);
b) permitir o cadastro das imagens das faces dos usuários (RF);
c) permitir que usuários efetuem autenticação através do reconhecimento facial (RF);
d) permitir que usuários efetuem autenticação através de um usuário e uma senha
(RF);
e) converter as imagens para níveis de cinza (RF);
f) normalizar a iluminação das imagens (RF);
g) localizar face em uma imagem (RF);
h) normalizar a pose da face (RF);
i) normalizar a dimensão da face (RF);
j) reduzir o ruído das imagens (RF);
k) efetuar a segmentação para as imagens das faces (RF);
l) extrair características da face (RF);
m) efetuar o reconhecimento da face (RF);
n) suportar banco de dados Oracle (Requisito Não-Funcional - RNF);
o) permitir a aquisição das imagens via web através de webcam (RNF);
p) suportar servidor Java EE GlassFish (RNF);
q) suportar Java Server Pages (JSP10
) (RNF);
r) permitir acesso web nos navegadores Internet Explorer e Chrome (RNF).
10
JSP é uma tecnologia utilizada no desenvolvimento de aplicações para web baseada na linguagem de
programação Java.

60
3.2 ESPECIFICAÇÃO
A especificação foi feita através da modelagem de diagramas de casos de uso, de
atividades, de sequência e de classes. Os diagramas de casos de uso, atividades, sequência e
classes foram criados com base nas definições da UML a partir da IDE do Eclipse com a
extensão de modelagem desenvolvida pela Senior Sistemas S/A.
3.2.1 Processo geral do funcionamento da ferramenta
Esta seção visa dar uma visão geral de forma ilustrativa dos dois processos principais
realizados pela ferramenta desenvolvida, sendo eles:
a) autenticar um usuário através da face;
b) cadastrar novos usuários efetuando a aquisição de imagens das faces.
A Figura 25 apresenta uma descrição do processo distribuído pelo ambiente de
reconhecimento efetuado pela ferramenta.
Figura 25 – Processo distribuído pelo ambiente para autenticação através de reconhecimento facial
Através da Figura 25 é possível verificar que o processo de reconhecimento e
cadastro do usuário é divido em duas partes (rede local e servidor remoto) e em duas
operações (autenticação e novo cadastro). Uma que acontece na máquina do usuário (rede
local) que estiver utilizando o sistema e outra no servidor (servidor remoto). Na máquina do
usuário, através de seu navegador de internet, após acessar o sistema, um applet é carregado e
acessa o dispositivo de vídeo (webcam) do usuário. O usuário pode optar por cadastrar-se ou
autenticar-se. Dependendo da operação desejada, autenticação ou novo cadastro, o usuário
deve capturar uma ou mais fotos e as submeter para o servidor, respectivamente. As imagens

61
antes de serem submetidas para o servidor passam por um processamento de redução de
resolução e ajuste da pose. Após, os dados do usuário e as imagens são submetidas via socket
para o servidor.
No servidor os dados são recebidos e processados de acordo com a operação. Para
uma operação de autenticação, a face recebida é processada utilizando a transformada PCA e
é submetida ao algoritmo de reconhecimento confrontando-a com as imagens dos demais
usuários existentes no banco de dados. O retorno desta operação são os dados do usuário,
quando este for reconhecido, e uma mensagem de erro, caso contrário. Quando a operação for
um novo cadastro, aplica-se a transformada PCA para cada face do usuário e efetua-se o
treinamento com as demais faces de todos os usuários já existentes na base de dados. Por
último os dados gerados através do treinamento juntamente com as amostras das faces e dados
do novo usuário são armazenados na base de dados. O retorno desta operação é uma
mensagem de sucesso quando for bem sucedida, ou uma mensagem de erro, caso contrário.
3.2.2 Diagrama de casos de uso
Esta seção contém o diagrama de casos de uso da ferramenta bem como seu ator.
Cada caso de uso é detalhado no Apêndice A, juntamente com a descrição do ator Usuário. A
Figura 26 exibe o diagrama com os casos de uso. O ator Usuário é o ator principal, ou ator
primário, é ele quem inicia os casos de uso da ferramenta. O ator primário é o beneficiário dos
resultados do caso de uso (BEZERRA, 2007, p. 81). Isto deve-se ao fato já exposto na seção
3.2.1 sobre o processo de reconhecimento e cadastro do usuário ser divido em duas partes. O
caso de uso UC02 – Autenticar através da face é sem dúvida o caso de uso principal e
possui um caso de uso que o estende, o UC03 – Reconhecer usuário automaticamente
que permite testar o reconhecimento do usuário em frente à câmera automaticamente, antes de
efetuar a autenticação propriamente dita.

62
Figura 26 – Diagrama de casos de uso da ferramenta
3.2.3 Diagramas de atividades
Nesta seção são apresentados os diagramas de atividades desde o acesso a página de
login, como o cadastro e a autenticação do usuário. A Figura 27 exibe o diagrama de
atividades do acesso á página de login. O diagrama está dividido em três raias para facilitar o
entendimento da atividade de cada elemento do fluxo de atividades. O usuário inicia a
atividade acessando o site, seguindo pela resposta do servidor web. A página de login
contendo o applet é retorna para o navegador de internet do usuário. O applet é carregado e
requisita os arquivos necessários para poder acessar o dispositivo de vídeo (webcam) do
usuário e iniciar o processo de captura de imagens e detecção da maior face na imagem. É
possível perceber pelas duas barras paralelas na horizontal, que o applet processa duas
operações simultâneas: permitir a interação com o usuário e acessar o dispositivo de vídeo
(webcam) do usuário detectando a maior face.

63
Figura 27 - Diagrama de atividades do acesso à tela de login

64
Na Figura 28 é apresentado o diagrama de atividades para cadastrar um novo usuário
no sistema. Apenas usuários cadastrados poderão ser reconhecidos pelo sistema e
consequentemente utilizá-lo.
Figura 28 - Diagrama de atividades para cadastrar usuário

65
Na Figura 29 é apresentado o diagrama de atividades para autenticar um usuário
através da face. Como a segunda e a terceira atividades da raia do usuário já são as opções
padrão da tela, o usuário apenas precisa acessar a tela de login e clicar no botão “Autenticar”.
Figura 29 - Diagrama de atividades para autenticação através da face
3.2.4 Diagramas de sequência
A Figura 30 demonstra a sequência de interações entre as classes participantes da
autenticação de usuário através da face.

66
Figura 30 - Diagrama de sequência do reconhecimento de usuário através da face
3.2.5 Diagramas de classes
Os diagramas apresentados nessa seção (Figura 31 à Figura 36) apresentam as
principais classes da ferramenta. Na Figura 31 estão as principais classes relacionadas ao
applet. A classe WebcamApplet especializa a classe JApplet e implementa algumas interfaces

67
para interagir com a webcam e com o aplicativo servidor que processa as requisições do
usuário. A classe OpenCVWebCam é a classe que acessa a webcam.
Na Figura 32 é apresentada a continuação das classes relacionadas ao applet. Estas
classes são as responsáveis por manter um painel com duas abas (classe PageControlFace),
sendo a aba da tela de login (classe PanelLogin) e a aba com a tela de cadastro de usuário
(classe PanelNewUser). As três classes mencionadas especializam a classe abstrata
CustomPanel, que possui uma área para exibir as imagens capturadas da webcam pela classe
OpenCVWebCam (Figura 31).
A Figura 33 apresenta mais algumas classes relacionadas ao applet, porém não
diretamente. A classe FaceProcessor é o core (núcleo de processamento) para o pré-
processamento das imagens e normalização da face. A classe OpenCVWebCam está associada a
esta classe. Ela fornece uma imagem capturada a partir da webcam e tem como retorno a
maior face detectada na imagem, pré-processada e com a pose normalizada.
As classes relacionadas ao usuário, seus dados e suas faces capturadas, são
apresentadas na Figura 34. A classe base User armazena as informações básicas do usuário. A
classe UserFaceList especializa a classe User, suportando armazenar uma lista de imagens
da face (objetos IplImage da API OpenCV) através da associação por composição com a
classe FaceList, sendo esta o container das imagens das faces. Este conjunto de classes do
usuário é utilizado tanto pelo applet como pelas classes do aplicativo servidor para o
processamento dos cadastros e requisições de autenticação.
Na Figura 35 são apresentadas as classes para processamento no aplicativo servidor.
A classe PCAProcessor é o core de processamento para treinamento e reconhecimento de um
usuário através da face. Ela especializa a classe abstrata PCABase que por sua vez realiza a
interface PCAInterface.
A Figura 36 mostra as classes de comunicação entre o aplicativo servidor e o applet.
A classe ServerSystemManager inicializa o servidor de socket (classe FaceServerSocket)
que fica escutando as requisições dos usuários da ferramenta. A classe
FaceServerClientSocket é responsável por atender as requisições de um usuário em
particular.
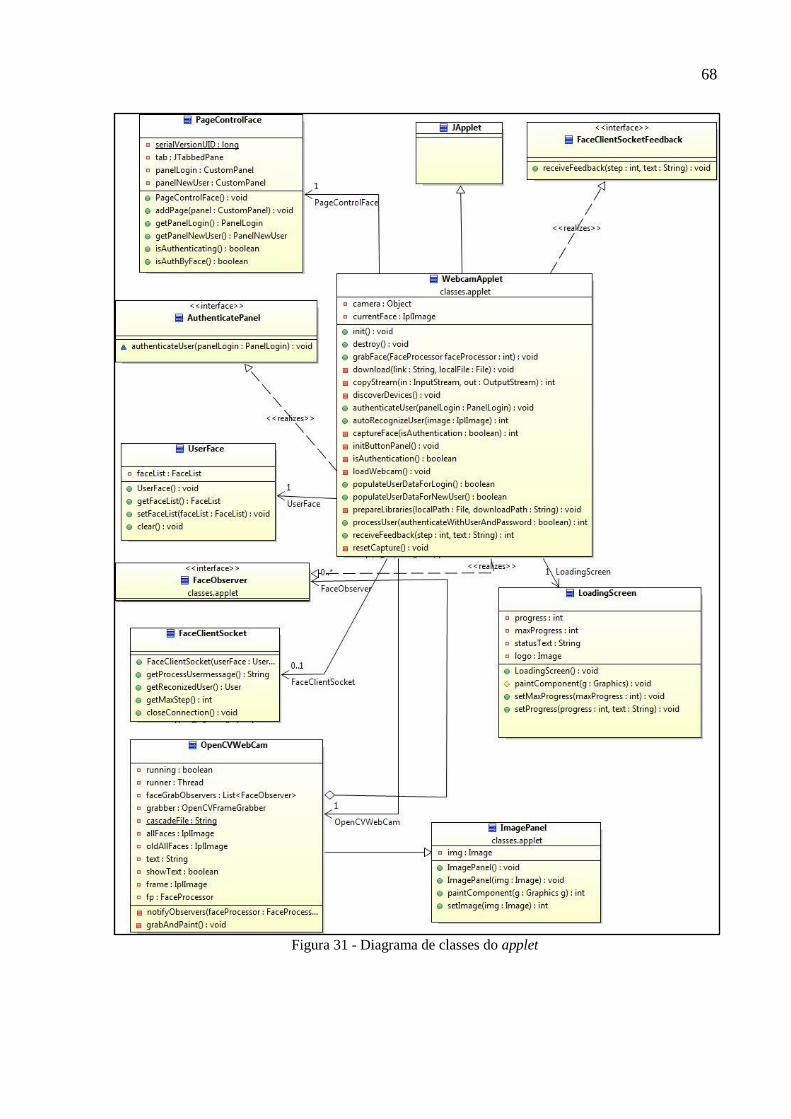
68
Figura 31 - Diagrama de classes do applet

69
Figura 32 - Diagrama de classes dos componentes das abas novo usuário e login do applet

70
Figura 33 - Diagrama de classes da classe FaceProcessor - principal classe de processamento de
imagem

71
Figura 34 - Diagrama da classe de usuário e seus relacionamentos

72
Figura 35 - Diagrama das classes para processamento PCA

73
Figura 36 - Diagrama das classes de socket no aplicativo servidor
3.3 IMPLEMENTAÇÃO
A seguir são mostradas as técnicas e ferramentas utilizadas e a operacionalidade da
implementação.

74
3.3.1 Técnicas e ferramentas utilizadas
A implementação da ferramenta foi realizada em linguagem Java sobre sistema
operacional Windows 7. Foram utilizadas as seguintes ferramentas:
a) Eclipse Java EE IDE for Web Developers, versão Indigo Release, como ambiente
de desenvolvimento integrado;
b) API JavaCV versão 20111001 como biblioteca auxiliar para visão computacional e
manipulação de imagens;
c) OpenCV versão 2.3.1 como biblioteca base para a biblioteca JavaCV;
d) GlassFish, versão 3.1, como servidor Java EE para publicação e execução de
páginas web;
e) SGBD Oracle Database 10g Express Edition, para persistência dos dados;
f) Oracle SQL Developer, versão 2.1.1.64, para criação e manutenção da base de
dados;
g) Google Chrome, versão 19.0.1084.46 m, como navegador de internet principal;
h) Internet Explorer 9, versão 9.0.6, como navegador de internet adicional;
i) Firefox 12.0, como navegador de internet adicional;
j) JDK, versão 1.6.0_29 - 64-bit, para execução do Eclipse, do GlassFish e da própria
ferramenta desenvolvida;
k) JRE versão 1.6.0_31-b05 – 64-bit, para execução do applet.
3.3.1.1 Applet no lado do usuário
Através do applet Java, carregado no navegador de internet, é que ocorre a maior
iteração com a ferramenta por parte do usuário. Este applet é baixado automaticamente pelo
navegador de internet quando o usuário acessa o site da ferramenta (e. g.
http://notedellmk:8080/TCC/login.jsp). O applet nada mais é do que um arquivo JAR
contendo outros arquivos, que neste caso, são as classes Java compiladas (.class) dos
pacotes necessários para a execução do applet, sendo que uma das classes especializa a classe
JApplet, conforme ilustrado na Figura 31 e no Quadro 27.
75
Quadro 27 – Classe WebcamApplet que especializa a classe JApplet
A exportação deste arquivo JAR e dos demais componentes necessários, pode ser
efetuada pelo Eclipse, conforme ilustrado na Figura 37.
Figura 37 - Exportar pacotes para um arquivo JAR utilizando o Eclipse
Para que o applet possa sair da sua sandbox (caixa de areia) e desempenhar o seu
propósito (como acessar o dispositivo de vídeo na máquina do usuário, efetuar comunicação

76
via socket , carregar as DLLs da API OpenCV entre outros) ele precisa ser assinado com um
certificado digital e precisa das devidas permissões no arquivo de políticas do Java .policy.
Na seção 2.11.1 há uma abordagem mais detalhada de como efetuar este procedimento.
Basicamente foi gerado, com a ferramenta keytool, um par de chaves pública e
privada juntamente com um .keystore para armazená-las no diretório padrão (diretório do
usuário). A chave pública já é adicionada em um certificado auto assinado que a ferramenta
keytool cria durante a geração das chaves. Este certificado deve ser disponibilizado para os
usuários que utilizarão a ferramenta. Foi utilizada a ferramenta jarsigner para assinar o JAR
contendo o applet e as classes dos demais pacotes necessários. As configurações efetuadas no
arquivo .java.policy já foram vistas no Quadro 26. Entre as configurações destaca-se o
caminho para o keystore, o alias para o certificado, o domínio (chave codeBase) ao qual o
certificado garante a confiabilidade e as chaves de permissão (permission). Finalmente, de
posse do certificado, o usuário deve importá-lo no seu keystore para ser reconhecido pelo
Java.
Com o intuito de demonstrar o controle efetuado pelo Java quanto à proteção de
código malicioso executado através de applets não assinados e que tentam ultrapassar os
limites impostos pela sandbox, foi gerado uma versão do JAR contendo o applet sem assiná-
lo. A Figura 38 mostra a mensagem de aviso de segurança apresentada pelo navegador de
internet Google Chrome ao acessar a ferramenta de autenticação através da face, com o JAR
contendo o applet não assinado.
Figura 38 - Aviso de segurança exibido pelo Java através do navegador Google Chrome
Mesmo que seja escolhido “Não” na mensagem questionando ao usuário se deseja
bloquear a execução do componente possivelmente não seguro, devido ao código dele, no
caso do applet, tentar ultrapassar a sandbox, o mecanismo de proteção do Java gera uma
exceção conforme exibido na Figura 39. Nos detalhes da exceção, representados na Figura 40,

77
é possível evidenciar a tentativa de ultrapassar a sandbox pelo applet, através do texto
selecionado na mensagem.
Figura 39 - Erro exibido pelo Java através do navegador Google Chrome
Figura 40 - Detalhes da exceção gerada pelo Java
Como já mencionado no Quadro 27, para desenvolver um applet, deve-se
especializar a classe JApplet. O applet desenvolvido inicia a sua execução através do método
virtual público e sem retorno init(), conforme ilustrado através do Quadro 28. A webcam
também é inicializada através deste método pela chamada de loadWebcam(), porém em uma
linha de execução (thread) em separado, para que, em paralelo o usuário possa interagir com
o applet e acessar a webcam.

78
Quadro 28 - Código fonte do método init() do applet
O Quadro 30 apresenta o código fonte do método loadWebcam(). Este método baixa
um arquivo comprimido chamado opencv231.zip localizado no diretório configurado no
servidor de internet onde o site da ferramenta está hospedado, por padrão o diretório é
http://notedellmk:8080/TCC/lib/ e está configurado na chave dll_path do applet. Este
arquivo possui as bibliotecas OpenCV necessárias para acessar o dispositivo de vídeo
(webcam) do usuário, efetuar pré-processamento das imagens das faces e detecta face e os
olhos. Também outros três arquivos XML estão contidos neste arquivo comprimido contendo
as configurações dos classificadores para detecção das faces e olhos. O Quadro 29 exibe todos
os arquivos contidos no arquivo compactado opencv231.zip.
Quadro 29 - Arquivos que serão compactados e baixados para a máquina do usuário automaticamente
pelo applet

79
Quadro 30 - Código fonte do método loadWebcam()
Os arquivos são baixados para o diretório temporário do usuário dentro da pasta
TCC_1-0-0 criada pelo applet. O método discoverDevices() localiza e testa os dispositivos
de vídeo do usuário. Caso encontre ao menos um dispositivo de vídeo operante, inicializa a
webcam e registra o próprio applet como sendo um observador (linha 152 do Quadro 30) das
imagens capturadas pela webcam. A chamada webCam.start() dá início à captura das
imagens. No Quadro 31 é exibido o código fonte do método de inicialização da webcam. O

80
método grabAndPaint() é o método responsável por capturar o frame (imagem), processar a
imagem (a fim de detectar a face) e exibi-la na tela para o usuário.
Quadro 31 - Código fonte do método start() da webcam
O Quadro 32 apresenta o código fonte do método grabAndPaint(). Este método é
chamado no run() da linha de execução (thread) criada na linha 89 do Quadro 31,
possibilitando assim que o usuário interaja com o applet ao mesmo tempo que o applet
interage com a webcam. Inicialmente é feita a captura da imagem através da chamada
grabber.grab(). O frame obtido é atribuído para o processador de faces que efetua a
detecção da maior face e pinta um retângulo verde ao seu redor. Na linha 70 (Quadro 32), são
notificados os observadores da webcam, que no caso é apenas o applet. Isto possibilita, por
exemplo, obter a face ao comando de captura realizado pelo usuário. Nas linhas 71 e 72 é
feito um tratamento para exibir logo abaixo da maior face detectada o nome do usuário
reconhecido, quando a opção Reconhecer automaticamente estiver marcada na tela de
login no site da ferramenta. Nas linhas 74 e 79 é, atribuída a imagem com a face detectada e é
feita a atualização do novo frame no painel que exibe a imagem da webcam na tela de login,
respectivamente, conforme mostrado no Quadro 33.

81
Quadro 32 - Código fonte do método grabAndPaint()
Quadro 33 - Código fonte do método para atribuição e sua pintura da imagem no painel do applet
3.3.1.2 Detecção facial
O objetivo da detecção facial neste trabalho é encontrar a maior face presente na
imagem capturada através da webcam. O acesso ao dispositivo de webcam para captura das
imagens é realizado utilizando a API OpenCV.
A técnica utilizada para a detecção facial é a proposta por Viola e Jones (BRADSKI;
KAEHLER, 2008, p. 506) e implementada na OpenCV. Esta técnica aplica a transformada de
Haar, que utiliza características que codificam a existência de contrastes orientados entre

82
regiões da imagem. Um conjunto destas características pode ser usado para codificar os
contrastes apresentados por um rosto humano e suas relações espaciais. Classificadores em
cascata são treinados com várias amostras de um objeto particular, (e. g. um rosto),
denominados de exemplos positivos, que são dimensionados para o mesmo tamanho, (e. g. 20
x 20 pixels) e exemplos negativos, imagens diferentes das amostras positivas também do
mesmo tamanho. Depois dos classificadores serem treinados, eles podem ser aplicados a uma
região de interesse em uma imagem de entrada. O classificador gera o valor 1 se a região é
aprovada e o valor 0 caso contrário. Para procurar o objeto em toda a imagem, move-se uma
janela de busca em toda a imagem e verifica-se todos os locais usando os classificadores. Os
classificadores podem ser facilmente redimensionados possibilitando encontrar objetos de
interesse em tamanhos diferentes, o que é mais eficiente do que redimensionar a própria
imagem.
A classificação é feita em cascata devido ao classificador resultante ser formado por
vários classificadores mais simples. Caso um classificador reprove uma região analisada, os
demais classificadores nem a testam a fim de evitar processamento desnecessário, ou seja,
todos os classificadores devem aprovar uma região para ela ser considerada aprovada.
O experimento apresentado na Figura 41 demonstra um exemplo de reconhecimento
facial utilizando a API OpenCV. É possível notar a variação no tamanho de cada face. O
algoritmo neste trabalho foi projetado para detectar e identificar apenas a maior face da
imagem (delimitada por um retângulo verde), pois a maior face será o objeto coletado para
amostra e teste durante o processo de cadastro de usuário e reconhecimento facial. Porém
nesta demonstração são demarcadas todas as faces detectadas na imagem para enfatizar a
eficiência do algoritmo de detecção facial da API OpenCV. Segundo Bradski e Kaehler
(2008, p. 507), o melhor modelo de treinamento fornecido pela OpenCV para detecção de
faces frontais (utilizado neste trabalho, apesar de ser possível criar um próprio), está no
arquivo …/opencv/data/haarcascades/haarcascade_frontalface_alt2.xml.

83
Figura 41 - Exemplo de detecção de faces, a maior face é pintada em verde
Para uma face ser detectada na imagem, algumas características são necessárias,
sendo elas:
a) a pose da face deve ser frontal;
b) os olhos devem estar abertos;
c) não é exigido expressão totalmente neutra;
d) deve ser a maior face presente na imagem.
O Quadro 34 mostra o código do método detectFaces(). Pode ser observado que
antes de efetuar a detecção propriamente dita das faces na imagem, são realizados pré-
processamentos visando maximizar a detecção. Na linha 115 é carregado o arquivo XML
contendo o modelo de detecção de faces frontais. As linhas 117 e 121 criam uma imagem
vazia com as mesmas propriedades da imagem original para armazenar a imagem em tons de
cinza. Conforme já mencionado na seção 2.3.2.4, uma imagem em tons de cinza possui
apenas um componente na banda de cores deixando o custo computacional para processá-la
menor. A redução da resolução da imagem para 50% do seu tamanho original é realizada na
linha 129. Os classificadores percorrem uma imagem menor com muito menos custo
computacional do que a imagem no seu tamanho original sem perder a sua eficiência. Na
linha 137 é feita a equalização do histograma da imagem já reduzida, mais detalhes sobre a

84
equalização do histograma podem ser encontradas na seção 2.3.2.6. A equalização do
histograma visa melhorar o contraste da imagem o que é muito importante para um
classificador de características. Por fim na linha 140 a função cvHaarDetecObjects() efetua
a detecção das faces presentes na imagem com as ações de pré-processamento acumuladas.
Quadro 34 – Método detectFaces() para detectar as faces em uma imagem
No Quadro 35 é exibido o código fonte do método getImageWithDetectedFace()
que identifica e marca com um retângulo na cor verde a maior face encontrada na imagem. A
função getBigRect() retorna as coordenadas do retângulo da maior face encontrada, baseado
na imagem com a resolução diminuída, para ajustar as dimensões do retângulo para a imagem
original, basta multiplicar cada ponto do retângulo pela escala. Para dar um efeito mais
moderno ao retângulo, ele é desenhado com segmentos de reta de forma que os centros de
cada lado fiquem sem cor.

85
Quadro 35 - Código fonte do método getImageWithDetectedFace()
No Quadro 36 o método getBigFaceRect() itera pela a lista de faces e compara as
dimensões de cada face guardando a que possuir a maior largura e altura. Ao final do método
retorna estas coordenadas através de um objeto FaceRect.
Quadro 36 - Código fonte do método getBigFaceRect()
Na Figura 42 é possível acompanhar o resultado de cada um dos passos descritos
acima, sendo que em (a) tem-se a imagem original, em (b) a imagem em tons de cinza, (c)
apresenta a imagem com sua resolução reduzida pela metade e (d) apresenta a imagem com a
face detectada e marcada com um retângulo verde em volta.

86
Figura 42- Processo executado pelo algoritmo de detecção facial: (a) imagem original, (b) imagem em
tons de cinza, (c) imagem com resolução reduzida em 50%, (d) imagem com histograma equalizado e
(e) imagem com a face detectada
3.3.1.3 Captura da face
A captura da face compreende o processo de obter a maior face detectada na imagem
obtida a partir do dispositivo de vídeo do usuário. A primeira parte deste processo foi
apresentada na seção 3.3.1.2. Porém a maior face detectada precisa passar por mais algumas

87
etapas de pré-processamento para estar em condições de ser submetida ao aplicativo servidor
para fins de reconhecimento ou treinamento e armazenamento na base de dados.
O método getBigFace() apresentado no Quadro 37, primeiramente obtém as
coordenadas da maior face, ajusta as dimensões multiplicando cada ponto do retângulo pela
escala. Na sequência, cria-se uma nova imagem para armazenar apenas a ROI que
compreende a face. O método cvSetImageROI() marca na imagem, já em tons de cinza, a
região de interesse. Esta região é extraída através do método cvCopy() para a imagem criada
para armazenar a face. A região de interesse deve ser redefinida com a chamada do método
cvResetImageROI().
Quadro 37 - Método getBigFace() retorna a imagem da maior face detectada
Um ponto muito importante neste processo de segmentação é que as imagens estejam
todas com os olhos alinhados horizontalmente, com as mesmas dimensões e com o contraste
ajustado. Como as imagens das pessoas foram obtidas nos mais variados ambientes variando a
iluminação, distância da câmera e inclinação da face, é necessário efetuar um pré-
processamento de forma automatizada em cada face.
A inclinação da face é ajustada baseada na correção do ângulo formado entre os

88
olhos de forma que fiquem na mesma linha horizontal. Isto é obtido pelo método
rotateFaceByEyes(). Este método é mais complexo e será discutido mais adiante no Quadro
38. O redimensionamento da imagem da face é efetuado através do método cvResize().
Normalmente se deseja que o mapeamento da imagem original para a de destino seja feito o
mais suave possível. O argumento de interpolação desta função controla exatamente como
isto será feito. Neste trabalho utilizamos o valor CV_INTER_LINEAR, que analisa o peso linear
dos valores de 2 por 2 pixels circundantes da origem, conforme estão pertos do pixel de
destino. Por último é feita a equalização do histograma, visando equilibrar o contraste (áreas
com muita sombra e as áreas claras da imagem).
A Figura 43 apresenta os paços resultantes da execução do método getBigFace().
Na face (a) temos a imagem original, porém já em níveis de cinza. A região obtida da face vai
desde a testa até a base do queixo. Quanto mais próximo à área do rosto, sofrerá menos
influência devido a cabelo e do próprio fundo da imagem. Na face (b) a imagem foi
rotacionada onze graus em sentido horário. Em (c) a imagem foi redimensionada para 100 x
100 pixels e na face (d) a imagem teve seu histograma equalizado.
Figura 43 - Resultado do método getBigFace(): (a) imagem original, (b) imagem rotacionada, (c)
imagem redimensionada e (d) imagem com histograma equalizado
No método getBigFace() (linha 302) apresentado no Quadro 37, é feita a chamada
ao método rotateFaceByEyes(), onde o único parâmetro passado é a face. O retorno desta
função é a imagem da face rotacionada de forma que os olhos estejam alinhados
horizontalmente (item (b) da Figura 43). No Quadro 38 é exposto o código fonte do método
rotateFaceByEyes(). Inicialmente o método detecta o olho esquerdo e o olho direito (o
código fonte da rotina que detecta os olhos está no Quadro 39).
Devido à imagens de face com poses não uniformes e inclinações da face das mais
variadas, a detecção de olhos em certos casos confunde outras partes da imagem como sendo
olhos (falsos positivos), como as narinas (face inclinada com a cabeça para trás, destaca as
narinas) e as sobrancelhas (pessoas com sobrancelhas acentuadas). Isto foi resolvido de duas
formas. Para a o caso das narinas foi diminuindo a ROI em volta dos olhos. Porém reduzir

89
demasiadamente as imagens com a face muito inclinada não permite detectar o olho na região
mais inclinada da face devido a esta ficar oclusa em relação à ROI. O tratamento para a
confusão com as sobrancelhas foi mais complexo e exige ordenação do tamanho dos olhos
encontrados e o cálculo de suas dimensões e posição obtendo os dois maiores olhos nas partes
mais extremas da face. Com os respectivos tratamentos descritos acima, obteve-se 100% de
acerto na detecção dos olhos. O ângulo de inclinação da face baseado nos olhos é obtido
calculando-se a tangente do cateto oposto dividido pela hipotenusa. A Figura 44 exibe uma
ilustração do triângulo retângulo formado pela linha horizontal entre os olhos.
Figura 44 - Imagem de face com inclinação baseada na linha horizontal entre o centro dos olhos

90
Quadro 38 - Código fonte do método rotateFaceByEyes()
A detecção dos olhos pode ser feita de forma muito semelhante como a já
mencionada na linha 140 do Quadro 34 para a detecção da face, inclusive com o método
cvHaarDetectObjects(). O que muda neste caso é o arquivo XML com as configurações de

91
treinamento para o classificador em cascata, onde chama-se o método uma vez para cada olho
e com seu respectivo arquivo de configurações (linhas 447 e 448 do Quadro 38). O Quadro 39
apresenta o código fonte do método para detecção os olhos.
Quadro 39 - Código fonte do método detectEyes()
A imagem passada como parâmetro para o método de detecção de olhos contém toda
a face. Porém, para diminuir o custo computacional e resolver problemas de falso positivos
para os olhos, conforme já mencionados acima, obtém-se apenas o ROI dos olhos com o
método apresentado no Quadro 40.
Quadro 40 - Código fonte do método getEyesSliceFromImage
Na linha 542 do método rotateFaceByEyes() (Quadro 38) é efetuada a rotação da
face com a chamada do método rotateImage(). Este método utiliza uma função do OpenCV

92
chamada cvGetQuadrangleSubPix(). Esta função utiliza uma função de transformação afim
e interpolação de pixels para reconstruir a imagem rotacionada.
Segundo Bradski e Kaehler (2008, p. 163), uma transformação afim é qualquer
transformação que pode ser expressa sob a forma de uma multiplicação de matrizes seguida
de uma adição de vector. Na API OpenCV o estilo padrão para representar esta transformação
é uma matriz 2 por 3. Pode-se pensar em uma transformação afim como desenhar uma
imagem em uma folha de borracha grande e em seguida, deformar a folha empurrando ou
puxando os cantos para fazer diferentes tipos de paralelogramos.
Morimoto (2005), explica que a interpolação de imagens consiste em adicionar
novos pontos a ela. Estes pontos são baseados nos pontos já existentes, aumentando a
quantidade de pontos, porém não aumentando os detalhes da imagem. Para uma imagem com
um ponto observado de tonalidade verde igual a 100 e outro ponto com tonalidade verde 20.
Deve-se somar os dois pontos, calcular a média e incluir um novo ponto com tonalidade verde
60 entre os dois pontos anteriores. Caso a interpolação continuasse, seria incluído em seguida
um ponto com tonalidade verde 40 entre o ponto 20 e o ponto 60, um ponto com tonalidade
verde 80 entre o ponto 60 e o 100 e assim sucessivamente com toda a imagem.
O método rotateImage() apresentado no Quadro 41, utiliza a função
cvGetQuadrangleSubPix(). Esta função calcula todos os pontos na imagem de destino
mapeando-os (com interpolação) a partir dos pontos em que foram calculados na imagem de
origem através da aplicação de uma transformação afim, realizada pela multiplicação pela
matriz de mapeamento 2 por 3. A conversão dos locais na imagem de destino para
coordenadas homogêneas para a multiplicação é feita automaticamente (BRADSKI;
KAEHLER, 2008, p. 166).

93
Quadro 41 - Método rotateImage() rotaciona a face baseado no ângulo passado
Em particular, os pontos de resultados na imagem de destino são calculados de
acordo com as equações do Quadro 42. Observa-se que o mapeamento de (x, y) a (x˝, y˝) tem o
efeito que, mesmo se o mapeamento M é um mapeamento de identidade, os pontos na
imagem de destino no centro serão tomados a partir da imagem fonte em sua origem. Se for
necessário obter pontos de fora da imagem, ela usa replicação para reconstruir estes valores.
Fonte: adaptado de Bradski e Kaehler (2008, p. 166).
Quadro 42 – Equação para cálculo dos pixels da imagem de destino
Na Figura 45 é possível verificar alguns processos e resultados obtidos com a rotação
da face na imagem original (a). A imagem (b) ilustra a ROI obtida através do método
getEyesSliceFromImage() para efetuar a detecção dos olhos e a verificação do ângulo

94
formado pela linha calculada entre os centros dos dois olhos. A imagem (c) foi rotacionada
manualmente onze graus no sentido horário em um editor de imagens (e. g. Adobe
Photoshop). Em (d) a imagem foi rotacionada pelo método rotateImage(), cujo ângulo
formado pela linha calculada novamente entre os centros dos dois olhos é zero e pode ser
visualizado na imagem (e).
Figura 45 – Exemplo de uma imagem da face rotacionada, (a) imagem original, (b) olhos não
alinhados horizontalmente, (c) face rotacionada em um editor de imagens, (d) face rotacionada pelo
método rotateImage()e (e) olhos alinhados horizontalmente
É possível verificar a diferença entre a rotação da face realizada por um editor de
imagens, na imagem (c) e a rotação efetuada pelo método rotateImage() na imagem (d). A
área em preto na imagem (c) foi toda reconstruída através de interpolação na imagem (d).
Pode-se ainda notar que as dimensões da imagem (c) são maiores do que da imagem (d), isto
deve-se ao fato de toda a imagem ser girada gerando áreas vazias nas laterais (áreas em preto)
e as dimensões da diagonal serem maiores do que a imagem na posição original. Já na
imagem (d) os pixels foram rearranjados preservando suas dimensões originais, apesar de, os
pixels nas áreas reconstruídas não ficaram exatamente como os da imagem original.

95
3.3.1.4 Envio das informações para o aplicativo servidor
Ao usuário efetuar uma submissão das informações para o aplicativo servidor, seja
devido a um novo cadastro de usuário ou a uma autenticação através da face ou de um usuário
e uma senha (método processUser() mostrado no Quadro 43), ou ainda pelo auto
reconhecimento de um usuário (método autoRecognizeUser() mostrado no Quadro 44), é
aberta uma conexão TCP/IP através de um soquete (socket) com o aplicativo servidor. Neste
trabalho a porta padrão utilizada foi a porta 7181, entretanto qualquer outra porta disponível
poderia ter sido utilizada. O Quadro 45 apresenta o código fonte da conexão com o servidor.
Quadro 43 - Código fonte do método processUser()

96
Quadro 44 - Código fonte do método autoRecognizedUser()
Quadro 45 - Código fonte do construtor da classe FaceClientSocket que abre uma conexão com o
aplicativo servidor
O método send()(Quadro 46) da classe FaceClientSocket dispara os processos de
envio dos dados da máquina do usuário para o servidor de aplicativos. O método
sendUserData() envia os dados do usuário e pode ser visto no Quadro 47. As faces do
usuário são enviadas ao aplicativo servidor através do método sendFaces(), tendo seu código
fonte apresentado no Quadro 48. Já o comando processUserOnServer() envia um comando

97
para o servidor, determinando que a operação pode ser processada e é exibido no Quadro 50.
O comando terminateProcess() é bem simples e apenas encerra a linha de execução
(thread) no servidor que atende este usuário. Finalmente o comando closeConnection()
fecha a conexão do soquete com o aplicativo servidor.
Quadro 46 - Código fonte do método send()
Quadro 47 - Código fonte do método sendUserData()

98
Quadro 48 - Código fonte do método sendFaces()
O método sendFaces() do Quadro 48 chama o método sendFace() para cada face a
ser enviada, conforme exibido no Quadro 49.
Quadro 49 - Código fonte do método sendFace()

99
Quadro 50 - Código fonte do método processUserOnServer()
3.3.1.5 Recebimento das informações pelo aplicativo servidor
O Quadro 51 mostra o código fonte da classe ServerSystemManager, classe
principal do aplicativo servidor. Apesar de ser muito simples, ela é responsável por criar a
linha de execução (thread) principal que atende a todas as requisições de cadastro de usuário e
reconhecimento, seja através da face ou através de um usuário e uma senha. Em especial a
linha 21, que cria a instância da classe FaceServerSocket que atenderá a todas as requisições
de usuários.
A classe FaceServerSocket apresentada no Quadro 52, é responsável por escutar a
porta configurada e criar uma linha de execução para atender cada usuário conectado à está
porta, através de uma instância da classe FaceServerClientSocket.
A classe FaceServerClientSocket, exibida no Quadro 53, atende a conexão de um
usuário em específico. Ela possui capacidade para atender desde um cadastro de um novo
usuário como o reconhecimento de um usuário, seja através da face ou de um usuário e uma
senha.
O método run() da classe FaceServerClientSocket, fica em loop (dentro de um
laço de repetição, no caso while), lendo pacotes e executando comandos, até que um comando

100
de término seja recebido. Dentro do laço, primeiramente o pacote de dados recebido é lido.
Cada pacote recebido deve ter um comando a ser processado pelo método
executeCommand().
Quadro 51 - Código fonte da classe ServerSystemManager
Quadro 52 - Código fonte da classe FaceServerSocket

101
Quadro 53 - Código fonte do método run() da classe FaceServerClientSocket
O método readPacked(), apresentado no Quadro 54, recupera do fluxo de dados
(stream) recebidos pelo soquete as informações enviadas pelo usuário e armazena em um
objeto da classe ByteBuffer. Em seguida lê o comando de início e os quatro bytes seguintes
que contém o comando a ser executado para este pacote de dados recebidos.
Na sequência do método run(), é executado o comando executeCommand(),
apresentado no Quadro 55. Os seguintes comandos podem ser processados dentro deste
método:
a) test: é um comando para testes, que simplesmente lê uma cadeia de caracteres
(string). Pode ser utilizado, por exemplo, para saber se o aplicativo servidor está
operante;
b) newuser, recognizeuser e authuser: sinaliza a operação: novo usuário,
reconhecimento de um usuário através da face e reconhecimento de um usuário
através de um usuário e uma senha respectivamente. Estes chamam direta ou

102
indiretamente o método readNewUserData(), que lê os dados de um usuário e
instância um objeto UserFace;
c) face: executa o método readFace(), que lê os bytes recebidos de uma imagem
contendo uma face. A imagem é reconstruída através de uma instância de um
objeto IplImage, que representa uma imagem na API OpenCV. Esta imagem é
adicionada ao objeto usuário que foi criado;
d) processuser: este comando, cujo código fonte pode ser visualizado através do
Quadro 55, executa a operação relacionada ao usuário, conforme descrito na
letra b;
e) distance: verifica se deve utilizar a distância euclidiana ou a distância de
mahalanobis para o cálculo do vizinho mais próximo no algoritmo de
reconhecimento do usuário;
f) terminate: ao receber este comando, a linha de execução que atende as
requisições do usuário conectado é encerrada.
Quadro 54 - Código fonte do método readPacked()

103
Quadro 55 - Código fonte do método executeCommand()

104
O método processUser() apresentado no Quadro 56, pode efetuar o cadastro de um
novo usuário, o reconhecimento através da face, ou ainda a autenticação da forma tradicional,
utilizando um usuário e uma senha. As operações de criar um novo usuário e reconhecimento
através da face são processadas através de um objeto PCAProcessor, enquanto que a
autenticação através de um usuário e uma senha, é efetuado através de uma pesquisa direta em
banco de dados pelo objeto StorageManager, objeto principal para acesso a banco de dados.
Quadro 56 - Código fonte do método processUser() da classe FaceServerClientSocket
3.3.1.6 Processando um novo usuário
O método processNewUser(), cujo código fonte é apresentado do Quadro 57,
calcula as componentes principais e armazena um usuário e suas faces, na base de dados.
Inicialmente é chamada a função loadTrainingImages() que carrega as imagens das faces
para treinamento já existentes na base de dados e armazena em um vetor de imagens do tipo
IplImage do OpenCV. Após efetuar a carga das imagens das faces, adiciona-se também ao
final do vetor as imagens das faces do novo usuário. Este vetor de imagens é retornado pela
chamada da função. Este processo é importante, pois para cada novo usuário são recalculados
os eigenfaces e eigenvalues com todas as faces já existentes.

105
Quadro 57 - Código fonte do método processNewUser()
Em seguida é efetuada a transformada PCA através do método transformPCA(), seu
código fonte é exibido no Quadro 58. Este método calcula os eigenvectors (auto-vetores),
eigenvalues (auto-valores) e gera a imagem média. O número de eigenvectors e eigenvalues
(nEigens no código fonte) será no máximo a quantidade de faces menos um. Pode-se
visualizar isto como se a distância entre uma face até a outra fosse um segmento de reta, cada
um destes segmentos é uma componente principal. Logo, se houver duas faces, há um
segmento de reta entre as duas, se tiver três faces, há dois segmentos, um entre a primeira e a

106
segunda face e outro entre a segunda e a terceira face e assim sucessivamente. É criado um
vetor Java do tipo IplImage para armazenar os eigenvectors.
Em seguida cria-se uma matriz com apenas uma linha e nEigens colunas para
armazenar os eigenvalues. Também é criado um objeto IplImage para armazenar a imagem
média. A imagem média é utilizada no cálculo da matriz de covariância utilizada para obter os
eigenvectors e eigenvalues. Estes elementos são calculados conforme descrito na seção 2.9.
Em seguida é configurado um objeto OpenCV calcLimit utilizado como critério de
terminação para o cálculo dos eigenvectors e eigenvalues. Na sequência é executado o método
cvCalcEigenObjects. Os principais parâmetros passados para esta função são a quantidade
de faces de treinamento, um ponteiro OpenCV para o vetor com as faces, um ponteiro
OpenCV para o vetor que armazenará os eigenvectors, o objeto calcLimit e um ponteiro
para o vetor de eigenvalues. Uma observação importante é que os eigenvalues serão
retornados ordenados de forma decrescente. Por fim, é chamado o método do OpenCV
cvNormalize para a normalização dos eigenvalues entre 1 e 0, sendo o maior valor igual a 1 e
o menor igual a 0.
Através da Figura 46 é apresentado um exemplo de processamento de seis pessoas,
cada uma com dez faces diferentes para treinamento. É possível visualizar a imagem média
gerada (a) e os eigenfaces (auto-vetores) calculados e salvos como imagem. No caso de
reconhecimento de faces, quando um auto-vetor é salvo como uma imagem, ele possui uma
aparência de face (fantasmagórica). Daí o nome eigenface. Cada eigenface é uma componente
principal. Observa-se a letra (b) de cima para baixo e da direita para a esquerda, onde
percebe-se que a primeira componente principal está na primeira imagem, a segunda
componente na segunda imagem a terceira componente na terceira imagem e assim
seguidamente. As últimas eigenfaces praticamente não possuem informações consideráveis, o
que sugere o seu descarte, pois não contribuirá para o reconhecimento, isto é redução da
dimensionalidade (vide Figura 15 e seção 2.7).

107
Figura 46 - (a) imagem média, (b) 59 eigenfaces (auto-vetores) calculados de forma ordenada da
esquerda para a direita e de cima para baixo
Após calcular os componentes principais da PCA, as faces são projetadas no
subespaço vetorial na forma de pontos. Esta projeção é efetuada para cada face através do
método cvEigenDecomposite. Os principais parâmetros deste método são a face de treino a
ser projetada, a quantidade de eigenvectors, um ponteiro OpenCV para o vetor contendo os
eigenvectors, a imagem média e um vetor do tipo número de ponto flutuante para receber os
coeficientes retornados.
Por último, os dados calculados são armazenados na base de dados, através do
método storeTrainingData()(Quadro 57, linha 105). Este método exclui os dados de
treinamento antigos (eigenvectors, eigenvalues, imagem média e coeficientes para projeção
dos pontos) e os substitui pelos novos dados calculados, juntamente com as imagens de
treinamento e os dados de cadastro do novo usuário.

108
Quadro 58 - Código fonte do método transformPCA()

109
3.3.1.7 Reconhecimento através da face
O reconhecimento de uma face é efetuado través do método recognizeFace()
conforme exposto no Quadro 59. Este método recebe como parâmetro uma imagem de face
normalizada (vide seção 3.3.1.3) e retorna um objeto UserFace com os dados do usuário
reconhecido, ou null caso não seja reconhecido. Primeiramente são carregados os dados de
treinamento já computados da base de dados. Para que os dados de treinamento não sejam
carregados a cada teste, usou-se o padrão de projeto singleton para carregar os dados apenas
na primeira chamada, e somente recarregá-los, caso um novo usuário seja incluído, devido ao
recálculo de todos os dados de treinamento.
Na sequência é calculado, através do método OpenCV cvEigenDecomposite(), os
coeficientes de projeção no subespaço PCA para a face de teste, baseados na imagem de teste,
nas eigenfaces e na face média. Após a obtenção dos coeficientes de projeção, é feito o
cálculo da soma da menor distância quadrada entre os pontos projetados da face de testes com
cada uma das faces de treinamento e suas respectivas projeções. Trata-se da utilização do
método do k-vizinho mais próximo, como pode ser observado através do código fonte do
método findNearestNeighbor() exposto no Quadro 60.
A imagem de treinamento que resultar na menor distância será a face mais
semelhante com a face de testes e será considerada a pessoa encontrada. Para a face
encontrada utilizando a distância euclidiana, ela apenas será considerada reconhecida caso o
cálculo da confidência ser maior ou igual ao valor configurado. Já para a distância de
mahalanobis, não há um nível de confidência estipulado. Os dados desta pessoa reconhecida
serão recuperados da base de dados e retornados pelo método.

110
Quadro 59 - Código fonte do método recognizeFace()

111
Quadro 60 - Código fonte do método findNearestNeighbor()
3.3.1.8 Reconhecimento através de um usuário e uma senha
O reconhecimento através de um usuário e uma senha utiliza a técnica tradicional de
autenticação. Basicamente efetua uma busca na tabela de usuários no banco de dados
procurando pelo usuário e senha passada. Caso um registro seja encontrado, retorna-se os
dados deste usuário através de um objeto UserFace. Caso nenhum registro seja encontrado é
retornado null. O método que dispara este processo pode ser verificado no Quadro 56.

112
3.3.2 Operacionalidade da implementação
Nesta seção será apresentada a utilização da ferramenta de reconhecimento facial em
nível de usuário. Nas seções seguintes serão abordadas as principais funcionalidades da
ferramenta.
3.3.2.1 Acesso à ferramenta
Antes de acessar a ferramenta, é necessário observar os seguintes pré-requisitos:
a) o servidor de páginas web Glassfish deve estar rodando com deploy da ferramenta
efetuado;
b) o aplicativo servidor deve estar executando.
A ferramenta pode ser acessada pelos seguintes navegadores: Chrome, Internet
Explorer e FireFox, conforme descrito na seção 3.3.1 através da Uniform Resource Locator
(URL), como por exemplo http://servidor:8080/TCC/login.jsp. Inicialmente aparece a
tela descrevendo a inicialização da ferramenta, conforme Figura 47.
Figura 47 - Tela de entrada da ferramenta

113
Após a ferramenta ser carregada e o applet iniciar, ele acessa o dispositivo de vídeo
do usuário, normalmente a webcam, exibe a tela principal, inicia a exibição das imagens
capturadas e efetua a detecção da face, conforme exibido na Figura 48. A maior face é
detectada é desenhado um retângulo verde em torno dela. A tela principal possui duas abas:
Autenticar usuário e Cadastrar novo usuário. A primeira aba é a que está ativa por
padrão ao acessar a ferramenta, pois é mais comum efetuar uma autenticação na ferramenta
do que cadastrar um novo usuário.
Figura 48 - Tela principal da ferramenta
3.3.2.2 Cadastrar um novo usuário
Inicialmente é necessário cadastrar algum usuário para poder acessar o sistema web,
caso contrário a ferramenta sempre reportará que o usuário é desconhecido. Para cadastrar um
novo usuário, deve-se acessar a aba Cadastrar novo usuário. A tela de cadastro de usuário
possui uma barra de ferramentas no topo da tela com as seguintes opções:

114
a) botão Capturar: ao clicar sobre este botão é efetuada a captura de uma face do
usuário posicionado na frente da câmera. Neste trabalho optou-se pela captura de
10 faces por usuário para treinamento. Cada face possui as dimensões de 64 x 64
pixels, isto engloba faces mesmo que a pessoa esteja mais afastada da câmera,
além de equilibrar custo computacional com qualidade da imagem (CAMPOS,
2001, p. 91). Ao atingir as 10 faces capturadas o botão é desabilitado;
b) capturas: esta opção exibe quantas capturas já foram realizadas do total de
capturas necessárias;
c) botão Cadastrar: esta opção envia as faces capturadas, juntamente com os
demais dados do usuário para o servidor e deixa a ferramenta em estado de
espera até que o servidor conclua o cadastro e retorne uma resposta para o applet.
Este botão permanece desabilitado enquanto a quantidade de capturas não atingir
a quantidade esperada (no caso, 10 capturas);
d) botão Reiniciar: esta opção limpa internamente a lista de faces capturadas e o
formulário com os dados do usuário. Antes de efetuar a operação é exibida uma
mensagem solicitando a confirmação pelo usuário.
Abaixo da barra de ferramentas há um formulário para o usuário preencher. Os
campos são o nome do usuário, o usuário de acesso ao sistema, a senha e a repetição da senha.
Os três últimos campos servem apenas para quando o usuário optar por efetuar a autenticação
através de um usuário e uma senha. Todos os campos são de preenchimento obrigatório. No
centro da tela aparece a área da câmera, onde são apresentadas as imagens de vídeo, de forma
que o usuário possa realizar as capturas da sua face. A Figura 49 exibe a tela de cadastro com
um usuário efetuando seu cadastro. Após todos os campos preenchidos e as dez faces terem
sido capturadas, o usuário submete os dados para o aplicativo servidor através de clique no
botão Cadastrar. O aplicativo servidor recebe os dados, efetua o treinamento das faces,
armazena os dados na base de dados e retorna mensagem para o usuário, conforme pode ser
observado na Figura 50, onde a mensagem reportada pelo aplicativo servidor está destacada
com uma borda vermelha.

115
Figura 49 - Tela para cadastro de um novo usuário

116
Figura 50 - Tela de cadastro após submissão ao aplicativo servidor
3.3.2.3 Autenticar usuário através da face
A autenticação do usuário através da sua face é muito simples e rápida de ser
efetuada. O usuário acessa a aba Autenticar usuário e clica no botão Autenticar. A face
capturada é submetida automaticamente pelo applet para o servidor de aplicativo, e fica em
estado de espera aguardando resposta. Caso o servidor reporte que o usuário foi reconhecido,
apresenta uma mensagem ao usuário, conforme exibido na Figura 51 e redireciona o usuário
para a página principal, conforme apresentado na Figura 52. Nesta forma de autenticação o
usuário pode optar por uma de duas formas de efetuar a medição entre as distâncias dos
pontos projetados no subespaço PCA, a euclidiana, que é a padrão, ou a de mahalanobis.

117
Figura 51 - Autenticação do usuário através da face com usuário reconhecido

118
Figura 52 - Usuário autenticado e redirecionado para a página principal
3.3.2.3.1 Reconhecer usuário através da face automaticamente
A tela de autenticação através da face possui um recurso para o usuário testar o
reconhecimento da sua face antes de se autenticar. Este processo visa verificar o estado de
calibração da ferramenta. É possível verificar se a ferramenta não esteja reconhecendo o
usuário, ou o esteja reconhecendo como falso positivo. Para acionar o recurso, basta que o
usuário marque a opção Reconhecer automaticamente. Que a cada três segundos o applet
captura a face do usuário e faz uma requisição de reconhecimento ao aplicativo servidor
automaticamente. A resposta do servidor é o nome do usuário caso ele seja reconhecido, ou o
texto “Usuário desconhecido” caso contrário. O resultado é impresso na própria imagem de
vídeo logo abaixo da face do usuário conforme exibido na Figura 53.

119
Figura 53 - Opção Reconhecer automaticamente a face do usuário marcada
3.3.2.4 Autenticar usuário através de um usuário e uma senha
Outra forma de autenticar o usuário na ferramenta é através de um usuário e uma
senha que foram fornecidos no momento de seu cadastro. Esta opção deve ser utilizada em
algumas situações:
a) o computador do usuário não possui um dispositivo de vídeo, como uma
webcam, por exemplo;
b) a ferramenta não está reconhecendo o usuário, mesmo ele já estando cadastrado
(falso negativo);
c) a ferramenta está reconhecendo o usuário como outra pessoa (falso positivo);
d) o usuário simplesmente deseja autenticar-se da forma tradicional.

120
Para efetuar este tipo de autenticação o usuário deve ativar a aba Autenticar
usuário e no grupo Tipo de autenticação deve marcar a opção Através de usuário e
senha. Marcando esta opção a tela de autenticação muda para uma tela com um formulário
que permite ao usuário informar seu usuário e senha e submeter através do botão Autenticar
ao aplicativo servidor. Caso o usuário e a senha sejam reconhecidos o usuário é redirecionado
para a mesma tela apresentada na Figura 52. Caso o usuário ou a senha sejam inválidos, é
apresentada uma mensagem ao usuário relatando o caso.
Figura 54 - Autenticação convencional através de um usuário e uma senha

121
3.4 RESULTADOS E DISCUSSÃO
Nesta seção são apresentados os resultados dos experimentos realizados utilizando-se
a abordagem proposta. Na subseção 3.4.1 a base de dados utilizada é mostrada. Na subseção
3.4.2 os resultados da detecção facial são apresentados. Na subseção 3.4.3 são apresentados os
resultados da etapa de normalização da face. Por fim, a subseção 3.4.4 apresenta os resultados
do reconhecimento facial.
3.4.1 Base de dados
A população da base de dados utilizada foi coletada em campo com autorização dos
participantes. Procurou-se obter um número superior a 200 pessoas, porém devido à
dificuldade em abordar tantas pessoas, foram obtidas imagens de 151 pessoas com 10
imagens por pessoa em média. Isto totalizou mais de 1500 imagens coletadas e adicionadas na
base de dados. A coleta foi efetuada pela própria ferramenta, efetuando-se o cadastro de cada
pessoa. Foi realizado um ajuste temporário na ferramenta, para que a cada captura da face,
seja manual, clicando no botão Capturar na tela de cadastro, ou marcando a opção
Reconhecer automaticamente na aba Autenticar usuário, fosse gravada a imagem
capturada em disco, a fim de poder utilizá-la a qualquer momento para armazenamento em
banco de dados e na execução de testes.
Observou-se que há forte correlação entre o tempo de treinamento e o número de
faces adicionadas na base de dados, isto deve-se a necessidade de retreinar utilizando todas as
faces já cadastradas a cada novo usuário processado.
Para a Figura 55, Figura 56 e Figura 58 são utilizadas dezesseis imagens das mesmas
pessoas e nas mesmas posições a fim de demonstrar o processo de detecção da face até obter-
se a face normalizada. Na Figura 55 é possível verificar amostras de imagens coletadas a
campo para constituir a base de dados dos usuários. Percebe-se uma grande variação em pose,
escala, iluminação, distância da câmera. São fatores comuns no dia a dia da utilização de uma
ferramenta com este objetivo.

122
Figura 55 - Amostra de imagens coletadas a campo para constituir a população da base de dados
3.4.2 Detecção da face
O algoritmo para detecção de faces mostrou-se muito robusto, visto que teve 100%
de sucesso na detecção de faces frontais e com inclinações leves para a direita, para esquerda,
para cima e para abaixo, inclusive com uma leve oclusão de partes da imagem, como quando
coçar-se os olhos.
A utilização de óculos de sol não impediu a detecção da face, apesar de ser
descartado este tipo de imagem para este trabalho, devido à necessidade da localização dos
olhos serem prejudicada com este tipo de situação. As imagens de faces capturadas com a
pessoa usando óculos de grau também tiveram a face detectada com sucesso e foram
utilizadas nos experimentos para reconhecimento, sendo estes bem sucedidos.
Experimentos realizados em um ambiente com apenas a luz do monitor de um
notebook mostraram que a face foi detectada com sucesso. A Figura 56 exibe uma imagem de
exemplo com a detecção facial em uma amostra de usuários submetidos à detecção para
posterior armazenamento na base de dados.

123
Figura 56 - A detecção facial atingiu 100% de sucesso nas faces apresentadas em pose frontal e sem
oclusões significativas
3.4.3 Normalização da face
A normalização das faces foi bem sucedida em praticamente 100% das imagens.
Ocorreram falhas apenas nas faces onde não foi possível localizar os olhos, ou o algoritmo
detectou falsos positivos para os olhos como apresentado na Figura 57 (maiores detalhes estão
descritos na seção 3.3.1.3). Porém a ferramenta não captura faces onde não consiga detectar
os olhos, prevenindo este problema. A Figura 58 apresenta amostras de faces normalizadas,
uma para cada uma das amostras da Figura 56.
Figura 57 - Problemas na detecção dos olhos, (a) confusão dos olhos com as sombrancelhas e (b)
confusão dos olhos com as narinas

124
Figura 58 - Amostras de faces normalizadas
3.4.4 Reconhecimento da face
Dois experimentos foram realizados: no primeiro foram utilizadas três imagens por
pessoa e uma imagem de teste. No segundo foram utilizadas cinco imagens por pessoa e duas
de teste. Nenhuma das imagens utilizadas para testes foram utilizadas para o treino.
Na Tabela 6 é possível visualizar o desempenho dos testes efetuados com três
imagens por pessoa e uma de teste. É efetuada uma comparação com os resultados obtidos por
Campos (2001, p. 93). A técnica utilizada para localizar a face de treinamento mais próxima
da face de testes foi a mesma, do k-vizinho mais próximo. Campos (2001, p. 93) estabiliza a
taxa de acertos a partir do décimo auto-vetor, enquanto nos testes realizados, a estabilização
foi obtida a partir do trigésimo terceiro auto-vetor com 98% de acerto, ou seja, uma boa taxa,
apesar da utilização de apenas uma imagem de testes por pessoa. A Figura 59 exibe os
resultados obtidos neste trabalho utilizando três imagens por pessoa e são comparados aos
resultados obtidos por Campos (2001, p. 93).
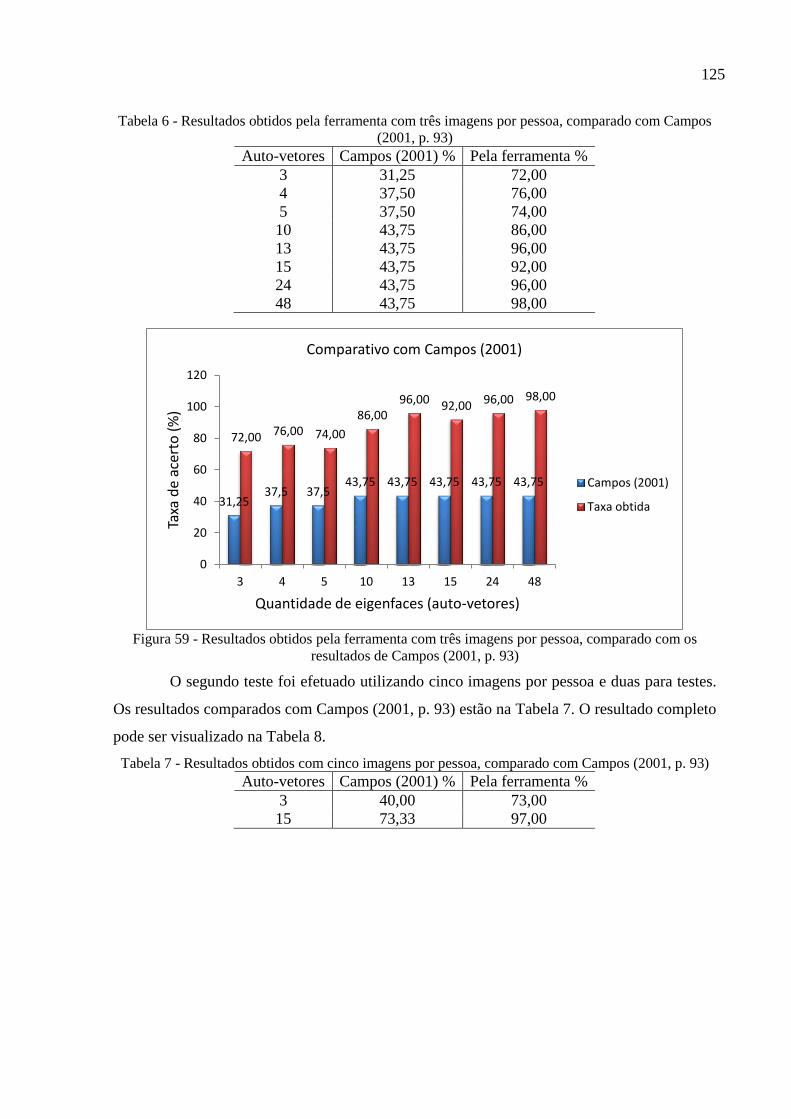
125
Tabela 6 - Resultados obtidos pela ferramenta com três imagens por pessoa, comparado com Campos
(2001, p. 93)
Auto-vetores Campos (2001) % Pela ferramenta %
3 31,25 72,00
4 37,50 76,00
5 37,50 74,00
10 43,75 86,00
13 43,75 96,00
15 43,75 92,00
24 43,75 96,00
48 43,75 98,00
Figura 59 - Resultados obtidos pela ferramenta com três imagens por pessoa, comparado com os
resultados de Campos (2001, p. 93)
O segundo teste foi efetuado utilizando cinco imagens por pessoa e duas para testes.
Os resultados comparados com Campos (2001, p. 93) estão na Tabela 7. O resultado completo
pode ser visualizado na Tabela 8.
Tabela 7 - Resultados obtidos com cinco imagens por pessoa, comparado com Campos (2001, p. 93)
Auto-vetores Campos (2001) % Pela ferramenta %
3 40,00 73,00
15 73,33 97,00
31,25 37,5 37,5
43,75 43,75 43,75 43,75 43,75
72,00 76,00 74,00
86,00 96,00 92,00 96,00 98,00
0
20
40
60
80
100
120
3 4 5 10 13 15 24 48
Taxa
de
acer
to (
%)
Quantidade de eigenfaces (auto-vetores)
Comparativo com Campos (2001)
Campos (2001)
Taxa obtida

126
Tabela 8 - Resultados obtidos pela ferramenta com cinco imagens por pessoa usadas para treinamento,
variando a quantidade de auto-vetores (eigenfaces)
Auto-vetores Taxa de acerto %
1 19 2 55 3 73 4 84 5 84 6 87 7 91 8 93 9 93
10 93 11 96 12 95 13 95 14 97 15 97 16 96 17 96 18 96 19 95 20 95 30 96 40 96 50 96
Na Tabela 8 é possível visualizar um fato interessante: nos auto-vetores quatorze e
quinze está a melhor solução para o problema da dimensionalidade para este problema.
Chegando a formar uma leve curva descendente do auto-vetor dezesseis ao trinta, onde ocorre
a estabilização da taxa de acerto pela quantidade de auto-vetores utilizados. Devido a isso é
muito importante executar testes para encontrar a dimensionalidade ideal para cada problema.
Para estes testes foram implementadas rotinas que automatizam este processo
separando as quantidades de imagens para treino, gerando os dados de treinamento e
inserindo-os na base de dados. De forma semelhante a submissão das imagens para testes
também possui rotinas automatizadas. Observando-se sempre tomar imagens aleatórias e não
repetidas entre as de treino e as de testes. Se forem comparadas as Figura 60 e a Figura 15 da
seção 2.7, é possível comprovar que a teoria e a prática andam juntas referentes ao problema
da dimensionalidade. Apesar de não haver um declive significativo da taxa de acerto, é
possível comprovar que adicionando-se mais auto-vetores não há aumento da taxa de acerto,
mas sim, pode resultar em redução.

127
Figura 60 - Visualização do problema da dimensionalidade obtido pela ferramenta
0
20
40
60
80
100
120
0 10 20 30 40 50 60
Taxa
de
acer
to (
%)
Número de eigenfaces (auto-vetores)
Problema da dimensionalidade

128
4 CONCLUSÕES
A utilização da biometria está cada vez mais presente em nosso dia a dia. Está
tornando-se cada vez mais comum em celulares e tornando-se um recurso opcional em
computadores. O emprego da biometria em empresas para controle de acesso e captura de
ponto já é largamente difundido. Outros órgãos, como bancos, investem muito dinheiro e dão
seus primeiros passos neste tipo de tecnologia para a identificação de seus usuários, com
especial destaque na utilização dos caixas eletrônicos.
A visão computacional é, sem dúvida, um dos principais pilares para a área de
segurança com o emprego da biometria. Neste trabalho ela foi combinada com a técnica
estatística da análise das componentes principais para o reconhecimento de face, voltada para
a identificação e autenticação de usuários na web. A técnica mostrou-se muito eficiente no
reconhecimento de pessoas através da face, principalmente com iluminação moderada, sem
excesso de brilho no ambiente, com pose neutra e frontal. Com estas características atingiu-se
mais de 96% de acerto, superando os objetivos deste trabalho. Também mostrou-se tolerante a
expressões faciais moderadas, desde que alguma face tenha sido treinada com alguma
expressão semelhante. Um caso típico em que obteve-se falsos positivos, foi em mulheres que
se cadastraram com cabelo solto e autenticaram-se com cabelo preso, ou vice-versa. Contudo,
adicionando-se apenas uma face com a condição contraditória foi o suficiente para reconhecer
com acerto.
Este trabalho atingiu seus objetivos específicos utilizando as técnicas de detecção,
processamento, identificação e autenticação através da face de uma pessoa em um ambiente
web, utilizando um applet como interface com o usuário, socket para transmitir as dados e
armazenou todas as informações em um banco de dados Oracle.
Pode-se citar alguns diferenciais e semelhanças deste trabalho com os trabalhos
correlatos. O trabalho de Pamplona Sobrinho (2010) identifica apenas um usuário como sendo
reconhecido ou não reconhecido, através da reconstrução da face, porém não identifica quem
é o usuário entre alguns outros. No presente trabalho o usuário testado é reconhecido e
identificado através do método do k-vizinho mais próximo, baseado na menor soma dos
quadrados das distâncias dos pontos projetados no subespaço PCA. Uma alternativa mais
barata computacionalmente para calcular as distâncias seria a sugerida por Loesch e
Hoeltgebaum (2012, p. 119), com a utilização do método dos centroides, sendo o centroide o
ponto médio dos objetos contidos em uma classe. Campos (2001) soluciona alguns problemas

129
deste trabalho extraindo apenas as partes da face mais relevantes e que sejam mais rígidas,
como os olhos. A boca sofre muitas alterações com expressões faciais, como por exemplo, o
sorriso. A projeção do nariz em um plano bidimensional faz com que a imagem sofra grandes
alterações com variações na orientação da cabeça. O trabalho de Reaes (2006) também
identifica um usuário através da face e recupera seus dados a partir da base, o que este
trabalho faz de forma semelhante.
Quanto à utilização da API OpenCV foi de extrema importância para algumas
operações como acessar um dispositivo de vídeo, pré-processamento e manipulação das
imagens. Também possui inúmeras funções matemáticas e estruturas para manipulação de
matrizes. Porém notou-se problemas quanto à liberação de memória, principalmente dentro de
threads, obrigando em certos casos efetuar um retardo de tempo para liberar a memória das
imagens capturadas através da webcam. Outro ponto a considerar é que com um número
muito grande de imagens, ocorrem erros Not a Number (NaN) nos eigenvalues retornados
pelo método cvCalcEigenObjects() e nos coeficientes dos pontos de projeção no subespaço
PCA calculados pelo método cvEigenDecomposite(). Os mesmos dois métodos também
ficaram instáveis ao tentar reduzir o número de eigenvetors utilizando apenas os autovalores
mais significativos.
4.1 EXTENSÕES
Algumas possibilidades de melhoria e continuidade deste trabalho são:
a) desenvolver métodos que calculem a matriz de covariância, a imagem média e
possam extrair os auto-vetores, auto-valores e projeções dos pontos no subespaço
PCA. Isto permite substituir a utilização dos métodos cvCalcEigenObjects() e
cvEigenDecomposite() da API OpenCV, devido a não permitirem em seus
parâmetros reduzir a quantidade de eigenfaces a serem utilizadas no cálculo para
redução das informações armazenadas na base de dados e carregadas na
memória;
b) permitir a utilização dos auto-vetores com os maiores auto-valores, isto reduzirá
o volume das informações gravadas na base de dados e carregadas em memória
para efetuar o reconhecimento;
c) melhorar a interface da etapa de cadastramento do usuário, por exemplo,

130
exibindo a imagem capturada e já pré-processada permitindo que o usuário
verifique a qualidade da imagem obtida, permitindo sua substituição caso
necessário;
d) trocar a interface do usuário de um applet pela utilização do HTML5 para acessar
os dispositivos de vídeo (até a data de conclusão deste trabalho, os navegadores
mais utilizados, ainda não suportam todas as especificações do HTML5; o acesso
aos dispositivos de vídeo é uma delas). Isto evitará que o usuário necessite:
instalar Java, configurar certificado digital, habilitar applets (risco de segurança),
configurar arquivos de permissão para o applet poder sair da sandbox, download
da biblioteca OpenCV e carregar os arquivos .JAR da biblioteca JavaCV para o
seu computador;
e) permitir dividir a carga de processamento do treinamento e reconhecimento das
faces em mais de um servidor;
f) incluir o cálculo da distância entre os pontos projetados no subespaço PCA
utilizando o método dos centroides (LOESCH; HOELTGEBAUM, 2012, p. 119);
g) permitir extrair apenas as características mais rígidas da face como, por exemplo,
os olhos;
h) explorar outras técnicas de extração de características podendo ser: análise das
discriminantes lineares (Linear Discriminant Analysis - LDA), classificador de
Bayes, Support Vector Machines (SVM), árvores de decisão, boosting, Gradient
Boosted Trees (GBT), árvores aleatórias e redes neurais;
i) permitir o reconhecimento da face com expressões e de perfil;
j) impedir tentativas de burlar o sistema com a utilização de uma foto do usuário,
por exemplo, através de técnicas de reconhecimento facial em 3D;
k) permitir via ferramenta, alterar uma imagem de treino com o objetivo da
ferramenta ir aprendendo como a pessoa muda com o passar do tempo;
l) criar um esquema de auto envelhecimento das faces de treinamento de forma que
continue reconhecendo a pessoa mesmo com o seu envelhecimento;
m) efetuar análise de performance e memória tanto do applet rodando no navegador
web do usuário como do aplicativo servidor.

131
REFERÊNCIAS BIBLIOGRÁFICAS
ADOBE SYSTEMS INCORPORATED. Adobe photoshop cs2: help. Version 9.0. [S.l.],
2005. Documento eletrônico disponibilizado com o Ambiente Adobe Photoshop CS2.
AFONSO, Rodrigo. Bradesco terá biometria em todos os ATMs em três anos. São Paulo,
2009. Disponível em: <http://computerworld.uol.com.br/gestao/2009/06/18/bradesco-tera-
biometria-em-todos-os-atms-em-tres-anos>. Acesso em: 13 set. 2011.
AMAZON.COM. Minoru 3D webcam (red/chrome). [S.l.], 2008. Disponível em:
<http://www.amazon.com/Minoru-3D-Webcam-Red-Chrome/dp/B001NXDGFY>. Acesso
em: 30 out. 2011.
ANÁGLIFO. In: WIKIPÉDIA, a enciclopédia livre. [S.l.]: Wikimedia Foundation, 2011.
Disponível em: <http://pt.wikipedia.org/wiki/An%C3%A1glifo>. Acesso em: 30 out. 2011.
BEZERRA, Eduardo. Princípios de análise e projeto de sistemas com UML. 2. ed. Rio de
Janeiro: Campus, 2007.
BLOG DO ROST. Joaninha. [S.l.], 2011. Disponível em:
<http://blogdorost.blogspot.com.br/2011/06/joaninha.html>. Acesso em: 18 maio 2012.
BRADSKI, Gary; KAEHLER, Adrian. Learning OpenCV. Sebastopol: O'Reilly books,
2008.
CAMPOS, Teófilo E. Técnicas de seleção de características com aplicação em
reconhecimento de faces. 2001. 160 f. Dissertação (Mestrado em Ciência da Computação) -
Instituto de Matemática e Estatística, Universidade de São Paulo, São Paulo.
ESTEREOSCOPIA. In: WIKIPÉDIA, a enciclopédia livre. [S.l.]: Wikimedia Foundation,
2011. Disponível em: <http://pt.wikipedia.org/wiki/Estereoscopia>. Acesso em: 30 out. 2011.
FACON, Jacques. Processamento e analise de imagens. Embalse: EBAI, 1993.
FUJIFILM. FinePix AX300. Manaus, [2012]. Disponível em:
<http://www.fujifilm.com.br/produtos/mundo_digital/cameras_amadoras/ax300/index.html>.
Acesso em: 01 maio 2012.
GONZALEZ, Rafael C.; WOODS, Richard E. Processamento de imagens digitais. São
Paulo: Edgard Blücher, 2000.
JACO WEB SECURITY. Assinatura de applet. [S.l.], 2010. Disponível em:
<http://gcseg.das.ufsc.br/jacoweb/restrito/documentos/assinatura/index.htm>. Acesso em: 18
maio 2012.

132
LOESCH, Cláudio; HOELTGEBAUM, Marianne. Métodos estatísticos multivariados. São
Paulo: Saraiva, 2012.
LOPES, Luis F. D. Análise de componentes principais aplicada à confiabilidade de
sistemas complexos. 2001. 121 f. Tese (Doutorado em Engenharia de Produção) - Programa
de Pós-graduação em Engenharia de Produção, Universidade Federal de Santa Catarina,
Florianópolis.
MARQUES, Jorge S. Reconhecimento de padrões: métodos estatísticos e neurais. 2. ed.
Lisboa: IST Press, 2005.
MARQUES FILHO, Ogê; VIEIRA NETO, Hugo. Processamento digital de imagens. Rio
de Janeiro: Brasport, 1999.
MINORU. Minoru is the worlds first consumer 3D webcam. [S.l.], [2008?]. Disponível
em: <http://www.minoru3d.com>. Acesso em: 30 out. 2011.
MORIMOTO, Carlos E. Interpolação. [S.l.], 2005. Disponível em:
<http://www.hardware.com.br/termos/interpolacao>. Acesso em: 01 mar. 2012.
MUNIZ, Diógenes. Entenda o que é e como funciona a biometria. São Paulo, 2007.
Disponível em: <http://www1.folha.uol.com.br/folha/informatica/ult124u21496.shtml>.
Acesso em: 01 maio 2012.
NÍVEL de cinza. In: WIKIPÉDIA, a enciclopédia livre. [S.l.]: Wikimedia Foundation, 2011.
Disponível em: <http://pt.wikipedia.org/wiki/N%C3%ADvel_de_cinza>. Acesso em: 02 nov.
2011.
OPENCV. In: WIKIPÉDIA, a enciclopédia livre. [S.l.]: Wikimedia Foundation, 2011.
Disponível em: <http://pt.wikipedia.org/wiki/OpenCV>. Acesso em: 06 nov. 2011.
PAMPLONA SOBRINHO, Luciano. Reconhecimento facial 2D para sistemas de
autenticação em dispositivos móveis. 2010. 55 f. Trabalho de Conclusão de Curso
(Bacharelado em Ciência da Computação) – Centro de Ciências Exatas e Naturais,
Universidade Regional de Blumenau, Blumenau.
REAES, Fabio M. Reconhecimento de faces em imagens: projeto Beholder. 2006. 27 f.
Trabalho de Formatura Supervisionado (Bacharelado em Ciência da Computação) – Instituto
de Matemática e Estatística, Universidade de São Paulo, São Paulo.
ROSE INDIA TECHNOLOGIES PVT. LTD. What is an applet. [S.l.], 2007. Disponível em:
<http://www.roseindia.net/java/example/java/applet/applet.shtml>. Acesso em: 08 maio 2011.
SHIRAI, Yoshiaki. Three-dimensional computer vision. Berlin: Springer-Verlag, 1987.

133
SMARTSEC. Biometria. São Paulo, [2012]. Disponível em:
<http://www.smartsec.com.br/biometria.html>. Acesso em: 01 maio 2012.
TRANSFORMADA DE HAAR. In: WIKIPÉDIA, a enciclopédia livre. [S.l.]: Wikimedia
Foundation, 2012. Disponível em: <http://pt.wikipedia.org/wiki/Transformada_de_Haar>.
Acesso em: 17 maio 2011.
WHATWG. Video conferencing and peer-to-peer communication: HTML standard. [S.l.],
2011. Disponível em: <http://www.whatwg.org/specs/web-apps/current-
work/multipage/video-conferencing-and-peer-to-peer-communication.html#introduction-10>.
Acesso em: 30 out. 2011.

134
APÊNDICE A – Detalhamento do ator e casos de uso especificados
Neste apêndice é apresentado o detalhamento do ator e dos casos de uso definidos para
especificar este trabalho, conforme diagramas ilustrados na seção 3.2.2. O Quadro 61 contém
o ator com sua respectiva descrição. Do Quadro 62 até o Quadro 65 são detalhados os casos
de uso.
Ator Descrição
Usuário
Ator principal do sistema (primário). É ele
quem inicia os casos de uso através do
navegador web.
Quadro 61 - Descrição do ator Usuário
UC01 - Cadastrar usuário
Sumário: Usuário usa o sistema para se cadastrar.
Ator principal: Usuário
Precondições:
- O Usuário possui pelo menos um dispositivo de captura de vídeo instalado e funcionando
em seu computador;
- O Usuário está na tela de login.
Fluxo principal:
1. O Usuário seleciona a aba “Cadastrar novo usuário”;
2. O sistema apresenta a tela de cadastro de usuário;
3. O Usuário preenche os campos Nome, Usuário, Senha e Repita a senha;
4. O Usuário efetua as capturas clicando no botão “Capturar”;
5. O sistema efetua a captura da imagem e atualiza o texto do campo “Capturas”
incrementando o valor do número antes da “/”;
6. O usuário clica no botão “Cadastrar”;
7. O sistema valida que todas as informações estão corretas e envia para o aplicativo
servidor;
8. O aplicativo servidor recebe as informações, efetua o treinamento e armazena as
informações com as faces do Usuário na base de dados;
9. O aplicativo servidor retorna mensagem de sucesso na operação;
10. O sistema recebe a mensagem do aplicativo servidor e exibe para o Usuário;
11. O caso de uso termina.
Fluxo alternativo: O usuário opta por reiniciar a operação
No passo 6 do fluxo principal, o usuário opta por reiniciar a operação.
1. O Usuário clica no botão “Reiniciar”;
2. O sistema exibe uma mensagem de confirmação;

135
3. O usuário confirma a mensagem;
4. O sistema limpa os campos da seção “Dados do usuário”, as faces capturadas e atualiza o
texto do campo “Capturas”;
5. Volta ao passo 4 do fluxo principal.
Fluxo de exceção: Usuário não informou o campo “Nome”
No passo 7 do fluxo principal, se o Usuário clicar no botão “Cadastrar” e não informar o
campo “Nome”, o sistema exibe uma mensagem reportando o fato e retorna ao passo 3 do
fluxo principal.
Fluxo de exceção: Usuário não informou o campo “Usuário”
No passo 7 do fluxo principal, se o Usuário clicar no botão “Cadastrar” e não informar o
campo “Usuário”, o sistema exibe uma mensagem reportando o fato e retorna ao passo 3 do
fluxo principal.
Fluxo de exceção: Usuário não informou o campo “Senha”
No passo 7 do fluxo principal, se o Usuário clicar no botão “Cadastrar” e não informar o
campo “Senha”, o sistema exibe uma mensagem reportando o fato e retorna ao passo 3 do
fluxo principal.
Fluxo de exceção: Usuário não informou o campo “Repita a senha”
No passo 7 do fluxo principal, se o Usuário clicar no botão “Cadastrar” e não informar o
campo “Repita a senha”, o sistema exibe uma mensagem reportando o fato e retorna ao passo
3 do fluxo principal.
Fluxo de exceção: Os campos “Senha” e “Repita a senha” são diferentes
No passo 7 do fluxo principal, se o Usuário clicar no botão “Cadastrar” e não informou o
mesmo valor para os campos “Senha” e “Repita a senha”, o sistema exibe uma mensagem
reportando o fato e retorna ao passo 3 do fluxo principal.
Fluxo de exceção: O correu algum erro no envio dos dados para o aplicativo servidor
No passo 6 do fluxo principal, se o Usuário clicar no botão “Cadastrar” e ocorrer algum erro
relacionado ao aplicativo servidor, o sistema reporta o fato e retorna ao passo 6 do fluxo
principal.
Pós condição: Usuário cadastrado na base de dados com suas faces e dados.
Quadro 62 - Descrição do UC01 - Cadastrar usuário

136
UC02 - Autenticar usuário através da face
Sumário: O Usuário se autentica no sistema através da sua face.
Ator principal: Usuário
Precondições:
- O Usuário possui pelo menos um dispositivo de captura de vídeo instalado e funcionando
em seu computador;
- O Usuário está na tela de login, com a aba “Autenticar usuário” ativa e selecionou a opção
“Através da face” em “Tipo de autenticação”.
Fluxo principal:
1. O sistema apresenta a tela de autenticação de usuário através da face;
2. O sistema acessa o dispositivo de vídeo do Usuário e exibe a sequência de imagens no
grupo “Câmera”;
3. O sistema detecta a maior face da imagem como sendo a face do Usuário e desenha um
retângulo verde em torno dela;
4. A qualquer momento o Usuário marca a opção “Reconhecer automaticamente”;
5. O Usuário clica no notão “Autenticar”;
6. O sistema:
a. detecta a face do usuário;
b. converte para tons de cinza;
c. reduz a resolução;
d. equaliza o histograma e;
e. ajusta a pose da face.
7. O sistema submete a face do usuário para o aplicativo servidor;
8. O aplicativo servidor recebe a face do usuário e processa o reconhecimento;
9. O aplicativo servidor envia resposta do reconhecimento para o sistema;
10. O sistema recebe a resposta do aplicativo servidor e exibe mensagem para o Usuário;
11. O Usuário é redirecionado para a página principal;
12. O caso de uso termina.
Fluxo alternativo: O Usuário opta por reconhecer automaticamente.
No passo 4 do fluxo principal, o Usuário marca a opção “Reconhecer automaticamente”.
1. O Usuário marca a opção “Reconhecer automaticamente”;
2. Vai para o caso de uso UC05 - Reconhecer usuário automaticamente;
3. Retorna ao passo 3 do fluxo principal.
Fluxo de exceção: Nenhuma face foi encontrada na imagem.
No passo 7 do fluxo principal, se o Usuário clicar no botão “Autenticar” e o sistema não
detectar nenhuma face na imagem capturada, ele exibe a mensagem “Nenhuma face foi
encontrada na imagem” e retorna ao passo 4 do fluxo principal.
Fluxo de exceção: Ocorreu algum erro no envio dos dados para o aplicativo servidor
No passo 8 do fluxo principal, se o Usuário clicar no botão “Autenticar” e ocorrer algum erro
relacionado ao aplicativo servidor, o sistema reporta o fato e retorna ao passo 5 do fluxo
principal.

137
Fluxo de exceção: Usuário não reconhecido.
No passo 8 do fluxo principal, se o Usuário clicar no botão “Autenticar” e o usuário não for
reconhecido pelo sistema, ele exibe a mensagem “Usuário NÃO reconhecido!” e retorna ao
passo 5 do fluxo principal.
Pós condição: Usuário reconhecido.
Quadro 63 - Descrição do UC02 - Autenticar usuário através da face
UC03 - Reconhecer usuário automaticamente
Sumário: O Usuário pode verificar se o sistema o reconhece automaticamente.
Ator principal: Usuário
Precondições:
- O Usuário possui pelo menos um dispositivo de captura de vídeo instalado e funcionando
em seu computador;
- O Usuário está na tela de login, com a aba “Autenticar usuário” ativa e a opção “Através da
face” está selecionada no grupo “Tipo de autenticação”.
Fluxo principal:
1. O Usuário marca a opção “Reconhecer automaticamente”;
2. O sistema:
a. detecta a face do usuário;
b. converte para tons de cinza;
c. reduz a resolução;
d. equaliza o histograma e;
e. ajusta a pose da face.
3. O sistema submete a face do usuário para o aplicativo servidor;
4. O aplicativo servidor recebe a face do usuário e processa o reconhecimento;
5. O aplicativo servidor envia resposta do reconhecimento para o sistema;
6. O sistema recebe a resposta do aplicativo servidor e exibe o nome do Usuário se ele foi
reconhecido ou o texto “Usuário desconhecido” caso contrário, na base do retângulo
verde em torno à face;
7. Retorna ao passo 2;
Fluxo alternativo: O Usuário desmarca a opção para reconhecer o usuário automaticamente.
A qualquer momento a partir do passo 1 do fluxo principal, o Usuário opta por desmarcar a
opção “Reconhecer automaticamente”.
1. O Usuário desmarca a opção “Reconhecer automaticamente”;
2. O sistema para de efetuar o reconhecimento automático e remove o texto exibido na base
do retângulo verde desenhado em torno da face do usuário;
3. Volta ao fluxo principal do UC03 - Autenticar usuário através da face;
4. O caso de uso termina.
Pós condição: Usuário reconhecido.
Quadro 64 - Descrição do UC03 - Reconhecer usuário automaticamente

138
UC04 - Autenticar usuário através de usuário e senha
Sumário: O Usuário se autentica no sistema através de um usuário e uma senha.
Ator principal: Usuário
Precondições:
- O Usuário possui pelo menos um dispositivo de captura de vídeo instalado e funcionando
em seu computador;
- O Usuário está na tela de login, com a aba “Autenticar usuário” ativa.
Fluxo principal:
1. O Usuário seleciona a opção “Através de usuário e senha” no grupo “Tipo de
autenticação”;
2. O sistema apresenta a tela de autenticação de usuário através de login e senha;
3. O Usuário informa os campos “Usuário” e “Senha” e clicar no botão “Autenticar”;
4. O sistema valida que os dados foram informados e os submete para o aplicativo servidor;
5. O aplicativo servidor recebe os dados e processa o reconhecimento;
6. O aplicativo servidor envia resposta do reconhecimento para o sistema;
7. O sistema recebe a resposta do aplicativo servidor e exibe mensagem para o Usuário;
8. O Usuário é redirecionado para página de faces coletadas;
9. O caso de uso termina.
Fluxo de exceção: O correu algum erro no envio dos dados para o aplicativo servidor
No passo 4 do fluxo principal, se o Usuário clicar no botão “Autenticar” e ocorrer algum erro
relacionado ao aplicativo servidor, o sistema reporta o fato e retorna ao passo 4 do fluxo
principal.
Fluxo de exceção: Usuário não reconhecido.
No passo 4 do fluxo principal, se o Usuário clicar no botão “Autenticar” e ele não for
reconhecido pelo sistema, o sistema exibe a mensagem “Usuário/senha inválido!” e retorna
ao passo 4 do fluxo principal.
Fluxo de exceção: O campo “Usuário” não foi informado.
No passo 4 do fluxo principal, se o Usuário clicar no botão “Autenticar” e o campo
“Usuário” não for informado, o sistema exibe a mensagem “O usuário deve se informado.” e
retorna ao passo 3 do fluxo principal.
Fluxo de exceção: O campo “Senha” não foi informado.
No passo 4 do fluxo principal, se o Usuário clicar no botão “Autenticar” e o campo “Senha”
não for informado, o sistema exibe a mensagem “A senha deve ser informada.” e retorna ao
passo 3 do fluxo principal.
Pós condição: Usuário reconhecido.
Quadro 65 - Descrição do UC04 - Autenticar usuário através de usuário e senha
Recommended

















