Embed Size (px)
Citation preview

TRABAJO FIN DE GRADO
ESCUELA UNIVERSITARIA POLITECNICA
Departamento de Ciencias Politécnicas
Grado en Ingeniería Informática
Desarrollo de un software de predicción financiera
Autor:
D. José Carlos Cano Lorente
Directores:
Dr. D. José María Cecilia Canales
Dr. D. Horacio Pérez Sánchez
Murcia, Junio de 2015




TRABAJO FIN DE GRADO
ESCUELA UNIVERSITARIA POLITECNICA
Departamento de Ciencias Politécnicas
Grado en Ingeniería Informática
Desarrollo de un software de predicción financiera
Autor:
D. José Carlos Cano Lorente
Directores:
Dr. D. José María Cecilia Canales
Dr. D. Horacio Pérez Sánchez
Murcia, Junio de 2015


Autorización
Dr. D. José María Cecilia Canales y Dr. D. Horacio Pérez Sánchez,
profesores de la UCAM
CERTIFICAN: que el Trabajo Fin de Grado titulado “Desarrollo de un
software de predicción financiera” que presenta D. José Carlos Cano Lorente,
para optar al título oficial de Grado en Ingeniería Informática, ha sido realizado
bajo su dirección.
A su juicio reúne las condiciones necesarias para ser presentado en la
Universidad Católica San Antonio de Murcia y ser juzgado por el tribunal
correspondiente.
Murcia, a de Junio de 2015


Agradecimientos
A mis directores de proyecto, José María Cecilia y Horacio Pérez, que
desde nuestra primera reunión para tratar el desarrollo de este TFG, mostraron
una gran confianza en lo que podríamos conseguir, y supieron transmitirme esa
ilusión. Sus enseñanzas e indicaciones han sido fundamentales para enfocar la
metodología y no perder de vista nunca los objetivos que perseguíamos.
A la empresa Artificial Intelligence Talentum, S.L., por haber colaborado
con la UCAM en definir este proyecto, y por darme la oportunidad de contribuir
humildemente en una parte del ambicioso proyecto del desarrollo de
herramientas de trading. Sus ánimos, desde nuestra primera entrevista, han
sido muy gratificantes.
A la Universidad Católica San Antonio de Murcia, por ofrecerme la
posibilidad de actualizar mi formación. Su plan de estudios on-line es de gran
calidad, y permite compaginar la vida profesional, familiar y académica de
muchas personas como yo.
Y a mi esposa y mis tres hijas, que me han acompañado con resignación
durante los dos últimos años en mis dedicación al estudio de las asignaturas y
a la elaboración de este TFG.


Índice de contenidos
Índice de contenidos ............................................................................................. 11
1 Introducción .................................................................................................... 25
1.1 Motivación .................................................................................................. 25
1.2 Definición .................................................................................................... 26
1.3 Objetivos propuestos .................................................................................. 26
2 Estudio del mercado ....................................................................................... 29
2.1 Conceptos relevantes del dominio de la aplicación ................................... 29
2.2 Relación con proyectos con la misma funcionalidad .................................. 35
2.3 Estudio de viabilidad ................................................................................... 37
2.3.1 Alcance del proyecto ............................................................................. 37
2.3.2 Estudio de la situación actual ................................................................ 37
2.3.3 Estudio y valoración de las alternativas de solución ............................. 38
2.3.4 Selección de la solución ......................................................................... 38
3 Metodologías usadas ...................................................................................... 41
3.1 Desarrollo en cascada o secuencial ............................................................ 41
3.2 Metodología Ágil ......................................................................................... 42
3.2.1 XP (Extreme Programming) ................................................................... 44
3.2.2 SCRUM ................................................................................................... 44
3.2.3 Otras metodologías ágiles ..................................................................... 47
3.3 Metodología elegida ................................................................................... 47
3.3.1 Los roles ................................................................................................. 48
3.3.2 Los eventos ............................................................................................ 49
3.3.3 Seguimiento ........................................................................................... 49
4 Tecnologías y herramientas utilizadas en el proyecto .................................... 51
4.1 Cygwin ......................................................................................................... 51
4.2 VMWare Player ........................................................................................... 52


4.3 Eclipse ......................................................................................................... 52
4.4 Subversion ................................................................................................... 52
4.5 Python y Matplotlib .................................................................................... 53
4.6 Libconfig ...................................................................................................... 53
4.7 TA-Lib .......................................................................................................... 54
4.8 Kunagi ......................................................................................................... 54
5 Estimación de recursos y planificación ........................................................... 57
5.1 Método de estimación utilizado ................................................................. 57
5.2 Planificación ................................................................................................ 59
5.3 Valoración de la dedicación y coste económico ......................................... 64
5.3.1 Costes de material ................................................................................. 64
5.3.2 Costes de consultoría ............................................................................ 65
6 Desarrollo del proyecto ................................................................................... 67
6.1 Preparativos ................................................................................................ 67
6.2 Sprint 1 ........................................................................................................ 71
6.2.1 Sprint Planning ...................................................................................... 71
6.2.2 Sprint Review ......................................................................................... 74
6.2.3 Sprint Retrospective .............................................................................. 76
6.2.4 Demos .................................................................................................... 77
6.3 Sprint 2 ........................................................................................................ 79
6.3.1 Sprint Planning ...................................................................................... 79
6.3.2 Sprint Review ......................................................................................... 83
6.3.3 Sprint Retrospective .............................................................................. 85
6.3.4 Demos .................................................................................................... 86
6.4 Sprint 3 ........................................................................................................ 89
6.4.1 Sprint Planning ...................................................................................... 89
6.4.2 Sprint Review ......................................................................................... 92
6.4.3 Sprint Retrospective .............................................................................. 93
6.4.4 Demos .................................................................................................... 94


6.5 Sprint 4 ........................................................................................................ 95
6.5.1 Sprint Planning ...................................................................................... 95
6.5.2 Sprint Review ....................................................................................... 101
6.5.3 Sprint Retrospective ............................................................................ 102
6.5.4 Demos .................................................................................................. 102
6.6 Sprint 5 ...................................................................................................... 104
6.6.1 Sprint Planning .................................................................................... 104
6.6.2 Sprint Review ....................................................................................... 110
6.6.3 Sprint Retrospective ............................................................................ 111
6.6.4 Demos .................................................................................................. 111
6.7 Sprint 6 ...................................................................................................... 113
6.7.1 Sprint Planning .................................................................................... 113
6.7.2 Sprint Review ....................................................................................... 117
6.7.3 Sprint Retrospective ............................................................................ 118
6.7.4 Demos .................................................................................................. 119
7 Pruebas y Despliegue de la solución ............................................................ 121
7.1 Pruebas ..................................................................................................... 121
7.2 Despliegue ................................................................................................. 136
8 Conclusiones ................................................................................................ 137
8.1 Objetivos alcanzados ................................................................................ 137
8.2 Conclusiones del trabajo y personales ..................................................... 138
8.3 Vías futuras ............................................................................................... 138
9 Bibliografía .................................................................................................... 141
10 Anexo I Diseño de la aplicación ................................................................. 145
10.1 Gestión de memoria .............................................................................. 145
10.1.1 Datos históricos ................................................................................. 145
10.1.2 Nuevos indicadores ........................................................................... 146
10.1.3 Datos de configuración y control del proceso................................... 148
10.2 Proceso .................................................................................................. 151


10.3 Módulos................................................................................................. 152
11 Anexo II Manual de Usuario ...................................................................... 155
11.1 Introducción .......................................................................................... 155
11.2 Preparando la ejecución ........................................................................ 156
11.3 Indicadores técnicos .............................................................................. 159
11.4 Definiendo los escenarios ..................................................................... 161
11.4.1 Indicadores técnicos .......................................................................... 161
11.4.2 Gráficos .............................................................................................. 163
11.4.3 Constantes ......................................................................................... 165
11.4.4 Operaciones ....................................................................................... 166
11.4.5 Precios ............................................................................................... 168
11.4.6 Uniéndolo todo .................................................................................. 168
11.5 Escritura de fórmulas ............................................................................ 169
11.6 Ejecución ............................................................................................... 170
11.7 Manejo de errores ................................................................................. 175
12 Anexo III Manual de Instalación................................................................. 177
12.1 Instalación en Linux ............................................................................... 177
12.1.1 Linux como máquina virtual sobre Windows (opcional) ................... 177
12.1.2 Instalación del IDE Eclipse (opcional) ................................................ 188
12.1.3 Instalación de TA-Lib ......................................................................... 191
12.1.4 Instalación de libconfig ...................................................................... 193
12.1.5 Instalación de Python ........................................................................ 195
12.1.6 Instalación de matplotlib ................................................................... 196
12.1.7 Instalación de MySQL ........................................................................ 197
12.2 Instalación en Windows ........................................................................ 197
12.2.1 Instalación del compilador ................................................................ 197
12.2.2 Instalación de TA-lib .......................................................................... 205
12.2.3 Instalación de libconfig ...................................................................... 209
12.2.4 Instalación de python ........................................................................ 210


12.2.5 Instalación de matplotlib ................................................................... 211
12.2.6 Instalación de subversion .................................................................. 211
12.2.7 Instalación del cliente MySql ............................................................. 213
12.3 Instalación de la aplicación “Trading” ................................................... 213
12.3.1 Instalación de un ejecutable ............................................................. 213
12.3.2 Instalación del código fuente ............................................................ 214
13 Lista de colores definidos en matplotlib ..................................................... 219
14 Lista de errores de ejecución..................................................................... 221
15 Índice de figuras ........................................................................................ 223
16 Índice de tablas ......................................................................................... 231
17 Glosario de términos ................................................................................. 235


21
Resumen
Los inversores, cuando actúan en el mercado, se mueven guiados por
las perspectivas de evolución de una u otra empresa, tipos de cambio, etc.
Estas perspectivas se ven influenciadas por datos fundamentales como pueden
ser resultados anuales, evolución del volumen de facturación o capacidad de
crecimiento, cuando trabajamos con empresas, o datos macroeconómicos y
acontecimientos a nivel mundial, cuando trabajamos en el Mercado de Divisas.
El éxito o fracaso de las inversiones vienen determinados por el
momento en el que el inversor entra o sale de los mercados, por lo que la
búsqueda de buenas estrategias de trading, entendidas éstas como una serie
de reglas (matemáticas, algorítmicas, analíticas o gráficas) que definan la
forma de operar, se ha convertido en objetivo primordial de los inversores.
El avance de la tecnología e Internet ha puesto al alcance de cualquier
persona suficiente información sobre empresas, naciones y mercados como
para que todos seamos potenciales inversores.
Pero también ha facilitado la creación de ingentes repositorios
informatizados de datos históricos, favoreciendo con ello el denominado
“análisis técnico”, encargado de predecir tendencias futuras basándose en la
evolución pasada de las cotizaciones.
Es en este punto donde se ha desarrollado este TFG, ofreciendo al
cliente una herramienta de software que evalúa varias estrategias o escenarios,
aplicando diferentes reglas e indicadores a un conjunto de datos de entrada,
simulando cómo se hubiera comportado y qué beneficios o pérdidas se
hubieran obtenido en cada caso.
Un buena estrategia de trading puede ser posteriormente el núcleo de
un sistema de trading automatizado (que opere sin intervención humana)
decidiendo cuándo entrar y salir del mercado, e interactuando con el mercado
real.
Palabras clave:
Mercado, Divisa, Bolsa, Análisis Técnico, Indicador

22

23
Abstract
Investors, when acting in the financial markets, are moved by the
evolutions perspective of the companies, exchange rates, etc. These
perspectives are influenced by fundamental data such as annual results,
evolution in turnover and growth capacity, (when working with company stocks)
or macroeconomic data and worldwide events (when working in the Forex
market).
The success or failure of investments are determined by the time at
which the investor enters or leaves the markets, so finding good trading
strategies, understanding these as a set of rules (mathematical, algorithmic,
analytical or graphical) that define the way we operate, has become a primary
target of investors.
The advancement of technology and the Internet has provided to anyone
with required information about companies, nations and markets to make we all
potential investors.
But it has also facilitated the creation of huge databases storing historical
data, favoring the so-called "technical analysis" in charge of predicting future
trends based on past prices development.
The present work has been developed in this area, offering the customer
a software tool that evaluates several strategies or scenarios by applying
different rules and indicators to a set of input data, simulating the behavior and
which profits or losses could have been obtained in each case.
A good trading strategy can subsequently be the nucleus of an
automated trading system (which operate without human intervention) deciding
when to enter and exit the market, and interacting with the real market.
Keywords:
Market, Currency, Exchange, Technical Analysis, Indicator.

24

25
1 Introducción
1.1 Motivación
Un operador de bolsa (o trader) puede realizar operaciones basándose
en decisiones individuales, considerando cuándo y qué comprar o vender en
cada momento. Sus decisiones se basarán en el conocimiento del que
disponga sobre la evolución de los diferentes valores bursátiles o tipos de
cambio. También debe ser capaz de inferir comportamientos futuros tomando
como base información económica precisa, pero también el “estado de ánimo”
de los mercados. Adicionalmente, un trader experimentado podrá aplicar
experiencias basadas, que influenciarán sus decisiones en un sentido u otro.
De esta forma, toda la responsabilidad recae en el individuo, por lo que
las emociones podrían influir en la toma de decisiones. Además, su eficacia
operativa estará relacionada con la capacidad que tenga de estar vigilando el
mercado continuamente, pero siempre concentrándose en unos productos, que
tenderán a ser unos pocos.
Sin embargo, un trading automático puede vigilar el mercado
continuamente, para tantos productos como se diseñe y, basándose en un
conjunto de reglas, actuará en los mercados, eliminado el componente de las
emociones en la toma de decisiones.
Obviamente, una y otra metodología presentan ventajas y desventajas, y
siempre podemos pensar que una combinación de ambas ofrecerá mejores
resultados.
A la hora de elaborar una estrategia, los profesionales del trading utilizan
diversos indicadores que, aplicados sobre un conjunto de datos, nos pueden
indicar la tendencia que puedan seguir los precios. El trader, usará su
creatividad para elegir la combinación de indicadores que determinarán las
entrada en el mercado. Las salidas del mercado vendrán determinados por lo
puntos de máxima pérdida aceptada (lo que se denomina Stop Loss) y del nivel
de recogida de beneficios (conocido como Take Profit).
La principal motivación de este proyecto ha sido ayudar al trader en la
fase del backtesting o, según define Holland [1], “[…] la evaluación de las
rentabilidades que caben esperar de una estrategia de trading basada en los
rendimientos calculados a partir de datos históricos”. Con una herramienta de
este tipo, se puede probar si una determinada combinación de parámetros
funcionó en el pasado e indica al trader lo acertado o equivocada que puede
ser una estrategia.

26
El desarrollo de una herramienta de backtesting, principal objetivo de
este proyecto, engloba varias disciplinas, incluyendo la economía, la
informática y la estadística. Este hecho contribuyó de manera decisiva a que el
autor lo seleccionara como TFG.
1.2 Definición
Durante este TFG se ha desarrollado la aplicación “Trading”, una
aplicación de escritorio enfocada principalmente a entornos de
supercomputación sobre Linux.
Se ha desarrollo en lenguaje C, buscando rapidez de ejecución y
eficiencia en el manejo de grandes volúmenes de datos.
Funcionalmente este software permite la lectura de datos históricos de
operaciones en mercados financieros, desde fichero o desde una base de
datos. Sobre esta información, y en base a archivos de configuración creados
por el usuario, es capaz de calcular índices financieros y, en combinación con
un conjunto de reglas, decidir entradas y salidas del mercado. Finalmente
reporta el rendimiento de las operaciones para decidir qué reglas son las más
beneficiosas.
Adicionalmente ofrece una salida gráfica donde, sobre diagramas de
velas con los precios, se pueden mostrar los indicadores técnicos y las
operaciones de entrada/salida.
1.3 Objetivos propuestos
Los objetivos marcados por nuestro cliente (Artificial Intelligence
Talentum, S.L.) para este proyecto quedan detallados a continuación:
Objetivo General 1 (OG1): Desarrollo de una aplicación eficiente
o Objetivos Específico 1 (OE1): Desarrollo de un programa
automatizable (mediante el uso de archivos de
configuración), para el funcionamiento en
supercomputadoras
o Objetivos Específico 2 (OE2): Uso de un lenguaje de
programación eficiente en términos de velocidad y
memoria
Objetivo General 2 (OG2): Desarrollo de una herramienta de
análisis visual de operaciones en los mercados
o Objetivos Específico 3 (OE3): Lectura de datos a través de
un fichero o directamente desde una base de datos

27
o Objetivos Específico 4 (OE4): Representación gráfica de
datos históricos e indicadores técnicos, mediante gráficos
de velas y líneas
Objetivo General 3 (OG3): Desarrollo de una herramienta de
backtesting
o Objetivo Específico 5 (OE5): Calcular indicadores técnicos
sobre un conjunto de datos históricos
o Objetivo Específico 6 (OE6): En base a un conjunto de
reglas, decidir el momento de realizar una operación en el
mercado y de finalizar la misma
o Objetivo Específico 7 (OE7): calcular el beneficio neto del
conjunto de operaciones que se produzcan en el periodo
de tiempo establecido
o Objetivo Específico 8 (OE8): elaborar un informe con datos
estadísticos sobre las operaciones realizadas

28

29
2 Estudio del mercado
2.1 Conceptos relevantes del dominio de la aplicación
Según podemos consultar en el “Diccionario Económico” de la edición
digital del diario expansión [8], “El mercado financiero es el lugar, mecanismo
o sistema electrónico donde se negocian los activos, productos e instrumentos
financieros o se ponen en contacto los demandantes y los oferentes del activo
y es donde se fija un precio público de los activos por la confluencia de la oferta
y la demanda”.
Otra definición la podemos encontrar en la enciclopedia financiera on-
line, donde se nos indica que “Un Mercado Financiero pude definirse como un
conjunto de mercados en los que los agentes deficitarios de fondos los
obtienen de los agentes con superávit” [9].
Según esta misma fuente, los principales mercados financieros son los
siguientes:
Bolsas de Valores: Una bolsa de valores es una organización que
establece "sistemas de negociación" para que los inversores
puedan comprar y vender acciones, derivados y otros valores.
Las bolsas de valores también proporcionan las instalaciones
para la emisión y amortización de valores, así como otros
instrumentos financieros y los rendimientos de capital incluyendo
el pago de dividendos. Se trata de una de las fuentes más
importantes de recaudación de capital para las empresas.
Mercados de Renta Fija: El mercado de bonos (también conocido
como de deuda, de crédito, o mercado de renta fija) es un
mercado financiero, donde los participantes compran y venden
títulos de deuda, normalmente en forma de bonos. Los mercados
de renta fija, en la mayoría de los países siguen siendo
descentralizados, al contrario del mercado de acciones, futuros y
del mercado de factores. Esto ha ocurrido, en parte, porque no
hay dos emisiones de bonos exactamente iguales, lo que hace
que el número de títulos en el mercado sea inmenso.
Mercados de Divisas: El mercado de divisas o FOREX, permite
que los bancos, empresas y otras instituciones fácilmente
compren y vendan divisas. El propósito del mercado de divisas es
facilitar el comercio internacional y la inversión. El mercado de
divisas ayuda a las empresas a convertir una moneda en otra.

30
Mercados de Factores: El comercio de materias primas consiste
en el comercio físico directo y a través de derivados financieros
para la compra/venta a plazo permitiendo asegurar un precio de
venta o compra en el futuro a productores y/o clientes.
El análisis técnico, como herramienta para analizar los mercados y los
movimientos de precios, viene siendo utilizado desde el siglo XIX, en tiempos
del analista Chales Dow (que da nombre a la teoría considerada el origen de
los sistemas de inversión que usan como base esta metodología). Dow publicó
sus ideas en una serie de editoriales que escribió para el diario Wal Street
Journal.
Según John J. Murphy, autor de una publicación conocida y considerada
por muchos en este ámbito como la Biblia del Análisis Técnico, “La teoría de
Dow todavía es la piedra angular del estudio de análisis técnico, incluso ante la
sofisticada tecnología informática actual y la proliferación de indicadores
técnicos supuestamente nuevos y mejores” [4]
Murphy define el análisis técnico como “[…]el estudio de los
movimientos del mercado, principalmente mediante el uso de gráficos, con el
propósito de pronosticar las futuras tendencias de los precios” [5] y entiende
que los fundamentos que lo soportan son:
Los movimientos del mercado los descuentan todo. Según esto, el técnico
cree que cualquier cosas que posiblemente pueda afectar al precio (por
razones fundamentales, políticas, psicológicas u otras) se refleja
realmente en el precio de ese mercado. Concluye por tanto que todo lo
que hace falta es un estudio de los movimientos de los precios, sin
importar la razón de los mismos.
Los precios se mueven por tendencias, y es el propósito de este enfoque
identificarlas dentro de sus primeras etapas de desarrollo, con el fin de
que las transacciones vayan en la dirección de dichas tendencias hasta
que los precios muestren señales de variar la dirección que llevan.
La historia se repite y una gran parte del análisis técnico y del estudio del
movimiento de los mercados tiene que ver con el estudio de la psicología
humana. Por ejemplo, los patrones gráficos recogidos durante los últimos
cien años reflejan imágenes concretas que aparecen en los gráficos de
precios y reflejan la psicología alcista o bajista del mercado y, dado que
la psicología humana tiene tendencia a no cambiar, podemos pensar que,
si ha funcionado bien en el pasado, también funcionará en el futuro.

31
En el estudio del comportamiento del mercado la principal herramienta
son los gráficos, donde se representan las cotizaciones del mercado. Los más
utilizados son las velas japonesas, pues aportan una idea de la volatilidad de
los precios, el precio de cierre, de apertura, el máximo y el mínimo en cada
período. Una vela corresponde a un período y, de un vistazo, se observa si al
terminar el período se ha elevado el precio o ha disminuido. La vela verde
indica una tendencia alcista y la roja una bajista:
Figura 2 Gráfico de velas. Evolución de los precios
John J. Murphy dedica varios capítulos de su libro “Análisis técnico de
los mercados financieros” a describir diferentes tipos de gráficos y su utilidad
[6].
Ahora bien, el análisis mediante gráficos suele ser subjetivo ya que
puede darse el caso de que dos analistas, analizando la misma información,
extraigan conclusiones diferentes sobre la situación del mercado.
Figura 1 Gráfico de velas. Descripción

32
La otra herramienta que ofrece el análisis técnico, y que busca eliminar
en lo posible esa subjetividad, son los indicadores, que podríamos considerar
como ejemplo de comportamiento objetivo de forma que, mediante unas
determinadas reglas, se decidirán operaciones de entrada y salida del
mercado. Los indicadores hacen uso únicamente de instrumentos matemáticos
y estadísticos lo que permite su inclusión en herramientas de software que
ejecutan automáticamente decisiones basándose en las tendencias.
Se debe tener en cuenta que la mayoría de estos indicadores analizan la
naturaleza de las tendencias. Es por ello que se desaconseja su uso en el caso
de períodos temporales donde los mercados apenas muestran tendencia (por
ejemplo en momentos que se denominan “de movimiento lateral”).
A la hora de definir una estrategia de trading basada en indicadores
técnicos, el trader dispone de una gran cantidad de ellos donde elegir (por
ejemplo, TAlib, librería usada en este proyecto, ofrece 200 indicadores [37]). Es
fácil encontrar abundante bibliografía y Sites en internet sobre este tema pero
hay coincidencia sobre cuáles son los más utilizados:
Media móvil simple: aplicada a los precios de apertura o cierre de las
cotizaciones. Para generar órdenes de compra y venta se utiliza una regla
sencilla: las señales de compra se usan cuando la media móvil corta por
arriba la línea de precios y las de venta, cuando corta por abajo la línea
de precios.
RSI: Índice de fuerza relativa. Marca aquellos momentos en los que el
mercado tiene un estado de sobrecompra o sobreventa y en los cuales
hay que entrar a operar. En un rango de valores de 0 a 100 lo normal es
comprar cuando este indicador es menor a 70 y vender cuando sobrepasa
el valor de 30.
MME: media móvil exponencial. Se utiliza este tipo de medias porque
asigna más importancia a los precios de cierre más cercanos y menor
importancia a los más alejados.
Bandas de Bollinger: analiza las fluctuaciones del mercado, mediante una
línea central obtenida con una media móvil y dos bandas laterales,
obtenidas sumando y restando un determinado número de desviaciones
típicas.
Una vez diseñada la estrategia basada en el análisis técnico hay que
evaluar su fiabilidad, ejecutando con herramientas informáticas una simulación
contra datos históricos y analizando las ganancias y pérdidas del sistema, y

33
también el modo en que la estrategia opera (por ejemplo, se podría querer
conocer si la estrategia inicia muchas operaciones de pocos márgenes o pocas
de grandes márgenes). Estamos hablando del backtesting, objetivo principal
del software desarrollado en este TFG y que ayuda al trader a “afinar” el
sistema, permitiendo cambios en los parámetros y relanzar la simulaciones
para observar el impacto en el comportamiento.
Para evaluar la bondad de un sistema de trading se utilizan varios
ratios. De entre todos ellos, podemos destacar:
Beneficio Neto (o Profit): en principio ésta debería ser la medida
principal del rendimiento o efectividad de un sistema. Cuanto más
beneficio neto, mejor. Sin embargo surge una duda: si escogemos
el sistema que gana más ¿podemos asegurar que esto se
repetirá en el futuro?. Por eso, este ratio, usado por sí solo
presenta dos inconvenientes:
o Pudiera ser que la ganancia que ha entregado se haya
debido a una única operación de mucho beneficio, aunque
el resto de operaciones hayan sido pérdidas ¿se repetirá
en el futuro una operación de este tipo?
o Aunque el sistema tenga ganancias constantes, si en un
momento determinado ocasiona una pérdida de capital
muy elevada será muy probable que se piense que ha
dejado de funcionar (aunque no sea así) y se deje de
operar. Para manejar esta situación se introduce un nuevo
ratio.
Drawdown: es la máxima disminución de capital desde un
máximo anterior. Mide cuánto dinero se está perdiendo en un
momento determinado respecto de un momento anterior en el que
el sistema tuvo su máxima ganancia. Cuando miremos el
beneficio neto de un sistema deberíamos mirar también el
drawdown que vamos a tener que soportar para conseguir dicho
beneficio
Recovery Factor: relaciona los dos anteriores (divide la ganancia
neta entre el máximo drawdown del sistema). Un sistema que
genera un beneficio de 100 con un máximo drawdown de 10,
tiene un Recovery Factor de 10:1. A mayor ratio mejor estrategia.
Profit Factor: se calcula dividiendo la ganancia de las operaciones
ganadores entre la pérdida de las operaciones perdedoras. Por

34
definición, si la estrategia es rentable, el Profit Factor sería mayor
que 1.
Número de operaciones: indica el total de operaciones realizadas
en los mercados. Si nos interesa que nuestro sistema no genere
demasiadas operaciones, hay que incluir este ratio en el análisis.
Basándose en todos esos indicadores, un trader puede decidir si un
sistema es bueno o no. Así, por ejemplo, podría pedir que tuviera un Profit
Factor > 2 y un Recovery Factor > 7.
Como ejemplo, Oscar Cagigas en su blog [7], considera que las
características de un sistema que merece la pena ser operado con dinero real
son que:
Tiene menos de 4 o 5 parámetros (es sencillo)
Está evaluado en suficientes datos. Al menos 2 años si es intradía
y al menos 10 años si es diario. Como mínimo buscando unas
200 operaciones.
Genera ganancias año tras año, aunque sean limitadas y es
robusto, o sea que, variando ligeramente sus parámetros, sus
resultados varían ligeramente (es decir, no está construido sobre
un pico de ganancia).
Funciona en la mayoría de instrumentos con características
similares (otra forma de robustez).
Recovery Factor >= 6
Profit Factor >= 2
Dependiendo de la complejidad de la estrategia (número de indicadores
y reglas de decisión) y del volumen de datos históricos sobre los que se quiere
simular, podría ser necesario disponer de un software que pueda ejecutarse en
sistemas de alto poder de computación, y esperar como resultado un informe
con las estrategias victoriosas de entre todas las ejecutadas basándose en los
indicadores usados (cuantas más veces se evalúe un sistema, y contra cuantos
más datos, más seguros podremos estar de su eficacia).

35
2.2 Relación con proyectos con la misma funcionalidad
Podemos encontrar en el mercado herramientas comerciales de
backtesting y también otras que, siendo herramientas de trading, incluyen
módulos de backtesting y optimización. Podemos destacar:
Metatrader (http://www.metatrader4.com/en): una plataforma de trading
creada en 2005 por MetaQuotes software para operar inicialmente en
Forex. Su punto más fuerte es la capacidad gráfica y la facilidad de uso.
Dispone de una gran variedad de indicadores y de un lenguaje de
programación que permite crear nuevos indicadores. Ofrece la opción de
realizar backtesting (y optimización) para comprobar el sistema que
programemos y una gestión incorporada de bases de datos históricos con
una función de importación/exportación de dichos datos.
TradeStation (http://www.tradestation.com/): creada en 1991 como tal, si
bien provenía de la compañía Omega Research, fundada en 1982.
Dispone de todo lo necesario para el backtesting y conexiones con los
servidores que operan en el mercado. Al igual que Metatrader, provee de
datos históricos y permite su descarga. Es posible también crear y
almacenar estrategias.
Wealth-Lab (http://www.wealth-lab.com): Es una plataforma de trading
propiedad de Fidelity Investments. Los usuarios pueden programar y
probar estrategias. Dispone de un entorno de programación basado en
C#. Se pueden tener varias fuentes de datos y es posible importar datos
de otras plataformas incluso de ficheros ASCII.
QuantConnect: (https://www.quantconnect.com/) proyecto que cuenta con
el apoyo de Fundación Chile y CORFO. Permite a los usuarios programar
en un entorno local y luego recibir un correo electrónico con el resultado
de su simulación, la cual se trabaja a través de la nube. Los traders que
usan este software deben tener conocimientos de programación para
poder sacar partido e interactuar con la API que comparte.
MultiCharts (http://www.multicharts.com/). Creada en 2005. Cuenta con un
lenguaje de programación llamado PowerLanguage y ofrece backtesting y
optimización.
NinjaTrader (http://www.ninjatrader.com/) . Empresa creada en 2004 y con
sede en Denver. Es gratuita cuando se usa para representación gráfica,
análisis de mercados y desarrollo y simulación de sistemas de trading y
únicamente se paga por la funcionalidad de interactuar con los mercados
para colocar órdenes.

36
Figura 8 Web Site de NinjaTrader
Figura 3 Web Site de MetaTrader Figura 4 Web Site de TradeStation
Figura 5 Web Site de Wealth-Lab Web Figura 6 Web Site de QuantConnect
Figura 7 Web Site de MultiCharts

37
2.3 Estudio de viabilidad
2.3.1 Alcance del proyecto
El resultado de este proyecto es un software financiero de backtesting
desarrollado en C y orientado a sistemas Linux, especialmente a
computadoras de alto rendimiento. El alcance lo hemos establecido en lograr
una buena capacidad de procesamiento, el manejo de grandes volúmenes de
datos históricos y la posibilidad de configuración flexible, en concreto
especificar de una manera sencilla combinaciones de parámetros que generen
un elevado número de combinaciones (escenarios) a probar.
El interfaz gráfico de usuario está excluido del producto, siendo la
ejecución desatendida el modo normal de explotación de este software. Una
vez suministrados los datos de entrada y las reglas que deben operar sobres
esos datos, el programa debe poder ejecutarse sin intervención del usuario,
ofreciendo como salida un informe con las mejores estrategias de trading.
2.3.2 Estudio de la situación actual
El backtesting es una herramienta de gran importancia en el diseño de
estrategias de trading, por lo que casi todo el software comercial existente
incorpora la capacidad de optimización.
Ahora bien, las herramientas disponibles en el mercado aportan como
ventaja para los usuarios la interfaz gráfica y los lenguajes de programación
propios que, si bien permiten elaborar complejas estrategias de trading,
también dificultan la curva de aprendizaje de las herramientas. Además,
aunque todas ellas manejan datos
históricos, lo hacen en formatos propietarios o en formatos públicos, pero con
poca flexibilidad.
El software desarrollado en el marco de este proyecto quiere ser una
alternativa:
Priorizando la velocidad de cálculo, eliminando el interfaz de
usuario

38
Posibilitando el acceso a bases de datos propias donde el cliente
pueda componer sus propios conjunto de datos, permitiendo así
analizar estrategias testeadas sobre valores agregados.
2.3.3 Estudio y valoración de las alternativas de solución
En función de las consideraciones expuestas en el apartado anterior, el
uso de software comercial queda excluido como una solución para las
necesidades de nuestro cliente.
Como alternativa, decidimos desarrollar una nueva herramienta que nos
aporte la funcionalidad que necesitamos, lo cual nos lleva a tener que
seleccionar entre varias alternativas:
El lenguaje de programación adecuado
el sistema operativo sobre el que ejecutar la aplicación: Windows,
Linux
Persistencia de datos: motores de bases de datos (Sql Server,
MySQL, Oracle), ficheros
Nuestro cliente tiene identificadas sus necesidades, con especial
hincapié en la rapidez de ejecución en un proceso iterativo de búsqueda del/los
mejores escenarios dentro de los diseñados. No tiene requerimientos
especiales en cuanto al interfaz de usuario, que será el objeto de otra
aplicación.
2.3.4 Selección de la solución
Descartamos, por tanto, desarrollar la herramienta para explotarla en un
entorno web. El objetivo de la aplicación, el proceso de optimización en sí, será
más rápido y consumirá menos memoria en una aplicación de escritorio.
A la hora de seleccionar el lenguaje de programación para un software
de escritorio, nos hemos decantado por el C (Ansi C), principalmente por su
rapidez (está cercano a los lenguajes de bajo nivel por lo que es muy popular
para la creación de software de sistema) y eficiencia.
Otras opciones habrían sido C++, C# o Java. Java lo descartamos por
ser un lenguaje interpretado, lo que lo hace más lento. C# lo descartamos por
estar enfocado a sistemas Windows. Sin embargo, C++, siendo también un
buen candidato, no lo hemos seleccionado porque es más complejo y porque la
orientación a objetos realmente no es un requerimiento en este proyecto.

39
En cuanto al sistema operativo, hemos seleccionado Linux por ser muy
robusto, estable y rápido. Además requiere poco hardware y el manejo de la
memoria de Linux evita que los errores de las aplicaciones detengan el núcleo
de Linux. Como última ventaja, aportamos que es un sistema operativo libre.
No obstante, también puede ser ejecutado sobre Windows (en concreto sobre
Cygwin [22]), que proporciona un entorno de funcionamiento similar a los
sistemas Unix, pero dentro de Microsoft Windows).
Para el cálculo de indicadores se ha confiado en la librería TA-lib [37],
que implementa el cálculo de 200 de estos indicadores y que ofrece interfaces
para diferentes lenguajes de programación.
Para facilitar su explotación en supercomputadores, la aplicación
“Trading” se lanza desde una consola de comandos, aceptando como entrada
los archivos de configuración que contienen las estrategias a probar y ofrece
como salida archivos de texto informando sobre los resultados de las pruebas y
también gráficos para un análisis visual del comportamiento de las estrategias.
La elaboración de los gráficos recae en matplotlib [34]. La lectura y análisis
sintáctico de los archivos de configuración se realiza mediante la librería
libconfig [36].
En cuanto al almacenamiento de información, realmente no es
necesaria, por lo que no usaremos ninguna. Únicamente debemos permitir el
acceso, en modo lectura, a bases de datos MySQL del cliente para recoger
datos históricos.

40

41
3 Metodologías usadas
Nos enfrentamos en este punto a la decisión de adoptar una de las dos
grandes corrientes metodológicas en el desarrollo de software existentes: o “En
Cascada” (o secuencial) o “Ágil”. Presentamos brevemente las características
de una y otra, con objeto de conocer las motivaciones que nos han hecho
decantarnos por la segunda.
3.1 Desarrollo en cascada o secuencial
El esquema de desarrollo en cascada propone actividades secuenciales,
donde el desarrollo fluye del punto inicial al final con varias etapas
diferenciadas, y el inicio de una etapa espera la finalización de la anterior:
Análisis de Requisitos
Diseño del Sistema
Implementación
Verificación
Mantenimiento
Nos propone realizar con antelación un análisis intensivo de
requerimientos. Esto es debido a que se hace complicado volver a etapas
previas cuando se encuentran diferencias en el alcance del proyecto. Una vez
que una fase se ha completado es casi imposible hacer cambios.
A pesar de que este modelo es el paradigma más antiguo utilizado en la
ingeniería del software, su eficacia se pone en duda por los problemas que se
encuentran algunas veces [10]. Mencionamos dos en concreto expuestos por
Pressman (2002) en su libro sobre Ingeniería del Software:
“A menudo es difícil que el cliente exponga explícitamente todos los
requisitos El modelo lineal secuencial lo requiere y tiene dificultades a la hora
de acomodar la incertidumbre natural al comienzo de muchos proyectos
El cliente debe tener paciencia. Una versión del programa no estará
disponible hasta que el proyecto esté muy avanzado. Un grave error puede ser
desastroso si no se detecta hasta que se revisa el programa”
Pero, a pesar de estos problemas, sigue siendo el modelo más utilizado
porque, frente a un desarrollo desorganizado, ofrece algunas ventajas, como
son el hecho de estar centrado en la planificación (exigiendo un plan y visión
claras), lo que facilita la estimación de costes y plazo. Además, en caso de que

42
un diseñador abandonara el equipo, el reemplazo sería fácil siguiendo el plan
de desarrollo que siempre está previamente documentado.
3.2 Metodología Ágil
Propone un diseño de software incremental e iterativo. Fue la respuesta
a las limitaciones de la metodología en cascada, dotando a los diseñadores de
una mayor libertad de responder a cambios en los requisitos a medida que
surgen.
Los doce principios que constituyen esta metodología son públicos y
están recogidos en el Manifiesto por el Desarrollo Ágil de Software [11] pero se
podrían resumir en la siguiente tabla, extraída de la misma fuente:
Tabla 1 Filosofía de desarrollo Ágil
Es importante Pero todavía lo es mas
Procesos y herramientas Individuos e interacciones
Documentación extensiva Software funcionando
Negociación contractual Colaboración con el cliente
Seguir un plan Respuesta ante el cambio
En definitiva, se ofrece un modelo de diseño flexible, donde se fomentan
planes adaptables y desarrollo evolutivo. Los desarrolladores trabajan en
pequeños módulos cada vez.
Especialmente destacable es la interacción con el cliente. Éste ofrece
realimentación simultáneamente al desarrollo, como las pruebas de software.
Por este motivo las metodologías ágiles son especialmente beneficiosas en los
casos en los que los objetivos finales de los proyectos no están claramente
definidos (casos de clientes cuyas necesidades y objetivos sean un poco
vagos). En estos casos los requisitos se clarifican a medida que el proyecto
evoluciona, dejando que el desarrollo pueda ser modificado para adaptarse a
los nuevos evolutivos.
Por el contrario, los plazos y costes son a priori difíciles de predecir
pues, sin un plan claro, todo presenta un aspecto de indefinición.

43
Los doce principios mencionado previamente son los siguientes [11]:
Nuestra mayor prioridad es satisfacer al cliente mediante la
entrega temprana y continua de software con valor.
Aceptamos que los requisitos cambien, incluso en etapas tardías
del desarrollo. Los procesos Ágiles aprovechan el cambio para
proporcionar ventaja competitiva al cliente.
Entregamos software funcional frecuentemente, entre dos
semanas y dos meses, con preferencia al periodo de tiempo más
corto posible.
Los responsables de negocio y los desarrolladores trabajan juntos
de forma cotidiana durante todo el proyecto.
Los proyectos se desarrollan en torno a individuos motivados.
Hay que darles el entorno y el apoyo que necesitan, y confiarles
la ejecución del trabajo.
El método más eficiente y efectivo de comunicar información al
equipo de desarrollo y entre sus miembros es la conversación
cara a cara.
El software funcionando es la medida principal de progreso.
Los procesos Ágiles promueven el desarrollo sostenible. Los
promotores, desarrolladores y usuarios debemos ser capaces de
mantener un ritmo constante de forma indefinida.
La atención continua a la excelencia técnica y al buen diseño
mejora la Agilidad.
La simplicidad, o el arte de maximizar la cantidad de trabajo no
realizado, es esencial.
Las mejores arquitecturas, requisitos y diseños emergen de
equipos auto-organizados.
A intervalos regulares el equipo reflexiona sobre cómo ser más
efectivo para, a continuación, ajustar y perfeccionar su
comportamiento en consecuencia.
Son varios los métodos ágiles existentes. XP (Extreme Programming) es
quizás el más conocido junto a SCRUM.

44
3.2.1 XP (Extreme Programming)
XP es un método que trata del “cómo se trabaja” en el proyecto. Fue
formulado por Kent Beck [12] y se basa en doce prácticas de obligado
cumplimiento que se pueden encontrar en la web [13]. Las características
fundamentales son [14]:
Desarrollo iterativo e incremental: pequeñas mejoras, unas tras
otras.
Pruebas unitarias continuas, frecuentemente repetidas y
automatizadas, incluyendo pruebas de regresión. Se aconseja
escribir el código de la prueba antes de la codificación.
Programación en parejas: se recomienda que las tareas de
desarrollo se lleven a cabo por dos personas en un mismo
puesto.
Frecuente integración del equipo de programación con el cliente o
usuario. Se recomienda que un representante del cliente trabaje
junto al equipo de desarrollo.
Corrección de todos los errores antes de añadir nueva
funcionalidad. Hacer entregas frecuentes.
Refactorización del código, es decir, reescribir ciertas partes del
código para aumentar su legibilidad y mantenimiento, pero sin
modificar su comportamiento. Las pruebas han de garantizar que
en la refactorización no se ha introducido ningún fallo.
Propiedad del código compartida: en vez de dividir la
responsabilidad en el desarrollo de cada módulo en grupos de
trabajo distintos, este método promueve el que todo el personal
pueda corregir y extender cualquier parte del proyecto.
Simplicidad en el código: es la mejor manera de que las cosas
funcionen.
3.2.2 SCRUM
Como hemos comentado, otro método ágil muy extendido es SCRUM
[15], que incide en “cómo se organiza y planifica” el proyecto. Consiste en un
conjunto de buenas prácticas para trabajar colaborativamente en equipo, y
obtener el mejor resultado posible de un proyecto. En SCRUM se realizan
entregas parciales y regulares del producto final, priorizadas por el beneficio

45
que aportan al receptor del proyecto. Por ello, SCRUM está especialmente
indicado para proyectos en entornos complejos, donde se necesita obtener
resultados pronto y donde los requisitos son cambiantes o poco definidos.
En SCRUM, un proyecto se ejecuta en bloques temporales cortos y fijos
(iteraciones de entre dos semanas y un mes natural). Cada iteración tiene que
proporcionar un resultado completo, un incremento de producto final que sea
susceptible de ser entregado con el mínimo esfuerzo al cliente cuando lo
solicite.
Figura 9 El Proceso en Scrum
El proceso se inicia con una lista de objetivos/requisitos del producto,
que actúa como plan del proyecto. En esta lista, denominada en SCRUM
Product Backlog, el cliente prioriza los objetivos balanceando el valor que le
aportan respecto a su coste y quedan repartidos en iteraciones y entregas.
Estos requisitos se denominan Historias de Usuario y están descritos en un
lenguaje no técnico, tal y como el cliente lo ve.
Los requisitos y prioridades se revisan y ajustan durante el curso del
proyecto a intervalos regulares.
Existen 4 eventos que caracterizan SCRUM y que se ven reflejados en
la figura 9:
1. Reunión de Planificación (Sprint Planning) [16]: Reunión durante
la cual el Product Owner presenta las historias de usuario por
orden de prioridad, según el valor que aporte al negocio. El
equipo determina la cantidad de historias que puede
comprometerse a completar en ese sprint para, en una segunda
parte de la reunión, decidir y organizar cómo lo va a conseguir.

46
2. SCRUM Diario (Daily SCRUM) [16]: Reunión de, como máximo,
15 minutos en la que el equipo se sincroniza para trabajar de
forma coordinada. Cada miembro comenta lo que hizo el día
anterior, que hará hoy y si hay impedimentos.
3. Revisión del Sprint (Sprint Review) [16]: Reunión que se celebra
al final del sprint y en la que el equipo presenta las historias
conseguidas mediante una demostración del producto
4. Retrospectiva del Sprint (Sprint Retrospective) [16]: Reunión
durante la cual el equipo analiza qué se hizo bien, qué procesos
serían mejorables y discute acerca de cómo perfeccionarlos.
El equipo de proyecto debe constar de al menos de tres personas, para
desempeñar como mínimo los tres roles que caracterizan SCRUM:
el SCRUM Master
el Producto Owner
el equipo de desarrollo.
En la siguiente tabla observamos un breve resumen de las tareas
principales de cada rol:
Tabla 2 Roles en SCRUM
SCRUM MASTER PRODUCT OWNER EQUIPO DE DESARROLLO
Lidera al equipo para que
cumpla las reglas y procesos
de SCRUM
Representa al cliente y se
asegura de que el equipo
trabaja en los temas
correctos, desde el punto
de vista del negocio
Tienen los conocimientos
técnicos necesarios para
llevar a cabo las historias a
las que se comprometen al
inicio de cada sprint
Elimina impedimentos,
asegurando el mejor
entorno para el desempeño
del equipo
Traslada la visión del
proyecto al equipo
Deciden cómo ordenar y
cómo asignar las tareas
Formaliza las
prestaciones en historias
a incorporar en el Product
Backlog y las reprioriza de
forma regular.
Cada uno debería
intercambiar tareas con
otro miembro del equipo
(no existen roles)

47
3.2.3 Otras metodologías ágiles
Aparte de la dos mencionadas, existen otras metodologías ágiles que
tiene como factor común el carácter iterativo y la entrega rápida al cliente de
versiones del producto para obtener una retroalimentación lo antes posible.
No entraremos en detalles de cada una, pero podemos mencionar las
siguientes:
RUP [17]
Kanban [18]
Lean-Agile [19]
3.3 Metodología elegida
A la hora de decantarnos por una u otra metodología hemos tenido en
cuenta la naturaleza de nuestro proyecto:
Tenemos una idea general del objetivo del proyecto, pero sin
detalles. Entendemos que el cliente irá concretando los requisitos
conforme vaya viendo las primeras versiones, ya que podrá
hacerse mejor una idea del potencial del software.
Dado el horizonte temporal del desarrollo del TFG, no queremos
invertir mucho tiempo en elaborar un plan detallado y
especificaciones a bajo nivel
Nos gustaría poder mantener contacto con el cliente durante el
proyecto, para asegurarnos de la satisfacción del mismo con el
producto final. Nos motiva establecer una comunicación frecuente
con el cliente, y aprender de sus ideas
El equipo de proyecto lo constituyen tres personas, los dos
tutores y el autor del TFG
Por disponibilidad del autor del TFG, preferimos establecer un
seguimiento periódico del proyecto, revisando las versiones
ejecutables disponibles en cada encuentro
Todas estas características quedarían cubiertas usando una
metodología Ágil, eliminando la restricción marcada por los métodos en
cascada de conocer de antemano todos los detalles del proyecto y disponer de
una documentación detallada previa al inicio del desarrollo del software. Esto

48
dilataría mucho el tiempo de entrega al cliente de las primeras versiones del
software.
Finalmente, entre XP y SCRUM nos decantamos por SCRUM,
principalmente porque el equipo de desarrollo lo forma únicamente el autor del
TFG, lo que violaría una de las reglas de XP (el pair programming, o
programación en parejas).
Una vez acordada la metodología, debemos tomar algunas decisiones
en cuanto a la configuración del equipo y a la planificación de los eventos que
marca SCRUM.
3.3.1 Los roles
Como indicábamos anteriormente, SCRUM marca claramente 3 roles,
que deben respetarse y que cumplen una misión muy concreta en esta
metodología.
Durante una reunión de coordinación previa del equipo de este TFG,
decidimos realizar la siguiente asignación de personas a roles, en función del
perfil de cada miembro:
Tabla 3 Asignación de roles en proyecto Trading
SCRUM MASTER PRODUCT OWNER EQUIPO DE DESARROLLO
José María Cecilia Horacio Pérez José Carlos Cano
Con este modo de organizarnos, Horacio Pérez (tutor del TFG) será el
punto de contacto con el cliente, la empresa Artificial Intelligence Talentum,
S.L, y por tanto será quien traduzca en historias de usuario los requerimientos
del negocio y validará las sucesivas entregas del producto.
José María Cecilia (tutor del TFG) será el facilitador del desarrollo del
proyecto, instruyendo al resto del equipo en la metodología SCRUM y
monitorizando el cumplimiento de los estándares. Ante cualquier impedimento
que pudiera surgir y que pudiera poner en riesgo el desarrollo normal del
proyecto, será el encargado de proveer soluciones.
José Carlos Cano (autor del TFG) será el único miembro de Equipo de
Desarrollo, que codificará y probará el software.

49
3.3.2 Los eventos
SCRUM nos marca algunos hitos esenciales durante el desarrollo del
proyecto, en concreto las reuniones de planificación y revisión del sprint.
Entendemos que estas reuniones serán presenciales por lo que buscamos una
frecuencia que sea sostenible en el tiempo, tanto por disponibilidad de los
tutores como del propio autor del TFG.
En esta línea, acordamos realizar sprints de 4 semanas de duración
(SCRUM recomienda una duración de entre 2-4 semanas) y cada reunión será
a la vez Sprint Planning y Sprint Review.
Los SCRUM Diarios y La Retrospectivas de cada sprint, con un marcado
carácter técnico, las realizará el autor del TFG, como miembro único del Equipo
de Desarrollo.
3.3.3 Seguimiento
Javier Garzás en su libro "Gestión de proyectos ágil”, [20] recomienda el
uso de tableros Kanban, como herramienta visual de seguimiento de las tareas
de cada sprint. Se pueden ver algunos ejemplos del uso de tableros en varias
instituciones que siguen metodología SCRUM para algunos proyectos visitando
la página web del autor [21].
Los tableros Kanban están enmarcados en una técnica del mismo
nombre que se creó en Toyota, y que se utiliza para controlar el avance del
trabajo, en el contexto de una línea de producción. Los componen tarjetas o
Post-It, que contienen una tarea con su descripción. Las tarjetas se colocan en
varias columnas, que componen el tablero, según se esté trabajando en ella,
esté pendiente o ya acabada.
Figura 10 Tablero Kanban

50
Estos tableros se pueden colocar en grandes paneles e incluso en
paredes, lo que las hace visibles a todo el equipo del proyecto, incluido al
cliente, ofreciendo de esta manera transparencia sobre lo que se está haciendo
y el ritmo al que se hace, lo que incrementa la confianza y la sensación de
equipo.
Pero también existen herramientas informáticas para el manejo de
tableros Kanban, especialmente útiles para:
Trabajo con equipos distribuidos, donde no es posible consultar
físicamente un tablero real
Conservar históricos
Realizar gráficos automatizados de evolución y carga de trabajo
En este proyecto utilizaremos una herramienta que nos facilitará la
creación y seguimientos de los tableros y nos creará en tiempo real los gráficos
Burn Down de cada sprint, que grafican el trabajo pendiente a lo largo del
tiempo y por tanto la velocidad a la que se están completando los
objetivos/requisitos. Permite extrapolar si el Equipo de Desarrollo podrá
completar el trabajo en el tiempo estimado.
Un ejemplo de este tipo de gráfico se puede observar en la imagen
adjunta
Figura 11 Burn Down Chart
Observamos en el gráfico que, dentro de un sprint, el Equipo de
Desarrollo controla su desempeño basándose en días de trabajo.
En nuestro proyecto, siguiendo las prácticas que se pueden encontrar en
la mayoría de los libros y artículos sobre SCRUM, estimaremos las tareas en
horas.

51
4 Tecnologías y herramientas utilizadas en el proyecto
4.1 Cygwin
En el apartado “4.3.4 Selección de la solución” de esta memoria
decidimos el desarrollo de una herramienta en C (Ansi C) con objeto de ser
explotada en entornos Linux.
Dado que el autor del TFG también trabaja en proyectos de desarrollo
para plataformas Microsoft Windows, y que las herramientas de documentación
utilizadas son de la familia Office, vamos a tomar como plataforma habitual la
de Microsoft, pero instalando los componentes necesario que nos permitan
portar el desarrollo a Linux.
En un intento de crear un entorno UNIX/POSIX completo sobre Windows
surgió en 1995 Cygwin [22], como un proyecto de Steve Chamberlain (un
ingeniero de Cygnus). En la actualidad, el paquete está mantenido
principalmente por trabajadores de Red Hat.
Al instalar un sistema Cygwin, se obtiene [23]:
Una biblioteca de enlace dinámico (cygwin1.dll) que implementa
la interfaz de programación de aplicaciones POSIX, usando para
ello llamadas a la API nativa de Windows.
Una cadena de desarrollo GNU (que incluye entre otras utilidades
GCC y GDB) para facilitar las tareas básicas de programación.
Aplicaciones equivalentes a los programas más comunes de los
sistemas UNIX. Incluso, cuenta con un sistema X (Cygwin/X)
desde 2001.
Existe otra alternativa similar a Cygwin, en concreto MinGW.
La diferencia está en que MinGW es una portabilidad a Windows de las
utilidades de compilación GNU, como son GCC, Make y Bash, pero sin
embargo no emula ni pretende aportar compatibilidad con sistemas UNIX. Es
decir, si compilamos algo usando MinGW lo estaremos haciendo para
Windows.
Sin embargo, cuando lo hacemos con Cygwin, lo haremos para el
entorno UNIX que proporcina Cygwin, y necesita la librería cygwin1.dll para
ejecutarse en Windows.

52
4.2 VMWare Player
VMWare player [24] es un sistema de virtualización por software que en
nuestro caso nos permitirá un ambiente de ejecución Linux corriendo en un
equipo con sistema operativo Windows, como si de otro hardware se tratara. Al
tratarse de una capa de software intermedia entre el hardware físico real y el
virtual, la velocidad de ejecución es evidentemente menor pero, para probar
nuestro desarrollo en un entorno Linux real, es suficiente.
Existen otras alternativas a VMWare Player, como puede ser Virtual PC.
La funcionalidad es similar pero varía en cómo se implementa. En el
caso de Virtual PC se está emulado una plataforma x86, mientras que VMWare
la virtualiza. La mayor parte de las instrucciones en VMware se ejecutan
directamente sobre el hardware físico, mientras que en el caso de Virtual PC se
traducen en llamadas al sistema operativo que se ejecuta en el sistema físico
[25].
4.3 Eclipse
Hemos seleccionado Eclipse [26] como IDE de desarrollo por ser una
herramienta muy extendida en el mundo de la programación, principalmente
para los lenguajes JAVA y C. Inicialmente creada por IBM, ahora es mantenida
y evolucionada por la Fundación Eclipse.
Ofrece gran cantidad de funcionalidades mediante la instalación de
módulos (extensión a múltiples lenguajes de programación, control de
versiones, sistemas de gestión de bases de datos, modelado de datos,
herramientas de red, etc) [27].
A favor de este IDE también ha jugado la fácil integración con el entorno
Cygwin, requerido para nuestro proyecto y con el control de versiones
Subversion por medio del módulo subversive [30].
4.4 Subversion
También reconocido por las siglas SVN [28] es una herramienta de
control de versiones Open Source basada en un repositorio cuyo
funcionamiento se asemeja enormemente al de un sistema de ficheros.
Utiliza el concepto de revisión para guardar los cambios producidos en el
repositorio. Entre dos revisiones sólo guarda el conjunto de modificaciones
(delta), optimizando así al máximo el uso de espacio en disco. SVN permite al
usuario crear, copiar y borrar carpetas con la misma flexibilidad con la que lo
haría si estuviese en su disco duro local.

53
Puede acceder al repositorio a través de redes, lo que le permite ser
usado por personas que se encuentran en distintas localizaciones [29].
La integración de Subversion (SVN) con Eclipse se realiza por medio del
plug-in desarrollado en el proyecto Subversive
GIT y CVS son alternativas a Subversion como herramienta de control
de versiones, aunque existen muchas más [31].
4.5 Python y Matplotlib
Python [32] es un lenguaje de programación interpretado y
multiplataforma. Es administrado por la Python Software Foundation y posee
una licencia de código abierto. Fue creado a finales de los ochenta por Guido
van Rossum. Se caracteriza principalmente por que hace hincapié en una
sintaxis que favorezca un código legible [33].
Matplotlib [34] es una biblioteca para la generación de gráficos a partir
de datos contenidos en listas o arrays, desarrollado en el lenguaje de
programación Python. Proporciona una API, pylab, diseñada para recordar a la
que ofrece MATLAB. Fue desarrollada por John D. Hunter en 2012. [35]
Hemos usado la combinación de Python y Matplotlib para generar los
gráficos de velas y de los indicadores técnicos en el desarrollo de nuestra
aplicación
4.6 Libconfig
Libconfig [36] es una librería simple para el procesado de ficheros de
configuración que contienen alguna estructura. El formato admitido es más
legible que un XML y, además, distingue entre tipos de datos, por lo que evita
que tengamos que realizar un análisis gramatical en nuestro código.
Ofrece interfaces tanto para C como para C++ y funciona en sistemas
UNIX compatibles con POSIX (GNU/Linux, Mac OS X, Solaris, FreeBSD) y
Windows (2000, XP, Windows 7, ….).
Observamos un ejemplo de la sintaxis en la siguiente imagen:

54
Figura 12 Fichero de ejemplo para uso con libconfig
4.7 TA-Lib
TA-Lib [37] es una librería que incluye el cálculo de 200 indicadores
(ADX, MACD, RSI, Stochastic, Bollinger Bands etc.) y que ofrece una API open
source para C/C++, Java, Perl, Python y .NET.
Constituye el núcleo encargado de los cálculos que se utilizan en
nuestra aplicación.
Una alternativa a TA-Lib es el paquete Quantmod [38] que se ofrece
para la librería R (un paquete estadístico y gráfico compatible con sistemas
UNIX, Windows y MAC OS [39]).
4.8 Kunagi
Como comentamos en el apartado “3.3.3 Seguimiento” vamos a
complementar la metodología SCRUM con los tableros propuestos por Kanban
y, para ello, nos decidimos por una herramienta accesible por Web, dado que

55
los miembros del Equipo, el Product Owner y el SCRUM Master no trabajan en
el mismo lugar. Queremos poder registrar el Product Backlog, los sucesivos
Sprint Backlogs y sus tareas asociadas.
Una búsqueda en Internet arroja bastantes resultados en lo referido a
herramienta Ágiles, incluso algunas realizan recopilaciones de las más usadas,
con comparativas en cuanto a funcionalidad y prestaciones (un ejemplo de ello
es http://agilescout.com/best-agile-scrum-tools [40]).
Revisando varias de estas recopilaciones y siempre buscando ediciones
freeware, seleccionamos, en base a las opiniones de usuarios, tres de ellas:
Sprintometer, Scrinch y Kunagi.
De entre ellas, la más intuitiva y con menos requerimientos de hardware
es Kunagi [41]. Contempla todos los aspectos de SCRUM y gráficamente es
sencilla, muy parecida a los tableros que recomienda Javier Garzás en su libro.
Es fácilmente desplegable (por medio de un archivo war) compatible con
Apache Tomcat [42] (un contenedor web de servlets open source que
implementa las especificaciones de los Java Servlets y de Java server Pages).
Apache Tomcat está desarrollado en Java, lo que facilita su portabilidad a
múltiples entornos. En nuestro caso lo hemos instalado en nuestro ordenador
de desarrollo en Microsoft Windows.
No requiere ninguna base de datos para almacenar información. Por el
contrario, usa ficheros XML que se almacenan en el directorio de la aplicación
del servidor donde se ejecuta Apache Tomcat.

56

57
5 Estimación de recursos y planificación
Como hemos indicado en el capítulo “5.3 Metodología elegida”, en este
proyecto no conocemos de antemano los detalles exactos del producto final,
por lo que hemos apostado por emplear la metodología SCRUM, que nos
permita tener el cliente vinculado al proyecto, entregándole regularmente
versiones del producto para que pueda ver a corto plazo el fruto de su inversión
y afine sus requerimientos, haciéndole partícipe del desarrollo y creando una
relación de confianza con el equipo.
Según Roman Pichler [2], una planificación conlleva una decisión
acerca de qué factores no deberían verse comprometidos de cara al
lanzamiento de un producto de éxito, lo cual nos lleva a hacernos una serie de
preguntas:
Tiempo: ¿es necesario respetar una fecha de lanzamiento o
finalización?
Coste: ¿hay un presupuesto fijo para el desarrollo del producto?
Funcionalidad: ¿deben desarrollarse todos los requerimientos que
figuran en la Pila de Producto?
Las tres restricciones no pueden satisfacerse de manera conjunta (al
menos una de ellas debe quedar libre como válvula de escape).
Fijar la funcionalidad no es una buena idea y, además, va en contra de
los principios de la metodología Ágil, donde esperamos evolucionar el producto
en base a las indicaciones del cliente.
Sin embargo, fijar la fecha de entrega de las diferentes versiones lleva a
una disciplina en el equipo de desarrollo, una mentalidad de producir resultados
periódicamente. Además, de esta manera, si el equipo de desarrollo es estable,
la elaboración del presupuesto es sencilla pues se reduce al cálculo: Nº de
desarrolladores x tiempo.
Flexibilizando el requisito de la funcionalidad permitimos que, en caso de
que el presupuesto se vea comprometido, el Propietario del Producto pueda
aceptar liberar un producto tras una reducción en las prestaciones.
5.1 Método de estimación utilizado
En SCRUM las tareas se estiman en Puntos Historia o Story Points (SP
a partir de ahora), que son una medida “relativa” del esfuerzo que es necesario
aplicar para desarrollar una Historia de Usuario. Cuando decimos “relativa”

58
estamos reflejando que una tarea etiquetada como 2SP conlleva el doble de
esfuerzo que otra etiquetada como 1SP.
Según Garzás [21], “un punto historia es una fusión entre la cantidad de
esfuerzo que supone desarrollar la historia de usuario, la complejidad de su
desarrollo y el riesgo inherente”. Al ser una medida relativa permite adaptarse
al equipo y nos deja libertad a la hora de asignar valores. Dado que debemos
usar rangos acotados, fijando un tope máximo, nos decantamos por la
siguiente serie: 1, 2, 3 ,5, 8, 13.
A la hora de calcular la duración del proyecto, sólo los Puntos Historia no
son suficientes, sino que necesitamos saber con qué rapidez el equipo es
capaz de desarrollar las Historias de Usuario. A este concepto se la denomina
Velocidad, que se calcula sumando el número de Puntos Historia de cada
Historia de Usuario “terminada” durante un Sprint. Dado que el Dueño del
Producto no consigue valor de las Historias de Usuario no acabadas, se
excluyen del cálculo todas aquéllas parcialmente desarrolladas.
Según Kenneth S. Rubin [3], “la velocidad mide el output (el tamaño de
lo que se entrega), no el outcome (el valor de lo que se entrega)”. Es decir,
completar una Historia de Usuario de 8SP no significa necesariamente que
aporte más valor al cliente que una de 5SP. Quizás interese trabajar más en la
de 5SP porque aporta más valor y es menos costosa.
La velocidad se suele mantener durante todo el proyecto, ya que es
inherente a la naturaleza de nuestro equipo y es conocida por proyectos
anteriores, o por sprints anteriores dentro del mismo proyecto. En nuestro caso,
esta información no está disponible y debemos realizar una estimación
adoptando alguna asunciones:
Nuestro equipo de desarrollo está compuesto por una persona
La jornada de trabajo dedicada al proyecto es 3 Horas/Día
El factor de disponibilidad será del 80% de esas 3 horas, donde el
20% restante lo dejamos como colchón para mejoras técnicas
que no aportan aparentemente valor al cliente, o bien para
imprevistos
Consideramos como punto de partida en nuestros cálculos que,
basándonos en nuestra experiencia, una Historia de Usuario de
1SP necesita una media de 3 horas para su desarrollo y prueba

59
Garzás [21] recomienda no considerar más de ese 80% de
disponibilidad.
Teniendo en cuenta que el Equipo de Desarrollo se compone de una
sola persona, con una dedicación de 3 horas al día durante 6 días a la semana,
durante 4 semanas, el número de horas de desarrollo es de 3 * 6 * 4 = 72 que,
aplicando un factor de disponibilidad del 80% nos deja el valor real de 58 horas
en cada iteración.
Por tanto la velocidad estimada será de 58 horas / 3 Horas por SP = 19
SP en cada Sprint.
5.2 Planificación
Sabemos que SCRUM trabaja en iteraciones o ciclos de, como máximo,
un mes de duración, llamados sprints, que presentan como características más
relevantes:
Tienen una fecha de inicio y de fin
Deben ser de corta duración (entre una semana y un mes)
Preferiblemente todos los Sprints deben tener la misma duración
El objetivo a cubrir durante cada ciclo no puede ser alterado y
debe ser completado al llegar el fin del Sprint
Según Kenneth S. Rubin [3], las ventajas de tener en mente una fecha
de fin son que:
Permite limitar el trabajo en curso (no terminado) porque el equipo
planificará sólo aquello que sabe que puede entregar en el Sprint
Fuerza la priorización y el llevar a cabo pequeños trabajos,
focalizándose en lo que aporta valor rápidamente al cliente
Muestra avances entregando nuevas versiones al fin de cada
ciclo
Evita perfeccionismos innecesarios, evitando perder tiempo
buscando algo “perfecto” cuando “suficientemente bueno” podría
valer
Motiva la conclusión de las tareas ya que los equipos tienen en
mente una fecha límite conocida

60
Mejora las predicciones sobre lo que se puede entregar porque es
razonable pensar que será parecido a lo entregado en el sprint
anterior
Por otro lado, una duración corta:
Facilita la planificación
Ofrece retroalimentación frecuente sobre el trabajo ya realizado y
en curso
Mejora el retorno de la inversión en el desarrollo al tener, al final
de cada sprint, una release
Limita la propagación de los posibles errores
Mantiene al equipo activo (en oposición a los proyecto de larga
duración, donde se pierde entusiasmo por el esfuerzo empleado)
Siguiendo esta indicaciones, nosotros nos decantamos por sprints de
cuatro semanas, que se alinean muy bien con la disponibilidad tanto del
Propietario del Producto, del SCRUM Master y del equipo de desarrollo.
En nuestra reunión inicial con el cliente queremos proponerle y acordar
una estimación de tiempos, en este caso, el número de sprints y, para ello,
basándonos en el documento de requerimientos proporcionados por la
empresa, se han podido identificar las siguientes Historias de Usuario:
STO001: Como cliente quiero poder leer un archivo con datos
históricos en formato csv para calcular sobre ellos indicadores
técnicos
STO002: Como cliente quiero que el software detecte el intervalo
de tiempos del archivo de datos para poder generar gráficos
intradía / interdía
STO003: Como cliente quiero que el software pueda manejar
grandes cantidades de datos para poder leer series históricas
STO004: Como cliente quiero poder leer uno o más archivos de
configuración para poder lanzar ejecuciones desatendidas
STO005: Como cliente quiero disponer de una lista de
indicadores técnicos disponibles, que sea ampliable para poder
utilizarla a la hora de declarar los escenarios

61
STO006: Como cliente quiero poder indicar rangos o listas de
parámetros de los indicadores para poder lanzar simulaciones
masivas
STO007: Como cliente quiero poder incluir constantes en los
ficheros de configuración de los escenarios para simplificar la
lectura de los mismos
STO008: Como cliente quiero poder escribir fórmulas o reglas en
formato matemático para que el software pueda interpretarlas
para dar versatilidad
STO009: Como cliente quiero poder indicar las fórmulas de
decisión en los archivos de configuración para poder generar
diferentes escenarios
STO010: Como cliente quiero poder generar un gráfico con
información diaria a partir de un archivo CSV (desde script) para
disponer de una herramienta visual de análisis
STO011: Como cliente quiero que los gráficos se puedan generar
dinámicamente en función a parámetros (estudiar solución
técnica) para decidir si se usan ficheros de configuración de
gráficos
STO012: Como cliente quiero que cada gráfico que se genere
lleve asociado un fichero csv con la información representada
para poder ser tratada con otras herramientas analíticas
STO013: Como cliente quiero que los gráficos puedan contener
varias ventanas, y se puedan asociar variables a cada ventana,
con tipos y colores parametrizables y que se pueda definir el
tamaño de la imagen resultante para ofrecer de esta manera
mayor versatilidad
STO014: Como cliente quiero indicar al software que me genere
gráficos siempre, nunca o en los n casos más favorables para no
sobrecargar en el caso de ejecución de escenarios masivos
STO015: Como cliente quiero poder mostrar en el gráfico las
operaciones de entrada/salida del mercado para permitir un
análisis visual
STO016: Como cliente quiero guardar en una matriz el resultado
de la ejecución de todos los escenarios para poder realizar
estudios posteriores

62
STO017: Como cliente quiero que el software ordene los
escenarios según uno o más ratios calculados tras su ejecución
para conocer las reglas de mercado más ventajosas
STO018: Como cliente quiero que, además de decidir entradas /
salidas del mercado en base a unas fórmulas, también contemple
Stop Loss y Take Profit para asimilarlo a las operaciones reales
del mercado
STO019: Como cliente quiero disponer de un LOG en un archivo
de texto indicando tiempos de ejecución para conocer el
rendimiento de la librería de indicadores técnicos usada y del
software en general
Ahora bien, ¿cómo calculamos el tamaño de cada historia en esta fase
inicial para poder presentar a la empresa un plan de proyecto? En realidad sólo
podemos hacerlo basarnos en estimaciones, seleccionando de la lista de
Historias de Usuario aquéllas con las que nos sintamos más confiados a la
hora de valorar su duración en Puntos de Historia y, haciendo uso de la
naturaleza relativa de este indicador, ponderando a continuación el resto.
Así, basándonos en nuestra experiencia como desarrolladores, sabemos
que STO001 (lectura de un fichero con cierto formato) no es una tarea
compleja y podríamos asignarle una duración de 1SP. Asimismo la ST008, que
supone el desarrollo de un analizador sintáctico (o parser), sin duda es una
tarea más compleja que la anterior, tanto en el desarrollo como en la fase de
pruebas, y creemos que debemos asignarle una duración de 5SP.
Mostramos a continuación una tabla donde hemos reflejado todas las
Historias de Usuario identificadas hasta la fecha y una estimación de
duración/complejidad en Puntos Historia tomando como referencia las
anteriores.
La columna nombrada como “Justificación” explica el razonamiento
seguido para asignar los Puntos de Historia a cada caso:

63
Tabla 4 Historias de usuario identificadas al inicio del proyecto
Historias de
Usuario
(STO)
Puntos de
Historia
(SP)
Justificación
STO001Como cliente quiero poder leer un archivo con datos históricos en
formato csv para calcular sobre ellos indicadores técnicos1 Tomada como base para el resto de estimaciones
STO002Como cliente quiero que el software detecte el intervalo de tiempos
del archivo de datos para poder generar gráficos intradía/interdía1
Serán cá lculos sobre el campo de fecha extra ído del
archivo de entrada
STO003Como cliente quiero que el software pueda manejar grandes
cantidades de datos para poder leer series históricas8
Esta tarea supone el diseño de la arquitectura y
gestión de la memoria que a lmacenará los datos
STO004Como cliente quiero poder leer uno o más archivos de configuración
para poder lanzar ejecuciones desatendidas13
En esta fase inicia l debemos decidi r s i desarrol lar
código para leer archivos con s intaxis a defini r o
buscar soluciones en el mercado
STO005Como cliente quiero disponer de una lista de indicadores técnicos
disponibles, que sea ampliable para poder utilizarla al declarar los 1 Usaremos un nuevo fichero de configuración
STO006Como cliente quiero poder indicar rangos o listas de parámetros de
los indicadores para poder lanzar simulaciones masivas5
El uso de rango y/o bucles aparentemente nos va a
l levar a elaborar a lgún proceso de l lamada recurs iva
STO007Como cliente quiero poder incluir constantes en los ficheros de
configuración de los escenarios para simplificar la lectura de los 1 Duración parecida a la STO005
STO008Como cliente quiero poder escribir fórmulas o reglas en formato
matemático y que el software pueda interpretarlas para dar
versatilidad
5Tomada como base para el resto de estimaciones .
Compleja .
STO009Como cliente quiero poder indicar las fórmulas de decisión en los
archivos de configuración para poder generar diferentes escenarios1 Duración estimada parecida a la STO005
STO010Como cliente quiero poder generar un gráfico con información diaria a
partir de un archivo csv (desde script)8
En esta fase inicia l sabemos la herramienta que
uti l i zaremos pero no tenemos el conocimiento sobre
su uso y debemos tener en cuenta el trabajo de
investigación
STO011Como cliente quiero que los gráficos se puedan generar
dinámicamente en función a parámetros (estudiar solución técnica)
para decidir si se usan ficheros de configuración de gráficos13
Supone la lectura del archivo de configuración, su
interpretación y la generación de sentencias que
generen el gráfico
STO012Como cliente quiero que cada gráfico que se genere lleve asociado un
fichero csv con la información representada para tratamientos en
otras herramientas
1 Simi lar en duración a la STO001
STO013
Como cliente quiero que los gráficos puedan contener varias ventanas,
y se puedan asociar variables a cada ventana, con tipos y colores
parametrizables y que se pueda definir el tamaño en pixels para
ofrecer mayor versatilidad
8 Simi lar en duración a la STO011
STO014Como cliente quiero indicar al software que me genere gráficos
siempre, nunca o en los n casos más favorables para no sobrecargar en
el caso de escenarios masivos5
Habrá que generar un módulo específico para gráficos .
La complejidad vendrá dada por la neces idad de
a lmacenar todos los parámetros usados en cada
escenario para reuti l i zarlos a la hora de graficar los
mejores
STO015Como cliente quiero poder mostrar en el gráfico las operaciones de
entrada/salida del mercado para permitir un análisis visual3 Simi lar a la STO013
STO016Como cliente quiero guardar en una matriz el resultado de la ejecución
de todos los escenarios para poder realizar estudios posteriores5
Almacenar los va lores no es en s í complejo pero s í el
trabajo posterior sobre el los
STO017Como cliente quiero que el software ordene los escenarios según uno
o más ratios calculados tras la ejecución para conocer las reglas más
ventajosas
5 Trabajo sobre cá lculos de ratios
STO018Como cliente quiero que, además de decidir entradas / salidas del
mercado en base a unas fórmulas, también contemple StopLoss y
TakeProfit para asimilarlo a las operaciones reales13
A tener en cuenta junto a las reglas de entrada / sa l ida
del mercado que se guiarán en base a las fórmulas
a lmacenadas en los archivos de los scripts
STO019Como cliente quiero disponer de un LOG de ejecución indicando
tiempos para conocer el rendimiento de la librería de indicadores
técnicos usada5
Desde cualquier punto del programa puede ser
necesario enviar mensajes a l fichero LOG
(especia lmente en caso de errores)
La suma de todos los SP arroja un total de 102 Puntos de Historia para
el desarrollo completo del proyecto que, convertido a horas por el factor
convenido en el apartado 7.1 de 1SP = 3 horas, nos da un valor de 306 horas
de trabajo del equipo de desarrollo.
Por tanto, ya estamos en disposición de estimar la duración del proyecto
en número de Sprints pues conocemos los Puntos de Historia totales y la
velocidad del equipo calculada al final del apartado 5.1:

64
102 SP / 19SP por Sprint = 5,4 ciclos, por lo que decidimos informar al
cliente de que vamos a trabajar durante 6 Sprints, con un margen de error
equivalente a 0,6 ciclos para imprevistos o nuevas Historias de Usuario que
pudieran ir surgiendo a lo largo del proyecto en la reuniones de revisión y
planificación de los sprints.
En la naturaleza de SCRUM está el hecho de revisar, al final de cada
Sprint, las desviaciones de la velocidad estimada frente a la real. Para ello
utilizaremos el gráfico del Sprint Burndown, que nos mostrará las tareas
estimadas durante el sprint y las desviaciones. La velocidad real en cada Sprint
se tomará como nueva velocidad del equipo para los siguientes Sprints y será
un factor decisivo a la hora de seleccionar Historias de Usuario para cada
nuevo Sprint cuando confeccionemos el Sprint Backlog.
5.3 Valoración de la dedicación y coste económico
En nuestro cálculos del coste económico del proyecto vamos a
considerar dos grupos:
Costes de material, donde reflejaremos el coste del material
empleado durante la realización del proyecto
Costes de consultoría, donde reflejaremos el coste de personal
basado en horas de trabajo
5.3.1 Costes de material
Incluiremos todos los costes de hardware y software empleados, que
son independientes de la duración del proyecto. Estos costes no se aplicarán al
cliente dado que esta misma infraestructura es utilizada para proyectos con
otros clientes.
La siguiente tabla identifica los distintos elementos considerados:

65
Tabla 5 Costes de material no facturables
Hardware Euros
Ordenador portátil Lenovo T420 800
Monitor Lenovo 24'' 350
Impresora HP Deskjet H450 60
HDD externo para copias de seguridad 60
Periféricos 50
1.320
Software Euros
Licencia Windows 7 Professional SP1 149
Licencia Microsoft Office 2010 Profesional (MS Word y MSExcel) 393
Virtual Machines Player (VMWare) 0
Linux (Ubuntu) 0
Entorno de desarrollo (Eclipse) 0
Entorno Linux para Windows (CygWin) 0
542
5.3.2 Costes de consultoría
Como indicamos en el capítulo 5 (metodología), en SCRUM
identificamos 3 roles: el SCRUM Mater, El Propietario del Producto y el Equipo
de Desarrollo.
Los roles de SCRUM Master y Propietario del Producto no implican una
dedicación completa al proyecto sino que requiere su intervención durante
momentos clave bien definidos dentro del proceso de SCRUM. Sin embargo, el
coste de los miembros del Equipo de Desarrollo asignados a este proyecto se
aplicará íntegramente al mismo.
De cara a negociar con un cliente el coste de un proyecto desarrollado
siguiendo la metodología SCRUM podemos ofrecer facturar cada Sprint
basándonos en los Puntos de Historia completados y aceptados. De esta
manera estamos creando una relación con el cliente en la que se asegura de
pagar únicamente por las funcionalidades que recibe y que previamente se han
solicitado y acordado al principio de cada sprint.
Usaremos el factor de conversión “1 Punto de Historia” = “3 Horas de
desarrollo”, sobre un coste de horas de consultoría de 30 Euros/Hora.
Según este criterio, y basándonos en la estimación inicial de 102 Puntos
de Historia, podremos informar al cliente de un coste del proyecto aproximado
de 7.500 Euros.

66
Tabla 6 Estimación de costes iniciales facturables al cliente
Puntos de
Historia
Horas de
desarrollo Euros
Sprint 1 19 57 1.710
Sprint 2 19 57 1.710
Sprint 3 19 57 1.710
Sprint 4 19 57 1.710
Sprint 5 19 57 1.710
Sprint 6 7 21 630
102 306 7.470
Consultoría
Como hemos comentado, la facturación real de cada Sprint se adaptará
a lo realmente entregado, e incluirá los impuestos aplicables en cada momento.
Si se decidiera un incremento en la funcionalidad que conllevara nuevos
Sprints o nuevos Puntos de Historia, se seguiría el mismo criterio a la hora de
facturarlo (así quedará reflejado en el contrato entre ambas partes).

67
6 Desarrollo del proyecto
6.1 Preparativos
Existe una gran controversia sobre cómo incluir en la metodología
SCRUM las tareas técnicas y no técnicas previas al inicio del desarrollo y, por
tanto, a la entrega de alguna funcionalidad al cliente.
Podríamos incluir en este grupo las siguientes:
preparar los entornos de desarrollo.
trabajar en el Product Backlog, principalmente en dejar listas las
historias de usuario, priorizadas y estimadas.
Hacer una previsión del reparto de historias de usuario por
iteración.
Hacer un estudio de la arquitectura.
Alcanzar un acuerdo sobre la definición de “Done”, es decir, de
cuándo una Historia de Usuario está acabada y aceptada
Existen tres corrientes que ofrecen diferentes soluciones:
1. Una corriente aboga por la existencia de un sprint 0, a pesar de
que no desarrolle ninguna Historia de Usuario, pero respetando la
naturaleza de SCRUM (asignándole una duración fija, realizando
SCRUM diarios y la Revisión del Sprint).
2. Otra corriente, contraria a la anterior, opina que un sprint de este
tipo presenta los siguientes inconvenientes:
No genera código funcional
Elimina el sentido de urgencia
Conduce a malentendidos sobre cómo funciona SCRUM
Disgusta al cliente
y aboga por evitar denominar como sprint a esta fase porque
considera que, si lo llamáramos así, estaríamos ejecutando SCRUM,
pero eso sería incompatible con los citados cuatro inconvenientes.
3. La tercera vía es incluirlas como tareas técnicas en el sprint 1,
junto a otras que sí aporten valor al cliente. De esta manera, en la
revisión del sprint, el Product Owner puede obtener una primera

68
versión entregable del software, aunque con funcionalidades
reducidas.
En este proyecto preferimos ceñirnos completamente a la metodología
SCRUM y, de acuerdo con el cliente, no comenzar el proyecto en su fase de
desarrollo hasta no estar en disposición de generar valor.
Por tanto, durante las primeras semanas, mantuvimos dos reuniones
para conocer los requerimientos del cliente, traducirlos a Historias de Usuario,
decidir la arquitectura e instalar los entornos de desarrollo y pruebas
necesarios.
Tabla 7 Fase inicial: Objetivos del cliente
OG1 Objetivo General 1: Desarrollo de una aplicación eficiente
OE1Objetivos Específico 1: Desarrollo de un programa scriptable, mediante archivos de configuración,
para el funcionamiento en supercomputadoras
OE2 Objetivos Específico 2: Lenguaje de programación eficiente en términos de velocidad y memoria
OG2 Objetivo General 2: Desarrollo de una herramienta de análisis visual de operaciones en los mercados
OE3 Objetivos Específico 3: Lectura de datos históricos
OE4 Objetivos Específico 4: Representación gráfica de datos históricos e indicadores técnicos
OG3 Objetivo General 3: Desarrollo de una herramienta de backtesting
OE5 Objetivo Específico 5: Cálculo de indicadores técnicos sobre un conjunto de datos históricos
OE6Objetivo Específico 6: Decisión acerca del momento de realizar una operación en el mercado y de
finalizar la misma
OE7Objetivo Específico 7: Calcular el beneficio neto del conjunto de operaciones que se produzcan en
el periodo de tiempo que se ha extraído de los históricos
OE8 Objetivo Específico 8: Elaborar un informe con datos estadísticos sobre las operaciones realizadas
Tabla 8 Fase inicial. Traducción a Historias de Usuario
Historias de Usuario
(STO)
Puntos de
Historia (SP)
STO001 Como cliente quiero poder leer un archivo con datos históricos en formato CSV para calcular sobre ellos indicadores técnicos
1
STO002 Como cliente quiero que el software detecte el intervalo de tiempos del archivo de datos para poder generar gráficos intradía/interdía
1
STO003 Como cliente quiero que el software pueda manejar grandes cantidades de datos para poder leer series históricas
8
STO004 Como cliente quiero poder leer uno o más archivos de configuración para poder lanzar ejecuciones desatendidas
13

69
STO005 Como cliente quiero disponer de una lista de indicadores técnicos disponibles, que sea ampliable para poder utilizarla al declarar los escenarios
1
STO006 Como cliente quiero poder indicar rangos o listas de parámetros de los indicadores para poder lanzar simulaciones masivas
5
STO007 Como cliente quiero poder incluir constantes en los ficheros de configuración de los escenarios para simplificar la lectura de los mismos
1
STO008 Como cliente quiero poder escribir fórmulas o reglas en formato matemático y que el software pueda interpretarlas para dar versatilidad
5
STO009 Como cliente quiero poder indicar las fórmulas de decisión en los archivos de configuración para poder generar diferentes escenarios
1
STO010 Como cliente quiero poder generar un gráfico con información diaria a partir de un archivo CSV (desde script)
8
STO011 Como cliente quiero que los gráficos se puedan generar dinámicamente en función a parámetros (estudiar solución técnica) para decidir si se usan ficheros de configuración de gráficos
13
STO012 Como cliente quiero que cada gráfico que se genere lleve asociado un fichero CSV con la información representada para tratamientos en otras herramientas
1
STO013 Como cliente quiero que los gráficos puedan contener varias ventanas, y se puedan asociar variables a cada ventana, con tipos y colores parametrizables y que se pueda definir el tamaño en pixels para ofrecer mayor versatilidad
8
STO014 Como cliente quiero indicar al software que me genere gráficos siempre, nunca o en los n casos más favorables para no sobrecargar en el caso de escenarios masivos
5
STO015 Como cliente quiero poder mostrar en el gráfico las operaciones de entrada/salida del mercado para permitir un análisis visual
3
STO016 Como cliente quiero guardar en una matriz el resultado de la ejecución de todos los escenarios para poder realizar estudios posteriores
5
STO017 Como cliente quiero que el software ordene los escenarios según uno o más ratios calculados tras la ejecución para conocer las reglas más ventajosas
5
STO018 Como cliente quiero que, además de decidir entradas / salidas del mercado en base a unas fórmulas, también contemple StopLoss y TakeProfit para asimilarlo a las operaciones reales
13
STO019 Como cliente quiero disponer de un LOG de ejecución indicando tiempos para conocer el rendimiento de la librería de indicadores técnicos usada
5
Por último, y no menos importante, también acordamos entre el Product
Owner y el el Equipo de Desarrollo que, en cada Historia de Usuario,
incluiremos un campo que especifique la definición de “Terminado” en modo de
criterios de aceptación, porque nos resulta difícil encontrar una definición
aplicable a todas en conjunto.

70
En este punto ya teníamos toda la información necesaria para plantear
al cliente los costes estimados del proyecto, el número de sprints y, por tanto,
una primera estimación de duración del proyecto. Los costes de esta fase de
análisis no se trasladaron al cliente.
También inicializamos en Kunagi el proyecto Trading, creando los
usuarios y asignando los roles a cada miembro del equipo:
Asimismo, dimos de alta las Historias de Usuario con su estimación en
Puntos de Historia y la velocidad estimada del Equipo de Desarrollo (Kunagi
realiza con toda esa información una estimación de fechas de entrega):
Figura 13 Trading en Kunagi: Roles

71
Figura 14 Trading en Kunagi: Historias de Usuario
Ya estábamos preparados para el Sprint 1.
6.2 Sprint 1
6.2.1 Sprint Planning
En la reunión de planificación de este primer sprint, el Product Owner ha
seleccionado dos Historias de Usuario estimadas en un total de 14 Puntos de
Historia.

72
STO001: Como cliente quiero poder leer un archivo con datos
históricos en formato csv para calcular sobre ellos indicadores
técnicos
STO004: Como cliente quiero poder leer uno o más archivos de
configuración para poder lanzar ejecuciones desatendidas
Una aclaración: la velocidad del equipo calculada en el aparatado “5.1
Método de estimación utilizado” era de 19 SP, que supera en 5 SP a la suma
de la duración estimada de las dos historias seleccionadas. Podríamos haber
incluido otra Historia de Usuario más pero, para el cliente, la siguiente en
prioridad tiene una duración de 8 SP, lo cual superaría la capacidad de trabajo
del equipo. Una opción podría haber sido fragmentar la tercera historia en dos
partes, una de las cuales hubiera entrado en este sprint. Pero en este primer
ciclo optamos por ser conservadores y no incluir nada. En el Sprint Review
podremos ajustar este dato.
Figura 15 Sprint 1 Backlog

73
Falta completar en cada Historia de Usuario el valor que aporta al
negocio (según indique el Product Owner) y los criterios de aceptación para
tener toda la información que SCRUM recomienda en su estándar.
ID
STO001DESCRIPCIONComo cliente quiero poder leer un archivo con datos históricos en formato csv para calcular sobre ellos indicadores técnicosVALOR2ESTIMACION1 SPACEPTACIONEl nombre del fichero podrá ser un parámetroSe debe controlar la existencia del ficheroControlar que los datos del fichero tienen el formato esperado
ID
STO004DESCRIPCIONComo cliente quiero poder leer uno o más archivos de configuración para poder lanzar ejecuciones
desatendidasVALOR10ESTIMACION13 SPACEPTACIONAdmitir campos individuales y listas como elementos en los archivosVerificar existencia de archivos de configuraciónAlmacenar en variables locales
Figura 16 Sprint 1 Historias de Usuario
Ahora el equipo detallará las tareas y, en base a ello, confirmará la
duración de estas Historias de Usuario.
A continuación se muestra una tabla con la lista de tareas identificadas
para el Sprint 1:
Tabla 9 Sprint 1 Tareas
Historia de
Usuario
Tarea Descripción Horas
STO001 TSK001 Crear función en C para control de existencia de fichero en
disco
1
STO001 TSK002 Crear bucle de lectura controlando número de columnas y tipo,
almacenando array en memoria
1
STO001 TSK003 Realizas las pruebas de acuerdo a los criterios de aceptación 1
STO004 TSK001 Crear una función que interprete un fichero de texto que
contenga nombre de parámetros y valores (individuales o listas)
24
STO004 TSK002 Crear funciones que recuperen parámetros concretos y los
almacene en variables en memoria
9
STO004 TSK003 Realizar control de errores: valor incorrecto en parámetros o no
existencia
3
STO004 TSK004 Realizas las pruebas de acuerdo a los criterios de aceptación 3

74
Una vez incorporadas las tareas en Kunagi, nuestro tablero Kanban
muestra el siguiente aspecto:
Figura 17 Sprint 1 Tablero al inicio del Sprint
6.2.2 Sprint Review
Este ha sido el primer Sprint de nuestro proyecto. Las tareas asociadas
a las Historias de Usuario fueron estimadas por el Equipo de Desarrollo en 42
horas (3 para la primera y 39 para la segunda).
Como podemos comprobar en el gráfico Burndown que mostramos a
continuación, la primera parte del Sprint fuimos con retraso debido a los
siguientes motivos:
1. Configuraciones iniciales
2. Cambio de estrategia en la segunda Historia de Usuario

75
Durante la realización de la primera Historia de Usuario realizamos
también tareas de preparación del proyecto en Eclipse (enlazado con Cygwin) y
el diseño de la arquitectura del software. Por ello no fue hasta el tercer día en
que comenzamos con su primera tarea. Una vez iniciada, esta Historia de
Usuario se desarrolló y probó en el plazo previsto.
Durante la segunda Historia de Usuario, que sabíamos compleja,
tuvimos que abordar un cambio de estrategia, que dilató la primera tarea en la
que el objetivo era el desarrollo de una función para interpretar ficheros de
texto donde almacenar los parámetros de la aplicación. Una vez iniciado el
desarrollo, vimos cómo la complejidad aumentaba ya que había que controlar
que la sintaxis de la información contenida en el fichero fuera correcta, e
implementar funciones que accedieran a contenidos concretos (un parámetro u
otro).
Pensamos que quizás habría software ya creado y decidimos detener el
desarrollo que habíamos iniciado e emprender una búsqueda. Con cierta
rapidez encontramos la librería libconfig que parecía responder a nuestros
requerimientos. Para asegurarnos, dedicamos tiempo a las tareas de
instalación y enlazado en nuestro proyecto, y unas primeras pruebas para
comprobar que funcionaba correctamente, antes de continuar el desarrollo en
torno a ella.
El tiempo invertido es investigar esta librería trajo sus frutos a partir de la
mitad del sprint, donde pudimos recuperar rápidamente el atraso de los
primeros días, confirmando lo acertado de nuestra apuesta por este producto.
Figura 18 Sprint 1 Burndown Chart

76
Como ejemplo del seguimiento en el tablero, adjuntamos situación que
nos muestra Kunagi justo antes de realizar las últimas pruebas del sprint (tarea
que podemos ver en la columna central):
Figura 19 Sprint 1 Tablero a falta de las pruebas de la Historia STO004
En cuanto al desarrollo general del proyecto, el Release Burndown Chart
nos muestra la entrega de 4 SP menos de lo esperado en función de nuestra
velocidad teórica debido a que inicialmente seleccionamos menos Historias de
Usuario.
6.2.3 Sprint Retrospective
Cabe en este punto hacernos las siguientes preguntas:
Si hiciéramos el sprint otra vez, ¿haríamos las cosas igual? ¿o haríamos
algunas cosas de forma diferente y cómo?
Figura 20 Sprint 1 Release Burndown Chart

77
De lo ocurrido en este sprint con el cambio de estrategia respecto a la
lectura de archivos de configuración, hemos aprendido que al valorar el
esfuerzo de una Historia de Usuario, debemos incluir un factor de incertidumbre
para aquéllos casos en los que no tengamos claro qué tecnología usar.
A pesar de ello, el equipo ha trabajado a la velocidad estimada al
principio del proyecto porque, al haber seleccionado menos Puntos de Historia,
este sprint ha sido llevado con soltura, especialmente en el último tercio del
mismo. Por este motivo mantenemos la velocidad del Equipo en 19 SP por
Sprint y nos hace sentirnos confiados para las siguientes iteraciones.
6.2.4 Demos
6.2.4.1 Lectura de fichero csv
Partimos de un fichero de datos históricos proporcionados por el cliente.
Figura 21 Sprint 1 Demo: fichero CSV de entrada
El programa muestra en consola el resultado de la lectura, indicando el
número de líneas leídas y los datos de las tres últimas lecturas.
Figura 22 Sprint 1 Demo: lectura de fichero csv

78
6.2.4.2 Lectura de fichero de configuración
Partimos de un fichero de configuración con sintaxis admitida por la
librería libconfig.
Figura 23 Sprint 1 Demo: fichero de configuración ejemplo
El software muestra los valores extraídos del fichero e incorporados en
memoria
Figura 24 Sprint 1 Demo: lectura fichero de configuración
6.2.4.3 Control de errores
A continuación se muestra el control de errores en la lectura del archivo
de datos históricos:
Figura 25 Sprint 1 Demo: error en lectura del fichero csv

79
6.3 Sprint 2
6.3.1 Sprint Planning
En la reunión de planificación de este primer sprint, el Product Owner ha
priorizado cinco Historias de Usuario estimadas en un total de 19 Puntos de
Historia.
STO010: Como cliente quiero poder generar un gráfico con
información diaria, inicialmente desde script, para disponer de una
herramienta visual de análisis
STO003: Como cliente quiero que el software pueda manejar
grandes cantidades de datos para poder leer series históricas
STO002: Como cliente quiero que el software detecte el intervalo
de tiempos del archivo de datos para poder generar gráficos
intradía/interdía
Figura 26 Sprint 2 Backlog

80
STO012: Como cliente quiero que cada gráfico que se genere
lleve asociado un fichero csv con la información representada
para tratamientos en otras herramientas analíticas
STO005: Como cliente quiero disponer de una lista de
indicadores a poder utilizar, que sea editable para poder utilizarla
al declarar los escenarios
Hemos acordado con el Product Owner seleccionar Historias cuya
duración completen la velocidad del equipo, estimada en 19 SP. Recordemos
que en Sprint 1 realizamos 14 SP pero que, conforme se desarrollaron las
tareas, somos optimistas en alcanzar las 19 SP.
Analizamos en detalle cada Historia de Usuario junto al Product Owner):
ID
STO010DESCRIPCIONComo cliente quiero poder generar un gráfico con información diaria (desde script),para disponer de una herramienta visual de análisisVALOR5ESTIMACION8 SPACEPTACIONSe debe controlar la existencia del ficheroQueremos guardar el gráfico como una imagen png en disco
ID
STO003DESCRIPCIONComo cliente quiero que el software pueda manejar grandes cantidades de datos, para poder leer series
históricasVALOR10ESTIMACION8 SPACEPTACIONManejar dinámicamente la memoriaControlar en todo momento errores de asignaciónReutilizar espacio de memoria ya reservado en ejecuciones anteriores
ID
STO002DESCRIPCIONComo cliente quiero que el software detecte el intervalo de tiempos del archivo de datos para poder generar gráficos intradía/interdíaVALOR1ESTIMACION1 SPACEPTACIONPoder distinguir entre minutos, horas y díasControlar que los datos fecha/hora son correctos antes de realizar los cálculos
ID
STO012DESCRIPCIONComo cliente quiero que cada gráfico que se genere lleve asociado un fichero csv con la información representada para tratamientos en otras herramientasVALOR3ESTIMACION1 SPACEPTACIONImplementar control de errores al escribir en discoIncluir en el fichero datos históricos y dejar preparado para incluir resultados del cálculo de indicadores

81
ID
STO005DESCRIPCIONComo cliente quiero disponer de una lista de indicadores a poder utilizar, que sea editable para poder utilizarla al declarar los escenariosVALOR1ESTIMACION1 SPACEPTACIONLeer un archivo de configuración de texto donde poder incluir los indicadores aceptados y sus parámetrosAlmacenar en memoria dinámicamente
Figura 27 Sprint 2 Historias de Usuario
Ahora el equipo detallará las tareas y, en base a ello, confirmará la
duración de estas Historias de Usuario.
A continuación se muestra la tabla que elaboramos con la lista de tareas
identificadas para el Sprint 2:
Tabla 10 Sprint 2 Tareas
Historia de
Usuario
Tarea Descripción Horas
STO010 TSK001 Análisis de alternativas que ofrece matplotlib para graficar
información financiera
18
STO010 TSK002 Crear función que compruebe existencia del script en el
directorio de la aplicación y lo ejecute
3
STO010 TSK003 Realizas las pruebas de acuerdo a los criterios de aceptación 3
STO003 TSK001 Diseñar y crear structs y arrays para toda la información a
manejar: indicadores técnicos, datos históricos parámetros
6
STO003 TSK002 Crear un módulo específico para manejo de memoria con
malloc, realloc y free (datos de texto y numéricos float e int)
12
STO003 TSK003 Implementar un control de errores de manejo de memoria 3
STO003 TSK004 Realizas las pruebas de acuerdo a los criterios de aceptación 3
STO002 TSK001 Desarrollar una función que valide que la información histórica
leída contiene el detalle necesario para permitir el cálculo
1

82
STO002 TSK002 Desarrollar función que calcule el salto temporal entre los dos
últimos datos consecutivos
1
STO002 TSK003 Realizas las pruebas de acuerdo a los criterios de aceptación 1
STO012 TSK001 Crear función que recorra la estructura de datos históricos y
genere información en fichero en formato tabular
1
STO012 TSK002 Controlar mensajes de error de acceso a ficheros del sistema
operativo
1
STO012 TSK003 Realizas las pruebas de acuerdo a los criterios de aceptación 1
STO005 TSK001 Ampliar la rutina de lectura de archivos de configuración y
estructuras en memoria
2
STO005 TSK002 Realizas las pruebas de acuerdo a los criterios de aceptación 1
A continuación activamos en Kunagi el sprint 2 y asignamos las Historia
de Usuario y sus tareas asociadas. Podemos ver a continuación el tablero
completo en el momento del inicio, justo antes de que el equipo comience a
trabajar con él.

83
Figura 28 Sprint 2 Tablero al inicio del Sprint
6.3.2 Sprint Review
En la fase inicial de este sprint nos vimos penalizados por las tareas de
investigación de las dos grandes Historias de Usuario seleccionadas: la
creación de gráficos usando matplotlib y el diseño de nuestra aplicación en lo
que se refiere al uso de memoria dinámica.
Fueron muchas las horas de trabajo dedicadas a la investigación de esta
librería y a su enlace con nuestra aplicación en C. Pronto pudimos ver que es
una magnífica utilidad y que proporciona gráficos de gran calidad estética y una

84
fantástica interface para los programadores. En este sprint trabajamos
básicamente con ficheros script propietarios de matplotlib, pero pudimos
vislumbrar que podríamos generar los gráficos dinámicamente con un poco
más de investigación.
En cuanto al manejo de memoria, nuestra decisión fue implementar
estructuras que contendrían la información recogida de los archivos de
configuraciones pero, además, un sistema de arrays de punteros a estructuras
en memoria para contener el grueso de la información, es decir, los datos
históricos sobre los que realizaremos el backtesting y los indicadores
calculados por la librería TA-Lib. En el apartado “10, Anexo I Diseño de la
aplicación” se explica en detalle la solución técnica aplicada.
Una vez concluida esta fase de diseño, la implementación fue rápida y
pudimos recuperar, e incluso adelantarnos, al calendario previsto.
El resto de Historias de Usuario no presentaron dificultades y se
mantuvo el buen ritmo.
La sensación que tenemos en el Equipo de Desarrollo es que podríamos
admitir cargas de más de 19SP
Adjuntamos a continuación el tablero justo al terminar la primera Historia
de Usuario del sprint, mostrando la primera tarea de la segunda Historia
seleccionada.
Figura 29 Sprint 2 Burndown Chart

85
Figura 30 Sprint 2 Tablero al finalizar la Historia de Usuario STO010
En cuanto al desarrollo general del proyecto, el Release Burndown Chart
nos muestra la entrega de 4 SP menos de lo esperado, en función de nuestra
velocidad teórica, debido al retraso acumulado desde el primer Sprint.
6.3.3 Sprint Retrospective
Al igual que en el sprint 1, las tareas de investigación en el uso de
nuevos productos pueden conducir a retrasos en las etapas iniciales. Sin
embargo hemos observado que en tareas de desarrollo nuestra velocidad está
por encima de los estimado.
Figura 31 Sprint 2 Release Burndown Chart

86
En el Sprint 3 intentaremos incluir alguna Historia que nos haga superar
nuestros 19SP. Creemos poder manejarla y, así, podríamos recuperar el
retraso inicial.
6.3.4 Demos
6.3.4.1 Gráfico de velas simple generado por matplotlib
Figura 32 Sprint 2 Demo: script de matplotlib
Figura 33 Sprint 2 Demo: gráficos de velas con matplotlib

87
6.3.4.2 Almacenamiento de información en estructuras C y cálculo del
intervalo temporal
Tomamos de nuevo el fichero csv de entrada del sprint 1:
Figura 34 Sprint 2 Demo: fichero CSV de entrada
El software lee y graba la información en la siguiente estructura:
Figura 35 Sprint 2 Demo: estructura para almacenar datos históricos
Adjuntamos un volcado de la información almacenada en la estructura
junto al resultado del cálculo del intervalo de tiempo entre muestras (en este
caso, 5 minutos):

88
Figura 36 Sprint 2 Demo: información almacenada en la estructura
6.3.4.3 Fichero generado
Adjuntamos imagen de una muestra del archivo generado por la
aplicación. Este fichero contiene la información leída del fichero CSV de
entrada, pero contendrá columnas adicionales para almacenar los resultados
de los indicadores técnicos (ver últimas columnas del fichero, con información
de ejemplo):
Figura 37 Sprint 2 Demo: fichero de salida generado

89
6.4 Sprint 3
6.4.1 Sprint Planning
Como comentamos en el Sprint Review del ciclo 2, en esta ocasión
pediremos abordar Historias de Usuario con una duración estimada superior a
nuestra velocidad inicial, ya que consideramos que somos capaces de
realizarlas, especialmente si no hay tareas de investigación implicadas.
Por tanto, según la prioridad marcada por el Product Owner, decidimos
aceptar las siguientes Historias de Usuario, con un peso total de 21 SP:
STO011: Como cliente quiero que los gráficos se puedan generar
dinámicamente en función a parámetros (estudiar solución
técnica) para decidir si se usan ficheros de configuración de
gráficos
STO013: Como cliente quiero que los gráficos puedan contener
varias ventanas, y se puedan asociar variables a cada ventana,
con tipos y colores parametrizables y que se pueda definir el
tamaño en pixels para ofrecer mayor versatilidad
Figura 38 Sprint 3 Backlog

90
Analizamos en detalle cada Historia de Usuario junto al Product Owner:
ID
STO011DESCRIPCIONComo cliente quiero que los gráficos se puedan generar dinámicamente en función a parámetros (estudiar solución técnica) para decidir si se usan ficheros de configuración de gráficosVALOR5ESTIMACION13 SPACEPTACIONQueremos prescindir del uso de ficheros de script estáticosQueremos poder crear o no los gráficosQueremos que la creación de gráficos sea desatendida y los genere con nombres que se puedan posteriormente identificar
ID
STO013DESCRIPCION
Como cliente quiero que los gráficos puedan contener varias ventanas, y se puedan asociar variables a cada ventana, con tipos y colores parametrizables y que pueda definir en pixels el tamaño para ofrecer mayor versatilidadVALOR8ESTIMACION8 SPACEPTACION
Definir el formato del gráfico en el archivo de configuraciónAceptar número de ventanas, tipos de gráficos, colores, variables a representar, mostrar/ocultar ejes, ...
Figura 39 Sprint 3 Historias de Usuario
Una vez completa toda la información que describe totalmente las
Histoias de Usuario para este sprint, el equipo de desarrollo identifica y valora
las tareas asociadas, obteniendo como resultado la siguiente tabla:
Tabla 11 Sprint 3 Tareas
Historia de
Usuario
Tarea Descripción Horas
STO011 TSK001 Estudiar solución técnica (llamadas desde C a matplotlib).
Seleccionar el paso de información por memoria o en base a
ficheros
24
STO011 TSK002 Crear un módulo sólo para la generación de los gráficos 12
STO011 TSK003 Realizas las pruebas de acuerdo a los criterios de aceptación 3
STO013 TSK001 Identificar las características de los gráficos parametrizables 14
STO013 TSK002 Modificar los ficheros de configuración de los escenarios para
incluir la información
4
STO013 TSK003 Realizar una función para recoger de los archivos de
configuración la información sobre los gráficos
3
STO013 TSK004 Realizas las pruebas de acuerdo a los criterios de aceptación 3
Procedemos a continuación a reflejar el contenido del sprint en Kunagi.
Primero incluimos las Historias de Usuario. En la siguiente imagen observamos
el paso de incluir la STO013 (“Pull to Spring”).

91
También vemos cómo la aplicación nos va mostrando la velocidad del
equipo en base a la conseguida en los sprints anteriores.
Figura 41 Sprint 3: Tablero a falta de incluir las tareas
Y ahora mostramos el tablero completo en el momento del inicio del
sprint:
Figura 40 Sprint 3: incluir Historias de Usuario en un Sprint

92
Figura 42 Sprint 3 Tablero al inicio del Sprint
6.4.2 Sprint Review
Este sprint 3 se ha desarrollado con total normalidad. Parte del esfuerzo
dedicado a la investigación de la librería matplotlib durante el ciclo anterior ha
dado sus frutos en éste, donde la mayor parte del trabajo se ha empleado en
implementar la solución en nuestro proyecto.
Dada la versatilidad y potencia de este módulo gráfico y de la librería
libconfig (para la lectura de los archivos de configuración), se ha podido crear
un completo paquete de gráficos financieros dentro de nuestra aplicación.
Podemos observar en el Burndown Chart cómo el desarrollo de las
tareas ha estado prácticamente en todo momento mejor de lo presupuestado,
sin encontrar grandes dificultades.
La única excepción fue le creación de gráficos intradía, donde el Equipo
de Desarrollo tardó en encontrar la configuración correcta para el eje de
abscisas (la documentación existente es muy extensa y lleva tiempo localizar
un aspecto en concreto).

93
Con este sprint el Equipo de desarrollo ha mostrado gran interés en
recuperar el terreno perdido a nivel general del proyecto, consiguiendo
acercarse al objetivo inicial. Véase el siguiente gráfico:
6.4.3 Sprint Retrospective
Definitivamente el Equipo ha sido capaz de trabajar por encima de las
19SP. En la reunión de planificación del siguiente sprint informaremos al
Product Owner de este hecho, de cara a la selección de las siguientes Historias
de Usuario.
Figura 43 Sprint 3 Burndown Chart
Figura 44 Sprint 3 Release Burndown Chart

94
6.4.4 Demos
6.4.4.1 Lectura de la configuración de gráficos
En esta demo mostramos al cliente cómo, a partir de un archivo de
configuración, el software almacena esta información en memoria para su
posterior uso al graficar los resultados de las simulaciones:
Figura 45 Sprint 3 Demo: configuración del formato de los gráficos
Figura 46 Sprint 3 Demo: salida por consola de la información leída

95
6.4.4.2 Gráfico dinámico: primera versión
Figura 47 Sprint 3 Demo: gráfico creado dinámicamente
6.5 Sprint 4
6.5.1 Sprint Planning
En este cuarto ciclo informamos al Product Owner que nuestra apuesta
por superar las 19SP ha sido acertada y proponemos modificar la velocidad a
21SP, actualización permitida por SCRUM si se produce en función del
resultado de las revisiones de rendimiento realizadas durante los Sprint Review
y Sprint Retrospective.
El Product Owner nos presenta sus requerimientos traducidos a
Historias de Usuario priorizadas:

96
STO008: Como cliente quiero poder escribir fórmulas en formato
matemático para que el software pueda interpretarlas
STO006: Como cliente quiero poder indicar rangos o listas de
parámetros de los indicadores para lanzar simulaciones masivas
STO009: Como cliente quiero poder indicar las fórmulas de
decisión en los archivos de configuración para poder generar
diferentes escenarios
STO019: Como cliente quiero disponer de un LOG de ejecución
indicando tiempos para conocer el rendimiento de la librería de
indicadores técnicos usada y del software en general
STO015: Como cliente quiero poder indicar en el gráfico las
operaciones de entrada/salida del mercado para permitir un
análisis visual (esta Historia de Usuario, en función de la
conversación mantenida con el cliente, y por su complejidad,
Figura 48 Sprint 4 Backlog

97
hemos decidido estimarla al alza en 5SP, en lugar de los 3SP
que tenía inicialmente)
Y el detalle de cada una se muestra a continuación:
ID
STO008DESCRIPCIONComo cliente quiero poder escribir fórmulas en formato matemático y que el software pueda interpretarlasVALOR8ESTIMACION5 SPACEPTACIONDebe ejecutar operaciones aritméticas básicasDebe contemplar el uso de paréntesisDebe poder evaluar condicione >,<,=Debe poder recoger el valor de variables e indicadoresDebe poder recoger el valor de constantesValor absoluto y negaciónAdmitir subíndices
ID
STO006DESCRIPCIONComo cliente quiero poder indicar rangos o listas de parámetros de los indicadores para lanzar simulaciones masivasVALOR8ESTIMACION5 SPACEPTACIONAceptar valores únicosAceptar lista de valoresAceptar rando: desde-hasta-salto
ID
STO009DESCRIPCIONComo cliente quiero poder indicar las fórmulas de decisión en los archivos de configuración para poder generar diferentes escenariosVALOR3ESTIMACION1 SPACEPTACIONDebe contemplar las fórmulas para cálculo de tendencia alcista y bajistaDebe permitir indicar las fórmulas para el volumen a contratar
ID
STO019DESCRIPCIONComo cliente quiero disponer de un LOG de ejecución indicando tiempos para poder conocer el rendimiento del softwareVALOR3ESTIMACION5 SPACEPTACIONDebe poder ser opcional su generaciónDebe mostrar tiempos de ejecuciónMostrar errores cuando se produzcan, y el motivoResultados de las simulacionesPoder seleccionar el directorio donde se genera

98
ID
STO015DESCRIPCIONComo cliente quiero poder indicar en el gráfico las operaciones de entrada/salida del mercado para poder realizar un análisis visualVALOR3ESTIMACION5 SPACEPTACIONIndicar el punto en el tiempo donde se realiza una operaciónDistinguir por colores/texto el tipo de entrada/salida
Tras el análisis de cada Historia, el Equipo de Desarrollo identifica las
siguientes tareas, y su duración en horas de trabajo:
Tabla 12 Sprint 4 Tareas
Historia de
Usuario
Tarea Descripción Horas
STO008 TSK001 Desarrollar un analizador sintáctico para expresiones
matemáticas
7
STO008 TSK002 Desarrollar una función que reemplace el nombre de las
variables por su valor numérico
5
STO008 TSK003 Realizas las pruebas de acuerdo a los criterios de aceptación 3
STO006 TSK001 Modificar la lectura de los archivos de configuración para poder
distinguir entre valores individuales, listas y rangos
5
STO006 TSK002 Almacenar en estructuras en memoria para su posterior uso por
el simulador
7
STO006 TSK003 Realizas las pruebas de acuerdo a los criterios de aceptación 3
STO009 TSK001 Preparar las estructuras en memoria para almacenar las
fórmulas
1
STO009 TSK002 Desarrollar la función de lectura del archivo de configuración
para el apartado de las fórmulas
1
STO009 TSK003 Realizas las pruebas de acuerdo a los criterios de aceptación 1
STO019 TSK001 Crear una función que, en función de un parámetro, genera el
archivo en un directorio seleccionado en el config
3
STO019 TSK002 Modificar todo el código fuente en los puntos que manejen 10

99
información relevante para ser enviada al fichero
STO019 TSK003 Realizas las pruebas de acuerdo a los criterios de aceptación 2
STO015 TSK001 Incluir una nueva columna en la estructura que almacena los
indicadores, para indicar la operación realizada en cada
momento (codificar numéricamente el tipo … p.e. 1: entrada 2:
salida …..)
4
STO015 TSK002 Modificar el módulo de los gráficos para recoger esta
información y dibujar una etiqueta en el gráfico según el color
de cada operación
8
STO015 TSK003 Realizas las pruebas de acuerdo a los criterios de aceptación 3
Ahora procedemos a recoger esta información en nuestra herramienta
de seguimiento del proyecto (Kunagi). Observamos en la imagen siguiente el
cambio del Product Backlog antes y después de enviar estas cinco Historias de
Usuario al sprint 4.
También podemos observar la nueva velocidad del equipo de 21 SP.
Figura 49 Sprint 4: Reducción del Product Backlog tras asignar al Sprint

100
Y éste es el tablero completo en el momento del inicio del Sprint:
Figura 50 Sprint 4 Tablero al inicio del Sprint
En la siguiente imagen podemos observar un momento del sprint con
una Historia de Usuario parcialmente completada (una tarea están en
desarrollo). Podemos observar en las líneas horizontales (verde y azul) el
estado de completitud de la misma.

101
Figura 51 Sprint 4 Tablero con dos tareas finalizadas y una en curso
6.5.2 Sprint Review
Este sprint ha resultado técnicamente muy interesante al incluir el
desarrollo de un analizador sintáctico de expresiones matemáticas y la lógica
para manejar parámetros que puedan tomar valores en un conjunto o en un
rango del tipo desde-hasta-salto.
Únicamente nos ha quedado por mejorar (no lo hemos hecho por
ceñirnos a las horas de trabajo estimadas) el tratamiento correcto de la
precedencia en las operaciones +, -, *, /. De momento, en esta versión,
indicaremos en el manual de usuario que se deben usar paréntesis para suplir
esta carencia.
Observamos el buen alineamiento de la ejecución de tareas con la
estimación realizada por el Equipo de Desarrollo:
Podemos observar en el gráfico Release Burn down global del proyecto
que, al aumentar nuestra velocidad, hemos conseguido recuperar el atraso con
que iniciamos el primer sprint. El Equipo es capaz de desarrollar de manera
sostenida a una velocidad de 21SP.
Figura 52 Sprint 4 Burndown Chart

102
6.5.3 Sprint Retrospective
No tenemos nada relevante que comentar en esta retrospectiva. Este
ciclo se ha desarrollado con total normalidad. El manejo de tiempos ha sido
adecuado y hemos sido incluso capaces de detectar el peligro de invertir
demasiado tiempo en el desarrollo de un analizador sintáctico que incluyera la
complejidad del manejo de la precedencia. Por el contrario, hemos preferido
concluir una versión sin esta funcionalidad, en aras de que el cliente pueda ver
una demo del producto.
6.5.4 Demos
6.5.4.1 Analizador sintáctico de fórmulas
Mostramos a continuación el resultado satisfactorio de un análisis de la
fórmula que determina una situación alcista. Se observa la sustitución de los
nombres de las variables/indicadores por sus posiciones en la tabla de datos.
En este caso:
Outmacd se encuentra almacenado en el índice 9 de la tabla
Outma se encuentra almacenado en el índice 7 de la tabla
Figura 53 Sprint 4 Release Burndown Chart
Figura 54 Sprint 4 Demo: analizador sintáctico de expresiones

103
6.5.4.2 Rangos de números
Se muestra la salida en la que, a partir del fichero de configuración
donde el parámetro optInFastPeriod del indicador MACD toma dos valores
(“12” y 14”), se generan dos líneas con el mismo id de parámetro, pero con
diferentes valores:
6.5.4.3 Ejemplo de fichero LOG
Figura 56 Sprint 4 Demo: fichero LOG
Figura 55 Sprint 4 Demo: parámetros con varios valores

104
6.5.4.4 Operaciones de entrada/salida en gráficos
6.6 Sprint 5
6.6.1 Sprint Planning
En la reunión de planificación del quinto sprint, el Product Owner había
seleccionado 4 Historias de Usuario, que en total sumaban 16 Puntos de
Historia (SP), lo cual quedaba por debajo de las 21 SP que éramos capaces de
desarrollar (-5SP).
La siguiente Historia de Usuario, priorizada según el valor para el
negocio tenía un tamaño de 13SP, lo que nos hacía imposible incluirla en su
totalidad.
SCRUM nos permite dividir una Historia de Usuario en otras de menores
dimensiones, siempre y cuando las resultantes sigan ofreciendo una
funcionalidad al cliente.
Solicitamos por tanto al Product Owner que analizara si era posible
dividir la historia STO018 (como cliente quiero que, además de decidir entradas
/ salidas del mercado en base a unas fórmulas, también contemple Stop Loss y
Figura 57 Sprint 4 Demo: indicadores de entrada/salida del mercado

105
Take Profit) en, al menos, otras dos, siendo una de ellas de tamaño entorno a
los 5SP para que pudiera ser incluida en este sprint.
Finalmente llegamos a un acuerdo, y la Historia de Usuario STO018 se
convirtió en dos:
La STO018, con un nuevo tamaño de 5SP: Como cliente quiero
que se puedan incluir en los archivos de configuración
información relativa al StopLoss y TakeProfit para asimilarlo a las
operaciones reales
Una nueva STO020, de tamaño 8SP: Como cliente quiero que las
simulaciones tengan en cuenta el efecto del StopLoss y
TakeProfit para generar órdenes de salida del mercado
Podemos observar en la siguiente figura esta división:
Figura 58 Sprint 5 Backlog

106
STO016: Como cliente quiero guardar en una matriz el resultado
de la ejecución de todos los escenarios para poder realizar
estudios posteriores
STO017: Como cliente quiero que el software me ordene los
escenarios según uno o más ratios para conocer las reglas de
mercado más ventajosas
STO014: Como cliente quiero indicar al software que me genere
gráficos siempre, nunca o en los n casos más favorables para no
sobrecargar en el caso de ejecución de escenarios masivos
STO007: Como cliente quiero poder incluir constantes en los
ficheros de configuración de los escenarios para simplificar la
lectura de los mismos
STO018: Como cliente quiero incluir en los archivos de
configuración información relativa al Stop Loss y Take Profit para
asimilarlo a las operaciones reales del mercado
Como en los sprint anteriores, ahora debemos documentar para cada
Historia de Usuario, los aspectos que la definen completamente, desde su
estimación en Puntos de Historia, hasta el valor que aportaría al negocio y los
criterios que, una vez satisfechos, determinarían que la Historia está
completamente realizada y aceptada:

107
ID
STO016DESCRIPCIONComo cliente quiero guardar en una matriz el resultado de la ejecución de todos los escenarios para poder realizar estudios posterioresVALOR3ESTIMACION5 SPACEPTACIONAlmacenar el detalle de las operaciones de entrada/salidaAlmacenar el profitCalcular y almacenar otros ratios
ID
STO017DESCRIPCIONComo cliente quiero que el software me ordene los escenarios según uno o más ratios para conocer las regla del mercado más ventajosasVALOR3ESTIMACION5 SPACEPTACIONComprobar que hay resultados para ordenarDebe contemplar que haya escenarios con el mismo resutado
ID
STO014DESCRIPCIONComo cliente quiero indicar al software que me genere gráficos siempre, nunca o en los n casos más favorables para no sobrecargar el sistema en ejecuciones masivasVALOR3ESTIMACION5 SPACEPTACIONComprobar que no queremos generar más gráficos que los disponiblesNombrar los ficheros para que se pueda distinguir si son parte de los n-mejores o del total
ID
STO007DESCRIPCIONComo cliente quiero poder incluir constantes en los ficheros de configuración de los escenarios para simplificar la lectura de los mismosVALOR1ESTIMACION1 SPACEPTACIONLas constantes deben ir para cada escenarioLos nombres de las constantes debe poder usarse en las fórmulas que interpreta el analizador sintáctico
ID
STO018DESCRIPCIONIncluir en los archivos de configuración información relativa al StopLoss y TakeProfit para asimiilarlo a las operaciones reales del mercadoVALOR11ESTIMACION5 SPACEPTACIONDebe poder basarse en fórmulasDebe estar por separado SL y TPIndicar una para compra (operaciones a largo) y venta (operaciones en corto)

108
Se muestran a continuación las tareas asociadas a cada Historia de Usuario:
Tabla 13 Sprint 5 Tareas
Historia de
Usuario
Tarea Descripción Horas
STO016 TSK001 Definir las estructuras para almacenar resultados de cada
iteración y el historial de operaciones de entrada/salida
3
STO016 TSK002 Desarrollar la función que almacene la información de cada
ciclo
10
STO016 TSK003 Realizas las pruebas de acuerdo a los criterios de aceptación 2
STO017 TSK001 Seleccionar un método de ordenación( burbuja, otros) 2
STO017 TSK002 Desarrollar la función Sort tomando como entradas las
estructuras del historial de simulaciones y operaciones de
entrada/salida
10
STO017 TSK003 Realizas las pruebas de acuerdo a los criterios de aceptación 3
STO014 TSK001 Modificar fichero de configuración general para incluir este
parámetros y realizar la función de lectura
1
STO014 TSK002 Revisar todo el código para generar gráficos o no, según el
valor del parámetro
10
STO014 TSK003 Realizas las pruebas de acuerdo a los criterios de aceptación 4
STO007 TSK001 Modificar ficheros de configuración de los escenarios para
incluir una lista de constantes, con nombre y valor
1
STO007 TSK002 Modificar el código del analizador sintáctico para que
reconozca los nombre de las constantes
1
STO007 TSK003 Realizas las pruebas de acuerdo a los criterios de aceptación 1
STO013 TSK001 Modificar ficheros de configuración de los escenarios para
incluir fórmulas de TP y SL
4
STO013 TSK002 Realizar la función de lectura y almacenamiento en memoria de
las fórmulas de TP y SL
8
STO013 TSK003 Realizas las pruebas de acuerdo a los criterios de aceptación 3

109
Ahora procedemos a recoger esta información en nuestra herramienta
de seguimiento del proyecto (Kunagi):
Figura 59 Sprint 5 Tablero al inicio del Sprint

110
6.6.2 Sprint Review
Durante este quinto sprint, hemos experimentado un poco de retraso en
las etapas iniciales, coincidiendo con las tareas de desarrollo del código fuente
para almacenar en un array los resultados que se van produciendo en cada
iteración del programa de simulación. El diseño de cómo implementar esta
función y las tareas asociadas ha sido algo más complicado de lo que
estimábamos, ya que también identificamos que teníamos que guardar
punteros a otras estructuras donde se almacenarían los apuntes financieros de
entradas/salidas del mercado.
Sin embargo, como podemos observar en el gráfico, hemos podido
terminar el ciclo apenas un poco peor de lo previsto, por lo que, de cara al
proyecto completo, la evolución es correcta y se van cumpliendo las
estimaciones. Lo podemos observar en la figura siguiente:
Figura 60 Sprint 5 Burndown Chart

111
6.6.3 Sprint Retrospective
No tenemos nada reseñable que comentar. Este ciclo se ha desarrollado
con total normalidad.
6.6.4 Demos
6.6.4.1 Matriz de resultados ordenada
Mostramos al cliente una captura del output del programa donde se
obtiene una tabla con las iteraciones de cada escenario ejecutado, ordenados
de mayor a menor beneficio neto. Es en sí la matriz solicitada en la historia
STO016, ordenada según pedía la historia STO017.
Figura 62 Sprint 5 Demo: Tabla de resultados
También se obtiene, al final de la ejecución, un informe con los
escenarios que ofrecen los mejores resultados:
Figura 61 Sprint 5 Release Burndown Chart

112
Figura 63 Sprint 5 Demo: Resultados ordenados
6.6.4.2 Lectura de constantes desde el fichero de configuración
En esta demo mostramos cómo los datos contenidos en el archivo de
configuración, en el apartado de constantes, son recogidos y almacenados
para su posterior tratamiento:
Figura 64 Sprint 5 Demo: constantes en los archivos de configuración
Figura 65 Sprint 5 Demo: constantes almacenadas en la aplicación

113
6.7 Sprint 6
6.7.1 Sprint Planning
Recordamos cómo en las primeras reuniones con el cliente, y
basándonos en los requerimientos del negocio (traducidos a Historias de
Usuario) y en la velocidad estimada del equipo, pudimos identificar un total de
6 sprints.
Conforme se ha ido desarrollando el proyecto, hemos llegado a este
sexto sprint con una Historia de Usuario pendiente de una duración estimada
de 8 Puntos de Historia (8SP) y, además, hemos podido confirmar que
podemos entregar hasta 21SP.
El cliente nos ha comunicado que la funcionalidad que hemos entregado
hasta el momento se ajusta a las expectativas. Este hecho, junto al remanente
de 13SP que quedan disponibles en este último ciclo, da al cliente la
oportunidad de enriquecer el producto final con más funcionalidades que se
han ido identificado conforme se han entregando las sucesivas versiones:
En esta última reunión de planificación, el Product Owner ha
informado que le gustaría aumentar la utilidad de la herramienta
permitiendo que los datos históricos usados para el backtesting
pudieran incorporarse desde una base de datos, alojada en un
servidor propiedad del cliente, y no sólo con desde el fichero csv
con el hemos trabajado durante todo el proyecto.
Adicionalmente, habiendo observado la demo que se recoge en el
apartado 6.6.4.1, el cliente pide que el criterio de ordenación de
los escenarios pueda ser en base a otros parámetros, y no sólo el
beneficio neto. De aquí ha surgido otra Historia de Usuario.
Por último, y a la vista de la versatilidad que ofrece la
funcionalidad de que los parámetros puedan tomar valores en
listas o en rangos, pide que el StopLoss y el TakeProfit puedan
también ser optimizados de esta manera.
Por tanto, a la Historia de Usuario que quedaba pendiente, se han unido
otras tres que, si el resultado del sprint es satisfactorio y aceptado por el
cliente, habrán supuesto completar la funcionalidad completa requerida al inicio
del proyecto.
Identificamos a continuación las Historias de Usuario para el sprint 6:

114
STO020: Como cliente quiero que las simulaciones tengan en
cuenta el efecto del StopLoss y TakeProfit para generar órdenes
de salida del mercado
[nueva] STO021: Como cliente quiero poder leer datos históricos
desde una base de datos MySQL, para poder diferenciar mi
producto de otras herramientas comerciales que manejan datos
en formato estándar
[nueva] STO022: Como cliente quiero que el software calcule
indicadores de eficacia de la estrategia de trading, aparte del
beneficio neto, para poder determinar cuál es el mejor escenario
[nueva] STO023: Como cliente quiero que el StopLoss y
TakeProfit puedan tratarse como un parámetro más, admitiendo
valores en listas o en rangos, al igual que el resto de parámetros
de los indicadores para poder generar escenarios múltiples
En la siguiente imagen podemos observar el proceso de asignar
Historias del Product Backlog al sprint que se inicia. Observamos cómo en el
Product Backlog ya no quedan Historias de Usuario por entregar.
Sólo queda ahora completar toda la información que identifica
totalmente a estas Historia de Usuario:
Figura 66 Sprint 6 Backlog

115
ID
STO020DESCRIPCIONComo cliente quiero que las simulaciones tengan en cuenta el efecto del StopLoss y TakeProfit para generar órdenes de salida del mercado VALOR11ESTIMACION8SPACEPTACIONPara cada operación a corto o a largo se debe poder marcar el SL y TPEn cada iteración el simulador debe evaluar la condición de SL y TPSi se dispara la condición, debe quedar registros del momento y del beneficio obtenido
ID
STO021DESCRIPCION
Como cliente quiero poder leer
datos históricos desde una base de
datos MySQL, para poder
diferenciar mi producto de otras
herramientas comerciales que
manejan datos en formato estándarVALOR8ESTIMACION5 SPACEPTACIONPoder indicar los parámetros de conexión en el archivo de configuraciónControlar cuando no se obtenga ningún resultado, que no genere errores
ID
STO022DESCRIPCIONComo cliente quiero que el software calcula indicadores de eficacia de la estrategia de trading, aparte del beneficio neto, para poder determinar cuál es el mejor escenarioVALOR1ESTIMACION3 SPACEPTACIONPermitir tener varios indicadores, no sólo el beneficioPoder ordenar por cualquiera de ellosPoder conocer los parámetros usados en cada iteación
ID
STO023DESCRIPCIONComo cliente quiero que el StopLoss y TakeProfit puedan calcularse como un parámetro más, admitiendo valores en listas o en rangos, al igual que el resto de parámetros de los indicadores para poder generar escenarios múltiplesVALOR5ESTIMACION3 SPACEPTACIONPoder considerar a SLy TP como un parámetro más, con valores discretos o en listas/rangoAlmacenar los valores que toman en cada iteración
Tabla 14 Sprint 6 Tareas
Un análisis detallado por parte del Equipo de Desarrollo, lleva a
identificar las siguientes tareas necesarias para desarrollar las Historias de
Usuario:
Historia de
Usuario
Tarea Descripción Horas
STO020 TSK001 Incluir en el bucle de cálculo el disparado del StopLoss y
TakeProfit, generando las órdenes de salida
10

116
STO020 TSK002 Incluir en el libro de apuntes, la salida debido a SL/TP y su
valor en beneficio/pérdida
10
STO020 TSK003 Realizas las pruebas de acuerdo a los criterios de aceptación 4
STO021 TSK001 Incluir en el archivo de configuración parámetros de conexión a
una BBDD
3
STO021 TSK002 Escribir una función similar a la que lee archivos csv, pero
desde tablas de una base de datos
10
STO021 TSK003 Realizas las pruebas de acuerdo a los criterios de aceptación 2
STO022 TSK001 Preparar espacio en las struct para alojar varios cálculos de
rendimiento
1
STO022 TSK002 Al final de cada simulación calcular todos los ratios 6
STO022 TSK003 Realizas las pruebas de acuerdo a los criterios de aceptación 2
STO023 TSK001 Modificar ficheros de configuración de los escenarios para
incluir una lista de constantes, con nombre y valor
1
STO023 TSK002 Modificar el código del analizador sintáctico para que
reconozca los nombre de las constantes
6
STO023 TSK003 Realizas las pruebas de acuerdo a los criterios de aceptación 2
Con toda esta información, actualizamos Kunagi, nuestra
herramienta de control y seguimiento del proyecto. Asignamos las Historias al
sprint y creamos las tareas dentro de cada Historia:

117
Figura 67 Sprint 6 Tablero al inicio del Sprint
6.7.2 Sprint Review
El Equipo de Desarrollo reconoce que nuevamente una tarea de
investigación, en este caso el acceso a una base de datos de MySQL ha
supuesto un ligero retraso en la implementación de una tarea. Si bien existe
una librería MySQL estándar de acceso a datos para C/C++, se ha dedicado
algo más tiempo del previsto a la configuración del acceso al servidor de
cliente. Además, para poder trabajar off-line, se ha preparado una base de
datos MySQL local para realizar más pruebas.
Una vez realizadas estas tareas, el sprint se ha desarrollado con
normalidad y los desarrollos siguientes han estado en plazo. Observamos en el
gráficos el efecto de este retraso a partir de la mitad del sprint.

118
C
Para poder reflejar en el gráfico del proyecto la inclusión de las tres
nuevas Historias de Usuario, hemos recalculado el Release Burndown Chart
con objeto de añadir los 11 Puntos de Historia, elevando el total del proyecto
desde los 102 estimados al principio, hasta los 116 conseguidos.
6.7.3 Sprint Retrospective
Como hemos venido observando durante los sucesivos Sprints, la
velocidad del equipo se ha ajustado bien a las estimaciones. El aumento
de19SP a 21SP ha sido muy efectivo y se ha podido recuperar el retraso con el
que iniciamos el sprint 1.
Figura 68 Sprint 6 Burndown Chart
Figura 69 Sprint 6 Release Burndown Chart

119
En los casos en los que alguna Historia de Usuario se ha desviado
respecto a lo previsto, siempre se ha reaccionado antes del final de la iteración,
consiguiendo entregar las funcionalidades previstas.
6.7.4 Demos
6.7.4.1 Uso de TakeProfit y StopLoss como parámetros
Observamos en primer lugar cómo se especifican estos elementos en el
archivo config. Un indicador del tipo KTE (constante) albergará todas aquéllas
variables que, sin ser parámetros de indicadores técnicos de TALib, van a
tomar valores cambiantes en las sucesivas iteraciones;
Mostramos a continuación una salida por consola donde el programa ha
leído y reconocido los parámetros, y cómo los usa (en el cálculo del Take
Profit) a la hora de realizar la siguiente operación en el mercado:
Figura 70 Sprint 6 Demo: Variables para cálculo de TP y SL
Figura 71 Sprint 6 Demo: Uso del parámetro en el cálculo del SoptLoss

120
6.7.4.2 Ejecución de las condiciones StopLoss y TakeProfit
En esta demo comprobamos que la aplicación tiene en cuenta los
valores de Stop Loss y Take Profit para generar operaciones de salida al
alcanzar los precios cierto umbral.
Vemos un log de operaciones con dos salidas por Stop Loss y una por
Take Profit:
6.7.4.3 Ratios de performance
En esta demo hemos mostrado al cliente tres ratios calculados en cada
iteración, en concreto el Profit, Profit Factor y Nº de Trades (operaciones):
Consultar el “apartado 2.1” de este TFG para la descripción de estos
ratios.
Figura 72 Sprint 6 Demo: Ejecuciones de Stop Loss y Take Profit
Figura 73 Sprint 6 Demo: Indicadores de rendimiento

121
7 Pruebas y Despliegue de la solución
7.1 Pruebas
Las metodologías de desarrollo ágil han surgido intentando generar
sistemas con alta calidad y a la vez, con una reducción y simplificación de
tareas. Bajo este enfoque, las pruebas de software han tomado un papel
crucial, dada la necesidad de realizar pequeñas liberaciones “funcionalmente”
estables, surgiendo así el testing ágil.
Mientras que en las metodologías tradicionales las actividades de
prueba normalmente no se pueden iniciar hasta que la especificación de
requisitos se encuentre completa, en el caso del testing ágil dichas tareas
quedan inmersas dentro de cada iteración.
Otra diferencia importante entre las metodologías tradicionales de
pruebas y las ágiles, es que mientras las primeras tienen como objetivo
primordial la validación del producto desarrollado, en las ágiles tiene gran peso
su utilización como medio para guiar el desarrollo del software, sustituyendo así
la definición formal de requisitos.
En nuestro proyecto, al elaborar cada historia de usuario habíamos
incluido los criterios de aceptación. A continuación detallamos el plan de
pruebas que cada criterio lleva asociado:
Tabla 15 Caso de prueba 001
CP-001 El nombre del fichero debe informarse como un parámetro y debe
verificarse que existe en el directorio de la aplicación
Usuario Cliente
Historia de
Usuario STO001
Prerrequisitos Debemos tener en el directorio de la aplicación el archivo config.cfg, o bien, el que
hayamos informado como argumento en la llamada a trading.exe
Descripción Incluir en config.cfg la línea inputDataFile =”xxxxxxx” y lanzar la aplicación trading.exe
Resultado
esperado Informar con un mensaje de error si el fichero no existe en el directorio de la aplicación
Probador José Carlos Cano

122
Tabla 16 Caso de prueba 002
CP-002 Comprobar que los datos del fichero de históricos tiene el formato
esperado
Usuario Cliente
Historia de
Usuario STO001
Prerrequisitos El fichero de configuración y el de datos históricos deben existir en el directorio de la
aplicación
Descripción Incluir en config.cfg la sección columnsInDataFile, conteniendo una lista de nombres
de campo y tipo de datos (d:date, t:time, f:float) y lanzar la aplicación
Resultado
esperado
El software abrirá el fichero y leerá todas las líneas del mismo, verificando que existen
el mismo número de columnas de entrada, y con el mismo formato, que el informado en
la sección columnsInDataFile. Mostrar un mensaje en caso de error o, por el contrario,
el número de líneas leídas en caso de éxito
Probador José Carlos Cano
Tabla 17 Caso de prueba 003
CP-003 El software debe poder recorrer los archivos de escenario y validar
su sintaxis
Usuario Cliente
Historia de
Usuario STO004
Prerrequisitos El fichero de configuración general config.cfg y el fichero de datos históricos existen en
el directorio de la aplicación
Descripción Situamos en el directorio de la aplicación los ficheros de los escenarios en formato:
scenarioXXXX.cfg y lanzamos trading.exe
Resultado
esperado
El sistema debe efectuar un recorrido por todos los ficheros con nombre
scenarioXXXXX.cfg, y abrirlos por medio de la librería libconfig, mostrando un error en
caso de que se encuentre un error en la sintaxis.
Probador José Carlos Cano

123
Tabla 18 Caso de prueba 004
CP-004 El software debe incorporar en memoria la información contenida
en los ficheros de escenarios
Usuario Cliente
Historia de
Usuario STO004
Prerrequisitos El fichero de configuración general config.cfg y el fichero de datos históricos existen en
el directorio de la aplicación
Descripción Situamos en el directorio de la aplicación los ficheros de los escenarios en formato:
scenarioXXXX.cfg y lanzamos trading.exe
Resultado
esperado
Cada vez que se abre y lee un fichero scenarioXXXXX.cfg por medio de la librería
libconfig, el sistema almacena su contenido en estructuras de datos en memoria,
informando si falta alguna sección requerida
Probador José Carlos Cano
Tabla 19 Caso de prueba 005
CP-005 El software genera un gráfico en formato png
Usuario Cliente
Historia de
Usuario STO010
Prerrequisitos
Existen en el directorio de la aplicación los ficheros de los escenarios en formato:
scenarioXXXX.cfg y se ha incluído en config.cfg la sección outputFolder, para indicar
dónde se deben generar las imágenes
Descripción Colocar un archivo con extensión .py (scripts de Python) en el directorio de la aplicación
y ejecutar
Resultado
esperado
Si la sintaxis del script es correcta, en el directorio indicado por outputFolder se
encuentra una imagen en formato png, o se captura un error si el script tiene sintaxis
incorrecta o no se puede acceder a la ruta en disco especificada
Probador José Carlos Cano
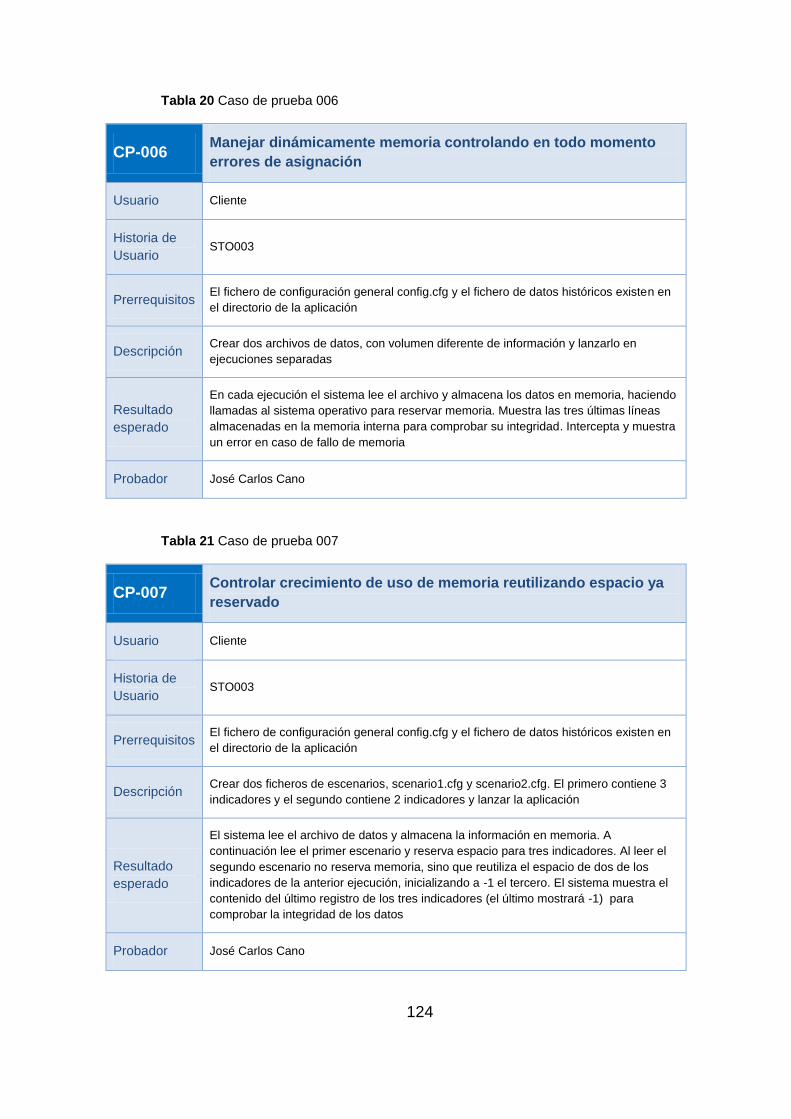
124
Tabla 20 Caso de prueba 006
CP-006 Manejar dinámicamente memoria controlando en todo momento
errores de asignación
Usuario Cliente
Historia de
Usuario STO003
Prerrequisitos El fichero de configuración general config.cfg y el fichero de datos históricos existen en
el directorio de la aplicación
Descripción Crear dos archivos de datos, con volumen diferente de información y lanzarlo en
ejecuciones separadas
Resultado
esperado
En cada ejecución el sistema lee el archivo y almacena los datos en memoria, haciendo
llamadas al sistema operativo para reservar memoria. Muestra las tres últimas líneas
almacenadas en la memoria interna para comprobar su integridad. Intercepta y muestra
un error en caso de fallo de memoria
Probador José Carlos Cano
Tabla 21 Caso de prueba 007
CP-007 Controlar crecimiento de uso de memoria reutilizando espacio ya
reservado
Usuario Cliente
Historia de
Usuario STO003
Prerrequisitos El fichero de configuración general config.cfg y el fichero de datos históricos existen en
el directorio de la aplicación
Descripción Crear dos ficheros de escenarios, scenario1.cfg y scenario2.cfg. El primero contiene 3
indicadores y el segundo contiene 2 indicadores y lanzar la aplicación
Resultado
esperado
El sistema lee el archivo de datos y almacena la información en memoria. A
continuación lee el primer escenario y reserva espacio para tres indicadores. Al leer el
segundo escenario no reserva memoria, sino que reutiliza el espacio de dos de los
indicadores de la anterior ejecución, inicializando a -1 el tercero. El sistema muestra el
contenido del último registro de los tres indicadores (el último mostrará -1) para
comprobar la integridad de los datos
Probador José Carlos Cano

125
Tabla 22 Caso de prueba 008
CP-008 El sistema calculará el lapso de tiempo entre dos datos leídos del
archivo de históricos
Usuario Cliente
Historia de
Usuario STO002
Prerrequisitos El fichero de configuración general config.cfg y el fichero de datos históricos existen en
el directorio de la aplicación
Descripción
Crear tres archivos de datos, dos de ellos con intervalo de tiempos diferentes (5 minutos
y 1 día) y el tercero con formato erróneo en el campo de fecha, y lanzarlos en
ejecuciones separadas
Resultado
esperado
El sistema lee el archivo de datos y almacena la información en memoria. A
continuación calcula el intervalo de tiempo y lo muestra junto al número de líneas
leídas. En caso de formato de fecha errónea, intercepta y muestra el error
Probador José Carlos Cano
Tabla 23 Caso de prueba 009
CP-009 El sistema generará un archivo csv conteniendo los datos
históricos y los indicadores calculados
Usuario Cliente
Historia de
Usuario STO012
Prerrequisitos El fichero de configuración general config.cfg y el fichero de datos históricos existen en
el directorio de la aplicación.
Descripción Crear dos archivos de datos, con volumen diferente de información, y lanzarlo en
ejecuciones separadas para comprobar la escritura a ficheros en las dos situaciones
Resultado
esperado
El sistema lee el archivo de datos y almacena la información en memoria. El sistema
simula el cálculo de indicadores reservando un espacio con números aleatorios. El
sistema vuelca toda la memoria a un archivo con formato separado por comas.
Intercepta y muestra error de manejo de ficheros en caso de producirse.
Probador José Carlos Cano
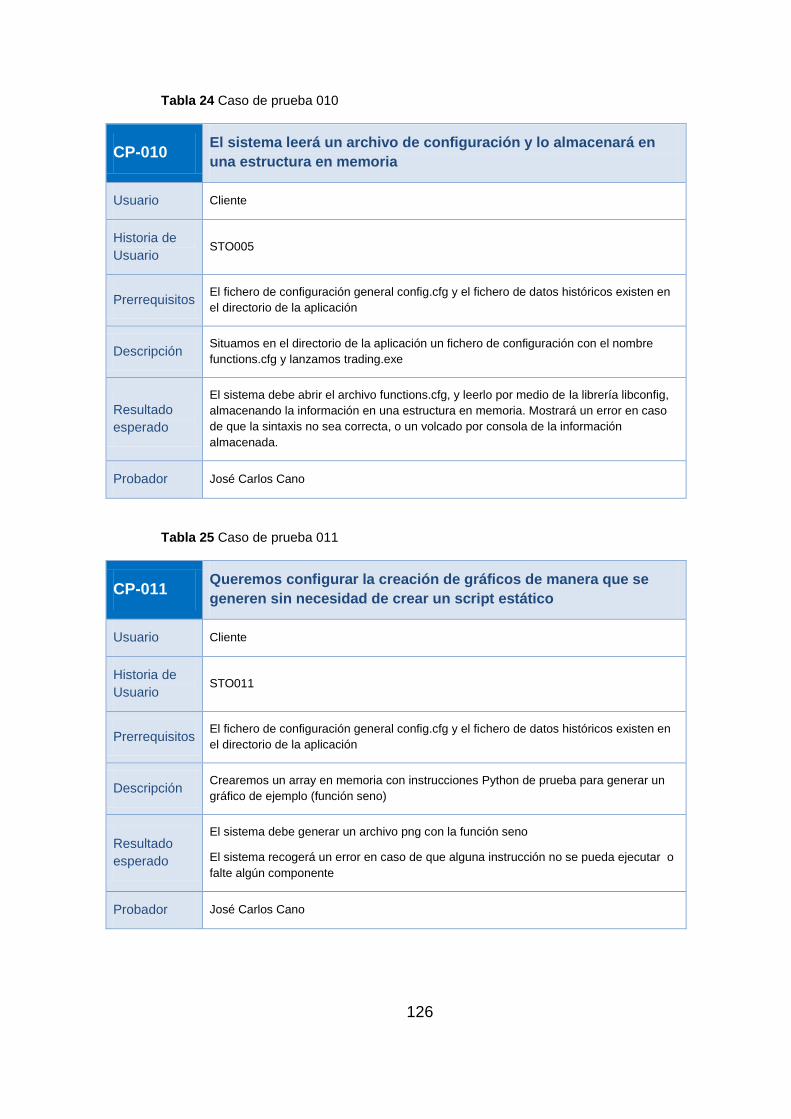
126
Tabla 24 Caso de prueba 010
CP-010 El sistema leerá un archivo de configuración y lo almacenará en
una estructura en memoria
Usuario Cliente
Historia de
Usuario STO005
Prerrequisitos El fichero de configuración general config.cfg y el fichero de datos históricos existen en
el directorio de la aplicación
Descripción Situamos en el directorio de la aplicación un fichero de configuración con el nombre
functions.cfg y lanzamos trading.exe
Resultado
esperado
El sistema debe abrir el archivo functions.cfg, y leerlo por medio de la librería libconfig,
almacenando la información en una estructura en memoria. Mostrará un error en caso
de que la sintaxis no sea correcta, o un volcado por consola de la información
almacenada.
Probador José Carlos Cano
Tabla 25 Caso de prueba 011
CP-011 Queremos configurar la creación de gráficos de manera que se
generen sin necesidad de crear un script estático
Usuario Cliente
Historia de
Usuario STO011
Prerrequisitos El fichero de configuración general config.cfg y el fichero de datos históricos existen en
el directorio de la aplicación
Descripción Crearemos un array en memoria con instrucciones Python de prueba para generar un
gráfico de ejemplo (función seno)
Resultado
esperado
El sistema debe generar un archivo png con la función seno
El sistema recogerá un error en caso de que alguna instrucción no se pueda ejecutar o
falte algún componente
Probador José Carlos Cano

127
Tabla 26 Caso de prueba 012
CP-012 Queremos configurar la apariencia de los gráficos
Usuario Cliente
Historia de
Usuario STO013
Prerrequisitos El fichero de configuración general config.cfg y el fichero de datos históricos existen en
el directorio de la aplicación
Descripción
Situamos en el directorio de la aplicación los ficheros de los escenarios en formato:
scenarioXXXX.cfg conteniendo las secciones:
graphicNbWindows, graphicWidth, graphicHeight, graphicFontSize,
graphicWindows, graphicData
Resultado
esperado
Según el valor de outputGraphMode seleccionado se generarán en el directorio
indicado en outputFolder imágenes según los parámetros informados sobre número
de ventanas, variables a representar en cada ventana, tipo de gráfico y tamaño en
pixels
Se mostrará un error en el caso de que el intérprete de Python no pueda generar los
gráficos por error de sintaxis en las instrucciones generadas a partir de la información
contenida en los archivos de los escenarios
Probador José Carlos Cano
Tabla 27 Caso de prueba 013
CP-013
Queremos poder escribir fórmulas matemáticas en los archivos de
configuración y que el sistema las verifique sintácticamente y
calcule su valor
Usuario Cliente
Historia de
Usuario STO008
Prerrequisitos Deben existir archivos de configuración de escenarios en el directorio de la aplicación
Descripción Se introducirá una fórmula matemática en las secciones buy-formula= o sell-formula =
, incluyendo números, operadores +,-,*,/ y paréntesis
Resultado
esperado
El sistema devolverá un número float correspondiente al valor resultante de la fórmula
El sistema devolverá la fórmula con un signo ^ señalando donde haya un error
sintáctico

128
Probador José Carlos Cano
Tabla 28 Caso de prueba 014
CP-014
Queremos poder escribir fórmulas matemáticas en los archivos de
configuración que reconozcan nombre de variables y los
sustituyan por su valor
Usuario Cliente
Historia de
Usuario STO008
Prerrequisitos Deben existir archivos de configuración de escenarios en el directorio de la aplicación
Descripción
Se introducirá una fórmula matemática en las secciones buy-formula= o sell-formula =
, incluyendo nombres de constantes y parámetros de indicadores, operadores +,-,*,/
y paréntesis
Resultado
esperado
El sistema devolverá un número float correspondiente al valor resultante de la fórmula
El sistema devolverá la fórmula con un signo ^ señalando donde haya un error
sintáctico
El sistema devolverá la fórmula con -1 sustituyendo el nombre de variable que no se
haya localizado en el escenario actual
Probador José Carlos Cano
Tabla 29 Caso de prueba 015
CP-015 Queremos hacer que los parámetros de los indicadores puedan
adoptar valores múltiples
Usuario Cliente
Historia de
Usuario STO006
Prerrequisitos Deben existir archivos de configuración de escenarios en el directorio de la aplicación
Descripción
En las secciones technicalIndicators-> indicatorParameters se introducirán:
parameterValue= lista de valores separados por comas
o
parameterValueRange=(valor desde,valor hasta, salto)

129
Resultado
esperado
El sistema interpretará la información del archivo de configuración y añadirá registros a
la estructura en memoria, un valor por cada elemento (caso de parameterValue) o
cada iteración del bucle ( en el caso de parameterValueRange)
El sistema nos mostrará un volcado de la estructura completa con la información
Probador José Carlos Cano
Tabla 30 Caso de prueba 016
CP-016
Queremos que las decisiones de situación alcista/bajista del
mercado se basen en el resultado de fórmulas introducidas en los
archivos de configuración de los escenarios
Usuario Cliente
Historia de
Usuario STO009
Prerrequisitos Deben existir archivos de configuración de escenarios en el directorio de la aplicación
Descripción
Se introducirá una fórmula matemática en las secciones buy-condition= o sell-
condition =, incluyendo nombres de constantes y parámetros de indicadores,
operadores +,-,*,/ y paréntesis
Resultado
esperado
El sistema devolverá el número 1 si la condición de buy es true (alcista) y devolverá 2 si
la condición de sell es true (bajista)
El sistema devolverá la fórmula con un signo ^ señalando donde haya un error
sintáctico
El sistema devolverá la fórmula con -1 sustituyendo el nombre de variable que no se
haya localizado en el escenario actual
Probador José Carlos Cano
Tabla 31 Caso de prueba 017
CP-017
Queremos que el volumen de las operaciones se decidan en base
al resultado de fórmulas introducidas en los archivos de
configuración de los escenarios
Usuario Cliente
Historia de
Usuario STO009

130
Prerrequisitos Deben existir archivos de configuración de escenarios en el directorio de la aplicación
Descripción
Se introducirá una fórmula matemática en las secciones buy- formula= o sell- formula=, incluyendo nombres de constantes y parámetros de indicadores,
operadores +,-,*,/ y paréntesis
Resultado
esperado
El sistema devolverá el volumen de la operación
El sistema devolverá la fórmula con un signo ^ señalando donde haya un error
sintáctico
El sistema devolverá la fórmula con -1 sustituyendo el nombre de variable que no se
haya localizado en el escenario actual
Probador José Carlos Cano
Tabla 32 Caso de prueba 018
CP-018 Queremos disponer de un LOG con tiempos de ejecución, informe
de errores y resultado de los escenarios
Usuario Cliente
Historia de
Usuario STO019
Prerrequisitos El fichero de configuración general config.cfg y el fichero de datos históricos existen en
el directorio de la aplicación así como los archivos de configuración de los escenarios
Descripción Se informará del nombre del fichero de Log en la sección logFile = del fichero config.cfg
Se dejará en blanco en la siguiente prueba
Resultado
esperado
Si el nombre se ha informado generará un fichero .txt con información de tiempos y
pasos en la ejecución y un apartado con la lista de escenarios, con los parámetros
usados en cada caso
Si el nombre no se ha informado no deberá aparecer ningún archivo y sólo se observará
la información por defecto en la consola
Probador José Carlos Cano
Tabla 33 Caso de prueba 019
CP-019 Queremos ver en el gráfico de salida etiquetas donde se
produzcan entradas/salidas del mercado
Usuario Cliente

131
Historia de
Usuario STO015
Prerrequisitos El fichero de configuración general config.cfg y el fichero de datos históricos existen en
el directorio de la aplicación así como los archivos de configuración de los escenarios
Descripción Asegurarse de que outputGraphMode tiene valor 0 (o mayor) para que se generen
gráficos. Ejecutar la aplicación
Resultado
esperado
El gráfico de salida deberá mostrar etiqueta B,S,SL,TP donde haya una operación a
largo, a corto, condición de StopLoss y TakeProfit respectivamente
Probador José Carlos Cano
Tabla 34 Caso de prueba 020
CP-020
Queremos que el sistema elabore un registro en memoria de todas
las ejecuciones, incluyendo resultado y lista de operaciones de
entrada/salida
Usuario Cliente
Historia de
Usuario STO016
Prerrequisitos El fichero de configuración general config.cfg y el fichero de datos históricos existen en
el directorio de la aplicación así como los archivos de configuración de los escenarios
Descripción Asegurarse de que outputOpBookMode tiene valor 0 o mayor para que se generen
libros de operaciones. Ejecutar la aplicación
Resultado
esperado
A lo largo de las iteraciones, se irá alimentando una estructura en memoria con las
operaciones realizadas. Se utilizará para calcular sobre ella los ratios que medirán la
validez del sistema.
Se generará un error en caso de que se produjera fallo en asignación de memoria
conforme crece el espacio requerido por la estructura
Probador José Carlos Cano
Tabla 35 Caso de prueba 021
CP-021 Los escenarios se deben ordenar por Profit
Usuario Cliente

132
Historia de
Usuario STO017
Prerrequisitos El fichero de configuración general config.cfg y el fichero de datos históricos existen en
el directorio de la aplicación así como los archivos de configuración de los escenarios
Descripción Ejecutar la aplicación
Resultado
esperado
Se mostrará en consola (y en el fichero LOG si así se ha informado) la lista de todos
los escenarios ejecutados, con todas sus iteraciones, ordenados de mayor a menor
Profit
En el caso de existir dos escenarios con el mismo resultado se mostrarán juntos,
ordenados por hora de ejecución
En caso de no haber escenarios por ordenar, no debe producirse ningún error
Probador José Carlos Cano
Tabla 36 Caso de prueba 022
CP-022 Los gráficos se deben generar de forma desatendida según valor
de un parámetro
Usuario Cliente
Historia de
Usuario STO014
Prerrequisitos Introducimos en el archivo config.cfg una línea outputGraphMode= -1 ,
outputGraphMode= 0 y outputGraphMode= 2, y ejecutamos por separado
Descripción Ejecutar la aplicación
Resultado
esperado
Para el caso outputGraphMode= -1, En el directorio indicado en outputFolder no
debe aparecer ninguna imagen
Para el caso outputGraphMode= 0, En el directorio indicado en outputFolder deben
aparecer tantos gráficos como escenarios se ejecuten cuyos nombres serán:
“nombre_del_escenario”+”número_del_escenario”+”.png”
Para el caso outputGraphMode= 2, En el directorio indicado en outputFolder deben
aparecer 2 imágenes, que corresponderán a los mejores escenarios ordenados por un
factor, cuyos nombres serán: “nombre_del_escenario”+”BEST”+ordinal+”.png”
Probador José Carlos Cano

133
Tabla 37 Caso de prueba 023
CP-023 Admitir una lista de contantes y su valor en los archivos de
configuración
Usuario Cliente
Historia de
Usuario STO007
Prerrequisitos El fichero de configuración general config.cfg y el fichero de datos históricos existen en
el directorio de la aplicación así como los archivos de configuración de los escenarios
Descripción
Introducir en un archivo de escenario la sección constants con las subsecciones name
y value donde se indicará una lista de constantes y su valor float, y una fórmula que
incluya alguno de estos nombres
Ejecutar la aplicación
Resultado
esperado
El sistema devolverá el valor de la fórmula, tras sustituir el nombre por su valor o bien
mostrará un error en caso de sintaxis incorrecta o nombre no encontrado
Probador José Carlos Cano
Tabla 38 Caso de prueba 024
CP-024 Incluir en los archivos de configuración fórmulas para definir Stop
Loss y Take Profit
Usuario Cliente
Historia de
Usuario STO018
Prerrequisitos El fichero de configuración general config.cfg y el fichero de datos históricos existen en
el directorio de la aplicación, así como los archivos de configuración de los escenarios
Descripción
Introducir en un archivo de escenario la sección stoploss y takeprofit dentro de buy y
sell. Escribir una fórmula que definirá el SL y TP en la operación que se realiza.
Ejecutar la aplicación
Resultado
esperado
El sistema leerá esta sección y la incluirá en la estructura en memoria para usarse en
las iteraciones posteriores
Mostrará un error de memoria en el caso de que no se puedan grabar la información.
En esta prueba no se exige análisis sintáctico de la fórmula
Probador José Carlos Cano

134
Tabla 39 Caso de prueba 025
CP-025 Incluir en la ejecución de los escenarios la detección de las
condiciones de StopLoss y TakeProfit
Usuario Cliente
Historia de
Usuario STO020
Prerrequisitos El fichero de configuración general config.cfg y el fichero de datos históricos existen en
el directorio de la aplicación así como los archivos de configuración de los escenarios
Descripción
Introducir en un archivo de escenario la sección stoploss y takeprofit dentro de buy y
sell. Escribir una fórmula que definirá el SL y TP en la operación que se realiza.
Ejecutar la aplicación
Resultado
esperado
El simulador debe evaluar la condición de SL y TP en cada iteración. En caso de
satisfacerse, generará la operación de salida del mercado y actualizará el libro de
operaciones
En caso de que la fórmula presente un error de sintaxis o variable no encontrada,
interceptará el error
Probador José Carlos Cano
Tabla 40 Caso de prueba 026
CP-026 Lectura de una base de datos MySQL y chequeo de las columnas
Usuario Cliente
Historia de
Usuario STO021
Prerrequisitos
El fichero de configuración general config.cfg debe existir en el directorio de la
aplicación
Incluir en config.cfg la sección columnsInDataFile, conteniendo una lista de nombres
de campo y tipo de datos (d:date, t:time, f:float) y lanzar la aplicación
Debe haber un motor de base de datos MySQL accesible en la red

135
Descripción
Introducir en el archivo config.cfg las siguientes líneas:
inputSQLServer=, inputSQLDatabase=, inputSQLUser=, inputSQLPassword=,
inputSQLQuery= con los datos de conexión y la consulta a ejecutar
Ejecutar la aplicación
Resultado
esperado
El sistema debe intentar acceder al servidor indicado en la configuración, y ejecutar la
consulta contra la base de datos seleccionada.
La aplicación debe mapear contra las columnas especificadas en columnsInDataFile y
verificar que son del mismo tipo. Devolver un error en caso contrario.
Devolver error si no se puede establecer la conexión o el motor MySQL.
Probador José Carlos Cano
Tabla 41 Caso de prueba 027
CP-027 Añadir ratios de medición de la eficacia de las estrategias
Usuario Cliente
Historia de
Usuario STO022
Prerrequisitos El fichero de configuración general config.cfg y el fichero de datos históricos existen en
el directorio de la aplicación así como los archivos de configuración de los escenarios
Descripción Ejecutar la aplicación
Resultado
esperado
El sistema mostrará junto al Profit, los siguientes indicadores calculados para cada
iteración de cada escenario:
Profit Factor y número de operaciones acertadas y fallidas.
Mostrará -1 en el caso de producirse algún error en los cálculos
Probador José Carlos Cano
Tabla 42 Caso de prueba 028
CP-028 Convertir las constantes que definen el Stop Loss y Take Profit en
parámetros
Usuario Cliente
Historia de
Usuario STO023

136
Prerrequisitos El fichero de configuración general config.cfg y el fichero de datos históricos existen en
el directorio de la aplicación
Descripción
Introducir en los archivos de configuración de los escenarios, en la sección
technicalIndicators, un nuevo indicador de nombre KTE y añadir “TakeProfit” y
“StopLoss” como nombres de indicadores, indicando en parameterValue y
parameterValueRange los valores que pueden adoptar.
Ejecutar la aplicación
Resultado
esperado
El sistema debe tratar este nuevo indicador ficticio como uno más y almacenar en las
estructuras en memoria la lista de valores que pueden adoptar.
Probador José Carlos Cano
7.2 Despliegue
Esta aplicación está orientada a entornos científicos y sistemas de
supercomputación. Con objeto de obtener una versión ejecutable que
aproveche el potencial del hardware en producción, es muy recomendable la
compilación en el mismo entorno, o en uno similar. Por tanto, su despliegue
será manual, efectuado por personal técnico del cliente, y no requiere por tanto
de herramientas específicas.
En el Anexo II (Manual de Instalación), figura un apartado que explica
cómo copiar una versión ejecutable de prueba en los diferentes entornos y
también cómo crear una nueva versión compilada, tanto del programa
desarrollado en este TFG, como de la librerías que utiliza.

137
8 Conclusiones
8.1 Objetivos alcanzados
Podemos concluir que hemos conseguido desarrollar un software de
backtesting, que ejecuta estrategias de trading sobre un conjunto de datos de
prueba, que en realidad son datos históricos de precios. Estos datos
inicialmente los incorporábamos desde un fichero de texto, pero hemos
ampliado el alcance permitiendo también el acceso a una base de datos
MySQL.
De cara a la simulación, creemos que la aportación principal de nuestro
software ha sido la libertad que ofrecemos al cliente de definir sus propios
escenarios, con reglas de decisión que se basan en operaciones con
indicadores técnicos con parámetros variables. Esta variabilidad hace que se
puedan probar en una sola ejecución todos los escenarios que resultan de la
combinatoria de los posibles valores que toman estos parámetros,
consiguiendo así un optimizador de estrategias.
Sumamos a esto su carácter desatendido, donde únicamente debemos
proporcionar como entrada ficheros de texto que guiarán el resto del proceso,
obteniendo como salida archivos con los resultados. De esta manera, y
dependiendo de la complejidad y del número de escenarios a simular, es
perfectamente posible ejecutar la optimización en ordenadores de alto
rendimiento.
Tabla 43 Objetivos alcanzados
OG1 Objetivo General 1: Desarrollo de una aplicación eficiente
OE1Objetivos Específico 1: Desarrollo de un programa scriptable, mediante archivos de configuración,
para el funcionamiento en supercomputadoras
OE2 Objetivos Específico 2: Lenguaje de programación eficiente en términos de velocidad y memoria
OG2 Objetivo General 2: Desarrollo de una herramienta de análisis visual de operaciones en los mercados
OE3 Objetivos Específico 3: Lectura de datos históricos
OE4 Objetivos Específico 4: Representación gráfica de datos históricos e indicadores técnicos
OG3 Objetivo General 3: Desarrollo de una herramienta de backtesting
OE5 Objetivo Específico 5: Cálculo de indicadores técnicos sobre un conjunto de datos históricos
OE6Objetivo Específico 6: Decisión acerca del momento de realizar una operación en el mercado y de
finalizar la misma
OE7Objetivo Específico 7: Calcular el beneficio neto del conjunto de operaciones que se produzcan en
el periodo de tiempo que se ha extraído de los históricos
OE8 Objetivo Específico 8: Elaborar un informe con datos estadísticos sobre las operaciones realizadas

138
8.2 Conclusiones del trabajo y personales
El backtesting es una parte de un objetivo más ambicioso: los sistemas
automáticos de trading, donde un ordenador, además de decidir las
operaciones de entrada y salida de un mercado, las ejecuta tal y como lo haría
un trader.
Dado lo crítico que es confiar nuestro dinero a las decisiones de un
ordenador, el backtesting se convierte en una herramienta primordial y,
personalmente, me siento satisfecho de haber participado en este área a través
de este proyecto. Hemos invertido tiempo en investigación y documentación
sobre estrategias de trading, porque considero que no es posible el desarrollo
de un software de calidad sin conocer al menos las bases de lo que se quiere
implementar. De esta manera, el diálogo con el cliente es más fácil y permite
enfocar mejor las tareas de desarrollo.
También considero enriquecedor el haber trabajado con la metodología
SCRUM. Ciertamente el carácter iterativo del desarrollo ofrece múltiples
ventajas en proyectos en los que no sabemos con exactitud las
especificaciones finales. Soy de la opinión de que esta manera de conducir un
proyecto ofrece al cliente lo que realmente necesita porque, en realidad, te lo
va indicando en cada planificación de cada sprint.
En lo relativo a la tecnología, me ha sorprendido positivamente la librería
matplotlib. La calidad y la variedad de las imágenes que ofrece está a la altura
de mucho software comercial. La posibilidad de generar un gráfico enviando
sentencias como cadenas de texto que generas en tu código ofrece una
potencia que no hemos querido desaprovechar.
8.3 Vías futuras
Si bien quedaban fuera del alcance de este proyecto, hemos podido
identificar algunas líneas de trabajo que contribuirían a enriquecer y mejorar la
aplicación “trading”:
Incluir el cálculo de más ratios para medir la bondad de los
sistemas de trading que se han simulado
Se podrían añadir pruebas estadísticas avanzadas, como el
análisis de Montecarlo o el estadístico t de student, para analizar
el riesgo potencial de nuestro sistema, con un determinado % de
confianza

139
Para afinar el cálculo del beneficio de un sistema, habría que
tener en cuenta el Slippage (diferencia entre el precio previsto de
una transacción y el precio en el que la transacción tiene lugar,
especialmente en momentos de gran volatilidad) y las comisiones.
En un sistema que arroja buenos resultados a través de
innumerables operaciones con unos beneficios muy reducidos por
operación, si tuviéramos en cuenta el Slippage y las comisiones
derivadas de la operativa, probablemente las ganancias del
sistema no sólo se reducirían, sino que podrían incluso
convertirse en pérdidas. La solución para cubrir estos factores
sería incluir en la definición de los escenarios una fórmula que
defina un valor a restar al cálculo de la rentabilidad
Es conocido que, aunque una estrategia de trading pueda resultar
válida en un conjunto de datos, pudiera mostrarse desfavorable
en otro. Podríamos modificar el programa para que, una vez
seleccionados los n mejores escenarios, se prueben sobre un
segundo conjunto de datos históricos, diferente del inicial
De cara a la integración con otras herramientas, se podría liberar
una versión como librería, de manera que pudiera recibir
parámetros de entrada y devolviera los resultados como una
estructura en memoria, evitando en este caso el uso de ficheros
Revisar el código C de cara a la utilización de GPU y
procesamiento paralelo
Complementar la simulación por iteración con otros métodos de
inteligencia artificial, como las redes neuronales y los algoritmos
genéticos

140

141
9 Bibliografía
[1] Holland , Marcus (2013), “Issues related to Back Testing”,
http://www.financialtrading.com/issues-related-to-back-testing/
[2] Pichler, Roman (2010) Agile Product Management with SCRUM : Creating
products that customers love
[3] Rubin , Kenneth S. (2013) Essential SCRUM: A practical Guide to the
most popular Agile Process
[4] Murphy , John .J (1999) Análisis técnico de los mercados financieros
pag.49
[5] Murphy , John .J (1999) Análisis técnico de los mercados financieros
pag.27
[6] Murphy , John .J (1999) Análisis técnico de los mercados financieros
caps. 3,8,11,12
[7] Cagigas, Oscar (2012), Pruebas para confirmar la validez de los sistemas
de trading, recuperado de http://www.rankia.com/blog/oscar-
cagigas/1341589-pruebas-para-confirmar-validez-sistemas-trading
[8] Mateu Gordon, José Luis y Palomo Zurdo, Ricardo Javier Recogido de
http://www.expansion.com/diccionario-economico/mercado-financiero.html
[9] Mercados financieros, recogido de
http://www.enciclopediafinanciera.com/sistemafinanciero/mercadosfinanci
eros.htm
[10] Pressman , Roger S (2002) Ingeniería del Software: Un enfoque práctico
Págs 20-21
[11] Manifiesto por el Desarrollo Ágil de Software
http://agilemanifesto.org/iso/es/
[12] Beck, Kent (1999) Extreme Programming Explained: Embrace Change
[13] The Rules of Extreme Programming, recuperado de
http://www.extremeprogramming.org/rules.html
[14] Programación extrema, recuperado de
http://es.wikipedia.org/wiki/Programaci%C3%B3n_extrema
[15] SCRUM Alliance, https://www.scrumalliance.org/

142
[16] Sutherland, Jeff y Schwaber , Ken (2013) La Guía de ScrumTM (2013)
Disponible en http://www.scrumguides.org/ Páginas 4 a 13
[17] Rational Unified Process. Accesible en
https://www.ibm.com/developerworks/rational/
[18] Kanba https://kanbanflow.com/
[19] Kniberg, Henrik (2011) Lean from the Trenches: Managing Large-Scale
Projects with Kanban
[20] Garzás, Javier (2014) Gestión de proyectos ágil. Capítulo 5.6
[21] Web site de Javier Garzas http://www.javiergarzas.com/
[22] Web Site de Cygwin https://www.cygwin.com/
[23] Cygwin, recuperado de http://es.wikipedia.org/wiki/Cygwin
[24] Web Site de VMWare http://www.vmware.com/
[25] VMWare, recuperado de http://es.wikipedia.org/wiki/VMware
[26] Web Site de Eclipse https://eclipse.org/
[27] Eclipse, recuperado de http://es.wikipedia.org/wiki/Eclipse_software
[28] Web Site de subversión https://subversion.apache.org/
[29] Subversion, recuperado de
http://es.wikipedia.org/wiki/Subversion_software
[30] Web Site de Subversive http://eclipse.org/subversive/
[31] Programas para control de versiones. Recuperado de
http://es.wikipedia.org/wiki/Programas_para_control_de_versiones
[32] Web Site de Python https://www.python.org/
[33] Python, recuperado de http://es.wikipedia.org/wiki/Python
[34] Web Site de matplotlib http://matplotlib.org/
[35] Matplotlib, recuperado de http://es.wikipedia.org/wiki/Matplotlib
[36] Web Site de libconfig http://www.hyperrealm.com/libconfig/
[37] Web site de TA-Lib: Technical Analysis Library http://ta-lib.org/
[38] Web Site de Quantmod http://www.quantmod.com/

143
[39] Web Site del proyecto R http://www.r-project.org/
[40] Top Agile and SCRUM tools: http://agilescout.com/best-agile-scrum-tools/ [41] Web Site de kunai http://kunagi.org/
[42] Web Site de Apache Tomcat http://tomcat.apache.org/

144

145
10 Anexo I Diseño de la aplicación
Los requerimientos de funcionalidad marcados por el cliente han sido:
Prioridad en la velocidad de ejecución
Enfocado a entornos sin interface gráfica de usuario
Todo debe ser configurable, desde los datos de entrada hasta la
definición de los escenarios
Entrada y salida mediantes archivos de texto
Estos requisitos han guiado el diseño de la arquitectura de la aplicación,
destacando los siguientes aspectos:
Gestión dinámica de memoria: no sabemos a priori el volumen de
información a manejar
Uso de archivos de configuración que admitan secciones y
permitan definir listas
Creación dinámica de gráficos: vendrán definidos en los archivos
de configuración
Analizador sintáctico de fórmulas: el cliente quiere crear sus
propios escenarios
10.1 Gestión de memoria
10.1.1 Datos históricos
Los datos históricos se almacenan en la siguiente estructura en C:
typedef struct HistData {
/* NUMBER OF COLUMNS: number of input data fiedls + indicators + 1 for buy/sell operations */ unsigned int nbColumns;
/* NUMBER OF ROWS: number of elements in the arrays */
unsigned int nbData; unsigned int intervalSize; const char* intervalType; char** operationDate; char** operationTime; float** data; } HistData;
Los campos operationDate, operationTime y data definen una matriz que
podemos representar visualmente de la siguiente manera:

146
Cada vez que leemos un nuevo dato desde el archivo de entrada, o
desde la base de datos:
Incrementamos en 1 unidad el campo nbData
Hacemos un realloc de operationDate, operationTime y data, con
el tamaño actual + 1
Todas las funciones encargadas de operaciones con memoria se
encuentran definidas en memory.h
Tabla 44 Código para redimensionar arrays de float y char
Redimensionar array de float Redimensionar array de textos de tamaño
stringLength
int resizeArray(float** finalArray, int newsize) { float* tempArray = NULL; tempArray = (float*) realloc(*finalArray, newsize * sizeof(float)); if (tempArray!=NULL) { *finalArray = tempArray; return 1;//Success } else { free(finalArray); printf("Error allocating memory"); return 0; //Fails } }
int resizeTextArray(char ***finalTextArray, int newsize, int individualSize, int stringLenght) { char **tempTextArray = (char**) realloc(*finalTextArray, newsize * individualSize); if (tempTextArray!=NULL) { tempTextArray[newsize – 1]=(char*) malloc(stringLenght * sizeof(char*)); if (tempTextArray[ newsize - 1] != NULL) { *finalTextArray = tempTextArray; return 1; //success } } else { free(finalTextArray); printf("Error allocating memory"); } return 0; //Fails }
De esta forma añadimos una nueva línea.
10.1.2 Nuevos indicadores
Pero si, además, queremos añadir una columna para almacenar el
resultado del cálculo de un nuevo indicador técnico, hacemos un realloc de la
tabla completa con el nuevo número de columnas:
Figura 74 Matriz de almacenamiento de datos

147
dataTable->data = (float**)realloc(dataTable->data, (fileFormatTable->nbNumeric + technicalIndicators.nbNumeric + 1 ) *
sizeof(float*)); if (dataTable->data == NULL) { return RET_MEMORY_MANAGEMENT_ERROR; } for (i = fileFormatTable->nbNumeric;
i < (fileFormatTable->nbNumeric + technicalIndicators.nbNumeric + 1 ); i++)
{ dataTable->data[i] = (float*)malloc(1 * sizeof(float));
}
Consiguiendo así el nuevo espacio:
Nunca destruimos o eliminamos columnas. Si en el próximo escenario
se usan menos indicadores, ese espacio queda en desuso pero disponible para
próximos escenarios donde puedan haber más indicadores. De este manera no
desfragmentamos memoria.
Vemos en la siguiente figura cómo la estructura de datos (que
representa una matriz bidimensional), crece inicialmente con la incorporación
de los datos históricos y, durante el proceso de cálculos, cada vez que
necesitamos espacio para un nuevo indicador.
Figura 75 Espacio para un nuevo indicador
Figura 76 Crecimiento bidimensional de la tabla de datos

148
10.1.3 Datos de configuración y control del proceso
Con este mismo diseño, disponemos de estructuras donde
almacenamos la información que nos viene de los archivos de configuración y
de los escenarios. Mostramos a continuación las más relevantes:
Form
ato
de
l
fichero
de e
ntr
ad
a typedef struct FileFormat
{ unsigned int nbData; /* number of elements in the arrays */ unsigned int nbNumeric; /* number of numeric columns */ char** fieldName; /* char(20) */ char** fieldFormat; /* char(2) */ float* fieldIndex; /* float */ } FileFormat;
Form
ato
de
l grá
fico
typedef struct GraphFormat { unsigned int nbData; /* number of elements in the arrays */ unsigned int nbWindows; /* number of windows in the chart */ unsigned int width; /* image width */ unsigned int height; /* image height */ unsigned int fontSize;/* image height */ char** variableName; /* char(20) */ char** chartWindow; /* char(1) */ char** chartType; /* char(20) */ char** variableLabel; /* char(20) */ char** variableColor; /* char(20) */ int* chartWindowLevel2; float* variableIndex; /* Index in HistData */ } GraphFormat;
Form
ato
de las
venta
nas d
el grá
fico
typedef struct GraphWindows { int* relativeSize; /* % height of window */ char** axisLabelTitle; /* char(20) */ int* showGrid; int* showXlabels; int* pruneYlabels; } GraphWindows;

149
Lis
ta d
e ind
icdore
s y
sus p
ará
metr
os
typedef struct ParametersList { char* parameterName; /* char(20) */ unsigned int nbValues; /* Number of possible values for the parameter in the case of values list */ char** parameterValueList; /* char(20) (for input parameters) several values possible (but only one for output) */ float* inputParameterIndex; /* float (for input parameters). Each value has an index. Index of existing variable in table of data. */ float parameterIndex; /* float (for output parameters).Index of existing variable in table of data. */ char* parameterDirection; /* char(1) */ char* parameterFormat; /* char(2) */ float parameterRangeFrom; /* float (for input parameters). For loops. */ float parameterRangeTo; /* float (for input parameters). For loops. */ float parameterRangeStep; /* float (for input parameters). For loops. */ unsigned int nbSteps; /* Number of steps in the case of RangeFrom RangeTo RangeStep loop */ unsigned int parameterID; /* Unique ID used in the loop recursive algorithm */ } ParametersList; typedef struct IndicatorsList { unsigned int nbData; /* number of elements in the arrays */ unsigned int nbNumeric; /* number of numeric output parameters -> results will be saved in datatable */ unsigned int nbAll; /* number of all parameters */ char** indicatorName; /* char(20) */ char** functionName; /* char(20) */ float* nbParameters; /* number of params for each indicator */ ParametersList **parList; /* parameters for each indicator */ } IndicatorsList;

150
Regis
tro e
n m
em
oria
de
l re
sultad
o d
e c
ada
escenari
o,
el va
lor
de los p
ará
metr
os u
sados y
el h
istó
rico d
e o
pera
cio
nes d
e
entr
ad
a y
salid
a d
el m
erc
ado
typedef struct operationsHist { unsigned int operationTime; /* index in the big matrix */ unsigned int exitTime; /* index in the big matrix */ int closeReason; /* 0: rules 1: SL 2: TP */ int operationStatus; /* 0:open / 1:closed */ int operationType; /* 1:buy / 2:sell */ float operationVolume; /* Quantitative information regarding the operation */ float operationPrice; /* operation price */ float exitPrice; /* closure price */ float StopLoss; /* Stop Loss price */ float takeProfit; /* Take Profit price */ float profit; /* result of the operation */ float balance; /* current balance */ } operationsHist;
//------------------------------------------------------------------------------//Matrix to store the different parameter values in each execution loop together //with the result //------------------------------------------------------------------------------typedef struct histLoopParameterValues { unsigned int nbData; /* number of loops executed --> number of records */ parameterCurrentValues **loopHist; operationsHist **loopOperations; char** scenarioName; float* loopValues; /* number of parameterCurrentValues for each loop */ float* loopOperationValues; /* number of buy/sell operations for each loop */ float* loopResult; /* profit of the simulation, used to compare how good the scenario is */ float* loopDrawDown; /* profit of the simulation, used to compare how good the scenario is */ float* loopProfitFactor; /* profit of the simulation, used to compare how good the scenario is */ float* loopSharpe; /* profit of the simulation, used to compare how good the scenario is */ float* loopNofTrades; /* profit of the simulation, used to compare how good the scenario is */ float* loopRecFactor; /* profit of the simulation, used to compare how good the scenario is */ char** loopStartTime; char** loopEndTime; float* loopDuration; float* loopRetCode; float* loopOrder; /* Based on loopResult, indicates the sorted order */ } histLoopParameterValues;

151
10.2 Proceso
Una vez tenemos en memoria toda la información, el bucle de ejecución
consiste en un recorrido por los archivos de escenarios que se encuentran en
el directorio de la aplicación. En la siguiente imagen se recogen las 5 etapas
que lo componen:
Es en el paso 4 donde se identifican y deciden las operaciones de
entrada y salida del mercado, en función del valor que nos devuelven las
fórmulas de posición alcista/bajista o de alcance del umbral del Stop Loss /
Take Profit.
Figura 77 Bucle principal de la aplicación

152
10.3 Módulos
El software está compuesto por los siguientes módulos:
main:
o Lee los parámetros generales informados en config.cfg
(configuración general de la aplicación)
o Abre el archivo LOG en caso de ser necesario
o Lee el archivo functions.cfg
o Lee la estructura del fichero de entrada informado en
config.cfg
o Llama a la lectura de los datos históricos, bien desde un
archivo, o desde una base de datos MySQL
o Busca los archivos scenario___.cfg y efectúa una llamada
a la ejecución del escenario para cada uno de ellos
o Ordena todos los escenarios para mostrar los de mejor
resultado
o Libera memoria y cierra el programa
scripts:
o Lee la definición de constantes del fichero del escenario
o Lee los indicadores técnicos a usar del fichero del
escenario
o Lee las fórmulas que definen el algoritmo de trading
o Lee la definición de los gráficos
o Redimensiona la matriz de datos para poder acoger a
todos los indicadores especificados
o Llama al proceso de simulación
o Ejecuta una ordenación para mostrar los escenarios
ordenados de mayor a menor profit
o Genera un gráfico, un log de operaciones y un archivo csv
en el caso de que se solicitase para n escenarios
filesystem:
o Contiene las funciones de acceso a disco: crear archivos,
borrar archivos, escribir en archivos

153
o Contiene las funciones que leen los datos que vienen en
los archivos de configuración (mediante llamadas a
libconfig)
o Contiene las funciones que leen datos de archivos csv
o Contiene las funciones que leen los datos del archivo de
datos históricos desde MySQL
trading:
o Ejecuta la simulación
o Almacena durante el proceso los valores de los parámetros
usados, y el resultado obtenido con cada uno de ellos
o Genera un gráfico, un log de operaciones y un archivo csv
en el caso de que se solicite para todos los escenarios
parse:
o Ejecuta el análisis sintáctico de las fórmulas
o Sustituye las variables por los valores que tienen en cada
momento y calcula el resultado de las fórmulas
graph:
o Contiene la creación de sentencias para llamar a matplotlib
utils:
o Contiene el algoritmo de ordenación por el método de la
burbuja
o Contiene funciones de validación de tipos de datos, de
máximos y mínimos, y para concatenar cadenas de texto
o Contiene funciones que crean la información para el LOG
sobre los escenarios, en formato tabular
error:
o Contiene la función que relaciona un número de error con
su descripción
memory:
o Contiene las funciones que redimensionan arrays en
memoria
El proceso completo de trading, con las llamadas a los distintos módulos
está descrito en la siguiente imagen:

154
Figura 78 Módulos de la aplicación

155
11 Anexo II Manual de Usuario
La aplicación “Trading” se ha diseñada para ejecutarse como un
proceso, sin interfaz de usuario, dando prioridad a la velocidad de ejecución.
Por tanto, tanto la entrada de datos como la salida se hacen a través de
ficheros de texto, con una determinada sintaxis que se describe en este
capítulo.
11.1 Introducción
En la siguiente imagen observamos los procesos implicados durante la
ejecución del software:
1. Partiendo de un conjunto de datos históricos (de un archivo csv o
de una base datos), se seleccionan las columnas que hayamos
especificado en un archivo de configuración.
2. Partiendo de estos datos, podemos realizar una selección
filtrando por fecha para quedarnos con el período de estudio que
interese.
Figura 79 Esquema general aplicación “Trading”

156
3. Sobre el conjunto de datos final se realizarán las estrategias de
trading que se describen en los archivos de configuración de
escenarios. Cada escenario trabaja usando indicadores técnicos
cuyos parámetros de cálculo pueden adoptar múltiples valores,
con lo que cada ejecución supone, en realidad, varias iteraciones.
4. Los resultados de cada escenario son almacenados, de manera
que se ofrece una lista ordenada en función de cualquier ratio
disponible
5. Se genera un LOG de ejecución, gráficos configurables y
documentos con las operaciones de entrada/salida del mercado
11.2 Preparando la ejecución
El control de la ejecución de la aplicación la gestiona un fichero de
configuración general. En este fichero se informa, por ejemplo, de la fuente de
los datos históricos sobre los que se realizará el backtesting de las estrategias
de trading.
A continuación podemos ver en detalle la información contenida en dicho
archivo:
Figura 80 Configuración general de la aplicación

157
Tabla 45 Parámetros aplicables en la configuración general
Parámetro
Descripción Ejemplo
logFile Nombre del fichero donde se almacenará
información sobre el proceso de ejecución:
tiempos consumidos, resultados obtenidos y
errores
logFile = "LOG.txt";
Si no se informa nombre de fichero, no se
generará el log
logFile = "";
outputFolder Directorio, a partir del directorio de la
aplicación, donde se generarán los gráficos y
el resto de outputs
outputFolder = "output";
outputGraphMode Especifica qué gráficos en formato png se
generarán. Puede tomar los siguientes
valores:
-1: no genera ningún gráfico
0: genera un gráficos para cada iteración
n: genera los gráficos de los n mejores
escenarios
outputGraphMode= -1;
outputCSVMode Especifica qué ficheros de datos en formato
csv (históricos e indicadores) se generarán.
Puede tomar los siguientes valores:
-1: no genera ningún archivo
0: genera un archivo para cada iteración
n: genera los archivos de los n mejores
escenarios
outputOpBookMode= -1;
outputOpBookMode Especifica qué ficheros de log de operaciones
de compra/venta se generarán en formato txt.
Puede tomar los siguientes valores:
-1: no genera ningún archivo
0: genera un archivo para cada iteración
n: genera los archivos de los n mejores
escenarios
En caso de seleccionar -1, tampoco se
mostrará información de las operaciones en
el archivo de LOG ni por consola
outputOpBookMode= -1;
maxRunningTime Especifica el número de segundos máximo de
ejecución del programa.
0 indica que no hay límite
maxRunningTime = 0;
maxLoopsNumber Especifica el número máximo de iteraciones
que ejecutará el programa
0 indica que no hay límite
maxLoopsNumber = 80;
maxNumData Especifica el número máximo de datos que se
leerán de un archivo o de una base de datos
0 indica que no hay límite
maxNumData = 0;
inputDataFile Especifica el nombre del fichero csv que
contiene los datos históricos
El fichero debe situarse en el directorio de la
aplicación
Si se informa en blanco, no se leerá ningún
archivo, y se deberá informar la base de
datos desde la que importar la información
histórica
inputDataFile= "EURUSD5.csv";

158
filterByColumn Este parámetro indica si se filtrará por alguna
columna (en el caso de haberse informado el
dato inputDataFile,)
-1 indica que no habrá filtros
filterByColumn = 1
filterFrom Si filterByColumn no es -1 y se ha informado
inputDataFile, este parámetro contiene el
valor “desde”
filterFrom = "2013.02.18";
filterTo Si filterByColumn no es -1 y se ha informado
inputDataFile, este parámetro contiene el
valor “hasta”
filterTo = "2013.02.19";
inputSQLServer Especifica el nombre del servidor MySQL inputSQLServer="192.168.1.34";
inputSQLDatabase Especifica la base de datos que contiene los
datos históricos
inputSQLDatabase = "trading";
inputSQLUser Especifica el usuario que tiene permisos para
ejecutar la consulta
inputSQLUser = "test";
inputSQLPassword Especifica la clave del usuario que tiene
permisos para ejecutar la consulta
inputSQLPassword = "test";
inputSQLQuery Consulta a ejecutar contra la base de datos select […] from
trading.indice_data where […]
columnsInDataFile Especifica las columnas de datos (nombre y
formato) que se esperan recibir en el fichero
csv o en la consulta contra la base de datos
El formato puede tomar estos valores:
d: fecha (date)
t: hora (time)
f: numérico (float)
columnsInDataFile = (
{columnName = "operationDate";
columnFormat="d" },
{columnName = "operationTime";
columnFormat="t" },
{columnName = "openPrice";
columnFormat="f" },
{columnName = "highPrice";
columnFormat="f" },
{columnName = "lowPrice";
columnFormat="f" },
{columnName = "closurePrice";
columnFormat="f" },
{columnName = "volume";
columnFormat="f" }
);
En la figura siguiente vemos un ejemplo del contenido de un archivo de
configuración típico:

159
Figura 81 Ejemplo de archivo de configuración general
A la hora de lanzar la aplicación, podemos añadir un argumento con el
nombre que hayamos dado al archivo de configuración. En caso de no añadir
este argumento, el programa usará el valor por defecto “config.cfg”.
El archivo de configuración debe estar localizado en el directorio de la
aplicación. En caso de no encontrarse, se informará del error.
11.3 Indicadores técnicos
La aplicación “trading” hace uso de la librería TA-Lib, que ofrece el
cálculo de hasta 200 indicadores técnicos y un interface para aplicaciones
desarrolladas en C/C++ y Java. Este interface, y toda la lista de funciones con
sus parámetros, pueden encontrarse en el archivo de cabecera ta_func.h, en el
directorio de instalación de TA-Lib.
Dado el gran número de indicadores disponibles, y con objeto de facilitar
su lectura, hemos creado un archivo donde recogeremos sólo los indicadores
que podremos usar en nuestra aplicación. Posteriormente, durante la
ejecución, se mapearán las llamadas a los indicadores contra las definiciones
incluidas en este archivo, cuyo nombre debe ser obligatoriamente
“functions.cfg”.

160
El contenido de este archivo tiene como raíz un parámetro functions
que contiene una lista de indicadores y sus parámetros, como se describe a
continuación:
Tabla 46 Parámetros aplicable a la lista de indicadores
Parámetro
Descripción Ejemplo
functionName Es el nombre de indicador técnico en
TALib
functionName = "MACD";
functionParameters Es, a su vez, una lista de elementos,
que serán los parámetros de llamada a
la función, con los siguientes campos:
Name, o nombre del parámetro functionParameters = (
{Name="startIdx";
Direction="i";
Type="i";
Optional=0;},
{Name="endIdx";
Direction="i";
Type="i";
Optional=0;},
…);
Direction, que puede tomar los
valores:
i: (input) parámetro de entrada
o: (output) parámetro de salida
Type, que puede tomar los valores:
i: (integer) un número entero
f (float) un número decimal
Mi: matriz de números enteros
Mf: matriz de números decimales
s: (string) un texto
Optional, que puede tomar los valores:
0: es obligatorio
1: es opcional
Podemos ver a continuación un ejemplo de archivo con dos indicadores:
Figura 82 Ejemplo de listado de indicadores

161
Para usar un nuevo indicador basta con incluirlo en este archivo,
copiando la definición que figura en la cabecera ta_func.h.
11.4 Definiendo los escenarios
El núcleo de esta aplicación radica en la ejecución de escenarios de
trading. Se pueden definir múltiples escenarios, cada uno de ellos descrito en
detalle en archivos de texto cuyos nombres tendrán la siguiente nomenclatura:
Por ejemplo, scenario1.cfg, scenario002.cfg, scenario1530.cfg
En estos archivos se reflejan los indicadores técnicos a utilizar en las
simulaciones, las reglas que determinan las entradas/salidas del mercado y el
tipo de gráficos que se generarán.
A continuación detallamos la información contenida en dichos archivos.
11.4.1 Indicadores técnicos
Debemos definir qué indicadores técnicos vamos a necesitar en cada
escenario. Estos indicadores los usaremos en nuestras fórmulas para decidir
los momentos alcistas y bajistas del mercado, y ayudarán a decidir los
momentos de entrada y salida. Se muestran a continuación los parámetros
necesarios para definirlos correctamente:
Tabla 47 Escenarios (1/5): indicadores técnicos
Parámetro
Descripción Ejemplo
scriptName Texto libre que describe el escenarios scriptName = "First";
technicalIndicators Lista que contendrá los indicadores
técnicos que son necesarios en este
escenario. Contiene los siguientes
campos:
indicatorName, texto libre que
describe el indicador
indicatorName = "MA90";
functionName, nombre de la función
en TA-Lib. Debe coincidir con algunos
de los parámetros functionName del
fichero functions.cfg
functionName = "MA";
indicatorParameters. Parámetros del
indicador. Contiene los siguientes
campos:
parameterName parameterName="startIdx";

162
parameterValue, indica un valor, o
una lista de valores separados por
comas
parameterValueRange, indica un
rango de valores, que se forman
usando el primer valor como
“desde”, el segundo como “hasta”
y el tercero como el “salto”
parameterValue=("26");
parameterValueRange=("2","3","1");
parameterDirection, que puede
tomar los valores:
i: (input) parámetro de entrada
o: (output) parámetro de salida
parameterDirection="i";
ParameterFormat que puede
tomar los valores:
i: (integer) un número entero
f (float) un número decimal
Mi: matriz de números enteros
Mf: matriz de números
decimales
s: (string) un texto
ParameterFormat="i";}
Es posible crear variables que, sin ser parámetros de indicadores
técnicos, adopten la ventaja de poder tomar valores múltiples. Para ello se
puede incluir un indicador con functionName = “KTE”, y se le añaden las
variables que necesitemos como parámetros de tipo “i” (input-entrada). A partir
de entonces ya podremos usar estas variables en nuestras fórmulas.
Vemos en esta imagen un ejemplo de definición de indicadores técnicos
para un escenario.
Figura 83 Escenarios (1/5): indicadores técnicos
Observamos el uso del indicador “KTE” para crear una variable
TakeProfit y otra StopLoss, adoptando éstas múltiples valores.

163
11.4.2 Gráficos
Definimos la configuración de los gráficos que se podrán generar
asociados a cada escenario. Podemos especificar las variables a representar
(correspondientes a un dato de entrada o a un valor calculado de un indicador)
y la apariencia del gráfico. Los parámetros necesarios son los siguientes:
Tabla 48 Escenarios (2/5): definición de gráficos
Parámetro
Descripción Ejemplo
graphicWidth Ancho en pixels del gráfico a generar graphicWidth = 1900;
graphicHeight Alto en pixels del gráfico a generar graphicHeight = 900;
graphicFontSize Tamaño de letra en el gráfico (para los
ejes, etiquetas, números)
graphicFontSize = 12;
graphicNbWindows Número de ventanas que compondrá el
gráfico que se genere
graphicNbWindows = 3;
graphicWindows Lista que contendrá el formato de cada
una de las ventanas que componen el
gráfico. Contiene los siguientes
campos:
Size Valor de 1 a 10 que indica el
tamaño relativo de la ventana. La suma
de los campos size de todas la
ventanas debe sumar 10, en caso
contrario se obtiene un error.
size=2;
AxisLabelTitle Título del eje Y de cada
ventana
AxisLabelTitle = "Test one ";
showGrid Indica si se debe mostrar la
cuadrícula en el gráfico
showGrid="true";
showXlabels Indica si se deben o no
mostrar los valores del eje X
showXlabels="false";
pruneYlabels Indica si se deben omitir
las etiquetas del eje X que solapan con
las de la ventana anexa
pruneYlabels="true"}
Figura 84 Especificación de los indicadores técnicos

164
graphicData Lista que contendrá los datos
(variables) que se mostrarán en el
gráfico. Contiene los siguientes
campos:
variableName Nombre del dato a
representar. Debe corresponder con un
nombre de campo del fichero de
entrada, o con un parámetro de salida
de un indicador técnico
variableName = "openPrice";
Window Número de la ventana donde
se mostrará la variable (la primera
ventana toma el valor 0, y es la que
muestra en la parte superior del gráfico)
window="1";
type Tipo de gráfico. Puede tomar
estos valores:
cO: precio de apertura en gráfico de
velas
cH: precio más alto en gráfico de velas
cL: precio más bajo en gráfico de velas
cC: precio de cierre en gráfico de velas
l: gráfico de línea
b: gráfico de barra
a: gráfico de área
type="b";
Label Etiqueta asociada a la variable label = "Volume";
color Color para la variable. Se puede
especificar de dos formas:
Usando el formato #aabbcc (con aa,
bb y cc números hexadecimales)
Usando un nombre de la lista
disponible en el apartado 13 de esta
memoria
color= "forestgreen"}
Vemos en esta imagen un ejemplo de definición de los gráficos
asociados a un escenario.
Figura 85 Escenarios (2/5): definición de gráficos

165
Observamos cómo la definición contenida en la sección de gráficos del
archivo de escenarios guía la búsqueda de información en el conjunto de datos
y genera un archivo csv que sirve de base para crear el gráfico:
11.4.3 Constantes
Podemos crear un número ilimitado de constantes que usaremos
posteriormente en las fórmulas, simplificando así la lectura de las mismas:
Tabla 49 Escenarios (3/5): definición de constantes
Parámetro
Descripción Ejemplo
constants Lista que contendrá constantes con un
valor que se podrán referenciar en las
fórmulas de cálculo de operaciones de
trading. Contiene los siguientes campos:
Name Nombre de la constante name = "factor";
Value Valor de la constante (debe ser
un valor float)
value=0.00001 }
Figura 87 Escenarios (3/5): definición de constantes
Hay cuatro constantes que se deben definir obligatoriamente:
Figura 86 Proceso de creación de un gráfico

166
Lots: Define el tamaño del lote (por ejemplo, 0.1)
LotsSize: Define el valor al que corresponde cada lote (por
ejemplo, un valor típico en operaciones FOREX podría ser
100000)
CloseOrders, indica si se puede cerrar una orden con tan sólo un
cambio de tendencia en el mercado:
o Un valor 0.0 (equivalente a false) indica que habrá que
esperar a una condición de StopLoss o TakeProfit para
cerrar las operaciones abiertas
o Un valor de 1.0 (equivalente a True) indica que se cerrarán
las operaciones abiertas al encontrar un cambio de
tendencia
Use_Closing_SL_TP:
o Un valor de 0.0 (equivalente a False) indica que el precio
que se usará como el de cierre de la operación será el
valor del precio de apertura de la vela del período en que
nos encontramos
o Un valor de 1.0 (equivalente a True) indica que el precio
que se usará como el de cierre de la operación será el
valor del Stop Loss o Take Profit, según el caso
11.4.4 Operaciones
Definimos las condiciones y fórmulas relacionadas con la identificación
de un momento alcista o bajista del mercado y las operaciones de entrada y
salida usando los siguientes parámetros:
Tabla 50 Escenarios (4/5): operaciones de trading
Parámetro
Descripción Ejemplo
buy Recoge toda la información relativa a
una operación alcista. Se compone de
los siguientes campos:

167
Condition Especifica la fórmula que,
de cumplirse, indica una situación
alcista del mercado. (ver siguiente
apartado para conocer más sobre el
uso de fórmulas)
condition = "(outmacd<0) & (outmacd >
outmacdsignal) &
(outmacd(1)<outmacdsignal(1)) & (
#outmacd > (3*factor)) &
(outma>outma(1))";
Formula Especifica la fórmula cuyo
resultado será el volumen invertido en
una operación “a largo”
formula="lots";
Stoploss Especifica una fórmula para
el Stop Loss
stoploss ="openprice-(StopLoss*factor)";
Takeprofit Especifica una fórmula
para el Tak Profit
takeprofit="openprice+(takeprofit*factor)";
Color Especifica un color para la
etiqueta que en el gráfico indica una
entrada en el mercado. Se puede
especificar de dos formas:
Usando el formato #aabbcc (con aa,
bb y cc números hexadecimales
Usando un nombre de la lista
disponible en el apartado 13 de esta
memoria
color="green"
sell Recoge toda la información relativa a
una operación bajista. Se compone de
los siguientes campos:
Condition Especifica la fórmula que,
de cumplirse, indica una situación
bajista del mercado. (ver siguiente
apartado para conocer más sobre las
fórmulas)
condition = "(outmacd>0) & (outmacd <
outmacdsignal) &
(outmacd(1)>outmacdsignal(1)) & (
outmacd > (3*factor)) &
(outma<outma(1))";
Formula Especifica la fórmula cuyo
resultado será el volumen invertido en
una operación “a corto”
formula="lots";
Stoploss Especifica una fórmula para
el Stop Loss
stoploss ="openprice+(StopLoss*factor)";
Takeprofit Especifica una fórmula
para el Tak Profit
takeprofit="openprice-
(TakeProfit*factor)";
Color Especifica un color para la
etiqueta que en el gráfico indica una
salida del mercado. Se puede
especificar de dos formas:
Usando el formato #aabbcc (con aa,
bb y cc números hexadecimales
Usando un nombre de la lista
disponible en el apartado 13
color="red"
Figura 88 Escenarios (4/5): operaciones de trading

168
11.4.5 Precios
Finalmente usaremos dos parámetros para especificar la variable que
contiene los precios de apertura y de cierre. Estos datos se usan habitualmente
como parámetro de entrada en el cálculo de los indicadores técnicos.
Tabla 51 Escenarios (5/5): asignación de precios
Parámetro
Descripción Ejemplo
openprice Variable que contiene el precio de
apertura
openprice = "openPrice";
closureprice Variable que contiene el precio de cierre closureprice = "openPrice";
En este último ejemplo, el programa de trading tomaría siempre como
valor del precio el de apertura de la vela (“openPrice”).
11.4.6 Uniéndolo todo
En la siguiente imagen se puede observar cómo el nombre de una
columna del archivo de datos (línea negra) declarada en config.cfg, se usa
posteriormente para calcular un indicador técnico declarado en un archivo de
escenarios, cuyo valor de salida (línea amarilla) se usa, a su vez, para
mostrarse en un gráfico o para ser parte de una fórmula que determina si el
mercado se encuentra en una situación alcista o bajista (declarada también en
un archivo de escenarios):
Figura 89 Ejemplo de relación entre variables

169
11.5 Escritura de fórmulas
Como hemos indicado en el apartado anterior, es posible especificar
fórmulas para calcular condiciones de entrada y salida del mercado, así como
el volumen de una operación, o el valor que tomarán las condiciones de Stop
Loss y Take Profit.
El analizador sintáctico incluido en el software admite las siguientes
operaciones:
Tabla 52 Operadores admitidos en fórmulas
+, -, *, / Operadores aritméticos
>, <, = Operadores lógicos
| OR
& AND
¡ NOT
# ABS
(, )
Tabla 53 Operandos admitidos en fórmulas
Números (enteros y float) Enteros y float
Nombres de variables:
parámetros de salida de indicadores técnicos
columnas del fichero (o base de datos) de entrada
constantes especificadas en los archivos de los
escenarios
Los nombre de las variables que hacen referencia a resultados del
cálculo de indicadores pueden llevar un índice, por ejemplo outmacd(n), para
hacer referencia a un dato de n períodos anteriores.
Por ejemplo, el bucle que realiza el backtesting de un juego de 200
datos, cuando evalúe la situación en el período 150, sustituirá la variable
outmacd por su valor en el momento 150. Sin embargo, cuando encuentre
outmacd(1) la sustituirá por su valor en el período 149, es decir, en el período
anterior. Cuando el período anterior se refiere a una fecha anterior a la inicial,
mantendrá el valor del período actual.
El analizador sintáctico desarrollado NO CONTEMPLA la precedencia
de operadores, por lo que cualquier orden en las operaciones que se quieran
ejecutar en primer lugar deberá ser especificado expresamente mediante el uso
de paréntesis.

170
Vemos a continuación algunos ejemplos de fórmulas válidas:
Tabla 54 Ejemplos de fórmulas
12+(34/28*2)
¡(4>2)
(precio*0.3)>(indicador-2)
Takeprofit>#variable
11.6 Ejecución
Para ejecutar la aplicación en Windows teclearemos:
trading [nombre_archivo_config]
Por ejemplo podríamos escribir trading myconfig.cfg para ejecutar
trading tomando como archivo de configuración myconfig.cfg
O podríamos escribir trading (sin argumentos) para ejecutar
tomando como entrada el archivo por defecto config.cfg
El contenido de myconfig.cfg o config.cfg debe ajustarse a lo descrito en
el apartado 11.1 de esta memoria.
Si el archivo de configuración especificado existe en el directorio de la
aplicación y contiene las secciones requeridas, comienza a buscar todos los
ficheros cuyos nombres son de la forma scenario____.cfg y procesa los
escenarios descritos en cada uno de ellos, mostrando por consola la operación
en curso:
Figura 90 Ejecución: información mostrada en la consola

171
y un resumen final con el tiempo total de ejecución y los mejores
escenarios ordenados por Profit:
Figura 91 Ejecución: resumen mostrado en la consola
A la vez crea varios ficheros, según se haya especificado así en el
archivo de configuración:
Parámetro en el fichero
de configuración
principal
Resultado Contenido
logFile=[nombre_de_archivo]
(no vacío)
Se crea el fichero [nombre_de_archivo].log
(en el directorio de la aplicación)
Informe sobre la
ejecución:
Tiempos de
ejecución
Etapas
completadas
Escenarios
completados
mejores
escenarios por
Profit
de los n mejores
escenarios
outputGraphMode = 0 Se crean los gráficos
[nombre_escenario]+[número_escenario].png
(en outputFolder)
Gráficos con la
información y
formato especificado
en el archivo del
escenario
de TODOS los
escenarios
outputGraphMode = n Se crean los gráficos
[nombre_escenario]+[número_escenario]+BEST+[orden].png
(en outputFolder)
Gráficos con la
información y
formato especificado
en el archivo del
escenario
outputCSVMode= 0 Se crean los ficheros
[nombre_escenario]+[número_escenario].csv
(en outputFolder)
Archivos CSV con:
información leída
del fichero de
datos históricos o
base de datos
valores
calculados de los
indicadores
de TODOS los
escenarios

172
Parámetro en el fichero
de configuración
principal
Resultado Contenido
outputCSVMode= n Se crean los ficheros
[nombre_escenario]+[número_escenario]+BEST+[orden].csv
(en outputFolder)
Archivos CSV con:
información leída
del fichero de
datos históricos o
base de datos
valores
calculados de los
indicadores
de los n mejores
escenarios
outputOpBookMode= 0 Se crean los ficheros
[nombre_escenario]+[número_escenario].txt
(en outputFolder)
Archivos txt con:
operaciones en
el mercado
(entradas y
salidas), con
fechas, precios y
profit
de TODOS los
escenarios
outputOpBookMode= n Se crean los ficheros
[nombre_escenario]+[número_escenario]+BEST+[orden].txt
(en outputFolder)
Archivos CSV con:
operaciones en
el mercado
(entradas y
salidas), con
fechas, precios y
profit
de los n mejores
escenarios

173
Vemos en las siguientes imágenes ejemplos de salidas del sistema.
Figura 92 Contenido del archivo LOG
Figura 93 Ficheros generados: gráficos y registro de operaciones

174
La información que figura en el archivo LOG referente a las operaciones
de entrada / salida del mercado sólo aparecerán en el caso de que el
parámetro outputOpBookMode no sea -1.
El proceso principal de “Trading” radica en la simulación de la realización
de operaciones de entrada/salida. El algoritmo usado es el siguiente:
Inicialmente se busca si se ha alcanzado el umbral de Stop Loss o Take
Profit, ejecutando en su caso la salida del mercado.
En caso contrario, se evalúan las fórmulas que determinan si nos
encontramos en mercado alcista o bajista y se toman decisiones.
En la siguiente imagen vemos en detalle el algoritmo encargado del
procesamiento del Stop Loss y el Take Profit:
Figura 94 Algoritmo de trading

175
11.7 Manejo de errores
Durante la ejecución se pueden producir errores. Normalmente, estos
errores se mostrarán por la consola y en el archivo LOG, y afectarán a la
iteración en curso, continuando con la ejecución del resto de escenarios. En
este caso, tanto en la consola como en el LOG, se podrá ver un mensaje
indicando que se han producido n errores.
Los errores más comunes son:
Errores de ejecución al asignar o reasignar memoria
Incongruencia o falta de información en los archivos de configuración
Formato incorrecto en los datos históricos
Fórmulas con errores
Error en las llamadas a la librería TA-Lib, generalmente por parámetros
incorrectos
Figura 95 Algoritmo para el procesamiento de SL y TP

176
Se puede consultar la lista completa de errores en el apartado 14 de
esta memoria.

177
12 Anexo III Manual de Instalación
El sistema operativo que se ha seleccionado para ejecutar en
producción la aplicación “Trading” es Linux (consultar “apartado 2.3.4 Selección
de la solución” en esta memoria para más detalles). Sin embargo, durante el
desarrollo de la misma se han seleccionado librerías y herramientas
disponibles tanto para Linux como para Microsoft Windows, de manera que sea
fácil preparar su ejecución en ambos entornos.
En esta sección de la memoria vamos a detallar los pasos a seguir para
instalar los componentes necesarios de la aplicación.
Para independizar la compilación del entorno de desarrollo
seleccionado, se proporciona un fichero MAKE estándar que asegura la
portabilidad.
Lo hemos dividido en dos secciones:
Instalación en Linux
Instalación en Windows
12.1 Instalación en Linux
12.1.1 Linux como máquina virtual sobre Windows (opcional)
En el caso de no disponer de un sistema ejecutando Linux, y se quiera
probar la aplicación, se puede preparar un entorno virtual donde instalar Linux
sobre un sistema operativo Windows. Evidentemente la velocidad de ejecución
será muy inferior a la que se conseguirá en un entorno real.
Para ello se puede seguir las siguientes acciones, que incluye la
instalación de VMWare, Ubuntu y el resto de componentes.
Accedemos a la página de descargas de VMWare:
https://my.vmware.com/web/vmware/downloads

178
Figura 96 Descargas del Web Site de VMWare
Buscamos el Player, según vemos en la siguiente imagen:
Figura 97 Enlace para descarga de VMWare Player
Para nuestro proyecto hemos usado la versión 4.0.2 por ser una versión
estable y de gran uso en el momento de inicio del trabajo.
Una vez hayamos descargado el instalador procedemos a su ejecución.

179
Figura 98 instalación de VMWare Player
Ahora ya podemos crear una máquina virtual Linux para lo que
necesitaremos una distribución, preferiblemente en formato .iso. Vamos a
mostrar un ejemplo de instalación de Ubuntu.
http://www.ubuntu.com/

180
Figura 99 Web Site de Ubuntu
En el momento de inicio de este TFG, la versión en uso es la 12.0.4.
Para descarga de versiones anteriores, podemos acceder directamente a la
página de releases, añadiendo la extensión que buscamos
http://releases.ubuntu.com/12.04/
Seleccionamos el formato iso y procedemos a su descarga a un
directorio local para usarlo después en la instalación de la máquina virtual:
Figura 100 Selección distribución Ubuntu iso

181
Ya podemos comenzar a crear la máquina virtual y para ello lanzamos
VMWare:
Figura 101 Creación de una máquina virtual
Introducimos el nombre que le daremos a la máquina virtual y el usuario
y contraseña de root

182
Figura 102 Credenciales de la máquina virtual
Elegimos ahora el directorio donde instalaremos los archivos de la
máquina virtual:
Figura 103 Directorio de instalación del disco virtual
Y asignamos un espacio en disco:

183
Figura 104 Tamaño en disco de la máquina virtual
Figura 105 Valores hardware para la máquina virtual
Podemos modificar los valores de emulación de hardware, aunque
dejaremos los valores por defecto, entre otros, 1 Gb de RAM:

184
Figura 106 Memoria asignada a la máquina virtual
Si la instalación nos solicitara permiso para instalar componentes
adicionales, aceptaremos:

185
Figura 107 Componentes adicionales para Linux
Los componentes utilizados (setup de VMWare y la distribución Ubuntu
en formato iso están disponibles en el DVD adjunto a la memoria de este TFG)
Se procede a la creación de la máquina virtual Linux (el proceso puede
tomar algún tiempo dependiendo del hardware de la máquina anfitriona). La
instalación ofrece mensajes del estado de la misma:
Figura 108 Instalación de Ubuntu

186
Figura 109 Instalación de componentes adicionales
Ya estamos preparados para trabajar en nuestra máquina virtual Ubuntu.
Iniciamos nuestra sesión con el usuario y contraseña que introdujimos en el
proceso de instalación, o bien como invitado
Figura 110 Inicio de sesión en Ubuntu
Pudiera ser necesario configurar la resolución, pero también añadir el
idioma y el teclado. Veremos a continuación un ejemplo de cómo añadir el
idioma castellano.

187
Figura 111 Añadir idioma en Ubuntu
Y ahora indicamos cómo añadir el layout del teclado para español:

188
Figura 112 Añadir teclado en Ubuntu
Una vez finalizado, ya podemos seleccionar el teclado en castellano,
que nos aparecerá en la lista de los disponibles:
Figura 113 Selección de teclado en Ubuntu
12.1.2 Instalación del IDE Eclipse (opcional)
Si quisiéramos instalar el entorno de desarrollo Eclipse, podemos utilizar
el entorno gráfico y abrir el Ubuntu Software Center, seleccionando developer
tools, IDEs y Eclipse y pulsando a continuación sobre “Instalar”:

189
Figura 114 Instalación de Eclipse IDE en Ubuntu
A continuación vamos a instalar el plug-in para desarrollo en C/C++ en
eclipse. Buscando, en el software center, por eclipse-cdt:
Figura 115 Instalación de C/C++ en Ubuntu

190
Ya podemos iniciar Eclipse y confirmar el directorio por defecto donde
Eclipse administrará los proyectos (el workspace).
Figura 116 Directorio de trabajo en Eclipse IDE
Figura 117 Pantalla principal de Eclipse IDE

191
12.1.3 Instalación de TA-Lib
Para instalar la librería de indicadores técnicos, accedemos al Site del
proyecto TA-Lib Technical Analysis Library
http://ta-lib.org/
Seleccionemos en “downloads”, buscamos el paquete para UNIX/Linux y
lo descargamos:
Figura 118 TA-Lib, selección de distribución

192
Figura 119 TA-Lib descarga de distribución
Ahora ya lo tenemos disponible en la carpeta de downloads para su
posterior pegado en nuestro directorio de trabajo, junto con el resto de
proyectos:
Figura 120 Mover TA-lib junto al resto de componentes
Ahora necesitamos compilar los fuentes para obtener las librerías.
Seguimos los siguientes pasos:
Desde un terminal de Linux debemos acceder a la carpeta donde hemos
copiado la carpeta ta-lib:

193
usuario@ubuntu:~$ cd workspace
usuario@ubuntu:~/workspace$ cd ta-lib
usuario@ubuntu:~/workspace/ ta-lib$ ./configure
usuario@ubuntu:~/workspace/ ta-lib$ ./configure
usuario@ubuntu:~/workspace/ ta-lib$ make clean
usuario@ubuntu:~/workspace/ ta-lib$ make
Una vez terminado el proceso, podremos encontrar las librerías
libta_abstract_csd.a, libta_common_csd.a, libta_func_csd.a y libta_libc_csd.a,
dentro de los directorios del mismo nombre y subdirectorio .libs, listas para ser
enlazadas en nuestro proyecto.
La instalación ofrece un ejecutable que permite realizar un test, llamando
a las funciones recién compiladas para verificar su funcionamiento. Podemos
ejecutarlo siguiendo las siguientes instrucciones:
usuario@ubuntu:~/workspace$ cd ta-lib
usuario@ubuntu:~/workspace/ta-lib$ cd src
usuario@ubuntu:~/workspace/ta-lib/src$ cd tools
usuario@ubuntu:~/workspace/ta-lib/src/tools$ cd ta_regtest
usuario@ubuntu:~/workspace/ta-lib/src/tools/ta_regtest$ ./ta_regtest
Figura 121 Test de TA-Lib en Ubuntu
12.1.4 Instalación de libconfig
Ahora procedemos a instalar libconfig (C/C++ Configuration file library),
componente necesario para la lectura de los archivos de configuración que
usaremos en este proyecto.

194
Accedemos al Site del proyecto http://www.hyperrealm.com/libconfig/ y
procedemos a su descarga:
Figura 122 Descarga de libconfig
Ahora lo movemos a la carpeta workspace, junto con el resto de
proyectos:
Figura 123 Mover libconfig junto al resto de componentes
Desde un terminal de Linux debemos acceder a la carpeta donde hemos
copiado la carpeta lib-config:
usuario@ubuntu:~$ Cd workspace
usuario@ubuntu:~/workspace$ cd libconfig-1.4.9
usuario@ubuntu:~/workspace/libconfig-1.4.9$ ./configure –disable-cxx
usuario@ubuntu:~/workspace/ libconfig-1.4.9$ make clean
usuario@ubuntu:~/workspace/ libconfig-1.4.9$ make

195
usuario@ubuntu:~/workspace/ libconfig-1.4.9$ make install
La librería libconfig.a ya se puede encontrar en el directorio lib/.libs
usuario@ubuntu:~/workspace/ libconfig-1.4.9$ cd lib
usuario@ubuntu:~/workspace/ libconfig-1.4.9/lib$ cd .libs
usuario@ubuntu:~/workspace/ libconfig-1.4.9/lib/.libs$ cp ./libconfig.a ../
(en este caso, para copiarlo al directorio lib)
12.1.5 Instalación de Python
(python2.7 en el momento de realización del presente TFG)
Accedemos a un terminal:
usuario@ubuntu:~$
Actualizamos los repositorios, es decir , la lista de todos los paquetes
usuario@ubuntu:~$ sudo apt-get update
usuario@ubuntu:~$ sudo apt-get install python-dev
Tras comprobar las dependencias con otros paquetes tendremos que
responder “y” al requerimiento adicional de espacio necesario para instalar este
paquete y sus dependencias:
Figura 124 Instalación de Python en Ubuntu
A partir de este momento ya tenemos el fichero “python.h” disponible
para usarlo en nuestro desarrollo en C (estará en /usr/include/python2.7)

196
Debemos tener en cuenta que los ficheros include no están por defecto en el path de include, ni la librería de Python está enlazada con el ejecutable por defecto. Necesitamos añadir los siguientes flags:
-I/usr/include/python2.7 -lpython2.7
12.1.6 Instalación de matplotlib
Es el componente necesario para crear los gráficos de velas, que forman
parte de la funcionalidad de la aplicación desarrollada.
Accedemos a un terminal:
usuario@ubuntu:~$
Actualizamos los repositorios, es decir, la lista de todos los paquetes de
software:
usuario@ubuntu:~$ sudo apt-get update
usuario@ubuntu:~$ sudo apt-get install python-matplotlib
Tras comprobar las dependencias con otros paquetes tendremos que
responder “y” al requerimiento adicional de espacio necesario para instalar este
paquete y sus dependencias:
Figura 125 Instalación de matplotlib en Ubuntu

197
12.1.7 Instalación de MySQL
Para poder acceder a extraer datos de una base de datos en MySQL
necesitamos instalar la librería de esta popular base de datos.
Accedemos al Ubuntu Software Center y filtrando por “MySQL”
obtendremos una lista de software similar a la que aparece en la siguiente
imagen. Seleccionaremos las utilidades para desarrolladores:
Figura 126 Instalación de MySQL dev tools en Ubuntu
12.2 Instalación en Windows
12.2.1 Instalación del compilador
El primer paso es instalar los siguientes componentes en nuestro
sistema Windows:
GCC, el compilador GNU C
MAKE: una utilidad para compilar y enlazar proyectos de software que
se componga de varios ficheros
Detallamos los pasos para instalar estos componentes desde CYGWIN:
A través de nuestro navegador visitamos el Site de CYGWIN
https://www.cygwin.com/

198
Figura 127 Web Site de Cygwin
Una vez aquí, seleccionamos el instalable adecuado a nuestro sistema
(32 o 64 bits):
Figura 128 Selección de la versión de Cygwin
y procedemos a la descarga sobre nuestro directorio preferido. Nos
creará el siguiente icono en el escritorio:

199
Ahora lo pinchamos dos veces con el ratón para lanzar la utilidad de
instalación:
Figura 129 Instalación de Cygwin (1)
A continuación nos aparecerá una segunda pantalla donde no debemos
olvidar seleccionar “Instalar desde Internet”:
Figura 130 Instalación de Cygwin (2)

200
Una tercera pantalla nos pide en qué directorio instalar los archivos de
Cygwin. Dejar el directorio C:\cygwin propuesto :
Figura 131 Instalación de Cygwin (3)
Una cuarta pantalla nos preguntará por el directorio donde el programa
de instalación guardará los archivos que descargue durante la instalación (en la
imagen adjunta seleccionamos el Escritorio):
Figura 132 Instalación de Cygwin (4)

201
La quinta pantalla en el proceso de instalación nos pregunta sobre
nuestra conexión a internet. Debemos seleccionar Direct Connection:
Figura 133 Instalación de Cygwin (5)
La sexta pantalla nos pregunta por el Site específico del que queremos
descargar Cygwin. En este punto podemos seleccionar el más cercano a
nuestra localización:
Figura 134 Instalación de Cygwin (6)

202
Pulsamos en siguiente:
Figura 135 Instalación de Cygwin (7)
Y después de un breve momento, nos aparecerá la séptima pantalla,
donde debemos elegir cuidadosamente los paquetes a instalar:
Figura 136 Instalación de Cygwin. Selección de paquetes

203
Empezamos expandiendo el nodo Devel, para ver los paquetes
relacionados con herramientas de desarrollo:
Figura 137 Instalación de Cygwin. Paquetes de desarrollo
Debemos seleccionar binutils, gcc-core, gcc GNU compiler, GNU
debugger, libtdl7, make, gcc pre-processor y pkg-config. Además marcaremos
subversion (usado durante este proyecto como repositorio para almacenar las
diferentes versiones del software).
Vemos a continuación el árbol completo de paquetes a seleccionar para
una instalación adecuada para nuestro proyecto:

204
Figura 138 Instalación de Cygwin. Paquetes a instalar
Tras ello, pulsamos en Siguiente y accedemos a incorporar en la
descarga los ficheros dependientes de las opciones que hemos elegido:
Figura 139 Instalación de Cygwin. Aceptar dependencias
Y esperamos a que acabe el proceso de descarga e instalación:

205
Figura 140 Instalación de Cygwin. Proceso
Figura 141 Instalación de Cygwin. Fin del proceso
12.2.2 Instalación de TA-lib
Para instalar la librería de indicadores técnicos, accedemos al Site del
proyecto TA-Lib Technical Analysis Library
http://ta-lib.org/

206
Seleccionemos en “downloads”, buscamos el paquete para UNIX/Linux y
lo descargamos:
Figura 142 TA-Lib, selección de distribución
Lo guardamos en nuestra carpeta eclipseworkspace, para tenerla junto
al resto de componentes:
Figura 143 TA-Lib, descarga de la distribución
A continuación descomprimimos el archivo tar-gz y extraemos la carpeta
ta-lib en el mismo directorio eclipseworkspace.
Ahora debemos compilar el código fuente para obtener las librerías
estáticas.

207
Para ello iniciamos el terminal de Cygwin:
usuario@ordenador~
Nos dirigimos al directorio eclipseworkspace:
usuario@ordenador~ $ cd /
usuario@ordenador $ cd cygdrive
(emula el disco de nuestro ordenador dentro del entorno Linux que ofrece Cygwin)
usuario@ordenador/cygdrive $ cd c
usuario@ordenador/cygdrive /c $ cd users
usuario@ordenador/cygdrive/c/users $ cd jcanolo
(nuestro usuario de Windows)
usuario@ordenador/cygdrive/c/users/jcanolo $ cd eclipseworkspace
usuario@ordenador/cygdrive/c/users/jcanolo/eclipseworkspace $ cd ta-
lib
usuario@ordenador/cygdrive/c/users/jcanolo/eclipseworkspace/ta-lib $
./configure
usuario@ordenador/cygdrive/c/users/jcanolo/eclipseworkspace/ta-lib $
make clean
usuario@ordenador/cygdrive/c/users/jcanolo/eclipseworkspace/ta-lib $
make
Una vez terminado el proceso, podremos encontrar las librerías
libta_abstract.a, libta_common.a, libta_func.a y libta_libc.a, dentro de los
directorios del mismo nombre y subdirectorio .libs, listas para ser enlazadas en
nuestro proyecto:

208
Figura 144 TA-Lib, árbol de directorios
La instalación ofrece un ejecutable que permite realizar un test llamando
a las funciones. Para ejecutarlo procedemos de la siguiente manera:
usuario@ordenador/cygdrive/c/users/jcanolo/eclipseworkspace/ta-lib $
cd src
usuario@ordenador/cygdrive/c/users/jcanolo/eclipseworkspace/ta-lib
/src$ cd tools
usuario@ordenador/cygdrive/c/users/jcanolo/eclipseworkspace/ta-lib
/src /tools$ cd ta_regtest
usuario@ordenador/cygdrive/c/users/jcanolo/eclipseworkspace/ta-lib
/src /tools /ta_regtest$ ./ta_regtest
Figura 145 Test de TA-Lib en Cygwin

209
12.2.3 Instalación de libconfig
Accedemos al Site del proyecto http://www.hyperrealm.com/libconfig/
Figura 146 Web Site de libconfig
Lo descargamos y copiamos a nuestro directorio eclipseworkspace.
Accedemos al terminal Cgywin donde, una vez situados en el directorio
libconfig, ejecutaremos los comandos:
usuario@ordenador/cygdrive/c/users/usuario/eclipseworkspace/libconf
ig$./configure –disable-cxx
Figura 147 Preparación de libconfig en Cygwin
usuario@ordenador/cygdrive/c/users/usuario/eclipseworkspace/libconf
ig$Make clean

210
usuario@ordenador/cygdrive/c/users/usuario/eclipseworkspace/libconf
ig$Make
usuario@ordenador/cygdrive/c/users/usuario/eclipseworkspace/libconf
ig$Make install
Una vez ejecutados todos estos pasos, la librería libconfig.a está
ubicada en libconfig/lib/.libs y la podemos copiar donde queramos tenerla para
enlazarla posteriormente en nuestro proyecto.
12.2.4 Instalación de python
(python2.7 en el momento de realización del presente TFG)
Dado que en Cygwin no disponemos de apt-get, usaremos el instalador
‘pip’. Al no venir por defecto en la instalación de Cygwin, accedemos al link del
archivo en https://raw.github.com/pypa/pip/master/contrib/get-pip.py y lo
descargamos en C:\cygwin\bin:
Figura 148 Descarga de get-pip.py en Cygwin
Ahora, desde el terminal de Cygwin, situados en C:\cygwin\bin,
ejecutamos:
usuario@ordenador/bin$ python get-pip.py install (debemos tener acceso a
internet)
Figura 149 Ejecutar get-pip en Cygwin

211
12.2.5 Instalación de matplotlib
Desde el terminal de Cygwin, situados en C:\cygwin\bin, ejecutamos:
usuario@ordenador/bin$ pip install matplotlib
Figura 150 Instalación de matplotlib en Cygwin
usuario@ordenador/bin$ pip install –upgrade numpy (doble guión)
Figura 151 Actualizar numpy en Cygwin
No olvidar incluir c:\cygwin\bin en la variable de entorno PATH de
Windows (necesario para ejecutar el compilador gcc desde la línea de
comandos de Windows)
12.2.6 Instalación de subversion
Primero debemos instalar el paquete de subversión en Cygwin. Para
ello, ejecutando el archivo setup-x86.exe que obtuvimos durante la instalación,
desplegaremos el grupo Devel, o bien tecleamos subversion directamente en el
campo de búsqueda:

212
Figura 152 Instalar subversion en Cygwin
El siguiente paso consiste en instalar el plug-in en Eclipse que nos
permitirá sincronizar nuestro código fuente con el repositorio desde nuestro
IDE.
Para ello, accederemos al menú Help y, desde ahí, a Install New
Software. En el campo Work with introducimos la dirección de Subversive
(nombre del proyecto que permite trabajar con subversion).
Podemos observar esta opción de Eclipse en la siguiente imagen:
Figura 153 Instalar plug-in de subversion en Eclipse IDE

213
12.2.7 Instalación del cliente MySql
Al igual que hicimos con subversion, accederemos al setup de Cygwin, y
buscaremos el texto mysql en el campo destinado a tal efecto (recuadro en rojo
en la siguiente imagen) y seleccionaremos entonces los componentes
remarcados:
Figura 154 Instalación del cliente de MySQL en Cygwin
12.3 Instalación de la aplicación “Trading”
Para ejecutar la aplicación podríamos copiar el ejecutable trading.exe
previamente compilado en un sistema compatible con el de destino, o bien
instalar Eclipse e importar el proyecto para poder compilar una versión
específica para el entorno (opción preferida).
12.3.1 Instalación de un ejecutable
En el DVD que acompaña a esta memoria, podemos encontrar una
carpeta llamada “ejecutables” que contiene una subcarpeta para Windows y
otra para Linux.
12.3.1.1 Ejecutable en Windows
Copiaremos el contenido de la carpeta \ejecutables\windows en el
directorio del ordenador que va a ejecutar la aplicación:
Figura 155 Fichero ejecutable para Windows en el DVD

214
En este caso se incluyen los archivos trading.exe (la aplicación) y
cygconfig-9.dll (librería que emula el entorno Linux en sistemas basados en
Windows).
12.3.1.2 Ejecutable en Linux
En el DVD se puede encontrar una versión compilada para Ubuntu en la
carpeta \ejecutables\linux.
Recordemos que, adicionalmente, la aplicación necesita ficheros de
configuración para ser ejecutada (ver Anexo II Manual de Usuario).
12.3.2 Instalación del código fuente
En el DVD que acompaña a esta memoria, podemos encontrar una
carpeta llamada “desarrollo” que contiene una subcarpeta ProyectoEclipse con
los códigos fuentes y otras dos carpetas (Windows y Linux) que contiene las
librerías adicionales que se deben instalar siguiente las instrucciones del Anexo
II Manual de Instalación.
Desde el menú de Eclipse podemos importar el proyecto que
encontramos en \desarrollo\ProyectoEclipse, seleccionando Import -> Existing
Project Into Workspace:
Figura 156 Fichero ejecutable para Linux en el DVD

215
Dependiendo del sistema operativo, debemos especificar el conjunto de
herramientas necesarias para construir el proyecto (toolchain).
En Linux debemos seleccionar Linux GCC y en Cygwin (sobre Windows)
seleccionaremos Cygwin GCC:
Figura 158 Toolchain en Linux
Figura 157 Incorporar proyecto Trading en Eclipse

216
Una vez importado, antes de compilar la aplicación, se debe limpiar el
proyecto e incluso eliminar los archivos objeto resultado de una compilación
anterior (basta con seleccionarlos y pulsar sobre el botón derecho y Delete:
Si, al ejecutar dentro del entorno Eclipse en Linux, obtuviéramos el
siguiente mensaje "error while loading shared libraries: libconfig.so.9: cannot open
shared object file: No such file or directory” tendríamos que especificar la ruta de las
librerías dinámicas:
Figura 159 Toolchain en Cygwin (Windows)
Figura 160 Eliminar ficheros objeto

217
Figura 161 Especificar ruta de librerías en Linux

218

219
13 Lista de colores definidos en matplotlib
Nombre Código Nombre Código
"aliceblue" #F0F8FF" "darkturquoise" #00CED1"
"antiquewhite" #FAEBD7" "darkviolet" #9400D3"
"aqua" #00FFFF" "deeppink" #FF1493"
"aquamarine" #7FFFD4" "deepskyblue" #00BFFF"
"azure" #F0FFFF" "dimgray" #696969"
"beige" #F5F5DC" "dodgerblue" #1E90FF"
"bisque" #FFE4C4" "firebrick" #B22222"
"black" #000000" "floralwhite" #FFFAF0"
"blanchedalmond" #FFEBCD" "forestgreen" #228B22"
"blue" #0000FF" "fuchsia" #FF00FF"
"blueviolet" #8A2BE2" "gainsboro" #DCDCDC"
"brown" #A52A2A" "ghostwhite" #F8F8FF"
"burlywood" #DEB887" "gold" #FFD700"
"cadetblue" #5F9EA0" "goldenrod" #DAA520"
"chartreuse" #7FFF00" "gray" #808080"
"chocolate" #D2691E" "green" #008000"
"coral" #FF7F50" "greenyellow" #ADFF2F"
"cornflowerblue" #6495ED" "honeydew" #F0FFF0"
"cornsilk" #FFF8DC" "hotpink" #FF69B4"
"crimson" #DC143C" "indianred" #CD5C5C"
"cyan" #00FFFF" "indigo" #4B0082"
"darkblue" #00008B" "ivory" #FFFFF0"
"darkcyan" #008B8B" "khaki" #F0E68C"
"darkgoldenrod" #B8860B" "lavender" #E6E6FA"
"darkgray" #A9A9A9" "lavenderblush" #FFF0F5"
"darkgreen" #006400" "lawngreen" #7CFC00"
"darkkhaki" #BDB76B" "lemonchiffon" #FFFACD"
"darkmagenta" #8B008B" "lightblue" #ADD8E6"
"darkolivegreen" #556B2F" "lightcoral" #F08080"
"darkorange" #FF8C00" "lightcyan" #E0FFFF"
"darkorchid" #9932CC" "lightgoldenrodyellow" #FAFAD2"
"darkred" #8B0000" "lightgreen" #90EE90"
"darksalmon" #E9967A" "lightgray" #D3D3D3"
"darkseagreen" #8FBC8F" "lightpink" #FFB6C1"
"darkslateblue" #483D8B" "lightsalmon" #FFA07A"
"darkslategray" #2F4F4F" "lightseagreen" #20B2AA"

220
Nombre Código Nombre Código
"lightskyblue" #87CEFA" "peru" #CD853F"
"lightslategray" #778899" "pink" #FFC0CB"
"lightsteelblue" #B0C4DE" "plum" #DDA0DD"
"lightyellow" #FFFFE0" "powderblue" #B0E0E6"
"lime" #00FF00" "purple" #800080"
"limegreen" #32CD32" "red" #FF0000"
"linen" #FAF0E6" "rosybrown" #BC8F8F"
"magenta" #FF00FF" "royalblue" #4169E1"
"maroon" #800000" "saddlebrown" #8B4513"
"mediumaquamarine" #66CDAA" "salmon" #FA8072"
"mediumblue" #0000CD" "sandybrown" #FAA460"
"mediumorchid" #BA55D3" "seagreen" #2E8B57"
"mediumpurple" #9370DB" "seashell" #FFF5EE"
"mediumseagreen" #3CB371" "sienna" #A0522D"
"mediumslateblue" #7B68EE" "silver" #C0C0C0"
"mediumspringgreen" #00FA9A" "skyblue" #87CEEB"
"mediumturquoise" #48D1CC" "slateblue" #6A5ACD"
"mediumvioletred" #C71585" "slategray" #708090"
"midnightblue" #191970" "snow" #FFFAFA"
"mintcream" #F5FFFA" "springgreen" #00FF7F"
"mistyrose" #FFE4E1" "steelblue" #4682B4"
"moccasin" #FFE4B5" "tan" #D2B48C"
"navajowhite" #FFDEAD" "teal" #008080"
"navy" #000080" "thistle" #D8BFD8"
"oldlace" #FDF5E6" "tomato" #FF6347"
"olive" #808000" "turquoise" #40E0D0"
"olivedrab" #6B8E23" "violet" #EE82EE"
"orange" #FFA500" "wheat" #F5DEB3"
"orangered" #FF4500" "white" #FFFFFF"
"orchid" #DA70D6" "whitesmoke" #F5F5F5"
"palegoldenrod" #EEE8AA" "yellow" #FFFF00"
"palegreen" #98FB98" "yellowgreen" "#9ACD32
"paleturquoise" #AFEEEE"
"palevioletred" #DB7093"
"papayawhip" #FFEFD5"
"peachpuff" #FFDAB9"

221
14 Lista de errores de ejecución
Id Descripción
0 "No error"
1 "Section 'columnsInDataFile' not found in config file"
2 "Historical data file not found in specified path"
3 "Historical data file contains more columns than expected according to 'columnsInDataFile' section"
4 "One of the columns in historical does not match expected format according to 'columnsInDataFile' section"
5 "Saving information in data table not possible due to out of range index"
6 "Date & Time fields does not compound a valid datetime information"
7 "Error allocating or reallocating memory"
8 "An error has been found when sending information to graphic csv file"
9 "Destination window according to 'graphicData.window' is bigger than 'graphicNbWindows'"
10 "Missing window definition in 'graphicWindows' section (expected 'graphicNbWindows')"
11 "Relative sizes of windows must sum up 10"
12 "Section 'graphicData' not found in config file"
13 "Section 'graphicWindows' not found in config file"
14 "There are no enough variables to draw a candlestick chart"
15 "Non integer values in windows definition"
16 "Valid chart types are l, a, cC, cL, cH, cO"
17 "Variable color not existing or with wrong format"
18 "The format or direction in one of the indicators is not correct"
19 "Output parameters can have only one value"
20 "Ranges for input parameters must have three numeric values"
21 "Indicator parameters need values or ranges to be declared"
22 "All indicators need to have informed parameters"
23 "It is not possible to inform both 'values' and 'ranges' for parameters in indicators"
24 "functions.cfg doens't exist"
25 "functions.cfg has not information about parameters"
26 "functions.cfg has not correct information"
27 "functions.cfg has format, type or optional type not allowed"
28 "Invalid data format specified in 'columnsInDataFile' section. Only f, d and t are allowed"
29 "A matrix input parameter has a value that does not match with any existing variable"
30 "A float value was expected as parameter value"
31 "An integer value was expected as parameter value"
32 "An indicators has been declare more than once in config file"
33 "Output parameters names must be unique"
34 "At least one indicator in config file does not match with function definition"
50 "invalid character in the formula to be calculated"
51 "The variable specified in the formula is not an output matrix indicator parameter"

222
Id Descripción
52 "Expected script file does not exist"
53 "Script file has incorrect syntax"
54 "No information about indicators have been found in the script file or is not correct"
55 "No information about graphics have been found in the script file or is not correct"
56 "No information about graphic windows have been found in the script file or is not correct"
57 "Cannot open output file for graphic information"
58 "Script file does not contain required parameters for buy formula"
59 "Script file does not contain required parameters for sell formula"
60 "No information about formulae have been found in the script file or is not correct"
61 "No information about colors for plotting buy/sell have been informed or is not correct"
62 "It is not possible to find the best scenario to plot"
63 "An error has been found in the buy condition formula"
64 "An error has been found in the buy formula"
65 "An error has been found in the sell condition formula"
66 "An error has been found in the sell formula"
67 "No information about constants have been found in the script file or is not correct"
68 "Open or closure price is not informed or found in script file"
69 "Error closing and order: lots, lotssize not informed"
70 "An error has been found in the take profit formula"
71 "An error has been found in the stop loss formula"
72 "Cannot open output file for operations information"
73 "An error has been found when sending information to txt operations file"
100 "Not possible to initialize TA-Lib library"
101 "TA-Lib library has raised an error when calculating an indicator"
150 "An error has been found connecting to database"
151 "An error has been found executing a query"
160 "An error has been found deleting a file"
170 "The maximum number of rows have been found in csv file or database"
180 "The maximum number of iterations has been reached"
190 "The maximum execution time has been reached"
0xF "Unknown error

223
15 Índice de figuras
Figura 1 Gráfico de velas. Descripción ........................................................ 31
Figura 2 Gráfico de velas. Evolución de los precios ..................................... 31
Figura 3 Web Site de MetaTrader ................................................................ 36
Figura 4 Web Site de TradeStation .............................................................. 36
Figura 5 Web Site de Wealth-Lab Web ........................................................ 36
Figura 6 Web Site de QuantConnect ........................................................... 36
Figura 7 Web Site de MultiCharts ................................................................ 36
Figura 8 Web Site de NinjaTrader ................................................................ 36
Figura 9 El Proceso en Scrum ..................................................................... 45
Figura 10 Tablero Kanban ........................................................................... 49
Figura 11 Burn Down Chart ......................................................................... 50
Figura 12 Fichero de ejemplo para uso con libconfig ................................... 54
Figura 13 Trading en Kunagi: Roles ............................................................. 70
Figura 14 Trading en Kunagi: Historias de Usuario ...................................... 71
Figura 15 Sprint 1 Backlog ........................................................................... 72
Figura 16 Sprint 1 Historias de Usuario ....................................................... 73
Figura 17 Sprint 1 Tablero al inicio del Sprint............................................... 74
Figura 18 Sprint 1 Burndown Chart .............................................................. 75
Figura 19 Sprint 1 Tablero a falta de las pruebas de la Historia STO004 .... 76
Figura 20 Sprint 1 Release Burndown Chart ................................................ 76
Figura 21 Sprint 1 Demo: fichero CSV de entrada ....................................... 77
Figura 22 Sprint 1 Demo: lectura de fichero csv .......................................... 77
Figura 23 Sprint 1 Demo: fichero de configuración ejemplo ......................... 78
Figura 24 Sprint 1 Demo: lectura fichero de configuración .......................... 78

224
Figura 25 Sprint 1 Demo: error en lectura del fichero csv ............................ 78
Figura 26 Sprint 2 Backlog ........................................................................... 79
Figura 27 Sprint 2 Historias de Usuario ....................................................... 81
Figura 28 Sprint 2 Tablero al inicio del Sprint............................................... 83
Figura 29 Sprint 2 Burndown Chart .............................................................. 84
Figura 30 Sprint 2 Tablero al finalizar la Historia de Usuario STO010 ......... 85
Figura 31 Sprint 2 Release Burndown Chart ................................................ 85
Figura 32 Sprint 2 Demo: script de matplotlib .............................................. 86
Figura 33 Sprint 2 Demo: gráficos de velas con matplotlib .......................... 86
Figura 34 Sprint 2 Demo: fichero CSV de entrada ....................................... 87
Figura 35 Sprint 2 Demo: estructura para almacenar datos históricos ......... 87
Figura 36 Sprint 2 Demo: información almacenada en la estructura ............ 88
Figura 37 Sprint 2 Demo: fichero de salida generado .................................. 88
Figura 38 Sprint 3 Backlog ........................................................................... 89
Figura 39 Sprint 3 Historias de Usuario ....................................................... 90
Figura 40 Sprint 3: incluir Historias de Usuario en un Sprint ........................ 91
Figura 41 Sprint 3: Tablero a falta de incluir las tareas ................................ 91
Figura 42 Sprint 3 Tablero al inicio del Sprint............................................... 92
Figura 43 Sprint 3 Burndown Chart .............................................................. 93
Figura 44 Sprint 3 Release Burndown Chart ................................................ 93
Figura 45 Sprint 3 Demo: configuración del formato de los gráficos ............ 94
Figura 46 Sprint 3 Demo: salida por consola de la información leída .......... 94
Figura 47 Sprint 3 Demo: gráfico creado dinámicamente ............................ 95
Figura 48 Sprint 4 Backlog ........................................................................... 96
Figura 49 Sprint 4: Reducción del Product Backlog tras asignar al Sprint ... 99
Figura 50 Sprint 4 Tablero al inicio del Sprint............................................. 100

225
Figura 51 Sprint 4 Tablero con dos tareas finalizadas y una en curso ....... 101
Figura 52 Sprint 4 Burndown Chart ............................................................ 101
Figura 53 Sprint 4 Release Burndown Chart .............................................. 102
Figura 54 Sprint 4 Demo: analizador sintáctico de expresiones ................ 102
Figura 55 Sprint 4 Demo: parámetros con varios valores .......................... 103
Figura 56 Sprint 4 Demo: fichero LOG ....................................................... 103
Figura 57 Sprint 4 Demo: indicadores de entrada/salida del mercado ....... 104
Figura 58 Sprint 5 Backlog ......................................................................... 105
Figura 59 Sprint 5 Tablero al inicio del Sprint............................................. 109
Figura 60 Sprint 5 Burndown Chart ............................................................ 110
Figura 61 Sprint 5 Release Burndown Chart .............................................. 111
Figura 62 Sprint 5 Demo: Tabla de resultados ........................................... 111
Figura 63 Sprint 5 Demo: Resultados ordenados ...................................... 112
Figura 64 Sprint 5 Demo: constantes en los archivos de configuración ..... 112
Figura 65 Sprint 5 Demo: constantes almacenadas en la aplicación ......... 112
Figura 66 Sprint 6 Backlog ......................................................................... 114
Figura 67 Sprint 6 Tablero al inicio del Sprint............................................. 117
Figura 68 Sprint 6 Burndown Chart ............................................................ 118
Figura 69 Sprint 6 Release Burndown Chart .............................................. 118
Figura 70 Sprint 6 Demo: Variables para cálculo de TP y SL .................... 119
Figura 71 Sprint 6 Demo: Uso del parámetro en el cálculo del SoptLoss .. 119
Figura 72 Sprint 6 Demo: Ejecuciones de Stop Loss y Take Profit ............ 120
Figura 73 Sprint 6 Demo: Indicadores de rendimiento ............................... 120
Figura 74 Matriz de almacenamiento de datos .......................................... 146
Figura 75 Espacio para un nuevo indicador ............................................... 147
Figura 76 Crecimiento bidimensional de la tabla de datos ......................... 147

226
Figura 77 Bucle principal de la aplicación .................................................. 151
Figura 78 Módulos de la aplicación ............................................................ 154
Figura 79 Esquema general aplicación “Trading”....................................... 155
Figura 80 Configuración general de la aplicación ...................................... 156
Figura 81 Ejemplo de archivo de configuración general ............................ 159
Figura 82 Ejemplo de listado de indicadores ............................................. 160
Figura 83 Escenarios (1/5): indicadores técnicos ....................................... 162
Figura 84 Especificación de los indicadores técnicos ................................ 163
Figura 85 Escenarios (2/5): definición de gráficos ..................................... 164
Figura 86 Proceso de creación de un gráfico ............................................. 165
Figura 87 Escenarios (3/5): definición de constantes ................................. 165
Figura 88 Escenarios (4/5): operaciones de trading ................................... 167
Figura 89 Ejemplo de relación entre variables ........................................... 168
Figura 90 Ejecución: información mostrada en la consola ......................... 170
Figura 91 Ejecución: resumen mostrado en la consola .............................. 171
Figura 92 Contenido del archivo LOG ........................................................ 173
Figura 93 Ficheros generados: gráficos y registro de operaciones ............ 173
Figura 94 Algoritmo de trading ................................................................... 174
Figura 95 Algoritmo para el procesamiento de SL y TP ............................. 175
Figura 96 Descargas del Web Site de VMWare ......................................... 178
Figura 97 Enlace para descarga de VMWare Player ................................. 178
Figura 98 instalación de VMWare Player ................................................... 179
Figura 99 Web Site de Ubuntu ................................................................... 180
Figura 100 Selección distribución Ubuntu iso ............................................ 180
Figura 101 Creación de una máquina virtual ............................................. 181
Figura 102 Credenciales de la máquina virtual .......................................... 182

227
Figura 103 Directorio de instalación del disco virtual ................................. 182
Figura 104 Tamaño en disco de la máquina virtual .................................... 183
Figura 105 Valores hardware para la máquina virtual ................................ 183
Figura 106 Memoria asignada a la máquina virtual .................................... 184
Figura 107 Componentes adicionales para Linux ...................................... 185
Figura 108 Instalación de Ubuntu .............................................................. 185
Figura 109 Instalación de componentes adicionales .................................. 186
Figura 110 Inicio de sesión en Ubuntu ....................................................... 186
Figura 111 Añadir idioma en Ubuntu .......................................................... 187
Figura 112 Añadir teclado en Ubuntu ......................................................... 188
Figura 113 Selección de teclado en Ubuntu .............................................. 188
Figura 114 Instalación de Eclipse IDE en Ubuntu ...................................... 189
Figura 115 Instalación de C/C++ en Ubuntu .............................................. 189
Figura 116 Directorio de trabajo en Eclipse IDE ........................................ 190
Figura 117 Pantalla principal de Eclipse IDE ............................................. 190
Figura 118 TA-Lib, selección de distribución ............................................. 191
Figura 119 TA-Lib descarga de distribución ............................................... 192
Figura 120 Mover TA-lib junto al resto de componentes ............................ 192
Figura 121 Test de TA-Lib en Ubuntu ........................................................ 193
Figura 122 Descarga de libconfig ............................................................... 194
Figura 123 Mover libconfig junto al resto de componentes ........................ 194
Figura 124 Instalación de Python en Ubuntu ............................................. 195
Figura 125 Instalación de matplotlib en Ubuntu ......................................... 196
Figura 126 Instalación de MySQL dev tools en Ubuntu ............................. 197
Figura 127 Web Site de Cygwin ................................................................. 198
Figura 128 Selección de la versión de Cygwin........................................... 198

228
Figura 129 Instalación de Cygwin (1) ......................................................... 199
Figura 130 Instalación de Cygwin (2) ......................................................... 199
Figura 131 Instalación de Cygwin (3) ......................................................... 200
Figura 132 Instalación de Cygwin (4) ......................................................... 200
Figura 133 Instalación de Cygwin (5) ......................................................... 201
Figura 134 Instalación de Cygwin (6) ......................................................... 201
Figura 135 Instalación de Cygwin (7) ......................................................... 202
Figura 136 Instalación de Cygwin. Selección de paquetes ........................ 202
Figura 137 Instalación de Cygwin. Paquetes de desarrollo ....................... 203
Figura 138 Instalación de Cygwin. Paquetes a instalar .............................. 204
Figura 139 Instalación de Cygwin. Aceptar dependencias ......................... 204
Figura 140 Instalación de Cygwin. Proceso ............................................... 205
Figura 141 Instalación de Cygwin. Fin del proceso .................................... 205
Figura 142 TA-Lib, selección de distribución ............................................. 206
Figura 143 TA-Lib, descarga de la distribución .......................................... 206
Figura 144 TA-Lib, árbol de directorios ...................................................... 208
Figura 145 Test de TA-Lib en Cygwin ........................................................ 208
Figura 146 Web Site de libconfig ............................................................... 209
Figura 147 Preparación de libconfig en Cygwin ......................................... 209
Figura 148 Descarga de get-pip.py en Cygwin .......................................... 210
Figura 149 Ejecutar get-pip en Cygwin ...................................................... 210
Figura 150 Instalación de matplotlib en Cygwin ......................................... 211
Figura 151 Actualizar numpy en Cygwin .................................................... 211
Figura 152 Instalar subversion en Cygwin ................................................. 212
Figura 153 Instalar plug-in de subversion en Eclipse IDE .......................... 212
Figura 154 Instalación del cliente de MySQL en Cygwin ........................... 213

229
Figura 155 Fichero ejecutable para Windows en el DVD ........................... 213
Figura 156 Fichero ejecutable para Linux en el DVD ................................. 214
Figura 157 Incorporar proyecto Trading en Eclipse ................................... 215
Figura 158 Toolchain en Linux ................................................................... 215
Figura 159 Toolchain en Cygwin (Windows) .............................................. 216
Figura 160 Eliminar ficheros objeto ............................................................ 216
Figura 161 Especificar ruta de librerías en Linux ....................................... 217
Figura 9 (proceso SCRUM) recuperada de http://commons.wikimedia.org/wiki/File:Scrum_process.svg
Figura 10 (Tablero kanban) recuperada de http://en.wikipedia.org/wiki/Kanban_board
Fgura 11 (Burn down chart) recuperada de http://en.wikipedia.org/wiki/Burn_down_chart
Figura 12 (Fichero de ejemplo para uso con libconfig) recuperada http://www.hyperrealm.com/libconfig

230

231
16 Índice de tablas
Tabla 1 Filosofía de desarrollo Ágil .............................................................. 42
Tabla 2 Roles en SCRUM ............................................................................ 46
Tabla 3 Asignación de roles en proyecto Trading ........................................ 48
Tabla 4 Historias de usuario identificadas al inicio del proyecto .................. 63
Tabla 5 Costes de material no facturables ................................................... 65
Tabla 6 Estimación de costes iniciales facturables al cliente ....................... 66
Tabla 7 Fase inicial: Objetivos del cliente .................................................... 68
Tabla 8 Fase inicial. Traducción a Historias de Usuario .............................. 68
Tabla 9 Sprint 1 Tareas ................................................................................ 73
Tabla 10 Sprint 2 Tareas .............................................................................. 81
Tabla 11 Sprint 3 Tareas .............................................................................. 90
Tabla 12 Sprint 4 Tareas .............................................................................. 98
Tabla 13 Sprint 5 Tareas ............................................................................ 108
Tabla 14 Sprint 6 Tareas ............................................................................ 115
Tabla 15 Caso de prueba 001 .................................................................... 121
Tabla 16 Caso de prueba 002 .................................................................... 122
Tabla 17 Caso de prueba 003 .................................................................... 122
Tabla 18 Caso de prueba 004 .................................................................... 123
Tabla 19 Caso de prueba 005 .................................................................... 123
Tabla 20 Caso de prueba 006 .................................................................... 124
Tabla 21 Caso de prueba 007 .................................................................... 124
Tabla 22 Caso de prueba 008 .................................................................... 125
Tabla 23 Caso de prueba 009 .................................................................... 125
Tabla 24 Caso de prueba 010 .................................................................... 126

232
Tabla 25 Caso de prueba 011 .................................................................... 126
Tabla 26 Caso de prueba 012 .................................................................... 127
Tabla 27 Caso de prueba 013 .................................................................... 127
Tabla 28 Caso de prueba 014 .................................................................... 128
Tabla 29 Caso de prueba 015 .................................................................... 128
Tabla 30 Caso de prueba 016 .................................................................... 129
Tabla 31 Caso de prueba 017 .................................................................... 129
Tabla 32 Caso de prueba 018 .................................................................... 130
Tabla 33 Caso de prueba 019 .................................................................... 130
Tabla 34 Caso de prueba 020 .................................................................... 131
Tabla 35 Caso de prueba 021 .................................................................... 131
Tabla 36 Caso de prueba 022 .................................................................... 132
Tabla 37 Caso de prueba 023 .................................................................... 133
Tabla 38 Caso de prueba 024 .................................................................... 133
Tabla 39 Caso de prueba 025 .................................................................... 134
Tabla 40 Caso de prueba 026 .................................................................... 134
Tabla 41 Caso de prueba 027 .................................................................... 135
Tabla 42 Caso de prueba 028 .................................................................... 135
Tabla 43 Objetivos alcanzados .................................................................. 137
Tabla 44 Código para redimensionar arrays de float y char ....................... 146
Tabla 45 Parámetros aplicables en la configuración general ..................... 157
Tabla 46 Parámetros aplicable a la lista de indicadores ............................ 160
Tabla 47 Escenarios (1/5): indicadores técnicos ........................................ 161
Tabla 48 Escenarios (2/5): definición de gráficos....................................... 163
Tabla 49 Escenarios (3/5): definición de constantes .................................. 165
Tabla 50 Escenarios (4/5): operaciones de trading .................................... 166

233
Tabla 51 Escenarios (5/5): asignación de precios ...................................... 168
Tabla 52 Operadores admitidos en fórmulas ............................................. 169
Tabla 53 Operandos admitidos en fórmulas .............................................. 169
Tabla 54 Ejemplos de fórmulas .................................................................. 170

234

235
17 Glosario de términos
Trading: consiste en comprar o vender un valor en un mercado
financiero con la intención de obtener un beneficio especulativo
Trader: es una persona o entidad que compra o vende
instrumentos financieros (acciones, bonos, materias primas,
derivados financieros, etc.)
FOREX: es una abreviatura de uso general para “foreign
exchange” o "cambio de divisas" y se suele utilizar para describir
el trading en el mercado de divisas por inversionistas y
especuladores
Profit: hace referencia al beneficio de las operaciones y se calcula
como diferencia entre las cantidades obtenidas y las invertidas
Stop Loss: es una orden de venta que sólo se ejecutará si el
precio cae lo suficiente como para causarte tu pérdida máxima
admisible
Take Profit: es una orden de cierre cuando se llega a un precio
objetivo (nuestra meta para esa operación), que le hemos dicho
con anterioridad
Movimiento lateral: Es un movimiento de la curva de cotizaciones,
que se mueve en un estrecho rango de fluctuación, prácticamente
horizontal
Drawdown: es el nivel de descenso de la curva de resultados
respecto a un máximo anterior. Es una forma de evaluar el riesgo
del sistema de trading, ya sea automático o no. Influye de manera
directa en el capital mínimo con el que hemos de contar para
invertir.
Backtesting: Es el proceso de probar una estrategia de operación
en períodos anteriores. En lugar de aplicar una estrategia para el
período de tiempo hacia delante, lo que podría llevar años, un
operador puede hacer una simulación de la estrategia de
operación con los datos del pasado con el fin de medir la eficacia.
Tablero Kanban: Es una herramienta de trabajo que consiste en
una tabla que tendrá tantas columnas como etapas compongan
nuestro proceso, de forma que los elementos de trabajo vayan

236
pasando etapas de izquierda a derecha. En nuestro caso, por
ejemplo, los elementos de trabajo son tareas, y comienzan en el
estado “To Do”, pasando a “Doing” en el momento en el que
alguien que tiene disponibilidad se asigna esa tarea. La última
etapa será “Done” (finalizada).
Burndown chart: es una representación gráfica del trabajo que
queda por hacer en un proyecto en el tiempo. Usualmente el
trabajo remanente se muestra en el eje vertical y el tiempo en el
eje horizontal.
Site (o Web Site): es una colección de páginas de Internet
relacionadas y comunes a alguna temática.





























