Embed Size (px)
DESCRIPTION
Citation preview

Биоинформатика - наука, занимающаяся анализом экспериментальных данных молекулярной биологии: секвенированных последовательностей биополимеров, экспериментально определенных пространственных структур биологических макромолекул, данных об экспрессии генов и т.д. Методами биоинформатики являются методы организации информации, широко понимаемые компьютерные методы, методы вычислительной математики и статистики. (М.С. Гельфанд et al)
Европейский Биоинформационный Институт: биоинформатика – это применение компьютерных технологий для администрирования и анализа биологических данных.

Биоинформатика – это способ заниматься биологией, не наблюдая живые существа, как зоологи, не делая опытов в пробирке, как экспериментальные биологи, а анализируя результаты массовых данных или целых проектов. Там есть два аспекта. Один – чисто практический. Оказывается, глядя на буковки, или на структуры белков, или на карты белковых взаимодействий, которые получены из таких массовых экспериментов, вы можете делать совершенно конкретные, проверяемые биологические утверждения. …………………
Вторая вещь. Это началось с чистой техники. Размер генома человека – 3 миллиарда нуклеотидов, 3 миллиарда букв. Их надо где-то хранить, ими надо уметь манипулировать. Это чисто техническая сторона. Но очень важная. ……… Этими колоссальными объемами данных надо уметь манипулировать. Кроме того, оказалось, что можно делать утверждения уже не настолько частные, что «этот белок делает это», а строить утверждения о системе взаимодействия белков в клетке. Описания общих свойств на уровне целой клетки.
М.Гельфанд.

Третий аспект биоинформатики, с моей точки зрения, самый интересный, потому что самая правильная биоинформатика – это биоинформатика эволюционная. Интереснее всего описывать не то, как клетка устроена сейчас, а то, как она такой получилась. Что происходило, что породило такие механизмы внутри клетки и т. д. Эволюционная биология - наука очень старая, а молекулярная эволюция, то есть использование молекулярных данных для реконструкции эволюционных событий, – вещь более новая. Она стала возможной, когда такие данные стали приходить в эволюционную биологию. Происходят, по-видимому, некие культурные войны между классическими эволюционными биологами и молекулярными эволюционистами. Причем они происходят в одну сторону.
М.Гельфанд.

Bioinformatics - A New Discipline
Взято из: D. Gilberts & C. Tan, 2002http://www.brc.dcs.gla.ac.uk/~drg/courses/bioinformatics_city/slides/slides1/sld018.htm
Large scale analysis and interpretation of genomics data.
Computing Math&Stats
Life sciences
Physical sciences

6
The BIG Goal
“The greatest challenge, however, is analytical. … Deeper biological insight is likely to emerge from examining datasets with scores of samples.”
Eric Lander, “array of hope” Nat. Gen.
volume 21 supplement pp 3 - 4, 1999.
Bio-informatics:
Provide methodologies for elucidating biological knowledge from biological data.

7
Goal: Enable the discovery of newbiological insights and create a global
perspective for life sciences.
Data produced by bio-labs and stored in database.
Better biological and medical understanding.Bio-InformaticsBio-Informatics
Algorithms Algorithms and Toolsand Tools
Это вычислительные методы для глобального понимания биологических данных.
Что такое биоинформатика?

Биоинформатика
Structural Genomics
Pharmaco-Genomics
Functional Genomics
Proteomics
Genomics
Bioinformatics

Задачи биоинформатики
• Функциональная аннотация биополимеров
• Структурная аннотация биополимеров
• Эволюция
• Геномика и протеомика

Биополимеры
ДНК
РНК
(дезоксирибонуклеиновые и рибонуклеиновые кислоты) –
обеспечивающих хранение, передачу из поколения в
поколение и реализацию генетической программы развития и
функционирования живых организмов
}Протеины (белки)

Последовательность (sequence, первичная структура)– цепь из мономеров (нуклеотиды или аминокислоты), составляющих ДНК, РНК или белок.
Последовательности ДНК – от 10-20 нуклеотидов (праймеры для ПЦР) до нескольких миллионов (хромосомная ДНК).
Последовательности белков – десятки-тысячи аминокислот.

ДНК

ДНК
OO=P-O O
Фосфатная группаФосфатная группа
NАзотистое основаниеАзотистое основание
(A, G, C, or T)(A, G, C, or T)
CH2
O
C1C4
C3 C2
5
СахарСахар(дезоксирибоза)(дезоксирибоза)

ДНК
ДНК состоит из двух цепей нуклеотидов, ДНК состоит из двух цепей нуклеотидов, соединённых попарносоединённых попарно::
ADENINEADENINE – – THYMINETHYMINE
CYTOSINECYTOSINE - - GUANINEGUANINE
Правило комплементарностиПравило комплементарности

Двойная спиральДвойная спираль
P
P
P
O
O
O
1
23
4
5
5
3
3
5
P
P
PO
O
O
1
2 3
4
5
5
3
5
3
G C
T A

Биополимеры – ДНК
Аденин Гуанин
ЦитозинТимин
Аденозинфосфат
Пурины
Пиримидины

Биополимеры - ДНК
J. Watson и F. Crick. Фото из архива Photo Researchers inc.

ДНК, дальнейшая упаковка.

ДНК
Функции ДНК — наследственность и изменчивость.

Репликация ДНК
Репликация ДНК

Биополимеры - белки
Аминокислоты - органические соединения, в молекуле которых одновременно содержатся карбоксильные и аминные группы.
Последовательность, цепь аминокислот составляет белок.

Биополимеры - белки

Форматы файлов, используемых в биоинформатике
FASTA
>roa1_drome Rea guano receptor type III >> 0.1MVNSNQNQNGNSNGHDDDFPQDSITEPEHMRKLFIGGLDYRTTDENLKAHEKWGNIVDVVVMKDPRTKRSRGFGFITYSHSSMIDEAQKSRPHKIDGRVEPKRAVPRQDIDSPNAGATVKKLFVGALKDDHDEQSIRDYFQHFGNIVDNIVIDKETGKKRGFAFVEFDDYDPVDKVVLQKQHQLNGKMVDVKKALPKNDQQGGGGGRGGPGGRAGGNRGNMGGGNYGNQNGGGNWNNGGNNWGNNRGNDNWGNNSFGGGGGGGGGYGGGNNSWGNNNPWDNGNGGGNFGGGGNNWNGGNDFGGYQQNYGGGPQRGGGNFNNNRMQPYQGGGGFKAGGGNQGNYGNNQGFNNGGNNRRY>roa2_drome Rea guano ligandMVNSNQNQNGNSNGHDDDFPQDSITEPEHMRKLFIGGLDYRTTDENLKAHEKWGNIVDVVVMKDPTSTSTSTSTSTSTSTSTMIDEAQKSRPHKIDGRVEPKRAVPRQDIDSPNAGATVKKLFVGALKDDHDEQSIRDYFQHLLLLLLLDLLLLDLLLLDLLLFVEFDDYDPVDKVVLQKQHQLNGKMVDVKKALPKNDQQGGGGGRGGPGGRAGGNRGNMGGGNYGNQNGGGNWNNGGNNWGNNRGNDNWGNNSFGGGGGGGGGYGGGNNSWGNNNPWDNGNGGGNFGGGGNNWNGGNDFGGYQQNYGGGPQRGGGNFNNNRMQPYQGGGGFKAGGGNQGNYGNNQGFNNGGNNRRY

GenBankLOCUS SCU49845 5028 bp DNA PLN 21-JUN-1999DEFINITION Saccharomyces cerevisiae TCP1-beta gene, partial cds, and Axl2p (AXL2) and Rev7p (REV7) genes, complete cds.ACCESSION U49845VERSION U49845.1 GI:1293613KEYWORDS .SOURCE Saccharomyces cerevisiae (baker's yeast) ORGANISM Saccharomyces cerevisiae Eukaryota; Fungi; Ascomycota; Saccharomycotina; Saccharomycetes; Saccharomycetales; Saccharomycetaceae; Saccharomyces.REFERENCE 1 (bases 1 to 5028) AUTHORS Torpey,L.E., Gibbs,P.E., Nelson,J. and Lawrence,C.W. TITLE Cloning and sequence of REV7, a gene whose function is required for DNA damage-induced mutagenesis in Saccharomyces cerevisiae JOURNAL Yeast 10 (11), 1503-1509 (1994) PUBMED 7871890REFERENCE 2 (bases 1 to 5028) AUTHORS Roemer,T., Madden,K., Chang,J. and Snyder,M. TITLE Selection of axial growth sites in yeast requires Axl2p, a novel plasma membrane glycoprotein JOURNAL Genes Dev. 10 (7), 777-793 (1996) PUBMED 8846915REFERENCE 3 (bases 1 to 5028) AUTHORS Roemer,T. TITLE Direct Submission JOURNAL Submitted (22-FEB-1996) Terry Roemer, Biology, Yale University, New Haven, CT, USAFEATURES Location/Qualifiers source 1..5028 /organism="Saccharomyces cerevisiae" /db_xref="taxon:4932" /chromosome="IX" /map="9" CDS <1..206 /codon_start=3 /product="TCP1-beta" /protein_id="AAA98665.1" /db_xref="GI:1293614" /translation="SSIYNGISTSGLDLNNGTIADMRQLGIVESYKLKRAVVSSASEA AEVLLRVDNIIRARPRTANRQHM" gene 687..3158 /gene="AXL2"
CDS 687..3158 /gene="AXL2" /note="plasma membrane glycoprotein" /codon_start=1 /function="required for axial budding pattern of S. cerevisiae" /product="Axl2p" /protein_id="AAA98666.1" /db_xref="GI:1293615" /translation="MTQLQISLLLTATISLLHLVVATPYEAYPIGKQYPPVARVNESF TFQISNDTYKSSVDKTAQITYNCFDLPSWLSFDSSSRTFSGEPSSDLLSDANTTLYFN ------------------------------------------//--------------------------------------------------------- YGSQKTVDTEKLFDLEAPEKEKRTSRDVTMSSLDPWNSNISPSPVRKSVTPSPYNVTK RNRHLQNIQDSQSGKNGITPTTMSTSSSDDFVPVKDGENFCWVHSMEPDRRPSKKRL VDFSNKSNVNVGQVKDIHGRIPEML" gene complement(3300..4037) /gene="REV7" CDS complement(3300..4037) /gene="REV7" /codon_start=1 /product="Rev7p" /protein_id="AAA98667.1" /db_xref="GI:1293616" /translation="MNRWVEKWLRVYLKCYINLILFYRNVYPPQSFDYTTYQSFNLPQ FVPINRHPALIDYIEELILDVLSKLTHVYRFSICIINKKNDLCIEKYVLDFSELQHVD KDDQIITETEVFDEFRSSLNSLIMHLEKLPKVNDDTITFEAVINAIELELGHKLDRNR RVDSLEEKAEIERDSNWVKCQEDENLPDNNGFQPPKIKLTSLVGSDVGPLIIHQFSEK LISGDDKILNGVYSQYEEGESIFGSLF"ORIGIN 1 gatcctccat atacaacggt atctccacct caggtttaga tctcaacaac ggaaccattg 61 ccgacatgag acagttaggt atcgtcgaga gttacaagct aaaacgagca gtagtcagct 121 ctgcatctga agccgctgaa gttctactaa gggtggataa catcatccgt gcaagaccaa 181 gaaccgccaa tagacaacat atgtaacata tttaggatat acctcgaaaa taataaaccg 241 ccacactgtc attattataa ttagaaacag aacgcaaaaa ttatccacta tataattcaa 301 agacgcgaaa aaaaaagaac aacgcgtcat agaacttttg gcaattcgcg tcacaaataa ------------------------------------------//---------------------------------------------- 4621 tcttcgcact tcttttccca ttcatctctt tcttcttcca aagcaacgat ccttctaccc 4681 atttgctcag agttcaaatc ggcctctttc agtttatcca ttgcttcctt cagtttggct 4741 tcactgtctt ctagctgttg ttctagatcc tggtttttct tggtgtagtt ctcattatta 4801 gatctcaagt tattggagtc ttcagccaat tgctttgtat cagacaattg actctctaac 4861 ttctccactt cactgtcgag ttgctcgttt ttagcggaca aagatttaat ctcgttttct 4921 ttttcagtgt tagattgctc taattctttg agctgttctc tcagctcctc atatttttct 4981 tgccatgact cagattctaa ttttaagcta ttcaatttct ctttgatc//

GenBank. Запись sequence

GenBank. Запись mRNA

Сплайсинг и восстановление последовательности mRNA
mRNA seq=(AF018429.1:282-561)+(AF018429.1:1034-1172)+(AF018430.1:560-651)+(AF018430.1:1-45)+………

GenBank. Запись genomic DNA

GenBank. Аннотация

Как добавить данные в GB?
http://www.ncbi.nlm.nih.gov/Genbank/submit.html
Зачем?•информация в community;•Журналы требуют это ДО публикации
Долго ли это?2 рабочих дня
Данные могу быть закрыты до выхода статьи (по запросу)
Что нужно?Последовательность, ее описание (аннотация), описание источника

Форматы описания белков
PDB
PDB-XML
MMDB-Cn3D

PDB – Protein Data Bank
HEADER LUMINESCENT PROTEIN 09-DEC-03 1RRX TITLE CRYSTALLOGRAPHIC EVIDENCE FOR ISOMERIC CHROMOPHORES IN 3-
TITLE 2 FLUOROTYROSYL-GREEN FLUORESCENT PROTEIN COMPND MOL_ID: 1; COMPND 2 MOLECULE: SIGF1-GFP FUSION PROTEIN; COMPND 3 CHAIN: A; COMPND 4 ENGINEERED: YES; COMPND 5 OTHER_DETAILS: CONTAINS 3-FLUORO-TYROSINE SOURCE MOL_ID: 1; SOURCE 2 ORGANISM_SCIENTIFIC: AEQUOREA VICTORIA; SOURCE 3 ORGANISM_COMMON: FUNGI; SOURCE 4 EXPRESSION_SYSTEM: ESCHERICHIA COLI; SOURCE 5 EXPRESSION_SYSTEM_COMMON: BACTERIA; SOURCE 6 EXPRESSION_SYSTEM_VECTOR_TYPE: PLASMID KEYWDS BETA-BARREL, EGFP, NON-CANONICAL AMINO ACID, CHROMOPHORE
KEYWDS 2 ISOMERISATION EXPDTA X-RAY DIFFRACTION AUTHOR J.H.BAE,P.PARAMITA PAL,L.MORODER,R.HUBER,N.BUDISA REVDAT 1 08-JUN-04 1RRX 0 JRNL AUTH J.H.BAE,P.PARAMITA PAL,L.MORODER,R.HUBER,N.BUDISA JRNL TITL CRYSTALLOGRAPHIC EVIDENCE FOR ISOMERIC JRNL TITL 2 CHROMOPHORES IN 3-FLUOROTYROSYL-GREEN FLUORESCENT
JRNL TITL 3 PROTEIN. JRNL REF CHEMBIOCHEM V. 5 720 2004 JRNL REF 2 EUROP.J.CHEM.BIOL. JRNL REFN GE ISSN 1439-4227 REMARK 1 REMARK 2 REMARK 2 RESOLUTION. 2.10 ANGSTROMS. REMARK 3 REMARK 3 REFINEMENT. --------------------------------------------//-----------------------------------------------------------
REMARK 500 M RES CSSEQI ATM1 ATM2 ATM3 REMARK 500 LEU A 44 CA - CB - CG ANGL. DEV. = 13.7 DEGREES REMARK 500 LEU A 64 N - CA - C ANGL. DEV. =-16.6 DEGREES REMARK 500 LEU A 64 CA - C - O ANGL. DEV. =-16.0 DEGREES REMARK 500 LEU A 64 CA - C - N ANGL. DEV. = 31.6 DEGREES REMARK 500 LEU A 64 O - C - N ANGL. DEV. =-15.9 DEGREES REMARK 500 THR A 97 N - CA - C ANGL. DEV. =-14.0 DEGREES REMARK 500 GLU A 115 N - CA - C ANGL. DEV. =-13.1 DEGREES REMARK 900 REMARK 900 RELATED ENTRIES REMARK 900 RELATED ID: 1EMG RELATED DB: PDB REMARK 900 THE WILD TYPE OF STUDIED NON-CANONICAL AMINO ACID-
REMARK 900 CONTAINING GFP
DBREF 1RRX A 2 227 UNP P42212 GFP_AEQVI 290 517 SEQADV 1RRX YOF A 39 UNP P42212 TYR 327 MODIFIED RESIDUE SEQADV 1RRX MFC A 66 UNP P42212 THR 353 MODIFIED RESIDUE SEQADV 1RRX MFC A 66 UNP P42212 TYR 354 MODIFIED RESIDUE SEQADV 1RRX MFC A 66 UNP P42212 GLY 355 MODIFIED RESIDUE SEQADV 1RRX YOF A 74 UNP P42212 TYR 362 MODIFIED RESIDUE SEQADV 1RRX YOF A 92 UNP P42212 TYR 380 MODIFIED RESIDUE SEQADV 1RRX YOF A 106 UNP P42212 TYR 394 MODIFIED RESIDUE SEQADV 1RRX YOF A 143 UNP P42212 TYR 431 MODIFIED RESIDUE SEQADV 1RRX YOF A 143 UNP P42212 TYR 433 MODIFIED RESIDUE SEQADV 1RRX YOF A 151 UNP P42212 TYR 439 MODIFIED RESIDUE SEQADV 1RRX YOF A 182 UNP P42212 TYR 470 MODIFIED RESIDUE SEQADV 1RRX YOF A 200 UNP P42212 TYR 488 MODIFIED RESIDUE SEQRES 1 A 226 SER LYS GLY GLU GLU LEU PHE THR GLY VAL VAL PRO ILE SEQRES 2 A 226 LEU VAL GLU LEU ASP GLY ASP VAL ASN GLY HIS LYS PHE SEQRES 3 A 226 SER VAL SER GLY GLU GLY GLU GLY ASP ALA THR YOF GLY SEQRES 4 A 226 LYS LEU THR LEU LYS PHE ILE CYS THR THR GLY LYS LEU SEQRES 5 A 226 PRO VAL PRO TRP PRO THR LEU VAL THR THR LEU MFC VAL SEQRES 6 A 226 GLN CYS PHE SER ARG YOF PRO ASP HIS MET LYS GLN HIS SEQRES 7 A 226 ASP PHE PHE LYS SER ALA MET PRO GLU GLY YOF VAL GLN SEQRES 8 A 226 GLU ARG THR ILE PHE PHE LYS ASP ASP GLY ASN YOF LYS SEQRES 9 A 226 THR ARG ALA GLU VAL LYS PHE GLU GLY ASP THR LEU VAL SEQRES 10 A 226 ASN ARG ILE GLU LEU LYS GLY ILE ASP PHE LYS GLU ASP SEQRES 11 A 226 GLY ASN ILE LEU GLY HIS LYS LEU GLU YOF ASN YOF ASN SEQRES 12 A 226 SER HIS ASN VAL YOF ILE MET ALA ASP LYS GLN LYS ASN SEQRES 13 A 226 GLY ILE LYS VAL ASN PHE LYS ILE ARG HIS ASN ILE GLU SEQRES 14 A 226 ASP GLY SER VAL GLN LEU ALA ASP HIS YOF GLN GLN ASN SEQRES 15 A 226 THR PRO ILE GLY ASP GLY PRO VAL LEU LEU PRO ASP ASN SEQRES 16 A 226 HIS YOF LEU SER THR GLN SER ALA LEU SER LYS ASP PRO SEQRES 17 A 226 ASN GLU LYS ARG ASP HIS MET VAL LEU LEU GLU PHE VAL SEQRES 18 A 226 THR ALA ALA GLY ILE MODRES 1RRX YOF A 39 TYR 3-FLUOROTYROSINE MODRES 1RRX YOF A 74 TYR 3-FLUOROTYROSINE MODRES 1RRX YOF A 92 TYR 3-FLUOROTYROSINE MODRES 1RRX YOF A 106 TYR 3-FLUOROTYROSINE MODRES 1RRX YOF A 143 TYR 3-FLUOROTYROSINE MODRES 1RRX YOF A 145 TYR 3-FLUOROTYROSINE MODRES 1RRX YOF A 151 TYR 3-FLUOROTYROSINE MODRES 1RRX YOF A 182 TYR 3-FLUOROTYROSINE MODRES 1RRX YOF A 200 TYR 3-FLUOROTYROSINE MODRES 1RRX MFC A 66 GLY CYCLIZED MODRES 1RRX MFC A 66 TYR CYCLIZED HETNAM YOF 3-FLUOROTYROSINE HETNAM MFC 5-[1-(3-FLUORO-4-HYDROXY-PHENYL)-METH-(Z)-YLIDENE]-3, HETNAM 2 MFC 5-DIHYDRO-IMIDAZOL-4-ONE FORMUL 1 YOF 9(C9 H10 F N O3) FORMUL 1 MFC C15 H16 F N3 O5 FORMUL 2 HOH *61(H2 O)

HELIX 1 1 GLU A 5 THR A 9 5 5 HELIX 2 2 ALA A 37 YOF A 39 5 3 HELIX 3 3 PRO A 56 VAL A 61 5 6 HELIX 4 4 VAL A 68 SER A 72 5 5 HELIX 5 5 PRO A 75 HIS A 81 5 7 HELIX 6 6 ASP A 82 ALA A 87 1 6 SHEET 1 A12 VAL A 12 VAL A 22 0 SHEET 2 A12 HIS A 25 ASP A 36 -1 O GLY A 31 N VAL A 16 SHEET 3 A12 LYS A 41 CYS A 48 -1 O THR A 43 N GLU A 34 SHEET 4 A12 HIS A 217 ALA A 227 -1 O LEU A 220 N LEU A 44 SHEET 5 A12 HIS A 199 SER A 208 -1 N SER A 202 O THR A 225 SHEET 6 A12 ASN A 149 ASP A 155 -1 N ILE A 152 O HIS A 199 SHEET 7 A12 GLY A 160 ASN A 170 -1 O GLY A 160 N ASP A 155 SHEET 8 A12 VAL A 176 PRO A 187 -1 O GLN A 177 N HIS A 169 SHEET 9 A12 YOF A 92 PHE A 100 -1 N GLU A 95 O GLN A 184 SHEET 10 A12 ASN A 105 GLU A 115 -1 O YOF A 106 N ILE A 98 SHEET 11 A12 THR A 118 ILE A 128 -1 O LYS A 126 N LYS A 107 SHEET 12 A12 VAL A 12 VAL A 22 1 N ASP A 21 O GLY A 127 CISPEP 1 MET A 88 PRO A 89 0 0.50 CRYST1 51.003 62.430 70.931 90.00 90.00 90.00 P 21 21 21 4 ORIGX1 1.000000 0.000000 0.000000 0.00000 ORIGX2 0.000000 1.000000 0.000000 0.00000 ORIGX3 0.000000 0.000000 1.000000 0.00000 SCALE1 0.019607 0.000000 0.000000 0.00000 SCALE2 0.000000 0.016018 0.000000 0.00000 SCALE3 0.000000 0.000000 0.014098 0.00000 ATOM 1 N SER A 2 28.277 8.150 50.951 1.00 57.00 N ATOM 2 CA SER A 2 27.454 9.223 51.584 1.00 55.40 C ATOM 3 C SER A 2 25.972 8.992 51.295 1.00 55.44 C ATOM 4 O SER A 2 25.576 7.932 50.799 1.00 54.37 O ATOM 5 CB SER A 2 27.883 10.601 51.046 1.00 70.82 C ATOM 6 OG SER A 2 27.150 11.676 51.622 1.00 71.45 O ATOM 7 N LYS A 3 25.157 9.993 51.619 1.00141.28 N ATOM 8 CA LYS A 3 23.716 9.932 51.398 1.00140.16 C -----------------------------------//----------------------------------------------------------------ATOM 47 CA PHE A 8 26.551 11.090 41.294 1.00 19.27 C ATOM 48 C PHE A 8 27.751 10.357 40.676 1.00 21.43 C ATOM 49 O PHE A 8 28.562 10.924 39.938 1.00 21.44 O ATOM 50 CB PHE A 8 27.022 12.362 41.991 1.00 21.68 C ATOM 51 CG PHE A 8 25.909 13.297 42.288 1.00 17.60 C ATOM 52 CD1 PHE A 8 25.488 14.212 41.321 1.00 14.95 C ATOM 495 CA VAL A 68 23.860 22.610 40.452 1.00 14.12 C ATOM 496 C VAL A 68 25.259 22.196 40.854 1.00 13.41 C ATOM 1164 CA SER A 147 37.123 31.083 35.325 1.00 21.88 C ATOM 1819 CD1 ILE A 229 38.888 21.450 53.055 1.00 29.11 C ATOM 1820 OXT ILE A 229 43.220 19.637 50.148 1.00 25.25 O TER 1821 ILE A 229
HETATM 1822 O HOH 1 30.450 20.682 37.367 1.00 15.75 O HETATM 1823 O HOH 2 26.443 24.175 38.999 1.00 18.82 O ---------------------------------//------------------------------------------------HETATM 1831 O HOH 10 29.132 18.648 45.101 1.00 13.77 O HETATM 1832 O HOH 11 24.076 46.248 42.794 1.00 22.62 O HETATM 1833 O HOH 12 31.870 32.426 52.146 1.00 36.77 O HETATM 1880 O HOH 59 37.243 14.571 53.463 1.00 31.12 O HETATM 1881 O HOH 60 40.360 20.483 56.144 1.00 32.74 O HETATM 1882 O HOH 61 13.483 49.374 33.179 1.00 30.77 O CONECT 267 268 CONECT 268 267 269 271 CONECT 819 820 CONECT 1594 1592 1596 1598 CONECT 1595 1593 1596 CONECT 1596 1594 1595 1597 CONECT 1597 1596 CONECT 1598 1594 MASTER 259 0 10 6 12 0 0 6 1881 1 140 18 END

PDB-XMLPDBML: the representation of archival macromolecular structure data in XML. John Wesbrook, Nobutoshi Ito, Haruki Nakamura, Kim Henrick and Helen M. Berman, Bioinformatics, 21(7), 988-992, 2005.
<?xml version="1.0" encoding="UTF-8" ?><PDBx:datablock datablockName="1CFC" xmlns:PDBx="http://pdbml.pdb.org/schema/pdbx-v32.xsd" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://pdbml.pdb.org/schema/pdbx-v32.xsd pdbx-v32.xsd"> <PDBx:atom_siteCategory> <PDBx:atom_site id="1"> <PDBx:B_iso_or_equiv>1.43</PDBx:B_iso_or_equiv> <PDBx:B_iso_or_equiv_esd xsi:nil="true" /> <PDBx:Cartn_x>14.550</PDBx:Cartn_x> <PDBx:Cartn_x_esd xsi:nil="true" /> <PDBx:Cartn_y>12.461</PDBx:Cartn_y> <PDBx:Cartn_y_esd xsi:nil="true" /> <PDBx:Cartn_z>-10.584</PDBx:Cartn_z> <PDBx:Cartn_z_esd xsi:nil="true" /> <PDBx:auth_asym_id>A</PDBx:auth_asym_id> <PDBx:auth_atom_id>N</PDBx:auth_atom_id> <PDBx:auth_comp_id>ALA</PDBx:auth_comp_id> <PDBx:auth_seq_id>1</PDBx:auth_seq_id> <PDBx:group_PDB>ATOM</PDBx:group_PDB> <PDBx:label_alt_id></PDBx:label_alt_id> <PDBx:label_asym_id>A</PDBx:label_asym_id> <PDBx:label_atom_id>N</PDBx:label_atom_id> <PDBx:label_comp_id>ALA</PDBx:label_comp_id>
<PDBx:label_entity_id>1</PDBx:label_entity_id> <PDBx:label_seq_id>1</PDBx:label_seq_id> <PDBx:occupancy>1.00</PDBx:occupancy> <PDBx:occupancy_esd xsi:nil="true" /> <PDBx:pdbx_PDB_ins_code xsi:nil="true" /> <PDBx:pdbx_PDB_model_num>1</PDBx:pdbx_PDB_model_num> <PDBx:pdbx_formal_charge xsi:nil="true" /> <PDBx:type_symbol>N</PDBx:type_symbol> </PDBx:atom_site> <PDBx:atom_site id="2">

MMDB-Cn3D
Cn3D – ПО для визуализации структур, последовательностей и выравниваний. Отличия от статичного PDB – связывает структурную и функциональную информацию (ключевые мутации-заболевания-активные сайты гомологов). Выравнивание структур и выравнивание последовательностей. Формат расширяемый – добавление информации. Работает как приложение в NCBI ENTREZ (но есть и локальная версия).

GCG

ClustalWCLUSTAL W (1.7) multiple sequence alignment
IPNS_STRJU -MPILMPSAEVPTIDISPLSGDDAKAKQRVAQEINKAARGSGFFYASNHGVDVQLLQDVVIPNS_STRGR -MPIPMLPAHVPTIDISPLSGGDADDKKRVAQEINKACRESGFFYASHHGIDVQLLKDVVIPNS_FLASS ----MNRHADVPVIDISGLSGNDMDVKKDIAARIDRACRGSGFFYAANHGVDLAALQKFTIPNS_PENCH --MASTPKANVPKIDVSPLFGDNMEEKMKVARAIDAASRDTGFFYAVNHGVDVKRLSNKTIPNS_CEPAC MGSVPVPVANVPRIDVSPLFGDDKEKKLEVARAIDAASRDTGFFYAVNHGVDLPWLSRET *.** **:* * *.: . * :* *: *.* :***** :**:*: *. .
IPNS_STRJU NEFHRNMSDQEKHDLAINAYNKDNP-HVRNGYYKAIKGKKAVESFCYLNPSFSDDHPMIKIPNS_STRGR NEFHRTMTDEEKYDLAINAYNKNNP-RTRNGYYMAVKGKKAVESWCYLNPSFSEDHPQIRIPNS_FLASS TDWHMAMSAEEKWELAIRAYNPANP-RNRNGYYMAVEGKKANESFCYLNPSFDADHATIKIPNS_PENCH REFHFSITDEEKWDLAIRAYNKEHQDQIRAGYYLSIPEKKAVESFCYLNPNFKPDHPLIQIPNS_CEPAC NKFHMSITDEEKWQLAIRAYNKEHESQIRAGYYLPIPGKKAVESFCYLNPSFSPDHPRIK .:* :: :** :***.*** : : * *** .: *** **:*****.*. **. *:
Выходной файл: aln formatФорматы наhttp://www.ebi.ac.uk/help/formats.html



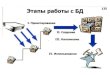
Источники информации и базы данных в Интернете

Типы баз данных
• Всеобъемлющие базы данных
• Организмоспецифические
• Молекулярноспецифические
• Дополнительные базы данных

Проблемы• Биологические базы данных росли последние 20 лет:
1. Избыточность: множественные записи.
2. Неверные последовательности и записи.
• Открытость (данные добавляются пользователями):1. Изменения вносятся владельцами записей.
2. Старые последовательности.
3. Неверные последовательности.
4. Неполные аннотации.

Пример GenBank• GenBank, база данных последовательностей NCBI.
В 1982 году: 700,000 bp,700 последовательностей.
В 2002 году :29,000,000,00022,000,000 последовательностей
В 2009 году:145,959,997,864 bp49,063,546 последовательностей

Полные базы данных
Большие базы данных ДНК, РНК и белков.
Примеры: GenBank, EMBL, swissprot.
Имеется обмен информацией между базами

NCBI (National center for biotechnology information)
NCBI
PubMed
Books
OMIM
Nucleotides
Proteins
GenomesTaxonomy
Structure
Domains
Exp’ profiles

NCBI - GenBank
• GenBank: открытая база данных нуклеотидных и аминокислотных последовательностей
• Источники информации: 1. Прямая подача от исследователей.
2. Литература.
3. Центры исследований последовательностей (Sanger, TIgr)
4. Обмен с другими базами (swiss-prot, PDB).

NCBI - GenBank
GenBank поделён на подбазы:
1. Organism specific (Human, Bacteria, etc).
2. Molecule specific (DNA, RNA, protein).
3. Sequence specific (Genome, mRNA, ESTs etc).

EMBL
Параллельная GenBank база данных.

Swiss prot
База данных белков:
1. Очень хорошо аннотированная.
2. Отсутствует избыточность.
3. Имеются перекрёстные ссылки.
4. ID для нескольких связанных файлов белков

Организмоориентированные базы

Молекулоспецифические базы
• Базы даных, ориентированные на группы молекул
GtRDB: The Genomic tRNA Database

PDB – Protein Data Bank
• Главная база данных 3D структур белков
• Включает порядка 65,000 белковых структур.
• Белки организованы в группы, семейства и т.д.

Swiss-Prot – одна из первых баз данных белковых последовательностей, “gold
standard” белковой аннотации.Аннотация выполнена вручную группой профессиональных экспертов на основе
экспериментальной информации, описанной в научных статьях.
Организована в 1986 году – SIB+EBI+PIR+GU = prof. Amos Bairoch
На сегодняшний день – Release 56.2 - 398181 последовательностей
Анализ белковых последовательностей: Swiss-Prot

UniProt DBUniProt = Swiss-Prot + TrEMBL (Translated EMBL
sequence database)
TrEMBL – Release 39.2 - 6534543 sequences

Поиск белка в Swiss-Prot (по названию)

Advances search

Результаты

Выборка гомологичных белков

Сохранить в FASTA формате

Стандартная запись Swiss-Prot

Стандартные поля: entry, name, origin
Название записи, уникальный идентификатор (ID), предыдущие идентификаторы соответствующей записи, даты первой и последней модификаций, распространенное название белка и его синонимы (EC номер для ферментов), название гена, организм и его таксономия, уровень подтверждения

NiceZyme (ферменты)

Taxonomy Browser

Ссылки на статьи, использованные для аннотации

Комментарии

Продолжение

Возможные разделы комментариев

Cross-References

Cross-References
регистрация

3D-Structure (список структур)

Reactome

GO terms
Определение термина, синонимы, родительские (Hierarchy) и дочерние термины, ключевые слова, дата последней модификации

Cross-References, Keywords

KEGG Kyoto Encyclopedia of Genes and Genomes http://www.genome.jp/kegg/

KEGG (pathway viewer)

DrugBank

Keywords

Словарь ключевых слов

Feature Table

Координаты в Feature table

Feature table, продолжение

Feature Table, продолжение
Только экспериментальные

Feature Table viewer(Sequence Element viewer)

Feature aligner
Можно построить множественное выравнивание подмножества этих элементов (ClustalW) или скопировать их в FASTA формате

Sequence

Sequence, продолжение

FASTA format
Программа FASTA (1988, WR Pearson & DJ Lipman):>(the definition line)_уникальный_ID + короткое описаниеПОСЛЕДОВАТЕЛЬНОСТЬ БЕЛКА (ИЛИ ДНК) В ОДНОБУКВЕННОМ КОДЕ
RAW format – без definition line

NiceProt view

Базы данных
Exp.Method Proteins Nucleic Acids Protein/NA Complexes
Other Total
На 22.02.2011
PDB

Базы данных OCA

SCOP - Structural Classification Of Proteins
• Организована в соответствии со структурными семействами белков.
• Иерархическая система.

NCBI - Entrez
• Entrez - поисковая машина для баз NCBI.
• Поиск начинается с выбора адекватной области для поикса (Nucleotide, белки).
• Можно использовать определители полей, логические операторы, условия и т.д.

NCBI - Entrez
Ограничения:

SRS (Sequence Retrieval System).
• Исталлирована на множестве серверов.
• Имеет связи со многими базами данных.
• Предоставляет множество инструментов и служб для анализа.
• Позволяет сохранить результаты работы и анализа и продолжить работу локально.

SRSРабочая среда
Выбор базы данных
Заполнение формы запроса
Страница результатов

Полные базы данных
Большие базы данных ДНК, РНК и белков.
Примеры: GenBank, EMBL, swissprot.
Имеется обмен информацией между базами

NCBI (National center for biotechnology information)
NCBI
PubMed
Books
OMIM
Nucleotides
Proteins
GenomesTaxonomy
Structure
Domains
Exp’ profiles

NCBI - GenBank
• GenBank: открытая база данных нуклеотидных и аминокислотных последовательностей
• Источники информации: 1. Прямая подача от исследователей.
2. Литература.
3. Центры исследований последовательностей (Sanger, TIgr)
4. Обмен с другими базами (swiss-prot, PDB).

NCBI - GenBank
• GenBank поделён на подбазы:
1. Organism specific (Human, Bacteria, etc).
2. Molecule specific (DNA, RNA, protein).
3. Sequence specific (Genome, mRNA, ESTs etc).

EMBL
Параллельная GenBank база данных.

Swiss prot
База данных белков:
1. Очень хорошо аннотированная.
2. Отсутствует избыточность.
3. Имеются перекрёстные ссылки.
4. ID для нескольких связанных файлов белков

Организмоориентированные базы

Молекулоспецифические базы
• Базы даных, ориентированные на группы молекул
GtRDB: The Genomic tRNA Database

PDB – Protein Data Bank
• Главная база данных 3D структур белков
• Включает порядка 23,000 белковых структур.
• Белки организованы в группы, семейства и т.д.
• Имеет порядка 5600 точных структур.

SCOP - Structural Classification Of Proteins
• Организована в соответствии со структурными семействами белков.
• Иерархическая система.

Текстовый поиск
Общие принципы:
1. Все главные базы предоставляют удобные средства для тектового поиска.
2. Поиск по ключевым словам или полям.
3. Одновременный поиск в нескольких базах.
4. Дополнительные условия (дата, длина и т.д.).

NCBI - Entrez
• Entrez - поисковая машина для баз NCBI.
• Поиск начинается с выбора адекватной области для поикса (Nucleotide, белки).
• Можно использовать определители полей, логические операторы, условия и т.д.

NCBI - Entrez
Ограничения:

Эффективность поискаЭффективность: время и адекватные результаты!

SRS (Sequence Retrieval System).
• Исталлирована на множестве серверов.
• Имеет связи со многими базами данных.
• Предоставляет множество инструментов и служб для анализа.
• Позволяет сохранить результаты работы и анализа и продолжить работу локально.

SRSРабочая среда
Выбор базы данных
Заполнение формы запроса
Страница результатов

Проект ENCODEhttp://genome.ucsc.edu/

Анализ белковой последовательности
Анализ только аминокислотную последовательность (первичную структуру) белка без боковых цепей.
Предсказание физико-химических параметров белка Предсказание продуктов расщепления протеазами Гидрофобные, гидрофильные участки: например,
трансмембранные сегменты Пост-трансляционные модификации Функциональные домены, принадлежность к функциональным
семействам Фолдинг Клеточная локализация

Анализ белковой последовательности
The ExPASy server – протеомика http://www.expasy.ch/tools/#primary
The Swiss EMBnet – coiled-coil участки, выравнивания и др.http://www.ch.embnet.org
The CBS Prediction Servers – локализация, пост-трансляционные модификации…
http://www.cbs.dtu.dk/services

ProtParam - предсказание физико-химических параметров белка

ProtParamМолекулярный весАминокислотный составExtinction coefficient – коэффициент поглощения
(280 nm) Instability (менее 40 – хорошо) – нестабильность в
эксперименте (test tube, статистика дипептидов)Half-life (yeast in vivo, mammalian reticulocytes in
vitro, Escherichia coli in vivo) Алифатический индексGrand average of hydropathicity (GRAVY)
гидрофильность – (-), гидрофобность – (+)

Compute pI/Mw

PeptideMass

PeptideMass - output

PeptideCutter

PeptideCutter - output

PeptideCutter - output

Метод скользящего окнаАнализируется последовательность в несколько аминокислот,
параметр усредняется по окну. Значение приписывается средней аминокислоте. Output – график
Seq. LQAPVLPSDLLSWSCVGAVGILALVSFTCV <---*---> Window 1 <---*---> Window 2 <---*---> Window 3
Размер окна должен соответствовать характерному размеру анализируемого свойства (для ТМ – 19!)
Методы, основанные на технике скользящего окна, как правило, не интерпретируют результаты. При интерпретации важно: Учитывать только очень четко выраженные сигналы Не зависящие от параметров программы – размера окна, конкретного метода и т.п.

Предсказание трансмембранных сегментов: ProtScale
56 аминокислотных шкал (с литературными ссылками),скользящее окно -> выбор ширины окна

ProtScale - output

Более сложное предсказание трансмембранных сегментов: TMHMM
Transmembrane beta barrel prediction: PROFtmb (http://rostlab.org/services/proftmb ); PRED-TMBB (http://biophysics.biol.uoa.gr/PRED-TMBB/); TBBPred (http://www.imtech.res.in/raghava/tbbpred )

TMHMM - результаты
TMHMM предсказывает сегменты, а также топологию межсегментных участков
Находит только 7! TMs

Домены• Домен – независимая глобулярная единица в
белке. Более функционально – часть белка, обладающая активностью (если отрезать, например). Как правило, каждый домен играет свою роль в функции белка (связывает ион или ДНК, содержит активный сайт и т.п.)
• Только небольшая часть известных доменов была изучена экспериментально, остальные описаны как сходные части гомологичных белков
• Очень сложно четко определить домен и его границы => существует много подходов и различных доменных коллекций. Какую выбрать?

История коллекций доменов1980ые – PROSITE: ручная выборка
паттернов в белках, определяющих функцию1987 – доменный профайл (Gribskov):
position specific scoring schema – это вероятность для каждой аминокислоты находиться в данной позиции домена
начало 1990х – BLOCKs, PRINTs, Prodom… PfamA – коллекция профайлов,
курированная вручную (сейчас также использует HMM)

Cерверы для поиска доменов InterProScan
http://www.ebi.ac.uk/InterProScanCD (Conserved Domain) server (NCBI)
http://www.ncbi.nlm.nih.gov/Structure/cdd/wrpsb.cgiPfscan
http://hits.isb-sib.ch/cgi-bin/PFSCANDomac http://www.bioinfotool.org/domac.htmlScooby http://www.ibi.vu.nl/programs/scoobywww/Dompro http://www.ics.uci.edu/~baldig/domain.html

InterPro Database
.

InterPro
InterPro is a database of protein families, domains and functional sites in which identifiable features found in known proteins can be applied to unknown protein sequences.
Классификация базируется на первичных классификациях целого ряда баз данных функциональных доменов и семейств, объединяет всю доступную информацию
С 2001 года – Release 18.0: 75.6% UniProt

Как это происходит
Каждое InterPro семейство объединяет первичные семейства других баз данных, описывающие один и тот же домен; включает все белки, принадлежащие хотя бы одной из первичных баз. Документация IP семейства подробно описывает функцию и структуру соответствующей белковой подписи.

Поиск доменов: InterProScan

InterProScan - результаты

Table View

CD server
Input - Accession number, gi или последовательность в FASTA формате

CD server – output
Красный – SMART, синий – Pfam, зеленый – COGsРваные концы указывают на неполные домены!!!!Курсор в графической части – краткое описание функции домена

CDART – поиск белков с аналогичной доменной структурой

Pfscan
Как правило, работает несколько минут

Pfscan - output Особенности вывода Pfscan
• Схема – легенда, как всегда под рисунком
• За легендой следует таблица с локализацией доменов
• Далее расшифровка каждого хита – с оценкой вероятности: ? или !
• Затем следует графическая схема для каждого хита и scores (высокий score = хороший хит)

Structure Classification Databases
3D structural similarities (~70%):• SCOP (MRC Cambridge) • CATH (University College, London) • Dali FSSP (EBI, Cambridge)• 3 Dee (EBI, Cambridge)
FOLD recognition: • 3D-pssm • TOPITS (EMBL) • UCLA-DOE Structre Prediction Server (UCLA) • 123D • UCSC HMM (UCSC) • FAS (Burnham Institute) • UCLA-DOE Fold-Recognition Benchmark Home Page

SCOP-Structural Classification of Proteins
• База данных содержит структурную и эволюционную информацию о взаимосвязях белков с известными структурами.
• Классификация белков отражает структурные и эволюционные отношения.
• Многоуровневая иерархия – семейство, суперсемейство и фолд.
• Ручное инспектирование.

Superfamily: Probable common evolutionary originБелки, имеющие низкую идентичность последовательностей, но чьи структурные и функциональные особенности позволяют предположить наличие общего предка, могут быть объединены в суперсемейства. Например, актин, the ATPase domain белков теплового шока и гексакиназы образуют суперсемейство
Fold: Major structural similarityОбщий фолд – одинаковая организация вторичной струкруры, с похожим пространственным расположением и с похожими соединениями.
Белки с одинаковым фолдом зачастую имеют концевые элементы вторичной структуры , изгибы и повороты различных разметов и конформаций (до половины всей структуры).
Белки, объединённые одним фолдом, могут не иметь общего предка (химия, физика упаковка и топология)
SCOP

SCOP
Family: Clear evolutionarily relationshipБелки, сгруппированные в семейство, тесно связаны эволюционно. Это значит, что парное выравнивание показывает 30% и выше.
Иногда похожие функция и структура показывают наличие общего предка и при отсутствии высокой идентичности последовательностей; например, многие глобины образуют семейство, хотя некоторые из них имеют идентичность 1D ~ 15%.

Archetype Structures of Domains

Поиск по SCOP

SCOP

CATH (Brookhaven protein databank )• Class, Architecture, Topology, Homology database – иерархическая
классификация доменов структур белков
Формируется автоматически, но инспектируется вручную

CATH
Class, C-level
– Класс определяется в соответствии с набором и упаковкой
вторичной структуры. Он может быть присвоен как
автоматически (90% of the known structures), так и вручную.
– 3 главных класса:
преимущественно-alpha
преимущественно-beta
alpha-beta (alpha/beta and alpha+beta)
Четвертый класс – белки, содержащие домены без
выраженной структуры..

CATHArchitecture, A-level
• Описывает общий вид доменной структуры, определяемой как ориентация элементов вторичной структуры, но без учета их соединений.
• Присваивается вручную (используя простое описание структуры).
• Разрабатываются способы автоматизации этого процесса.
Topology (fold family), T-level
• Структуры группируются в зависимости как от общего вида, так и от соединений элементов вторичной структуры. Алгоритмы сравнения структур.

CATH
Homologous superfamily, H-level
• Этот уровень объединяет белки, которые, по-видимому, имеют общего
предка (гомологи).
• Похожесть и идентичнсть – сначала по сравнению последовательностей,
затем – сравнение структур.
Sequence families, S-level
• Структуры в каждом H-level затем группируются по идентичности последовательностей.
• Домены, объединенные в семейства последовательностей, имеют идентичноcть 1D >35% , что показывает похожие структуру и функции.

SCOP / CATH SCOP CATH
class classarchitecture
fold topologyhomologous superfamily
superfamilyfamily sequence familydomain domain
CATH - преимущественно структурная классификация,SCOP - эволюционные взаимосвязи CATH - один класс, представляющий смешанную α-β структуруSCOP - 2 класса:
α/β: beta структуры параллельны, образуют βαβ мотивыα+β: alpha и beta структуры присутствуют в различных частях протеина

SCOP / CATH -> DALISCOP & CATHSCOP & CATH
• Иерахические, базирующиеся на абстракциях
• Создаются (частично) и курируются вручную экспертами
Presentation of results of the classification, where the methods that underlie the classification remain internal
Structure comparison

DALI
anti parallel barrel
meander
More information about DALI
Touring protein fold space with Dali/FSSP: Liisa Holm and Chris Sander
Comparing protein structures in 3D

DALI
• The FSSP database (Fold classification based on Structure-Structure alignment of Proteins) базируется на all-against-all сравнении 3D структур белков в Protein Data Bank (PDB).
Классификация и выравнивание структур автоматически поддерживается и обновляется сервисом Dali search engine.
Dali Domain Dictionary
• Структурные домены выделяются автоматически. Каждый получает Domain Classification number.

DALI
Fold types
• Типы фолдов – кластеры структур в пространстве фолдов с средним парным Z-scores (by Dali) выше 2.
Высокий Z-score соответствует структурам с близкой архитектурой.

DALI • Базируется на выравненных 2D матрицах внутримолекулярных дистанций
• Считает лучший subset соответствующих аминокислот в двух белках – максимальная похожесть 2D матриц дистанций
• Поиск по всем возможным выравниваниям остатков – Monte-Carlo и branch-and-bound algorithms
An intra-molecular distance plot for myoglobin

Pfam Database
Pfam – коллекция результатов множественного выравнивания последовательностей и HMM, содержащая большое количество доменов и семейств белков. Для каждого семейства в Pfam:
•Просмотреть результаты MSA
•Увидеть архитектуру доменов
•Распределение по видам
•Перекрестные ссылки
•Получить известные 3D структуры
•Pfam can be accessed directly or from the PDB description.

Homstrad Database •HOMologous STRucture Alignment Database
•Предоставлляет выровненные 3D структуры гомологичных белков.
•Homstrad - структурный эквиваллент Pfam. Вначале структуры белков поступают из PDB, кандидаты семейств традиционно идентифицируются поиском по Pfam. Используются определения доменов из SCOP и информация о белках собирается из SwissProt, Pfam and Interpro.
• Аннотирование – в программе Joy, которая предоставляет следующую информацию:
• Тип вторичной структуры
• Относительную доступность боковых цепей
• Наличие водородных связей между амидом и карбонилом
• Дисульфидные связи
•Положительные phi торзионные углы

PClass Database
Инструмент для классификации, базирующийся на иерархии 600 белков-представителей из PDB. Структурное выравнивание 600 структур было выполнено при помощи алгоритма 3dSearch.

3D Structure Validation Теория: Белки – молекулы несложные:
- Линейная структура цепей. - Только 20 различных аминокислот.
На практике: Мы не понимаем в деталях механизм сворачивания белковых структур.
Единственные «силы», используемые для уточнения, «улучшения» новой структуры – это данные измерений и некоторые факты, присущие для ВСЕХ молекул
В общем случае используемая информация недостаточна для распознавания уникальной структуры.
Значительная часть работы по уточнению структуры – взгляд эксперта и ручные корректировки.
Белки содержат тысячи атомов и невозможно постоянно выполнять ручные корректировки.
Это – источник неправильных структур и «слабых мест» в глобьально верных структурах.

Оценка качества стереохимии
«Исходя исключительно из координат атомов, есть ли методы, дающие оценку общему стереохимическому качеству структуры? Такие методы могут оказаться полезными для идентификации неправильно построенных структур во время циклов уточнения, или после завершения моделирования. Большинство PDB файлов содержат некоторую авторскую информацию о параметрах кристаллографии. В то же время эта информация обычно короткая, количественная не готовая к machine-reading и не предоставляет качественных оценок надёжности предоставленной структуры».
Morris et al (PROTEINS: Structure, Function, and Genetics 12:345-364, 1992)
Очень полезная информация для верификации посылаемой структуры белка
Introduction to structure verificationhttp://www.cmbi.kun.nl/gv/pdbreport/checkhelp/

Мы можем использовать эту PDB структуру?
Год публикации
Разрешение X-ray структуры
Проблемные остатки (отсутствующие аминокислоты/атомы/боковые цепи)
Растворитель/вода
Какая цель?

Важные параметры Judging the Quality of Macromolecular Models
http://www.cmbi.kun.nl/gv/pdbreport/checkhelp/
R-factor: величина, показывающая согласие между кристаллографической моделью и полученными данными X-ray. Оценивая построенную модель кристаллографер рассчитывает ожидаемую интенсивность рефлексов в образце дифракции и затем сравнивает его с экспериментальными данными, содержащими измеренные позиции и интенсивности. -R-factor используется для проверки прогресса в уточнении структуры. Финальный R-factor – единая мера качества модели. Чем меньше, тем лучше.
Разрешение: В X-ray кристаллографии "2-Å model" означает, что модель учитывает дифракцию в группе одинаковых, параллельных плоскостей с атомами с промежутком в 2 Å.
Точность атомных позиций: В кристаллографии, в отличии от световой микроскопии, термин «разрешение» означает количество данных, в конечном счете используемое для определения структуры. Напротив, точность атомной позиции частично зависит от разрешения, но в большей степени зависит от качества данных – R-factor.
- Хорошие данные могут приносить атомные полиции с точностью 0.2–0.1 от заявленного разрешения.

WHAT IF WHAT IF – CMBI (Centre for Molecular and Biomolecular Informatics)
CHECK - качество структуры/модели белка
FULCHK – наиболее подробный отчёт о проверке.
Производимые проверки – от простых проверок длин связей, торзионных углов и проверок поверхности до глубокого анализа контактов и сети водородных связей.
Stand alone versions: Unix, Windows
Server: WHAT_CHECK http://www.cmbi.kun.nl/gv/whatcheck/
Может посчитать и некоторые свойства:
Атомарные дистанции, столкновения, окружения, контакты с водой, «внутренняя» вода, водородные связи…..

WHAT_IF Validation Parameters
1. Доступность боковых цепей
2. Длины связей – данные экспериментов
3. Углы связей – данные экспериментов
4. Торзионные (трёхгранные) углы, Phi/Psi (ramachandran plot) – данные экспериментов
5. Планарность боковых цепей у His, Phe, Tyr – данные экспериментов
6. Хиральность (D or L) – данные экспериментов
7. Ротамеры (χ-1 and χ-2 комбинации) - моделирование
8. Столкновения атомов – данные экспериментов
9. Абсолютное внутреннее/внешнее распределение аминокислот
10. Погруженные доноры водородов – данные экспериментов
11. Упаковка (сравнение с базами данных)
http://www.cmbi.kun.nl/~richardn/intromodelValidation.html

The PDBREPORT Database
The PDBREPORT Database http://www.cmbi.kun.nl/gv/pdbreport/
Index of all diagnostic messages http://www.cmbi.kun.nl/gv/pdbreport/pdbreport/revindex.html

WHAT_CHECK CriteriaPeptide-Pl: RMS distance of the backbone oxygen from the oxygen in similar backbone conformations found in the database, distances in the range [3..1] are mapped to [0..9]Rotamer: Probability that the sidechain rotamer (chi-1 only) is correct, probabilities in the range [0.1 .. 0.9] are mapped to [0..9]Chi-1/Chi-2: Z-score for the sidechain chi-1/chi-2 combination, Z-scores in the range probabilities in the range [-4..+4] are mapped to [0..9]Bumps: Sum of bumps per residue, distances in the range [0.1 .. 0] are mapped to [0..9].Packing 1: First packing quality Z-score, Z-scores in the range [-5..+5] are mapped to [0..9].Packing 2: Second packing quality Z-score, Z-scores in the range [-3..+3] are mapped to [0..9].In/Out: Absolute inside/outside distribution Z-score per residue, Z-scores in the range [4..2] are mapped to [0..9].H-Bonds: 9 minus number of unsatisfied hydrogen bonds, 2 is subtracted for buried backbone nitrogen, 5 for buried sidechain.Flips: Indicates flipped Asn/Gln/His sidechain, 9=OK, 0=needs flipping.

WHAT_CHECK Criteria
Access: Relative side chain accessibility, 0=buried, 9=exposed.Quality: Several quality estimators from the PDBREPORTs.0=is oh no, 9=perfect.
B-Factors: Crystallographic B-factors, the range [10..60] is mapped to [9..0]Bonds: Absolute Z-score of the largest bond deviation per residue, absolute Z-Scores in the range [5..2] are mapped to [0..9].Angles: Absolute Z-score of the largest angle deviation per residue, absolute Z-Scores in the range [5..2] are mapped to [0..9].Torsions: Average Z-score of the torsion angles per residue, Z-Scores in the range [-3..+3] are mapped to [0..9].Phi/Psi: Ramachandran Z-score per residue, Z-Scores in the range [-4..+4] are mapped to [0..9].Planarity: Z-score for the planarity of the residue sidechain, Z-Scores in the range [6..2] are mapped to [0..9].Chirality: Average absolute Z-score of the chirality deviations per residue, average absolute Z-Scores in the range [4..2] are mapped to [0..9].Backbone: Number of similar backbone conformations found in the database, numbers in the range [0..10] are mapped to [0..9]

Procheckhttp://www.biochem.ucl.ac.uk/~roman/procheck/procheck.html
Procheck – программа и сервер для проверки геометрии структуры белка.
1. Геометрия ковалентных связей
2. Планарность
3. Торзионные углы
4. Хиральность
5. Нековалентные взаимодействия
6. Водородные связи основной цепи
7. Дисульфидные мостики
8. Сравнение параметров
9. Поаминокислотный анализ

Procheck. Отчёты

PDB Validation Tools
Ad it! http://pdb.rutgers.edu/validate/
The PDB Validation Suite - набор инструментов, используемый в PDB для обработки и проверки структурных данных http://pdb.rutgers.edu/mmcif/VAL/index.html

ERRAT•ERRAT - алгоритм верификации белковых структур, который особенно подходит для оценки процесса построения и улучшения моделей в кристаллографии.
• Программа анализирует статистики нековалентных взаимодействий между атомами различных типов.
• Общая диаграмма даёт значения функции ошибки (скоринг) vs позиция9-residue окна. Путём сравнения с статистиками из очень качественных структур функция ошибки калибруется.
http://www.doe-mbi.ucla.edu/Services/Errat.html

PROVE
• PROVE: PROtein Volume Evaluation, a validation package
• PROVE - ПО для проверки качества атомарной модели макромолекулярной структуры
• Базируется на расчете атомных объемов. PROVE считает объемы атомов в макромолекуле, используя алгоритм SURVOL (SURVOL обрабатывает атомы как твёрдые сферы с определенными радиусами, зависящими от типа атома)
• Использовались высококачественные структуры для выяснения ожидаемых (средних) объемов погруженных атомов.
• Отклонения в атомных объемах оценивается в Z-score (how many standard deviations their volume is away from the mean for that atom type). Ожидаемое Z-score – 0.
http://www.ucmb.ulb.ac.be/UCMB/PROVE/

Biotech Validation Suite
Biotech Validation Suite – EMBL http://biotech.ebi.ac.uk:8400/

SAV
SAV- Structure Analysis and Verification Server http://www.doe-mbi.ucla.edu/Services/SV/
Information about the server – Before you starthttp://www.doe-mbi.ucla.edu/Services/SV/Info.php

Способы визуализации

Для чего визуализация?ALLSFERKYRVRGGTLIGGDLFDFWVGPYFVGFFGVSAIFFIFLGVSLIGYAASQGPTWDPFAISINPPDLKYGLAAPLLEGGFWQAITVCALGAFISWMLREVEISRKLGIGWHVPLAFCVPIFMFCVLQVFRPLLLGSWGHAFPYGILSHLDWVNNFGYQYLNWHYNPGHMSSVSFLFVNAMALGLHGGLILSVANPGDGDKVKTAEHENQYFRDVVGYSIGALSIHRLGLFLASNIFLTGAFGTIASGPFWTRGWPEWWGWWLDIPFWS

An Introduction to Protein Architecture By A. M. Lesk

Инструменты визуализацииRasMol / RasTop
Chime
Protein Explorer
Cn3D
YASARA
WebLab Viewer
SwissPDB Viewer
VMD
DINO

RasTop

Chime
• Plugin для Netscape Communicator и других браузеров
• Основное предназначение – позволяет визуализировать биомолекулы на компьютерах, лишённых каких-либо других инструментов для структурной биологии, работает как надстройка в браузере.
• Подобен RasMol, но не поддерживает командной строки
• Дополнительная информация доступна по
http://www.umass.edu/microbio/chime/chimehow/chimehow.htm
• Не включает дополнений и усовершенствований RasMol

Protein Explorer
• Улучшенная версия RasMol
• Графический интерфейс похож на Chime, но с более развитой системой помощи и автоматизации
• Доступен для работы новичкам, нет нужды изучать команды
• Обеспечивает углублённое изучение молекул и их свойств для профессионалов

Protein Explorer

Protein Explorer

ExPASy

SwissPdbViewer - Deep view• Инструмент, обладающий огромными возможностями
• Позволяет анализировать множественные структуры
• Позволяет изменять углы химических связей и производить перенос атомов или групп атомов
• Моделирование мутаций
• Моделирование с использованием гомологов (при подключении к удалённому серверу)
• Базовые минимизации энергии
• Карты электронных полей

YASARA
• Yet Another Scientific Artificial Application
• Молекулярная графика на очень хорошем уровне
• Моделирование и симуляции (not free!)

RasMol – Главное меню

RasMol - Дисплей

RasMol - Цвет

RasMol – Опции Сечение

RasMol – Опции Атомы H

RasMol – Опции Зеркальная поверхность

RasMol – Опции Тени

RasMol – Опции Стерео

RasMol – Опции Метки

RasMol - Экспорт

RasMol - Help

RasMol Manual
RasMol 2.6 Manual http://www.umass.edu/microbio/rasmol/getras.htm#rasmanual
RasMol 2.7 Manual http://www.rasmol.org/

RasTop • Download RasTop and install it.
• Repeat RasMol assignment 2 with RasTop.

Swiss-PDBViewer
Домашняя страница: http://ca.expasy.org/spdbv/
Руководство пользователя http://ca.expasy.org/spdbv/text/tutorial.htm.

Swiss-PDBViewer