Embed Size (px)
Citation preview

СУБД
Лекция 2
Павел Щербинин
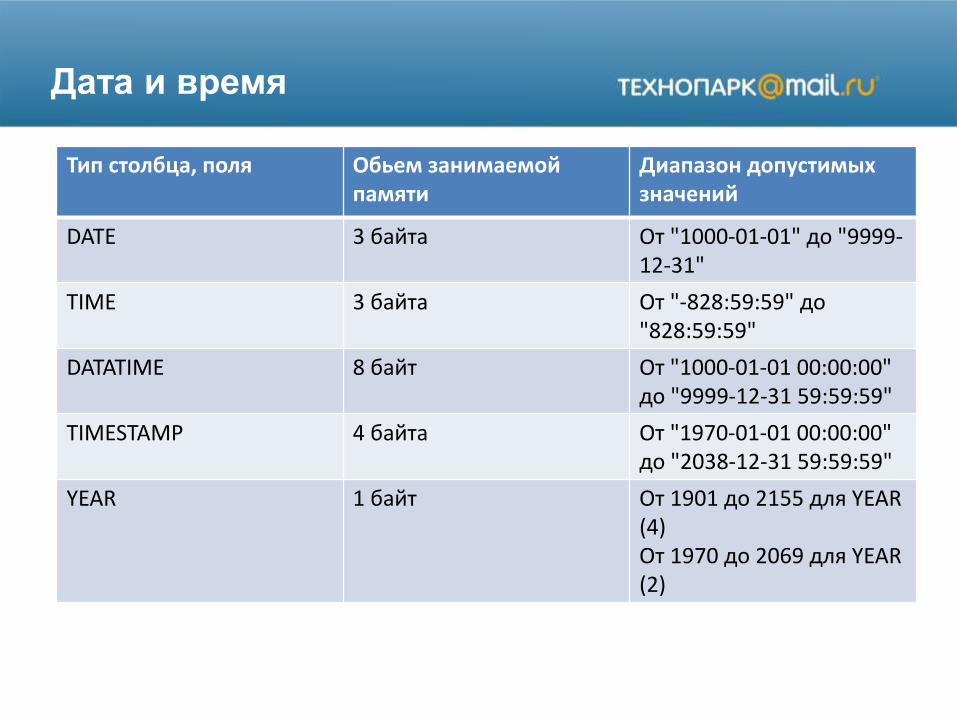
Дата и время
Тип столбца, поля Обьем занимаемой памяти
Диапазон допустимых значений
DATE 3 байта От "1000-01-01" до "9999-12-31"
TIME 3 байта От "-828:59:59" до "828:59:59"
DATATIME 8 байт От "1000-01-01 00:00:00"до "9999-12-31 59:59:59"
TIMESTAMP 4 байта От "1970-01-01 00:00:00"до "2038-12-31 59:59:59"
YEAR 1 байт От 1901 до 2155 для YEAR (4)От 1970 до 2069 для YEAR (2)

Create Table
CREATE [TEMPORARY] TABLE [IF NOT EXISTS] tbl_name
(create_definition,...)
[table_options]
[partition_options]
Or:
CREATE [TEMPORARY] TABLE [IF NOT EXISTS] tbl_name
[(create_definition,...)]
[table_options]
[partition_options]
select_statement
Or:
CREATE [TEMPORARY] TABLE [IF NOT EXISTS] tbl_name
{ LIKE old_tbl_name | (LIKE old_tbl_name) }

create_definition
create_definition:
col_name column_definition
| [CONSTRAINT [symbol]] PRIMARY KEY [index_type]
(index_col_name,...)
[index_option] ...
| {INDEX|KEY} [index_name] [index_type] (index_col_name,...)
[index_option] ...
| [CONSTRAINT [symbol]] UNIQUE [INDEX|KEY]
[index_name] [index_type] (index_col_name,...)
[index_option] ...
| {FULLTEXT|SPATIAL} [INDEX|KEY] [index_name]
(index_col_name,...)
[index_option] ...
| [CONSTRAINT [symbol]] FOREIGN KEY
[index_name] (index_col_name,...) reference_definition
| CHECK (expr)

column_definition
reference_definition
column_definition:
data_type [NOT NULL | NULL] [DEFAULT default_value]
[AUTO_INCREMENT] [UNIQUE [KEY] | [PRIMARY] KEY]
[COMMENT 'string']
[COLUMN_FORMAT {FIXED|DYNAMIC|DEFAULT}]
[STORAGE {DISK|MEMORY|DEFAULT}]
[reference_definition]
reference_definition:
REFERENCES tbl_name (index_col_name,...)
[ON DELETE reference_option]
[ON UPDATE reference_option]
reference_option:
RESTRICT | CASCADE | SET NULL | NO ACTION

Обновление кортежа в
родительском отношении
RESTRICT (Ограничить)
CASCADE (Изменить каскадно)
SET NULL (Установить в NULL)
SET DEFAULT (Установить знаечени по умолчанию)
IGNORE (Игнорировать)

Create Table Examples
CREATE TABLE shop (
article INT(4) UNSIGNED ZEROFILL DEFAULT '0000' NOT
NULL,
dealer CHAR(20) DEFAULT '‘ NOT NULL,
price DOUBLE(16, 2) DEFAULT '0.00' NOT NULL,
PRIMARY KEY(article, dealer)
)
CREATE TABLE test (
a INT NOT NULL AUTO_INCREMENT,
PRIMARY KEY (a)
) SELECT b,c FROM test2;
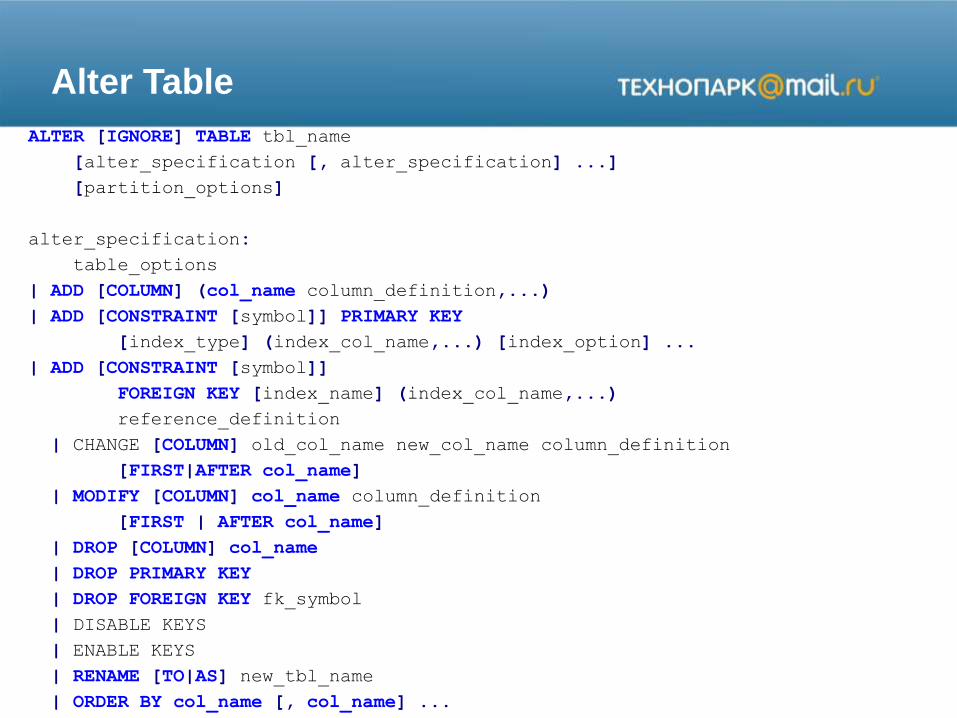
Alter Table
ALTER [IGNORE] TABLE tbl_name
[alter_specification [, alter_specification] ...]
[partition_options]
alter_specification:
table_options
| ADD [COLUMN] (col_name column_definition,...)
| ADD [CONSTRAINT [symbol]] PRIMARY KEY
[index_type] (index_col_name,...) [index_option] ...
| ADD [CONSTRAINT [symbol]]
FOREIGN KEY [index_name] (index_col_name,...)
reference_definition
| CHANGE [COLUMN] old_col_name new_col_name column_definition
[FIRST|AFTER col_name]
| MODIFY [COLUMN] col_name column_definition
[FIRST | AFTER col_name]
| DROP [COLUMN] col_name
| DROP PRIMARY KEY
| DROP FOREIGN KEY fk_symbol
| DISABLE KEYS
| ENABLE KEYS
| RENAME [TO|AS] new_tbl_name
| ORDER BY col_name [, col_name] ...

INFORMATION_SCHEMA
CHARACTER_SETS COLLATIONS COLUMNS COLUMN_PRIVILEGES ENGINES EVENTS GLOBAL_STATUS and SESSION_STATUSGLOBAL_VARIABLES and SESSION_VARIABLESKEY_COLUMN_USAGE PARTITIONS PLUGINS PROCESSLIST
PROFILING REFERENTIAL_CONSTRAINTS ROUTINES SCHEMATA SCHEMA_PRIVILEGES STATISTICS TABLES TABLE_CONSTRAINTS TABLE_PRIVILEGES TRIGGERS USER_PRIVILEGES VIEWS
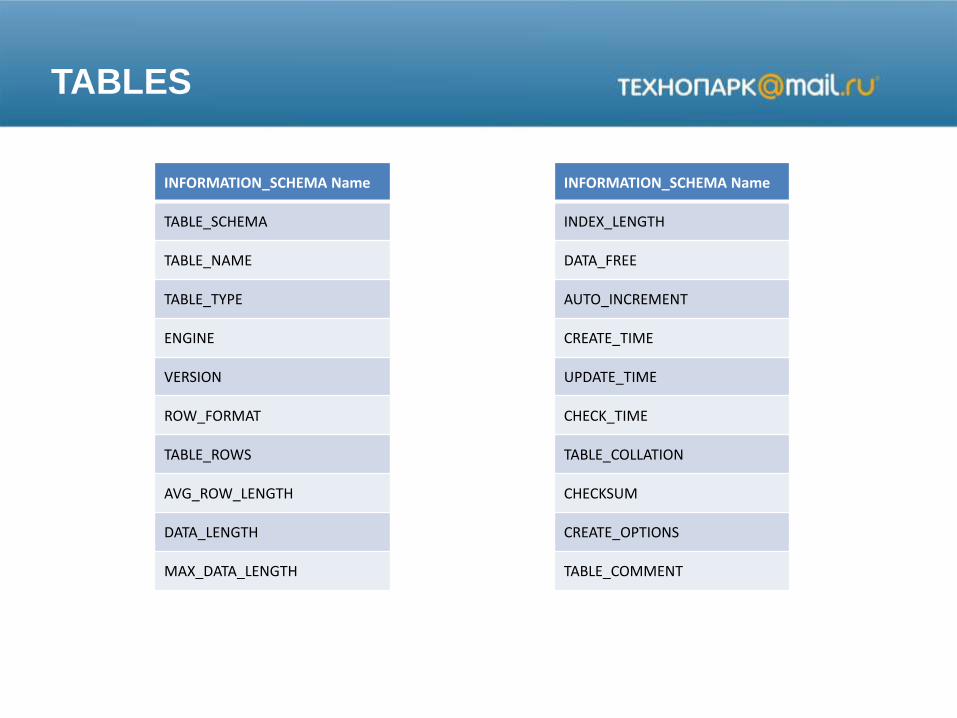
TABLES
INFORMATION_SCHEMA Name
TABLE_SCHEMA
TABLE_NAME
TABLE_TYPE
ENGINE
VERSION
ROW_FORMAT
TABLE_ROWS
AVG_ROW_LENGTH
DATA_LENGTH
MAX_DATA_LENGTH
INFORMATION_SCHEMA Name
INDEX_LENGTH
DATA_FREE
AUTO_INCREMENT
CREATE_TIME
UPDATE_TIME
CHECK_TIME
TABLE_COLLATION
CHECKSUM
CREATE_OPTIONS
TABLE_COMMENT
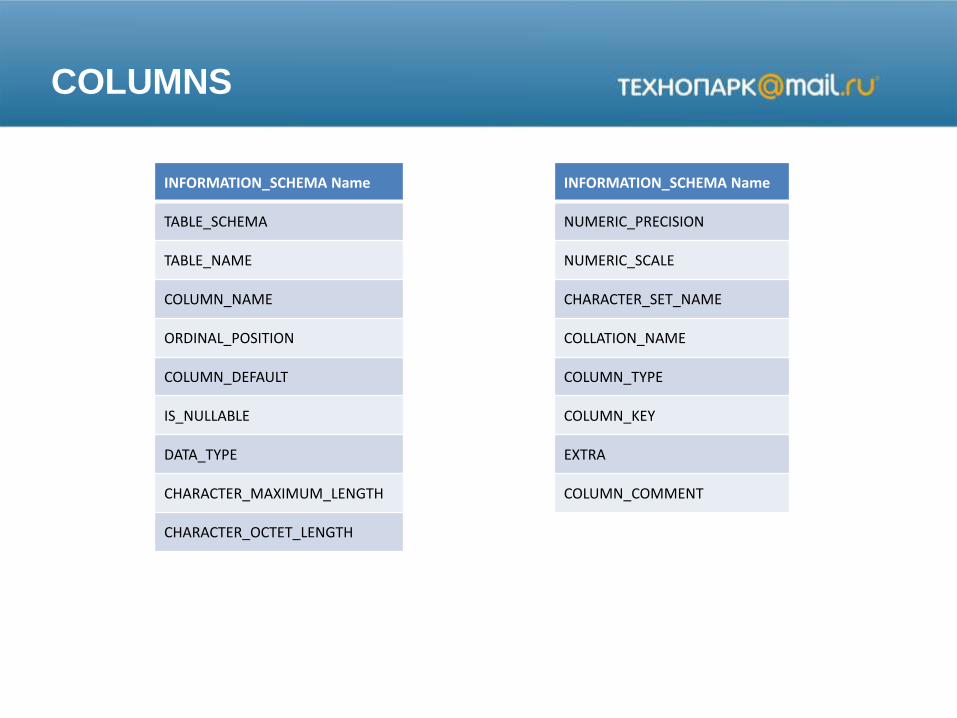
COLUMNS
INFORMATION_SCHEMA Name
TABLE_SCHEMA
TABLE_NAME
COLUMN_NAME
ORDINAL_POSITION
COLUMN_DEFAULT
IS_NULLABLE
DATA_TYPE
CHARACTER_MAXIMUM_LENGTH
CHARACTER_OCTET_LENGTH
INFORMATION_SCHEMA Name
NUMERIC_PRECISION
NUMERIC_SCALE
CHARACTER_SET_NAME
COLLATION_NAME
COLUMN_TYPE
COLUMN_KEY
EXTRA
COLUMN_COMMENT

Версионирование схемы БД
• любую версию базы данных можно обновить до любой (обычно,
самой последней) версии;
• набор SQL-запросов, реализующих миграцию между любыми двумя
версиями, можно было получить как можно быстрее и проще;
• всегда можно создать с нуля базу данных со структурой самой
последней версии
• в случае работы над разными ветками, при последующем их слиянии
ручное редактирование файлов БД было сведено к минимуму;
• откатить БД на более раннюю версию так же просто, как и обновить на
более новую
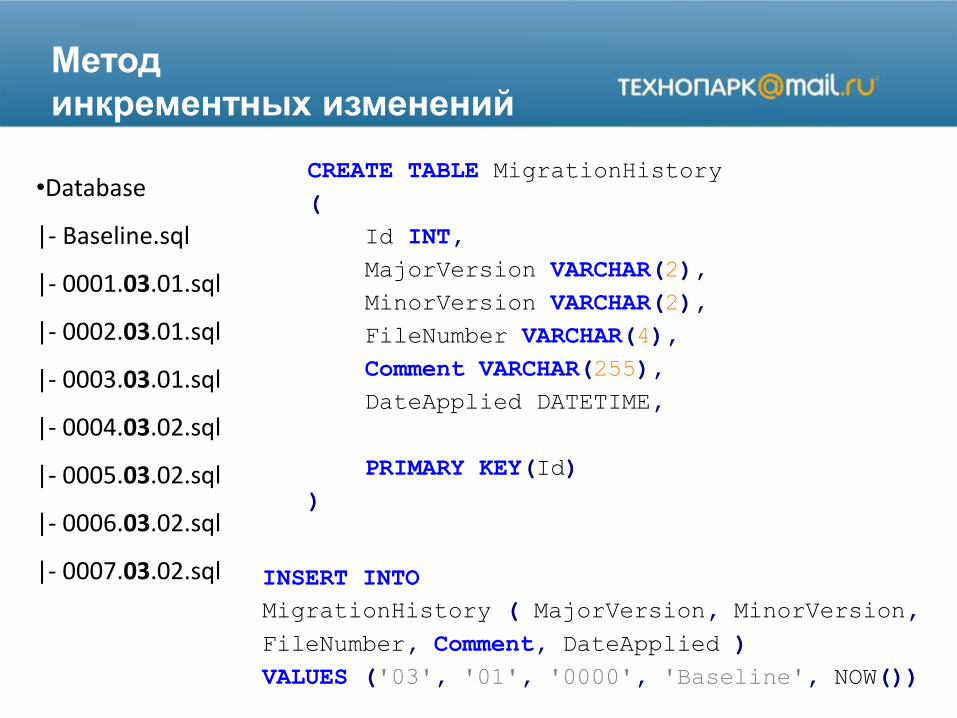
Метод
инкрементных изменений
•Database
|- Baseline.sql
|- 0001.03.01.sql
|- 0002.03.01.sql
|- 0003.03.01.sql
|- 0004.03.02.sql
|- 0005.03.02.sql
|- 0006.03.02.sql
|- 0007.03.02.sql
CREATE TABLE MigrationHistory
(
Id INT,
MajorVersion VARCHAR(2),
MinorVersion VARCHAR(2),
FileNumber VARCHAR(4),
Comment VARCHAR(255),
DateApplied DATETIME,
PRIMARY KEY(Id)
)
INSERT INTO
MigrationHistory ( MajorVersion, MinorVersion,
FileNumber, Comment, DateApplied )
VALUES ('03', '01', '0000', 'Baseline', NOW())

Метод
инкрементных изменений
• Быстрое и удобное выполнение миграции до последней версии;
• Механизм нумерации версий. Номер текущей версии хранится прямо в БД;
• Для максимального удобства нужны средства автоматизации выполнения миграций;
• Неудобно добавлять комментарии к структуре БД.;
• Возникают проблемы в процессе параллельной разработки в нескольких ветках репозитория.

Метод
идемпотентных изменений
•Database
|- 3.01
| |- Baseline.sql
| | - Changes.sql
|
| - 3.02
|- Baseline.sql
|- Changes.sql
IF NOT EXISTS
(
SELECT *
FROM information_schema.tables
WHERE table_name = 'myTable'
AND table_schema = 'myDb'
)
THEN
CREATE TABLE myTable
(
id INT(10) NOT NULL,
myField VARCHAR(255) NULL,
PRIMARY KEY(id)
);
END IF;

Метод
идемпотентных изменений
• Очень удобное выполнение миграций с любой промежуточной версии до последней — нужно всего лишь выполнить на базе данных один файл (Changes.sql);
• Потенциально возможны ситуации, в которых будут теряться данные, за этим придется следить.
• Для того, чтобы изменения были идемпотентными, нужно потратить больше времени (и кода) на их написание.

Метод уподобления структуры
БД исходному коду
Удобно наблюдать изменения в структуре между версиями при помощи средств системы контроля версий;
Как и любой исходный код, структуру БД удобно комментировать;
Для того, чтобы с нуля создать чистую базу данных последней версии, нужно выполнить всего лишь один файл;
Скрипты-миграции более надежны, чем в других методах, так как генерируются автоматически;
Мигрировать с новых версий на старые почти так же просто, как со старых на новые (проблемы могут возникнуть только с пресловутыми изменениями данных);
В случае слияния двух веток репозитория, merge структуры БД осуществляется проще, чем при использовании других подходов;

Метод уподобления структуры
БД исходному коду
Изменения данных придется хранить отдельно, и затем вручную вставлять в сгенерированные скрипты-миграции;
Вручную выполнять миграции очень неудобно, необходимы автоматизированные средства.

Выполнение запросов
1. Есть ли у вас разрешение на выполнение
выражения?
2. Есть ли у вас разрешения на доступ к необходимым
данным?
3. Правилен ли синтаксис выражения?
4. Оптимизация
5. План выполнения
6. Результирующий набор
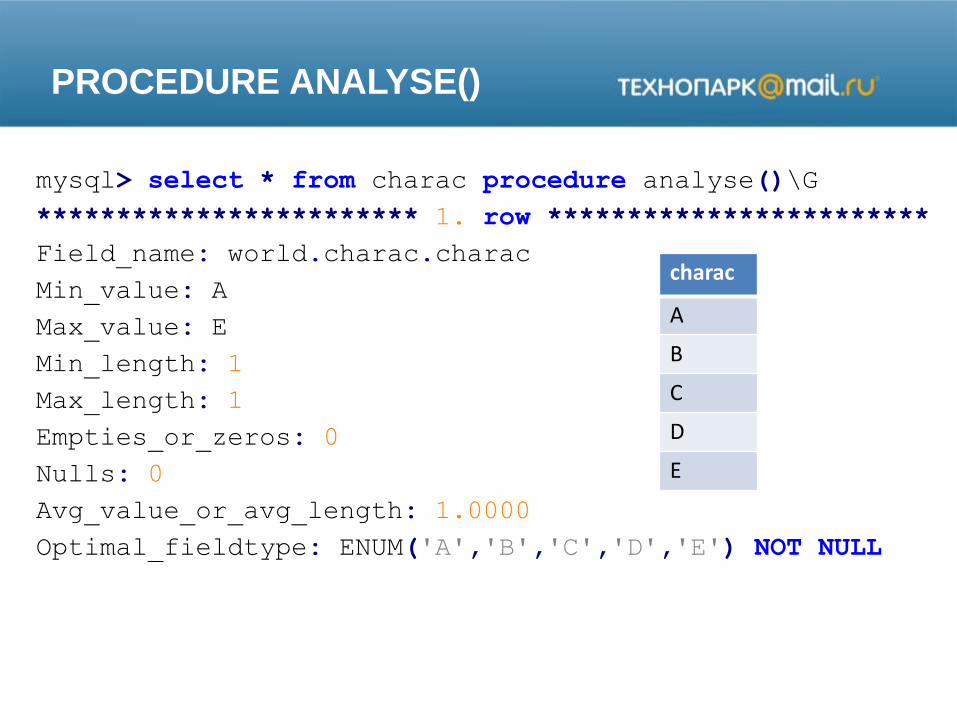
PROCEDURE ANALYSE()
charac
A
B
C
D
E
mysql> select * from charac procedure analyse()\G
************************ 1. row ************************
Field_name: world.charac.charac
Min_value: A
Max_value: E
Min_length: 1
Max_length: 1
Empties_or_zeros: 0
Nulls: 0
Avg_value_or_avg_length: 1.0000
Optimal_fieldtype: ENUM('A','B','C','D','E') NOT NULL

SELECT
SELECT
[ALL | DISTINCT | DISTINCTROW ]
[HIGH_PRIORITY]
[STRAIGHT_JOIN]
[SQL_CACHE | SQL_NO_CACHE] [SQL_CALC_FOUND_ROWS]
select_expr [, select_expr ...]
[FROM table_references
[WHERE where_condition]
[GROUP BY {col_name | expr | position}
[ASC | DESC], ... [WITH ROLLUP]]
[HAVING where_condition]
[ORDER BY {col_name | expr | position}
[ASC | DESC], ...]
[LIMIT {[offset,] row_count | row_count OFFSET
offset}]

Типы таблиц
1. Постоянные таблицы
2. Временные таблицы
3. Виртуальные таблицы (представления)

1. =
2. !=, <>
3. >, <, >=, <=
4. BETWEEN
5. IN
6. LIKE (_, %)
Фильтрация
1. OR
2. AND
3. NOT
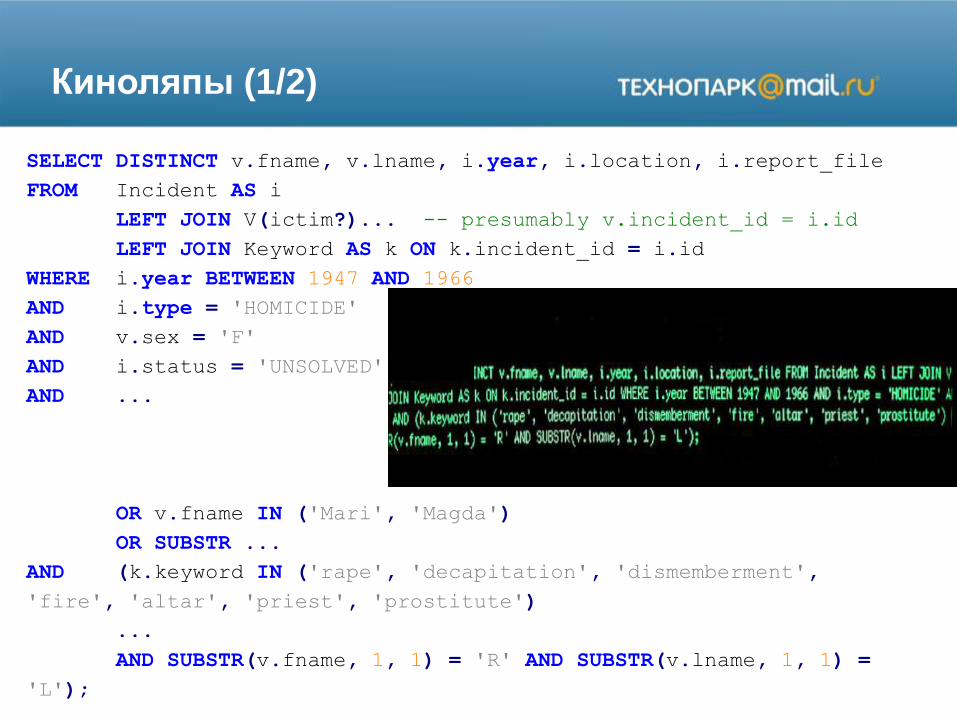
SELECT DISTINCT v.fname, v.lname, i.year, i.location, i.report_file
FROM Incident AS i
LEFT JOIN V(ictim?)... -- presumably v.incident_id = i.id
LEFT JOIN Keyword AS k ON k.incident_id = i.id
WHERE i.year BETWEEN 1947 AND 1966
AND i.type = 'HOMICIDE'
AND v.sex = 'F'
AND i.status = 'UNSOLVED'
AND ...
OR v.fname IN ('Mari', 'Magda')
OR SUBSTR ...
AND (k.keyword IN ('rape', 'decapitation', 'dismemberment',
'fire', 'altar', 'priest', 'prostitute')
...
AND SUBSTR(v.fname, 1, 1) = 'R' AND SUBSTR(v.lname, 1, 1) =
'L');
Киноляпы (1/2)
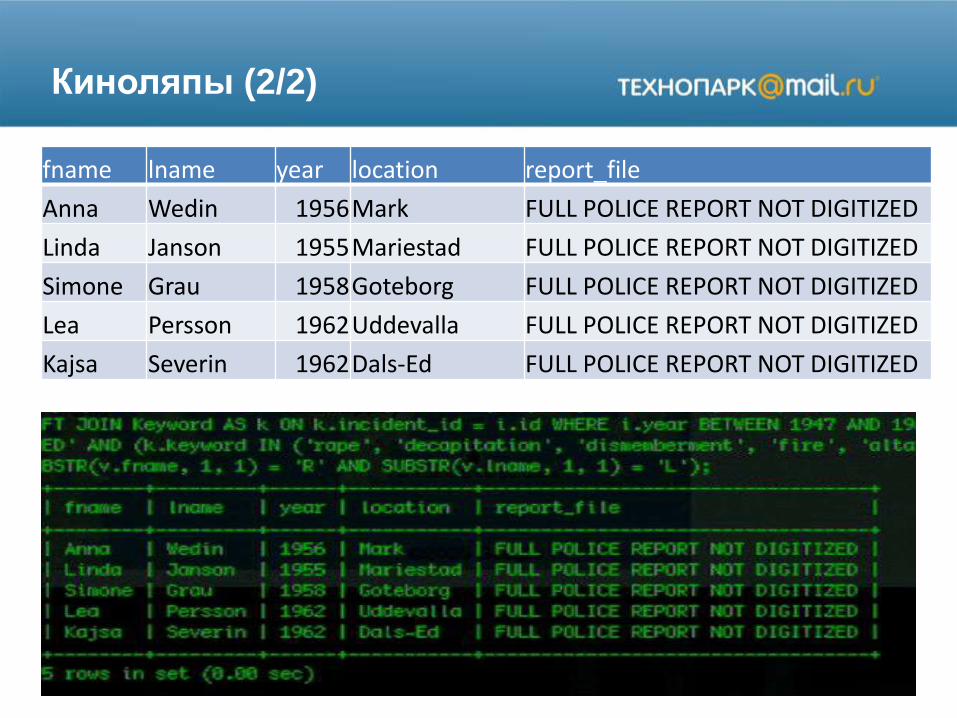
Киноляпы (2/2)
fname lname year location report_file
Anna Wedin 1956Mark FULL POLICE REPORT NOT DIGITIZED
Linda Janson 1955Mariestad FULL POLICE REPORT NOT DIGITIZED
Simone Grau 1958Goteborg FULL POLICE REPORT NOT DIGITIZED
Lea Persson 1962Uddevalla FULL POLICE REPORT NOT DIGITIZED
Kajsa Severin 1962Dals-Ed FULL POLICE REPORT NOT DIGITIZED

CASE
CASE case_value
WHEN when_value
THEN statement_list
[WHEN when_value
THEN statement_list] ...
[ELSE statement_list]
END CASE
Or:
CASE
WHEN search_condition THEN statement_list
[WHEN search_condition THEN statement_list] ...
[ELSE statement_list]
END CASE
IF (EXP1, EXP2, EXP3)

Формирование групп
1. Группировка по одному столбцу
2. Группировка по нескольким столбцам
3. Группировка по средствам выражений
4. WITH ROLLUP
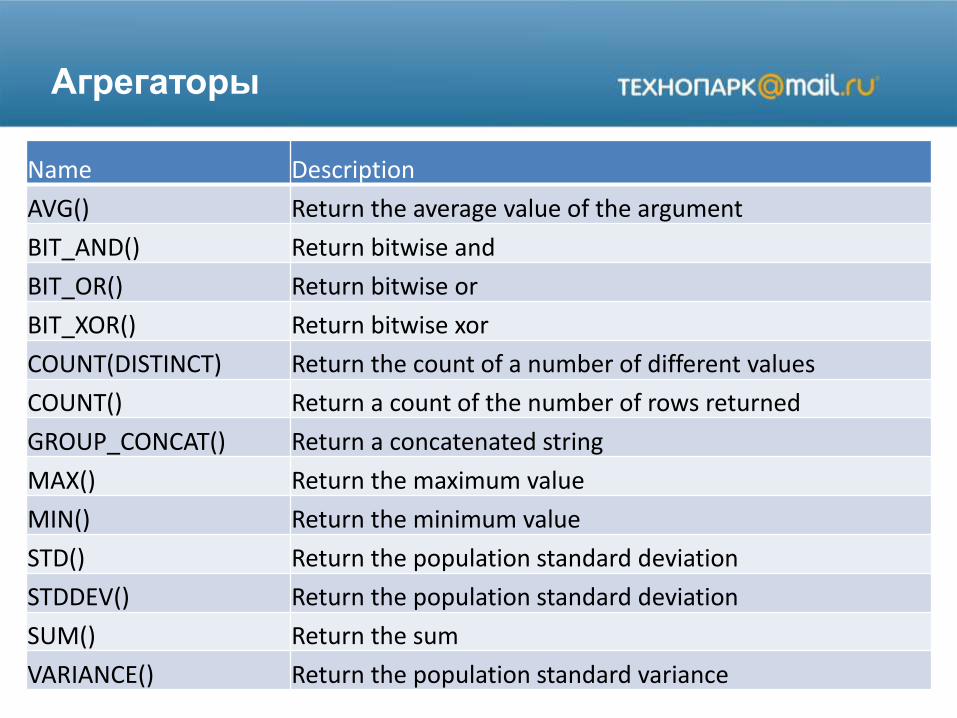
Агрегаторы
Name Description
AVG() Return the average value of the argument
BIT_AND() Return bitwise and
BIT_OR() Return bitwise or
BIT_XOR() Return bitwise xor
COUNT(DISTINCT) Return the count of a number of different values
COUNT() Return a count of the number of rows returned
GROUP_CONCAT() Return a concatenated string
MAX() Return the maximum value
MIN() Return the minimum value
STD() Return the population standard deviation
STDDEV() Return the population standard deviation
SUM() Return the sum
VARIANCE() Return the population standard variance

HAVING
SELECT
column_name, aggregate_function(column_name)
FROM
table_name
WHERE
column_name operator value
GROUP BY
column_name
HAVING
aggregate_function(column_name) operator value

ORDER BY, LIMIT
ORDER BY {col_name | expr | position}
[ASC | DESC], ...
LIMIT {[offset,] row_count | row_count OFFSET offset}

INSERT
INSERT [LOW_PRIORITY | DELAYED | HIGH_PRIORITY]
[IGNORE]
[INTO] tbl_name [(col_name,...)]
{VALUES | VALUE} ({expr | DEFAULT},...),(...),...
[ ON DUPLICATE KEY UPDATE
col_name=expr
[, col_name=expr] ... ]
Or:
INSERT [LOW_PRIORITY | DELAYED | HIGH_PRIORITY]
[IGNORE]
[INTO] tbl_name
SET col_name={expr | DEFAULT}, ...
[ ON DUPLICATE KEY UPDATE
col_name=expr
[, col_name=expr] ... ]

INSERT
INSERT [LOW_PRIORITY | HIGH_PRIORITY] [IGNORE]
[INTO] tbl_name [(col_name,...)]
SELECT ...
[ ON DUPLICATE KEY UPDATE
col_name=expr
[, col_name=expr] ... ]

INSERT
INSERT INTO tbl_temp2 (fld_id)
SELECT
tbl_temp1.fld_order_id
FROM
tbl_temp1
WHERE
tbl_temp1.fld_order_id > 100;
INSERT INTO table (a,b,c) VALUES (1,2,3)
ON DUPLICATE KEY UPDATE c=c+1;
INSERT INTO table (a,b,c) VALUES (1,2,3),(4,5,6)
ON DUPLICATE KEY UPDATE c=VALUES(a)+VALUES(b);

UPDATE
UPDATE [LOW_PRIORITY] [IGNORE] table_reference
SET col_name1={expr1|DEFAULT} [,
col_name2={expr2|DEFAULT}] ...
[WHERE where_condition]
[ORDER BY ...]
[LIMIT row_count]
Multiple-table syntax:
UPDATE [LOW_PRIORITY] [IGNORE] table_references
SET col_name1={expr1|DEFAULT} [,
col_name2={expr2|DEFAULT}] ...
[WHERE where_condition]

DELETE
DELETE [LOW_PRIORITY] [QUICK] [IGNORE] FROM tbl_name
[WHERE where_condition]
[ORDER BY ...]
[LIMIT row_count]
Multiple-table syntax:
DELETE [LOW_PRIORITY] [QUICK] [IGNORE]
tbl_name[.*] [, tbl_name[.*]] ...
FROM table_references
[WHERE where_condition]
Or:
DELETE [LOW_PRIORITY] [QUICK] [IGNORE]
FROM tbl_name[.*] [, tbl_name[.*]] ...
USING table_references
[WHERE where_condition]

DELETE
DELETE
t1, t2
FROM
t1 INNER JOIN t2
INNER JOIN t3
WHERE
t1.id=t2.id AND t2.id=t3.id;
Or:
DELETE FROM
t1, t2
USING
t1 INNER JOIN t2
INNER JOIN t3
WHERE
t1.id=t2.id AND t2.id=t3.id;

![1 БАЗЫ ДАННЫХ. 2 ПРЕДЛОЖЕНИЯ SQL ВЫБОРКА - SELECT SELECT [предикат] { * | таблица.* | [таблица.]поле_1 [AS псевдоним_1]](https://img.pdfslide.tips/doc/110x75/5a4d1b437f8b9ab0599a23dc/1-2-sql-select.jpg)









![МАТЕРИАЛЫ И ИЗДЕЛИЯ СТРОИТЕЛЬНЫЕ · 3.17 случайная выборка [(random) sample]: Одна или более единиц продукции,](https://img.pdfslide.tips/doc/110x75/5ece439b8e3c2e6dd4287511/oe-317-f.jpg)


















