Embed Size (px)
Citation preview

20
15 W
inte
r M
ach
ine L
earn
ing S
em
inar
TJS
SM
Machine Learning SeminarK-means clustering
24-1 권용훈

20
15 W
inte
r M
ach
ine L
earn
ing S
em
inar
TJS
SM
Chapter03. Unsupervised Learning

20
15 W
inte
r M
ach
ine L
earn
ing S
em
inar
TJS
SM
Unsupervised Learning
20
15 W
inte
r M
ach
ine L
earn
ing S
em
inar
TJS
SM
Unsupervised LearningBasic theory
Semi- Supervised Learning
Supervised Learning
Unspervised Learning
20
15 W
inte
r M
ach
ine L
earn
ing S
em
inar
TJS
SM
Unsupervised LearningBasic theory
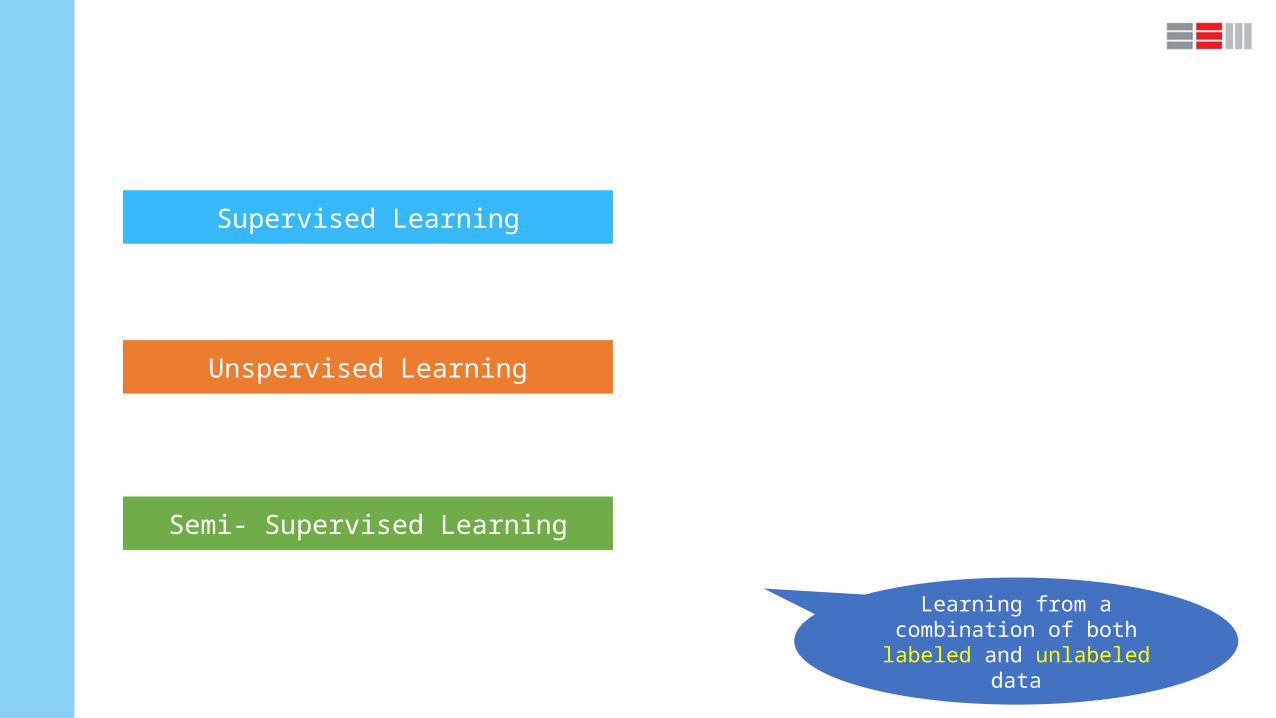
Require enough labeled training data to learn reasonably accurate classifiers
Supervised Learning
Semi- Supervised Learning
Unspervised Learning
Are employed to discover structure(cluster) in unlabeled data
Allows taking advantage of the strengths of bothLearning from a combina-
tion of both labeled and un-labeled data
20
15 W
inte
r M
ach
ine L
earn
ing S
em
inar
TJS
SM
Unsupervised LearningBasic theory
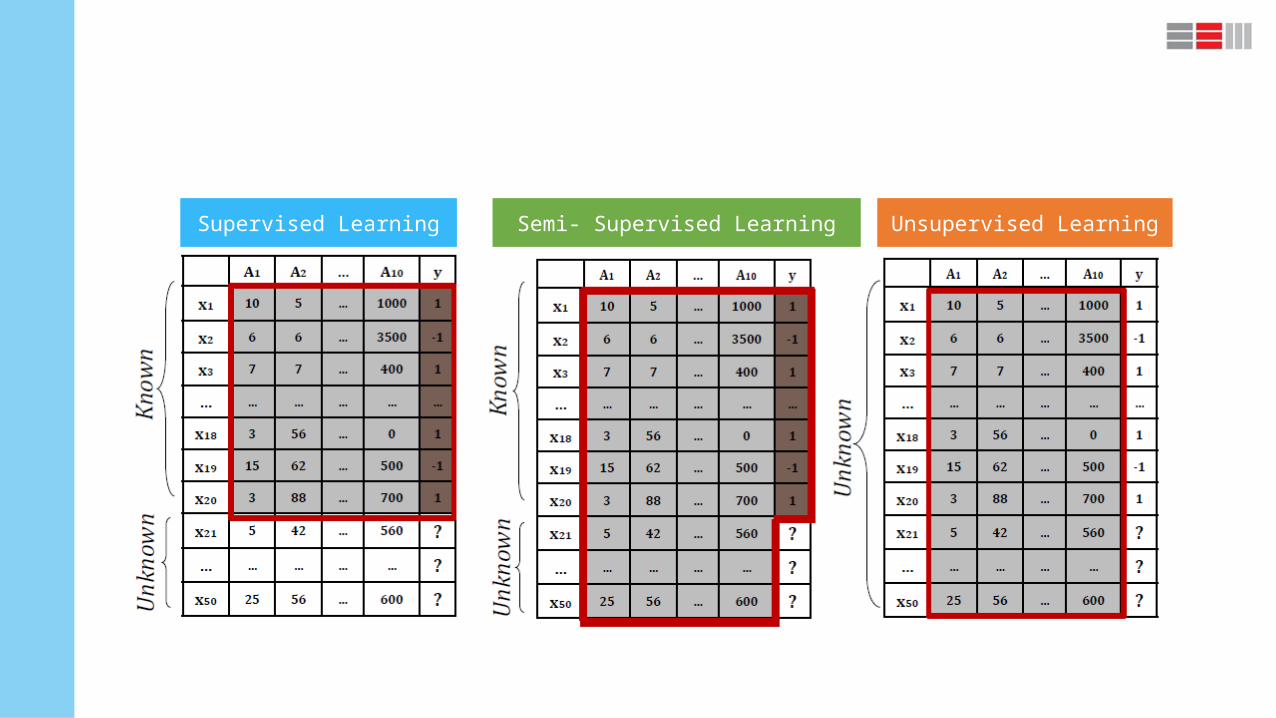
Semi- Supervised LearningSupervised Learning Unsupervised Learning
20
15 W
inte
r M
ach
ine L
earn
ing S
em
inar
TJS
SM
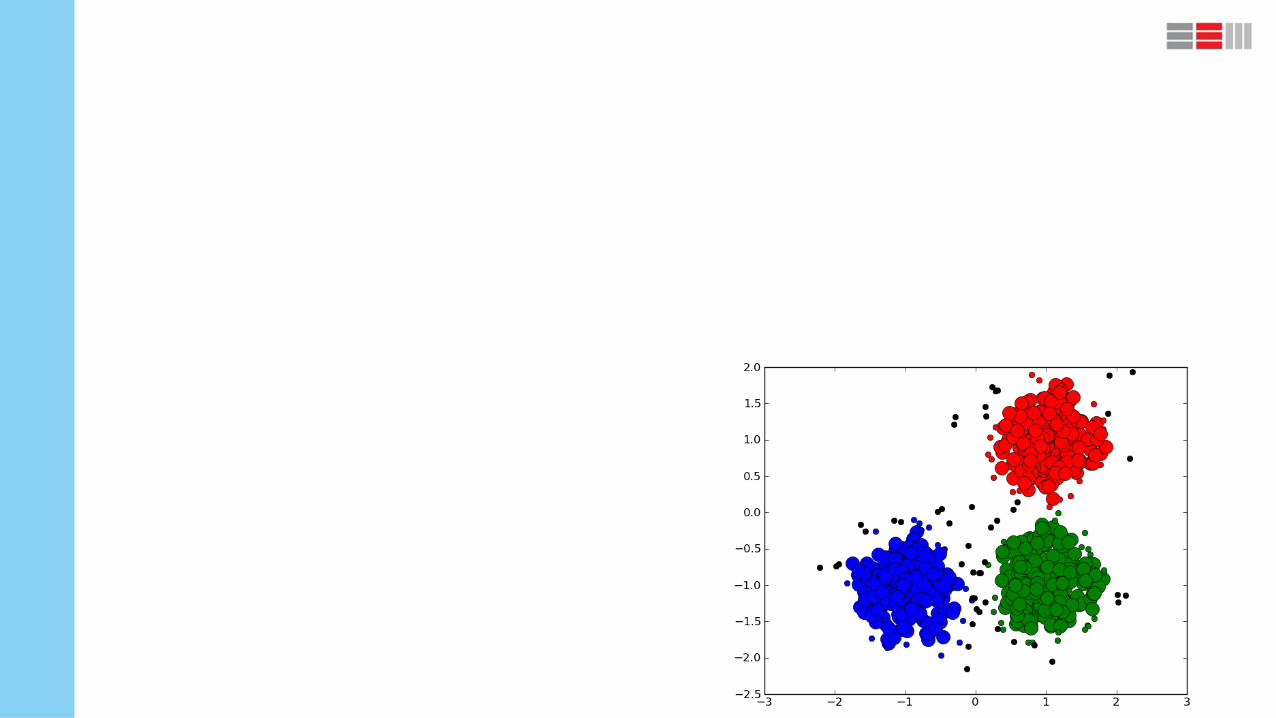
What is clustering?
Clustering is the classification of objects into different groups, or more precisely,
the partitioning of a data set into subsets (clusters), so that the data in each sub-
set share some common trait - often according to some defined distance measure
20
15 W
inte
r M
ach
ine L
earn
ing S
em
inar
TJS
SM
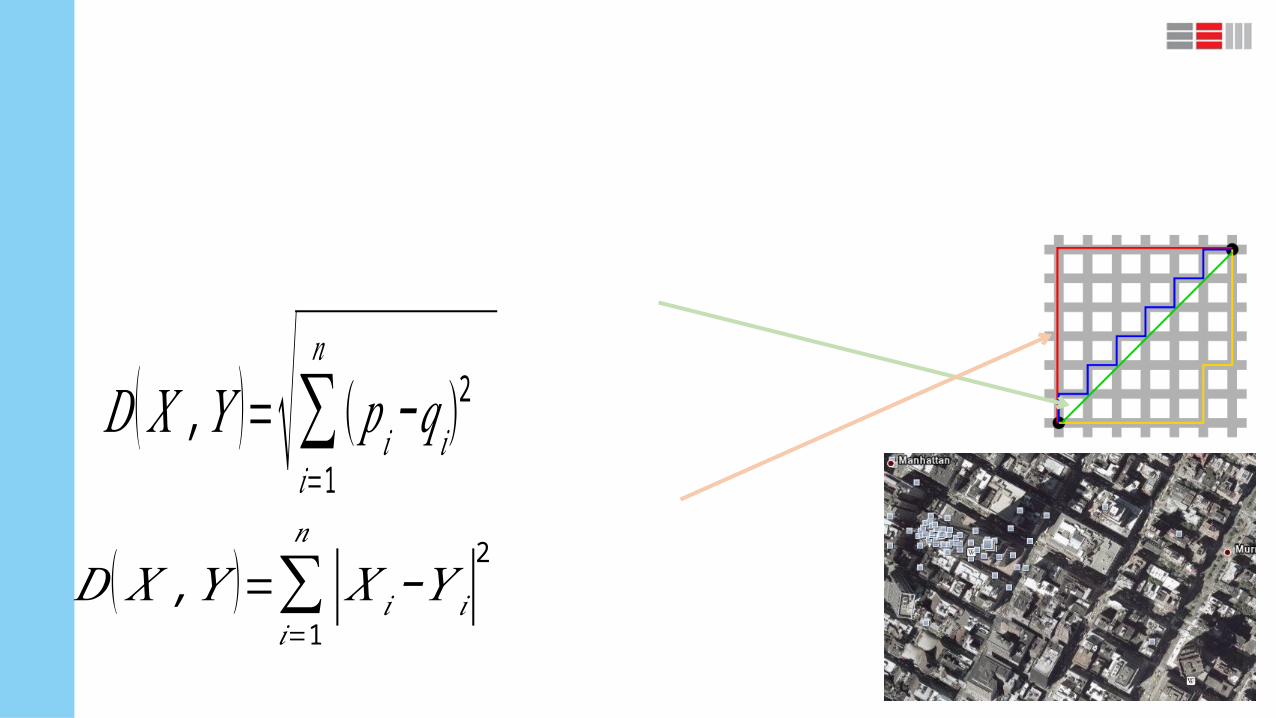
Distance measures
Distance measure will determine how the similarity of two elements is calculated and it will
influence the shape of the clusters
1. Euclidean distance(2-norm distance)P = ( and Q = ()
2. Manhattan distance(taxicab norm or 1-norm distance)
𝐷 ( 𝑋 ,𝑌 )=∑𝑖=1
𝑛
|𝑋 𝑖−𝑌 𝑖|2
𝐷 ( 𝑋 ,𝑌 )=√∑𝑖=1
𝑛
(𝑝𝑖−𝑞𝑖)2
20
15 W
inte
r M
ach
ine L
earn
ing S
em
inar
TJS
SM
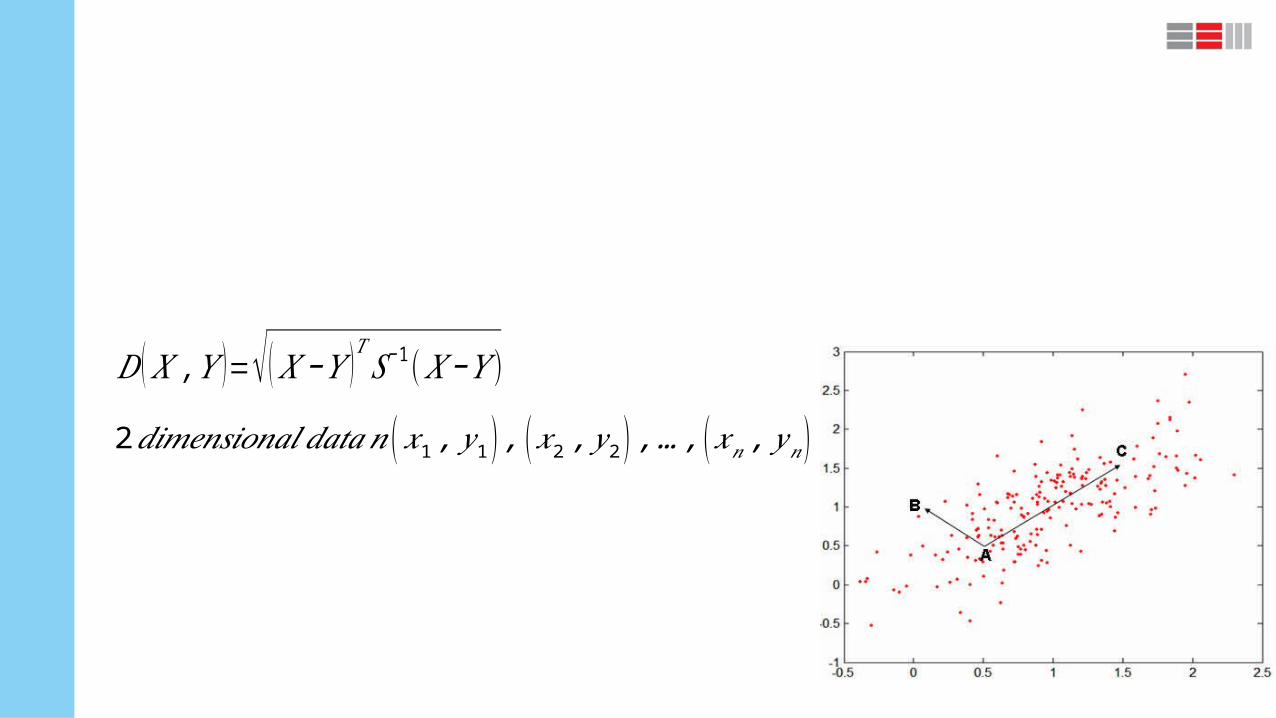
Distance measures
Distance measure will determine how the similarity of two elements is calculated and it will
influence the shape of the clusters
3. mahalanobis distance
𝐷 ( 𝑋 ,𝑌 )=√ ( 𝑋−𝑌 )𝑇 𝑆−1(𝑋 −𝑌 ), (S = covariance matrix)
2𝑑𝑖𝑚𝑒𝑛𝑠𝑖𝑜𝑛𝑎𝑙 𝑑𝑎𝑡𝑎𝑛 (𝑥1 , 𝑦1 ) , (𝑥2 , 𝑦2 ) ,…, (𝑥𝑛 , 𝑦𝑛)
20
15 W
inte
r M
ach
ine L
earn
ing S
em
inar
TJS
SM
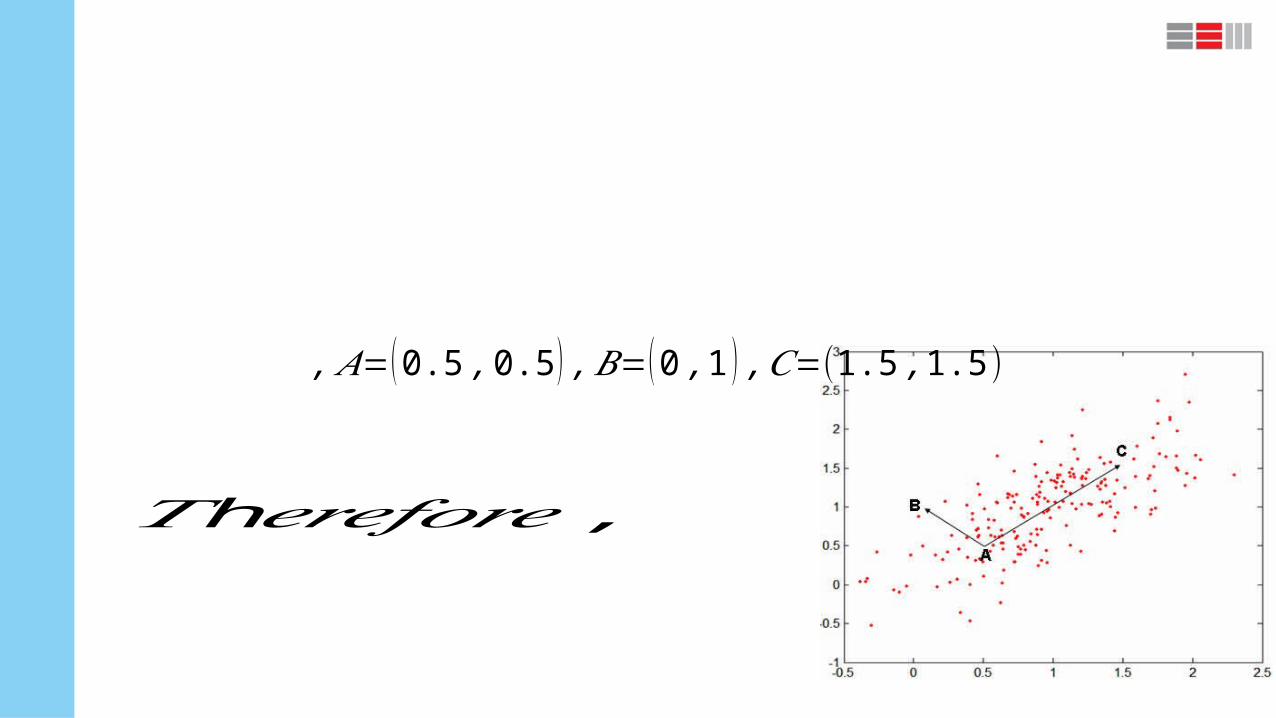
Distance measures
Distance measure will determine how the similarity of two elements is calculated and it will
influence the shape of the clusters
3. mahalanobis distance
, 𝐴=(0.5 ,0.5 ) ,𝐵=(0 ,1 ) ,𝐶=(1.5 ,1.5)
h𝑇 𝑒𝑟𝑒𝑓𝑜𝑟𝑒 ,





























