Embed Size (px)
Citation preview

15.06.17
変分ベイズ法の説明尾崎 遼
http://research.microsoft.com/en-us/um/people/cmbishop/outreach.htm

目次
概要
点推定とベイズ推定
最尤推定と EM アルゴリズム
変分ベイズ推定と VB-EM アルゴリズム
変分ベイズ推定の性質
生物学への応用

概要
変分ベイズ法• 確率モデルの潜在変数およびパラメータの事後分布を求
める手法の一種• 事後分布を近似することで計算を簡単にしている
• 因子分解可能という仮定を置く• 決定論的な手法
• MCMC などのサンプリング法は確率的

点推定とベイズ推定例えば、 というモデルで予測分布を求めるには?
• 点推定• 特定のパラメータの値 ( というモデル ) による
推定
• ベイズ推定 • パラメータの事後分布 を用いて周辺化
最尤推定や MAP 推定で点推定したパラメータの値
x の新しい予測値
推定に用いたデータ

最尤推定と EM アルゴリズム
観測変数 X と潜在変数 Z があるとき、
を最大にするパラメータ θ を求めるのが最尤推定
この最尤推定を行うための2段階の繰り返し最適化がEM アルゴリズム

最尤推定と EM アルゴリズム : 下界
方針 : 対数尤度 の下界 を最大化する
ln p(X|θ) の下界(Lower bound)
Jensen の不等式より
E step
M step

最尤推定と EM アルゴリズム : E step
のとき、下限 が最大となる
KL ダイバージェンスなので 0 以上
q が含まれていないので定数
は θ の現在の値とする

最尤推定と EM アルゴリズム : M step
エントロピー( θ がはいっていないので定数)
Q 関数(完全データ対数尤度の
q に関する期待値)
の解を新しい θ にする
は現在の Z の事後分布とする
Q 関数を最大化するために

点推定の欠点
点推定では分布がなだらかな場合や単峰でない場合に偏った推定になる
隠れ変数が1層だけのときしか適用できない
過学習
→ ベイズ推定
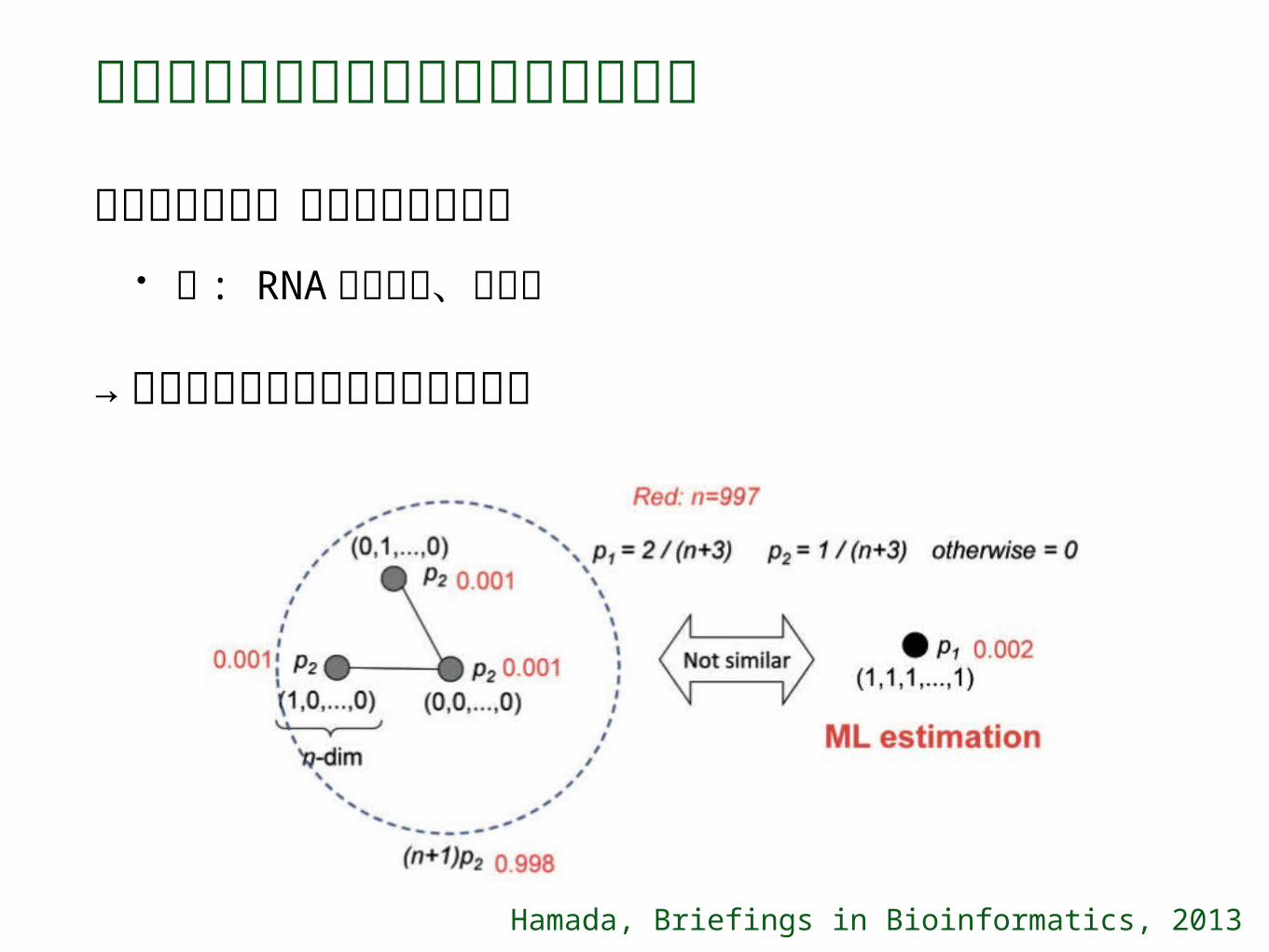
バイオインフォマティクスと推定問題
解空間が巨大・各解の尤度は微小• 例 : RNA 二次構造、系統樹
→ 点推定がよい予測につながらない
Hamada, Briefings in Bioinformatics, 2013

変分ベイズの目的と手段
最尤法• 目的 : 尤度 を最大にするパラメータを求める• 実現手段 : EM アルゴリズム(二段階の繰り返し最適化)
変分ベイズ• 目的 : 周辺尤度 ( モデルエビデンス ) を最大にする
パラメータの事後分布を求める
• 手段 : VB-EM アルゴリズム(二段階の繰り返し最適化)

変分ベイズと VB-EM アルゴリズム : 下限
Jensen の不等式より
ln p(X) の下限
最尤法の時と異なり、この下限はそのままでは最大化できない(とする)
そこで因子分解可能という仮定を置き、計算しやすい形に近似する

変分ベイズと VB-EM アルゴリズム : 因子分解
因子分解可能 (factorization) な分布によって、真の事後分布を近似します
• Z を独立な因子に分解し、潜在変数およびパラメータの同時事後分布を各因子の事後分布の積で近似する
「事後分布を求める」問題から「因子分解可能な近似分布の中でできるだけ真の事後分布に近い分布を求める」問題に変換
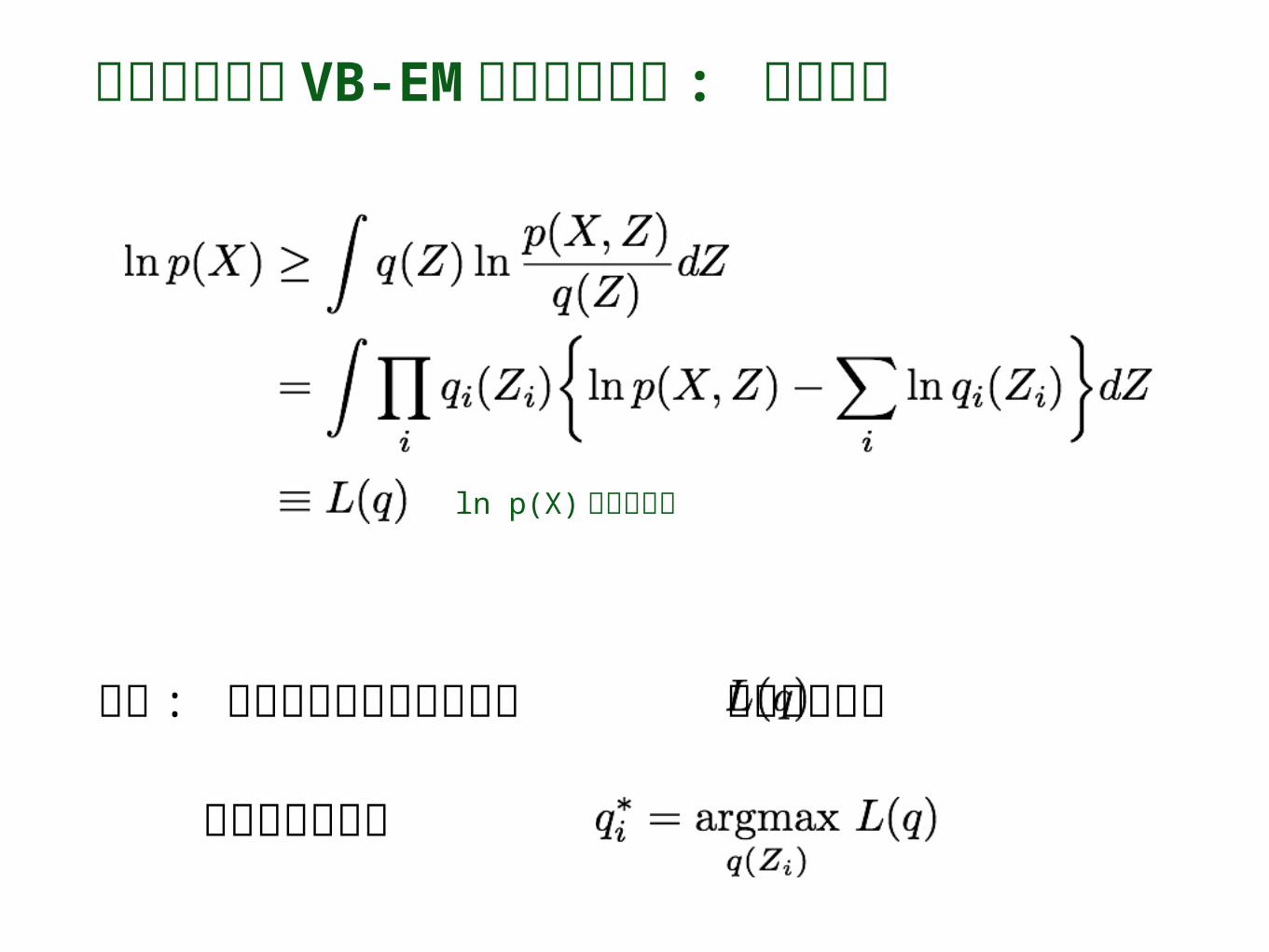
変分ベイズと VB-EM アルゴリズム : 変分下限
方針 : 対数周辺尤度の変分下限 を最大化する
各因子について
ln p(X) の変分下限

変分ベイズと VB-EM アルゴリズム : 更新式
qi は Zi の確率分布だから
j 以外の因子に関する対数同時分布の期待値
の exp() と q_j の間の KL ダイバージェンス→ これをゼロにすることが最大化につながる
変分下限 L(q) を q_j = q_j(Z_j) について整理する

変分ベイズと VB-EM アルゴリズム : 更新式
PRML 下巻の式 (10.9)
前頁の結果から、 KL ダイバージェンスをゼロにするのは以下のとき :
この式を各因子の現在の事後分布を用いて順番に計算する
j 以外の因子の現在の事後分布に関してX と Z の対数同時分布の期待値をとることに相当

変分ベイズと VB-EM アルゴリズム : 具体的なモデル
XZπ
因子分解可能という仮定により、潜在変数とパラメータの事後分布は以下のようになる

変分ベイズと VB-EM アルゴリズム : 具体的なモデル変分下限(最大化する対象)を計算していく
π の事後分布が事前分布と離れないようにする制約項とみなせる→ 過学習を防いでいる
π の事前分布を導入せずに π の点推定を行えば、最尤推定( EM アルゴリズム)と同じになる(ある θ の値でのみ分布関数のクラスを仮定すると考えてもよい)

変分ベイズと VB-EM アルゴリズム
変分 E step
変分 M step潜在変数の現在の事後分布を用いてパラメータの事後分布を改良する
パラメータの現在の事後分布を用いて潜在変数の事後分布を改良する
この式
or変分下限を具体的に計算しパラメータおよび潜在変数について最適化する
を解く
更新式の導出方法

まとめ最尤法 変分ベイズ
与えられているもの 同時分布 p(X,Z|θ) 同時分布 p(X,Z)
目的 対数尤度 ln p(X|θ) を最大にするパラメータを求める
対数周辺尤度 ( =モデルエビデンス ) ln p(X) を最大にするパラメータの事後分布
を求める
目的関数の分解 ln(X|θ)= L(q, θ) + KL(q||p) ln(X) = L(q) + KL(q||p)
目的の再定義 下界 L(q, θ) の q(Z) と θ に関する最大化 変分下限 L(q) の q(Z) に関する最大化
手続き EM アルゴリズムによる繰り返し最適化 VB-EM アルゴリズムによる繰り返し最適化
潜在変数に関する最適化
パラメータの現在の値を用いて潜在変数の事後分布を改良する
パラメータの現在の事後分布を用いて潜在変数の事後分布を改良する
パラメータに関する最適化
潜在変数の現在の事後分布を用いてパラメタを更新する
潜在変数の現在の事後分布を用いてパラメータの事後分布を改良する
注目した因子以外の因子に関して同時分布の期待値を計算したものを新しい値 or 分布にする

参考文献
C. M. ビショップ「パターン認識と機械学習 下」 9-10 章
渡辺澄夫「ベイズ統計の理論と方法」 5 章• 平均場近似から自己無矛盾条件を導く形で説明している
佐藤一誠「トピックモデルによる統計的潜在意味解析」自然言語処理シリーズ 8 コロナ社
Daichi Mochihashi “ 自然言語処理のための変分ベイズ法”• http://www.ism.ac.jp/~daichi/paper/vb-nlp-tutorial.pdf

生物学への応用
個々の遺伝子発現の状態がいくつあるか問題• Nikaido et al., PLOS One, 2011• 混合ガウスの K の数も推定
RNA-seq による転写産物量推定問題• Nariai et al., Bioinformatics, 2013• 複雑な生成モデルの計算を容易にした
DNA断片からのハプロタイプ推定問題• Matsumoto et al., BMC Genomics, 2013• 複雑な生成モデルの計算を容易にした

余談
下界の導出方法には2通りある• Jensen の不等式を使う• 対数周辺尤度を KL divergence との和の形にする
具体的な更新式の導出方法には2通りある• 一般的な最適解の式にモデルの式を代入する• ラグランジュの未定乗数法で各パラメータについて変分
下限を最大化する

「事後分布を探すのが難しい」から始まる説明 (1)
ベイズ推定の問題の一つは事後分布の計算が困難であるということだ
代わりに、事後分布を因子分解可能という仮定を置いて近似した近似事後分布を考える
この近似事後分布 (q) をなるべく真の事後分布 (p) に近づけるために、 q と p の KL ダイバージェンスを考える

「事後分布を探すのが難しい」から始まる説明 (2)
しかし、目的関数に計算が困難である p が含まれているため、この最適化問題は計算が困難である
一方、対数周辺尤度は以下のように分解できる
左辺は q に関して一定なので、 KL の最小化問題は変分下限 L の最大化問題と同じである。そこで、変分下限の最大化を考える。

余談
EM アルゴリズムで下界、変分ベイズで下限と呼ぶ理由はよくわかりませんでした
• 原著ではどちらも lower bound となっていた

余談
「 10.4 指数分布族」の変分 E ステップと変分 M ステップの記述( p. 206 )は E と M が逆な気がする