Embed Size (px)
Citation preview

Introdução à Inferência Estatística
1. População: conjunto de indivíduos, ou itens, com pelo menos uma característica em comum.
Também será denotada por população objetivo, que é sobre a qual
desejamos obter informações e/ou fazer inferências.
Pode, ainda, ser chamada de Universo.
Será denotada por: Nu,,u,u,uU 321
iu unidades elementares, i = 1, 2, . . . , N.
N = no de elementos, ou tamanho, da população.
Exemplos: a) Residentes da cidade de São Carlos; b) Lote de peças produzido numa linha de produção de uma indústria; c) Eleitores do município de São Paulo, aptos a votar na eleição; d) Indivíduos do sexo masculino que sofrem de diabetes; etc, etc, etc ...
1.1. Amostra: subconjunto, necessariamente finito, de uma
população.
é selecionada de forma que todos os elementos da população tenham a mesma chance de serem escolhidos.
1.1.1. Planejamentos Amostrais: são esquemas para coletas de dados
numa pesquisa amostral.
Existem vários tipos de planejamentos dos quais destacaremos: Amostra Aleatória Simples – AAS
Amostra Aleatória Estratificada – AAE
Amostra Aleatória por Conglomerados – AAC

1.2. Estudo Experimental: experimento no qual um tratamento é
deliberadamente aplicado aos indivíduos (ou itens) a fim de
observar a sua resposta.
Exemplos: a) ensaios para se verificar a dureza de materiais; b) estudos caso-controle em epidemiologia; c) pesos de cobaias submetidas à diferentes dietas;
“Requer um Planejamento Experimental.”
No estudo experimental é muito importante determinar o número de elementos necessários, ou seja, o tamanho da amostra;
É importante, também, planejar adequadamente a amostra de maneira a não interferir nos resultados.
2. Levantamentos de dados: a seguir, serão apresentadas algumas situações envolvendo levantamentos de dados.
2.1. Uma amostra: sortear ao acaso n elementos de uma população para
participar da amostra. Exemplos: a) dentre os eleitores de um município, sortear uma amostra para
participar de uma pesquisa de intenção de votos; b) produzir uma amostra de peças de espuma, segundo uma específica
formulação, para serem colocadas num teste de resistência à tração.
Normalmente compara-se a amostra com um padrão já conhecido; Espera-se que a população seja homogênea (pouca variabilidade).

1
2 1 3 2 n
N
População Amostra
2.2. Duas Amostras: amostras são retiradas de uma ou duas populações.
quando dispomos de duas amostras, geralmente queremos realizar uma comparação entre as mesmas.
2.2.1. Amostras independentes: nenhum elemento da primeira amostra interfere nos da segunda.
a) dois tratamentos: tomar n elementos de uma única população e dividí-los em dois grupos, de preferência de mesmo tamanho.
(ou sortear, independentemente, duas amostras de uma mesma população)
1 1 2 2 3 n1
n1 + n2 = n
1 2
N n2
População Amostras
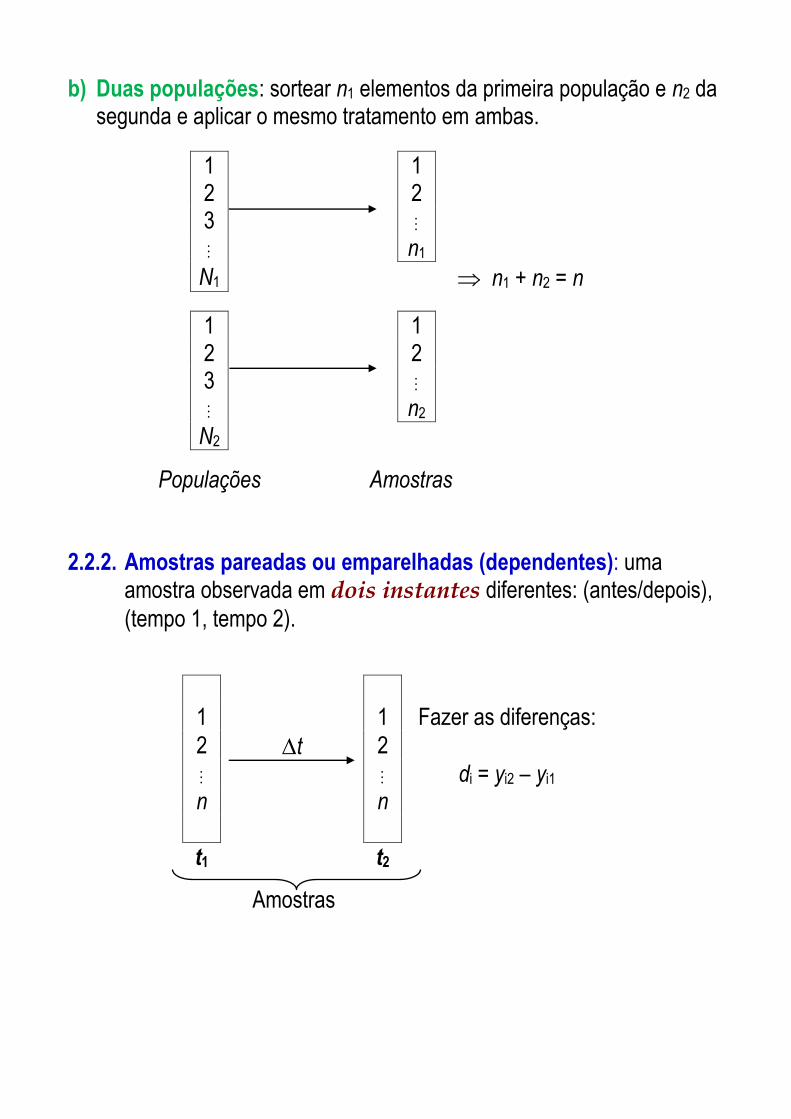
b) Duas populações: sortear n1 elementos da primeira população e n2 da segunda e aplicar o mesmo tratamento em ambas.
1 1 2 2 3
n1
N1 n1 + n2 = n
1 1 2 2 3
n2
N2
Populações Amostras
2.2.2. Amostras pareadas ou emparelhadas (dependentes): uma
amostra observada em dois instantes diferentes: (antes/depois),
(tempo 1, tempo 2).
1 1 Fazer as diferenças:
2 t 2
di = yi2 – yi1 n n
t1 t2
Amostras

2.2.3. k amostras: quando se tem k ≥ 3 amostras para comparar. a) k grupos independentes: classificar, ao acaso, n elementos em k
grupos tal que n = n1 + n2 + . . . + nk.
O ideal é que todos os grupos sejam de mesmo tamanho: n1 = n2 = . . . = nk
A1 : 1, 2, . . . , n1
k grupos independentes
A2 : 1, 2, . . . , n2
Ak : 1, 2, . . . , nk
A variável A é chamada de fator e os grupos A1, A2, . . . , Ak são os
tratamentos ou níveis do fator A.
b) Medidas Repetidas: o mesmo grupo, de tamanho n, é observado em k instantes diferentes.
1 1 1 1 2 2 2 . . . 2
n n n n
t1 t2 t3 tk
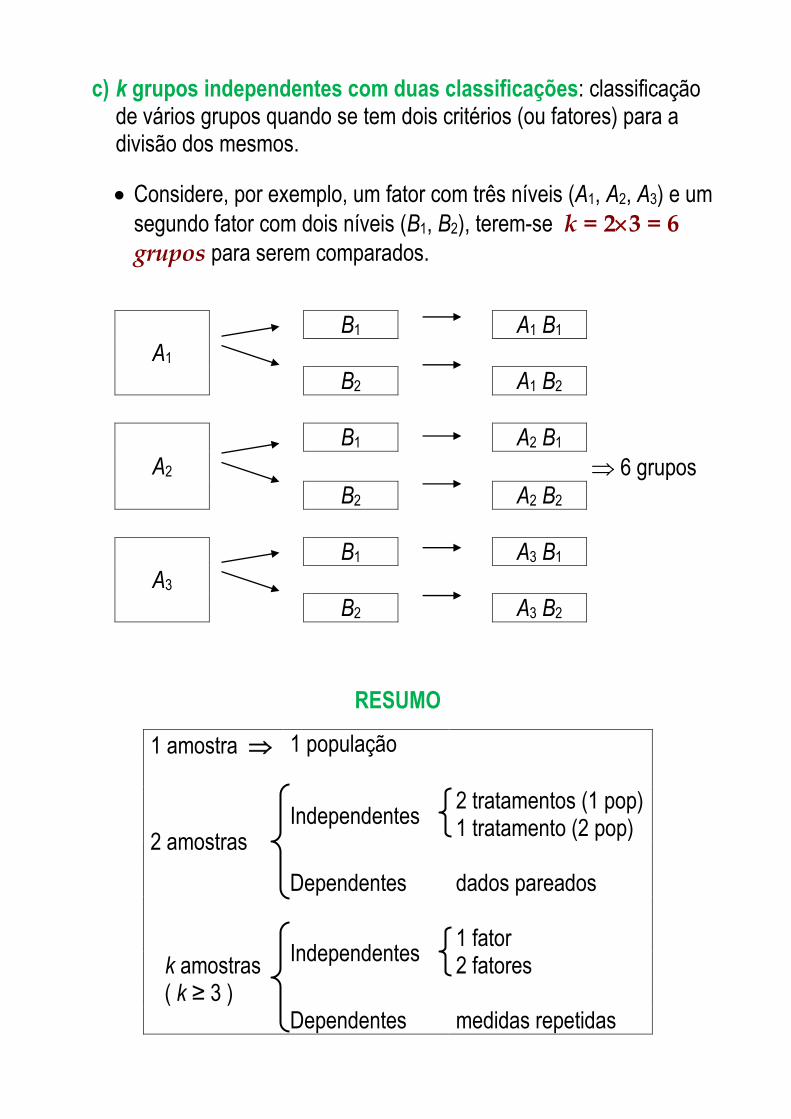
c) k grupos independentes com duas classificações: classificação de vários grupos quando se tem dois critérios (ou fatores) para a divisão dos mesmos.
Considere, por exemplo, um fator com três níveis (A1, A2, A3) e um
segundo fator com dois níveis (B1, B2), terem-se k = 23 = 6 grupos para serem comparados.
A1
B1 A1 B1
B2 A1 B2
A2
B1 A2 B1
6 grupos
B2 A2 B2
A3
B1 A3 B1
B2 A3 B2
RESUMO
1 amostra 1 população
2 amostras
Independentes 2 tratamentos (1 pop) 1 tratamento (2 pop)
Dependentes dados pareados
k amostras ( k ≥ 3 )
Independentes 1 fator 2 fatores
Dependentes medidas repetidas

3. Conceitos em Inferência
3.1. Parâmetro Populacional
Geralmente denotado por , é uma característica populacional de interesse que pode ser expressa através de uma quantidade numérica.
É desconhecido e fixo. Exemplos: no de desempregados, salário médio de uma categoria ou população, opinião a respeito de uma dada atitude, casos de dengue, tempo gasto com filhotes, tamanho da população tempo de vida no de votos para um determinado candidato, produção agrícola, etc...
3.2. Espaço Paramétrico
Denotado por , é o conjunto dos possíveis valores de .
Exemplos:
= { | –∞ < < ∞ };
= { | 0 < < ∞ };
= { | 0 ≤ ≤ 1 };
= { (1, 2 ) | –∞ < 1 < ∞ e 0 < 2 < ∞ }.

3.3. Amostra aleatória: representada pelas iniciais aa, é formada pela
observação de n variáveis aleatórias X1, X2, . . . , Xn, independentes
e identicamente distribuídas, iid.
nXXX ,,, 21 )(xF
3.4. Variável aleatória: uma variável aleatória ou va, é uma característica
desconhecida, que pode variar de um indivíduo para outro da
população e que, ao ser observada ou mensurada, deve gerar uma única resposta.
Tipos de variáveis: a) Variáveis qualitativas: variáveis cujos possíveis resultados são
atributos ou qualidades. São NÃO NUMÉRICAS.
Podem ser classificadas em: ORDINAIS, quando obedecem a uma ordem natural ou
NOMINAIS, quando não seguem nenhuma ordem. b) Variáveis quantitativas: variáveis cujos possíveis resultados são
valores NUMÉRICOS, resultantes de mensuração ou contagem.
Podem ser classificadas em: DISCRETAS, quando assumem valores num espaço finito ou infinito
enumerável ou CONTÍNUAS, quando assumem valores num conjunto não
enuméral (conjunto dos números reais).
iid

3.5. Estatística: é uma medida numérica, S(X), que descreve uma
característica da amostra e que não depende de parâmetros
desconhecidos.
A estatística é uma função da amostra: S(X) = f (X1, X2, . . . , Xn)
toda estatística S(X) é uma va
Exemplos:
n
XX
n
ii
1 – média amostral,
1
1
2
2
n
XX
s
n
ii
– variância amostral,
X(1) = mínimo 1ª estatística de ordem,
X(n) = máximo n-ésima estatística de ordem.
PARÂMETROS E ESTATÍSTICAS
Nome ESTATÍSTICA
Amostra PARÂMETRO
População
Média X
Variância s2 2
Correlação rX,Y X,Y
Proporção p p
3.6. Estimador: é uma quantidade, obtida a partir de uma amostra, que
“estima” o valor de um parâmetro populacional.
Será denotado por T(X).
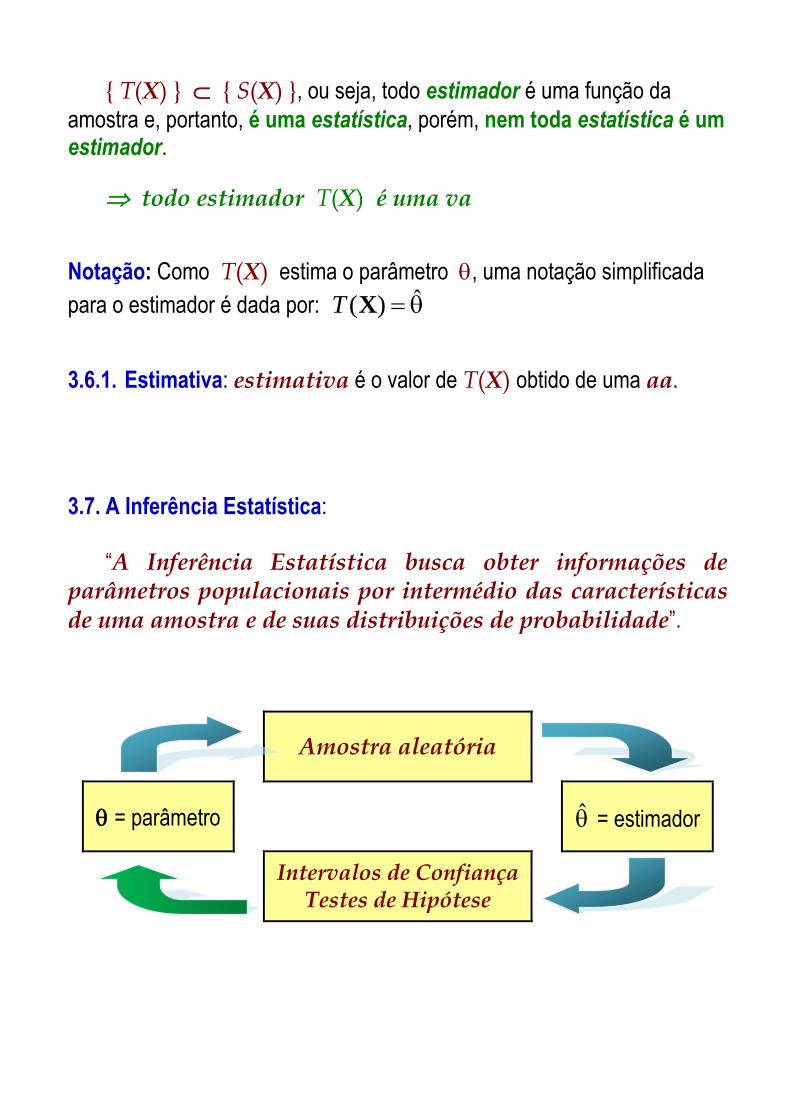
{ T(X) } { S(X) }, ou seja, todo estimador é uma função da
amostra e, portanto, é uma estatística, porém, nem toda estatística é um estimador.
todo estimador T(X) é uma va
Notação: Como T(X) estima o parâmetro , uma notação simplificada
para o estimador é dada por: ˆ)(XT
3.6.1. Estimativa: estimativa é o valor de T(X) obtido de uma aa.
3.7. A Inferência Estatística:
“A Inferência Estatística busca obter informações de parâmetros populacionais por intermédio das características de uma amostra e de suas distribuições de probabilidade”.
Amostra aleatória
= parâmetro
= estimador
Intervalos de Confiança Testes de Hipótese
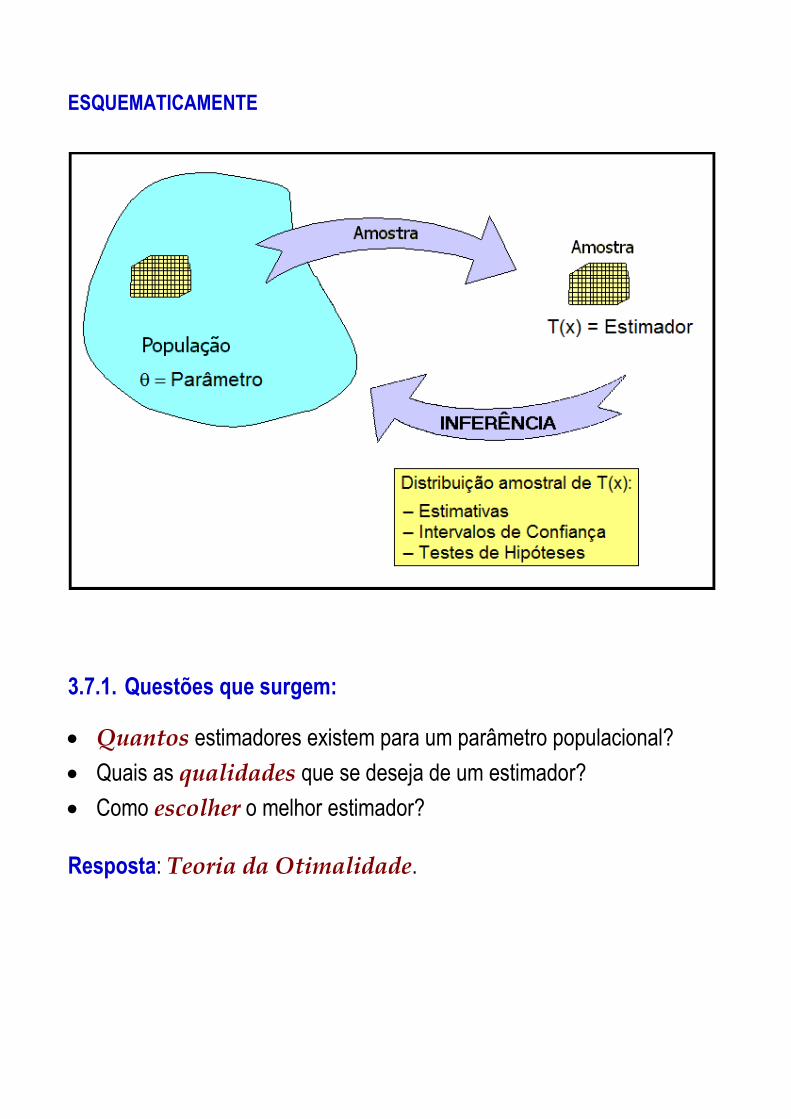
ESQUEMATICAMENTE
3.7.1. Questões que surgem:
Quantos estimadores existem para um parâmetro populacional?
Quais as qualidades que se deseja de um estimador?
Como escolher o melhor estimador?
Resposta: Teoria da Otimalidade.

3.8. O Estimador Ótimo
A teoria da Otimalidade estuda as propriedades dos estimadores e
define critérios para a escolha do estimador ótimo.
Segundo essa teoria um estimador é ótimo basicamente se for:
não viesado e de mínima variância.
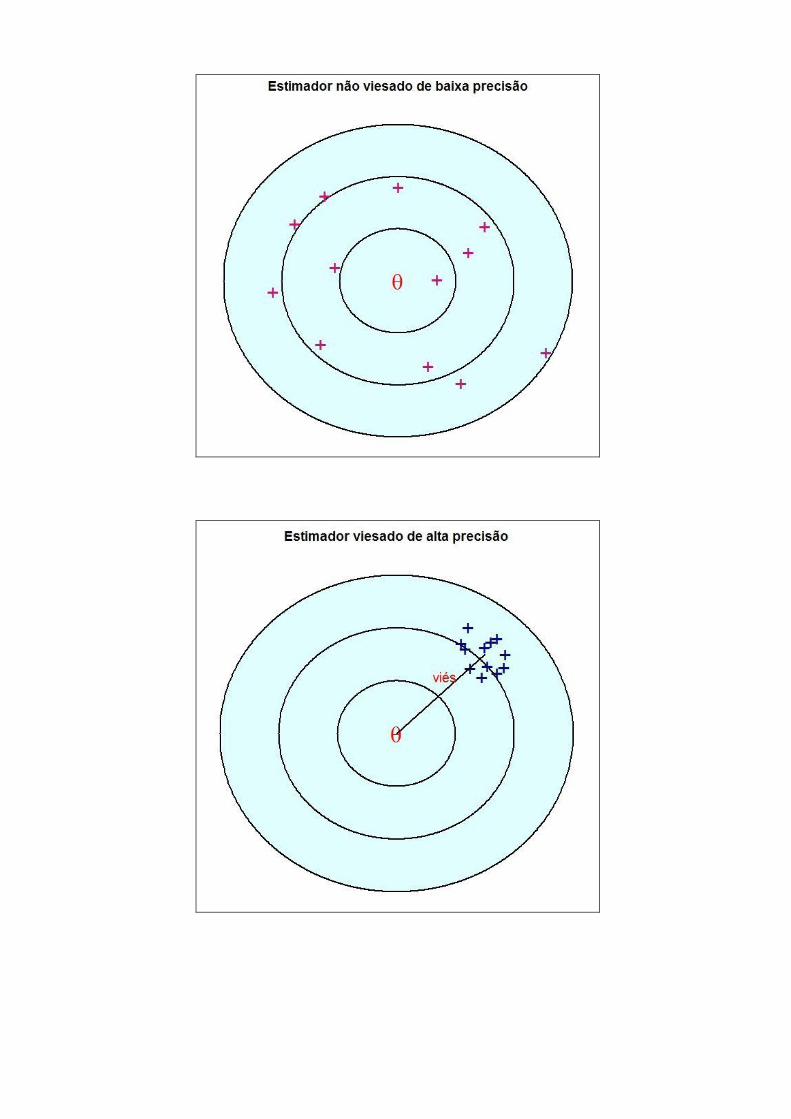
3.8.1. Estimador não viesado (não viciado): o viés, do inglês bias, é
definido pela diferença entre o valor esperado do estimador e
o parâmetro o qual este está estimando.
Seja , estimador de , então o viés de é definido por:
B( ) = E( ) –
em que é o espaço paramétrico.
Se E( ) = , é dito não viesado (ou não viciado) e
B( ) = 0
3.8.2. Precisão: uma propriedade importante para um estimador é que
seja preciso, em outras palavras, que tenha baixa variabilidade
deve ser escolhido tal que sua variância seja a menor
possível
)ˆ(|ˆ Var seja mínima

3.8.3. Consistência: além de ser não viesado e de variância mínima
deseja-se que o estimador seja consistente.
Um estimador é dito ser consistente para se
)ˆ(lim En
e
0)ˆ(lim
Varn
Conforme aumenta o tamanho da amostra, mais se aproxima de .
3.8.4. O Erro Quadrático Médio (EQM): o erro quadrático médio de
um estimador é definido por
EQM( )= E[(– )2 ]
Prova-se facilmente que
EQM( ) = Var( ) + [B()]2
Logo, se o estimador é não viesado, então, seu EQM é mínimo e
EQM( ) = Var( )
Assim, a teoria da otimalidade procura, dentre os estimadores
não viesados, aquele de menor variância.
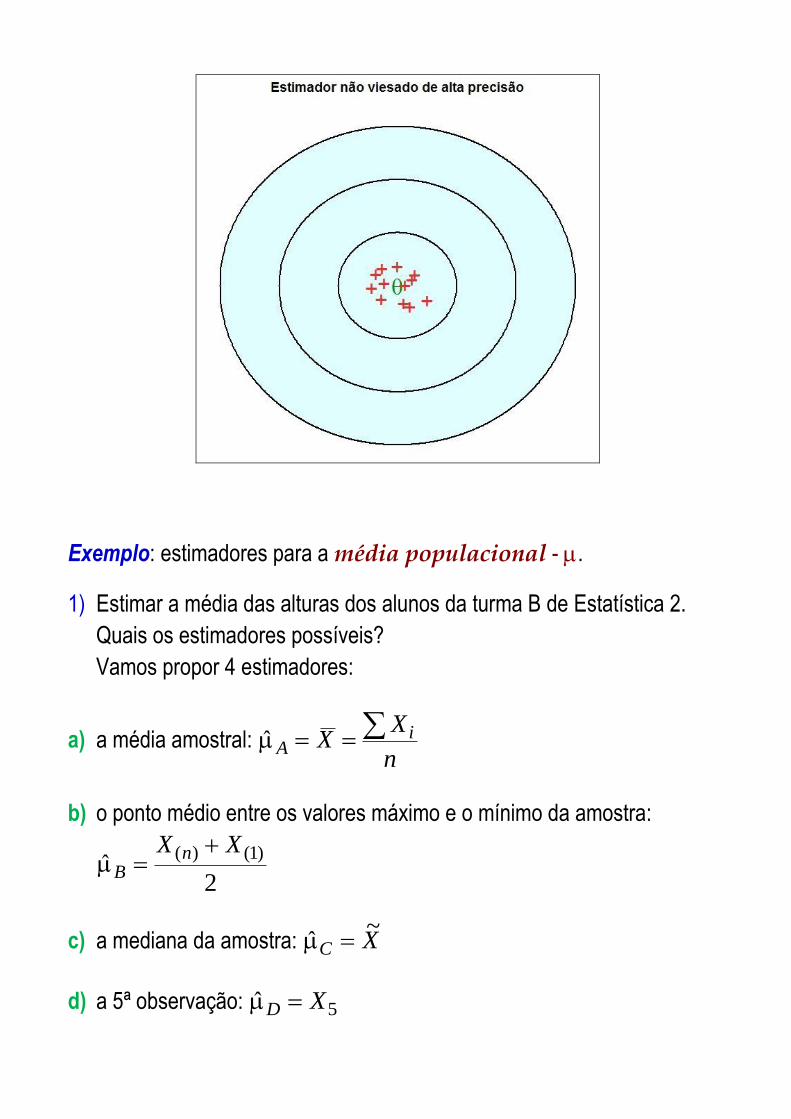
Exemplo: estimadores para a média populacional - .
1) Estimar a média das alturas dos alunos da turma B de Estatística 2.
Quais os estimadores possíveis?
Vamos propor 4 estimadores:
a) a média amostral: n
XX i
A
b) o ponto médio entre os valores máximo e o mínimo da amostra:
2ˆ
)1()( XX nB
c) a mediana da amostra: XC~
ˆ
d) a 5ª observação: 5ˆ XD

4. Estimadores para a média
A maioria das aplicações em estatística envolvem a estimação da
média populacional .
Quais os possíveis estimadores e qual deles é o melhor
(estimador ótimo).
Média aritmética ou média amostral ( X );
Média geométrica;
Média harmônica;
Média aparada;
Média ponderada;
Mediana amostral ( X~
);
Extimadores do tipo B e D (ver exemplo).
Qual desses estimadores é o melhor para estimar ?
a) 1º - escolher os não viesados;
b) 2º - dentre os não viesados, encontrar o de menor variância.
A teoria estatística (otimalidade) resolve esse problema e mostra
qual o estimador ótimo para .
Segundo essa teoria, o estimador ótimo para é a média amostral
(aritmética) X .
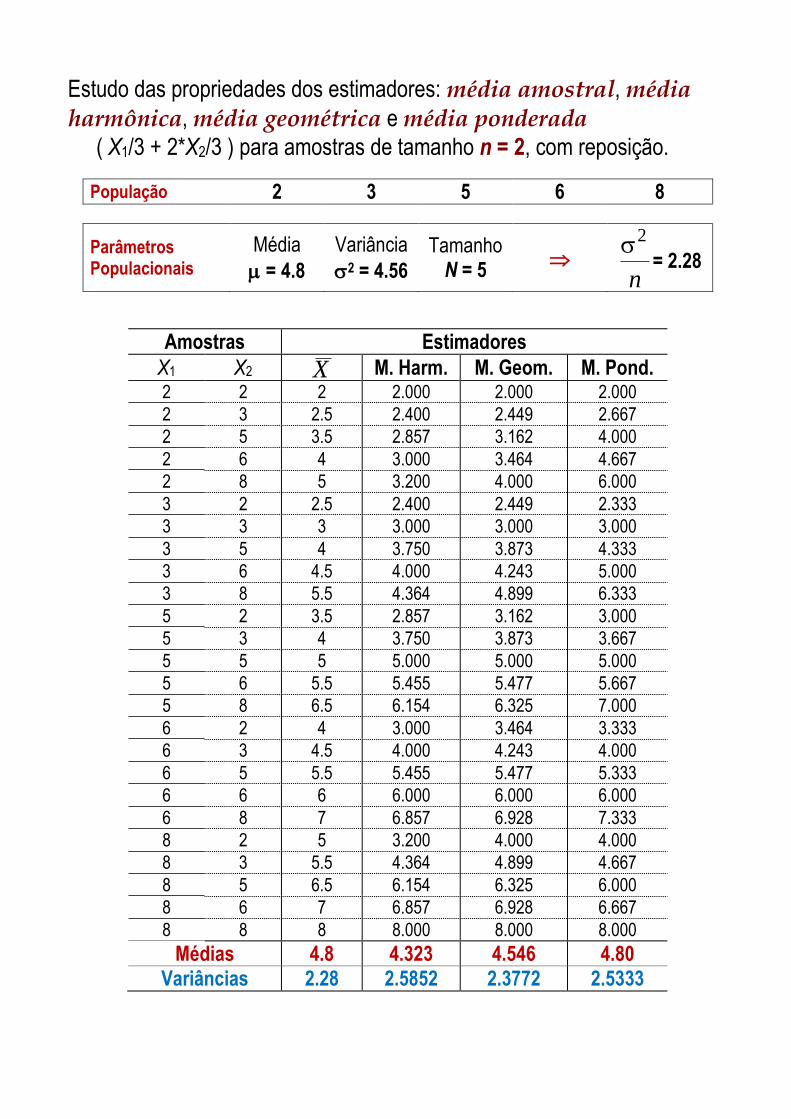
Estudo das propriedades dos estimadores: média amostral, média harmônica, média geométrica e média ponderada
( X1/3 + 2*X2/3 ) para amostras de tamanho n = 2, com reposição.
População 2 3 5 6 8
Parâmetros Populacionais
Média
= 4.8
Variância
2 = 4.56
Tamanho N = 5
n
2= 2.28
Amostras Estimadores
X1 X2 X M. Harm. M. Geom. M. Pond. 2 2 2 2.000 2.000 2.000
2 3 2.5 2.400 2.449 2.667
2 5 3.5 2.857 3.162 4.000
2 6 4 3.000 3.464 4.667
2 8 5 3.200 4.000 6.000
3 2 2.5 2.400 2.449 2.333
3 3 3 3.000 3.000 3.000
3 5 4 3.750 3.873 4.333
3 6 4.5 4.000 4.243 5.000
3 8 5.5 4.364 4.899 6.333
5 2 3.5 2.857 3.162 3.000
5 3 4 3.750 3.873 3.667
5 5 5 5.000 5.000 5.000
5 6 5.5 5.455 5.477 5.667
5 8 6.5 6.154 6.325 7.000
6 2 4 3.000 3.464 3.333
6 3 4.5 4.000 4.243 4.000
6 5 5.5 5.455 5.477 5.333
6 6 6 6.000 6.000 6.000
6 8 7 6.857 6.928 7.333
8 2 5 3.200 4.000 4.000
8 3 5.5 4.364 4.899 4.667
8 5 6.5 6.154 6.325 6.000
8 6 7 6.857 6.928 6.667
8 8 8 8.000 8.000 8.000
Médias 4.8 4.323 4.546 4.80 Variâncias 2.28 2.5852 2.3772 2.5333

Tabela resumo dos estimadores para a Média Populacional.
Estimadores
X M. Harm. M. Geom. M. Pond.
Média do Estimador 4.8 4.3229 4.5456 4.8
Vício 0 -0.4771 -0.2544 0
Vício ao quadrado 0 0.2277 0.0647 0
Variância do Estimador 2.28 2.5852 2.3772 2.5333
EQM 2.28 2.8129 2.4419 2.5333
Relação da variância de X com as demais 1 1.1339 1.0426 1.1111

Métodos de Estimação:
A teoria estatística define diversos métodos de estimação, dentre os
quais destacamos:
4.1. Método da máxima verossimilhança: o estimador é dado pelo valor
que maximiza a distribuição conjunta da amostra, também chamada de
função de verossimilhança.
n
iixfdadosL
1
)()|( )]([maxˆ
LMV
4.2. Métodos dos momentos: o estimador é obtido igualando os
momentos amostrais com os momentos populacionais.
Depende da distribuição de probabilidade da população
O momento de ordem k de uma va é definido como
)( kk XE , k ≥ 1, se k = 1 )(1 XE
O momento amostral de ordem k de uma va é definido como
n
Xm
ki
k
, se k = 1 Xm 1
Para estimar a média populacional , faz-se:
11ˆˆ m
ou seja, X

Para um parâmetro qualquer, se
)()( fXE kk )ˆ(ˆ 1
kMM f .
Se k = 1, 1)( f e o estimador dos momentos para é
)(ˆ 1 XfMM
4.3. Método mínimos quadrados: o estimador é aquele que minimiza
uma soma de quadrados de erros entre os valores da amostra e uma
função do parâmetro )(g .
Se queremos estimar a média , então )()( XEg .
Nesse caso, o erro e para cada observação é calculado por
)]([ iii gxe , i = 1, 2, . . . n, e
n
iii gxSQE
1
2)]([)( .
O estimador de mínimos quadrados é dado pelo valor de
que minimiza SQE():
)]([minˆ
SQEMQ
O estimador de mínimos quadrados é mais utilizado no ajuste de
modelos de regressão linear.

4.4. Estimador Bayesiano: o estimador Bayesiano é obtido a partir
de uma ponderação da função de verossimilhança por uma
distribuição de probabilidade para .
Seja uma distribuição de probabilidade (), denominada de
distribuição a priori de , então
(|dados) ()L(|dados),
(|dados) é a distribuição a posteriori de , dada a amostra.
Um estimador Bayesiano muito utilizado é dado pelo valor que
maximiza a posteriori, ou seja, pela moda de (|dados):
)]|([maxˆ dadosBay
5. O Estimador para a média .
5.1. Mostrar que a média amostral X atende às propriedades de
estimador ótimo para .
5.2. A distribuição da média amostral X .
5.2.1. O Teorema do Limite Central (TLC).
5.3. O estimador para a proporção p.
5.3.1. A distribuição da proporção amostral p .

5.4. Determinação do tamanho da amostra na estimação da média
5.5. O estimador para a variância populacional 2 .
5.5.1. A distribuição da variância amostral 2s .
Exemplos: 1) Um elevador de capacidade 500kg serve um edifício. Se a distribuição
do peso dos usuários for N(70, 100), determine: a) A probabilidade de que 7 passageiros ultrapassem esse limite.
b) E 6 passageiros?
2) Um produto da marca XIS é comercializado em pacotes de 1kg, sendo
que a distribuição do peso dos pacotes, em gramas, é N(1000, 51.2).
A fiscalização inspeciona o produto por amostras de 5 pacotes e aplica
uma multa se a média for menor do que 4g a menos do peso
especificado.
a) Qual a probabilidade de que o produto XIS seja multado?
Os produtores de XIS pretendem diminuir essa probabilidade. Para
isso o Estatístico da empresa deu duas sugestões: deslocar a média,
aumentando o peso dos pacotes ou aplicar ações visando reduzir a
variabilidade do processo de empacotamento.
b) Para quanto deve ser regulada a nova média de tal forma que a
probabilidade em (a) seja de no máximo 0.03?
c) Caso se escolha a segunda opção, de quanto deve ser a nova
variância para se obter o mesmo resultado?

Considere, agora, que a produtora tenha um custo adicional de 25
centavos por cada pacote com peso acima de 1008g. Qual a alteração
no custo em cada um dos casos para um produção de 5 toneladas?
3) Para estimar o nível de dureza de peças de espuma injetada com boa
precisão o técnico responsável decide selecionar uma amostra da
produção para medição. Como os ensaios de medição são destrutivos,
o número de peças para análise deve ser bem determinado para evitar
gastos desnecessários. (dados históricos registram a variância do
processo de produção como 2 = 2.96).
Inicialmente fixou-se como precisão = 0.5ud.
a) Determinar o número de peças tal que a probabilidade de que a
precisão seja alcançada seja de 0.99.
b) A gerência achou esse número muito elevado e decidiu reduzir a
precisão para 0.75ud. Que o número de peças deve ser
inspecionado com esse novo valor?
4) Numa pesquisa eleitoral foi realizada uma pré-amostra de tamanho 40
obtendo-se 24.0ˆ p de eleitores que votam no candidato do partido
PX.
a) Qual deve ser o tamanho da amostra para que, com probabilidade
0.95, a estimativa p não se distancie de p mais do que 0.02?
b) Refazer o cálculo do tamanho da amostra pelo método conservativo.
5) Seja uma população com 20 e 567.22 .
a) Numa amostra de tamanho n = 9, qual a probabilidade de que a
variância amostral seja superior a 4.3?
b) Determine um limite inferior k para o qual a probabilidade de que 2s
ser menor do que k seja de 0.025.

Exercícios de Revisão
6) Um produto pesa em média 10g com desvio-padrão de 3g. Este é embalado em caixas de 150 unidades. A caixa vazia pesa, em média, 200g com desvio-padrão de 9g. Admitindo que as variáveis em questão tenham distribuições normais e que as 150 unidades que são colocadas em uma caixa são tomadas ao acaso, determine a probabilidade de uma caixa cheia pesar mais de 1610g.
Resolução: Sejam as va’s
XP : peso do produto N( 10 ; 9 )
XC : peso da caixa N( 200 ; 81 )
XT : peso total da caixa cheia ?
Resultados:
i) Se X1 N( 1 ; 12 ) e X2 N( 2 ; 2
2 ), independentes, então
X1 ± X2 N(1 ± 2 ; 12 + 2
2 )
ii) Se X1, X2, . . . , Xn N( ; 2 ), iid
X1 + X2 + . . . + Xn N(n ; n2 )
De (i) e (ii), temos que XT = XP1 + XP2 + . . . + XP150 + XC e,
XT N( T ; 2T ), em que:
T = 15010 + 200 = 1700g
2T = 1509 + 81 = 1431g2
ou seja, XT N( 1700 ; 1431 ).
9913.0)38.2()1610( ZPXP T .

7) Uma máquina automática enche latas, baseada no peso bruto das mesmas. O peso bruto tem distribuição normal com média 1.000g e desvio padrão 20g. As latas têm pesos distribuídos normalmente com média 90g e desvio padrão 10g. Qual a probabilidade de que uma lata escolhida ao acaso tenha de peso líquido: a) menor do que 830g? b) maior do que 870 g? c) entre 860 e 930g?
Resolução: Sejam as va’s
XB : peso do produto N( 1000 ; 400 )
XL : peso da caixa N( 90 ; 100 )
XQ : peso total da caixa cheia N( Q ; 2Q ),
De (i) temos que XQ = XB – XL e,
Q = 1000 – 90 = 910g
2Q = 400 + 100 = 500g2
ou seja, XQ N( 910 ; 500 ).
a) 0.0001718)58.3()830( ZPXP Q
b) 0.96330367.01)79.1()870( ZPXP Q
c) 0.01250.8133)89.024.2()930860( ZPXP Q
0.80)930860( QXP
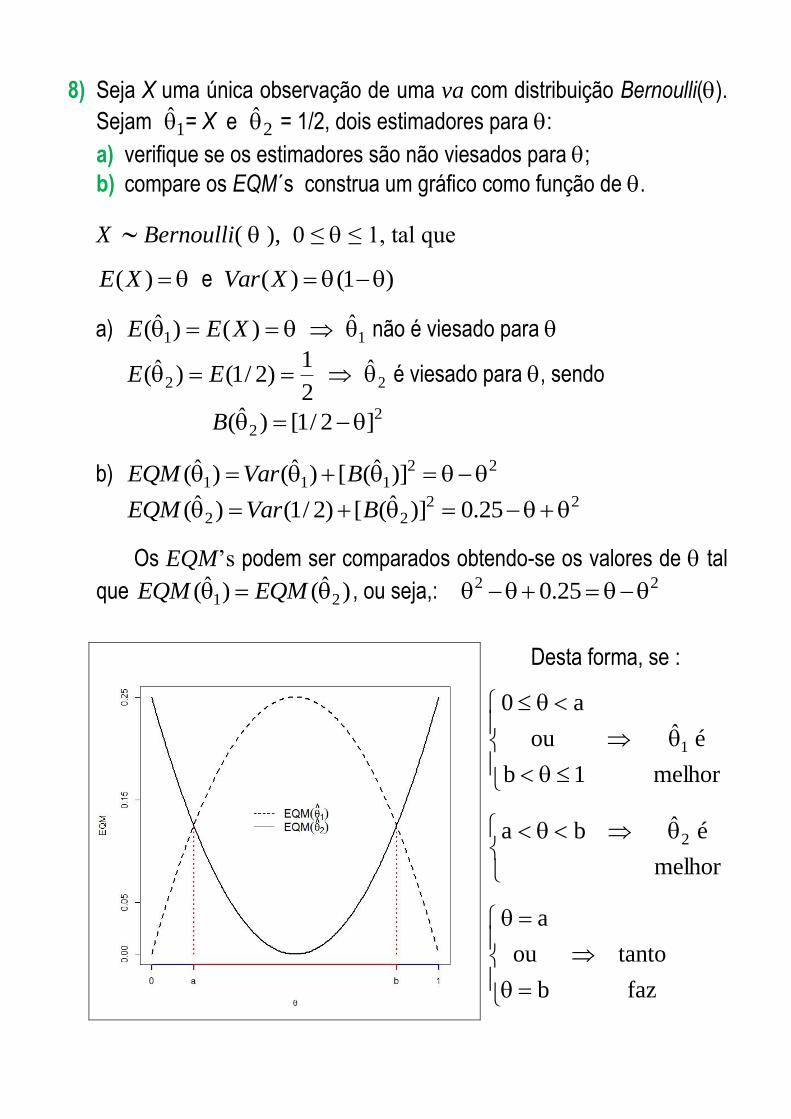
8) Seja X uma única observação de uma va com distribuição Bernoulli().
Sejam 1 = X e 2 = 1/2, dois estimadores para :
a) verifique se os estimadores são não viesados para ;
b) compare os EQM´s construa um gráfico como função de .
X Bernoulli( ), 0 ≤ ≤ 1, tal que
)(XE e )1()( XVar
a) )()ˆ( 1 XEE 1 não é viesado para
2
1)2/1()ˆ( 2 EE 2 é viesado para , sendo
22 ]2/1[)ˆ( B
b) 22111 )]ˆ([)ˆ()ˆ( BVarEQM
2222 25.0)]ˆ([)2/1()ˆ( BVarEQM
Os EQM’s podem ser comparados obtendo-se os valores de tal
que )ˆ()ˆ( 21 EQMEQM , ou seja,: 22 25.0
Desta forma, se :
melhor1b
éˆou
a0
1
melhor
éˆba 2
fazb
tantoou
a

9) Sejam X1, X2, . . . , Xn uma aa de tamanho n da distribuição uniforme no
intervalo (0, ).
Considere os estimadores Xc11ˆ e
2ˆ 1
22nXX
c .
a) Ache c1 e c2 tais que 1 e 2 sejam não viesados para ;
b) encontre os EQM´s dos dois estimadores
X U( 0, ),
2
)(XE e 22
12)(
XVar
a) 2
)()ˆ( 111
cXcEE
para 21 c , 1 não é viesado para
22
)()(
2)ˆ( 2
212
122
c
XEXEc
XXcEE n
para 22 c , 2 não é viesado para
Logo, X2ˆ1 e
22ˆ 21
2
XX não são viesados para .
b) 2)]ˆ([)ˆ()ˆ( BVarEQM
12
)/(4)2()ˆ()ˆ(
2
11
nXVarVarEQM
nEQM
3)ˆ(
2
1
12
2)()(2
4)ˆ(2
211
2
XVarXVar
XXVarEQM n
6
)ˆ(2
2
EQM





























