Embed Size (px)
DESCRIPTION
Citation preview

金融業菜鳥實習生的python project 初體驗
2013/9/28Yen @ PyLadies Meeting

台大經濟所碩二Python, R user
Who am I ?
Yen ( 顏嘉儀 )

Why I am here ?
聽說..你暑假實習...用python…寫了啥碗糕...是吧....
怎麼了嗎 (警戒= =+)
那來PyLadies分享一下吧(遠目)
1
2
3

What wil happen if you were a Python programmer
in Financial Community ?
Take my Internship experiment as an Example
- Crawler -

It’sabout 4month ago...
__ __ 人壽信託部
__ __ 人壽精算部
__ __ 券商自營部

Python 可以吃嗎?
你用py…(欸,這怎麼念阿) python 寫過爬蟲阿, 可是我們都寫C# 跟VBA耶。
不過沒關係,
上班前學會C#, VBA, SQL就OK了!
迷之聲:有這麼容易嗎QQ...
__ __ 券商自營部

三項任務
簡單來說就是:資料的蒐集、整理與分析
#1. 大連期貨商品研究
#2. 股票節稅 報價估計
#3. 每日期權strike, price戰力分佈圖

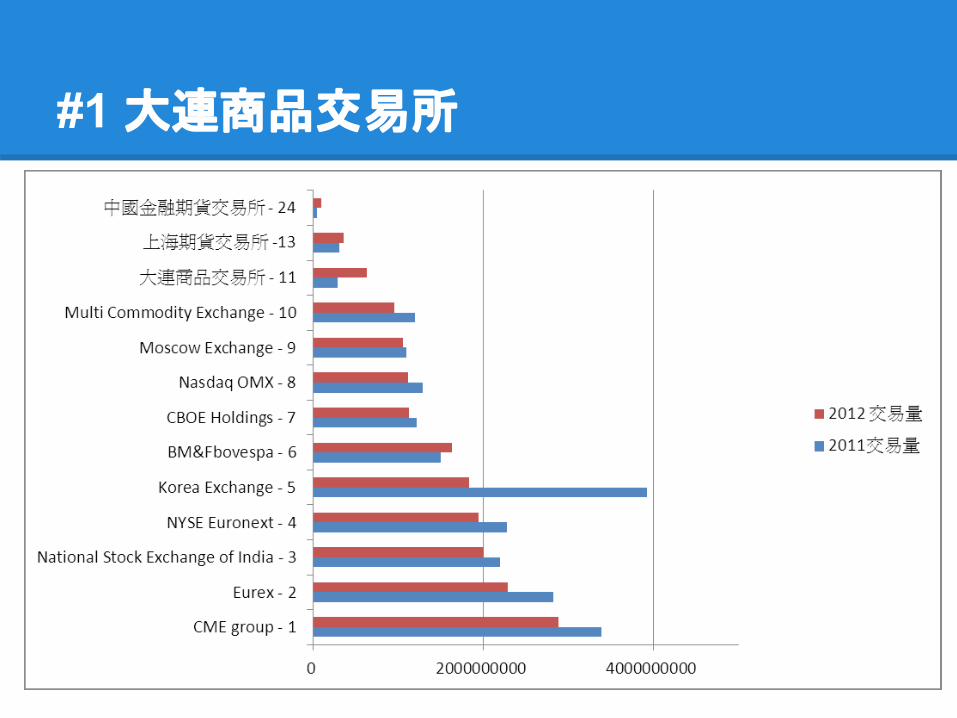
#1 大連商品交易所
根據 FIA統計,
2012 年全球期貨市場萎縮
15.3%除了, 中國 & 印度
所謂期貨,是一種合約,承諾在固定期限內以一個特定價格買入或賣出固定數量的商品或金融產品。
#1 大連商品交易所
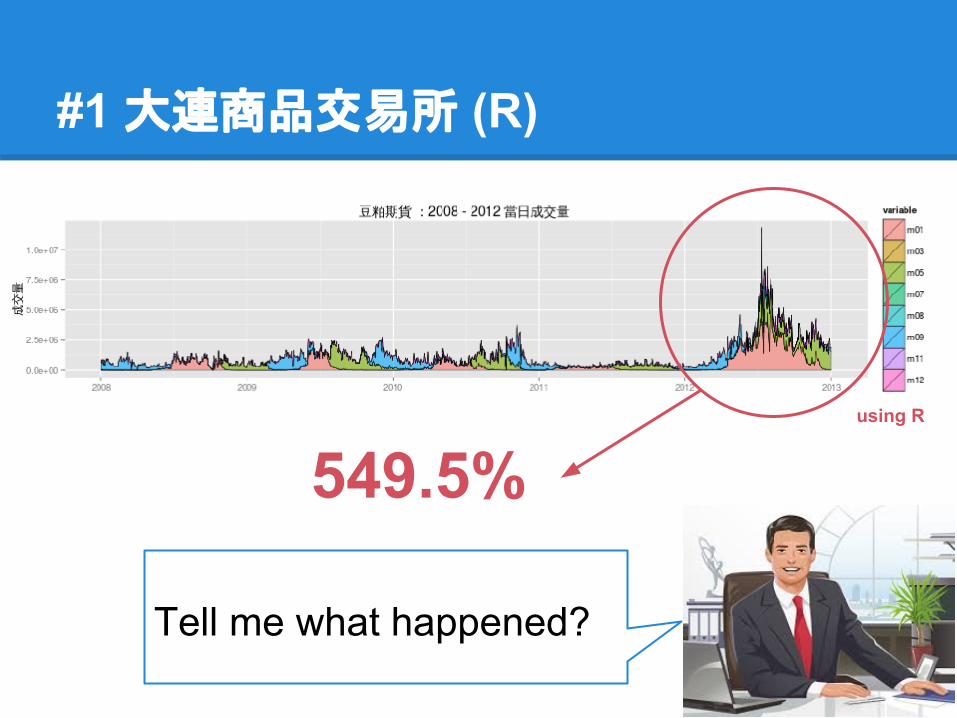
#1 大連商品交易所 (R)
549.5%
Tell me what happened?
using R

#2 股票節稅報價估計 (VBA)
什麼是股票節稅?
summary: 平均來說,報價0.7%沒超過500萬不太會做~

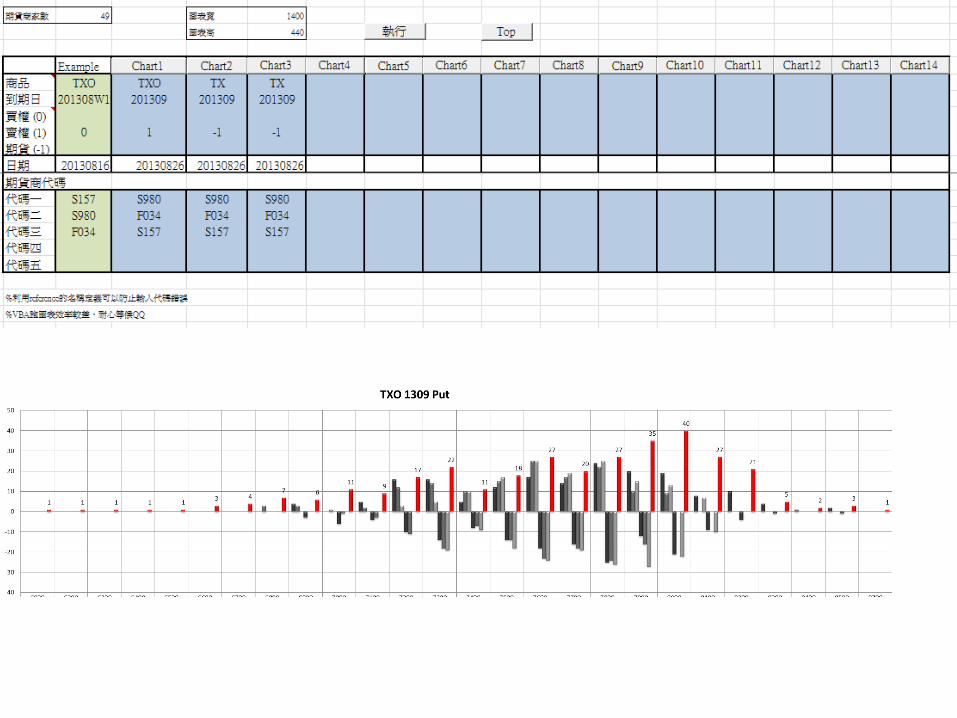
#3 每日期權strike, price戰力分佈圖
去年我們想做一件事, 但是沒完成...
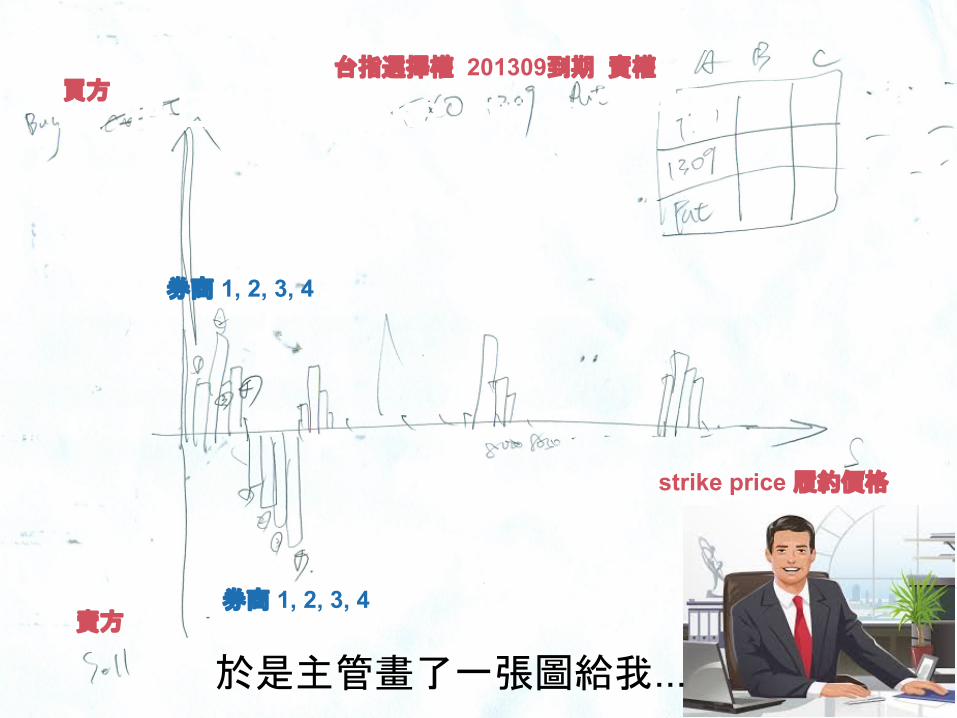
#3 每日期權strike, price分佈圖台指選擇權 201309到期 賣權
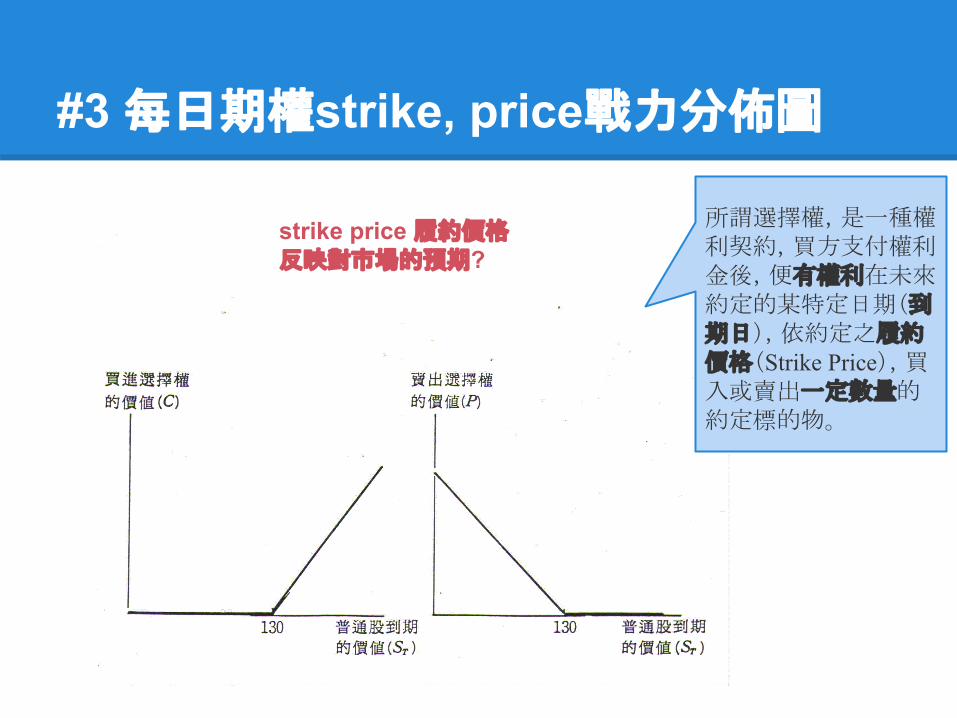
strike price 履約價格
買方
賣方
券商 1, 2, 3, 4
券商 1, 2, 3, 4
於是主管畫了一張圖給我...
#3 每日期權strike, price戰力分佈圖
所謂選擇權,是一種權利契約,買方支付權利金後,便有權利在未來約定的某特定日期(到期日),依約定之履約價格(Strike Price),買入或賣出一定數量的約定標的物。
strike price 履約價格反映對市場的預期?
#3每日期權strike, price戰力分佈圖
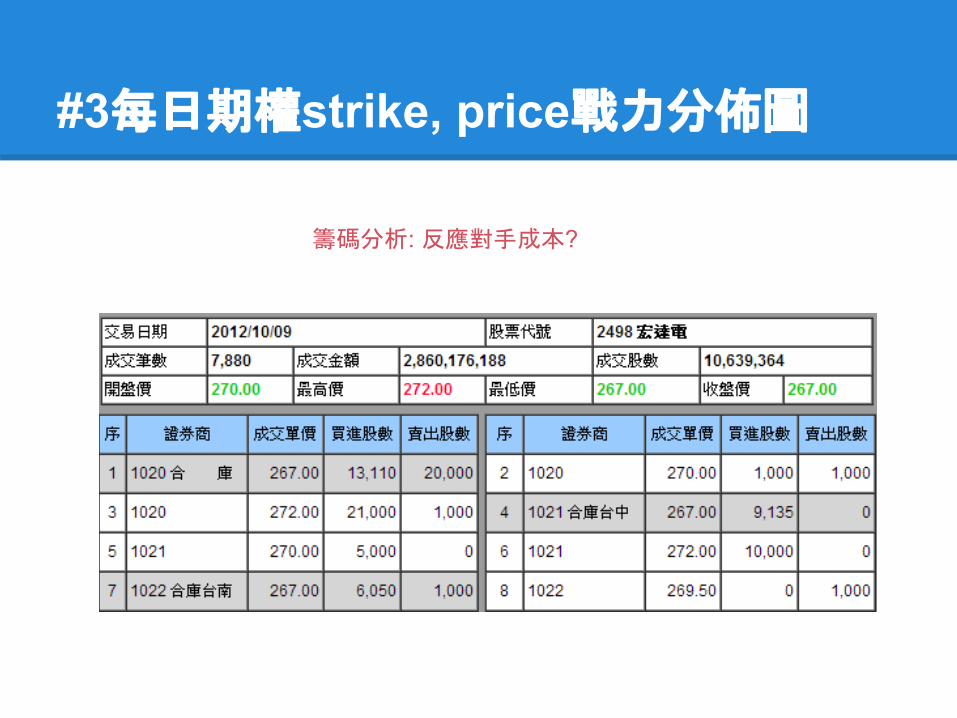
籌碼分析: 反應對手成本?
#3 每日期權strike, price戰力分佈圖
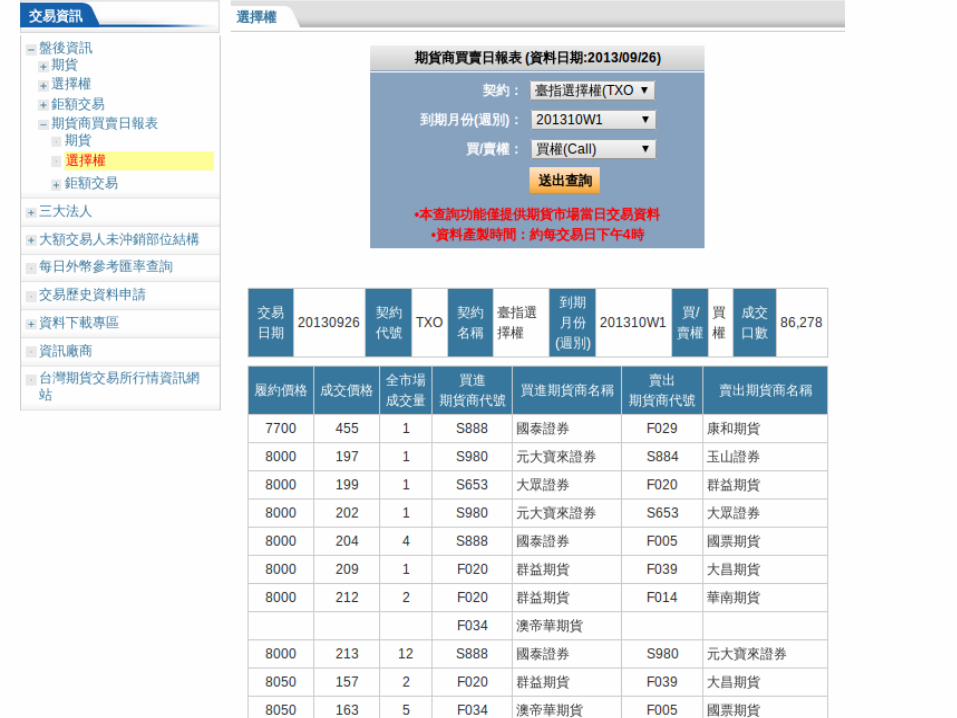
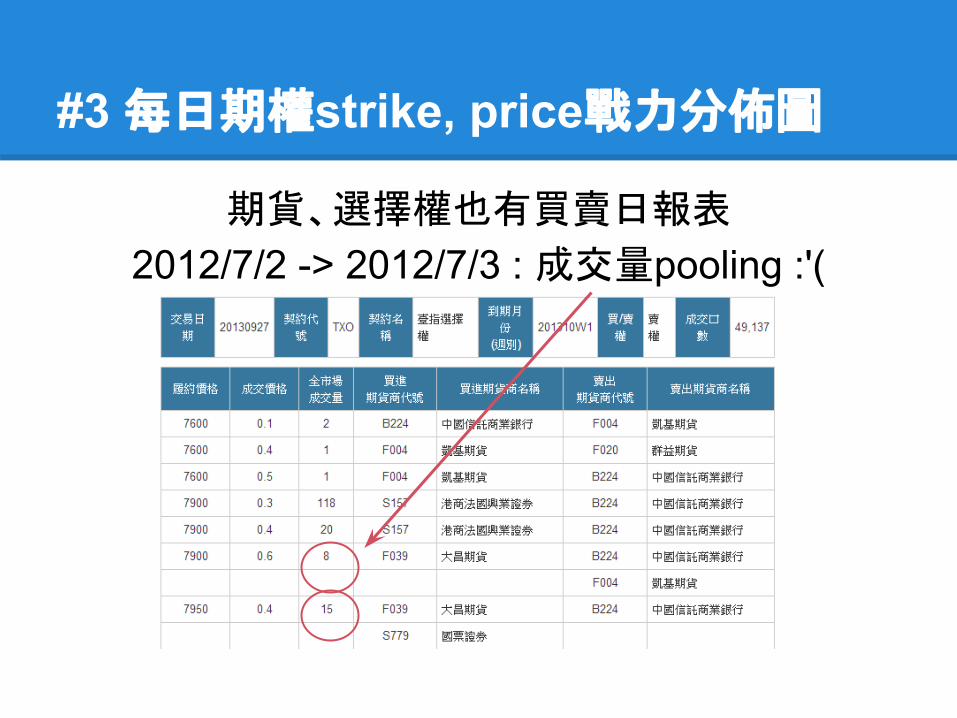
期貨、選擇權也有買賣日報表
2012/7/2 -> 2012/7/3 : 成交量pooling :'(

Our Guess: 造市者
XX證券/法國興業證券/奧帝華證券/中信銀行
(there’s a graph but, for some reason, we skip it here )

簡單來說,就是抓資料麻~
We had done it in C# , but…一次只能抓一頁 orz...
Target:可以一次抓很多頁就贏了 XD

簡單來說,就是抓資料嘛~
[ C# ] Arachnode.net ? (not free)R is slowerTry Python Solution:Scrapy
Windows Platform : C#
C#

Scrapy
(official)is a web crawling framework, used to crawl websites and extract structured data from their pages.
是一個可以讓你快速開發網路爬蟲的套件。
多快? 為什麼快?
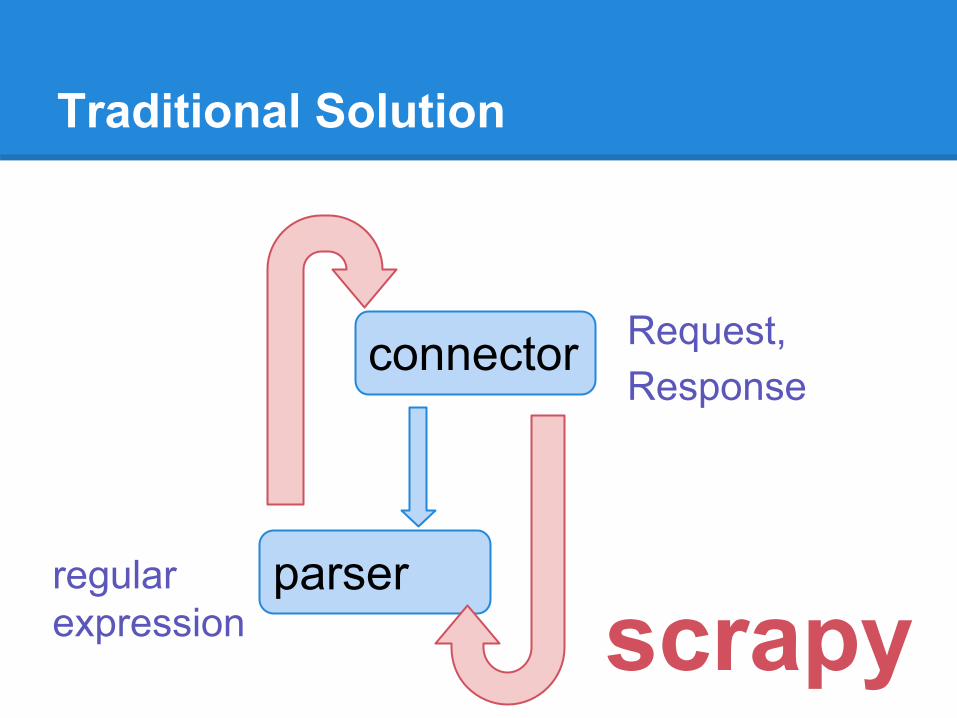
Traditional Solution
connector
parser
scrapy
Request,Response
regular expression
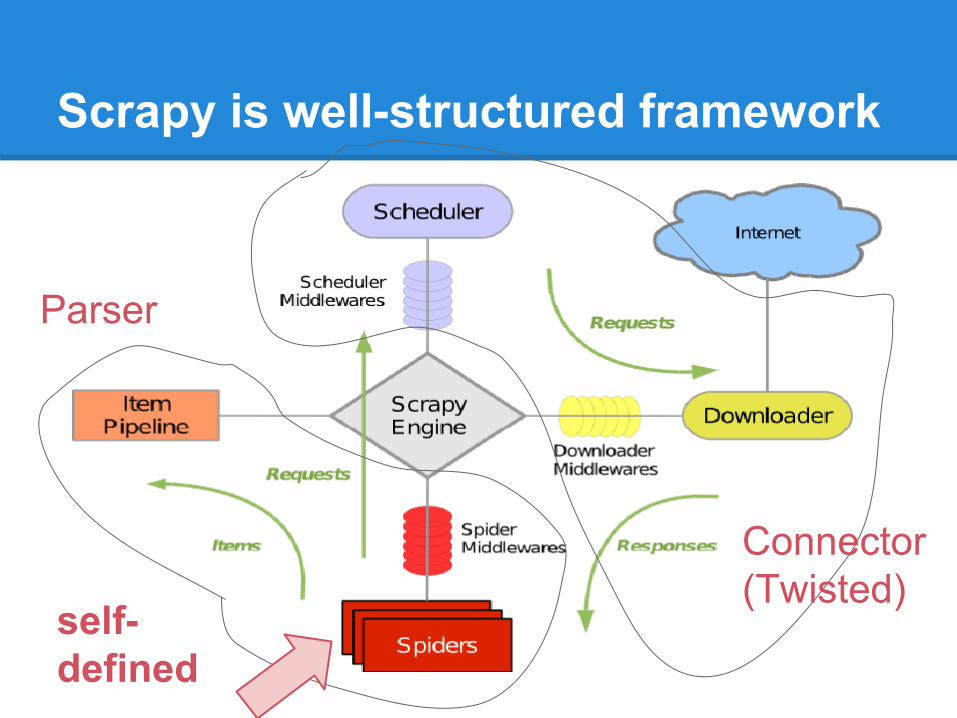
Scrapy is well-structured framework
Connector(Twisted)
Parser
self-defined

XPath Parser
Scrapy, is a web crawling framework, used to crawl websites and extract
structured data from their pages.
# Regular ExpressionEvery characters aretreated as the same
# Alternatives: XPathhtml doc can be astrudtured data
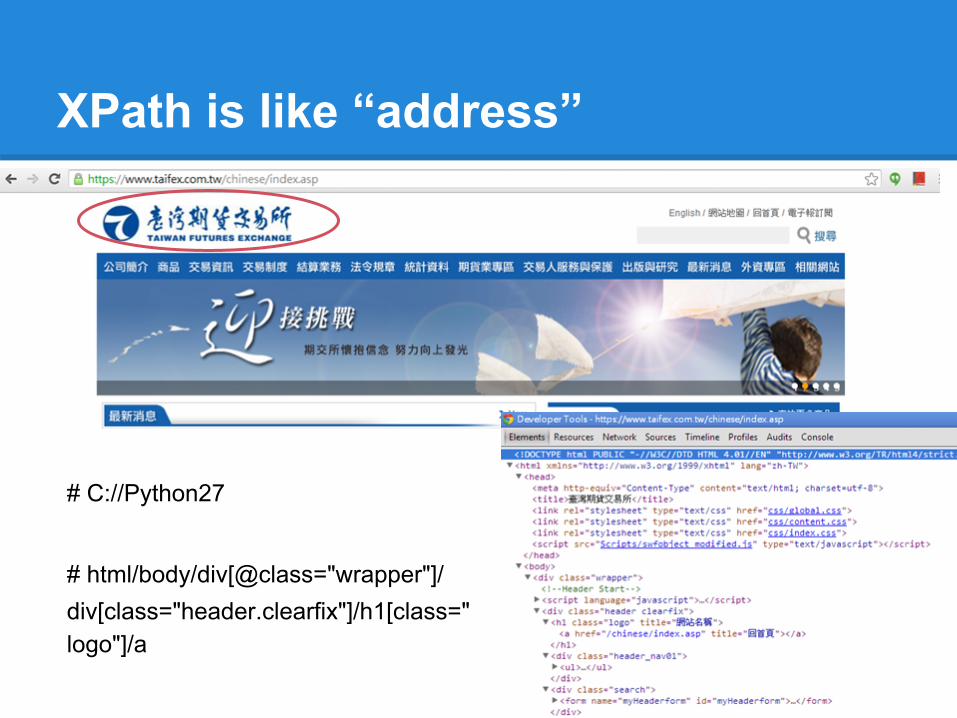
XPath is like “address”
# C://Python27
# html/body/div[@class="wrapper"]/div[class="header.clearfix"]/h1[class="logo"]/a
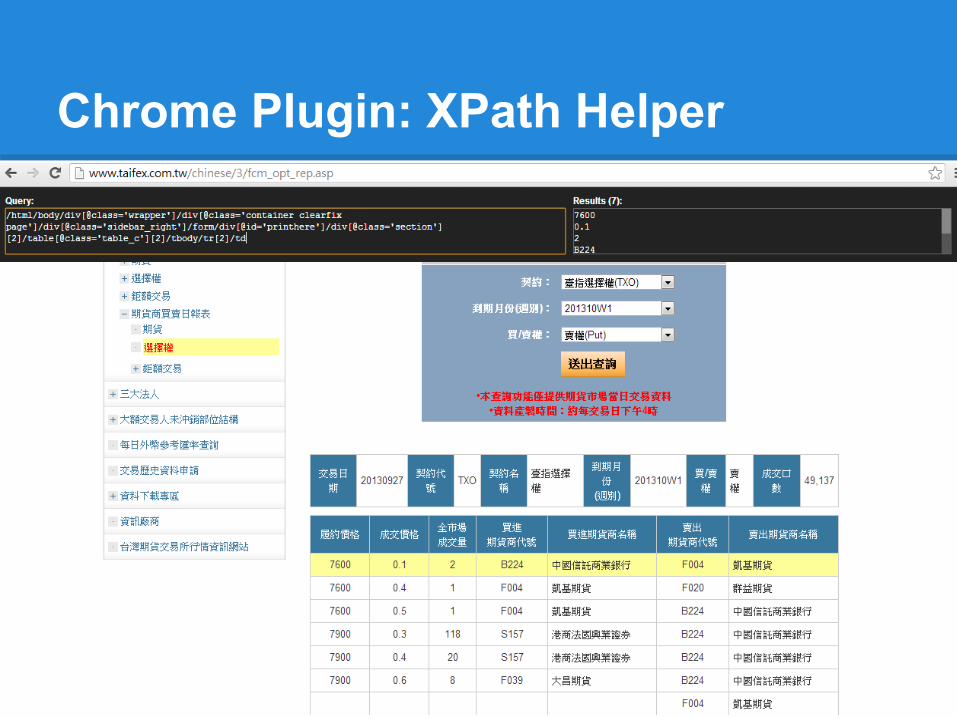
Chrome Plugin: XPath Helper
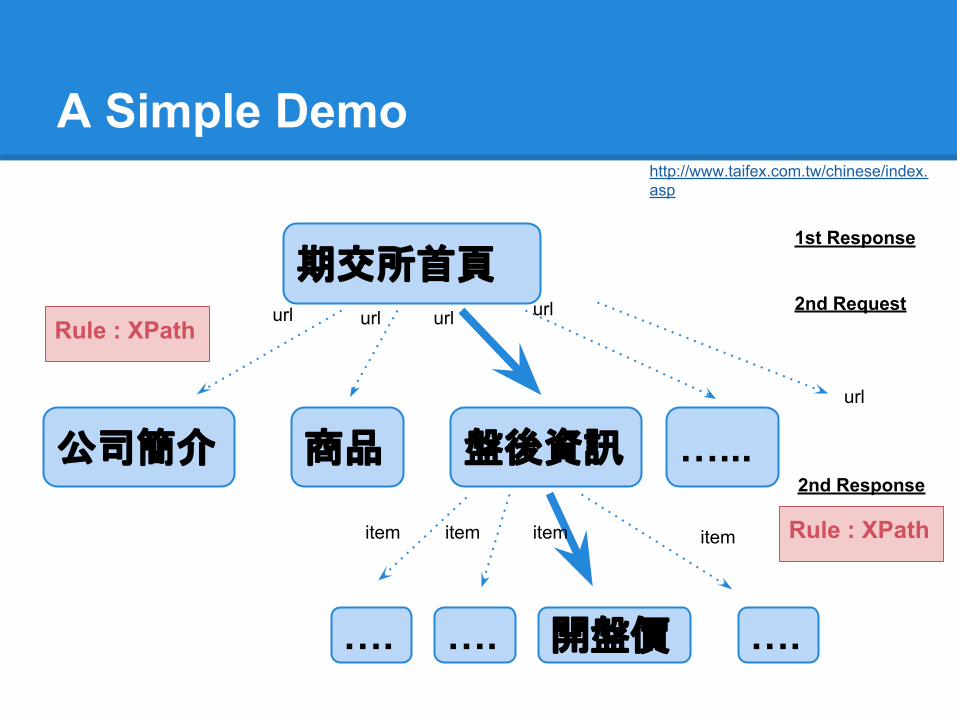
A Simple Demo
期交所首頁
盤後資訊公司簡介 商品 …...
Rule : XPath url urlurlurl
url
…. …. 開盤價 ….
item itemitemitem Rule : XPath
http://www.taifex.com.tw/chinese/index.asp
1st Response
2nd Request
2nd Response

Pseudo Codeimport scrapy工具
class my_Spider( 繼承scrapy寫好的spider ): name ="爬蟲名字" start_urls=[initial request(URL)] i.e. 最上層的root
def parse(self, first_response): 第一個parse函式寫死的 !!
hxs = HtmlXPathSelector( first_response ) html_response => Xpath 結構化物件
Xpath = "爬取url的Rule" extracted data = hxs.select(Xpath).extract() yield Request(url=爬到的url, callback=self.next_parser)
def next_parser(self, second_response): 函式名字隨便訂
hxs = HtmlXPathSelector(second_response) Xpath = "爬取資料的Rule" extracted data = hxs.select(Xpath).extract()

cmd command
# 建立scrapy 專案[cmd]scrapy startproject PyLadiesDemo
# 執行name = "TaiTex" 的爬蟲[cmd]scrapy crawl TaiFex
請參考官方文件:http://doc.scrapy.org/en/latest/intro/tutorial.html
Demo
# sample code
# Good Tools: (error detect : try except)[cmd] scrapy Shell url_that_u_want_2_crawl

例外處理 + pdb 下中斷點
# 例外處理def parse(self, response):
try:...
except:…
# 下中斷點import pdb
pdb.set_trace()
網站難免有些例外
or 弄錯XPath,可以很即時的修正。

With Scrapy,
Everything seems easy and wonderful !
只要可以畫成線性節點圖
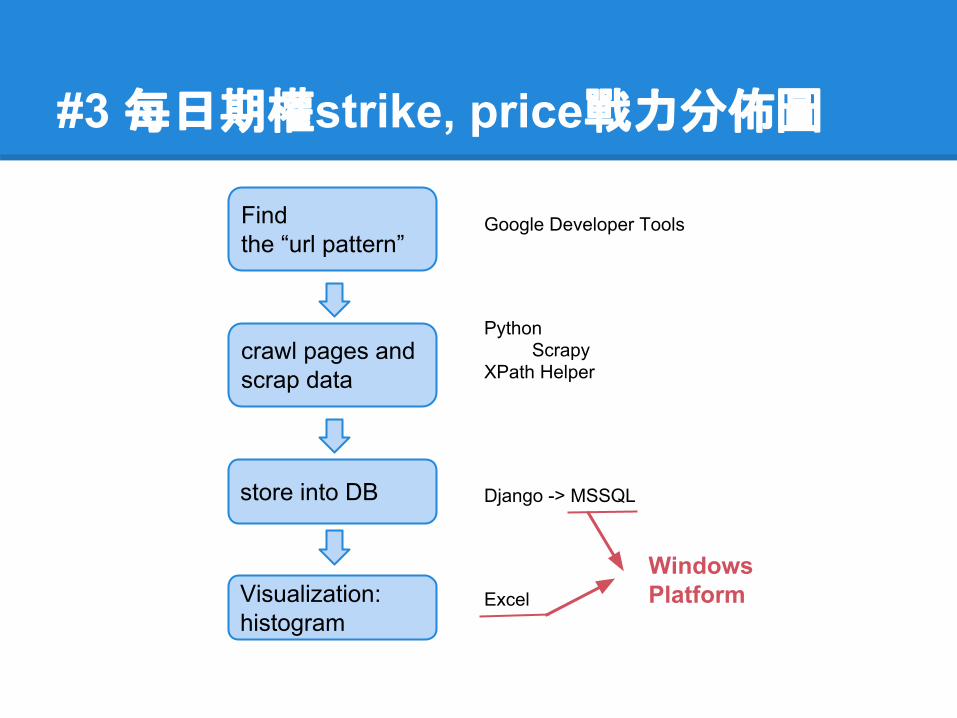
#3 每日期權strike, price戰力分佈圖
Find the “url pattern”
crawl pages and scrap data
store into DB
Visualization: histogram
Google Developer Tools
PythonScrapy
XPath Helper
Django -> MSSQL
Excel
Windows Platform
事情沒有你想的容易...之一
Step 1Find the “url pattern”
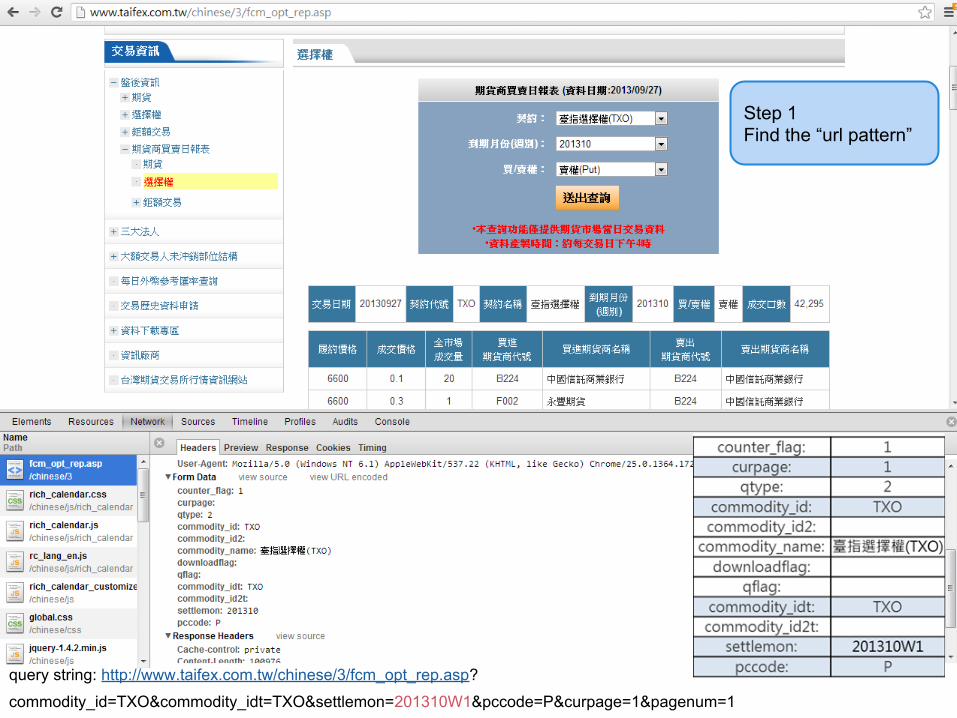
query string: http://www.taifex.com.tw/chinese/3/fcm_opt_rep.asp?
commodity_id=TXO&commodity_idt=TXO&settlemon=201310W1&pccode=P&curpage=1&pagenum=1
Step 1Find the “url pattern”

換月時點有許多例外
[TXO] 3近2季一般選擇權:每個月第3個禮拜三結算
週選擇權:每週星期三結算
what if 颱風假,連假?
[TGO] 6 近偶數月份
Step 1Find the “url pattern”

事情沒有你想的容易...之二
Step 2crawl pages and scrap data

什麼!! pip 不能用 !!!!!
因為公司擋網站 !!!
◢ ▆ ▅ ▄ ▃ 崩╰ (〒皿〒)╯ 潰▃ ▄ ▅ ▇ ◣
(installer using .bat file)
Step 2crawl pages and scrap data

Python is beautiful ...
python crawler 49 行 (ver1) 150行 (final ver)
v.s.
C# crawler 700 行 (還只能爬一頁!!)
大勝!
事情沒有你想的容易...之三
Step 3store into DB

可以用MSSQL嗎?
Django 可以接M$SQL嗎?
YES !< Solution > install “Django-mssql”
modify “settings.py”http://django-mssql.readthedocs.org/en/latest/

如果可以重來一次的話
我會直接寫txt出來再進MSSQL... = =a
因為1. 不用跟主管解釋django是啥(?)2. 快3. 寫code測試

事情沒有你想的容易...之四
Step 4Visualization: histogram

好慢阿~
DB 膨脹的速度很快(200萬)
Excel 很慢,很慢,很~慢~~
<Solution>分成history table, today table

事情沒有你想的容易...之五
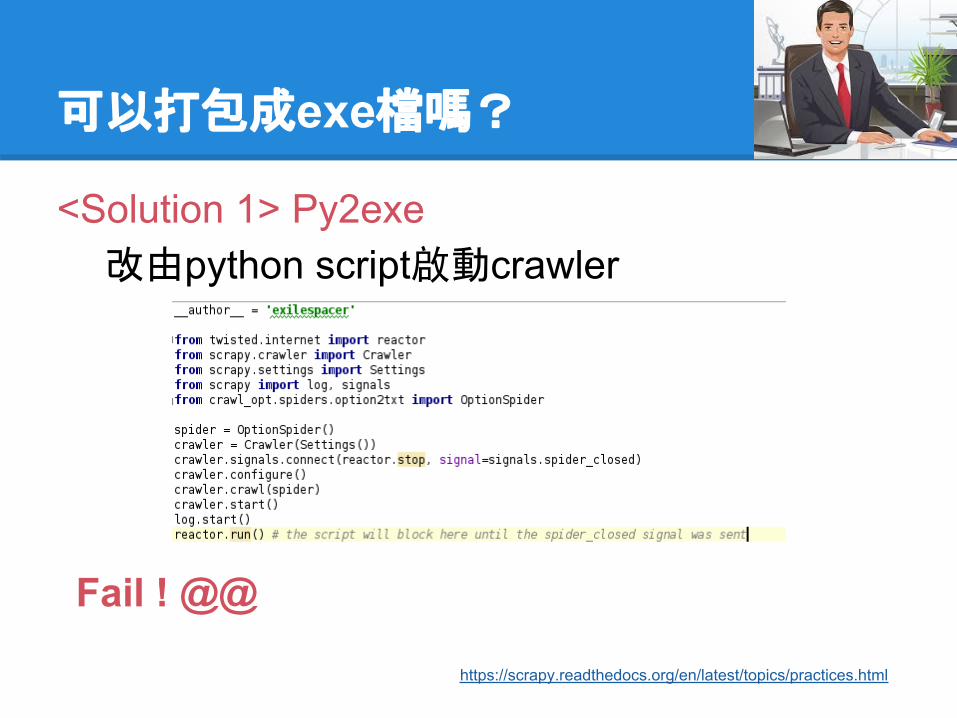
可以打包成exe檔嗎?
<Solution 1> Py2exe改由python script啟動crawler
https://scrapy.readthedocs.org/en/latest/topics/practices.html
Fail ! @@

可以打包成exe檔嗎?
<Solution 2> Installer.batuse pip offline(no update)
it works !(while fails at a few machines)

Conclusion
# scrapy :還不錯的輕量級crawler框架
快速開發,專注在parser上簡單易學,好維護
Remember 例外處理
# django: 殺雞用牛刀了
若不考慮發展其他產品,
直接寫txt出來也許更省力
# 收穫:主管終於知道Python怎麼念了! <( ̄︶ ̄)>

what will happened ….
你可能會沒有 pip 可以用XD正經的: C #, VBA

Reference
# official website tutorialwww.scrapy.org
# Taipei.py Thoen’s slidehttp://files.meetup.com/6816242/%28Pycon%20Taipei%29%20Scrapy-20130328.pdf
# Thanks Tim & c3h3 !





























