Embed Size (px)
Citation preview

QAシステム山本泰智

質問応答システム
自然言語による質問を受け付けられるシステム*
*テンプレートも含む

歴史1
• ‘natural language front-ends to databases’
• 15以上の英語でのQAシステムが過去5年で開発された (Simmons, 1965)
• 例: BASEBALL (1961), LUNAR (1971) ← 名前の通りのシステム
• 人と機械の対話システムという観点から開発
• 人の対話を研究するためのシステム
• チューリングテストからの影響
• 例: SHRDLU (1972), GUS (1977)

歴史2
• 話を理解するという観点から開発
• 質問の意図を汲むシステム
• 以下のような問題に対処“Do you know the time?” にyes/noで答える“How did John pass the exam?” にpenと答える
• 例: QUALM (1977)
質問を、確認、要求など13のカテゴリに分類
• 心理学の分野で発展

歴史3
• 情報検索 (IR)、情報抽出 (IE)という観点から開発
• IR: 入力(質問)は検索語で、出力は答えが含まれてると思しき文書
参考: “Who killed Lee Harvey Oswald?” と ”Who did Lee Harvey Oswald kill?”
• 1950年代から今に至るまで開発されている
• TREC (Text REtrieval Conference, 1992 -)が後押し
• IE: 予め設定されたテンプレートを埋める
• テンプレートが質問で、埋められたテンプレートを回答と見ることができる
• MUC (Message Understanding Conference, 1987 - 1998)
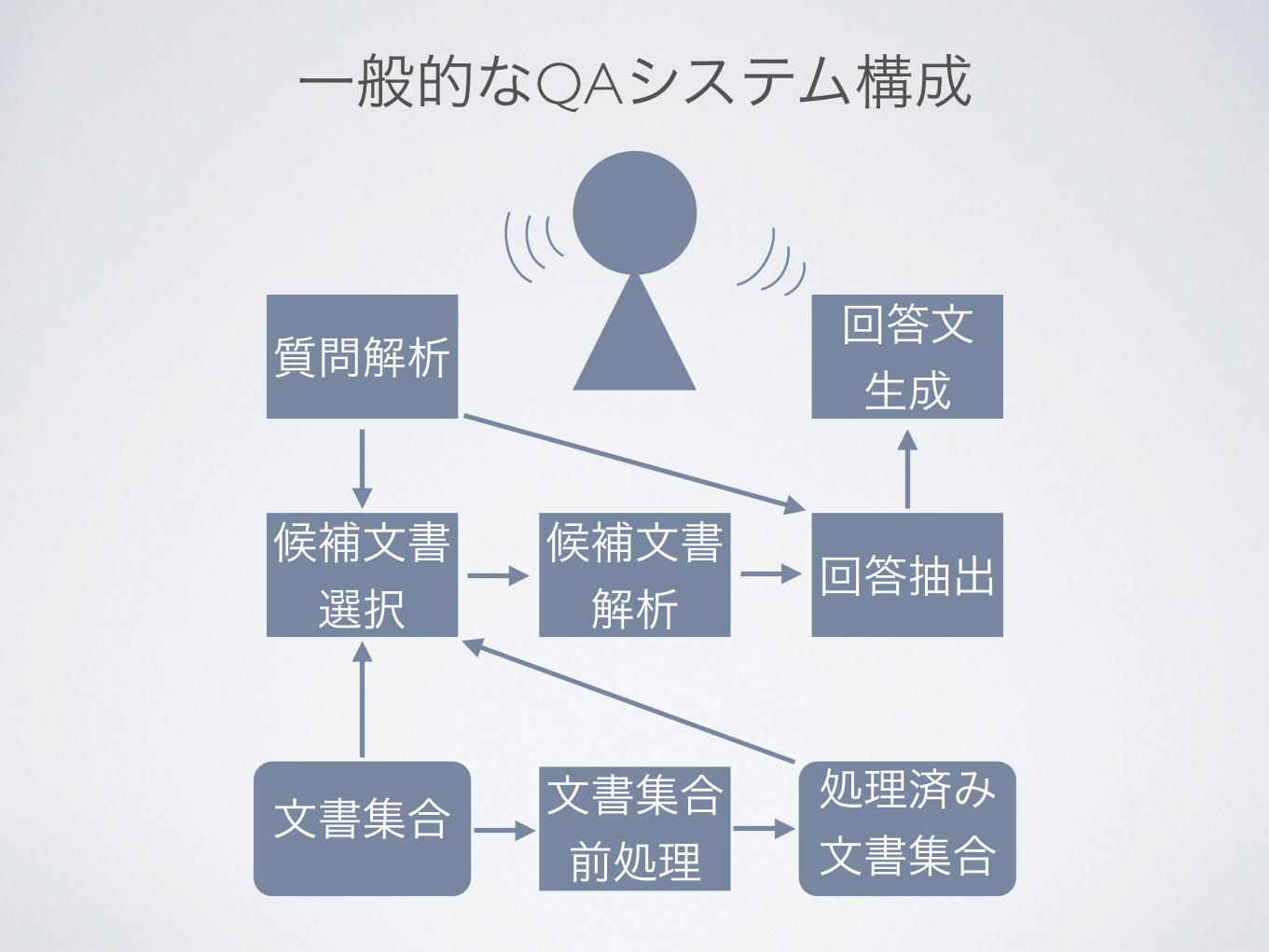
一般的なQAシステム構成
質問解析
候補文書選択
文書集合前処理
文書集合 処理済み文書集合
候補文書解析 回答抽出
回答文生成

研究の軸• 適用対象
• 入力の型: 構造データ / 非構造データ
• 入力データのサイズ: 固定 / 可変
• 領域: オープン / クローズ
• 利用者
• 対象領域の専門家 or not
• 質問
• 回答の型から質問を分類: 事実 / 意見 / 要約
• 質問の型で分類: yes-no / “wh” / 婉曲 / 命令

研究の軸• 回答
• 長短
• リスト / 説明
• 回答生成: 元文書内から抽出 / 回答文生成
抽出元: 複数文 / 複数文書
一貫性の保ち方
• 評価
• 必要十分な回答とは?
• 提示
• インターフェース: テキスト / 音声 / 画像
• 対話的 or not

• アメリカのNIST (National Institute of Standards and
Technology) が主催する会議
• 毎年文献検索に関する課題(track)が複数設置される
• 課題ごとに期限を設定して結果を募集し、11月に成果を比較し合う会議を開催する
• 興味を持つ人は誰でも結果を送付することで参加できる
参考: Text REtrieval Conference

• 1999年から2007年まで設置されていたtrack
• 500のfact-based、の質問に答えるシステムを構築して結果を比較する
• 例: “When was Mozart born?”.
• 情報源は下記新聞の記事100万件、3GBのテキスト
• AP newswire
• New York Times newswire
• Xinhua News Agency newswire
TREC QA Track

評価軸• Factoid
• incorrect / not supported / not exact / locally correct / globally correct
• List
• Each instance was evaluated in the same manner as the factoid questions,
• Let S be the number of such answers, D be the number of distinct globally correct answers returned by the system, and N be the total number of instances returned by the system. Then IP = D/N and IR = D/S.
• S: |complete list of known distinct globally correct answers|
• Other / Definition

生命科学分野のQA
• 問題点: 従来のIR (PubMed想定) ではヒット文献数は多いし本来必要としている情報ではなく書誌情報を返す
• QAにより解決:
• NLPのみ
• NLP+RDFの利用

Hristovski D, Dinevski D, Kastrin A, Rindflesch TC.Biomedical question answering using semantic relations.
BMC Bioinformatics. 2015 Jan 16;16:6.
• NLPツールSemRepを利用して予め知識ベースを構築
• 質問に対する回答を当該知識ベースから取得
• 自然言語での質問は受け付けない型のQA
該当する回答を列挙するList型
• MEDIEと類似だが、言及なし
• http://nactem2.mc.man.ac.uk/medie/search.cgi

背景
• EBM (Evidence-based Medicine, 根拠に基づく医学) の重要性
• 臨床医は素早く関連情報を見つけたい
• 実際は30分以上かかる
• 結果として答えが得られないままであることが多い

SemRep
• NLMが開発している、MEDLINE処理用NLPツール
• 英語の一文から意味的な記述を抽出
• UMLSを領域固有知識として利用し、そこで用いられている述語を利用
• 例: 入力文 We used hemofiltration to treat a patient with digoxin overdose that was complicated by refractory hyperkalemia.
• 出力データHemofiltration-TREATS-Patients Digoxin overdose-PROCESS_OF-Patients hyperkalemia-COMPLICATES-Digoxin overdoseHemofiltration-TREATS(INFER)-Digoxin overdose
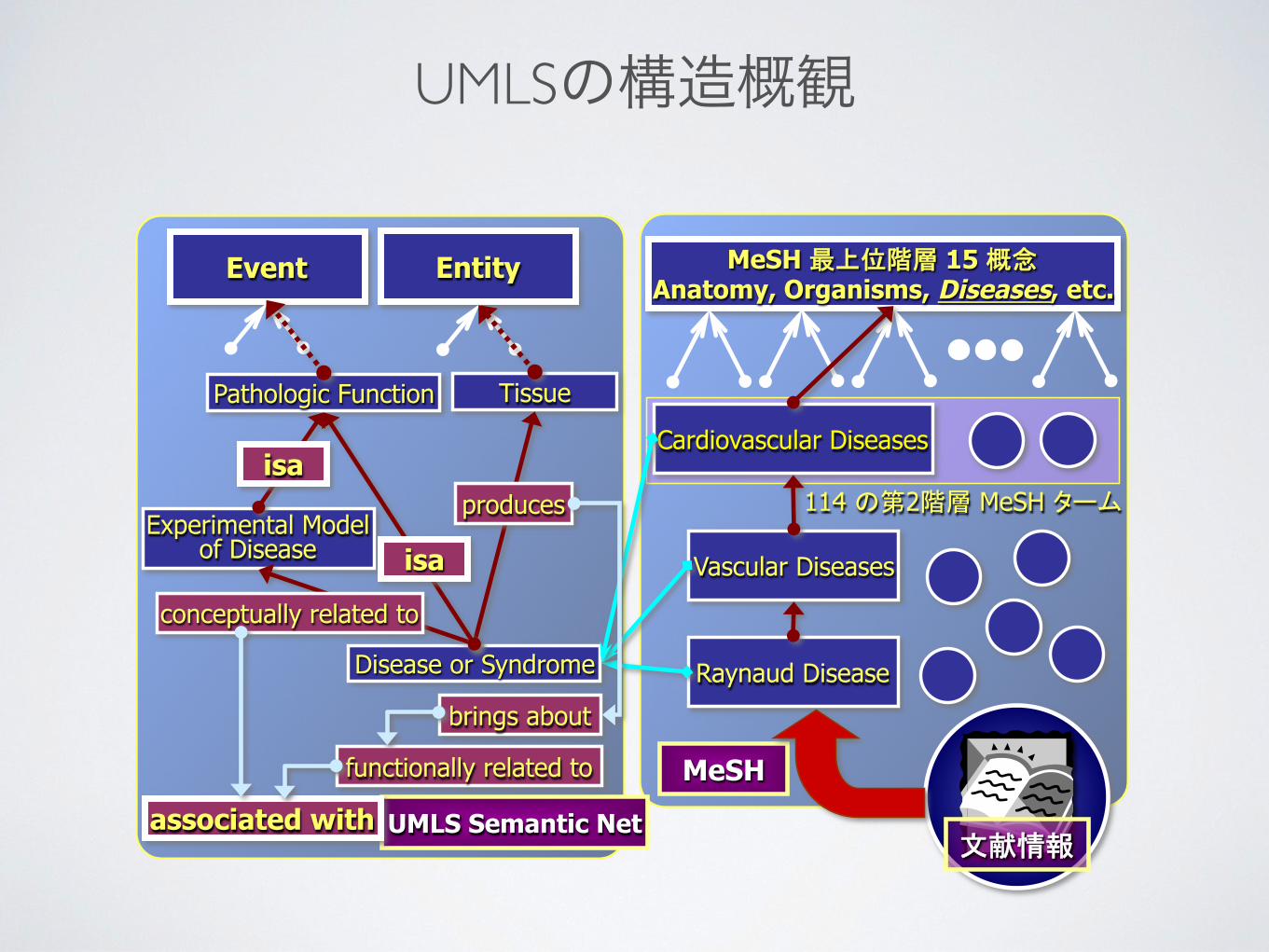
UMLSの構造概観
Event Entity MeSH 15 Anatomy, Organisms, Diseases, etc.
MeSH
114 2 MeSH
UMLS Semantic Net
Disease or Syndrome
Pathologic Function Tissue
Experimental Model of Disease
Cardiovascular Diseases
Vascular Diseases
Raynaud Disease
associated with
isa
isa
produces
conceptually related to
brings about
functionally related to

知識ベース
• 情報源:
全MEDLINE書誌情報21,014,382件、計122,421,765文(2012年末時点)
• 58,879,300件の意味的関係をSemRepを利用して取得
• Entrez GENE (SemRepから)、PubMed書誌情報と関連付け
• MySQLに格納、テキスト検索用にApache Lucene

意味的関係に関する情報
• 抽出元の文
• 意味的関係を構成するテキストの位置の情報 (結果のハイライト表示のため)
• 意味的関係の信頼性 (計算方法不明)
• 関係を示す語と関係を構成する語の間の距離
順位付けに利用 → 信頼性もこれから計算か?

評価
• 80人の領域専門家により抽出された意味的関係を評価20人毎の4グループに分けて、各関係を3グループに配分
それぞれ独立に評価
• 7,510の意味的関係が得られ、重複を除いて2,675の関係に
• それらがのべ12,083回評価され、うち、8,228が適切 (68%)

Asiaee AH, Minning T, Doshi P, Tarleton RL.A framework for ontology-based question answering with
application to parasite immunology. J Biomed Semantics. 2015 Jul 17;6:31
• 自然言語で質問を受け、SPARQLクエリを構築し、RDFデータを検索するフレームワークOntoNLQAを開発
• 質問文中の重要語間の意味関係を見つける手法が特徴
• 寄生虫免疫関連研究分野で試すためにAskCuebeeを開発
• 意味処理のためのオントロジーはparasite experiment ontology (PEO)
とOntology for Parasite Lifecycle

課題
• 質問文から得られる意味構造と対象データベースで利用しているオントロジーとの間の橋渡し
• 質問文中の概念と対象データベースに収められているデータとの橋渡し

OntoNLQAの質問理解1. 質問文を解析(parse)して重要語を同定する
→ 自然言語処理と機械学習
2. 各重要語について、対応するオントロジーのクラス、プロパティ、インスタンスを見つける
→ 文字列マッチ
3. オントロジーに従う意味的な関係を見つける
→ パス探索
4. 得られた関係からSPARQLクエリを生成してデータベースに問い合わせする

OntoNLQAの二つの意義
1. 予め質問対象のオントロジーに関する知識が不要it improves on the disadvantages of existing biomedical data retrieval systems. A major limitation is that scientists using these systems require an understanding of the ontology structure in order to quickly formulate queries.
2. 自然言語による質問を受けるmotivation derives from the fact that a capability to pose questions in plain language is a natural way of obtaining answers.

重要語の同定と認識• 同定手法: Conditional Random Field (CRF)
• CRFに用いる特徴量:
• 単語を構成する大文字/小文字、数字、記号の有無など
• 前後の単語、オントロジーに含まれる語との類似度など
• オントロジーとのマッチ: ISUB
• Case (1): 一つだけマッチ → それを認識語とする。
• Case (2): 複数マッチ → 文脈を考える。
質問分中の他の認識語とのオントロジーにおける近さなど。
• Case (3): 何もマッチしない → インスタンスを探す。rdf:typeの主語など。
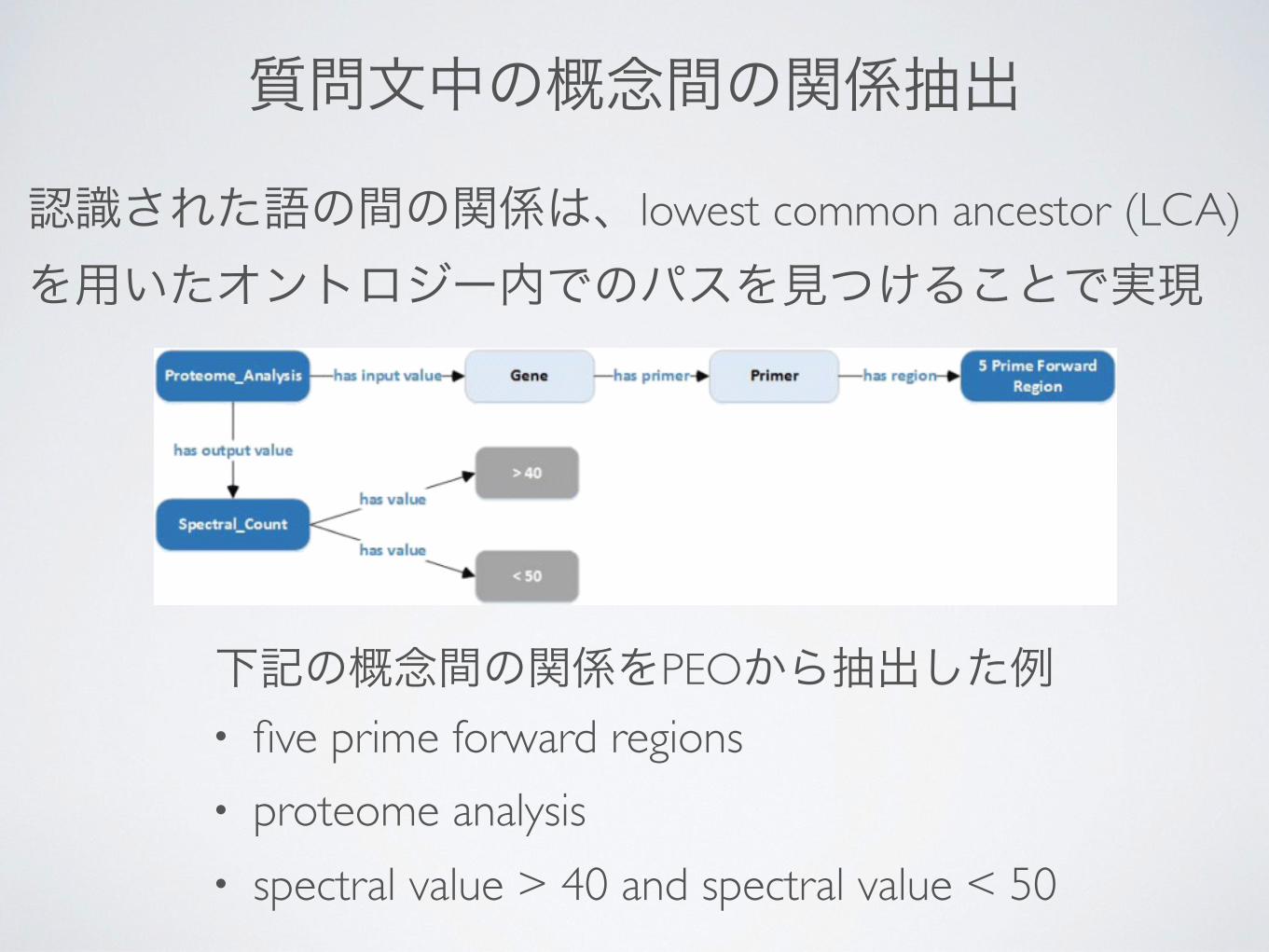
質問文中の概念間の関係抽出
認識された語の間の関係は、lowest common ancestor (LCA)を用いたオントロジー内でのパスを見つけることで実現
• five prime forward regions• proteome analysis• spectral value > 40 and spectral value < 50
下記の概念間の関係をPEOから抽出した例

LCAを見つけてSPARQLクエリを生成
• 以下の何れかの方法でLCAを取得
1. 予め対象オントロジーに対して全てのパスを取得しておく
2. SPARQL 1.1のプロパティパス検索機能を用いて取得
• 得られたLCAからSPARQLクエリを生成
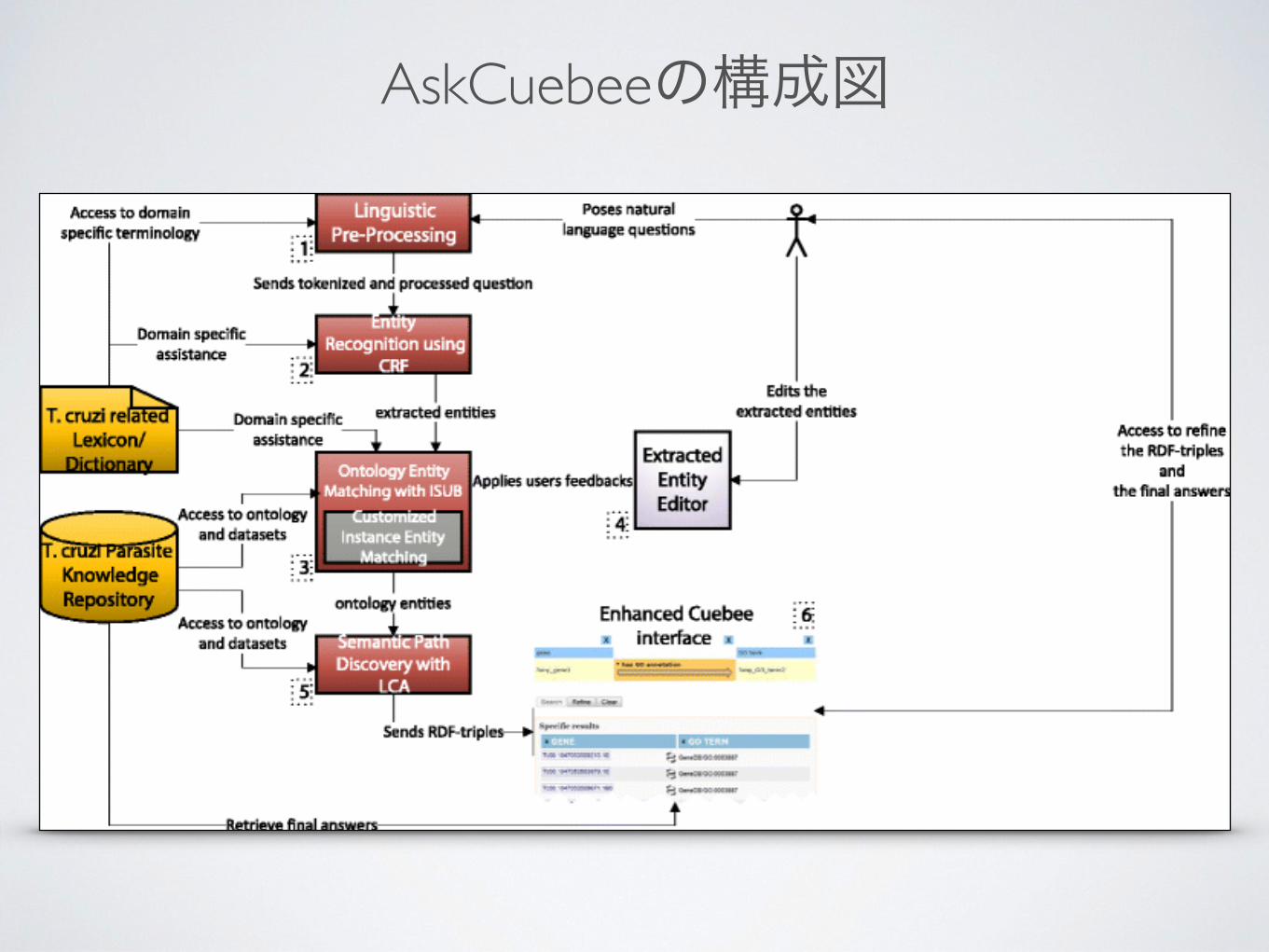
AskCuebeeの構成図

AskCuebeeの利用するデータベース• 下記の手持ち及び公共データをトリプルストアに格納
• Gene knockout: data on DNA cloning steps required to generate gene knockout plasmids
• Strain creation: data on creation of gene knockout strains in T. cruzi by transfection of parasites with gene knockout plasmids
• Microarray: data on genome relative transcript abundances for the life-cycle stages of T. cruzi
• Proteome: data on protein identification based on peptide spectra retrieved from T. cruzi’s life-cycle stages
• TriTrypDB and KEGG

評価• T. cruzi (Trypanosoma cruzi*)の研究者が学習用に125、テスト用に40
の質問それぞれ2セットを用意
• 当該研究者が日頃持つ疑問を網羅
• 例: What are the metabolic pathways related to protein group 271 for
the orthologous genes with spectral score below 2.0?
• それらについて、各コンポーネントについての評価と全体の評価、更にはエラー訂正など人為的な介入を行った上での評価を実施
• CRFの評価については学習用125質問を5群に分けて交差検証を実施* 鞭毛虫類キネトプラスト類トリパノソーマ属に属する原虫

結果• CRF: 92.28 (F1、5交差)
• ISUB: 81.69 (F1、5交差)
• オフラインLCAアプローチ: 90.80 (F1、5交差)
• 全体:
• 69.07 (F1、5交差)
• 60.76 (F1、テスト用40質問、人為介入無し)

考察
• 制限
• 質問文を構成する文法タイプに結果が依存
• 機械学習は沢山の訓練データが必要だがそれを補償するためにオントロジーマッチを追加している
• 特定の質問の型には意味的関係が適切に抽出できない
• 否定形、複雑な比較関係、オントロジーに関連づけられた概念が一つのみ、入れ子の質問や集合に対する質問など

困難な質問例
1. Find all gene knockout targets in amastigote stage that have orthologs in Leishmania but not in T. brucei
2. Give the strain summaries for all amastigote genes that have a standard deviation less than 1.5 of the log2 ratio
3. Show proteins that are downregulated in the epimastigote stage and exist in a single metabolic pathway

そのほかの関連研究
http://nlp.uned.es/clef-qa/CLEF Question Answering Track
LODQAhttp://lodqa.org/

参考文献UCSB (University of California Santa Barbara) のヤン先生の資料
http://www.cs.ucsb.edu/~tyang/
東大の中川先生の資料http://www.r.dl.itc.u-tokyo.ac.jp/~nakagawa/infoDB/ir-esti.ppt
TREC16 QA trackに関する文献http://trec.nist.gov/pubs/trec16/papers/QA.OVERVIEW16.pdf
BMC Bioinformatics. 2015 Jan 16;16:6. doi: 10.1186/s12859-014-0365-3. Biomedical question answering using semantic relations. Hristovski D1, Dinevski D2, Kastrin A3, Rindflesch TC4.
J Biomed Inform. 2003 Dec;36(6):462-77. The interaction of domain knowledge and linguistic structure in natural language processing: interpreting hypernymic propositions in biomedical text. Rindflesch TC1, Fiszman M.
Hirschman L, Gaizauskas R: Natural language question answering: the view from here.Nat Lang Eng 2002, 7:275–300.
J Biomed Semantics. 2015 Jul 17;6:31. doi: 10.1186/s13326-015-0029-x. eCollection 2015. A framework for ontology-based question answering with application to parasite immunology. Asiaee AH1, Minning T2, Doshi P1, Tarleton RL2.





























