Embed Size (px)
Citation preview

Эффективные
алгоритмы поиска
подобных объектов
для терабайтов данных
Евгений Журин,
data scientist,
Segmento
2
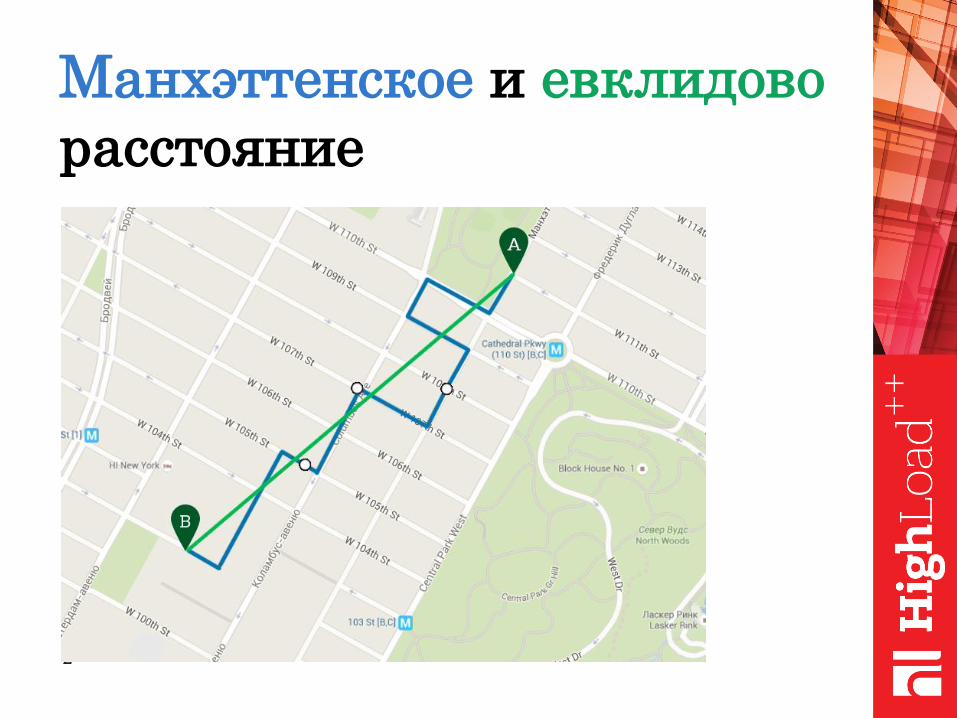
Манхэттенское и евклидово
расстояние
3
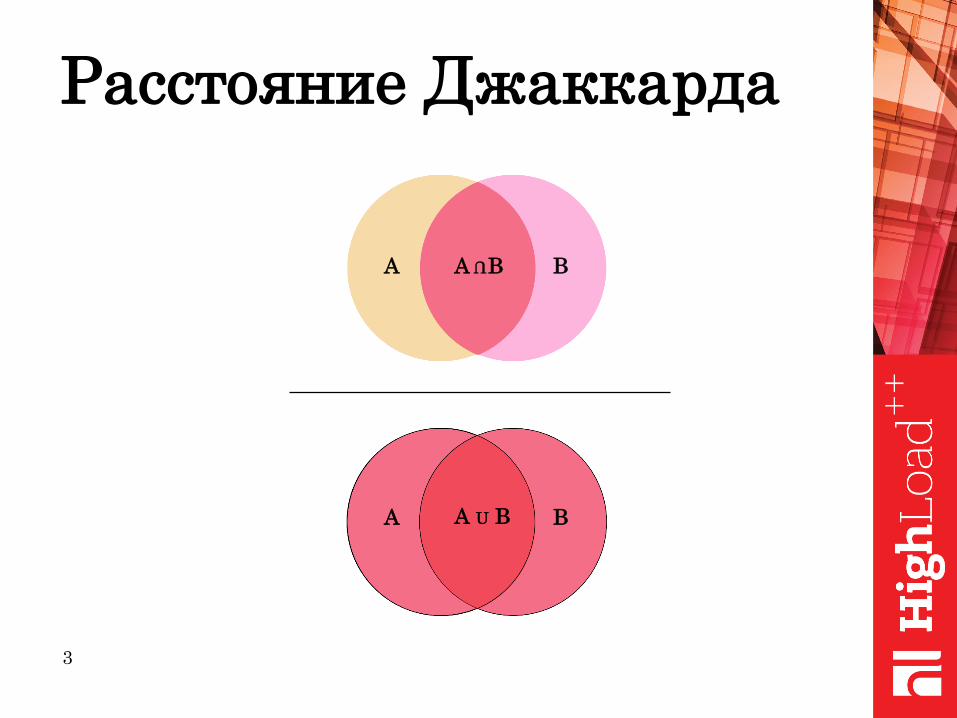
Расстояние Джаккарда
А ВА В
U
А ВА U В

4
Look aLike
5
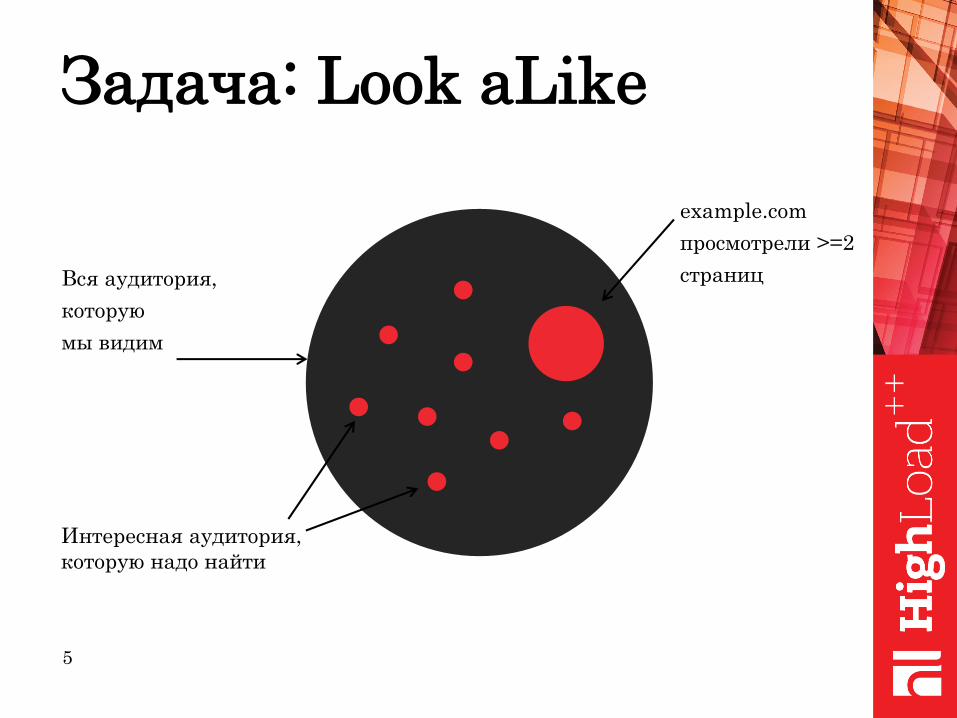
Задача: Look aLike
Вся аудитория,
которую
мы видим
Интересная аудитория,
которую надо найти
example.com
просмотрели >=2
страниц

6

7
У нас было
1. 250 000 000 + профилей
2. 1 000 000 +- площадок
3. 30000 RPS (2.5 млрд. в
день)

8
Что такое для нас профиль?
offline данные
История поведения
в интернете
Контекстная
информация
(где, откуда,
с какого устройства)
9
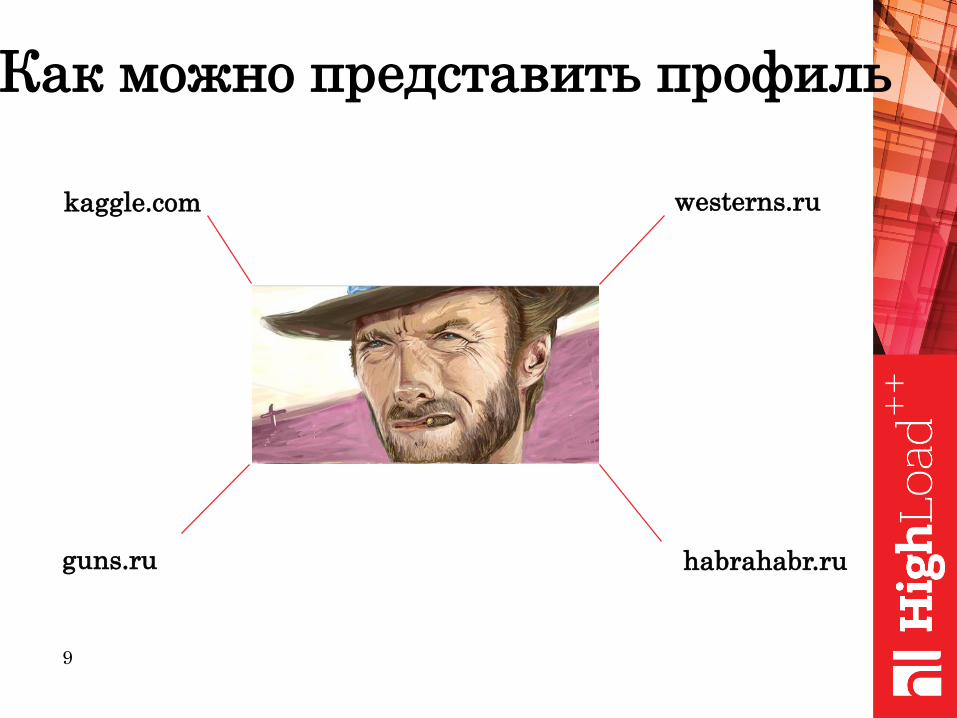
Как можно представить профиль
kaggle.com westerns.ru
habrahabr.ruguns.ru
10
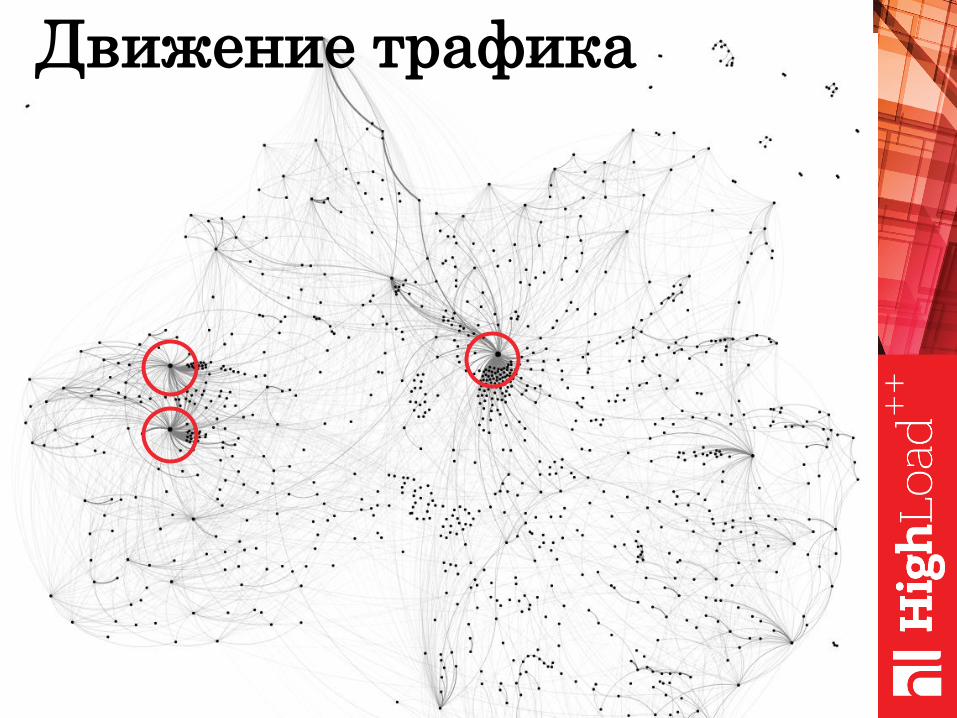
Движение трафика

11
Чистим данные
1. Выкидываем профили
с недостаточной статистикой
2. И сайты, с которых идет больше
всего и меньше всего трафика

12
MinHash и расстояние
Джаккарда
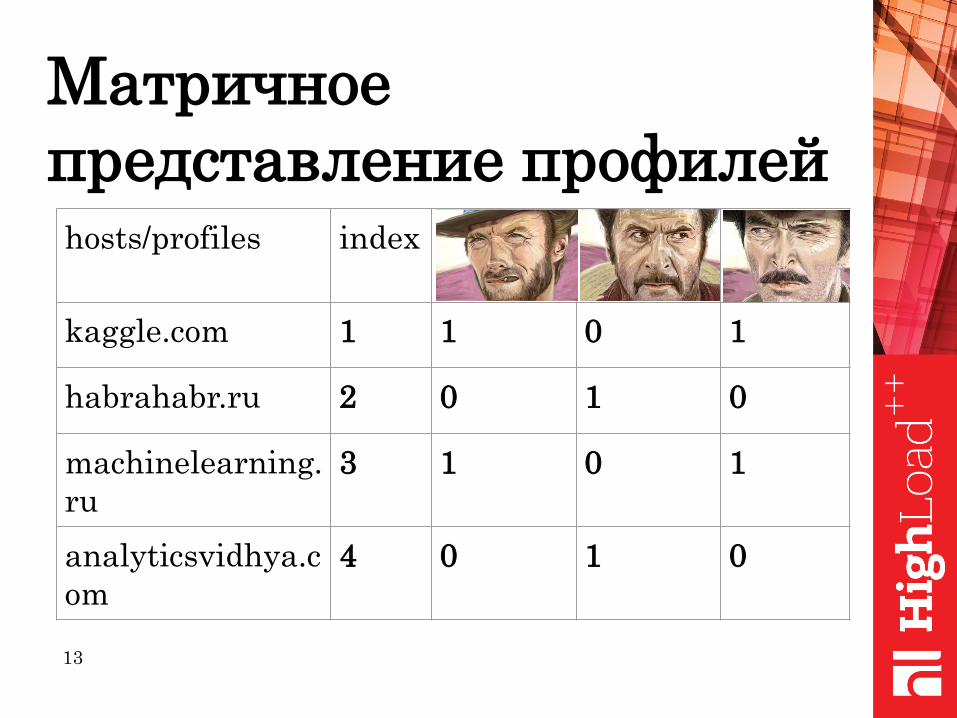
13
Матричное
представление профилейhosts/profiles index
kaggle.com 1 1 0 1
habrahabr.ru 2 0 1 0
machinelearning.
ru
3 1 0 1
analyticsvidhya.c
om
4 0 1 0
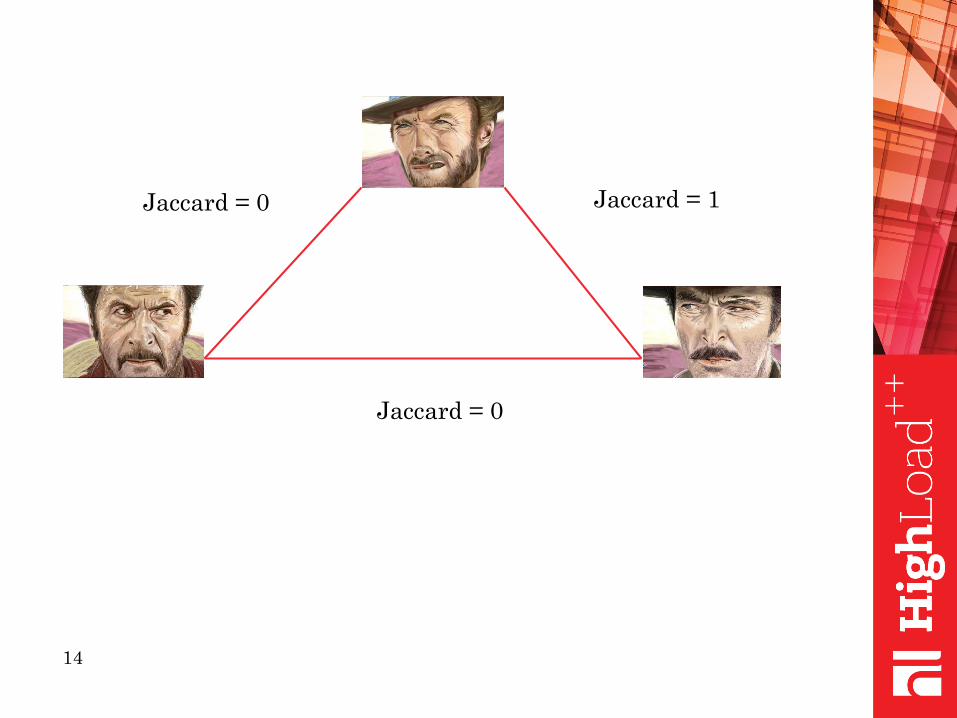
14
Jaccard = 0 Jaccard = 1
Jaccard = 0
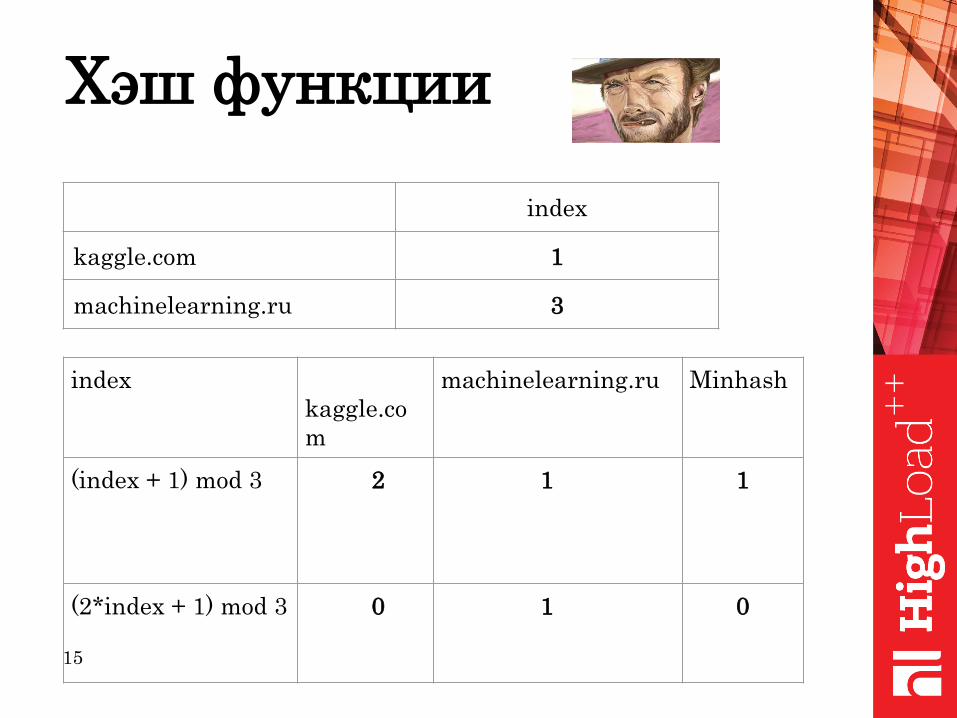
15
Хэш функции
index
kaggle.com 1
machinelearning.ru 3
index
kaggle.co
m
machinelearning.ru Minhash
(index + 1) mod 3 2 1 1
(2*index + 1) mod 3 0 1 0

16
MinHash представление
(x + 1) mod 3 1 0 1
(2x + 1) mod 3 0 0 0
17
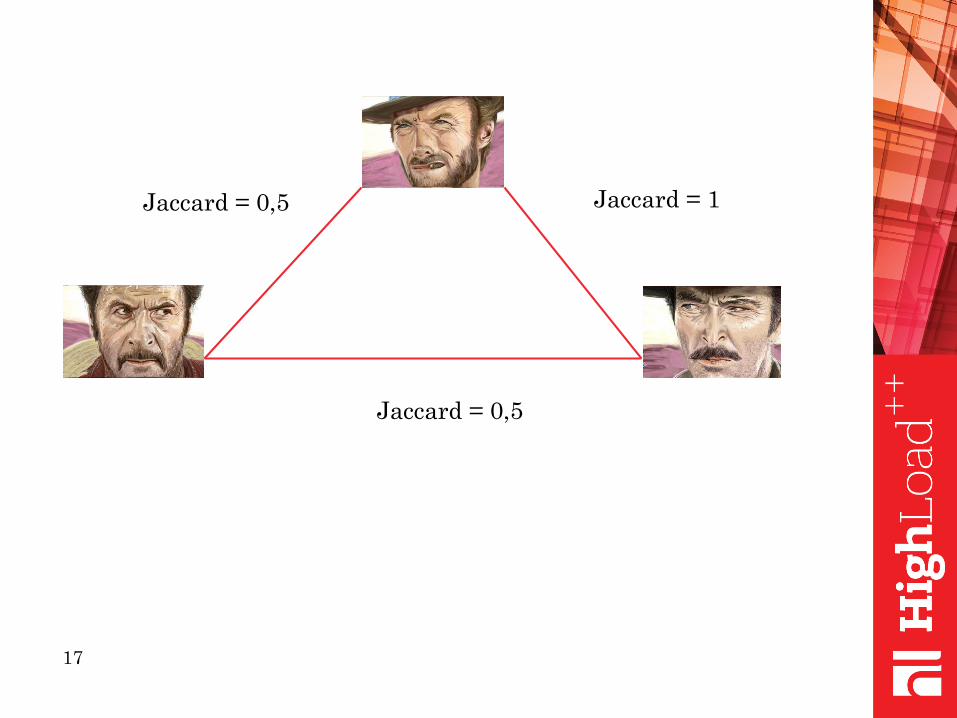
Jaccard = 0,5 Jaccard = 1
Jaccard = 0,5
18
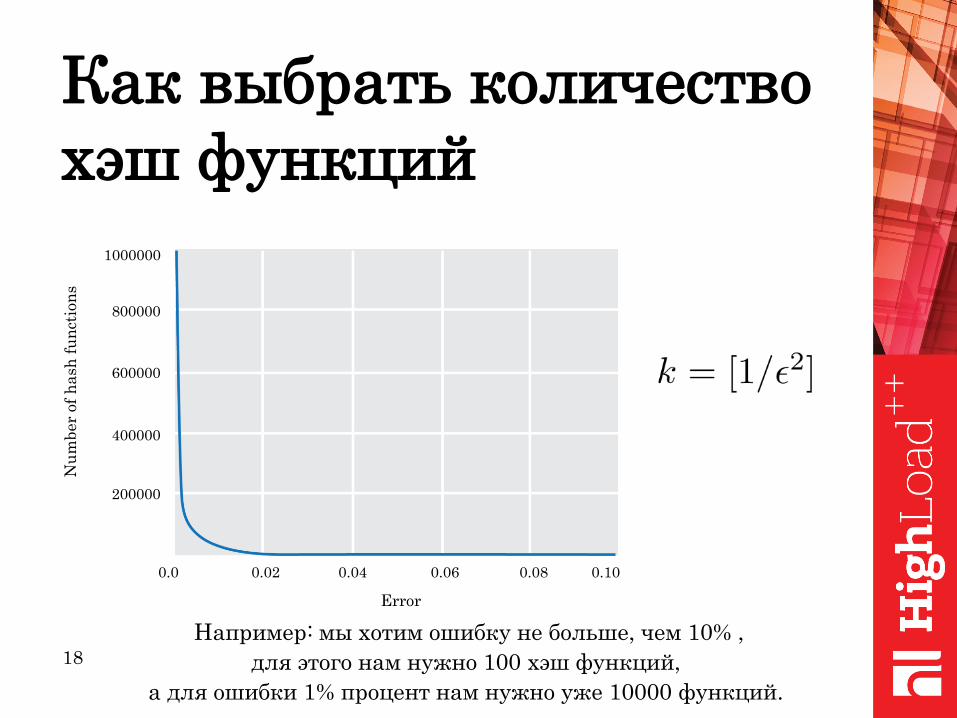
Как выбрать количество
хэш функций
0.0 0.02 0.04 0.06 0.08 0.10
200000
400000
600000
800000
1000000
Nu
mb
er
of
ha
sh f
un
ctio
ns
Error
Например: мы хотим ошибку не больше, чем 10% ,
для этого нам нужно 100 хэш функций,
а для ошибки 1% процент нам нужно уже 10000 функций.

19
Как выбрать параметры
хэш функций?
a, b — случайные целые числа < max(x)
c — простое число, чуть большее чем max(x), общее для всех
h(x) = (ax + b) mod c

20
Locality Sensitive Hashing
21
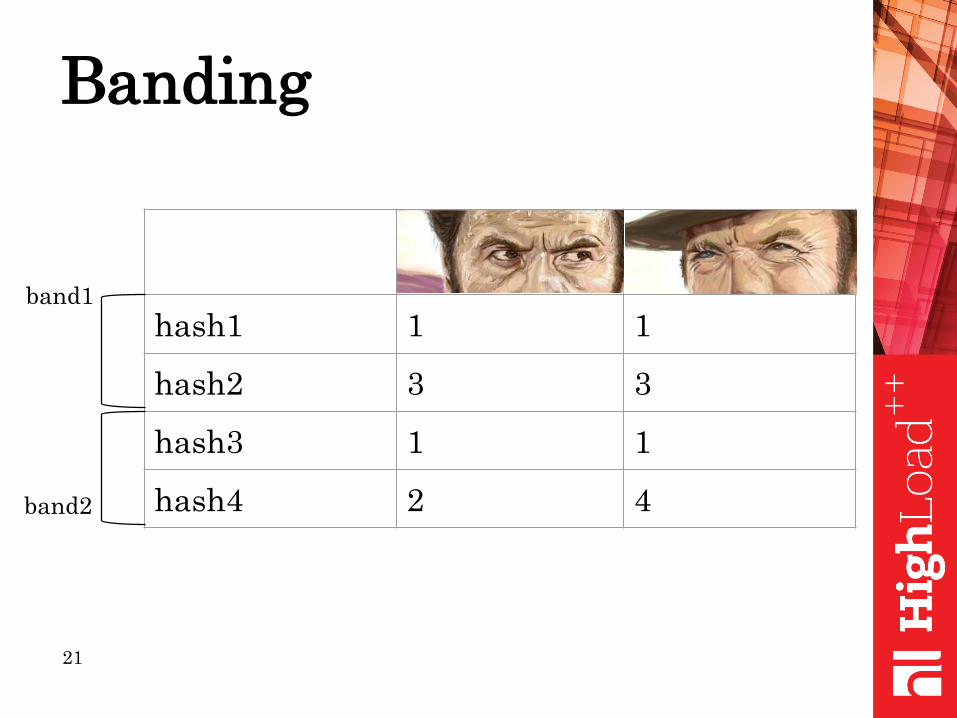
Banding
hash1 1 1
hash2 3 3
hash3 1 1
hash4 2 4
band1
band2
22
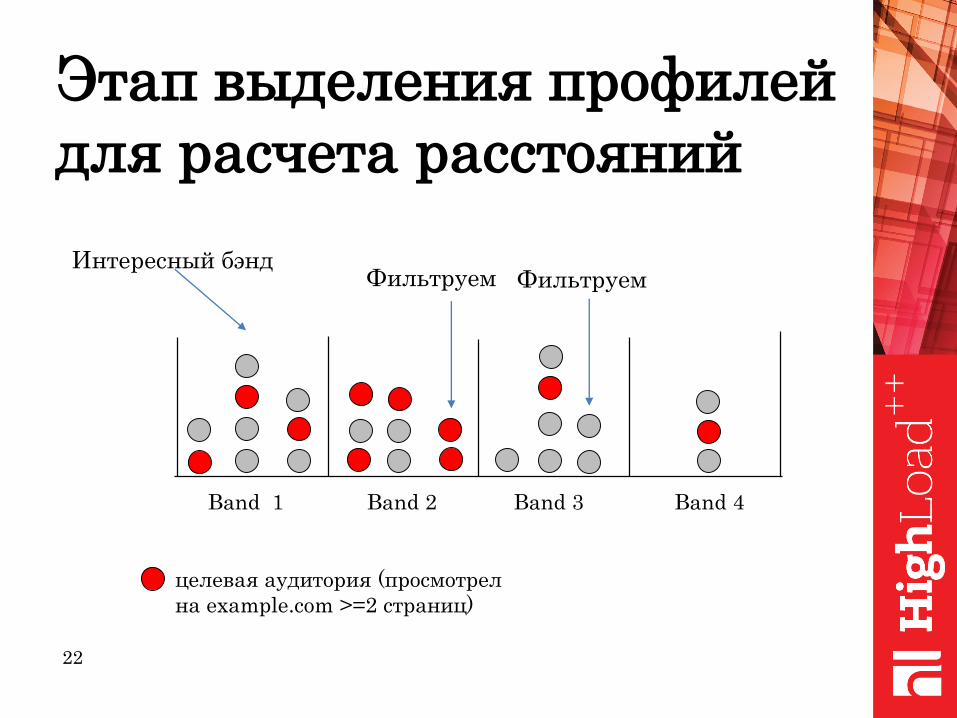
Этап выделения профилей
для расчета расcтояний
Band 1 Band 2 Band 3 Band 4
целевая аудитория (просмотрел
на example.com >=2 страниц)
ФильтруемИнтересный бэнд
Фильтруем
23
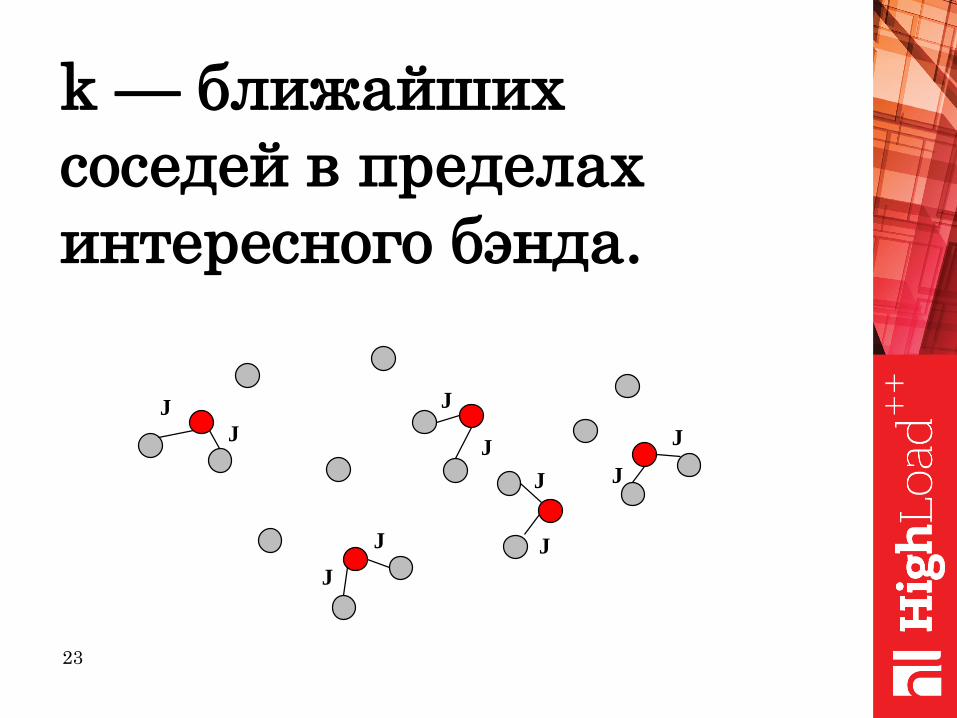
k — ближайших
соседей в пределах
интересного бэнда.
J J
JJ
J
J
J
J J
J
24
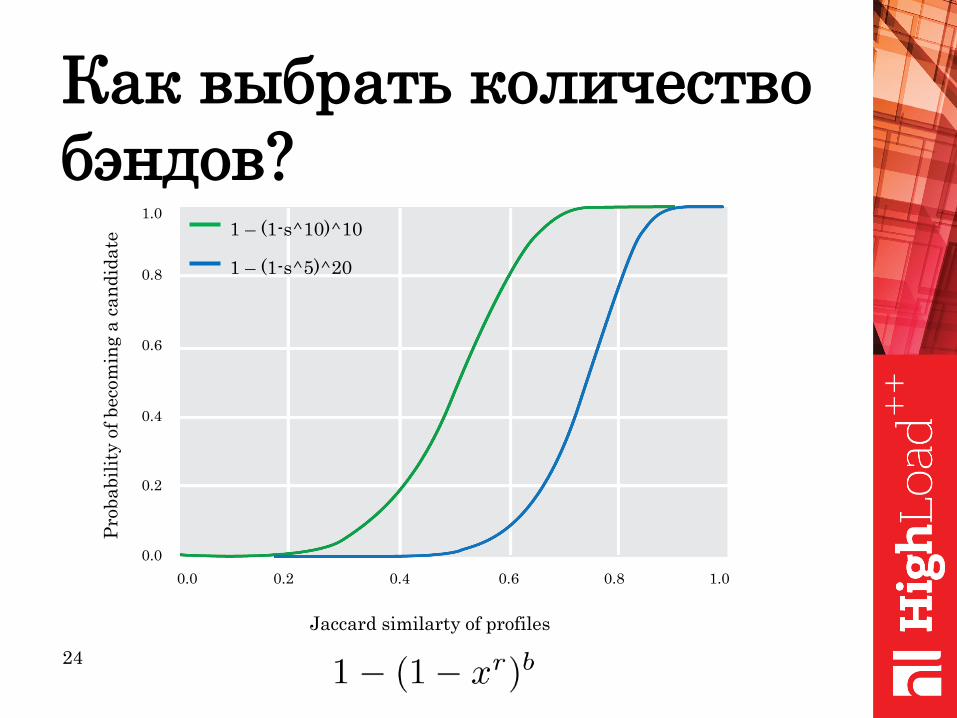
1 – (1-s^10)^10
Jaccard similarty of profiles
0.0 0.2 0.4 0.6 0.8 1.0
1.0
0.8
0.6
0.4
0.2
0.0
Pro
ba
bil
ity o
f b
eco
min
g a
ca
nd
ida
te
1 – (1-s^5)^20
Как выбрать количество
бэндов?

25
Но эксперимент никто
не отменял
Долго, дорого и очень хорошо Быстро, дешево и не очень хорошо

26
Куда еще смотрим?

27

28
DIMSUM
Dimension Independent Matrix
Square using MapReduce

29
Что у нас есть?machinelearning.ru habrahabr.ru
1 4
8 1
7 9
Матрица A
размерности MxN, где M >> N и 0 <= a <=1 и
кол-во ненулевых элементов в строке <= L << N

30
Что хотим найти?
Похожесть сайтов на основе
их посещения аудиторией.
Более формально и в более общем виде –
задача расчета матрицы расстояний
между столбами.

31
Зачем?
1) Снижение размерности
2) Нужно в маркетинговых исследованиях

32
Наивно, долго, точно
Dimsum, быстро и почти точно

33
Стэк используемых
технологий:
1.Python
2.Hadoop
3.Luigi
4.Hbase

34
Спасибо !





























