Embed Size (px)
Citation preview

本当にあった Apache Spark障害の話
株式会社サイバーエージェント 井上 ゆり

自己紹介>
井上 ゆり
株式会社サイバーエージェント
アドテク本部 AMoAd所属
twitter: @iyunoriue
GitHub: x1-
HP: バツイチとインケンのエンジニアブログ http://x1.inkenkun.com/

2014年3月、ApacheSparkの
メジャー・バージョンがリリースされました。
1年半経った現在1.5.2がリリースされています。
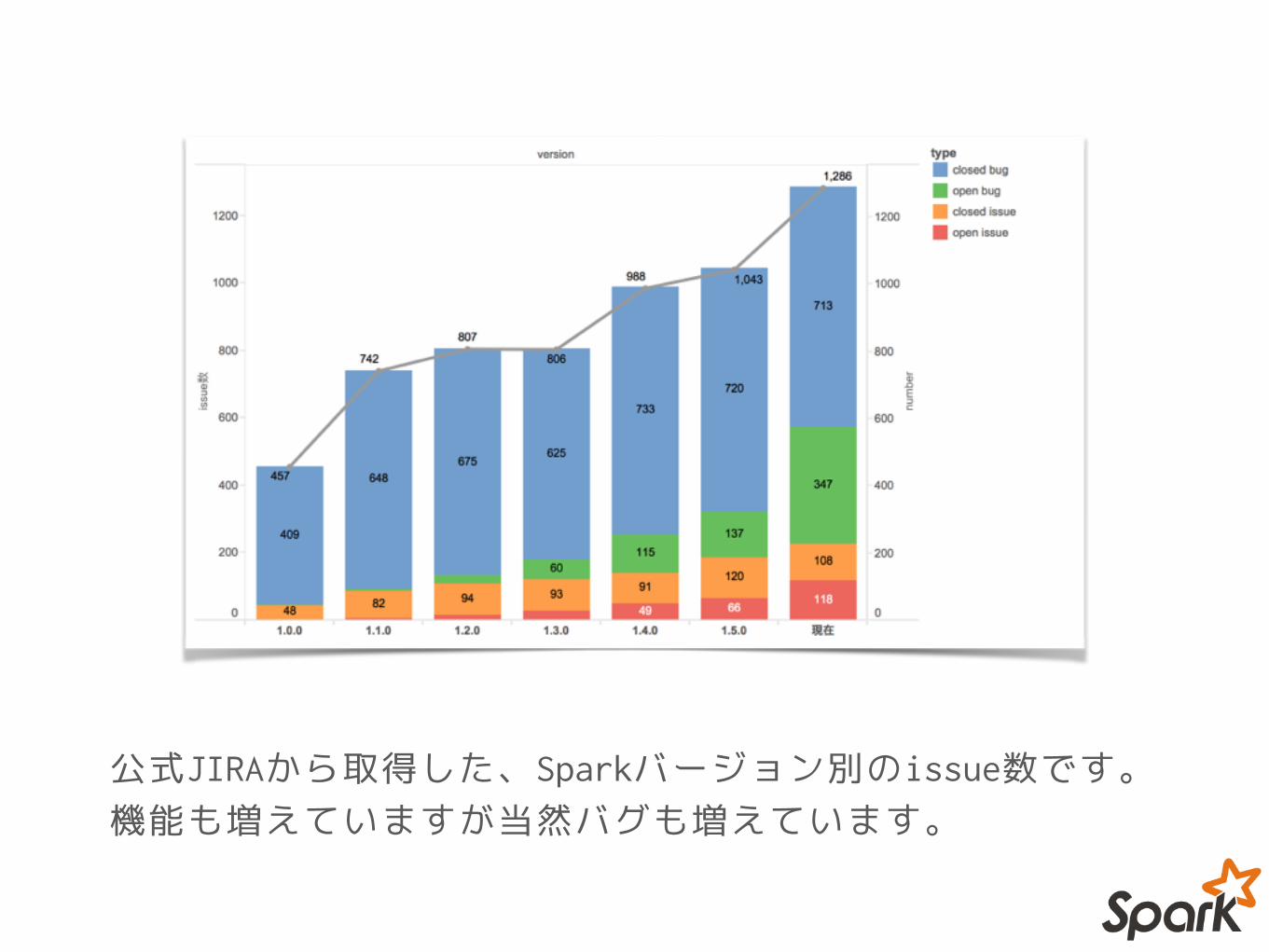
公式JIRAから取得した、Sparkバージョン別のissue数です。 機能も増えていますが当然バグも増えています。

1年近くApacheSparkと付き合って、
その間に行ってきた
トラブルシューティングを
3つほどお話させて頂きます。

その前に・・・

Spark環境と用途• Sparkクラスタ : N十台, オンプレ
• Sparkクラスタ化: zookeeper + Mesos
• SparkノードのFS: HDFS-HA + GCS + S3
• GUI : Apache Zeppelin, iPython
• 開発言語 : scala
• ジョブのビルド : sbt
• 用途 : 定常ジョブ(cron実行)
アドホック分析

Sparkのバージョンを1.4.0から1.5.1に アップグレードしたら、HDFS-HAでエラー
case.1

case.1 Spark1.5系&HDFS-HAでエラー
Sparkクラスタを1.4.0から1.5.1へバージョンアップしたところ、ジョブがfailするようになりました。
NameNodeが解決できていないようなエラーメッセージです。 ※nameservice1はHDFS-HAクラスタに設定した論理サービス名です。
内容
15/10/21 15:22:12 WARN scheduler.TaskSetManager: Lost task 0.0 in stage 0.0 (TID 0, spark003.example.com):
java.lang.IllegalArgumentException: java.net.UnknownHostException: nameservice1
at org.apache.hadoop.security.SecurityUtil.buildTokenService(SecurityUtil.java:374)
at org.apache.hadoop.hdfs.NameNodeProxies.createNonHAProxy(NameNodeProxies.java:312)
at org.apache.hadoop.hdfs.NameNodeProxies.createProxy(NameNodeProxies.java:178)
at org.apache.hadoop.hdfs.DFSClient.<init>(DFSClient.java:665)
at org.apache.hadoop.hdfs.DFSClient.<init>(DFSClient.java:601)
:

case.1 Spark1.5系&HDFS-HAでエラー
• HDFSのHighAvailabilityを無効にすると正常に終了します。
• また、クラスタのバージョンを1.4系に戻すと正常に終了します。
• JIRAにバグ報告するものの、HDFSの設定ファイルを見なおせとのこと。
SPARK-11227: Spark1.5+ HDFS HA mode throw java.net.UnknownHostException: nameservice1
https://issues.apache.org/jira/browse/SPARK-11227
Try

case.1 Spark1.5系&HDFS-HAでエラー
• Apache Zeppelinで同じ内容を実行すると正常終了するので差異を調べました。
• Zeppelinで使われているSQLContextはHiveContext。
• 私たちが使っていたSQLContextはデフォルトのSQLContext。
どうやらHiveContextが鍵のようです。
原因
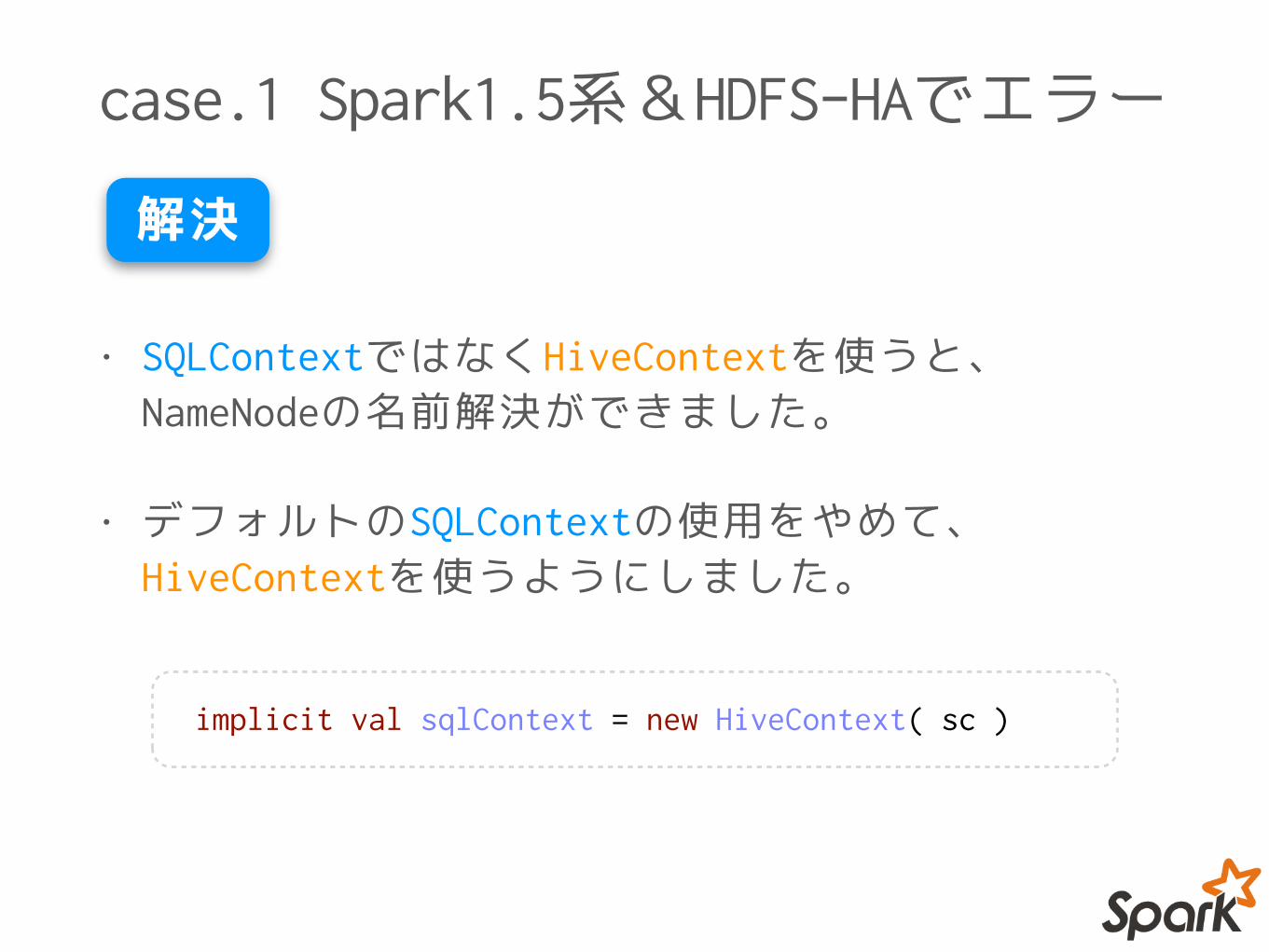
case.1 Spark1.5系&HDFS-HAでエラー
• SQLContextではなくHiveContextを使うと、NameNodeの名前解決ができました。
• デフォルトのSQLContextの使用をやめて、HiveContextを使うようにしました。
解決
implicit val sqlContext = new HiveContext( sc )

executorからの応答がなくなる
case.2

case.2 executorからの応答がなくなる
Sparkでジョブを実行すると、タスクはdriverによって複数個に分割されてexecutorで実行されます。
内容
分割タスクが完了するとexecutorはdriverにレスポンスを返します。
driver
executor
executor
executor
driverタスク 結果
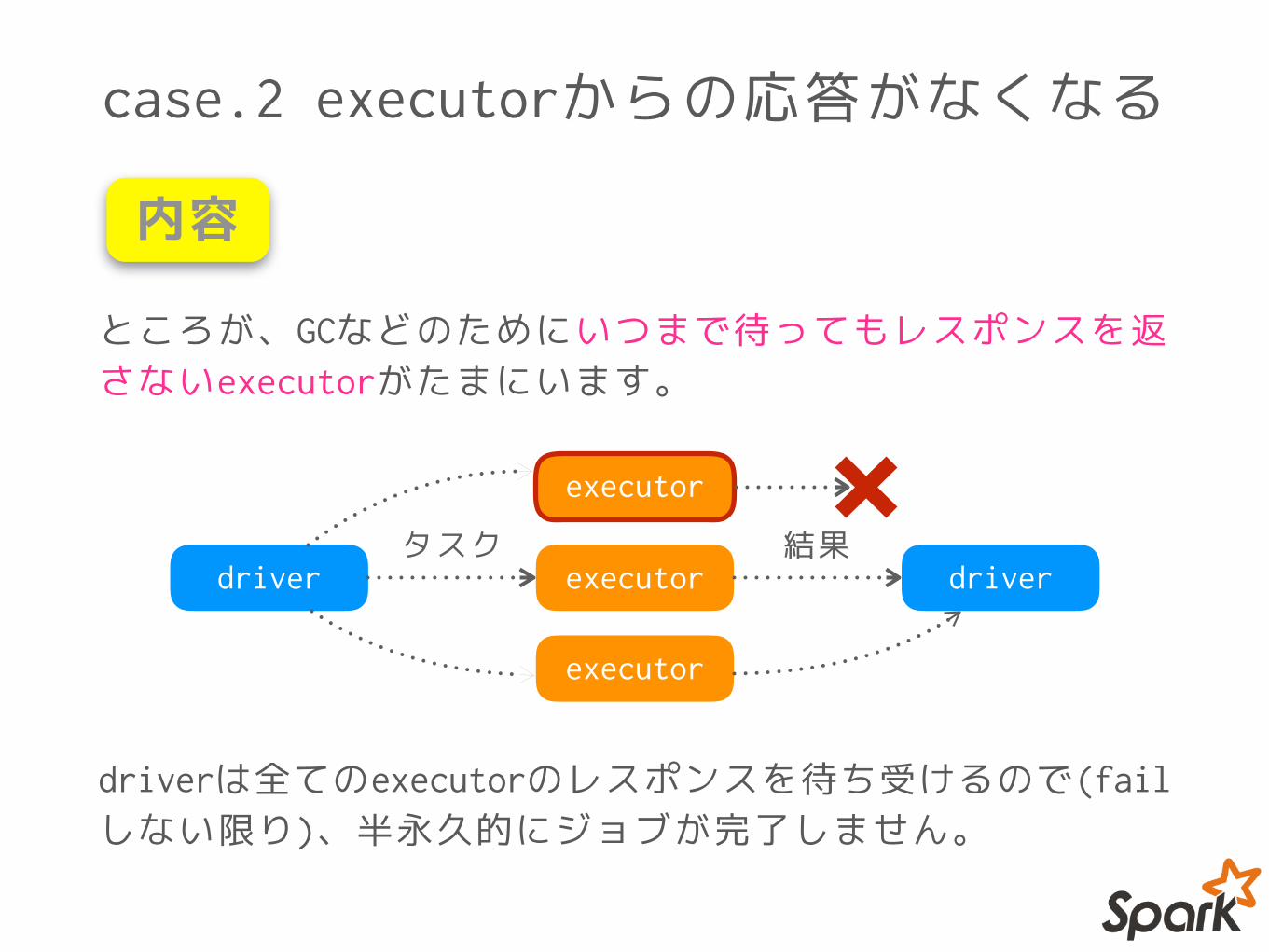
case.2 executorからの応答がなくなる
ところが、GCなどのためにいつまで待ってもレスポンスを返さないexecutorがたまにいます。
内容
driverは全てのexecutorのレスポンスを待ち受けるので(failしない限り)、半永久的にジョブが完了しません。
driver
executor
executor
executor
driverタスク 結果

a a
case.2 executorからの応答がなくなる
• 完了しないジョブがSparkクラスタ内のメモリ資源を確保し続けてしまいました。
• 別のジョブが開始されると、クラスタ内のメモリ解放を待ち続けるという負の待ち行列が発生してしまいました。
問題
ジョブAが確保したメモリ 空きメモリ
ジョブBが必要なメモリ
クラスタの総メモリ
不足!メモリに空きができるまで待つ
ジョブCが必要なメモリ

case.2 executorからの応答がなくなる
•spark.network.timeout: 120s
spark.network.timeoutに設定した値は、ほとんど全ての通信系タイムアウト(下記)のデフォルト値になります。
* spark.core.connection.ack.wait.timeout
* spark.akka.timeout
* spark.storage.blockManagerSlaveTimeoutMs
* spark.shuffle.io.connectionTimeout
* spark.rpc.askTimeout
* spark.rpc.lookupTimeout
Try
まずはタイムアウト関連の設定を見直しました。

case.2 executorからの応答がなくなる
•spark.dynamicAllocation.executorIdleTimeout: 60s
ダイナミック・アロケーションが有効な場合のexecutorのアイドル時間です。 ※ダイナミック・アロケーションを有効にしていないので関係ありませんでした。
Try
タイムアウトの設定ではなさそうです。
その他のタイムアウト設定。

case.2 executorからの応答がなくなる
遅延タスクを再起動するspark.speculationを設定しました。
spark.speculationがtrueに設定されていると、遅いタスクの再起動を実施します。
※DatabicksのMatei Zahariaがここ↓で回答しているように、stragglersをkillするような仕組みはないようです。 http://apache-spark-user-list.1001560.n3.nabble.com/Does-Spark-always-wait-for-stragglers-to-finish-running-td14298.html
解決.1
spark.speculation true spark.speculation.multiplier 1.5 spark.speculation.quantile 0

case.2 executorからの応答がなくなる
更に、OSのtimeoutコマンドで終了しないジョブを強制タイムアウトさせました。
タスクの強制再起動で予想外に時間がかかってしまったジョブは、強制終了させます。
解決.2
timeout 600 $SPARK_HOME/bin/spark-submit job.jar

CIツール(Jenkins)でジョブの sbtテストがfailする
case.3

case. ジョブのsbtテストがfailする
各テスト内でSparkコンテキストを生成してテストを実施していました。
内容
sc = new SparkContext( conf ) val rdd = sc.parallelize( Seq( 1, 2 ) ).map( id => Row( id, 0d, "", "http://example.com/" ) ) val df = sqlContext.createDataFrame( rdd, schema )
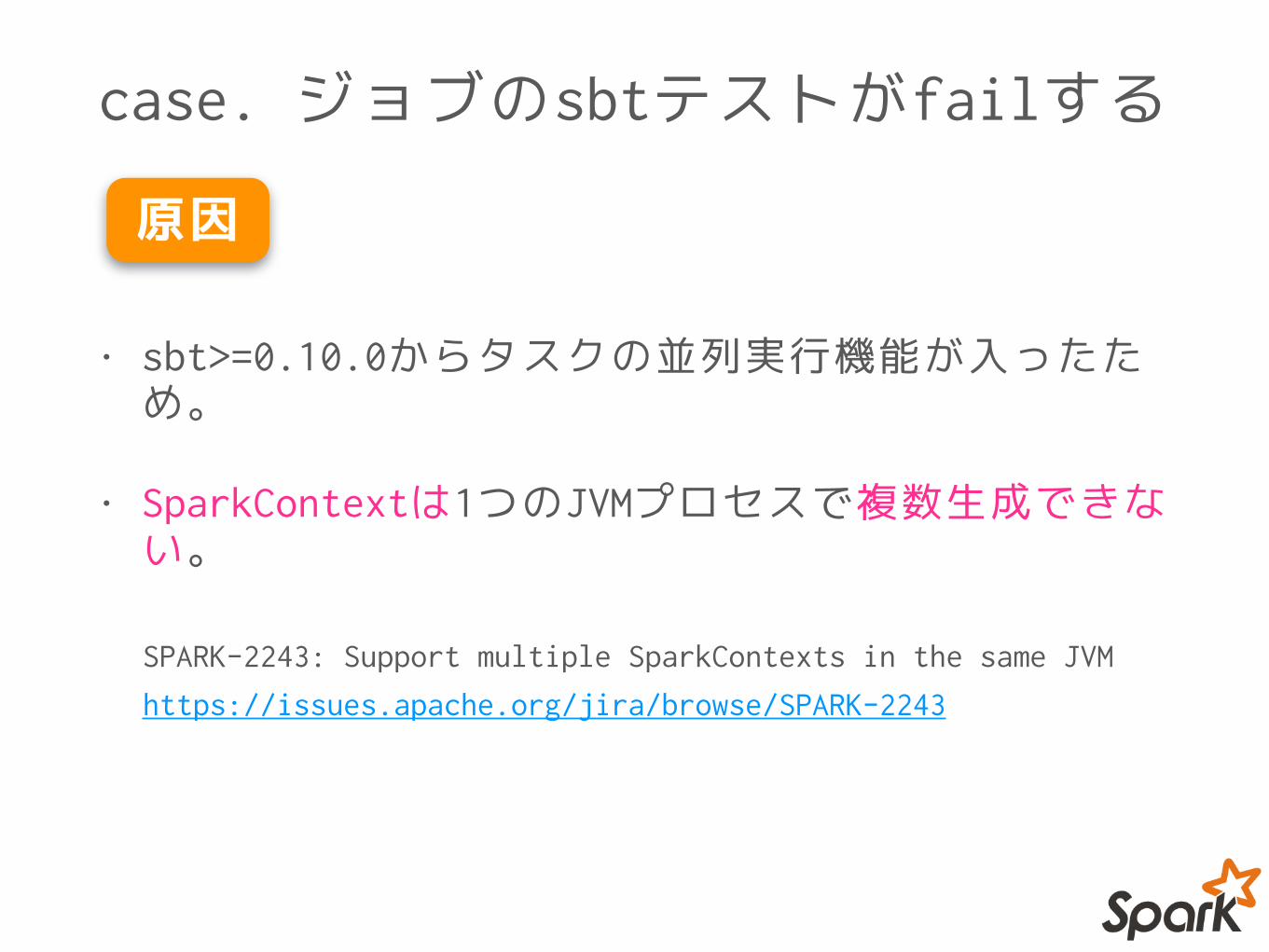
case. ジョブのsbtテストがfailする
• sbt>=0.10.0からタスクの並列実行機能が入ったため。
• SparkContextは1つのJVMプロセスで複数生成できない。
SPARK-2243: Support multiple SparkContexts in the same JVM https://issues.apache.org/jira/browse/SPARK-2243
原因

case. ジョブのsbtテストがfailする
• テスト実行時のタスク並列実行をやめました。
• build.sbtに下記を追加したところ、正常に実行されるように・・・!
解決
parallelExecution in Test := false

まとめ

solv 1. Spark1.5系ではHiveContextを使ったほうが幸せ
solv 2. executorから応答がなくなって困ったときはspark.speculationを使おう
timeout付きでジョブを実行すると安心
solv 3. sbt testの前にparallelExecutionの設定を!





























