Embed Size (px)
Citation preview

Distributed Representations of Words and Phrases and their Compositionally
長岡技術科学大学 自然言語処理研究室高橋寛治
Mikolov, T., Sutskever, I., Chen, K., Corrado, G., & Dean, J. (2013).Distributed Representations of Words and Phrases and theirCompositionality. Advances in Neural Information ProcessingSystems 26 (NIPS 2013)「word2vecによる自然言語処理」の図を利用
文献紹介 2016年4月13日

概要•MikolovらのWord2vecの論文
•前のモデルと比べ、計算が早くなり高精度化•フレーズも考慮
Ø“Canada”と“Air”→”Air Canada”
DistributedRepresentationsofWordsandPhrasesandtheirCompositionally

はじめに•ベクトルによる単語の表現は1986年から研究•Mikolovら(2013)がSkip-gram modelを提案
•vec(“Madrid”) – vec(“Spain”) + vec(“France”)≒ vec(“Paris”)
DistributedRepresentationsofWordsandPhrasesandtheirCompositionally

Skip-gramモデル Mikolov(2013)
DistributedRepresentationsofWordsandPhrasesandtheirCompositionally
•入力単語の文脈中の単語を推定
•これを拡張

Skip-gramモデル•単語列w1,w2,w3…wT,文脈サイズc
•W(105~107)が大きすぎて計算は非現実的DistributedRepresentationsofWordsandPhrasesandtheirCompositionally
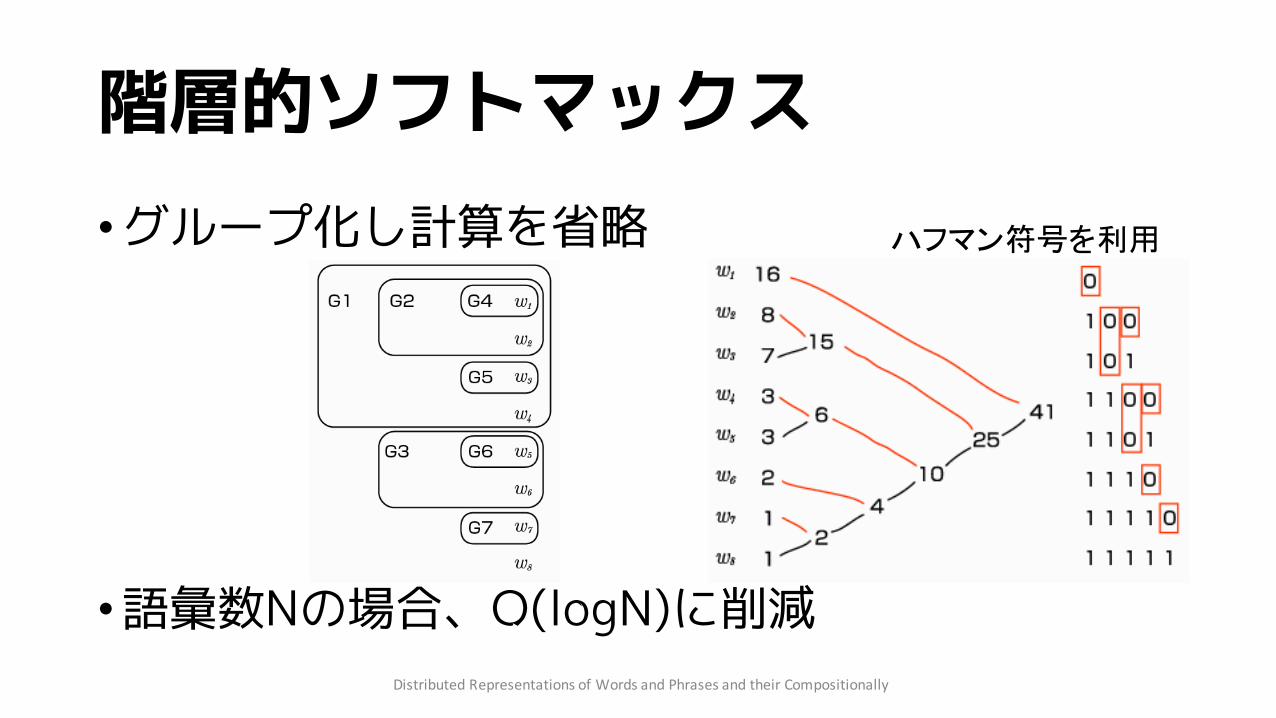
階層的ソフトマックス•グループ化し計算を省略
•語彙数Nの場合、O(logN)に削減DistributedRepresentationsofWordsandPhrasesandtheirCompositionally
ハフマン符号を利用
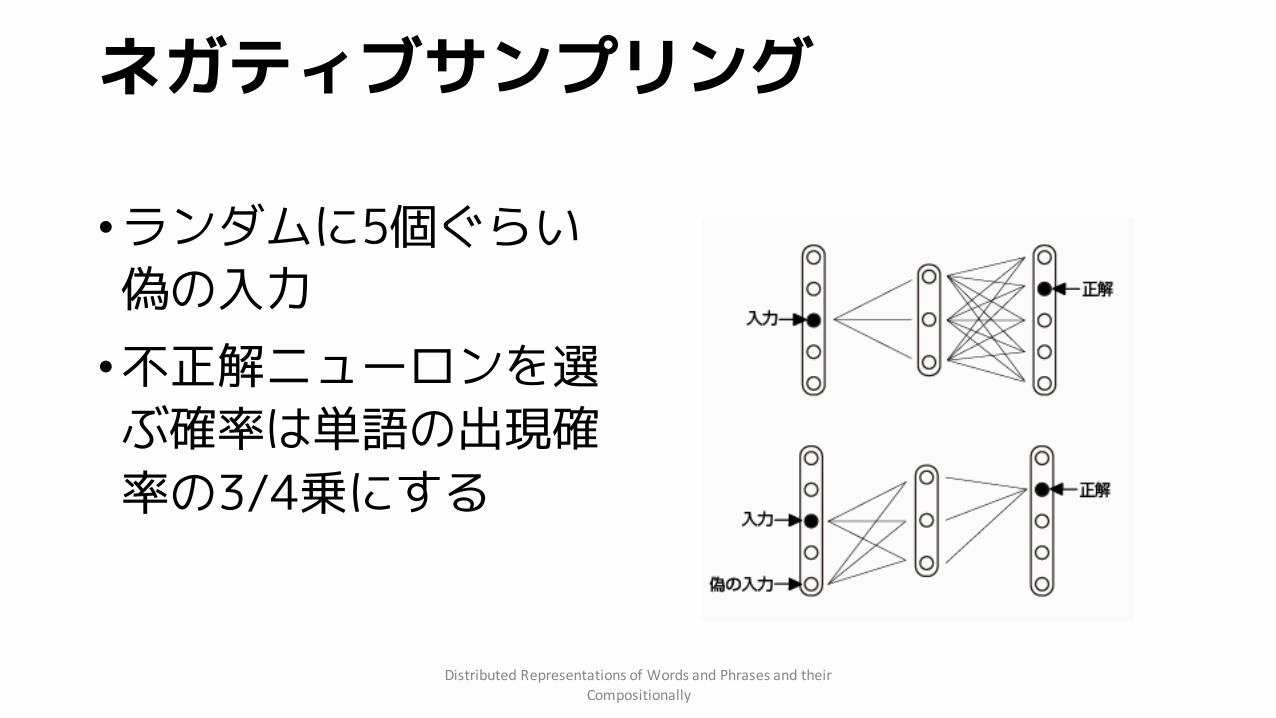
ネガティブサンプリング
•ランダムに5個ぐらい偽の入力•不正解ニューロンを選ぶ確率は単語の出現確率の3/4乗にする
DistributedRepresentationsofWordsandPhrasesandtheirCompositionally

高頻度語のサブサンプリング• “in”, “the”, “a”などの頻出語をサブサンプリング
•f(wi)は単語wiの相対頻度•t(スレッショルド)は10-5
•高頻度語がよく間引かれるDistributedRepresentationsofWordsandPhrasesandtheirCompositionally
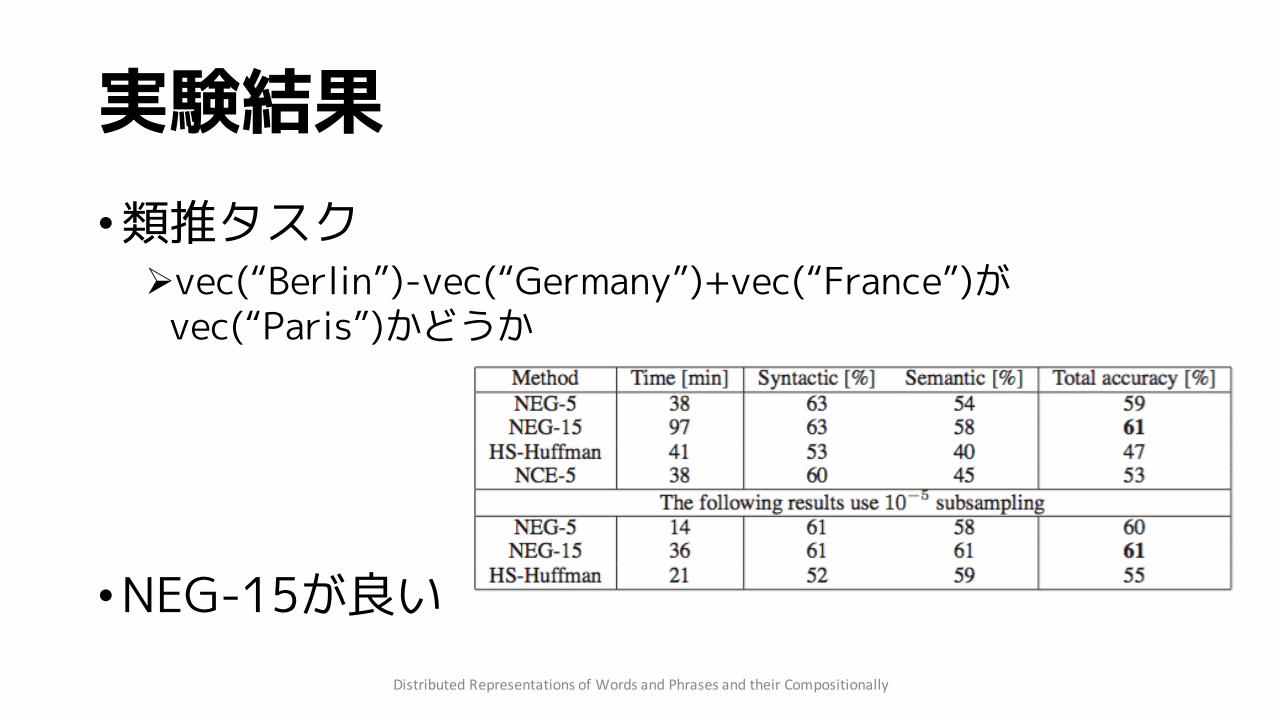
実験結果•類推タスク
Øvec(“Berlin”)-vec(“Germany”)+vec(“France”)がvec(“Paris”)かどうか
•NEG-15が良いDistributedRepresentationsofWordsandPhrasesandtheirCompositionally

複合語の学習•複合語は単純な意味の合算ではない•δは割引係数•ユニグラムとバイグラムでスコアを計算
DistributedRepresentationsofWordsandPhrasesandtheirCompositionally
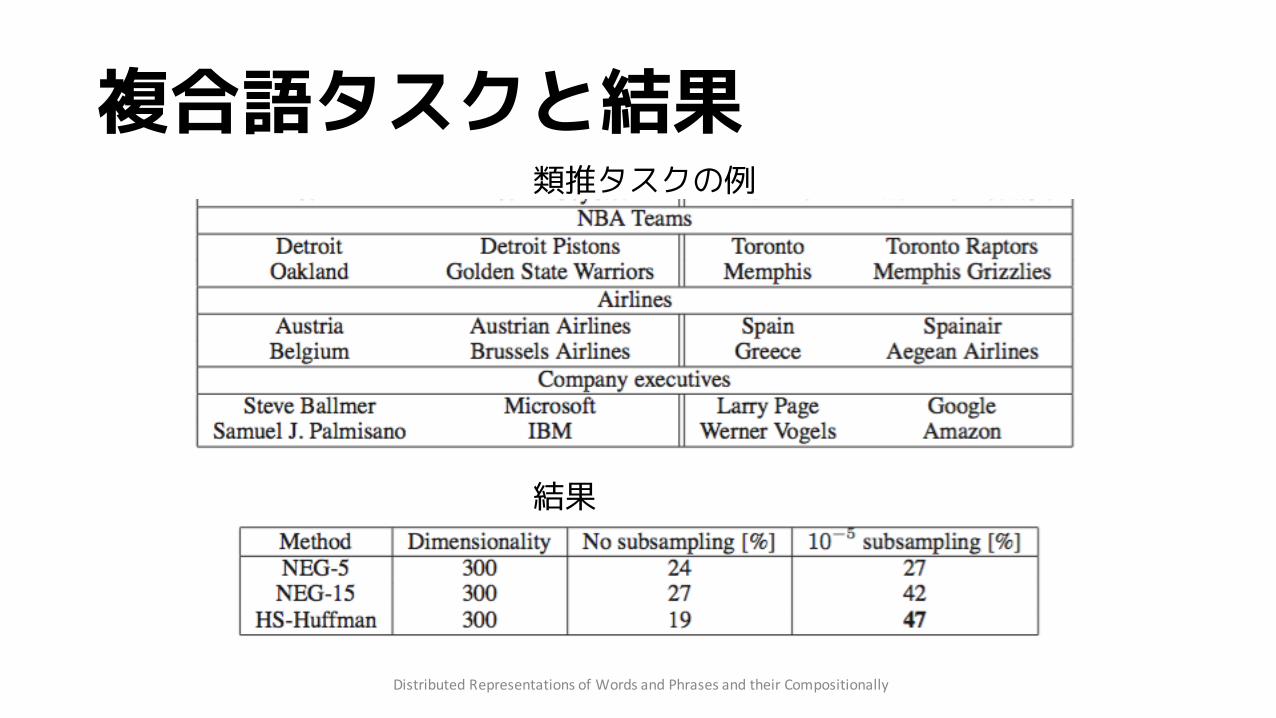
複合語タスクと結果
DistributedRepresentationsofWordsandPhrasesandtheirCompositionally
類推タスクの例
結果
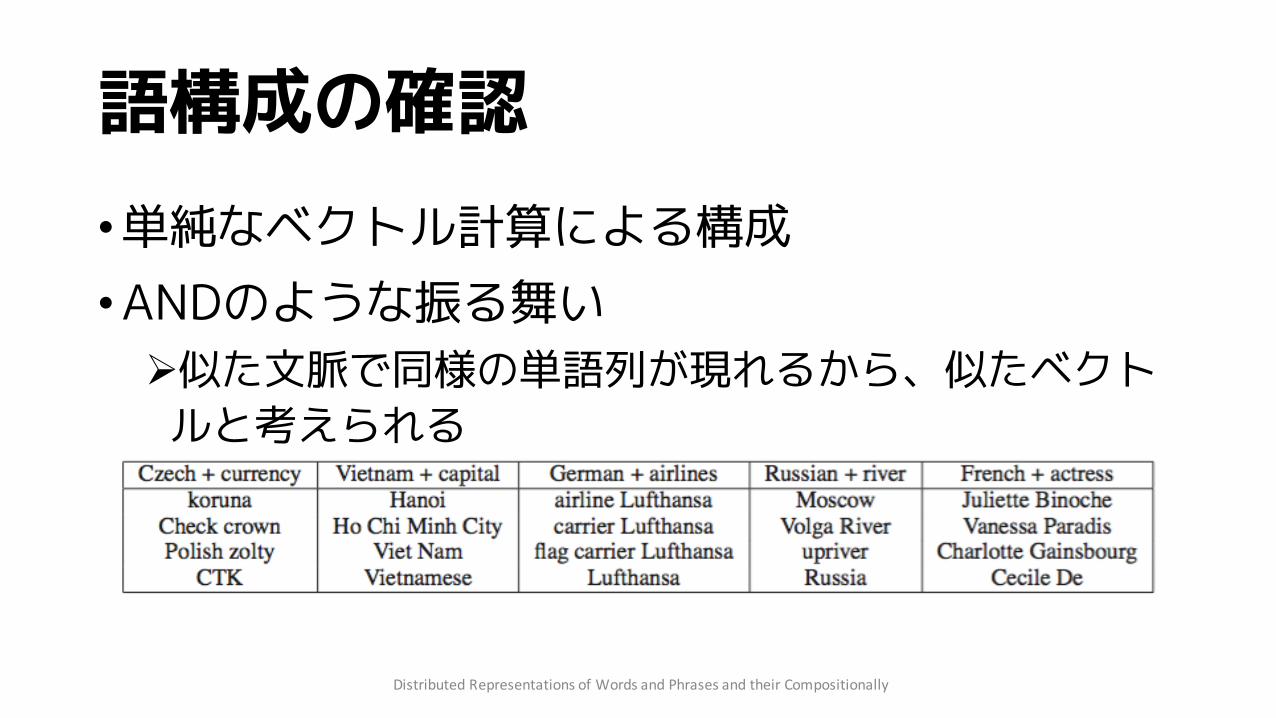
語構成の確認•単純なベクトル計算による構成•ANDのような振る舞い
Ø似た文脈で同様の単語列が現れるから、似たベクトルと考えられる
DistributedRepresentationsofWordsandPhrasesandtheirCompositionally
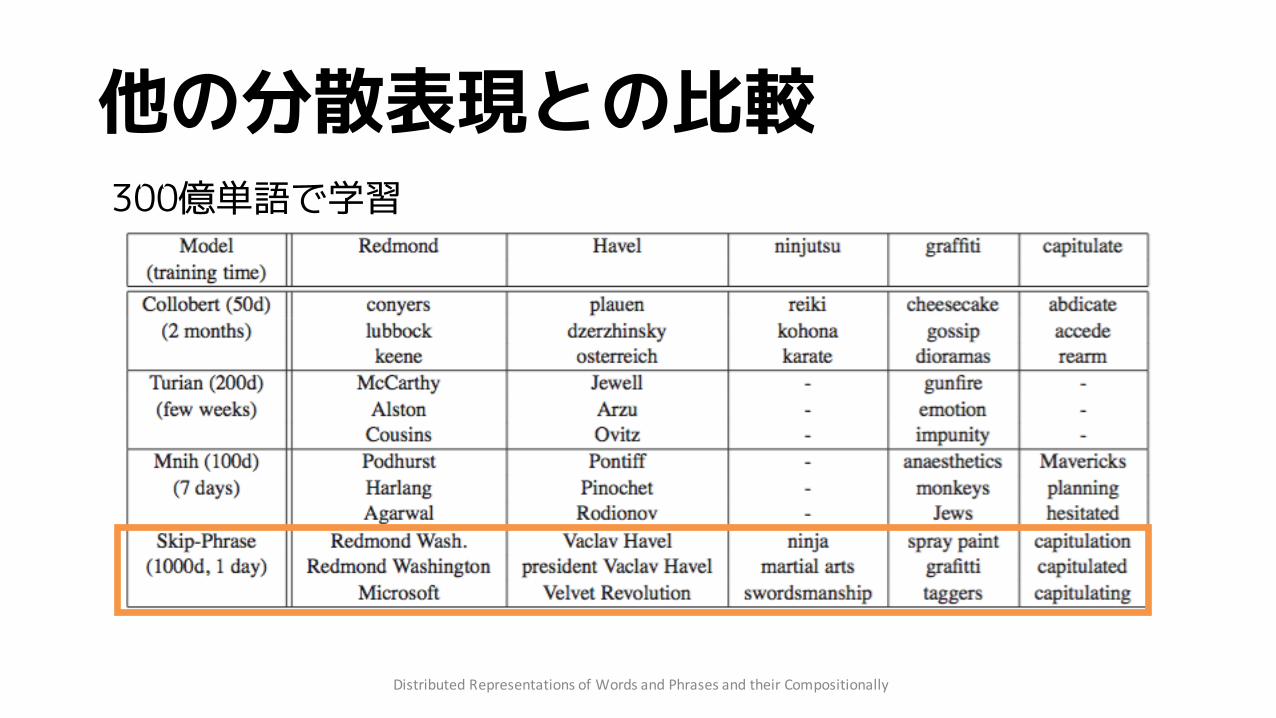
他の分散表現との比較
DistributedRepresentationsofWordsandPhrasesandtheirCompositionally
300億単語で学習

まとめ•Skip-gramモデルによる単語・複合語の単語ベクトル表現•省略による学習の高速化と高精度化•単純なベクトル演算で意味を表現できた
DistributedRepresentationsofWordsandPhrasesandtheirCompositionally





























