Embed Size (px)
Citation preview

GPGPU講習会GPU最適化ライブラリの利用(その2)
長岡技術科学大学電気電子情報工学専攻 出川智啓

本講習会の目標
GPGPU先端シミュレーションシステムの使用方法の習得
GPUの活用方法の修得
CUDAプログラミング技法の修得
並列計算手法の修得
2015/10/21GPGPU講習会2

本日の内容
GPU最適化ライブラリの利用(その2)
cuSPARSEの紹介
cuSPARSEによる共役勾配法実装の改良(メモリ利用の効率化)
連立一次方程式を解くプログラムの作成
ライブラリを利用
関数(およびCUDA API)の呼出のみで作成
3回に分けて徐々に効率化
今回は行列の格納方法を変更してメモリ利用効率を改善
2015/10/21GPGPU講習会3
GPU最適化ライブラリ

ライブラリ
2015/10/21GPGPU講習会5
特定の処理を行う複数のプログラムを再利用可能な形でまとめた集合体
動画像処理やファイル圧縮,数値計算などが有名
自作のプログラムよりも性能が高いため,関数を置き換えるだけで処理速度の向上に貢献

数値計算ライブラリ
2015/10/21GPGPU講習会6
FFT(Fast Fourier Transform) FFTW
線形代数演算(ベクトル処理,行列処理)
BLAS(Basic Linear Algebra Subprogram)
BLASを利用した線形代数演算ライブラリ LAPACK LINPACK ScaLAPACK
BLASやLAPACKのメーカー別実装 MKL Intel Math Kernel Library ACML AMD Core Math Library IMSL International Mathematics and Statistics Library

CUDA付属のライブラリ
2015/10/21GPGPU講習会7
cuBLAS 密行列向け線形代数演算
cuSPARSE 疎行列向け線形代数演算
cuFFT フーリエ変換
cuRAND 乱数生成
Thrust ソート,縮約,スキャン等
NPP 画像処理,信号処理
など
NVIDIAホームページに一覧がある
https://developer.nvidia.com/gpu‐accelerated‐libraries

その他GPU向けライブラリ
2015/10/21GPGPU講習会8
cuDNN https://developer.nvidia.com/cudnn
Deep Neural Network用のライブラリ
機械学習用のフレームワークをサポート
Caffe Theano Torch
cuDNNを使ったDIGITSというシステムを利用してNeural Networkのトレーニングを行うことが可能

その他GPU向けライブラリ
2015/10/21GPGPU講習会9
MAGMA http://icl.cs.utk.edu/magma/
NVIDIA GPU向けの線形代数ライブラリ
CPUも同時に使うハイブリッド型のライブラリであるため,GPU単体より高速
BLAS, LAPACKに準ずるような形で関数形が定められている
cuBLASに取り込まれている関数もある
ソースコードが配布されており,無料で入手できる

その他GPU向けライブラリ
2015/10/21GPGPU講習会10
cuBLAS‐XT https://developer.nvidia.com/cublasxt
cuBLASライブラリのマルチGPU向け実装
CUDA 6.0, 6.5から利用可能
共役勾配法

共役勾配法
2015/10/21GPGPU講習会12
連立一次方程式を解くためのアルゴリズム
係数行列が対称・正定値である連立一次方程式が対象
Hestenes and Stiefel(1952)によって提案
反復解法の性質を持ちながら,直接解法のように有限回の計算で解が得られる
「世紀の大解法」ともてはやされた
丸め誤差に弱く,有限回の計算で終わらないこともある
Hestenes, Magnus R., Stiefel, Eduard (December, 1952). "Methods of Conjugate Gradients for Solving Linear Systems". Journal of Research of the National Bureau of Standards 49 (6).

連立一次方程式の解法
2015/10/21GPGPU講習会13
直接法
係数行列を単位行列(や上三角,下三角行列)に変形することで未知数を求める方法
所定の計算回数で解が得られる
計算量が多く,大規模な問題には適用が難しい
反復法
係数行列を変更せず,未知数に推定値を代入して所定の計算を行い,推定値が解に十分近づくまで計算を繰り返す方法
よい推定値を選べば非常に高速に解が得られる

共役勾配法のアルゴリズム
2015/10/21GPGPU講習会14
連立一次方程式Ax=bに対する共役勾配法
Ap 係数行列Aとベクトルpの積
( , ) ベクトル同士の内積
Compute r(0)=b−Ax(0). Set p(0)=0,c2(0)=0.
For k=1,…, until ||r||/||b|| < , Do
p(k) = r(k)+c2(k−1)p(k−1)
c1(k) = (r(k), r(k))/(p(k), Ap(k))
x(k+1) = x(k)+c1(k)p(k)
r(k+1) = r(k)−c1(k)Ap(k)
c2(k) = (r(k+1), r(k+1))/{c1
(k)(p(k), Ap(k))}
EndDo
A 係数行列x 解ベクトルb 右辺ベクトルr 残差ベクトルp 補助ベクトル||・|| l2−ノルム

共役勾配法のバリエーション
2015/10/21GPGPU講習会15
自乗共役勾配法(CGS法)
非対称行列に対応
Compute r(0)=b−Ax(0). Set p(0)=0,c2(0)=0, r*=r(0).
For k=1,…, until ||r||/||b|| < , Dop(k) = r(k)+c2
(k−1)z(k−1)
u(k) = p(k)+c2(k−1)(z(k−1)+c2
(k−1)u(k−1))c1
(k) = (r*, r(k))/(r*, Au(k))z(k) = p(k)−c1
(k)Au(k)
x(k+1) = x(k)+c1(k)(p(k)+z(k))
r(k+1) = r(k)−c1(k)A(p(k)+z(k))
c2(k) = (r*, r(k+1))/{c1
(k)(r*, Au(k))}EndDo
r* 疑似残差u 補助ベクトルz 補助ベクトル

共役勾配法のバリエーション
2015/10/21GPGPU講習会16
安定化双共役勾配法(Bi‐CGSTAB法)
非対称行列に対応
Compute r(0)=b−Ax(0). Set p(0)=0,c2(0)=0, r*=r(0).
For k=1,…, until ||r||/||b|| < , Dop(k) = r(k)+c2
(k−1)(p(k−1)−c3(k−1)Ap(k−1))
c1(k) = (r*, r(k))/(r*, Ap(k))
t(k) = r(k)−c1(k)Ap(k)
c3(k) = (At(k), t(k))/(At(k), At(k))
x(k+1) = x(k)+c1(k)p(k)+c3
(k)t(k)
r(k+1) = r(k)−c3(k)At(k)
c2(k) = (r*, r(k+1))/{c3
(k)(r*, Ap(k))}EndDo
r* 疑似残差t 補助ベクトル

連立一次方程式
2015/10/21GPGPU講習会17
3重対角行列
2次元Poisson方程式から導かれる係数行列を簡略化
解(x)が0, 1, 2・・・N−1となるようbを設定
N
N
N
N
bb
bb
xx
xx
1
2
1
1
2
1
41141
14114
0
0

CPUプログラム(制御部分)
2015/10/21GPGPU講習会18
#include<stdlib.h>#include<stdio.h>#include<math.h>int main(void){
int N = 1 << 10; //未知数の数210const double err_tol = 1e‐9; //許容誤差const int max_ite = 1<<20;//反復回数の上限
double *x; //近似解ベクトルdouble *b; //右辺ベクトルdouble *A; //係数行列double *sol; //厳密解double *r, rr; //残差ベクトル, 残差の内積double *p, *Ax; //補助ベクトル,行列ベクトル積double c1, c2, dot; //計算に使う係数int i, k;//メモリの確保A = (double *)malloc(sizeof(double)*N*N);x = (double *)malloc(sizeof(double)*N);b = (double *)malloc(sizeof(double)*N);sol= (double *)malloc(sizeof(double)*N);r = (double *)malloc(sizeof(double)*N);p = (double *)malloc(sizeof(double)*N);
Ax = (double *)malloc(sizeof(double)*N);
for (i = 0; i < N; i++){sol[i] = (double)i; //厳密解を設定
x[i] = 0.0; //近似解を0で初期化}//係数行列Aの生成setTridiagonalMatrix(A, N);//右辺ベクトルbの生成setRightHandSideVector(b, A, sol, N);// :// ここで共役勾配法を実行// ://確保したメモリを解放free(x);free(b);free(A);free(sol);free(r);free(p);free(Ax);
} cg_cpu.c
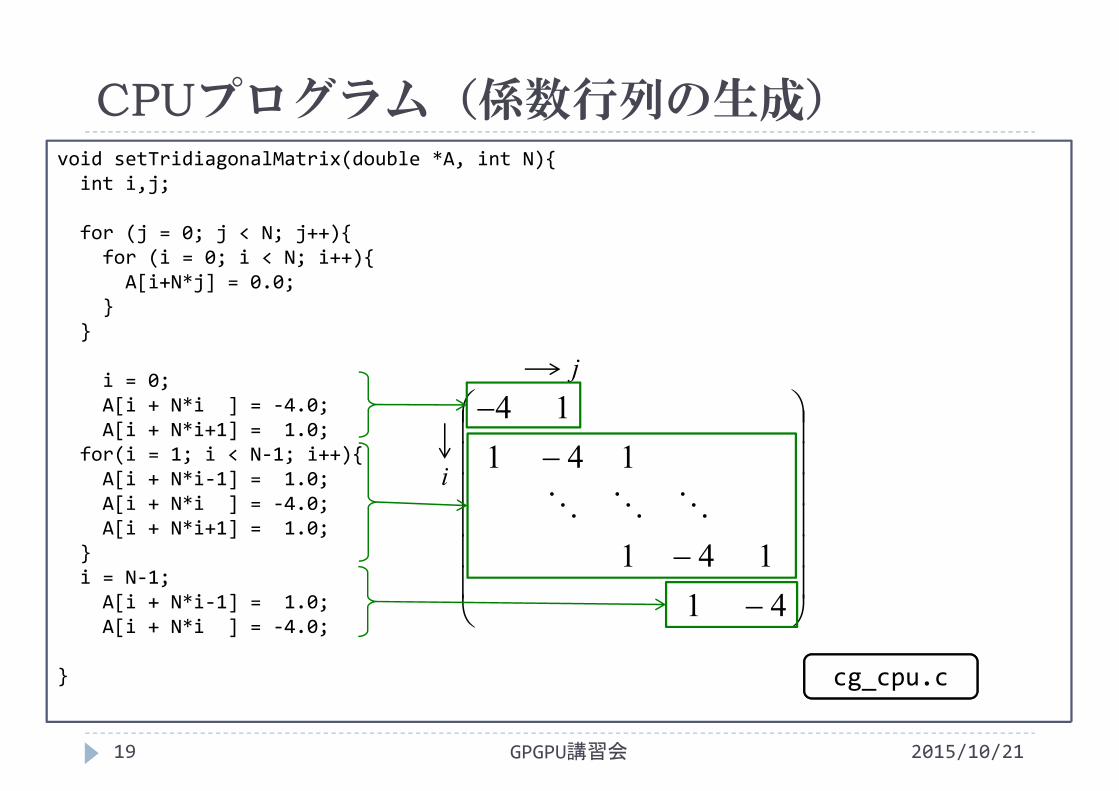
CPUプログラム(係数行列の生成)
2015/10/21GPGPU講習会19
void setTridiagonalMatrix(double *A, int N){int i,j;
for (j = 0; j < N; j++){for (i = 0; i < N; i++){
A[i+N*j] = 0.0;}
}
i = 0;A[i + N*i ] = ‐4.0;A[i + N*i+1] = 1.0;
for(i = 1; i < N‐1; i++){A[i + N*i‐1] = 1.0;A[i + N*i ] = ‐4.0;A[i + N*i+1] = 1.0;
}i = N‐1;
A[i + N*i‐1] = 1.0;A[i + N*i ] = ‐4.0;
}
41141
14114
cg_cpu.c
i
j

CPUプログラム(右辺ベクトルの生成)
2015/10/21GPGPU講習会20
void setRightHandSideVector(double *b, double *A, double *x, int N){
int i,j;
for (i = 0; i < N; i++){b[i] = 0.0;for (j = 0; j < N; j++){ //係数行列と厳密解ベクトルを用いて行列-ベクトル積を計算し,
b[i] += A[i + N*j] * x[j]; //結果を右辺ベクトルに代入}
}
}
cg_cpu.c

CPUプログラム(共役勾配法部分)
2015/10/21GPGPU講習会21
//残差ベクトルの計算 r(0)=b−Ax(0)
computeResidual(r, b, A, x, N);//残差ベクトルの内積を計算rr = innerProduct(r, r, N);
k = 1;while(rr>err_tol*err_tol && k<=max_ite){
if (k == 1){//p(k) = r(k)+c2
(k−1)p(k−1) c2とpが0のためp(k) = r(k)
copy(p, r, N);}else{
c2 = rr / (c1*dot);//p(k) = r(k)+c2
(k−1)p(k−1)
computeVectorAdd(p, c2, r, 1.0, N);}
//(p(k), Ap(k))を計算//行列ベクトル積Apを実行し,結果とpの内積computeMxV(Ax, A, p, N);dot = innerProduct(p, Ax, N);c1 = rr / dot;
//x(k+1) = x(k)+c1(k)p(k)
//r(k+1) = r(k)−c1(k)Ap(k)
computeVectorAdd(x, 1.0, p, c1, N);computeVectorAdd(r, 1.0, Ax,‐c1, N);
//残差ベクトルの内積を計算rr = innerProduct(r, r, N);
k++;}
/*Compute r(0)=b−Ax(0). Set p(0)=0,c2
(0)=0.For k=1,…, until ||r||/||b|| < , Do
p(k) = r(k)+c2(k−1)p(k−1)
c1(k) = (r(k), r(k))/(p(k), Ap(k))
x(k+1) = x(k)+c1(k)p(k)
r(k+1) = r(k)−c1(k)Ap(k)
c2(k) = (r(k+1), r(k+1))/{c1
(k)(p(k), Ap(k))}EndDo*/ cg_cpu.c

CPUプログラム(共役勾配法内の関数)
2015/10/21GPGPU講習会22
//残差ベクトルr(0)=b−Ax(0)の計算void computeResidual(double *r, double *b,
double *A, double *x,int N){
int i,j;double Ax;for (i = 0; i < N; i++){
Ax = 0.0;for (j = 0; j < N; j++){
Ax += A[i + N*j] * x[j];}r[i] = b[i]‐Ax;
}
}
//内積の計算double innerProduct(double *vec1,
double *vec2, int N){
int i;double dot;
dot=0.0;for (i = 0; i < N; i++){
dot += vec1[i]*vec2[i];}
return dot;
}
cg_cpu.c

CPUプログラム(共役勾配法内の関数)
2015/10/21GPGPU講習会23
//値のコピー(単純代入)p(k) = r(k)
void copy(double *lhs, double *rhs, int N){
int i;for (i = 0; i < N; i++){
lhs[i] = rhs[i];}
}
//ベクトル和y(k) = ax(k) + by(k)の計算void computeVectorAdd(
double *y, const double b, double *x, const double a,
int N){
int i;for (i = 0; i < N; i++){
y[i] = a*x[i] + b*y[i];}
}
//行列-ベクトル積Axの計算void computeMxV(double *Ax,
double *A, double *x, int N){
int i,j;for (i = 0; i < N; i++){
Ax[i] = 0.0;for (j = 0; j < N; j++){
Ax[i] += A[i + N*j] * x[j];}
}
}
cg_cpu.c

実行結果(N=210)
2015/10/21GPGPU講習会24
iteration = 1, residual = 2.098826e+003iteration = 2, residual = 4.308518e+002iteration = 3, residual = 1.102497e+002:
iteration = 21, residual = 5.547180e‐009iteration = 22, residual = 1.486358e‐009iteration = 23, residual = 3.982675e‐010x[0] = ‐0.000000x[1] = 1.000000x[2] = 2.000000:
x[1021] = 1021.000000x[1022] = 1022.000000x[1023] = 1023.000000Total amount of Absolute Error = 5.009568e‐010
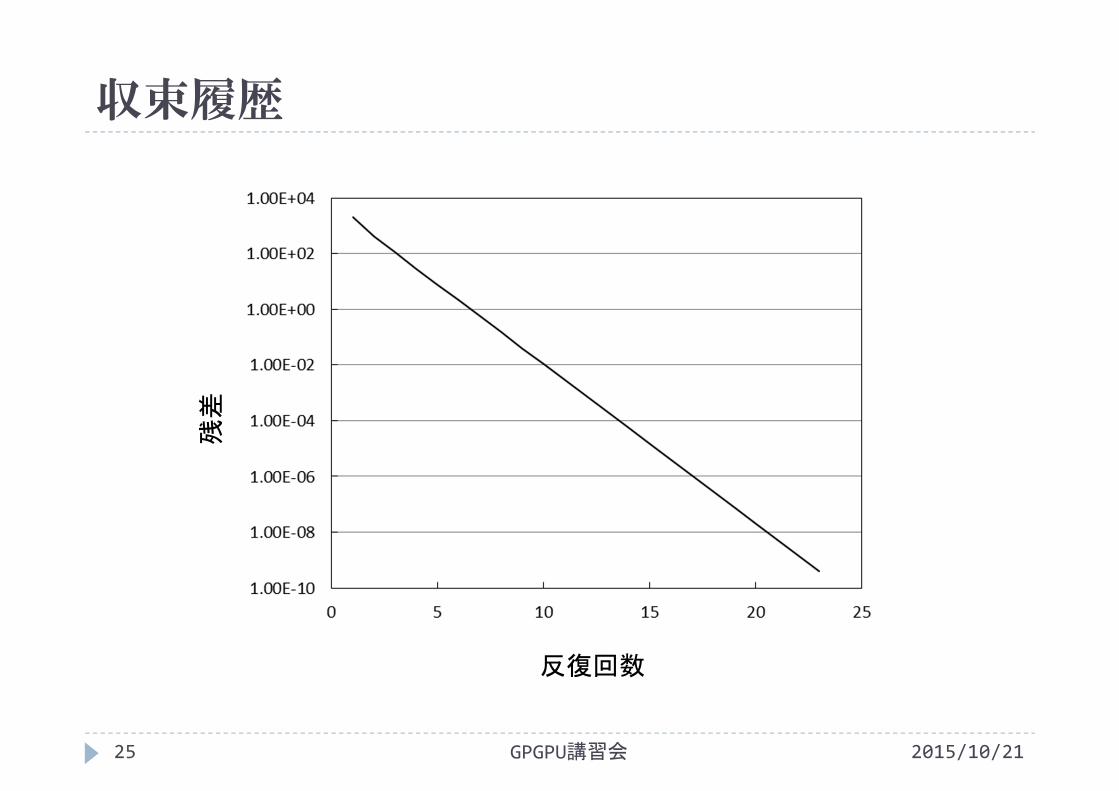
収束履歴
2015/10/21GPGPU講習会25
反復回数
残差

cuSPARSEの紹介

cuSPARSE*
2015/10/21GPGPU講習会27
BLASのGPU向け実装(疎行列向け)
cuBLASは密行列向け
Level 1, Level 2, Level 3が存在
行列の格納形式の操作に関するHelper Function
疎行列
要素の大半が0の行列
非ゼロ要素がまばらに存在
非ゼロ要素のみを格納
格納形式
疎行列 密行列
ゼロ要素
非ゼロ要素
*CUSPARSEやcusparseと書かれる事もあるが,NVIDIAのCUDA Toolkit Documentationの標記に従う

cuSPARSE
2015/10/21GPGPU講習会28
計算内容に対応した関数を呼ぶ事で計算を実行
cusparse<型>axpyi() ベクトル和
cusparse<型>gemvi() 行列‐ベクトル積
cusparse<型><格納形式>mv() 行列‐ベクトル積
y[] = y[] + x[]
y[] = OP(A[][])x[] + y[]
疎な(0要素を格納しない)ベクトル
密な(全要素を格納した)ベクトル
疎なベクトル
密なベクトル
密な行列
y[] = OP(A[][])x[] + y[]密なベクトル
密なベクトル
疎な行列

cuSPARSE
2015/10/21GPGPU講習会29
計算内容に対応した関数を呼ぶ事で計算を実行
cublas<型><格納形式>mm() 行列‐行列積
cublas<型><格納形式>gemm() 行列‐行列積
コンパイルの際はオプションとして –lcusparse を追加
cuSPARSEは関数を使うよりも疎行列を作る方が大変
C[][] = OP(A[][])B[][] + C[][]密な行列
密な行列
疎な行列
C[][] = OP(A[][])B[][] + C[][]疎な行列
疎な行列
疎な行列

疎行列格納形式
2015/10/21GPGPU講習会30
疎行列
行列の要素の大半が0 実際には8割~9割程度の要素が0 全てを保持するのは効率が悪い
疎行列格納形式
非ゼロ要素だけを保持してメモリを有効に利用
COO形式(Coordinate Format) CSR形式(Compressed Sparse Row Format) CSC形式(Compressed Sparse Column Format) その他色々
9080760540300201
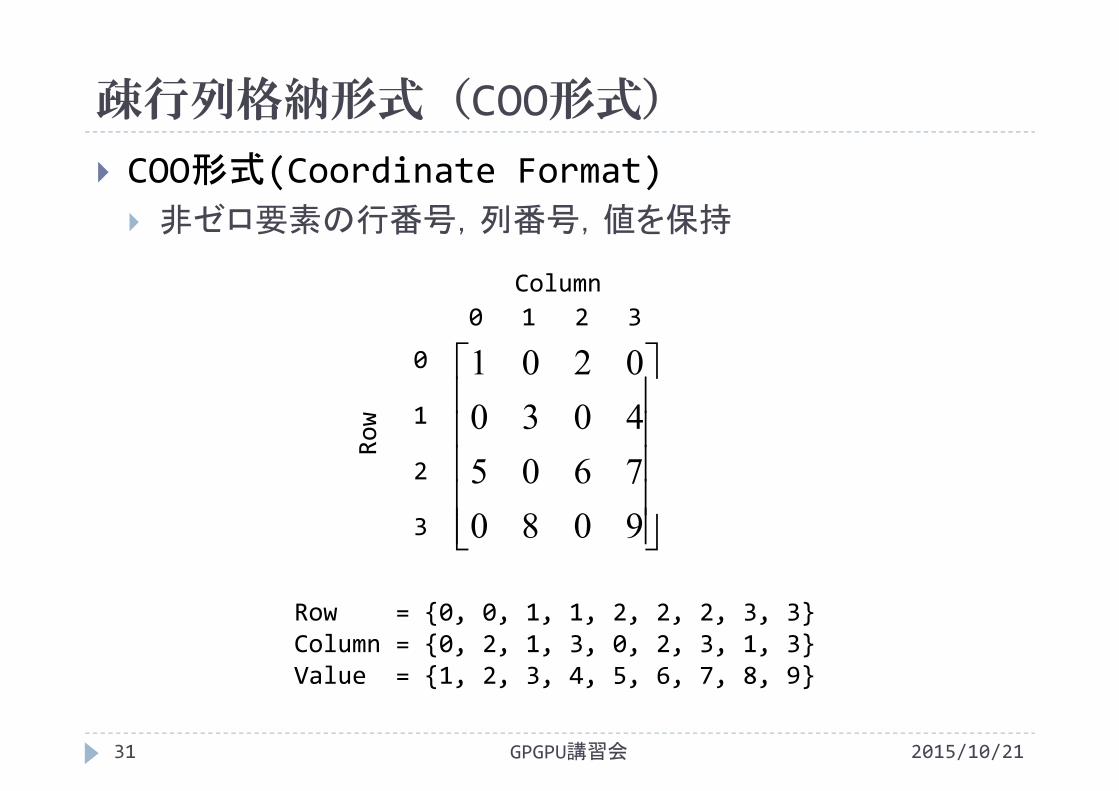
疎行列格納形式(COO形式)
2015/10/21GPGPU講習会31
COO形式(Coordinate Format) 非ゼロ要素の行番号,列番号,値を保持
9080760540300201
Row = {0, 0, 1, 1, 2, 2, 2, 3, 3}Column = {0, 2, 1, 3, 0, 2, 3, 1, 3}Value = {1, 2, 3, 4, 5, 6, 7, 8, 9}
0 1 2 3Column
0
1
2
3
Row
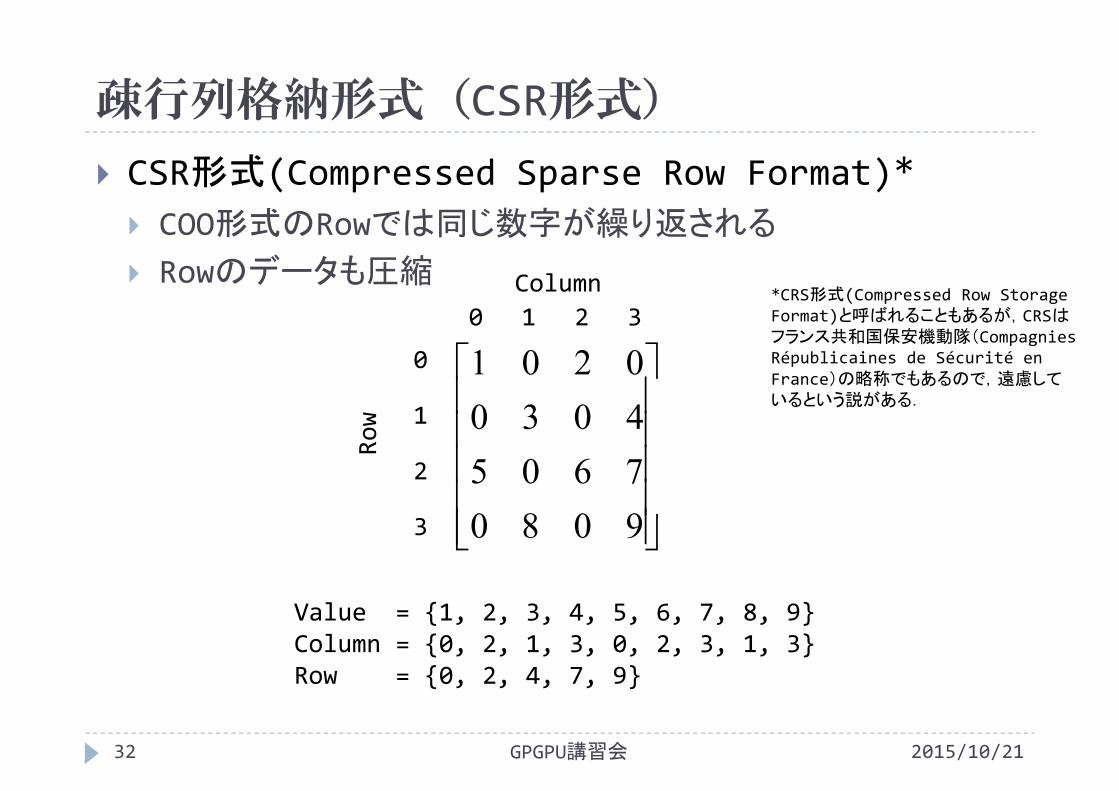
疎行列格納形式(CSR形式)
2015/10/21GPGPU講習会32
CSR形式(Compressed Sparse Row Format)* COO形式のRowでは同じ数字が繰り返される
Rowのデータも圧縮
9080760540300201
Value = {1, 2, 3, 4, 5, 6, 7, 8, 9}Column = {0, 2, 1, 3, 0, 2, 3, 1, 3}Row = {0, 2, 4, 7, 9}
0 1 2 3Column
0
1
2
3
Row
*CRS形式(Compressed Row Storage Format)と呼ばれることもあるが,CRSはフランス共和国保安機動隊(Compagnies Républicaines de Sécurité en France)の略称でもあるので,遠慮しているという説がある.

疎行列格納形式(CSR形式)
2015/10/21GPGPU講習会33
9080760540300201
0 1 2 3Column
0
1
2
3Row
Value = {1, 2, 3, 4, 5, 6, 7, 8, 9}Column = {0, 2, 1, 3, 0, 2, 3, 1, 3}
Row = {0, 2, 4, 7, 9}
Column配列の0,1は0行目のデータ
i行目のデータの個数は Row[i+1]‐Row[i]forループが簡単に書ける for(j=row[i]; j<row[i+1];j++)

疎行列格納形式(CSR形式)
2015/10/21GPGPU講習会34
9080760540300201
0 1 2 3Column
0
1
2
3Row
Value = {1, 2, 3, 4, 5, 6, 7, 8, 9}Column = {0, 2, 1, 3, 0, 2, 3, 1, 3}
Row = {0, 2, 4, 7, 9}
Column配列の2,3は1行目のデータ
i行目のデータの個数は Row[i+1]‐Row[i]forループが簡単に書ける for(j=row[i]; j<row[i+1];j++)

疎行列格納形式(CSR形式)
2015/10/21GPGPU講習会35
9080760540300201
0 1 2 3Column
0
1
2
3Row
Value = {1, 2, 3, 4, 5, 6, 7, 8, 9}Column = {0, 2, 1, 3, 0, 2, 3, 1, 3}
Row = {0, 2, 4, 7, 9}
Column配列の4,5,6は2行目のデータ
i行目のデータの個数は Row[i+1]‐Row[i]forループが簡単に書ける for(j=row[i]; j<row[i+1];j++)

疎行列格納形式(CSR形式)
2015/10/21GPGPU講習会36
9080760540300201
0 1 2 3Column
0
1
2
3Row
Value = {1, 2, 3, 4, 5, 6, 7, 8, 9}Column = {0, 2, 1, 3, 0, 2, 3, 1, 3}
Row = {0, 2, 4, 7, 9}
Column配列の7,8は3行目のデータ
i行目のデータの個数は Row[i+1]‐Row[i]forループが簡単に書ける for(j=row[i]; j<row[i+1];j++)

疎行列格納形式(CSR形式)
2015/10/21GPGPU講習会37
9080760540300201
0 1 2 3Column
0
1
2
3Row
Value = {1, 2, 3, 4, 5, 6, 7, 8, 9}Column = {0, 2, 1, 3, 0, 2, 3, 1, 3}
Row = {0, 2, 4, 7, 9}
Column配列の要素数
i行目のデータの個数は Row[i+1]‐Row[i]forループが簡単に書ける for(j=row[i]; j<row[i+1];j++)

cuSPARSEの疎行列-ベクトル積
2015/10/21GPGPU講習会38
正方行列とベクトルの積
C[N] = OP(A[N][N])B[N] + C[N]
cuBLASの場合
cublasDgemv(handle, OPERATION, N, N, , A, N, B, 1, , C, 1)
cuSPARSEの場合
cusparseDcsrmv(handle,OPERATION, N, N, Nnz,, descr(A), csrVal(A), csrRow(A), csrCol(A),
B, , C)
行列サイズ
ストライド ストライド
行列転置の有無
行列サイズ 非ゼロ要素数
Aの行数
行列転置の有無
配列Aの情報 配列Aの値 配列Aの行情報 配列Aの列情報
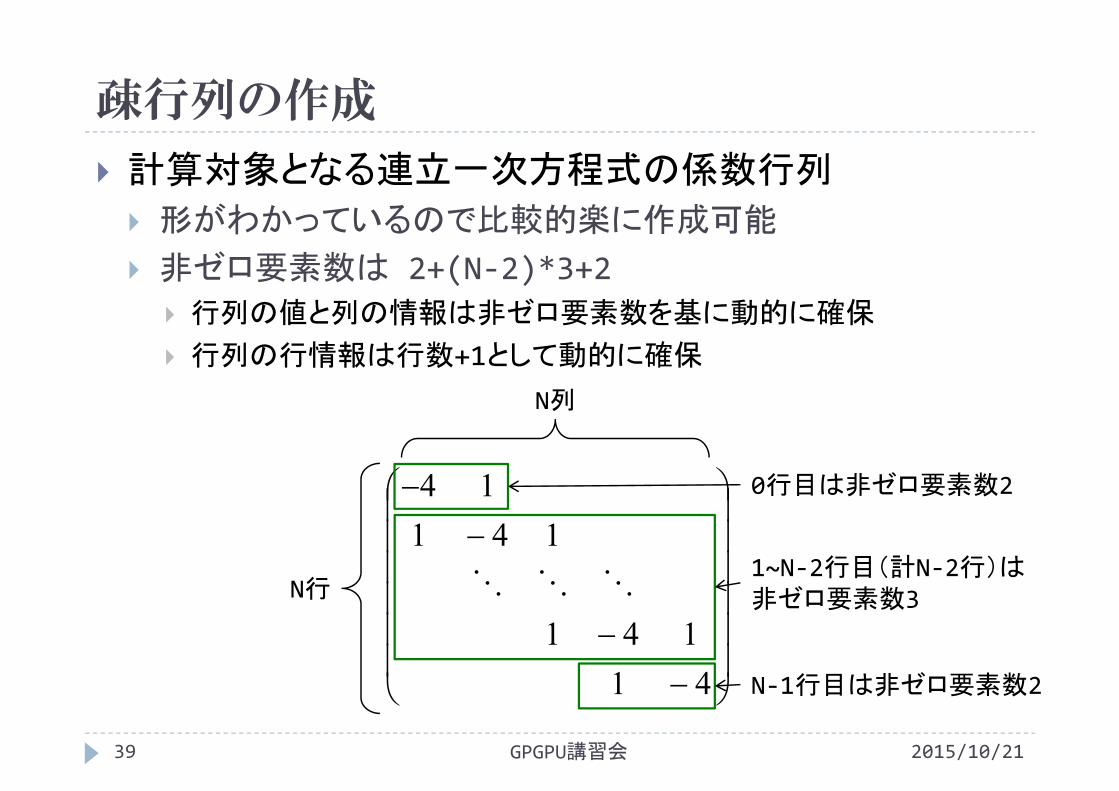
疎行列の作成
2015/10/21GPGPU講習会39
計算対象となる連立一次方程式の係数行列
形がわかっているので比較的楽に作成可能
非ゼロ要素数は 2+(N‐2)*3+2 行列の値と列の情報は非ゼロ要素数を基に動的に確保
行列の行情報は行数+1として動的に確保
41141
14114
N列
N行
0行目は非ゼロ要素数2
N‐1行目は非ゼロ要素数2
1~N‐2行目(計N‐2行)は非ゼロ要素数3
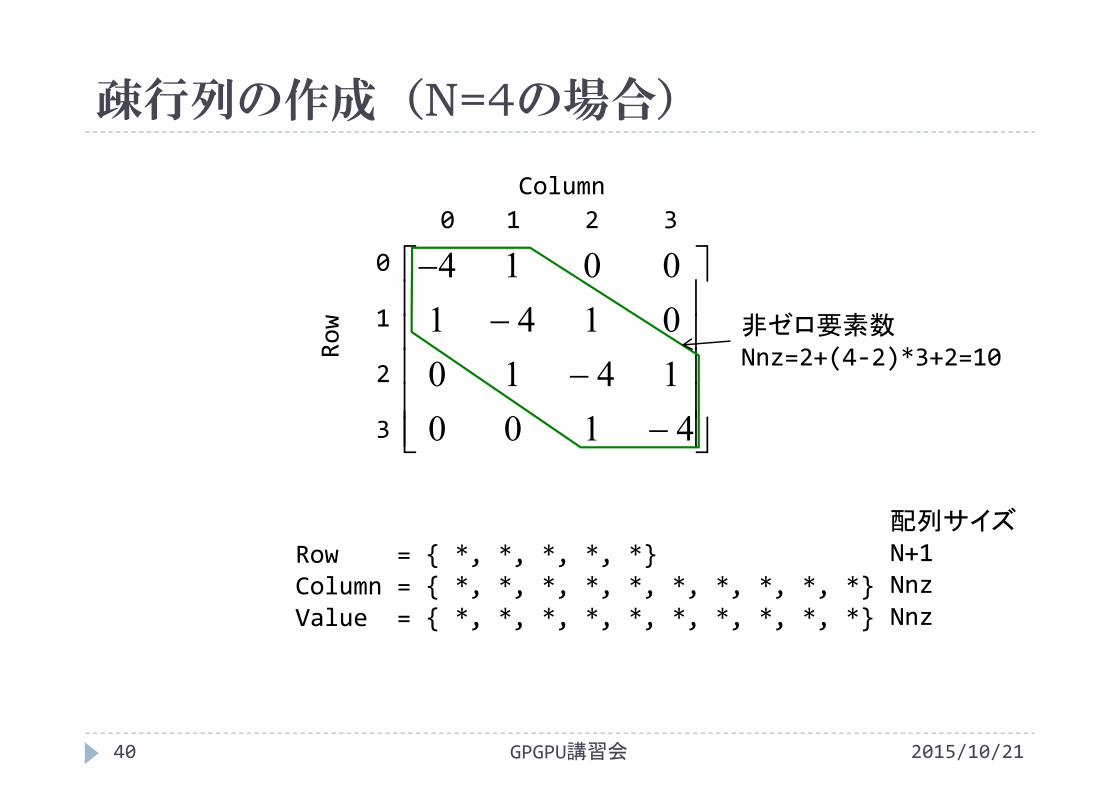
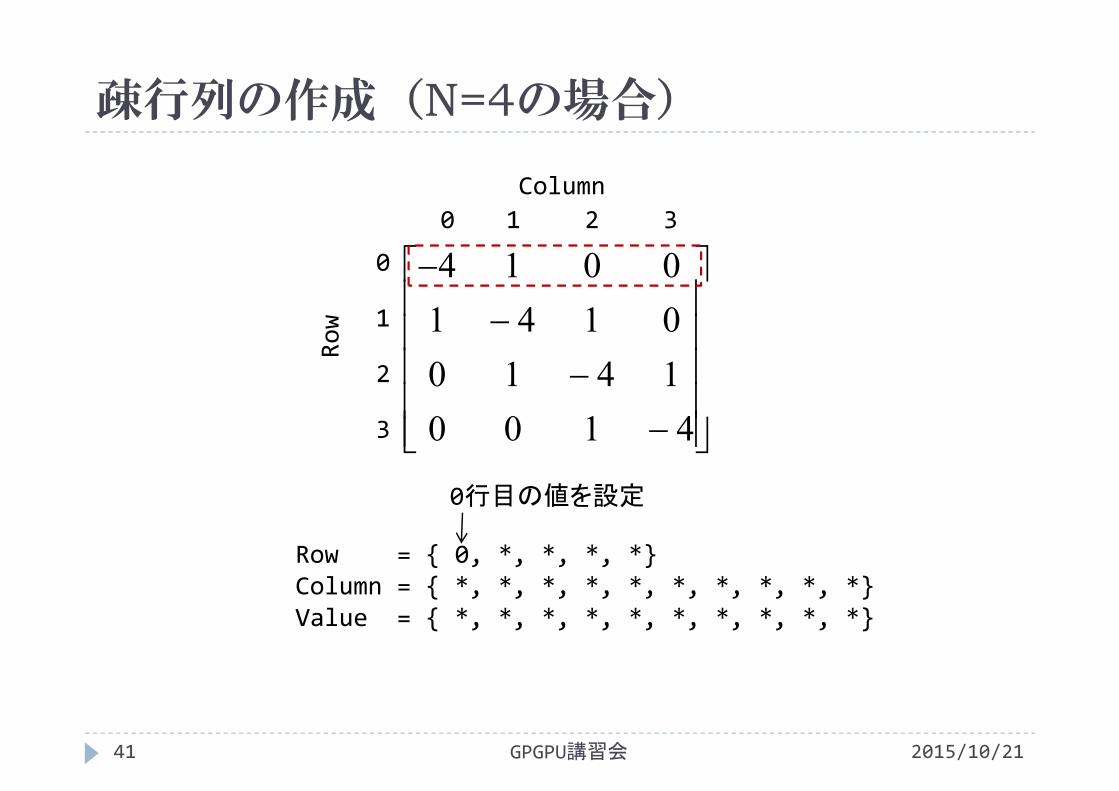
疎行列の作成(N=4の場合)
2015/10/21GPGPU講習会40
4100141001410014
0 1 2 3Column
0
1
2
3
Row
Row = { *, *, *, *, *}Column = { *, *, *, *, *, *, *, *, *, *}Value = { *, *, *, *, *, *, *, *, *, *}
非ゼロ要素数Nnz=2+(4‐2)*3+2=10
配列サイズN+1NnzNnz
疎行列の作成(N=4の場合)
2015/10/21GPGPU講習会41
4100141001410014
0 1 2 3Column
0
1
2
3
Row
Row = { 0, *, *, *, *}Column = { *, *, *, *, *, *, *, *, *, *}Value = { *, *, *, *, *, *, *, *, *, *}
0行目の値を設定
疎行列の作成(N=4の場合)
2015/10/21GPGPU講習会42
4100141001410014
0 1 2 3Column
0
1
2
3
Row
Row = { 0, *, *, *, *}Column = { 0, *, *, *, *, *, *, *, *, *}Value = { *, *, *, *, *, *, *, *, *, *}
0列目に非ゼロ要素がある

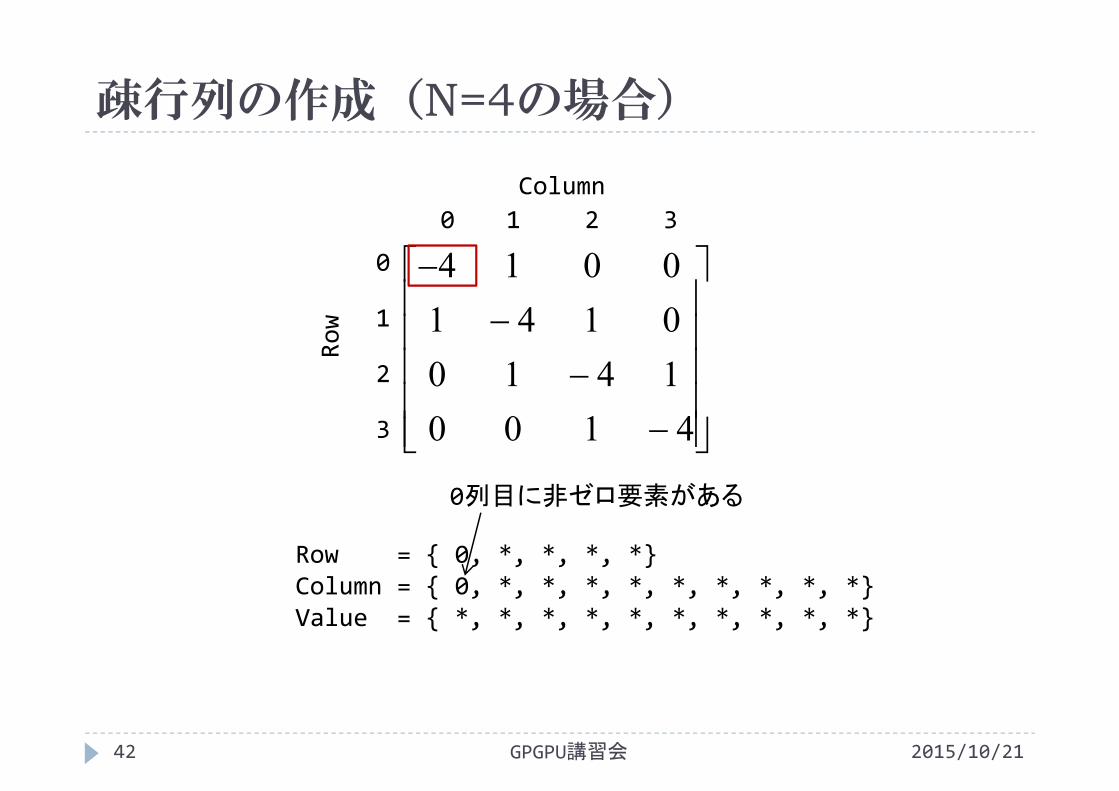
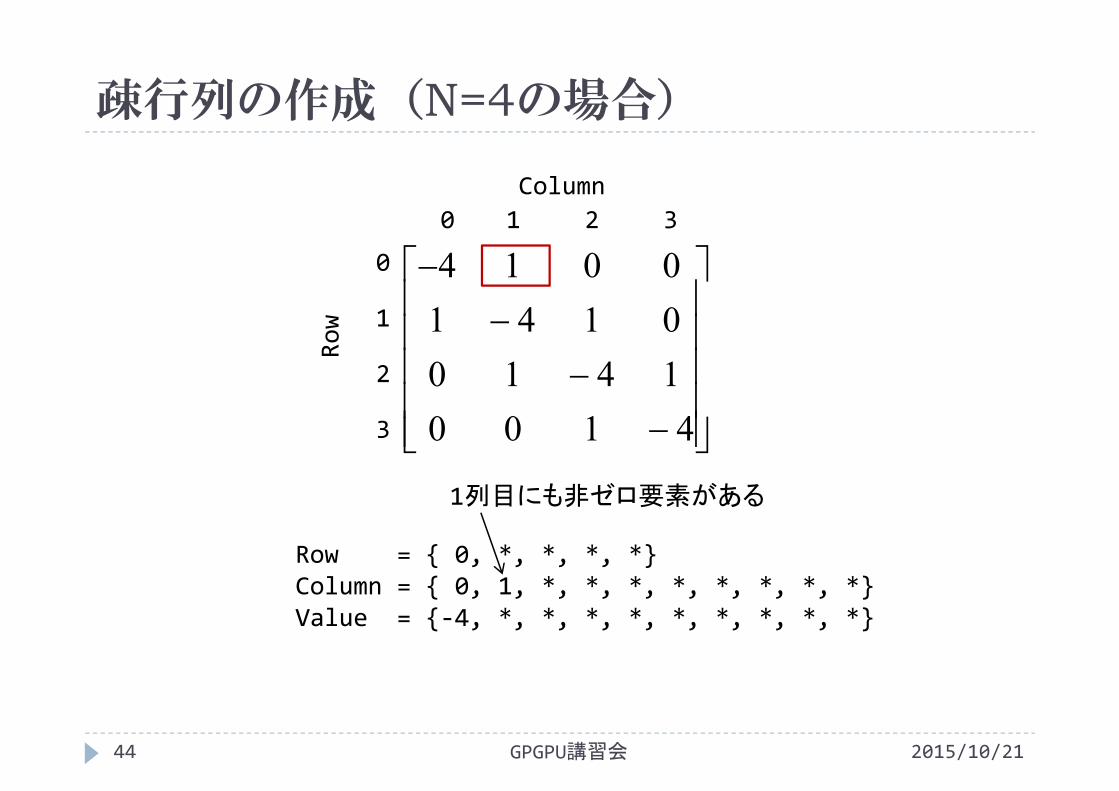
疎行列の作成(N=4の場合)
2015/10/21GPGPU講習会43
4100141001410014
0 1 2 3Column
0
1
2
3
Row
Row = { 0, *, *, *, *}Column = { 0, *, *, *, *, *, *, *, *, *}Value = {‐4, *, *, *, *, *, *, *, *, *}
非ゼロ要素の値は‐4
疎行列の作成(N=4の場合)
2015/10/21GPGPU講習会44
4100141001410014
0 1 2 3Column
0
1
2
3
Row
Row = { 0, *, *, *, *}Column = { 0, 1, *, *, *, *, *, *, *, *}Value = {‐4, *, *, *, *, *, *, *, *, *}
1列目にも非ゼロ要素がある
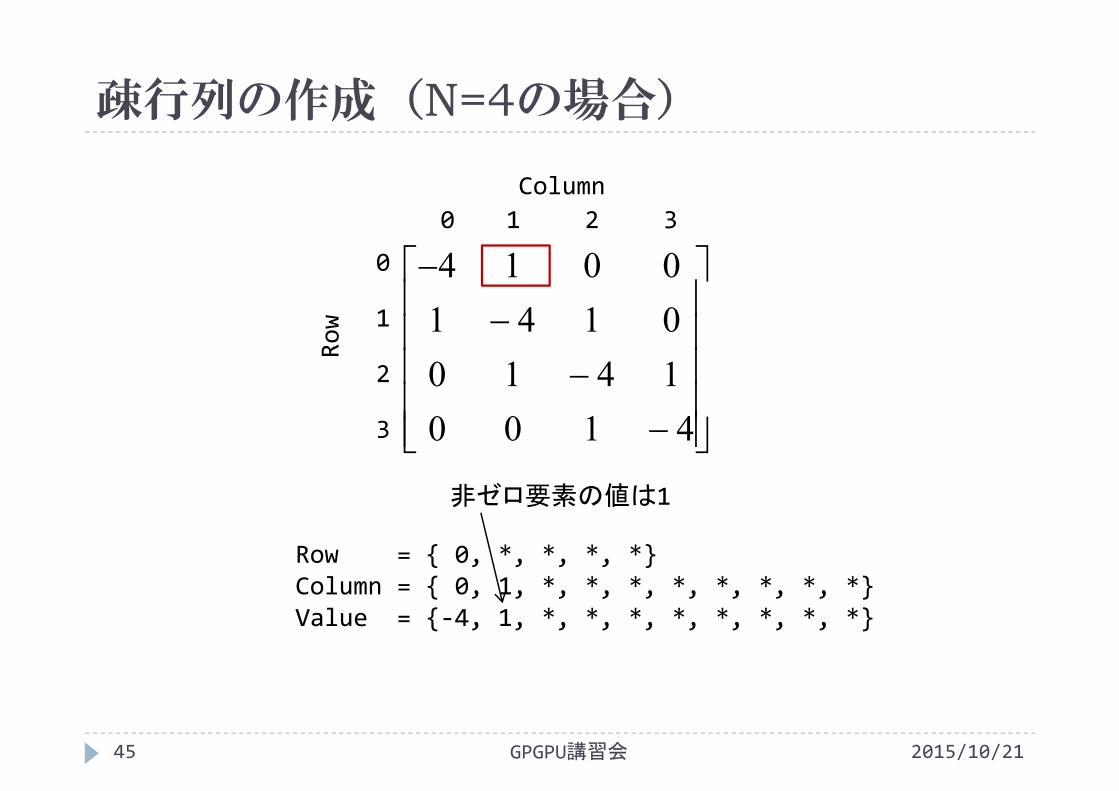
疎行列の作成(N=4の場合)
2015/10/21GPGPU講習会45
4100141001410014
0 1 2 3Column
0
1
2
3
Row
Row = { 0, *, *, *, *}Column = { 0, 1, *, *, *, *, *, *, *, *}Value = {‐4, 1, *, *, *, *, *, *, *, *}
非ゼロ要素の値は1
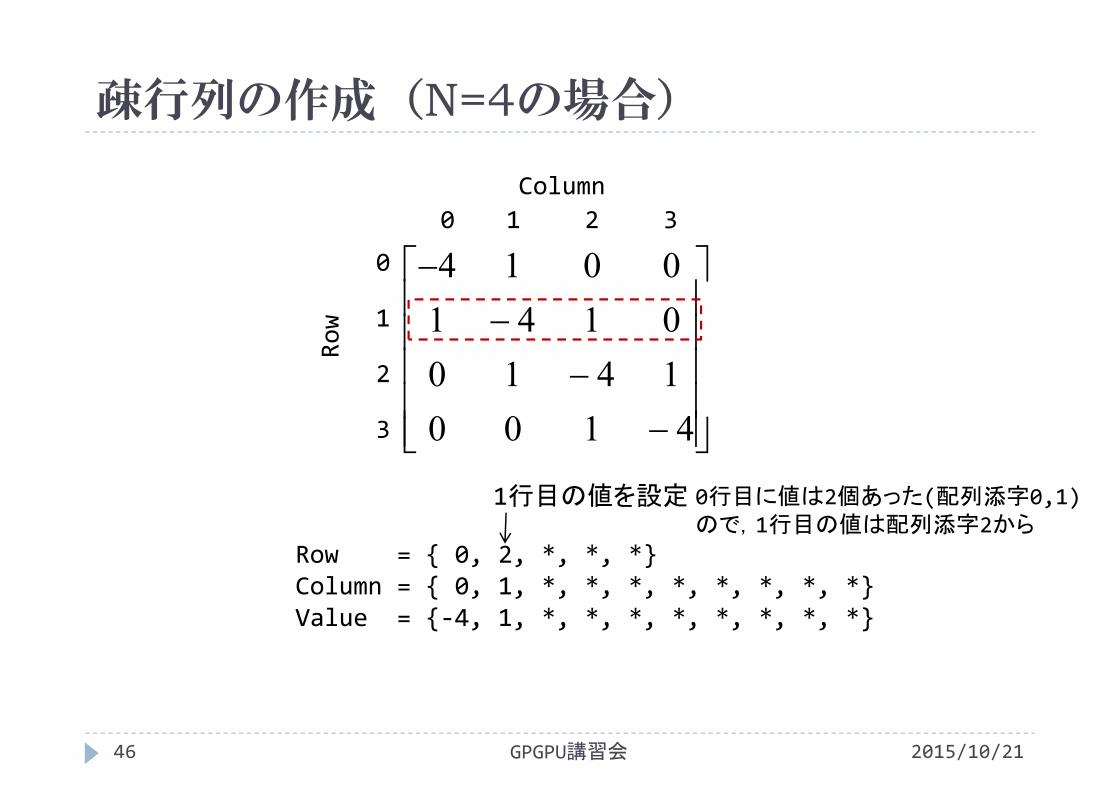
疎行列の作成(N=4の場合)
2015/10/21GPGPU講習会46
4100141001410014
0 1 2 3Column
0
1
2
3
Row
1行目の値を設定
Row = { 0, 2, *, *, *}Column = { 0, 1, *, *, *, *, *, *, *, *}Value = {‐4, 1, *, *, *, *, *, *, *, *}
0行目に値は2個あった(配列添字0,1)ので,1行目の値は配列添字2から
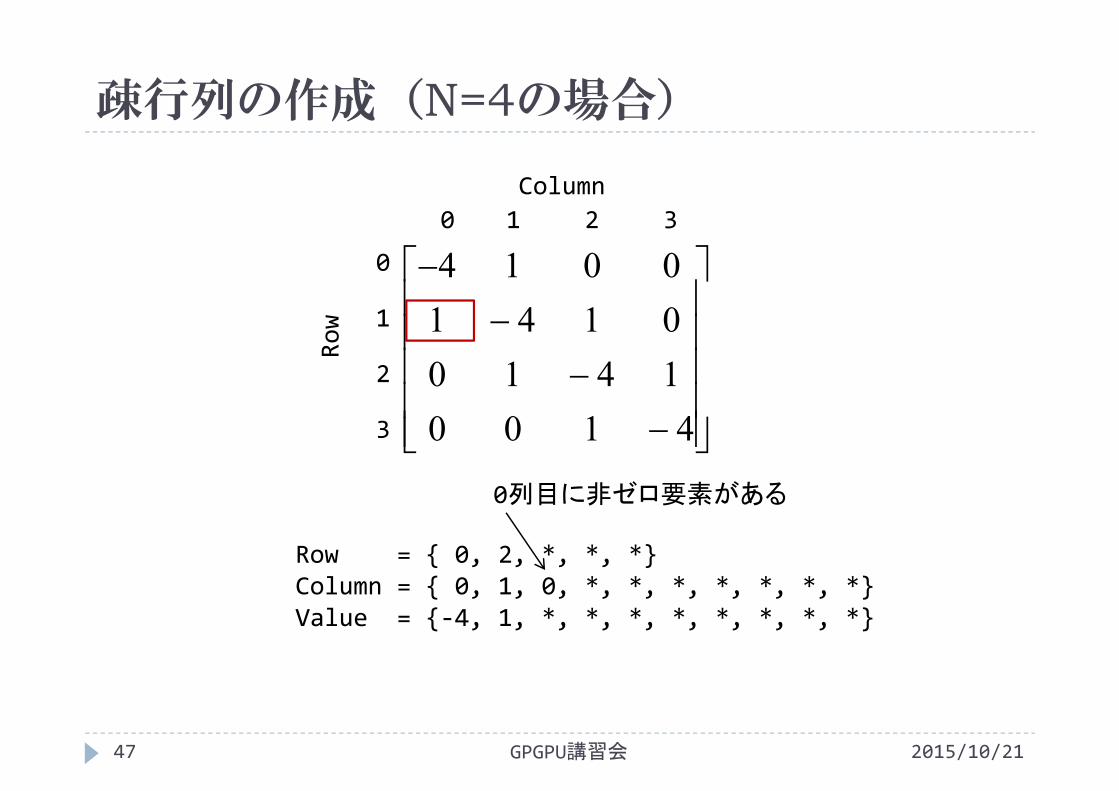
疎行列の作成(N=4の場合)
2015/10/21GPGPU講習会47
4100141001410014
0 1 2 3Column
0
1
2
3
Row
0列目に非ゼロ要素がある
Row = { 0, 2, *, *, *}Column = { 0, 1, 0, *, *, *, *, *, *, *}Value = {‐4, 1, *, *, *, *, *, *, *, *}

疎行列の作成(N=4の場合)
2015/10/21GPGPU講習会48
4100141001410014
0 1 2 3Column
0
1
2
3
Row
非ゼロ要素の値は1
Row = { 0, 2, *, *, *}Column = { 0, 1, 0, *, *, *, *, *, *, *}Value = {‐4, 1, 1, *, *, *, *, *, *, *}
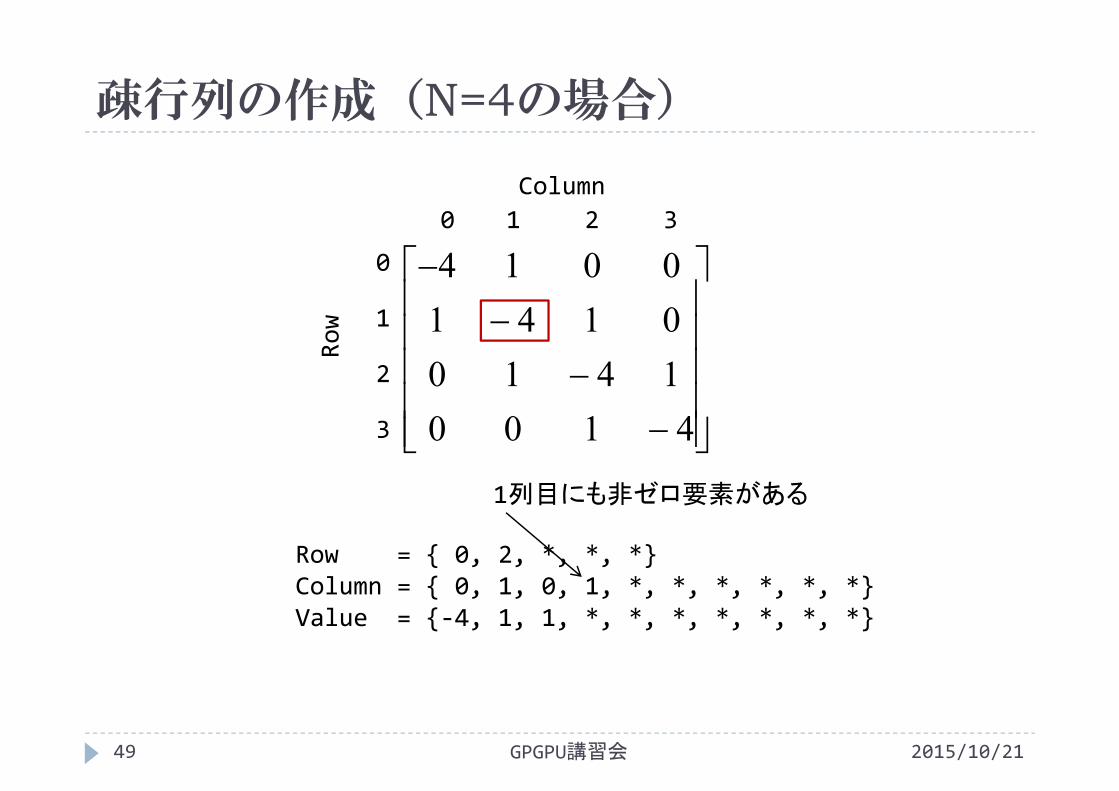
疎行列の作成(N=4の場合)
2015/10/21GPGPU講習会49
4100141001410014
0 1 2 3Column
0
1
2
3
Row
1列目にも非ゼロ要素がある
Row = { 0, 2, *, *, *}Column = { 0, 1, 0, 1, *, *, *, *, *, *}Value = {‐4, 1, 1, *, *, *, *, *, *, *}
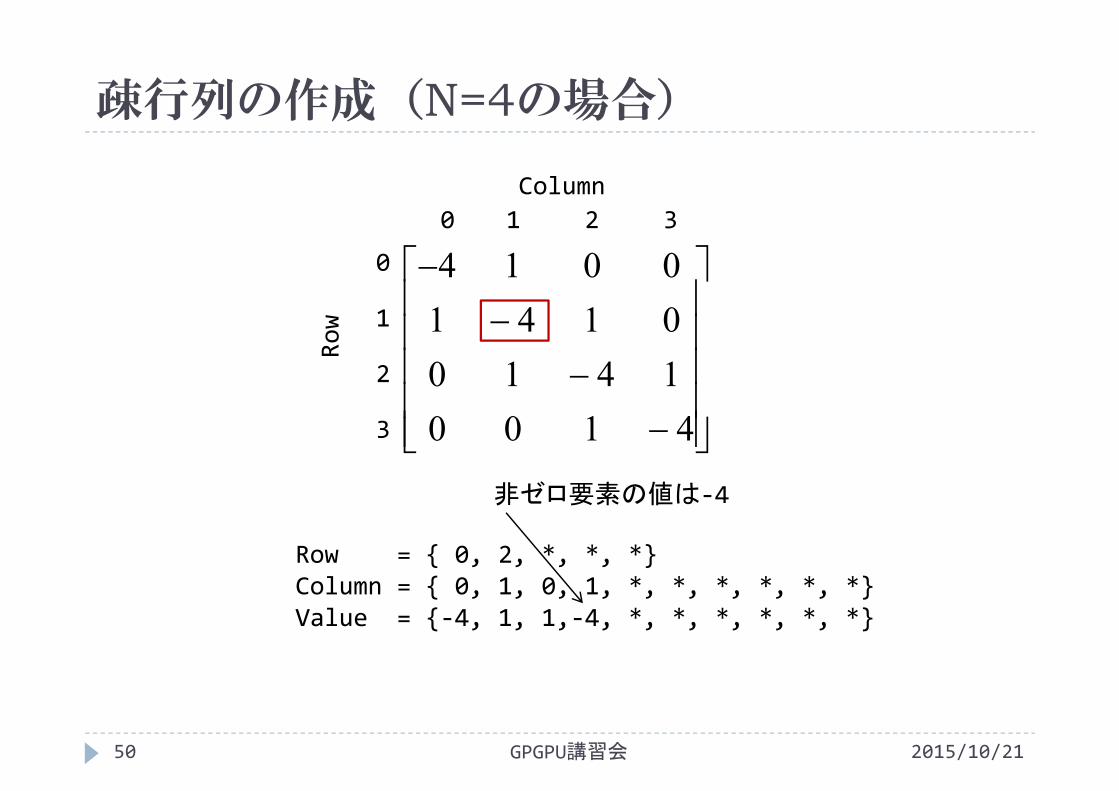
疎行列の作成(N=4の場合)
2015/10/21GPGPU講習会50
4100141001410014
0 1 2 3Column
0
1
2
3
Row
非ゼロ要素の値は‐4
Row = { 0, 2, *, *, *}Column = { 0, 1, 0, 1, *, *, *, *, *, *}Value = {‐4, 1, 1,‐4, *, *, *, *, *, *}
疎行列の作成(N=4の場合)
2015/10/21GPGPU講習会51
4100141001410014
0 1 2 3Column
0
1
2
3
Row
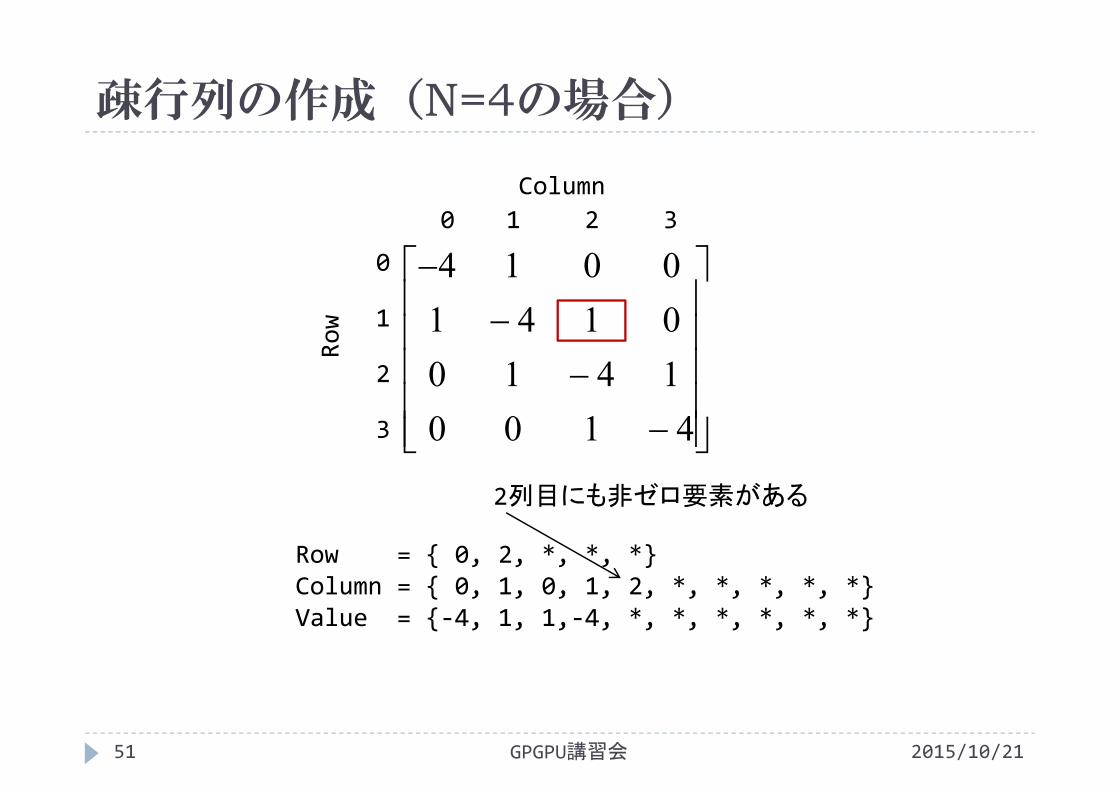
2列目にも非ゼロ要素がある
Row = { 0, 2, *, *, *}Column = { 0, 1, 0, 1, 2, *, *, *, *, *}Value = {‐4, 1, 1,‐4, *, *, *, *, *, *}
疎行列の作成(N=4の場合)
2015/10/21GPGPU講習会52
4100141001410014
0 1 2 3Column
0
1
2
3
Row
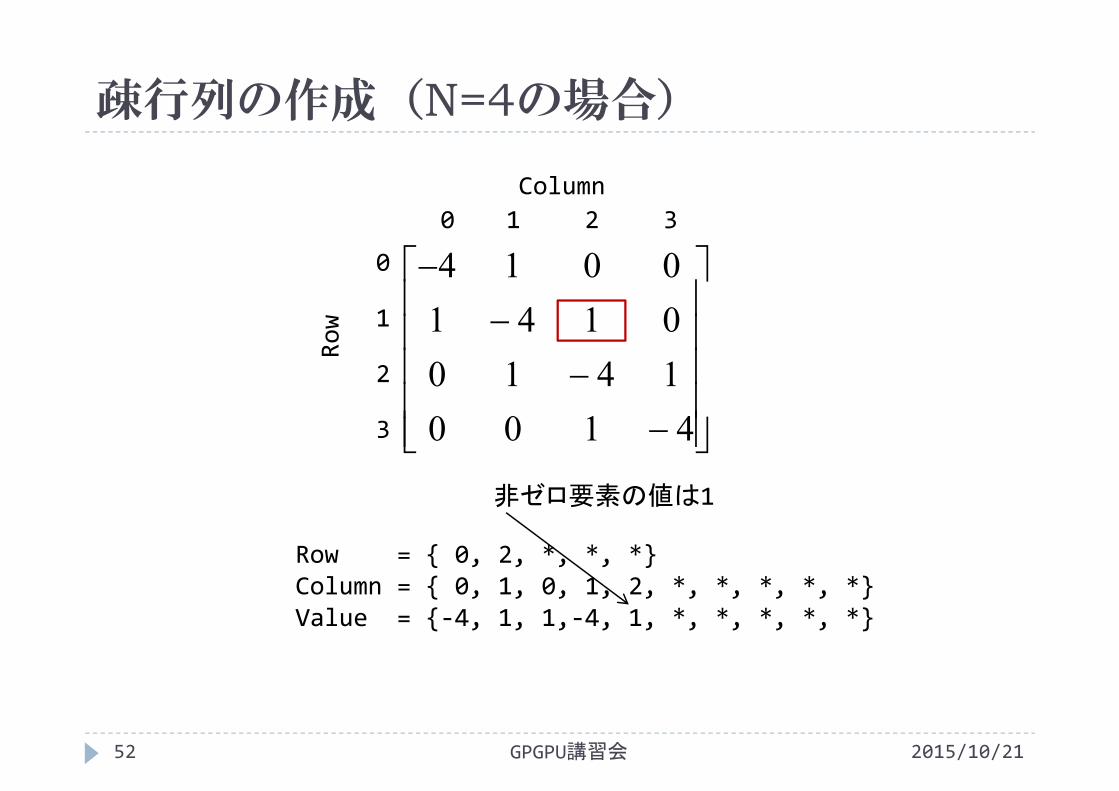
非ゼロ要素の値は1
Row = { 0, 2, *, *, *}Column = { 0, 1, 0, 1, 2, *, *, *, *, *}Value = {‐4, 1, 1,‐4, 1, *, *, *, *, *}
Row = { 0, 2, 5, *, *}Column = { 0, 1, 0, 1, 2, *, *, *, *, *}Value = {‐4, 1, 1,‐4, 1, *, *, *, *, *}
疎行列の作成(N=4の場合)
2015/10/21GPGPU講習会53
4100141001410014
0 1 2 3Column
0
1
2
3
Row
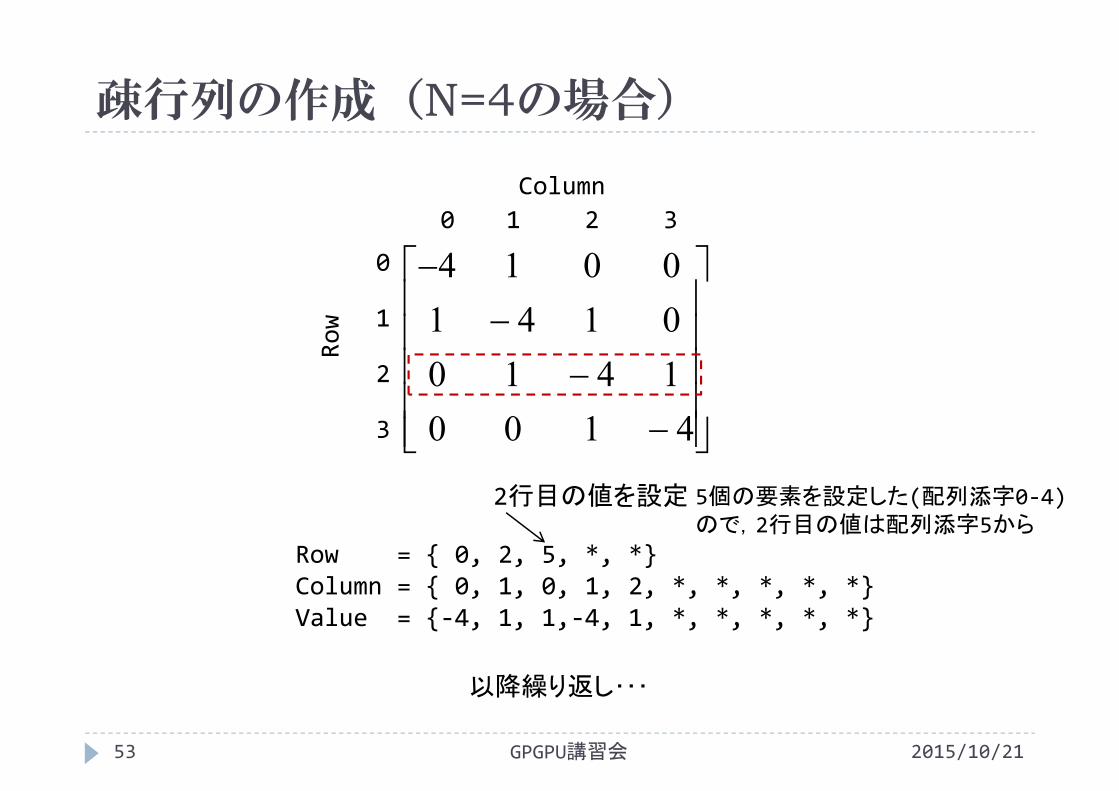
2行目の値を設定 5個の要素を設定した(配列添字0‐4)ので,2行目の値は配列添字5から
以降繰り返し・・・

疎行列の作成(N=4の場合)
2015/10/21GPGPU講習会54
4100141001410014
0 1 2 3Column
0
1
2
3
Row
Row = { 0, 2, 5, 8,10}Column = { 0, 1, 0, 1, 2, 1, 2, 3, 2, 3}Value = {‐4, 1, 1,‐4, 1, 1,‐4, 1, 1,‐4}

疎行列の作成
2015/10/21GPGPU講習会55
void setTridiagonalMatrix(double *Aval, int *AcolIdx, int *ArowPtr,const int N, const int NonZero){
int i,ij;
i = 0; ij = 0;ArowPtr[i] = 0;AcolIdx[ij] = i ; Aval[ij] = ‐4.0; ++ij;AcolIdx[ij] = i+1; Aval[ij] = 1.0; ++ij;
for(i = 1; i < N‐1; i++){ArowPtr[i] = 2+ (i‐1)*3;AcolIdx[ij] = i‐1; Aval[ij] = 1.0; ++ij;AcolIdx[ij] = i ; Aval[ij] = ‐4.0; ++ij;AcolIdx[ij] = i+1; Aval[ij] = 1.0; ++ij;
}i = N‐1;
ArowPtr[i] = 2 + (i‐1)*3;AcolIdx[ij] = i‐1; Aval[ij] = 1.0; ++ij;AcolIdx[ij] = i ; Aval[ij] = ‐4.0;
ArowPtr[N] = NonZero;
}
i(=0)行目までのデータ数は0I 列目の値は‐4.配列添字を一つ先に進めるi+1列目の値は 1.配列添字を一つ先に進める
i行目までのデータ数は2+(i‐1)*3i‐1列目の値は 1.配列添字を一つ先に進めるi 列目の値は‐4.配列添字を一つ先に進めるi+1列目の値は 1.配列添字を一つ先に進める
N‐1行目までのデータ数は2+((N‐1)‐1)*3i‐1列目の値は 1.配列添字を一つ先に進めるi 列目の値は‐4.
最後に行情報の配列に総データ数を書き込む
※非ゼロ要素が複雑に分布している場合はもっと複雑になる
行列-ベクトル積
2015/10/21GPGPU講習会56
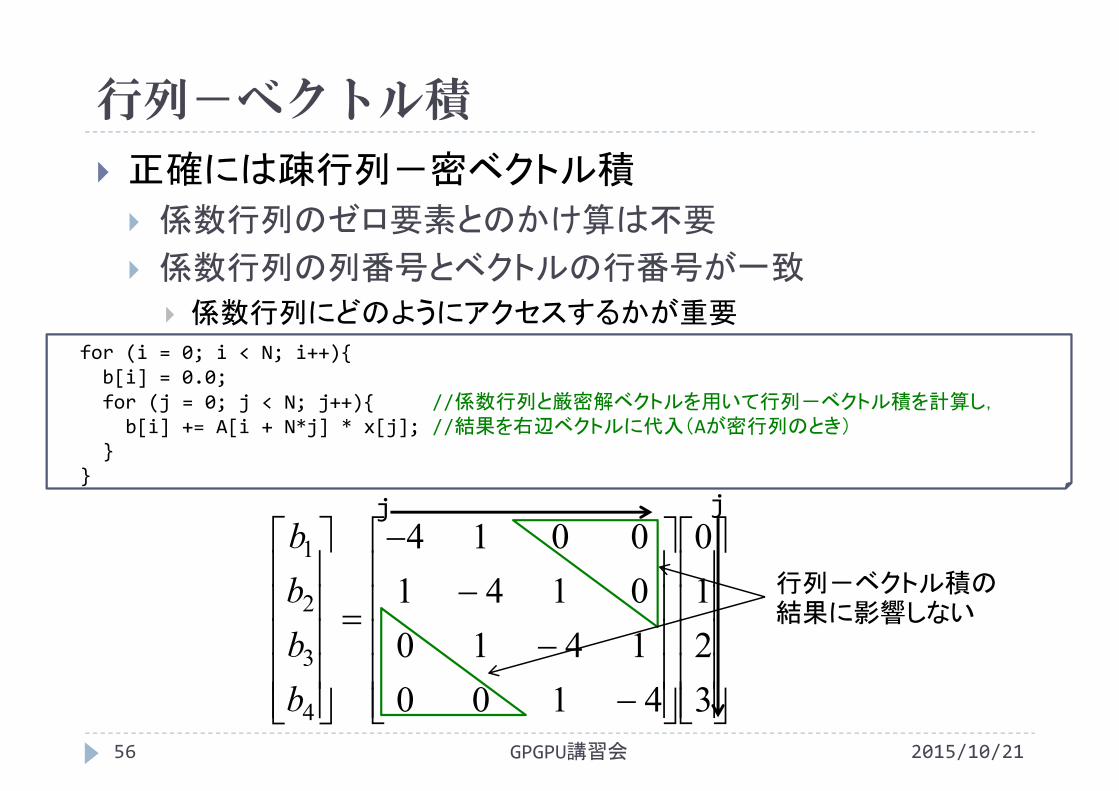
正確には疎行列-密ベクトル積
係数行列のゼロ要素とのかけ算は不要
係数行列の列番号とベクトルの行番号が一致
係数行列にどのようにアクセスするかが重要
3210
4100141001410014
4
3
2
1
bbbb
j j
行列-ベクトル積の結果に影響しない
for (i = 0; i < N; i++){b[i] = 0.0;for (j = 0; j < N; j++){ //係数行列と厳密解ベクトルを用いて行列-ベクトル積を計算し,
b[i] += A[i + N*j] * x[j]; //結果を右辺ベクトルに代入(Aが密行列のとき)}
}

疎行列-ベクトル積
2015/10/21GPGPU講習会57
CSR形式で格納された疎行列と密ベクトルの積
行列の非ゼロ要素へのアクセス
4100141001410014
int i;for (i = 0; i < N; i++){ //i行目の要素for (ij = ArowPtr[i]; ij < ArowPtr[i+1]; ij++){printf("%d行%d列目の要素は%f¥n", i, AcolIdx[ij], Aval[ij]);
}}
ArowPtr = { 0, 2, 5, 8,10}AcolIdx = { 0, 1, 0, 1, 2, 1, 2, 3, 2, 3}Aval = {‐4, 1, 1,‐4, 1, 1,‐4, 1, 1,‐4}
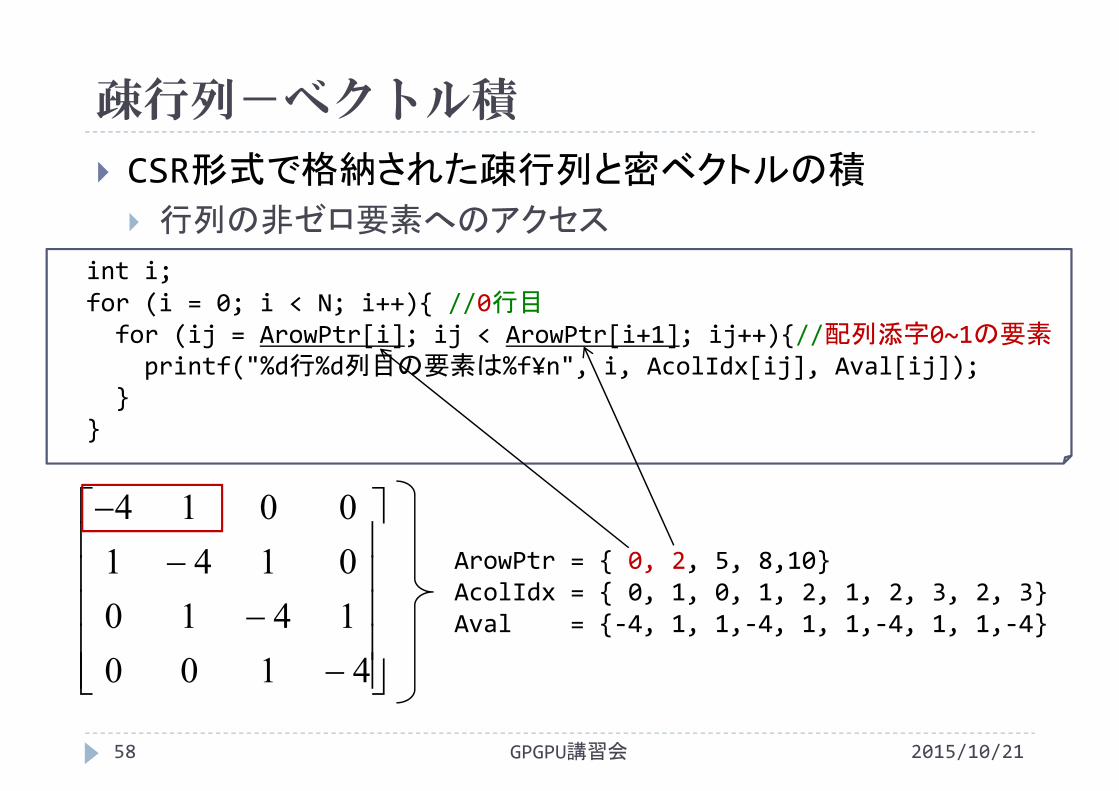
疎行列-ベクトル積
2015/10/21GPGPU講習会58
CSR形式で格納された疎行列と密ベクトルの積
行列の非ゼロ要素へのアクセス
4100141001410014
int i;for (i = 0; i < N; i++){ //0行目for (ij = ArowPtr[i]; ij < ArowPtr[i+1]; ij++){//配列添字0~1の要素printf("%d行%d列目の要素は%f¥n", i, AcolIdx[ij], Aval[ij]);
}}
ArowPtr = { 0, 2, 5, 8,10}AcolIdx = { 0, 1, 0, 1, 2, 1, 2, 3, 2, 3}Aval = {‐4, 1, 1,‐4, 1, 1,‐4, 1, 1,‐4}
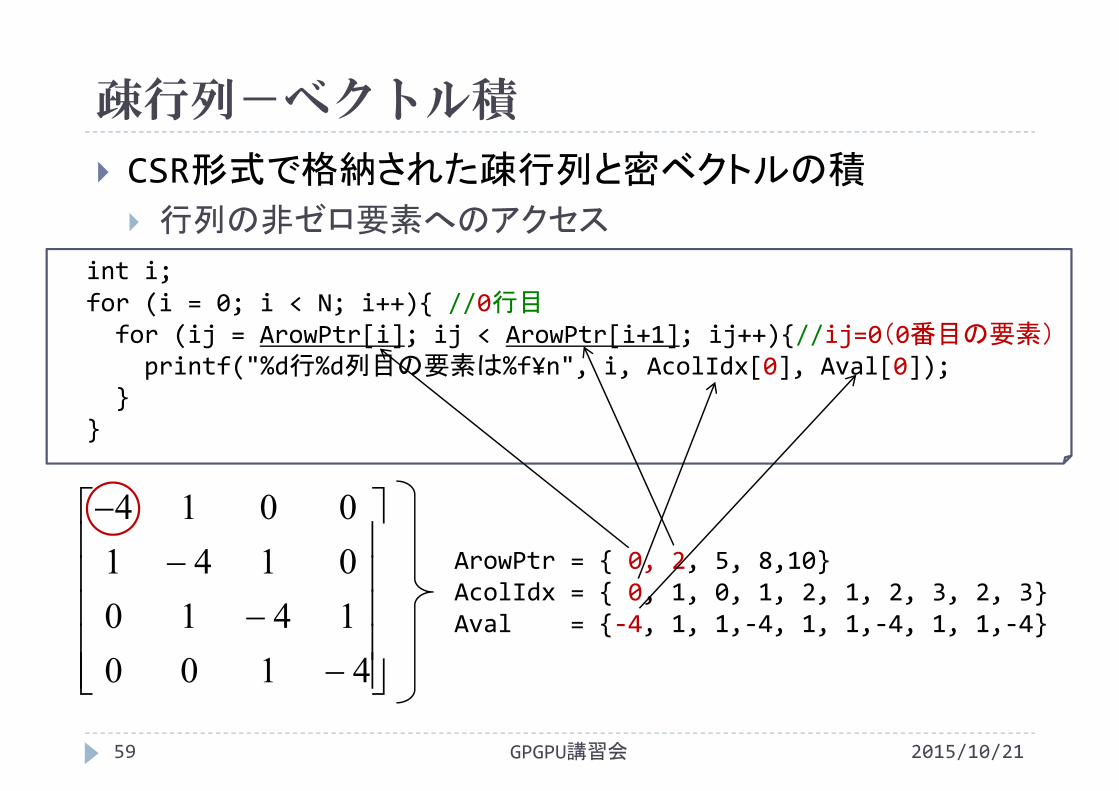
疎行列-ベクトル積
2015/10/21GPGPU講習会59
CSR形式で格納された疎行列と密ベクトルの積
行列の非ゼロ要素へのアクセス
4100141001410014
int i;for (i = 0; i < N; i++){ //0行目for (ij = ArowPtr[i]; ij < ArowPtr[i+1]; ij++){//ij=0(0番目の要素)printf("%d行%d列目の要素は%f¥n", i, AcolIdx[0], Aval[0]);
}}
ArowPtr = { 0, 2, 5, 8,10}AcolIdx = { 0, 1, 0, 1, 2, 1, 2, 3, 2, 3}Aval = {‐4, 1, 1,‐4, 1, 1,‐4, 1, 1,‐4}
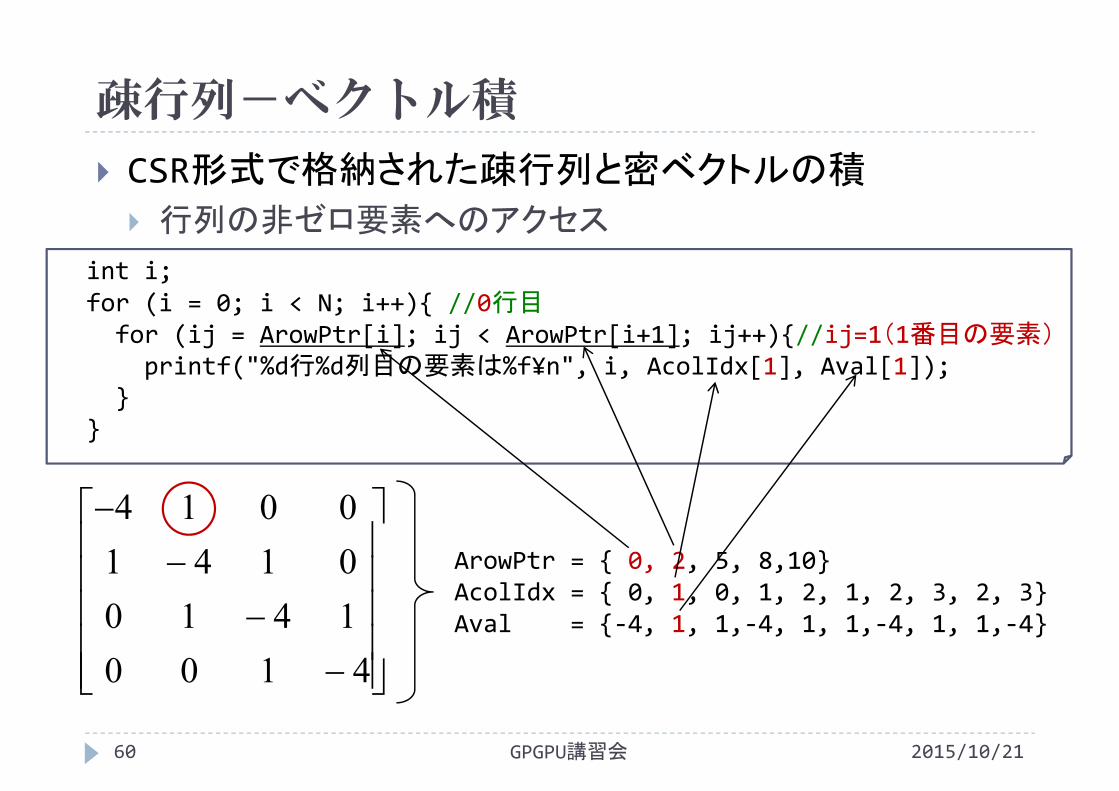
疎行列-ベクトル積
2015/10/21GPGPU講習会60
CSR形式で格納された疎行列と密ベクトルの積
行列の非ゼロ要素へのアクセス
4100141001410014
int i;for (i = 0; i < N; i++){ //0行目for (ij = ArowPtr[i]; ij < ArowPtr[i+1]; ij++){//ij=1(1番目の要素)printf("%d行%d列目の要素は%f¥n", i, AcolIdx[1], Aval[1]);
}}
ArowPtr = { 0, 2, 5, 8,10}AcolIdx = { 0, 1, 0, 1, 2, 1, 2, 3, 2, 3}Aval = {‐4, 1, 1,‐4, 1, 1,‐4, 1, 1,‐4}
疎行列-ベクトル積
2015/10/21GPGPU講習会61
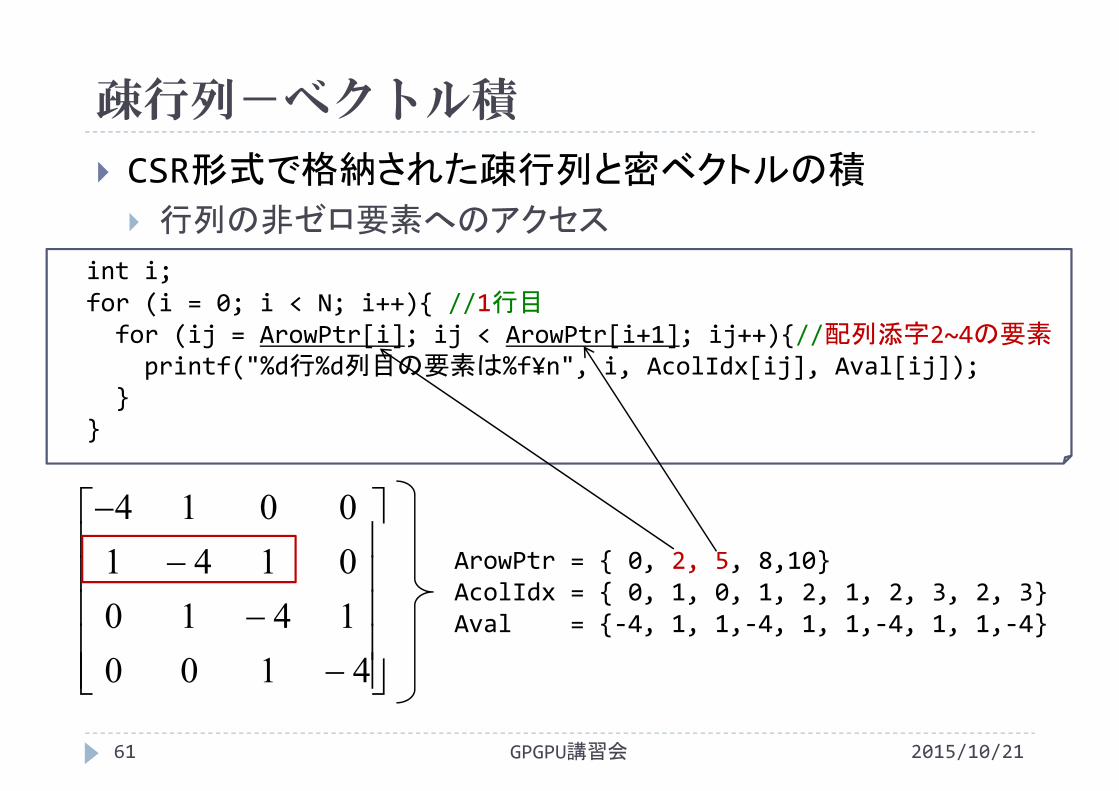
CSR形式で格納された疎行列と密ベクトルの積
行列の非ゼロ要素へのアクセス
4100141001410014
int i;for (i = 0; i < N; i++){ //1行目for (ij = ArowPtr[i]; ij < ArowPtr[i+1]; ij++){//配列添字2~4の要素printf("%d行%d列目の要素は%f¥n", i, AcolIdx[ij], Aval[ij]);
}}
ArowPtr = { 0, 2, 5, 8,10}AcolIdx = { 0, 1, 0, 1, 2, 1, 2, 3, 2, 3}Aval = {‐4, 1, 1,‐4, 1, 1,‐4, 1, 1,‐4}
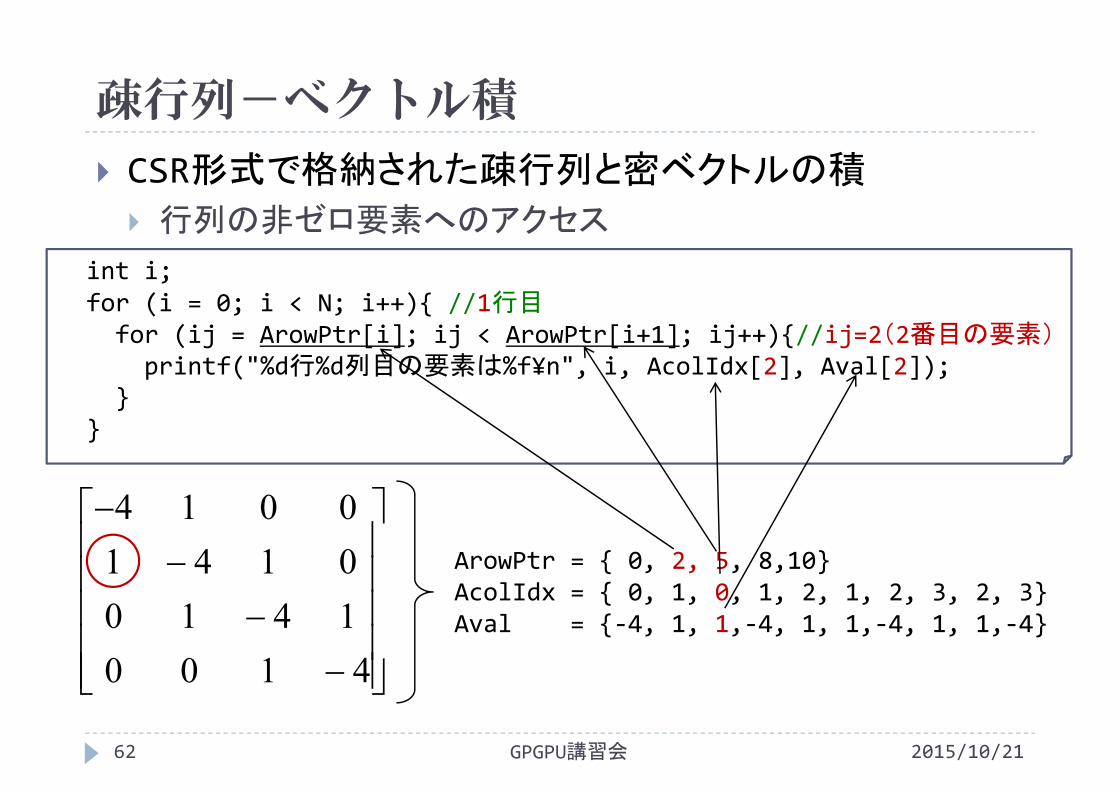
疎行列-ベクトル積
2015/10/21GPGPU講習会62
CSR形式で格納された疎行列と密ベクトルの積
行列の非ゼロ要素へのアクセス
4100141001410014
int i;for (i = 0; i < N; i++){ //1行目for (ij = ArowPtr[i]; ij < ArowPtr[i+1]; ij++){//ij=2(2番目の要素)printf("%d行%d列目の要素は%f¥n", i, AcolIdx[2], Aval[2]);
}}
ArowPtr = { 0, 2, 5, 8,10}AcolIdx = { 0, 1, 0, 1, 2, 1, 2, 3, 2, 3}Aval = {‐4, 1, 1,‐4, 1, 1,‐4, 1, 1,‐4}
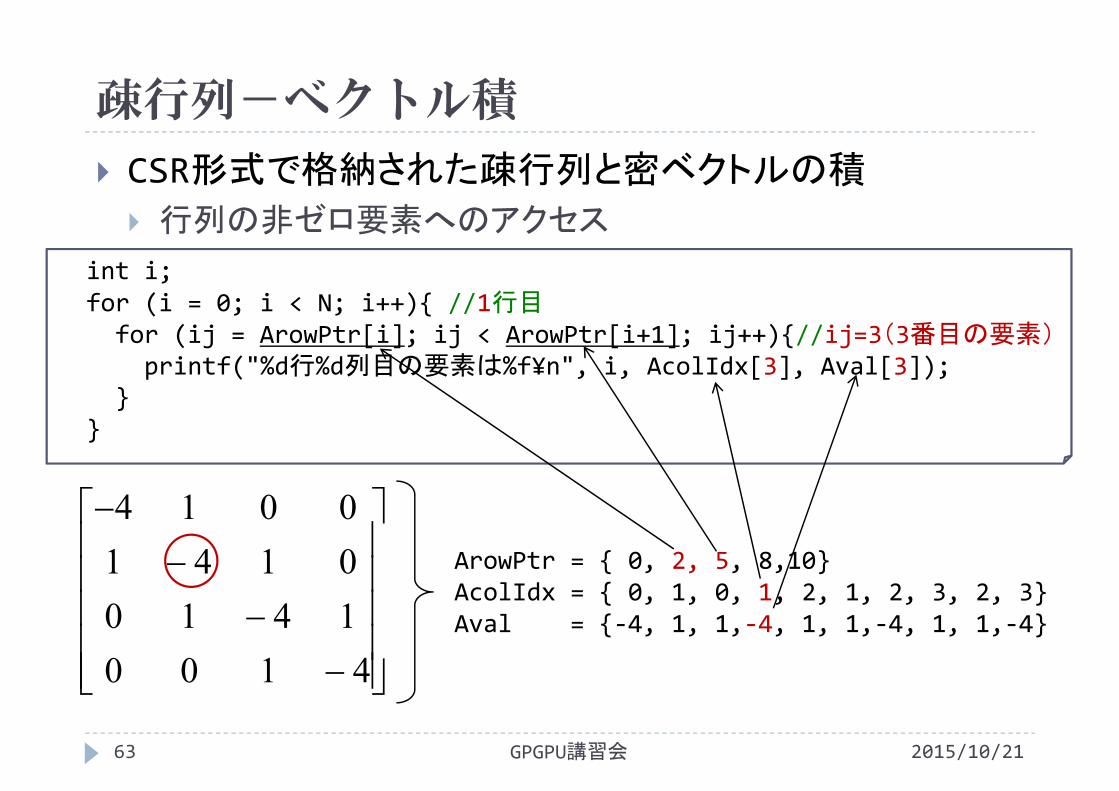
疎行列-ベクトル積
2015/10/21GPGPU講習会63
CSR形式で格納された疎行列と密ベクトルの積
行列の非ゼロ要素へのアクセス
4100141001410014
int i;for (i = 0; i < N; i++){ //1行目for (ij = ArowPtr[i]; ij < ArowPtr[i+1]; ij++){//ij=3(3番目の要素)printf("%d行%d列目の要素は%f¥n", i, AcolIdx[3], Aval[3]);
}}
ArowPtr = { 0, 2, 5, 8,10}AcolIdx = { 0, 1, 0, 1, 2, 1, 2, 3, 2, 3}Aval = {‐4, 1, 1,‐4, 1, 1,‐4, 1, 1,‐4}
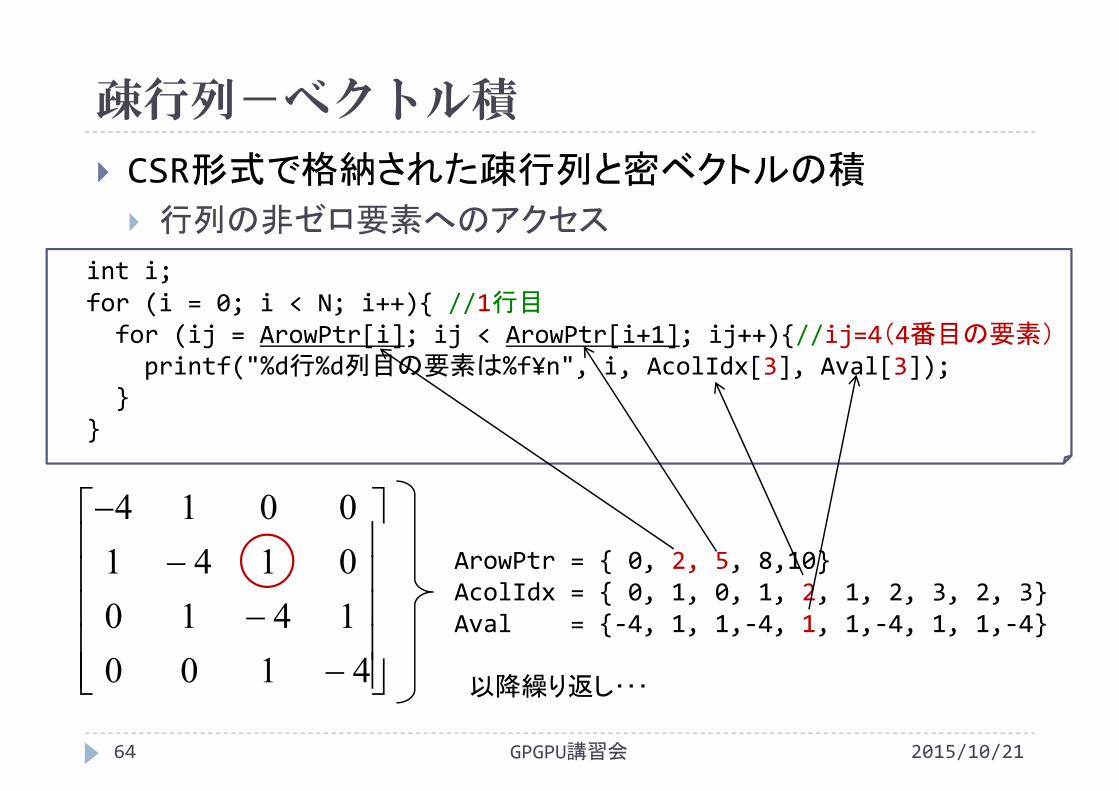
疎行列-ベクトル積
2015/10/21GPGPU講習会64
CSR形式で格納された疎行列と密ベクトルの積
行列の非ゼロ要素へのアクセス
4100141001410014
int i;for (i = 0; i < N; i++){ //1行目for (ij = ArowPtr[i]; ij < ArowPtr[i+1]; ij++){//ij=4(4番目の要素)printf("%d行%d列目の要素は%f¥n", i, AcolIdx[3], Aval[3]);
}}
ArowPtr = { 0, 2, 5, 8,10}AcolIdx = { 0, 1, 0, 1, 2, 1, 2, 3, 2, 3}Aval = {‐4, 1, 1,‐4, 1, 1,‐4, 1, 1,‐4}
以降繰り返し・・・

疎行列-ベクトル積
2015/10/21GPGPU講習会65
CSR形式で格納された疎行列と密ベクトルの積
行列の非ゼロ要素へのアクセス
係数行列の列番号とベクトルの行番号が一致
係数行列Aの一つの要素とそれに乗ずるベクトルxの成分
Aval[ij]*x[AcolIdx[ij]]
int i;for (i = 0; i < N; i++){ for (ij = ArowPtr[i]; ij < ArowPtr[i+1]; ij++){
このループの中で 行情報はi,列情報はAcolIdx[ij]*,係数行列の非ゼロ要素はAval[ij]とすることで参照できる
}}
*列情報の参照においてカウンタ変数名ijは最適ではないかも・・・

疎行列-ベクトル積
2015/10/21GPGPU講習会66
void setRightHandSideVector(double *b, double *Aval, int *AcolIdx, int *ArowPtr, double *x, int N){
int i,ij;
for (i = 0; i < N; i++){b[i] = 0.0;for (ij = ArowPtr[i]; ij < ArowPtr[i+1]; ij++){
b[i] += Aval[ij] * x[AcolIdx[ij]];}
}
}

cuBLASによる共役勾配法の実装とcuSPARSEによるメモリ利用効率の改善

共役勾配法のアルゴリズム(再掲)
2015/10/21GPGPU講習会68
連立一次方程式Ax=bに対する共役勾配法
Compute r(0)=b−Ax(0). Set p(0)=0,c2(0)=0.
For k=1,…, until ||r||/||b|| < , Do
p(k) = r(k)+c2(k−1)p(k−1)
c1(k) = (r(k), r(k))/(p(k), Ap(k))
x(k+1) = x(k)+c1(k)p(k)
r(k+1) = r(k)−c1(k)Ap(k)
c2(k) = (r(k+1), r(k+1))/{c1
(k)(p(k), Ap(k))}
EndDo
行列-ベクトル積
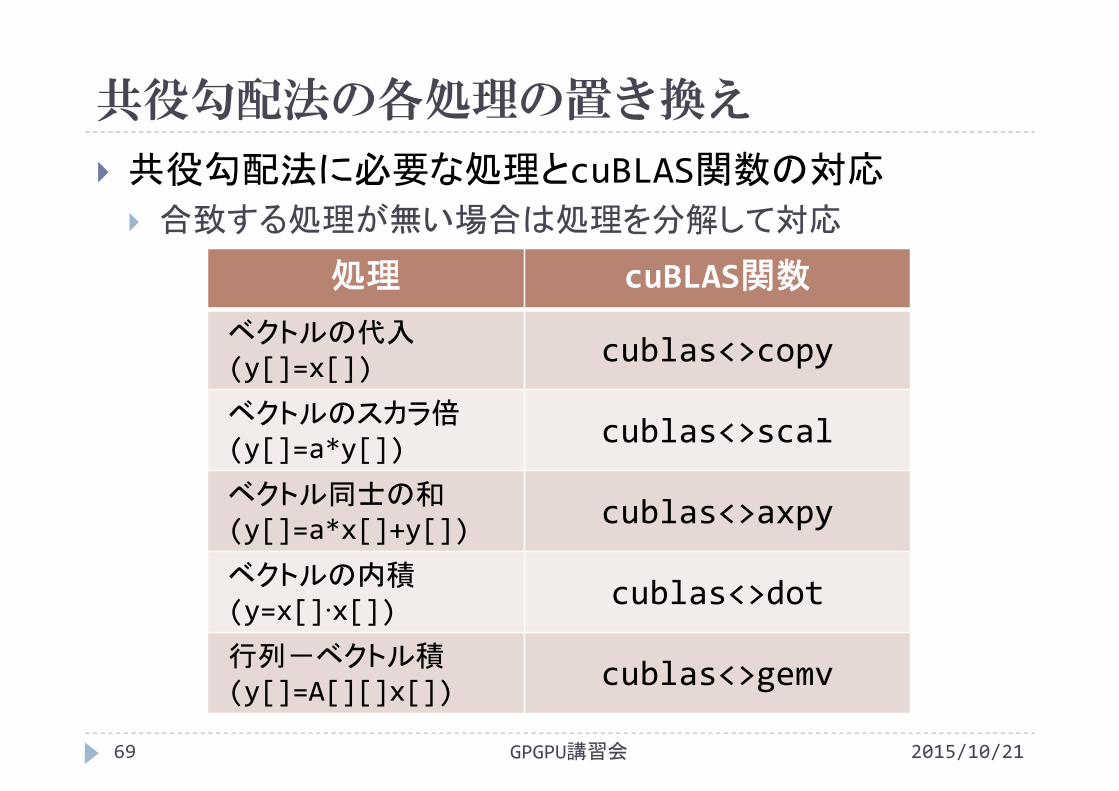
共役勾配法の各処理の置き換え
2015/10/21GPGPU講習会69
共役勾配法に必要な処理とcuBLAS関数の対応
合致する処理が無い場合は処理を分解して対応
処理 cuBLAS関数
ベクトルの代入(y[]=x[]) cublas<>copy
ベクトルのスカラ倍(y[]=a*y[]) cublas<>scal
ベクトル同士の和(y[]=a*x[]+y[]) cublas<>axpy
ベクトルの内積(y=x[]·x[]) cublas<>dot
行列-ベクトル積(y[]=A[][]x[]) cublas<>gemv

GPUプログラム(制御部分)
2015/10/21GPGPU講習会70
#include <stdlib.h>#include <stdio.h>#include <cublas_v2.h>int main(void){
int N = 1 << 10; //未知数の数210const double err_tol = 1e‐9; //許容誤差const int max_ite = 1<<20;//反復回数の上限
double *x; //近似解ベクトルdouble *b; //右辺ベクトルdouble *A; //係数行列double *sol; //厳密解
//GPU用変数double *d_x;double *d_b;double *d_A;double *d_r, rr;double *d_p, *d_Ax;double c1, c2, minusC1, dot;
//cublasで利用する定数const double one = 1.0;const double zero = 0.0;const double minusOne = ‐1.0;int i, k;
A = (double *)malloc(sizeof(double)*N*N);x = (double *)malloc(sizeof(double)*N);b = (double *)malloc(sizeof(double)*N);sol= (double *)malloc(sizeof(double)*N);
for (i = 0; i < N; i++){sol[i] = (double)i; //厳密解を設定
x[i] = 0.0; //近似解を0で初期化}//係数行列Aの生成setTridiagonalMatrix(A, N);//右辺ベクトルbの生成setRightHandSideVector(b, A, sol, N);
cg_cublas.cu
疎行列に置換
疎行列に対応
疎行列に置換
(cuBLAS版再掲)

GPUプログラム(制御部分)
2015/10/21GPGPU講習会71
//cuBLASハンドルの生成cublasHandle_t cublasHandle = 0;cublasStatus_t cublasStatus;cublasStatus=cublasCreate(&cublasHandle);
cudaMalloc((void **)&d_A, N*N*sizeof(double));
cudaMalloc((void **)&d_x, N *sizeof(double));
cudaMalloc((void **)&d_b, N *sizeof(double));
cudaMalloc((void **)&d_r, N *sizeof(double));
cudaMalloc((void **)&d_p, N *sizeof(double));
cudaMalloc((void **)&d_Ax,N *sizeof(double));
cublasSetMatrix(N, N, sizeof(double), A, N, d_A, N);
cublasSetVector(N, sizeof(double), x, 1, d_x, 1);
cublasSetVector(N, sizeof(double), b, 1, d_b, 1);
// :// ここで共役勾配法を実行// :
//ハンドルの破棄cublasDestroy(cublasHandle);
//確保したメモリを解放free(x);free(b);free(A);free(sol);cudaFree(d_x);cudaFree(d_b);cudaFree(d_A);cudaFree(d_r);cudaFree(d_p);cudaFree(d_Ax);
} cg_cublas.cu
疎行列に置換
疎行列に置換
(cuBLAS版再掲)

GPUプログラム(共役勾配法部分)
2015/10/21GPGPU講習会72
//残差ベクトルの計算 r(0)=b−Ax(0)
cublasDgemv(cublasHandle, CUBLAS_OP_N, N, N, &one, d_A, N, d_x, 1, &zero, d_Ax, 1);cublasDcopy(cublasHandle, N, d_b, 1, d_r, 1);cublasDaxpy(cublasHandle, N, &minusOne, d_Ax, 1, d_r, 1);//残差ベクトルの内積を計算cublasDdot(cublasHandle, N, d_r, 1, d_r, 1, &rr);
k = 1;while(rr>err_tol*err_tol && k<=max_ite){
if (k == 1){//p(k) = r(k)+c2
(k−1)p(k−1) c2とpが0のためp(k) = r(k)
cublasDcopy(cublasHandle, N, d_r, 1, d_p, 1);}else{
c2 = rr / (c1*dot);//p(k) = r(k)+c2
(k−1)p(k−1)
cublasDscal(cublasHandle, N, &c2, d_p, 1);cublasDaxpy(cublasHandle, N, &one, d_r, 1, d_p, 1);
}cg_cublas.cu
この行を疎行列に対応させる必要がある
(cuBLAS版再掲)

GPUプログラム(共役勾配法部分)
2015/10/21GPGPU講習会73
//(p(k), Ap(k))を計算//行列ベクトル積Apを実行し,結果とpの内積cublasDgemv(cublasHandle, CUBLAS_OP_N, N, N, &one, d_A, N, d_p, 1, &zero, d_Ax, 1);cublasDdot(cublasHandle, N, d_p, 1, d_Ax, 1, &dot);c1 = rr / dot;
//x(k+1) = x(k)+c1(k)p(k)
//r(k+1) = r(k)−c1(k)Ap(k)
cublasDaxpy(cublasHandle, N, &c1, d_p, 1, d_x, 1);cublasDaxpy(cublasHandle, N, &minusC1, d_Ax, 1, d_r, 1);
//残差ベクトルの内積を計算cublasDdot(cublasHandle, N, d_r, 1, d_r, 1, &rr);
cudaDeviceSynchronize();k++;
}
//計算結果をGPUからCPUへコピーcublasGetVector(N, sizeof(double), d_x, 1, x, 1);
cg_cublas.cu
この行を疎行列に対応させる必要がある
(cuBLAS版再掲)

cuSPARSEの疎行列-ベクトル積
2015/10/21GPGPU講習会74
CSR形式で格納された疎行列と密ベクトルの積
cusparseDcsrmv(全てのcublasDgemvを置き換え)
cusparseDcsrmv(handle,CUSPARSE_OPERATION_NON_TRANSPOSE,N, N, NonZero†,&one‡, descr, d_Aval,d_ArowPtr, d_AcolIdx,d_x,&zero‡, d_Ax);
Ax[N] = one*A[N][N]x[N] + zero*Ax[N]
one =1.0;zero=0.0;
†cuSPARSEのバージョンが古いときは非ゼロ要素数は渡さない(GROUSEはこれに該当)‡cuSPARSEのバージョンが古いときはアドレスではなく値を渡す(GROUSEはこれに該当)

GPUプログラム(制御部分)
2015/10/21GPGPU講習会75
#include <stdlib.h>#include <stdio.h>#include <cublas_v2.h>#include <cusparse.h>int main(void){
int N = 1 << 10; //未知数の数210const double err_tol = 1e‐9; //許容誤差const int max_ite = 1<<20;//反復回数の上限
double *x; //近似解ベクトルdouble *b; //右辺ベクトルdouble *Aval; //係数行列Aの情報int *AcolIdx; //要素数の列の情報int *ArowPtr; //行にある要素数の情報int NonZero; //非ゼロ要素数double *sol; //厳密解
//GPU用変数double *d_x;double *d_b;double *d_Aval; //GPU用変数int *d_AcolIdx; //int *d_ArowPtr; //
cg_cusparse.cu

GPUプログラム(制御部分)
2015/10/21GPGPU講習会76
double *d_r, rr;double *d_p, *d_Ax;double c1, c2, minusC1, dot;
//cublas,cusparseで利用する定数const double one = 1.0;const double zero = 0.0;const double minusOne = ‐1.0;int i, k;
NonZero = 2 + (N‐2)*3 + 2;Aval = (double *)malloc(sizeof(double)*NonZero);AcolIdx = (int *)malloc(sizeof(int) *NonZero);ArowPtr = (int *)malloc(sizeof(int) *N+1 );x = (double *)malloc(sizeof(double)*N);b = (double *)malloc(sizeof(double)*N);sol= (double *)malloc(sizeof(double)*N);
for (i = 0; i < N; i++){sol[i] = (double)i; //厳密解を設定
x[i] = 0.0; //近似解を0で初期化} cg_cusparse.cu

GPUプログラム(制御部分)
2015/10/21GPGPU講習会77
//係数行列Aの生成setTridiagonalMatrix(Aval, AcolIdx, ArowPtr, N, NonZero);//右辺ベクトルbの生成setRightHandSideVector(b, Aval, AcolIdx, ArowPtr, sol, N);
//cuBLASハンドルの生成cublasHandle_t cublasHandle = 0;cublasStatus_t cublasStatus;cublasStatus=cublasCreate(&cublasHandle);
//cuSPARSハンドルの生成cusparseHandle_t cusparseHandle = 0;cusparseStatus_t cusparseStatus;cusparseStatus = cusparseCreate(&cusparseHandle);
//疎行列の詳細情報を扱う変数descrを生成cusparseMatDescr_t descr = 0;cusparseStatus = cusparseCreateMatDescr(&descr);cusparseSetMatType(descr, CUSPARSE_MATRIX_TYPE_GENERAL); //行列の種類の指定cusparseSetMatIndexBase(descr, CUSPARSE_INDEX_BASE_ZERO);//配列が0開始であることを明記
cg_cusparse.cu

GPUプログラム(制御部分)
2015/10/21GPGPU講習会78
cudaMalloc((void **)&d_Aval , NonZero*sizeof(double));cudaMalloc((void **)&d_AcolIdx, NonZero*sizeof(int) );cudaMalloc((void **)&d_ArowPtr, (N+1) *sizeof(int) );cudaMalloc((void **)&d_x, N *sizeof(double));cudaMalloc((void **)&d_b, N *sizeof(double));cudaMalloc((void **)&d_r, N *sizeof(double));cudaMalloc((void **)&d_p, N *sizeof(double));cudaMalloc((void **)&d_Ax,N *sizeof(double));
cublasSetVector(NonZero, sizeof(double), Aval , 1, d_Aval , 1);cublasSetVector(NonZero, sizeof(int) , AcolIdx, 1, d_AcolIdx, 1);cublasSetVector(N+1 , sizeof(int) , ArowPtr, 1, d_ArowPtr, 1);cublasSetVector(N, sizeof(double), x, 1, d_x, 1);cublasSetVector(N, sizeof(double), b, 1, d_b, 1);
// :// ここで共役勾配法を実行// :
cg_cusparse.cu

GPUプログラム(制御部分)
2015/10/21GPGPU講習会79
//ハンドルの破棄cublasDestroy(cublasHandle);cusparseDestroy(cusparseHandle);
//確保したメモリを解放free(x);free(b);free(Aval);free(AcolIdx);free(ArowPtr);free(sol);cudaFree(d_x);cudaFree(d_b);cudaFree(d_Aval);cudaFree(d_AcolIdx);cudaFree(d_ArowPtr);cudaFree(d_r);cudaFree(d_p);cudaFree(d_Ax);
} cg_cusparse.cu

GPUプログラム(共役勾配法部分)
2015/10/21GPGPU講習会80
//残差ベクトルの計算 r(0)=b−Ax(0)
cusparseDcsrmv(cusparseHandle, CUSPARSE_OPERATION_NON_TRANSPOSE, N, N, one, descr, d_Aval, d_ArowPtr, d_AcolIdx, d_x, zero, d_Ax);
//cusparseDcsrmv(cusparseHandle, CUSPARSE_OPERATION_NON_TRANSPOSE, N, N, NonZero,// &one, descr, d_Aval, d_ArowPtr, d_AcolIdx, d_x, &zero, d_Ax);cublasDcopy(cublasHandle, N, d_b, 1, d_r, 1);cublasDaxpy(cublasHandle, N, &minusOne, d_Ax, 1, d_r, 1);//残差ベクトルの内積を計算cublasDdot(cublasHandle, N, d_r, 1, d_r, 1, &rr);
k = 1;while(rr>err_tol*err_tol && k<=max_ite){
if (k == 1){//p(k) = r(k)+c2
(k−1)p(k−1) c2とpが0のためp(k) = r(k)
cublasDcopy(cublasHandle, N, d_r, 1, d_p, 1);}else{
c2 = rr / (c1*dot);//p(k) = r(k)+c2
(k−1)p(k−1)
cublasDscal(cublasHandle, N, &c2, d_p, 1);cublasDaxpy(cublasHandle, N, &one, d_r, 1, d_p, 1);
}
cusparseが新しいバージョンの場合
cg_cusparse.cu

GPUプログラム(共役勾配法部分)
2015/10/21GPGPU講習会81
//(p(k), Ap(k))を計算//行列ベクトル積Apを実行し,結果とpの内積cusparseDcsrmv(cusparseHandle, CUSPARSE_OPERATION_NON_TRANSPOSE, N, N,
one, descr, d_Aval, d_ArowPtr, d_AcolIdx, d_p, zero, d_Ax);cublasDdot(cublasHandle, N, d_p, 1, d_Ax, 1, &dot);c1 = rr / dot;
//x(k+1) = x(k)+c1(k)p(k)
//r(k+1) = r(k)−c1(k)Ap(k)
cublasDaxpy(cublasHandle, N, &c1, d_p, 1, d_x, 1);cublasDaxpy(cublasHandle, N, &minusC1, d_Ax, 1, d_r, 1);
//残差ベクトルの内積を計算cublasDdot(cublasHandle, N, d_r, 1, d_r, 1, &rr);
cudaDeviceSynchronize();k++;
}
//計算結果をGPUからCPUへコピーcublasGetVector(N, sizeof(double), d_x, 1, x, 1); cg_cusparse.cu

実行結果(CPU, 密行列, N=210)
2015/10/21GPGPU講習会82
iteration = 1, residual = 2.098826e+003iteration = 2, residual = 4.308518e+002iteration = 3, residual = 1.102497e+002:
iteration = 21, residual = 5.547180e‐009iteration = 22, residual = 1.486358e‐009iteration = 23, residual = 3.982675e‐010x[0] = ‐0.000000x[1] = 1.000000x[2] = 2.000000:
x[1021] = 1021.000000x[1022] = 1022.000000x[1023] = 1023.000000Total amount of Absolute Error = 5.009568e‐010

実行結果(CPU, 疎行列, N=210)
2015/10/21GPGPU講習会83
iteration = 1, residual = 2.098826e+03iteration = 2, residual = 4.308518e+02iteration = 3, residual = 1.102497e+02:
iteration = 21, residual = 5.547180e‐09iteration = 22, residual = 1.486358e‐09iteration = 23, residual = 3.982675e‐10x[0] = ‐0.000000x[1] = 1.000000x[2] = 2.000000:
x[1021] = 1021.000000x[1022] = 1022.000000x[1023] = 1023.000000Total amount of Absolute Error = 5.009568e‐10

実行結果(GPU, 疎行列, N=210)
2015/10/21GPGPU講習会84
iteration = 1, residual = 2.098826e+03iteration = 2, residual = 4.308518e+02iteration = 3, residual = 1.102497e+02:
iteration = 21, residual = 5.547180e‐09iteration = 22, residual = 1.486358e‐09iteration = 23, residual = 3.982675e‐10x[0] = ‐0.000000x[1] = 1.000000x[2] = 2.000000:
x[1021] = 1021.000000x[1022] = 1022.000000x[1023] = 1023.000000Total amount of Absolute Error = 5.008786e‐10
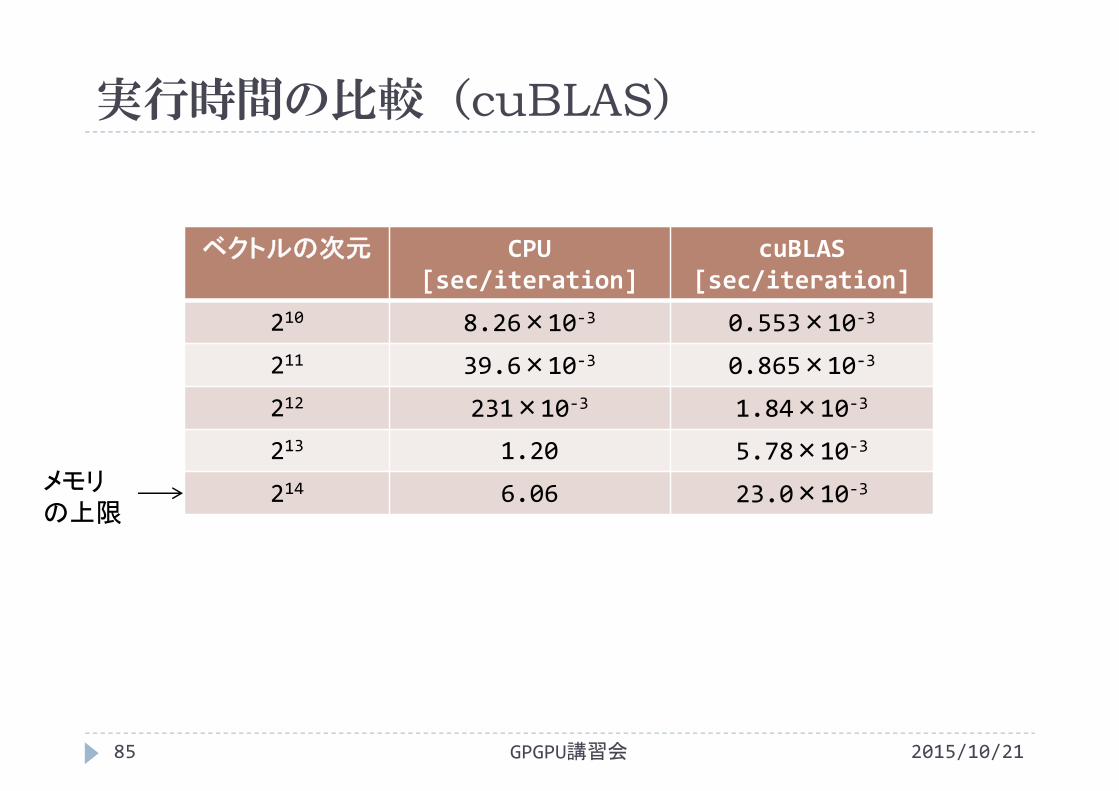
実行時間の比較(cuBLAS)
2015/10/21GPGPU講習会85
ベクトルの次元 CPU [sec/iteration]
cuBLAS[sec/iteration]
210 8.26×10‐3 0.553×10‐3
211 39.6×10‐3 0.865×10‐3
212 231×10‐3 1.84×10‐3
213 1.20 5.78×10‐3
214 6.06 23.0×10‐3メモリの上限
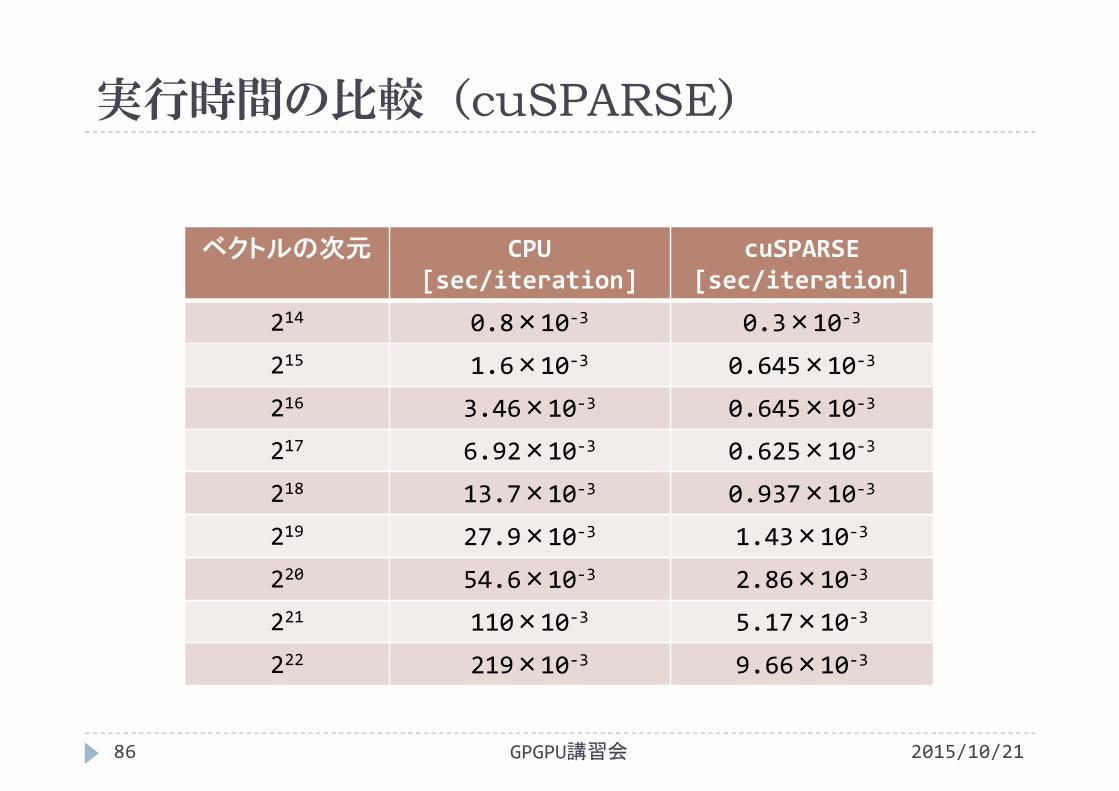
実行時間の比較(cuSPARSE)
2015/10/21GPGPU講習会86
ベクトルの次元 CPU [sec/iteration]
cuSPARSE[sec/iteration]
214 0.8×10‐3 0.3×10‐3
215 1.6×10‐3 0.645×10‐3
216 3.46×10‐3 0.645×10‐3
217 6.92×10‐3 0.625×10‐3
218 13.7×10‐3 0.937×10‐3
219 27.9×10‐3 1.43×10‐3
220 54.6×10‐3 2.86×10‐3
221 110×10‐3 5.17×10‐3
222 219×10‐3 9.66×10‐3
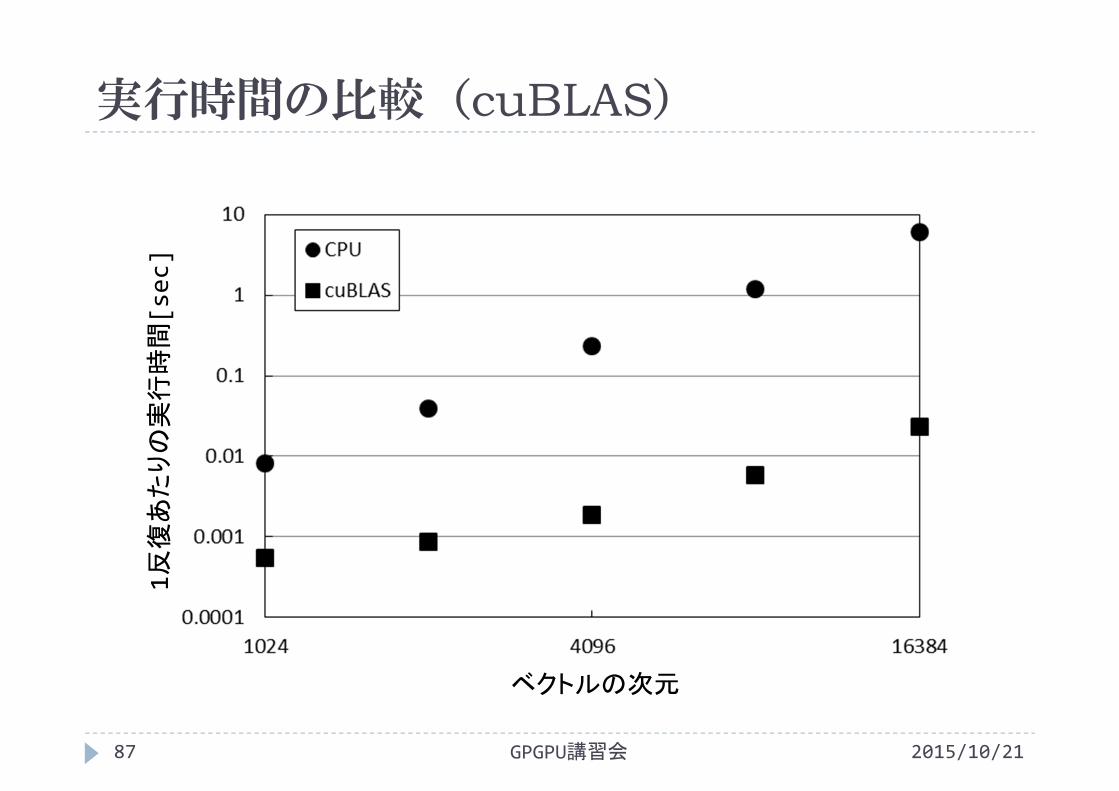
実行時間の比較(cuBLAS)
2015/10/21GPGPU講習会87
ベクトルの次元
1反復あたりの実行時間[sec]
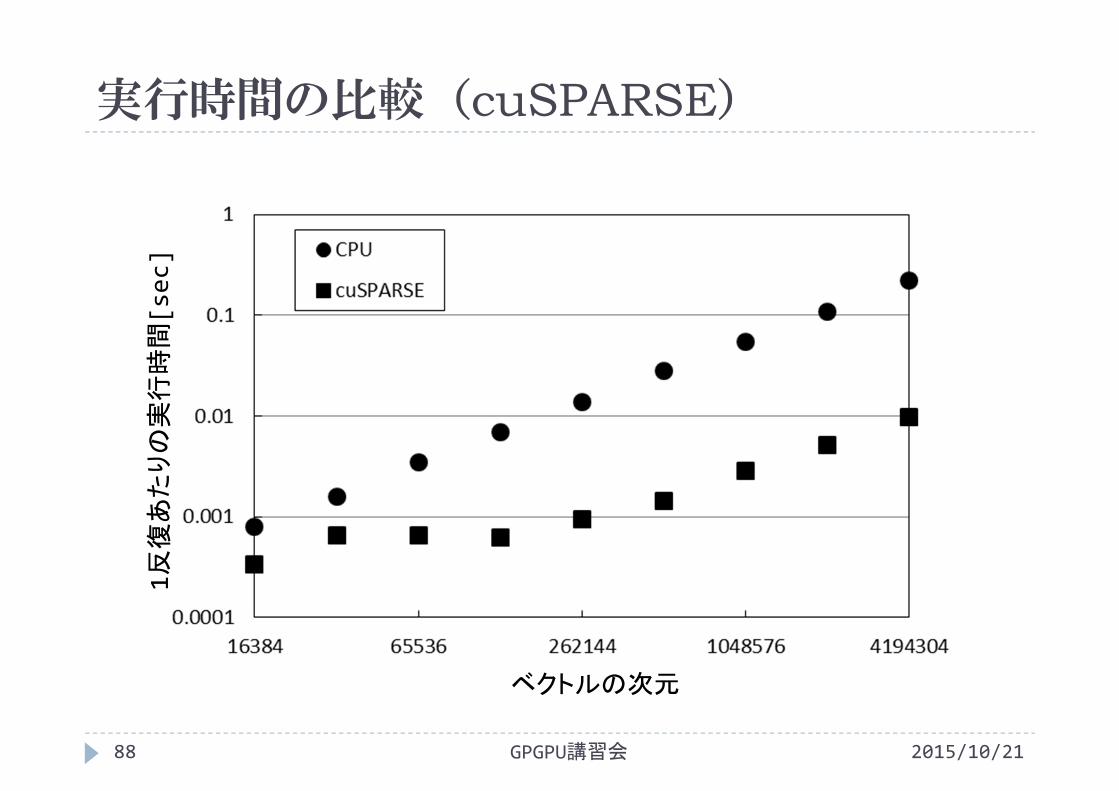
実行時間の比較(cuSPARSE)
2015/10/21GPGPU講習会88
ベクトルの次元
1反復あたりの実行時間[sec]

改善点
2015/10/21GPGPU講習会89
一つの式を複数の式に分解するのは非効率
行列-ベクトル積は仕方ないが,それ以外は何とかしたい
r=b−Ax → Ax=A×x, r=b, r=b−1×Ax
p=r+c2p → p=c2p, p=r+1×p
CPUコードとGPUコードの乖離が大きい
保守管理がわずらわしい
メモリの確保や解放,コピーなどが煩わしい
他のライブラリとの併用
さらに柔軟に設計されたライブラリを利用
Thrust

補足

A. cuBLAS関数のリファレンス
2015/10/21GPGPU講習会91
cublasCreate cublasStatus_tcublasCreate(cublasHandle_t *handle)
cublasDestroy cublasStatus_tcublasDestroy(cublasHandle_t handle)
cuBLASのハンドルのアドレス
cuBLASのハンドル

A. cuBLAS関数のリファレンス
2015/10/21GPGPU講習会92
cublasSetVector y[n]<‐x[n] cublasStatus_tcublasSetVector(int n,
int elemSize,const void *x,int incx,void *y,int incy)
ベクトルの要素数
1要素のバイト数
コピー元ベクトルのアドレス
コピー元ベクトルのストライド
コピー先ベクトルのアドレス
コピー先ベクトルのストライド

A. cuBLAS関数のリファレンス
2015/10/21GPGPU講習会93
cublasGetVector y[n]<‐x[n] cublasStatus_tcublasGetVector(int n,
int elemSize,const void *x,int incx,void *y,int incy)
ベクトルの要素数
1要素のバイト数
コピー元ベクトルのアドレス
コピー元ベクトルのストライド
コピー先ベクトルのアドレス
コピー先ベクトルのストライド

A. cuBLAS関数のリファレンス
2015/10/21GPGPU講習会94
cublasSetMatrix B[rows][cols]<‐A[rows][cols] cublasStatus_tcublasSetMatrix(int rows,
int cols,int elemSize,const void *A,int lda,void *B,int ldb)
行の要素数
列の要素数
1要素のバイト数
コピー元行列のアドレス
コピー元行列の1次元の要素数
コピー先行列のアドレス
コピー先行列の1次元の要素数

A. cuBLAS関数のリファレンス
2015/10/21GPGPU講習会95
cublasGetMatrix B[rows][cols]<‐A[rows][cols] cublasStatus_tcublasGetMatrix(int rows,
int cols,int elemSize,const void *A,int lda,void *B,int ldb)
行の要素数
列の要素数
1要素のバイト数
コピー元行列のアドレス
コピー元行列の1次元の要素数
コピー先行列のアドレス
コピー先行列の1次元の要素数

A. cuBLAS関数のリファレンス
2015/10/21GPGPU講習会96
cublasDcopy y[n]<‐x[n] cublasStatus_tcublasDcopy(cublasHandle_t handle,
int n,const double *x,int incx,double *y,int incy)
ハンドル
ベクトルの要素数
コピー元ベクトルのアドレス
コピー元ベクトルのストライド
コピー先ベクトルのアドレス
コピー先ベクトルのストライド

A. cuBLAS関数のリファレンス
2015/10/21GPGPU講習会97
cublasDdot result <‐ (x[n]·y[n]) cublasStatus_tcublasDdot (cublasHandle_t handle,
int n,const double *x,int incx,const double *y,int incy,double *result)
ハンドル
ベクトルの要素数
一つ目のベクトルのアドレス
一つ目のベクトルのストライド
二つ目のベクトルのアドレス
二つ目のベクトルのストライド
内積の結果を格納する変数のアドレス

A. cuBLAS関数のリファレンス
2015/10/21GPGPU講習会98
cublasDscal x[n]<‐alpha*x[n] cublasStatus_tcublasDscal(cublasHandle_t handle,
int n,const double *alpha,double *x,int incx)
ハンドル
ベクトルの要素数
かける数を代入した変数のアドレス
入出力ベクトルのアドレス
入出力ベクトルのストライド

A. cuBLAS関数のリファレンス
2015/10/21GPGPU講習会99
cublasDaxpy y[n]<‐alpha*x[n] + y[n] cublasStatus_tcublasDaxpy(cublasHandle_t handle,
int n,const double *alpha,const double *x,int incx,double *y,int incy)
ハンドル
ベクトルの要素数
かける数を代入した変数のアドレス
加算するベクトルのアドレス
加算するベクトルのストライド
加算されるベクトルのアドレス
加算されるベクトルのストライド

A. cuBLAS関数のリファレンス
2015/10/21GPGPU講習会100
cublasDgemv y[m] = alpha*OP(A[m][n])x[n] + beta*y[m] cublasStatus_tcublasDgemv(cublasHandle_t handle,
cublasOperation_t trans,
int m, int n,
const double *alpha,
const double *A, int lda,
const double *x, int incx,
const double *beta,
double *y, int incy)
ハンドル
行列に対する操作
行列の行と列の要素数
かける数を代入した変数のアドレス
行列と1次元の要素数
行列にかけるベクトルのアドレスとストライド
計算結果のベクトルにかける数を代入した変数のアドレス
計算結果のベクトルのアドレスとストライド

B. cuSPARSE関数のリファレンス
2015/10/21GPGPU講習会101
cusparseCreate cusparseStatus_tcusparseCreate(cusparseHandle_t *handle)
cusparseDestroy cusparseStatus_tcusparseDestroy(cusparseHandle_t handle)
cuSPARSEのハンドルのアドレス
cuSPARSEのハンドル

B. cuSPARSE関数のリファレンス
2015/10/21GPGPU講習会102
cusparseCreateMatDescr cusparseStatus_tcusparseCreateMatDescr(
cusparseMatDescr_t *descr)
cusparseSetMatType cusparseStatus_tcusparseSetMatType(cusparseMatDescr_t descrA,
cusparseMatrixType_t type)
行列の種類は一般,対称,エルミート,三角の4通り
疎行列の情報(デスクリプタ)
疎行列の情報
行列の種類

B. cuSPARSE関数のリファレンス
2015/10/21GPGPU講習会103
cusparseSetMatIndexBase cusparseStatus_tcusparseSetMatIndexBase(
cusparseMatDescr_t descrA,cusparseIndexBase_t base)
BLASはFortranのサブルーチンとして開発
Fortranでは配列添字の開始は1 Cでは0 その違いを吸収するための指示
疎行列の情報
配列の添字の開始

B. cuSPARSE関数のリファレンス
2015/10/21GPGPU講習会104
cusparseDcsrmv y[m] = alpha*OP(A[m][n])x[n] + beta*y[m] cusparseStatus_tcusparseDcsrmv(cusparseHandle_t handle,
cusparseOperation_t transA,int m, int n,int nnz,const double *alpha,const cusparseMatDescr_t descrA,const double *csrValA,const int *csrRowPtrA,const int *csrColIndA,const double *x,const double *beta,double *y)
ハンドル
行列に対する操作
行列の行と列の要素数と非ゼロ要素数
かける数を代入した変数のアドレス
非ゼロ要素の値
非ゼロ要素の列情報
計算結果のベクトルにかける数を代入した変数のアドレス
疎行列の情報
非ゼロ要素の行情報
行列にかけるベクトルのアドレス
計算結果のベクトルのアドレス

C. CPUコードの実行時間の測定
GPGPU講習会105
#include<time.h> // clock_t型や関数clock()を利用
int main(void){clock_t start_c, stop_c;float time_s;
start_c = clock(); //プログラム実行時からの経過時間を取得: //: //ここに処理を記述: //
stop_c = clock(); //プログラム実行時からの経過時間を取得
//処理に要した時間を秒に変換time_s = (stop_c‐start_c)/(float)CLOCKS_PER_SEC;printf(...); //画面表示
return 0;}
2015/10/21
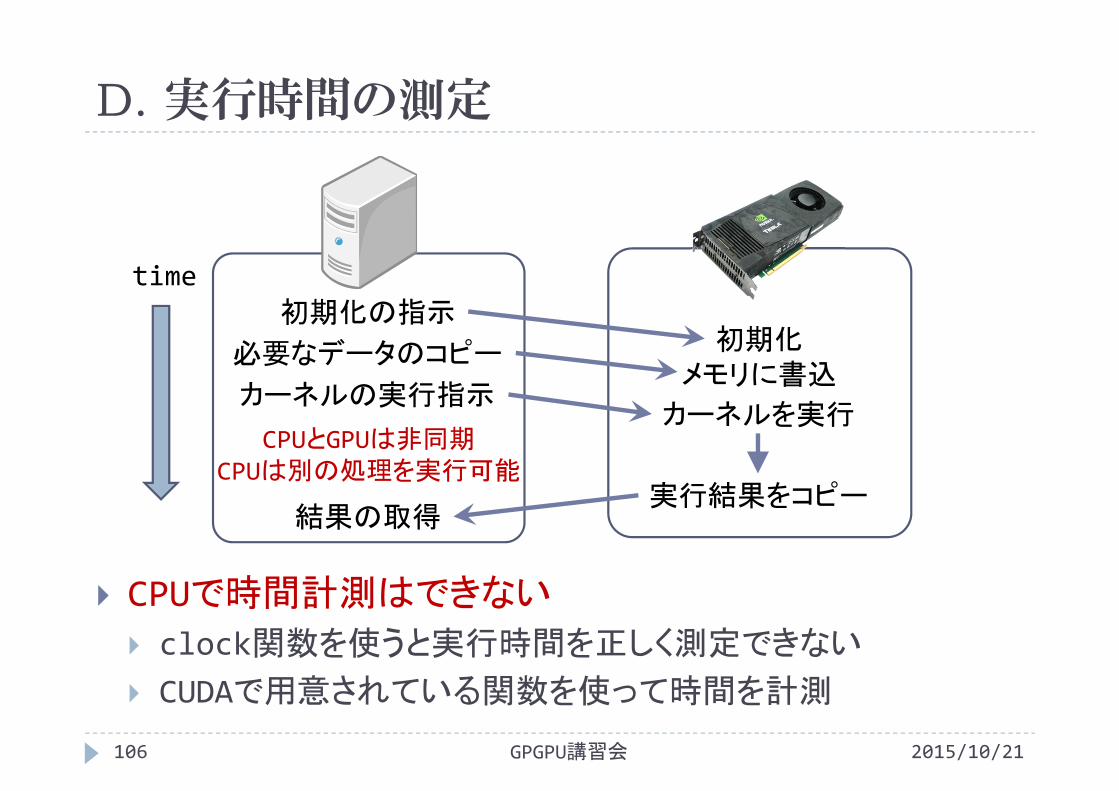
D. 実行時間の測定
CPUで時間計測はできない
clock関数を使うと実行時間を正しく測定できない
CUDAで用意されている関数を使って時間を計測
2015/10/21GPGPU講習会106
初期化の指示初期化
カーネルの実行指示カーネルを実行
結果の取得実行結果をコピー
time
CPUとGPUは非同期CPUは別の処理を実行可能
必要なデータのコピーメモリに書込

D. CUDA Eventで時間測定*
GPUへの指示をEventと呼び,そのEventが発生した時間の差から時間を測定
準備 どのEventを取り扱うかを宣言
kernelの呼び出し(startイベント)と実行終了(stopイベント)
イベントを取り扱う変数の宣言と利用準備
*http://gpu.fixstars.com/index.php/CUDA_Eventで時間計測
2015/10/21GPGPU講習会107
cudaEvent_t start,stop; ・・・イベントを取り扱う変数float elapsed_time_ms = 0.0f; ・・・経過時間保存用
cudaEventCreate(&start); ・・・イベントのクリエイトcudaEventCreate(&stop);

D. CUDA Eventで時間測定
Event発生時間を記録
Eventの同期
startとstopの時間を正しく記録し終わっていることを保証
2015/10/21GPGPU講習会108
cudaEventRecord(start, 0);//ここでkernelを実行cudaEventRecord(stop, 0);
cudaEventSynchronize(stop);

D. CUDA Eventで時間測定
Eventが発生した時間差を計算(ミリ秒単位)
Eventの時間を記録した変数を破棄
2015/10/21GPGPU講習会109
cudaEventElapsedTime(&elapsed_time_ms, start,stop);
cudaEventDestroy(start);cudaEventDestroy(stop);

D. CUDA Eventで時間測定
int main(void){float *a,*b,*c;//イベント記録の準備
cudaMalloc((void **)&a, Nbytes);cudaMalloc((void **)&b, Nbytes);cudaMalloc((void **)&c, Nbytes);
init<<< , >>>(a,b,c);
//イベント発生時間の記録add<<< , >>>(a,b,c);//イベント発生時間の記録//イベントの同期//イベント間の時間差を計算printf("%f¥n", elapsed_time_ms);//イベントの破棄return 0;
}
2015/10/21GPGPU講習会110





























