Embed Size (px)
Citation preview

PostgreSQL9.6
パラレルクエリの
第34回 PostgreSQL勉強会 2017.1.21
株式会社アシスト
データベース技術本部 喜田 紘介
自己紹介
名前:喜田 紘介(きだ こうすけ)
所属:日本PostgreSQLユーザ会 広報・企画担当
株式会社アシスト データベース技術本部
EDB Postgres の技術支援、新機能検証、
プリセールス等を担当しています。
一言:いろいろあって、改めてPostgreSQL、DB技術の
普及とか頑張りたいと思っています!
Japan PostgreSQL User's Group 2
初心者向け 情報発信
地方需要の 活性化
エコシステム拡大
ご参加、応援、よろしくお願いします!

EDB Postgresについて
Japan PostgreSQL User's Group 3
本日は、EDB Postgres 9.6 β検証の経験からお話します。
EDB Postgres Tools / Oracle Compatibility
PostgreSQL ソースコード
企業ユーザーのニーズ
性能 可用性 拡張性 セキュリティ 運用管理
PostgreSQL 9.1
EDB Postgres 9.1
PostgreSQL 9.2
EDB Postgres 9.2
PostgreSQL 9.x
EDB Postgres 9.x
メニーコア環境での スケールアップ
外部データ連携 マテリアライズド・ビュー
各種性能改善 パラレル・クエリ

アジェンダ
EDB Postgres 9.6 β検証を経て、いろいろなケースで パラレルクエリを試して得られた情報をご報告します。
パラレルクエリの基本解説
期待される効果
使い方
実行計画
パラレルクエリの課題
意外と間違う実行計画
EDBのパラレル・ヒント
現状パラレルクエリが使えないケース
Japan PostgreSQL User's Group 4
PostgreSQL 9.6 パラレルクエリの本当のところ

パラレルクエリに期待される効果
Japan PostgreSQL User's Group 5
大規模データのIn-Database処理を実現
2016年11月16日 アシストテクニカルフォーラム講演資料より。 PostgreSQL が9.xで目指して きた「あるべき姿」が9.6で実現

9.6 大規模データ環境での期待
Japan PostgreSQL User's Group 6
巨大なテーブルで生じる問題を解消する複数の機能
テーブルサイズ肥大化による 読み込みの長時間化
パラレル・クエリ パーティショニング(*)
データ増に伴うメンテナンス コストの肥大化
パーティショニング(*) VACUUMの改良 BRINインデックス
パラレル・ヒント による最適なパラレル処理の制御 パーティショニング による性能向上とメンテナンス性の向上
(*)PostgreSQLのパーティショニングは、テーブル継承と CHECK制約、自作のトリガ関数で独自に定義が必要

パラレルクエリの動作
Japan PostgreSQL User's Group 7
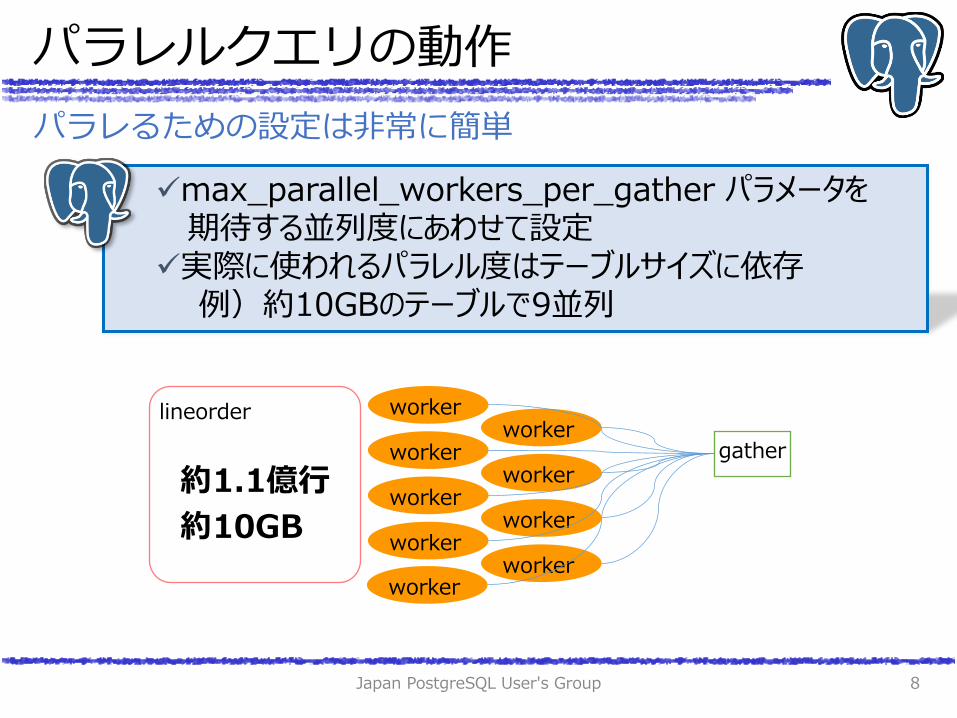
パラレるための設定は非常に簡単
max_parallel_workers_per_gather パラメータを 期待する並列度にあわせて設定 実際に使われるパラレル度はテーブルサイズに依存 例)約100GBのテーブルで9並列
Oracleのオプティマイザ・ヒントと同様の書式で指定 例)SELECT /*+ PARALLEL(emp 9) */ ename,sal,job FROM emp;
パラレルクエリの動作
Japan PostgreSQL User's Group 8
パラレるための設定は非常に簡単
max_parallel_workers_per_gather パラメータを 期待する並列度にあわせて設定 実際に使われるパラレル度はテーブルサイズに依存 例)約10GBのテーブルで9並列
lineorder
約1.1億行
約10GB
worker
worker
worker
worker
worker
worker
worker
worker
gather
worker

パラレルクエリの動作
Japan PostgreSQL User's Group 9
いくつかのパラメータでパラレル数を制御
パラメータ デフォルト 説明
max_parallel_workers_per_gather 0 1クエリで稼働するワーカー数の上限を設定
max_worker_processes 8 サーバー起動時のみ設定可 ワーカープロセス数の上限を決定
min_parallel_relation_size 1024 MB パラレルクエリが選択されるテーブルサイズの下限
parallel_setup_cost 1000 パラレルクエリの初動コスト
parallel_tuple_cost 0.1 パラレルクエリで1行を読み取るコスト
force_parallel_mode off コスト計算を無視してパラレルで動作した場合の効果を検証
テーブルの格納パラメータ デフォルト 説明
parallel_workers なし テーブルを走査する際に稼働するワーカー数の上限を設定
パラレルクエリの動作
Japan PostgreSQL User's Group 10
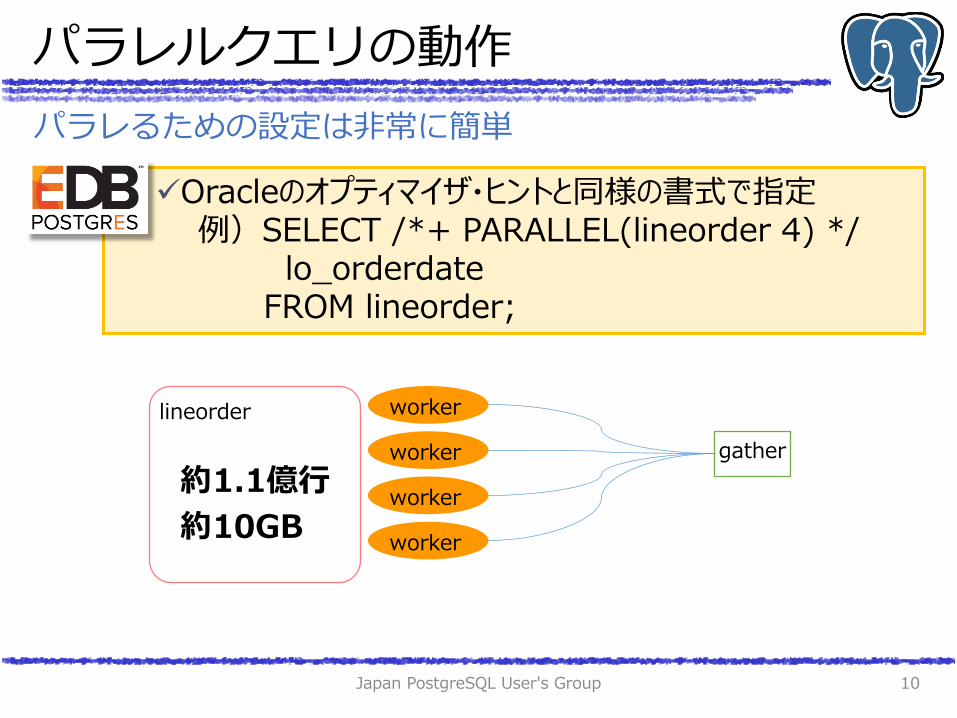
パラレるための設定は非常に簡単
Oracleのオプティマイザ・ヒントと同様の書式で指定 例)SELECT /*+ PARALLEL(lineorder 4) */ lo_orderdate FROM lineorder;
lineorder
約1.1億行
約10GB
worker
worker
worker
worker
gather

パラレルクエリの動作
パラレル・ヒントの種類
パラレル実行 /*+ PARALLEL (emp 8) */ --- 並列度を指定
/*+ PARALLEL (emp default) */ --- デフォルトの並列度
/*+ PARALLEL (emp) */ --- 並列度はお任せ
パラレル実行を禁止 /*+ NO_PARALLEL (emp) */ --- パラレルしない
/*+ PARALLEL (emp 0) */ --- パラレルしない
ヒントを書く位置
SELECT句の直後
複数のヒントを並べて書ける/*+ PARALLEL (emp 8) PARALLEL (dept 2)*/
WITH句や副問い合わせの中でも使える
Japan PostgreSQL User's Group 11
パラレル・ヒントの細かいところ

パラレルクエリの動作
ヒントの競合
PARALLELヒントを指定すると、同じ表に対する以下の指定は無視される FULL
INDEX
NO_PARALLEL
競合に関するあれこれ SQL開始時にSET trace_hints TO on; としておくと、有効
化されたヒントを確認できる。
マニュアルでは、どちらが優先か明記されていないが、実際に試すとPARALLELヒントが一番強い。
Japan PostgreSQL User's Group 12
パラレル・ヒントの細かいところ
パラレルクエリの実行計画
実行例
Japan PostgreSQL User's Group 13
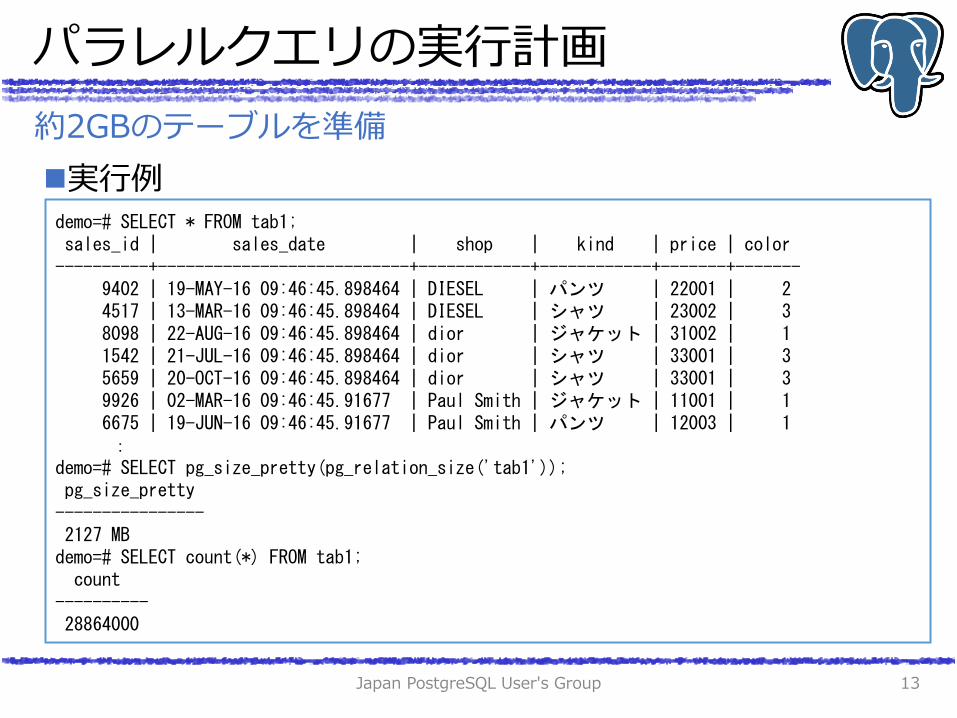
約2GBのテーブルを準備
demo=# SELECT * FROM tab1; sales_id | sales_date | shop | kind | price | color ----------+---------------------------+------------+------------+-------+------- 9402 | 19-MAY-16 09:46:45.898464 | DIESEL | パンツ | 22001 | 2 4517 | 13-MAR-16 09:46:45.898464 | DIESEL | シャツ | 23002 | 3 8098 | 22-AUG-16 09:46:45.898464 | dior | ジャケット | 31002 | 1 1542 | 21-JUL-16 09:46:45.898464 | dior | シャツ | 33001 | 3 5659 | 20-OCT-16 09:46:45.898464 | dior | シャツ | 33001 | 3 9926 | 02-MAR-16 09:46:45.91677 | Paul Smith | ジャケット | 11001 | 1 6675 | 19-JUN-16 09:46:45.91677 | Paul Smith | パンツ | 12003 | 1 : demo=# SELECT pg_size_pretty(pg_relation_size('tab1')); pg_size_pretty ---------------- 2127 MB demo=# SELECT count(*) FROM tab1; count ---------- 28864000

パラレルクエリの実行計画
実行例
Japan PostgreSQL User's Group 14
みんなで1つの表をスキャンする
demo=# EXPLAIN ANALYZE SELECT count(*) FROM tab1; QUERY PLAN -------------------------------------------------------------------------------------------- Finalize Aggregate (cost=333435.96..333435.97 rows=1 width=8) (actual time=1061.313..1061.313 rows=1 loops=1) -> Gather (cost=333435.33..333435.94 rows=6 width=8) (actual time=1061.240..1061.304 rows=7 loops=1) Workers Planned: 6 Workers Launched: 6 -> Partial Aggregate (cost=332435.33..332435.34 rows=1 width=8) (actual time=1055.119..1055.119 rows=1 loops=7) -> Parallel Seq Scan on tab1 (cost=0.00..320408.67 rows=4810667 width=0) (actual time=0.050..663.461 rows=4123429 loops=7)
7並列でscan (loops=7)
並列に集計(loops=7)
結果を集めて (rows=7)
全体を集計(rows=1)

パラレルクエリの実行計画
捏造です!すみません。が、こんな感じ。
起動済みのワーカーがみんなで各子表を見に行く
Japan PostgreSQL User's Group 15
パーティショニングの場合
demo=# EXPLAIN ANALYZE SELECT count(*) FROM tab; -- tab1 や tab2 を子表にもつ親表 QUERY PLAN -------------------------------------------------------------------------------------------- Finalize Aggregate (cost=333435.96..333435.97 rows=1 width=8) (actual time=1061.313..1061.313 rows=1 loops=1) -> Gather (cost=333435.33..333435.94 rows=6 width=8) (actual time=1061.240..1061.304 rows=7 loops=1) Workers Planned: 6 Workers Launched: 6 -> Partial Aggregate とか Append とか -> Parallel Seq Scan on tab (cost=0.00..0.00 rows=0 width=0) (actual time=0.00..0.00 rows=0 loops=7) -> Parallel Seq Scan on tab1 (cost=0.00..320408.67 rows=4810667 width=0) (actual time=0.050..663.461 rows=4123429 loops=7) -> Parallel Seq Scan on tab2 (cost=0.00..320408.67 rows=4810667 width=0) (actual time=0.050..663.461 rows=4123429 loops=7)
パラレルクエリの実行計画
Japan PostgreSQL User's Group 16
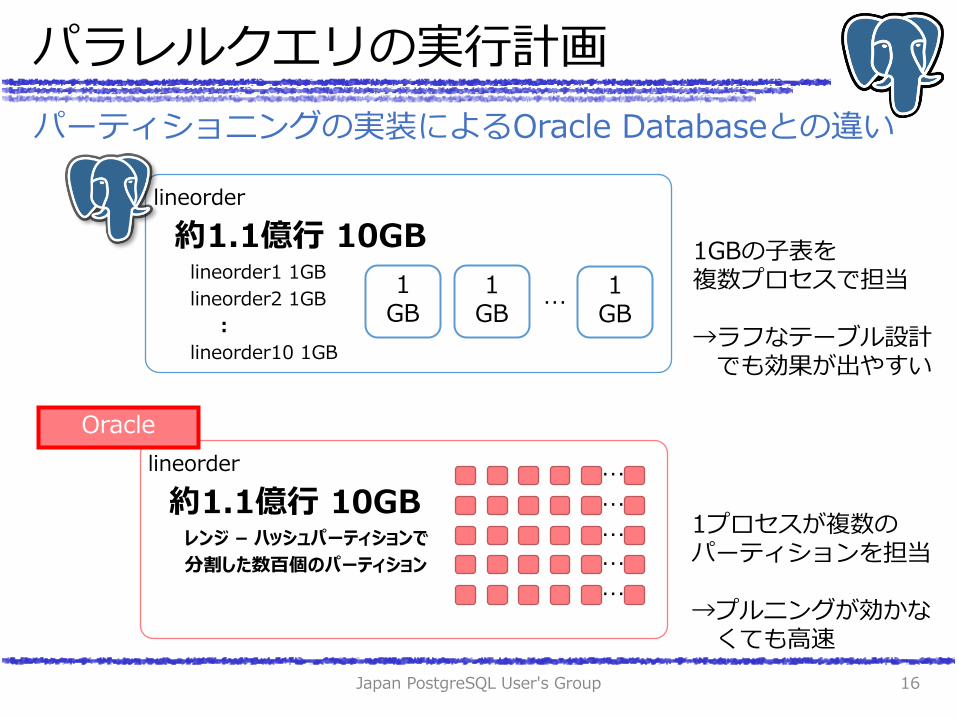
パーティショニングの実装によるOracle Databaseとの違い
lineorder
約1.1億行 10GB lineorder1 1GB
lineorder2 1GB
:
lineorder10 1GB
lineorder
約1.1億行 10GB レンジ – ハッシュパーティションで
分割した数百個のパーティション
Oracle
1GB
1GB
1GB …
1GBの子表を 複数プロセスで担当 →ラフなテーブル設計 でも効果が出やすい
…
…
… …
…
1プロセスが複数の パーティションを担当 →プルニングが効かな くても高速

アジェンダ
EDB Postgres 9.6 β検証を経て、いろいろなケースで パラレルクエリを試して得られた情報をご報告します。
パラレルクエリの基本解説
期待される効果
使い方
実行計画
パラレルクエリの課題
意外と思い通りにならない実行計画
EDBのパラレル・ヒント
現状パラレルクエリが使えないケース
Japan PostgreSQL User's Group 17
PostgreSQL 9.6 パラレルクエリの本当のところ
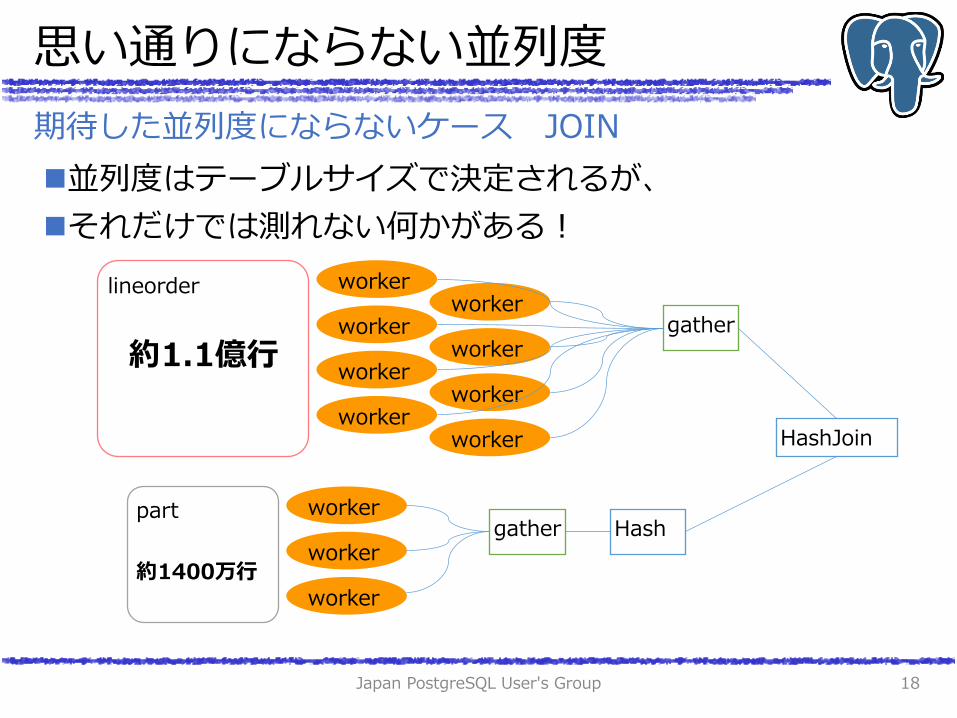
思い通りにならない並列度
並列度はテーブルサイズで決定されるが、
それだけでは測れない何かがある!
Japan PostgreSQL User's Group 18
期待した並列度にならないケース JOIN
lineorder
約1.1億行
part
約1400万行
worker
worker
worker
worker
worker
worker
worker
worker
worker
worker
worker
gather Hash
gather
HashJoin

思い通りにならない並列度
普通に実行すると、part表が4並列に
Japan PostgreSQL User's Group 19
期待した並列度にならないケース JOIN
gather
-> Hash Join (cost=28661.34..3682122.56 rows=1111820 width=9)
(actual time=67.061..57496.965 rows=1286337 loops=1)
-> Seq Scan on lineorder2_lo2_p1 (cost=0.00..3214594.56 rows=114066256 width=9)
(actual time=0.010..27750.208 rows=114066226 loops=1)
-> Hash (cost=28490.76..28490.76 rows=13646 width=4)
(actual time=66.904..66.904 rows=15731 loops=1)
Buckets: 16384 Batches: 1 Memory Usage: 682kB
-> Gather (cost=1000.00..28490.76 rows=13646 width=4)
(actual time=0.342..61.640 rows=15731 loops=1)
Workers Planned: 3
Workers Launched: 3
-> Parallel Seq Scan on part (cost=0.00..26126.16 rows=4402 width=4)
(actual time=0.029..59.519 rows=3933 loops=4)
Filter: ((p_name)::text ~~ 'k%'::text)
Rows Removed by Filter: 346067
lineorder
part gather
HashJoin
より大きいlineorderの方を パラって欲しいのが人情。。。
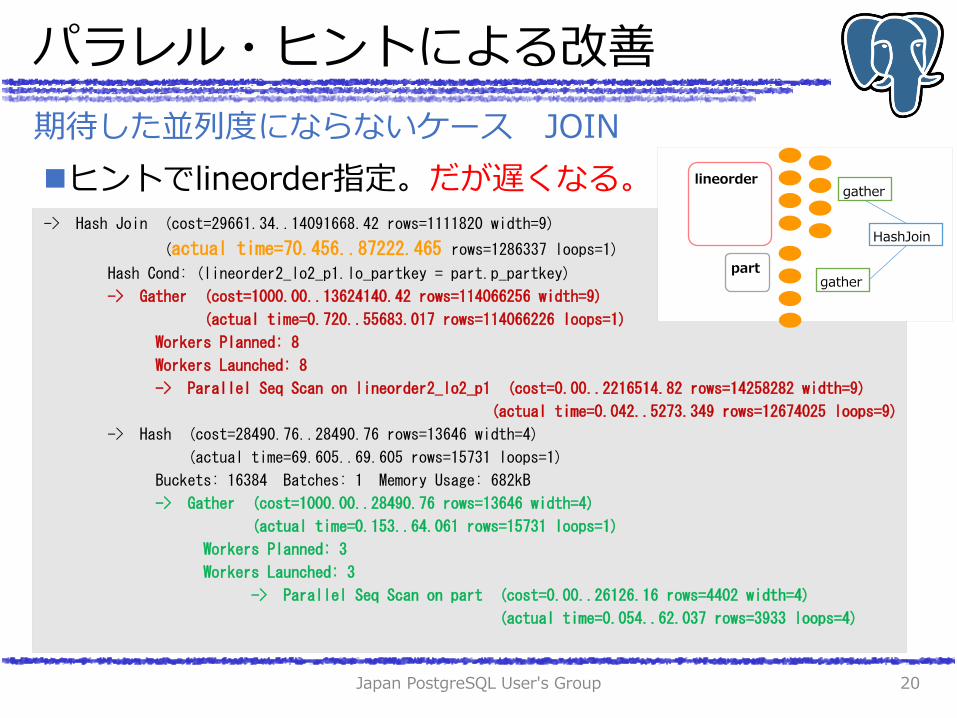
パラレル・ヒントによる改善
ヒントでlineorder指定。だが遅くなる。
Japan PostgreSQL User's Group 20
期待した並列度にならないケース JOIN
HashJoin
-> Hash Join (cost=29661.34..14091668.42 rows=1111820 width=9)
(actual time=70.456..87222.465 rows=1286337 loops=1)
Hash Cond: (lineorder2_lo2_p1.lo_partkey = part.p_partkey)
-> Gather (cost=1000.00..13624140.42 rows=114066256 width=9)
(actual time=0.720..55683.017 rows=114066226 loops=1)
Workers Planned: 8
Workers Launched: 8
-> Parallel Seq Scan on lineorder2_lo2_p1 (cost=0.00..2216514.82 rows=14258282 width=9)
(actual time=0.042..5273.349 rows=12674025 loops=9)
-> Hash (cost=28490.76..28490.76 rows=13646 width=4)
(actual time=69.605..69.605 rows=15731 loops=1)
Buckets: 16384 Batches: 1 Memory Usage: 682kB
-> Gather (cost=1000.00..28490.76 rows=13646 width=4)
(actual time=0.153..64.061 rows=15731 loops=1)
Workers Planned: 3
Workers Launched: 3
-> Parallel Seq Scan on part (cost=0.00..26126.16 rows=4402 width=4)
(actual time=0.054..62.037 rows=3933 loops=4)
lineorder
part gather
HashJoin
gather
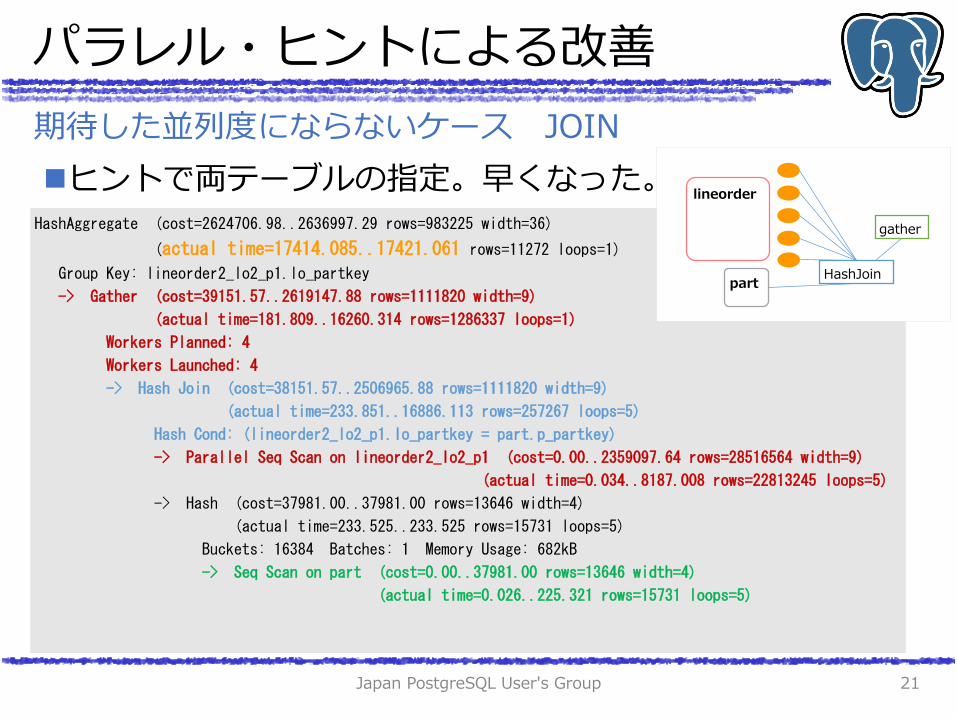
パラレル・ヒントによる改善
ヒントで両テーブルの指定。早くなった。
Japan PostgreSQL User's Group 21
期待した並列度にならないケース JOIN
lineorder
約1.1億行
part
約1400万行
worker
worker
worker
worker
worker
worker
worker
worker
worker
worker
worker
gather
gather
HashJoin
HashAggregate (cost=2624706.98..2636997.29 rows=983225 width=36)
(actual time=17414.085..17421.061 rows=11272 loops=1)
Group Key: lineorder2_lo2_p1.lo_partkey
-> Gather (cost=39151.57..2619147.88 rows=1111820 width=9)
(actual time=181.809..16260.314 rows=1286337 loops=1)
Workers Planned: 4
Workers Launched: 4
-> Hash Join (cost=38151.57..2506965.88 rows=1111820 width=9)
(actual time=233.851..16886.113 rows=257267 loops=5)
Hash Cond: (lineorder2_lo2_p1.lo_partkey = part.p_partkey)
-> Parallel Seq Scan on lineorder2_lo2_p1 (cost=0.00..2359097.64 rows=28516564 width=9)
(actual time=0.034..8187.008 rows=22813245 loops=5)
-> Hash (cost=37981.00..37981.00 rows=13646 width=4)
(actual time=233.525..233.525 rows=15731 loops=5)
Buckets: 16384 Batches: 1 Memory Usage: 682kB
-> Seq Scan on part (cost=0.00..37981.00 rows=13646 width=4)
(actual time=0.026..225.321 rows=15731 loops=5)
lineorder
part HashJoin
gather
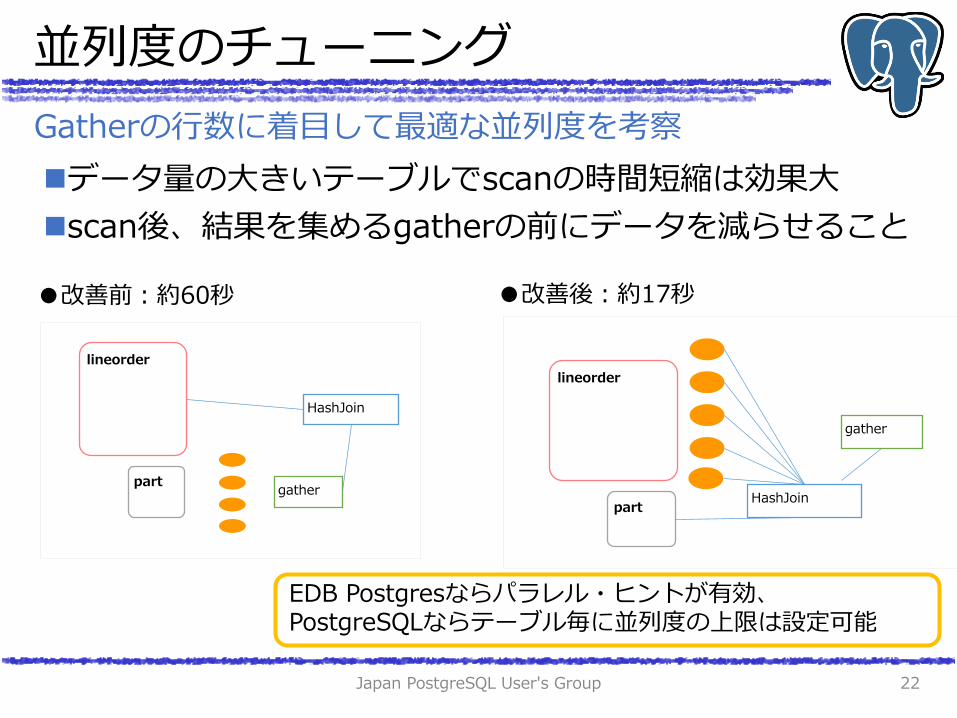
並列度のチューニング
データ量の大きいテーブルでscanの時間短縮は効果大
scan後、結果を集めるgatherの前にデータを減らせること
Japan PostgreSQL User's Group 22
Gatherの行数に着目して最適な並列度を考察
lineorder
part gather
HashJoin
●改善前:約60秒 ●改善後:約17秒
EDB Postgresならパラレル・ヒントが有効、 PostgreSQLならテーブル毎に並列度の上限は設定可能
lineorder
part HashJoin
gather

その他の上手くいかない事例
原因はイマイチわかっていませんが。
Japan PostgreSQL User's Group 23
期待した並列度にならないケース メモリソート
/* window関数 */ EXPLAIN ANALYZE SELECT *, rank() OVER (PARTITION BY "ブランド" ORDER BY "売上" DESC) AS "順位" FROM ( SELECT sales_date::date as "売上日" ,shop as "ブランド" ,sum(price) as "売上" FROM tab1 GROUP BY "売上日","ブランド") AS "集計";

その他の上手くいかない事例
原因はイマイチわかっていませんが。
Japan PostgreSQL User's Group 24
期待した並列度にならないケース メモリソート
/* window関数 */ EXPLAIN ANALYZE SELECT *, rank() OVER (PARTITION BY "ブランド" ORDER BY "売上" DESC) AS "順位" FROM ( SELECT sales_date::date as "売上日" ,shop as "ブランド" ,sum(price) as "売上" FROM tab1 GROUP BY "売上日","ブランド") AS "集計";
/* 結果イメージ。 ブランド毎に売上の多かった日ランキング */ 売上日 | ブランド | 売上 | 順位 ------------+------------+-----------+------ 2016-05-11 | DIESEL | 632141504 | 1 2016-07-31 | DIESEL | 622096896 | 2 2016-11-29 | DIESEL | 620818688 | 3 : 2016-04-06 | Dior | 962435003 | 1 2016-03-23 | Dior | 889015872 | 2 :

ソート方式による並列度の変動
原因はイマイチわかっていませんが。パラってた処理が
Japan PostgreSQL User's Group 25
期待した並列度にならないケース メモリソート
/* この時の実行計画がこちら。パラレルになってる。約9秒。 */ WindowAgg (cost=3430456.39..3454473.19 rows=1200840 width=52) (actual time=9776.175..9777.199 rows=1095 loops=1) -> Sort (cost=3430456.39..3433458.49 rows=1200840 width=44) (actual time=9776.165..9776.300 rows=1095 loops=1) Sort Key: "集計"."ブランド", "集計"."売上" DESC Sort Method: quicksort Memory: 134kB -> Subquery Scan on "集計" (cost=3115228.89..3235312.89 rows=1200840 width=44) (actual time=9764.055..9773.283 rows=1095 loops=1) -> Finalize GroupAggregate (cost=3115228.89..3223304.49 rows=1200840 width=44) (actual time=9764.054..9773.062 rows=1095 loops=1) Group Key: ((tab1.sales_date)::date), tab1.shop -> Sort (cost=3115228.89..3133241.49 rows=7205040 width=44) (actual time=9764.012..9765.509 rows=7665 loops=1) Sort Key: ((tab1.sales_date)::date), tab1.shop Sort Method: quicksort Memory: 1270kB -> Gather (cost=1064650.75..1851272.12 rows=7205040 width=44) (actual time=6412.121..9757.054 rows=7665 loops=1) Workers Planned: 6 Workers Launched: 6 -> Partial GroupAggregate (cost=1063650.75..1129768.12 rows=1200840 width=44) (actual time=6518.572..9655.286 rows=1095 loops=7) Group Key: ((tab1.sales_date)::date), tab1.shop -> Sort (cost=1063650.75..1075676.95 rows=4810477 width=19) (actual time=6516.858..8298.955 rows=4123429 loops=7) Sort Key: ((tab1.sales_date)::date), tab1.shop Sort Method: external merge Disk: 125680kB
-> Parallel Seq Scan on tab1 (cost=0.00..332432.96 rows=4810477 width=19) ★(actual time=0.071..1195.131 rows=4123429loops=7)

ソート方式による並列度の変動
ディスクソートをメモリソートにしたらパラれなくなった。
Japan PostgreSQL User's Group 26
期待した並列度にならないケース メモリソート
/* 実行計画がこちら。メモリソートになったらなぜか非パラレルに。約20秒かかっている。 */ WindowAgg (cost=1000838.70..1024855.50 rows=1200840 width=52) (actual time=21083.366..21084.609 rows=1095 loops=1) -> Sort (cost=1000838.70..1003840.80 rows=1200840 width=44) (actual time=21083.347..21083.521 rows=1095 loops=1) Sort Key: "集計"."ブランド", "集計"."売上" DESC Sort Method: quicksort Memory: 134kB -> Subquery Scan on "集計" (cost=849559.20..879580.20 rows=1200840 width=44) (actual time=21075.482..21080.224 rows=1095 loops=1) -> HashAggregate (cost=849559.20..867571.80 rows=1200840 width=44) (actual time=21075.480..21080.024 rows=1095 loops=1) Group Key: (tab1.sales_date)::date, tab1.shop -> Seq Scan on tab1 (cost=0.00..633087.75 rows=28862860 width=19) ★(actual time=0.064..7888.289 rows=28864000 loops=1) Planning time: 0.234 ms Execution time: 21097.712 ms
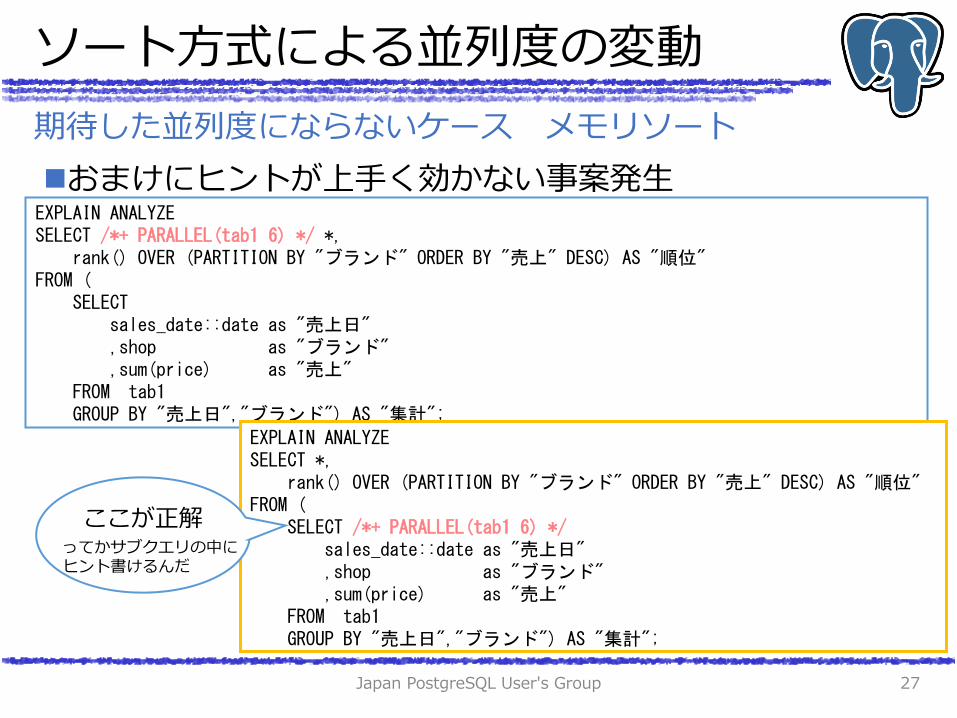
ソート方式による並列度の変動
おまけにヒントが上手く効かない事案発生
Japan PostgreSQL User's Group 27
期待した並列度にならないケース メモリソート
EXPLAIN ANALYZE SELECT /*+ PARALLEL(tab1 6) */ *, rank() OVER (PARTITION BY "ブランド" ORDER BY "売上" DESC) AS "順位" FROM ( SELECT sales_date::date as "売上日" ,shop as "ブランド" ,sum(price) as "売上" FROM tab1 GROUP BY "売上日","ブランド") AS "集計";
EXPLAIN ANALYZE SELECT *, rank() OVER (PARTITION BY "ブランド" ORDER BY "売上" DESC) AS "順位" FROM ( SELECT /*+ PARALLEL(tab1 6) */ sales_date::date as "売上日" ,shop as "ブランド" ,sum(price) as "売上" FROM tab1 GROUP BY "売上日","ブランド") AS "集計";
ここが正解 ってかサブクエリの中に
ヒント書けるんだ

ソート方式による並列度の変動
ディスクソートをメモリソートにしたらパラれなくなった。
Japan PostgreSQL User's Group 28
期待した並列度にならないケース メモリソート
WindowAgg (cost=1327297.76..1351662.32 rows=1218228 width=56) (actual time=9667.291..10095.048 rows=441334 loops=1) -> Sort (cost=1327297.76..1330343.33 rows=1218228 width=48) (actual time=9667.270..9746.242 rows=441334 loops=1) Sort Key: "集計"."ブランド", "集計"."売上" DESC Sort Method: quicksort Memory: 46768kB -> Subquery Scan on "集計" (cost=1176747.00..1204157.13 rows=1218228 width=48) (actual time=8986.449..9216.731 rows=441334 loops=1) -> Finalize HashAggregate (cost=1176747.00..1191974.85 rows=1218228 width=48) (actual time=8986.447..9129.055 rows=441334 loops=1) Group Key: tab1.sales_date, tab1.shop -> Gather (cost=357488.67..1103653.32 rows=7309368 width=48) (actual time=3751.793..5775.296 rows=3081355 loops=1) Workers Planned: 6 Workers Launched: 6 -> Partial HashAggregate (cost=356488.67..371716.52 rows=1218228 width=48) (actual time=3736.607..4506.717 rows=440194 loops=7) Group Key: tab1.sales_date, tab1.shop -> Parallel Seq Scan on tab1 (cost=0.00..320408.67 rows=4810667 width=23) (actual time=0.041..870.314 rows=4123429 loops=7)
EDBで解決

パラレルクエリの制限事項
現状のパラレルクエリで得られる性能
並列度が期待通りにできれば効果大
ざっくり言うと、利用シーンを選びましょう、SQLチューニング頑張りましょう、となるのですが、
むしろ以下の制限事項が期待に反して問題ではないか
クエリがデータを書き込むか、データベースの行をロックする場合。
クエリが実行中に一時停止する場合。
ほか
夜間に集計Mビューのリフレッシュをしておき、
コアタイムはMビューを参照させる使い方ができない
Japan PostgreSQL User's Group 29
更新処理でパラレルクエリが使えない

パラレルクエリの制限事項
以下、いずれもパラレルクエリにならない
Mビューのリフレッシュ
COPY TO
INSERT SELECT
CREATE TABLE AS SELECT
Japan PostgreSQL User's Group 30
更新処理でパラレルクエリが使えない
demo=# SELECT count(*) FROM tab1; count ---------- 28864000 時間: 669.988 ms --- パラレルの時は1秒以下、非パラレルだと4秒強かかることを確認済み。 demo=# CREATE MATERIALIZED VIEW mv1 AS SELECT count(*) FROM tab1; 時間: 4510.077 ms --- む、この時間は・・・。 demo=# REFRESH MATERIALIZED VIEW mv1; 時間: 4451.020 ms --- む、この時間は・・・。

パラレルクエリの制限事項
結果を保存したいクエリをパラレルにするには
psqlの機能で¥o(クエリの結果をファイルに出力)
プログラム側で取り出した結果を配列に格納する
Japan PostgreSQL User's Group 31
更新処理でパラレルクエリが使えない
/* psqlから実行するなら */ demo=# ¥o demo.copy --- psqlの ¥o コマンドで結果をファイルに出力 demo=# SELECT count(*) FROM tab1; 時間: 699.871 ms -- OK /* スクリプトに書くなら */ $ time psql -U postgres demo -At -c 'SELECT count(*) FROM tab1' -o demo.copy real 0m0.725s -- OK $ time psql -U postgres demo -At -c "COPY tab_count FROM '/home/hoge/demo.copy' " real 0m0.132s -- demo.copyに書かれた結果は集計された1行のみなので、COPY文は一瞬で完了

まとめ
EDB Postgres 9.6 β検証を経て、いろいろなケースで パラレルクエリを試して得られた情報をご報告しました。
パラレルクエリの基本解説
期待される効果
使い方
実行計画
パラレルクエリの課題
意外と思い通りにならない実行計画
EDBのパラレル・ヒント
現状パラレルクエリが使えないケース
Japan PostgreSQL User's Group 32
PostgreSQL 9.6 パラレルクエリの本当のところ
上手く使えば効果は大きい。 使用時は実行計画を確認して、 gatherの行数に着目すると チューニングがやりやすい。
今後に期待! ・・・やりたいことは 明白なので、何か できないかな?
![012 %3 )456789#$ +,3 )456789"#$ +, !"#$ %&'(& ) :;< => ?@ AB C401 2 DE %FGHIJ @ KLMNO PQ RS, ?@T KUVW O PQ RS, ?@T KXY O PQ RS, ?@T KXY O PQ Z4[U M\$] ^%_)I PQ )H@/T?` DE %FGHIJ](https://img.pdfslide.tips/doc/110x75/5b4499f97f8b9a3c158b723a/012-3-456789-3-456789-ab-c401-2-de-fghij-.jpg)




























