Embed Size (px)
Citation preview

Transitioning Compute Models: Hadoop MapReduce To Spark
Chicago Hadoop Users Group (CHUG) February 12, 2015
Slim Baltagi SparkBigData.com

Your Presenter – Slim Baltagi
2
• Big Data Solutions Architect living in Chicago.
• Over 17 years of IT/Business experience.
• Over 4 years of Big Data experience working on over a dozen Hadoop projects.
• Speaker at a few Big Data conferences
• Creator and maintainer of the Apache Spark Knowledge Base:www.SparkBigData.com
• @SlimBaltagi • [email protected]
Disclaimer: This is a vendor-independent talk that expresses my own opinions and not necessarily those of my current employer: Hortonworks Inc.
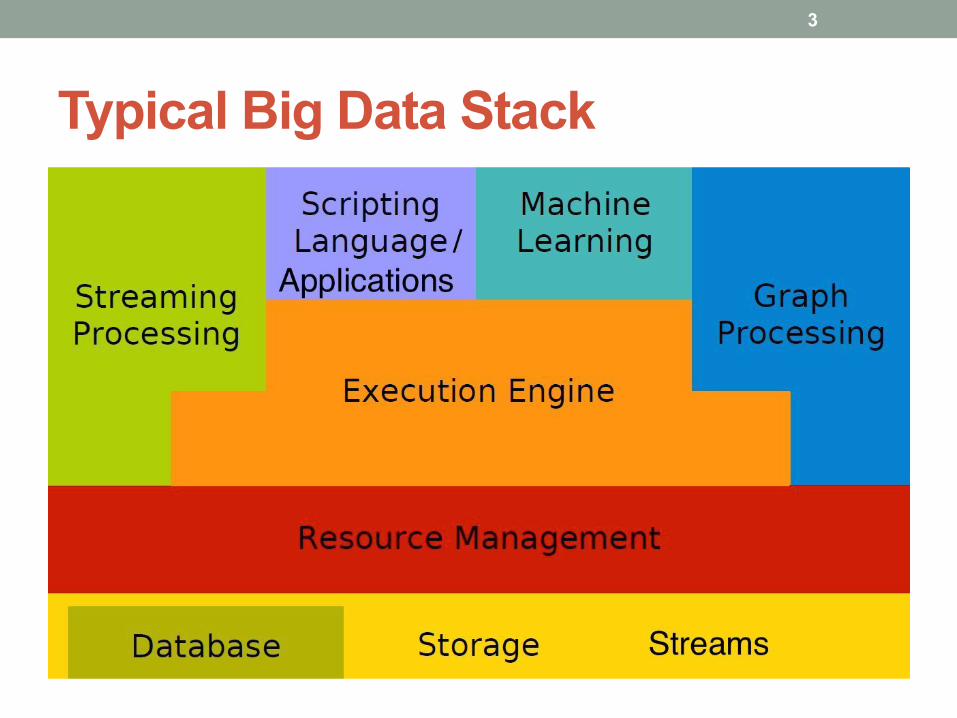
Typical Big Data Stack
3

Agenda
1. Evolution 2. Transition 3. Integration 4. Alternatives 5. Complementarity 6. Key Takeaways + Q&A
4

1. Evolution of Compute Models • When the Apache Hadoop project started in 2007,
MapReduce v1 was the only choice as a compute model (Execution Engine) on Hadoop. Now we have:
5
• Batch • Batch • Interactive
• Batch • Interactive • Near-Real
time
• Batch • Interactive • Real-Time • Iterative

1. Evolution:
• This is how Hadoop MapReduce is branding itself: “A YARN-based system for parallel processing of large data sets. http://hadoop.apache.org
• Batch • Scalability • User Defined Functions (UDFs) • Hadoop MapReduce (MR) works pretty well if you can
express your problem as a single MR job. In practice, most problems don't fit neatly into a single MR job.
• Need to integrate many disparate tools for advanced Big Data Analytics for Queries, Streaming Analytics, Machine Learning and Graph Analytics.
6

1. Evolution: • Tez: Hindi for “speed” • This is how Apache Tez is branding itself: “The Apache Tez project is aimed at building an application framework which allows for a complex directed-acyclic-graph of tasks for processing data. It is currently built atop YARN.”
Source: http://tez.apache.org/
• Apache™ Tez is an extensible framework for building high performance batch and interactive data processing applications, coordinated by YARN in Apache Hadoop.
7

1. Evolution: • ‘Spark’ for lightning fast speed. • This is how Apache Spark is branding itself: “Apache Spark™ is a fast and general engine for large-scale data processing.” https://spark.apache.org
• Apache Spark is a general purpose cluster computing framework, its execution model supports wide variety of use cases: batch, interactive, near-real time.
• The rapid in-memory processing of resilient distributed datasets (RDDs) is the “core capability” of Apache Spark.
8

1. Evolution: Apache Flink • Flink: German for “nimble, swift, speedy” • This is how Apache Flink is branding itself: “Fast and reliable large-scale data processing engine”
• Apache Flink http://flink.apache.org/ offers: • Batch and Streaming in the same system • Beyond DAGs (Cyclic operator graphs) • Powerful, expressive APIs • Inside-the-system iterations • Full Hadoop compatibility • Automatic, language independent optimizer
9
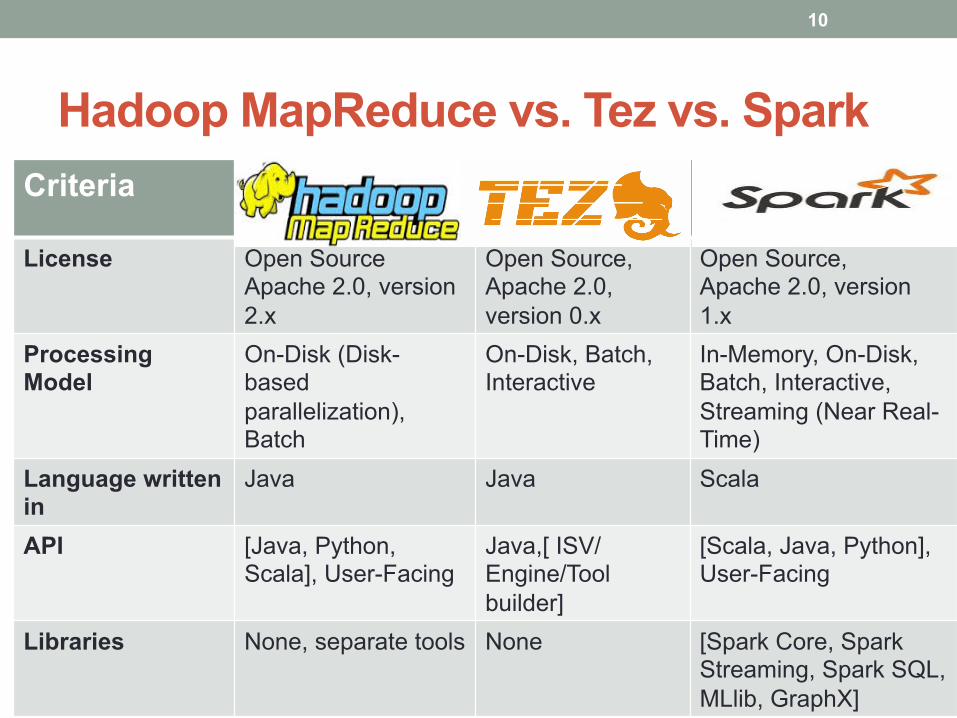
Hadoop MapReduce vs. Tez vs. Spark Criteria
License Open Source Apache 2.0, version 2.x
Open Source, Apache 2.0, version 0.x
Open Source, Apache 2.0, version 1.x
Processing Model
On-Disk (Disk- based parallelization), Batch
On-Disk, Batch, Interactive
In-Memory, On-Disk, Batch, Interactive, Streaming (Near Real-Time)
Language written in
Java Java Scala
API [Java, Python, Scala], User-Facing
Java,[ ISV/Engine/Tool builder]
[Scala, Java, Python], User-Facing
Libraries None, separate tools None [Spark Core, Spark Streaming, Spark SQL, MLlib, GraphX]
10
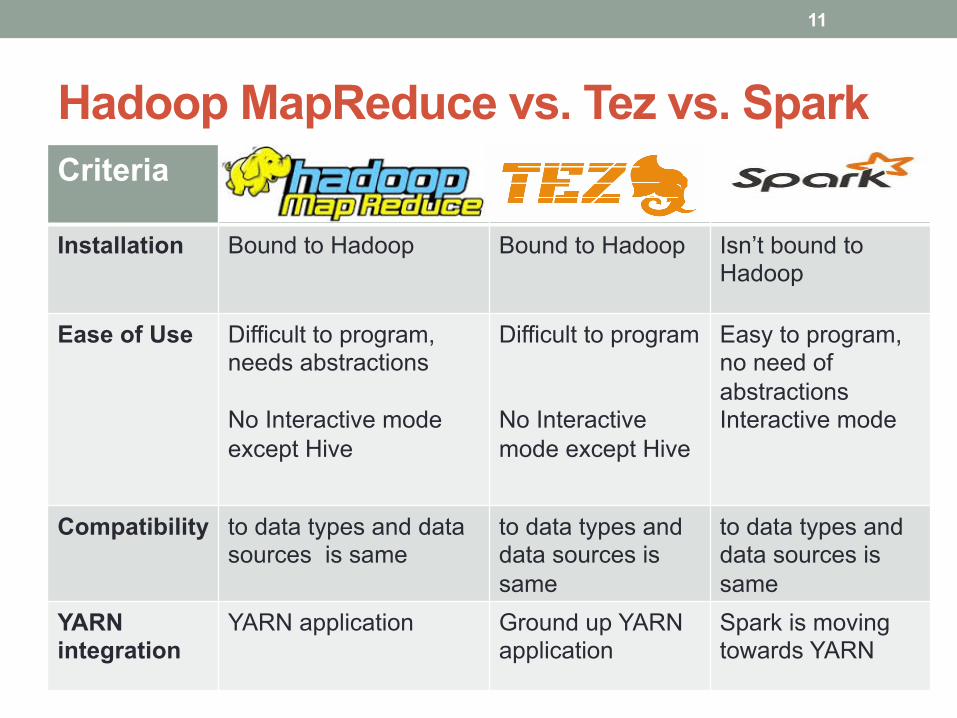
Hadoop MapReduce vs. Tez vs. Spark Criteria
Installation Bound to Hadoop Bound to Hadoop Isn’t bound to Hadoop
Ease of Use Difficult to program, needs abstractions No Interactive mode except Hive
Difficult to program No Interactive mode except Hive
Easy to program, no need of abstractions Interactive mode
Compatibility to data types and data sources is same
to data types and data sources is same
to data types and data sources is same
YARN integration
YARN application Ground up YARN application
Spark is moving towards YARN
11

Hadoop MapReduce vs. Tez vs. Spark Criteria
Deployment YARN YARN [Standalone, YARN*, SIMR, Mesos]
Performance - Good performance when data fits into memory
- performance degradation otherwise
Security More features and projects
More features and projects
Still in its infancy
12
* Partial support

Agenda
1. Evolution 2. Transition 3. Integration 4. Alternatives 5. Complementarity 6. Key Takeaways + Q&A
13

2. Transition • Existing Hadoop MapReduce projects can migrate to Spark and leverage Spark Core as execution engine: 1. You can often reuse your mapper and
reducer functions and just call them in Spark, from Java or Scala.
2. You can translate your code from MapReduce to Apache Spark. How-to: Translate from MapReduce to Apache Spark
http://blog.cloudera.com/blog/2014/09/how-to-translate-from-mapreduce-to-apache-spark/
14
2. Transition 3. The following tools originally based on Hadoop MapReduce are being ported to Apache Spark:
• Pig, Hive, Sqoop, Cascading, Crunch, Mahout, …
15

è Pig on Spark (Spork)
• Run Pig with “–x spark” option for an easy migration without development effort.
• Speed up your existing pig scripts on Spark ( Query, Logical Plan, Physical Pan)
• Leverage new Spark specific operators in Pig such as Cache
• Still leverage many existing Pig UDF libraries • Pig on Spark Umbrella Jira (Status: Passed end-to-end
test cases on Pig, still Open) https://issues.apache.org/jira/browse/PIG-4059
• Fix outstanding issues and address additional Spark functionality through the community
16

èHive on Spark (Expected in Hive 1.1.0)
• New alternative to using MapReduce or Tez: hive> set hive.execution.engine=spark; • Help existing Hive applications running on
MapReduce or Tez easily migrate to Spark without development effort.
• Exposes Spark users to a viable, feature-rich de facto standard SQL tool on Hadoop.
• Performance benefits especially for Hive queries, involving multiple reducer stages
• Hive on Spark Umbrella Jira (Status: Open).Q1 2015 https://issues.apache.org/jira/browse/HIVE-7292
17
èHive on Spark (Expected in Hive 1.1.0)
• Design http://blog.cloudera.com/blog/2014/07/apache-hive-on-apache-spark-motivations-and-design-principles/
• Demo http://blog.cloudera.com/blog/2014/11/apache-hive-on-apache-spark-the-first-demo/
• Hands-on sandbox http://blog.cloudera.com/blog/2014/12/hands-on-hive-on-spark-in-the-aws-cloud/
• Getting Started https://cwiki.apache.org/confluence/display/Hive/Hive+on+Spark:+Getting+Started
18

è Sqoop on Spark (Expected in Sqoop 2)
• Sqoop ( a.k.a from SQL to Hadoop) was initially developed as a tool to transfer data from RDBMS to Hadoop.
• The next version of Sqoop, referred to as Sqoop2 supports data transfer across any two data sources.
• Sqoop 2 Proposal is still under discussion.https://cwiki.apache.org/confluence/display/SQOOP/Sqoop2+Proposal
• Sqoop2: Support Sqoop on Spark Execution Engine (Jira Status: Work In Progress). The goal of this ticket is to support a pluggable way to select the execution engine on which we can run the Sqoop jobs. https://issues.apache.org/jira/browse/SQOOP-1532
19

(Expected in 3.1 release)
• Cascading http://www.cascading.org is an application development platform for building data applications on Hadoop.
• Support for Apache Spark is on the roadmap and will be available in Cascading 3.1 release.
Reference : http://www.cascading.org/new-fabric-support/
• Spark-scalding is a library that aims to make the transition from Cascading/Scalding to Spark a little easier by adding support for Cascading Taps, Scalding Sources and the Scalding Fields API in Spark. Reference :http://scalding.io/2014/10/running-scalding-on-apache-spark/
20

Apache Crunch • The Apache Crunch Java library provides a framework for writing, testing, and running MapReduce pipelines. https://crunch.apache.org
• Apache Crunch 0.11 releases with a SparkPipeline class, making it easy to migrate data processing applications from MapReduce to Spark. https://crunch.apache.org/apidocs/0.11.0/org/apache/crunch/impl/spark/SparkPipeline.html
• Running Crunch with Spark http://www.cloudera.com/content/cloudera/en/documentation/core/v5-2-x/topics/cdh_ig_running_crunch_with_spark.html
21

(Expec (Expected in Mahout 1.0 )
• Mahout News: 25 April 2014 - Goodbye MapReduce: Apache Mahout, the original Machine Learning (ML) library for Hadoop since 2009, is rejecting new MapReduce algorithm implementations.http://mahout.apache.org
• Integration of Mahout and Spark: • Reboot with new Mahout Scala DSL for Distributed
Machine Learning on Spark: Programs written in this DSL are automatically optimized and executed in parallel on Apache Spark.
• Mahout Interactive Shell: Interactive REPL shell for Spark optimized Mahout DSL.
• Example: http://mahout.apache.org/users/recommender/intro-cooccurrence-spark.html
22

Agenda
1. Evolution 2. Transition 3. Integration 4. Alternatives 5. Complementarity 6. Key Takeaways + Q&A
23
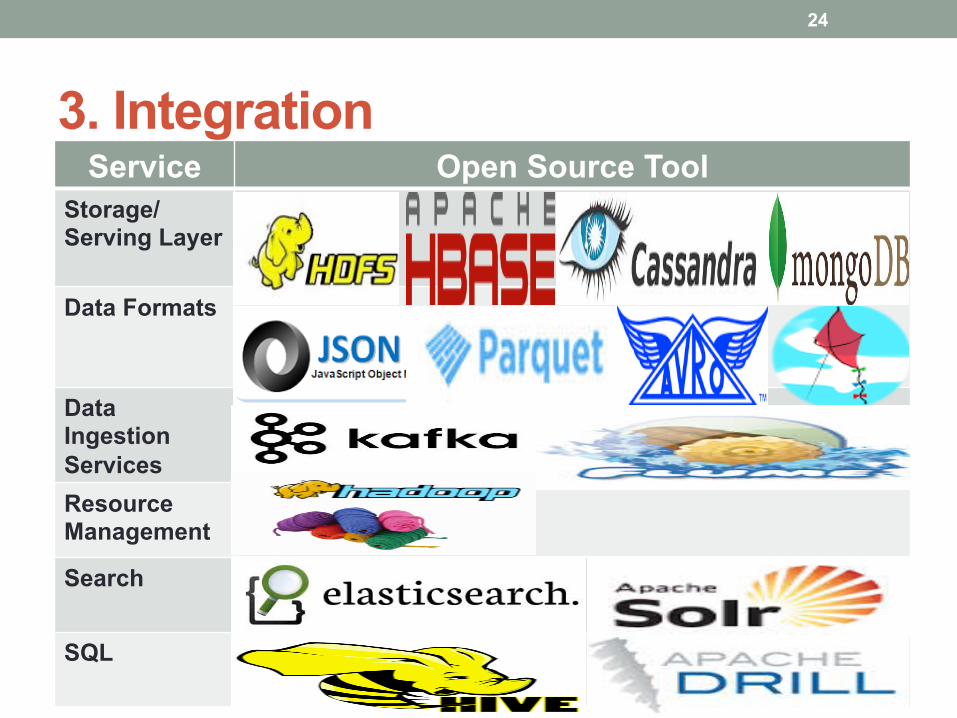
3. Integration Service Open Source Tool
Storage/Serving Layer
Data Formats
Data Ingestion Services Resource Management
Search
SQL
24

3. Integration: • Spark was designed to read and write data from and to
HDFS, as well as other storage systems supported by Hadoop API, such as your local file system, Hive, HBase, Cassandra and Amazon’s S3.
• Stronger integration between Spark and HDFS caching
(SPARK-1767) to allow multiple tenants and processing frameworks to share the same in-memory https://issues.apache.org/jira/browse/SPARK-1767
• Use DDM: Discardable Distributed Memory http://hortonworks.com/blog/ddm/ to store RDDs in memory.This allows many Spark applications to share RDDs since they are now resident outside the address space of the application. Related HDFS-5851 is planned for Hadoop 3.0 https://issues.apache.org/jira/browse/HDFS-5851
25

3. Integration: • Out of the box, Spark can interface with HBase as it has
full support for Hadoop InputFormats via newAPIHadoopRDD. Example: HBaseTest.scala from Spark code.https://github.com/apache/spark/blob/master/examples/src/main/scala/org/apache/spark/examples/HBaseTest.scala
• There are also Spark RDD implementations available for reading from and writing to HBase without the need of using Hadoop API anymore: Spark-HBase Connector https://github.com/nerdammer/spark-hbase-connector
• SparkOnHBase is a project for HBase integration with Spark. Status: Still in experimentation and no timetable for possible support. http://blog.cloudera.com/blog/2014/12/new-in-cloudera-labs-sparkonhbase/
26

3. Integration: • Spark Cassandra Connector This library lets you expose Cassandra tables as Spark RDDs, write Spark RDDs to Cassandra tables, and execute arbitrary CQL queries in your Spark applications. Supports also integration of Spark Streaming with Cassandra https://github.com/datastax/spark-cassandra-connector
• Spark + Cassandra using Deep: The integration is not based on the Cassandra's Hadoop interface. http://stratio.github.io/deep-spark/
27

3. Integration: • Benchmark of Spark & Cassandra Integration using different approaches. http://www.stratio.com/deep-vs-datastax/
• Calliope is a library providing an interface to consume data from Cassandra to spark and store Resilient Distributed Datasets (RDD) from Spark to Cassandra. http://tuplejump.github.io/calliope/
• Cassandra storage backend with Spark is opening many new avenues.
• Kindling: An Introduction to Spark with Cassandra (Part 1) http://planetcassandra.org/blog/kindling-an-introduction-to-spark-with-cassandra/
28

3. Integration: • MongoDB is not directly served by Spark, although it can be used from Spark via an official Mongo-Hadoop connector. • MongoDB-Spark Demo
https://github.com/crcsmnky/mongodb-spark-demo
• MongoDB and Hadoop: Driving Business Insights • http://www.slideshare.net/mongodb/mongodb-and-hadoop-driving-
business-insights
• Spark SQL also provides indirect support via its support for reading and writing JSON text files. https://github.com/mongodb/mongo-hadoop
29
3. Integration: • There is also NSMC: Native Spark MongoDB Connector for reading and writing MongoDB collections directly from Apache Spark (still experimental) • GitHub https://github.com/spirom/spark-mongodb-connector • Examples https://github.com/spirom/spark-mongodb-examples/tree/depends-v0.3.0
• Blog http://www.river-of-bytes.com/2015/01/nsmc-native-mongodb-connector-for.html
30

3. Integration: YARN • Integration still improving.
https://issues.apache.org/jira/issues/?jql=project%20%3D%20SPARK%20AND%20summary%20~%20yarn%20AND%20status%20%3D%20OPEN%20ORDER%20BY%20priority%20DESC%0A
• Some issues are critical ones. http://spark.apache.org/docs/latest/running-on-yarn.html
Running Spark on YARN http://spark.apache.org/docs/latest/running-on-yarn.html
• Get the most out of Spark on YARN https://www.youtube.com/watch?v=Vkx-TiQ_KDU
31

3. Integration: • Spark SQL provides built in support for Hive tables: • Import relational data from Hive tables • Run SQL queries over imported data • Easily write RDDs out to Hive tables
• Hive 0.13 is supported in Spark 1.2.0. • Support of ORCFile (Optimized Row Columnar file) format is targeted in Spark 1.3.0 Spark-2883 https://issues.apache.org/jira/browse/SPARK-2883
• Hive can be used both for analytical queries and for fetching dataset machine learning algorithms in MLlib.
32

3. Integration: • Drill is intended to achieve the sub-second latency
needed for interactive data analysis and exploration. http://drill.apache.org
• Drill and Spark Integration is work in progress in 2015 to address new use cases: • Use a Drill query (or view) as the input to Spark. Drill
extracts and pre-processes data from various data sources and turns it into input to Spark.
• Use Drill to query Spark RDDs. Use BI tools to query in-memory data in Spark. Embed Drill execution in a Spark data pipeline.
• Reference: What's Coming in 2015 for Dri l l?http://drill.apache.org/blog/2014/12/16/whats-coming-in-2015/
33

3. Integration: • Apache Kafka is a high throughput distributed messaging system. http://kafka.apache.org/
• Spark Streaming integrates natively with Kafka: Spark Streaming + Kafka Integration Guide http://spark.apache.org/docs/latest/streaming-kafka-integration.html
• Tutorial: Integrating Kafka and Spark Streaming: Code Examples and State of the Game http://www.michael-noll.com/blog/2014/10/01/kafka-spark-streaming-integration-example-tutorial/
34

3. Integration: • Apache Flume is a streaming event data ingestion system that is designed for Big Data ecosystem. http://flume.apache.org/
• Spark Streaming integrates natively with Flume. There are two approaches to this: • Approach 1: Flume-style Push-based Approach • Approach 2 (Experimental): Pull-based Approach using a Custom Sink.
• Spark Streaming + Flume Integration Guide https://spark.apache.org/docs/latest/streaming-flume-integration.html
35

3. Integration: • Spark SQL provides built in support for JSON that is vastly simplifying the end-to-end-experience of working with JSON data.
• Spark SQL can automatically infer the schema of a JSON dataset and load it as a SchemaRDD. No more DDL. Just point Spark SQL to JSON files and query. Starting Spark 1.3, SchemaRDD will be renamed to DataFrame.
• An introduction to JSON support in Spark SQL http://databricks.com/blog/2015/02/02/an-introduction-to-json-support-in-spark-sql.html
36

3. Integration: • Apache Parquet is a columnar storage format available to any project in the Hadoop ecosystem, regardless of the choice of data processing framework, data model or programming language. http://parquet.incubator.apache.org/
• Built in support in Spark SQL allows to: • Import relational data from Parquet files • Run SQL queries over imported data • Easily write RDDs out to Parquet files http://spark.apache.org/docs/latest/sql-programming-guide.html#parquet-files
• This is an illustrating example of integration of Parquet and Spark SQL http://www.infoobjects.com/spark-sql-parquet/
37

3. Integration: • Spark SQL Avro Library for querying Avro data
with Spark SQL. This library requires Spark 1.2+. https://github.com/databricks/spark-avro
• This is an example of using Avro and Parquet in Spark SQL. http://www.infoobjects.com/spark-with-avro/
• Avro/Spark Use case: http://www.slideshare.net/DavidSmelker/bdbdug-data-types-jan-2015 • Problem
• Various inbound data sets • Data Layout can change without notice • New data sets can be added without notice Result • Leverage Spark to dynamically split the data • Leverage Avro to store the data in a compact binary format
38

3. Integration: Kite SDK • The Kite SDK provides high level abstractions to work with datasets on Hadoop, hiding many of the details of compression codecs, file formats, partitioning strategies, etc. http://kitesdk.org/docs/current/
• Spark support has been added to Kite 0.16 release, so Spark jobs can read and write to Kite datasets.
• Kite Java Spark Demo https://github.com/kite-sdk/kite-examples/tree/master/spark
39

3. Integration: • Elasticsearch is a real-time distributed search and analytics
engine. http://www.elasticsearch.org • Apache Spark Support in Elasticsearch added in 2.1
http://www.elasticsearch.org/guide/en/elasticsearch/hadoop/master/spark.html
• Deep-Spark provides also an integration with Spark. https://github.com/Stratio/deep-spark
• elasticsearch-hadoop provides native integration between Elasticsearch and Apache Spark, in the form of RDD that can read data from Elasticsearch. Also, any RDD can be saved to Elasticsearch as long as its content can be translated into documents.
• Great use case by NTT Data integrating Apache Spark Streaming and Elasticsearch. http://www.intellilink.co.jp/article/column/bigdata-kk02.html
40

3. Integration:
• Apache Solr, added a Spark-based indexing tool for fast and easy indexing, ingestion, and serving searchable complex data. “CrunchIndexerTool on Spark”
• Solr-on-Spark solution using Apache Solr, Spark, Crunch, and Morphlines: • Migrate ingestion of HDFS data into Solr from
MapReduce to Spark • Update and delete existing documents in Solr at scale
• Ingesting HDFS data into Solr using Spark http://www.slideshare.net/whoschek/ingesting-hdfs-intosolrusingsparktrimmed
41

3. Integration: • HUE is the open source Apache Hadoop Web UI that lets users use Hadoop directly from their browser and be productive. http://www.gethue.com
• A Hue application for Apache Spark called Spark Igniter lets users execute and monitor Spark jobs directly from their browser and be more productive.
• Demo of Spark Igniter http://vimeo.com/83192197
• Big Data Web applications for Interactive Hadoop https://speakerdeck.com/bigdataspain/big-data-web-applications-for-interactive-hadoop-by-enrico-berti-at-big-data-spain-2014
42

Agenda
1. Evolution 2. Transition 3. Integration 4. Alternatives 5. Complementarity 6. Key Takeaways + Q&A
43
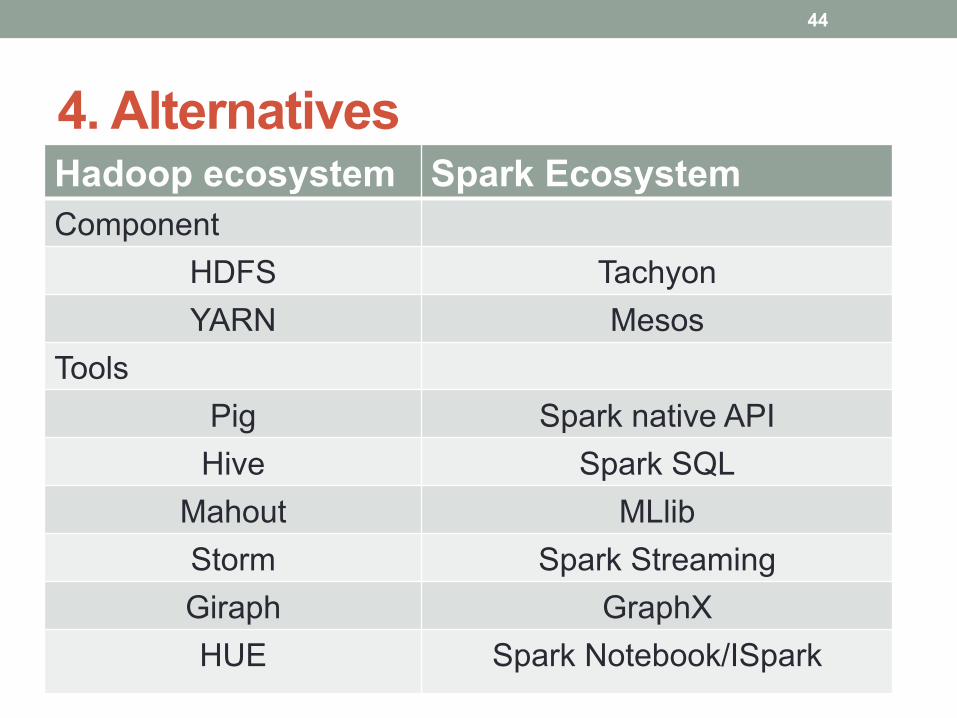
4. Alternatives Hadoop ecosystem Spark Ecosystem Component
HDFS Tachyon YARN Mesos
Tools Pig Spark native API Hive Spark SQL
Mahout MLlib Storm Spark Streaming Giraph GraphX HUE Spark Notebook/ISpark
44

è • Tachyon is a memory-centric distributed file system enabling reliable file sharing at memory-speed across cluster frameworks, such as Spark and MapReduce. https://http://tachyon-project.org
• Tachyon is Hadoop compatible. Existing Spark and MapReduce programs can run on top of it without any code change.
• Tachyon is the storage layer of the Berkeley Data Analytics Stack (BDAS) https://amplab.cs.berkeley.edu/software/
45

è • Mesos enables fine grained sharing which allows a Spark job to dynamically take advantage of the idle resources in the cluster during its execution.
• This leads to considerable performance improvements, especially for long running Spark jobs. • Mesos as Datacenter “OS”:
• Share datacenter between multiple cluster computing apps.
• Provide new abstractions and services • Mesosphere DCOS: Datacenter services, including
Apache Spark, Apache Cassandra, Apache YARN, Apache HDFS…
46

YARN vs. Mesos Criteria
Resource sharing
Yes Yes
Written in Java C++ Scheduling Memory only CPU and Memory Running tasks Unix processes Linux Container groups
Requests Specific requests and locality preference
More generic but more coding for writing frameworks
Maturity Less mature Relatively more mature
47

è Spark Native API • Spark Native API in Scala, Java and Python. • Interactive shell in Scala and Python. • Spark supports Java 8 for a much more concise Lambda expressions to get code nearly as simple as the Scala API.
48

è Spark SQL • Spark SQL is a new SQL engine designed from ground-
up for Spark • Spark SQL provides SQL performance and maintains
compatibility with Hive. It supports all existing Hive data formats, user-defined functions (UDF), and the Hive metastore.
• Spark SQL also allows manipulating (semi-) structured data as well as ingesting data from sources that provide schema, such as JSON, Parquet, Hive, or EDWs. It unifies SQL and sophisticated analysis, allowing users to mix and match SQL and more imperative programming APIs for advanced analytics.
49
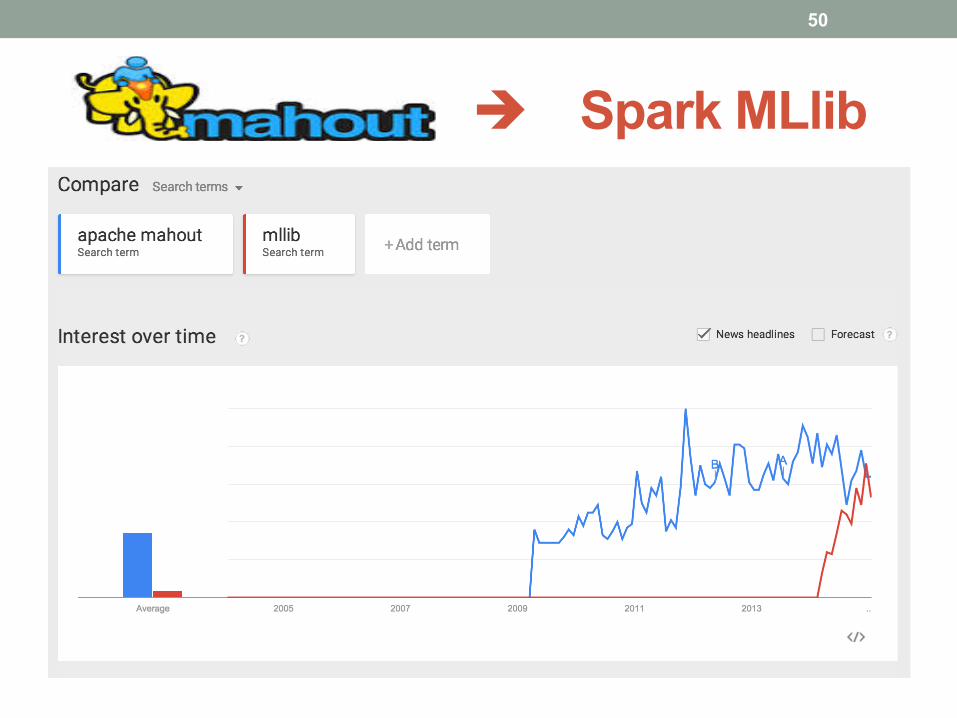
è Spark MLlib
50
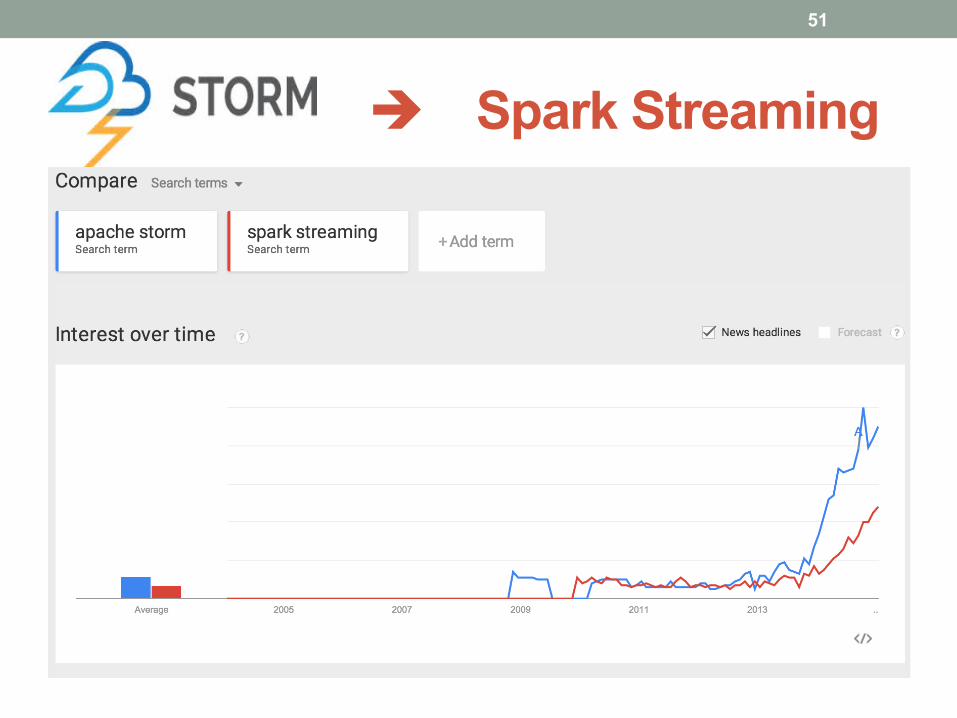
è Spark Streaming
51

Storm vs. Spark Streaming Criteria
Processing Model Record at a time Mini batches
Latency Sub second Few seconds
Fault tolerance– every record processed
At least one ( may be duplicates)
Exactly one
Batch Framework integration
Not available Core Spark API
Supported languages
Any programming language
Scala, Java, Python
52
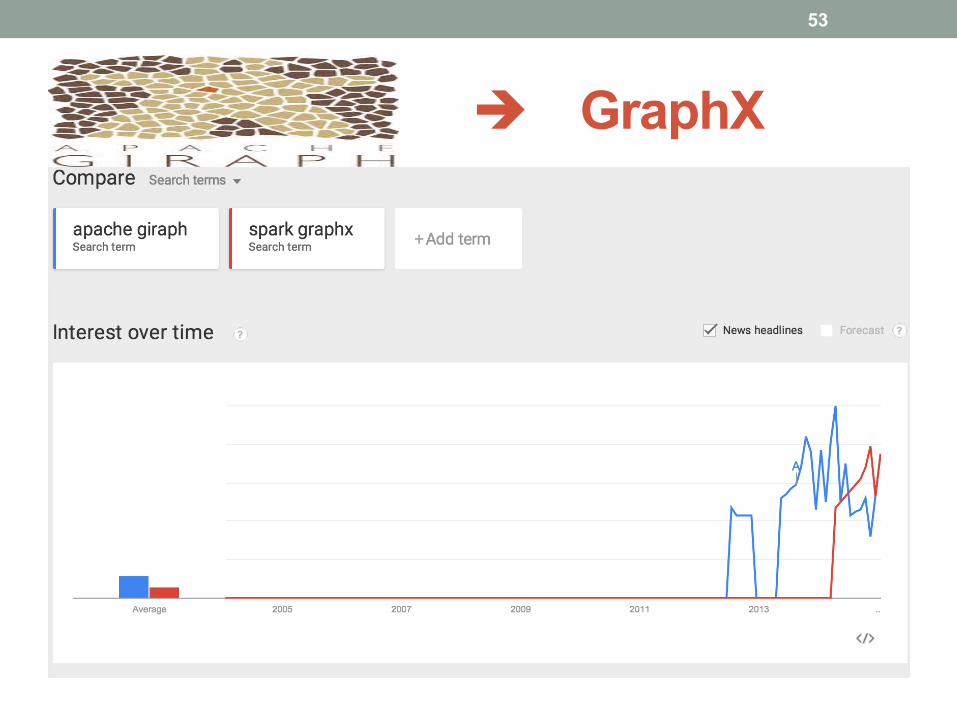
è GraphX
53

è Notebook 54
• Zeppelin http://zeppelin-project.org, is a web-based notebook that enables interactive data analytics. Has built-in Apache Spark support.
• Spark Notebook is an interactive web-based editor that can combine Scala code, SQL queries, Markup or even JavaScript in a collaborative manner. https://github.com/andypetrella/spark-notebook
• ISpark is an Apache Spark-shell backend for IPython https://github.com/tribbloid/ISpark

Agenda
1. Evolution 2. Transition 3. Integration 4. Alternatives 5. Complementarity 6. Key Takeaways + Q&A
55

5. Complementarity ‘Pillars’ of Hadoop ecosystem and Spark ecosystem can work together: each for what it is especially good at, rather than choosing one of them.
56
Hadoop ecosystem Spark ecosystem

5. Complementarity: + + • Tachyon is an memory distributed file system. By storing
the file-system contents in the main memory of all cluster nodes, the system achieves higher throughput than traditional disk-based storage systems like HDFS.
• The Future Architecture of a Data Lake: In-memory Data Exchange Platform Using Tachyon and Apache Sparkhttp://blog.pivotal.io/big-data-pivotal/news-2/the-future-architecture-of-a-data-lake-in-memory-data-exchange-platform-using-tachyon-and-apache-spark
• Spark and in-memory databases:Tachyon leading the packhttp://dynresmanagement.com/1/post/2015/01/spark-and-in-memory-databases-tachyon-leading-the-pack.html
57

5. Complementarity: + • Mesos and YARN can work together: each for what it is especially good at, rather than choosing one of the two for Hadoop deployment.
• Big data developers get the best of YARN’s power for Hadoop-driven workloads, and Mesos’ ability to run any other kind of workload, including non-Hadoop applications like Web applications and other long-running services.”
58

5. Complementarity: + References:
• Apache Mesos vs. Apache Hadoop YARN https://www.youtube.com/watch?v=YFC4-gtC19E Jim Scott, MapR
• Myriad: A Mesos framework for scaling a YARN cluster https://github.com/mesos/myriad
• Myriad Project Marries YARN and Apache Mesos Resource Management http://ostatic.com/blog/myriad-project-marries-yarn-and-apache-mesos-resource-management
• YARN vs. MESOS: Can’t We All Just Get Along? http://strataconf.com/big-data-conference-ca-2015/public/schedule/detail/40620
59

5. Complementarity: + • Spark on Tez for efficient ETL:
https://github.com/hortonworks/spark-native-yarn
• Tez could takes care of the pure Hadoop optimization strategies (building the DAG with knowledge of data distribution, statistics or… HDFS caching).
• Spark execution layer could be leveraged without the need of a nasty Spark/Hadoop coupling.
• Tez is good on fine-grained resource isolation with YARN (resource chaining in clusters)
• Tez supports enterprise security
60

5. Complementarity: + • Data >> RAM: Processing huge data volumes, much bigger than cluster RAM: Tez might be better, since it is more “stream oriented” , has more mature shuffling implementation, closer YARN integration.
• Data << RAM: Since Spark can cache in memory parsed data, it can be much better when we process data smaller than cluster’s memory.
• Improving Spark for Data Pipelines with Native YARN Integration http://hortonworks.com/blog/improving-spark-data-pipelines-native-yarn-integration/
• Get the most out of Spark on YARN https://www.youtube.com/watch?v=Vkx-TiQ_KDU
61

Agenda
1. Evolution 2. Replacement 3. Integration 4. Alternatives 5. Complementarity 6. Key Takeaways + Q&A
62

6. Key Takeaways + Q&A 1. Evolution: of compute models is still ongoing. Watch
out Apache Flink project for true low-latency and iterative use cases and better performance!
2. Transition: Tools from the Hadoop ecosystem are still being ported to Spark. Keep watching general availability and balance risk and opportunity.
3. Integration: Healthy dose of Hadoop ecosystem integration with Spark. More integration is on the way.
4. Alternatives: Do your due diligence based on your own use case and research pros and cons before picking a specific tool or switching from one tool to another.
5. Complementarity: Components and tools from Hadoop ecosystem and Spark ecosystem can work together: each for what it is especially good at. One size doesn’t fit all!
63





























