Embed Size (px)
Citation preview

OPTIMIZACIÓN DE PROCESOS CON ALGORITMOS GENÉTICOS, REDES NEURONALES Y LÓGICA DIFUSA.
Por: Dr. Ing. Juan Manuel Cevallos AmpueroResumen En la actualidad en muchos casos se requiere optimizar varias respuestas de forma simultánea. Un enfoque común para la optimización de los problemas de respuesta múltiple comienza con el uso de modelos de regresión polinómica para estimar las relaciones entre las respuestas y factores de control. Luego se usa una técnica para combinar diferentes funciones de respuesta en un escalar único, como una función de deseabilidad, y, finalmente, se usa un método de optimización se utiliza para encontrar los mejores valores para los factores controlables. En algunos casos, las relaciones entre las respuestas y los factores controlables son demasiado complejas para ser eficiente estimadas por los modelos de regresión polinómicas. Asimismo, en muchos casos de fabricación se presentan encuentran respuestas cualitativas, que no pueden ser fácilmente representados por números. Un enfoque alternativo propuesto en este trabajo es utilizar redes neuronales artificiales (RNA) para estimar las funciones de respuesta cuantitativa y cualitativa. Para procesar los valores cualitativos e usa lógica difusa. Finalmente, en la fase de optimización, se usa algoritmos genéticos (GA), aplicados a una función de deseabilidad para determinar los valores óptimos de los factores de controlables. Se presenta un ejemplo de aplicación de la metodología propuesta. Palabras clave de Diseño de experimentos, Metodología de Superficie de respuesta, Redes neuronales artificiales, Algoritmos genéticos, Funciones de Base Radial.1 IntroducciónEn el mundo altamente competitivo de hoy, las empresas están mejorando constantemente la calidad de sus productos y servicios. El diseño de experimentos (DOE) es un método recomendado de mejorar de la calidad efectivo recomendado por la mayoría de los expertos para optimizar el rendimiento de los procesos de fabricación. El Diseño de experimentos nos ayuda a investigar los efectos de los factores controlables y de ruido sobre una o más las respuestas de interés. Los factores controlables son aquellos factores cuyos valores pueden ser controladas durante las operaciones de fabricación, mientras que los factores de ruido son factores cuyos valores no pueden controlarse ni mantenerse constantes en la vida real. El objetivo del DOE es determinar los valores óptimos de los factores controlables de modo que la característica de calidad o respuesta de interés alcanza su objetivo con una variación mínima. Dicho producto se denomina comúnmente como un producto robusto. En muchos casos, la evaluación de la calidad de productos o procesos pueden involucrar el estudio simultáneo de varias características de calidad, con cada una teniendo su propia importancia relativa para los clientes. Este problema es conoce comúnmente como el problema de optimización de respuestas múltiples. El objetivo final de este problema de optimización es determinar los valores para los factores controlables que permiten la mejor combinación de las respuestas.(Montgomery, 2006) 2 Revisión de la literatura Diferentes métodos han sido propuestos en la literatura para problemas de optimización de respuesta múltiple. Ortiz et al., 2004, sostiene la clasificación de los métodos existentes en tres categorías. El desempeño de cada método depende del tamaño y la complejidad del problema. La primera categoría consiste en de la superposición de los trazos de curvas de
1

contorno de cada respuesta y con base a ellos se encuentra la región de interés que por las diferentes respuestas es satisfecha. El problema principal con este enfoque es que no se puede identificar la solución más dominante. Myers y Montgomery, 2009, manifiestan que este enfoque es eficaz sólo cuando se tiene pocos factores controlables. La segunda categoría discutida propuesta por Ortiz et al, 2004, consiste en loa enfoques que se pueden utilizar para formular el problema en la forma de un problema de optimización restringida. Kim y Lin, 2006, se refieren a esta categoría, como enfoques basados en en prioridades. Este enfoque utiliza la respuesta más importante como la función objetivo y el resto de las respuestas son considerados como restricciones. Este enfoque es uno de los enfoques más utilizados en los problemas de toma de decisiones de múltiples objetivos. Ejemplos de este enfoque se puede encontrar trabajos sobre metodología de superficie de respuesta, como Del Castillo y Montgomery, 1993, y Kim y Lin, 2006. La principal desventaja de estos enfoques es que no se ajustan a la idea básica de optimización de la superficie de respuesta para considerar de forma simultánea todas las respuestas. La tercera categoría y más general consiste en enfoques que utilizan los siguientes tres pasos para encontrar el la solución. En primer lugar, construir modelos para las respuestas de interés. En segundo lugar, combinar los modelos en un solo valor escalar. En tercer lugar, optimizar el modelo de un solo valor por medio de un método de optimización. Los mínimos cuadrados ordinarios (MCO) es el enfoque más común para llevar a cabo el primer paso, es decir, la construcción del modelo. Sin embargo, Shah et al., 2004, utilizó regresiones no relacionadas (RNR) para estimar los parámetros del modelo. Este método es muy útil cuando las variables de respuesta múltiple de los problemas están correlacionadas. El segundo paso, se puede realizar con diferentes técnicas, como son funciones de deseabilidad, Derringer y Suich ,1980, funciones de distancia, Khuri y Conlon, 1981, funciones pérdida de error cuadrático, Pignatiello, 1993, y Vining, 1998, y la proporción de conformidad, Chiao y Hamada, 2001. El método de las funciones de deseabilidad es el más práctico de aplicar; y la ventaja de las otras tres técnicas es su capacidad para considerar la correlación que pueda existir entre las respuestas. El método de optimización en el tercer paso depende de las propiedades del valor del modelo de la superficie de respuesta. Las técnicas de búsqueda, tales como la simplex Nelder-Mead, Melder y Mead, 1965, y Hooke-Jeeves, Derringer y Suich, 1980, son comúnmente utilizadas para funciones de superficie de respuesta no diferenciables. Para las funciones objetivo diferenciables, se puede considerar que los métodos basados en gradiente, como gradiente reducido generalizado (GRG), Del castillo et al., 1996. Asimismo, procedimientos heurísticos de búsqueda, tales como los algoritmos genéticos (GA), recocido simulado (SA), o la búsqueda tabú (TS), pueden aplicarse a superficies altamente no lineales y complejas, Ortiz, et al., 2004. Estos métodos heurísticos son los más prometedores hasta ahora para abordar los problemas de optimización de respuesta múltiple (MRO). El principal problema en estos métodos se presenta cuando el error cuadrado medio (MSE) de los modelos de regresión son altos. Esto sucede en dos situaciones. En primer lugar, cuando la premisa de la interdependencia de las variables de entrada se viola; y en segundo lugar, cuando la relación entre las respuestas y los factores de control son demasiado complejas, de tal manera que los coeficientes de regresión no puede ser estimar con precisión. En este trabajo se trata de desarrollar un nuevo enfoque basado en redes neuronales artificiales (RNA) primero para los problemas en que los modelos de regresión dan valores altos de MSE. El uso de las RNA nos ayuda primero en la
2

detección de los factores de control significativos de cada respuesta y, a continuación para calcular la relación entre dicha respuesta y los factores controlables significativos.Otro problema que a menudo se produce en el mundo real aplicaciones es que los usuarios encuentran respuestas cualitativas. Las respuestas cualitativas son aquellas características de calidad que no pueden ser convenientemente representados numéricamente. En muchos de los casos, se clasifica a cada elemento de inspección, ya sea como "Conforme" o "no conforme" a las especificaciones de esa característica de calidad. Las características de calidad de este tipo se llaman atributos, Montgomery, 201. En muchos otros casos, la naturaleza del una característica de calidad es tal que no puede definirse numéricamente. Tong y Hsieh, 2000, presentan su enfoque de redes neuronales RNA indicando que no es capaz de manejar los problemas con respuestas cualitativas y que es un área para investigar. En este trabajo, se presenta un procedimiento basado en lógica difusa para abordar el problema con respuestas cualitativas.El resto del trabajo presenta el enfoque propuesto en la Sección 3, en la Sección 4 se presenta un ejemplo del enfoque propuesto y en la sección final se presentan las conclusiones.3. Enfoque propuestoLas RNA son aproximadores de funciones muy utilizados. Las RNA son principalmente utilizadas para la aproximación y la función de reconocimiento de patrones. Dependiendo de qué tipo de RNA se utiliza, existen diferentes parámetros que ajustar, pero el concepto común compartido es que todas necesitan ser entrenadas. Se utilizan ejemplos, datos patrón, para entrenar la red neuronal. Cada ejemplo se compone de un par de datos, entrada - salida: una señal de entrada y su correspondiente respuesta deseada para la red neuronal. Así, un conjunto de ejemplos representa el conocimiento sobre el tema de interés, Haykin, 1994. Dada esta serie de ejemplos, el diseño de una red neuronal puede proceder como sigue. En primer lugar, una adecuada arquitectura es seleccionada para la red neuronal. En segundo lugar, un subconjunto de los ejemplos se utiliza para entrenar la red por medio de un algoritmo adecuado (de aprendizaje). En tercer lugar, el desempeño de la red entrenada se prueba con datos que no se ha utilizado inicialmente (generalización).El enfoque propuesto sigue básicamente los mismos de tres pasos para la tercera categoría mencionada antes. Se utiliza redes neuronales RNA para estimar la relación entre los factores controlables como las entradas y salidas como las respuestas en la primera fase; funciones de deseabilidad FD sin restricciones combinadas con funciones de restricción en la segunda fase, y, finalmente, Algoritmos genéticos AG como una potente herramienta de optimización en la fase de optimización. Este procedimiento nos permite tomar ventaja de las capacidades de las redes neuronales para la función de la aproximación; del potencial de las funciones de deseabilidad en la ponderación de las respuestas individuales, y también la aptitud de los AG en la optimización altamente no lineal y complejo de las funciones. En situaciones en las que tenemos respuestas cualitativas, el sistema se basa en dos etapas de preprocesamiento, primero la expresión lingüística se transforma en vectores, de modo que puedan ser analizados por las redes neuronales. 3.1 Diseño del experimentoEl enfoque propuesto se inicia con diseñar un experimento. El diseño experimental nos ayuda a recoger los datos necesarios para la formación de las redes neuronales. Se usan Diseños de Metodología de Superficie de Respuesta MSR como el Diseño compuesto
3

central (CCD) o el de Box Behnken, debido a su capacidad para proporcionar la información requerida, mediante la cobertura del espacio experimental. Tales diseños ayudan a las redes neuronales a aproximar la función del proceso.3.2 Respuestas CualitativasRespuestas cualitativas, en forma de expresiones metalingüísticas como "Muy Bueno", "bueno", "medio", etc, conjuntos difusos son definidos. En la definición de conjuntos difusos, las opiniones de los expertos son comúnmente considerados. Este es uno de los más pasos importantes en la fuzificación de una variable cualitativa. La fuzzificación de una respuesta cualitativa significa definir diferentes funciones de membresía para diferentes valores cualitativos de que la respuesta pertenecen un dominio predefinido, Rajasekaran, 2003. Las RNA no son capaces de procesar los conjuntos difusos en la forma de funciones de pertenencia o membresía. Por ello, se alimentan a las redes neuronales con la información en la forma de vectores. Para ello, el dominio de los conjuntos difusos se divide en n intervalos iguales y en n +1 puntos de resultados, los grados de pertenencia están representados por un vector con n+1 elementos. El vector de n +1 elementos es una aproximación de la función de pertenencia. Al aumentar el valor de n resultará en un mejor aproximación. La determinación de un valor apropiado para n depende de la naturaleza de la función de pertenencia.3.3 Aplicación de una red neuronal para la estimación de la respuestaEn esta fase, una red neuronal se entrena para cada la respuesta para aproximar su relación con los factores controlables. El número de redes neuronales entrenadas es igual al número de las respuestas. Las entradas para estas redes son factores controlables y las salidas son respuestas. La capa de salida de las redes para respuestas cuantitativas tienen una sola neurona, y la capa de salida de las redes para respuestas cualitativas tienen n +1 neuronas. Para evitar la memorización de la red, un subconjunto de 10-15% del total datos se seleccionan al azar como datos de prueba y el resto Se considera que datos de entrenamiento3.3.1 Identificación de factores controlables significativos para cada respuesta Antes del entrenamiento de las redes, los factores significativos para cada respuesta tiene que ser identificados en forma de un subconjunto de todos de los factores controlables que producen el mínimo MSE. RNA con función de base radial (RBF) se consideran para este propósito, la razón es la consistencia de las redes RBF en el entrenamiento. Cuando una red RBF es entrenada con el mismo conjunto de datos varias veces, se producirá el mismo MSE para la datos de prueba y de entrenamiento. Sin embargo, la redes con perceptrón multicapa (MLP) son altamente dependientes de sus pesos sinápticas iniciales, así la evaluación de la resultados sería difícil. Los parámetros ajustables en Redes RBF son: (1) el número máximo de neuronas ocultas, (2) valor de la constante de propagación (SC), que está comúnmente en el intervalo de 0,01 a 5, y (3) un valor mínimo para el MSE, que también se conoce como el objetivo. El valor común de 1 que se recomienda para el SC también se considera en este trabajo. Al establecer el valor del objetivo igual a 0 y el número máximo de neuronas ocultas igual al número de vectores de entrenamiento disponibles, la red será entrenada hasta que se alcanza un MSE = 0 para el datos de entrenamiento. En tal caso, el MSE para los datos de prueba se utilizan como un criterio para comparar diferentes subconjuntos de factores controlables (xi , i = 1, ..., k). A través de este procedimiento, los modelos completos incluyendo todos los factores controlables y todos sus subconjuntos de modelos k-1 elementos, modelos de k-2 elementos, etc pueden ser comparación entre sí. El modelo que produce el más bajo MSE para los datos de prueba contiene los factores
4

significativos. Si la diferencia entre el modelo completo y un modelo de subconjunto no es significativa, el modelo completo se prefiere. Debe ser observado que, cuando un factor es eliminado del modelo completo, un modelo replicado en un espacio reducido se genera automáticamente. En esta situación, se debe tener cuidado de no considerar una réplica como el entrenamiento y la otra réplica como los datos de prueba de forma simultánea. Si esto sucede, entonces nuestro resultado será deficiente. 3.3.2 El diseño de la más adecuada RNA para estimar cada respuesta Después de identificar los factores significativos para cada respuesta, la mejor red con el menor MSE será diseñado. En este paso, se puede considerar las redes MLP ó RBF para modelar la relación entre cada respuesta y sus correspondientes factores significativos. Para aprobar el entrenamiento adecuado de cada red, la salida de la red para los datos de prueba y de entrenamiento deben ser comparados contra los datos deseados obtenidos del experimento inicial.3.4 Combinando diferentes respuestas a través de funciones de deseabilidad Uno de los métodos más poderosos para la toma de decisiones de objetivos múltiples (MODM) es la función de deseabilidad, que transforma un problema de objetivos múltiples en un problema de objetivo único. Este enfoque consiste de transformar cada una de las m respuestas en su respectiva deseabilidad de acuerdo con un objetivo específico. La deseabilidad individual, d j (y j ), j = 1, 2, ..., m, transforma una respuesta en un valor dentro de una escala en el rango 0 <d j (y j ) <1. Un mayor valor de dj (yj) muestra una respuesta más deseable. Por último, las deseabilidades individuales se combinan mediante el uso de modelos aditivos o multiplicativos o mixtos que producen un solo valor total de deseabilidad D(x) 3.4.1 Definición de funciones de deseabilidad individuales para respuestas cuantitativas.Para respuestas cuantitativas, el uso de las funciones de deseabilidad individuales inicialmente propuestas por Derringer y Suich, 1980, y posteriormente modificadas por Ortiz et al., 2004, se recomiendan. Derringer y Suich, 1980, definen las deseabilidades individuales como:
5

para el caso de dos lados, donde yj, j = 1, ..., m es la salida de la j-ésima neurona (red) y el ymin j , y máx j , y T j son el mínimo, máximo, y valor objetivo, respectivos. En la ecuación anterior, r, s, y t indican los pesos que permiten el comportamiento lineal (s = t = 1) o no lineal entre un límite (frontera) (y min j o y máx j ) y el valor objetivo (T j ). Ortiz et al., 2004, añadió el término de penalización al modelo propuesto por Derringer y Suich, 1980, que ayuda a los Algoritmos Genéticos a mantener una solución no viable mientras no se le permita tener una deseabilidad total mayor que una solución factible- viable. El término de penalización recomendado por Ortiz et. al., 2004, es el siguiente:
.donde c es relativamente una constante pequeña, tal como 0,0001, lo cual fuerza a p j ( y j) a ser mayor que 0.3.4.2 Definiendo funciones de deseabilidad individuales para respuestas cualitativasLas salidas de las redes neuronales para las respuestas cualitativas son de la forma de vectores de n +1 elemento. Por lo tanto, en este punto, la definición de la deseabilidad de un vector se necesita. La deseabilidad individual para un vector puede ser calcula como sigue:
.donde yj es el vector de salida de la red jth, T j es el vector objetivo, y W j es el complemento del vector objetivo. Esta fórmula primero calcula la distancia estadística normalizada del vector de salida y j de su vector objetivo T j ; seguidamente, restando de 1, se determina su deseabilidad individual. El objetivo vector T j es un vector con un elemento
6

igual a 1 y n elementos iguales a 0, en donde la ubicación del 1 en el vector debe ser definido por el experto de acuerdo con el conjunto difuso más deseable. W j es el complemento del vector objetivo con n elementos iguales a 1 y un elemento igual a 0, en donde la ubicación del elemento 0 es la misma que la ubicación del elemento 1 en el vector objetivo. El término penalización se fija igual a c para todas las respuestas cualitativas. Después de determinar las deseabilidades individuales para las respuestas de tipo cualitativo y cuantitativo y teniendo en cuenta los términos de penalización, la deseabilidad total definida por D * (x) puede se calcula como sigue
donde D DS (x), la deseabilidad global definida por Derringer y Suich, 1980, es la media geométrica de las deseabilidades individuales d j (Y j )). Además, P (x), que es el función combinada de las respuestas individuales ajustadas, es la función de penalización global. La función P (x) muestra el gravedad global de la inviabilidad. Las penalidades individuales p j ( y j) asegurar una penalidad global P(x) distinta de cero. De otra manera, P (x) será cero para cualquier solución factible. El Deseabilidad Total D * (x) es el criterio para comparar las diferentes soluciones y es la función que queremos maximizar.3.5 Optimización con Algoritmos Genéticos GAUn GA es elegido para llevar a cabo la optimización para dos razones. En primer lugar, el gradiente basado en métodos de optimización tales como GRG, no se puede utilizar debido a que requieren superficies de respuesta para calcular el gradiente y la dirección de mejoramiento. Sin embargo, cuando las redes neuronales se utilizan, no hay ninguna superficie de respuesta. En segundo lugar, loa GA se conoce como un método de búsqueda heurístico potente para la optimización de funciones no lineales y complejos. Un GA tiene distintos parámetros cuyos valores deben ser determinados antes de iniciar la fase de optimización. Diferente autores, entre ellos Ortiz et al., 2004, han propuesto el uso de diseños de experimentos robustos para determinar el mejor conjunto de los parámetros del GA. Por lo tanto, tenemos que incorporar un diseño experimental robusto para encontrar los mejores valores de los parámetros. El variables controlables y ruido del GA sus niveles se muestran en la Tabla 1. Tabla 1 Niveles de variables controlables y ruido utilizados en el diseño experimental robusto.
variable nivel bajo nivel alto Tipopadres de la población 20 50 controlratio padres / hijos 01:01 01:07 controltipo de selección posicion torneo controlnumero de las elites 2 6 controlratio de cruce 0.5 0.85 controltipo de mutación uniforme gaussiano control
7

numero de factores 4 8 ruidonúmero de respuestas 4 16 ruidorestricción de ancho (% delobjetivo) 5 15 ruido
Las medidas de desempeño de GA son los mismos que en Ortiz et al., 2004. Los conjuntos de parámetros finales para los GA robustos se muestran en la Tabla 2.
Tabla 2 Conjuntos de parámetros finales para los algoritmos genéticos (GA)
Parámetro valorpadres de la población 20Ratio padres / hijos 01:07tipo de selección torneonumero de las elites 2Ratio de cruce 0.85Tipo de mutación gauss
El GA ajustado se corre por 1.000 repeticiones y la solución más deseable con la mayor deseabilidad total es la solución final. (Todos los cálculos y codificación se realizan en el entorno de MATLAB.)4 Ejemplos El enfoque propuesto se ilustra con dos ejemplos. El primer ejemplo incluye sólo respuestas cuantitativas. El segundo ejemplo es de un proceso de fusión de hilados, con variables cualitativas.4.1 Optimización de un proceso de fabricación semiconductores con respuestas múltiples.Ejemplo presentado por Del Castillo et al.,1996, se basa en el proceso de alambre de unión en la industria de semiconductores. Durante este proceso, el fabricante debe ensamblar un módulo híbrido en un paquete pre-moldeado por medio de la unión cables entre los conductores (posición A, Fig. 3 ) y los chips de silicio (posición B, fig. 3 ).
Figura 3. Sistema de calentamiento de alambre de unión, Del Castillo et al., 1996.
8
Calentador del bloquePosición BPosición A
N2 Flujo

Los factores controlables que influyen en la temperatura de los alambre de unión son la N2 velocidad de flujo (x1), la N2 la temperatura (x 2 ), y la temperatura del bloque calentador (x3 ). Las respuestas para el experimento son Y1 = Temperatura máxima en la posición A, Y 2 = Temperatura al comienzo de la unión en la posición A, Y3 = Temperatura al término de la unión en la posición A, Y 4 = Temperatura máxima en la posición B, Y 5 = Temperatura al inicio de la unión en la posición B, Y 6 = Temperatura al término de la unión en la posición B. Para investigar el efecto de los tres factores controlables, un dieño Box-Behnken Se empleó. Los factores controlables, junto con sus niveles utilizados en el diseño, se muestran en la Tabla 3. Los resultados experimentales se muestran en la Tabla 4.Tabla 3 Factores y niveles para el diseño experimental de Box-BehnkenFactor Nombre
Unidades Bajo Nivel Alto nivel
A Tasa de flujo SCFM 40 120B Temp. de flujo °C 200 450C Temp. Bloque °C 150 350Tabla 4: Resultados de corridas experimentales:
Tasa de flujo
Temp. de flujo
Temp.de bloque Y1 Y2 Y3 Y4 Y5 Y6
40 200 250 139 103 110 110 113 126120 200 250 140 125 126 117 114 13140 450 250 184 151 133 147 140 147
120 450 250 210 176 169 199 169 17140 325 150 182 130 122 134 118 115
120 325 150 170 130 122 134 118 11540 325 350 175 151 153 143 146 164
120 325 350 180 152 154 152 150 17180 200 150 132 108 103 111 101 10180 450 150 206 143 138 176 141 13580 200 350 183 141 157 131 139 16080 450 350 181 180 184 192 175 19080 325 250 175 135 133 155 138 14580 325 250 190 149 145 161 141 14980 325 250 180 141 139 158 140 148
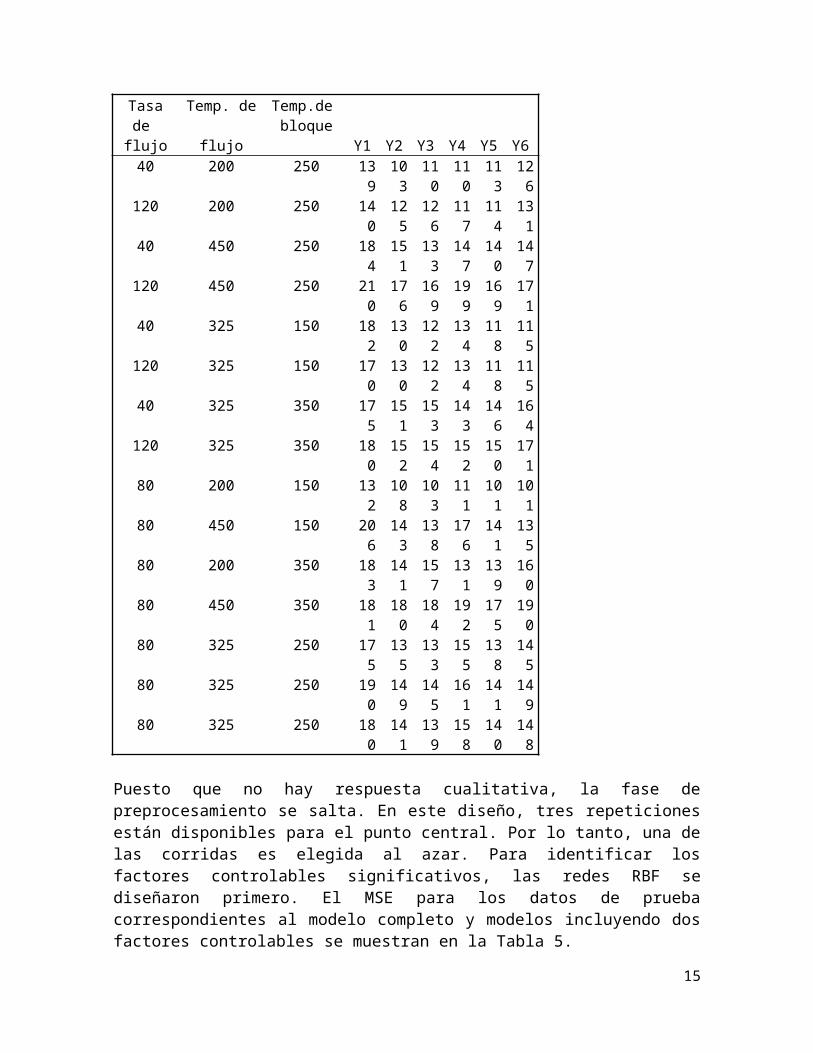
Puesto que no hay respuesta cualitativa, la fase de preprocesamiento se salta. En este diseño, tres repeticiones están disponibles para el punto central. Por lo tanto, una de las corridas es elegida al azar. Para identificar los factores controlables significativos, las redes RBF se diseñaron primero. El MSE para los datos de prueba correspondientes al modelo completo y modelos incluyendo dos factores controlables se muestran en la Tabla 5.Tabla 5 Error cuadrático medio (MSE) para los datos de pruebaFACTORE
SY1 Y2 Y3 Y4 Y5 Y6
A,B,C 446 460.3 419 143.1 67.4 21.7
9

B,C 5.6 15.8139.
71135.
4 206.6 151.2
A,C4049.
4 1551415.
73117.
51379.
1 776.5
A,B 260.93501.
5 1141 284.8 215.11169.
3Los factores controlables significativos para cada una de las seis respuestas se muestran en la Tabla 6.
Cuando no hay significativa diferencia entre un modelo completo y un modelo que incluye un subconjunto de factores controlables, el modelo completo es seleccionado. Al comparar los factores controlables significativos logrados por nuestro enfoque y los que fueron utilizados en los modelos de regresión de Del Castillo et al., 1996, se puede ver que, excepto para Y 2 e Y 3 , todos los modelos comparten el mismo factores. Para estas dos respuestas, su modelo incluye el factor A, que es excluido en nuestro enfoque. Sin embargo, se observó que el coeficiente de regresión calculado para el factor A en ambos de sus modelos es menor que el resto de coeficientes. A continuación, teniendo en cuenta los factores controlables mencionados en el Tabla 6 para cada respuesta, diferentes redes de MLP y RBF con diferentes parámetros fueron entrenados. Las redes más apropiadas con el menor CME son las que se presentan en la Tabla 7.
Como puede verse, la red MLP se selecciona como la mejor red para todas las respuestas. Todas las redes MLP tienen dos capas ocultas con funciones de activación tangente hiperbólica. Las neuronas de salida tienen las funciones lineales de activación. El algoritmo de entrenamiento en todas las seis redes es Levenberg- Marquardt. La proporción de datos de prueba para el total de datos para las tres primeras redes es de 11.11% y para las otras
10

tres redes es 15,39%. El MSE de los seis modelos de regresión de (presentado por Del Castillo, 1996) también se calcularon y se presentan en la Tabla 8.
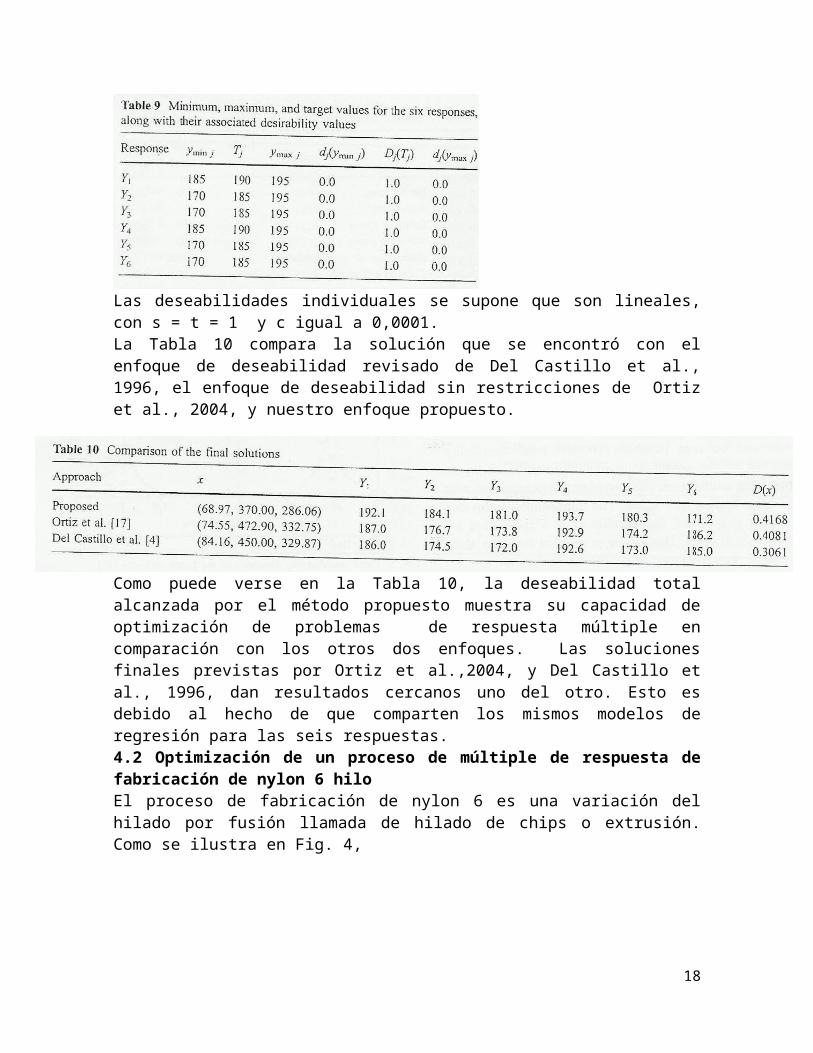
Como puede ser visto, los MSE calculados a partir de los modelos de regresión son altos, y esto muestra un pobre ajuste de los modelos. Sin embargo, las seis redes neuronales producen MSE absolutamente menores, por lo tanto, pueden aproximar la función del proceso con más precisión. Para utilizar el enfoque de deseabilidad, el ingeniero de procesos selecciona los valores mínimos, máximos, y objetivo para las deseabilidades individuales, como se muestra en la Tabla 9.
Las deseabilidades individuales se supone que son lineales, con s = t = 1 y c igual a 0,0001. La Tabla 10 compara la solución que se encontró con el enfoque de deseabilidad revisado de Del Castillo et al., 1996, el enfoque de deseabilidad sin restricciones de Ortiz et al., 2004, y nuestro enfoque propuesto.
Como puede verse en la Tabla 10, la deseabilidad total alcanzada por el método propuesto muestra su capacidad de optimización de problemas de respuesta múltiple en comparación con los otros dos enfoques. Las soluciones finales previstas por Ortiz et al.,2004, y Del Castillo et al., 1996, dan resultados cercanos uno del otro. Esto es debido al hecho de que comparten los mismos modelos de regresión para las seis respuestas.4.2 Optimización de un proceso de múltiple de respuesta de fabricación de nylon 6 hilo
11

El proceso de fabricación de nylon 6 es una variación del hilado por fusión llamada de hilado de chips o extrusión. Como se ilustra en Fig. 4,
El proceso comienza con la alimentación de los gránulos de polímero de nylon 6 a la tolva de alimentación. El polímero de nylon 6 es entonces fundido por ser sometido a un calentador (A) y es luego mezclado a fondo por la rotación de un extrusor de tornillo (C). A continuación, la solución anti-estática (B) se añade a la mezcla. La rotación del tornillo extrusor empuja la mezcla hacia adelante en el colector. El flujo de polímero fundido es ayudado la bomba dosificadora (D). El polímero fundido se hizo girar a continuación para pasar a través del hilador (E) y toma la forma del filamento. Los filamentos luego se solidifican al pasar por la torre de enfriamiento. Por último, se lubrican y se recogen a través del rodillo de recogida (F). Las respuestas del experimento que deben ser optimizadas son el número de hilos, que se define como el peso por unidad longitud y se mide en dtex (Y 1 ), La tensión específica del hilo en cN / tex (Y 2 ), y la condición aparente los hilados (Y 3 ). Las dos primeras respuestas son cuantitativos y la tercera, que muestra el número de snarls (gruñidos) en una unidad de longitud y es definida por un experto observando el hilo bajo un microscopio, es cualitativa. El propósito de este experimento es alcanzar un valor objetivo igual a 140 para Y 1 , maximizar Y 2 , y alcanzar la mejor condición de hilo con el mínimo posible de snarls (Y 3 ). El ingeniero de procesos identifica seis factores controlables que afectan a estas tres respuestas. Los factores controlables se presentan en la Tabla 11.
12

Las ecuaciones consideradas para simular el proceso y generar los datos son:
En el siguiente paso, un diseño compuesto central con un punto central fue elegido y las respuestas se calcularon utilizando ecuaciones de simulación. Para generar los valores cualitativos en la forma de expresiones multilingüísticas para Y 3, el intervalo de 80 a 136, que contiene los resultados de la tercera ecuación, se divide en tres secciones y sus correspondientes expresiones lingüísticas son utilizadas como sigue:
Los resultados experimentales que contienen 65 carreras no son incluidos en el trabajo, sin embargo, ellos están disponibles para el lector que los solicite. A continuación, la respuesta cualitativa Y3 es fuzificada. Tres conjuntos difusos y sus funciones de pertenencia se definen a continuación. La figura 5 ilustra la composición funciones de pertenencia:
13

Figura. 5 Tres funciones de pertenencia de la respuesta difusa (Y3)Posteriormente, con el fin de alimentar estas funciones de pertenencia a las redes neuronales, deben ser expresadas como un vector. Para ello, el intervalo [70, 140] se divide en 28 de secciones iguales (n = 28). De acuerdo con lo mencionado en 3.2, los 29 elementos de los vectores de los tres conjuntos difusos se muestran en la Tabla 12. Tabla 12 Vectores relevantes para los tres conjuntos difusos
14
Para identificar los factores controlables significativos, el MSE de la datos de prueba para el modelo completo y los modelos que incluyen cinco factores de control (k -1) figuran en la Tabla 13.
Según la Tabla 13, son identificados como factores controlables significativos, los factores D, E y F para la respuesta Y1, los factores A y D para la respuesta Y 2 , y los factores A, B, C y D para la respuesta Y3. A continuación, el Redes RBF se formaron con los factores significativos como las entradas de cada red. Los resultados se muestran en la Tabla 14
Dado que el MSE de los modelos con factores significativos son no significativamente menores que el MSE del modelo completo, los modelos completos son elegidos para la optimización. Posteriormente, las redes más adecuadas con el menor MSE fueron entrenadas. Las mejores redes de las tres respuestas son MLP con el algoritmo de entrenamiento Levenberg-Marquardt. La funciones de activación de las capas de neuronas ocultas en todas las redes son tangente hiperbólica. Otras propiedades de la redes se muestran en la Tabla 15.
15

El porcentaje de los datos de prueba del total de datos de las tres redes es 11,69%. El entrenamiento adecuada de las redes para evitar el fenómeno de la memorización ha sido controlada por el graficado de la salida de cada red para datos de entrada de prueba y de entrenamiento y su asignación a lo largo de sus valores deseados. Además, la tendencia disminución MSE ha sido controlada con el fin de no tienen una disminución instantánea, lo que ocurre por la memorización. Los gráficos confirmatorios para el entrenamiento apropiados de la segunda red se muestran en la figura 6.
Los gráficos confirmatorios para el resto de las redes de este ejemplo y también todos los de las seis redes del primer ejemplo no se han incluido en este trabajo para reducir su tamaño, aunque todas las redes cuentan con el entrenamiento adecuado. El ingeniero de procesos selecciona los valores mínimo, máximo y objetivo para deseabilidades individuales, como se muestra en la Tabla 16.
16

Para la respuesta cualitativa, el vector objetivo T 3 y su complemento W 3 son como sigue. Las deseabilidades individuales se asumen que son lineales con s = t = 1:
Con los conjuntos de parámetros obtenidos, con los GA se realizaron 1.000 corridas. La solución más deseable encontrada por el algoritmo, se pronosticaron los valores de respuesta (definidos por la red neuronal), y los valores de respuesta reales (definidos por las ecuaciones de simulación) y se muestran en la Tabla 17.
La salida de la tercera red de la solución final se muestra en la figura 7. Como puede verse en la Tabla 17, los valores de predicción de la primera y segunda respuesta alcanzado mediante la primera y segunda redes están cerca de sus valores reales obtenidos por ecuaciones de simulación. Además, la salida de la tercera red para la solución final está cerca del vector objetivo. Esto muestra el entrenamiento adecuado de las tres redes y aprueba el enfoque propuesto para enfrentar problemas que incluyan respuestas cualitativas.
17
5 ConclusiónEn este trabajo se propone un enfoque para la optimización de los problemas de respuesta múltiple con o sin respuestas cualitativas. El enfoque considera una red neuronal para cada respuesta para estimar su relación con los factores controlables, funciones de deseabilidad sin restricciones para combinar diferentes respuestas en una sola, y un algoritmo genético (GA) para realizar la optimización. El enfoque propuesto es novedoso debido a tres aspectos principales. En primer lugar, se utiliza redes neuronales para estimar las respuestas de interés. En segundo lugar, se identifica los factores controlables significativos de cada una de las respuestas a través del uso de las redes de función de base radial (RBF). Por último, se puede hacer frente a los problemas que contienen respuestas cualitativas. El desempeño del enfoque propuesto fue evaluado a través de dos ejemplos de fabricación. El primer ejemplo de la industria de fabricación de semiconductores fue elegido debido al alto error cuadrático medio (MSE) de la modelos de regresión propuestos por Del Castillo et al., 1996, que muestran la pobre calidad del método. Como se muestra, el uso de los resultados de las redes neuronales resulta en un menor MSE, por lo que su solución final es más confiable.Además, el desempeño de las redes RBF para identificar los factores controlables significativos de cada respuesta fue comparado con los de Del Castillo et al., 1996. En el segundo ejemplo de la industria de fabricación de hilos sintéticos, en un problema de optimización se consideró en la presencia de una respuesta cualitativa. El enfoque fue capaz de desempeñarse bien y alcanza los objetivos de optimización. La razón para esto radica en la cercanía de los valores de respuesta predichos definidos por las redes neuronales con los
18

valores calculados a partir de ecuaciones de simulación. Además, la salida de la tercera red en forma de un conjunto difuso es mucho más cercana a su forma deseada. Es de notar, que el enfoque de optimización propuesto sólo implica la localización de los efectos de las respuestas. Además, se puede extender el enfoque para incluir el efecto de la dispersión de las respuestas. En estas situaciones, son necesarias repeticiones para estimar la desviación estándar de diferentes respuestas para conjuntos diferentes de factores controlables.
19




















![[Paradoja Difusa]](https://img.pdfslide.tips/doc/110x75/58aa4f731a28ab10578b4f3d/paradoja-difusa.jpg)






