Embed Size (px)
Citation preview

PG - Q@shohu33
ATARI

PG
PG

(policy)

PG
PG

PG
Q
( ) ( or
) (
) Q

"Q-Learning Tutorial". Mnemosyne Studio. http://mnemstudio.org/path-finding-q-learning-tutorial.htm
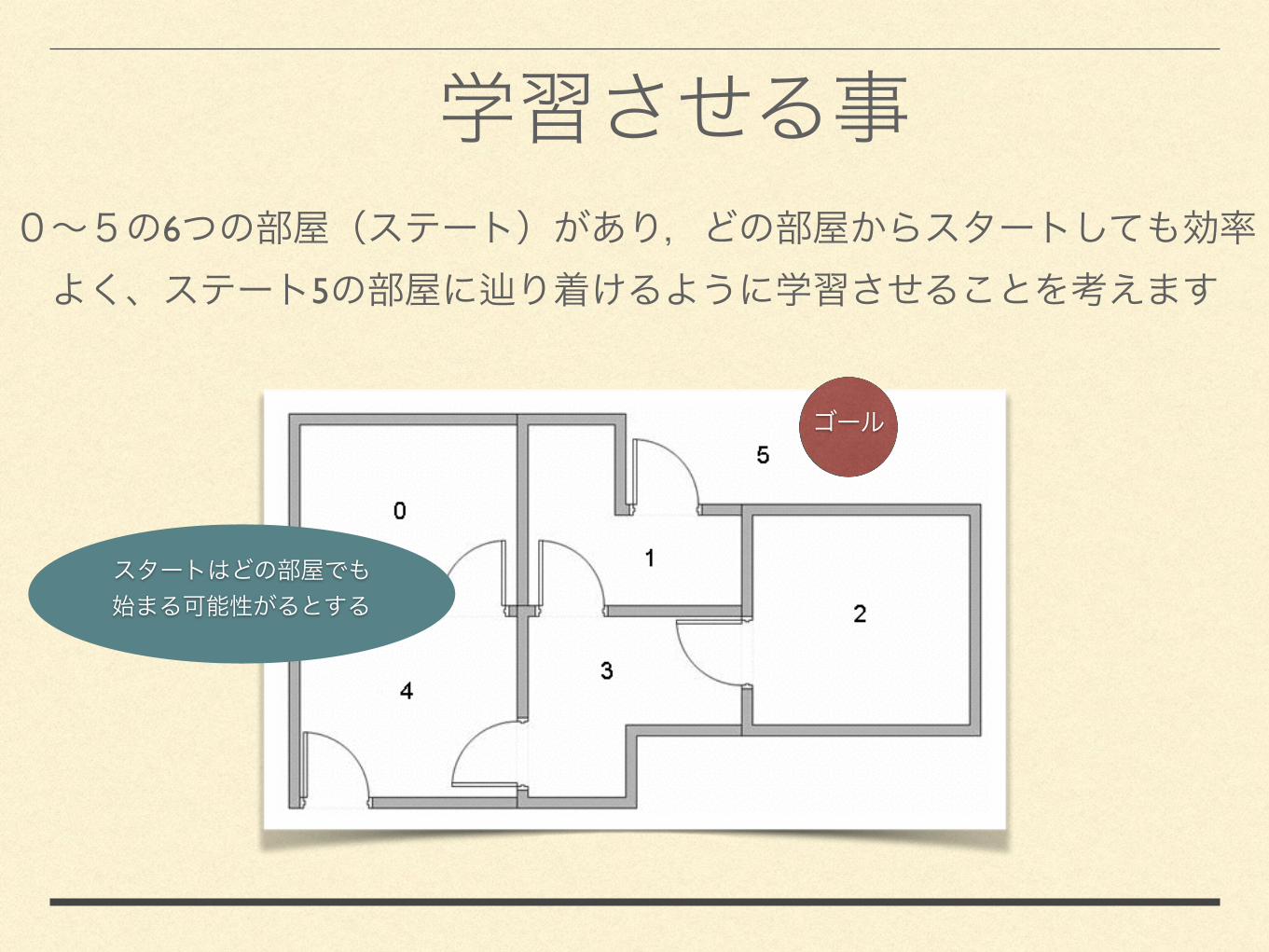
6
5

1. (Gamma)
2. Q 0
3. :
3.1
3.2 5 :
3.2.1
3.2.2
3.2.3 Q
Q(state, action) = R(state, action) + Gamma * Max[Q(next state, all actions)]* Q
3.2.4
3.2.5 5
3.3


1. (Gamma)

(Gamma) 0 1
0 ( )
0.8

[ ]
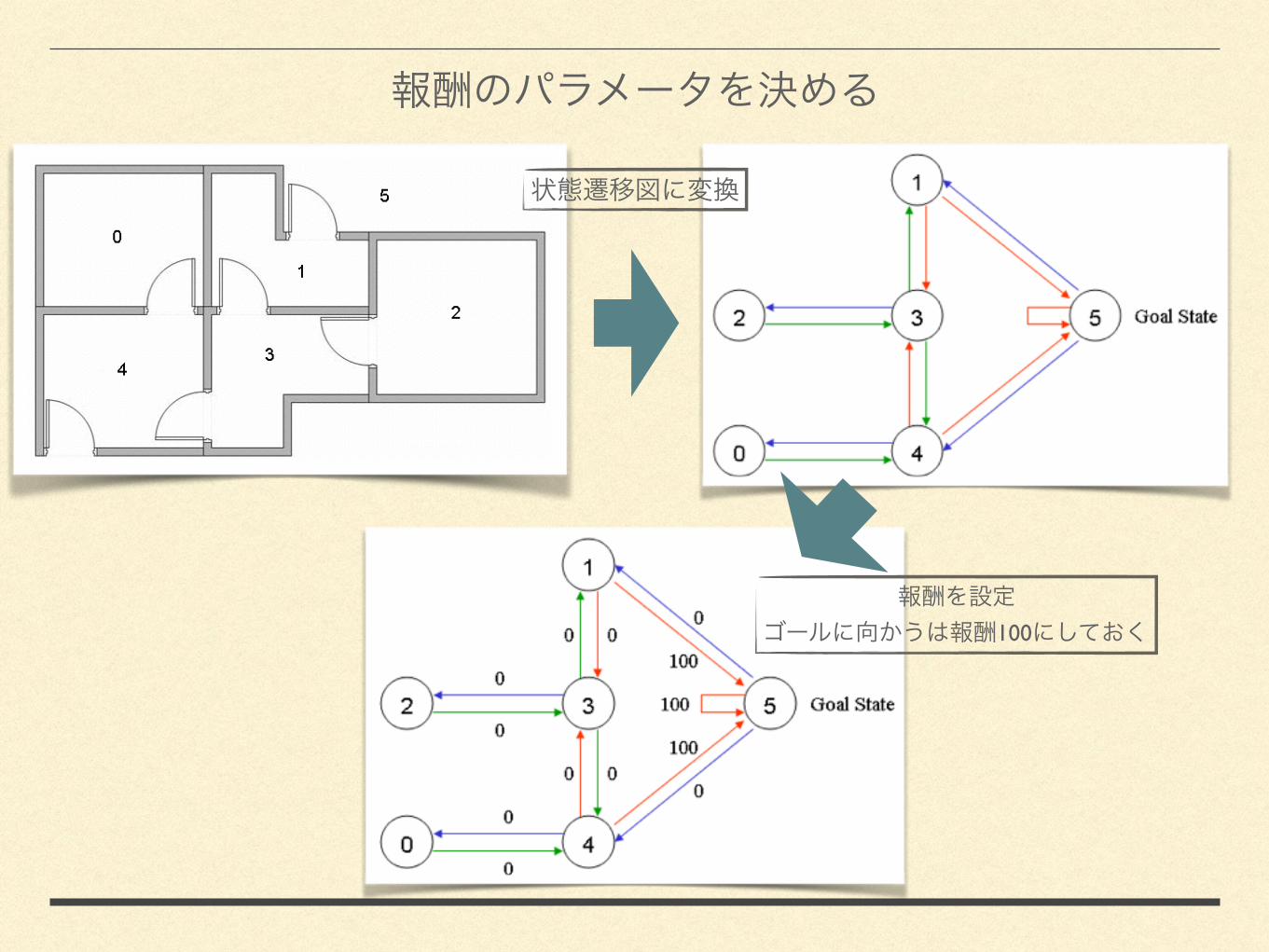
100
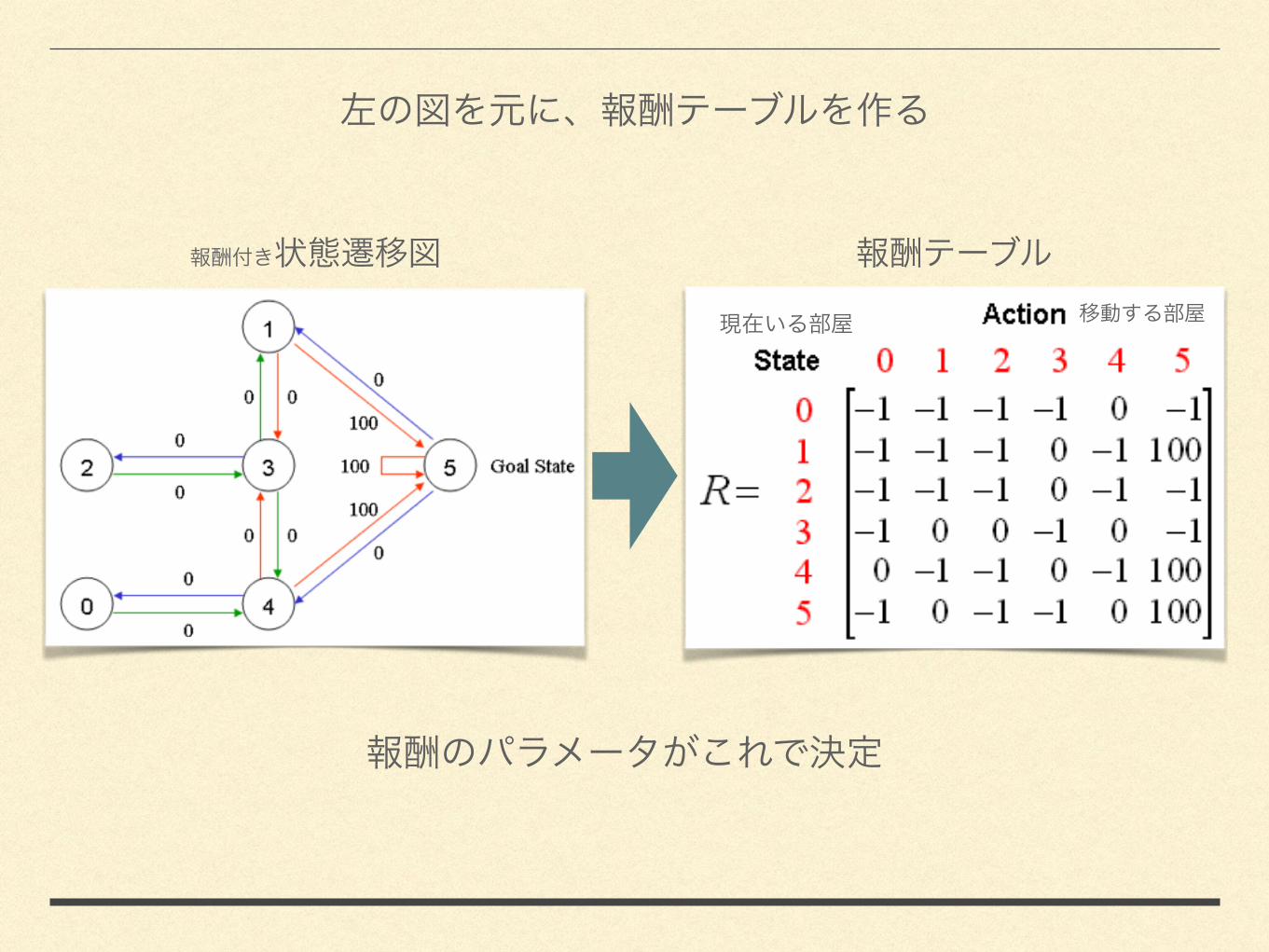

2. Q( ) 0
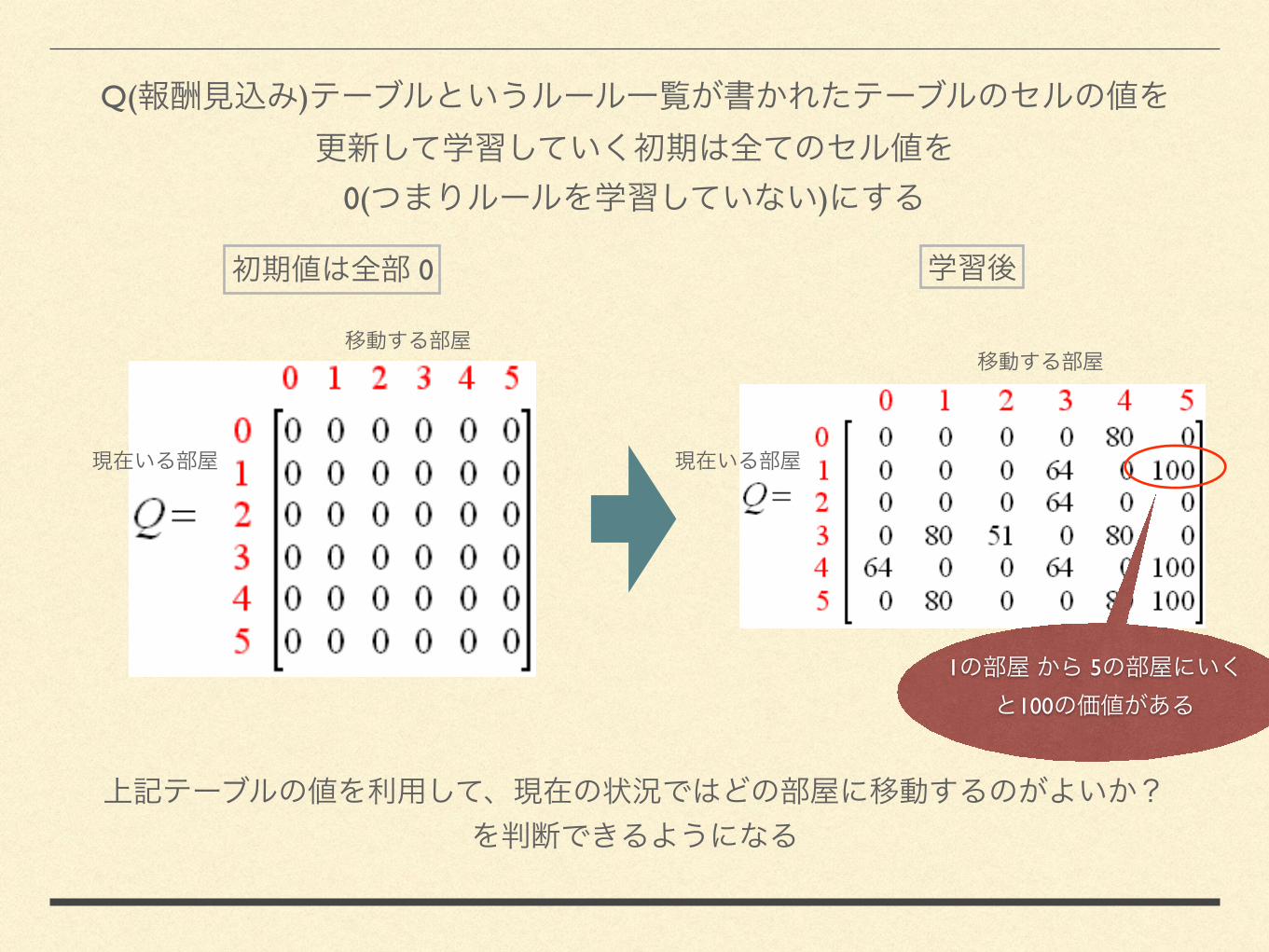
0
1 5
100
Q( )
0( )


3.1
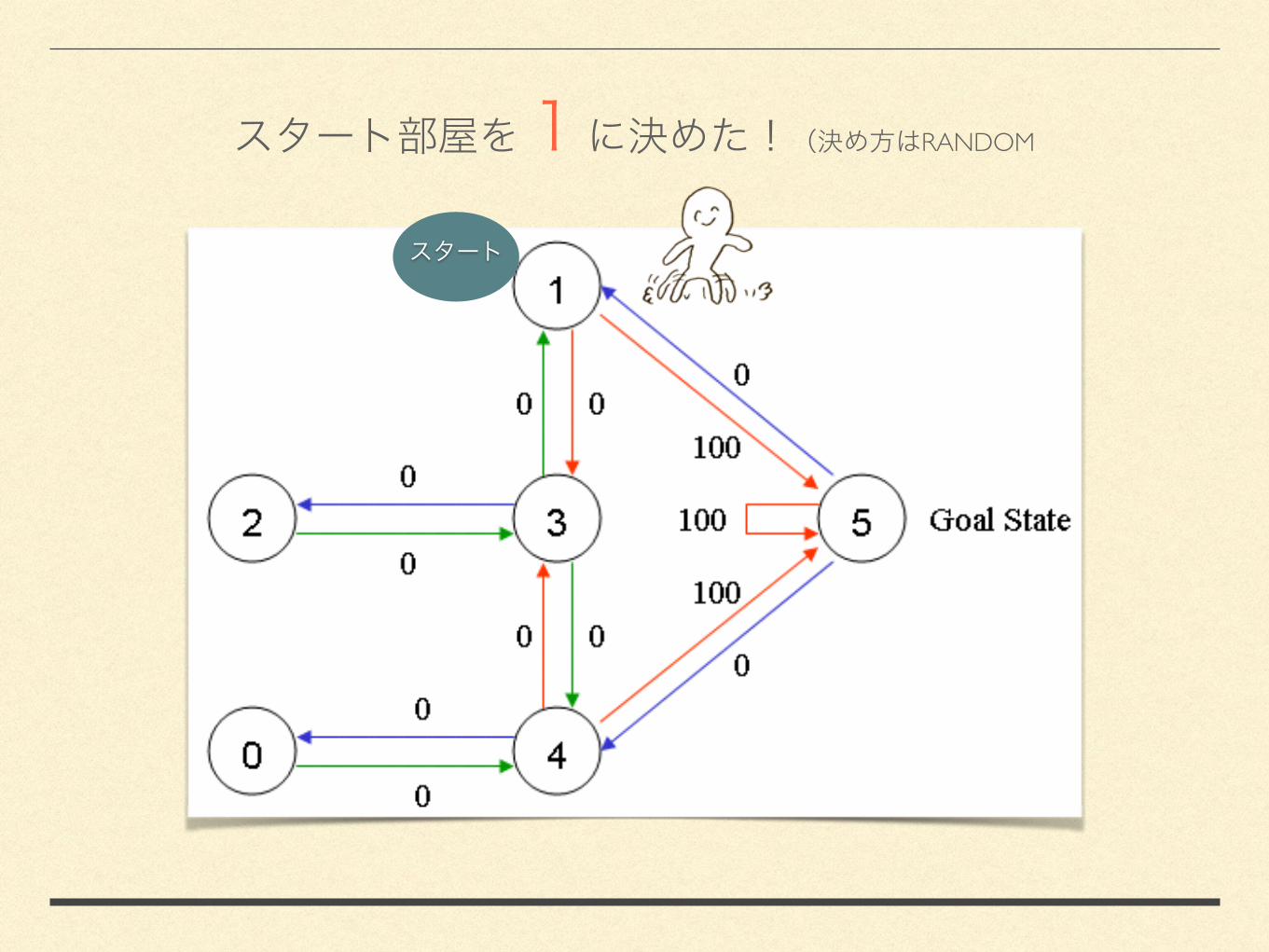
RANDOM

3.2 5

3.2.1
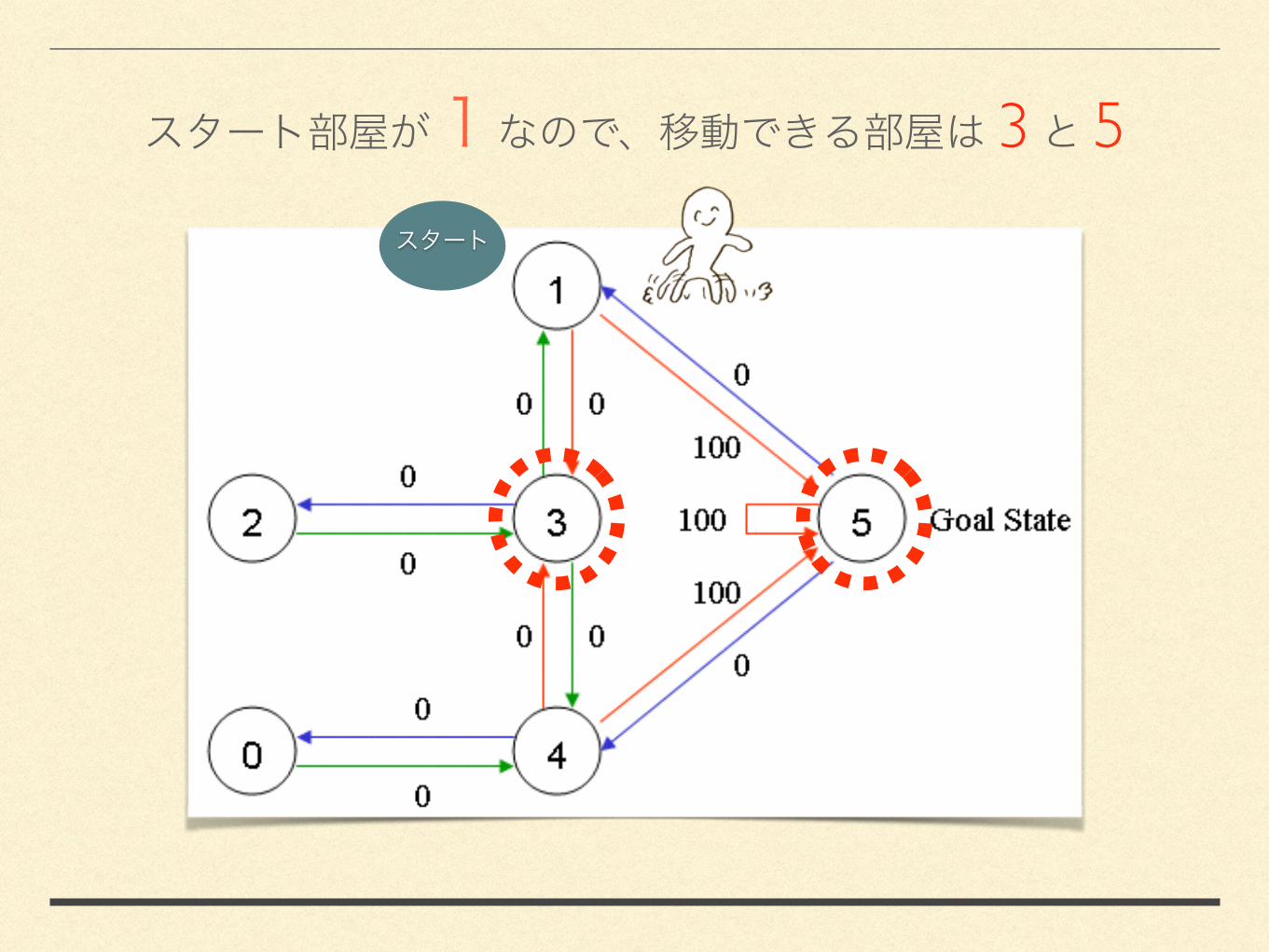
3 5

3.2.2

5

3.2.3 Q
Q(state, action) = R(state, action) + Gamma * Max[Q(next state, all actions)]

今回、部屋1 から 部屋5 に移動する⾏動を選んだので
Q
state=1, action=5, Gamma=0.8, next state=5, all actions = 1,4,5
Q

Q
Q
5
1,4,5
Q

3.2.4

5

3.2.6 5
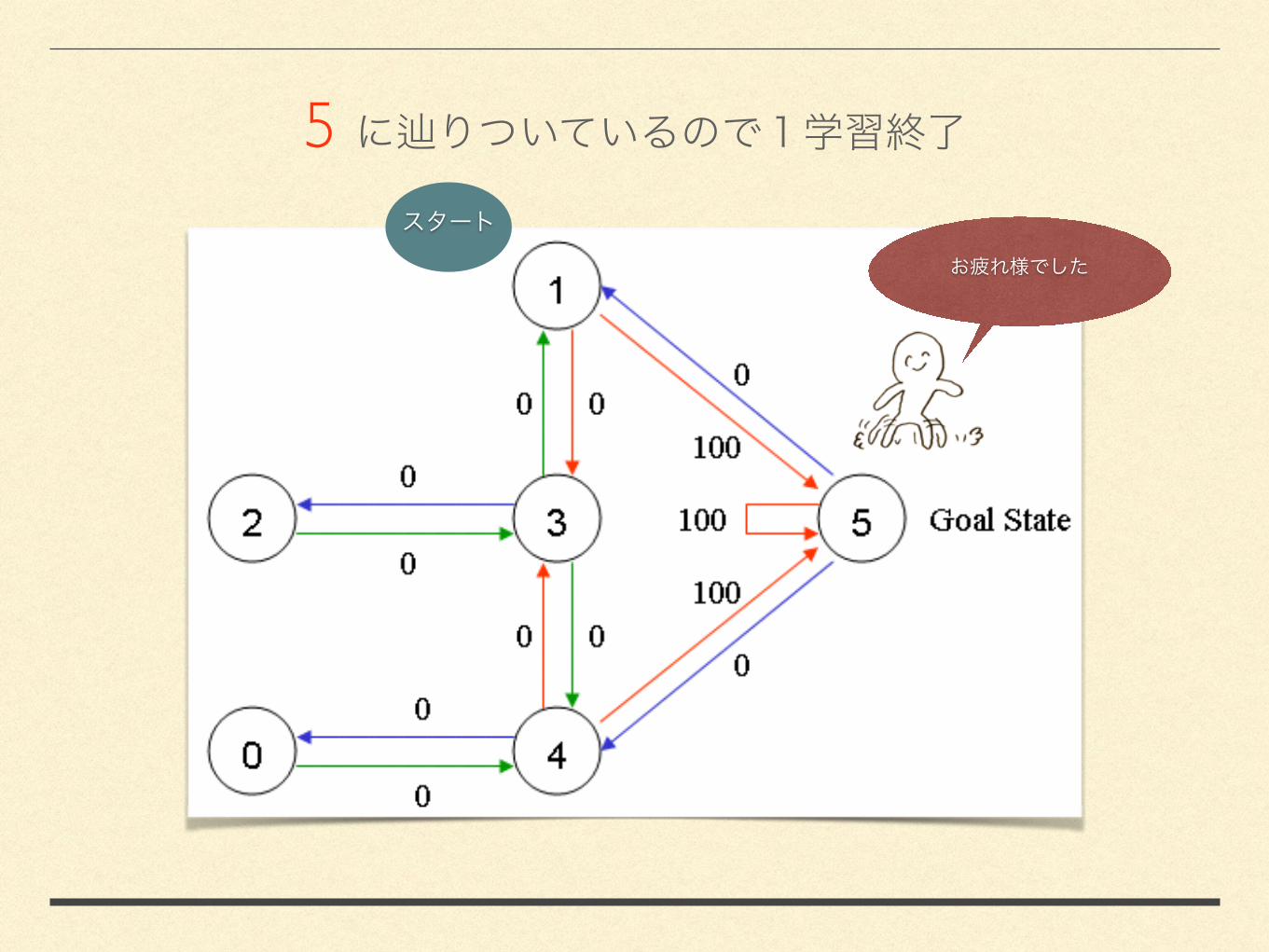
5

3.3

3.1

31
Q(state, action) = R(state, action) + Gamma * Max[Q(next state, all actions)]
Q(3, 1) = R(3, 1) + 0.8 * Max[Q(1, 3), Q(1, 5)] = 0 + 0.8 * Max(0, 100) = 80
1

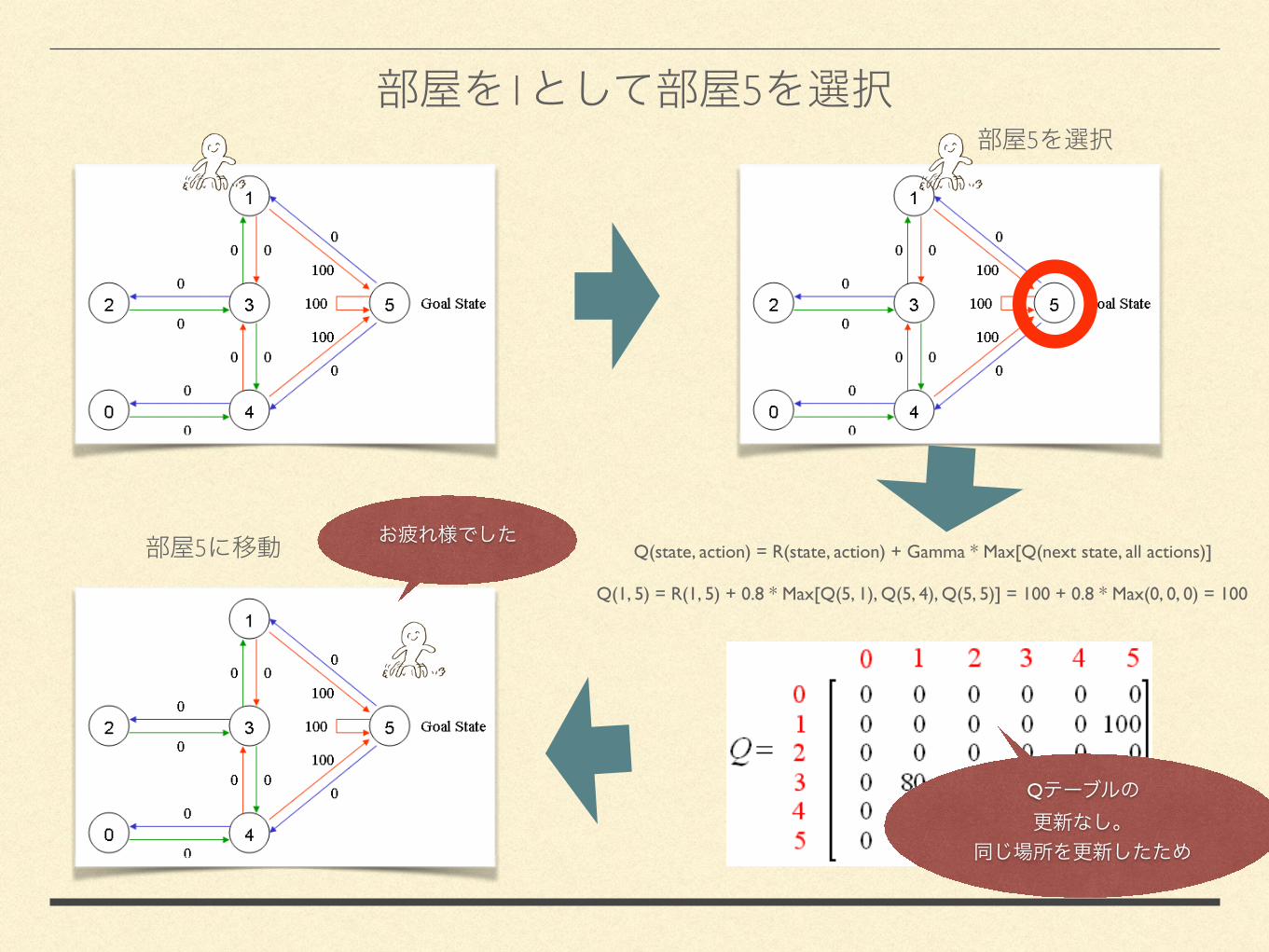
1 55
5 Q(state, action) = R(state, action) + Gamma * Max[Q(next state, all actions)]
Q(1, 5) = R(1, 5) + 0.8 * Max[Q(5, 1), Q(5, 4), Q(5, 5)] = 100 + 0.8 * Max(0, 0, 0) = 100
Q

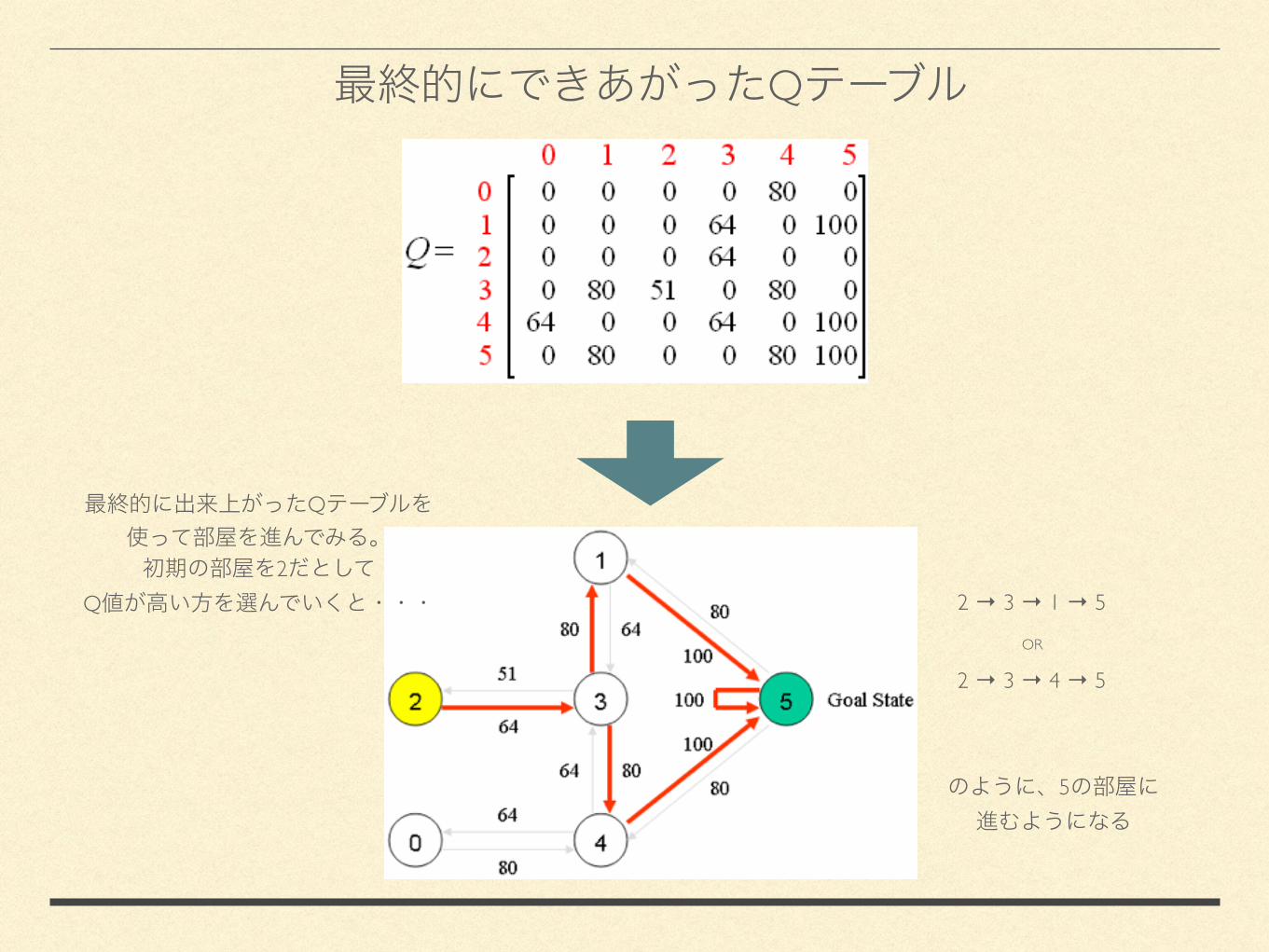
Q
Q
2Q 2 → 3 → 1 → 5
OR
2 → 3 → 4 → 5
5

Q

Q












![仮想サーバを利用した協調学習支援方式 · い目的を協調学習という学習方法を用いて達成しようとす るグループウェアの検討がなされてきた[₁]。学習者間の](https://img.pdfslide.tips/doc/110x75/5f03c5e37e708231d40ab2a2/fffcec-cceccce.jpg)
















