Embed Size (px)
Citation preview

Map – reduce og andre teknikker for parallellisering
- Bjørn Nordlund
Hvorfor Parallellisering?
03.05.23s.2
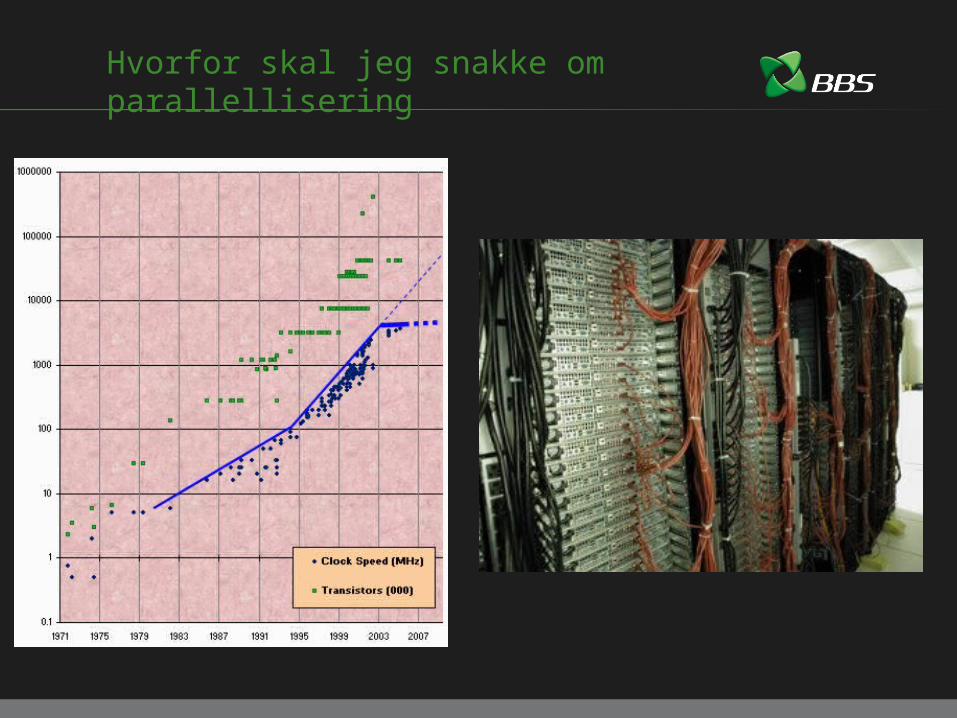
Hvorfor skal jeg snakke om parallellisering
Outline
• Litt intro til parallellisering og noen begreper• java concurrency, parallellisering innen en javaprosess• Distribuert parallellisering og noen modeller for det med demo av
hadoop(mapreduce)• Eksempel fra bbs
Hva er parallellisering?
Parallellprosessering er prosessering der mange instruksjoner blir utført i parallell. Etter splitt og hersk metoden. Større problemer blir delt i mindre, som blir utført samtidig (concurrent)

Hva er samtidighet (concurrency)?
Samtidig (concurrent) prosessering er samtidig prosessering av flere interagerende oppgaver. Oppgavene kan bli implementert som separate programmer, eller et sett av prosesser eller tråder i samme program. De kan bli utført på en enkel prosessor (multitasking), flere prosessorer på samme maskin, eller distribuert over et nettverk av maskiner.
Relatert til parallellprosessering, men med fokus på interaksjon/kommunikasjon mellom oppgaver.
Tilstand(state) og samtidighet, thread safety
Når flere tråder kan aksessere de samme tilstands variablene uten noen form for låsing oppstår det problemer (klassevariable, static..)
Løsning:- Ikke del tilstand mellom tråder
- Gjør tilstandsvariable immutable- Bruk låser/synchronization
Objekter uten tilstand (stateless) er alltid threadsafe
Race conditions, deadlocksog contention
Race conditions, to eller flere prosesser/tråder forsøker å oppdatere samme tilstand
Dead lock, to eller flere prosesser/tråder venter på hverandres låser
Recource contention er når det er konkurranse om å bruke samme ressurser på samme tid. Eks prosessor, filer, køer, database etc..

Parallellisering på flere nivåer
Fin kornet – Innenfor en prosess. Eks Threads
Grov kornet – Dele og distribuere oppgaver til flere servere i et nettverk. Flere prosesser. Bruk av filer, meldingskøer, database etc.

Finkornet parallellisering i Java
Java 1.4 og før, java.util.concurrent i 1.5
Tekst endres i Topp- og Bunntekst 03.05.23s.11
Synchronized eksempel?

Executor og Future
Executors håndterer livssyklusen til trådene dine
Executor kan eksekverer en Callable eller en Runnable og kan få tilbake en Future.
Callable tilsvarer Runnable, men med en resultatverdi,
Fork/Join jsr 166
• Håndterer skalering over et titals tråder• Skal brukes til rene compute oppgaver• Består av:
– ForkJoinTask– ForkJoinPool– Parallel*Array
Distribuert parallellisering
Hvordan?Parallellisering er oppsplitting
Man kan parallellisere distribuert med mange maskiner i et nettverk, eller man kan håndtere det innenfor jvm’en.
Dersom du skal distribuere oppgaver trenger du en måte å distribuere de oppsplittede delene på
Du trenger noen som kan prosessere hver enkelt del
Og du trenger kanskje noe som samler sammen og sørger for at alt er gjort.
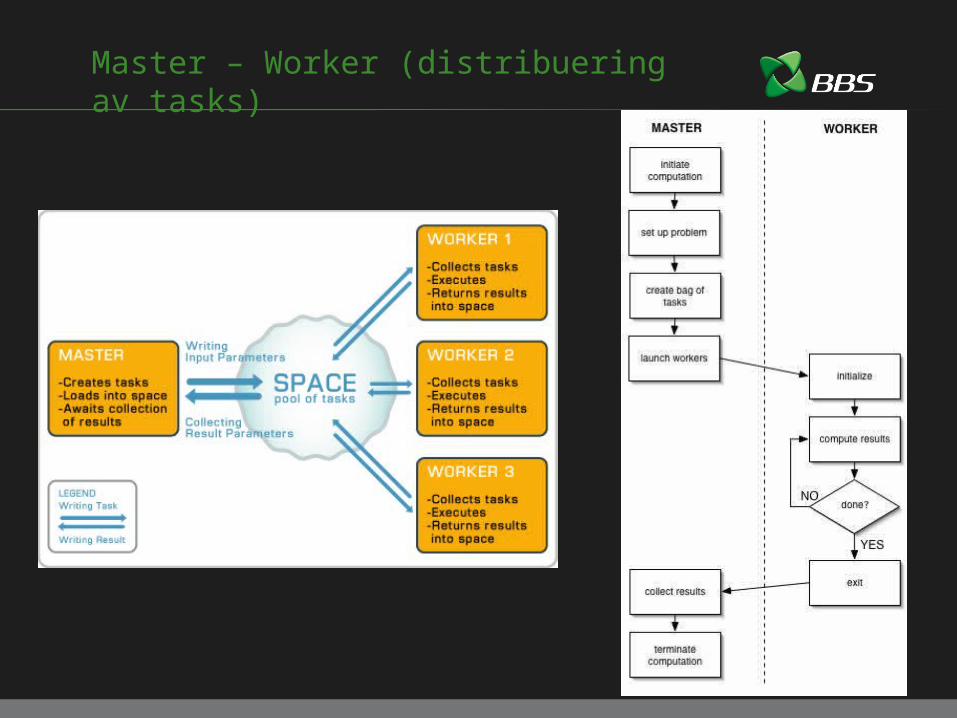
Master – Worker (distribuering av tasks)
Map - Reduce
• Hvordan håndtere massiv parallellisering• På hundrevis og tusenvis av CPU’er
– OG DET SKAL VÆRE ENKELT FOR UTVIKLERE
• Automatisk distribuering og parallellisering• Feiltoleranse• I/O• Monitorering
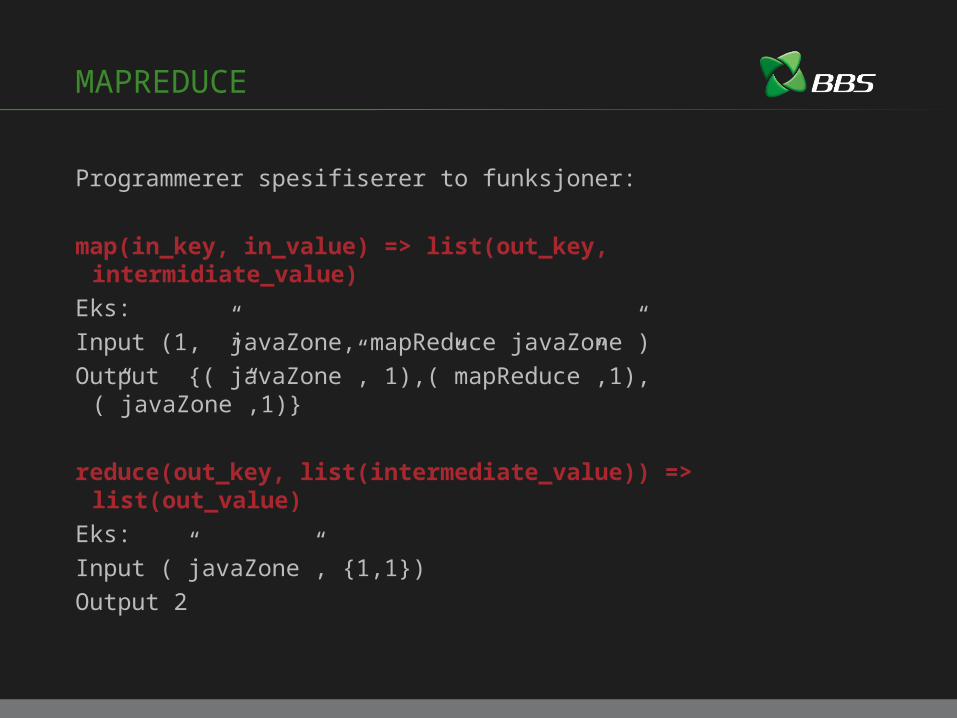
MAPREDUCE
Programmerer spesifiserer to funksjoner:
map(in_key, in_value) => list(out_key, intermidiate_value)Eks:Input (1, ”javaZone, mapReduce javaZone”) Output {(”javaZone”, 1),(”mapReduce”,1),(”javaZone”,1)}
reduce(out_key, list(intermediate_value)) => list(out_value)Eks:Input (”javaZone”, {1,1})Output 2
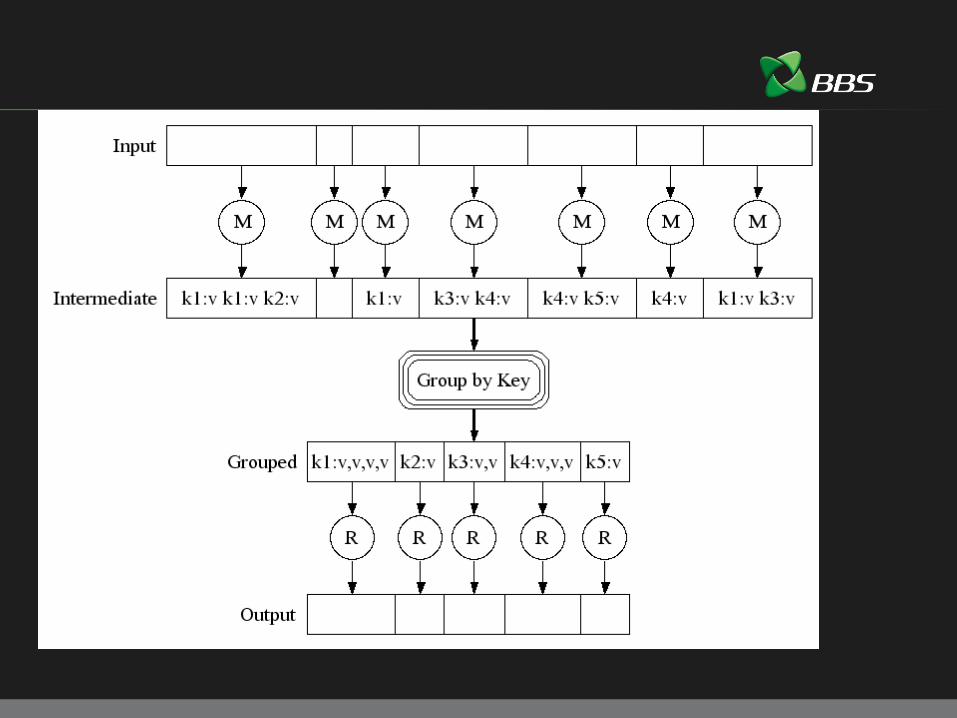
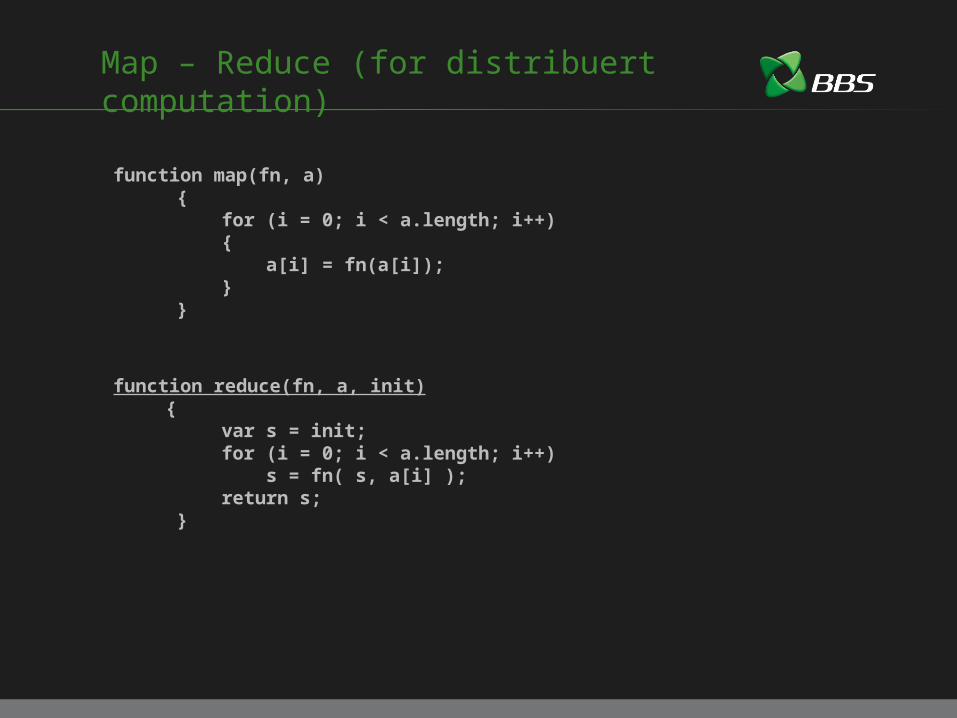
Map – Reduce (for distribuert computation)
function map(fn, a) { for (i = 0; i < a.length; i++) { a[i] = fn(a[i]); } }
function reduce(fn, a, init) { var s = init; for (i = 0; i < a.length; i++) s = fn( s, a[i] ); return s; }
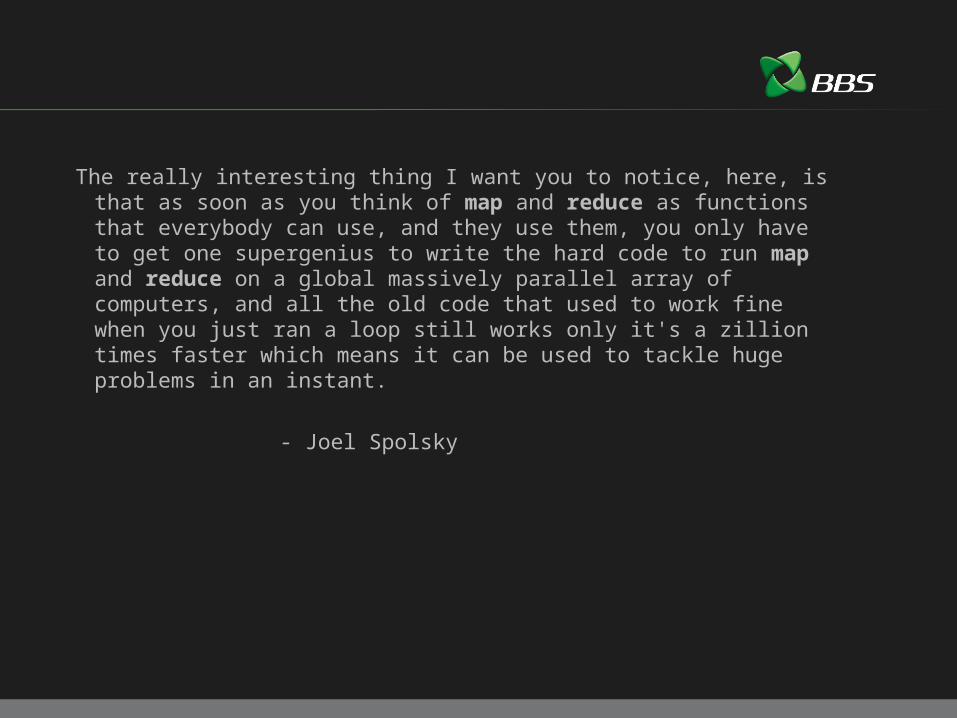
The really interesting thing I want you to notice, here, is that as soon as you think of map and reduce as functions that everybody can use, and they use them, you only have to get one supergenius to write the hard code to run map and reduce on a global massively parallel array of computers, and all the old code that used to work fine when you just ran a loop still works only it's a zillion times faster which means it can be used to tackle huge problems in an instant.
- Joel Spolsky
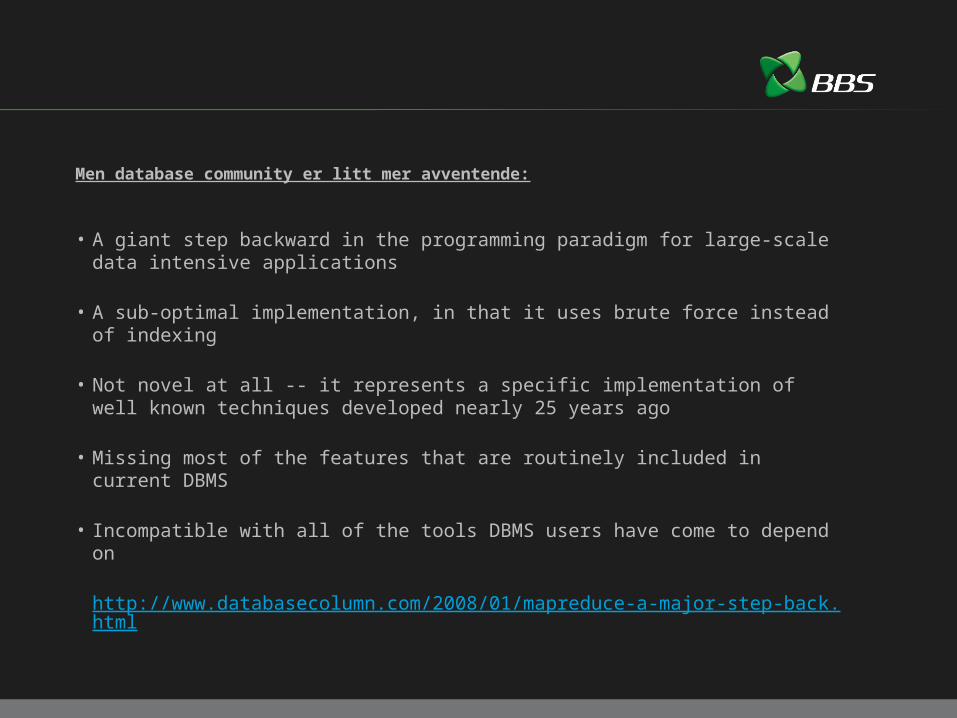
Men database community er litt mer avventende:
• A giant step backward in the programming paradigm for large-scale data intensive applications
• A sub-optimal implementation, in that it uses brute force instead of indexing
• Not novel at all -- it represents a specific implementation of well known techniques developed nearly 25 years ago
• Missing most of the features that are routinely included in current DBMS
• Incompatible with all of the tools DBMS users have come to depend on http://www.databasecolumn.com/2008/01/mapreduce-a-major-step-back.html
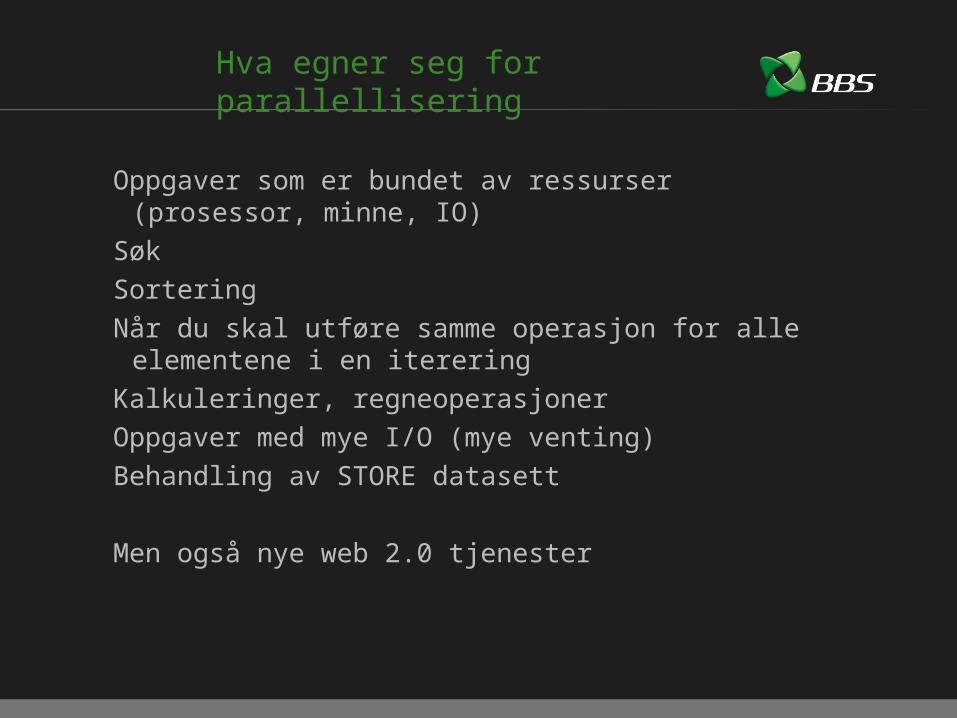
Hva egner seg for parallellisering
Oppgaver som er bundet av ressurser (prosessor, minne, IO)SøkSorteringNår du skal utføre samme operasjon for alle elementene i en
itereringKalkuleringer, regneoperasjonerOppgaver med mye I/O (mye venting)Behandling av STORE datasett
Men også nye web 2.0 tjenester
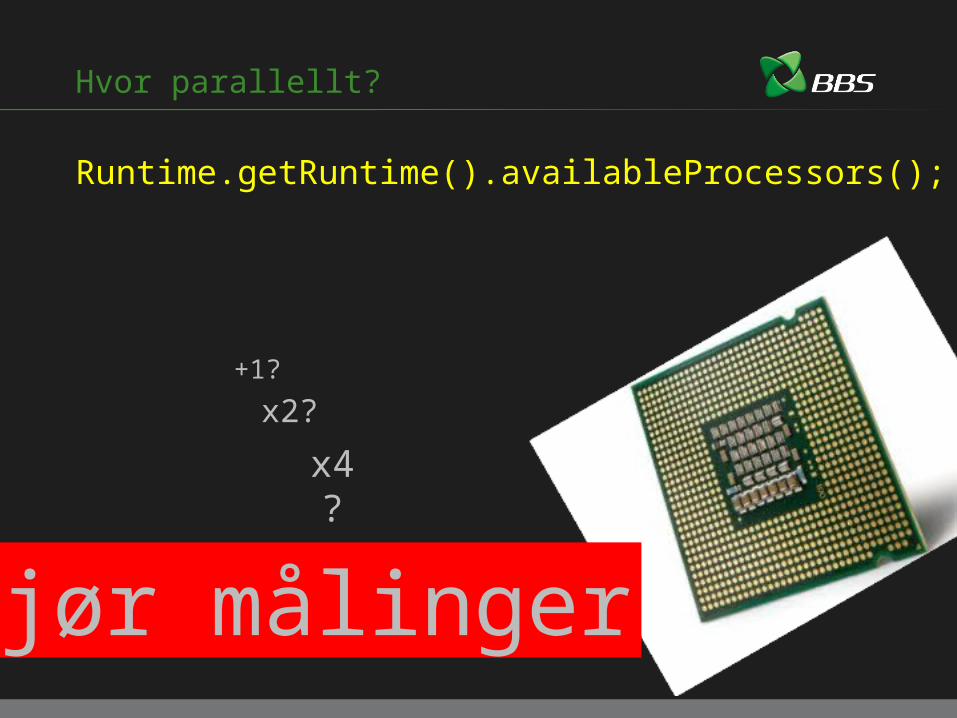
Hvor parallellt?
Runtime.getRuntime().availableProcessors();
+1?
x2?
x4?
Gjør målinger
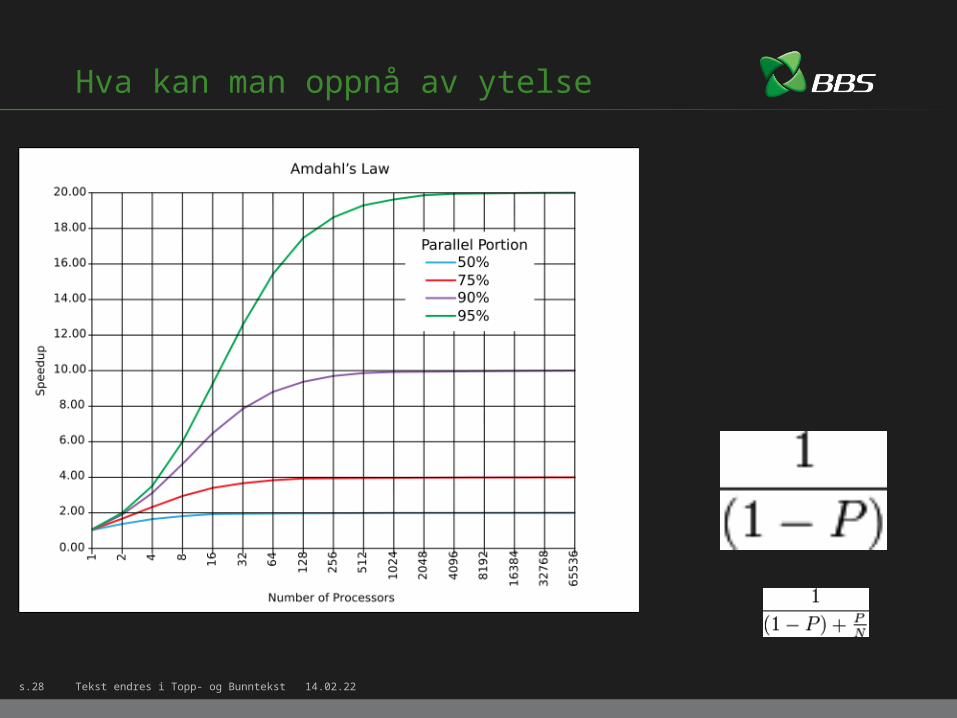
Hva kan man oppnå av ytelse
Tekst endres i Topp- og Bunntekst 03.05.23s.28

Parallellisering
FOR MOT
Tekst endres i Topp- og Bunntekst 03.05.23s.29
•Redusert ytelse (contention, context switcher etc)•Økt kompleksitet•Vanskelig å debugge•Samtidighetsproblematikk •Mer feil!
•Bedre troughput•Bedre lastbalansering•Bedre skalering•Kortere transaksjoner•Utnytter tilgjengelig hardware bedre
Performance: samme ytelse med mindre ressurserSkalering: mer ytelse med mer ressurser

Ikke overdriv
Parallellisering skal ikke brukes over alt, men dersom du har krav som krever det, målinger som sier at kravene ikke er nådd, og prøvd ”alt” annet.
Eksempel fra BBS
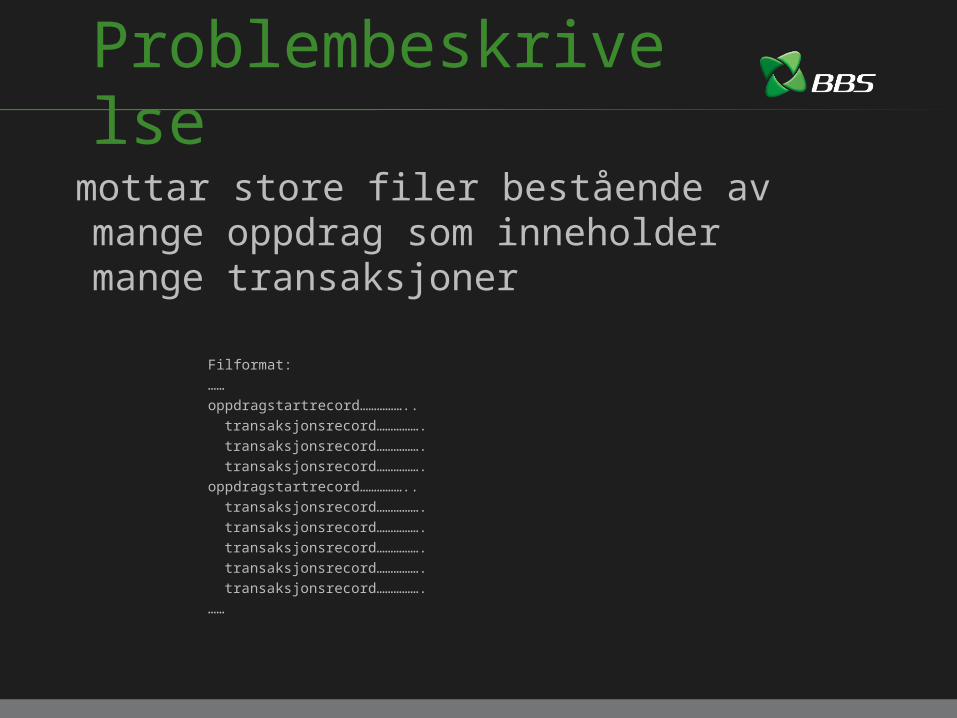
Problembeskrivelsemottar store filer bestående av mange oppdrag som inneholder mange transaksjoner
Filformat:……oppdragstartrecord……………..
transaksjonsrecord…………….transaksjonsrecord…………….transaksjonsrecord…………….
oppdragstartrecord……………..transaksjonsrecord…………….transaksjonsrecord…………….transaksjonsrecord…………….transaksjonsrecord…………….transaksjonsrecord…………….
……
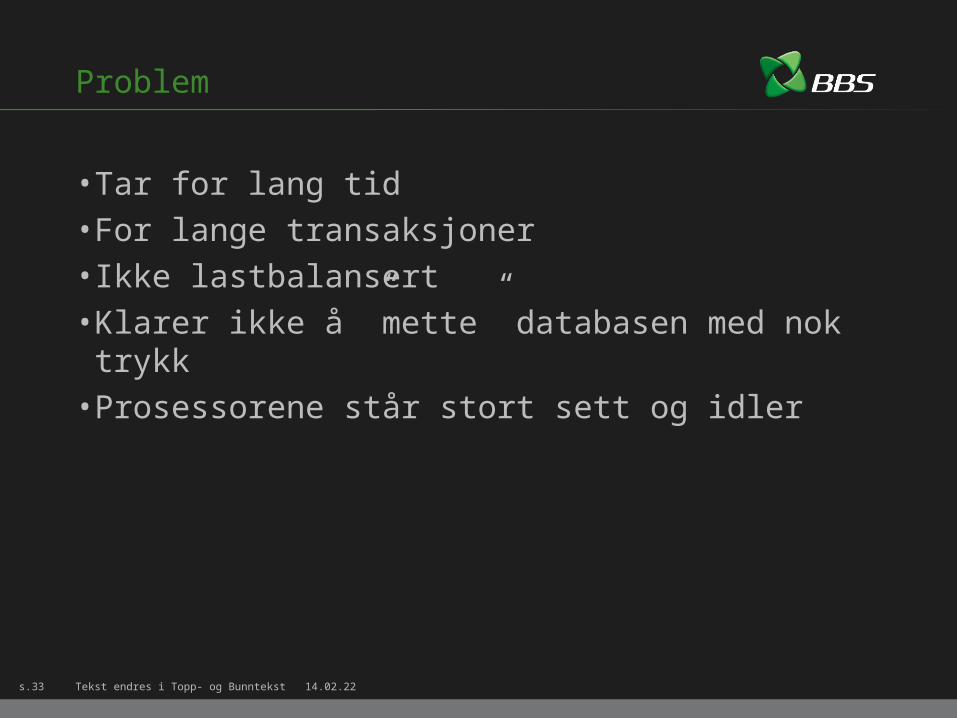
Problem
• Tar for lang tid• For lange transaksjoner• Ikke lastbalansert• Klarer ikke å ”mette” databasen med nok trykk• Prosessorene står stort sett og idler
Tekst endres i Topp- og Bunntekst 03.05.23s.33
Løsning
• På hver server kjører en prosess som regelmessig skanner et filområde etter nye filer
• Når det kommer en fil splitter vi opp store filer i mindre filer (splitter på hele oppdrag)
• Lagrer de mindre filene som filer i databasen (blob)• Lagrer et WorkItem (ticket) i databasen som beskriver et stykke arbeid
som skal gjøres (behandling av fil)• Hver server har en workerprosess som skanner databasen
regelmessig etter work_item’s. • Når workerprosessen finner work_items utføres de i tråder.
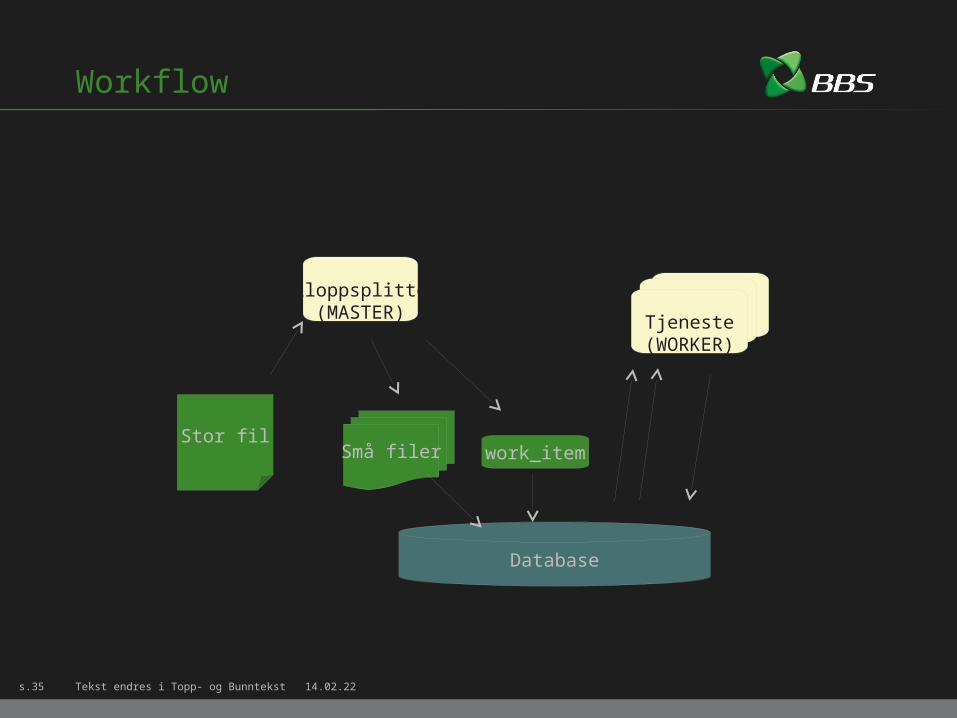
Workflow
Tekst endres i Topp- og Bunntekst 03.05.23s.35
Database
Små filer
Filoppsplitter(MASTER) Tjeneste
(WORKER)
Stor filwork_item
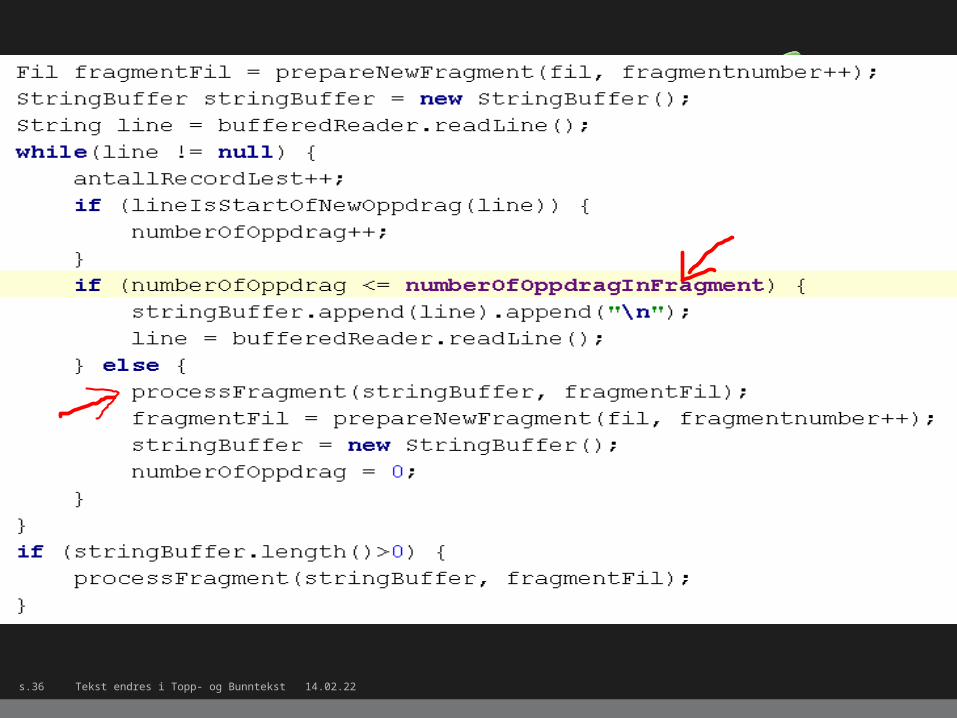
Tekst endres i Topp- og Bunntekst 03.05.23s.36
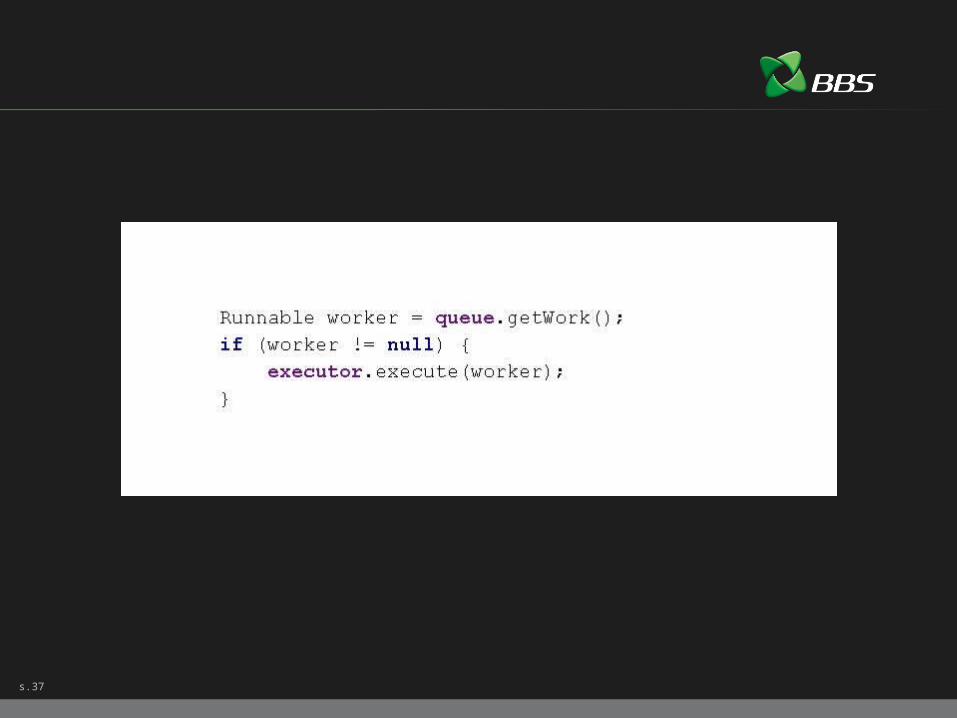
s.37
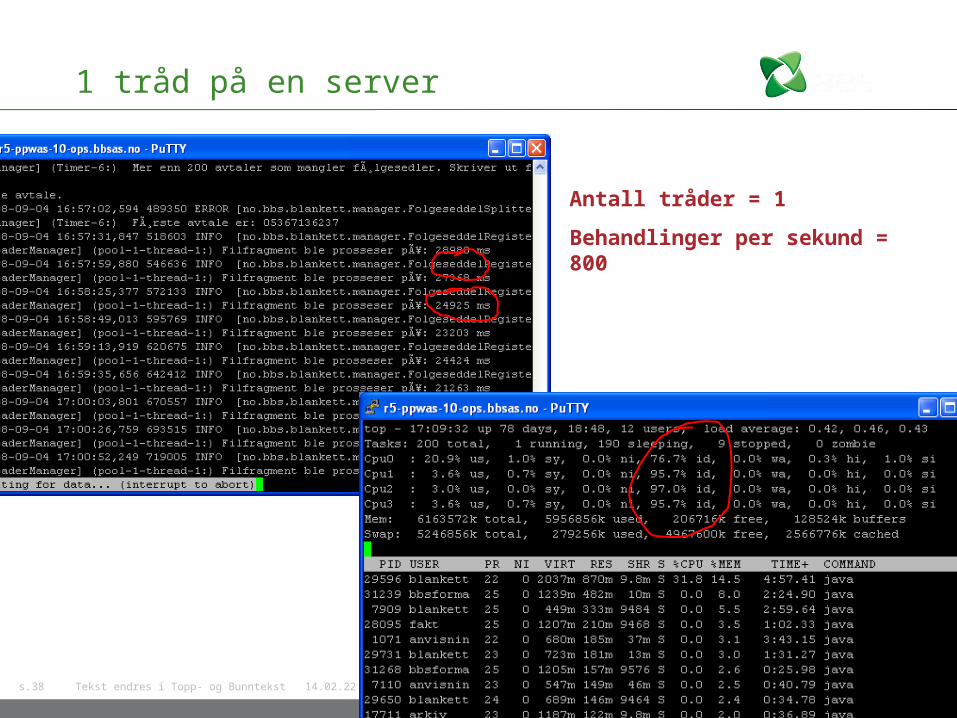
1 tråd på en server
Tekst endres i Topp- og Bunntekst 03.05.23s.38
Antall tråder = 1
Behandlinger per sekund = 800
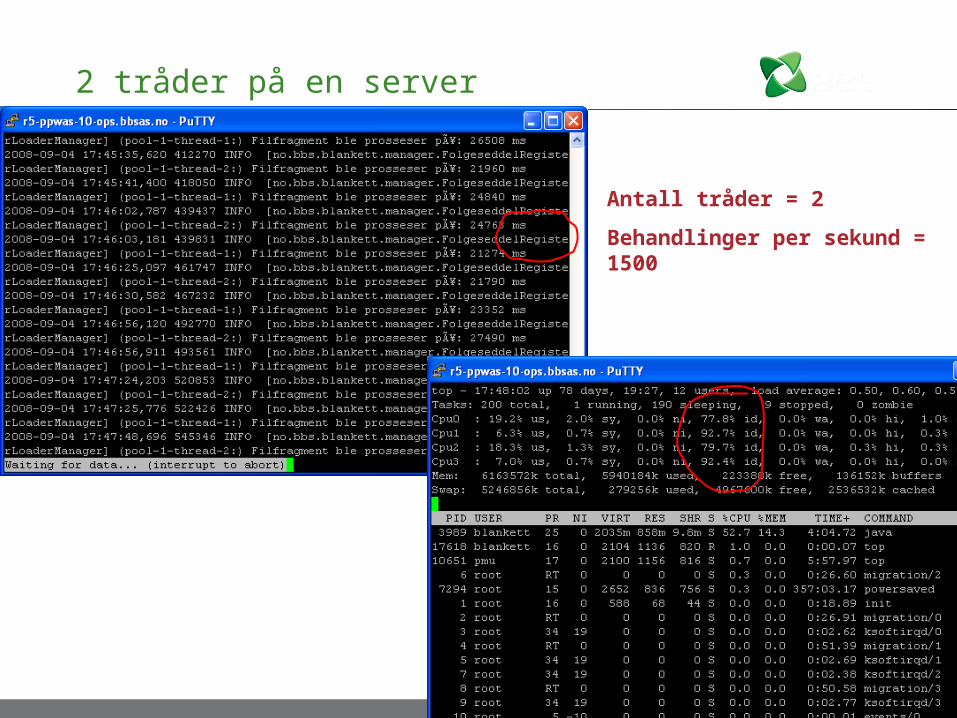
2 tråder på en server
Antall tråder = 2
Behandlinger per sekund = 1500
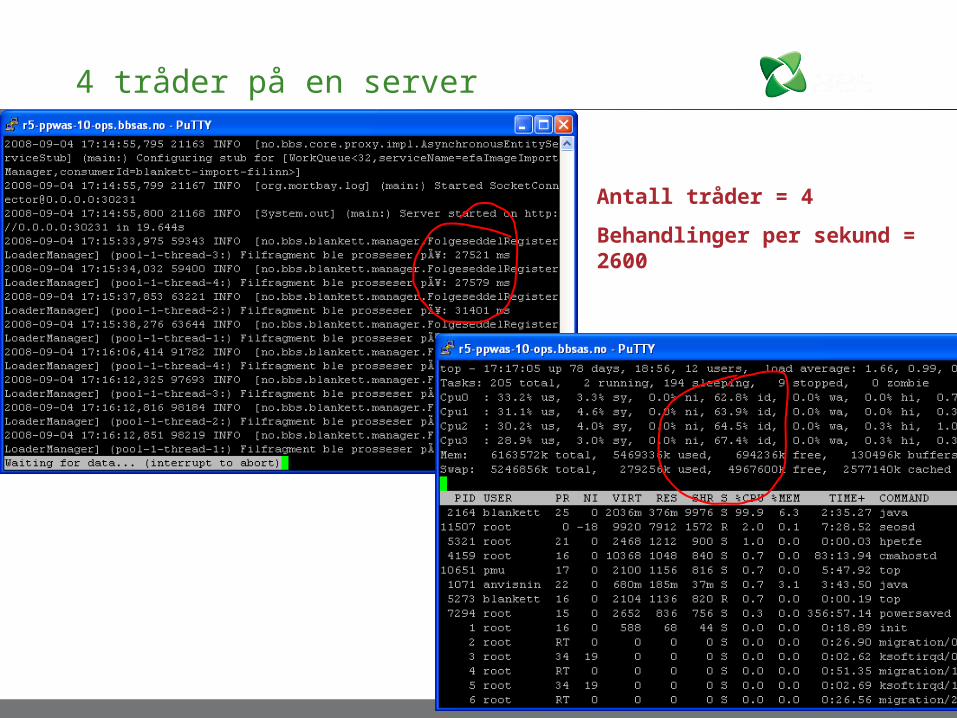
4 tråder på en server
Antall tråder = 4
Behandlinger per sekund = 2600
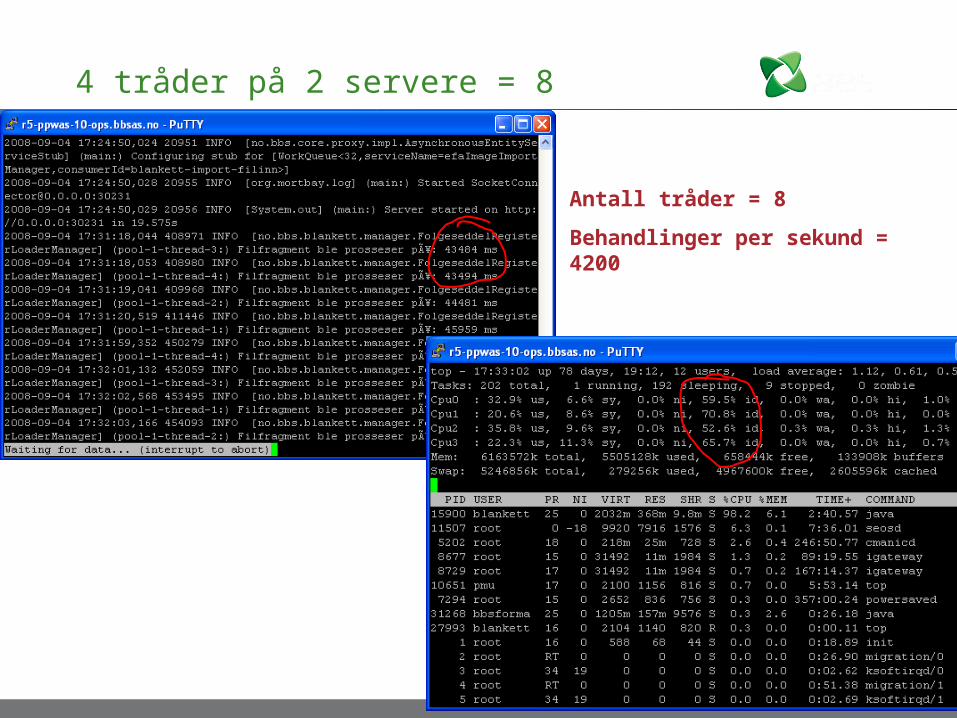
4 tråder på 2 servere = 8
Antall tråder = 8
Behandlinger per sekund = 4200
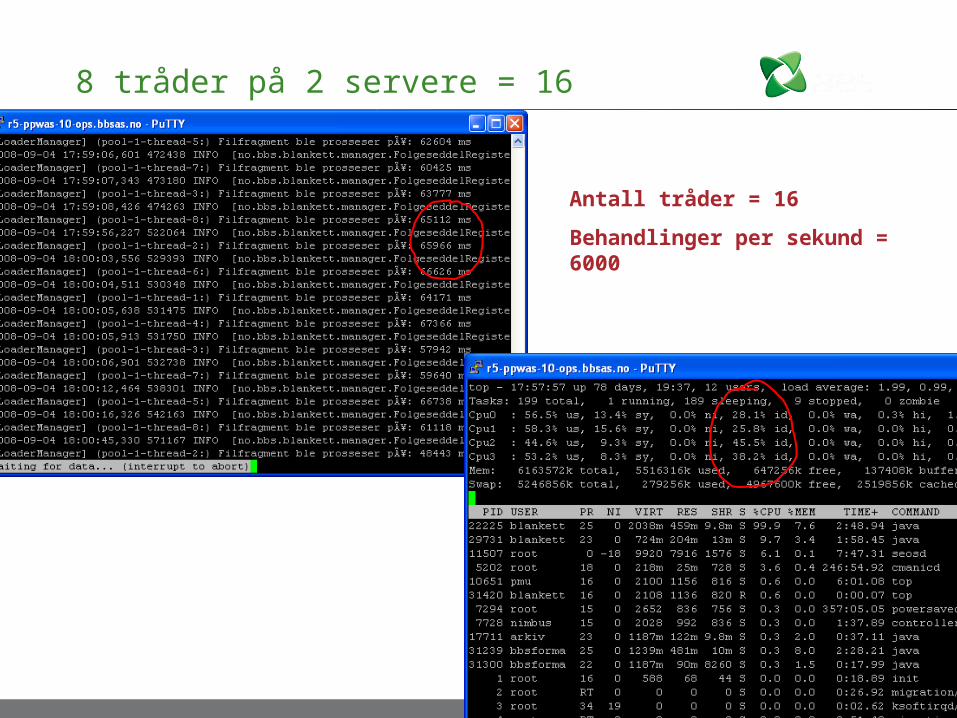
8 tråder på 2 servere = 16
Antall tråder = 16
Behandlinger per sekund = 6000
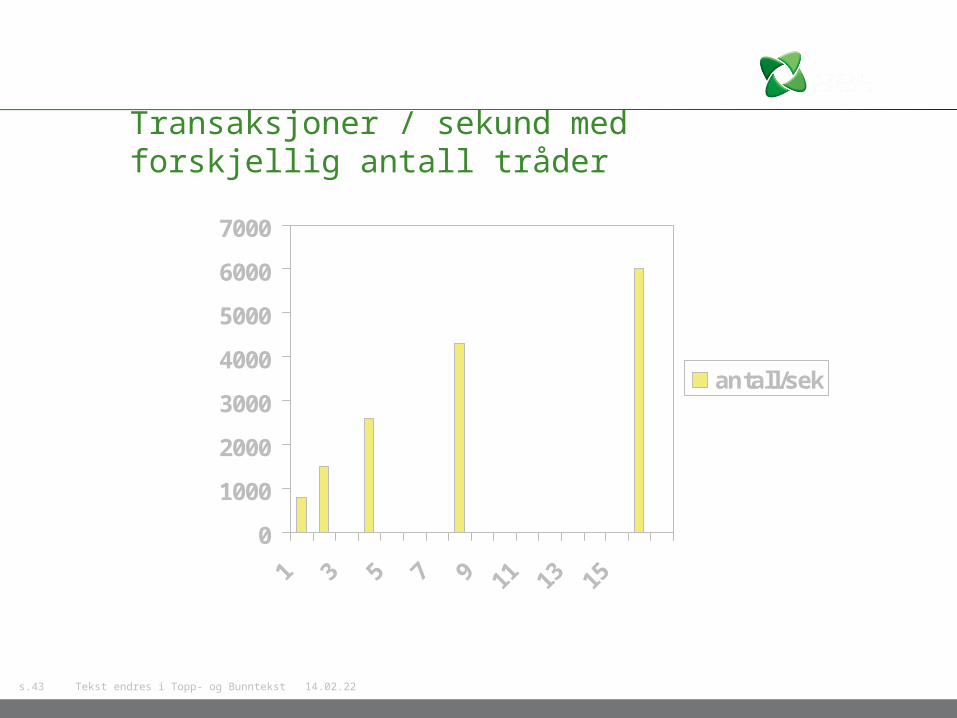
Transaksjoner / sekund med forskjellig antall tråder
Tekst endres i Topp- og Bunntekst 03.05.23s.43
0
1000
2000
3000
4000
5000
6000
7000
1 3 5 7 9 11 13 15
antall/sek
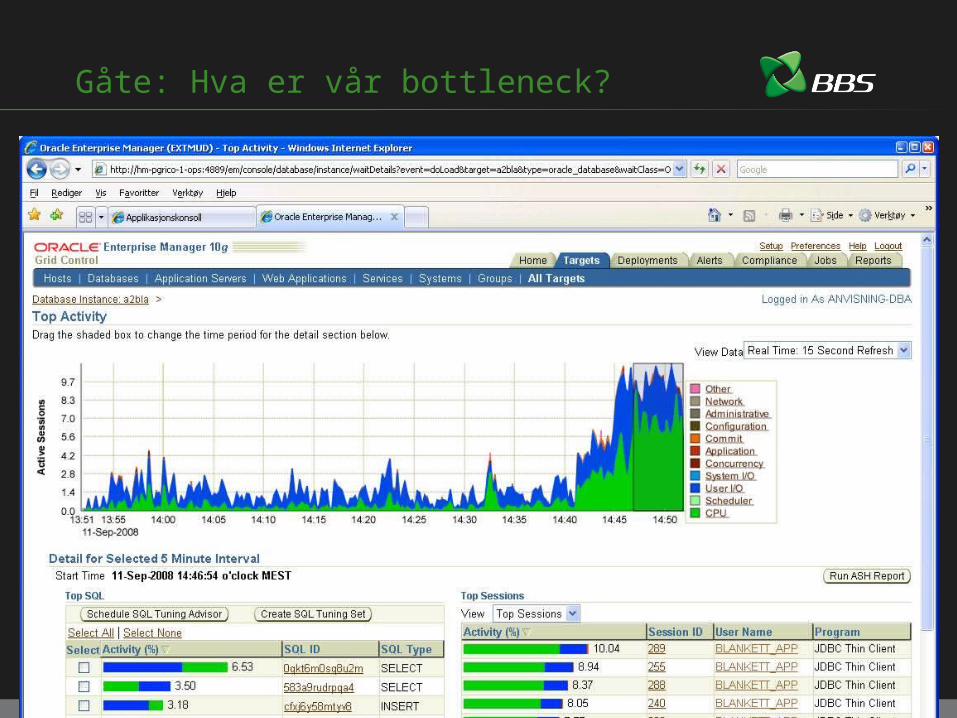
Gåte: Hva er vår bottleneck?

Oppsummering
Ikke beveg deg ut på glattisen uten videre• Lag det riktig først• Baser deg på krav• Baser deg på målinger/tester – ikke gjett• Ikke parallelliser over alt, kun små deler der
du trenger det og får uttelling for det
Men• God støtte i java• Trenger ikke skrive om hele applikasjonen• Begynn forsiktig, gå gradvis• Hadoop og ec2 gjør dette enkelt, billig og tilgjengelig for alle

Noen referanser
• Java Concurrency in Practice (Brian Goetz)• The Free Lunch Is Over Dr. Dobbs Journal, 30 mars 2005• Jsr-166• Java Concurrency Wiki • Hadoop• Amazon ec2

www.bbs.no