Embed Size (px)
Citation preview

市 川 周 平国⽴⼤学法⼈ 三重⼤学⼤学院 医学系研究科
地域医療学講座 助教
クラスター分析の⼊⾨
REQUIRE-262016/10/01 (⼟) 13:00-18:20
東京医科⻭科⼤学湯島キャンパス 1号館⻄7階⼝腔保健学科第3講義室

分類すること (5min)クラスター分析とは (15min) Proximity (10min)クラスタリング (13min) Rコード (5min)参考⽂献 (2min)
2016/10/01 REQUIRE26 4
Agenda

Taxonomy
2016/10/01 REQUIRE26 11

⾨ : プロテオバクテリア⾨ (Proteobacteria) 綱 : γプロテオバクテリア綱 (gamma-
Proteobacteria)⽬ : エンテロバクター⽬ (Enterobacteriales)科 : 腸内細菌科 (Enterobacteriaceae)属 : エスケリキア属 (Escherichia)種 : E. coli
2016/10/01 REQUIRE26 12
Taxonomy

たくさんのデータの中から、類似した特徴をもつ集団を同定すること事前情報あり事前情報なし
世の中や事象を要約し (= 抽象化)、理解するための枠組みを提供する
2016/10/01 REQUIRE26 13
分類すること

分類すること (5min)クラスター分析とは (15min) Proximity (10min)クラスタリング (13min) Rコード (5min)参考⽂献 (2min)
2016/10/01 REQUIRE26 16
Agenda

多変量・教師なしでのデータ分類⼿法
階層型 (hierarchical clustering)ウォード法
⾮階層型 k平均法 (k means clustering)
2016/10/01 REQUIRE26 17
クラスター分析

分類されてできたグループ別名 : グループ、クラス、et al…
クラスターの条件クラスター内の凝集性クラスター間の分離性
2016/10/01 REQUIRE26 18
クラスター
Everitt et al, 2011

遺伝⼦研究
テキストマイニング
マーケティング
……etc.
2016/10/01 REQUIRE26 19
広範囲な使途

2016/10/01 REQUIRE26 20
遺伝系統発⽣解析
Rajilic-Stojanovic M and de Vos WM. FEMS Microbiol Rev 2014; 38: 996-1047.

2016/10/01 REQUIRE26 24
テキストマイニング
⽯⽥・⼩林 (2013)
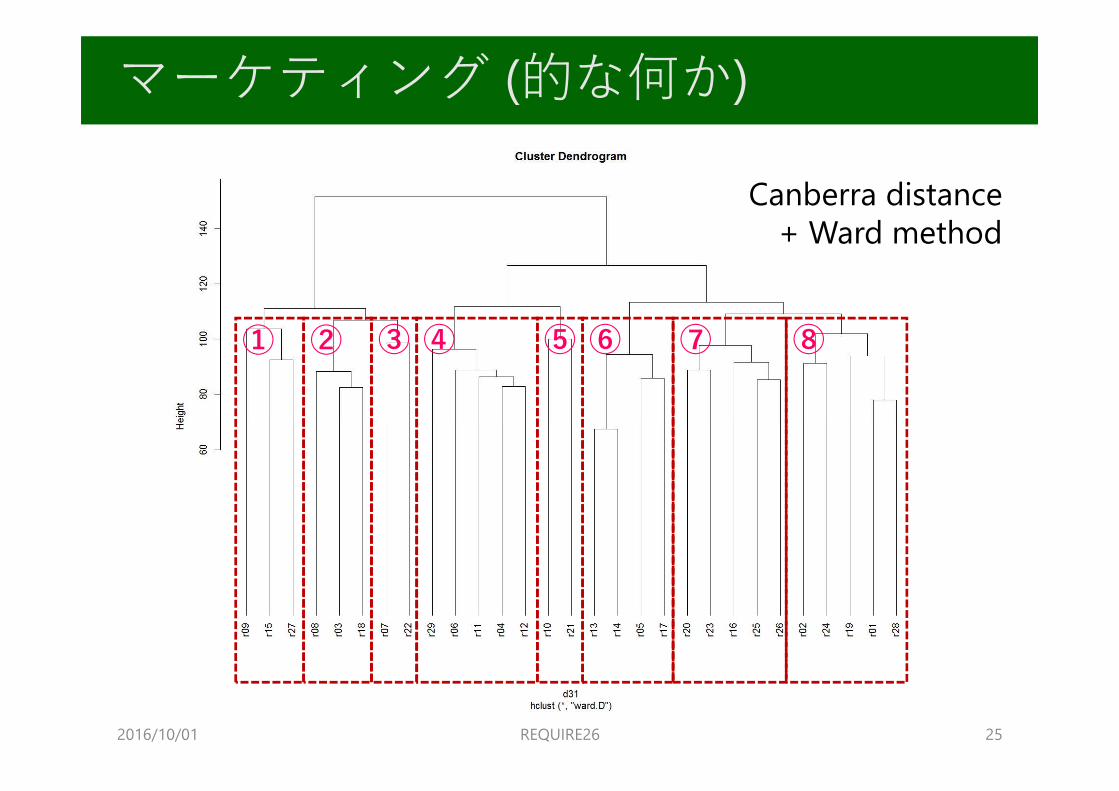
2016/10/01 REQUIRE26 25
マーケティング (的な何か)
① ② ③ ④ ⑤ ⑥ ⑦ ⑧
Canberra distance+ Ward method

2016/10/01 REQUIRE26 26
マーケティング (的な何か)
-2
-1
0
1
2
3麺
スープチャーシュー
醤油味噌
餃⼦
そば
ネギ
野菜
⽟⼦
つけ
トンコツ
普通ご飯
こってり脂
⾁⾟い
中華背
太
多い
濃い
胡⿇
あっさり
ニンニク
鶏
唐
トッピング塩
細坦々
カテゴリー6
該当店舗
該当店舗

1. 距離を数値化する
2. データを分類する
3. クラスターの妥当性を検証する
2016/10/01 REQUIRE26 27
クラスター分析の⼿順

分類すること (5min)クラスター分析とは (15min) Proximity (10min)クラスタリング (13min) Rコード (5min)参考⽂献 (2min)
2016/10/01 REQUIRE26 28
Agenda

Proximity distance dissimilarity similarity
算出法直接法
† ⼆者が似ているか/異なるかどうかを質問する間接法
† いくつかの特徴を組み合わせ、距離⾏列を算出
2016/10/01 REQUIRE26 29
Proximity (近接性)

2016/10/01 REQUIRE26 30
間接法 (⽣データ)
Everitt et al, 2011

2016/10/01 REQUIRE26 31
間接法 (距離⾏列)
Everitt et al, 2011

Sim (A, B) = 0.4 Sim (A, C) = 0.3 Sim (B, C) = 0.3
2016/10/01 REQUIRE26 32
カテゴリデータの近接性個体 v01 v02 v03 v04 v05 v06 v07 v08 v09 v10A a a a b c c b a a bB a b c b a a b b c bC b a c b b c a a c a
A B CA -B 0.4 -C 0.3 0.3 -

ポイント : dに積極的な意味があるか?ある例 : 性別難しい例 : ⽣物の特徴の有無
† 翼の有無† 毒性の有無
2016/10/01 REQUIRE26 33
⼆値データの近接性個体A
Outcome 1 0 Total個体B 1 a b a+b
0 c d c+dTotal a+c b+d a+b+c+d

2016/10/01 REQUIRE26 34
⼆値データの近接性
Similarity measure 数式S1: Matching coefficient sij = (a + d) / (a + b + c + d)S2: Jaccard coefficient (1908) sij = a / (a + b + c)S3: Rogers and Tanimoto (1960) sij = (a + d) / [a + 2(b + c) + d]S4: Sneath and Sokal (1973) sij = a / [a + 2(b + c)]S5: Gower and Legendre (1986) sij = (a + d) / [a + (1/2) * (b + c) + d]S6: Gower and Legendre (1986) sij = a / [a + (1/2) * (b + c)]
Everitt et al, 2011

dij + dim ≧ djmなら、幾何学的に算出
ユークリッド距離 (l2 norm)
2016/10/01 REQUIRE26 35
連続データの距離の算出
⊿ =
i
j
m
dij
dim djm
0
0
0
dij = Σ wk(xik – xjk)2k = 1
p 1/2

マンハッタン距離 (City block distance)
ミンコフスキ距離
2016/10/01 REQUIRE26 36
連続データの距離の算出
dij = Σ wk | xik – xjk|k = 1
p
dij = Σ wrk (xik – xjk)r
k = 1
p 1/r

キャンベラ距離 xik = xjk = 0 の場合 : 0
xik ≠ 0 or xjk ≠ 0の場合 :
ピアソンの相関係数 -1 < dij < 1尺度系が合わない測度間の距離には使えない
† cf. xi = (1, 2, 3) vs xj = (3, 6, 9)
2016/10/01 REQUIRE26 37
連続データの距離の算出
dij = Σ wk |xik – xjk| / (|xik| + |xjk|)k = 1
p

2016/10/01 REQUIRE26 38
ユークリッド距離を取れない状況
⊿ =
A
B
C
2
2 2
0
0
0
D 01.1 1.1 1.1
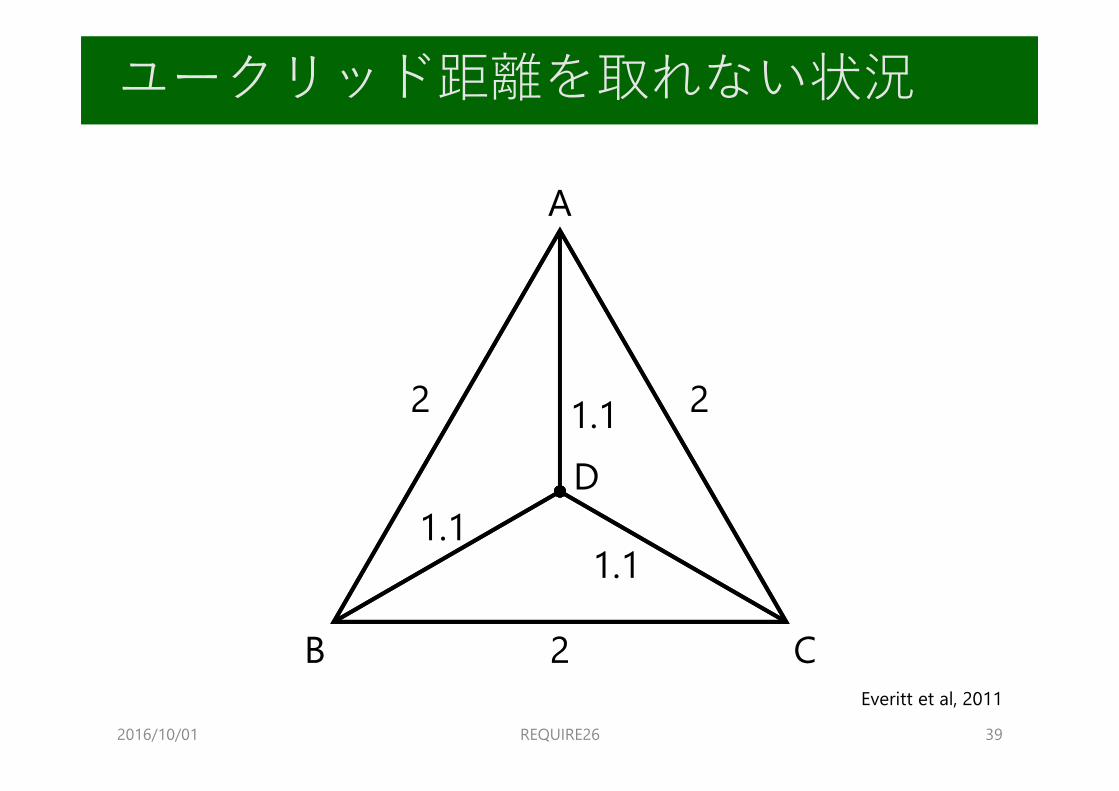
2016/10/01 REQUIRE26 39
ユークリッド距離を取れない状況
2 2
2
1.1
1.11.1
B C
A
D
Everitt et al, 2011

研究者の判断で決める項⽬の分散に基づいて決める SDの逆数幅の逆数
クラスター内の分散に基づいて決める前向きの変数選択を⾏う clustrerabilityに基づいて決める
2016/10/01 REQUIRE26 40
重みづけdij = Σ wk(xik – xjk)2
k = 1
p 1/2
変数の標準化変数の標準化

2016/10/01 REQUIRE26 41
重みづけ
Everitt et al, 2011

重みづけなし、SD、rangeは良好ではないクラスター内の分散を基にした重みづけは概して良好
clusterabilityに基づいた重みづけは、データに強いクラスター構造がある場合に良好
階層構造に当てはまるように最適化した重みづけは、SDに基づいた重みづけより不良
前向きの変数選択は概して良好
2016/10/01 REQUIRE26 42
重みづけ⼿法の選択

研究者の主観に基づいた判断は避ける⇔クラスター分析では、未知のクラスターが浮かび上がることが望ましい
以下2つの (代表的な) 戦略は⾮効果的重要な変数を漏らさないために、多くの変数を距離ベースのモデルに投⼊する
項⽬内のSDに基づいて重みづけをする
2016/10/01 REQUIRE26 43
重みづけ⼿法の選択

Gower and Legendre (1986)近接性係数は、記述統計やデータの性質、計画している解析⼿法によって決めるべし
近接性指標の選択に影響するもの1. データの特徴2. データの尺度3. クラスタリング⼿法
2016/10/01 REQUIRE26 44
Proximityの指標の選択法

分類すること (5min)クラスター分析とは (15min) Proximity (10min)クラスタリング (13min) Rコード (5min)参考⽂献 (2min)
2016/10/01 REQUIRE26 45
Agenda

n個の個体を含む1つの⼤きなクラスターから、1個体のみを含むn個のクラスターまで、階層性を以て分類する、⼀連の分類法
凝集型 (agglomerative)分割型 (divisive)
2016/10/01 REQUIRE26 46
階層クラスター分析とは

2016/10/01 REQUIRE26 47
凝集型と分割型
Everitt et al, 2011

最近隣法 (nearest-neighbor method)
2016/10/01 REQUIRE26 48
凝集型クラスタリング
⊿ =
1
2
3
2.0
6.0 5.0
0
0
0
4 010.0 9.0 4.0
03.05.08.09.05
d(12)3= min(d13, d23)= d23 = 5.0d(12)4= min(d14, d24)= d24 = 9.0d(12)5= min(d15, d25)= d25 = 8.0

最近隣法 (nearest-neighbor method)
2016/10/01 REQUIRE26 49
凝集型クラスタリング
⊿ =
(12)
3
4 9.0 4.0
0
0
0
5 08.0 5.0 3.0
d(45)(12)= min(d14, d15, d24, d25)= d25 = 8.0d(45)3= min(d34, d35)= d34 = 4.0d(12)3= 5.0
5.0

最近隣法 (nearest-neighbor method)
2016/10/01 REQUIRE26 50
凝集型クラスタリング
⊿ =
(12)
3
(45) 8.0 4.0
0
0
0
5.0

最近隣法 (nearest-neighbor method)
2016/10/01 REQUIRE26 51
凝集型クラスタリング
Everitt et al, 2011

重⼼法 (Centroid clustering)
2016/10/01 REQUIRE26 52
凝集型クラスタリング
Object V1 V21 1.0 1.02 1.0 2.03 6.0 3.04 8.0 2.05 8.0 0.0
⊿ =
1
23
1.00
5.39 5.10
0
0
0
4 07.07 7.00 2.24
02.003.617.287.075
C12 = (1.0+1.0, 1.0+2.0)/2= (1.0, 1.5)
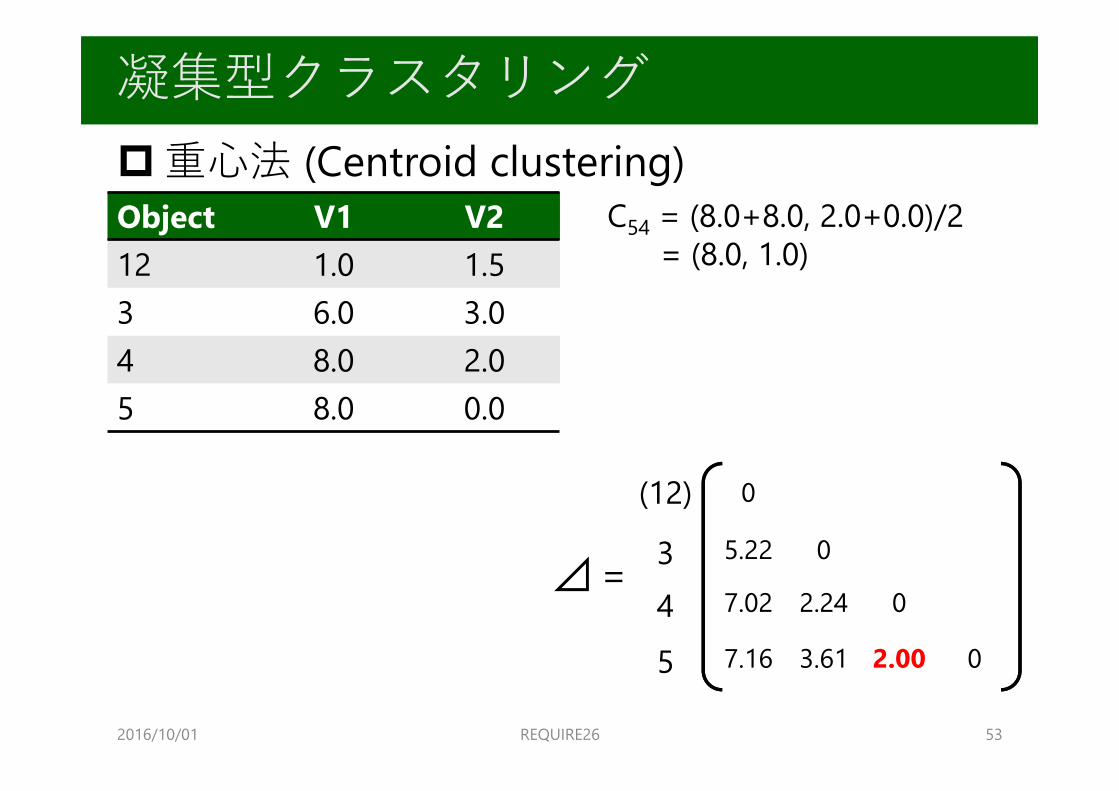
重⼼法 (Centroid clustering)
2016/10/01 REQUIRE26 53
凝集型クラスタリング
Object V1 V212 1.0 1.53 6.0 3.04 8.0 2.05 8.0 0.0
⊿ =
(12)
34
5.22
7.02 2.24
0
0
0
5 07.16 3.61 2.00
C54 = (8.0+8.0, 2.0+0.0)/2= (8.0, 1.0)

2016/10/01 REQUIRE26 54
凝集型クラスタリングの⽅法
Cluster A
Cluster B
最遠隣法Complete Linkage
最遠隣法Complete Linkage 最近隣法
Single Linkage
最近隣法Single
Linkage
12
3 45
Cluster B
Cluster A
平均法AverageLinkage
平均法AverageLinkage
dAB = (d13 + d14 + d15 + d23+ d24 + d25)/6
Everitt et al, 2011

ウォード法項⽬/クラスターを結合した際の、クラスター内誤差の⼆乗和を最⼩化する
2016/10/01 REQUIRE26 55
凝集型クラスタリング
E = Σ Emm = 1
g
Em = Σ Σ (xml,k – xm,k)2k=1
Pk -nm
l=1

Methodその他の呼称
Proximity
クラスター間の距離 特徴
Single 最近隣法 類似性距離
クラスター間の最も近しいデータ間
不均⼀なクラスター (Chaining) を作りやすい。クラスター構造を考慮に⼊れない。
Complete 最遠隣法 類似性距離
クラスター間の最も遠いデータ間
均質で等距離のクラスターを作りやすい。クラスター構造を考慮に⼊れない。
Average 平均法(UPGMA)
類似性距離
クラスター間でのすべてのデータ間の距離の平均
分散の⼩さいクラスターを加えやすい。最近隣法と最遠隣法の中間の性質を持つ。⽐較的頑健。
Centroid 重⼼法(UPGMC)
距離⽣データ 重⼼間のユークリッド距離 ユークリッド空間内に (すべての点が) 存在するこ
とを前提とする。反転しやすい。
Weighted average
加重平均法(WPGMA)
類似性距離
クラスター間でのすべてのデータ間の距離の平均
UPGMAに準じるが、⼩さいクラスターに属する点により重みづける
Median 加重重⼼法(WPGMC)
距離⽣データ 重⼼間のユークリッド距離
ユークリッド空間内に (すべての点が) 存在することを前提とする。新しいクラスタは、結合された2つのクラスタの中間点となる。
Ward’s method 最⼩⼆乗法 距離
⽣データ結合後のクラスター内の誤差⼆乗和増加量をすべての変数で加算
ユークリッド空間内に (すべての点が) 存在することを前提とする。同じサイズの、球形のクラスターを作りやすい。外れ値に敏感。
2016/10/01 REQUIRE26 56
凝集型クラスタリングの特徴
Everitt et al, 2011
* Ward法以外はLinkageを省略

2016/10/01 REQUIRE26 57
凝集型と分割型
Everitt et al, 2011

⼤きな1つのクラスターを、2つのクラスターへと分割していき、1個体で1クラスターを形成するまで繰り返す
分割のパターンは2k-1-1個データの⼤まかな構造を明らかにしやすいMonotheticとPolytheticに⼤別されるmonothetic : 分割の基準は単変量 potlythetic : 分割の基準は多変量
2016/10/01 REQUIRE26 58
分割型クラスタリング

monotheticデータが⼆値変数のみで構成される場合のみ使⽤可
分割の基準となるのは特定の変数pクラスター内の同質性と、クラスター間の関連性を最適化するようにpを決める
polythetic分割元データは距離⾏列分割の基準として、各段階ごとにすべての変数を使⽤
2016/10/01 REQUIRE26 59
分割型クラスタリング

分割の基準となるのは特定の変数p変数pが表す属性を有するかどうかで分割データが⼆値変数のみで構成される場合のみ使⽤可
クラスター内の同質性と、クラスター間の関連性を最適化するようにpを決める
データが追加と⽋損値への対応が容易希少な属性に弱い
2016/10/01 REQUIRE26 60
Monothetic

距離⾏列を⽤いる 1回の分割ごとに、すべての変数を使うMacNaughton-Smithら (1964) の⽅法
1. クラスター内のすべての個体間距離を算出し、その平均値が最も⼤きい個体を分割候補とする
2. 次に平均値が⼤きい個体の、分割先・分割元それぞれの全ての個体との距離の平均を算出† 分割先>分割元 : 分割しない (分割元に残す)† 分割先<分割元 : 分割する
3. 全ての個体に対して2を実⾏
2016/10/01 REQUIRE26 61
Polythetic

デンドログラム (有根型)
2016/10/01 REQUIRE26 62
階層性の表現
0.01.02.03.04.05.0
A
B
C
LabelLabel
Terminal nodesTerminal nodes
Internal nodesInternal nodes
Branch / EdgeBranch / EdgeRootRoot
Height / WeightHeight / Weight

デンドログラム (無根型)
2016/10/01 REQUIRE26 63
階層性の表現
Rajilic-Stojanovic M and de Vos WM. FEMS Microbiol Rev 2014; 38: 996-1047.

2016/10/01 REQUIRE26 65
ChainingとReversal
Euclidean distance+ Centroid Linkage
Chaining
Reversal
Ultrametric Property全てのi, j, kで hij ≦ max(hij, hjk)破綻するとReversalになりやすい

分類すること (5min)クラスター分析とは (15min) Proximity (10min)クラスタリング (13min) Rコード (5min)参考⽂献 (2min)
2016/10/01 REQUIRE26 66
Agenda

1. パッケージの準備2. データの準備3. 距離⾏列の作成4. クラスタリング5. デンドログラムの描画・保存
2016/10/01 REQUIRE26 67
Rでの実践

1. パッケージの準備• readxl : .xlsxを⾼速に読み込むことができる• psych : 散布図⾏列を書く (今回は省略)
2. データの準備
2016/10/01 REQUIRE26 68
Rでの実践

3. 距離⾏列の作成 euclidean : ユークリッド距離 manhattan : マンハッタン距離 canberra : キャンベラ距離 minkowski : ミンコフスキ距離 binary : ⼆値変数
2016/10/01 REQUIRE26 69
Rでの実践

4. クラスタリング single : 最近隣法 complete : 最遠隣法 average : 平均法mcquitty : 加重平均法 centroid : 重⼼法median : メディアン法 ward : ウォード法
2016/10/01 REQUIRE26 70
Rでの実践

5. デンドログラムの描画・保存 hang = -1 : ラベルの縦位置を揃える
2016/10/01 REQUIRE26 71
Rでの実践

5. デンドログラムの描画・保存 (hang = -1)
2016/10/01 REQUIRE26 72
Rでの実践

分類すること (5min)クラスター分析とは (15min) Proximity (10min)クラスタリング (13min) Rコード (5min)参考⽂献 (2min)
2016/10/01 REQUIRE26 74
Agenda

Everitt BS, et al. Cluster Analysis. 5th ed. Chichester: Wiley, 2011.
2016/10/01 REQUIRE26 75
参考⽂献

⽯⽥基広・⼩林雄⼀郎. Rで学ぶ⽇本語テキストマイニング. 東京: ひつじ書房, 2013.
2016/10/01 REQUIRE26 76
参考⽂献

2016/10/01 REQUIRE26 77
参考⽂献 Rajilic-Stojanovic M, de Vos WM. The first
1000 cultured species of the human gastrointestinal microbiota. FEMS MicrobiolRev 2014; 38: 996-1047.

FIN
2016/10/01 REQUIRE26





























