Embed Size (px)
Citation preview

Copyright©2016 NTT corp. All Rights Reserved.
2016年6月18日
NTTセキュアプラットフォーム研究所
サイバーセキュリティプロジェクト
岡野 靖
データ圧縮アルゴリズムを用いた マルウェア感染通信ログの判定

2 Copyright©2016 NTT corp. All Rights Reserved.
NTT Confidential
はじめに
•Proxyサーバ等、NW機器のログを分析し、 マルウェアによる通信由来の悪性通信ログを判定、マルウェア感染端末を検出
•機械学習手法適用時、ログの特徴抽出手法は課題の一つ •N-Gram、情報エントロピー、正規表現パターン化、
etc,etc….
•文書を特徴抽出せずに分類可能な手法、 データ圧縮による分類を悪性通信ログ判定に適用可能かを検討
3 Copyright©2016 NTT corp. All Rights Reserved.
NTT Confidential
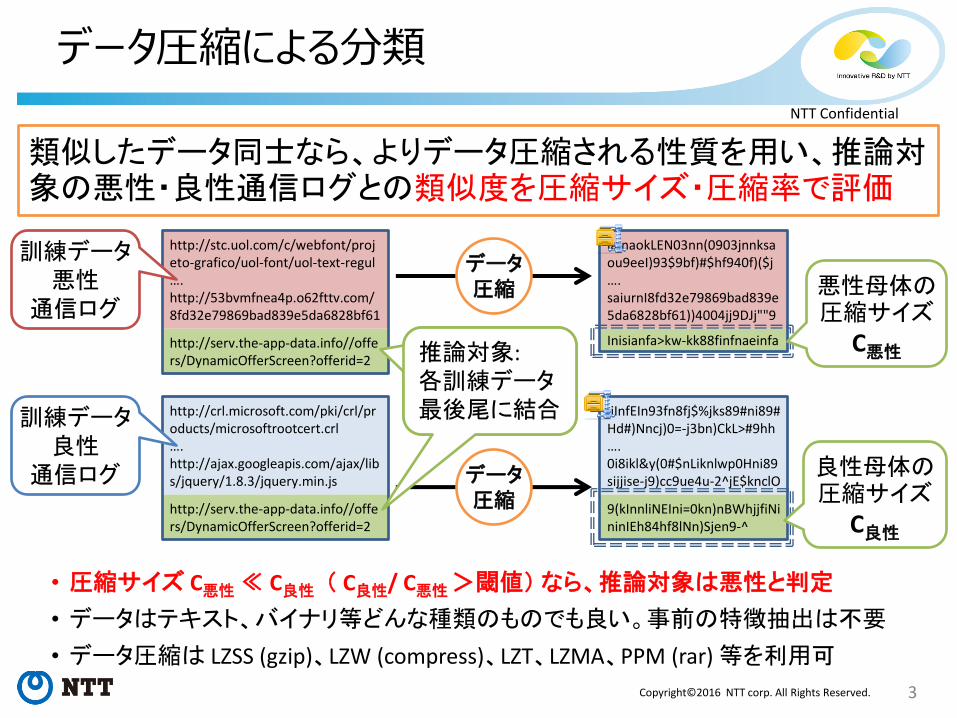
データ圧縮による分類
類似したデータ同士なら、よりデータ圧縮される性質を用い、推論対象の悪性・良性通信ログとの類似度を圧縮サイズ・圧縮率で評価
• 圧縮サイズ C悪性 ≪ C良性 ( C良性/ C悪性 >閾値) なら、推論対象は悪性と判定
• データはテキスト、バイナリ等どんな種類のものでも良い。事前の特徴抽出は不要
• データ圧縮は LZSS (gzip)、LZW (compress)、LZT、LZMA、PPM (rar) 等を利用可
http://stc.uol.com/c/webfont/projeto-grafico/uol-font/uol-text-regul …. http://53bvmfnea4p.o62fttv.com/8fd32e79869bad839e5da6828bf61
http://serv.the-app-data.info//offers/DynamicOfferScreen?offerid=2
http://crl.microsoft.com/pki/crl/products/microsoftrootcert.crl …. http://ajax.googleapis.com/ajax/libs/jquery/1.8.3/jquery.min.js
http://serv.the-app-data.info//offers/DynamicOfferScreen?offerid=2
訓練データ 悪性
通信ログ
訓練データ 良性
通信ログ
尾に結合
推論対象: 各訓練データ 最後尾に結合
iaInaokLEN03nn(0903jnnksaou9eeI)93$9bf)#$hf940f)($j …. saiurnI8fd32e79869bad839e5da6828bf61))4004jj9DJj""9
Inisianfa>kw-kk88finfnaeinfa
jiInfEIn93fn8fj$%jks89#ni89#Hd#)Nncj)0=-j3bn)CkL>#9hh …. 0i8ikl&y(0#$nLiknlwp0Hni89sijjise-j9)cc9ue4u-2^jE$knclO
9(kInnliNEIni=0kn)nBWhjjfiNininIEh84hf8lNn)Sjen9-^
データ 圧縮
データ 圧縮 悪性母体の
圧縮サイズ
C悪性
良性母体の圧縮サイズ
C良性

4 Copyright©2016 NTT corp. All Rights Reserved.
NTT Confidential
データ圧縮による分類 関連研究
• 「情報量」としてデータ圧縮による算出量 (relative entropy) を提案 Benedetto, et.al., "Language trees and zipping", Phys. Rev. Lett., vol.88, 2002.
• 分類問題 Keogh, et.al., "Towards Parameter-Free DataMining", KDD, pp. 206-215 ,2004.
• 著作者判定 (Authorship Identification)
• 文書: Marton, et.al., "On compression-based text classification", European Conference on Information Retrieval, pp. 300-314 , 2005.
• 楽曲: 足達 他、「圧縮類似度による楽譜からの作曲者の判定」、DEIM2013.
• SPAMメール判定 Bratko, et.al., “Spam filtering using statistical data compression”, Journal of Machine Learning Research, vol.7, pp.2673-2698, 2006.
• Twitter分類 西田他, 「データ圧縮によるツイート話題分類」, 日本データベース学会論文誌, Vol.10, No.1, 2011.
5 Copyright©2016 NTT corp. All Rights Reserved.
NTT Confidential
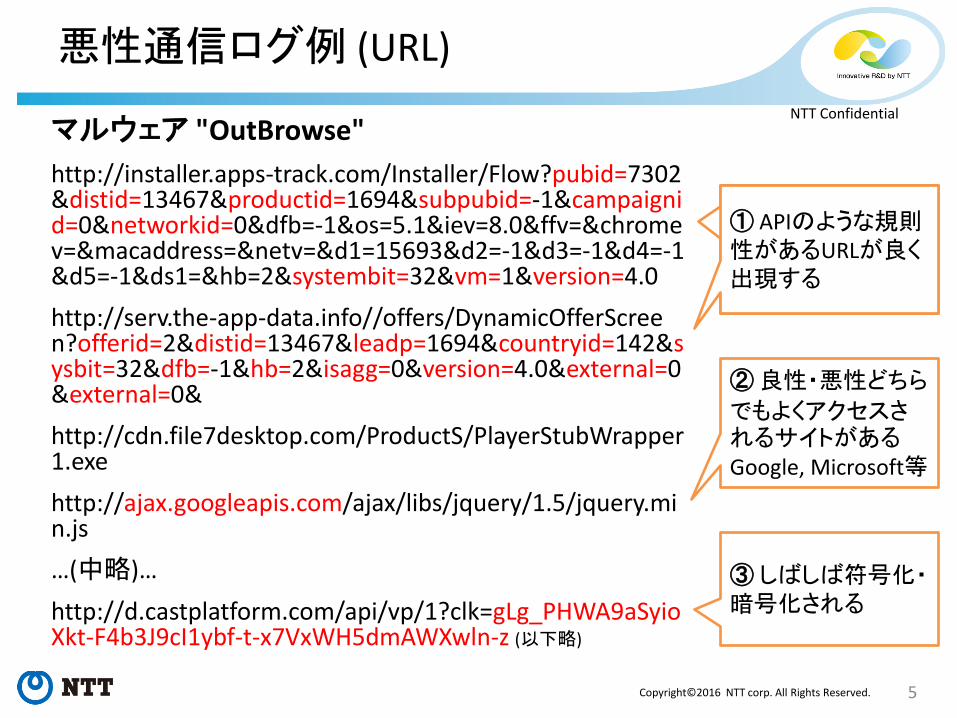
悪性通信ログ例 (URL)
マルウェア "OutBrowse"
http://installer.apps-track.com/Installer/Flow?pubid=7302&distid=13467&productid=1694&subpubid=-1&campaignid=0&networkid=0&dfb=-1&os=5.1&iev=8.0&ffv=&chromev=&macaddress=&netv=&d1=15693&d2=-1&d3=-1&d4=-1&d5=-1&ds1=&hb=2&systembit=32&vm=1&version=4.0
http://serv.the-app-data.info//offers/DynamicOfferScreen?offerid=2&distid=13467&leadp=1694&countryid=142&sysbit=32&dfb=-1&hb=2&isagg=0&version=4.0&external=0&external=0&
http://cdn.file7desktop.com/ProductS/PlayerStubWrapper1.exe
http://ajax.googleapis.com/ajax/libs/jquery/1.5/jquery.min.js
…(中略)…
http://d.castplatform.com/api/vp/1?clk=gLg_PHWA9aSyioXkt-F4b3J9cI1ybf-t-x7VxWH5dmAWXwln-z (以下略)
① APIのような規則性があるURLが良く出現する
② 良性・悪性どちら
でもよくアクセスされるサイトがある Google, Microsoft等
③ しばしば符号化・暗号化される

6 Copyright©2016 NTT corp. All Rights Reserved.
NTT Confidential
実験
方式 概要 大規模ログデータ対応
BoW+ 線形SVM
対象実験。URLの特徴抽出は '/', '?','&',=' を区切りとしたBoW、 分類器に線形SVMを使用
-
LZSS (LZ77) gzip. スライド辞書方式。圧縮対象の直前領域(スライド窓 32kB)中の最長一致文字列を探索、相対位置を出力
分割圧縮: 複数分割した学習データ+推論対象で圧縮、最小サイズを採用
LZW (LZ78) compress(gif形式). 動的辞書方式。
新規文字列を辞書に順次登録、最長一致文字列の辞書登録No.を出力
Jubatus Classifier に実装:学習: 辞書登録あり圧縮 推論: 辞書登録なし圧縮
bzip2 ブロックソートで同一文字が連続した文字列を得やすいことを利用
ブロックサイズ最大(Level9: 900kB) を使用
悪性通信ログ: マルウェア検体の動的解析により収集 良性通信ログ: 社内NWの NW装置ログ Holdout検証: 訓練データ(前) 悪性6.5万件 良性10万件 推論データ(後) 悪性10万件 良性10万件
7 Copyright©2016 NTT corp. All Rights Reserved.
NTT Confidential
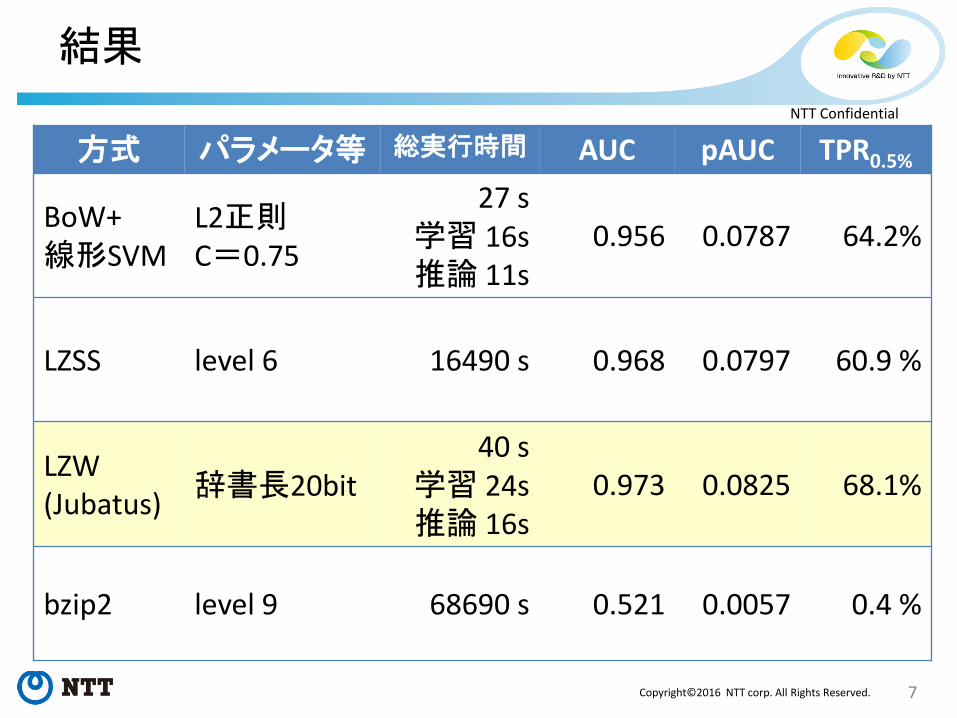
結果
方式 パラメータ等 総実行時間 AUC pAUC TPR0.5%
BoW+ 線形SVM
L2正則 C=0.75
27 s 学習 16s 推論 11s
0.956 0.0787 64.2%
LZSS level 6 16490 s 0.968 0.0797 60.9 %
LZW (Jubatus)
辞書長20bit 40 s
学習 24s 推論 16s
0.973 0.0825 68.1%
bzip2 level 9 68690 s 0.521 0.0057 0.4 %

8 Copyright©2016 NTT corp. All Rights Reserved.
NTT Confidential
悪性通信URL LZW圧縮結果: ①API的URL
[未圧縮: 1352bit] http://serv.the-app-data.info//offers/DynamicOfferScreen?offerid=2&distid=13467&leadp=1694&countryid=142&sysbit=32&dfb=-1&hb=2&isagg=0&version=4.0&external=0&external=0&
[良性母体: 900bit] |http://serv|.the|-ap|p-|data.|info/|/of|fers|/D|yna|mic|Off|erS|cre|en|?o|ffe|rid=2|&dis|tid=1|3467|&le|adp|=16|94&c|ountry|id=14|2&s|ys|bit|=32&|dfb|=-1&|hb=|2&is|agg|=0&ver|sion=|4.0|&ex|ternal|=0&e|xter|nal|=0&|
[悪性母体: 220bit] |http://serv.the-app-data.info//offers/DynamicOfferScreen?offerid=2|&distid=1|3467|&leadp=1694&|countryid=142&sysbit=32&df|b=-1&hb=2|&isagg=0&versio|n=4|.0&e|xternal=0&e|xternal=0&|
*圧縮時、|| 間の文字列は1Code (本実験では20bit)で表現
| |

9 Copyright©2016 NTT corp. All Rights Reserved.
NTT Confidential
悪性通信URL LZW圧縮結果: ③符号化URL
[未圧縮: 4688bit] http://d.castplatform.com/api/vp/1?clk=gLg_PHWA9aSyioXkt-F4b3J9cI1ybf-t-x7VxWH5dmAWXwln-z (以下略)
[良性母体: 4420bit] |http://d.|cast|platform|.com/api/|vp|/1|?cl|k=|gLg|_PH|WA9|aS|yio|Xkt|-F4|b3J|9cI|1y|bf-|t-|x7|VxW|H5d|mAW|Xwl|n-|z (以下略)
[悪性母体: 4980bit] |http://d.|cast|platform|.com/api/v|p/1|?cl|k=|gL|g_|PH|WA|9a|Sy|io|Xk|t-|F4|b3|J9|cI|1yb|f-|t-x|7V|xWH|5d|mA|WX|wl|n-|z (以下略)
*圧縮時、|| 間の文字列は1Code (本実験では20bit)で表現
10 Copyright©2016 NTT corp. All Rights Reserved.
NTT Confidential
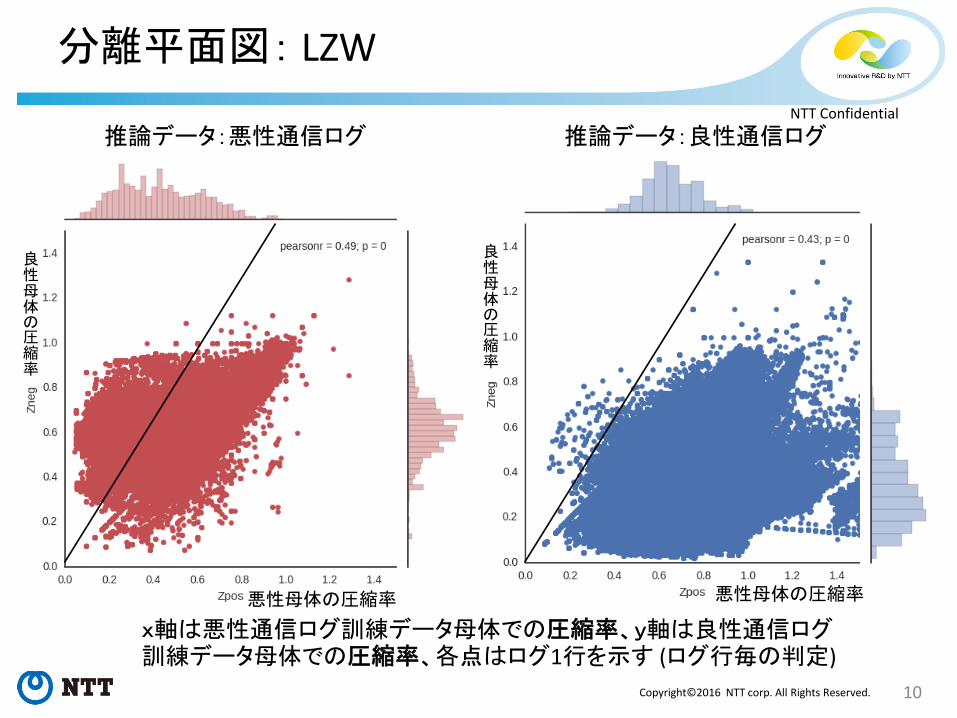
分離平面図: LZW
x軸は悪性通信ログ訓練データ母体での圧縮率、y軸は良性通信ログ訓練データ母体での圧縮率、各点はログ1行を示す (ログ行毎の判定)
推論データ:悪性通信ログ 推論データ:良性通信ログ
悪性母体の圧縮率 悪性母体の圧縮率
良性母体の圧縮率
良性母体の圧縮率
11 Copyright©2016 NTT corp. All Rights Reserved.
NTT Confidential
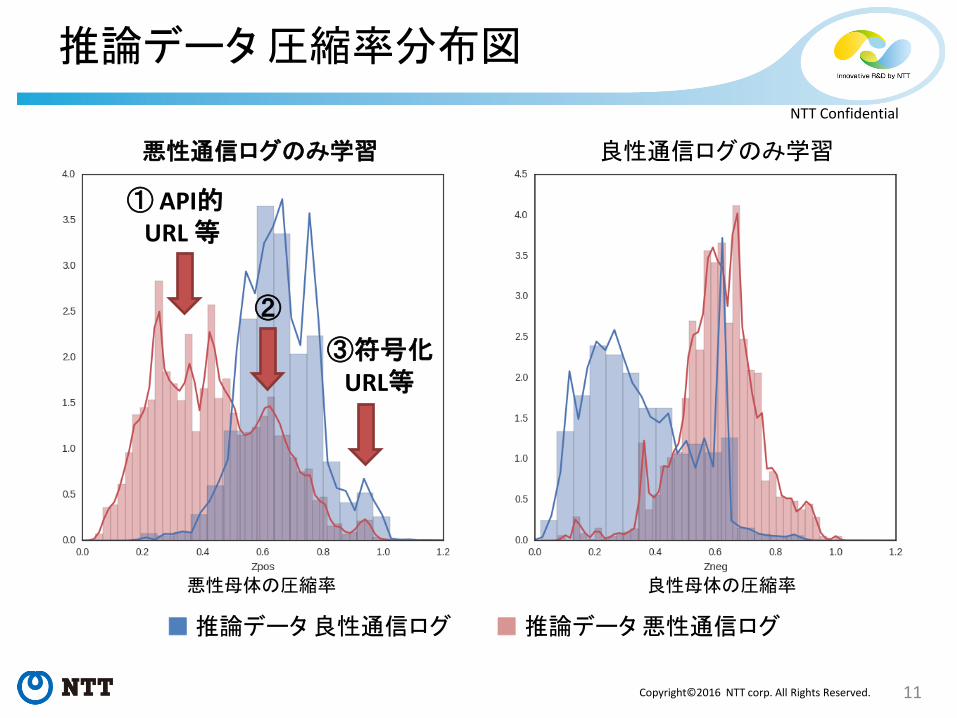
推論データ 圧縮率分布図
悪性通信ログのみ学習 良性通信ログのみ学習
■ 推論データ 良性通信ログ ■ 推論データ 悪性通信ログ
悪性母体の圧縮率 良性母体の圧縮率
②
① API的 URL 等
③符号化 URL等

12 Copyright©2016 NTT corp. All Rights Reserved.
NTT Confidential
[参考] JubaclassifierへのLZW実装概要
jubatus_coreライブラリを修正し、 分類アルゴリズム lzwクラスを実装;
• jubatus::core::classifier::linear_classifier を継承
• 以下のメソッドを実装: コンストラクタ, train (学習), name, classify_with_scores (推論)
• LZWの辞書(Trie木)はKVS型のJubatus学習モデル(local_strage)で代用
• 学習、推論ともにLZW圧縮を実施。 辞書登録は学習時あり、推論時なし。
圧縮データは生成せず、圧縮サイズのみ算出。
• 推論時スコアはクラス毎に「1/圧縮率」を出力
KVSによるLZW圧縮サンプルコード (Python) 出典: http://rosettacode.org/wiki/LZW_compression
def compress(uncompressed): dict_size = 256 dictionary = dict((chr(i), chr(i)) for i in
xrange(dict_size)) w = "" result = [] for c in uncompressed: wc = w + c if wc in dictionary: w = wc else: result.append(dictionary[w]) # Add wc to the dictionary. dictionary[wc] = dict_size dict_size += 1 w = c if w: result.append(dictionary[w]) return result

13 Copyright©2016 NTT corp. All Rights Reserved.
NTT Confidential
まとめ
•圧縮アルゴリズムでの分類でURLによる悪性通信ログ判定を行えた
•特にAPI的URLの判定に優れる
•訓練データの運用が楽。オンライン学習可能、 悪性と良性を別々に学習させるのも可。
•符号化URLの判定に関しては、より検討が必要
•たまにはこういう「変化球」もいかがでしょうか?









![[AWS Black Belt Online Seminar] Amazon Athena · • Amazon EMR ログ • AWS Global Accelerator ログ • Amazon GuardDuty ログ • Amazon VPC フローログ • AWS WAF ログ](https://img.pdfslide.tips/doc/110x75/601d01fb736ace68ef3b87a8/aws-black-belt-online-seminar-amazon-athena-a-amazon-emr-f-a-aws-global.jpg)