Embed Size (px)
Citation preview

リレーショナルリレーショナルデータベースデータベースとのとの上手な付き合い方 上手な付き合い方 long versionlong version
奥野 幹也Twitter: @nippondanjimikiya (dot) okuno (at) gmail (dot) com
@Hacker Tackle 2016

免責事項本プレゼンテーションにおいて示されている見解は、私自身の見解であって、オラクル・コーポレーションの見解を必ずしも反映したものではありません。ご了承ください。

自己紹介
● MySQLサポートエンジニア– 日々のしごと
● トラブルシューティング全般● Q&A回答● パフォーマンスチューニングなど
● ライフワーク– 自由なソフトウェアの普及
● オープンソースではない● GPL万歳!!
– 最近はまってる趣味はリカンベントに乗ること● ブログ
– 漢のコンピュータ道– http://nippondanji.blogspot.com/

問題提起
● DBの使い方があまりに適当ではないか。– DBは単なるデータの入れ物!?– インデックスさえ貼れば何とかなる!?
● データモデルへの無理解– 正規化なんて必要ない!?– スキーマレスは柔軟で最高!?
● トランザクションへの無理解– 無くてもアプリを作りこめばOK !?– アトミックな処理なら良いんでしょ!?
● 実装への無理解– 動けば中身を知らなくてもいい!?

なぜデータベースを使うべきか

一言で表すと・・・
開発や運用で楽をするため!!
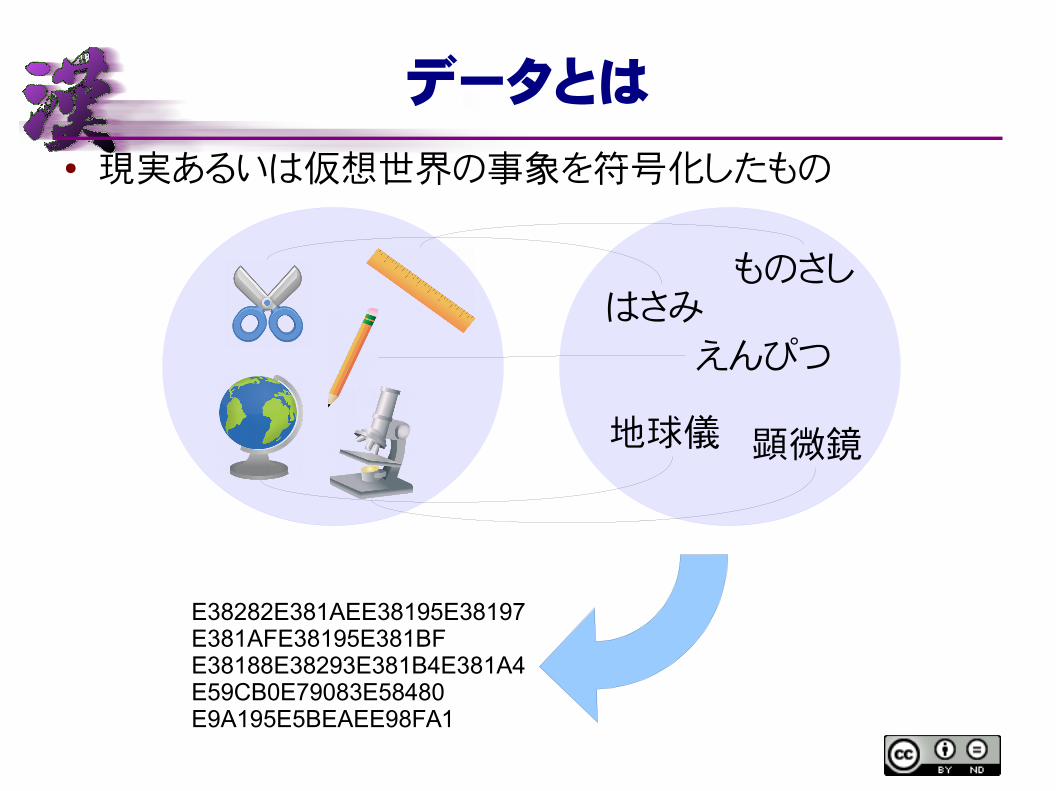
データとは
● 現実あるいは仮想世界の事象を符号化したもの
はさみものさし
えんぴつ
地球儀 顕微鏡
E38282E381AEE38195E38197E381AFE38195E381BFE38188E38293E381B4E381A4E59CB0E79083E58480E9A195E5BEAEE98FA1

データに対する要求
● 整理して格納しておきたい– データを構造化してどこに何があるか分かるようにしたい– データに合った構造を選択
● 好きなときに取り出したい– 容易にアクセスできる手段– 正しい結果が欲しい!!
● 自由自在に更新したい– データの整合性を保ちたい– 複数のユーザーから同時に更新したい

ファイルではダメなのか
● 構造が一切定義されていない– データの位置を先頭からのオフセットをバイト数で指定– データは単なるバイト列
● seekや read/write といった低レベルのAPIのみ– 複雑なアプリケーションによるデータ操作を表現するには貧弱過ぎる
– 高度なデータ操作はアプリケーション側で実装しなければならない
– 壮大なる車輪の再発明の危険性● 同時アクセス時の排他制御● マシンクラッシュにおけるデータの完全性

表計算ソフトではダメなのか
● 表計算ソフトはあくまでも二次元の表– データの場所を列と行で指定– 表同士の演算はできない
● JOIN 、 UNION等● インデックスによる高速な検索や演算ができない● 同時アクセスができない● トランザクションがない

データベースは便利な道具
● 小難しいけれどもただの厄介者ではない。– リレーショナルモデル– トランザクション
● データ管理や操作における課題を解決するためのもの– データを矛盾なく格納したい– 安全に並列処理を行いたい– クラッシュしてもデータが失われないようにしたい

トランザクションはなぜ必要か

同時アクセスによる様々な異常
● ロストアップデート● インコンシステントリード● ダーティーリード● ノンリピータブルリード● ファントムリード
トランザクションで防げる!!
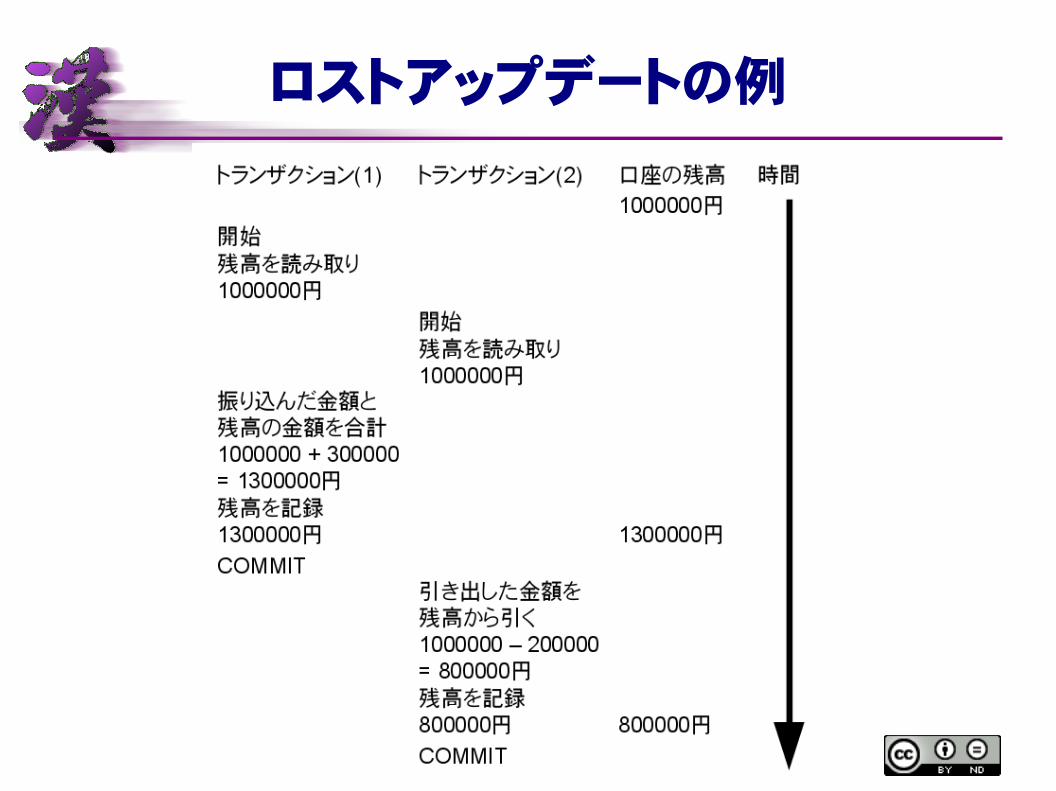
ロストアップデートの例

データの正しさを保証したい!!
● それがトランザクションの役割– しかも超かんたん!!
● トランザクションによってできること– 同時アクセスによる異常を防ぐ– システムがクラッシュしてもデータが失われない

異常とは
● 異常とは並列実行やクラッシュなどに起因して、想定外の結果になること。
● 異常は例えば複数のクライアントから同時にデータが操作されることで起きる。
– かといって、並列処理をしないのは性能上受けう入れられない。
– 操作の内容によっては同時に実行しても互いに影響がないものがある。
● 同じデータアイテムを R/Wするような操作は影響がある。
– どのような順序で個々の操作を行えば異常が起きないか?

正しい結果
● 並列で実行しているトランザクションが、ひとつずつ順番に実行した場合と同じ結果になること。
– トランザクションの順序に保証はない。数ある順序の組み合わせの中のひとつと同じになる。
– アプリ側で排他制御を考えなくていい。
Tx1 Tx2 Tx3
=Tx2
Tx1
Tx3

同時アクセス制御
● 複数のトランザクションが実行する個々の操作を、矛盾が起きないような順序(スケジュール)で実行する。
– 矛盾が起きる可能性のあるスケジュールが起きないよう、一部のトランザクションの実行をブロックあるいはアボートする。
– 計算量大。● 現在の RDBMSでは、ロッキングスケジューラーを用いることで、同時アクセスによる異常を防いでいる。

クラッシュリカバリ
● クラッシュが発生してもデータの一貫性は保たれる– COMMIT 済みのデータは失われない– COMMIT されていないデータはロールバック
● アプリケーションがやるべきことは完了しなかったトランザクションの再実行のみ。

ACID● トランザクションが満たすべき性質
– 原子性● トランザクションに含まれる操作全てが成功
( Commit )か失敗( Abort )になるという性質– 一貫性
● トランザクションを実行した前後ではデータの一貫性が損なわれてはならないという性質
– 分離性(独立性)● 同時に実行している複数のトランザクションが、互いに影
響を与えないという性質– 永続性
● いったんコミットが完了したトランザクションが消失しないという性質

データの正しさについての考察

正しいデータを得られないデータベースは無価値
● 正しい答えが欲しいからデータベースを使う– デタラメな答えで良いのなら /dev/urandom でも使ったほうがマシ
● 速いしリソース食わないし文句なし!!● データの正しさとは一体何か?

なぜデータベースを使うのか
既存のデータに基づいた正しい答えが欲しいから!!

RDB上でデータの正しさを保つ● トランザクション
– 同時アクセス時の整合性– クラッシュリカバリ
● リレーショナルモデル– リレーション = 論理的に真となる命題の集合
● 正規化理論– 重複を排除することによる論理的な矛盾の回避
● 制約– ビジネスロジック– ACIDのC
● アプリケーションによる検算– 制約だけでは表現できない部分

ACIDのC● 一貫性って何?● トランザクション理論自体は一貫性を規定しない
– 一貫性を定義するのはアプリケーションの役目– 制約などを使う
● 制約という仕組みを使って一貫性を記述するのはアプリケーション

NoSQL上でデータの正しさを保つ
● RDBのような便利な道具はない– トランザクションなし– リレーショナルモデルなし– 制約なし
● データの正しさの保証はすべてアプリケーションに委ねられる
– データの正しさを保証するためのコードを量産– バグはデータの不整合に直結する– テストコードが増殖する

分離レベルとデータの正しさ
● 分離レベルはトランザクションの概念であって、リレーショナルモデル上にはそんな概念はない
– リレーショナルモデルでは、データは全てある瞬間のスナップショットであり、同時アクセスによって他のセッションから変更されることは考慮されていない
● 分離レベルと整合性– SERIALIZABLE: リレーショナルモデルをもっとも忠実に体現できる。ただしロック多し。
– REPEATABLEREAD: 少し時間が遅れても良いのなら、参照系処理においてリレーショナルモデルを体現できる。ただしファントムを除いて。
– READCOMMITTED: 本当は使うのが難しいんだけど、みんな分かって使ってるのか・・・
– READUNCOMMITTED: 一体何に使うのか。

分離レベルの注意点
● 製品によって違いがあるんだな、これが。– 名称が違ったり、 4つ以上のレベルがあったり– RRでファントムが出ない( SQL 標準上は出るのが正しいけど、実際にアプリを作る上ではこっちのほうが好ましい)
– RCが読むのはどのデータ?– ロッキングリード vs ノンロッキングリード– RUは本当に性能が高いのか
各製品の実装に詳しくなろう!

トランザクションがない場合に起きること
● 排他制御が不在– 同時に同じデータへアクセスする場合、更新異常を防ぐにはどうする?
– アプリケーション側で大量のロックを記述する?● トランザクションがあれば、分離性があるので勝手にやってくれる。
● エラー処理が超複雑に– どこまで処理が進んだかによってエラー処理も場合分け
● 10の更新から成るトランザクションは、 10のケースについてエラー処理が必要。
– トランザクションがあれば原始性があるので、処理が中断するとすべての更新をロールバック。
– クラッシュ後のデータは正しいか?● そもそもどうやって確かめる?
– トランザクションの永続性があればCOMMIT したデータが存在することが保証される。

つまりトランザクションを使うと・・・
開発や運用が楽!!

リレーショナルモデルはなぜ必要か

リレーショナルモデルがない世界
● データモデルの不在– データモデルはデータ取得のための演算を定義
● 効率よくコンパクトにデータの問い合わせを記述できる– データの演算をアプリケーションで自前で記述する?
● データベースはただの入れ物という考え● 実際そういう現場が多いからデスマーチに・・・
● 正規化理論の不在– 正規化理論は、更新によって生じるデータの矛盾を、データベース設計そのものにより防ぐ理論。
● ACIDのC– データの矛盾をアプリケーションで自前で記述する?
● チェックのための処理が大量に必要に・・・

そもそもデータモデルとは

データモデルとは
● データの論理的な表現方法– データを表現するためにどんな方法が使えるか
● データを構成する要素● データに対する演算
– 物理じゃないよ!!● 物理的な表現方法は、データがどのようなレイアウトでファイルに格納されているか等
● データベース設計のことじゃないよ!!

データは格納するだけで終わりではない
● 格納して終わりではない!!– アプリケーションから利用してこそ意味がある– 入れっぱなしでOKなら、そもそもデータを格納する意味はあるのか?
● どのように出し入れするかが重要– できるだけ簡単かつ的確に出し入れしたい– 必要なデータは何かを簡潔に定義できること– ≒ データに対する演算

データモデルと演算
● データモデル上に定義された演算– データの意味から演算の種類が必然的に決まる
● 整数の四則演算、文字列の分解・連結● リレーショナルモデルの射影、制限、結合
etc– 処理系に最初から用意されている
● 高速で信頼できる操作● 用意された演算を適切に使えば簡素に書ける
– 反例:文字列で配列を実装するケースを考えよ● 遅い● 実装できてもバグだらけ● そもそも実装する意味がない

データベースを単なる入れ物だと考えてはいけない理由
● データベースはデータモデルを意識して作られている– データモデルに沿った演算が用意されている
● データモデルに沿った使い方が得意● そうでない処理は苦手
– データモデルを実践できるかどうかで、データベースのパワーを利用できるかどうかが決まる
● データベースが単なる入れ物だと考える背景– 「自分で書けば何でもできる」という考え– データモデルを知らない

プログラミングパラダイムとデータモデル
● プログラミングパラダイム– 手続き型– オブジェクト指向– 関数型
etc etc● プログラミング言語にはそれぞれ適した書き方がある!!
– Javaはオブジェクト指向で使うべき● main メソッドに全てのロジックを記述するべきではない
● データモデルにはそれぞれ適したDB設計がある!!– 「データベースは単なるデータの入れ物だ」という考え方は、 Javaでmain メソッドに全てを記述するのに等しい

代表的なデータモデル
● リレーショナルモデル● グラフ● 階層型● キーバリュー● オブジェクト● XML● ドキュメント

適切なデータモデルを選ぶ
● 双方向でマッチングする– そのデータモデルはどのような演算が得意か– アプリケーションが必要とする演算は何か
● 最大公約数を取る– データモデルは万能ではない
● 演算がうまく表現できないものも存在する– データモデルに合致しない部分はアプリケーション側で作りこむ
● データベースソフトウェアが備えている、データモデルから逸脱した演算を活用する
– ソートやストアドプロシージャ、マテリアライズドビューなど

一つのデータモデルでは足りない場合
● 複数の製品を組み合わせる– 異なるデータモデルを持つ製品を組み合わせる– データの同期が課題
● 分散トランザクションがあれば理想● トランザクションがない製品はキャッシュとして
● マルチモデル– ひとつの製品が複数のデータモデルを持つ
● RDB + JSONetc
– データの同期について考える必要がない– スケーラビリティが課題

様々なデータ構造
● 配列● ハッシュ● 線形リスト● グラフ、ツリー● 集合● 構造体、クラス、オブジェクト● ドキュメント
etc

集合がメインなら RDBMS● 集合論に基づいたリレーショナルモデルがベース● トランザクションが利用可能
– 同時実行制御● 行レベルロック等
– クラッシュリカバリ● その他開発を手助けする豊富な機能
– 制約– SQLによる柔軟な演算– 集計、ソート– ストアドプログラム
etc etc

リレーショナルモデルをマスターしよう!

RDBMSを使う上で必須の知識● リレーショナルモデルは道具
– 道具には道具に合った使い方、使いみちがある– 道具の性質や使い方を知らずして、使いみちは分からない
● RDBMSを使うべきかどうか● 使うとしたらどう使うのがベストなのか
● 必須だが蔑ろにされがち・・・

巷に溢れるあやふやな情報
● リレーショナルモデルに触れない SQLの解説– SQLは書けるようになるけれども・・・
● 理論に基づかないノウハウの解説– リレーションは 2次元の表です– データベースは単なる入れ物です– 正規化の目的は冗長性の排除です– 正規形は第 3まででOKです– すべてのテーブルにサロゲートキーをつけるべきです– ORMを使えば SQLは知らなくても良い
etc etc

そして、真実を知る者は現場からいなくなった・・・
● それでも世の中回ってる– 率直なところ「意外といけるもんだね・・・」という感想
● とはいえ効率は悪い– クエリの実行効率– RDBMSを用いた開発効率– 無駄三昧!!デスマーチ三昧!!

どげんかせんといかん・・・・・!!

そこで、私はペンを取り立ち上がった!!

リレーショナルモデル

リレーショナルモデルとは!
● 集合に根ざしたデータモデル● リレーションという名前のデータ構造を用いてデータを表現する
– リレーションを単位として様々な演算を行う● リレーション=集合● 集合演算+ α
– リレーションはデータそのもの– テーブル同士の関係性(リレーションシップ)ではない

リレーションとは
● 現実世界のある物事に対する事実の集合
テーブル≒
リレーション
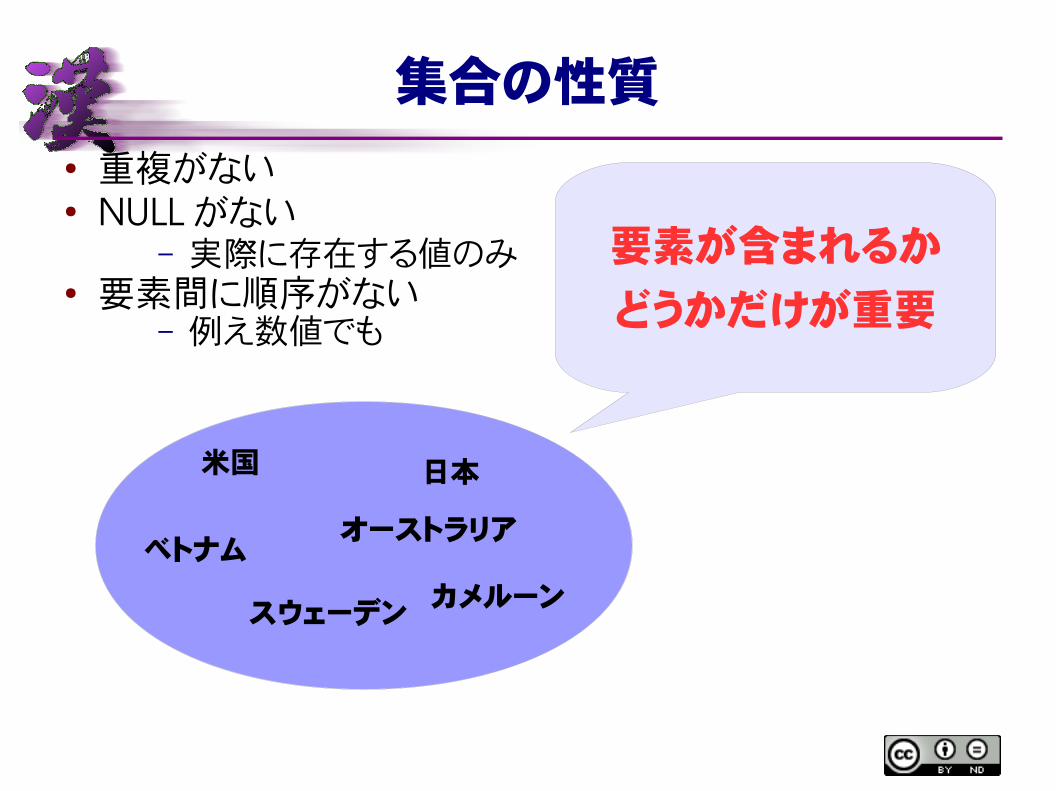
集合の性質
● 重複がない● NULLがない
– 実際に存在する値のみ● 要素間に順序がない
– 例え数値でも
米国
ベトナム
日本
オーストラリア
スウェーデンカメルーン
要素が含まれるか
どうかだけが重要

リレーショナルモデル≠ SQL
リレーショナルモデル SQL
関係(リレーション) 表(テーブル)
属性 [ 値 ] (アトリビュート) 列(カラム)
組(タプル) 行(ロー)
対応する概念だが性質は異なる。

SQLにあってリレーショナルモデルにないもの
● 行データの重複● 行データの順序● カラムの順序● テーブル(リレーション)の更新● ストアドプロシージャ、トリガー● トランザクション● NULL

なぜSQLとリレーショナルモデルは違うのか
● リレーショナルモデルには限界がある– 格納できるデータは集合として表現できるものに限る– 実行できる演算はリレーションの演算のみ
● 集合演算+ α● アプリケーションが必要とするデータは多種多様
– リレーショナルモデルだけでは足りなかった– 更新という概念が実装上どうしても必要だった
● トランザクション● つまり、純粋なリレーショナルモデルよりも SQLのほうが適
用範囲が広い

ただしそれは諸刃の剣だった・・・

NULLの功罪
● NULLによって、 SQLはリレーショナルモデル以上の表現力を手に入れた!!
● しかしその代償は大きかった・・・– Unknownな値とは一体何なのか– 3 値論理による複雑さの上昇– 閉世界仮設の崩壊– オプティマイザも真価を発揮できない
● 今扱っているデータがリレーショナルモデルの範疇かどうかを見極めることが重要!!
– NULLがあってもいいかどうか

リレーショナルモデルが置き去りに
● リレーショナルモデルに沿わない使い方もできてしまう● セオリーを無視したDB 設計が横行
– データベースはただの入れ物– インデックスさえ効いていればOK
● 当然問題に直面する– うまくクエリを書けない– 結果が間違っている– クエリが難解になる– 性能が出ない
etc etc SQLの知識だけでは不十分

つまりリレーショナルモデルを使うと・・・
開発やメンテが楽!!

リレーショナルモデルをマスターしたい方へ・・・

パフォーマンス
パフォーマンス
パフォーマンス
パフォーマンス
パフォーマンス
パフォーマンス

パフォーマンスは超重要
● データモデルに沿ってDBを設計するだけでは片手落ち– 満足な性能が出るとは限らない
● 何を表現したかということと、その表現がどのように処理されるかは別
● 性能が出ないアプリケーションは役に立たない!!– アプリケーションは実用的であってこそ意味がある– 実用的なレスポンスが得られることは絶対条件

性能を向上させるためのポイント
● 己を知る– 利用可能な機能を知る– 製品の実装を知る
● どんな処理が得意なのか● 敵を知る
– 遅いクエリを特定する● クエリの仕事量を測定する● 仕事量を減らすようチューニング
– ボトルネックを特定する● 時間が掛かっている箇所● アクセスが集中している箇所
彼を知り己を知れば百戦殆うからず(孫子)

データがどのようにアクセスされるかを知る
● 行データがどのようにクライアントへ届くか– オプティマイザー– インデックス– I/O– バッファプール– ネットワーク– それぞれの処理の仕事量は?
● それぞれの時点での改善点はないか– 実行計画は適切か?– もっと良いインデックスはないか?– I/Oの効率は改善できるか?– より速いディスクが必要か?– バッファプールその他のキャッシュは十分か?– ネットワーク帯域は十分か?– ボトルネックはどこか?

実装について知ることの意義
● 実装を知り、仕事の量を見積もる– それぞれの処理は十分に高速なのか– どのリソースをどれだけ消費するか
● I/O処理● メモリ● CPU
– アーキテクチャから推測する● ベンチマークするべし!!
– 机上の計算では全てはわからない

クエリの改善
● 不必要なデータにアクセスしていないか– 不要な結果をクライアントへ送信していないか
● アプリケーション側で結果を絞り込む等– 効率の悪い書き方をしていないか
● RDBMSの機能を活用する– より効率的な実行計画のクエリへの書き換え
● 非効率な書き方を避ける– ストアドファンクションを使わない
● 同じ結果を産むより良い実行計画– サブクエリを JOIN に書き換える

クエリの改善その 2
● インデックスを活用する– 基本中の基本– 意外と何とかなることが多い
● そもそもDB 設計は問題ないか?– クエリはテーブルを入力とした演算– 入力の設計が良くなければ、クエリが遅くなるのは必然– 更新は正規化でシンプルに

ベンチマークのすすめ
● コンピュータシステムは複雑過ぎて、実際にどの程度の性能が出るかということの予測は極めて難しい
● やってみるのが早い!!● 測定可能な結果が数値で分かる
– 改善の具体的な目標に– 具体的な数値無しに性能改善はあり得ない
● システムの限界性能を知る– キャパシティプランニングの指標に

まとめ

RDBMS と上手に付き合うためのポイント
● リレーショナルモデルを知ろう– 道具を使うには、使い方を理解する必要がある– 使い方を知ることで、正しい用途も見えてくる– なぜその使い方が良いのか、あるいは良くないのかを説明できる
● トランザクションを知ろう– トランザクションは開発を大幅に効率化する– エラー処理が簡略化
● パフォーマンスを向上するための仕組みを知ろう– RDBMSの実装– クエリの改善
アーキテクチャや理論の理解は超重要

これからもデータベースと上手く付き合うには
● テクノロジーは進化する– CPU 、メモリ、ディスク、OS 、言語・・・ etc– 最新テクノロジーは次々登場する
● 原理原則は変わらない– リレーショナルモデル– トランザクション– アーキテクチャ
● CPUがどのように命令を実行するか● データベースの基本的な仕組み
理論+トレンド

宣伝: 新書籍「詳解 MySQL 5.7 」● MySQL 5.7の新機能を網羅
– 175 もの新機能を解説– 新機能の理解に欠かせないアーキテクチャの話も盛りだくさん
– MySQLの実装について詳しくなれる!!

Q&Aご静聴ありがとうございました。

![データベース - cg.ces.kyutech.ac.jp · • 「リレーショナルデータベース入門[第3版]」 増永良文著、サイエンス社 –4章(4.8~4.13節) • 「データベースシステム」](https://img.pdfslide.tips/doc/110x75/5f440b58cbdb1e73c9624bb3/ffff-cgces-a-oeffffffffffec3c.jpg)



























