Embed Size (px)
Citation preview

NLP4L meetup #12015.06.03
@moco_beta

アジェンダ
NLP4Lとは (@kojisays)
NLP4Lをはじめよう (@moco_beta)
Luceneのインデックスを知る (@moco_beta)
休憩
NLPツールとして使う (@moco_beta, @kojisays)

NLP4Lをはじめよう

NLP4L のインストール!
ソースコードチェックアウト
ビルド
対話シェル起動
手順はこちら
$ git clone https://github.com/NLP4L/meetups.git $ cat meetups/20150603/01_install.md

テキストコーパスのインデックス
ライブドアコーパスのダウンロードとインデックス
手順はこちら
$ cat meetups/20150603/02_index_ldcc.md

Luceneのインデックスを知る

Luceneインデックスのアーキテクチャ
(その前に)転置インデックスのおさらい

Luceneインデックスのアーキテクチャ
http://opensearchlab.otago.ac.nz/paper_10.pdf より抜粋

LuceneインデックスのアーキテクチャA 4-dimension view of the Inverted Index
(と、Lucene デベロッパーは呼ぶ)
API上は, Iterator の階層
field
field
field
field
field
term
term
term
term
term
document
document
document
document
document
position
position
position
position
position
………フィールド
…
フィールドに含まれるターム辞書
タームを含むdocument の ID
タームの出現位置、回数など
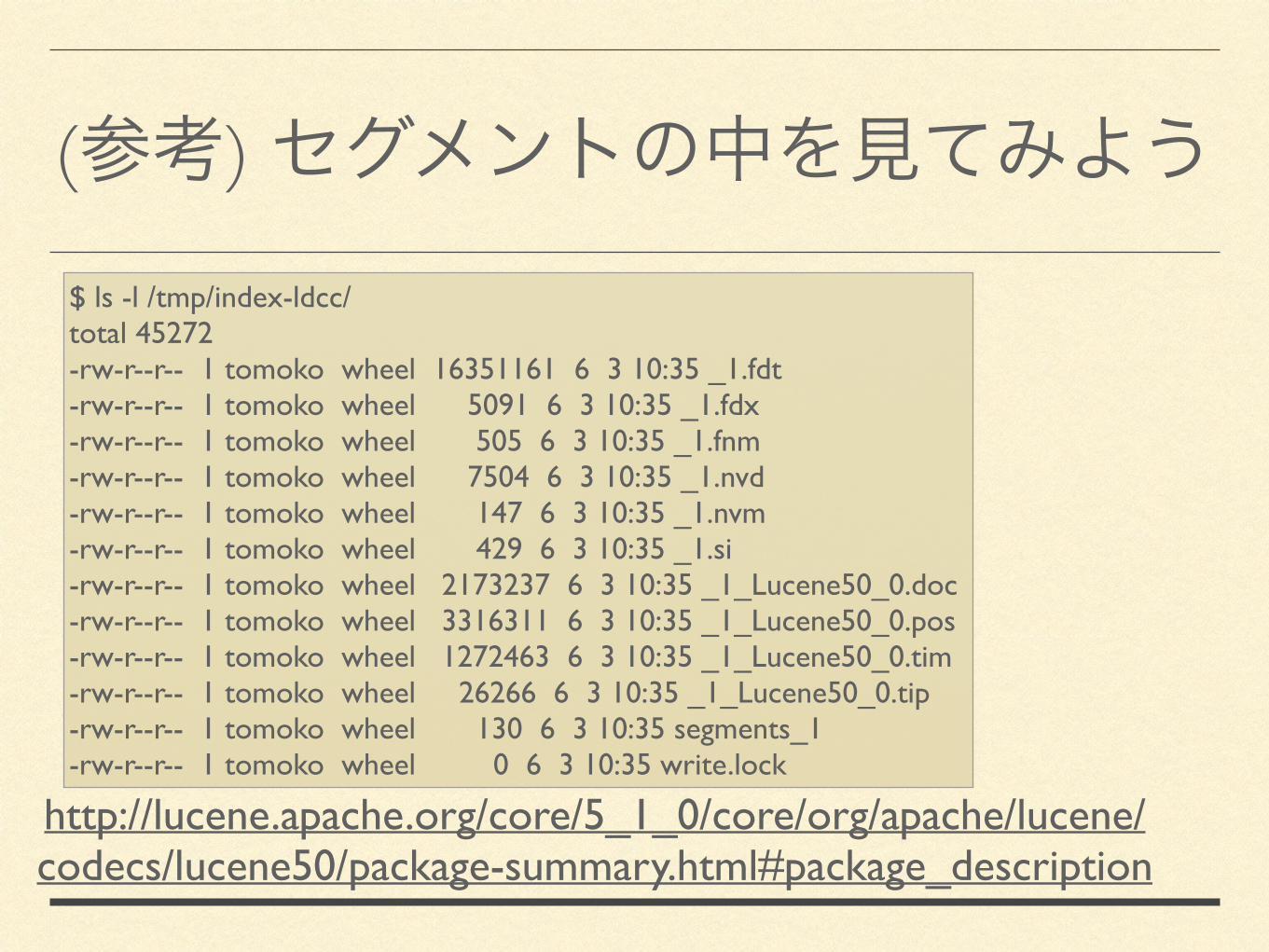
(参考) セグメントの中を見てみよう$ ls -l /tmp/index-ldcc/ total 45272 -rw-r--r-- 1 tomoko wheel 16351161 6 3 10:35 _1.fdt -rw-r--r-- 1 tomoko wheel 5091 6 3 10:35 _1.fdx -rw-r--r-- 1 tomoko wheel 505 6 3 10:35 _1.fnm -rw-r--r-- 1 tomoko wheel 7504 6 3 10:35 _1.nvd -rw-r--r-- 1 tomoko wheel 147 6 3 10:35 _1.nvm -rw-r--r-- 1 tomoko wheel 429 6 3 10:35 _1.si -rw-r--r-- 1 tomoko wheel 2173237 6 3 10:35 _1_Lucene50_0.doc -rw-r--r-- 1 tomoko wheel 3316311 6 3 10:35 _1_Lucene50_0.pos -rw-r--r-- 1 tomoko wheel 1272463 6 3 10:35 _1_Lucene50_0.tim -rw-r--r-- 1 tomoko wheel 26266 6 3 10:35 _1_Lucene50_0.tip -rw-r--r-- 1 tomoko wheel 130 6 3 10:35 segments_1 -rw-r--r-- 1 tomoko wheel 0 6 3 10:35 write.lock
http://lucene.apache.org/core/5_1_0/core/org/apache/lucene/codecs/lucene50/package-summary.html#package_description

コーパスのインデックスをブラウズする
ライブドアコーパスのテキストファイルを見る
NLP4L 対話シェルでインデックスをブラウズする
http://nlp4l.github.io/tutorial_ja.html#indexBrowser
(参考) GUI だと Luke があるよ!
https://github.com/DmitryKey/luke (4.x 対応)
https://github.com/mocobeta/luke/tree/5x_support (5.x 対応版, 絶賛開発中…)

休憩

NLPツールとして使う

単語の数を数えるフィールド中の頻出単語とその回数を求める
IReader.topTermsByDocFreq()
IReader.topTermsByTotalTermFreq()
特定の単語の出現回数を求める
WordCounts.count()
WordCounts.countDF()
サンプルスクリプト (NLP4L対話シェルから実行してください)
meetups/20150603/03_wordcount.scala

TF-IDF文書ベクトルを作る
TFIDF.tfVector()
TFIDF.tfIdfVector()
サンプルスクリプト (NLP4L対話シェルから実行してください)
meetups/20150603/04_tfidf.scala
(参考) 機械学習ソフト向けの特徴ベクトル生成
org.nlp4l.spark.mllib (Spark MLlib向け)
org.nlp4l.mahout (Mahout向け)






























