Embed Size (px)
Citation preview

DATA STRUCTURESamugona study 2 회
20150731 mjh

INDEX
• Chapter 8
• 일반 트리• 이진 트리• 이진 트리의 순회와 연산• 스레드 이진 트리• 이진 탐색 트리• 이진 탐색 트리의 균형• 요점 정리• 연습 문제

TREE
Tree
Binary Tree
Heap Binary Search Tree
AVL-Tree BB-Tree Splay Tree
m-way Tree
Trie m-way Search Tree
B-Tree
B*-tree B+-tree 2-3tree
2-3-4 tree
Red-Black tree
노드 사이의 관계가 계급적 관련성을 갖는다
TREE
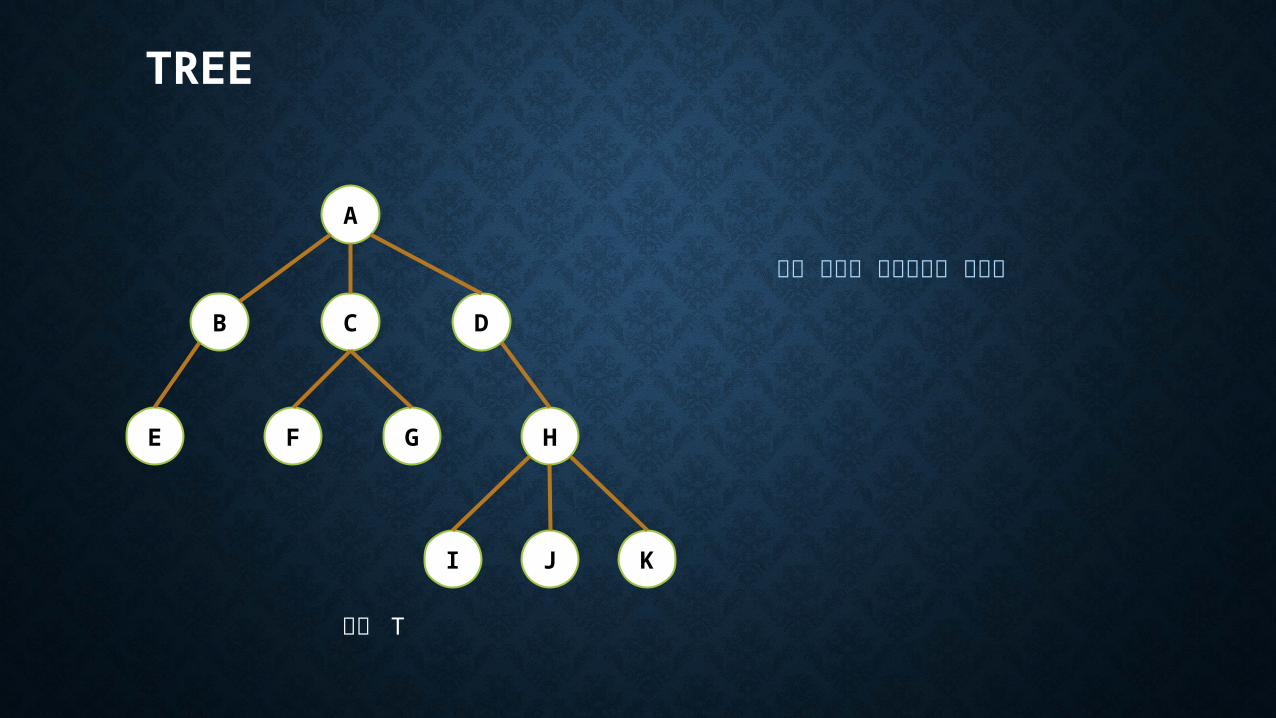
A
B C
FE
D
KJI
HG
트리 T
루트 노드와 서브트리로 나뉜다
TREE
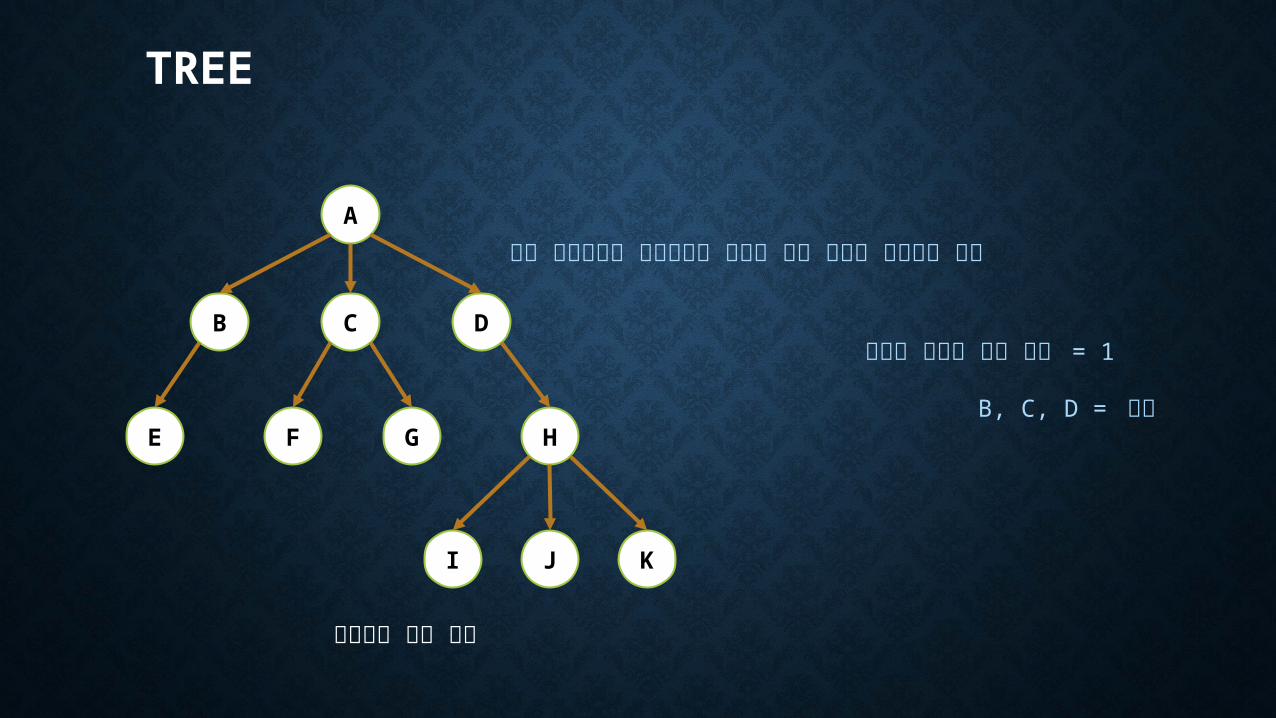
A
B C
FE
D
KJI
HG
방향성을 가진 트리
루트 노드로부터 서브트리의 루트로 방향 간선이 존재하는 트리
B, C, D = 형제
루트를 제외한 진입 차수 = 1

BINARY TREE
https://ko.wikipedia.org/wiki/%EC%9D%B4%EC%A7%84_%ED%8A%B8%EB%A6%AC
한 노드가 최대 두 개의 자식 노드를 가지는 트리
부모 노드 , 자식 노드 , left, right
정렬
• Chapter 13
• 정렬• 내부 정렬• 외부 정렬• 삽입 정렬• 셸 정렬• 콤 정렬• 퀵 정렬• 리스트 정렬• 2- 원 합병 정렬• 기수 정렬• 히프 정렬• 테이블 정렬• 자연 합병• 균형 m- 원 합병
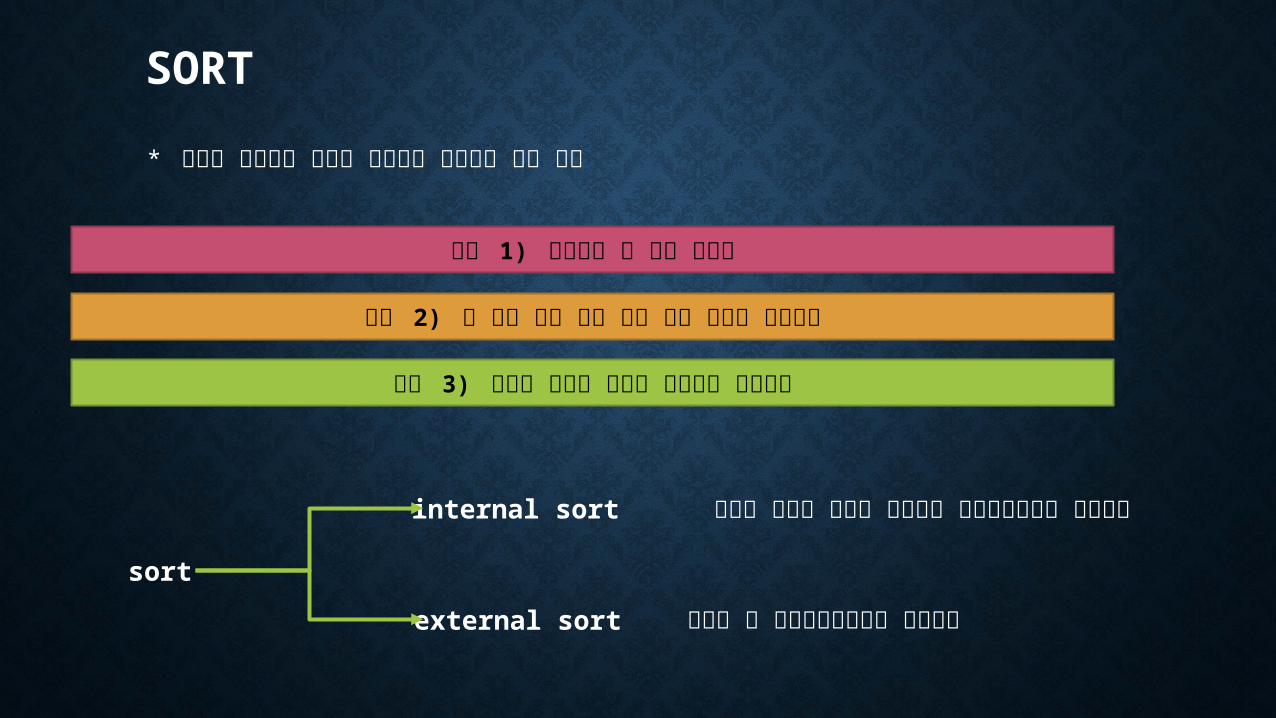
SORT
* 주어진 데이터를 원하는 순서대로 배열하는 연산 작업
단계 1) 레코드의 키 값을 읽는다
단계 2) 키 값에 의해 해당 파일 내의 위치를 결정한다
단계 3) 위에서 결정된 위치로 레코드를 이동한다
sort
internal sort
external sort
정렬할 파일의 크기가 적당하여 주기억장치에서 이루어짐
용량이 커 보조기억장치에서 이루어짐
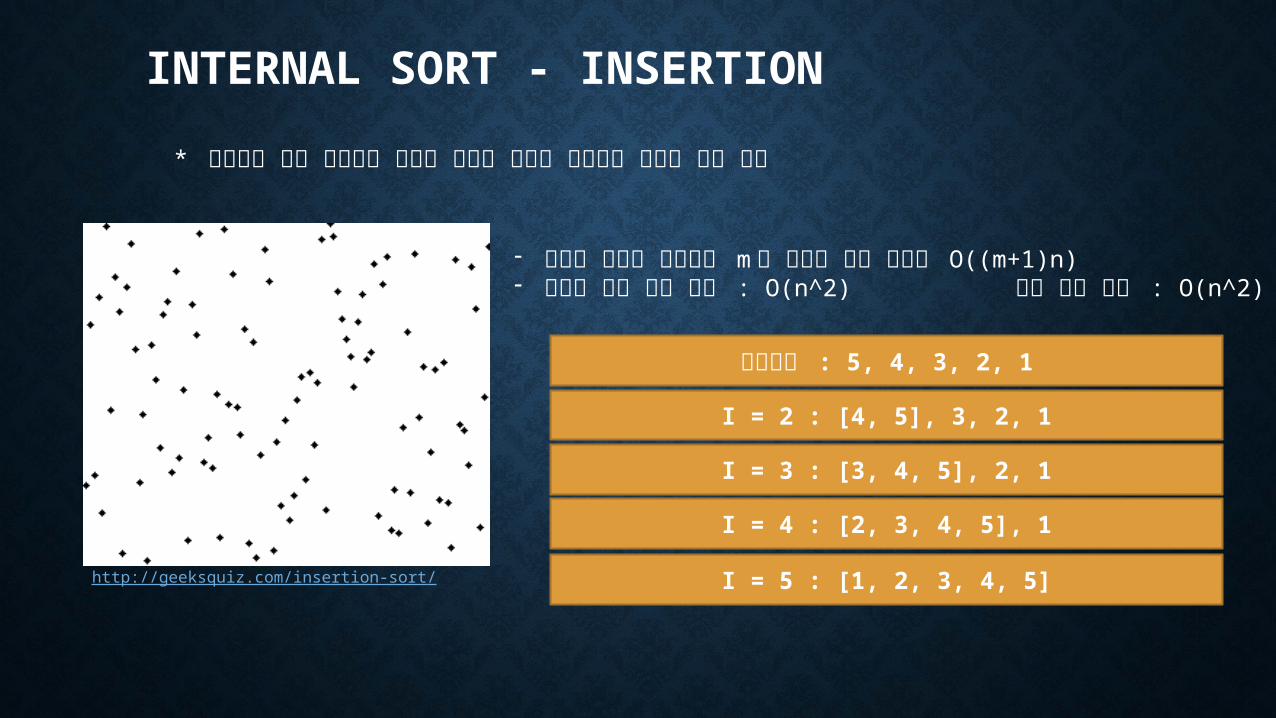
INTERNAL SORT - INSERTION
* 정렬되지 않은 리스트의 레코드 하나를 정렬된 리스트로 순서에 맞게 삽입
http://geeksquiz.com/insertion-sort/
- 순서가 벗어난 레코드가 m 개 있다면 연산 시간은 O((m+1)n)- 최악의 경우 연산 시간 : O(n^2) 평균 연산 시간 : O(n^2)
초기상태 : 5, 4, 3, 2, 1
I = 2 : [4, 5], 3, 2, 1
I = 3 : [3, 4, 5], 2, 1
I = 4 : [2, 3, 4, 5], 1
I = 5 : [1, 2, 3, 4, 5]

INTERNAL SORT - SELECTION
• 리스트에서 가장 큰 키를 갖는 레코드를 찾아서 마지막 위치에 있는 원소와 교환 , 그 다음 키를 갖는 레코드를 찾아서 마지막 전 위치에 있는 레코드와 교환
https://en.wikipedia.org/wiki/Selection_sort
초기상태 : 4, 3, 1, 2, 5
I = 5 : 4, 3, 1 2, [5]
I = 4 : [2], 3, 1, [4], 5
I = 3 : 2, [1], [3], 4, 5
I = 2 : [1], [2], 3, 4, 5
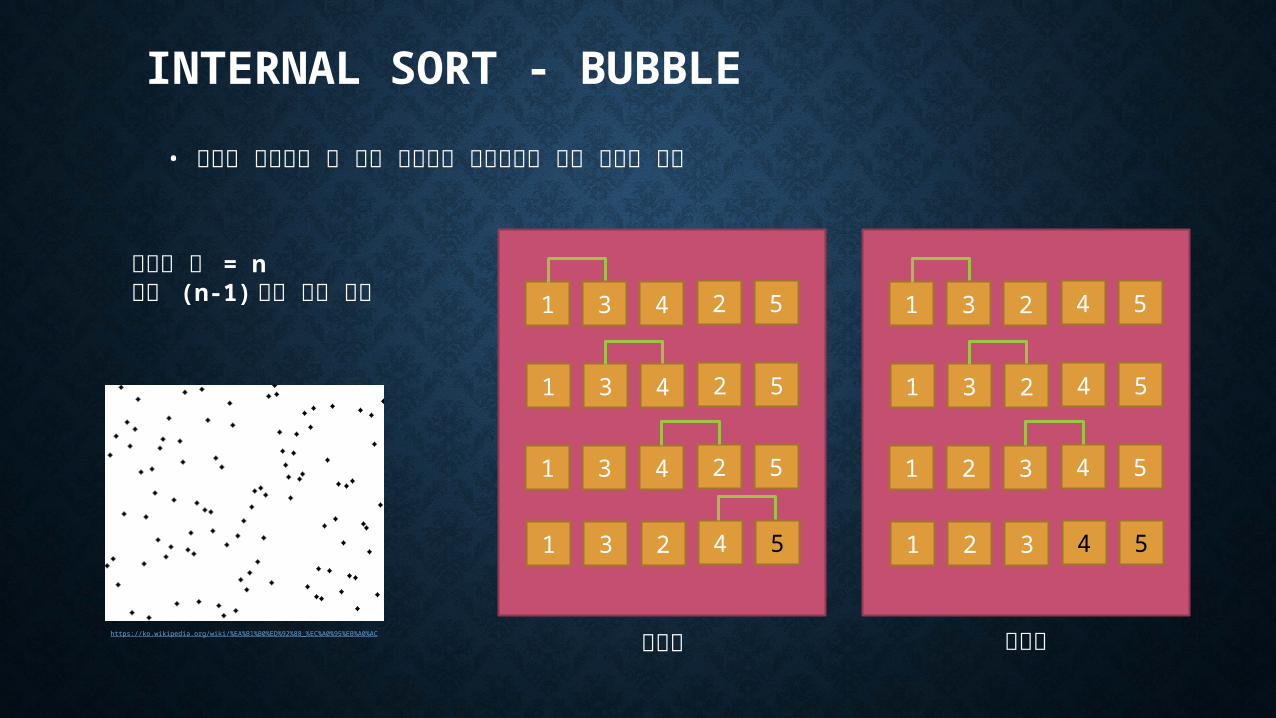
INTERNAL SORT - BUBBLE
• 인접한 레코드의 키 값을 비교해서 순서화되어 있지 않으면 교환
1 3 4 2 5
1 3 4 2 5
1 3 4 2 5
1 3 2 4 5
1 3 2 4 5
1 3 2 4 5
1 2 3 4 5
1 2 3 4 5
첫번째 두번째https://ko.wikipedia.org/wiki/%EA%B1%B0%ED%92%88_%EC%A0%95%EB%A0%AC
레코드 수 = n최대 (n-1) 회의 단계 수행

INTERNAL SORT - BUBBLE
• n = 10 레코드 (4, 1, 2, 5, 3, 6, 7, 8, 9, 10)• 입력 레코드의 내용은 키 값 자체라 가정
초기상태 : 4, 1, 2, 5, 3, 6, 7, 8, 9, 10
1 단계 : 1, 2, 4, 3, 5*, 6, 7, 8, 9, 10
2 단계 : 1, 2, 3, 4*, 5, 6, 7, 8, 9, 10
3 단계 : 1, 2, 3, 4, 5, 6, 7, 8, 9, 10
정렬 완료 부분을 기억하여불필요 연산 횟수 단축
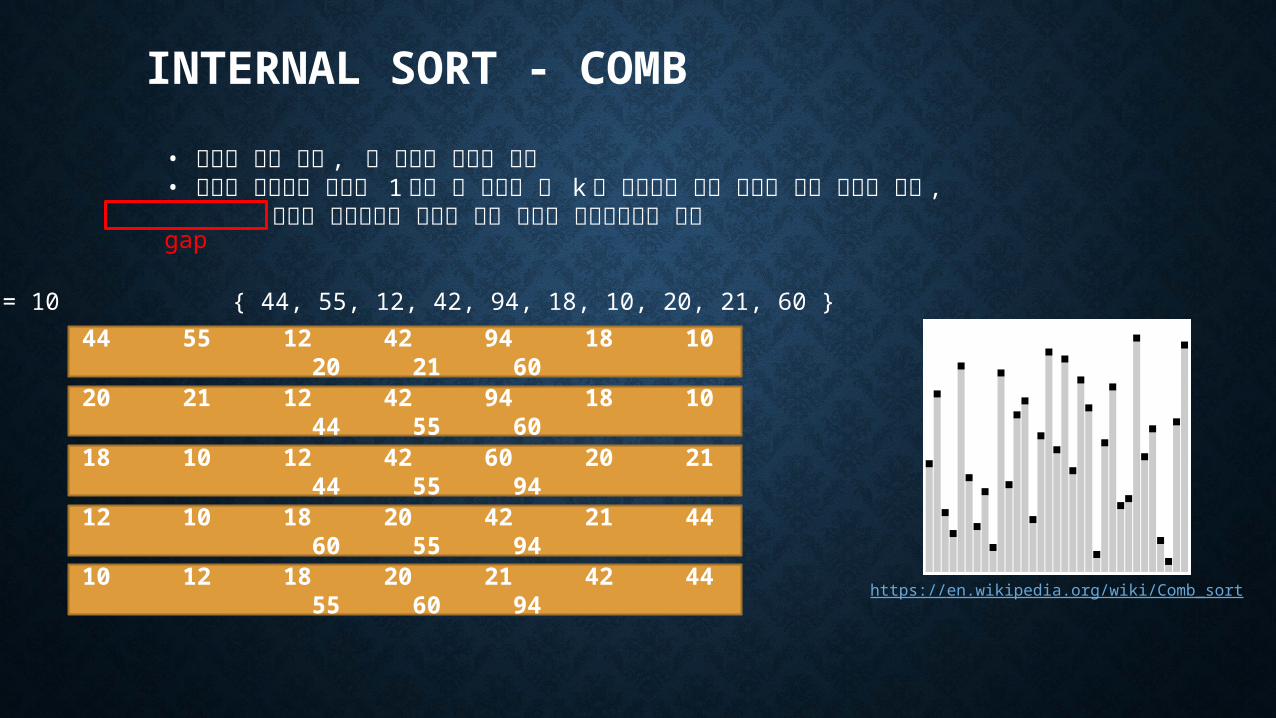
INTERNAL SORT - COMB
• 버블과 유사 코드 , 셸 정렬에 가까운 성능• 주어진 리스트의 크기를 1 보다 큰 적당한 값 k 로 나누어서 나온 결과의 정수 부분을 이용 , 계산된 정수값만큼 떨어진 곳에 위치한 데이터들끼리 비교
https://en.wikipedia.org/wiki/Comb_sort
gap
44 55 12 42 94 18 10 20 21 60
ex ) n = 10 { 44, 55, 12, 42, 94, 18, 10, 20, 21, 60 }
20 21 12 42 94 18 10 44 55 60
18 10 12 42 60 20 21 44 55 94
12 10 18 20 42 21 44 60 55 94
10 12 18 20 21 42 44 55 60 94
INTERNAL SORT - QUICK
• 다른 원소와의 비교만으로 정렬을 수행하는 비교 정렬
Quick ?
- n 개의 데이터를 정렬할 때 , 최악의 경우에는 O() 번의 비교를 수행하고 , 평균적으로 O(n log n) 번의 비교를 수행- 내부 루프는 대부분의 컴퓨터 아키텍처에서 효율적으로 작동하도록 설계 ( 메모리 참조가 지역화되어 있기 때문에 CPU 캐시의 히트율이 높아지기 때문 )- 대부분의 실질적 데이터 정렬 시 , 제곱 시간이 걸릴 확률이 없도록 설계 가능- 때문에 일반적인 경우 다른 O(n log n) 알고리즘에 비해 훨씬 빠르게 동작- 정렬을 위해 O(n log n) 만큼의 memory 를 필요로 하며 , 불안정 정렬에 속함
https://ko.wikipedia.org/wiki/%ED%80%B5_%EC%A0%95%EB%A0%AC
Q. n = 9, 입력 데이터 {2, 10, 7, 1, 8, 6, 9, 4, 3)
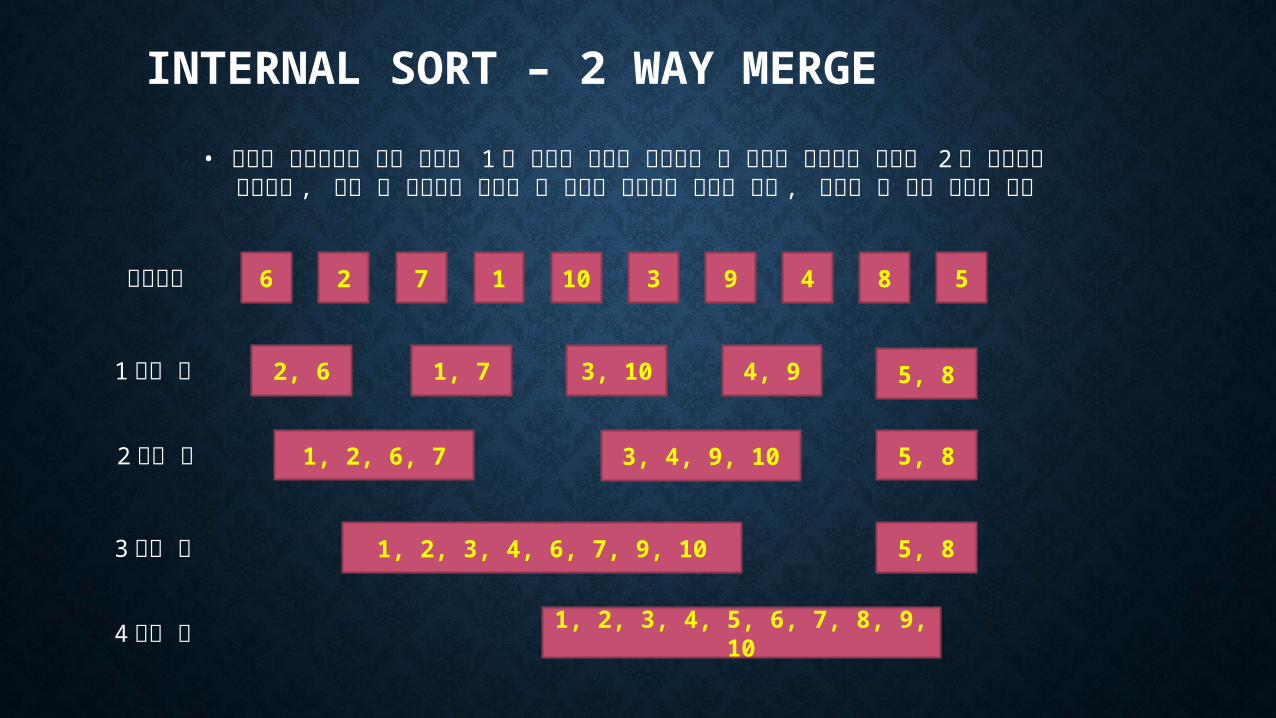
INTERNAL SORT – 2 WAY MERGE
• 주어진 레코드들을 각각 크기가 1 인 정렬된 파일로 간주하고 두 화일씩 합병하여 크기가 2 인 화일들을 생성하며 , 다시 이 화일들에 대하여 두 화일씩 합병하는 과정을 반복 , 최후의 한 개의 파일을 생성
6 2 7 110
3 9 4 8 5초기상태
2, 6 1, 7 3, 10 4, 9 5, 8
1, 2, 6, 7 3, 4, 9, 10 5, 8
1, 2, 3, 4, 6, 7, 9, 10 5, 8
1, 2, 3, 4, 5, 6, 7, 8, 9, 10
1 회전 후
2 회전 후
3 회전 후
4 회전 후
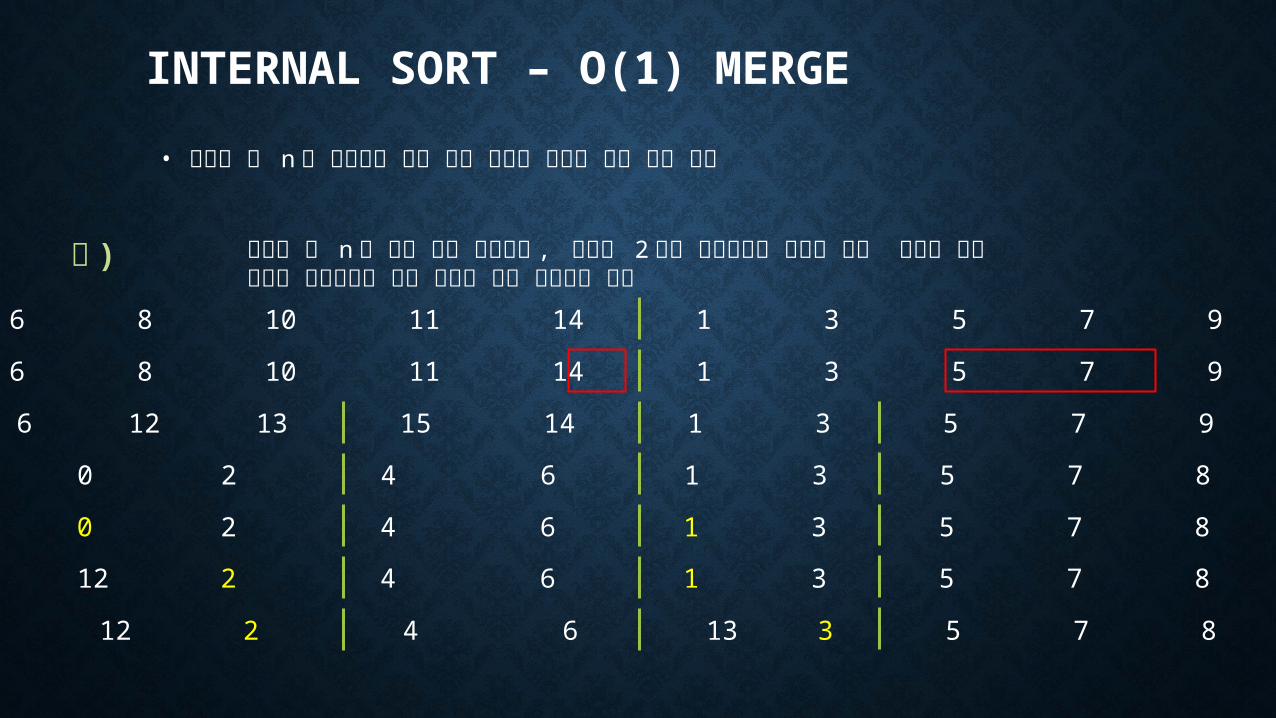
INTERNAL SORT – O(1) MERGE
• 원소의 수 n 에 비례하는 추가 기억 장소를 필요로 하는 문제 해결
예 ) 원소의 수 n 이 어떤 수의 제곱수고 , 합병될 2 개의 서브화일의 원소의 수는 배수로 가정따라서 서브화일은 개의 원소를 갖는 블록들로 구성
0 2 4 6 8 10 11 14 1 3 5 7 9 12 13 15
0 2 4 6 8 10 11 14 1 3 5 7 9 12 13 15
0 2 4 6 12 13 15 14 1 3 5 7 9 8 10 11
12 13 15 14 0 2 4 6 1 3 5 7 8 9 10 11
12 13 15 14 0 2 4 6 1 3 5 7 8 9 10 11
0 13 15 14 12 2 4 6 1 3 5 7 8 9 10 11
0 1 15 14 12 2 4 6 13 3 5 7 8 9 10 11
INTERNAL SORT – MERGE
• 합병 정렬의 문제점
n 개의 원소를 갖는 경우 대개 n 에 비례하는 추가적인 기억 장소 요구1
n 이 작을 때는 삽입 정렬보다도 비효율적2
순환을 사용할 경우 시스템 운영 ( 스택 운영 ) 비용 추가3
INTERNAL SORT – MERGE
• 리스트의 절반을 복사
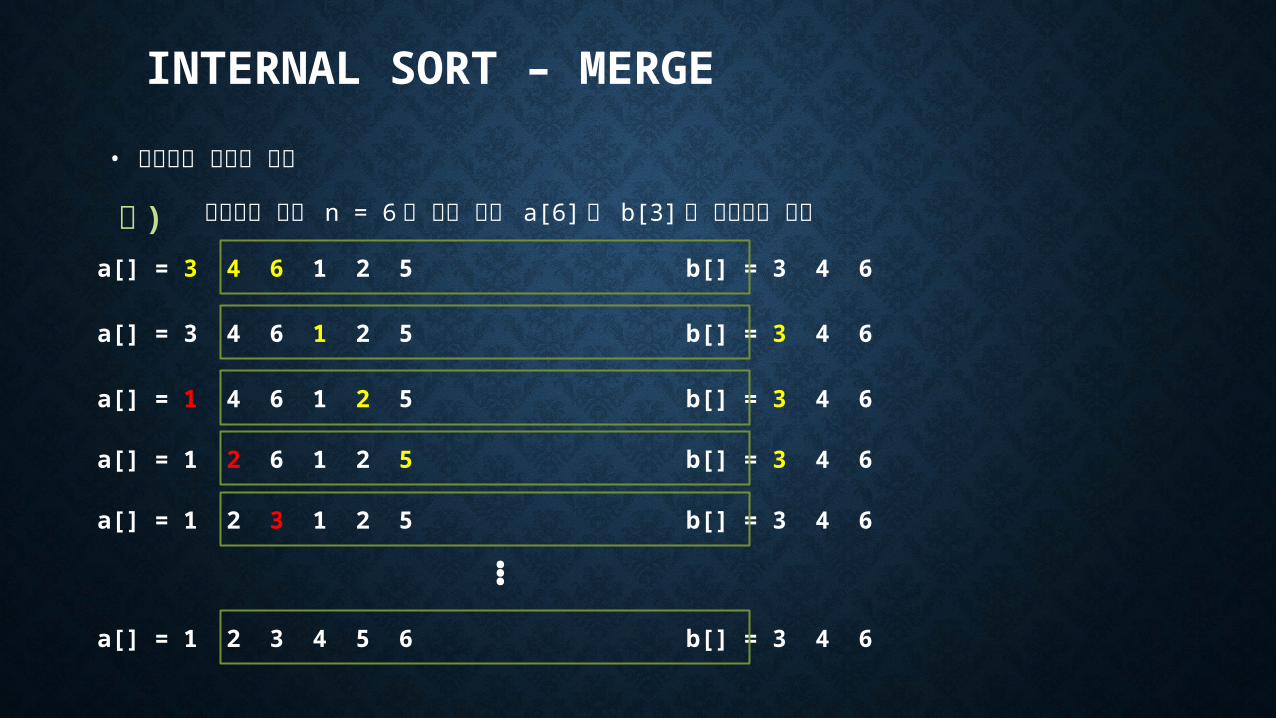
예 ) 리스트의 크기 n = 6 인 경우 배열 a[6] 과 b[3] 을 이용하여 정렬
a[] = 3 4 6 1 2 5 b[] = 3 4 6
a[] = 3 4 6 1 2 5 b[] = 3 4 6
a[] = 1 4 6 1 2 5 b[] = 3 4 6
a[] = 1 2 6 1 2 5 b[] = 3 4 6
a[] = 1 2 3 1 2 5 b[] = 3 4 6
…
a[] = 1 2 3 4 5 6 b[] = 3 4 6
INTERNAL SORT – MERGE
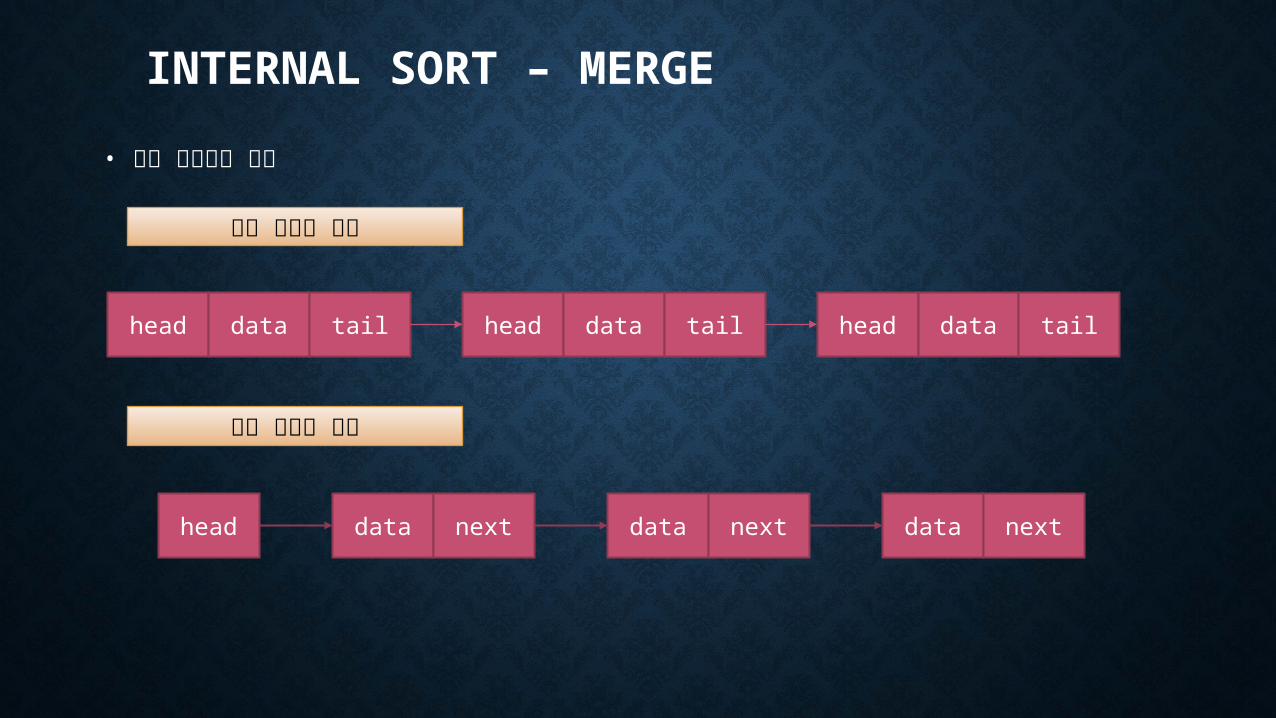
• 연결 리스트를 사용
기존 데이터 구조
연결 리스트 구조
data next data next data nexthead
head data tailhead data tail head data tail

INTERNAL SORT – MERGE
• 그외
순환을 반복으로 수정하는 방법 순환은 source 외형은 단순하나 stack 운영 등의 추가 경비가 요구 순환을 비순환으로 변경
다른 정렬 방법을 이용 불필요한 합병을 가능한 막는 방법 즉 , 합병 시 크기가 작은 서브화일을 다른 정렬 방법을 사용하여 정렬함으로써 전반적인 합병의 속도를 향상시킬 수 있도록 하는 방법 정렬할 서브화일의 크기를 결정하는 기준을 정한 후 그 크기보다 작으면 다른 방법의 내부 정렬을 사용 , 그렇지 않은 경우 합병 이 때 삽입 정렬이 자주 이용
INTERNAL SORT – HEAP
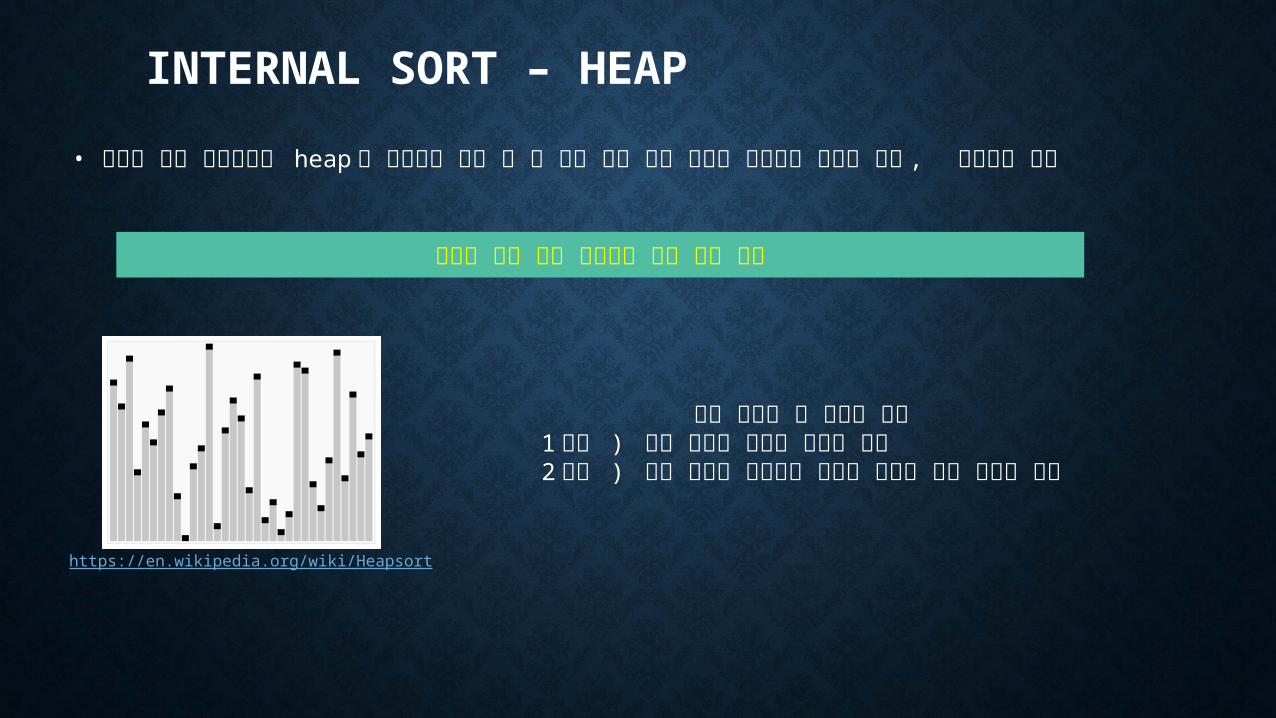
• 정렬할 입력 레코드들을 heap 로 구성하고 가장 큰 키 값을 갖는 루트 노드를 제거하는 과정을 반복 , 정렬하는 기법
추가의 기억 장소 낭비없이 높은 수행 효율
https://en.wikipedia.org/wiki/Heapsort
히프 정렬은 두 단계로 수행1 단계 ) 입력 리스트 파일을 히프로 변환2 단계 ) 루트 노드를 출력하고 나머지 트리를 다시 히프로 구성

INTERNAL SORT – LIST
• 대개 정렬 방법들은 많은 데이터 이동을 요구• 연결 리스트로 구성하여 데이터 이동을 줄임
• 물리적으로 데이터 이동 연결 링크를 수정함으로 정렬
n = 10, 입력 데이터 리스트 (23, 3, 29, 1, 27, 7, 25, 13, 24, 19)
key 23 3 29 1 27 7 25 13 24 19
link 8 5 -1 1 2 7 4 9 6 0
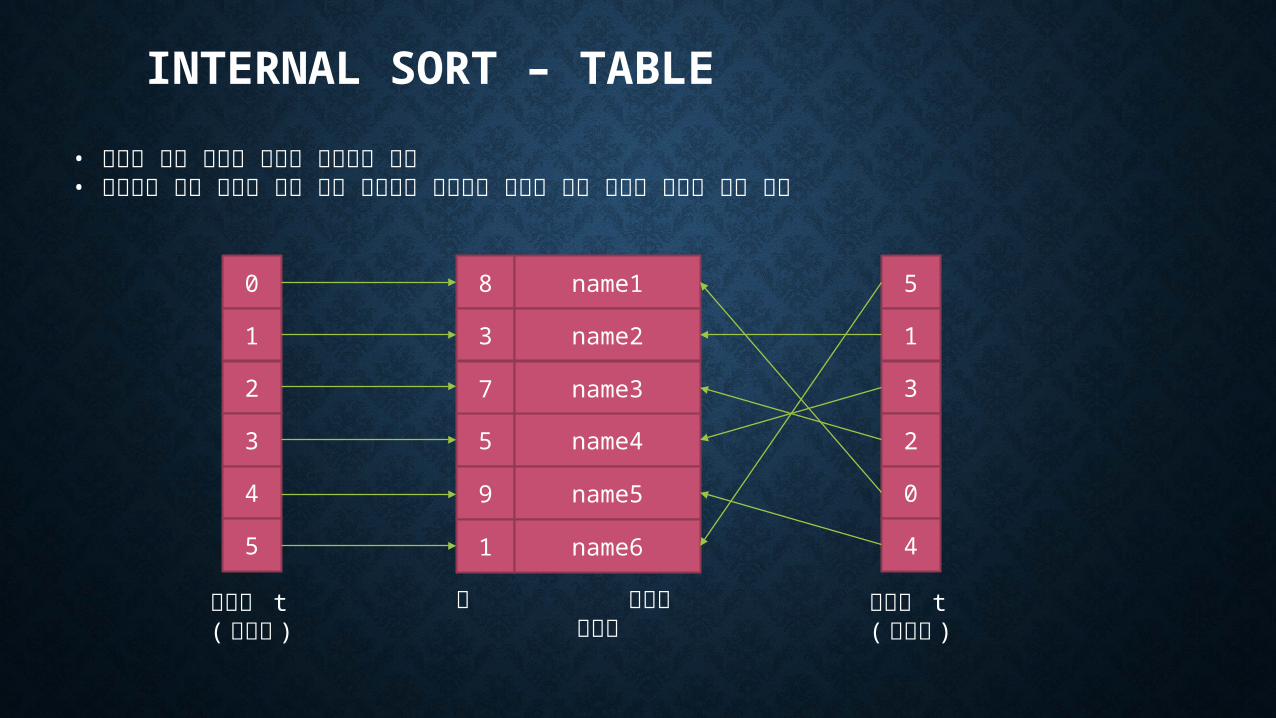
INTERNAL SORT – TABLE
• 히프나 퀵은 리스트 정렬이 적합하지 않음• 데이터의 간접 참조를 위한 보조 테이블을 이용하여 데이터 이동 횟수를 줄이는 정렬 방법
0
1
2
3
4
5
5
1
3
2
0
4
8 name1
3 name2
7 name3
5 name4
9 name5
1 name6
테이블 t( 정렬전 )
테이블 t( 정렬후 )
키 데이터 리스트

INTERNAL SORT – RADIX
• 수치 데이터를 정렬하는 데에서 시작• 정렬될 숫자의 자릿수에 순서의 기준을 둠
10 진수 (117, 116, 121) 10 진수 (121, 116, 117)
10 진수 (121, 116, 117) 10 진수 (116, 117, 121)
1
2

INTERNAL SORT 정리
• insertion method• 한 번에 한 원소씩 이미 정렬되어 있는 리스트 내에 적절한 위치에 이동
• exchange method• 순서가 맞지 않는 두 원소를 찾아 서로의 위치를 바꿔주는 방법• 더 이상 순서가 맞지 않는 두 원소를 찾지 못하면 종료
• merge method• 두 개 이상의 정렬된 파일을 하나의 정렬된 파일로 만드는 방법
• selection method• 전체 리스트에서 가장 작은 원소 또는 가장 큰 원소를 선택하여 그 리스트로부터 분리한 다음 ,• 다시 나머지 리스트에 대해 동일한 방법을 반복하되 리스트에 원소가 남지 않을 때까지 반복
• distribution method• 원소들을 적절하게 나누는 방식을 취하고 있어서 합병법과 반대되는 방법• 기수 정렬이 대표적

EXTERNAL SORT
• 외부 정렬 기법의 작동 방식• 정렬될 레코드들을 여러 개의 서브리스트들로 나눔• 각각을 내부 정렬 방식으로 정렬 ( 정렬된 각각의 서브리스트 런 (run))• run 순차화일 , 화일들을 합병하는 과정을 반복하여 정렬 파일 생성
• 파일 정렬 / 합병 기법의 구분• 내부 정렬 방법의 종류• 주기억장치의 용량• 외부 파일에 정렬된 서브리스트들을 분배하는 방법• 한번의 합병 단계에서 합병되는 서브리스트의 수
• 외부 기억장치 종류에 따른 제약 조건• 자기 테이프 : 순차적인 방법에 의해서만 자료접근이 가능• 디스크 : 임의 접근 방법에 의해 데이터의 접근이 가능

EXTERNAL SORT
• 디스크 이용시 고려해야 하는 오버헤드 시간• 탐색 시간 : 판독 / 기록 헤드를 디스크 내의 원하는 트랙으로 위치시키는 데 필요한 시간으로 헤드가
지나가야 하는 트랙의 수에 따라 달라짐• 회전 지연 시간 : 판독 / 기록 헤드를 디스크의 결정된 트랙 내에서 원하는 섹터로 위치시키는 데 필요한
시간• 전송 시간 : 디스크에서 주기억장치로 또는 주기억장치에서 디스크로 전송하는데 필요한 시간
• 외부 정렬 기법의 성능 향상• 합병 단계에 앞서 서브리스트의 크기를 가능한 한 크게 함으로써 합병되어야 할 서브리스트의 수를
최소화 가능• 한번에 합병되는 서브리스트의 수가 많을수록 외부 파일의 정렬에 필요한 단계의 횟수가 줄어든다• 합병을 수행할 때 뿐만 아니라 합병을 위해 서브리스트들을 외부 기억장치에 분배할 때도 입출력작업이
필요
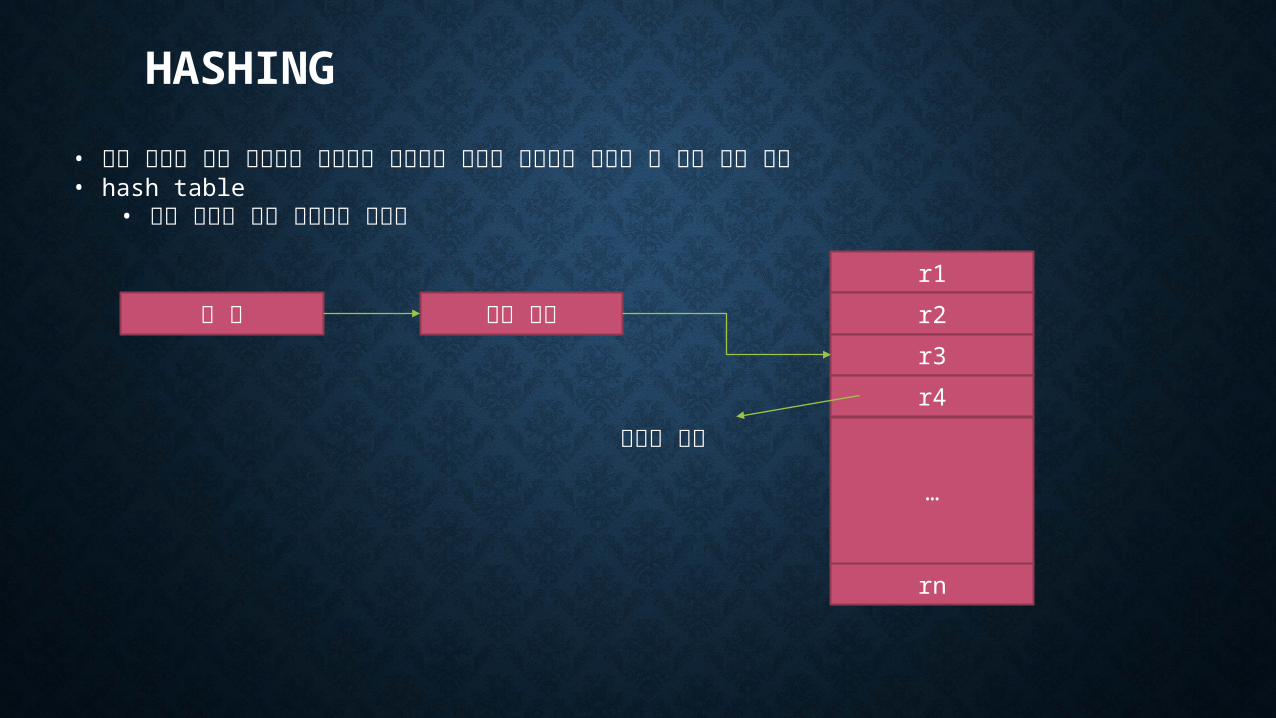
HASHING
• 해시 함수와 해시 테이블을 이용하여 데이터를 빠르게 저장하고 탐색할 수 있게 하는 방법• hash table
• 해시 함수에 의해 참조되는 테이블
키 값 해시 함수r1
r2
r3
r4
…
rn
데이터 버킷

HASH FUNCTION
• 해시 테이블에서 키 값을 주소로 변환하는 데 사용되는 함수• 즉 , 해시 함수는 데이터들의 키 값의 집합 K 에서 해시 테이블의 주소 집합 A 로 가는 함수 h: KA 이다 .