Embed Size (px)
DESCRIPTION
Л5 Байесовские алгоритмы
Citation preview

Введение в Data ScienceЗанятие 4. Naive Bayes
и классификация текстов
Николай Анохин Михаил Фирулик
23 марта 2014 г.

План занятия
Обработка текстов
Naive Bayes

Data Mining vs Text Mining
Data Mining:извлечение неочевиднойинформации
Text Mining:извлечение очевиднойинформации
ТрудностиI Огромные объемыI Отстутсвие структуры

Задачи Text Mining
I Суммаризация текстааггрегация новостей
I Классификация и кластеризация документовкатегоризация, фильтрация спама, эмоции
I Извлечение метаданныхопределение языка, автора, тегирование
I Выделение сущностейместа, люди, компании, почтовые адреса
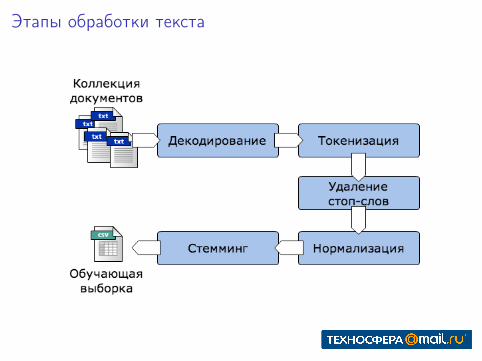
Этапы обработки текста

Декодирование
Def.перевод последовательности байт в последовательность символов
I Распаковкаplain/.zip/.gz/...
I КодировкаASCII/utf-8/Windows-1251/...
I Форматcsv/xml/json/doc...
Кроме того: что такое документ?

Разбиение на токены
Def.разбиение последовательности символов на части (токены),возможно, исключая из рассмотрения некоторые символы
Наивный подход: разделить строку пробелами и выкинуть знакипрепинания
Трисия любила Нью-Йорк, поскольку любовь к Нью-Йоркумогла положительно повлиять на ее карьеру.
Проблемы:I [email protected], 127.0.0.1I С++, C#I York University vs New York UniversityI Зависимость от языка
(“Lebensversicherungsgesellschaftsangestellter”, “l’amour”)Альтернатива: n-граммы

Разбиение на токены
>>> from nltk.tokenize import RegexpTokenizer>>> tokenizer = RegexpTokenizer(’\w+|[^\w\s]+’)>>> s = u’Трисия любила Нью-Йорк, поскольку любовь \... к Нью-Йорку могла положительно повлиять на ее карьеру.’>>> for t in tokenizer.tokenize(s)[:7]: print t + " ::",...Трисия :: любила :: Нью :: - :: Йорк :: , :: поскольку ::

Стоп-слова
Def.Наиболее частые слова в языке, не содержащие никакойинформации о содержании текста
>>> from nltk.corpus import stopwords>>> for sw in stopwords.words(’russian’)[1:20]: print sw,...в во не что он на я с со как а то все она так его но да ты
Проблема: “To be or not to be"

Нормализация
Def.Приведение токенов к единому виду для того, чтобы избавиться отповерхностной разницы в написании
ПодходыI сформулировать набор правил, по которым преобразуется токен
Нью-Йорк → нью-йорк → ньюйорк → ньюиорк
I явно хранить связи между токенамимашина → автомобиль, Windows 6→ window

Нормализация
>>> s = u’Нью-Йорк’>>> s1 = s.lower()>>> print s1нью-йорк>>> s2 = re.sub(ur"\W", "", s1, flags=re.U)>>> print s2ньюйорк>>> s3 = re.sub(ur"й", u"и", s2, flags=re.U)>>> print s3ньюиорк

Стемминг и Лемматизация
Def.Приведение грамматических форм слова и однокоренных слов кединой основе (lemma):
I Stemming – с помощью простых эвристических правилI Porter (1980)
5 этапов, на каждом применяется набор правил, таких как
sses → ss (caresses → caress)
ies → i (ponies → poni)I Lovins (1968)I Paice (1990)I еще 100500
I Lemmatization – с использованием словарей иморфологического анализа

Стемминг
>>> from nltk.stem.snowball import PorterStemmer>>> s = PorterStemmer()>>> print s.stem(’tokenization’); print s.stem(’stemming’)tokenstem>>> from nltk.stem.snowball import RussianStemmer>>> r = RussianStemmer()>>> print r.stem(u’Авиация’); print r.stem(u’национальный’)авиацнациональн
Наблюдениедля сложных языков лучше подходит лемматизация
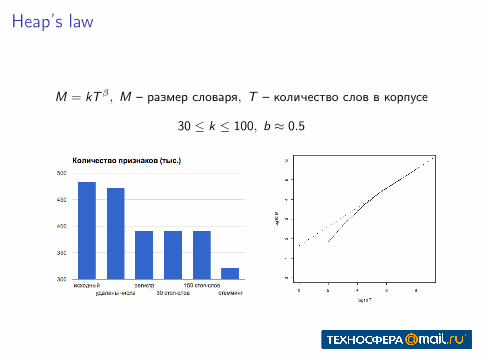
Heap’s law
M = kTβ , M – размер словаря, T – количество слов в корпусе
30 ≤ k ≤ 100, b ≈ 0.5

Представление документов
Boolean Model. Присутствие или отсутствие слова в документе
Bag of Words. Порядок токенов не важенПогода была ужасная, принцесса была прекрасная.Или все было наоборот?
КоординатыI Мультиномиальные: количество токенов в документеI Числовые: взвешенное количество токенов в документе
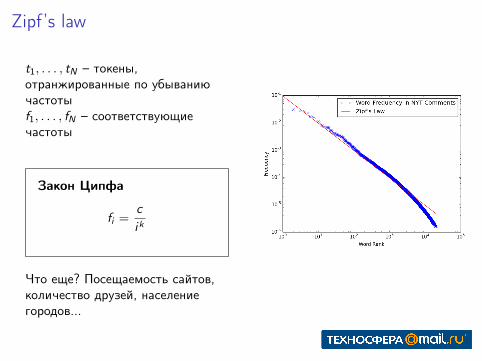
Zipf’s law
t1, . . . , tN – токены,отранжированные по убываниючастотыf1, . . . , fN – соответствующиечастоты
Закон Ципфа
fi =c
ik
Что еще? Посещаемость сайтов,количество друзей, населениегородов...

Задача
Дана коллекция, содержащая 106 (не уникальных) токенов.Предполагая, что частоты слов распределены по закону
fi =c
(i + 10)2,
оценитеI количество вхождений наиболее часто встречающегося словаI количество слов, котоые встречаются минимум дважды
Подсказка:∑∞
i=111i2 ≈ 0.095

BoW & TF-IDF
Количество вхождений слова t в документе d
TFt,d = term−frequency(t, d)
Количество документов из N возможных, где встречается t
DFt = document−fequency(t)
IDFt = inverse−document−frequency(t) = logN
DFt
TF-IDFTF−IDFt,d = TFt,d × IDFt
ПримерКоллекция документов: Cersei Lannister, Tyrion Lannisterd1 = {cersei:1, tyrion:0, lannister:0}d2 = {cersei:0, tyrion:1, lannister:0}

Байесовский классификатор
Даноx ∈ X – описание документа d из коллекции DCk ∈ C , k = 1, . . . ,K – целевая переменная
Теорема Байеса
P(Ck |x) =p(x|Ck)p(Ck)
p(x)∝ p(x|Ck)p(Ck)
Принцип Maximum A-Posteriori
CMAP = argmaxk
p(Ck |x)

Naive BayesXj – токен на j-м месте в документе x, xi ∈ V – слово из словаря V
Предположения1. conditional independence
p(Xi = xi ,Xj = xj |Ck) = p(Xi = xi |Ck)p(Xi = xi |Ck)
2. positional independence
P(Xi = xi |Ck) = P(Xj = xi |Ck) = P(X = xi |Ck)
Получаем
p(x|Ck) = p(X1 = x1, . . . ,X|x| = x|x||Ck) =
|x|∏i=1
p(X = xi |Ck)
Почему NB хорошо работает?Корректная оценка дает правильное предсказание, но правильноепредсказание не требует корректной оценки

Варианты NB
MAP
CMAP = argmaxk
|x|∏i=1
p(X = xi |Ck)P(Ck) =
= argmaxk
logP(Ck) +
|x|∑i=1
logP(X = xi |Ck)
Априорные вероятности
P(Ck) = NCk/N
Likelihood p(X = xi |Ck)
I BernoulliNB P(X = xi |Ck) = Dxi ,Ck/DCk
, D – кол-во документовI MultinomialNB P(X = xi |Ck) = Txi ,Ck
/TCk, T – кол-во токенов
I GaussianNB P(X = xi |Ck) = N (µk , σ2k), параметры из MLE

Обучение NB
train_nb(D, C):V = словарь токенов из DN = количество документов в Dfor Ck ∈ C:
NCk= количество документов класса Ck
p(Ck) = NCk/N
DCk= документы класса Ck
for xi ∈ V :p(X = xi |Ck) = считаем согласно выбранному варианту
возвращаем V , p(Ck), p(X = xi |Ck)
Алгоритмическая сложность: O(|D|〈|x|〉+ |C ||V |)

Применение MultinomialNB
apply_nb(d, V , p(Ck), p(xi |Ck), C):x = разбиваем d на токены, используя Vfor Ck ∈ C:
score(Ck |x)+= log p(Ck)for xi ∈ x:
score(Ck |x)+= log p(xi |Ck) считаем согласно выбранномуварианту
возвращаем argmax score(Ck |x)
Алгоритмическая сложность: O(|C ||x|)

Задача
d Текст Класс1 котики такие котики мимими2 котики котики няшки мимими3 пушистые котики мимими4 морские котики мокрые не мимими5 котики котики мокрые морские котики ???
С помощью алгоритма MultinomialNB вычислить p(мимими|d5)

Сглаживание
Проблема: p(пушистые|не мимими) = 0
Решение:p(X = xi |Ck) =
Txi ,Ck+ α
TCk+ α|V |
если α ≥ 1 – сглаживание Лапласа, если 0 ≤ α ≤ 1 – Лидстоуна
УпражнениеС учетом сглаживания вычислить
p(пушистые|не мимими), p(пушистые|мимими).
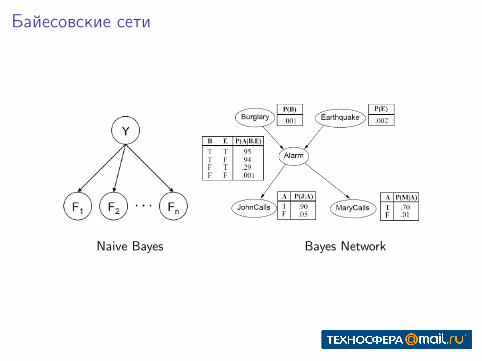
Байесовские сети
Naive Bayes Bayes Network

Итоги
+ Генеративная модель+ (Удивительно) неплохо работает+ Стабилен при смещении выборки (aka concept drift)+ Оптимальный по производительности
– Наивные предположения– Требует отбора признаков

Определение языка текста
Определение языка на основании n-грамм
I НормализацияНижний регистр, заменяем акценты на обычные буквы
I ТокенизацияРазбиваем документы на n-граммы
I Выбор признаковБерем топ-k признаков из каждого языка
I Инициализация моделиИспользуем один из вариантов NB из sklearn
I АнализКак зависит точность предсказания от n и k?

Домашнее задание 3
Байесовский классификаторРеализовать
I алгоритм Naive Bayes для задачи классификацииI алгоритм Naive Bayes для задачи регрессии
Варианты: multinomial, bernoulli, gaussian
Ключевые датыI До 2014/03/29 00.00 выбрать задачу и ответственного в группеI До 2014/04/05 00.00 предоставить решение задания

Спасибо!
Обратная связь





























