Embed Size (px)
Citation preview

Quality in CloudsMichał Dec

Czym jest Voluum Tracker?
1. dedykowany system dla marketingu afiliacyjnego (cloud hosted),2. prawie 250 mln transakcji obsługiwanych każdego dnia,3. w szczycie blisko 3500 transakcji na sekundę,4. serwery w każdym regionie AWS (9 regionów): łącznie ok. 50-55 serwerów,5. 85GB danych produkcyjnych każdego dnia,6. 80GB logów z poziomu LB,7. 8GB logów systemowych,8. własne rozwiązanie DB

Amazon Webservices“Amazon Web Services offers a broad set of global compute, storage, database, analytics, application,
and deployment services that help organizations move faster, lower IT costs, and scale applications.”
● Obrazy instancji (AMI)
● Serwery (Elastic Cloud Computing)
● Load Balancing + AutoScaling + Launch Config
● Routing
● S3, SQS, SNS
● DynamoDB
● ….
AWS - 5 razy większy niż 14 pozostałych konkurentów...razem wziętych.
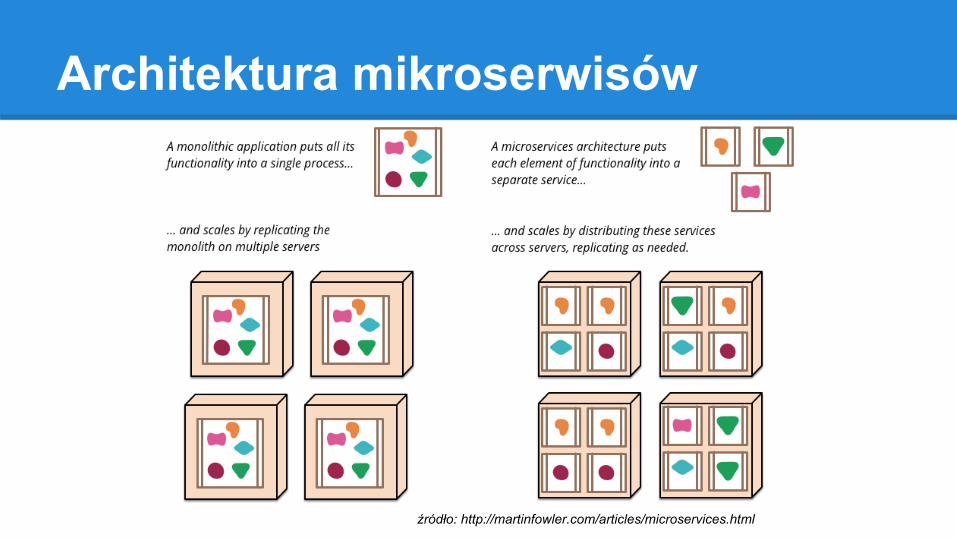
Architektura mikroserwisów
źródło: http://martinfowler.com/articles/microservices.html
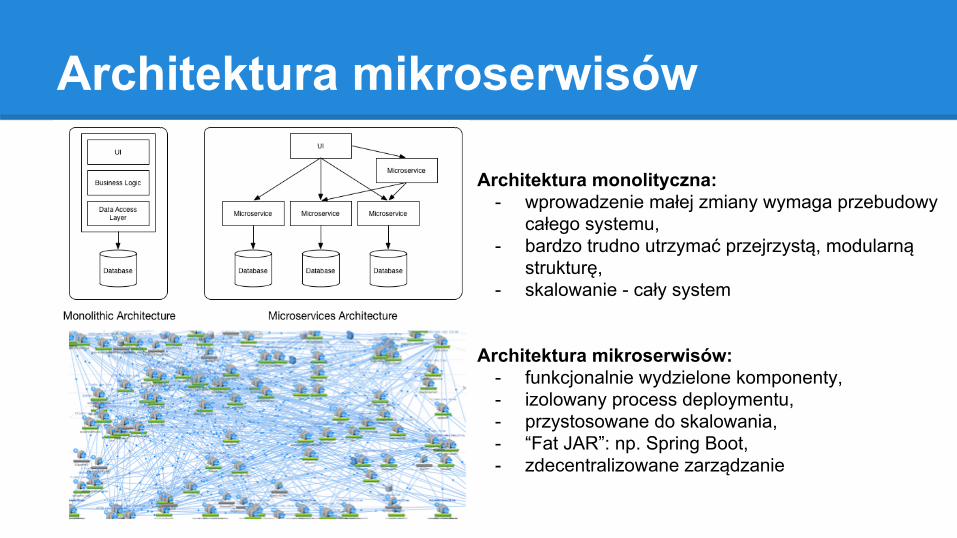
Architektura mikroserwisów
Architektura monolityczna:- wprowadzenie małej zmiany wymaga przebudowy
całego systemu,- bardzo trudno utrzymać przejrzystą, modularną
strukturę,- skalowanie - cały system
Architektura mikroserwisów:- funkcjonalnie wydzielone komponenty,- izolowany process deploymentu,- przystosowane do skalowania,- “Fat JAR”: np. Spring Boot,- zdecentralizowane zarządzanie

“Rambo Architecture”1. każdy serwis powinien funkcjonować mimo degradacji serwisów, od których zależy
(przynajmniej przez jakiś czas...),2. każdy serwis powinien być odporny na degradację jakości odpowiedzi serwisów, od
których zależy,3. automatyczne analiza w czasie rzeczywistym stanu serwisów - odłączanie
niestabilnych elementów systemu,4. testy serwisu w sytuacji degradacji zależnych systemów.
cache, failover policy, retry policy, data replication
Serwis zależy od 30 innych serwisów - każdy ma 99,99% uptime -> sam serwis ma 99,7% uptime - 2h downtime każdego miesiąca!

Testowalny system (?)Problem: niskie pokrycie testami, które są fatalnej jakości a może… system, którego nie można efektywnie testować!
● powszechny dostęp do kodu źródłowego + kod testów jest kodem produkcyjnym,● łatwy i przejrzysty proces deploymentu (“Fat JAR”, Spring Boot, AWS deployment),● reużywalne komponent (commons) + “bill of materials” (BOM) DM,● przejrzysty proces migracji DB (Flyway),● przejrzyste i ujednolicone API

Developer + STE● deployment kilkanaście razy w tygodniu -> nie ma testów manualnych,
● developer odpowiada za swój kod (również o 4 nad ranem:),
● developerzy piszą kod testowy,
● STE odpowiada za architekturę testów (“..tworzy kod, który pozwala developerom
testować swój kod...”)
● bug fixing ma priorytet,
● review + pair programming
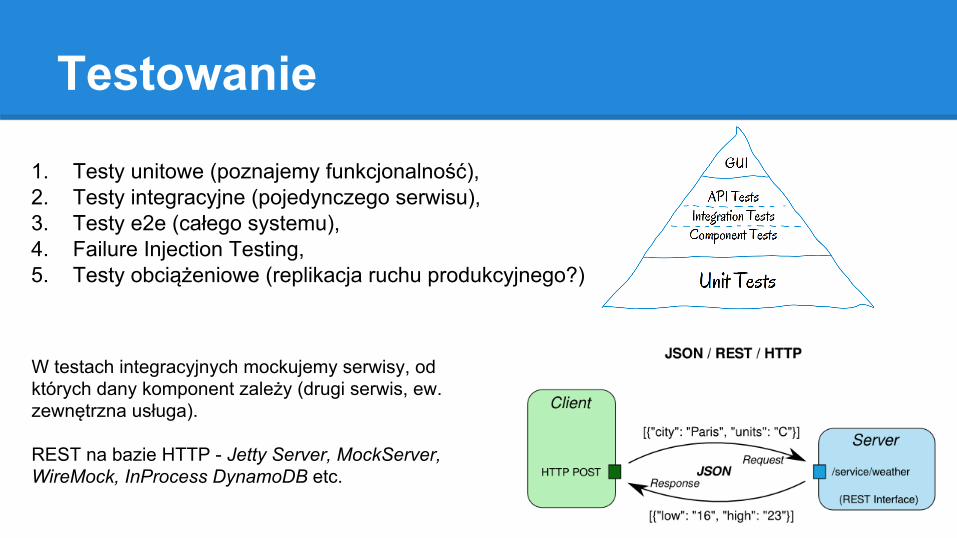
Testowanie
1. Testy unitowe (poznajemy funkcjonalność),2. Testy integracyjne (pojedynczego serwisu),3. Testy e2e (całego systemu),4. Failure Injection Testing,5. Testy obciążeniowe (replikacja ruchu produkcyjnego?)
W testach integracyjnych mockujemy serwisy, od których dany komponent zależy (drugi serwis, ew. zewnętrzna usługa).
REST na bazie HTTP - Jetty Server, MockServer, WireMock, InProcess DynamoDB etc.

Testowanie - mockingnew MockServerClient("localhost", 9999) .when( request() .withMethod("POST") .withPath("/login") .withQueryStringParameters( new Parameter("returnUrl", "/account") ) .withCookies( new Cookie("sessionId", "2By8LOhBmaW5nZXJwcmludCIlMDAzMW") ) .withBody("{username: 'foo', password: 'bar'}"), Times.exactly(1) ) .respond( response() .withStatusCode(401) .withHeaders( new Header("Content-Type", "application/json; charset=utf-8"), new Header("Cache-Control", "public, max-age=86400") ) .withBody("{ message: 'incorrect username and password combination' }") .withDelay(new Delay(TimeUnit.SECONDS, 1)) );

DSL
@Test(expectedExceptions = {ResponseValidationException.class})
public void shouldNotCreateLanderIfUrlContainsDoublequote() throws Exception {
//Given
LanderModelBuilder lander =
newLander().withUrl("http://landers.com/bestlander?param1={country}¶m2={os}\"></head><body><script>alert('asd')</script>")
.withCountry(CountryModel.PL)
.withNamePostfix("NewLander1")
.withNumberOfOffers(2);
//When
createLander(lander);
//Then
fail("Exception due to validation error should be thrown");
}
public EntityResponse<T, JsonNode> create(T modelBean) {
log.debug("About to create entity of type {}. Entity: \'{}\'", this.type, modelBean);
Response response = this.restClient.executeJsonPost(this.getPath(), this.resourceCodec.serialize(modelBean));
log.info("Created entity of type {} with id: {} - \'{}\'", new Object[]{this.type, this.getId(modelBean), this.getName(modelBean)});
return this.createResponse(response, modelBean, this.resourceCodec);
}
DSL + Fluent Interface

DSL
DSL + Fluent Interface//When
LanderModel lander = createLander(
//Given
newLander()
.withUrl("http://landers.com/bestlander?param1={country}¶m2={os")
.withCountry(CountryModel.PL)
.withNamePostfix("NewLander1")
.withNumberOfOffers(2)
);
//Then
assertThat(lander)
.hasName("Poland - NewLander1")
.hasNamePostfix("NewLander1")
.hasClientId(null)
.hasCountry(CountryModel.PL)
.hasNumberOfOffers("2")
.hasUrl("http://landers.com/bestlander?param1={country}¶m2={os");

TestowanieCzy infrastruktura testowa jest identyczna z produkcyjną?
Jak długo jesteśmy w stanie pozwolić sobie na replikację ruchu produkcyjnego?
Zawsze nadchodzi moment gdy koszty replikacji ruchu produkcyjnego/utrzymania infrastruktury są zby wysokie. Testujmy na Produkcji:)

Chaos engineer - Simian ArmyChaos Monkey - zabija losowo wybraną inctancję na środowisku produkcyjnym,Latency Monkey - wprowadz opóźnienia w komunikacji klient - serwer symulując degradację stanu systemuConformity Monkey - skanuje instance w poszukiwaniu, tych które odbiegaja pod względem konfiguracji/wydajności itd.Chaos Gorilla - symuluję degradację całego regionu AWS
EC2 Maintenance Update - blisko 2700 serwerów Cassandry, 218 zostało zresetowanych, 22 serwery nie wstały po restarcie.
“...data was deleted by a maintenance process that was inadvertently run against the production ELB state data” - 24 December 2012, AWS outage

Production Code CoverageCanary Deployment
Production Code Coverage● wykrywanie martwych funkcjonalności,● uszczelnianie testów najczęściej wykorzystywanych funkcjonalności
Canary Deployment● deployment na niewielką część instancji (jeden region, 1/10 serwerów, 2 klientów...),● analiza zachowanie zdeployowanego serwisu,● szybki rollback, niewielki negatywny wpływ regresji

Monitoring aplikacjiZbieranie i raportowanie (Codehale Metrics) metryk do zewnętrznego systemu (Graphite):
● wskaźników (np. długość kolejki)● liczników (np. ilość requestów/sekunda)● histogramy● czas operacji (np. czas odpowiedzi DB)
Amazon CloudWatch - metryki z poziomu instancji (CPU, dysk, sieć...) lub LoadBalancera (czas odpowiedzi, ilość requestów, błędy...)
Loggly - analiza logów aplikacji






























