Embed Size (px)
Citation preview

@doanduyhai
Real time data processing with Spark & Cassandra DuyHai DOAN, Technical Advocate

@doanduyhai
Who Am I ?!Duy Hai DOAN Cassandra technical advocate • talks, meetups, confs • open-source devs (Achilles, …) • OSS Cassandra point of contact
[email protected] @doanduyhai
2

@doanduyhai
Datastax!• Founded in April 2010
• We contribute a lot to Apache Cassandra™
• 400+ customers (25 of the Fortune 100), 200+ employees
• Headquarter in San Francisco Bay area
• EU headquarter in London, offices in France and Germany
• Datastax Enterprise = OSS Cassandra + extra features
3

Spark & Cassandra Integration!
Spark & its eco-system!Cassandra & token ranges!
Stand-alone cluster deployment!!

@doanduyhai
What is Apache Spark ?!Created at Apache Project since 2010 General data processing framework MapReduce is not the A & ΩΩ One-framework-many-components approach
5

@doanduyhai
Spark characteristics!Fast • 10x-100x faster than Hadoop MapReduce • In-memory storage • Single JVM process per node, multi-threaded
Easy • Rich Scala, Java and Python APIs (R is coming …) • 2x-5x less code • Interactive shell
6

@doanduyhai
Spark code example!Setup
Data-set (can be from text, CSV, JSON, Cassandra, HDFS, …)
val$conf$=$new$SparkConf(true)$$ .setAppName("basic_example")$$ .setMaster("local[3]")$$val$sc$=$new$SparkContext(conf)$
val$people$=$List(("jdoe","John$DOE",$33),$$$$$$$$$$$$$$$$$$$("hsue","Helen$SUE",$24),$$$$$$$$$$$$$$$$$$$("rsmith",$"Richard$Smith",$33))$
7

@doanduyhai
RDDs!RDD = Resilient Distributed Dataset val$parallelPeople:$RDD[(String,$String,$Int)]$=$sc.parallelize(people)$$val$extractAge:$RDD[(Int,$(String,$String,$Int))]$=$parallelPeople$$ $ $ $ $ $ .map(tuple$=>$(tuple._3,$tuple))$$val$groupByAge:$RDD[(Int,$Iterable[(String,$String,$Int)])]=extractAge.groupByKey()$$val$countByAge:$Map[Int,$Long]$=$groupByAge.countByKey()$
8

@doanduyhai
RDDs!RDD[A] = distributed collection of A • RDD[Person] • RDD[(String,Int)], …
RDD[A] split into partitions Partitions distributed over n workers à parallel computing
9

@doanduyhai
Spark eco-system!
Local Standalone cluster YARN Mesos
Spark Core Engine (Scala/Java/Python)
Spark Streaming MLLib GraphX Spark SQL
Persistence
Cluster Manager
…
10

@doanduyhai
Spark eco-system!
Local Standalone cluster YARN Mesos
Spark Core Engine (Scala/Java/Python)
Spark Streaming MLLib GraphX Spark SQL
Persistence
Cluster Manager
…
11

@doanduyhai
What is Apache Cassandra?!Created at Apache Project since 2009 Distributed NoSQL database Eventual consistency (A & P of the CAP theorem) Distributed table abstraction
12
@doanduyhai
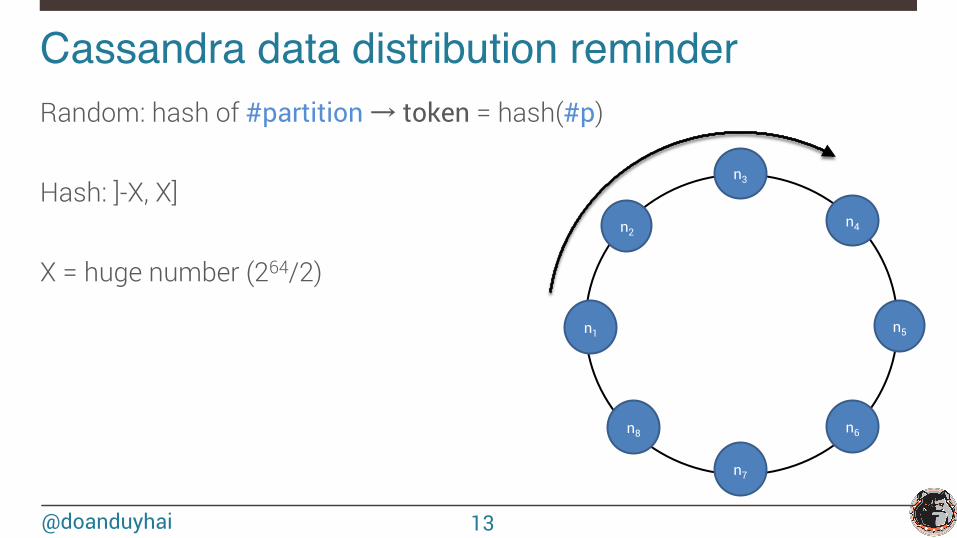
Cassandra data distribution reminder!Random: hash of #partition → token = hash(#p) Hash: ]-X, X] X = huge number (264/2)
n1
n2
n3
n4
n5
n6
n7
n8
13

@doanduyhai
Cassandra token ranges!A: ]0, X/8] B: ] X/8, 2X/8] C: ] 2X/8, 3X/8] D: ] 3X/8, 4X/8] E: ] 4X/8, 5X/8] F: ] 5X/8, 6X/8] G: ] 6X/8, 7X/8] H: ] 7X/8, X] Murmur3 hash function
n1
n2
n3
n4
n5
n6
n7
n8
A
B
C
D
E
F
G
H
14
@doanduyhai
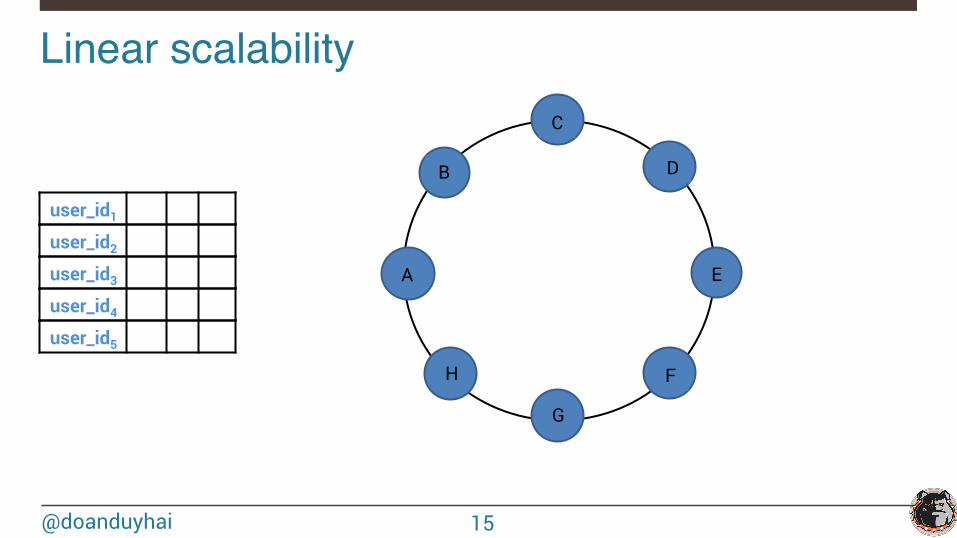
Linear scalability!
n1
n2
n3
n4
n5
n6
n7
n8
A
B
C
D
E
F
G
H
user_id1
user_id2
user_id3
user_id4
user_id5
15

@doanduyhai
Linear scalability!
n1
n2
n3
n4
n5
n6
n7
n8
A
B
C
D
E
F
G
H
user_id1
user_id2
user_id3
user_id4
user_id5
16

@doanduyhai
Cassandra Query Language (CQL)!
INSERT INTO users(login, name, age) VALUES(‘jdoe’, ‘John DOE’, 33);
UPDATE users SET age = 34 WHERE login = ‘jdoe’;
DELETE age FROM users WHERE login = ‘jdoe’;
SELECT age FROM users WHERE login = ‘jdoe’;
17

@doanduyhai
Why Spark on Cassandra ?!Reliable persistent store (HA)
Structured data (Cassandra CQL à Dataframe API)
Multi data-center !!!
For Spark
18

@doanduyhai
Why Spark on Cassandra ?!Reliable persistent store (HA)
Structured data (Cassandra CQL à Dataframe API)
Multi data-center !!!
Cross-table operations (JOIN, UNION, etc.)
Real-time/batch processing
Complex analytics (e.g. machine learning)
For Spark
For Cassandra
19

@doanduyhai
Use Cases!
Load data from various sources
Analytics (join, aggregate, transform, …)
Sanitize, validate, normalize data
Schema migration, Data conversion
20

@doanduyhai
Cluster deployment!C*
SparkM SparkW
C* SparkW
C* SparkW
C* SparkW
C* SparkW
Stand-alone cluster
21

@doanduyhai
Cluster deployment!
Spark Master
Spark Worker Spark Worker Spark Worker Spark Worker
Executor Executor Executor Executor
Driver Program
Cassandra – Spark placement 1 Cassandra process ⟷ 1 Spark worker
C* C* C* C*
22

Spark & Cassandra Connector!
Core API!SparkSQL!
SparkStreaming!Data Locality Implementation!

@doanduyhai
Connector architecture!All Cassandra types supported and converted to Scala types Server side data filtering (SELECT … WHERE …) Use Java-driver underneath !Scala and Java support
24

@doanduyhai
Connector architecture – Core API!Cassandra tables exposed as Spark RDDs
Read from and write to Cassandra
Mapping of C* tables and rows to Scala objects • CassandraRow • Scala case class (object mapper) • Scala tuples
25

@doanduyhai
Connector architecture – Spark SQL !
Mapping of Cassandra table to SchemaRDD • CassandraSQLRow à SparkRow • custom query plan • push predicates to CQL for early filtering
SELECT * FROM user_emails WHERE login = ‘jdoe’;
26

@doanduyhai
Connector architecture – Spark Streaming !
Streaming data INTO Cassandra table • trivial setup • be careful about your Cassandra data model !!!
Streaming data OUT of Cassandra tables ? • work in progress …
27

@doanduyhai
Remember token ranges ?!A: ]0, X/8] B: ] X/8, 2X/8] C: ] 2X/8, 3X/8] D: ] 3X/8, 4X/8] E: ] 4X/8, 5X/8] F: ] 5X/8, 6X/8] G: ] 6X/8, 7X/8] H: ] 7X/8, X]
n1
n2
n3
n4
n5
n6
n7
n8
A
B
C
D
E
F
G
H
28

@doanduyhai
Data Locality!C*
SparkM SparkW
C* SparkW
C* SparkW
C* SparkW
C* SparkW
Spark partition RDD
Cassandra tokens ranges
29

@doanduyhai
Data Locality!C*
SparkM SparkW
C* SparkW
C* SparkW
C* SparkW
C* SparkW
Use Murmur3Partitioner
30

@doanduyhai
Read data locality!Read from Cassandra
Spark shuffle operations
31

@doanduyhai
Async batch writes!Async fan-out writes to Cassandra
Spark shuffle operations
32

@doanduyhai
CassandraRDD Impl!Implementing RDD interface
abstract'class'RDD[T](…)''' @DeveloperApi'' def'compute(split:'Partition,'context:'TaskContext):'Iterator[T]''' protected'def'getPartitions:'Array[Partition]'' '' protected'def'getPreferredLocations(split:'Partition):'Seq[String]'='Nil''''''''''''''''
33

@doanduyhai
CassandraRDD Impl!getPartitions : 1. fetch all token ranges and their corresponding nodes from C*
(describe_ring method)
2. group token ranges together so that 1 Spark partition = n token ranges belonging to the same node
34

@doanduyhai
CassandraRDD Impl!def getPreferredLocations(split: Partition): Cassandra node IP corresponding to this Spark partition compute(split: Partition, context: TaskContext): read from Cassandra
35

Connector API & Usage!
Connector API!Live demo!

@doanduyhai
Connector API!Connecting to Cassandra
!//!Import!Cassandra.specific!functions!on!SparkContext!and!RDD!objects!!import!com.datastax.driver.spark._!!!!//!Spark!connection!options!!val!conf!=!new!SparkConf(true)!! .setMaster("spark://192.168.123.10:7077")!! .setAppName("cassandra.demo")!! .set("cassandra.connection.host","192.168.123.10")!//!initial!contact!! .set("cassandra.username",!"cassandra")!! .set("cassandra.password",!"cassandra")!!!val!sc!=!new!SparkContext(conf)!
37

@doanduyhai
Connector API!Preparing test data
CREATE&TABLE&test.words&(word&text&PRIMARY&KEY,&count&int);&&INSERT&INTO&test.words&(word,&count)&VALUES&('bar',&30);&INSERT&INTO&test.words&(word,&count)&VALUES&('foo',&20);&
38

@doanduyhai
Connector API!Reading from Cassandra
!//!Use!table!as!RDD!!val!rdd!=!sc.cassandraTable("test",!"words")!!//!rdd:!CassandraRDD[CassandraRow]!=!CassandraRDD[0]!!!rdd.toArray.foreach(println)!!//!CassandraRow[word:!bar,!count:!30]!!//!CassandraRow[word:!foo,!count:!20]!!!rdd.columnNames!!!!//!Stream(word,!count)!!rdd.size!!!!!!!!!!!//!2!!!val!firstRow!=!rdd.first!!//firstRow:CassandraRow=CassandraRow[word:!bar,!count:!30]!!!firstRow.getInt("count")!!//!Int!=!30!
39

@doanduyhai
Connector API!Writing data to Cassandra
!val!newRdd!=!sc.parallelize(Seq(("cat",!40),!("fox",!50)))!!!//!newRdd:!org.apache.spark.rdd.RDD[(String,!Int)]!=!ParallelCollectionRDD[2]!!!!!newRdd.saveToCassandra("test",!"words",!Seq("word",!"count"))!
SELECT&*&FROM&test.words;&&&&&&word&|&count&&&&&&999999+9999999&&&&&&bar&|&&&&30&&&&&&foo&|&&&&20&&&&&&cat&|&&&&40&&&&&&fox&|&&&&50&&
40

Demo
https://github.com/doanduyhai/Cassandra-Spark-Demo

Q & R
! " !

Dear Ladies and Gentlemen,
you are now welcome to ”Göteborg 1” for a lovely lunch that is sponsored by






























