Embed Size (px)
Citation preview

論文輪読:Instance-sensi,veFullyConvolu,onalNetworks
JifengDai,KaimingHe,YiLi,ShaoqingRen,JianSun
hFp://arxiv.org/abs/1603.08678

この論文について
• What– FCNを用いたInstanceproposal手法の提案– おそらくFCNによるinstanceproposalは初
• How– Instance-sensi,vescoremapwithFCN
• Contribu,on
– Fast&Accurateproposals
• Experiment– PASCALVOC2012&MSCOCOsegmenta,on– stateoftheartresults

MSCOCOval(赤線+白で塗りつぶしされている領域はmissedgroundtruth)

書誌情報
• Title:Instance-sensi,veFullyConvolu,onalNetworks• Author:JifengDai,KaimingHe,YiLi,ShaoqingRen,JianSun– MSRA, 清華大学,中国科学技術大学
• hFp://arxiv.org/abs/1603.08678 (29Mar2016,TechnicalReport)

書誌情報
• 著者の最近の研究
今回紹介する手法はProposalに関してはこれより概ね性能が良い

(余談)CVPR’16面白そうなの
• CNN-RNN:AUnifiedFrameworkforMul,-labelImageClassifica,on– hFps://arxiv.org/abs/1604.04573
• Mul,-OrientedTextDetec,onwithFullyConvolu,onalNetworks– hFps://arxiv.org/abs/1604.04018
• ProNet:LearningtoProposeObject-specificBoxesforCascadedNeuralNetworks– hFps://arxiv.org/abs/1511.03776
FCN利用

Classifica,on Detec,onSeman,c
Segmenta,on
InstanceObject
Proposals
AlexNet
VGG
GoogLeNet
2012
2013
2014
2015
2016
OverFeatR-CNN
FastR-CNN
FasterR-CNN
FCN
FCN+CRF(DeepLabetc..)
DeepMask
CaffeNet
Residual
(BatchNormaliza,on)
ObjectProposals
(Selec,veSearch)2011
(BING)
(GOP)(MCG)(MCG)
(EdgeBoxes)(RIGOR)
(DPM)
InstanceFCN [今回紹介する手法]
※独断と偏見で作成(適当)空白≠研究がない

Classifica,onvsDetec,on
• Detec,on=What+Where
Classifica,on Detec,on
PersonMotorbike
Person
Motorbike

Seman,cSegmenta,onvsInstanceSegmentProposals
• Seman,cSegmenta,on=Pixel-wiselabeling• InstanceSegmenta,on=インスタンスを区別する
• InstanceSegmentProposals:物体領域候補を抽出– 各領域が何であるかを識別するのは別の問題– 基本的にRecallの方が重要
Original Seman,cSegmenta,on InstanceSegmenta,on
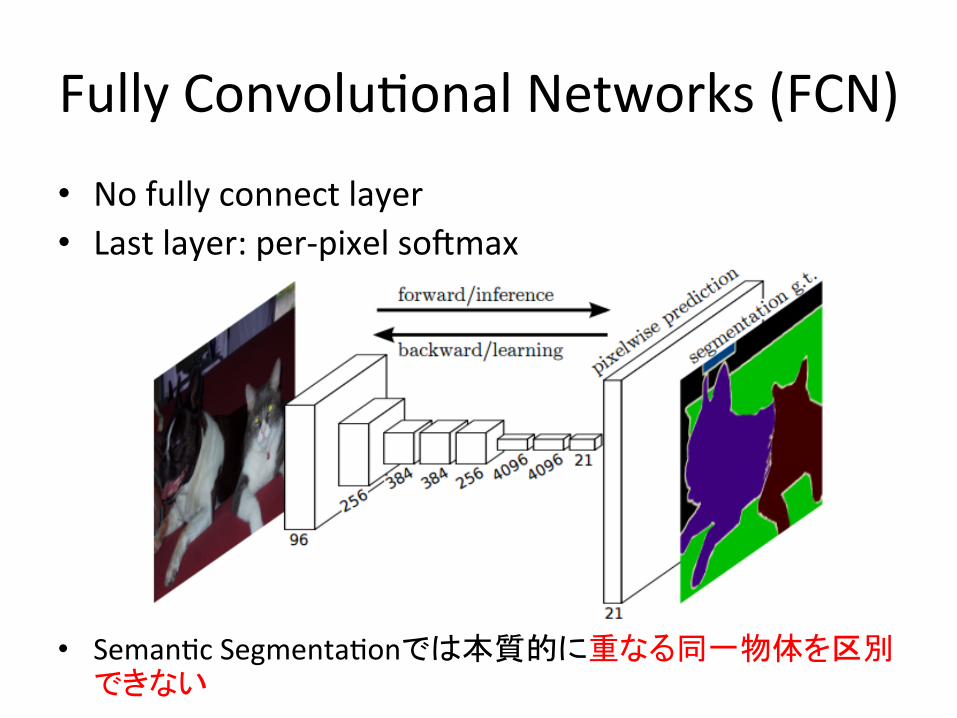
FullyConvolu,onalNetworks(FCN)
• Nofullyconnectlayer• Lastlayer:per-pixelsommax
• Seman,cSegmenta,onでは本質的に重なる同一物体を区別できない

FCNの応用
• Seman,cSegmenta,on
• ContourDetec,on
• Denoising
• ImageSuperResolu,on
• ImageEnhancement
• RegionProposalNetwork(RPN)– FasterR-CNN
基本的にはピクセルごとの分類問題に適用できる
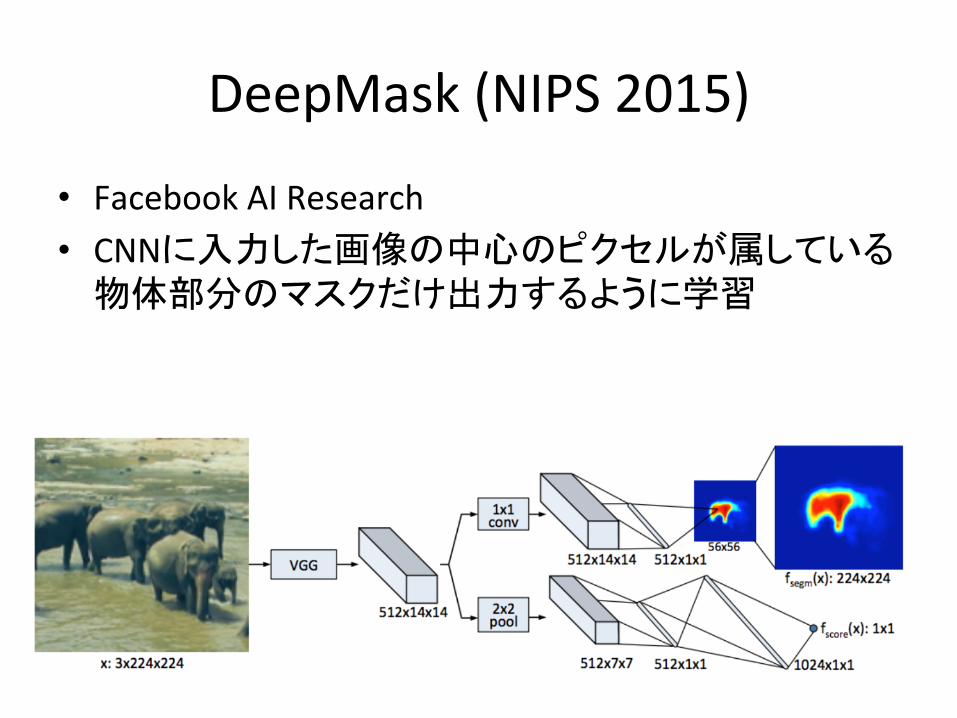
DeepMask(NIPS2015)
• FacebookAIResearch• CNNに入力した画像の中心のピクセルが属している
物体部分のマスクだけ出力するように学習
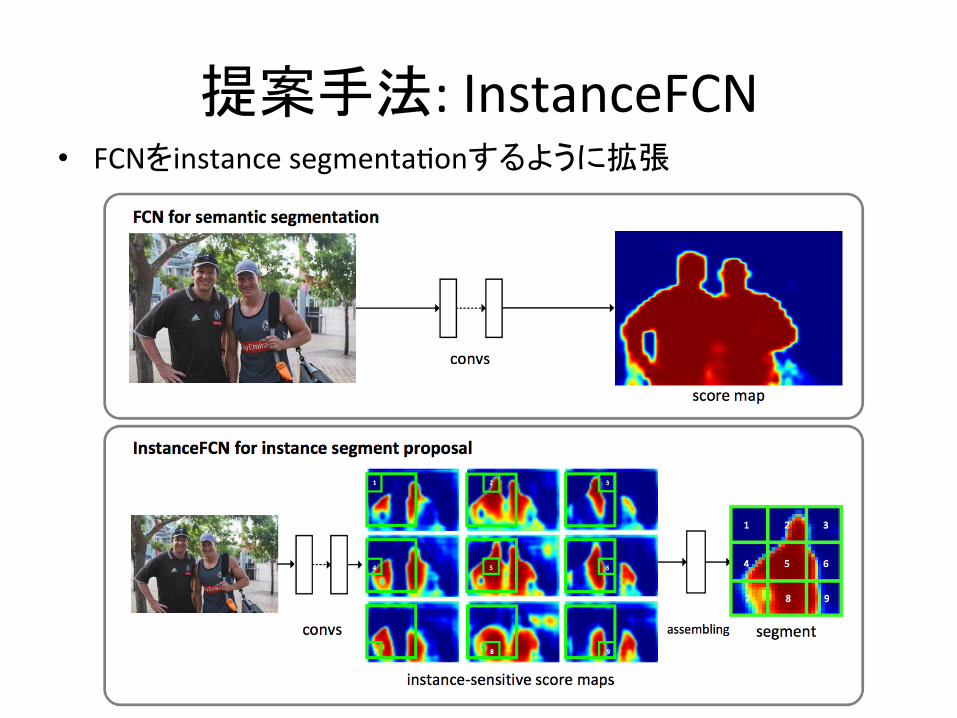
提案手法:InstanceFCN• FCNをinstancesegmenta,onするように拡張

fromFCNtoInstanceFCN
• インスタンスが1つ=>FCNでOK• インスタンスが2つ以上の場合:– 左のインスタンスから見ると,右のインスタンスが区別で
きれば良い
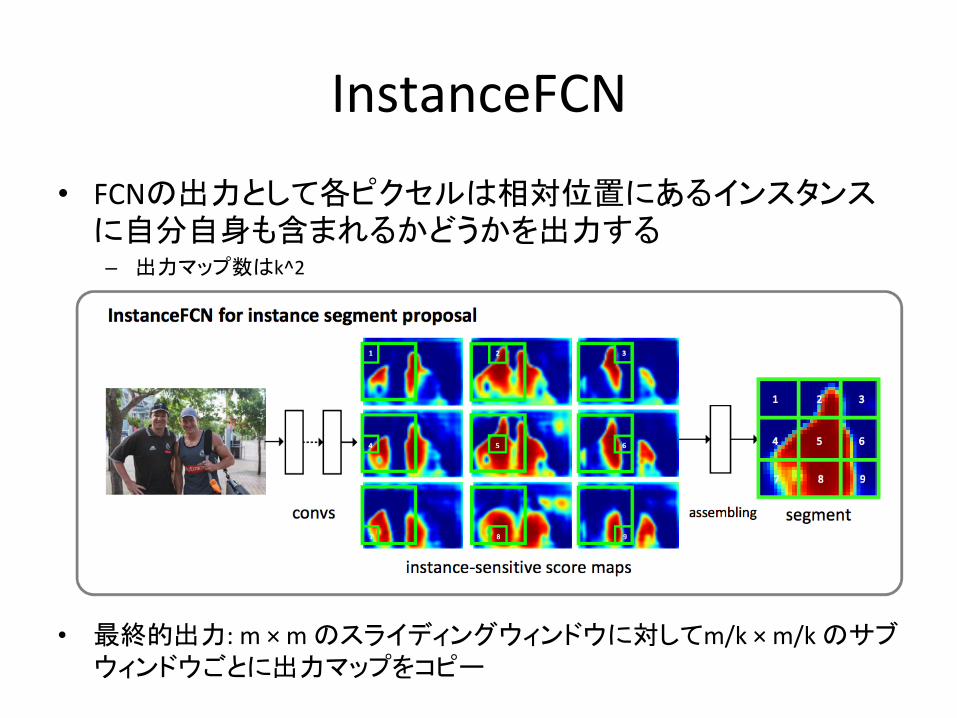
InstanceFCN
• FCNの出力として各ピクセルは相対位置にあるインスタンスに自分自身も含まれるかどうかを出力する– 出力マップ数はk^2
• 最終的出力:m×mのスライディングウィンドウに対してm/k×m/kのサブウィンドウごとに出力マップをコピー

DeepMaskとの比較
DeepMaskはm^2の層からマスクを生成する
InstanceFCNの場合全結合層がなくFCNからマスクを生成する
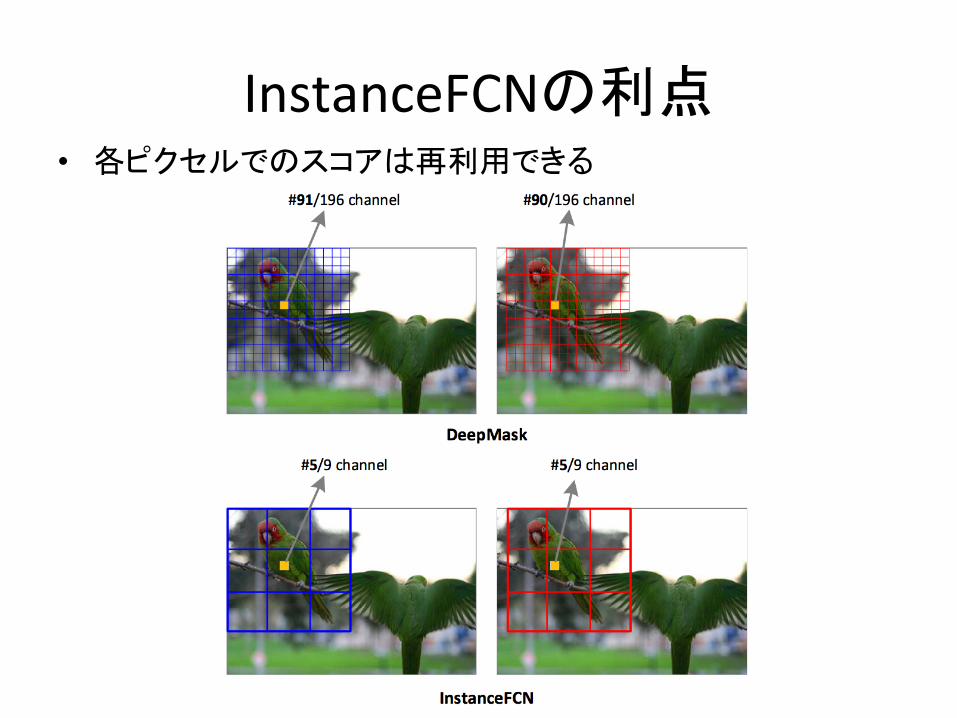
InstanceFCNの利点• 各ピクセルでのスコアは再利用できる
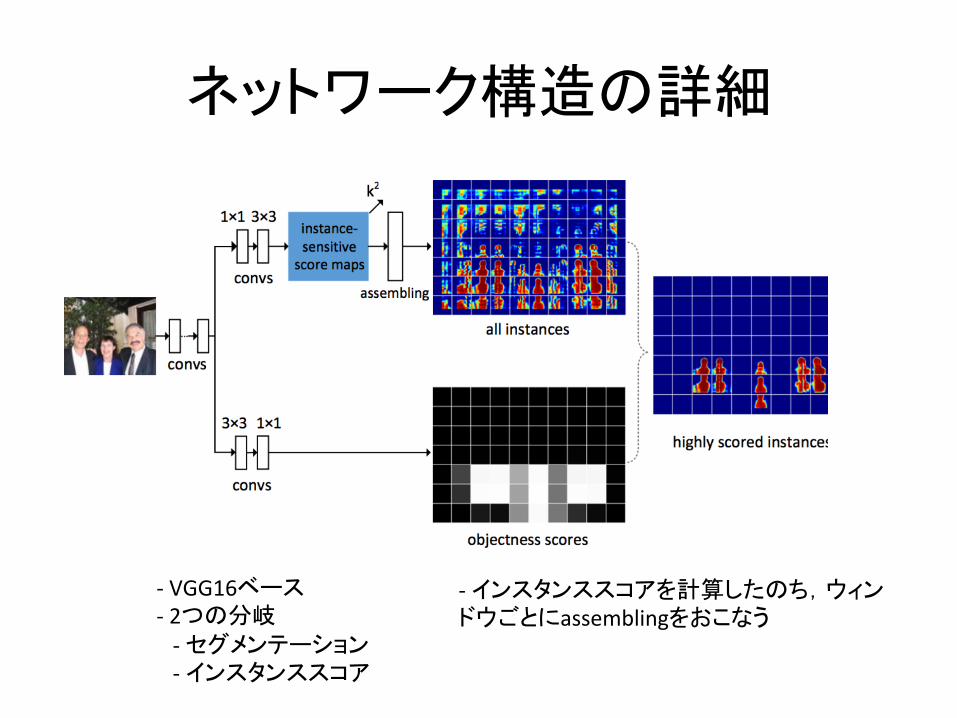
ネットワーク構造の詳細
-VGG16ベース-2つの分岐-セグメンテーション-インスタンススコア
-インスタンススコアを計算したのち,ウィンドウごとにassemblingをおこなう

訓練/テスト 方法
• 訓練時:スライディングウィンドウを適当に動かして,各スライディングウィンドウごとに評価– 損失関数
– SGDで訓練
• テスト時:端から端までスライディングウィンドウを動かして,各評価を合計する – 1枚あたり約1.5s
-pi*=1(posi,vesampleの場合)-Si*:groundtruthsegmentinstance-L:logis,cregression
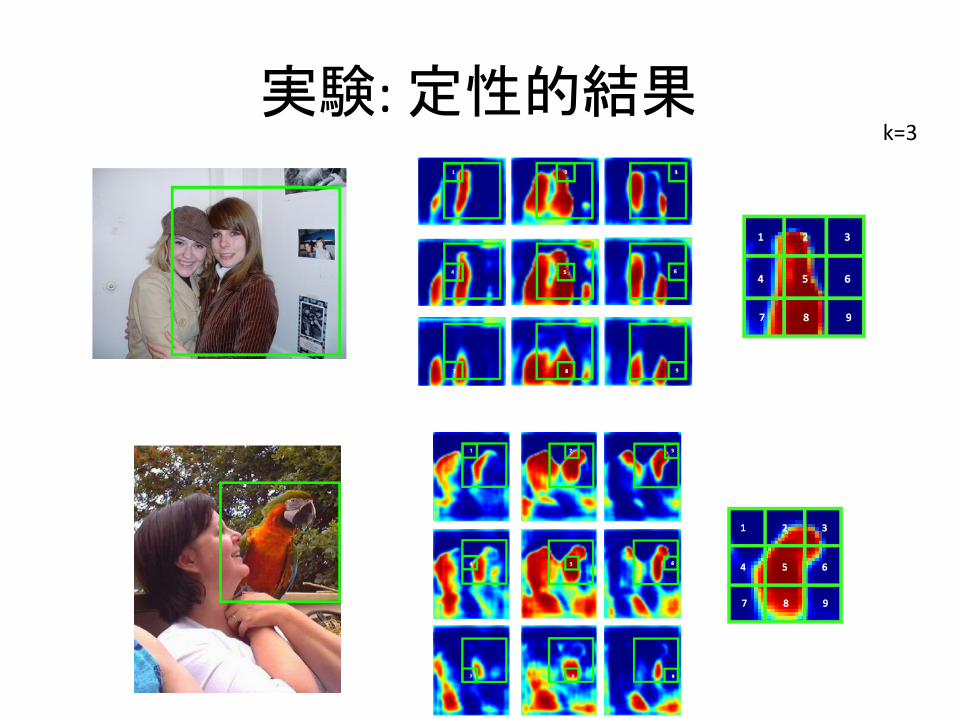
実験:定性的結果k=3
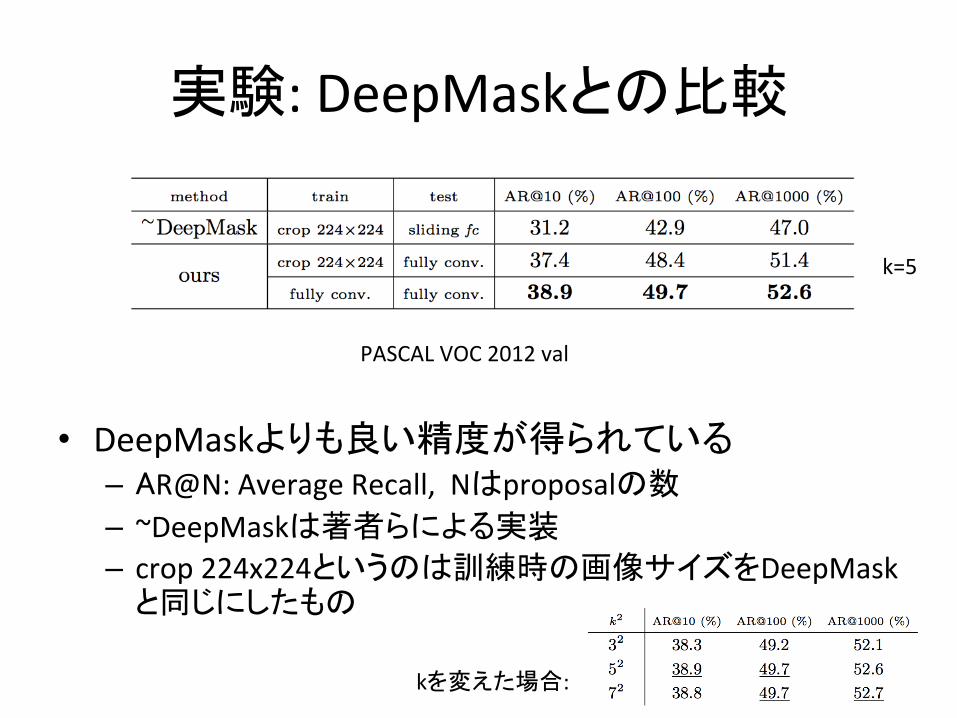
実験:DeepMaskとの比較
• DeepMaskよりも良い精度が得られている– AR@N:AverageRecall,Nはproposalの数– ~DeepMaskは著者らによる実装– crop224x224というのは訓練時の画像サイズをDeepMask
と同じにしたもの
PASCALVOC2012val
kを変えた場合:
k=5
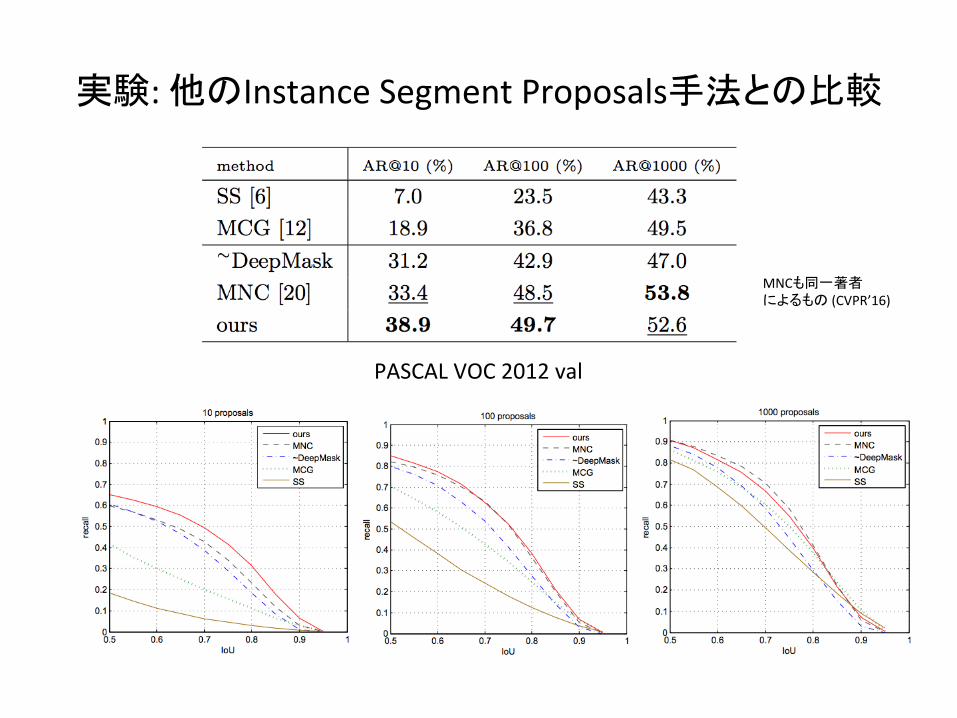
実験:他のInstanceSegmentProposals手法との比較
PASCALVOC2012val
MNCも同一著者によるもの(CVPR’16)
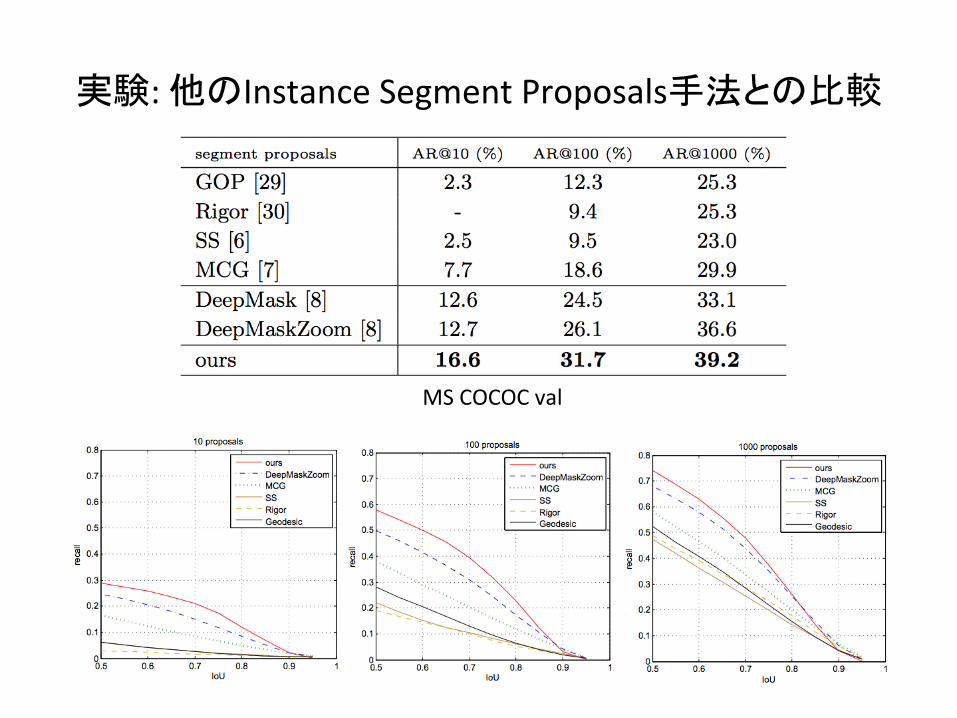
実験:他のInstanceSegmentProposals手法との比較
MSCOCOCval
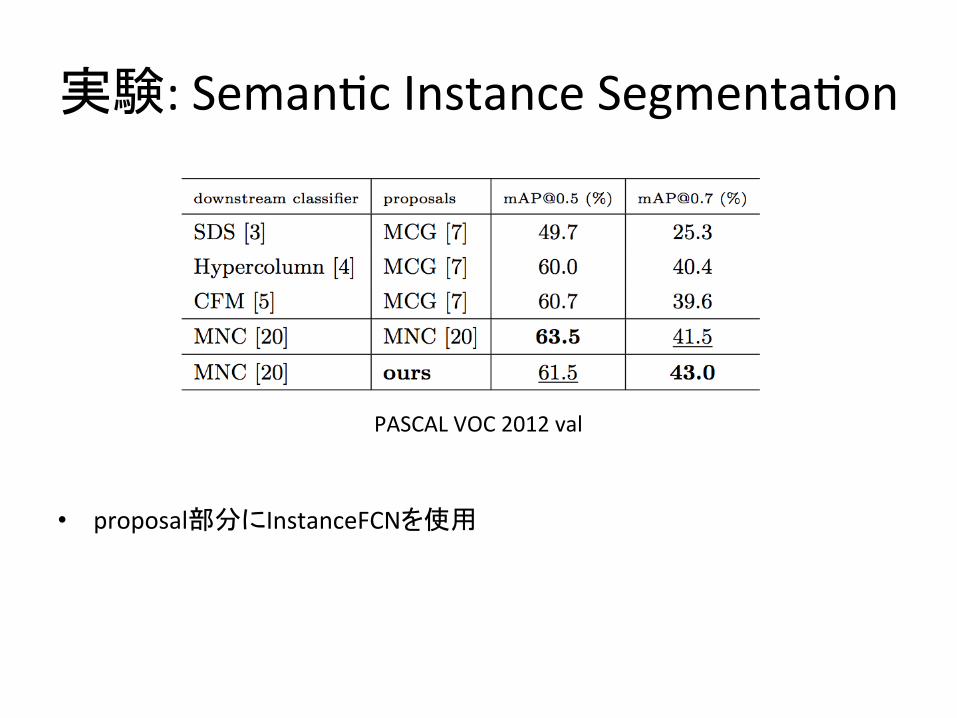
実験:Seman,cInstanceSegmenta,on
• proposal部分にInstanceFCNを使用
PASCALVOC2012val

ResultDeepMaskとの比較





























