Embed Size (px)
Citation preview

마이크로소프트연구소 인재 육성 플랫폼 교수 협력 사례 발표 연세대학교 전기전자 공학과 강홍구 교수
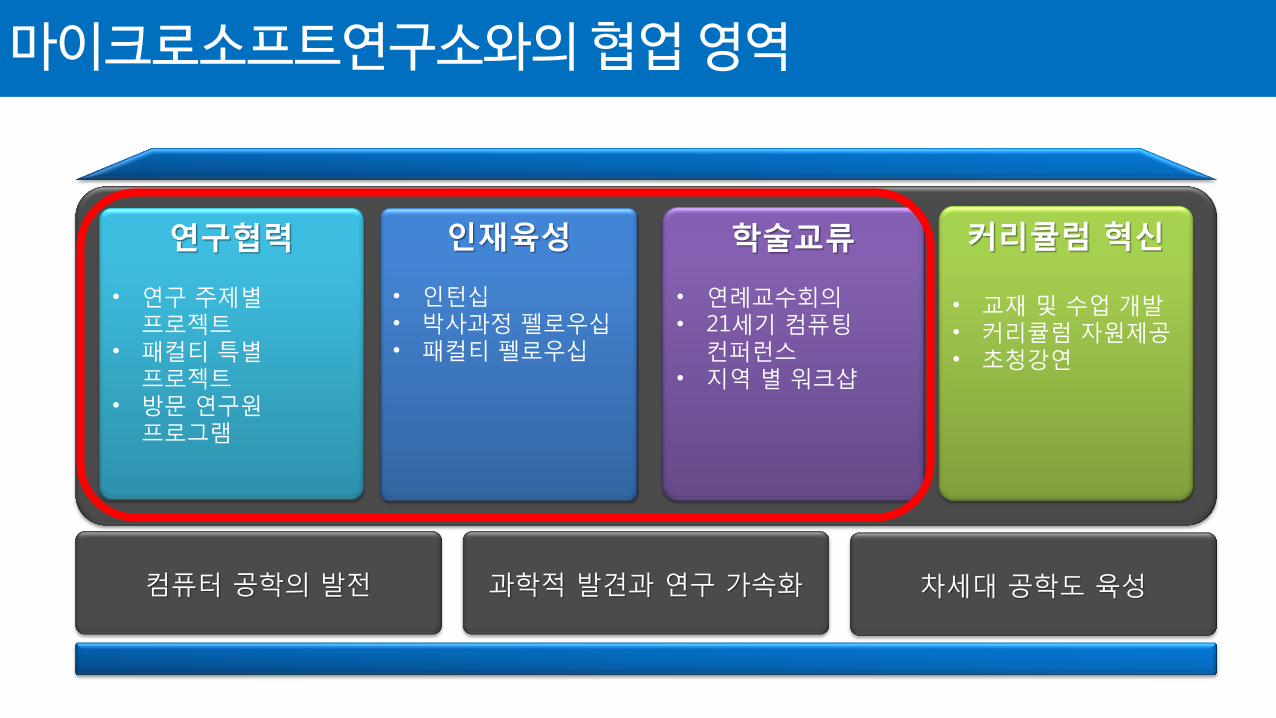
마이크로소프트연구소와의 협업 영역
커리큘럼 혁신 • 교재 및 수업 개발 • 커리큘럼 자원제공 • 초청강연
인재육성
• 인턴십 • 박사과정 펠로우십 • 패컬티 펠로우십
연구협력
• 연구 주제별 프로젝트
• 패컬티 특별 프로젝트
• 방문 연구원 프로그램
학술교류 • 연례교수회의 • 21세기 컴퓨팅
컨퍼런스 • 지역 별 워크샵
컴퓨터 공학의 발전 과학적 발견과 연구 가속화 차세대 공학도 육성

마이크로소프트연구소와의 협업 소개
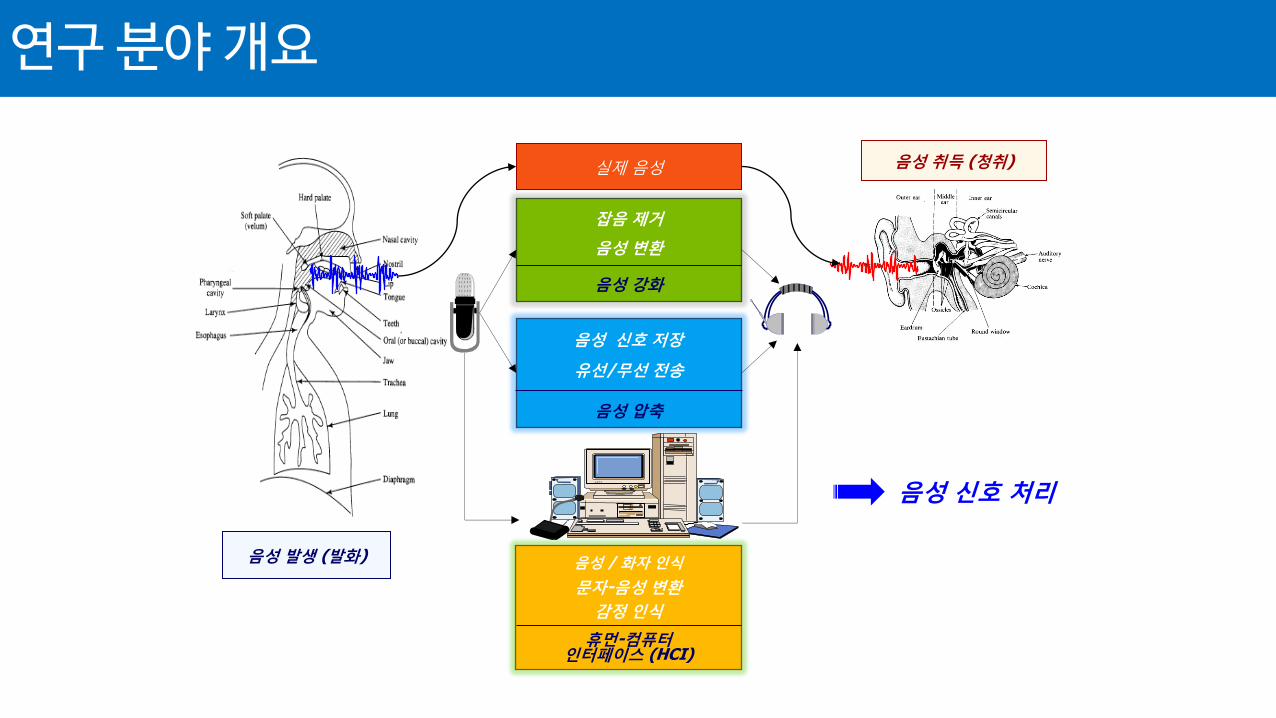
연구 분야 개요
유선/무선 전송
음성 신호 저장
음성 압축
음성 변환
잡음 제거
음성 강화
음성 발생 (발화)
음성 취득 (청취)
1472
실제 음성
문자-음성 변환
음성 / 화자 인식
휴먼-컴퓨터 인터페이스 (HCI)
감정 인식
음성 신호 처리

• 연구 협력 개요 • 지난 7년간 마이크로소프트연구소 아시아 Speech 그룹(그룹장: Dr. Frank Soong)과 지속적으로 진행
• 연구 주제
• 2008~09년 : 음성/음악 신호로부터 사용자 정보 추출
• 2010~11년 : 동영상 캡션을 위한 통합 음성인식 시스템
• 2011~12년 : 키넥트의 오디오-비디오 정보를 이용한 다중 사용자 위치 추정
• 2012~13년 : 여기 신호 모델링 개선을 이용한 HMM 기반의 TTS시스템 성능 향상
• 2013~14년 : 통계적 모델 기반의 TTS 시스템을 위한 효율적인 파형 모델링 기술
• 2014~현재 : 신경망 구조 기반의 다중 언어 TTS 시스템의 효과적인 구현
• 진행 방법: 순환 구조 연구 협력 • 마이크로소프트연구소 아시아 자체 지원 혹은 마이크로소프트연구소 아시아/정부 공동 지원 프로젝트
• 연구 주제 및 목표 도출
• 온라인 논의 혹은 그룹 직접 미팅을 통한 결과 분석 및 논의
• 마이크로소프트연구소 아시아 연구소 방문 그룹 미팅
• 프로젝트 성과 발표
• 연구 결과 및 향후 연구 방향에 대한 토의
연구협력 분야에서의 협업
마이크로소프트연구소 Speech group과의 미팅 中
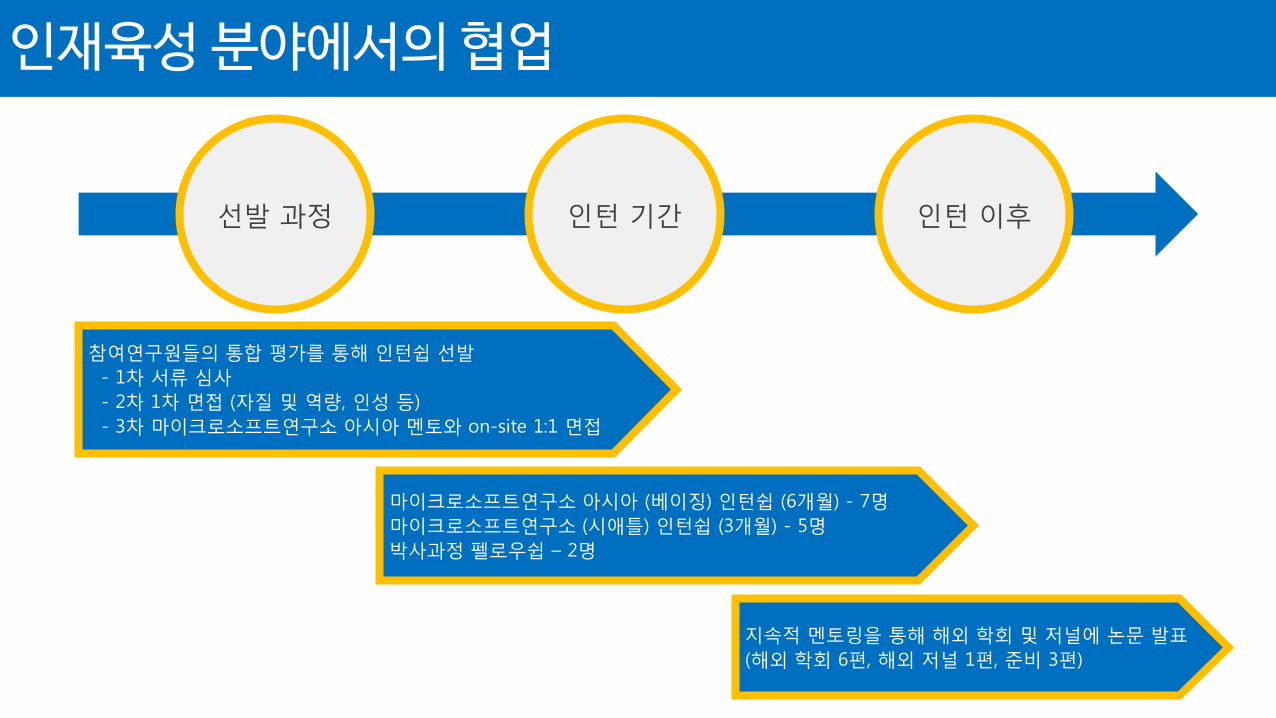
인재육성 분야에서의 협업
선발 과정 인턴 기간 인턴 이후
참여연구원들의 통합 평가를 통해 인턴쉽 선발
- 1차 서류 심사
- 2차 1차 면접 (자질 및 역량, 인성 등)
- 3차 마이크로소프트연구소 아시아 멘토와 on-site 1:1 면접
마이크로소프트연구소 아시아 (베이징) 인턴쉽 (6개월) - 7명
마이크로소프트연구소 (시애틀) 인턴쉽 (3개월) - 5명
박사과정 펠로우쉽 – 2명
지속적 멘토링을 통해 해외 학회 및 저널에 논문 발표
(해외 학회 6편, 해외 저널 1편, 준비 3편)

• 마이크로소프트연구소 Speech Group의 기술 발표 및 데모 시연 • 최신 기술 동향 및 향후 발전 방향 파악
• Korean Day를 통한 학술 교류 • 마이크로소프트연구소와 프로젝트에 참여했던 연구팀들의 기술 발표 및 데모 시연을 통해 다양한 분야의 기술 접할 수 있는 기회
학술교류 분야에서의 협업
2013년도 Korean day
Korean day에서 참여 연구팀들의 기술 발표 및 데모 시연 中

• 국제적으로 명성이 높은 해외 기관 연구팀으로부터 본 연구팀에서 기획한 연구 과제의 수행 방법 및 결과에 대한 질적인 평가를 객관적으로 받을 수 있음
• 학문으로만 존재하는 연구 결과가 아니라 사회에 도움이 될 수 있는 기술에 관한 연구, 그리고 단기적 성과 보다는 장기적 관점 하에 꾸준히 연구를 진행할 수 있다는 측면에서 매우 바람직함
• 연구 능력이 뛰어나고, 동기가 뚜렷한 참여 대학원생들에게 해외기관에서 인턴쉽을 수행할 기회를 부여하므로 차세대 리더로 성장할 젊은 인재들의 국제화 감각을 높일 수 있음
마이크로소프트연구소와의 협업의 특징

• 세계 시장 선점을 위해서는 국내에서 자체적으로 기술력을 확보하는 노력 뿐만 아니라
관련 연구 분야를 선도하는 글로벌 기업과의 공동 연구를 활성화하여 보다 적극적으로
기술력을 향상시키기 위한 노력이 필요함
• 치열한 글로벌 시장에서의 경쟁력을 높이기 위해서는 뛰어난 연구 능력과 열린 마음을
가진 젊은 인재를 양성하기 위한 다양한 연구/교육 프로그램이 확대되어야 함
• 정부와 마이크로소프트가 함께 지원하는 본 프로그램은 국내 대학에 재학 중인 많은
대학원생들에게 매우 독특하고 특별한 기회와 경험을 제공하고 있으므로 이를 더욱
확대할 수 있는 방안 마련이 필요함
향후 협업 계획 및 발전 방향

연구 내용 상세 소개 (최근 3년간)
문자-음성 변환(Text-to-Speech)
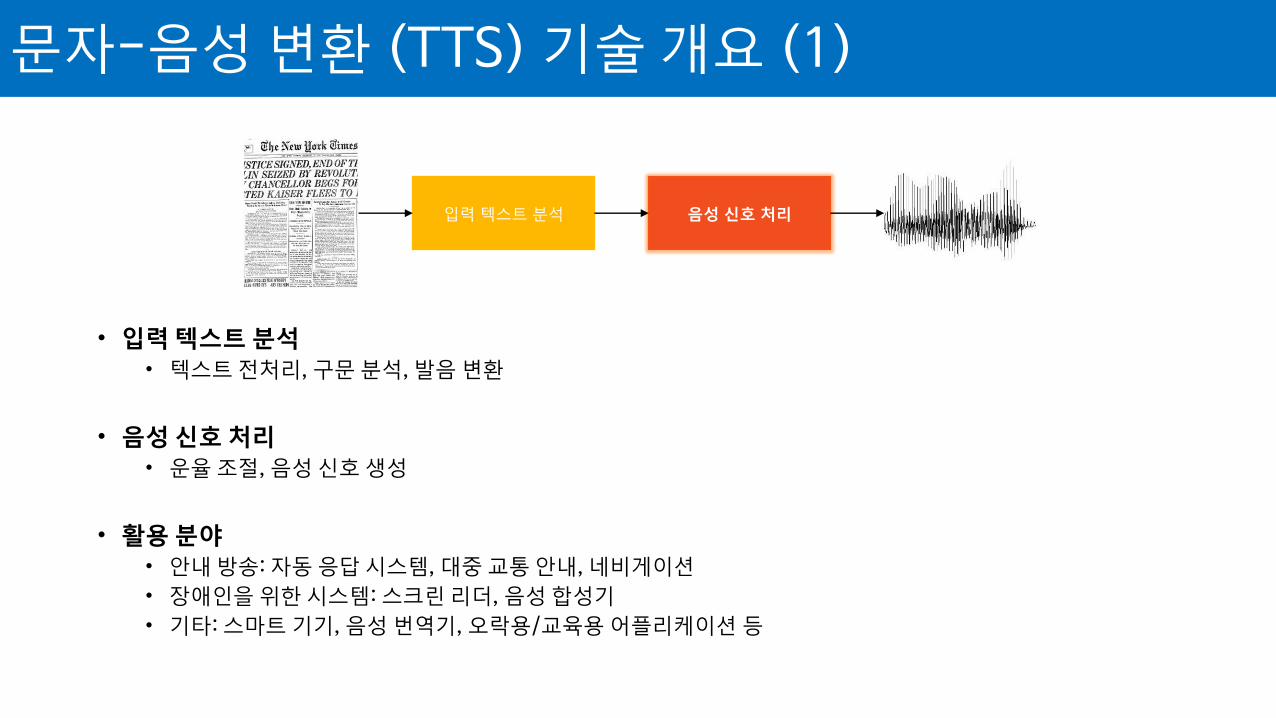
• 입력 텍스트 분석 • 텍스트 전처리, 구문 분석, 발음 변환
• 음성 신호 처리 • 운율 조절, 음성 신호 생성
• 활용 분야 • 안내 방송: 자동 응답 시스템, 대중 교통 안내, 네비게이션 • 장애인을 위한 시스템: 스크린 리더, 음성 합성기 • 기타: 스마트 기기, 음성 번역기, 오락용/교육용 어플리케이션 등
문자-음성 변환 (TTS) 기술 개요 (1)
입력 텍스트 분석 음성 신호 처리

• 현재 지하철 안내 방송 • 여러명의 성우가 직접 녹음
• 추가 녹음이 필요할 時, • 성우가 아프거나 부재중이거나 목소리에 변화가 있다면 녹음을 하기까지 시간이 걸리며 다시 처음부터 녹음해야 하는 경우도 발생 가능
문자-음성 변환 (TTS) 기술 개요 (2) - 필요성
TTS 사용 時 편리성 증가 & 음성의 일관성 유지 & 시간 및 비용 절감 가능

문자-음성 변환 (TTS) 기술 개요 (3) – 기술동향
• 기술 동향 • 음성은 차세대 보조 입·출력 방식이 될 가능성
이 매우 높음 • 예) Microsoft Cortana는 음성 인식 및 합성 기
술로 사용자에게 서비스 제공
• 활용 분야가 매우 다양함 • 웨어러블 기기 • 인공지능 로봇 • 자동차
마이크로소프트 밴드
인공지능 로봇 (영화 ‘빅히어로’, ‘인터스텔라’ 中)
감정 로봇 ‘Pepper’
자동차 내부 환경
[출처]
”Get Started with Cortana” - http://youtube.com/watch?v=tQFrd6SEiLM
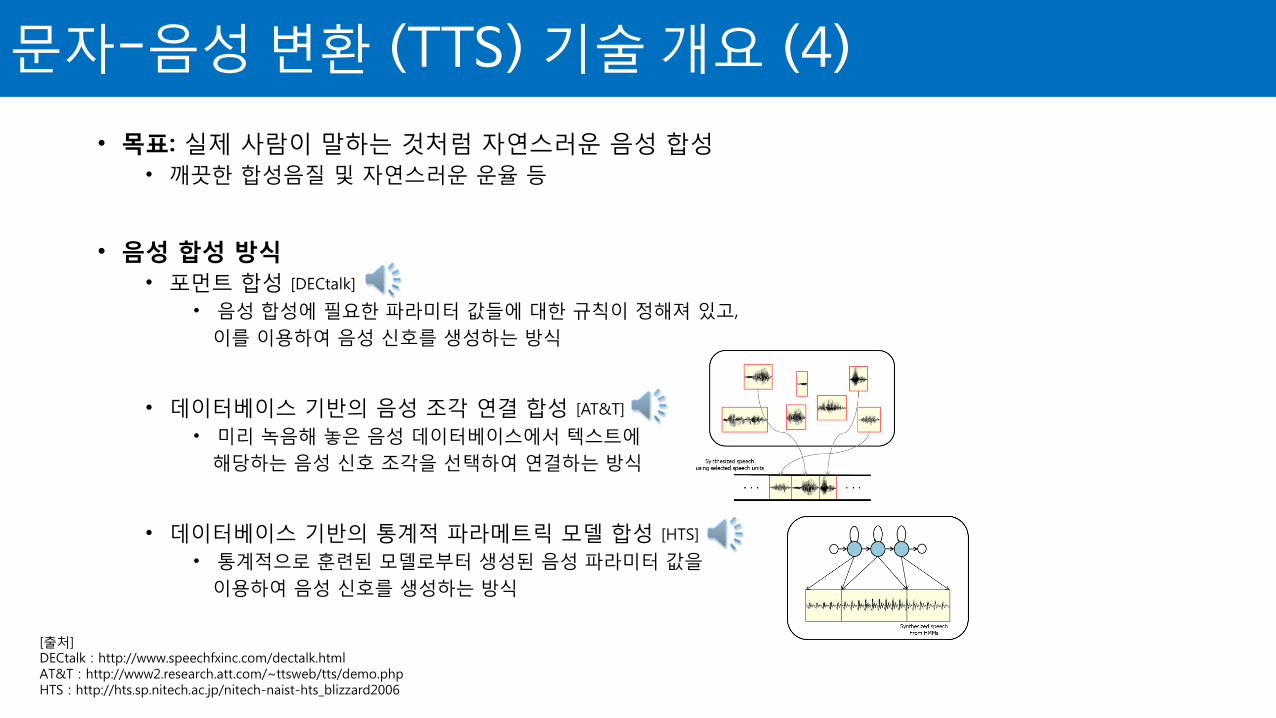
• 목표: 실제 사람이 말하는 것처럼 자연스러운 음성 합성
• 깨끗한 합성음질 및 자연스러운 운율 등
• 음성 합성 방식
• 포먼트 합성 [DECtalk]
• 음성 합성에 필요한 파라미터 값들에 대한 규칙이 정해져 있고,
이를 이용하여 음성 신호를 생성하는 방식
• 데이터베이스 기반의 음성 조각 연결 합성 [AT&T]
• 미리 녹음해 놓은 음성 데이터베이스에서 텍스트에
해당하는 음성 신호 조각을 선택하여 연결하는 방식
• 데이터베이스 기반의 통계적 파라메트릭 모델 합성 [HTS]
• 통계적으로 훈련된 모델로부터 생성된 음성 파라미터 값을
이용하여 음성 신호를 생성하는 방식
문자-음성 변환 (TTS) 기술 개요 (4)
[출처] DECtalk : http://www.speechfxinc.com/dectalk.html AT&T : http://www2.research.att.com/~ttsweb/tts/demo.php HTS : http://hts.sp.nitech.ac.jp/nitech-naist-hts_blizzard2006
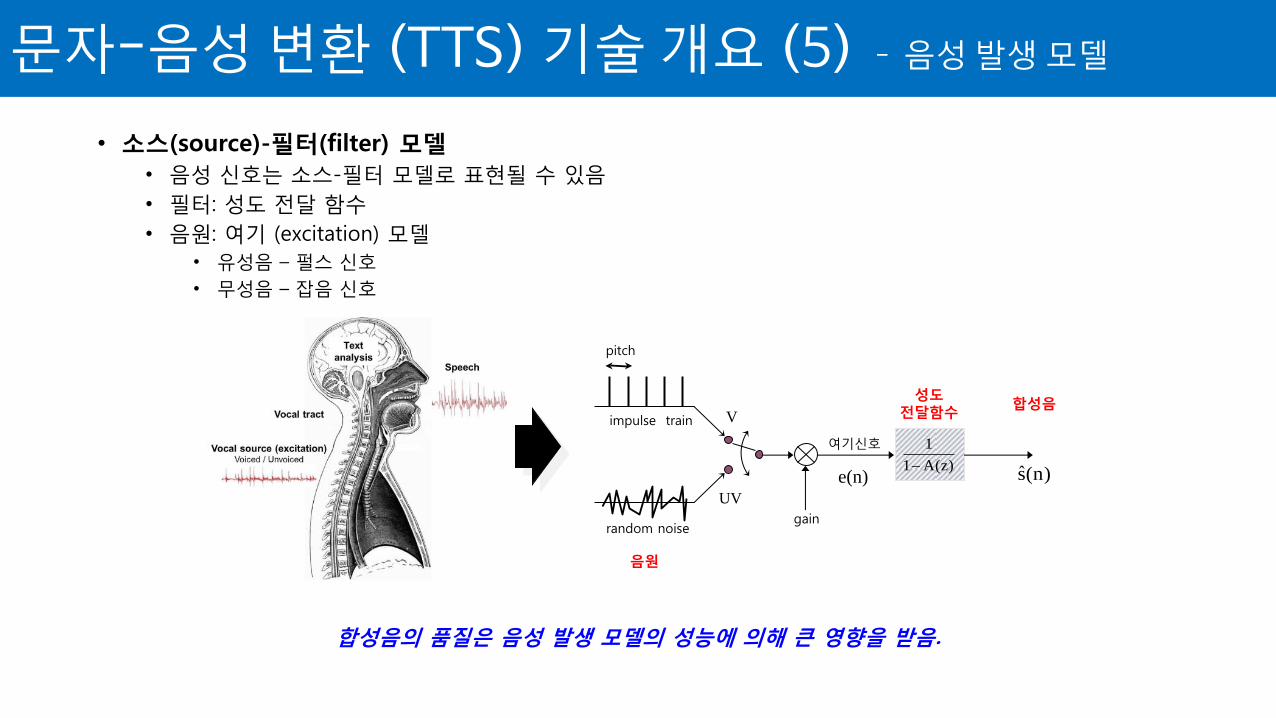
• 소스(source)-필터(filter) 모델
• 음성 신호는 소스-필터 모델로 표현될 수 있음
• 필터: 성도 전달 함수
• 음원: 여기 (excitation) 모델
• 유성음 – 펄스 신호
• 무성음 – 잡음 신호
문자-음성 변환 (TTS) 기술 개요 (5) – 음성 발생 모델
)n(s)z(A1
1
e(n)
gain
impulse train
random noise
pitch
V
UV
여기신호
음원
성도 전달함수
합성음
합성음의 품질은 음성 발생 모델의 성능에 의해 큰 영향을 받음.

• 연구 분야
• 사람과 기계 (Human-Computer), 혹은 사람과 사람 (Human-Human)과의 자연스러운 인터페이스를 위한
핵심 기술인 ‘음성합성 (Speech synthesis, Text-to-Speech)’ 시스템의 성능 향상을 위한 연구
• 연구 내용 및 성과
• 연산량 및 메모리가 제한된 경우에 적용 가능한 은닉 마르코프 모델 (HMM; Hidden Markov Model)을
이용한 통계 기반 합성 방법의 성능 개선 연구
• 최근 기계 학습 (machine learning) 분야에서 각광받고 있는 deep learning (DNN; Deep Neural
Network) 기반의 음성 합성 시스템 구현 및 성능 향상을 통한 기술 선도
• 다국어 지원이 가능한 음성합성 시스템으로 확장하기 위한 필수 기술 연구를 통해 향후 개인별 맞춤
시스템으로 활용 가능성 타진
• 공동연구를 주도했던 연구원들이 해외 인턴십에 참여하여 연구의 연속성 유지
• 마이크로소프트연구소 아시아 멘토와의 1:1 멘토링을 통한 연구 능력 향상 및 다양한 연구 수행 방법 경험
지난 3년간 공동 연구 내용 요약
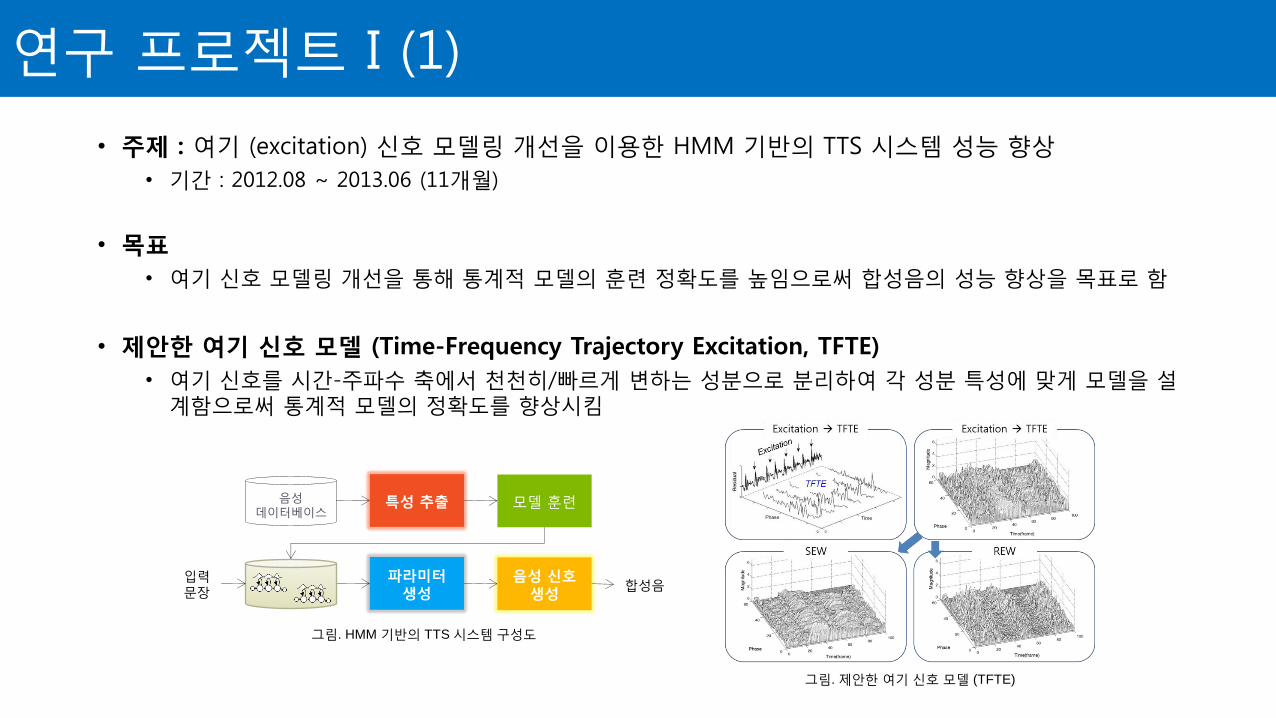
• 주제 : 여기 (excitation) 신호 모델링 개선을 이용한 HMM 기반의 TTS 시스템 성능 향상
• 기간 : 2012.08 ~ 2013.06 (11개월)
• 목표
• 여기 신호 모델링 개선을 통해 통계적 모델의 훈련 정확도를 높임으로써 합성음의 성능 향상을 목표로 함
• 제안한 여기 신호 모델 (Time-Frequency Trajectory Excitation, TFTE)
• 여기 신호를 시간-주파수 축에서 천천히/빠르게 변하는 성분으로 분리하여 각 성분 특성에 맞게 모델을 설계함으로써 통계적 모델의 정확도를 향상시킴
연구 프로젝트 I (1)
음성 데이터베이스
특성 추출
음성 신호 생성
합성음 파라미터 생성
모델 훈련
입력 문장
그림. HMM 기반의 TTS 시스템 구성도
그림. 제안한 여기 신호 모델 (TFTE)
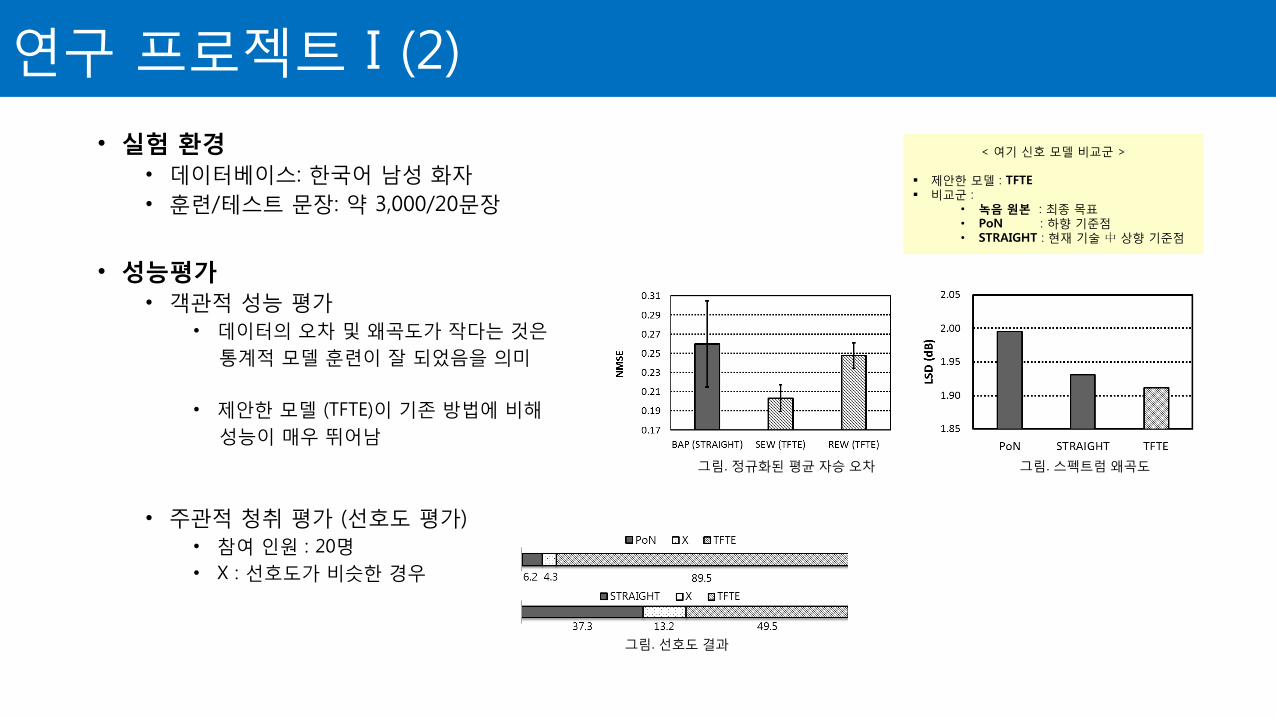
• 실험 환경
• 데이터베이스: 한국어 남성 화자
• 훈련/테스트 문장: 약 3,000/20문장
• 성능평가
• 객관적 성능 평가
• 데이터의 오차 및 왜곡도가 작다는 것은
통계적 모델 훈련이 잘 되었음을 의미
• 제안한 모델 (TFTE)이 기존 방법에 비해
성능이 매우 뛰어남
• 주관적 청취 평가 (선호도 평가)
• 참여 인원 : 20명
• X : 선호도가 비슷한 경우
연구 프로젝트 I (2)
그림. 정규화된 평균 자승 오차 그림. 스펙트럼 왜곡도
그림. 선호도 결과
< 여기 신호 모델 비교군 >
제안한 모델 : TFTE 비교군 :
• 녹음 원본 : 최종 목표 • PoN : 하향 기준점 • STRAIGHT : 현재 기술 中 상향 기준점
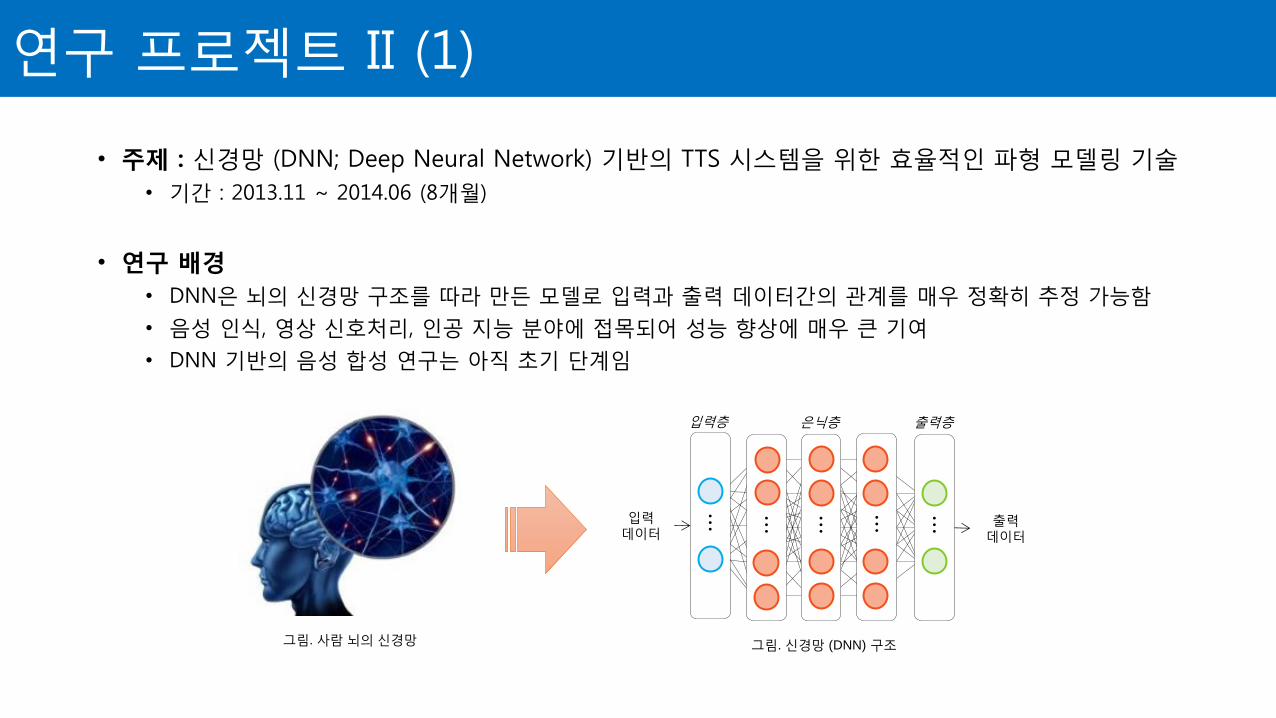
• 주제 : 신경망 (DNN; Deep Neural Network) 기반의 TTS 시스템을 위한 효율적인 파형 모델링 기술
• 기간 : 2013.11 ~ 2014.06 (8개월)
• 연구 배경
• DNN은 뇌의 신경망 구조를 따라 만든 모델로 입력과 출력 데이터간의 관계를 매우 정확히 추정 가능함
• 음성 인식, 영상 신호처리, 인공 지능 분야에 접목되어 성능 향상에 매우 큰 기여
• DNN 기반의 음성 합성 연구는 아직 초기 단계임
연구 프로젝트 II (1)
︙ ︙ ︙ ︙ ︙
은닉층 입력층 출력층
입력 데이터
출력 데이터
그림. 신경망 (DNN) 구조 그림. 사람 뇌의 신경망
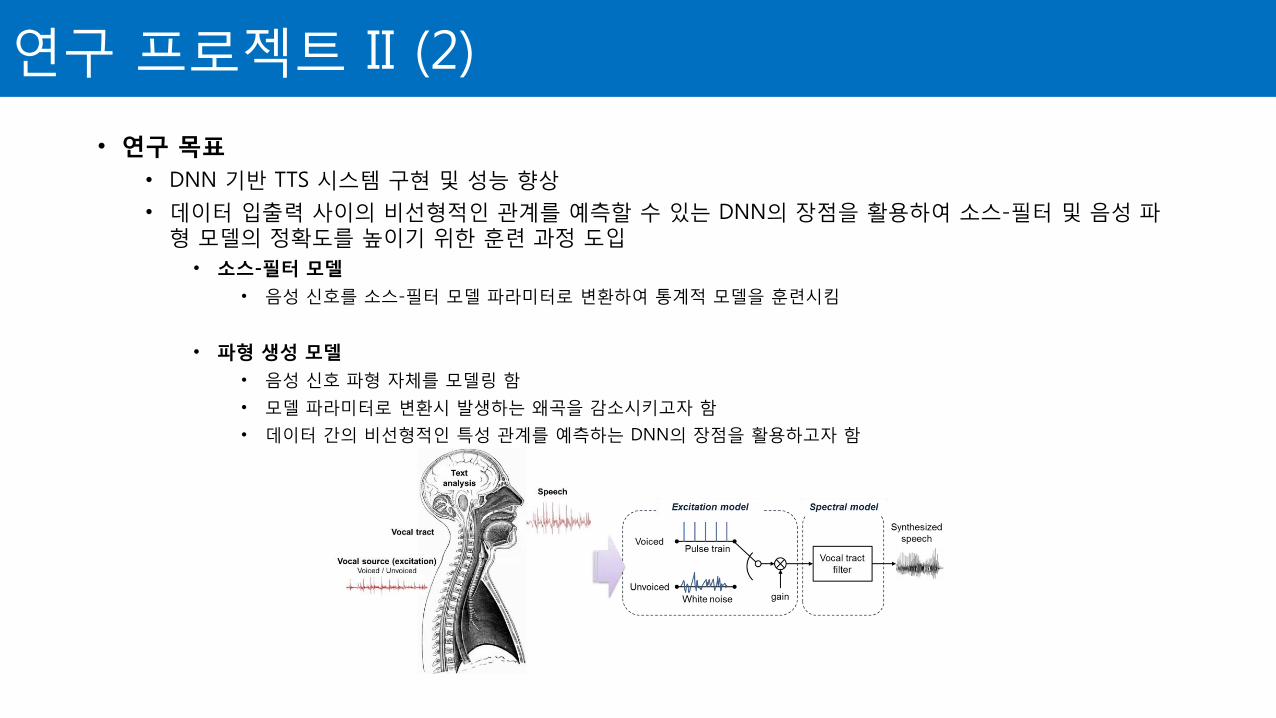
• 연구 목표
• DNN 기반 TTS 시스템 구현 및 성능 향상
• 데이터 입출력 사이의 비선형적인 관계를 예측할 수 있는 DNN의 장점을 활용하여 소스-필터 및 음성 파형 모델의 정확도를 높이기 위한 훈련 과정 도입
• 소스-필터 모델
• 음성 신호를 소스-필터 모델 파라미터로 변환하여 통계적 모델을 훈련시킴
• 파형 생성 모델
• 음성 신호 파형 자체를 모델링 함
• 모델 파라미터로 변환시 발생하는 왜곡을 감소시키고자 함
• 데이터 간의 비선형적인 특성 관계를 예측하는 DNN의 장점을 활용하고자 함
연구 프로젝트 II (2)

• 실험 환경
• 데이터베이스: 한국어 남성 화자
• 훈련/테스트 문장: 약 3,000/20 문장
• 성능 평가
• 객관적 성능 평가
• 데이터의 오차 및 왜곡도가 적다는 것은 통계적 모델 훈련이 잘 되었음을 의미
• DNN을 이용한 방법이 기존의 통계적 모델 방법인 HMM보다 성능이 더 우수함
연구 프로젝트 II (3)
시스템
측정 항목
TFTE-DNN (duration: known)
TFTE-HMM
512*3 1024*3
스펙트럼 왜곡도 (LSD) [dB] 3.10 3.12 5.27
SEW 정규화 평균 제곱 오차 (NMSE)
0.31 0.31 0.39
F0 표준 오차 (RMSE) [Hz] 24.11 24.12 26.91

• 주제 : 신경망 (DNN) 기반의 다중 언어 TTS 시스템 구현
• 기간 : 2014.09 ~ 2015.06 (10개월)
• 연구 배경
• 여러 언어의 단어가 포함되어 있는 문장에 대해
자연스러운 합성음 제공
• 특정 언어용으로 설계된 TTS 시스템을 다른 언어의
시스템으로 쉽게 확장 가능
• 고려 사항
• 다중 언어 데이터베이스를 어떻게 구축할 것인가?
• 다중 화자 및 언어의 공통 특징 정보를 어떻게 추출할 것인가?
• 다중 언어 TTS 시스템 구현을 위하여 어떤 방식의 DNN 훈련 방법을 사용해야 하는가?
연구 프로젝트 III (1)
여러분, 왼쪽에 보이는 것은 Paris의 la tour Eiffel입니다.
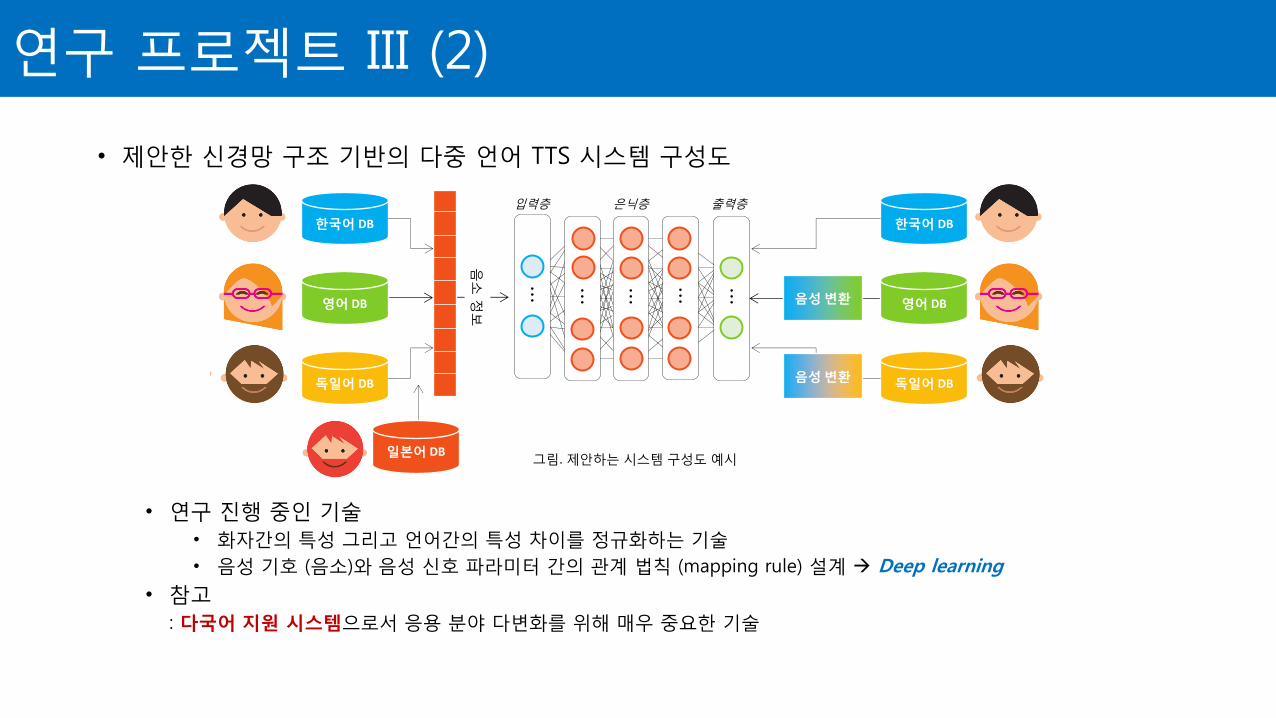
• 제안한 신경망 구조 기반의 다중 언어 TTS 시스템 구성도
• 연구 진행 중인 기술
• 화자간의 특성 그리고 언어간의 특성 차이를 정규화하는 기술
• 음성 기호 (음소)와 음성 신호 파라미터 간의 관계 법칙 (mapping rule) 설계 Deep learning
• 참고
: 다국어 지원 시스템으로서 응용 분야 다변화를 위해 매우 중요한 기술
연구 프로젝트 III (2)
그림. 제안하는 시스템 구성도 예시
︙ ︙ ︙ ︙ ︙
은닉층 입력층 출력층
일본어 DB
음소
정보
음성 변환
한국어 DB
영어 DB
독일어 DB 음성 변환
한국어 DB
영어 DB
독일어 DB

• 음성을 이용한 HCI (Human Computer Interface or Interaction) 기술
• 자연스럽고 매우 편리하다는 장점으로 인해 지난 수 십 년 동안 활발히 연구되어 왔으며, 앞으로도 꾸준히
연구가 진행될 것으로 예측됨
• 음성 합성 기술
• 관련 IT 기술의 발전과 컴퓨터 성능 향상으로 인해 합성된 음성의 품질이 자연스러워지고 있음
• 글로벌 통신 및 인터넷 확장, 그리고 문화 교류가 활발해짐에 따라 국가/지역간의 심리적 거리가 좁혀지고
있으며, 이에 따라 다국어 지원 시스템에 대한 필요성은 지속적으로 높아질 수 밖에 없음
• 한 명의 화자가 단순하게 책을 읽는 톤의 목소리에서 다양한 목소리 특성을 지닌 화자가 자연스럽게 감정
을 표현하는 듯한 시스템으로 확장 연구도 활발히 진행 중임
발표 요약

Q&A





























