Embed Size (px)
Citation preview

Size matters: on-demand analytics in healthcare

Big Data in 2016+?

Big Data in 2016+? No more an exotic buzzword
Mature enough and already adopted by majority of businesses/companies
Set of well-defined tools and processes… questionable
Data Analysis at scale - taking value from your data!
Descriptive - real time analytics (stocks, healthcare..)
Diagnostic - past analysis, shows what had happened and why (classic)
Predictive - analysis of likely scenarios of what might happen
Prescriptive - reveals what action should be taken

Big Data analysis challengesIntegration - ability to have needed data in needed place
Latency - data have to be presented for processing immediately
Throughput - ability to consume/process massive volumes of data
Consistency - data mutation in one place must be reflected everywhere
Teams collaboration - inconvenient interface for inter-teams communication
Technology adoption - typical technologies stack greatly complicates entire project ecosystem -
another world of hiring, deployment, testing, scaling, fault tolerance, upgrades, monitoring,
etc.

It’s a challenge!
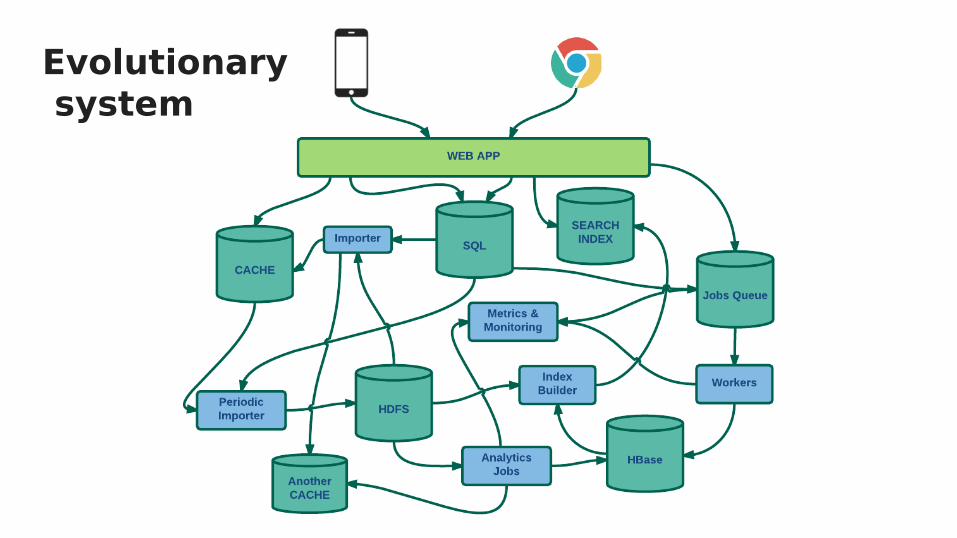
Evolutionary system

Solution
The Event LOG
What every software engineer should know about
real-time data's unifying abstraction

The event Log

Reference architecture

Transition case

Unified ordered event log

KafkaFast - single Kafka broker can handle hundreds of megabytes of reads and
writes per second from thousands of clients
Scalable - can be elastically and transparently expanded without downtime
Durable - Messages are persisted on disk and replicated within the cluster to
prevent data loss. Each broker can handle terabytes of messages without
performance impact
Reliable - has a modern cluster-centric design that offers strong durability and
fault-tolerance guarantees

Kafka - high level view

Kafka - building blocksProducer - process that publishes messages to a Kafka
Topic - a category or feed name to which messages are published. For each topic,
the Kafka cluster maintains a partitioned log
Partition - part of a topic: level of parallelism in Kafka. Write/Read order is
guaranteed at partition level

Kafka - building blocksProducer - process that publishes messages to a Kafka
Topic - a category or feed name to which messages are published. For each topic,
the Kafka cluster maintains a partitioned log
Partition - part of a topic: level of parallelism in Kafka. Write/Read order is
guaranteed at partition level
Replica - up-to-date partition’s copy. Each partition is replicated across a
configurable number of servers for fault tolerance (like HDFS block)
Consumer - process that subscribes to topics and processes published messages

Kafka - building blocksConsumer - process that subscribes to topics and processes published messages

Stream Processing - high level

Apache Storm
Apache Spark
Apache Samza
Apache Flink
Apache Flume
...
Stream Processing - implementation frameworks

Stream Processing - implementation frameworks
Pros
Automatic fault tolerance
Scaling
No data loss guarantees
Stream processing DSL/SQL (joins, filters, count aggregates, etc)
Cons
Overall system complexity significantly grows
New cluster to maintain/monitor/upgrade/etc (Apache Storm)
Multi-pattern (mixed) data access (Spark/Samza on YARN)
Another framework to learn for your team

Stream Processing - microservices

Stream Processing - microservices
Small, independent processes that communicate with each other to form complex applications which utilize language-agnostic APIs.
These services are small building blocks, highly decoupled and focused on doing a small task, facilitating a modular approach to system-building.
The microservices architectural style is becoming the standard for building modern applications.

Stream Processing – microservices comunications
Three most commonly used protocols are :
Synchronous request-response calls (mainly via HTTP REST API)
Asynchronous (non blocking IO) request-response communication
(Akka, Play Framework, etc)
Asynchronous messages buffers (RabbitMQ, JMS, ActiveMQ, etc)

Stream Processing – microservices comunicationsMicroservices deployment platforms :
Apache Mesos with a framework like Marathon
Swarm from Docker
Kubernetes
YARN with something like Slider
Various hosted container services such as ECS from Amazon
Cloud Foundry
Heroku

Stream Processing – microservices
Why can’t I just package and deploy my events processing code on Yarn / Mesos / Docker / Amazon cluster and let it take care of fault tolerance, scaling and other weird things?

Stream Processing – microservices

Stream Processing – Kafka & microservces

Stream Processing – Kafka
New Kafka Consumer 0.9.+
Light - consumer client is just a thin JAR without heavy 3rd party dependencies (ZooKeeper, scala runtime, etc)
Acts as Load Balancer Fault tolerant Simple to use API
Kafka Streams - elegant DSL (should be officially released this month)

Stream Processing – Kafka & microservces

Stream Processing – Kafka & microservces
1. Language agnostic logs of events (buffers)
2. No backpressure on consumers (API endpoints with sync approach)
3. Fault tolerance - no data loss
4. Failed service doesn’t bring entire chain down
5. Resuming from last committed offset position
6. Smooth configs management across all nodes and services

Stream Processing – Kafka & microservces

Lambda Architecture

Kappa Architecture

Kappa Architecture

Architectures comparison
Lambda Kappa
Processing paradigm Batch + Streaming Streaming
Re-processing paradigm Every batch cycles Only when code changes
Resource consumption Higher Lower
Maintenance/Support complexity
Higher Lower
Ability to re-create dataset Per any point of time
No (or very hard) Yes


Even more interesting comparison
Hadoop-centric system
Kafka-centric system
Data Replication + +
Fault Tolerance + +
Scaling + +
Random Reads With HBase With Elasticsearch/Solr
Ordered Reads - +
Secondary indices With Elasticsearch/Solr With Elasticsearch/Solr
Storage for Big Files (>10M)
+ -
TCO higher lower

Summary
1.Events Log centric system design - from chaos to structured
architecture

Summary
1.Events Log centric system design - from chaos to structured
architecture
2.Kafka as an Events Log reference storage implementation

Summary
1.Events Log centric system design - from chaos to structured
architecture
2.Kafka as an Events Log reference storage implementation
3.Microservices as distributed events processing approach

Summary
1.Events Log centric system design - from chaos to structured
architecture
2.Kafka as an Events Log reference storage implementation
3.Microservices as distributed events processing approach
4.Kappa Architecture as Microservices & Kafka symbiosis


Useful links
1. “I heart Logs” by Jay Krepps
http://shop.oreilly.com/product/0636920034339.do
2. http://confluent.io/blog
3. https://engineering.linkedin.com/distributed-systems/log-what-every-software-engineer-should-know-about-real-time-datas-unifying
4. “Making sense of stream processing” by Martin Kleppmann
5. http://kafka.apache.org/
6. http://martinfowler.com/articles/microservices.html