Embed Size (px)
Citation preview

Перевод с "плохого" английского на "хороший"
How to correct errors and improve text

Current methods of error correction
1. Constituency Parsing

Current methods of error correction
2. Dependency Parsing

Current methods of error correction
Mike showed Melissa how to use computer.
(“use”, “computer”) => 100,000
(“use”, “a”, “computer”) => 300,000
Mike showed Melissa how to use computer software.
3. Ngrams can be tricky

4. Classical ML algorithms like SVM or Random Forest which are trained on several features:
- Ngrams- Syntactic Ngrams (dependency arcs)- POS-tags- Length of words- Count of synonyms- etc
Current methods of error correction

Why Deep Learning?

2. Possible to create generative models1. Possible to use a wider context preserving the order of words

What we use in Deep Learning in NLP for words?

1. The first try: one-hot encoding
Word vectors
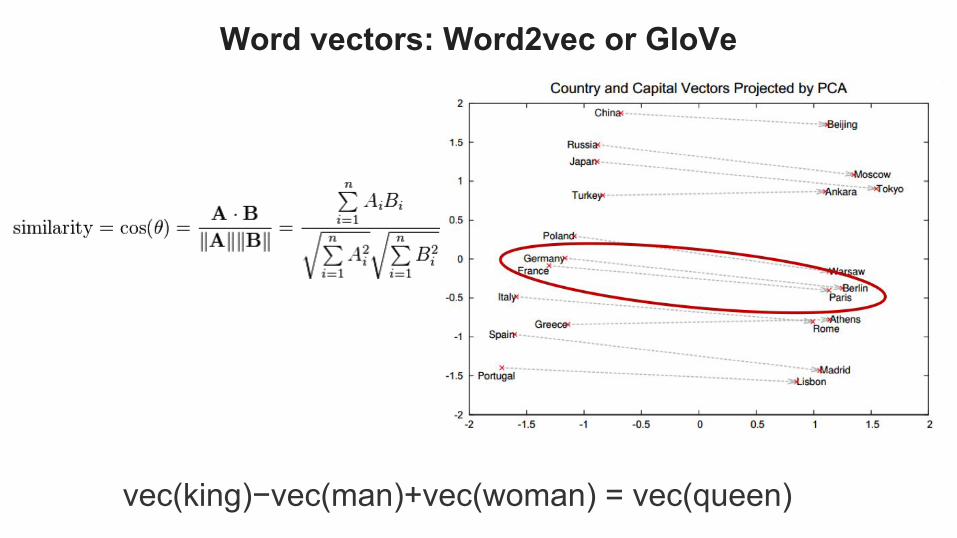
vec(king)−vec(man)+vec(woman) = vec(queen)
Word vectors: Word2vec or GloVe
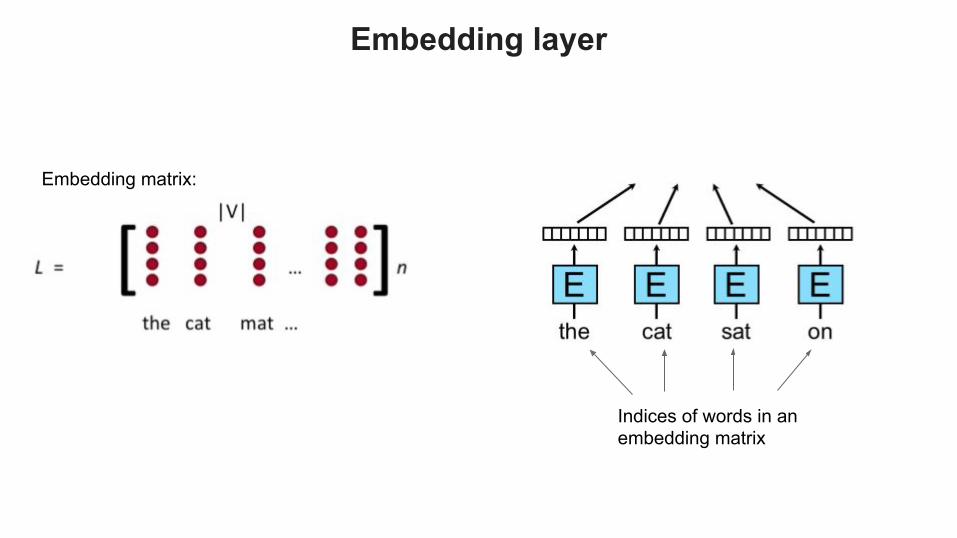
Embedding matrix:
Embedding layer
Indices of words in an embedding matrix
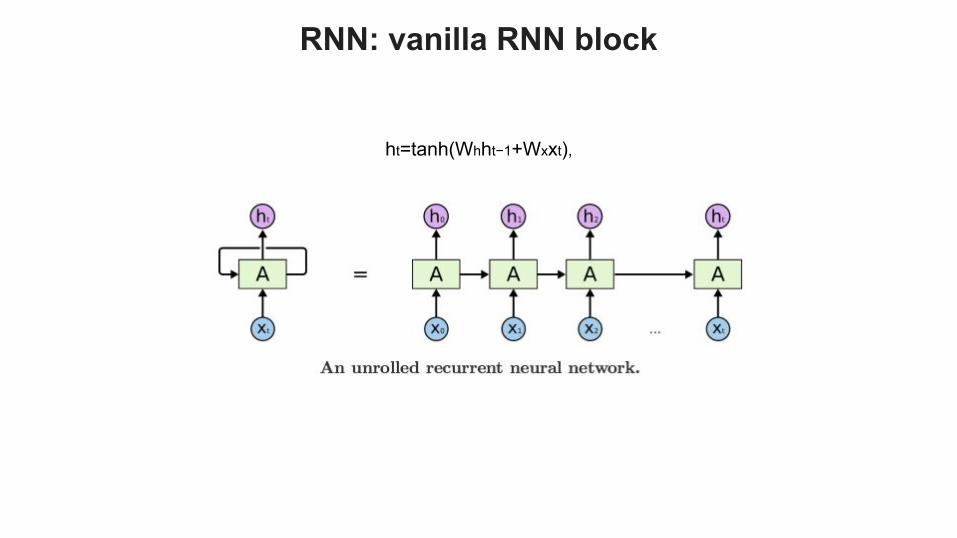
ht=tanh(Whht−1+Wxxt),
RNN: vanilla RNN block
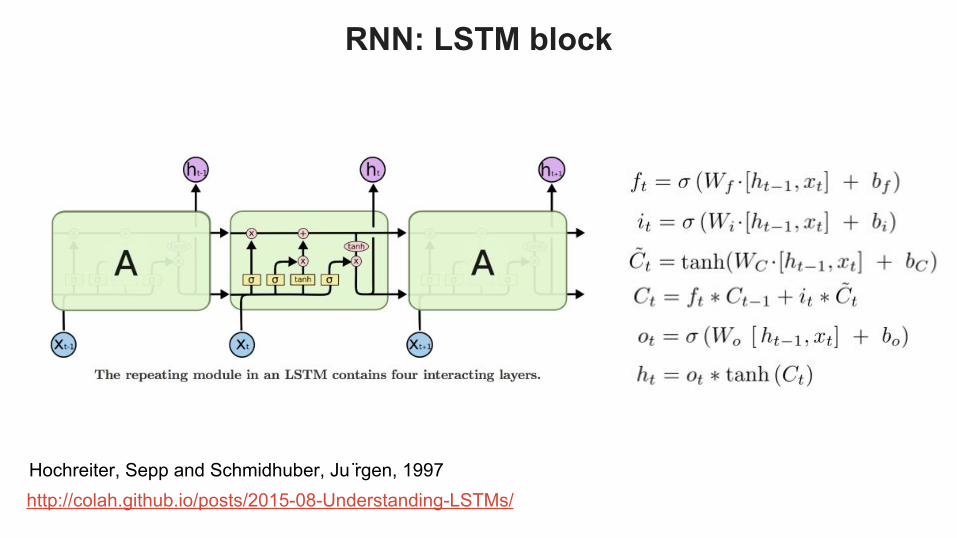
http://colah.github.io/posts/2015-08-Understanding-LSTMs/
RNN: LSTM block
Hochreiter, Sepp and Schmidhuber, Ju ̈rgen, 1997
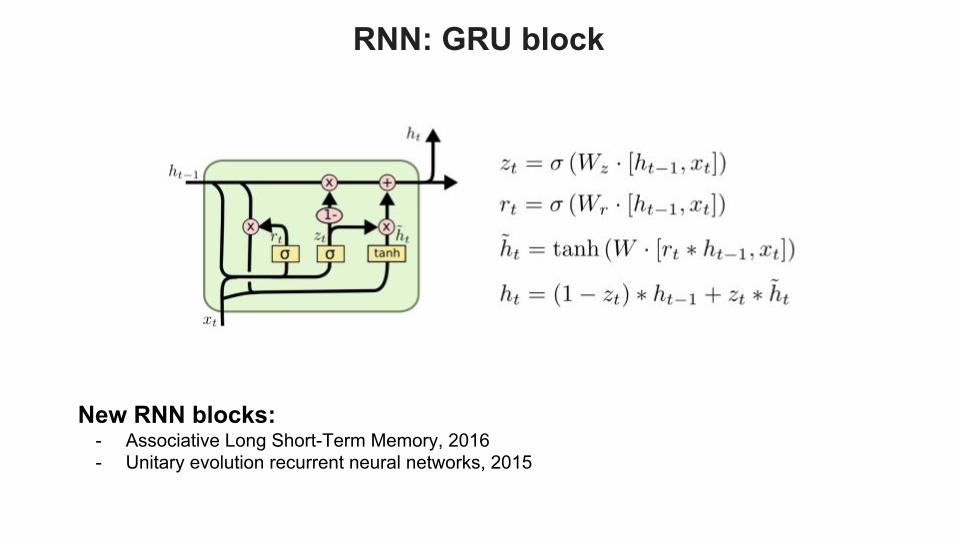
RNN: GRU block
New RNN blocks:- Associative Long Short-Term Memory, 2016- Unitary evolution recurrent neural networks, 2015
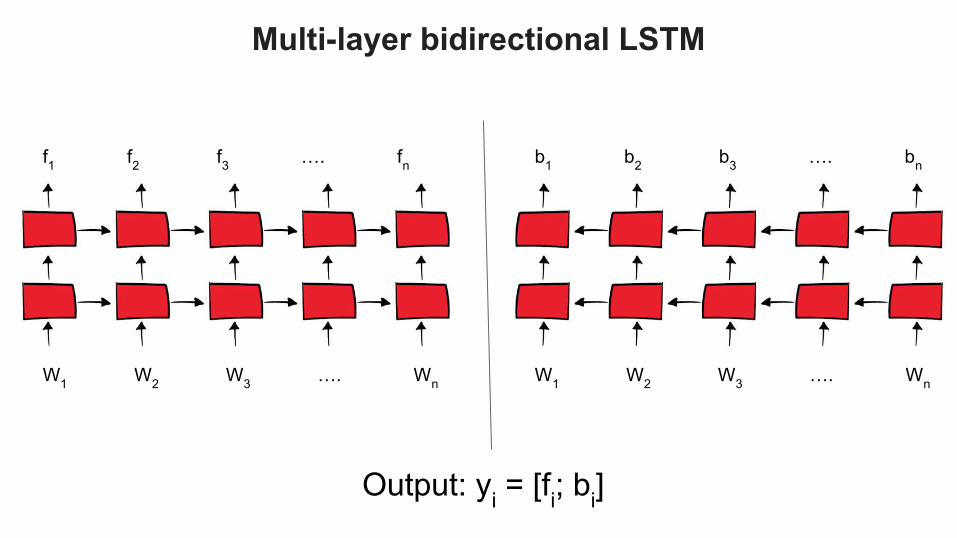
Multi-layer bidirectional LSTM
W1 W2 W3 …. Wn
f1 f2 f3 …. fn
W1 W2 W3 …. Wn
b1 b2 b3 …. bn
Output: yi = [fi; bi]
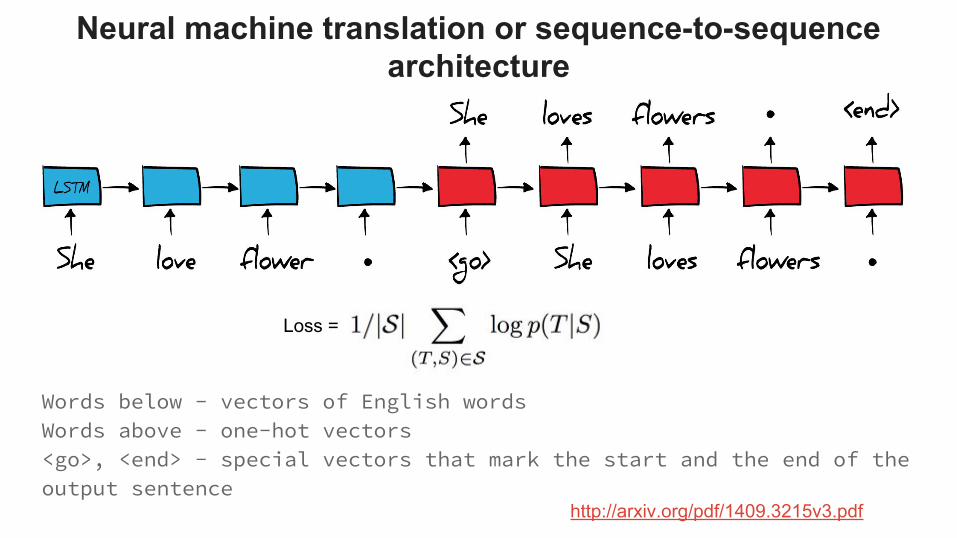
Words below - vectors of English wordsWords above - one-hot vectors<go>, <end> - special vectors that mark the start and the end of the output sentence
http://arxiv.org/pdf/1409.3215v3.pdf
Loss =
Neural machine translation or sequence-to-sequence architecture
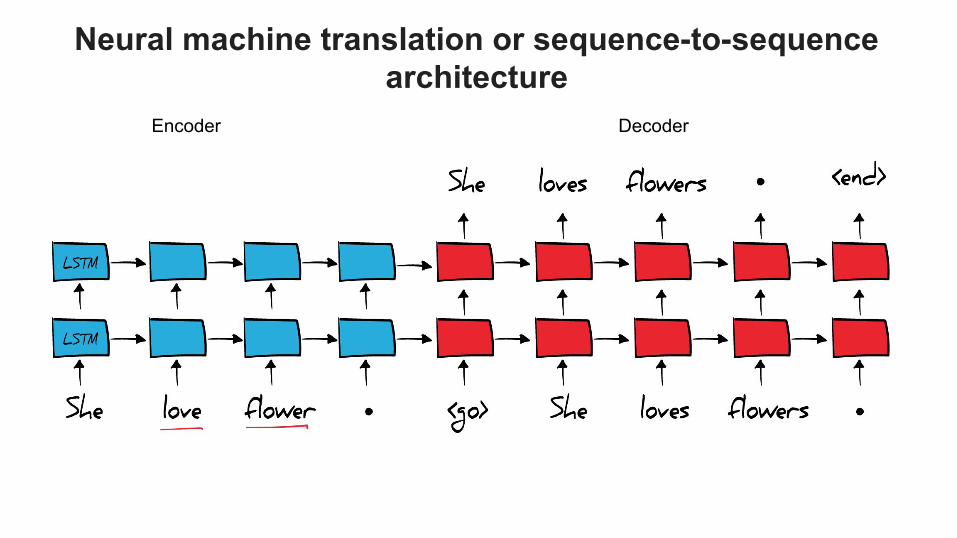
Neural machine translation or sequence-to-sequence architecture
Encoder Decoder
http://arxiv.org/pdf/1409.0473v6.pdfhttp://www.aclweb.org/anthology/D15-1166
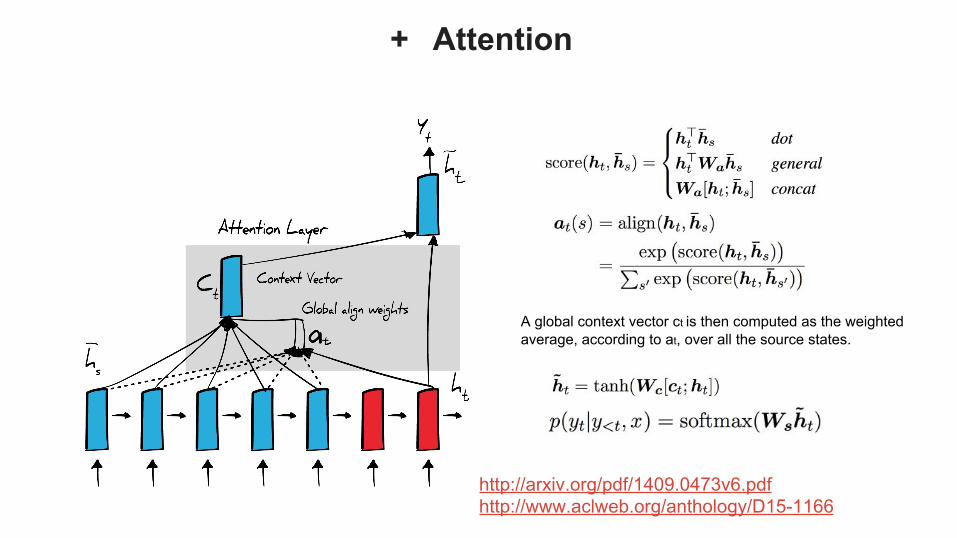
A global context vector ct is then computed as the weighted average, according to at, over all the source states.
+ Attention

What’s wrong with words?
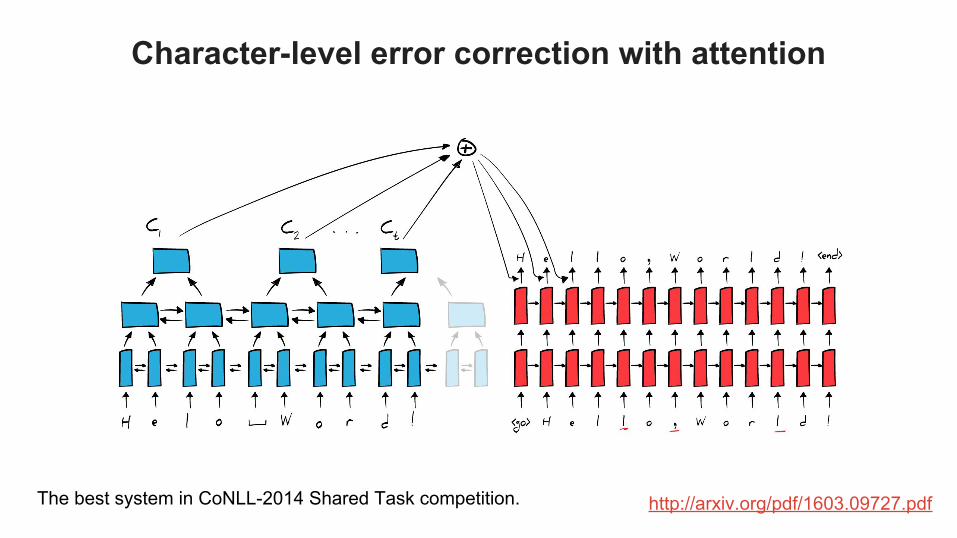
Character-level error correction with attention
http://arxiv.org/pdf/1603.09727.pdfThe best system in CoNLL-2014 Shared Task competition.
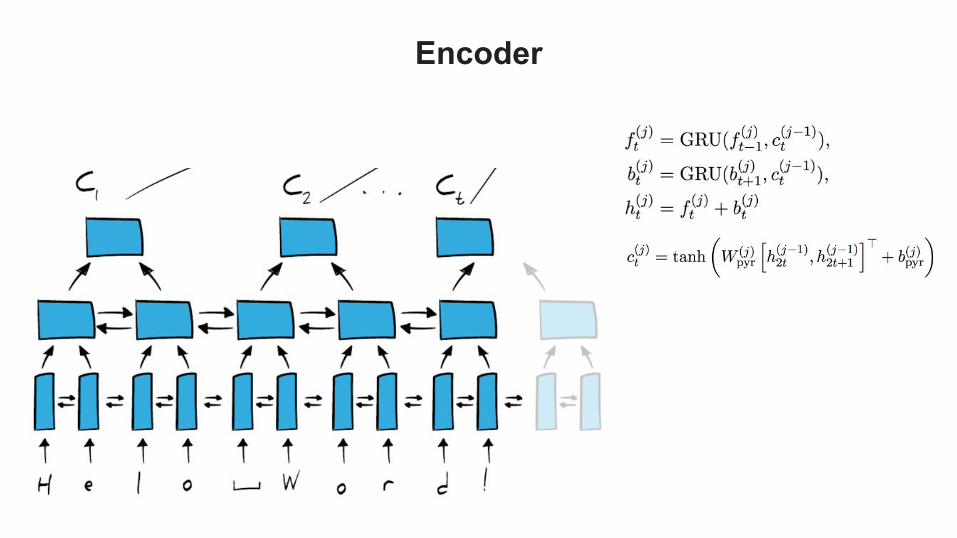
Encoder
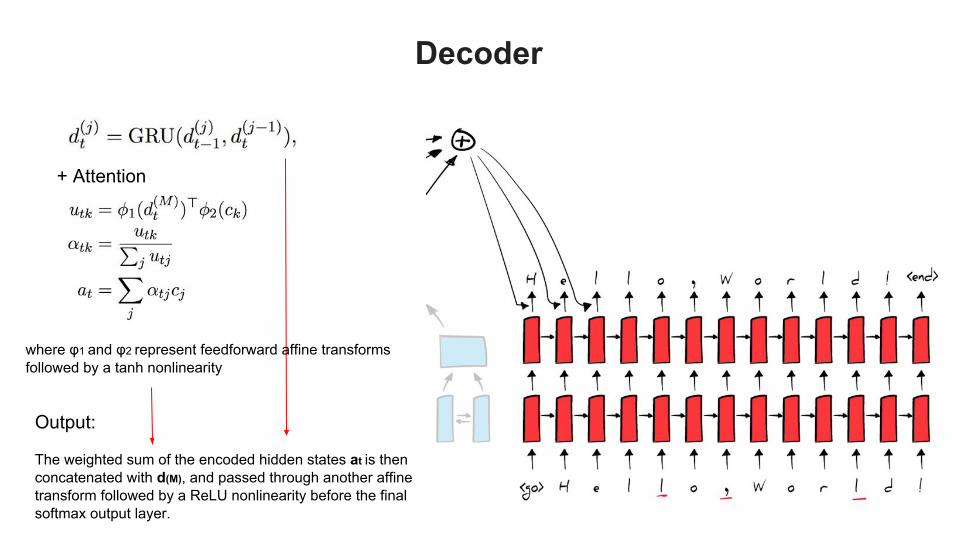
Decoder
+ Attention
Output:
The weighted sum of the encoded hidden states at is then concatenated with d(M), and passed through another affine transform followed by a ReLU nonlinearity before the final softmax output layer.
where φ1 and φ2 represent feedforward affine transforms followed by a tanh nonlinearity
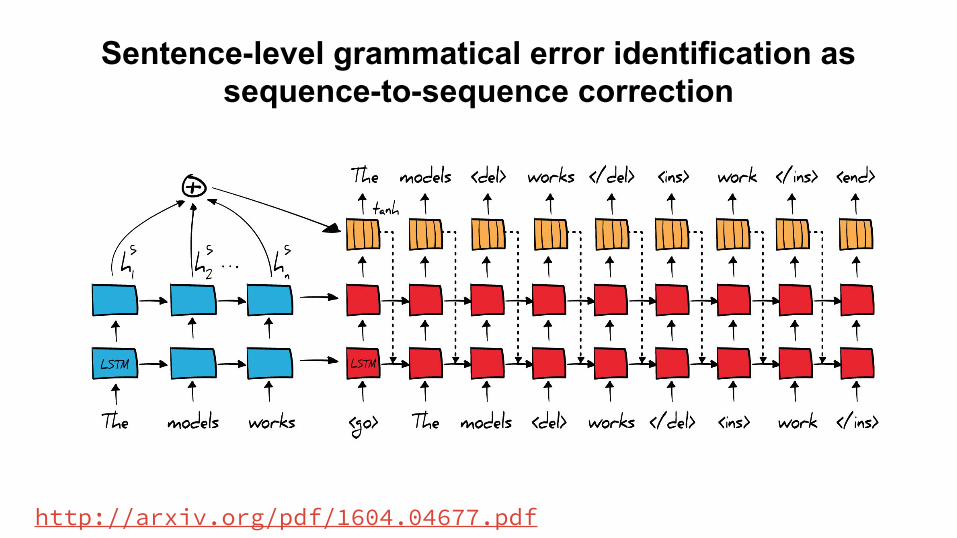
Sentence-level grammatical error identification as sequence-to-sequence correction
http://arxiv.org/pdf/1604.04677.pdf

Formulas for word/character level
Encoder with attention to get context vector cj: Decoder:
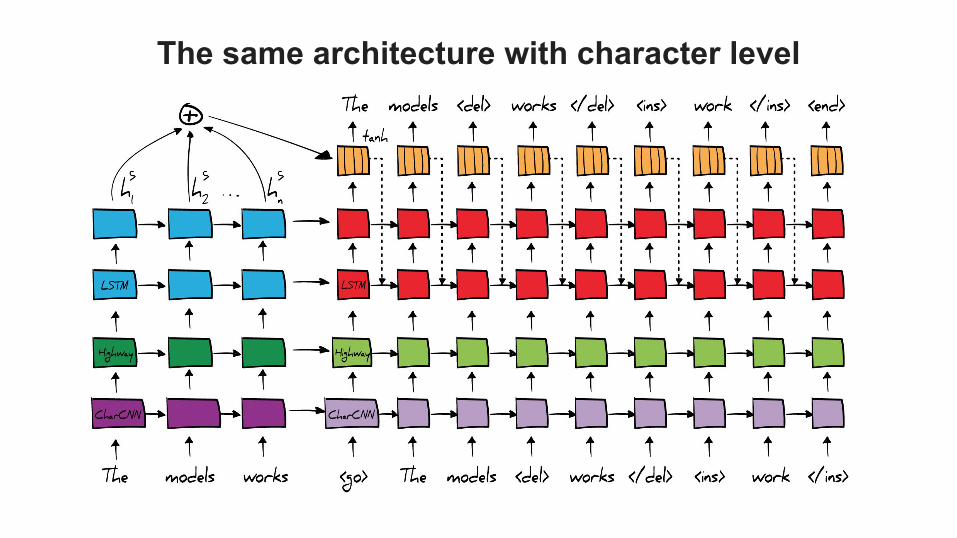
The same architecture with character level
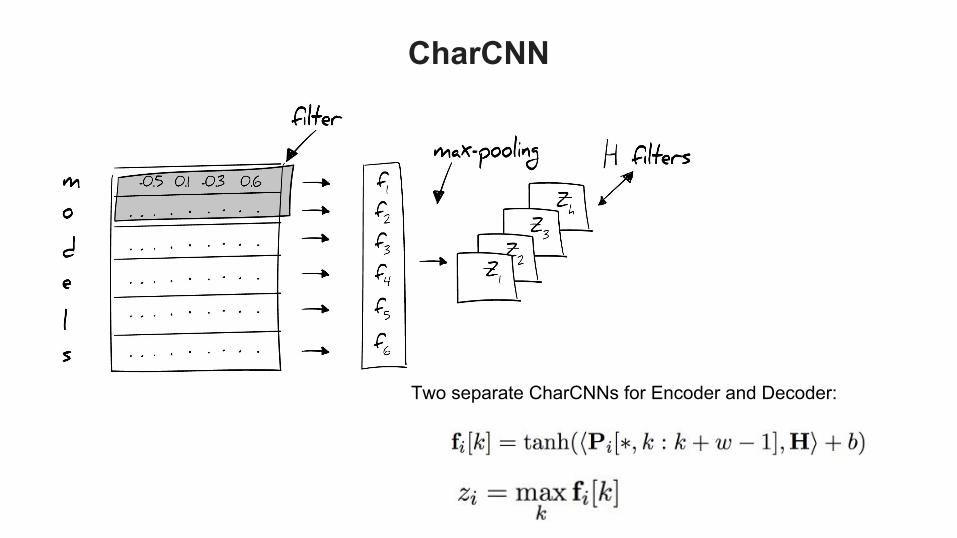
CharCNN
Two separate CharCNNs for Encoder and Decoder:
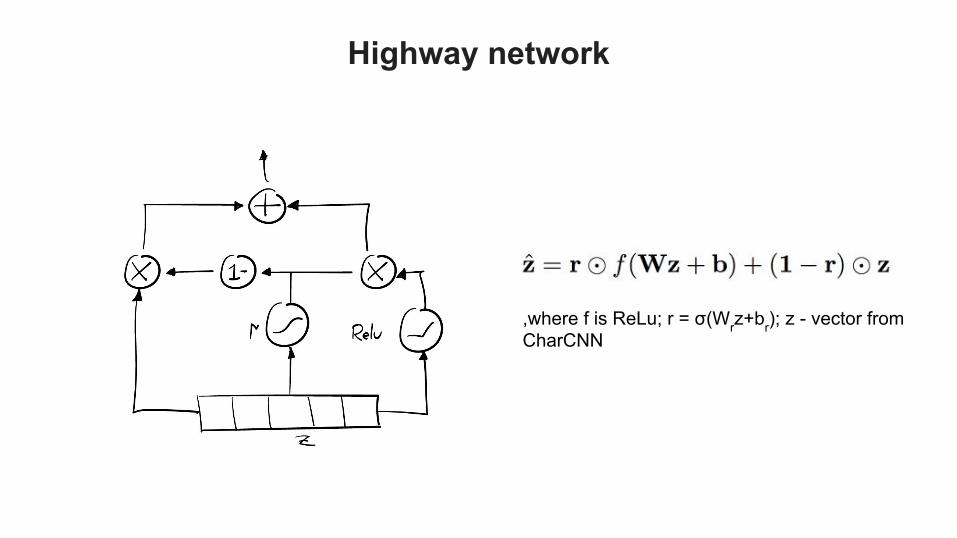
Highway network
,where f is ReLu; r = σ(Wrz+br); z - vector from CharCNN

Thank you!
Design of slides: Elena Godina
My contacts:[email protected]
Anatoly Vostryakov at linkedin





























