Embed Size (px)
Citation preview

Joane M. De Jesús Dátiz
Estadística Avanzada
Profesor Balbino García
20 de mayo de 2010

ANCOVA es apropiada para experimentos y
estudios de observación que incluyen uno o
mas portadores numéricos (covariables).
Las covariables corresponden a influencias
molestosas que hacen a las unidades
muestrales o experimentales diferentes.
Por lo tanto se dificulta la comparación de
tratamientos o poblaciones distintas.


Incluyendo covariables en el modelo:
Se puede reducir tendencia, ajustando por
diferencias entre grupos tratados
Se puede reducir el residuo de la suma de los
cuadrados, ajustando y removiendo la
variabilidad sistemática.


Supongamos que queremos diseñar un
estudio para saber si ver Plaza Sésamo
durante un año incrementará el
entendimiento numérico de niñas de cuatro
años.
Es natural administrar una pre-prueba antes
de realizar el estudio y una post-prueba un
año después.

Control “Tratados”
Pre-prueba Post-
prueba
Pre-prueba Post-
prueba
4 0 0 2
8 8 2 12
10 8 6 4
10 8 8 14
Promedio 8 6 4 8

Una de las posibilidades podría ser utilizar las puntuaciones de la pre-prueba para definir los pares y realizar el estudio como un experimento de bloques completos al azar.
Otro enfoque sería utilizar el cambio en puntuaciones, post-pre, como la respuesta.
El análisis de covarianza es similar a este segundo enfoque, pero en vez de decidir de antemano como ajustar las puntuaciones de la pre-prueba, ANCOVA utiliza la relación observada entre las puntuaciones de la pre y la post-prueba para escoger el ajuste.

Los sujetos se dividieron en dos grupos: Tratados Los que vieron Plaza Sésamo durante un año
Control Los que no vieron el programa por el periodo de
tiempo estipulado
La respuesta son las puntuaciones de la post-prueba.
Cada sujeto fue sometido a una pre y post prueba, donde la post-prueba es la covariable.

Las puntuaciones de la post-prueba
(respuesta) muestran mucha variabilidad.
En promedio, los dos grupos tienen valores
bastante diferentes para la pre-prueba.
(covariable)
Un análisis de covarianza nos puede ayudar a
lidiar con ambos problemas.


Ajustando para las puntuaciones de la pre-
prueba se incrementa la diferencia en el
promedio de las respuestas de 2 a 6, y se
reduce el residuo de la suma de los
cuadrados de 152 a 88.
Aquí ANCOVA tiene dos ventajas sobre
ANOVA:
Se ajusta para la tendencia de promedios
desiguales para las dos condiciones
Reduce significativamente el residuo de la suma
de los cuadrados.

Los modelos de ANCOVA pueden ser no
apropiados si:
La relación entre la respuesta y la covariable no
es lineal.
Si la relación es lineal, pero las líneas ajustadas
al grupo de puntos tienen pendientes diferentes
Si el ajuste de las diferencias de los grupos viola
el sentido común


En ocasiones la forma del diagrama de
dispersión (“scatterplot”) excluye ANCOVA.
A pesar de que el diseño de tu estudio sugiera
que este tipo de análisis es viable.
El experimento de actividad mental sugiere
esto.

24 temas proporcionan bloques de horarios
en un diseño RCB para comparar los efectos
del placebo, morfina e inyecciones de
heroína en índices de actividad mental.
Los índices tomados dos horas después de las
inyecciones nos sirven de respuesta y los
tomados justo antes de la inyección como la
covariable.


Notemos que aunque la gráfica del placebo sugiere un globo ovalado, las gáaficas para la morfina y la heroína no tienen esta forma.
Esto debido a que muchos de los puntos de ambas tienen un resultado después=0.
Si ignoramos la forma de las gráficas y ajustamos líneas de todos modos, las líneas de morfina y especialmente la de la heroína son mucho menos empinadas que la línea del placebo.
Este conjunto de datos no es un buen candidato para un análisis de covarianza.

En el ejemplo de Plaza Sésamo, se
comparaban dos grupos.
De acuerdo con las puntuaciones de la pre-
prueba los grupos comenzaron desiguales.
Uno tenia una puntuación promedio que era el doble
de la del grupo anterior.
Utilizando el análisis de covarianza, se ajustó el
promedio de las respuestas para lograr la
comparación que tendríamos si las dos grupos
hubiesen tenido la misma puntuación promedio
en la pre-prueba.

En el ejemplo de actividad mental:
El estudio fue planificado para ser analizado
mediante el análisis de covarianza.
Sin embargo, las formas de los diagramas de
dispersión nos demostraron que el modelo
ANCOVA no se ajustaría bien y que por lo tanto
no deberíamos utilizar este análisis.
Existen otras situaciones en las que a pesar
de que el modelo de líneas paralelas se
ajusta bien, el ajuste de covarianza violaría
el sentido común.


Supongamos que queremos comparar la altura de estudiantes de primer grado con estudiantes de décimo grado, utilizando el tamaño de zapatos como la covariable.
Los dos grupos comienzan don valores diferentes para la covariable, y por lo tanto utilizamos ANCOVA para ajustar las diferencias en una altura promedio. Para calcular la diferencia tenemos que
encontrar si los dos grupos comenzaron con promedios iguales para la covariable.

Por lógica, sabemos que los estudiantes de
primer grado son bajos de estatura y tienen
pies pequeños, mientras que los estudiantes
de décimo grado son más altos y tienen pies
grandes.
Para obtener una manera más significativa
para comparar las alturas de los dos grupos,
“ajustamos” el tamaño de zapatos, esto es,
calculamos cual sería el promedio de las
alturas si en promedio los estudiantes de
primer y décimo grado tuvieran el mismo
tamaño de zapatos.

Esto resulta en que los estudiantes de primer
y décimo grado tienen la misma altura.
En principio, podemos realizar este tipo de
análisis pero es mucho más sensato pensar
en los estudiantes de primer y decimo grado
como dos poblaciones diferentes.
O sea, no utilizar un método que intente hacer
ambos grupos equivalentes.


Si el valor de la covariable es conocido antes
de que se asignen tratamientos, utilizar la
covariable para definir los bloques es mejor
que ANCOVA.
Si las condiciones que queremos comparar
son experimentales, y es posible organizar
las unidades en bloques con valores similares
de la covariable en cada uno, entonces el
bloqueo es una estrategia ordinariamente
mejor que ANCOVA.

Esto sucede porque ANCOVA es más
restrictiva pues requiere que la relación
entre la respuesta y la covariable sea lineal,
con una pendiente sencilla para todos los
grupos tratados.
El bloqueo trabaja aun si las pendientes son
desiguales, o sea la relación no es lineal.
De todas formas, el bloqueo no debe ser una
opción.

Plaza Sésamo
Era posible usar la covariable para organizar los
datos de las 8 niñas en 4 bloques de 2 niñas cada
uno.
Para esto se parean las puntuaciones de la pre-prueba
de la siguiente forma:
0 y 2; 4 y 6; 8 y 8; 10 y 10
Si fuera posible asignar las condiciones (vio o no
vio la serie), entonces el modelo de bloque sería
mejor que ANCOVA.
Porque no solo se controlaría la influencia de las
molestias, sino que estaremos seguros de que
comparamos niños similares.

El diseño ANCOVA en el ejemplo requiere la
comparación de niñas diferentes.
En la realidad, no podemos forzar a las niñas en
el grupo en tratamiento a ver la serie, de la
misma forma que no podemos prevenir que los
componentes del grupo control vean el
programa.
En este ejemplo la condición de interés es
observada, por lo que el bloqueo no es una
opción.
Es por esto, que como en la mayoría de los
experimentos en los que se comparan los
resultados de la condición, ANCOVA es la mejor
opción.

Actividad de nivel mental
Dado que el tratamiento eran inyecciones de
drogas, pues entonces estamos haciendo un
experimento.
Las unidades experimentales son intervalos de
tiempo, un bloque por tema, por lo que no es
practico usar la covariable para pre-organizar
estas unidades en bloques de acuerdo con la pre-
prueba de actividad mental.
En este ejemplo, ANCOVA parece ser la mejor
estrategia, esto hasta que los patrones en los
datos hacen de este análisis no viable.


Ajustar el modelo ANCOVA requiere tres
pasos:
Un conjunto para ajustar el modelo
Un segundo conjunto para ajustar los efectos del
tratamiento
Un tercer conjunto para probar la hipótesis de
que los efectos del tratamiento son cero.

Nuestra meta es ajustar líneas paralelas, una
para cada grupo en tratamiento y para el
diagrama de dispersión de respuesta versus
la covariable.
Hacer esto requiere dos pasos, los cuales
son:
Calcular el punto promedio para cada grupo
Encontrar la pendiente común

Comenzamos utilizando ANOVA para
descomponer la respuesta y luego la
covariable utilizando el modelo BF.
Este paso nos brinda el promedio de
tratamiento para la respuesta y la covariable
para cada grupo en tratamiento.
Gr Avg + Tr Eff

Deseamos que las pendientes para ambas líneas
ajustadas sean iguales, el paso anterior ya ha
ajustado los puntos anclas, la pendiente que
deseamos es la misma que obtendríamos del
diagrama de dispersión de los conjuntos de los
residuos del paso de ANOVA, ajustando una sola
línea a todos los puntos.
En otras palabras, los residuos de la respuesta
sirven como el “cambio en y” y los residuos de la
covariable como el “cambio en x”.

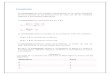
pendiente = Suma
de
(respuesta
residual)
(covariable
residual)
= ∑ y’ x’ donde y’= respuesta
residual,
Suma
de
(covariable
residual)
(covariable
residual)
∑ x’ x’ y x’= covariable residual

Ya que se han dibujado las líneas paralelas:
El paso ANOVA nos da un punto ancla para cada
grupo
El paso de la regresión nos da la pendiente para
cada línea.

Las descomposiciones en los de ANOVA y de
regresión nos muestra la necesidad que
tenemos de graficar dos líneas paralelas del
modelo ajustado de ANCOVA.
Sin embargo numéricamente hay más de un
paso de ajuste del modelo:
Ajuste de los efectos del tratamiento

Los efectos del tratamiento calculados en el
paso de ANOVA se basan simplemente en los
promedios y no toman en consideración la
covariable.
El ajuste que queremos corresponde a
escoger un valor x común para todos los
grupos, localizando nuevos puntos anclas
todos con este mismo valor x y utilizando los
valores de y para compararlos grupos
tratados.

La covariable de los efectos de tratamiento
nos dice cuanto cambio en x es necesario
para cada grupo, y multiplicando por la
pendiente común obtenemos el cambio
correspondiente en y.

Desafortunadamente, la lógica simple de
comparación de hipótesis que funciona en
diseños balanceados no funciona con
ANCOVA.
Esto sucede porque los valores de la
covariable no están balanceados con
respecto al resto del diseño.

Para probar que los efectos del tratamiento
son cero, ajustamos dos modelos, uno con
efectos de tratamiento, uno sin efectos, y
comparamos por el residual de la suma de los
cuadrados.
El modelo completo, el que tiene efectos del
tratamiento, es la línea paralela al modelo
anterior.

El modelo nulo, sin efectos de tratamiento,
corresponde a una línea de regresión,
ajustada a todos los puntos del diagrama de
dispersión de la respuesta versus la
covariable.
Modelo completo
Líneas paralelas, una por cada grupo
Modelo nulo
Una línea para todos los grupos juntos

Para comparar los dos modelos, calculamos el residual de la suma de los cuadrados para cada uno.
Para el modelo completo tenemos SSRES(adj) para el denominador de la razón-F.
Para el modelo nulo, el residual de la suma de los cuadrados proviene en parte del riesgo de error, pero (a menos que el efecto de tratamiento sea cero) en parte de la diferencia de tratamiento, los cuales no son parte del modelo.

La suma de los cuadrados funciona como
Pitágoras.
La razón-F para probar los efectos del
tratamiento corresponde a la pendiente.
Cambio en x/cambio en y

Si los efectos de tratamiento son grandes, el
modelo nulo no se ajusta tan bien como el
modelo completo, por lo que tendremos un
residual de la suma de los cuadrados mas
grande.


Fuente Grados de libertad Suma de los
cuadrados
Tratamiento
(ajustado)
# tratados-1 SST+E -SSRes(adj)
Residual (ajustado) #observaciones - #
tratados - 1
SSRes(adj)
F = MSTr(adj)/MSRes(adj)


La siguiente tabla resume la descomposición
utilizando el modelo completo.
Fuente Grados de
libertad
Suma de los
cuadrados
Promedio
principal
1 392
Tratamiento
(sin ajustar)
1 8
Covariable 1 64
Residual
(ajustado)
5 88
TOTAL 8 552

Para ajustar el modelo nulo, ajustamos una
líneas a los ocho puntos de los datos.
Podemos verificar que el punto promedio es
(7,6), la pendiente es 0.5 y la
descomposición es la siguiente:Obs
=
Gr Avg
+
Cov Eff
+
T+E
0 2 7 7 -1 -3 -6 -2
8 12 7 7 1 -2 0 7
8 4 7 7 2 0 -1 -3
8 14 7 7 2 1 -1 6
SS 552 = 392 + 24 + 136
df 8 = 1 + 1 + 6

Modelo completo Residual suma de los cuadrados ajustado = 88
Grados de libertad = 5
Modelo nulo Suma de los cuadrados del tratamiento mas el
efecto = 136
Grados de libertad = 6
La diferencia de la suma de los cuadrados es 136-88=48. Lo que quiere decir que 48 es la reducción en la
suma de los cuadrados dado el tratamiento y entonces los grados de libertad son 6-1=5


Sin ajustar Ajustado para la
covariable
Fuente Df SS MS F Df SS MS F
Promedio
principal
1 392 1 392
Tratamientos 1 8 8.0 0.32 1 48 48.0 2.73
Covariable - - -
Residual 6 152 25.3 5 88 17.6
TOTAL 8 552
La suma de los cuadrados va de 8 a 48, mientras que el residual de esta
suma va de 152 a 88. La razón-F ajustada (2.73) es mas de 8 veces tan
grande como la razón-F no ajustada (0.32)