Embed Size (px)
Citation preview

Amazon Aurora는어떻게다른가?김일호 | Solutions Architect

MySQL-compatible relational database
Performance and availability of commercial databases
Simplicity and cost-effectiveness of open source databases
What is Amazon Aurora?
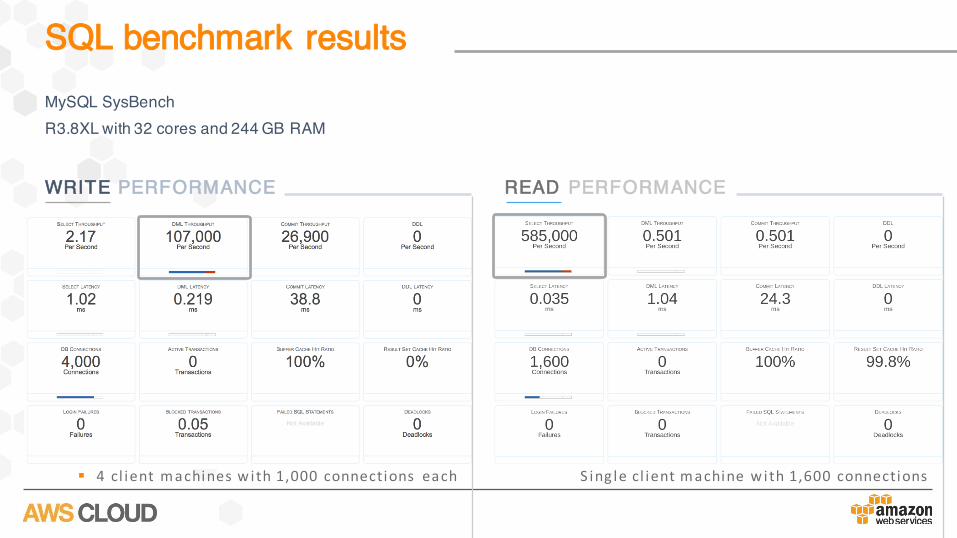
§ 4cl ientmachines w ith1,000connections each
WRITE PERFORMANCE READ PERFORMANCE
S ing lecl ientmachinew ith1,600connections
MySQL SysBenchR3.8XL with 32 cores and 244 GB RAM
SQL benchmark results
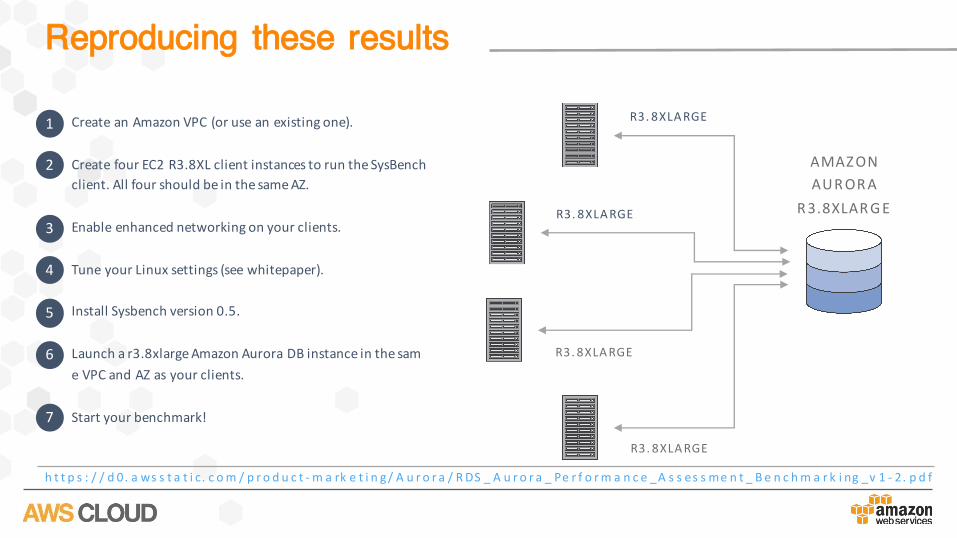
Reproducing these results
h t t p s : / / d 0. a ws s t a t i c. c om / p r o d u c t - m a rk e t i n g / A u r o r a / RDS _ A u r o r a _ Pe r f o rm a n c e _A s s es s me n t _ B e n c hm a r k i ng _v 1 - 2. p d f
AMAZONAURORA
R3.8XLARGE
R3. 8XLARGE
R3. 8XLARGE
R3. 8XLARGE
R3. 8XLARGE
• CreateanAmazonVPC(oruseanexistingone).
• CreatefourEC2R3.8XLclientinstancestoruntheSysBenchclient.AllfourshouldbeinthesameAZ.
• Enableenhancednetworkingonyourclients.
• TuneyourLinuxsettings(seewhitepaper).
• InstallSysbenchversion0.5.
• Launchar3.8xlargeAmazonAuroraDBinstanceinthesameVPCandAZasyourclients.
• Startyourbenchmark!
1
2
3
4
5
6
7

What makes Aurora fast.

Do fewer IOs
Minimize network packets
Cache prior results
Offload the database engine
DO LESS WORKProcess asynchronously
Reduce latency path
Use lock-free data structures
Batch operations together
BE MORE EFFICIENT
How do we achieve these results?
DATABASES ARE ALL ABOUT I/O
NETWORK-ATTACHED STORAGE IS ALL ABOUT PACKETS/SECOND
HIGH-THROUGHPUT PROCESSING DOES NOT ALLOW CONTEXT SWITCHES
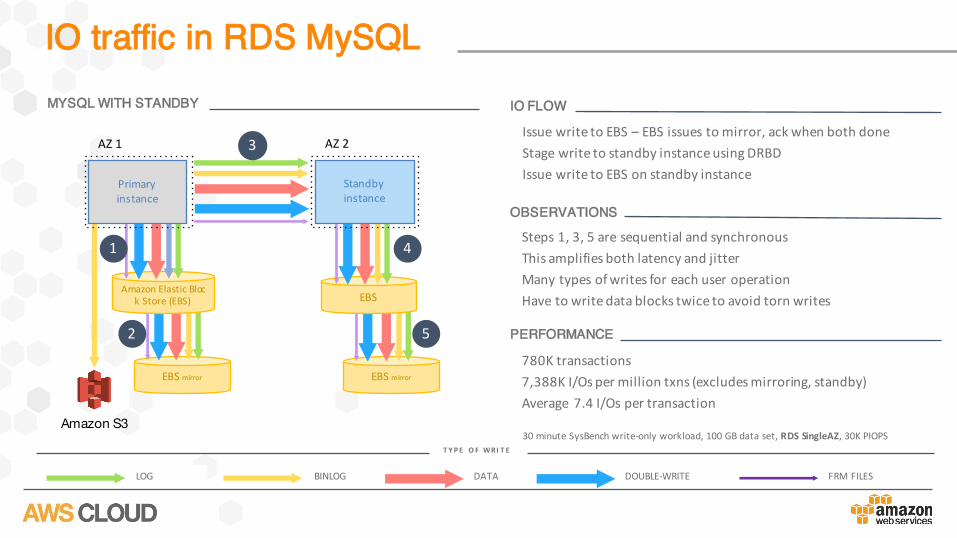
IO traffic in RDS MySQL
BINLOG DATA DOUBLE-WRITELOG FRMFILES
T YPE O F WRI T E
MYSQL WITH STANDBY
IssuewritetoEBS– EBSissuestomirror,ack whenbothdoneStagewritetostandbyinstanceusingDRBDIssuewritetoEBSonstandbyinstance
IO FLOW
Steps1,3,5aresequentialandsynchronousThisamplifiesbothlatencyandjitterManytypesofwritesforeachuseroperationHavetowritedatablockstwicetoavoidtornwrites
OBSERVATIONS
780Ktransactions7,388KI/Os permilliontxns (excludesmirroring,standby)Average 7.4I/Os pertransaction
PERFORMANCE
30minuteSysBenchwrite-onlyworkload,100GBdataset,RDSSingleAZ,30KPIOPS
EBSmirrorEBSmirror
AZ1 AZ2
Amazon S3
EBSAmazonElasticBloc
kStore(EBS)
Primaryinstance
Standbyinstance
1
2
3
4
5
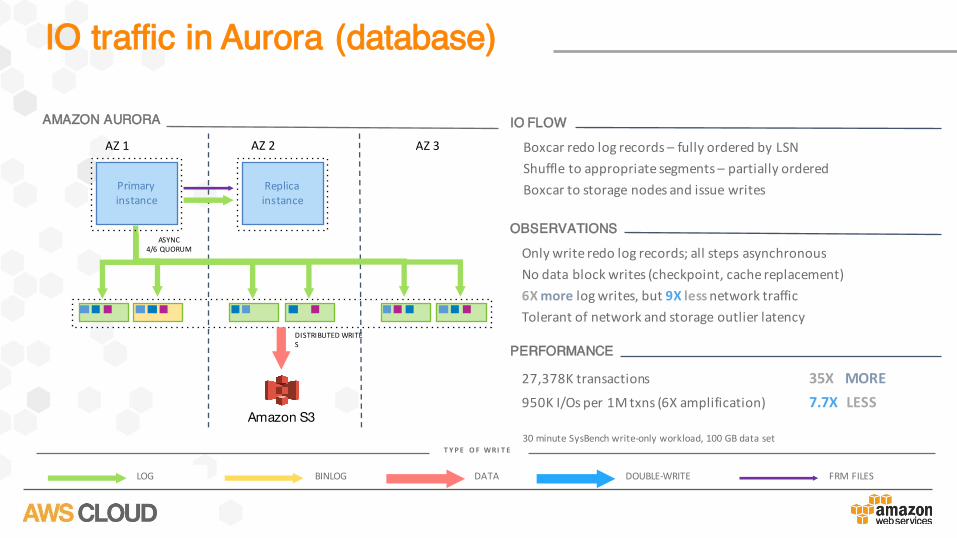
IO traffic in Aurora (database)
AZ1 AZ3
Primaryinstance
Amazon S3
AZ2
Replicainstance
AMAZON AURORA
ASYNC4/6QUORUM
DISTRIBUTEDWRITES
BINLOG DATA DOUBLE-WRITELOG FRMFILES
T YPE O F WRI T E30minuteSysBenchwrite-onlyworkload,100GBdataset
IO FLOW
Onlywriteredologrecords;allstepsasynchronousNodatablockwrites(checkpoint,cachereplacement)6Xmore logwrites,but9X lessnetworktrafficTolerantofnetworkandstorageoutlierlatency
OBSERVATIONS
27,378Ktransactions 35X MORE950KI/Os per1Mtxns (6Xamplification) 7.7X LESS
PERFORMANCE
Boxcarredologrecords– fullyorderedbyLSNShuffletoappropriatesegments– partiallyorderedBoxcartostoragenodesandissuewrites
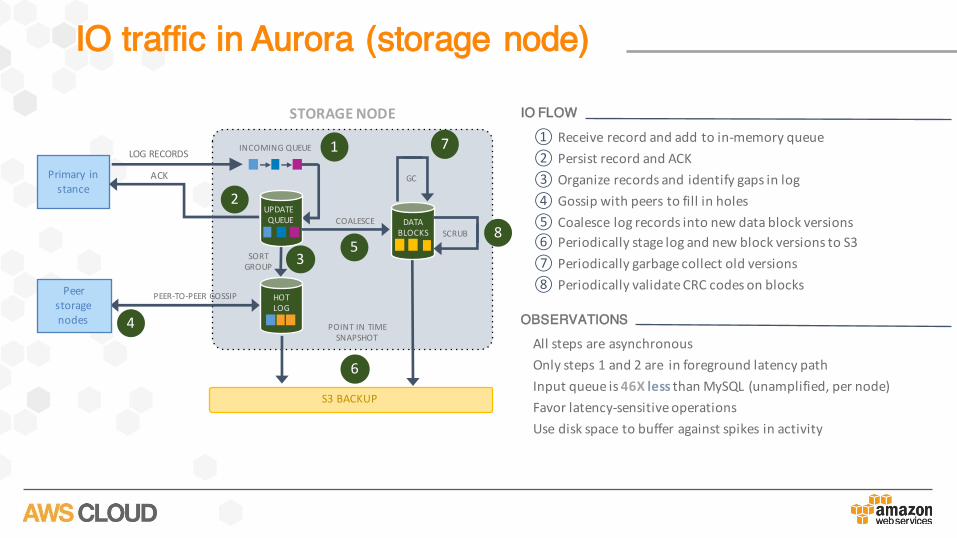
IO traffic in Aurora (storage node)
LOGRECORDS
Primary instance
INCOMINGQUEUE
STORAGENODE
S3BACKUP
1
2
3
4
5
6
7
8UPDATEQUEUE
ACK
HOTLOG
DATABLOCKS
POINTINTIMESNAPSHOT
GC
SCRUBCOALESCE
SORTGROUP
PEER-TO-PEERGOSSIPPeerstoragenodes
AllstepsareasynchronousOnlysteps1and2are inforegroundlatencypathInputqueueis46X less thanMySQL(unamplified,pernode)Favorlatency-sensitiveoperationsUsediskspacetobufferagainstspikesinactivity
OBSERVATIONS
IO FLOW
① Receiverecordandaddtoin-memoryqueue② PersistrecordandACK③ Organizerecordsandidentifygapsinlog④ Gossipwithpeerstofillinholes⑤ Coalescelogrecordsintonewdatablockversions⑥ PeriodicallystagelogandnewblockversionstoS3⑦ Periodicallygarbagecollectoldversions⑧ PeriodicallyvalidateCRCcodesonblocks
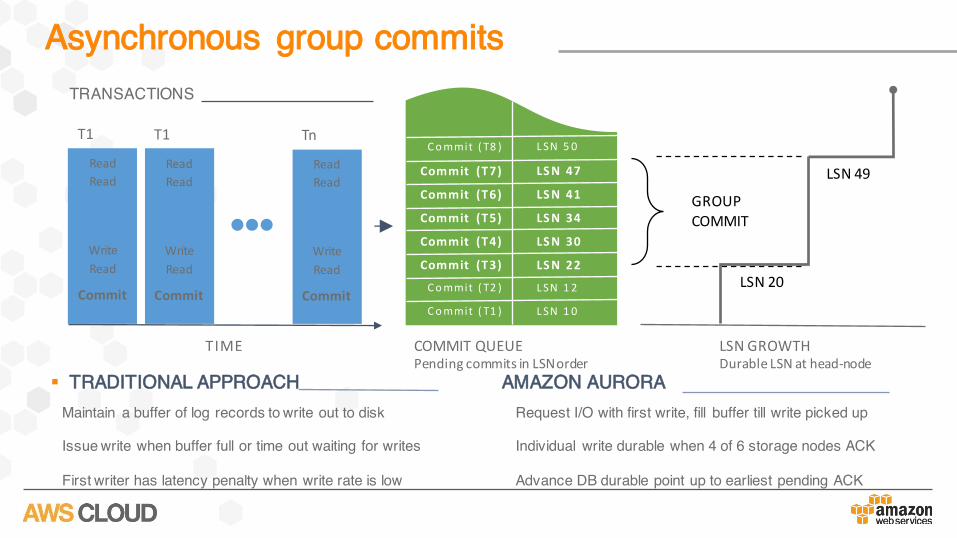
Asynchronous group commits
Read
Write
Commit
Read
Read
T1
Commit ( T1 )
Commit ( T2 )
Commit (T3)
L SN 1 0
LSN 1 2
LSN 22
L SN 5 0
LSN 30
LSN 34
LSN 41
LSN 47
LSN20
LSN49
Commit (T4)
Commit (T5)
Commit (T6)
Commit (T7)
Commit ( T8 )
LSNGROWTHDurableLSNathead-node
COMMITQUEUEPendingcommitsinLSNorder
TIME
GROUPCOMMIT
TRANSACTIONS
Read
Write
Commit
Read
Read
T1
Read
Write
Commit
Read
Read
Tn
§ TRADITIONAL APPROACH AMAZON AURORAMaintain a buffer of log records to write out to disk
Issue write when buffer full or time out waiting for writes
First writer has latency penalty when write rate is low
Request I/O with first write, fill buffer till write picked up
Individual write durable when 4 of 6 storage nodes ACK
Advance DB durable point up to earliest pending ACK

§ Re-entrant connections multiplexed to active threads
§ Kernel-space epoll() inserts into latch-free event queue
§ Dynamically size threads pool
§ Gracefully handles 5,000+ concurrent client sessions on r3.8xl
Standard MySQL – one thread per connection
Doesn’t scale with connection count
MySQL EE – connections assigned to thread group
Requires careful stall threshold tuning
CLIENT
CONN
ECTION
CLIENT
CONN
ECTION
LATCHFREETASKQUEUE
epoll()
MYSQL THREAD MODEL AURORA THREAD MODEL
Adaptive thread pool
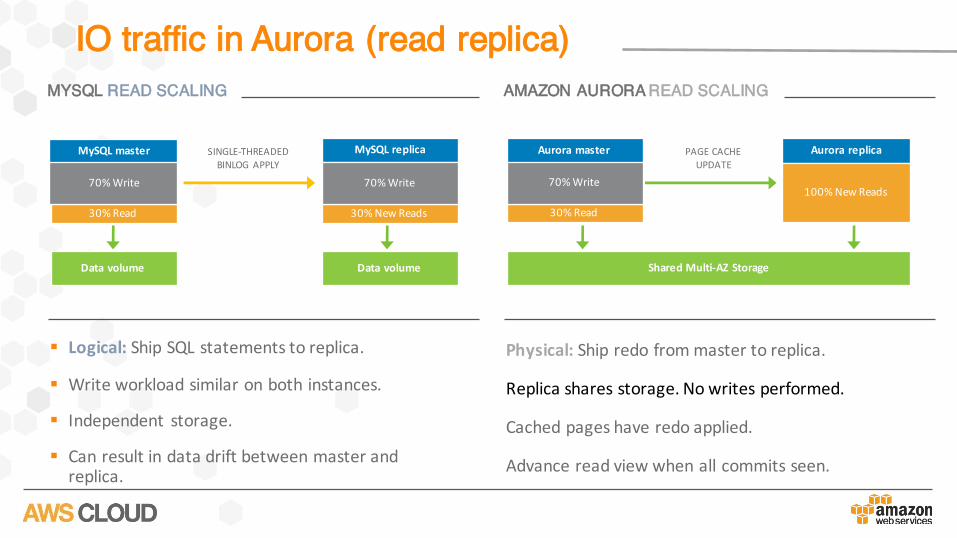
IO traffic in Aurora (read replica)
PAGECACHEUPDATE
Auroramaster
30%Read
70%Write
Aurora replica
100%NewReads
SharedMulti-AZStorage
MySQLmaster
30%Read
70%Write
MySQLreplica
30%NewReads
70%Write
SINGLE-THREADEDBINLOG APPLY
Datavolume Datavolume
§ Logical: ShipSQLstatementstoreplica.
§ Writeworkloadsimilaronbothinstances.
§ Independent storage.
§ Canresultindatadriftbetweenmasterandreplica.
Physical: Shipredofrommastertoreplica.
Replicasharesstorage.Nowritesperformed.
Cachedpageshaveredoapplied.
Advancereadviewwhenallcommitsseen.
MYSQL READ SCALING AMAZON AURORA READ SCALING

Improvements over the past few months
WritebatchsizetuningAsynchronous sendforread/writeI/OsPurgethreadperformanceBulk insert performance
BATCH OPERATIONS
FailovertimereductionsMalloc reductionSystemcallreductionsUndoslotcachingpatternsCooperative log apply
OTHERBinlog anddistributedtransactionsLock compressionRead-ahead
CUSTOMER FEEDBACK
HotrowcontentionDictionarystatisticsMini-transactioncommitcodepathQuerycacheread/writeconflictsDictionary system mutex
LOCK CONTENTION

What makes Aurora highly available.
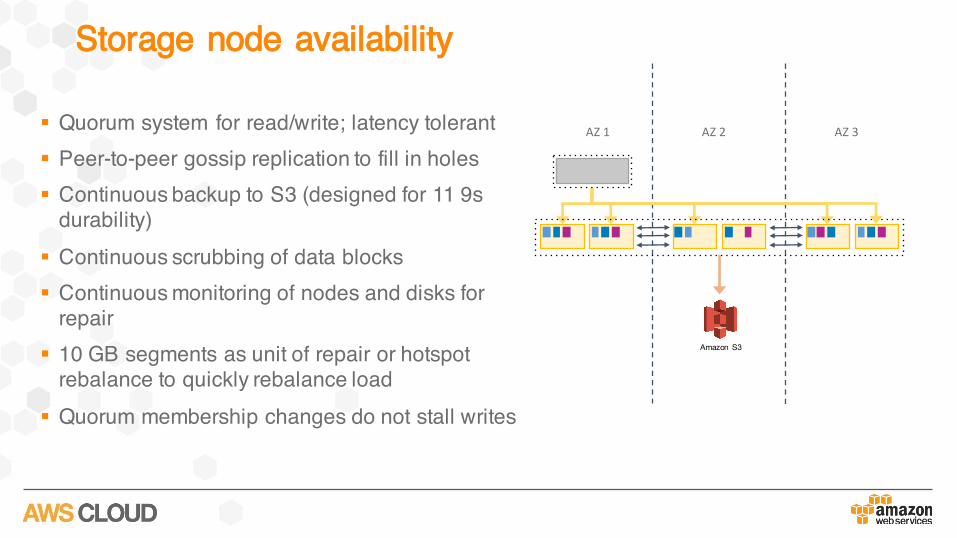
Storage node availability
§ Quorum system for read/write; latency tolerant§ Peer-to-peer gossip replication to fill in holes§ Continuous backup to S3 (designed for 11 9s
durability)§ Continuous scrubbing of data blocks § Continuous monitoring of nodes and disks for
repair § 10 GB segments as unit of repair or hotspot
rebalance to quickly rebalance load§ Quorum membership changes do not stall writes
AZ1 AZ2 AZ3
Amazon S3
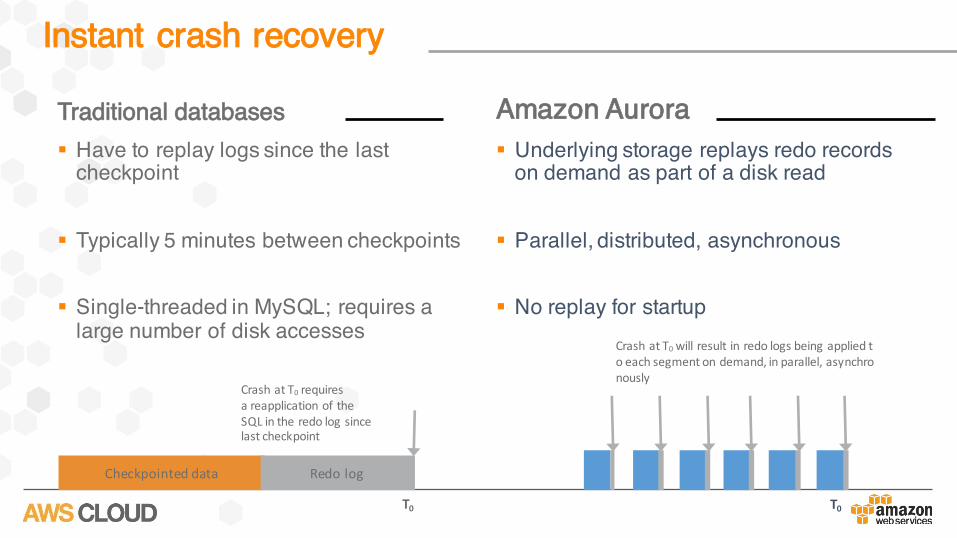
Traditional databases§ Have to replay logs since the last
checkpoint
§ Typically 5 minutes between checkpoints
§ Single-threaded in MySQL; requires a large number of disk accesses
Amazon Aurora§ Underlying storage replays redo records
on demand as part of a disk read
§ Parallel, distributed, asynchronous
§ No replay for startup
Checkpointed data Redolog
CrashatT0 requiresareapplicationoftheSQLintheredologsincelastcheckpoint
T0 T0
CrashatT0 willresultinredologsbeingappliedtoeachsegmentondemand,inparallel,asynchronously
Instant crash recovery
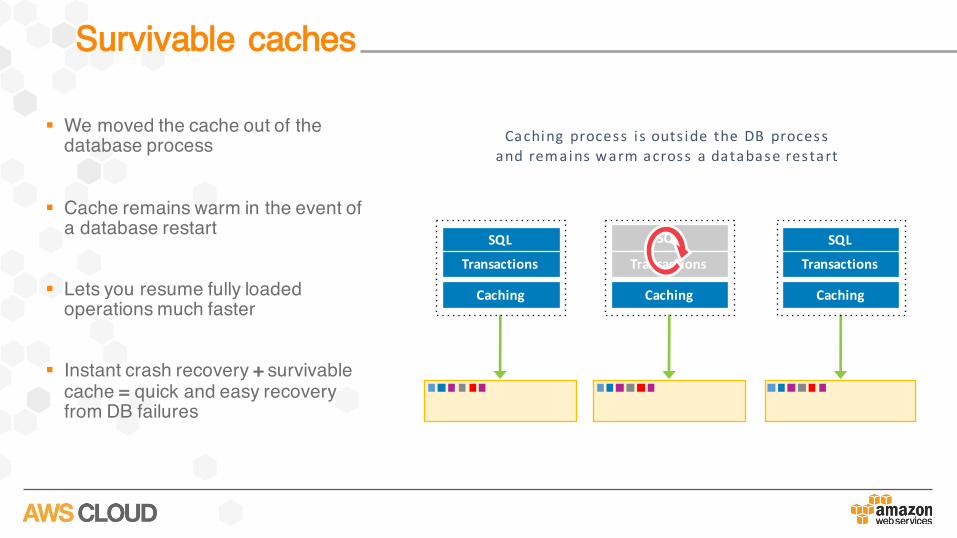
Survivable caches
§ We moved the cache out of the database process
§ Cache remains warm in the event of a database restart
§ Lets you resume fully loaded operations much faster
§ Instant crash recovery + survivable cache = quick and easy recovery from DB failures
SQL
Transactions
Caching
SQL
Transactions
Caching
SQL
Transactions
Caching
Caching process i s outs ide theDB process and remains warmacross a databaserestart
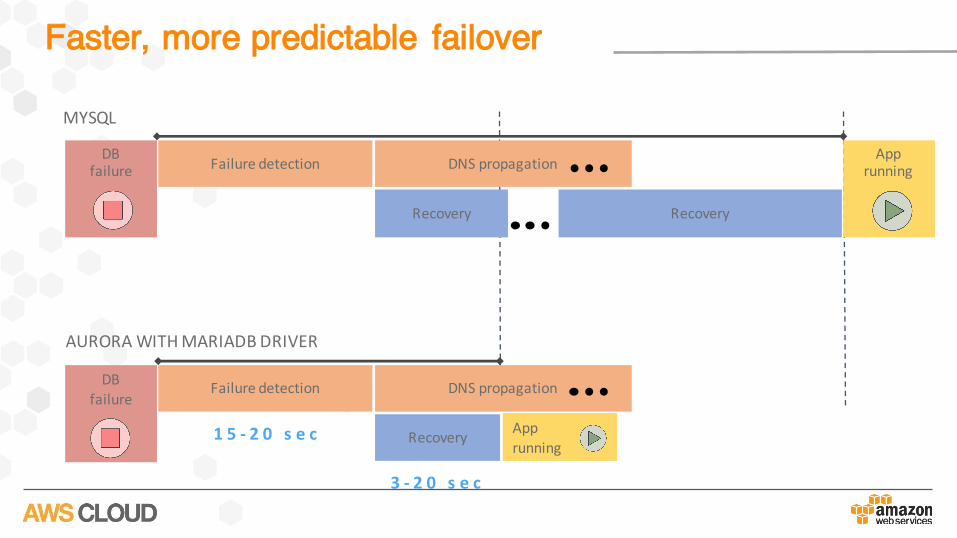
Faster, more predictable failover
ApprunningFailuredetection DNSpropagation
Recovery Recovery
DBfailure
MYSQL
Apprunning
Failuredetection DNSpropagation
Recovery
DBfailure
AURORAWITHMARIADBDRIVER
1 5 - 2 0 s e c
3 - 2 0 s e c

Amazon Aurora Testimonials

§ “Amazon Aurora was able to satisfy all of our scale requirements with no degradation in performance. With Alfresco on Amazon Aurora we scaled to 1 billion documents with a throughput of 3 million per hour, which is 10 times faster than our MySQL environment. It just works!"
- John Newton, Founder and CTO of Alfresco

§ “We ran our compatibility test suites against Amazon Aurora and everything just worked. Amazon Aurora paired with Tableau means data users can take advantage of the 5x throughput Amazon Aurora provides and deliver faster analytic insights throughout their organizations. We look forward to offering our Amazon Aurora Tableau connector."
- Dan Jewett, Vice President of Product Management at Tableau

§ "기존 RDS는 스토리지의 용량과 IOPS의 필요치를 예측해서설정해야 했습니다.�하지만
Aurora에서는 이를예측할 필요 없이필요한 만큼사용할 수있습니다.덕분에 비용절감은
물론이고,�I/O�병목에대한 걱정을덜 수있었습니다."
§ "기존 DB에서 Aurora로 migration하는 데에 어려움이있었습니다.하지만 최근에 나온 AWS�
Database�Migration�Service를 활용하면좀 더쉽게 migration을 진행할 수있으리라
봅니다."

Thank you!





























